1. Introduction
Managing road traffic flow is one of the biggest challenges for smart cities—a subset of the Internet of Things (IoT) infrastructure. Thanks to smart surveillance applications [
1] for presenting a number of practical solutions for detecting road traffic events. The extensive installation of closed-circuit television (CCTV) cameras in smart cities has changed the infrastructure of urban areas for effective monitoring and safety of people in addition to traffic on roads. Artificial intelligence (AI) is gaining traction in the area of object detection from CCTV video recordings for video analytics. As a result, people are getting accustomed to AI-based intelligent surveillance systems. CCTV cameras installed in smart cities can easily be used to detect an event like an accident, robbery, assault, etc. If these mentioned events are detected in time, swift action can be taken by the relevant service authorities. There are two significant research challenges for surveillance data, i.e., event identification and privacy preservation of visual data.
For event identification, computer vision and image processing play a vital role in computer technology for detecting and classifying objects. Numerous algorithms are proposed by researchers in the past to detect and classify objects from images and videos. The most popular among object detection and classification algorithms include convolutional neural network (CNN) [
2], region-based CNN (R-CNN) [
3], Fast R-CNN [
4], Faster R-CNN [
5,
6], and YOLO [
7]. This paper has targeted You Only Look Once (YOLO), a deep learning model [
8] for the detection of road traffic events such as accidents (in our use-case). YOLO is basically an object detection algorithm and researchers have already utilised it for several applications including abandoned baggage detection [
9], mask detection [
10], license plate recognition [
11], shuttlecock detection [
12], pothole detection [
13], and many more to mention.
While dealing with visual data, another challenge is to ensure the privacy of sensitive data in recorded videos. European General Data Protection Regulation (EU-GDPR) [
14] recommends data minimisation and data protection by design for all types of collected data. Therefore, besides traffic events detection from the recorded data, this study also proposed a solution for minimal data storage. For this purpose, a short video (summary) for the detected traffic events (accident only) was generated and stored in a secure manner. EU-GDPR principle of “data minimisation” (Article 5) specifies that a data controller should limit the collection of information to what is directly relevant and necessary to accomplish a certain task, while “data protection by design” (Article 25) states that embedding data privacy features and technologies directly into the design of the project ensures better cost-effective protection for data privacy. The research goals of reduced and also secured video storage through an encrypted video summarization approach are aligned with the data minimisation and data protection by design criteria of the EU-GDPR. Moreover, limited data storage will also help in the quick retrieval of desired traffic event (accident) data (from massive stored videos) for required future video analytics and legal investigations.
Deep learning models require a huge amount of data for training, which is a major challenge due to the scarcity of publicly available real-world datasets. To overcome this issue, this research study has utilised synthetic data for the training of a supervised learning model, i.e., YOLO. As an added benefit, synthetic data have a privacy-related advantage over real-world data. Finally, the summarized data needs to be protected before storing them on a device. EU-GDPR recommends only encryption as a reversible data protection safeguard [
15,
16]. In order to ensure GDPR compliance, we have implemented encryption to ensure that summarized videos cannot be accessed by unauthorised stakeholders. A symmetric key, naive encryption [
17] was implemented for securing stored videos.
1.1. Research Questions
To make a GDPR-compliant technological solution for smart infrastructures (cities and surveillance systems), the following research questions are addressed in this paper:
RQ1: Can an object detection model trained on synthetic data (e.g., YOLO) produce optimum event detection results on real-time captured CCTV footage?
RQ2: For an event alert, can a CCTV video segment be extracted and stored in an encrypted format with foolproof security of encryption/decryption keys?
1.2. Research Contributions
By considering the aforementioned questions, the research contributions are:
RC1: YOLO is trained for event detection (rather than object detection) using a customised synthetic video dataset (accident and non-accident video frames).
RC2: The testing of the trained model is performed on real-time CCTV footage to classify the accidental and non-accidental video frames with different environmental conditions such as videos recorded at night and during rain.
RC3: Event-based video summaries of CCTV footage are stored in an encrypted format using Diffie–Hellman key exchange and Fernet cipher. The SHA256 hash is applied to tackle key and data-level security.
RC4: An annotated customised synthetic dataset (accident and non-accident video frames) for YOLOv5 model training is provided for future researchers.
The remainder of this research paper is organised as follows:
Section 2 sheds a light on related work,
Section 3 elaborates on methodology, results and discussion is given in
Section 4,
Section 5 shows comparative analysis with existing techniques,
Section 6 explains limitations with some future work, and in the last,
Section 7 concludes this research.
3. Methodology
Synthetic data is data generated artificially to appear like real-time data. The importance of synthetic data cannot be denied as a large number of training datasets can artificially be generated which is hard to collect in real-time scenarios. Furthermore, the privacy of recorded individuals/objects is compromised when datasets are made publicly available. Hence, the use of synthetic data is appreciable in privacy preservation.
Figure 1 shows two synthetic data video frames with non-accident and accident road events.
