
Triple Attention Mechanism with YOLOv5s for Fish Detection


Abstract
1. Introduction
- (1)
- Experimental data collection has problems, such as uneven illumination, the turbidity of the water environment, obstruction of underwater cameras, and shooting angles. As a result, the collected data cannot provide sufficient information to match the target, thus resulting in unstable and inconsistent target detection.
- (2)
- With changes in fish aggregation, the obscured area between the fish also changes, which presents a challenge to detection performance.
2. Related Work
3. The YOLOv5s Network with Triple Attention Mechanism
3.1. Exponential Moving Average
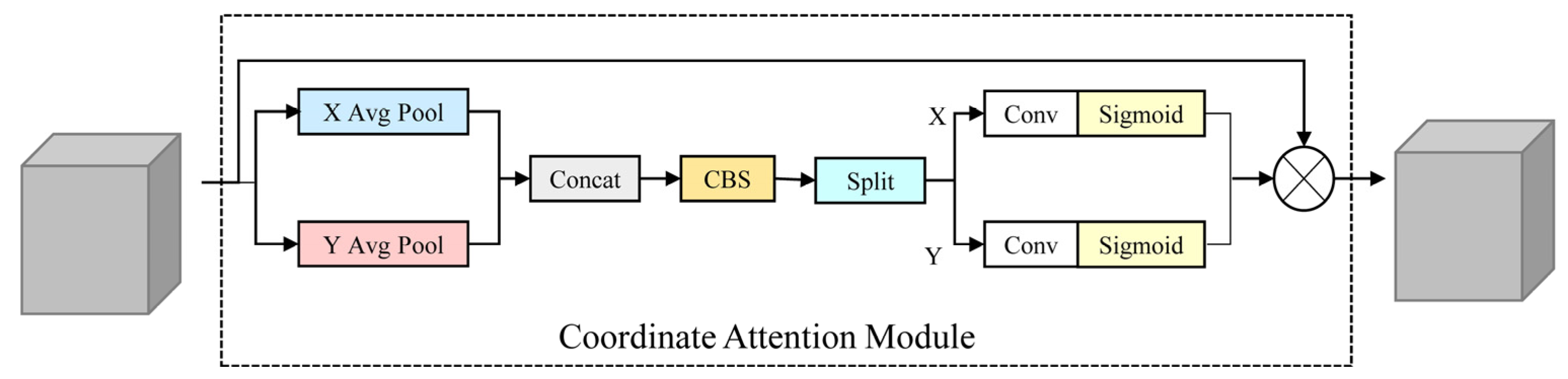
3.2. Coordinate Attention Module
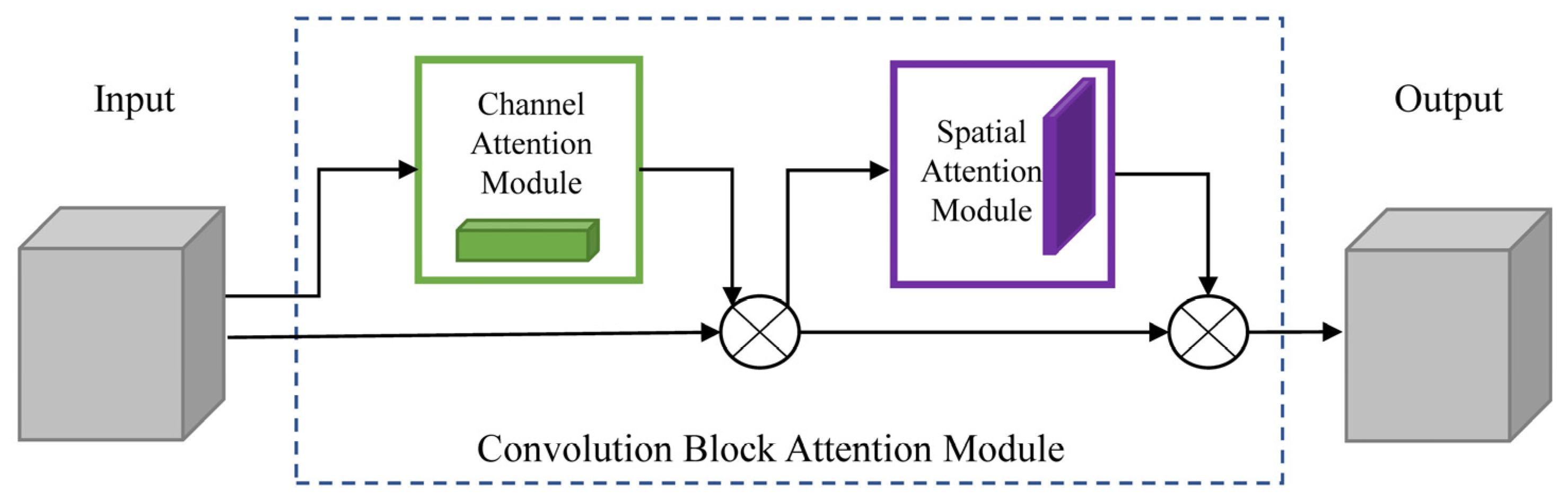
3.3. Convolution Block Attention Module
- (1)
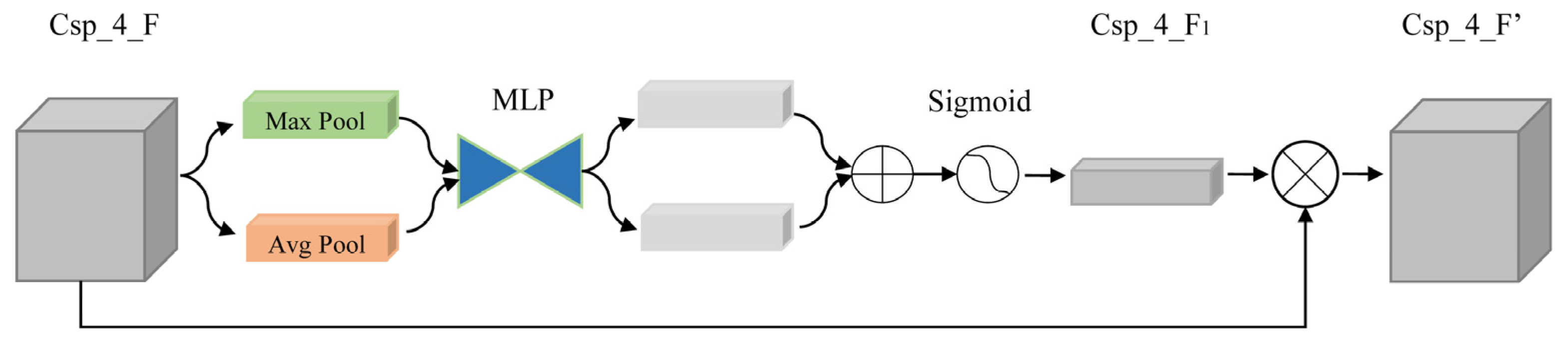
- Channel Attention Module
- (2)
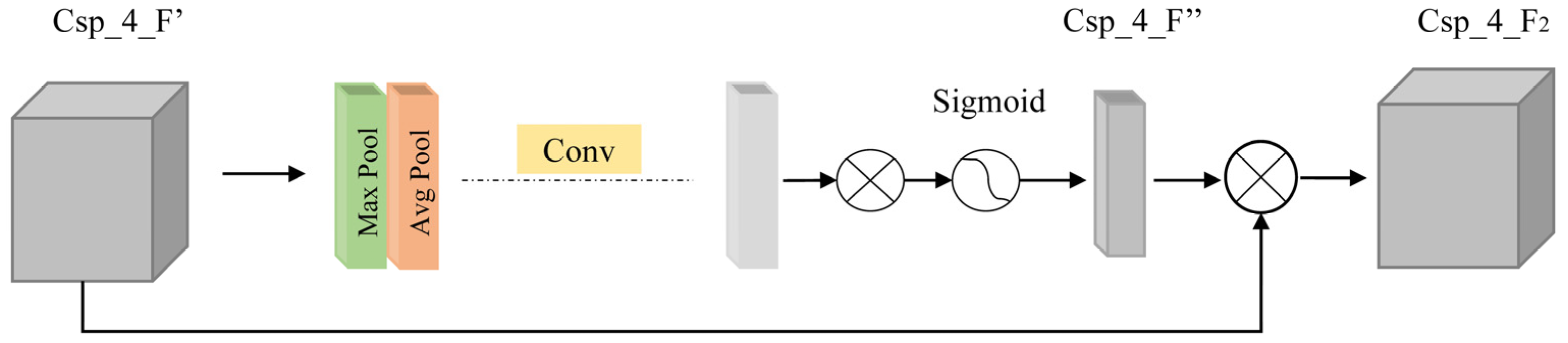
- Spatial Attention Module
4. Model Training
4.1. Dataset Preparation
4.2. Hyperparameter Settings
4.3. Evaluation Criteria
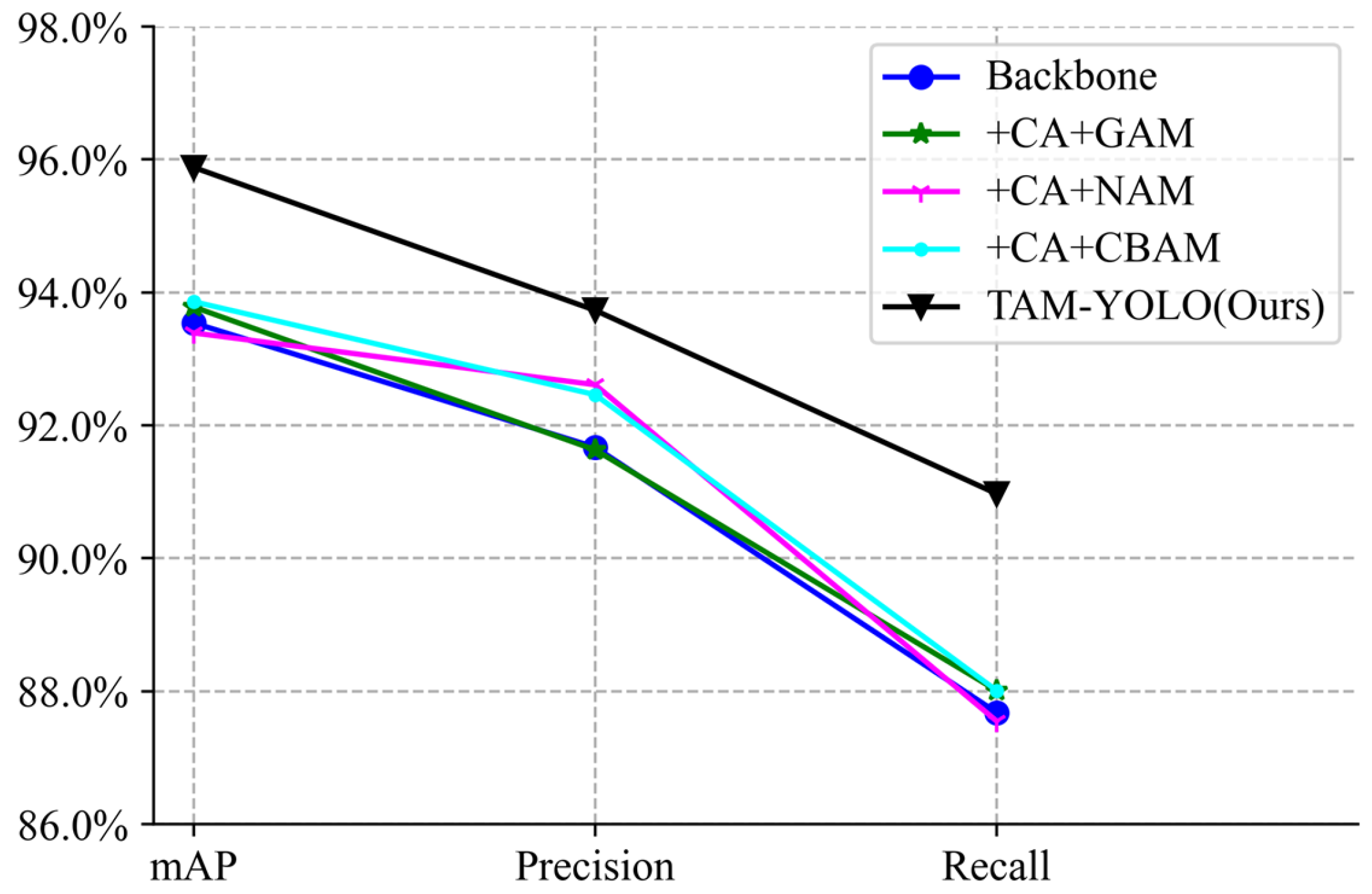
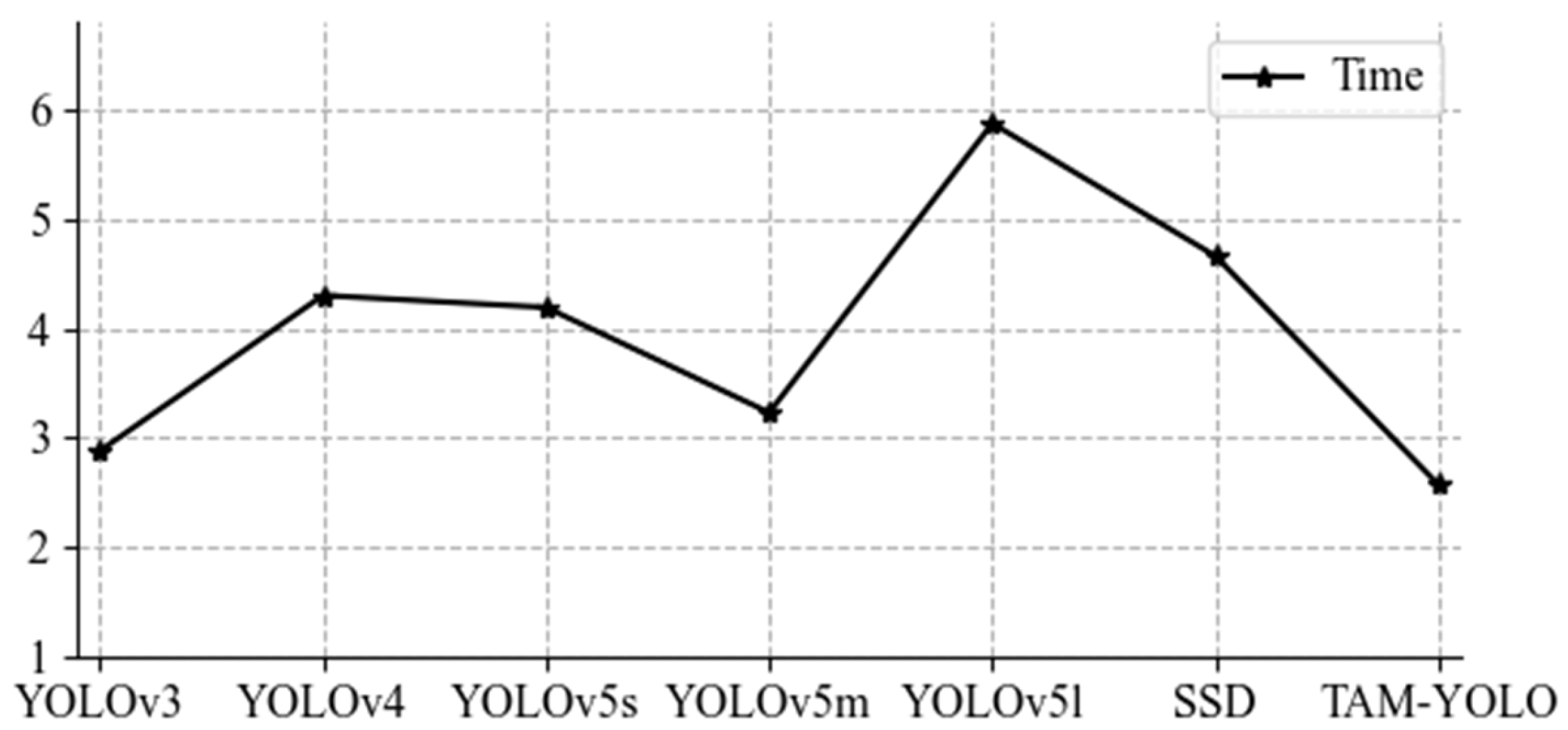
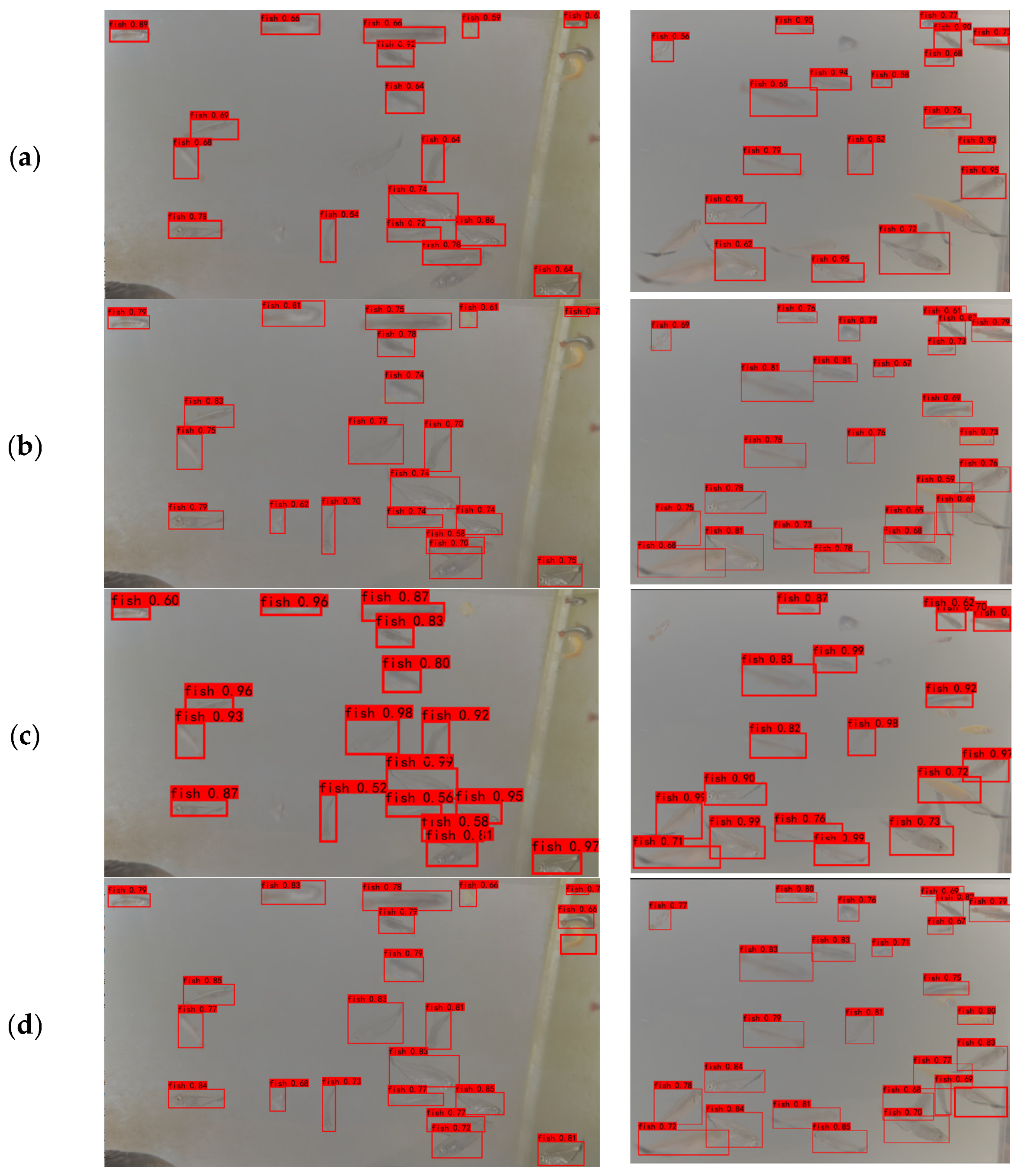
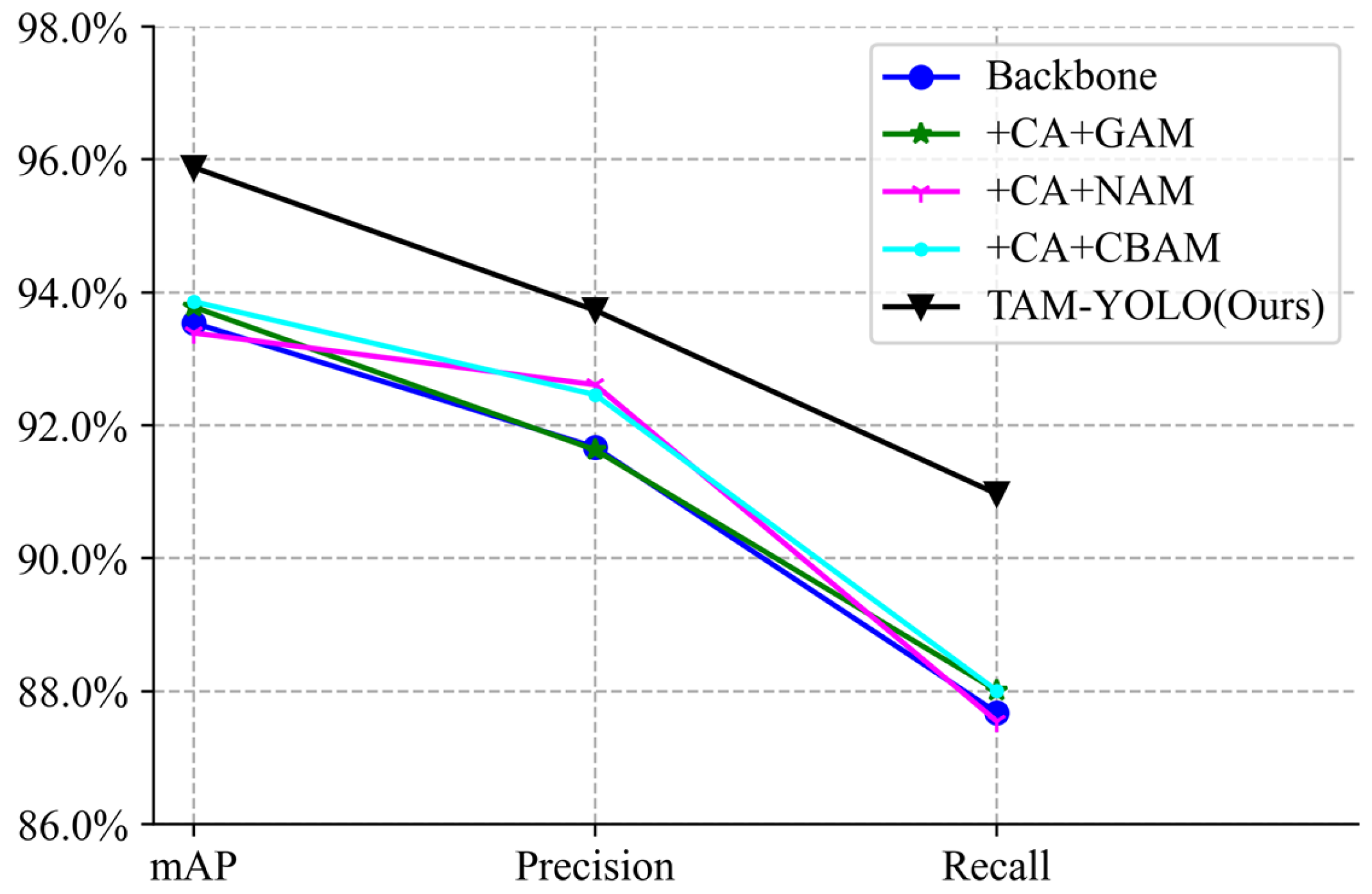
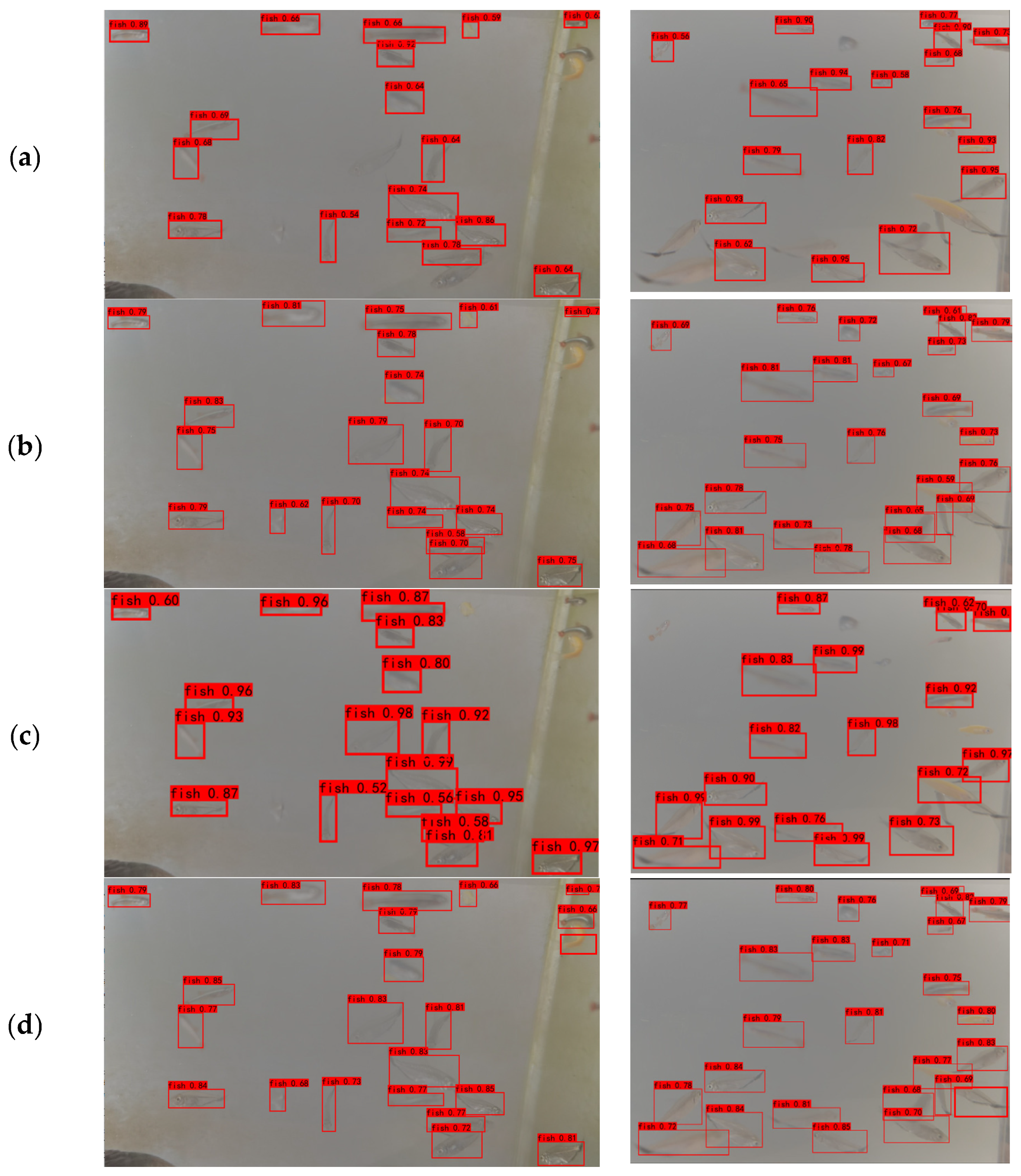
5. Analysis of Experimental Results
