
UM-YOLOv10: Underwater Object Detection Algorithm for Marine Environment Based on YOLOv10 Model

Abstract
1. Introduction
- (1)
- Establishing a high-quality underwater biological image dataset after image enhancement;
- (2)
- A novel residual attention mechanism module is proposed in this study;
- (3)
- Improving the YOLOv10 model by integrating an attention mechanism, a bidirectional feature pyramid, and a Focal Loss function;
- (4)
- The optimized YOLOv10 model is tested and validated against other mainstream target detection models.
2. Materials and Methods
2.1. Materials
2.1.1. Image Data Source
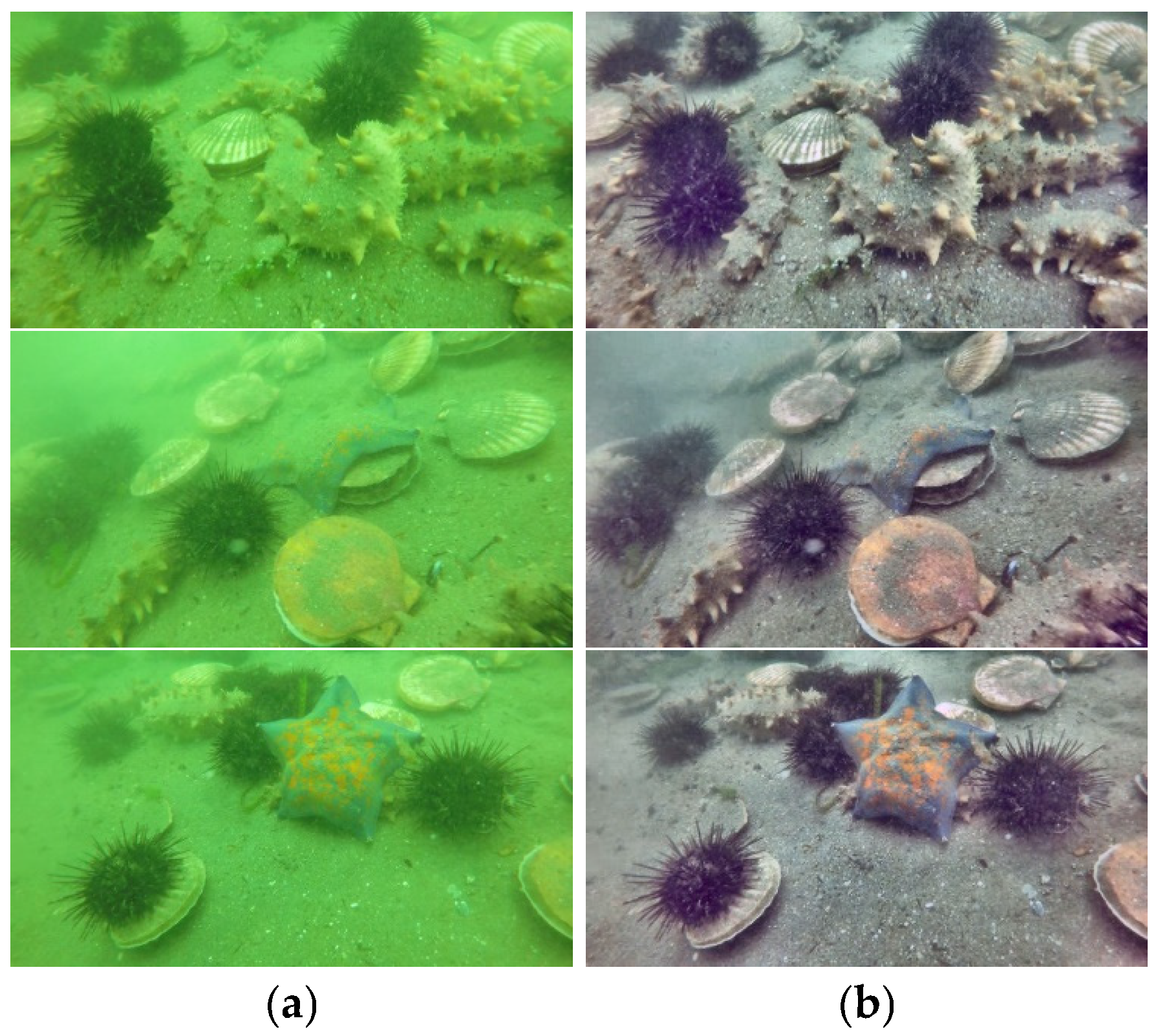
2.1.2. Images Enhancement and Dataset Production
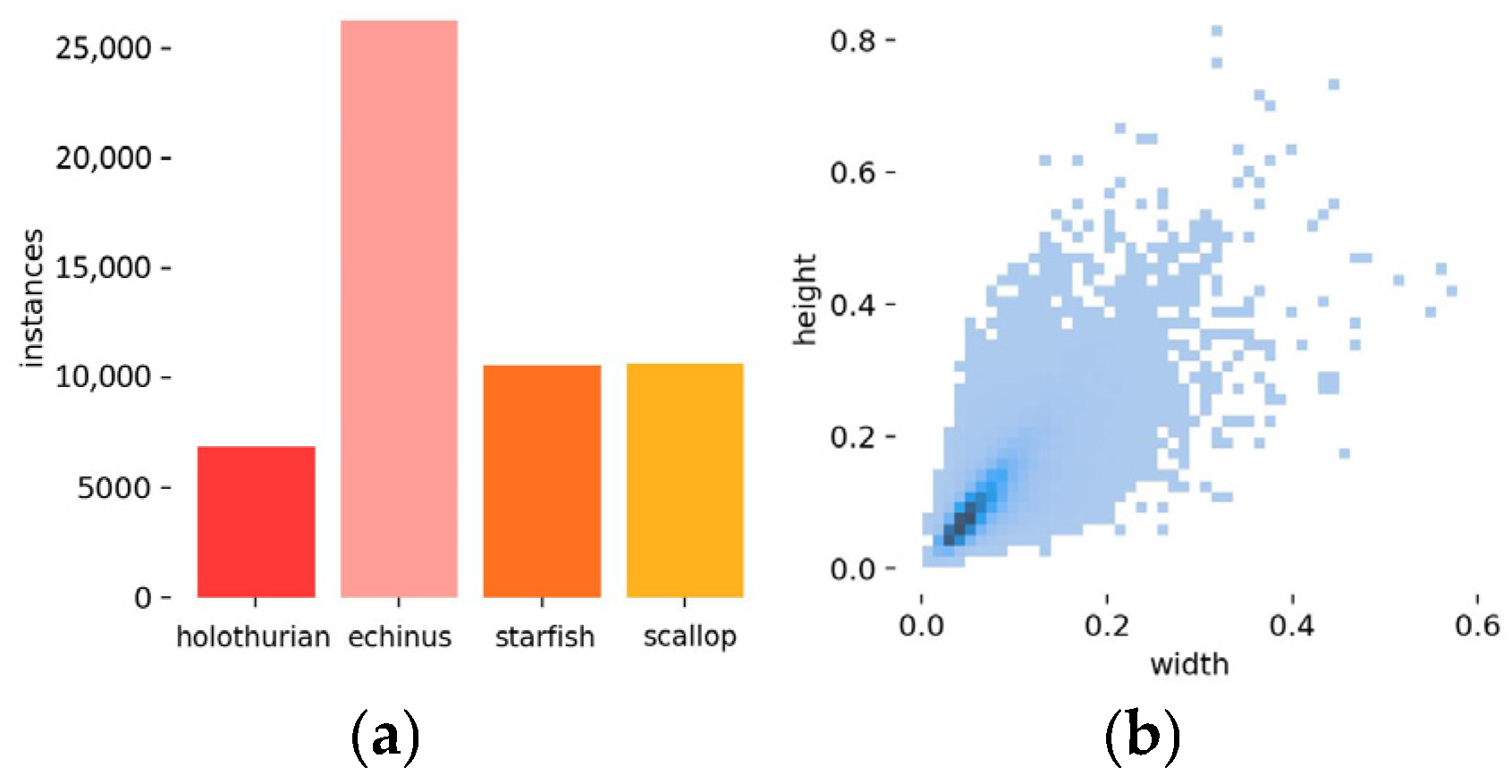
2.1.3. Dataset Statistical Analysis
2.2. Methods
2.2.1. YOLOv10 Network
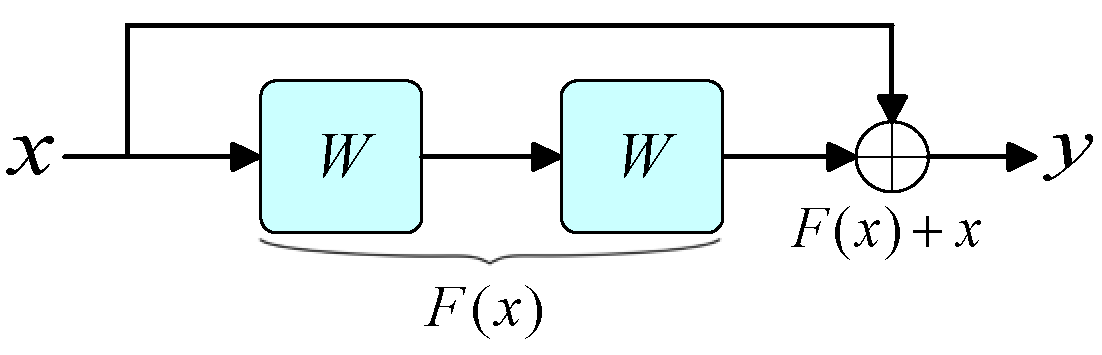
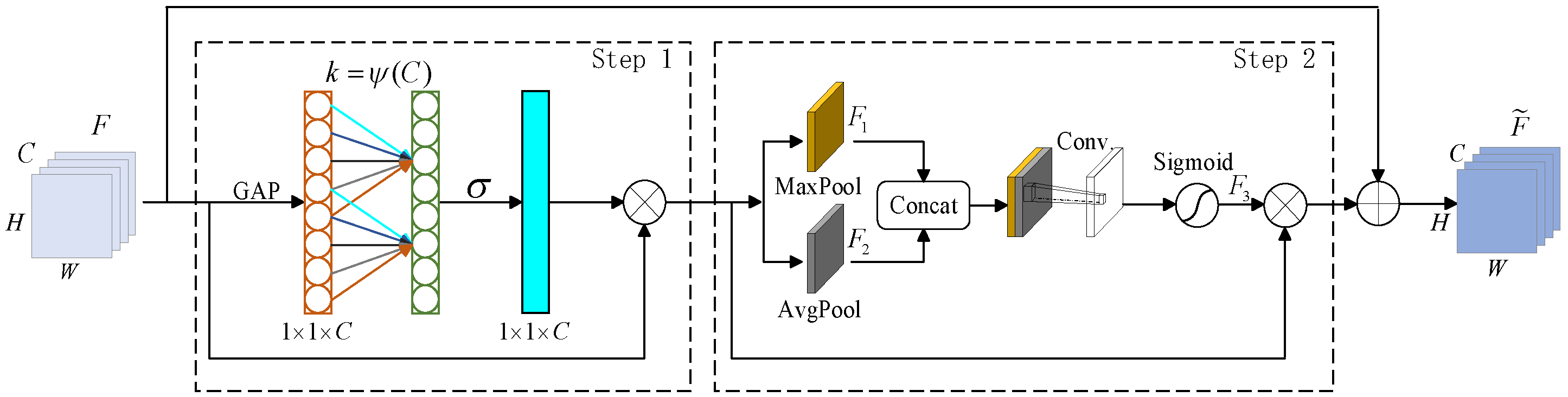
2.2.2. Residual Attention Mechanism
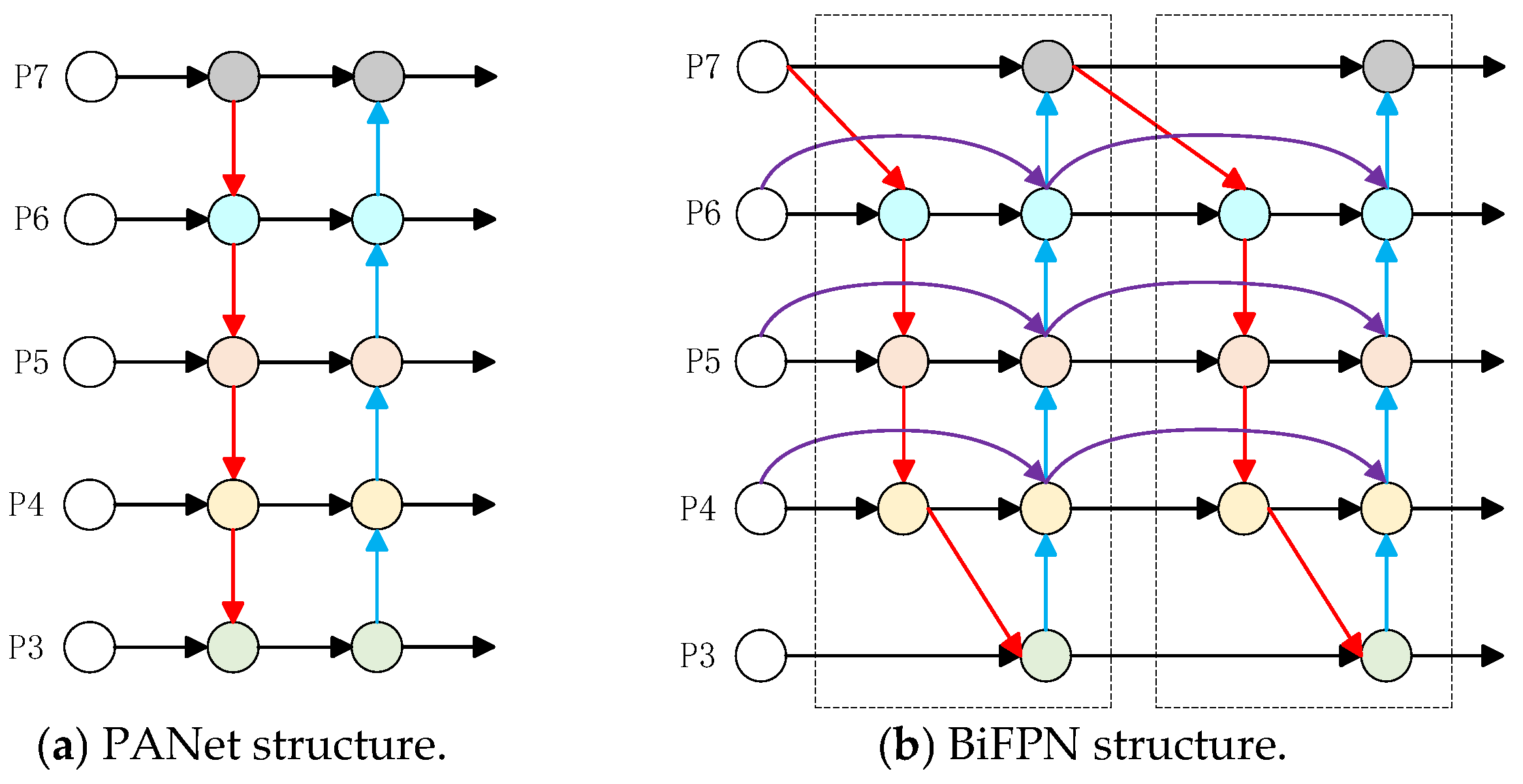
2.2.3. Bidirectional Feature Pyramid Network
2.2.4. Focal Loss
2.2.5. The Proposed Model
