
Predicting Energy Generation in Large Wind Farms: A Data-Driven Study with Open Data and Machine Learning

 , , , ,
, , , ,  , and
, and 
Abstract
:1. Introduction
- The design of three accurate, well-behaved machine learning approaches for long-term forecasting: the RF-, XGB-, and LSTM-based models. Unlike most predictive proposals in the wind energy context, which focus on short-term results, the designed models excel in delivering precise long-range wind power outputs.
- The creation of a comprehensive database sourced from multiple open platforms, enabling a thorough analysis of the regional characteristics of the wind farm.
- The implementation of customized tuning strategies to optimize the machine intelligence models, leading to significant improvements in long-range predictions.
- An in-depth data-driven study of key meteorological variables that most influence wind power generation throughout different seasons and months, providing detailed insights and contextualization for local grid operators and power plant owners.
2. Materials and Methods
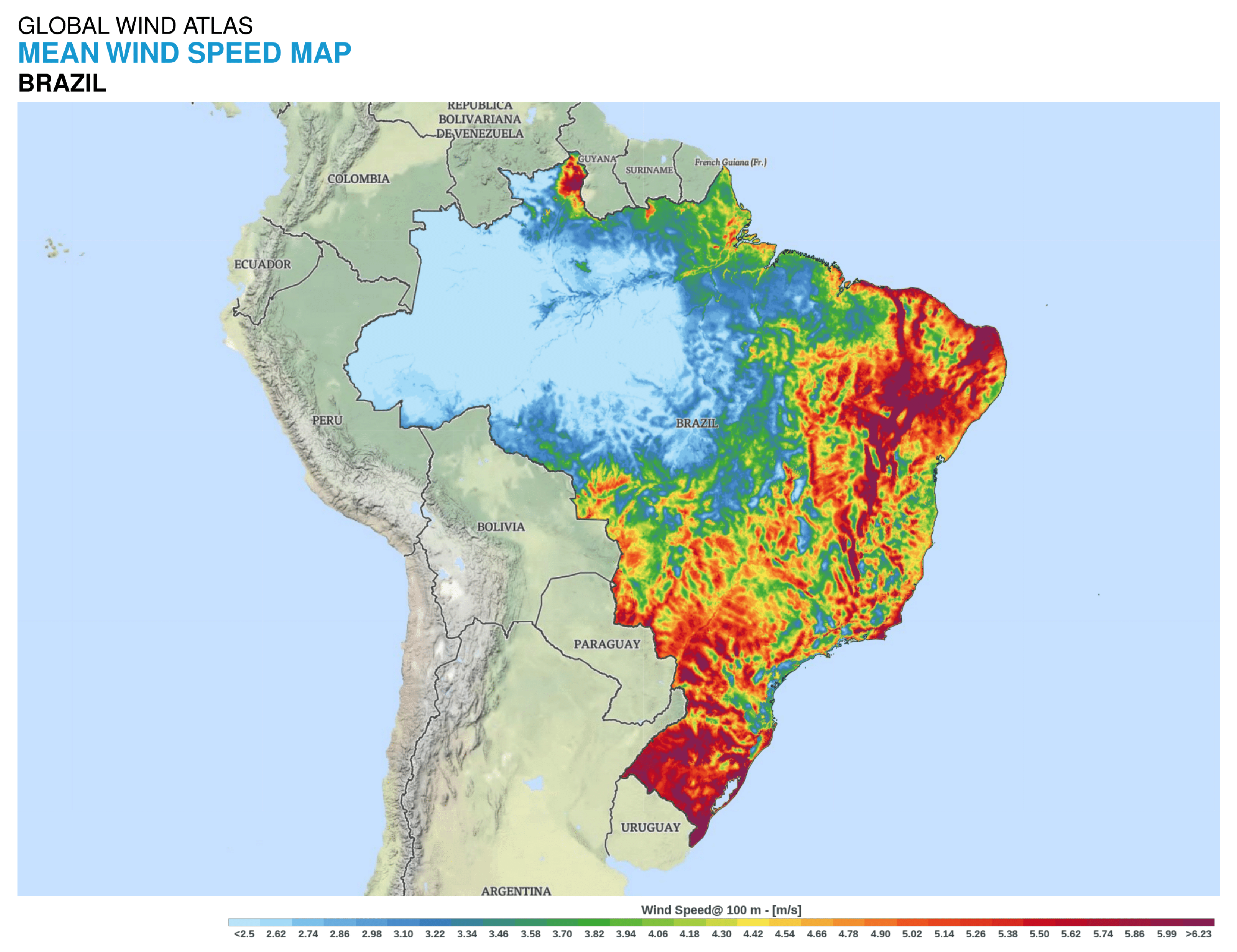
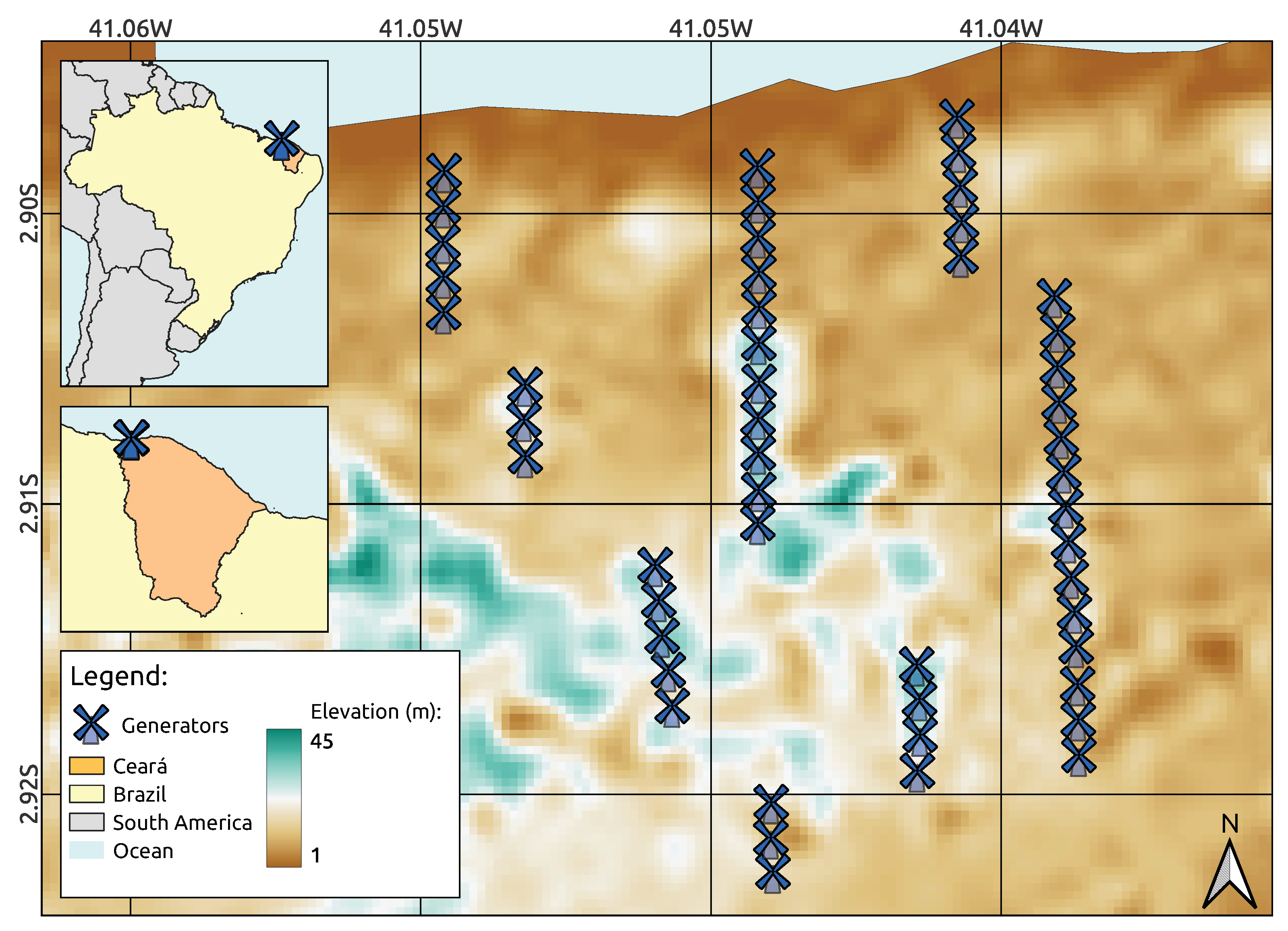
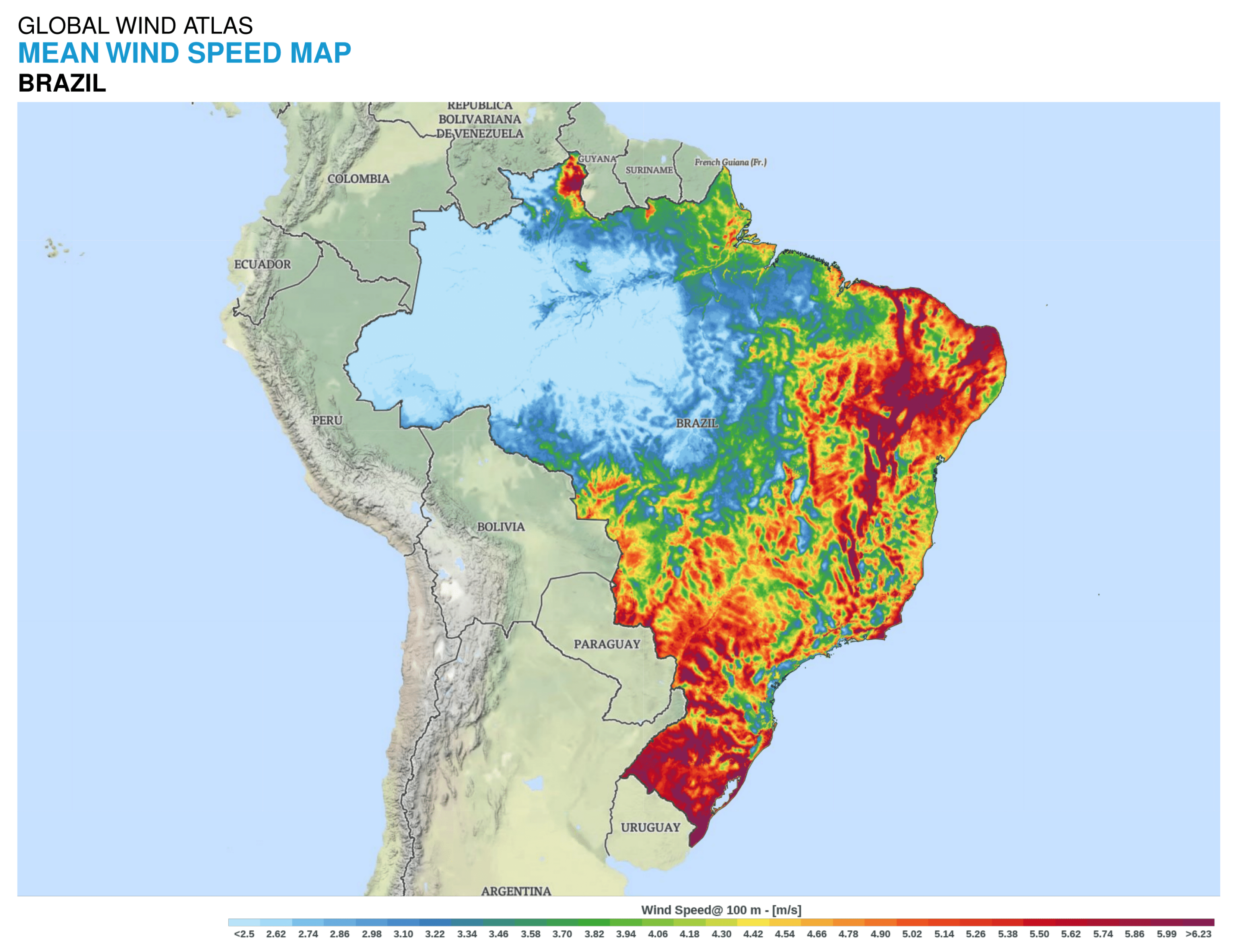
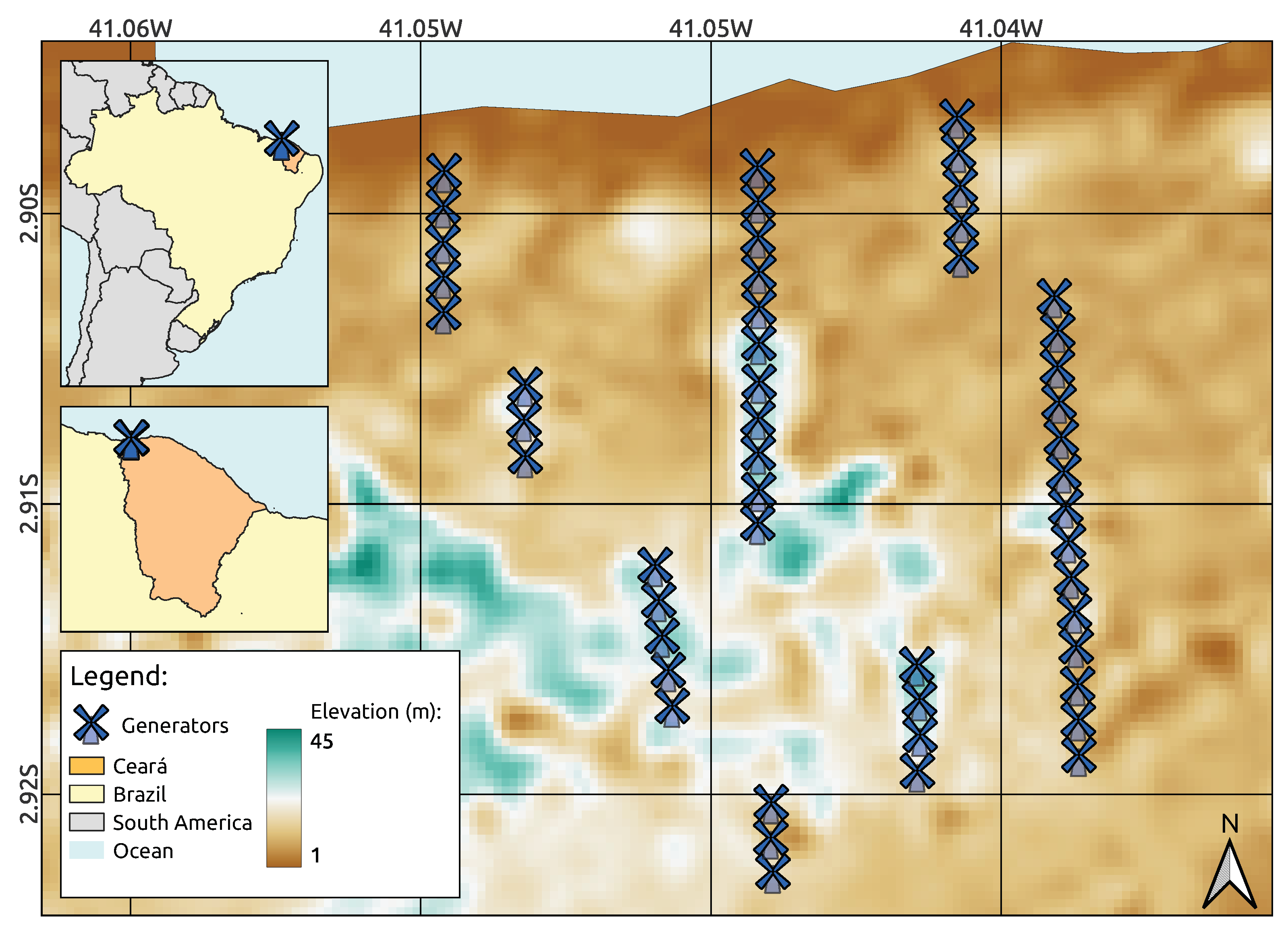
2.1. Study Area
2.2. Data Repositories
2.3. Machine Learning Algorithms for Wind Energy Prediction
2.3.1. Extreme Gradient Boosting-Based Model
- The cost function, Equation (1), to be optimized.
- The predictive models, which are defined as decision trees.
- Weak learners, to improve the minimization of the cost function.
- Regularization terms.
2.3.2. Random Forest-Based Model
- Generate X sets of bootstrap samples for the training dataset.
- For each sample, build a regression tree (without adjustment) with the following modification: at each node, generate a random sample P of the input variables from the training dataset and choose the best split of these, where , and V is the number of variables in the dataset.
- Predict the new output, from averaging the outputs of M regression trees when new variables are inserted into the model.
2.3.3. Long Short-Term Memory-Based Model
2.4. Data Preparation and Standardization
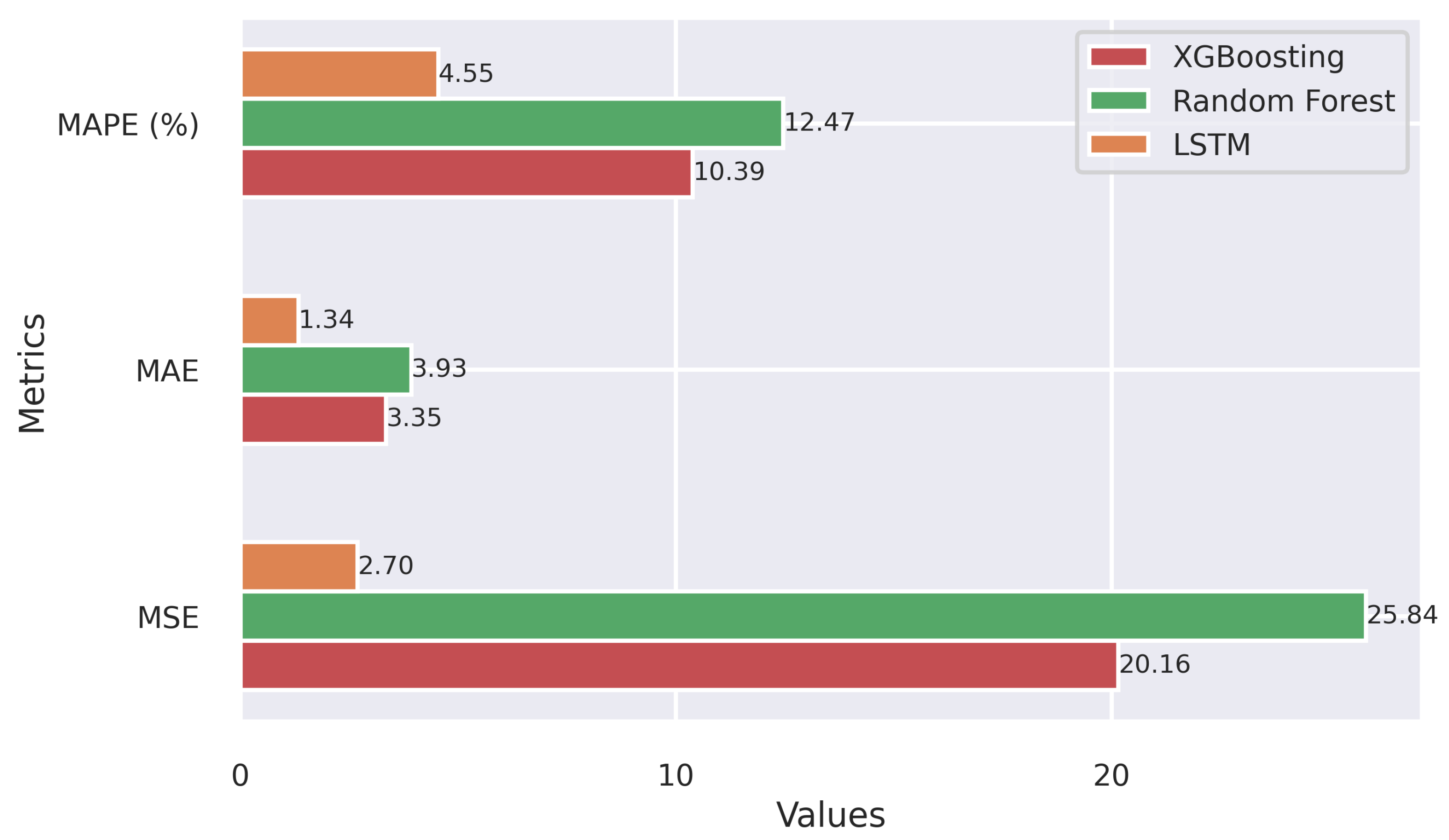
2.5. Evaluation Metrics
2.6. Model’s Design, Implementation Schemes, and Tuning Strategies
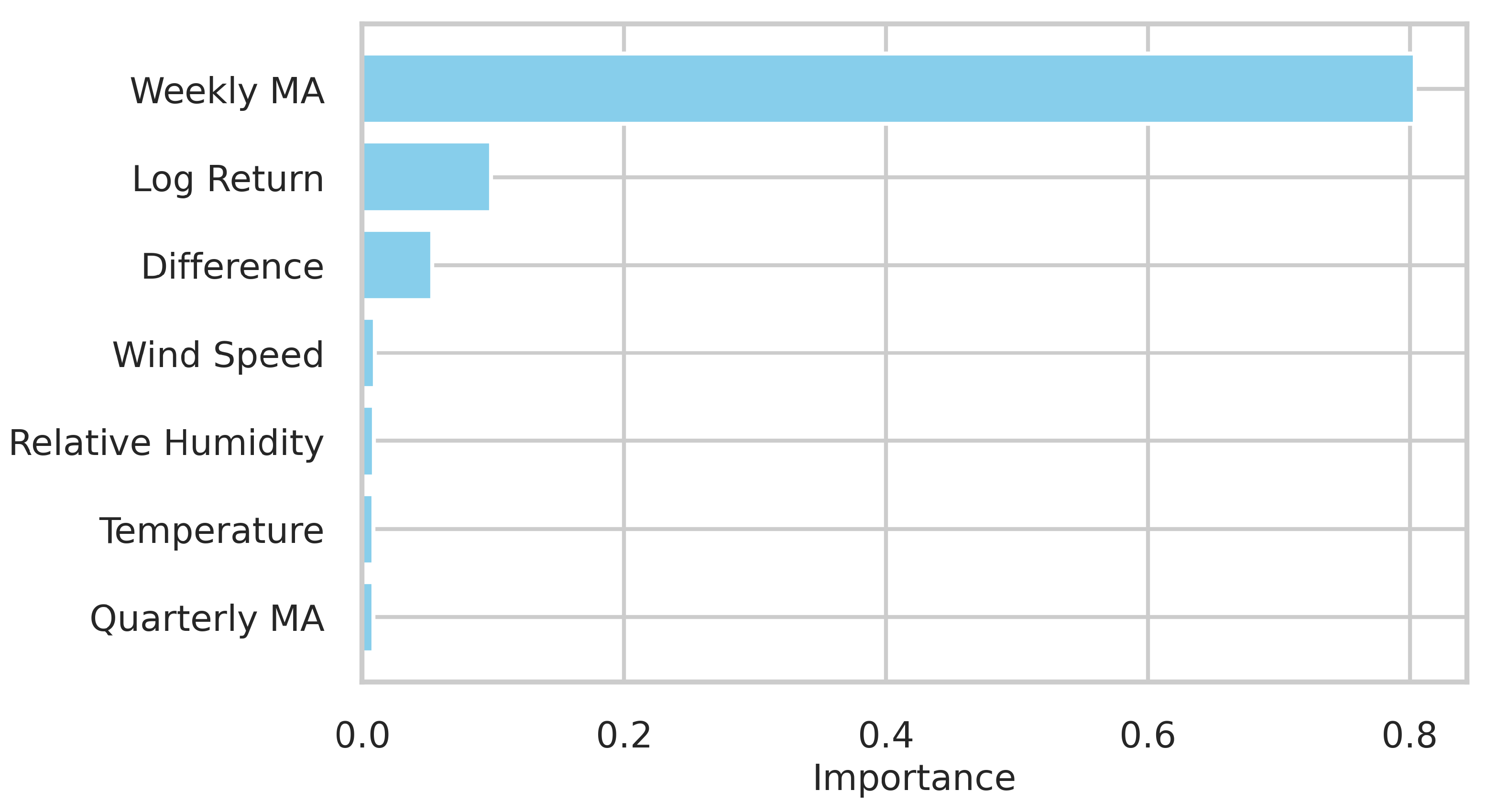
2.6.1. Artificially Created Features
