Coherent Interpretation of Entire Visual Field Test Reports Using a Multimodal Large Language Model (ChatGPT)


Abstract
1. Introduction
2. Methods
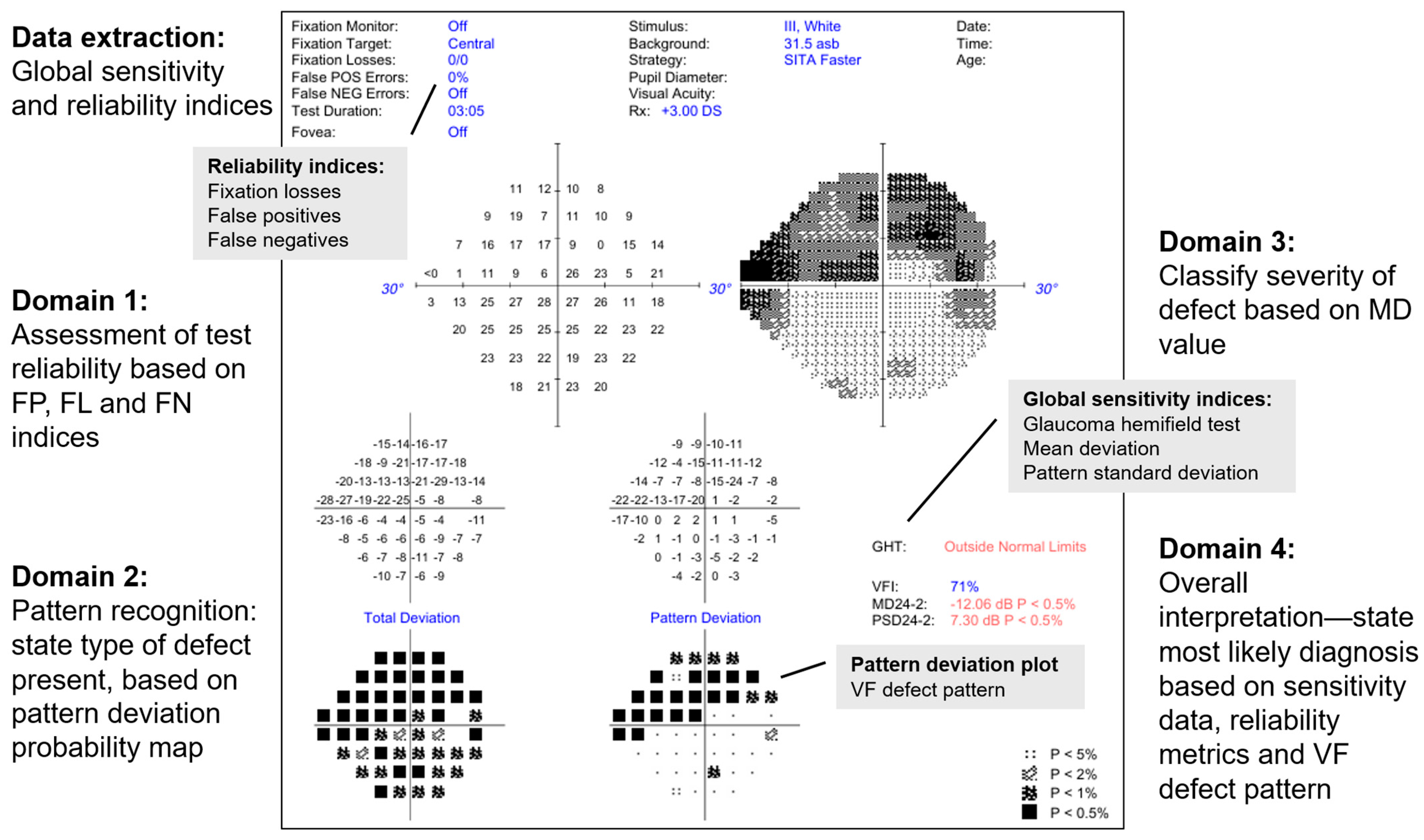
2.1. Analysis of Raw Imaging Data by LLM
- Is this a reliable VF test? (Reliability)
- The model is expected to consider FP, FL and false negative values to judge if the test reliability is acceptable for interpretation
- What type of VF defect is present? (Type of defect)
- This is based on the PD grid (e.g., nasal step defect)
- If this patient has glaucoma, what is the severity of the disease based on this defect? (Severity)
- The model is expected to classify the severity (mild, moderate or severe) based on the MD value.