Ablation Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Honarmand Ebrahimi, S.; Ossewaarde, M.; Need, A. Smart fishery: A systematic review and research agenda for sustainable fisheries in the age of AI. Sustainability 2021, 13, 6037–6057. [Google Scholar] [CrossRef]
- Føre, M.; Frank, K.; Norton, T.; Svendsen, E.; Alfredsen, J.A.; Dempster, T.; Eguiraun, H.; Watson, W.; Stahl, A.; Sunde, L.M. Precision fish farming: A new framework to improve production in aquaculture. Biosyst. Eng. 2018, 173, 176–193. [Google Scholar] [CrossRef]
- Wang, C.; Li, Z.; Wang, T.; Xu, X.; Zhang, X.; Li, D. Intelligent fish farm—The future of aquaculture. Aquac. Int. 2021, 29, 2681–2711. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Zhang, S.; Liu, J.; Gao, Q.; Dong, S.; Zhou, C. Deep learning for smart fish farming: Applications, opportunities and challenges. Rev. Aquac. 2021, 13, 66–90. [Google Scholar] [CrossRef]
- Bradley, D.; Merrifield, M.; Miller, K.M.; Lomonico, S.; Wilson, J.R.; Gleason, M.G. Opportunities to improve fisheries management through innovative technology and advanced data systems. Fish Fish. 2019, 20, 564–583. [Google Scholar] [CrossRef]
- Bekkozhayeva, D.; Cisar, P. Image-Based Automatic Individual Identification of Fish without Obvious Patterns on the Body (Scale Pattern). Appl. Sci. 2022, 12, 5401–5417. [Google Scholar] [CrossRef]
- Li, D.; Li, X.; Wang, Q.; Hao, Y. Advanced Techniques for the Intelligent Diagnosis of Fish Diseases: A Review. Animals 2022, 12, 2938. [Google Scholar] [CrossRef]