2.3. Experimental Environment Resource Configuration
3. Results
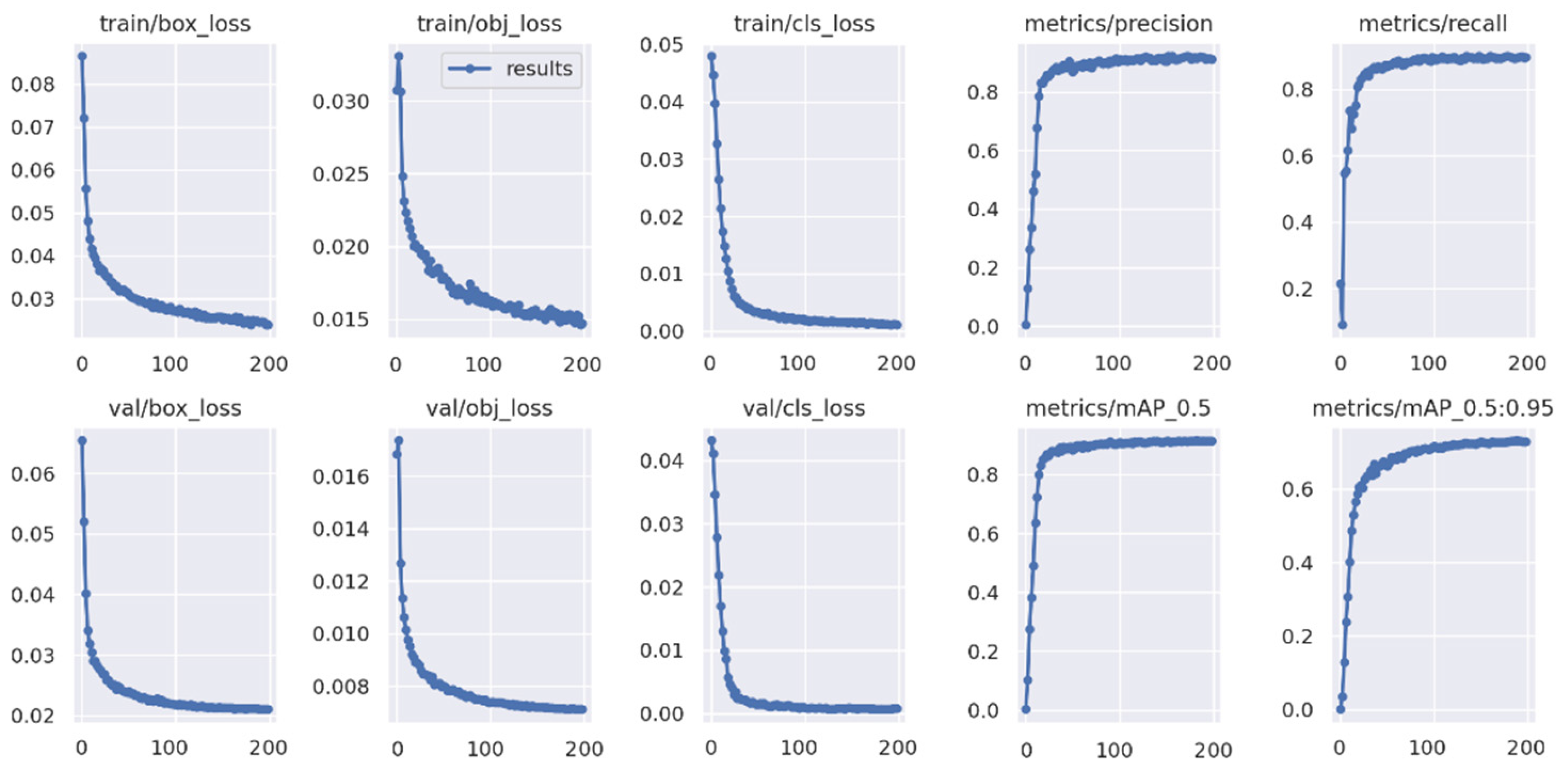
3.1. Ablation Experiment
3.2. The Impact of Image Enhancement on Model Performance
3.3. The Impact of Different Attention Mechanisms
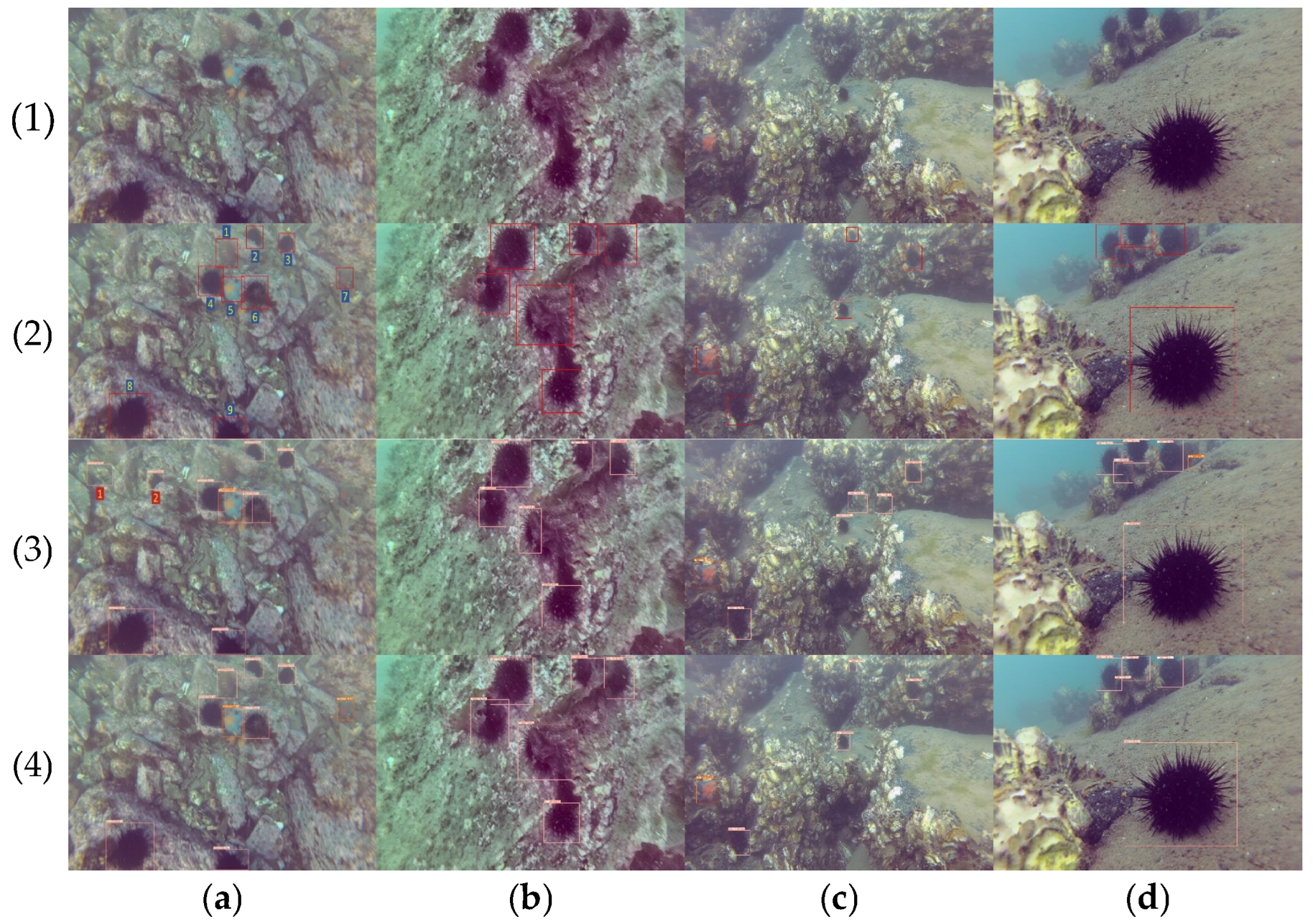
3.4. Comparison of Model Detection Effects
3.5. Comparison with Different Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| UM-YOLOv10 | An underwater object detection algorithm for marine environment based on the YOLOv10 model |
| R-AM | Residual attention module |
| BiFPN | Bidirectional feature pyramid network |
References
- Lee, M.F.R.; Chen, Y.C. Artificial intelligence based object detection and tracking for a small underwater robot. Processes 2023, 11, 312. [Google Scholar] [CrossRef]
- Low, D.G. Distinctive image features from scale-invariant keypoints. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Computer Vision and Pattern Recognition, (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Liu, H.; Ma, X.; Yu, Y.; Wang, L.; Hao, L. Application of deep learning-based object detection techniques in fish aquaculture: A review. J. Mar. Sci. Eng. 2023, 11, 867. [Google Scholar] [CrossRef]