- What is the most likely diagnosis based on this VF test alone? (Diagnosis)
- The model is expected to consider the global sensitivity and reliability indices and what type of VF defect is present, to provide a verdict as to whether the VF test result is consistent with healthy, suspect or manifest glaucoma.
2.2. Assessment of Model Outputs
3. Results
3.1. Baseline Characteristics of Cohort
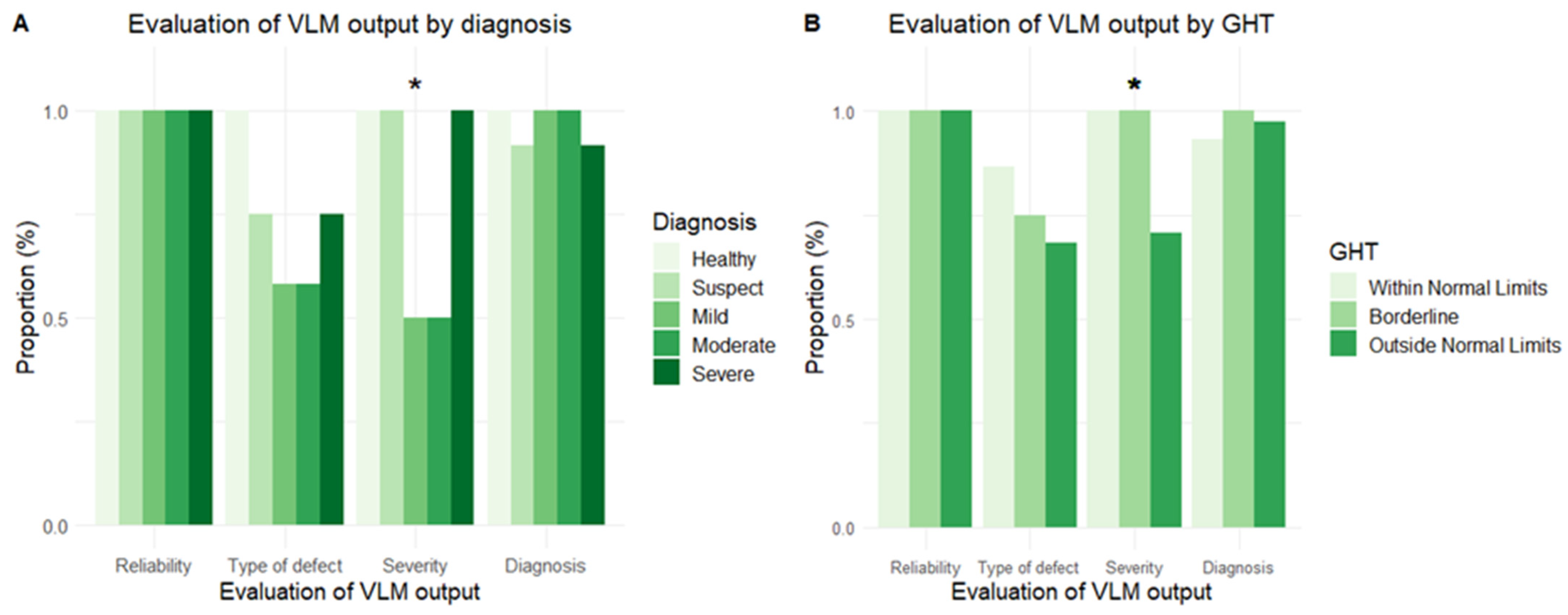
3.2. Performance Across Domains of VF Analysis
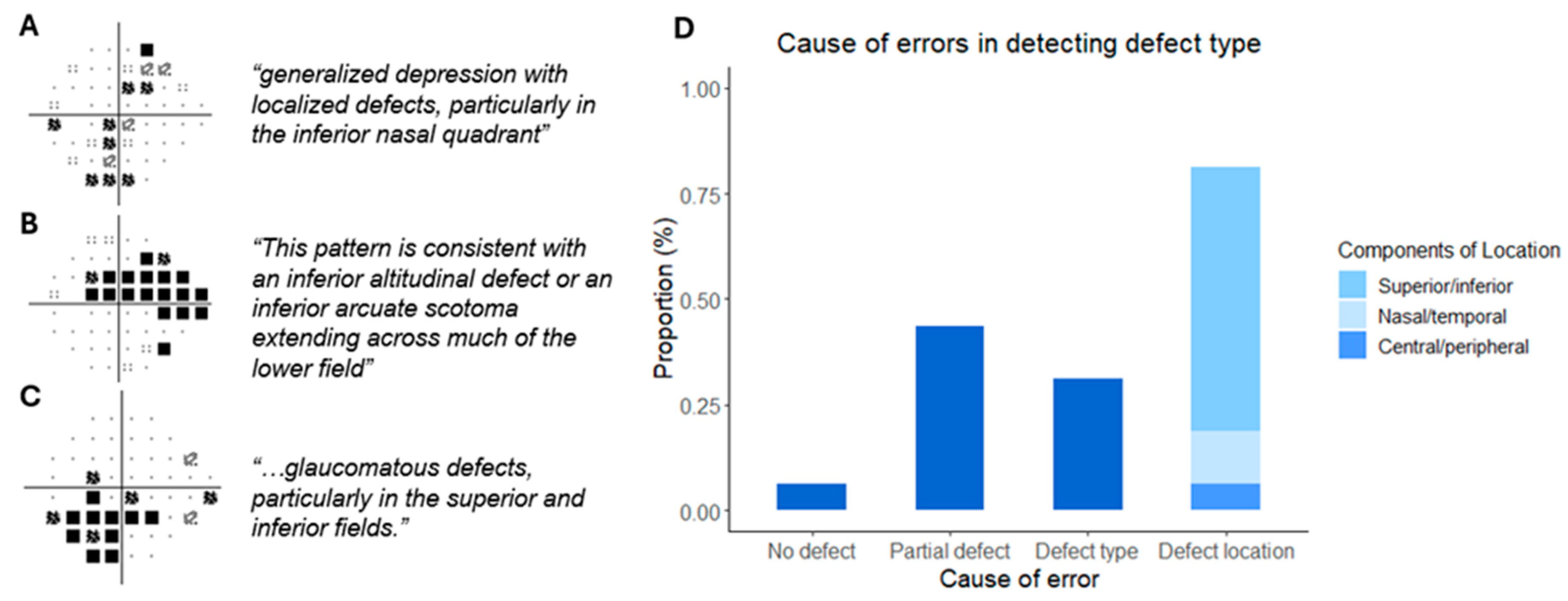
3.3. Test–Retest Performance and Investigating Errors in Defect Type
3.4. VF Report Interpretation in Cases of Suspected Glaucoma
4. Discussion
4.1. LLM in the Interpretation of VF Test Reports
4.2. Integrating LLM into Clinical Workflow
4.3. Limitations
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Tan, J.C.; Yohannan, J.; Ramulu, P.Y.; Kalloniatis, M.; Crabb, D.P.; Crowston, J.; Phu, J. Visual field testing in glaucoma using the Swedish Interactive Thresholding Algorithm (SITA). Surv. Ophthalmol. 2024, 70, 141–152. [Google Scholar] [CrossRef] [PubMed]
- Ng, M.; Sample, P.A.; Pascual, J.P.; Zangwill, L.M.; Girkin, C.A.; Liebmann, J.M.; Weinreb, R.N.; Racette, L. Comparison of visual field severity classification systems for glaucoma. Eur. J. Gastroenterol. Hepatol. 2012, 21, 551–561. [Google Scholar] [CrossRef]
- Werner, E.B.; Bishop, K.I.; Koelle, J.; Douglas, G.R.; LeBlanc, R.P.; Mills, R.P.; Schwartz, B.; Whalen, W.R.; Wilensky, J.T. A comparison of experienced clinical observers and statistical tests in detection of progressive visual field loss in glaucoma using automated perimetry. Arch. Ophthalmol. 1988, 106, 619–623. [Google Scholar] [CrossRef]
- Tanna, A.P.; Bandi, J.R.; Budenz, D.L.; Feuer, W.J.; Feldman, R.M.; Herndon, L.W.; Rhee, D.J.; Vos, J.W.-D. Interobserver agreement and intraobserver reproducibility of the subjective determination of glaucomatous visual field progression. Ophthalmology 2011, 118, 60–65. [Google Scholar] [CrossRef] [PubMed]
