1. Introduction
Olive,
Olea europaea, is an essential evergreen subtropical fruit. Its fruits are utilized for both table olives and olive oil. Certain varieties are specifically cultivated for oil production, while others, renowned for their larger fruit sizes, are preferred for canning products. Moreover, the production of dual-purpose olive varieties is growing [
1]. In Iran, the ‘Roghani’ cultivar stands out as a vital local dual-purpose olive variety, known for its adaptability to diverse environmental conditions and ability to withstand winter cold [
2]. The type of canned olives and the quality of olive oil depend on various factors, including the variety, cultivation conditions, and fruit ripening stage [
3,
4,
5]. Olive fruits can be harvested at different stages, ranging from immature green to fully mature black, and even during over-ripened stages. The ripening stage of the fruit profoundly affects the oil content, chemical composition, sensory characteristics of olive oil, and industrial yield [
6,
7]. Fruit homogeneity at the same ripening stage is crucial for canned olives, and the quality of olive oil directly depends on the fruit’s ripening stage.
The timing of olive harvesting is typically determined by evaluating the maturity index (MI) of each olive cultivar [
5,
8,
9]. This evaluation of MI is based on changes in both the skin and flesh color of mature fruit [
10]. Decisions about when to harvest fruit from an orchard are made by conducting MI assessments on fruit samples collected from different trees. However, it is common to come across olives with varying degrees of ripeness during processing, as mechanical harvesters that use trunk shakers can harvest one hectare of an intensive olive grove (consisting of 300–400 trees) within a timeframe of 2 to 5 days [
10]. Due to factors such as the location of the fruit on outer or inner branches and exposure to sunlight, even a single tree may have olives in different stages of maturity, and there may be variations between each tree due to differences in horticultural practices and management. Moreover, some orchards may cultivate multiple olive varieties, each with distinct ripening stages during harvest, while others with a single cultivar may also have variations in fruit ripeness. In olive processing facilities, it is possible for different growers to bring olives with varying degrees of ripeness that must be categorized before processing.
Given the importance of olive ripening in the production of various post-harvest products, such as pickles, oil, and canned olives, it is essential to separate and sort olive fruits before processing. However, manually sorting olives through human visual inspection is a challenging and inefficient task. To address this challenge, integrating a computer vision system into olive processing units as part of the automatic separation machinery offers a potential solution. The system consists of an image-capturing unit, which relies on a robust image processing model to ensure rapid and accurate results for mechanical separation [
11].
Numerous researchers have investigated various methods for assessing olive fruit maturity, with a focus on Near Infrared Spectroscopy (NIRS) [
10,
12,
13]. These studies aimed to predict diverse quality parameters and characterize table olive traits utilizing NIRS technology. In addition to NIRS, Convolutional Neural Networks (CNNs), a subset of deep learning, have emerged as a powerful tool for image processing tasks, allowing for the extraction of high-level features independent of imaging condition and structure [
14], making them a valuable tool for agricultural applications.
