
Dead Fish Detection Model Based on DD-IYOLOv8


Abstract
1. Introduction
2. Related Works
2.1. Object Detection Methods
2.2. Methods for Incorporating Prior Knowledge
2.3. DD-IYOLOv8 Network Model Structure
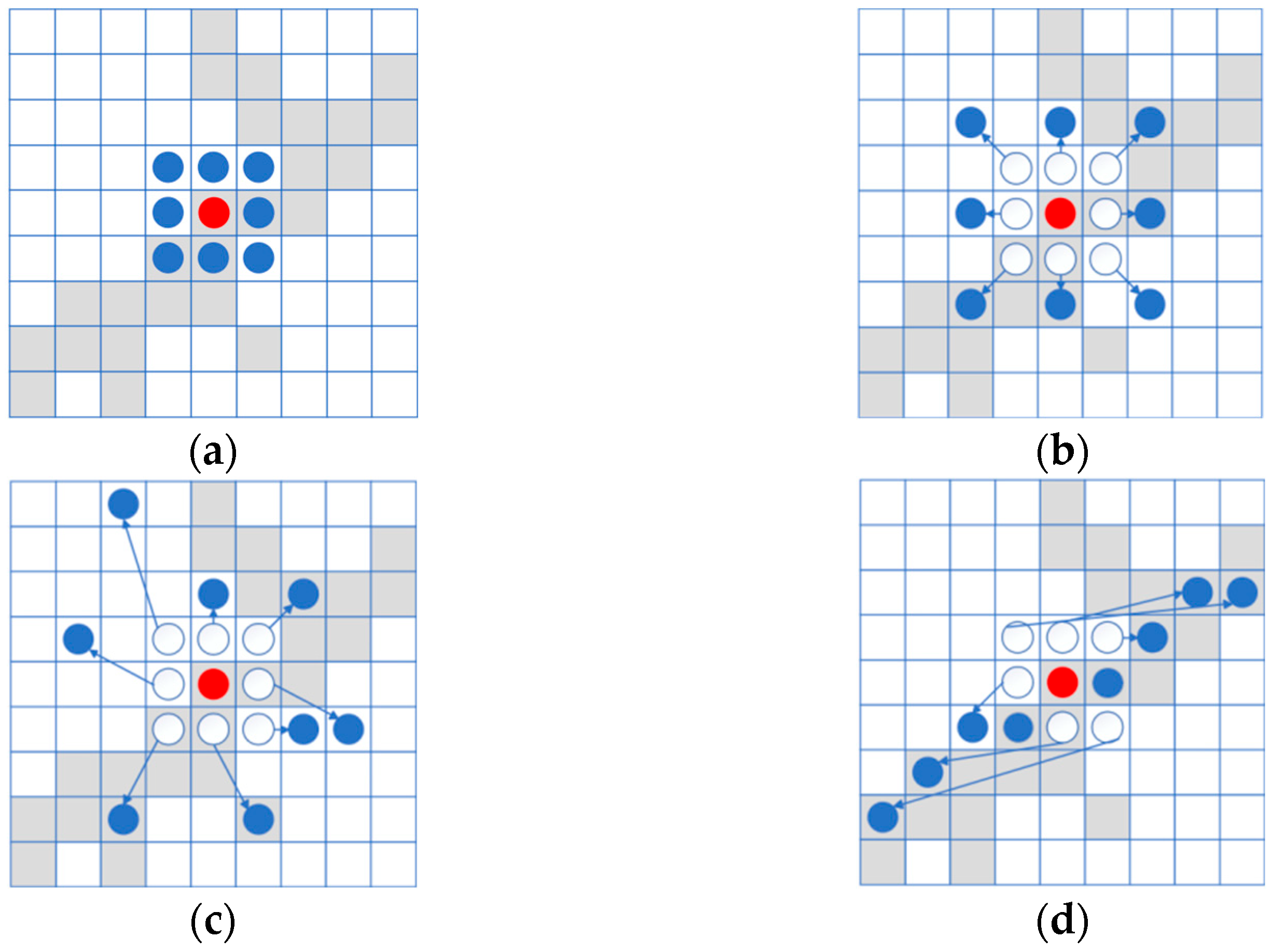
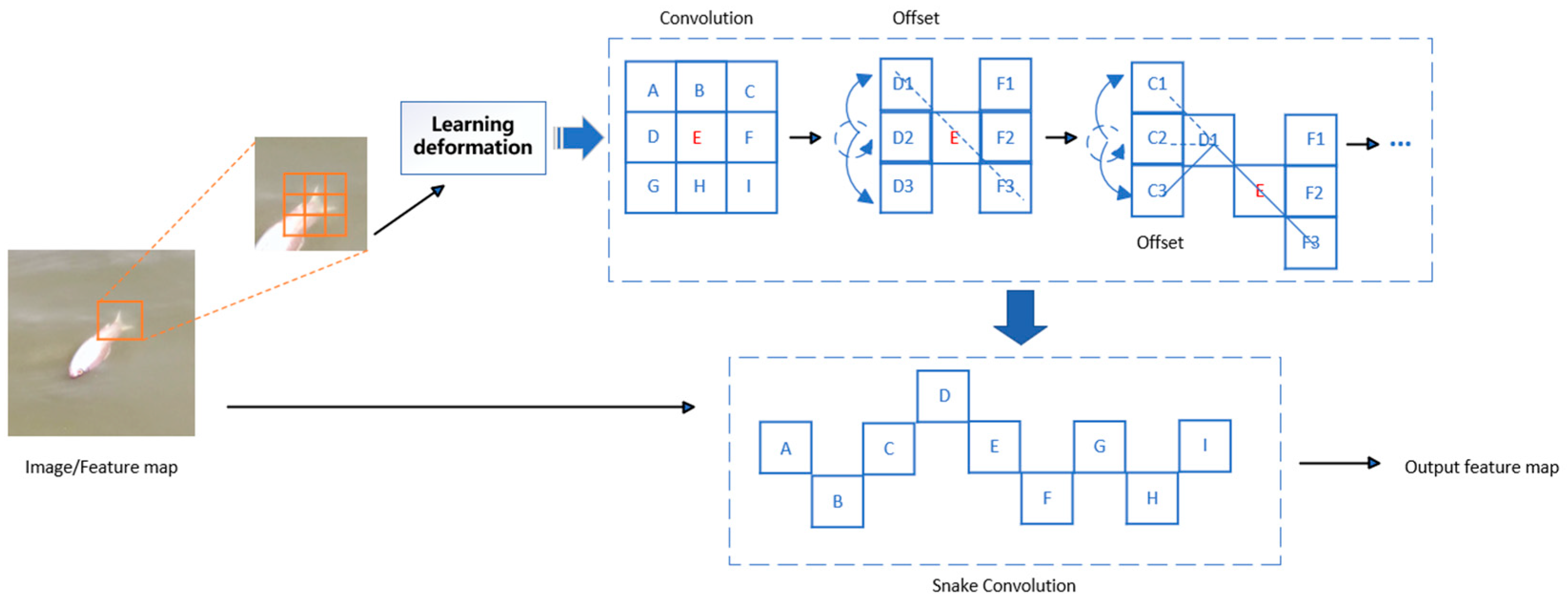
2.3.1. Feature Extraction: C2f_DySnakeConv
2.3.2. Small Target Detection Head
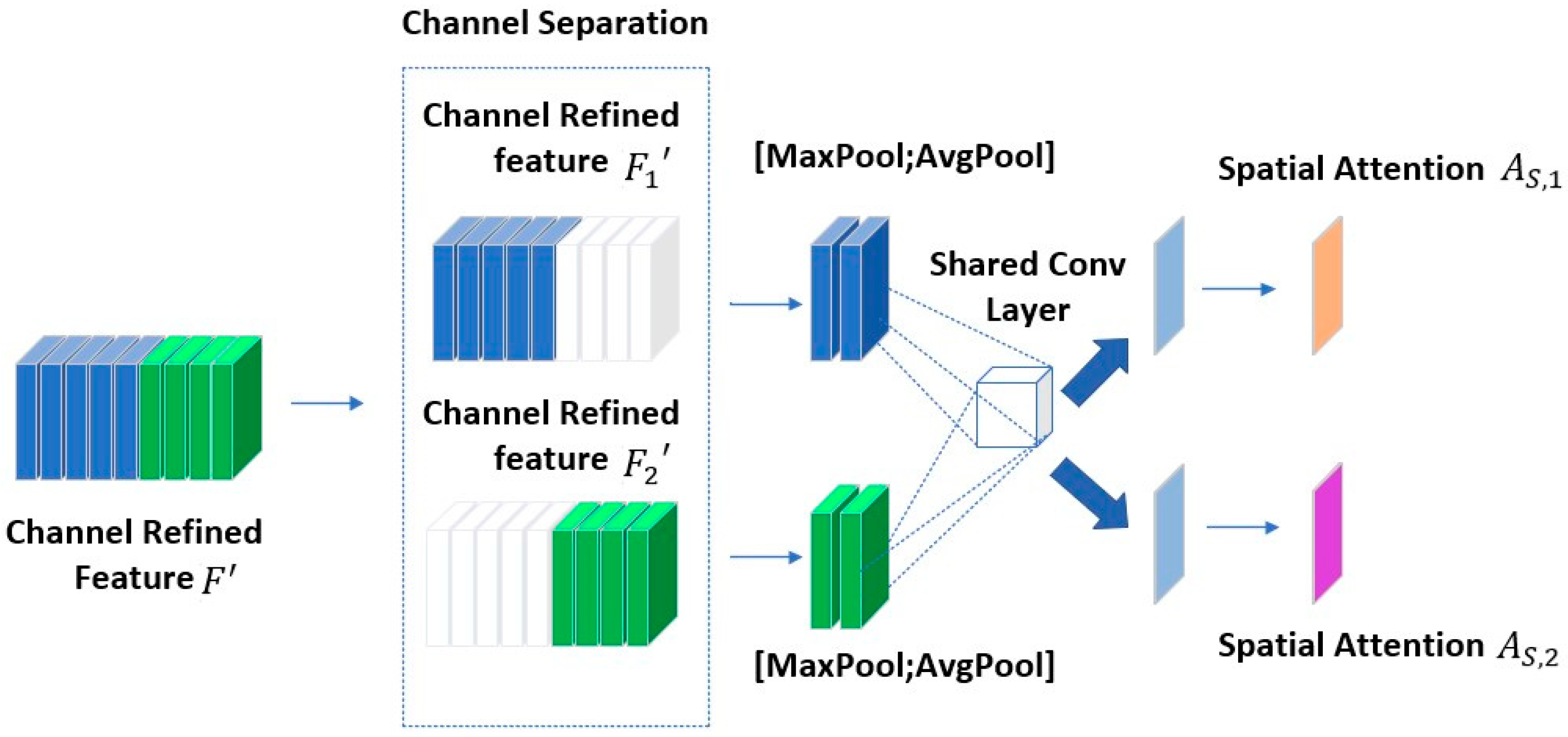
2.3.3. Hybrid Attention Mechanism
3. Collection and Construction of Dataset
4. Experimental Results and Analysis
4.1. Experimental Environment and Evaluation Metrics
4.2. Experimental Comparison with Prior Knowledge Integration
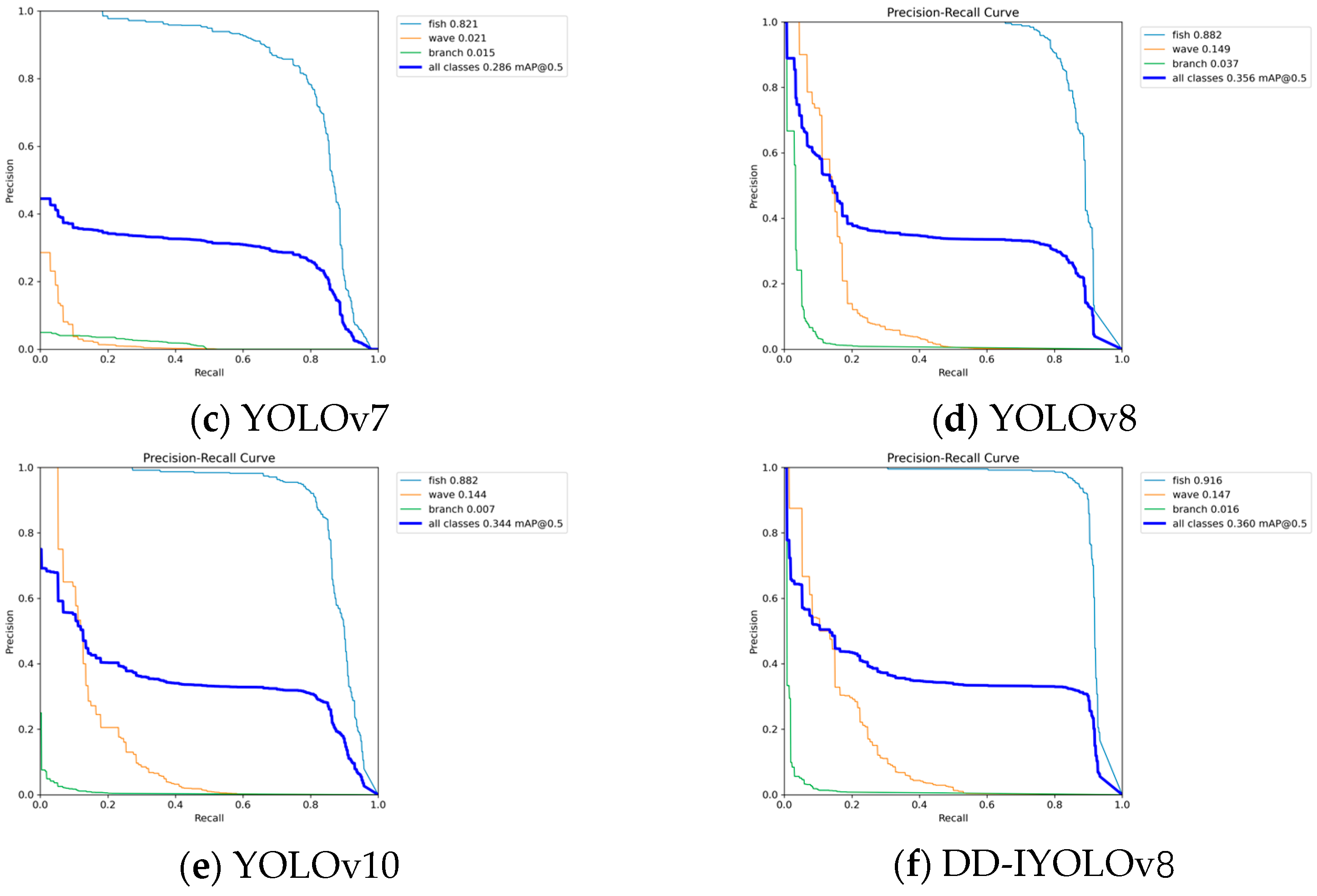
4.3. Comparative Experiments with Different Models
4.4. Comparative Experiments in Different Scenes
4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, M.; Pan, S.; Chen, Y.; Deng, Y. Development status, problems and countermeasures of blue granary industry in China. Hubei Agric. Sci. 2023, 62, 214–219. [Google Scholar]
- Bao, Z. Marine Ranching: Paving the way for a sustainable blue granary. Anim. Res. One Health 2024, 2, 119–120. [Google Scholar] [CrossRef]
- Zhao, J.; Bao, W.; Zhang, F.; Zhu, S.; Liu, Y.; Lu, H.; Shen, M.; Ye, Z. Modified motion influence map and recurrent neural network-based monitoring of the local unusual behaviors for fish school in intensive aquaculture. Aquaculture 2018, 493, 165–175. [Google Scholar] [CrossRef]