- Sum (S) of temperature (T) and humidity (H): .;
- Subtraction (D) of temperature and humidity: ;
- Division (Q) of temperature by wind speed (W): ;
- Moving subtraction () of wind power: ;
- Moving subtraction of temperature.
2.6.2. Machine Learning Hyperparameters’ Optimization
3. Results
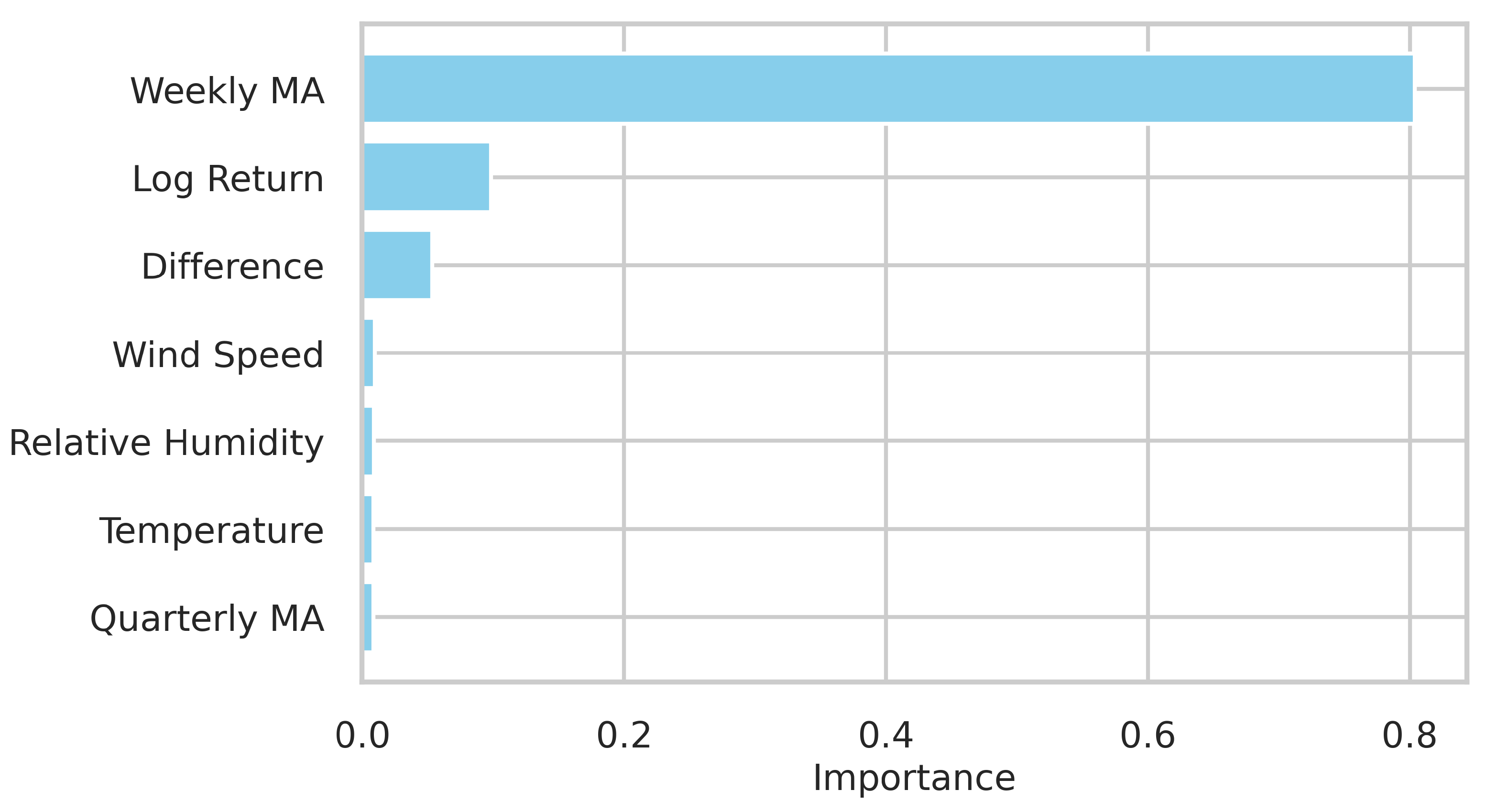
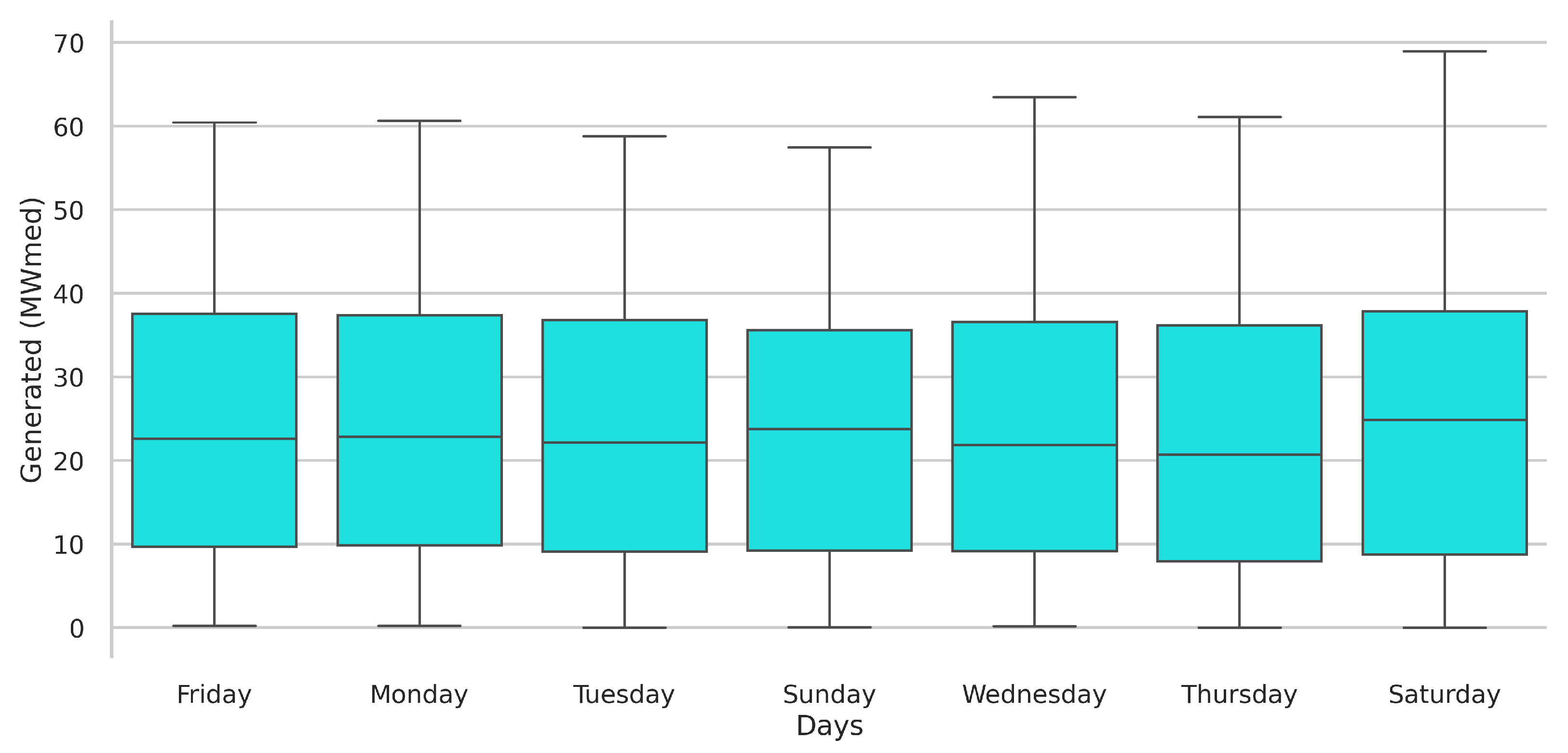
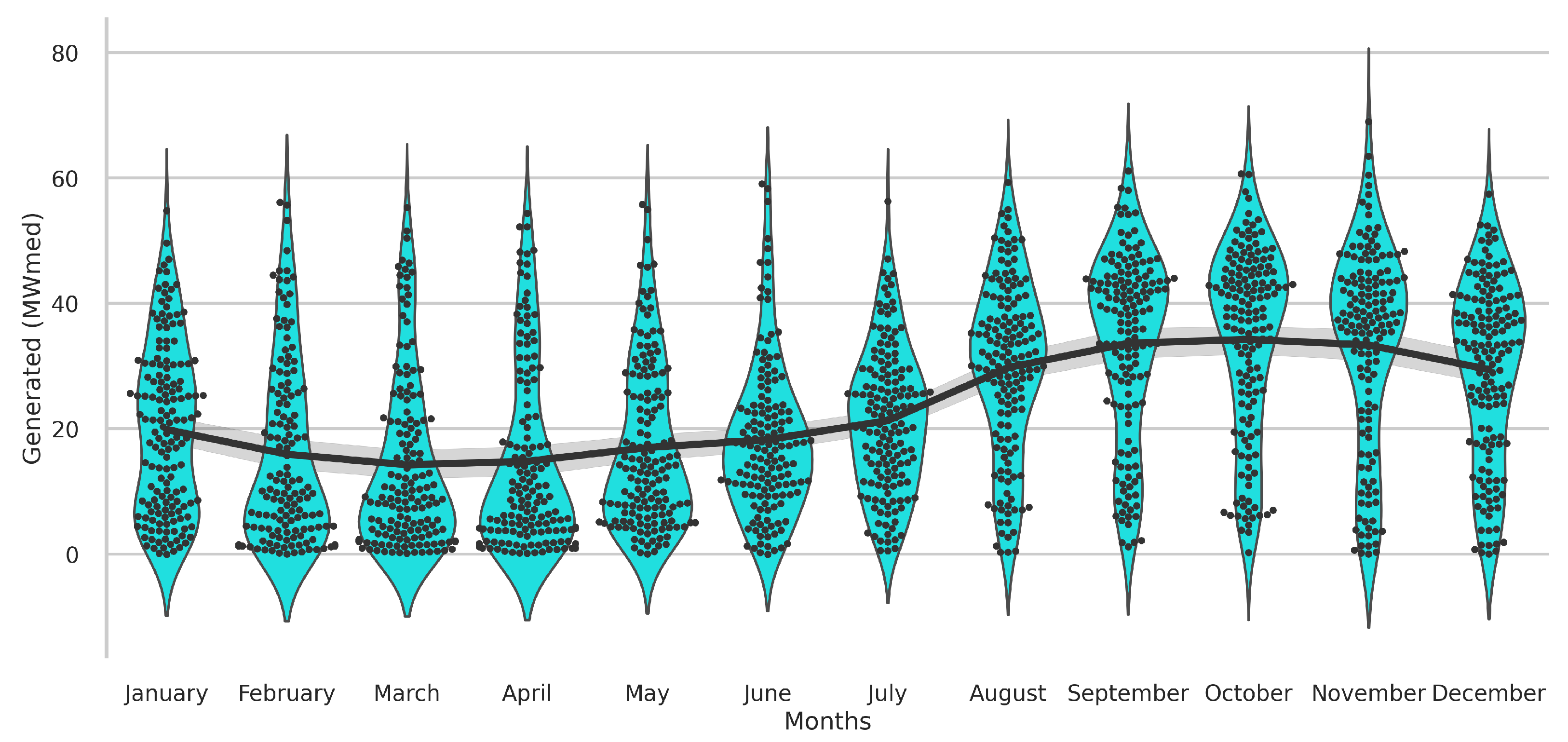
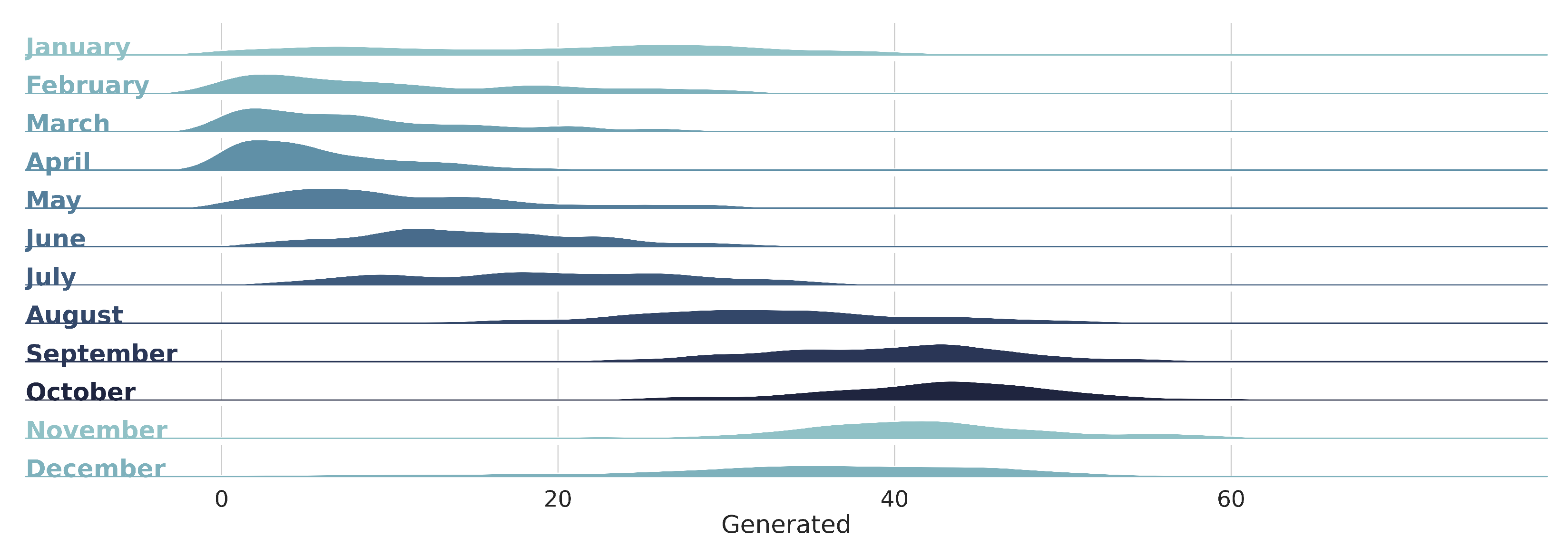
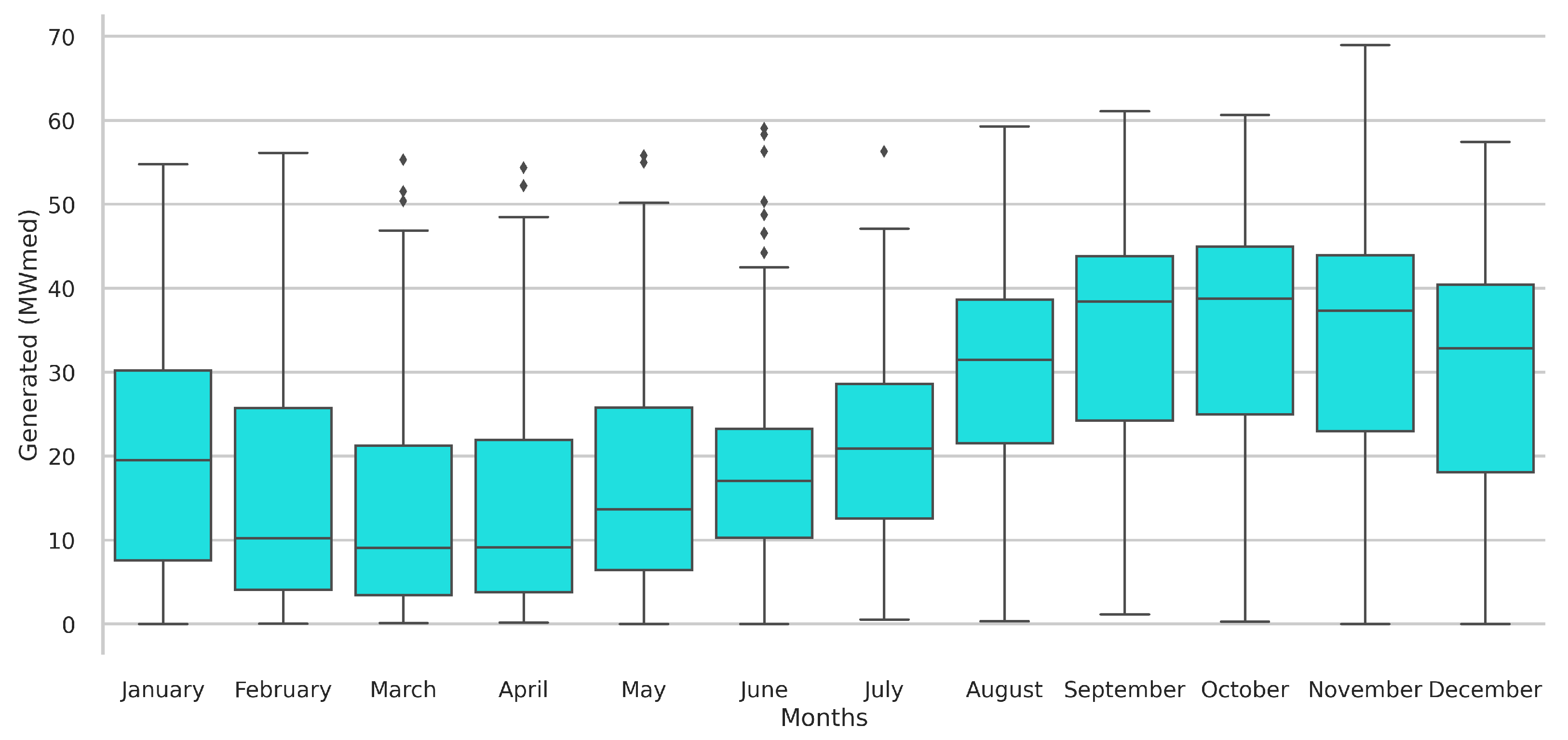
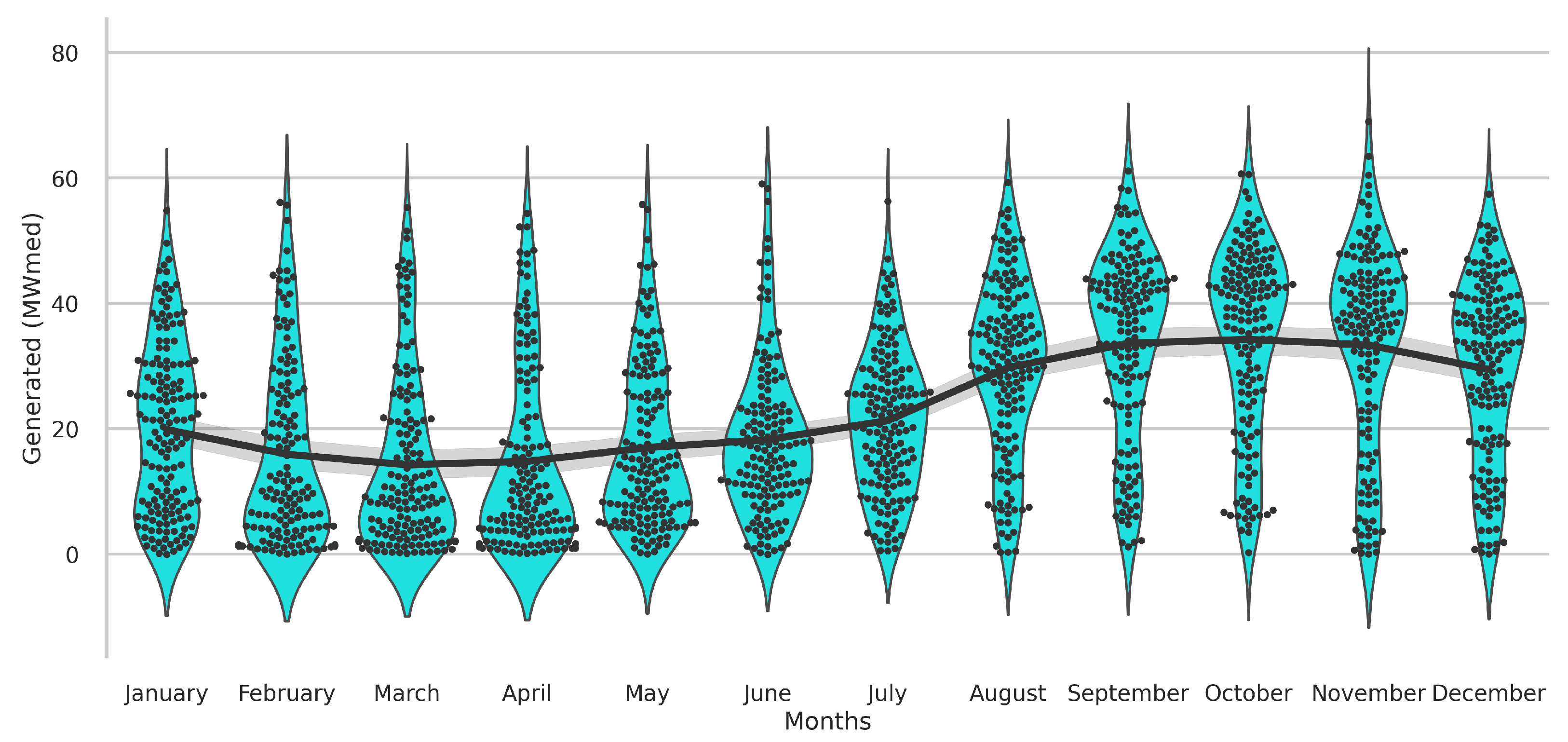
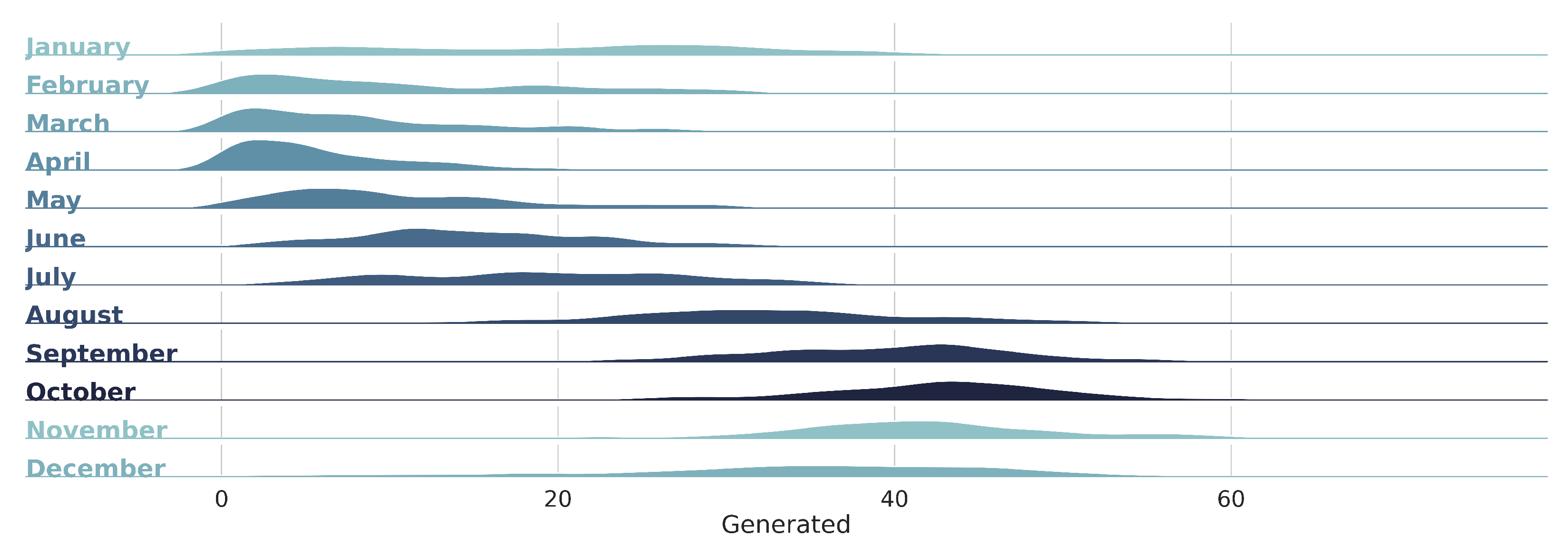
3.1. Knowledge Data Discovery
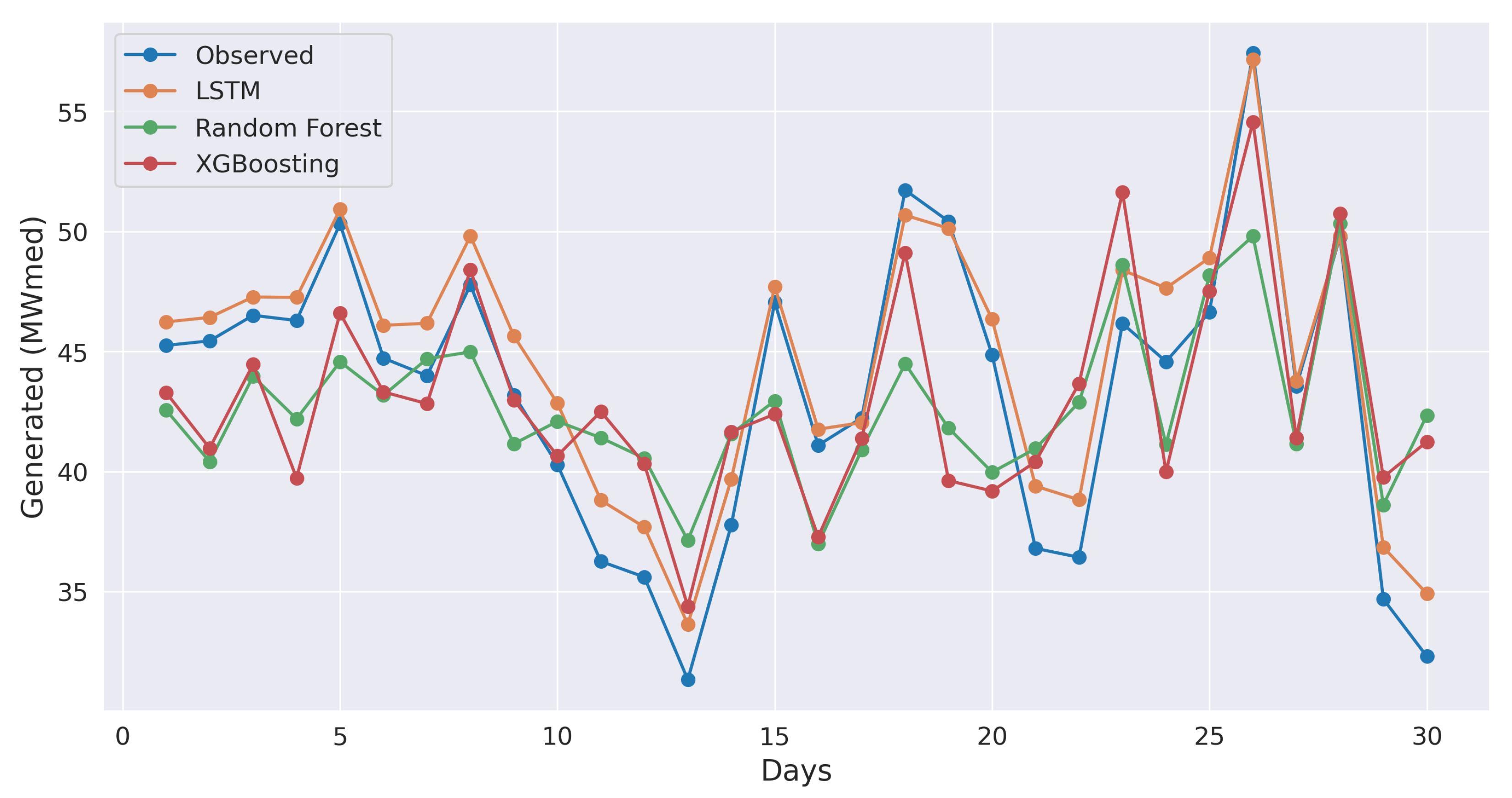
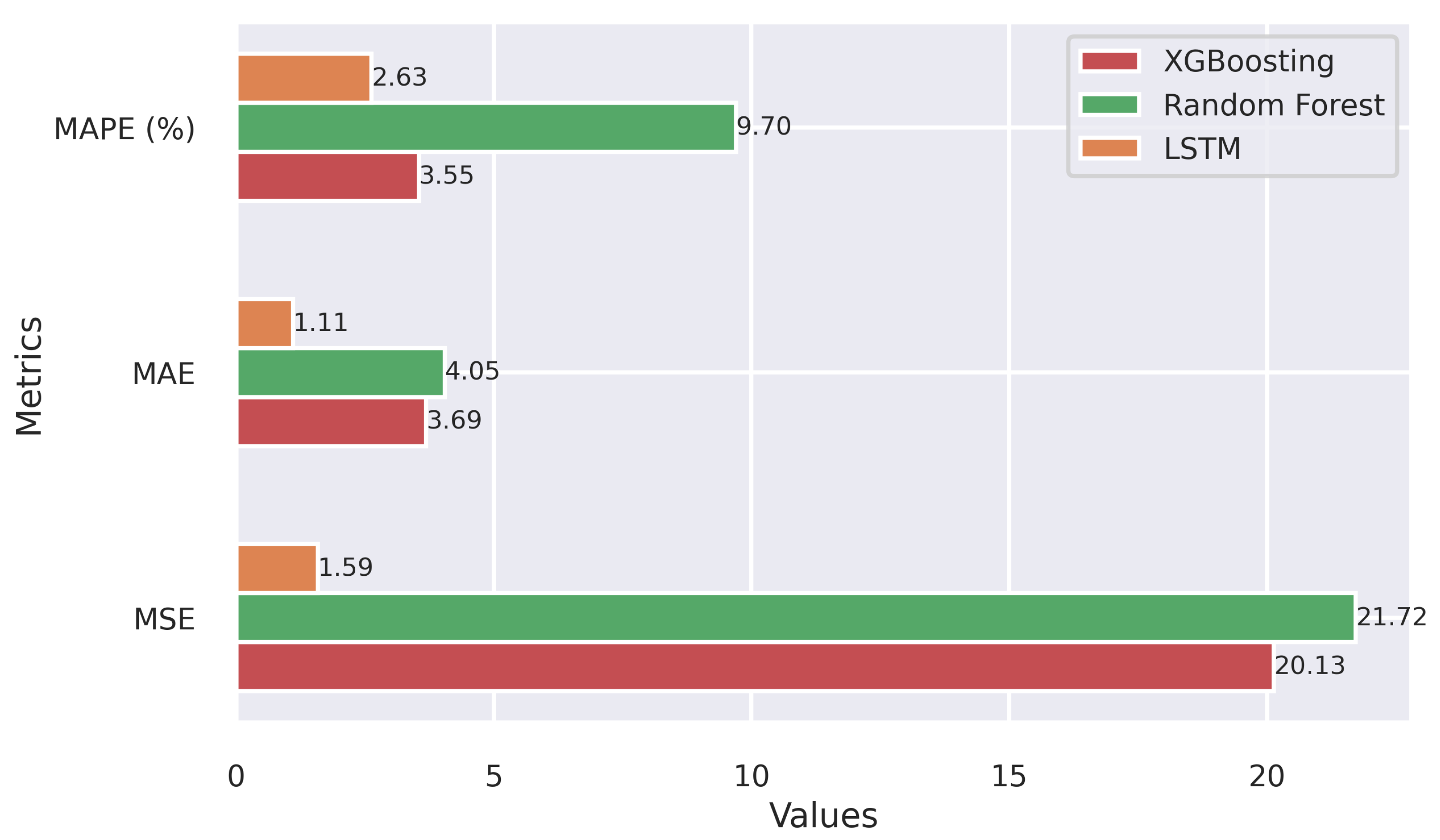
3.2. Application of the Machine Learning Models for Wind Energy Forecasting
4. Discussion and Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- GWEC. Global Wind Report 2023; GWEC: Brussels, Belgium, 2023. [Google Scholar]
- Nazir, M.S.; Bilal, M.; Sohail, H.M.; Liu, B.; Chen, W.; Iqbal, H.M. Impacts of renewable energy atlas: Reaping the benefits of renewables and biodiversity threats. Int. J. Hydrogen Energy 2020, 45, 22113–22124. [Google Scholar] [CrossRef]
- Olabi, A.G.; Obaideen, K.; Abdelkareem, M.A.; AlMallahi, M.N.; Shehata, N.; Alami, A.H.; Mdallal, A.; Hassan, A.A.M.; Sayed, E.T. Wind Energy Contribution to the Sustainable Development Goals: Case Study on London Array. Sustainability 2023, 15, 4641. [Google Scholar] [CrossRef]
- IRENA. Renewable Power Generation Costs in 2020. 2021. Available online: https://www.irena.org/publications/2021/Apr/Renewable-Power-Costs-in-2020 (accessed on 5 May 2023).
- Wolniak, R.; Skotnicka-Zasadzień, B. Development of Wind Energy in EU Countries as an Alternative Resource to Fossil Fuels in the Years 2016–2022. Resources 2023, 12, 96. [Google Scholar] [CrossRef]
- Fidalgo, J.N.; Matos, M.A. Forecasting Portugal Global Load with Artificial Neural Networks. In Proceedings of the Artificial Neural Networks (ICANN), Porto, Portugal, 9–13 September 2007; pp. 728–737. [Google Scholar]
- Zheng, H.; Wu, Y. A XGBoost Model with Weather Similarity Analysis and Feature Engineering for Short-Term Wind Power Forecasting. Appl. Sci. 2019, 9, 3019. [Google Scholar] [CrossRef]
- Demolli, H.; Dokuz, A.S.; Ecemis, A.; Gokcek, M. Wind power forecasting based on daily wind speed data using machine learning algorithms. Energy Convers. Manag. 2019, 198, 111823. [Google Scholar] [CrossRef]