The use of cutting-edge technologies, such as deep learning, offers a more promising solution to address this challenge, garnering the attention of scientists across multiple agricultural domains [
15,
16,
17]. Noteworthy applications of CNNs include olive classification, as demonstrated by Riquelme et al. [
18], who employed discriminant analysis to classify olives based on external damage in images, achieving validation accuracies ranging from 38% to 100%. Guzmán et al. [
9] leveraged algorithms based on color and edge detection for image segmentation, resulting in an impressive 95% accuracy in predicting olive maturity. Ponce et al. [
19] utilized the Inception-ResNetV2 model to classify seven olive fruit varieties, achieving a remarkable maximum accuracy of 95.91%. Aguilera Puerto et al. [
20] developed an online system for olive fruit classification in the olive oil production process, employing Artificial Neural Networks (ANN) and Support Vector Machines (SVM) to attain high accuracies of 98.4% and 98.8%, respectively. Aquino et al. [
21] created an artificial vision algorithm capable of classifying images taken in the field to identify olives directly from trees, enabling accurate yield predictions. Studies such as Khosravi et al. [
17] have also utilized RGB image acquisition and CNNs for the early estimation of olive fruit ripening stages on-branch, which has direct implications for orchard production quality and quantity. Furferi et al. [
22] proposed an ANN-based method for automatic maturity index evaluation, considering four classes based on olive skin and pulp color, while ignoring the presence of defects. In contrast, Puerto et al. [
23] implemented a static computer vision system for olive classification, employing a shallow learning approach using an ANN with a single hidden layer. In a recent study by Figorilli et al. [
24], olive fruits were classified based on the state of external color, “Veraison”, and the presence of visible defects using AI algorithms with RGB imaging. Despite the commendable efforts in olive fruit detection modeling, however, previous studies have primarily focused on identifying defective olives, inadvertently overlooking the comprehensive assessment of distinct stages crucial for olive fruit ripening, impacting both oil quality and canned olive production [
18,
20]. This trend, compounded by the reliance on limited datasets, has significantly hindered the models’ capacity for effective generalization. Moreover, the dependency of these models on specific imaging modalities has constrained their adaptability to varying environmental conditions, lighting disparities, and diverse olive cultivars. Additionally, one of our primary objectives is to enhance model efficiency and recognition speed. Therefore, we endeavored to address these gaps by conducting a comprehensive exploration of olive fruit ripening stages and developing new high-performance models to better address this critical area.
The field of machine learning has seen significant advancements in recent years, particularly in agriculture. According to Benos et al. [