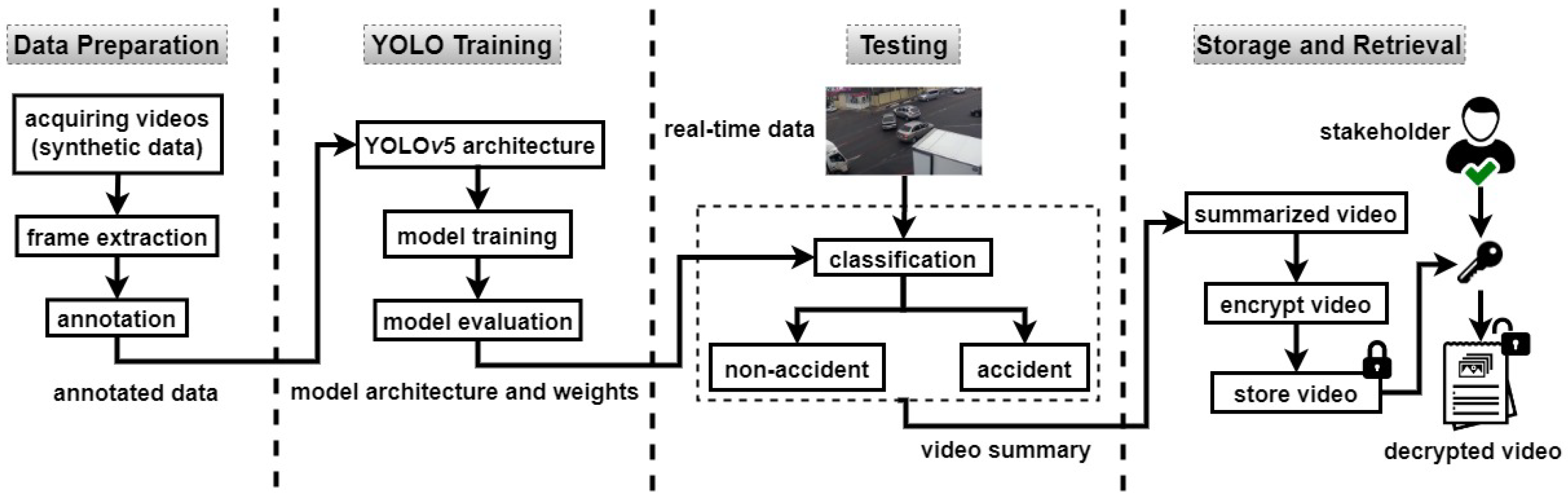
The proposed methodology shown in
Figure 2 is based on training of YOLO on a customised dataset (synthetic video frames). The most stable version of YOLO, i.e., YOLO
v5 is used for the experiments. There are four main phases in the methodology of the proposed research to implement the privacy preserved video summarization: (1) dataset preparation, (2) YOLO training, (3) testing, and (4) storage and retrieval. Below is the elaboration of the phases included in the methodology:
3.1. Dataset Preparation
The dataset preparation includes further three steps: (1) acquiring videos, (2) frame extraction, and (3) annotation. The description is as follows:
3.2. YOLO Training
YOLO sees the whole frame at once making it faster to detect objects in real-time scenarios. During the training phase, YOLO is trained on the customised (annotated) synthetic dataset. This process is completed in three steps: (1) YOLOv5 architecture, (2) model training, and (3) model evaluation. The details of each step are given below:
YOLO
v5 is pre-trained model on the COCO dataset [
32]. In this research, YOLO
v5 is trained on customised synthetic dataset, as this version is lighter and faster than previous versions. It can easily be implemented on custom datasets by making necessary modifications for the classification task at hand. As this research entailed the classification of only two classes, therefore, we re-trained it on our dataset with the existing base layers. The head of YOLO
v5 consists of three convolutional layers that predict the location of bounding boxes (x, y, height, width) where an event has occurred, scores (certainty of the predicted event), and class of the event. YOLO
v5 uses sigmoid linear unit (SILU) and sigmoid activation functions. SILU is also known as swish activation function and it is used in the hidden layers with convolutional operations. On the other hand, sigmoid is used in the output layer with convolutional operations.
YOLO
v5 model training was done with Google Colab [
33]. The dataset was split into training (80%) and validation (20%) data. The model summary comprised of number of layers, parameters, gradients, and GFLOPs is shown in
Table 1. YOLO keeps the aspect ratio of the images, therefore, all the training images (1920 × 1080 resolution) were resized (416 × 234 resolution) for use in a 416 × 416 network. It took 3.939 h to train the model for 30 epochs with batch size 16. Initially, the training started on pre-trained weights, and on completion of training, two new weight files were created with the names
and
. We selected the file containing the best weights, i.e.,
, to test real-time videos, whereas
holds the weights for last epoch in the training. The training results for one batch are shown in
Figure 3.
The model was evaluated on synthetic data during training phase. Sample results on the validation data along with ground truth labels are shown in
Figure 4a and predicted classes in validation phase are shown in
Figure 4b, which shows model has learned good enough from the training dataset. However, testing is performed on real-time videos footage rather than synthetic dataset which is discussed in
Section 3.3.