- Ulutas, G.; Ustubioglu, B. Underwater image enhancement using contrast limited adaptive histogram equalization and layered difference representation. Multimed. Tools Appl. 2021, 80, 15067–15091. [Google Scholar] [CrossRef]
- Badawi, U.A. Fish classification using extraction of appropriate feature set. Int. J. Electr. Comput. Eng. (IJECE) 2022, 12, 2488–2500. [Google Scholar] [CrossRef]
- Le, J.; Xu, L. An automated fish counting algorithm in aquaculture based on image processing. In Proceedings of the 2016 International Forum on Mechanical, Control and Automation (IFMCA 2016), Shenzhen, China, 30–31 December 2016; pp. 358–366. [Google Scholar]
- Zhao, S.; Zhang, S.; Liu, J.; Wang, H.; Zhu, J.; Li, D.; Zhao, R. Application of machine learning in intelligent fish aquaculture: A review. Aquaculture 2021, 540, 736724. [Google Scholar] [CrossRef]
- Alsmadi, M.K.; Almarashdeh, I. A survey on fish classification techniques. J. King Saud Univ. Comput. Inf. Sci. 2020, 34, 1625–1638. [Google Scholar] [CrossRef]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 214–230. [Google Scholar]
- Zhao, T.; Shen, Z.; Zou, H.; Zhong, P.; Chen, Y. Unsupervised adversarial domain adaptation based on interpolation image for fish detection in aquaculture. Comput. Electron. Agric. 2022, 198, 107004. [Google Scholar] [CrossRef]
