
Road Anomaly Detection with Unknown Scenes Using DifferNet-Based Automatic Labeling Segmentation

 ,
,  ,
,  ,
, 

Abstract

1. Introduction
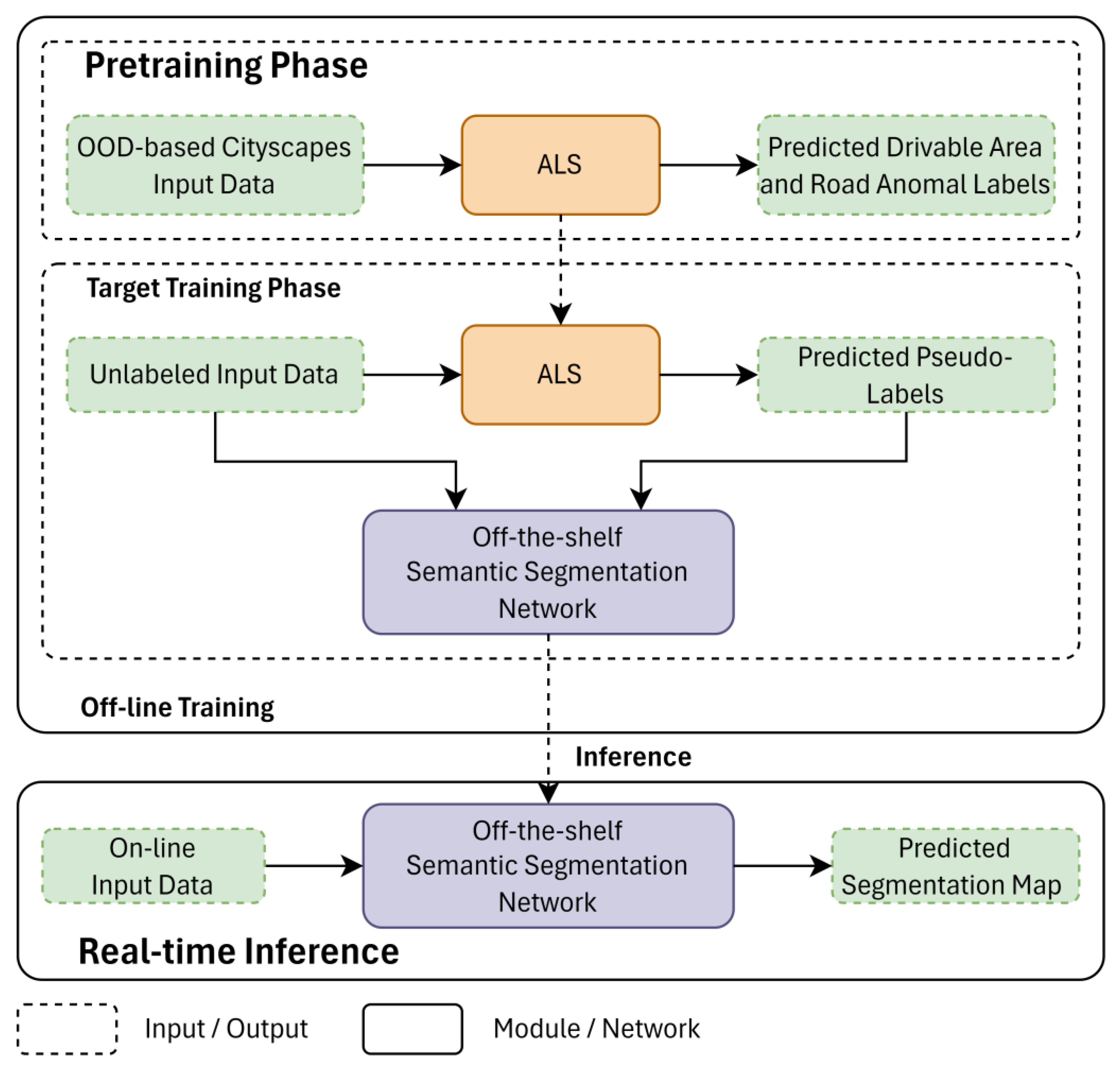
- The framework of TL-based automatic labeling system (ALS) is proposed as an automatic labeling system for unknown road scenes. It takes advantage of the uncertainty in deep learning for training the OOD-based model (DifferNet) to detect road anomalies. The proposed ALS framework could produce a high-quality pseudo-label map within approximately 2 s and can be used for off-the-shelf RGB-D semantic segmentation networks.