- Wang, N.; Chen, T.; Liu, S.; Wang, R.; Karimi, H.R.; Lin, Y. Deep learning-based visual detection of marine organisms: A survey. Neurocomputing 2023, 532, 1–32. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings 2016, Part I 14. pp. 21–37. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Ross, T.Y.; Dollár, G.K.H.P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Ge, L.; Sadhu, A. Deep learning-enhanced smart ground robotic system for automated structural damage inspection and mapping. Autom. Constr. 2025, 170, 105951. [Google Scholar] [CrossRef]
- Ge, L.; Singh, P.; Sadhu, A. Advanced deep learning framework for underwater object detection with multibeam forward-looking sonar. Struct. Health Monit. 2024. [Google Scholar] [CrossRef]
- Sriram, S.; Aburvan, P.; Kaarthic, T.A.; Nivethitha, V.; Thangavel, M. Enhanced YOLOv10 Framework Featuring DPAM and DALSM for Real-Time Underwater Object Detection. IEEE Access 2025, 13, 8691–8708. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, H.; Qin, H.; Chen, Q. Self-supervised pre-training joint framework: Assisting lightweight detection network for underwater object detection. J. Mar. Sci. Eng. 2023, 11, 604. [Google Scholar] [CrossRef]
- Yi, W.; Wang, B. Research on Underwater small target Detection Algorithm based on improved YOLOv7. IEEE Access 2023, 11, 66818–66827. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Zhou, K.; Zhang, Y.; Chen, H.; Yan, X. An improved YOLOv5-based underwater object-detection framework. Sensors 2023, 23, 3693. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Peng, L.; Tang, S. Underwater object detection using TC-YOLO with attention mechanisms. Sensors 2023, 23, 2567. [Google Scholar] [CrossRef]
- Yu, G.; Cai, R.; Su, J.; Hou, M.; Deng, R. U-YOLOv7: A network for underwater organism detection. Ecol. Inform. 2023, 75, 102108. [Google Scholar] [CrossRef]