25], there was a remarkable 745% increase in articles related to machine learning in agriculture between 2018 and 2020, indicating the growing use of machine learning algorithms for crop and animal analysis based on input data from satellites and drones. This surge in interest is attributed to the development of novel models that exhibit high performance and optimized detection times. For instance, Fan et al. [
26], successfully utilized a YOLOV4 network to detect defects in apple fruits using near-infrared (NIR) images, achieving an average detection accuracy of 93.9% and processing five fruits per second.
In the realm of fruit recognition, the Xception deep learning model has been gainfully employed [
27]. Built upon the Inception architecture, Xception is a powerful neural network that excels in image classification tasks owing to its efficiency and accuracy [
28]. By taking the concept of separable convolutions to an extreme level, Xception becomes a highly efficient and powerful network, demonstrating the potential of CNNs for image processing tasks.
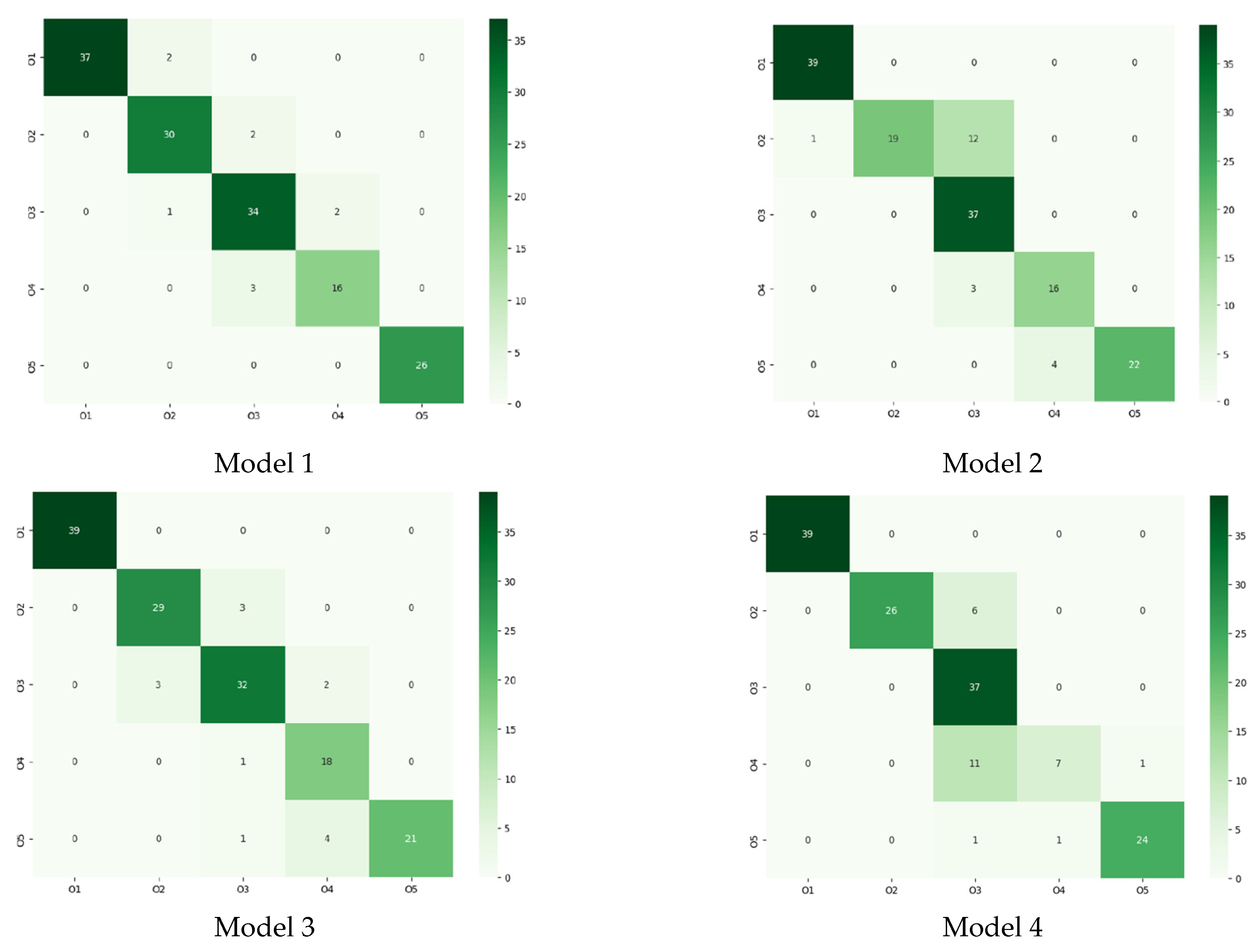
This study aims to leverage the Xception deep learning model for the automated sorting of olives based on color images, given the critical role of olive fruit sorting in producing diverse end products (e.g., pickles, oil, canned goods). Our ultimate goal is to create a highly accurate and robust computer vision system capable of categorizing Roghani olives into five distinct ripening stages. We evaluated the system’s performance using test dataset accuracy, classification performance metrics (such as classification reports and confusion matrices), and its capacity to generalize across varied datasets.
The significance of our research lies in its potential to offer olive processing facilities efficient and reliable tools for automating the sorting process, thus distinguishing between olives of differing ripeness levels. This, in turn, may enhance the quality of various post-harvest products and differentiate olive oil qualities, ultimately benefiting the olive industry as a whole. By providing a more accurate method for sorting olives according to their maturity, we can improve the overall quality of downstream products such as pickles, oil, and canned goods. Moreover, our proposed approach could potentially reduce waste and increase efficiency within the olive processing industry.
2. Material and Methods
2.1. Data Preparation
To develop an image-based CNN model for classifying olive fruits based on their ripening stages, we considered an Iranian olive cultivar named Roghani at five distinct ripening stages. A total of 761 images of different classes were captured in an unstructured laboratory setting using a smartphone camera (Samsung Galaxy A51, India). One of the most important advantages of deep learning-based image processing techniques and convolutional neural networks is that unlike the traditional image processing methods, they are not dependent on environmental conditions including lighting, background, distance to object, camera properties, etc., making them more powerful and robust tools in processing images taken in natural conditions. By addressing this fact, we did not consider a special capturing condition or structure. The captured images had an initial resolution of 3000 × 4000 pixels.