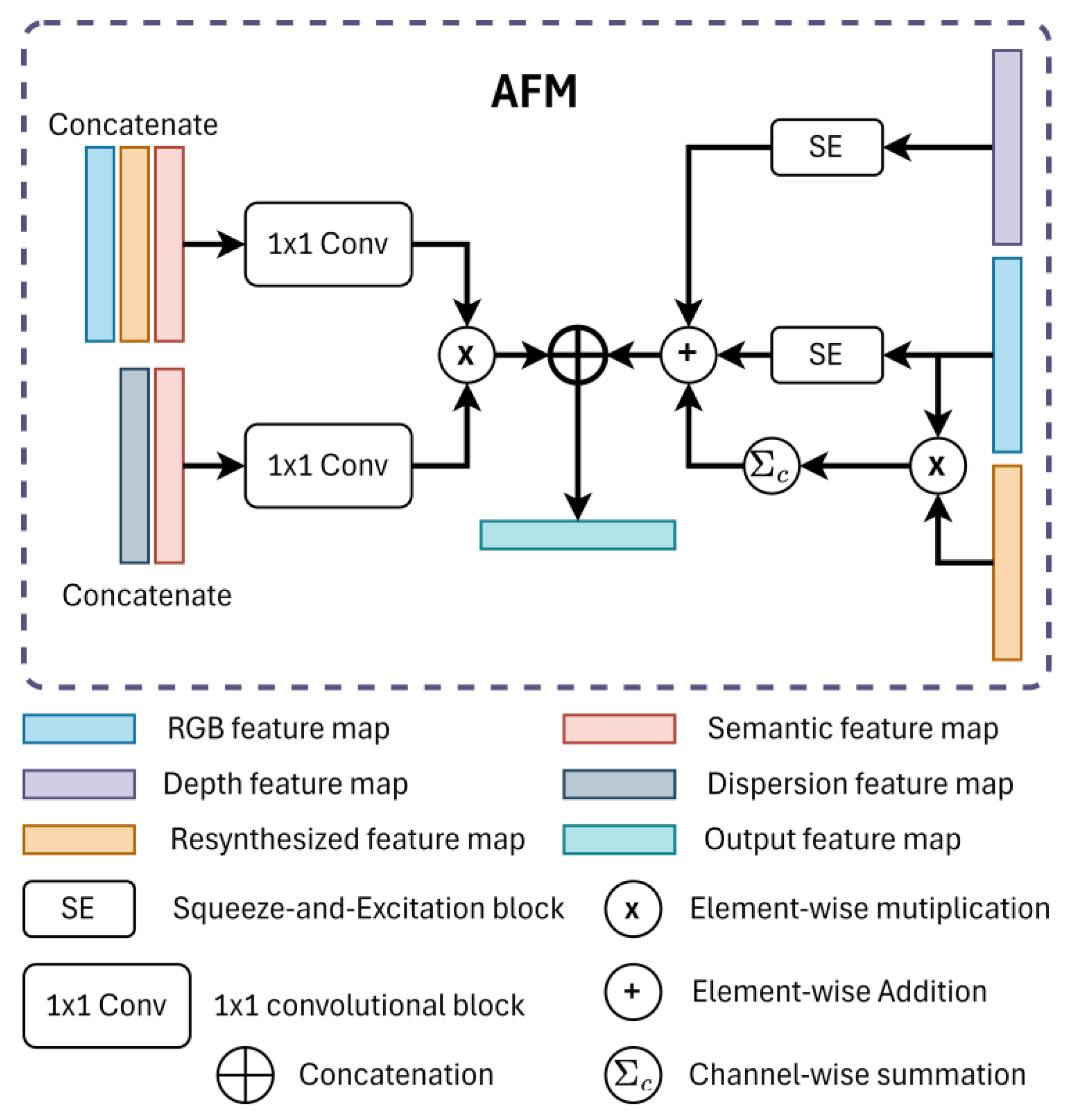
- We propose a new DifferNet module which contains squeeze-and-excitation (SE) blocks based on some common concepts, cooperates with RGB-D input data and uncertainty maps calculated from SoftMax probabilities of semantic maps and the perceptual different between the RGB input image and the resynthesized image. By redefining the OOD labels in the Cityscape dataset, our pretrained model could improve the accuracy of detecting road anomalies without external OOD datasets.
