4.1. Dataset
Several datasets have been introduced in the intrusion detection literature, among which are KDD-CUP99, NSL-KDD, UNSW-NB15, CIC-DoS-2017, and CSE-CIC-IDS. There is a lack of availability of realistic datasets, which is a major challenge when working on IDS models. Organizations hesitate to disclose their network traffic data due to privacy concerns, as it can reveal sensitive configuration information. The KDD-CUP99 dataset is the most widely used dataset for evaluating intrusion detection models. However, KDD-CUP99 suffers from several weaknesses, including redundant rows, irrelevant features, and the non-stationary nature of the dataset [
19]. NSL-KDD is a refined version of the KDD-CUP99 dataset which has only selected records, and overcomes the drawbacks of KDD-CUP99 dataset. However, NSL-KDD dataset lacks observations related to low-footprint attacks and modern cyberattacks. The UNSW-NB15 dataset has modern cyberattacks included in it. The CIC-DoS-2017 has records of DoS attacks, as there has been an increase in such attacks. The CSE-CIC-IDS consists of seven different types of attacks. However, there are no datasets specific to IoT used for IDS evaluation. The Bot-IoT dataset focuses on IoT network architecture. It has five types of classes: DDoS, DoS, Reconnaissance, Theft, and Normal [
2]. The dataset has 72 million rows and 46 features, including three class categories. Because large dataset size can hinder computation, a 5% version of the original dataset has been released. In this study we use the smaller dataset, which has only the ten best features, meaning that a few irrelevant features have been discarded. The feature selection process is described in
Appendix A. As LAD is a binary classification technique, in our experiments all attacks are denoted by 1 and normal observations are denoted by 0.
4.4. Experimental Results
During the binarization step of LAD, 751 binary variables were generated. Only those features with cutpoints less than 175 were considered. This was done to limit the number of level variables in order to avoid long computation. A large number of cutpoints for a feature indicate that there is more randomness in the feature, which means that it does not influence the classification process. Such features were eliminated during the binarization phase.
The next step is support set generation, in which redundant variables are removed. The information gain ratio method was used to obtain the support set of features, with a total of 23 features selected.
In the pattern generation step, positive and negative patterns were generated. Algorithm 1 was used to generate the patterns. Eight positive patterns and six negative patterns of degrees 2 and 3 were generated. Here, each positive pattern covers at least ten positive observations and no negative observation. Similarly, negative observations cover at most one negative observation. A hybrid classifier was built using both positive and negative patterns together and tested on the Bot-IoT test dataset.
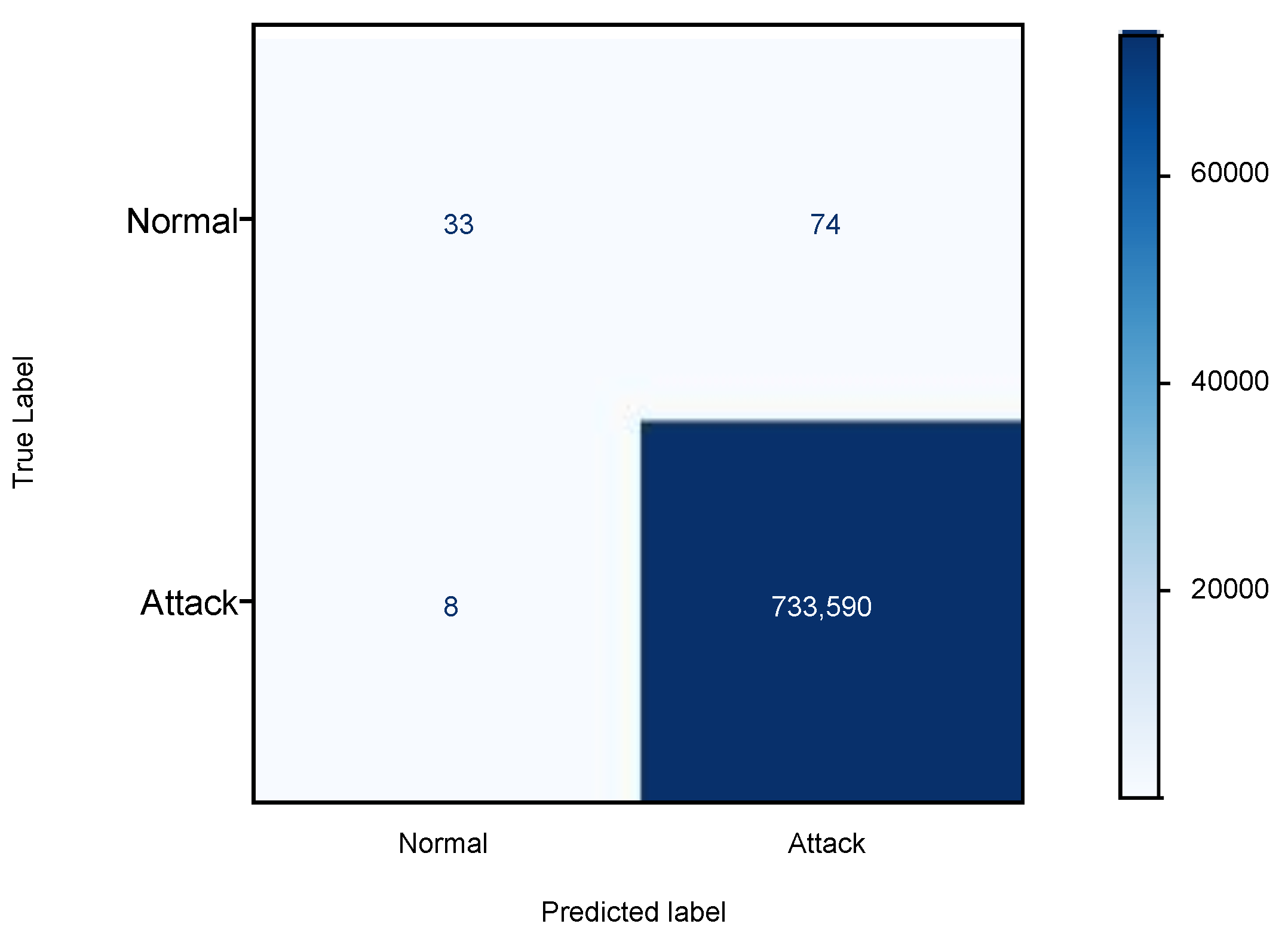
The classifier has fourteen rules, which were validated using the test dataset. The confusion matrix for the Bot-IoT test dataset is shown in
Figure 1. It can be concluded from
Figure 1 that the normal observations are far fewer compared to the attack observations in the test dataset. While most of the attack observations are classified correctly, 74 normal observations are misclassified as attacks. The LAD-based IDS has an accuracy of 99.98% and recall of 99.99%. As the training dataset has a higher number of attack observations compared to normal observations, our IDS model is able to detect attacks 99% correctly. Normal observations have been misclassified due to a lower number of normal records in the training dataset, and thus the false positive rate is high. The precision and F1 score values in