- Acaroğlu, H.; Márquez, F.P.G. Comprehensive Review on Electricity Market Price and Load Forecasting Based on Wind Energy. Energy Convers. Manag. 2021, 14, 7473. [Google Scholar] [CrossRef]
- Qian, W.; Sui, A. A novel structural adaptive discrete grey prediction model and its application in forecasting renewable energy generation. Expert Syst. Appl. 2021, 186, 115761. [Google Scholar] [CrossRef]
- Leme, J.V.; Casaca, W.; Colnago, M.; Dias, M.A. Towards Assessing the Electricity Demand in Brazil: Data-Driven Analysis and Ensemble Learning Models. Energies 2020, 13, 1407. [Google Scholar] [CrossRef]
- Paula, M.; Colnago, M.; Fidalgo, J.N.; Wallace, C. Predicting Long-Term Wind Speed in Wind Farms of Northeast Brazil: A Comparative Analysis Through Machine Learning Models. IEEE Lat. Am. Trans. 2020, 18, 2011–2018. [Google Scholar] [CrossRef]
- Li, J.; Armandpour, M. Deep Spatio-Temporal Wind Power Forecasting. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4138–4142. [Google Scholar]
- Singh, U.; Rizwan, M.; Alaraj, M.; Alsaidan, I. A machine learning-based gradient boosting regression approach for wind power production forecasting: A step towards smart grid environments. Energies 2021, 14, 5196. [Google Scholar] [CrossRef]
- Optis, M.; Perr-Sauer, J. The importance of atmospheric turbulence and stability in machine-learning models of wind farm power production. Renew. Sustain. Energy Rev. 2019, 112, 27–41. [Google Scholar] [CrossRef]
- Li, L.L.; Zhao, X.; Tseng, M.L.; Tan, R.R. Short-term wind power forecasting based on support vector machine with improved dragonfly algorithm. J. Clean. Prod. 2020, 242, 118447. [Google Scholar] [CrossRef]
- Malska, W.; Mazur, D. Electric energy production in a wind farm—The statistical analysis of measurement results using the time series. In Proceedings of the Progress in Applied Electrical Engineering (PAEE), Koscielisko, Poland, 25–30 June 2017; pp. 1–5. [Google Scholar]
- Shabbir, N.; Kütt, L.; Jawad, M.; Amadiahanger, R.; Iqbal, M.N.; Rosin, A. Wind Energy Forecasting Using Recurrent Neural Networks. In Proceedings of the Big Data, Knowledge and Control Systems Engineering (BdKCSE), Sofia, Bulgaria, 21–22 November 2019; pp. 1–5. [Google Scholar]