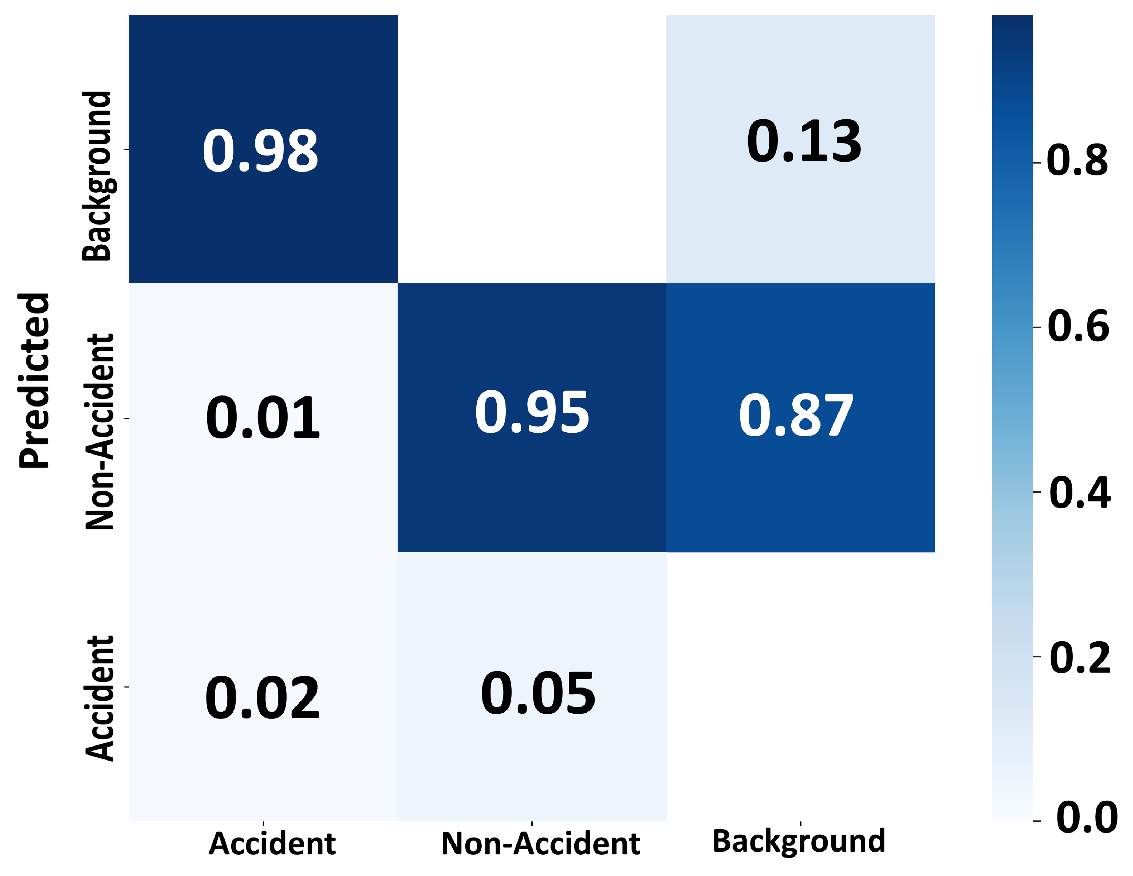
Confusion matrix shown in
Figure 5 also represents good training on customised synthetic dataset with 98% correct prediction for accidents and 95% prediction for non-accidents.
The model training was also evaluated through precision recall (PR) curve and F1-confidence curve. The details of both curves are as follows:
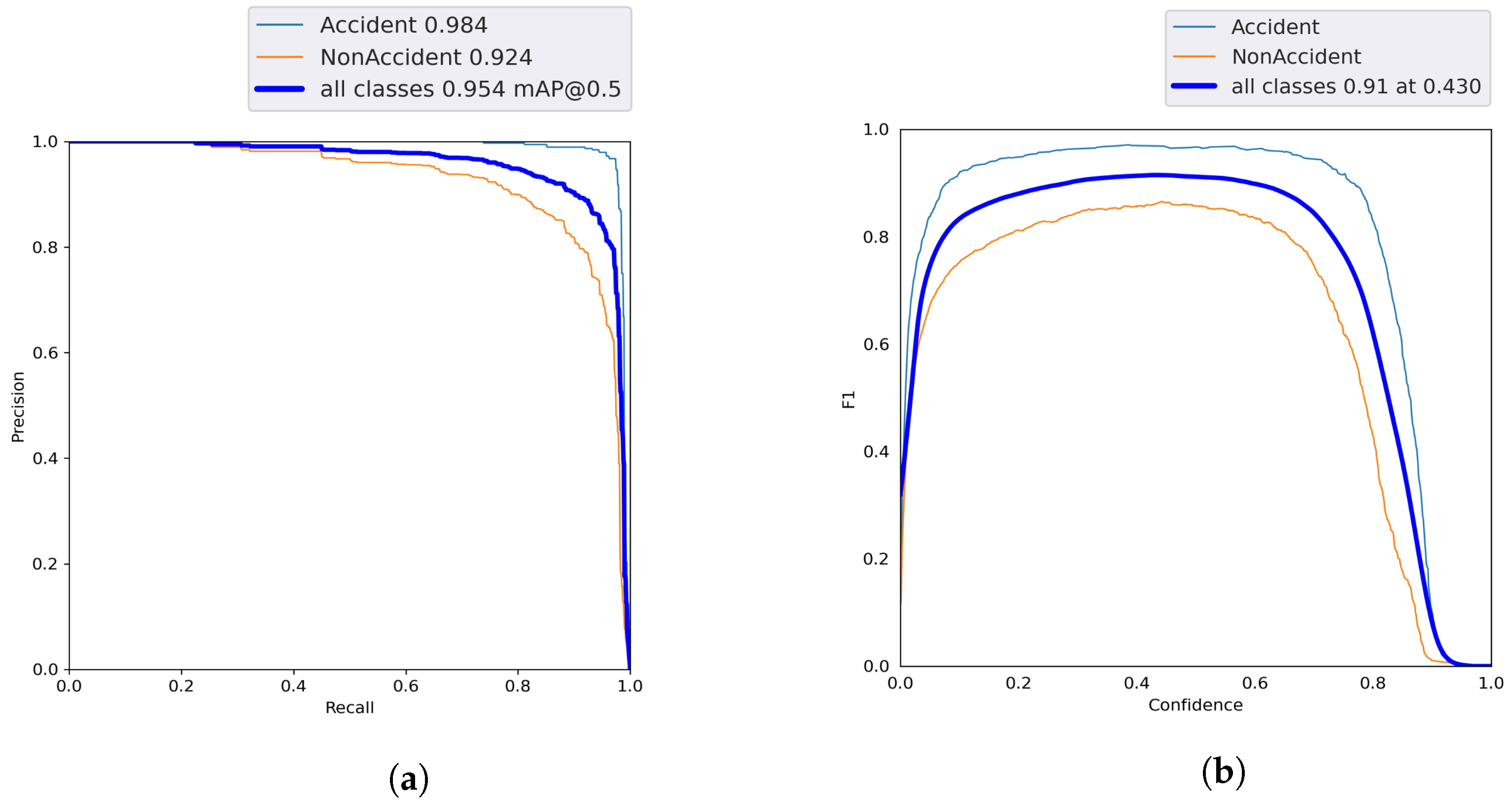
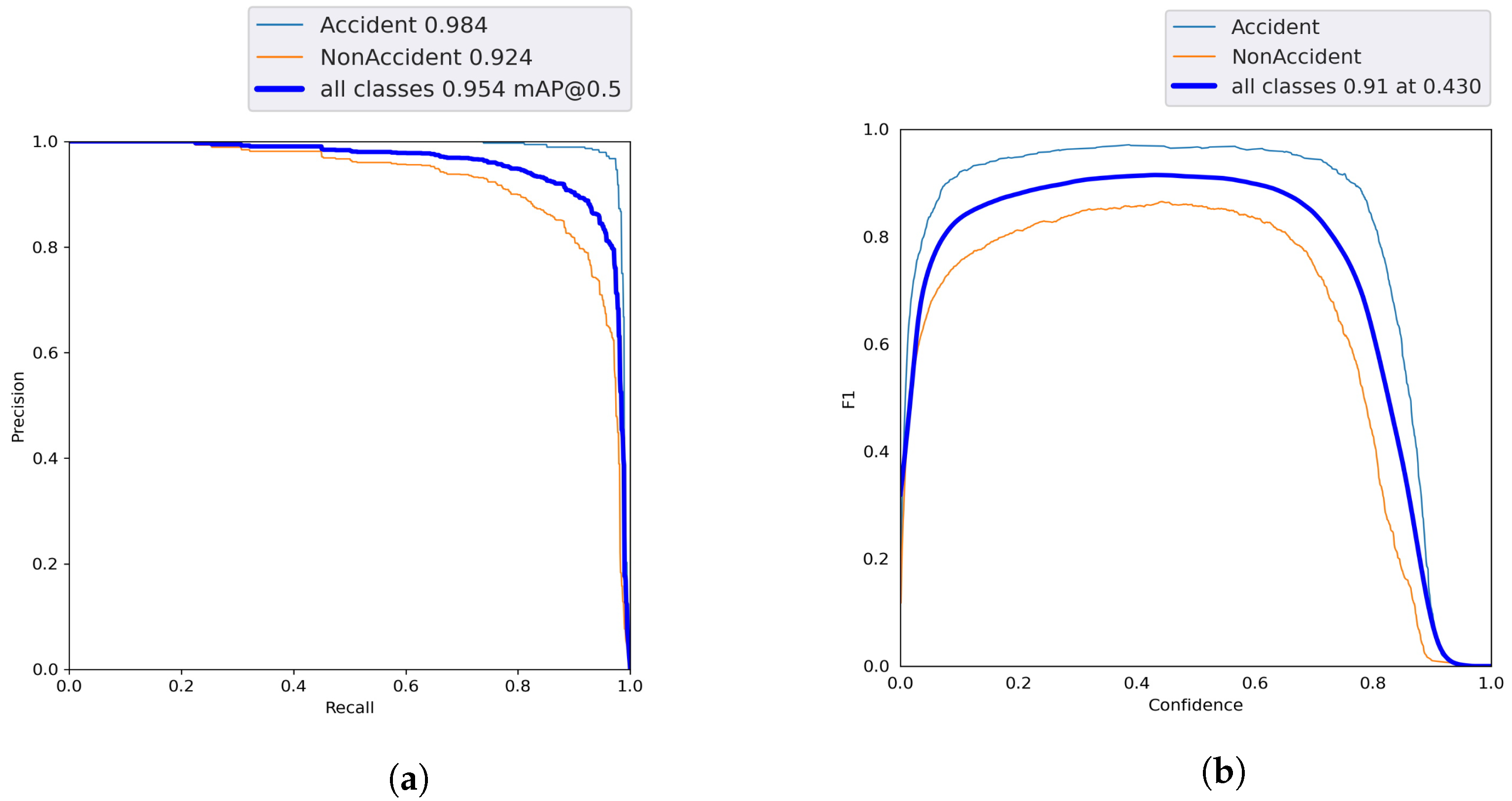
PR curve shown in
Figure 6a represents that model can predict accident and non-accident classes with a score of 0.984 and 0.924, respectively, with
mAP@0.5, where
mAP is mean average precision threshold. The graphs contain precision (
P) values on y-axis and recall (
R) values on x-axis. Equations (
1) and (
2) were used for calculation of
P and
R values, where:
is true positive,
is false negative, and
is false positive.
F1-Confidence Curve is a measure of
P and
R values at any specific threshold value, i.e., 0.91 here for both classes at 0.430, as shown in
Figure 6b.
-confidence curve value is near 1, which shows model is trained well.
score is calculated as:
Results of the trained model are given in
Table 2. There were total 600 images used in the training, having total 985 instances (398 for accidents and 587 for non-accidents).