- Hu, J.; Zhao, D.; Zhang, Y.; Zhou, C.; Chen, W. Real-time nondestructive fish behavior detecting in mixed polyculture system using deep-learning and low-cost devices. Expert Syst. Appl. 2021, 178, 115051. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Zhao, S.; Wang, Q.; Li, D.; Zhao, R. Real-time detection and tracking of fish abnormal behavior based on improved YOLOV5 and SiamRPN++. Comput. Electron. Agric. 2022, 192, 106512. [Google Scholar] [CrossRef]
- Zhang, Z.; Shen, Y.; Zhang, Z. Recognition of Feeding Behavior of Fish Based on Motion Feature Extraction and 2D Convolution. Trans. Chin. Soc. Agric. Mach. 2024, 55, 246–253. [Google Scholar]
- Chen, X. The Method of Fish Abnormal Behavior Detection Based on Deep Learning. Master’s Thesis, Shanghai Ocean University, Shanghai, China, 2024. [Google Scholar]
- Yang, Y. Fish Behavior Recognition Method Based on Acoustic and Visual Features Fusion under Complex Conditions. Master’s Thesis, Dalian Ocean University, Liaoning, China, 2024. [Google Scholar]
- Hu, Z.; Li, X.; Xie, X.; Zhao, Y. Abnormal Behavior Recognition of Underwater Fish Body Based on C3D Model. In Proceedings of the 2022 6th International Conference on Machine Learning and Soft Computing, Haikou, China, 15–17 January 2022. [Google Scholar]