Figure 1 depicts the five ripening stages of the olive fruits and their corresponding average mass. The color attributes of the samples served as the basis for discriminating between ripening stages. Specifically, Stage 1 refers to samples with green colors, Stage 2 is characterized by olives with 10–30% browning, while Stages 3, 4, and 5 represent approximately 50, 90, and 100% browning (fully black), respectively. The number of images taken at each ripening stage, and the average mass of samples at each class, are presented in
Table 1.
The image data was divided into three distinct parts: the training set, the validation set, and the testing set. To accomplish this, 20% of the total data (equivalent to 153 images) were assigned to the test dataset. The remaining data consisted of 609 images, with 15% (92 images) being allocated for the validation set, and the remaining 516 images being utilized for the training set.
The training process involved passing the input data through several layers, obtaining the output, and comparing it with the desired output. The difference between the two, which served as the error, was then calculated. Using this error, the network parameters were adjusted and fed the data back into the network to compute new results and errors. This process was repeated multiple times, adjusting the parameters after each iteration to minimize the error. There are various formulas and functions to calculate the network error. Once the error was computed, the parameters were updated to move closer to minimizing it; that is, optimizing the weights to achieve the lowest possible error.
Preprocessing the input images is crucial to enhance the model’s accuracy, prevent overfitting, and boost its generalization capability. First, we resized all images to two different sizes: 224 × 224 and 299 × 299. Next, we normalized the pixel values by dividing them by the maximum pixel values of the captured images. Subsequently, we applied data augmentation techniques, including random translation, random flip, random contrast, and random rotation, to artificially increase the number of images used in model development. The data augmentation parameters are presented in
Table 2.
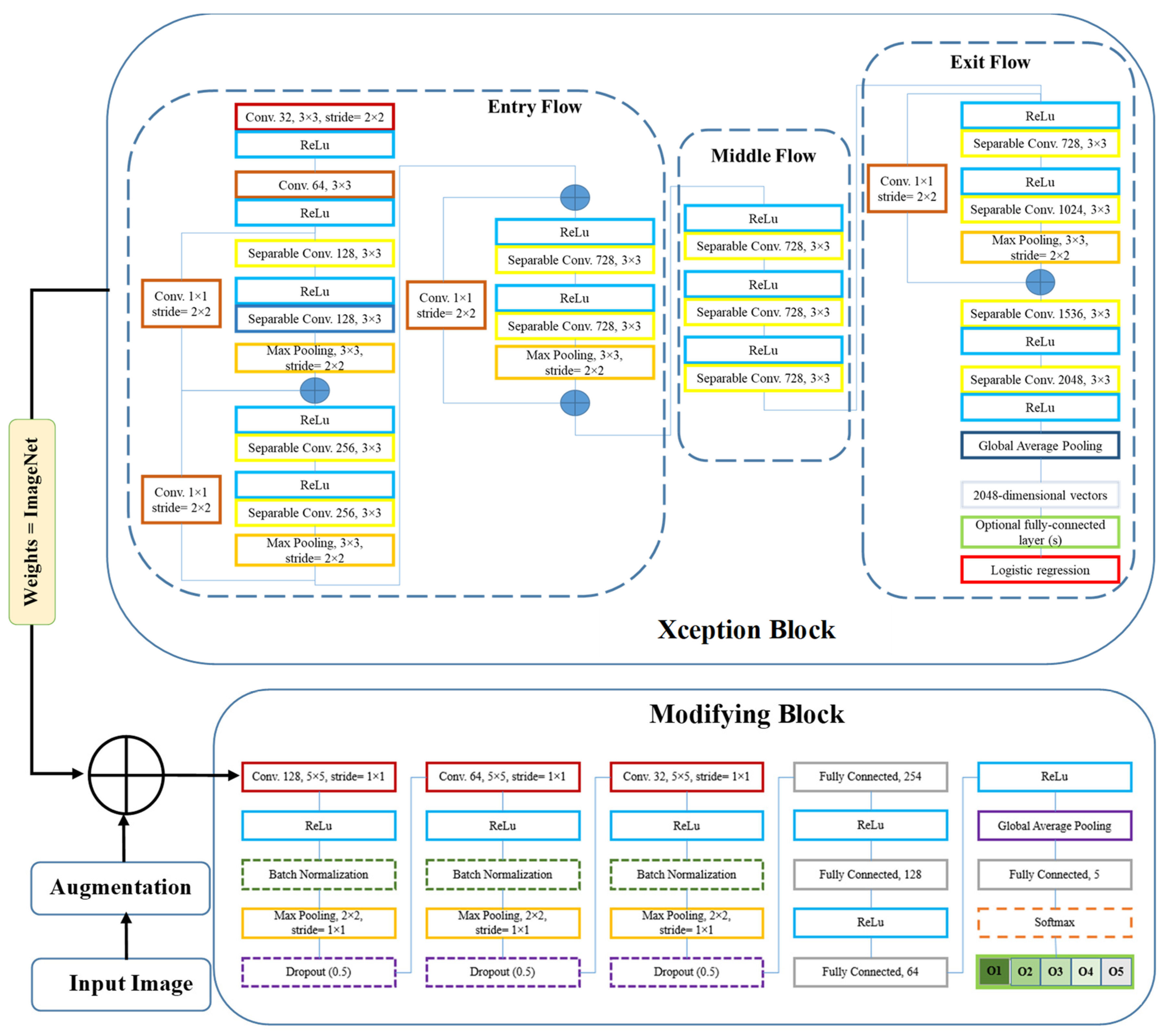
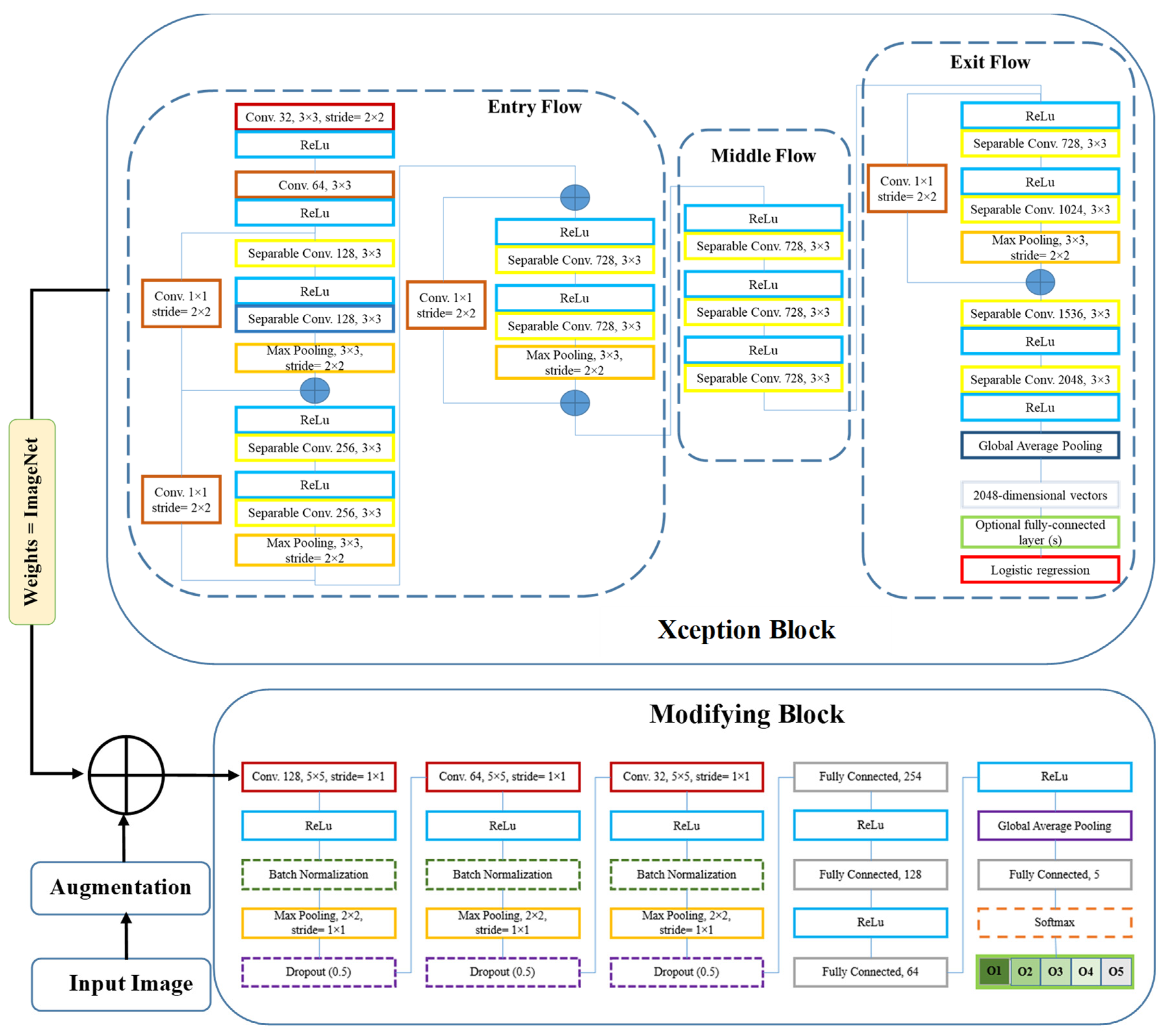
To develop the deep neural network model, we utilized the transfer learning technique. Initially, we invoked the Xception model and loaded its weights from the ImageNet dataset. Subsequently, we embarked on a fine-tuning process by adding additional layers to the base model. Diverse structures for the fine-tuning layers were experimented with, varying their type, position, and arguments to identify the optimal configuration. We explored several layer types and arrangements, with the most commonly used being 2D convolution, Global Average Pooling, Dropout, Batch Normalization, and others. The comprehensive architecture of the resulting model is illustrated in
Figure 2.
2.2. Xception Architecture
In this study, we employed the Xception deep learning architecture, a novel deep convolutional neural network model introduced by Google, Inc. (Mountain View, CA, USA) [
28]. Xception features Depth Wise Separable Convolutions (DSC) to enhance performance and efficiency. Unlike traditional convolution, DSC divides the computation into two stages: depth wise convolution applies a single convolutional filter per input channel, followed by point wise convolution to create a linear combination of the depth wise convolution outputs.
Xception is a variant of the Inception architecture where Inception modules act as an intermediate step between regular convolution and DSC. With the same number of parameters, Xception surpasses Inception V3 on the ImageNet dataset due to its more efficient use of model parameters. The Xception architecture consists of 36 convolutional layers forming the feature extraction base of the network. In image classification tasks, the convolutional base is succeeded by a logistic regression layer. The 36 convolutional layers are organized into 14 modules, all with linear residual connections around them, excluding the first and last modules. In summary, the Xception architecture is a linear stack of depth wise separable convolution layers with residual connections [
28].
2.3. Fine-Tuning and Modification
We first pre-trained the base model (Xception) using ImageNet weights. Next, the trainable attribute of all layers in the base model were frozen, ensuring that their weights remained fixed during training. This allowed us to use the pre-trained model as a starting point for further training on a new dataset. We then unfroze the last 20 layers in the Middle Flow and Exit Flow, making them trainable. By doing so, the pre-trained layers were prevented from overfitting on the new dataset while allowing the newly added layers to adapt to the new data. Finally, we added three blocks on top of the pre-trained base model, each containing Convolution, Batch Normalization, Max Pooling, and Dropout layers, followed by Fully Connected and Global Average Pooling layers. We called it the modifying block (
Figure 2).