P value for accidents is 0.967 and 0.838 for non-accidents, on the other hand,
R value is 0.971 and 0.882 for accidents and non-accidents, respectively. Overall
P value is 0.903 and
R value is 0.927. The
at threshold 50 is 0.984 for accidents, 0.924 for non-accidents, and overall, it is 0.954. The
value from threshold 50 to 95 is 0.704 for accidents, 0.584 for non-accidents, and overall it is 0.646. The result shows that model has achieved sufficient level of feature learning on customised synthetic data.
3.3. Testing on Real-Time Videos Footage
The trained YOLO
v5 model was tested on real-time road accident videos footage [
34]. The testing is performed on 15 different videos footage. The details of the videos footage along with average time taken by each video frame are given in
Table 3, that includes video no, frames, length (sec), and, pre-process, inference, and post-process time in ms (millisecond). The pre-processing converted an image from Numpy n-dimensional arrays to Pytorch tensors and normalized the pixel values from 0 to 255 to 0.0–1.0. Time spent inside the model is known as the inference time. Similarly, time taken by non-maximum suppression (NMS) is called post-processing. The model can predict many bounding boxes, all having different positions, sizes, and confidence levels, and there is possibility of overlapping when multiple bounding boxes are predicted. Therefore, NMS keeps bounding boxes with more confidence values and discard the other overlapping bounding boxes. The sample original frames along with the frames after event detection through YOLO is shown in
Figure 7. The results show that all video frames with events are successfully classified as accident and non-accidents.
3.4. Storage and Retrieval
After event detection, real-time test videos footage were summarized. All frames with detected accidents were collected for making a video summary. In every second, if an accident was detected in 50% or more of the frames, then all the frames of that second were kept for the storage. Otherwise, frames were discarded. This threshold was set to provide a context to the detected event (accident) in the video summary. For example, if a video was of 30 FPS (frames per second) and an accident was detected in 20 frames only, the remaining 10 frames were also saved with the accidental frames to show a few frames before or after the accident.