- Wang, X.; Xue, G.; Huang, S.; Liu, Y. Underwater object detection algorithm based on adding channel and spatial fusion attention mechanism. J. Mar. Sci. Eng. 2023, 11, 1116. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An improved YOLO algorithm for fast and accurate underwater object detection. Symmetry 2022, 14, 1669. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, Q.; Liu, P.; Gao, S.; Pan, X.; Zhang, C. Underwater image enhancement using deep transfer learning based on a color restoration model. IEEE J. Ocean. Eng. 2023, 48, 489–514. [Google Scholar] [CrossRef]
- Chang, S.; Gao, F.; Zhang, Q. Underwater Image Enhancement Method Based on Improved GAN and Physical Model. Electronics 2023, 12, 2882. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, D.; Zhang, Y.; Shen, M.; Zhao, W. A two-stage network based on transformer and physical model for single underwater image enhancement. J. Mar. Sci. Eng. 2023, 11, 787. [Google Scholar] [CrossRef]
- Park, J. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A general survey on attention mechanisms in deep learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 3279–3298. [Google Scholar] [CrossRef]
- Wang, R.; An, S.; Liu, W.; Li, L. Invertible residual blocks in deep learning networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 10167–10173. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. Available online: https://www.arxiv.org/abs/1911.09070v7 (accessed on 7 April 2025).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| Operating system | Ubuntu 22.04 |
| Framework | PyTorch 2.1.2 |
| GPU | RTX 4090D (24 GB) |
| CPU | 18 vCPU AMD EPYC 9754 128-Core Processor |
| RAM | 60 GB |
| Language | Python 3.10 |
| Model | mAP@0.5/% | mAP@0.5:0.95/% | P/% | R/% | F1-Score/*100 |
|---|---|---|---|---|---|
| A | 91.58 | 73.42 | 91.57 | 89.39 | 90.47 |
| A + B | 92.14 | 74.93 | 92.14 | 89.86 | 90.99 |
| A + C | 91.79 | 73.80 | 90.45 | 89.64 | 90.04 |
| A + D | 92.02 | 74.82 | 91.96 | 89.60 | 90.76 |
| A + B + C | 92.22 | 75.72 | 91.89 | 90.77 | 91.33 |
| A + B + D | 92.56 | 75.94 | 92.43 | 90.96 | 91.69 |
| A + C + D | 92.43 | 75.78 | 93.21 | 90.17 | 91.66 |