- Zheng, J.; Zhao, R.; Yang, G.; Liu, S.; Zhang, Z.; Fu, Y.; Lu, J. An Underwater Image Restoration Deep Learning Network Combining Attention Mechanism and Brightness Adjustment. J. Mar. Sci. Eng. 2024, 12, 7. [Google Scholar] [CrossRef]
- Wageeh, Y.; Mohamed, H.E.-D.; Fadl, A.; Anas, O.; El Masry, N.; Nabil, A.; Atia, A. YOLO fish detection with Euclidean tracking in fish farms. J. Ambient Intell. Humaniz. Comput. 2021, 12, 5–12. [Google Scholar] [CrossRef]
- Wang, J.-H.; Lee, S.-K.; Lai, Y.-C.; Lin, C.-C.; Wang, T.-Y.; Lin, Y.-R.; Hsu, T.-H.; Huang, C.-W.; Chiang, C.-P. Anomalous Behaviors Detection for Underwater Fish Using AI Techniques. IEEE Access 2020, 8, 224372–224382. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, S.; Lu, J.; Wang, H.; Feng, Y.; Shi, C.; Li, D.; Zhao, R. A lightweight dead fish detection method based on deformable convolution and YOLOV4. Comput. Electron. Agric. 2022, 198, 107098. [Google Scholar] [CrossRef]
- Zhang, P.; Zheng, J.; Gao, L.; Li, P.; Long, H.; Liu, H.; Li, D. A novel detection model and platform for dead juvenile fish from the perspective of multi-task. Multimed. Tools Appl. 2024, 83, 24961–24981. [Google Scholar] [CrossRef]