- The performance of the proposed ALS framework and DifferNet approaches achieved highly accurate and reliable labels for unseen driving scenes compared with the existing methods in terms of comprehensive experiments. We also evaluated our automatic labeling system (ALS) in real-time for the robustness of its capability under semantic segmentation networks for road anomalies.
2. Related Works
2.1. Detection of Drivable Areas
2.2. Detection of Road Obstacles
3. Proposed Method
- The pretrained semantic segmentation module was trained on the Cityscapes RGB dataset [9], and served as prior knowledge to compute the maps of the dispersion scores.
- The pretrained synthesizing module was also trained on Cityscapes [9] and was used to compute maps of the dispersion scores.
- The discrepancy network utilized maps of prior knowledge to predict uncertainty in the drivable area.
- The postprocessor was used to estimate the map of pseudo-labels.
3.1. Pretrained Semantic Segmentation Module
3.2. Pretrained Synthesizing Module
3.3. DifferNet Module
3.3.1. Encoder Module
3.3.2. Attention Fusion Module (AFM)
3.3.3. Decoder Module
3.4. DifferNet’s Training Procedure
3.5. Postprocessor
4. Experimental Results and Discussion
4.1. Datasets
4.2. Training Details
4.3. Comparison of the Results of Detecting Road Anomalies with Public Datasets
4.4. Results of ALS Segmentation
4.5. Execution Experiment
4.6. Limitation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ozkan, Z.; Bayhan, E.; Namdar, M.; Basgumus, A. Object Detection and Recognition of Unmanned Aerial Vehicles Using Raspberry Pi Platform. In Proceedings of the 2021 5th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Türkiye, 21 October 2021; pp. 467–472. [Google Scholar]
- Tao, M.; Zhao, C.; Wang, J.; Tang, M. ImFusion: Boosting Two-Stage 3D Object Detection via Image Candidates. IEEE Signal Process. Lett. 2024, 31, 241–245. [Google Scholar] [CrossRef]
- Wang, X.; Li, K.; Chehri, A. Multi-Sensor Fusion Technology for 3D Object Detection in Autonomous Driving: A Review. IEEE Trans. Intell. Transp. Syst. 2023, 25, 1–18. [Google Scholar] [CrossRef]
- Zhang, C.; Zheng, S.; Wu, H.; Gu, Z.; Sun, W.; Yang, L. AttentionTrack: Multiple Object Tracking in Traffic Scenarios Using Features Attention. IEEE Trans. Intell. Transport. Syst. 2024, 25, 1661–1674. [Google Scholar] [CrossRef]
- Xing, Y.; Wang, J.; Chen, X.; Zeng, G. Coupling Two-Stream RGB-D Semantic Segmentation Network by Idempotent Mappings. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1850–1854. [Google Scholar]
- Bakalos, N.; Katsamenis, I.; Protopapadakis, E.; Montoliu, C.M.-P.; Handanos, Y.; Schmidt, F.; Andersson, O.; Oleynikova, H.; Cantero, M.; Gkotsis, I.; et al. Chapter 11. Robotics-Enabled Roadwork Maintenance and Upgrading. In Robotics and Automation Solutions for Inspection and Maintenance in Critical Infrastructures; Loupos, K., Ed.; Now Publishers: Delft, The Netherlands, 2024; ISBN 978-1-63828-282-2. [Google Scholar]