- Mathur, M.; Goel, N. FishResNet: Automatic Fish Classification Approach in Underwater Scenario. SN Comput. Sci. 2021, 2, 273. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Y.; Sun, X.; Liu, J.; Yang, X.; Zhou, C. Composited FishNet: Fish detection and species recognition from low-quality underwater videos. IEEE Trans. Image Process. 2021, 30, 4719–4734. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Yu, G.; Wang, L.; Hou, M.; Liang, Y.; He, T. An adaptive dead fish detection approach using SSD-MobileNet. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 1973–1979. [Google Scholar]
- Zhao, S.; Zhang, S.; Lu, J.; Wang, H.; Feng, Y.; Shi, C.; Li, D.; Zhao, R. A lightweight dead fish detection method based on deformable convolution and YOLOV4. Comput. Electron. Agric. 2022, 198, 107098. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, H.; Zhang, G.; Yang, X.; Wen, L.; Zhao, W. Diseased Fish Detection in the Underwater Environment Using an Improved YOLOV5 Network for Intensive Aquaculture. Fishes 2023, 8, 169. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Zhao, S.; Wang, Q.; Li, D.; Zhao, R. Real-time detection and tracking of fish abnormal behavior based on improved YOLOV5 and SiamRPN++. Comput. Electron. Agric. 2022, 192, 106512. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Li, H.; Yu, H.; Gao, H.; Zhang, P.; Wei, S.; Xu, J.; Cheng, S.; Wu, J. Robust detection of farmed fish by fusing YOLOv5 with DCM and ATM. Aquac. Eng. 2022, 99, 102301. [Google Scholar] [CrossRef]