- Yang, S.; Li, H.; Liu, J.; Fu, Z.; Zhang, R.; Jia, H. A Method for Detecting Dead Fish on Water Surfaces Based on Multi-scale Feature Fusion and Attention Mechanism. Zhengzhou Univ. (Nat. Sci. Ed.) 2024, 56, 32–38. [Google Scholar]
- Yan, R.; Shang, Z.; Wang, Z.; Xu, W.; Zhao, Z.; Wang, S.; Chen, X. Challenges and Opportunities of XAI in Industrial Intelligent Diagnosis: Priori-empowered. J. Mech. Eng. 2024, 60, 1–20. [Google Scholar]
- Ding, X.; Luo, Y.; Li, Q.; Cheng, Y.; Cai, G.; Munnoch, R.; Xue, D.; Yu, Q.; Zheng, X.; Wang, B. Prior knowledge-based deep learning method for indoor object recognition and application. Syst. Sci. Control Eng. 2018, 6, 249–257. [Google Scholar] [CrossRef]
- Qin, S.; Liu, H.; Chen, L.; Zhang, L. Outlier detection algorithms for penetration depth data of concrete targets combined with prior knowledge. Combust. Explos. Shock Waves 2024, 44, 70–79. [Google Scholar]
- Xie, Z.; Shu, C.; Fu, Y.; Zhou, J.; Jiang, J.; Chen, D. Knowledge-Driven Metal Coating Defect Segmentation. J. Electron. Sci. Technol. China 2024, 53, 76–83. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Fawzi, A.; Samulowitz, H.; Turaga, D.; Frossard, P. Adaptive data augmentation for image classification. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3688–3692. [Google Scholar]