- Najeebullah, A.Z.; Khan, A.; Javed, S.G. Machine Learning based short term wind power prediction using a hybrid learning model. Comput. Electr. Eng. 2015, 45, 122–133. [Google Scholar] [CrossRef]
- Puri, V.; Kumar, N. Wind energy forecasting using artificial neural network in Himalayan region. Model. Earth Syst. Environ. 2022, 8, 59–68. [Google Scholar] [CrossRef]
- Solari, G.; Repetto, M.P.; Burlando, M.; De Gaetano, P.; Pizzo, M.; Tizzi, M.; Parodi, M. The wind forecast for safety management of port areas. J. Wind. Eng. Ind. Aerodyn. 2012, 104–106, 266–277. [Google Scholar] [CrossRef]
- Cheng, W.Y.; Liu, Y.; Bourgeois, A.J.; Wu, Y.; Haupt, S.E. Short-term wind forecast of a data assimilation/weather forecasting system with wind turbine anemometer measurement assimilation. Renew. Energy 2017, 107, 340–351. [Google Scholar] [CrossRef]
- Vaitheeswaran, S.S.; Ventrapragada, V.R. Wind Power Pattern Prediction in time series measuremnt data for wind energy prediction modelling using LSTM-GA networks. In Proceedings of the International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–5. [Google Scholar]
- Jaseena, K.; Kovoor, B.C. Deep learning based multi-step short term wind speed forecasts with LSTM. In Proceedings of the International Conference on Data Science, E-Learning and Information Systems, Dubai, United Arab Emirates, 2–5 December 2019; pp. 1–6. [Google Scholar]
- Sowmya, C.; Kumar, A.G.; Kumar, S.S. Stacked LSTM recurrent neural network: A deep learning approach for short term wind speed forecasting. In Proceedings of the 2021 International Conference on Intelligent Technologies (CONIT), Hubli, India, 25–27 June 2021; pp. 1–7. [Google Scholar]
- Papazek, P.; Schicker, I. A deep learning LSTM forecasting approach for renewable energy systems. EGU Gen. Assem. 2021, 2021, 19–30. [Google Scholar]
- Ziaei, D.; Goudarzi, N. Short-Term Wind Characteristics Forecasting Using Stacked LSTM Networks. In Proceedings of the ASME Power Conference, Virtual, 20–22 July 2021; Volume 85109, p. V001T09A013. [Google Scholar]
- Kumar, D.; Mathur, H.; Bhanot, S.; Bansal, R.C. Forecasting of solar and wind power using LSTM RNN for load frequency control in isolated microgrid. Int. J. Model. Simul. 2021, 41, 311–323. [Google Scholar] [CrossRef]
- Wilczak, J.; Finley, C.; Freedman, J.; Cline, J.; Bianco, L.; Olson, J.; Djalalova, I.; Sheridan, L.; Ahlstrom, M.; Manobianco, J.; et al. The Wind Forecast Improvement Project (WFIP): A Public–Private Partnership Addressing Wind Energy Forecast Needs. Bull. Am. Meteorol. Soc. 2015, 96, 1699–1718. [Google Scholar] [CrossRef]