- Zhao, M.; Yu, H.; Li, H.; Cheng, S.; Gu, L.; Zhang, P. Detection of fish stocks by fused with SKNet and YOLOv5 deep learning. J. Dalian Ocean. Univ. 2022, 37, 312–319. [Google Scholar]
- Han, F.; Zhu, J.; Liu, B.; Zhang, B.; Xie, F. Fish shoals behavior detection based on convolutional neural network and spatiotemporal information. IEEE Access 2020, 8, 126907–126926. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Nabi, M.; Shah, C.; Prior, J.; Campbell, M.D.; Wallace, F.; Ball, J.E.; Moorhead, R. Class-aware fish species recognition using deep learning for an imbalanced dataset. Sensors 2022, 22, 8268. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Liu, Y.; Yu, H.; Fang, X.; Song, L.; Li, D.; Chen, Y. Computer vision models in intelligent aquaculture with emphasis on fish detection and behavior analysis: A review. Arch. Comput. Methods Eng. 2021, 28, 2785–2816. [Google Scholar] [CrossRef]
- Kim, T.-H.; Solanki, V.S.; Baraiya, H.J.; Mitra, A.; Shah, H.; Roy, S. A smart, sensible agriculture system using the exponential moving average model. Symmetry 2020, 12, 457. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Du, Z.; Jiang, G.; Cui, M.; Li, D.; Liu, C.; Li, W. A Real-Time Individual Identification Method for Swimming Fish Based on Improved Yolov5. Available at SSRN 4044575. 2022; 1–20. [Google Scholar] [CrossRef]