- Reid Turner, C.; Fuggetta, A.; Lavazza, L.; Wolf, A.L. A conceptual basis for feature engineering. J. Syst. Softw. 1999, 49, 3–15. [Google Scholar] [CrossRef]
- Liu, S.; Davison, A.J.; Johns, E. Self-Supervised Generalisation with Meta Auxiliary Learning. arXiv 2019, arXiv:1901.08933. [Google Scholar]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6070–6079. [Google Scholar]
- Li, G.; Fang, Q.; Zha, L.; Gao, X.; Zheng, N. HAM: Hybrid attention module in deep convolutional neural networks for image classification. Pattern Recognit. 2022, 129, 108785. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 618–626. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | AP | F1 | |
|---|---|---|---|---|
| No data augmentation | 0.890 | 0.800 | 0.874 | 0.842 |
| Data augmentation | 0.928 | 0.894 | 0.917 | 0.911 |
| Precision | Recall | AP | F1 | |
|---|---|---|---|---|
| lr = 0.1 | 0.825 | 0.700 | 0.809 | 0.757 |
| lr = 0.01 | 0.928 | 0.894 | 0.917 | 0.911 |
| lr = 0.001 | 0.863 | 0.861 | 0.897 | 0.862 |
| Dataset 1 | Dataset 2 | Precision | Recall | AP | F1 | |
|---|---|---|---|---|---|---|
| DD-IYOLOv8 | √ | 0.946 | 0.816 | 0.901 | 0.876 | |
| DD-IYOLOv8 | √ | 0.928 | 0.894 | 0.917 | 0.911 |
| Model | Precision | Recall | AP | F1 | Params/MB |
|---|---|---|---|---|---|
| Faster R-CNN | 0.732 | 0.463 | 0.827 | 0.574 | 495 |