Table 3 provides detailed information about the various layers used, their output shapes, and the total number of parameters. The table covers both input image sizes studied (224 × 224 and 299 × 299). The developed model has approximately 27 million parameters for both image sizes, with only about 0.5% being non-trainable. Notably, Max Pooling, Dropout, and Global Average Pooling layers do not contribute to the total number of trainable parameters since they lack trainable parameters. As seen in
Table 3, the number of parameters remains constant across both input image sizes, because the CNN architectures were totally the same for the two input image sizes.
2.4. Network Training
To optimize the performance of the deep learning model for classifying olive fruits based on their ripening stages, several aspects required careful consideration. First, we needed to select the most appropriate optimizer among popular choices such as RMSprop, SGD, Adam, and Nadam. Accuracy was chosen as the evaluation metric to assess the model’s performance. Additionally, we employed the categorical cross-entropy function as the loss function.
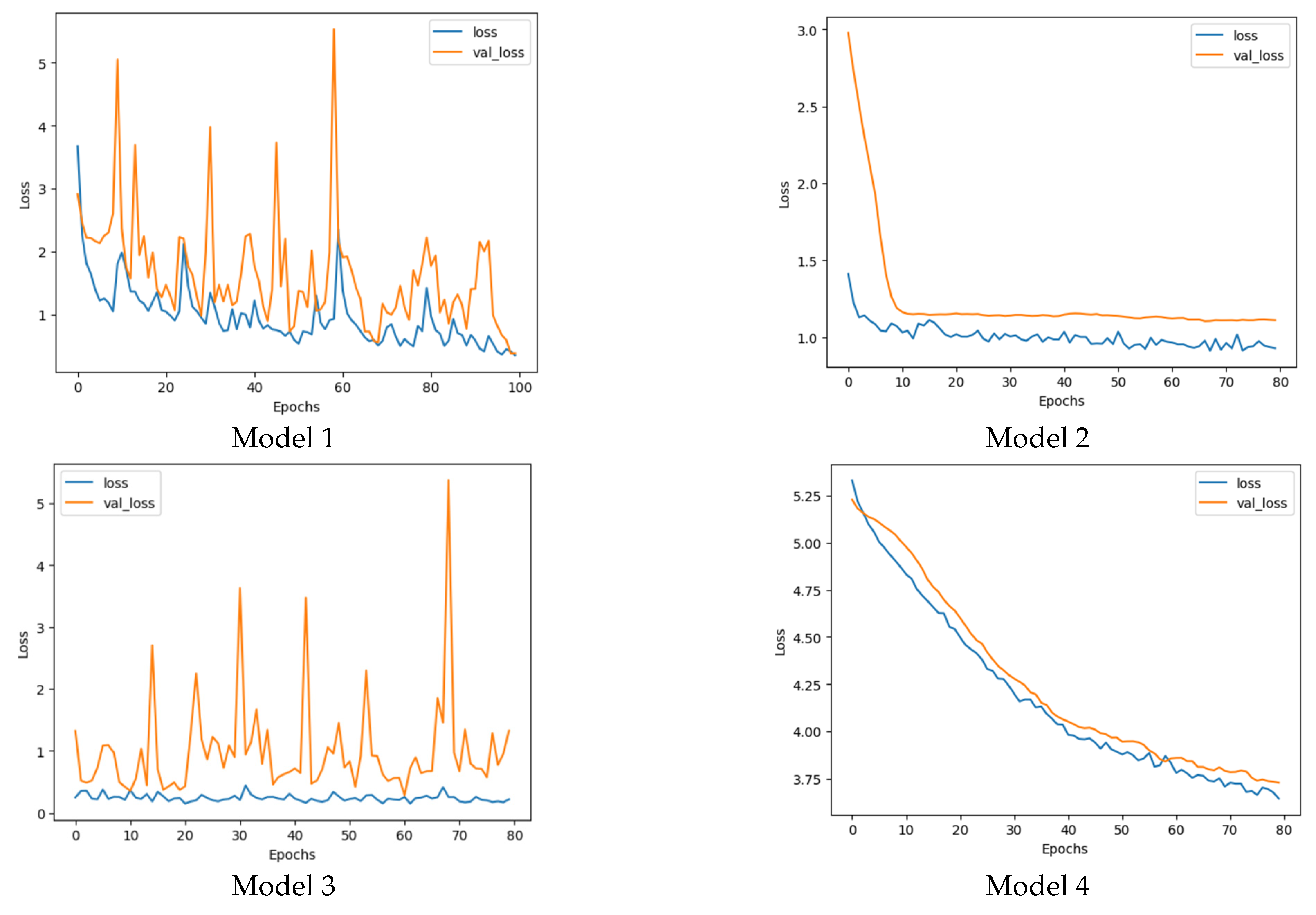
Training the model involved a series of experiments to identify the best combination of hyper parameters and architectural components. Initially, we trained the base model (Xception) using a batch size of 8 and 20 epochs. Subsequently, we trained the modified model with a batch size of 32 and 80 epochs (with an optional extension to 100 epochs for Model 1). Throughout the training process, we monitored the loss and accuracy trends for both the train and validation datasets at each epoch. This allowed us to analyze the models’ performance and make informed decisions regarding their suitability for our task. Four promising candidates emerged from our experiments, each distinguished by its unique combination of image size and optimizer. They were:
- −
Model 1: Best performer with 224 × 224 image size and Nadam optimizer
- −
Model 2: Best performer with 224 × 224 image size and SGD optimizer
- −
Model 3: Best performer with 299 × 299 image size and RMSprop optimizer
- −
Model 4: Best performer with 299 × 299 image size and SGD optimizer
When evaluating these models, we considered multiple factors, such as accuracy, loss, and resistance to overfitting. Accuracy measures the proportion of correctly predicted instances, while loss represents the average error per instance. A lower loss value generally indicates better model performance. However, a model with high accuracy but relatively high loss may still encounter challenges in unseen data, signaling potential overfitting issues. Therefore, we assessed the risk of overfitting when comparing the four candidates.