- Si, G.; Zhou, F.; Zhang, Z.; Zhang, X. Tracking Multiple Zebrafish Larvae Using YOLOv5 and DeepSORT. In Proceedings of the 2022 8th International Conference on Automation, Robotics and Applications (ICARA), Prague, Czech Republic, 18–20 February 2022; pp. 228–232. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input | Kernel Size | Stride | Output Channel | Active Function | |
|---|---|---|---|---|---|---|
| Backbone | Input | 640 × 640 × 3 | 1 × 1 | 2 | 12 | SiLU |
| Focus | 320 × 320 × 12 | 3 × 3 | 1 | 32 | SiLU | |
| CBS | 320 × 320 × 32 | 3 × 3 | 2 | 64 | SiLU | |
| CBS | 160 × 160 × 64 | 3 × 3 | 1 | 64 | SiLU | |
| Csp_1 | 160 × 160 × 64 | 1 × 1, 3 × 3 | 2 | 128 | SiLU | |
| CBS | 80 × 80 × 128 | 3 × 3 | 1 | 128 | SiLU | |
| Csp_2 | 80 × 80 × 128 | 1 × 1, 3 × 3 | 1 | 128 | SiLU | |
| CA | 80 × 80 × 128 | 1 × 1 | 2 | 256 | H-Swish | |
| CBS | 40 × 40 × 256 | 3 × 3 | 1 | 256 | SiLU | |
| Csp_3 | 40 × 40 × 256 | 1 × 1, 3 × 3 | 2 | 512 | SiLU | |
| CBS | 20 × 20 × 512 | 3 × 3 | 1 | 512 | SiLU | |
| SPP | 20 × 20 × 512 | 5 × 5, 9 × 9, 13 × 13 | 1 | 512 | SiLU | |
| Csp_4 | 20 × 20 × 512 | 1 × 1, 3 × 3 | 1 | 512 | SiLU | |
| CBAM | 20 × 20 × 512 | 1 × 1, 7 × 7 | 1 | 512 | H-Swish | |
| Neck | CBS | 20 × 20 × 512 | 1 × 1 | 1 | 256 | SiLU |
| UnSampling | 20 × 20 × 256 | 1 × 1 | 1 | 256 | SiLU | |
| Concat+Csp | 40 × 40 × 256 | 1 × 1, 3 × 3 | 1 | 256 | SiLU | |