- Mesa-Jiménez, J.; Tzianoumis, A.; Stokes, L.; Yang, Q.; Livina, V. Long-term wind and solar energy generation forecasts, and optimisation of Power Purchase Agreements. Energy Rep. 2023, 9, 292–302. [Google Scholar] [CrossRef]
- Wang, X.; Liu, Y.; Hou, J.; Wang, S.; Yao, H. Medium- and Long-Term Wind-Power Forecasts, Considering Regional Similarities. Atmosphere 2023, 14, 430. [Google Scholar] [CrossRef]
- Jørgensen, K.L.; Shaker, H.R. Wind Power Forecasting Using Machine Learning: State of the Art, Trends and Challenges. In Proceedings of the IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–14 August 2020; pp. 44–50. [Google Scholar]
- EPE Brazil. Empresa de Pesquisa Energetica. 2022. Available online: https://www.epe.gov.br/en/publications/publications/brazilian-energy-balance (accessed on 8 January 2023).
- SIIF Praia Formosa Wind Farm. Global Wind Power Tracker Project. 2023. Available online: https://www.gem.wiki/SIIF_Praia_Formosa_wind_farm (accessed on 3 February 2023).
- Ribeiro, R.; Fanzeres, B. Identifying Representative Days of Wind Speed in Brazil Using Machine Learning Techniques. In Proceedings of the 2022 IEEE Power & Energy Society General Meeting (PESGM), Denver, CO, USA, 17–21 July 2022; pp. 1–5. [Google Scholar]
- Gilliland, J.M.; Keim, B.D. Position of the South Atlantic Anticyclone and its impact on surface conditions across Brazil. J. Appl. Meteorol. Climatol. 2018, 57, 535–553. [Google Scholar] [CrossRef]
- de Almeida Yanaguizawa Lucena, J.; Lucena, K.A.A. Wind energy in Brazil: An overview and perspectives under the triple bottom line. Clean Energy 2019, 3, 69–84. [Google Scholar] [CrossRef]
- GWA. Global Wind Atlas. 2023. Available online: https://globalwindatlas.info/ (accessed on 8 January 2023).
- ONS Brazil. National Electrical System Operator. 2022. Available online: http://ons.org.br (accessed on 3 November 2022).
- INMET Brazil. National Institute of Meteorology. 2023. Available online: http://www.inmet.gov.br/portal/index.php?r=home2/index (accessed on 3 January 2023).