- Yang, X.; He, X.; Liang, Y.; Yang, Y.; Zhang, S.; Xie, P. Transfer Learning or Self-Supervised Learning? A Tale of Two Pretraining Paradigms. arXiv 2020, arXiv:2007.04234. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A Survey of Uncertainty in Deep Neural Networks. Artif. Intell. Rev. 2023, 56, 1513–1589. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Cong, Y.; Peng, J.-J.; Sun, J.; Zhu, L.-L.; Tang, Y.-D. V-Disparity Based UGV Obstacle Detection in Rough Outdoor Terrain. Acta Autom. Sin. 2010, 36, 667–673. [Google Scholar] [CrossRef]
- Dixit, A.; Kumar Chidambaram, R.; Allam, Z. Safety and Risk Analysis of Autonomous Vehicles Using Computer Vision and Neural Networks. Vehicles 2021, 3, 595–617. [Google Scholar] [CrossRef]
- Park, J.-Y.; Kim, S.-S.; Won, C.S.; Jung, S.-W. Accurate Vertical Road Profile Estimation Using V-Disparity Map and Dynamic Programming. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Mayr, J.; Unger, C.; Tombari, F. Self-Supervised Learning of the Drivable Area for Autonomous Vehicles. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 362–369. [Google Scholar]
- Ma, F.; Liu, Y.; Wang, S.; Wu, J.; Qi, W.; Liu, M. Self-Supervised Drivable Area Segmentation Using LiDAR’s Depth Information for Autonomous Driving. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1 October 2023; pp. 41–48. [Google Scholar]
- Han, X.; Lu, J.; Zhao, C.; You, S.; Li, H. Semisupervised and Weakly Supervised Road Detection Based on Generative Adversarial Networks. IEEE Signal Process. Lett. 2018, 25, 551–555. [Google Scholar] [CrossRef]
- Ma, W.; Zhu, S. A Multifeature-Assisted Road and Vehicle Detection Method Based on Monocular Depth Estimation and Refined U-V Disparity Mapping. IEEE Trans. Intell. Transport. Syst. 2022, 23, 16763–16772. [Google Scholar] [CrossRef]
- Ali, A.; Gergis, M.; Abdennadher, S.; El Mougy, A. Drivable Area Segmentation in Deteriorating Road Regions for Autonomous Vehicles Using 3D LiDAR Sensor. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11 July 2021; pp. 845–852. [Google Scholar]
- Jiang, F.; Wang, Z.; Yue, G. A Novel Cognitively Inspired Deep Learning Approach to Detect Drivable Areas for Self-Driving Cars. Cogn. Comput. 2024, 16, 517–533. [Google Scholar] [CrossRef]
- Asgarian, H.; Amirkhani, A.; Shokouhi, S.B. Fast Drivable Area Detection for Autonomous Driving with Deep Learning. In Proceedings of the 2021 5th International Conference on Pattern Recognition and Image Analysis (IPRIA), Kashan, Iran, 28 April 2021; pp. 1–6. [Google Scholar]
- Rabiee, S.; Biswas, J. IVOA: Introspective Vision for Obstacle Avoidance. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 1230–1235. [Google Scholar]
- Ghosh, S.; Biswas, J. Joint Perception and Planning for Efficient Obstacle Avoidance Using Stereo Vision. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1026–1031. [Google Scholar]