- Viswanathan, A.C.; Crabb, D.P.; I McNaught, A.; Westcott, M.C.; Kamal, D.; Garway-Heath, D.F.; Fitzke, F.W.; A Hitchings, R. Interobserver agreement on visual field progression in glaucoma: A comparison of methods. Br. J. Ophthalmol. 2003, 87, 726–730. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Jain, N.; Sanghera, R.; Lattuada, F.; Mahmood, S.; Economou, A.; Yu, H.C.Y.; Bourne, R. A validated web-application (GFDC) for automatic classification of glaucomatous visual field defects using Hodapp-Parrish-Anderson criteria. NPJ Digit. Med. 2024, 7, 131. [Google Scholar] [CrossRef]
- Sommer, A.C.; Blumenthal, E.Z. Telemedicine in ophthalmology in view of the emerging COVID-19 outbreak. Graefe’s Arch. Clin. Exp. Ophthalmol. 2020, 258, 2341–2352. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef] [PubMed]
- Tan, J.C.M. Using a large language model to process biometry reports and select intraocular lens for cataract surgery. J. Cataract. Refract. Surg. 2025. [Google Scholar] [CrossRef]
- Tan, J.C.; Phu, J.; Go, D.; Nguyen, D.; Masselos, K.; Bank, A.; Kalloniatis, M.; Agar, A. Evaluation of the Consistency of Glaucomatous Visual Field Defects Using a Clustered SITA-Faster Protocol. Ophthalmology 2023, 130, 1138–1148. [Google Scholar] [CrossRef]
- Tan, J.C.; Kalloniatis, M.; Phu, J. Frontloading SITA-Faster Can Increase Frequency and Reliability of Visual Field Testing at Minimal Time Cost. Ophthalmol. Glaucoma 2023, 6, 445–456. [Google Scholar] [CrossRef] [PubMed]
- Tan, J.C.; Agar, A.; Kalloniatis, M.; Phu, J. Quantification and Predictors of Visual Field Variability in Healthy, Glaucoma Suspect, and Glaucomatous Eyes Using SITA-Faster. Ophthalmology 2024, 131, 658–666. [Google Scholar] [CrossRef] [PubMed]
- Broadway, D.C. Visual field testing for glaucoma—A practical guide. Community Eye Health 2012, 25, 66–70. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Kucur, Ş.S.; Holló, G.; Sznitman, R. A deep learning approach to automatic detection of early glaucoma from visual fields. PLoS ONE 2018, 13, e0206081. [Google Scholar] [CrossRef] [PubMed]
- Akgun, G.G.; Altan, C.; Balci, A.S.; Alagoz, N.; Çakır, I.; Yaşar, T. Using ChatGPT-4 in visual field test assessment. Clin. Exp. Optom. 2025, 1–6. [Google Scholar] [CrossRef]
- Varnosfaderani, S.M.; Forouzanfar, M. The Role of AI in Hospitals and Clinics: Transforming Healthcare in the 21st Century. Bioengineering 2024, 11, 337. [Google Scholar] [CrossRef]