The training, development, and testing procedures were executed using Python 3.7.10 and the Google Colab environment (K80 GPU and 12 GB RAM) with Keras, TensorFlow backend (version 2.13.0), OpenCV, and other relevant libraries.
4. Conclusions
Olives are a vital crop with various post-harvest applications, including pickling, canning, and oil production, each requiring a specific ripening stage. To address this challenge, a reliable classification system is crucial to sort olives according to their maturity levels. This study aimed to develop an automated deep learning model utilizing color images to classify ‘Roghani’, an Iranian olive cultivar, into five ripening stages. We employed a modified and fine-tuned Xception architecture, harnessing cutting-edge image processing and deep learning techniques to effectively categorize olives. Four Xception-based models were shortlisted and evaluated based on their performance, using metrics such as loss, accuracy, classification reports, confusion matrices, and overfitting risk. While all four models showed comparable performance, Model 1 stood out. However, considering model generality and stability, Model 1 raised concerns due to substantial fluctuations in validation losses and accuracies during training, indicating a high risk of overfitting. Model 3 boasted a remarkable accuracy, but its reliability was compromised by its susceptibility to overfitting. Models 2 and 4 demonstrated stable validation losses and accuracies throughout training, rendering them superior in terms of generality and stability. Although their accuracies were not the highest among all models, they were still satisfactory. Of the two, Model 2 is preferred owing to its lower loss value. When selecting a model, a trade-off between classification performance and model generality must be considered. For the present study, Model 2 emerges as the optimal choice, striking a balance between respectable classification results and minimal risk of overfitting, suggesting that it may generalize well to unseen data. The findings of this research constitute a significant breakthrough in olive sorting and classification, providing a potent tool for enhancing the efficiency and precision of olive processing and production.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}