- Wang, H.; Sun, Y.; Liu, M. Self-Supervised Drivable Area and Road Anomaly Segmentation Using RGB-D Data For Robotic Wheelchairs. IEEE Robot. Autom. Lett. 2019, 4, 4386–4393. [Google Scholar] [CrossRef]
- Rahman, Q.M.; Sunderhauf, N.; Corke, P.; Dayoub, F. FSNet: A Failure Detection Framework for Semantic Segmentation. IEEE Robot. Autom. Lett. 2022, 7, 3030–3037. [Google Scholar] [CrossRef]
- Oberdiek, P.; Rottmann, M.; Fink, G.A. Detection and Retrieval of Out-of-Distribution Objects in Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1331–1340. [Google Scholar]
- Di Biase, G.; Blum, H.; Siegwart, R.; Cadena, C. Pixel-Wise Anomaly Detection in Complex Driving Scenes. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16913–16922. [Google Scholar]
- Lis, K.; Nakka, K.K.; Fua, P.; Salzmann, M. Detecting the Unexpected via Image Resynthesis. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2152–2161. [Google Scholar]
- Liao, J.; Xu, X.; Nguyen, M.C.; Goodge, A.; Foo, C.S. COFT-AD: COntrastive Fine-Tuning for Few-Shot Anomaly Detection. IEEE Trans. Image Process. 2024, 33, 2090–2103. [Google Scholar] [CrossRef] [PubMed]
- Lis, K.; Honari, S.; Fua, P.; Salzmann, M. Detecting Road Obstacles by Erasing Them. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 2450–2460. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Liu, Y.; Pang, G.; Liu, F.; Chen, Y.; Carneiro, G. Pixel-Wise Energy-Biased Abstention Learning for Anomaly Segmentation on Complex Urban Driving Scenes. In Computer Vision–ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2022; Volume 13699, pp. 246–263. ISBN 978-3-031-19841-0. [Google Scholar]
- Lis, K.; Honari, S.; Fua, P.; Salzmann, M. Perspective Aware Road Obstacle Detection. IEEE Robot. Autom. Lett. 2023, 8, 2150–2157. [Google Scholar] [CrossRef]
- Nayal, N.; Yavuz, M.; Henriques, J.F.; Güney, F. RbA: Segmenting Unknown Regions Rejected by All. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; pp. 711–722. [Google Scholar]
- Rai, S.N.; Cermelli, F.; Fontanel, D.; Masone, C.; Caputo, B. Unmasking Anomalies in Road-Scene Segmentation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; pp. 4014–4023. [Google Scholar]
- Katsamenis, I.; Protopapadakis, E.; Bakalos, N.; Varvarigos, A.; Doulamis, A.; Doulamis, N.; Voulodimos, A. A Few-Shot Attention Recurrent Residual U-Net for Crack Segmentation. In Advances in Visual Computing; Bebis, G., Ghiasi, G., Fang, Y., Sharf, A., Dong, Y., Weaver, C., Leo, Z., LaViola, J.J., Kohli, L., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2023; Volume 14361, pp. 199–209. ISBN 978-3-031-47968-7. [Google Scholar]
- Wan, B.; Zhou, X.; Sun, Y.; Wang, T.; Lv, C.; Wang, S.; Yin, H.; Yan, C. ADNet: Anti-Noise Dual-Branch Network for Road Defect Detection. Eng. Appl. Artif. Intell. 2024, 132, 107963. [Google Scholar] [CrossRef]
- Li, G.; Zhang, C.; Li, M.; Han, D.-L.; Zhou, M.-L. LHA-Net: A Lightweight and High-Accuracy Network for Road Surface Defect Detection. IEEE Trans. Intell. Veh. 2024, 1–15. [Google Scholar] [CrossRef]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11207, pp. 418–434. ISBN 978-3-030-01218-2. [Google Scholar]