- Alowais, S.A.; Alghamdi, S.S.; Alsuhebany, N.; Alqahtani, T.; Alshaya, A.I.; Almohareb, S.N.; Aldairem, A.; Alrashed, M.; Bin Saleh, K.; Badreldin, H.A.; et al. Revolutionizing healthcare: The role of artificial intelligence in clinical practice. BMC Med. Educ. 2023, 23, 689. [Google Scholar] [CrossRef]
- Wang, H.; Masselos, K.; Tong, J.; Connor, H.R.; Scully, J.; Zhang, S.; Rafla, D.; Posarelli, M.; Tan, J.C.; Agar, A.; et al. ChatGPT for Addressing Patient-centered Frequently Asked Questions in Glaucoma Clinical Practice. Ophthalmol. Glaucoma 2025, 8, 157–166. [Google Scholar] [CrossRef]
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef] [PubMed]
- Murdoch, B. Privacy and artificial intelligence: Challenges for protecting health information in a new era. BMC Med. Ethics 2021, 22, 122. [Google Scholar] [CrossRef] [PubMed]
- Bae, H.W.; Lee, K.H.; Lee, N.; Hong, S.; Seong, G.J.; Kim, C.Y. Visual fields and OCT role in diagnosis of glaucoma. Optom. Vis. Sci. 2014, 91, 1312–1319. [Google Scholar] [CrossRef]
- Alhadeff, P.A.; De Moraes, C.G.; Chen, M.B.; Raza, A.S.; Ritch, R.; Hood, D.C. The Association Between Clinical Features Seen on Fundus Photographs and Glaucomatous Damage Detected on Visual Fields and Optical Coherence Tomography Scans. Eur. J. Gastroenterol. Hepatol. 2017, 26, 498–504. [Google Scholar] [CrossRef] [PubMed]
- Tran, V.; Posarelli, M.; Coroneo, M.T.; Batterbury, M.; Tan, J.C. Rates of change and longitudinal variability of using multiple OCT retinal nerve fibre layer ring sizes in glaucoma. AJO Int. 2025, 2, 100092. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diagnosis | |||
|---|---|---|---|
| Healthy | Suspect | Glaucoma | |
| Number | 12 | 12 | 36 |
| Age | 64.5 (17.1) | 62.0 (9.5) | 66.1 (15.3) |
| Eye, right | 8 | 4 | 18 |
| SITA Strategy | |||
| Standard | 4 | 4 | 12 |
| Fast | 4 | 4 | 12 |
| Faster | 4 | 4 | 12 |
| MD | 0.03 (1.0) | −0.53 (0.9) | −9.0 (6.2) |
| PSD | 1.6 (0.3) | 2.2 (0.5) | 8.1 (3.6) |
| GHT | |||
| Within normal limits | 12 | 2 | 0 |
| Borderline | 0 | 4 | 0 |
| Outside normal limits | 0 | 6 | 36 |
| FP | 5.3 (4.8) | 13.2 (16.0) | 4.3 (6.4) |
| FP > 15% | 2 | 6 | 8 |