| A + B + C + D | 92.89 | 77.13 | 94.26 | 90.66 | 92.42 |
| Dataset | Model | mAP@0.5/% | mAP@0.5:0.95/% | P/% | R/% |
|---|---|---|---|---|---|
| OUBID | YOLOv10 | 90.74 | 70.21 | 90.34 | 88.20 |
| UM-YOLOv10 | 91.90 | 73.65 | 91.69 | 90.05 | |
| EUBID | YOLOv10 | 91.58 | 73.42 | 91.57 | 89.39 |
| UM-YOLOv10 | 92.89 | 77.13 | 94.26 | 90.66 |
| Model | mAP@0.5/% | mAP@0.5:0.95/% | P/% | R/% |
|---|---|---|---|---|
| YOLOv10 | 91.58 | 73.42 | 91.57 | 89.39 |
| YOLOv10 + ECANet | 91.75 | 74.27 | 90.45 | 89.64 |
| YOLOv10 + SAM | 91.63 | 73.65 | 90.31 | 89.03 |
| YOLOv10 + SENet [16] | 88.69 | 66.75 | 88.18 | 86.05 |
| YOLOv10 + CAM [18] | 90.22 | 70.25 | 90.11 | 88.19 |
| YOLOv10 + SFPAM [21] | 89.83 | 68.16 | 88.91 | 87.60 |
| YOLOv10 + R-AM | 92.14 | 74.93 | 92.14 | 89.86 |
| Model | mAP@0.5/% | P/% | R/% | F1-Score/*100 | FPS | Param./M |
|---|---|---|---|---|---|---|
| Faster R-CNN | 91.39 | 92.41 | 88.39 | 90.36 | 7.5 | 102.5 |
| SSD | 91.19 | 91.43 | 89.38 | 90.39 | 44.8 | 34.1 |
| RetinaNet | 88.83 | 87.82 | 88.19 | 88.00 | 19.3 | 19.8 |