- Rottmann, M.; Colling, P.; Paul Hack, T.; Chan, R.; Huger, F.; Schlicht, P.; Gottschalk, H. Prediction Error Meta Classification in Semantic Segmentation: Detection via Aggregated Dispersion Measures of Softmax Probabilities. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Liu, X.; Yin, G.; Shao, J.; Wang, X.; Li, H. Learning to Predict Layout-to-Image Conditional Convolutions for Semantic Image Synthesis. Adv. Neural Inf. Process. Syst. 2020; 32, 570–580. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Computer Vision– ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9906, pp. 694–711. ISBN 978-3-319-46474-9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Park, T.; Liu, M.-Y.; Wang, T.-C.; Zhu, J.-Y. Semantic Image Synthesis With Spatially-Adaptive Normalization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 2332–2341. [Google Scholar]
- Hirschmuller, H. Accurate and Efficient Stereo Processing by Semi-Global Matching and Mutual Information. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 10–26 June 2005; Volume 2, pp. 807–814. [Google Scholar]
- Pinggera, P.; Ramos, S.; Gehrig, S.; Franke, U.; Rother, C.; Mester, R. Lost and Found: Detecting Small Road Hazards for Self-Driving Vehicles. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 1099–1106. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-Based CNN Architecture. In Computer Vision–ACCV 2016; Lai, S.-H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2017; Volume 10111, pp. 213–228. ISBN 978-3-319-54180-8. [Google Scholar]
- Sun, Y.; Zuo, W.; Liu, M. RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Wang, W.; Neumann, U. Depth-Aware CNN for RGB-D Segmentation. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11215, pp. 144–161. ISBN 978-3-030-01251-9. [Google Scholar]
- Nguyen, T.-K.; Nguyen, P.T.-T.; Nguyen, D.-D.; Kuo, C.-H. Effective Free-Driving Region Detection for Mobile Robots by Uncertainty Estimation Using RGB-D Data. Sensors 2022, 22, 4751. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Sapra, K.; Reda, F.A.; Shih, K.J.; Newsam, S.; Tao, A.; Catanzaro, B. Improving Semantic Segmentation via Video Propagation and Label Relaxation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 8848–8857. [Google Scholar]
- Vojir, T.; Sipka, T.; Aljundi, R.; Chumerin, N.; Reino, D.O.; Matas, J. Road Anomaly Detection by Partial Image Reconstruction with Segmentation Coupling. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15631–15640. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Architecture | Data | Lost and Found [44] | GMRPD [22] | ||
|---|---|---|---|---|---|---|
| AP ↑ | FPR95 ↓ | AP ↑ | FPR95 ↓ | |||
| Resynthesis [26] | PSPNet | RGB | 61.90 | 46.60 | - | - |
| JSR-Net [51] | ResNet-101 | RGB | 79.40 | 3.60 | - | - |
| Synboost [25] | Wider-ResNet | RGB | 83.51 | 1.39 | 73.37 | 12.50 |