Cryptography for Summarized Videos
For securing data, naive symmetric encryption was applied to the summarized videos and stored on the server. A lightweight symmetric encryption algorithm, Fernet [
35,
36] was implemented to encrypt video summaries in the proposed research. Fernet uses Advanced Encryption Standard (AES) [
26], i.e., Cipher Block Chaining (CBC) with a 128-bit key for encryption and a secure hash algorithm (
) for authentication of data. The secure way of key management (generation and exchange) is a big challenge for robust encryption, therefore, Diffie–Hellman (DH) [
37] key exchange method was applied to generate password keys that were run through a key derivative function and should be salted to generate encryption/decryption keys for the parties. To increase the security of a password key that has been hashed, the process of salting involves adding random characters to the password key that have a specific length. DH can be used on unsecured channels for exchanging encryption keys without knowing each other. The safety of encryption keys is mandatory, so we proposed using a hardware wallet [
38] to store the DH-generated password keys. Keys can be further securely handled through key management algorithms [
39], which could be taken as future work for this research.
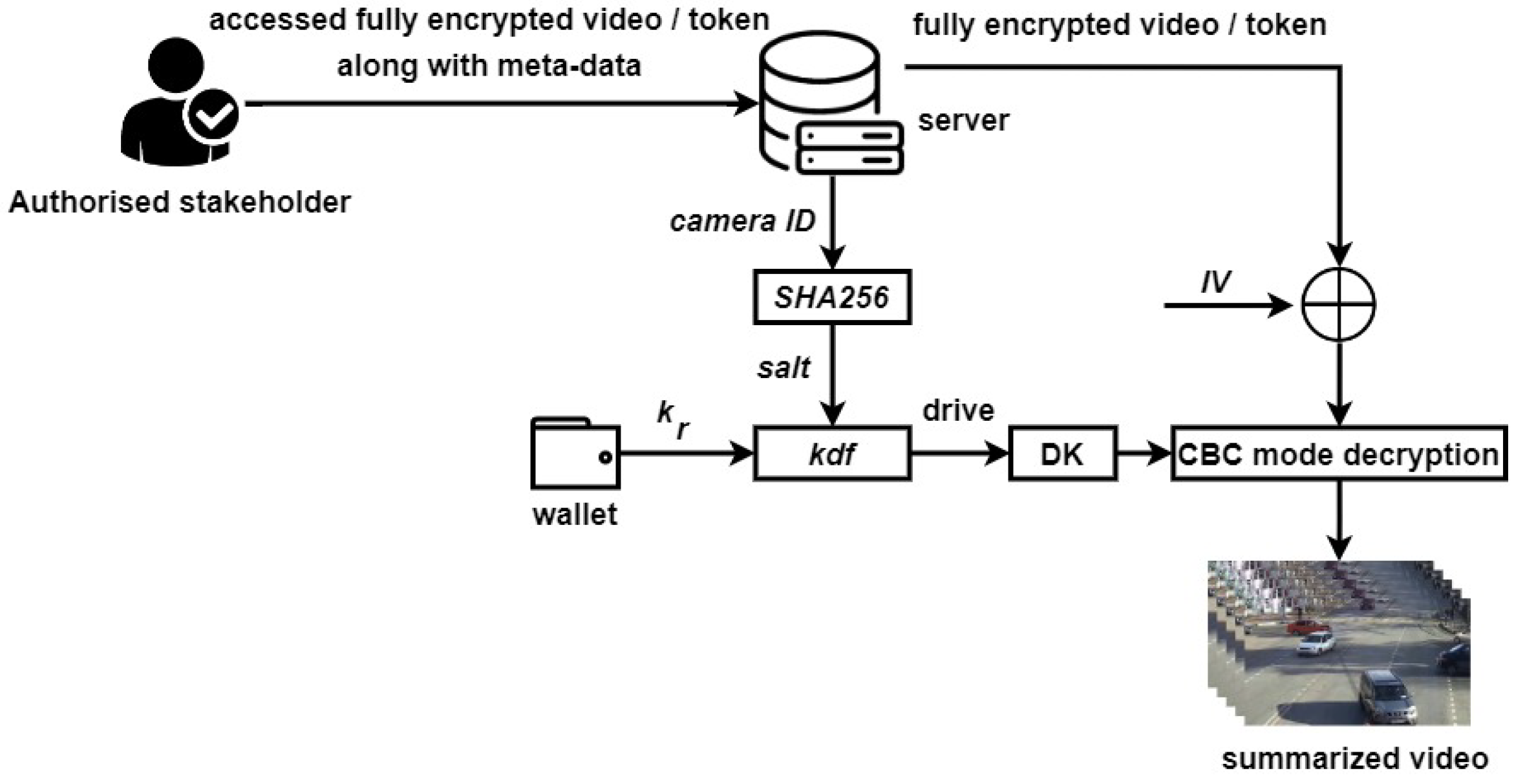
The basic structure of Fernet encryption is XORing (exclusive-OR) data with an initialization vector (
) followed by encryption with Fernet generated key. The decryption process decrypts the encrypted data by XORing it with an
followed by decryption with stored Fernet generated key. Algorithm 1 presents the pseudo-code for implementing cipher on video summaries. The steps included in encrypting a summarized video through Fernet encryption, DH, and
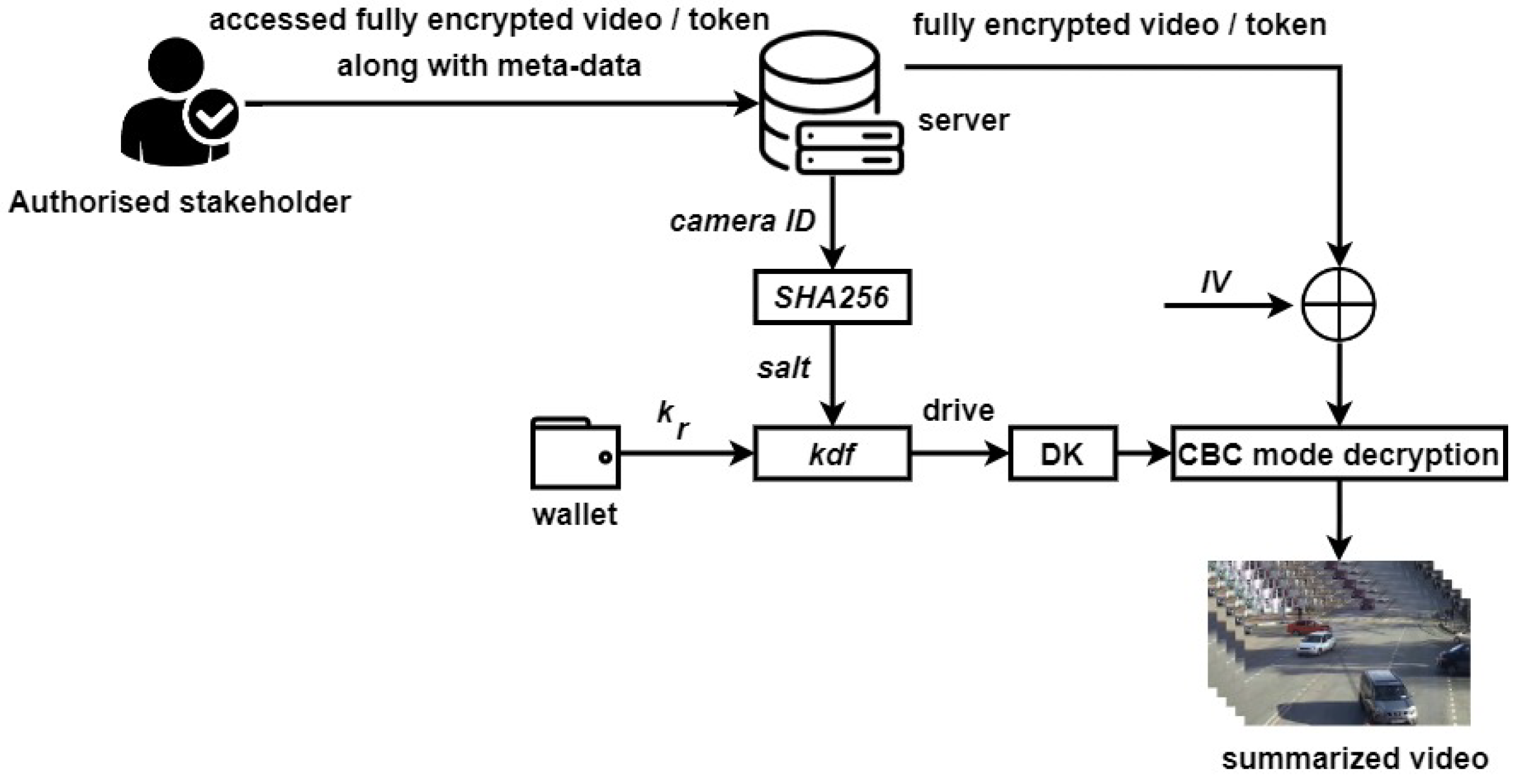
SHA256 are also presented in
Figure 8.
Firstly, two password keys ( and ) were generated by DH key exchange algorithm.
A hash value (h) was calculated for camera ID and stored as a digest in .
The password key was used along with to derive an encryption key (), whereas was stored in a hardware wallet for generating the decryption key () at the time of decryption.
was further used for preserving the privacy of a summarized video.