| YOLOv5n | 0.934 | 0.873 | 0.915 | 0.902 | 3.9 |
| YOLOv7-tiny | 0.837 | 0.767 | 0.821 | 0.800 | 12.3 |
| YOLOv8n | 0.865 | 0.827 | 0.884 | 0.845 | 6.3 |
| YOLOv10n | 0.907 | 0.815 | 0.882 | 0.858 | 5.8 |
| DD-IYOLOv8 | 0.928 | 0.894 | 0.917 | 0.911 | 7.5 |
| DySnake Conv | Detection Head | HAM | Precision | Recall | AP | F1 | |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 0.865 | 0.827 | 0.884 | 0.845 | |||
| YOLOv8-A | √ | 0.904 | 0.873 | 0.906 | 0.888 | ||
| YOLOv8-B | √ | √ | 0.895 | 0.897 | 0.918 | 0.896 | |
| DD-IYOLOv8 | √ | √ | √ | 0.928 | 0.894 | 0.917 | 0.911 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Fu, Y.; Zhao, R.; Lu, J.; Liu, S. Dead Fish Detection Model Based on DD-IYOLOv8. Fishes 2024, 9, 356. https://doi.org/10.3390/fishes9090356
Zheng J, Fu Y, Zhao R, Lu J, Liu S. Dead Fish Detection Model Based on DD-IYOLOv8. Fishes. 2024; 9(9):356. https://doi.org/10.3390/fishes9090356
Chicago/Turabian StyleZheng, Jianhua, Yusha Fu, Ruolin Zhao, Junde Lu, and Shuangyin Liu. 2024. "Dead Fish Detection Model Based on DD-IYOLOv8" Fishes 9, no. 9: 356. https://doi.org/10.3390/fishes9090356
APA StyleZheng, J., Fu, Y., Zhao, R., Lu, J., & Liu, S. (2024). Dead Fish Detection Model Based on DD-IYOLOv8. Fishes, 9(9), 356. https://doi.org/10.3390/fishes9090356