| Erasing road obstacles [28] | ResNeXt-101 | RGB | 82.30 | 68.5 | - | - |
| PEBAL [29] | WireResnet38 | RGB | 78.29 | 0.81 | - | - |
| Mask2Anomaly [32] | Vision Transformer | RGB | 86.59 | 5.75 | - | - |
| AGSL [49] | Wider-ResNet | RGBD | 82.85 | 2.92 | 78.03 | 6.67 |
| DifferNet w/o depth (our) | Wider-ResNet | RGB | 82.38 | 1.10 | 77.02 | 6.37 |
| DifferNet w/o SE block (our) | Wider-ResNet | RGB-D | 83.00 | 1.21 | 77.72 | 6.49 |
| DifferNet (our) | Wider-ResNet | RGB-D | 84.19 | 1.10 | 79.82 | 6.97 |
| Method | Unknown Area | Drivable Area | Road Obstacles | Overall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | IoU | Pre | Rec | IoU | Pre | Rec | IoU | Pre | Rec | IoU | |
| SSLG [22] | 89.62 | 80.36 | 75.09 | 75.70 | 86.91 | 65.87 | 33.15 | 22.92 | 16.03 | 66.16 | 63.40 | 52.33 |
| SSLG++ (ours) | 97.82 | 90.25 | 87.80 | 88.63 | 96.46 | 84.42 | 33.41 | 39.91 | 22.23 | 73.29 | 75.54 | 64.82 |
| ALS (ours) | 94.87 | 90.91 | 86.65 | 89.44 | 93.62 | 84.30 | 56.62 | 68.72 | 45.02 | 80.31 | 84.42 | 71.99 |
| FSL++ | 99.67 | 87.58 | 87.32 | 83.59 | 97.99 | 82.17 | 29.26 | 43.90 | 21.30 | 70.84 | 76.49 | 63.60 |
| FAL | 96.99 | 89.90 | 87.47 | 86.04 | 95.30 | 82.54 | 71.64 | 82.44 | 62.15 | 84.89 | 89.21 | 77.39 |
| FML | 98.59 | 99.13 | 97.75 | 98.69 | 97.37 | 96.13 | 82.80 | 99.63 | 82.55 | 93.36 | 98.71 | 92.14 |
| DSL++ | 99.83 | 85.77 | 85.64 | 81.49 | 97.13 | 79.58 | 26.72 | 50.73 | 21.21 | 69.35 | 77.88 | 62.14 |
| DAL | 98.07 | 92.11 | 90.47 | 88.97 | 96.39 | 86.10 | 58.21 | 79.50 | 50.62 | 81.75 | 89.33 | 75.73 |
| DML | 98.44 | 96.96 | 95.50 | 95.40 | 97.03 | 92.69 | 78.11 | 96.23 | 75.79 | 90.65 | 96.74 | 87.99 |
| RSL++ | 99.37 | 98.07 | 97.47 | 97.64 | 97.51 | 95.26 | 54.04 | 84.78 | 49.26 | 83.68 | 93.45 | 80.66 |
| RAL | 95.34 | 98.97 | 94.40 | 98.84 | 93.64 | 92.63 | 64.39 | 94.30 | 61.98 | 86.19 | 95.64 | 83.00 |
| RML | 99.58 | 98.00 | 97.60 | 97.04 | 98.69 | 95.80 | 77.52 | 99.64 | 77.30 | 91.38 | 98.78 | 90.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, P.T.-T.; Nguyen, T.-K.; Nguyen, D.-D.; Su, S.-F.; Kuo, C.-H. Road Anomaly Detection with Unknown Scenes Using DifferNet-Based Automatic Labeling Segmentation. Inventions 2024, 9, 69. https://doi.org/10.3390/inventions9040069
Nguyen PT-T, Nguyen T-K, Nguyen D-D, Su S-F, Kuo C-H. Road Anomaly Detection with Unknown Scenes Using DifferNet-Based Automatic Labeling Segmentation. Inventions. 2024; 9(4):69. https://doi.org/10.3390/inventions9040069
Chicago/Turabian StyleNguyen, Phuc Thanh-Thien, Toan-Khoa Nguyen, Dai-Dong Nguyen, Shun-Feng Su, and Chung-Hsien Kuo. 2024. "Road Anomaly Detection with Unknown Scenes Using DifferNet-Based Automatic Labeling Segmentation" Inventions 9, no. 4: 69. https://doi.org/10.3390/inventions9040069
APA StyleNguyen, P. T.-T., Nguyen, T.-K., Nguyen, D.-D., Su, S.-F., & Kuo, C.-H. (2024). Road Anomaly Detection with Unknown Scenes Using DifferNet-Based Automatic Labeling Segmentation. Inventions, 9(4), 69. https://doi.org/10.3390/inventions9040069