| Number | Sensitivity Indices | Reliability Indices | Defect | Model Output | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MD | PSD | GHT | FL | FN (%) | FP (%) | Diagnosis | Severity | Certainty | ||
| 1 | 0.59 | 2.21 | Within Normal Limits | 12 | 0 | 12 | Present | Healthy | NA | Nil |
| 2 | −0.33 | 2.88 | Outside Normal Limits | 2 | 0 | 0 | Present | Early/suspect | mild | Flagged GHT, defect |
| 3 | −0.43 | 2.58 | Borderline | 4 | 6 | 3 | Present | Suspect | mild | Flagged GHT, reliability |
| 4 | −1.31 | 2.3 | Outside Normal Limits | 4 | 8 | 18 | Present | Suspect | mild | Flagged GHT, defect, reliability |
| 5 | −0.74 | 1.72 | Borderline | 0 | 0 | 3 | Present | Suspect | mild | Flagged GHT, defect |
| 6 | −0.01 | 1.96 | Borderline | 0 | 0 | 0 | Present | Suspect | mild | Flagged GHT, defect |
| 7 | −0.41 | 2.75 | Outside Normal Limits | 0 | NA | 30 | Present | Suspect | mild | Flagged GHT, defect |
| 8 | −0.71 | 2.72 | Outside Normal Limits | 0 | 0 | 37 | Present | Suspect | mild | Flagged GHT, defect |
| 9 | −0.43 | 1.42 | Within Normal Limits | 0 | 0 | 0 | Nil | Healthy | NA | Nil |
| 10 | 0.82 | 2.75 | Outside Normal Limits | 5 | 17 | 46 | Present | Healthy/suspect | NA | Flagged reliability |
| 11 | −2.8 | 1.68 | Outside Normal Limits | 0 | 0 | 0 | Non-specific | Healthy/suspect | NA | Nil |
| 12 | −0.63 | 1.86 | Borderline | 0 | 11 | 7 | Present | Healthy/suspect | NA | Flagged GHT, reliability |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, J.C.K. Coherent Interpretation of Entire Visual Field Test Reports Using a Multimodal Large Language Model (ChatGPT). Vision 2025, 9, 33. https://doi.org/10.3390/vision9020033
Tan JCK. Coherent Interpretation of Entire Visual Field Test Reports Using a Multimodal Large Language Model (ChatGPT). Vision. 2025; 9(2):33. https://doi.org/10.3390/vision9020033
Chicago/Turabian StyleTan, Jeremy C. K. 2025. "Coherent Interpretation of Entire Visual Field Test Reports Using a Multimodal Large Language Model (ChatGPT)" Vision 9, no. 2: 33. https://doi.org/10.3390/vision9020033
APA StyleTan, J. C. K. (2025). Coherent Interpretation of Entire Visual Field Test Reports Using a Multimodal Large Language Model (ChatGPT). Vision, 9(2), 33. https://doi.org/10.3390/vision9020033