| CBS | 40 × 40 × 256 | 1 × 1 | 1 | 128 | SiLU | |
| UnSampling | 40 × 40 × 128 | 1 × 1 | 1 | 128 | SiLU | |
| Concat+Csp | 80 × 80 × 128 | 1 × 1, 3 × 3 | 1 | 128 | SiLU | |
| DownSampling | 80 × 80 × 128 | 3 × 3 | 2 | 128 | SiLU | |
| Concat+Csp | 40 × 40 × 128 | 1 × 1, 3 × 3 | 1 | 256 | SiLU | |
| DownSampling | 40 × 40 × 256 | 3 × 3 | 2 | 512 | SiLU | |
| Concat+Csp | 20 × 20 × 512 | 1 × 1, 3 × 3 | 1 | SiLU | ||
| Head | Conv1 | 80 × 80 × 128 | 1 × 1 | 1 | 18 | SiLU |
| Conv 2 | 40 × 40 × 256 | 1 × 1 | 1 | 18 | SiLU | |
| Conv 3 | 20 × 20 × 512 | 1 × 1 | 1 | 18 | SiLU | |
| Model | Csp_2 | Csp_3 | Csp_4 | mAP/% | Precision/% | Recall/% |
|---|---|---|---|---|---|---|
| Backbone | 93.54 | 91.67 | 87.68 | |||
| +GAM | √ | 89.61 | 90.5 | 81.62 | ||
| √ | 90.41 | 90.4 | 84.39 | |||
| √ | 93.59 | 92.64 | 87.88 | |||
| +CBAM | √ | 93.48 | 91.94 | 87.88 | ||
| √ | 93.26 | 91.52 | 87.48 | |||
| √ | 93.6 | 92.01 | 90.87 | |||
| +NAM | √ | 93.6 | 92.39 | 88.01 | ||
| √ | 93.38 | 92.03 | 87.48 | |||
| √ | 93.68 | 92.4 | 87.75 | |||
| +CA | √ | 93.63 | 91.67 | 88 | ||
| √ | 93.28 | 91.89 | 87.29 | |||
| √ | 93.17 | 91.51 | 87.35 |
| Model | Csp_2+CA | Csp_4+CBAM | Csp_4+NAM | Csp_4+GAM | mAP/% | Precision/% | Recall/% |
|---|---|---|---|---|---|---|---|
| Backbone 1 | 93.54 | 91.67 | 87.68 | ||||
| +CA+GAM 2 | √ | √ | 93.78 | 91.63 | 88.01 | ||