- Lee, J.; Wang, W.; Harrou, F.; Sun, Y. Wind power prediction using ensemble learning-based models. IEEE Access 2020, 8, 61517–61527. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgo, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Wade, C. Hands-on Gradient Boosting with XGBoost and Scikit-Learn: Perform Accessible Machine Learning and Extreme Gradient Boosting with Python; Packt Publishing: Birmingham, UK, 2020. [Google Scholar]
- Munir, S.; Seminar, K.B.; Sudradjat; Sukoco, H.; Buono, A. The Use of Random Forest Regression for Estimating Leaf Nitrogen Content of Oil Palm Based on Sentinel 1-A Imagery. Information 2022, 14, 10. [Google Scholar] [CrossRef]
- Dudek, G. A Comprehensive Study of Random Forest for Short-Term Load Forecasting. Energies 2022, 15, 7547. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent Neural Networks for Time Series Forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Mahjoub, S.; Chrifi-Alaoui, L.; Marhic, B.; Delahoche, L. Predicting Energy Consumption Using LSTM, Multi-Layer GRU and Drop-GRU Neural Networks. Sensors 2022, 22, 4062. [Google Scholar] [CrossRef]
- Han, S.; Qiao, Y.H.; Yan, J.; Liu, Y.Q.; Li, L.; Wang, Z. Mid-to-long term wind and photovoltaic power generation prediction based on copula function and long short term memory network. Appl. Energy 2019, 239, 181–191. [Google Scholar] [CrossRef]
- Malhan, P.; Mittal, M. A novel ensemble model for long-term forecasting of wind and hydro power generation. Energy Convers. Manag. 2022, 251, 114983. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Keitsch, K.A.; Bruckner, T. Input data analysis for optimized short term load forecasts. In Proceedings of the IEEE Innovative Smart Grid Technologies-Asia (ISGT-Asia), Melbourne, Australia, 28 November–1 December 2016; pp. 1–6. [Google Scholar]
- de Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean Absolute Percentage Error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef]
- Yang, Y.; Han, L.; Wang, Y.; Wang, J. China’s energy demand forecasting based on the hybrid PSO-LSSVR model. Wirel. Commun. Mob. Comput. 2022, 2022, 7584646. [Google Scholar] [CrossRef]
- Hudson, R.S.; Gregoriou, A. Calculating and comparing security returns is harder than you think: A comparison between logarithmic and simple returns. Int. Rev. Financ. Anal. 2015, 38, 151–162. [Google Scholar] [CrossRef]
- Chen, B.; Choi, J.; Escanciano, J.C. Testing for fundamental vector moving average representations. Quant. Econ. 2017, 8, 149–180. [Google Scholar] [CrossRef]