| YOLOv6 | 88.19 | 85.97 | 88.42 | 87.18 | 46.7 | 15.0 |
| YOLOv7 | 91.47 | 92.19 | 89.64 | 90.90 | 58.2 | 36.9 |
| YOLOv10 | 91.58 | 91.57 | 89.39 | 90.47 | 67.4 | 7.2 |
| Ours | 92.89 | 94.26 | 90.66 | 92.42 | 63.8 | 8.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mai, R.; Wang, J. UM-YOLOv10: Underwater Object Detection Algorithm for Marine Environment Based on YOLOv10 Model. Fishes 2025, 10, 173. https://doi.org/10.3390/fishes10040173
Mai R, Wang J. UM-YOLOv10: Underwater Object Detection Algorithm for Marine Environment Based on YOLOv10 Model. Fishes. 2025; 10(4):173. https://doi.org/10.3390/fishes10040173
Chicago/Turabian StyleMai, Rengui, and Ji Wang. 2025. "UM-YOLOv10: Underwater Object Detection Algorithm for Marine Environment Based on YOLOv10 Model" Fishes 10, no. 4: 173. https://doi.org/10.3390/fishes10040173
APA StyleMai, R., & Wang, J. (2025). UM-YOLOv10: Underwater Object Detection Algorithm for Marine Environment Based on YOLOv10 Model. Fishes, 10(4), 173. https://doi.org/10.3390/fishes10040173