| +CA+NAM 3 | √ | √ | 93.39 | 92.61 | 87.55 | ||
| +CA+CBAM 4 | √ | √ | 93.86 | 92.46 | 88.01 | ||
| TAM-YOLO (Ours)5 | √ | √ | 95.88 | 93.73 | 90.97 |
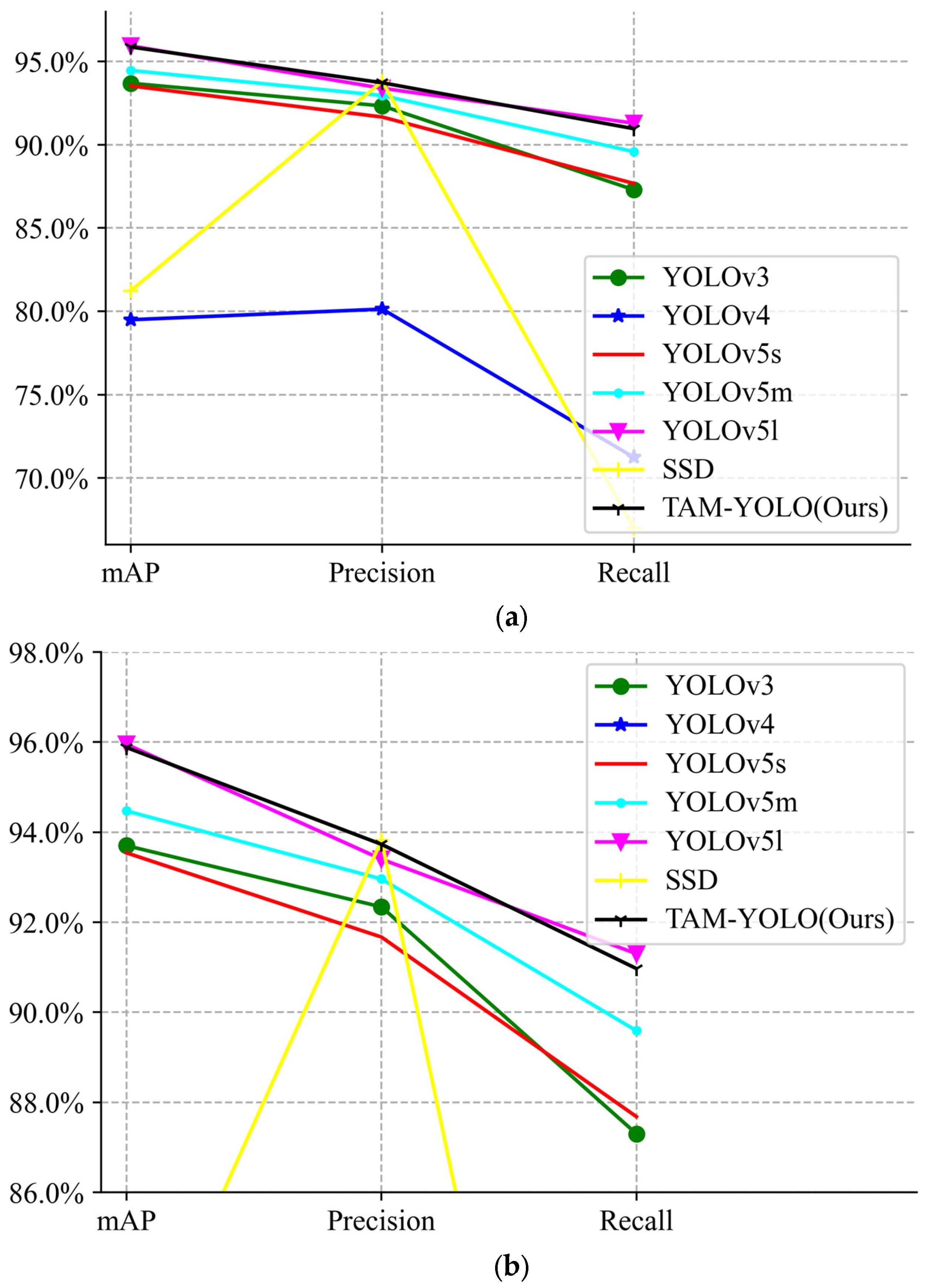
| Model | mAP/% | Precision/% | Recall/% | Time/s |
|---|---|---|---|---|
| YOLOv3 | 93.7 | 92.34 | 87.3 | 2.88 |
| YOLOv4 | 79.34 | 80.13 | 71.24 | 4.3 |
| YOLOv5s | 93.54 | 91.67 | 87.68 | 4.19 |
| YOLOv5m | 94.47 | 92.96 | 89.59 | 3.23 |
| YOLOv5l | 95.95 | 93.4 | 91.3 | 5.87 |
| SSD | 81.23 | 93.82 | 67 | 4.66 |
| TAM-YOLO (Ours) | 95.88 | 93.73 | 90.97 | 2.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Long, W.; Wang, Y.; Hu, L.; Zhang, J.; Zhang, C.; Jiang, L.; Xu, L. Triple Attention Mechanism with YOLOv5s for Fish Detection. Fishes 2024, 9, 151. https://doi.org/10.3390/fishes9050151
Long W, Wang Y, Hu L, Zhang J, Zhang C, Jiang L, Xu L. Triple Attention Mechanism with YOLOv5s for Fish Detection. Fishes. 2024; 9(5):151. https://doi.org/10.3390/fishes9050151
Chicago/Turabian StyleLong, Wei, Yawen Wang, Lingxi Hu, Jintao Zhang, Chen Zhang, Linhua Jiang, and Lihong Xu. 2024. "Triple Attention Mechanism with YOLOv5s for Fish Detection" Fishes 9, no. 5: 151. https://doi.org/10.3390/fishes9050151
APA StyleLong, W., Wang, Y., Hu, L., Zhang, J., Zhang, C., Jiang, L., & Xu, L. (2024). Triple Attention Mechanism with YOLOv5s for Fish Detection. Fishes, 9(5), 151. https://doi.org/10.3390/fishes9050151