- Dahouda, M.K.; Joe, I. A deep-learned embedding technique for categorical features encoding. IEEE Access 2021, 9, 114381–114391. [Google Scholar] [CrossRef]
- Saarela, M.; Jauhiainen, S. Comparison of feature importance measures as explanations for classification models. SN Appl. Sci. 2021, 3, 272. [Google Scholar] [CrossRef]
- Li, X.; Chen, W.; Zhang, Q.; Wu, L. Building auto-encoder intrusion detection system based on random forest feature selection. Comput. Secur. 2020, 95, 101851. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Gong, L.; Zeng, Q.; Li, W.; Xiao, F.; Lei, J. Imputation of gps coordinate time series using missforest. Remote Sens. 2021, 13, 2312. [Google Scholar] [CrossRef]
- Hanifi, S.; Liu, X.; Lin, Z.; Lotfian, S. A critical review of wind power forecasting methods—Past, present and future. Energies 2020, 13, 3764. [Google Scholar] [CrossRef]
- García, C.L.; Grimoni, J.A.B.; Morales Udaeta, M.E. Integrating Wind Power to the National Interconnected System in Brazil. Int. J. Electr. Energy 2016, 4, 48–53. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
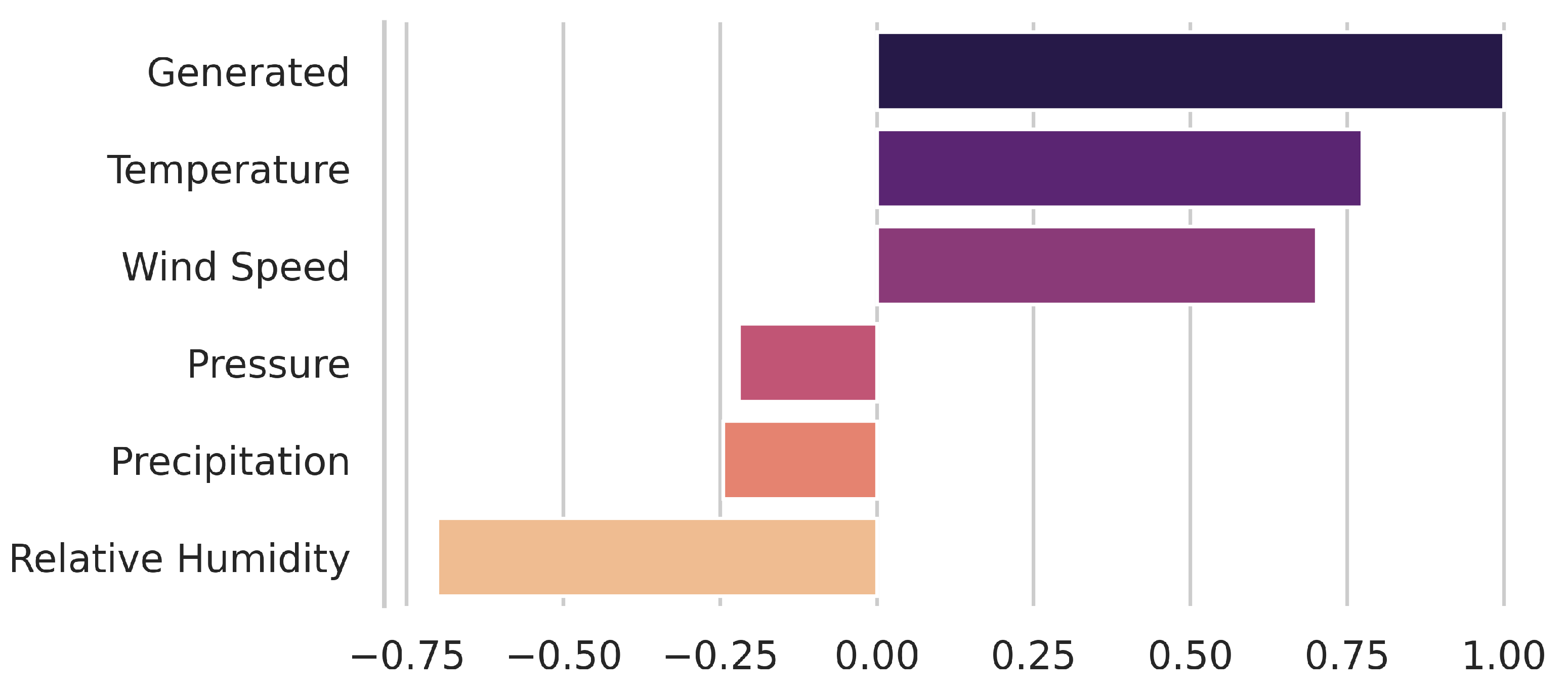{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description | Unity | Repository |
|---|---|---|---|
| Date | Day, month, year and season | - | - |
| Temperature | Average temperature | C | INMET |
| Relative humidity | Average relative humidity | % | INMET |
| Pressure | Average pressure | hPa | INMET |
| Precipitation | Average precipitation rate | mm/d | INMET |
| Wind speed | Average wind speed | m/s | INMET |
| Max energy demand | Wind energy load demand peak | MWmed | ONS |
| Wind energy generation | Total generated by the power plants | MWmed | ONS |
| Hyperparameter | Description | Tuning Universe | Optimal Parameter |
|---|---|---|---|
| max_depth | Maximum tree depth | 2, 3, 4, 5, 6, 7, 10 | 4 |
| subsample | Subsample ratio of the training instances | 0.1, 0.5, 0.7, 0.8, 0.9, 1 | 0.7 |
| colsample_bytree | Subsample ratio of feature-like columns when constructing each tree | 0.1, 0.4, 0.7, 0.8, 0.9, 1 | 1 |
| n_estimators | Number of trees generated | 25, 50, 100, 200, 300, 500 | 300 |
| learning_rate | Learning rate of the model | 0.01, 0.1, 0.2, 0.3 | 0.1 |
| Hyperparameter | Description | Tuning Universe | Optimal Parameter |
|---|---|---|---|
| n_estimators | Number of trees generated | 25, 50, 100, 200, 500, 1K | 50 |