Table 7 are 99.98% and 99.99%, respectively. The False Positive Rate (FPR) is 69.15%, which is very high, and is due to misclassification of normal (negative) instances. This could be reduced if a greater number of normal observations were present in the training dataset. The False Negative Rate (FNR) is 0.001%, which shows that very few attack (positive) instances were misclassified as normal (negative).
The performance of our LAD-based IDS model was compared with various machine learning and deep learning techniques, as shown in
Table 8. In [
4], the authors used a Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Deep Neural Network (DNN) on the 5% Bot-IoT dataset, achieving an accuracy of 98.37%, 98.31%, and 98.22%, respectively. In [
2], Support Vector Machine (SVM), Recurring neural network (RNN), and Long Short-Term Memory RNN (LSTM) were used, obtaining an accuracy of 88.37%, 99.74%, and 99.74%, respectively. The precision of RNN (99.99%) and LSTM (99.99%) were higher than our LAD-based IDS (99.89%). The accuracies of Gaussian Naive Bayes, K-Nearest Neighbour (KNN), and Multi-layer Perception–Artificial Neural Network (MLP-ANN) were 99.4%, 99.6%, and 87.4%, respectively. Thus, it can be concluded that the LAD-based IDS model performed well on the Bot-IoT dataset with an accuracy of 99.98%. The recall of 99.99% shows that the attacks were correctly classified by our IDS model.
We developed a LAD classifier for each category of attack in the Bot-IoT dataset. The dataset consists of four types of attack: DDoS, DoS, Reconnaissance, and Theft. Four different datasets were created by separating all the attack types along with normal observations. These datasets were used to train four LAD classifiers. Each LAD classifier was tested against its attack type and again using the entire test dataset.
Table 9 shows the results of all the LAD classifiers for specific attacks and the whole test dataset. The LAD classifiers developed for DDoS, DoS, and Reconnaissance attacks perform well on the entire dataset, which means that the LAD classifier is able to classify unknown attacks even when these attacks are not present in the training set. The classifier for Theft attacks performs well when detecting theft attacks on the test dataset, although it is not able to classify other attacks; however, its precision is 100%, which shows that all the normal instances are correctly classified. The performance of this classifier is low on the entire dataset, because its training set did not contain other types of attacks and because the size of the dataset is very small. This performance can be improved by using a larger number of theft instances. The False Positive rate for the DoS and Reconnaissance LAD classifiers is high due to misclassification of normal observations. These four classifiers were built using different datasets of specific attack types. Hence, the features involved in the detection of these attacks are quite different.
Appendix B discusses the features used to detect specific types of attacks. The Bot-IoT dataset has a higher number of attack observations compared to normal instances. Classifiers built on this dataset have low false negative rates, as they are able to classify all the attacks correctly.




{kind=link}