Fully encrypted video or token was stored on the server.
was deleted.
| Algorithm 1: Pseudo-code for applied cryptography on summarized videos |
| /* Calculate password keys for encryption and decryption key generation | /* |
| Initialization: p ← any_random_number, g ← any_random_number; |
| Output: , ; |
| |
| /* Calculate password keys and through Diffie–Hellman key exchange algorithm | /* |
| s ← select any random number; |
| r ← select any random number; |
| x ← calculate exchange key (); |
| y ← calculate exchange key (); |
| ← calculate password key for encyrption (); |
| ← calculate password key for decryption (); |
| Store on wallet; |
| |
| /* Calculation of | /* |
| h ← calculate hash value for camera ID; |
| ← store digest of h; |
| |
| /* Generate encryption key and apply Fernet encryption | /* |
| ← define key derivative function PBKDF2HMAC with calculated ; |
| ← convert into byte array; |
| ← base64.urlsafe_b64encode(kdf.derive(converted_)); |
| Input: summarized video; |
| ← generate randomly; |
| ← apply Fernet encryption on summarized video by using and ; |
| Delete ; |
| Output: fully encrypted video or token; |
| |
| /* Generate decryption key and apply Fernet decryption | /* |
| Read: camera ID, ; |
| ← define key derivative function PBKDF2HMAC with calculated ; |
| ← convert into byte array; |
| ← base64.urlsafe_b64encode(kdf.derive(converted_)); |
| Input: fully encrypted video or token; |
| ← apply Fernet decryption on fully encrypted video by using IV and ; |
| Output: summarized video; |
The Fernet generated token was based on the concatenation of version (8 bits), timestamp (64 bits), (128 bits), cipher (multiple of 128 bits), and HMAC (hash-based message authentication code). The version number tells the used version of Fernet, a timestamp is the token creation time, is the initialization vector that was used for AES encryption, the ciphertext is the encrypted data, and authentication in Fernet was achieved through HMAC that uses hash function. The token generated in the encryption process was further used at the time of decryption. was deleted immediately after the encryption process and was generated in the system of an authorised stakeholder who has access to decrypt the video.
The process shown in
Figure 9 was used to retrieve original summarized video from the encrypted video by XORing the encrypted video with
followed by decryption with
. The summarized video was decrypted with the same key (symmetric encryption) that was used to encrypt the video. Therefore, the key (
) calculated through DH and stored in wallet was used to calculate decryption key (
). Below are the details of the decryption process:
Authorised stakeholder accessed the fully encrypted video along with meta-data stored on the server.
Calculate using camera ID.
DH generated key was read from the wallet and the same key generation process was repeated to generate .
was read from Fernet token to decrypt the video with and .
The summarized video was decrypted for the authorised stakeholder.
4. Results and Discussion
For testing the trained YOLO over real-time videos footage, the system specifications were: NVIDIA Geforce RTX 3070 GPU, an Intel(R) Core(TM) i7-10700F CPU @ 2.90GHz 2.90 GHz processor, 16 GB of RAM, a 64-bit operating system, an x64-based processor, and Windows 11.
According to the details in
Table 3, 0.4 ms were consumed for pre-processing, 9.3 ms for inference, and 1.2 ms for post-processing by each frame, which means on average it took 10.9 ms to classify a frame in the video. For example, a video with 200 frames, 30 fps and 7 s length will take 2.18 s for event detection as calculated by:
where
T is the total time taken by a video to detect events,
F is the total number of frames in a video footage, and
A is the average time taken by each video frame to detect an event.
The accuracy of 5 videos was calculated based on bounding boxes (BB) drawn for each detected accident, as shown in
Table 4. Videos were summarized only if an accident occurs, therefore, only the accident class was used for calculating accuracy of the model. The model’s accuracy varies from 55% to 85%, when tested on real-time videos footage. These promising results ensure that YOLO can be trained for event detection as well. Equation (
5) is used to calculate accuracy for each video, where
TrueBB is the number of true bounding boxes detected for accidents in a video and
TotalBB is the total number of bounding boxes detected for accidents in a video.
The number of frames of original and summarized videos are given in
Table 5 along with the sizes of original, summarized and encrypted summarized videos. The results show that number of frames and sizes of summarized videos are mostly less than the original videos even if encryption is applied before storage.
Table 6 shows a reduction in the duration (video length) of every original video. According to the details, video 1 is reduced by 20%, video 2 by 51.14%, video 3 and 5 by 50%, and video 4 by 43.75%. On average, videos are reduced by 42.97%, which is quite a good reduction in the duration of any video.
Key generation for encryption and decryption processes took 1.25 s on average.
Table 7 shows the time (sec) consumed by encryption and decryption processes. All the videos consumed approximately 1 s for encryption and 1 s for decryption, excluding video 4, which took 1.25 s for each encryption and decryption process.