| max_depth | Maximum tree depth | 2, 5, 10, 20, 30 | 20 |
| min_samples_split | Minimum number of samples to split an internal node | 2, 4, 6, 10 | 4 |
| min_samples_leaf | Minimum number of samples for a leaf node | 1, 2, 4, 6, 8 | 2 |
| max_features | Maximum number of features for each split when constructing a decision tree | auto, sqrt, log2, none | log2 |
| Hyperparameter | Description | Tuning Universe | Optimal Parameter |
|---|---|---|---|
| num_units_list | Number of units (or neurons) in the LSTM layer | 32, 64, 128 | 64 |
| activation | Activation function | identity, logistic, sigmoid, relu | sigmoid |
| solver | Mathematical solver for weight optimization | lbfgs, sgd, adam | adam |
| learning_rate_list | Manages weight update size during training | 0.001, 0.01, 0.1 | 0.001 |
| window_size_list | Number of past time steps LSTM considers for predicting the next step | 5, 10, 15, 20 | 15 |
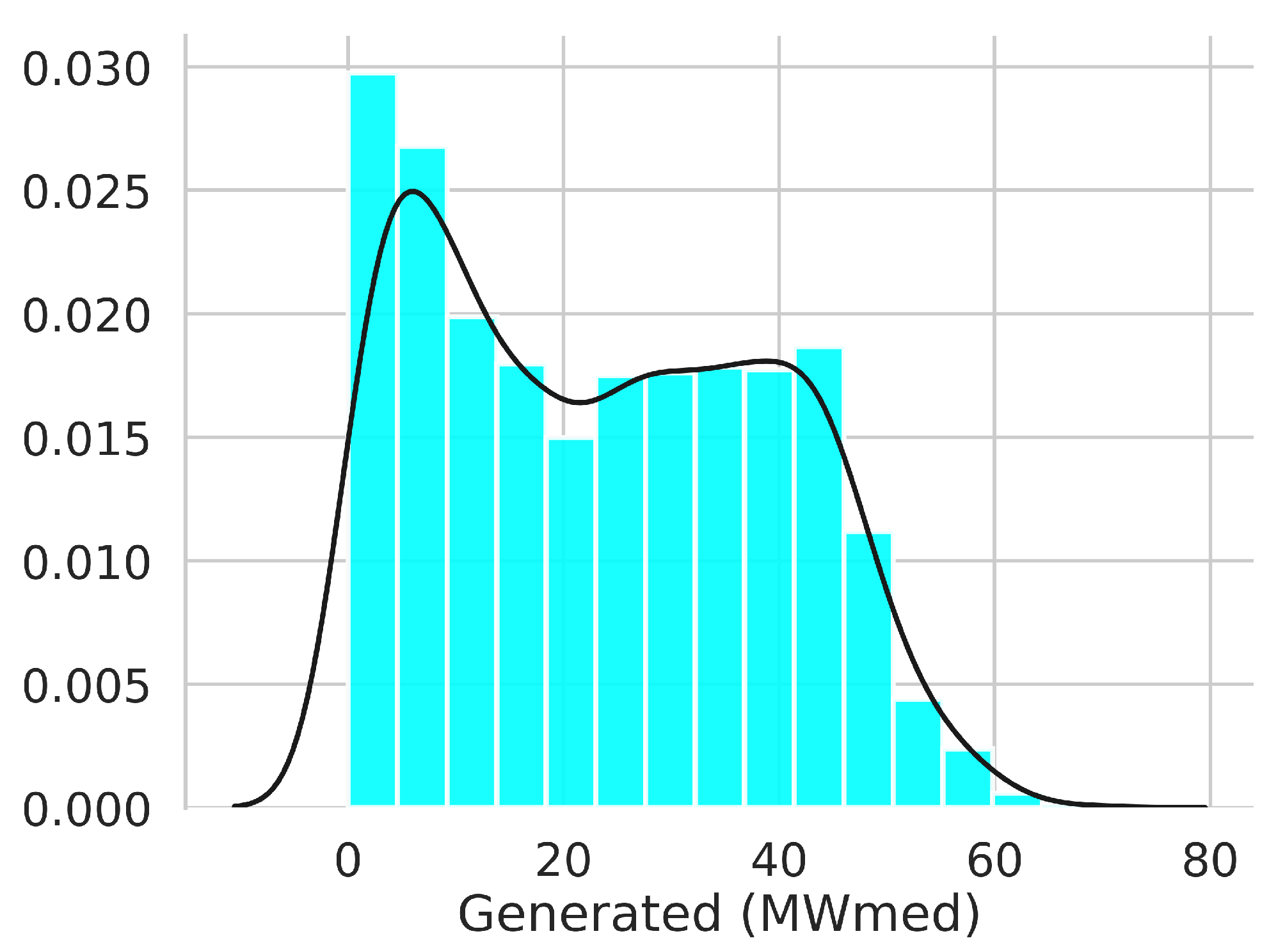
| Statistics | Wind Energy Generated (MWmed) |
|---|---|
| Average | 23.98 |
| Standard Deviation | 15.27 |
| 25% | 10.11 |
| 50% | 23.85 |
| 75% | 36.56 |
| Models | Training | Testing |
|---|---|---|
| XGBoosting | 1.66 | 1.21 |
| Random Forest | 2.80 | 1.05 |
| LSTM | 55.80 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paula, M.; Casaca, W.; Colnago, M.; da Silva, J.R.; Oliveira, K.; Dias, M.A.; Negri, R. Predicting Energy Generation in Large Wind Farms: A Data-Driven Study with Open Data and Machine Learning. Inventions 2023, 8, 126. https://doi.org/10.3390/inventions8050126
Paula M, Casaca W, Colnago M, da Silva JR, Oliveira K, Dias MA, Negri R. Predicting Energy Generation in Large Wind Farms: A Data-Driven Study with Open Data and Machine Learning. Inventions. 2023; 8(5):126. https://doi.org/10.3390/inventions8050126
Chicago/Turabian StylePaula, Matheus, Wallace Casaca, Marilaine Colnago, José R. da Silva, Kleber Oliveira, Mauricio A. Dias, and Rogério Negri. 2023. "Predicting Energy Generation in Large Wind Farms: A Data-Driven Study with Open Data and Machine Learning" Inventions 8, no. 5: 126. https://doi.org/10.3390/inventions8050126
APA StylePaula, M., Casaca, W., Colnago, M., da Silva, J. R., Oliveira, K., Dias, M. A., & Negri, R. (2023). Predicting Energy Generation in Large Wind Farms: A Data-Driven Study with Open Data and Machine Learning. Inventions, 8(5), 126. https://doi.org/10.3390/inventions8050126