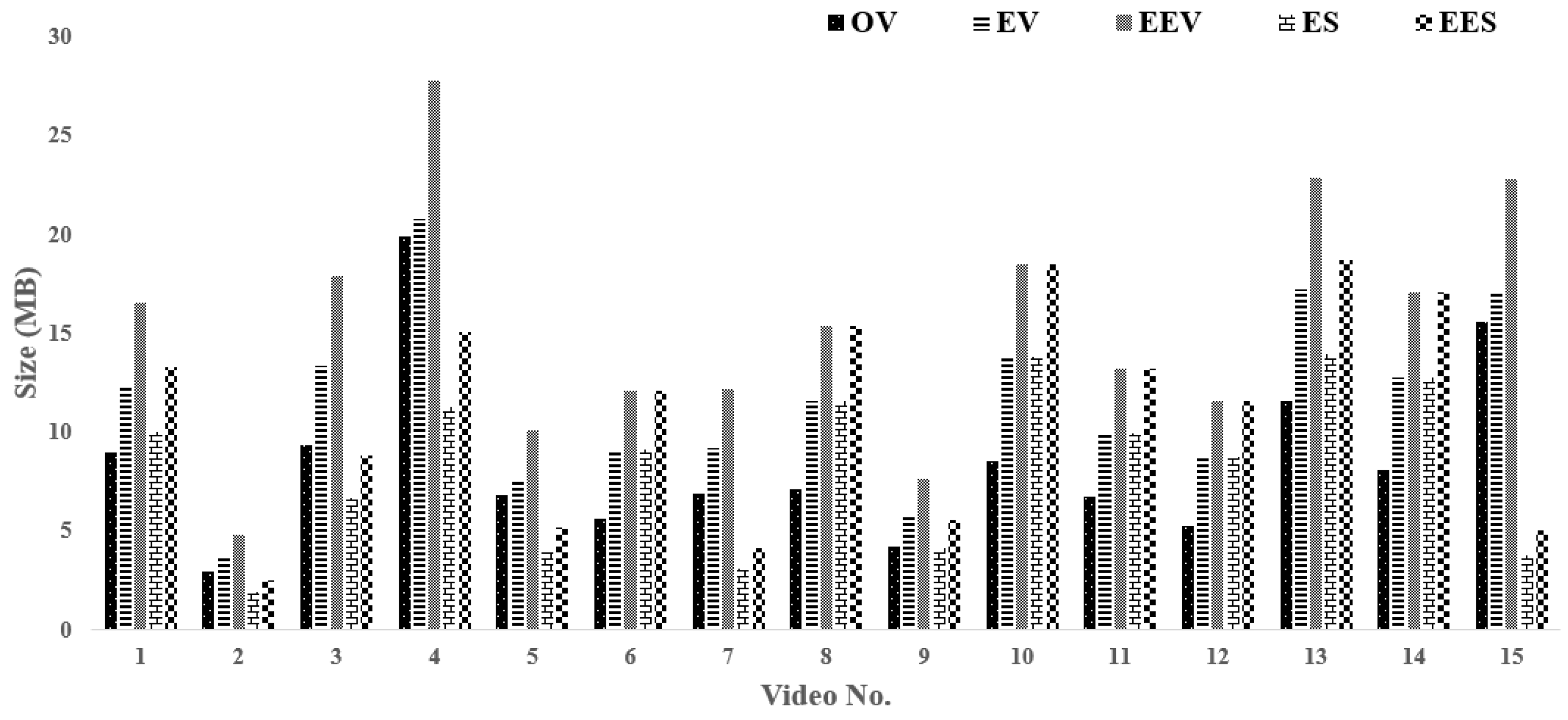
According to the test results, YOLO detects an event and draws a bounding box around the event which increases the size of video. A graph for storage space analysis of videos is shown in
Figure 10. The comparison of videos in their original form is done with the videos after event detection, video summarization, and encryption. Results show that size of the original video is increased after event detection due to bounding boxes information in the videos. Furthermore, when this video is encrypted, the size is increased again. Whereas, when a summary is detected based on accidents detected in each video, the size of video is reduced. Consequently, if the encryption is applied on this summarized video, the size of video is increased but it is less than the size of the original video. The duration of real-time test videos footage is only a few seconds, therefore, the size difference is not as much notable. However, in real-time scenarios where CCTV cameras are working all day (24/7), this technique would save a large number of storage space and will also reduce the time to access the video after an event has occurred.
6. Limitations and Future Work
There are certain identified limitations of the proposed solution, which are as follows:
Unavailability of synthetic data for training on multiple road events rather than just accidents/non-accidents.
Model is tested on fixed position CCTV recorded videos footage only.
Only vehicular accidents are focused in this research, while pedestrian crashes are not considered.
In the extension of this research work, the security of keys can be further enhanced by integrating a standard key management protocol. Another future direction could be to take test videos from dynamic cameras, i.e., dashcams and drones to validate the trained model. A new pedestrian dataset can also be added to the existing model for training and testing to provide a solution for pedestrian accidents, which would be a promising application of the proposed work for smart vehicles.
7. Conclusions
Video surveillance is a pervasive phenomenon throughout the world and their intelligent utilisation can assist in enhancing the smartness of smart cities in terms to reduce action response time. A smart surveillance application offers many benefits, but protecting an individual’s privacy along with their associated objects is equally important. In the context of regulation, data protection by design is still at an immature stage and requires reliable secure technologies for the privacy protection of digitised visual data.
To facilitate EU-GDPR compliance in smart cities’ infrastructure, this paper proposed a privacy preserved solution for smart cities by training YOLO on synthetic and annotated road traffic accident data containing accident and non-accident events for video summarization. The trained YOLO model is tested on real-time CCTV videos footage, but to protect the sensitive event records, symmetric encryption with Fernet cipher is applied on the summarized videos along with Diffie–Hellman key exchange algorithm, and SHA256 hash algorithm. The encryption key is deleted immediately after the encryption process and the key stored in a hardware wallet is later on used by the authorised stakeholders to generate a decryption key to avoid MITM attacks on keys. The results calculated on five (5) test videos show that the model achieved 55% to 85% accuracy for event (accident) detection and this accuracy is measured by the number of true bounding boxes drawn on each accident area. The accuracy of the model can be increased by increasing the training dataset, as this research is conducted on limited synthetic training data available for accidents and non-accidents road traffic events.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}