
Improved Filtering Techniques for Single- and Multi-Trace Side-Channel Analysis



Abstract
:1. Introduction
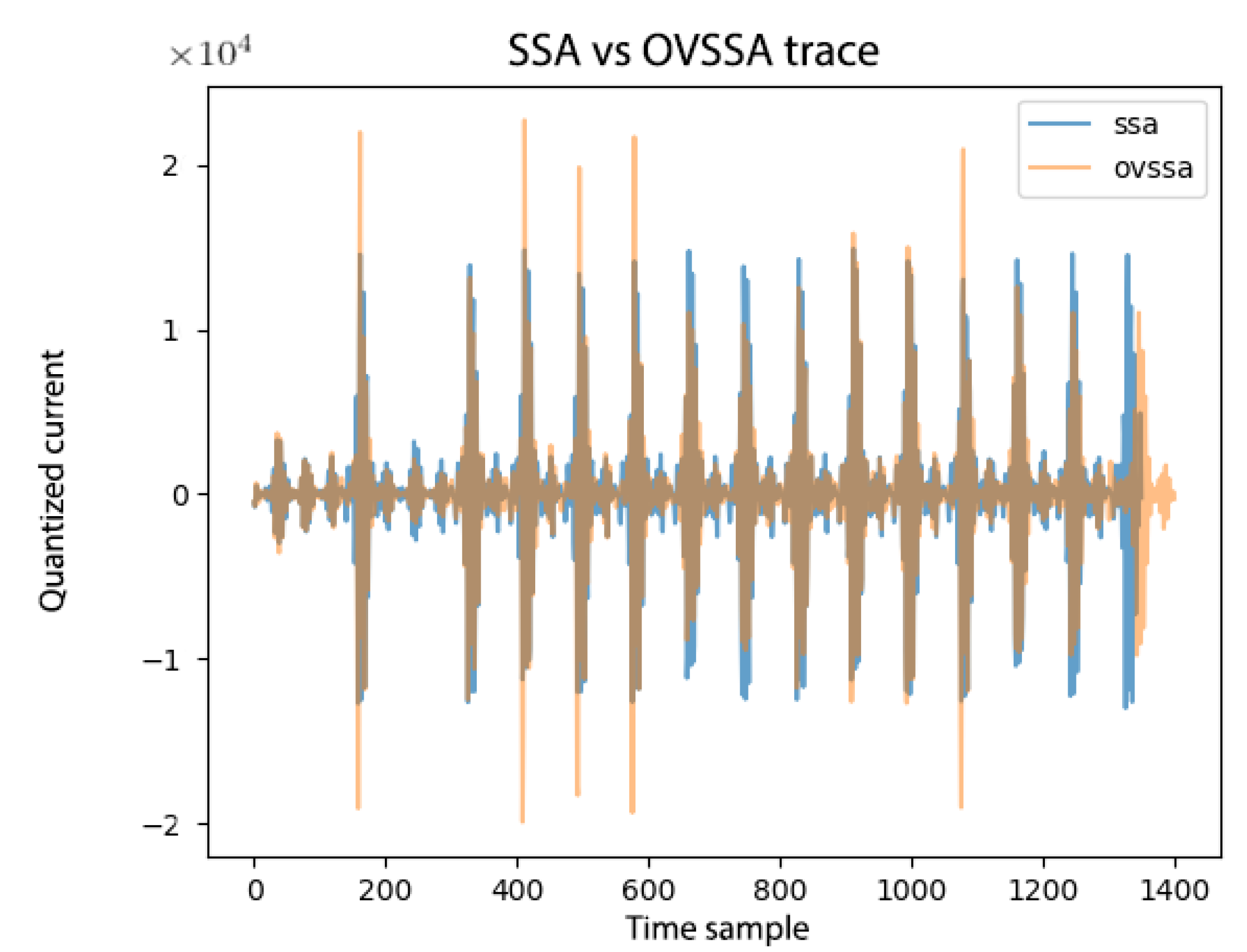
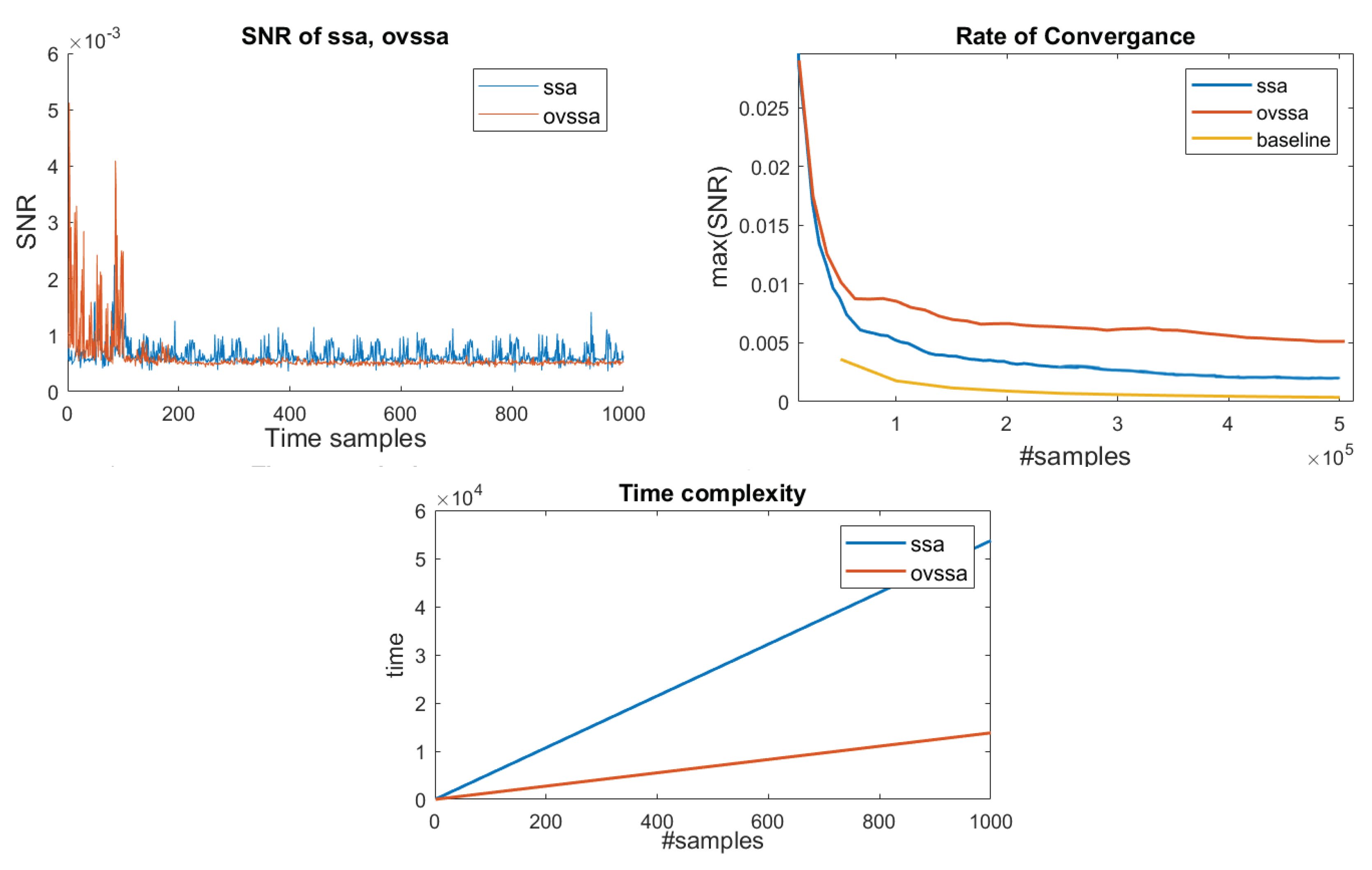
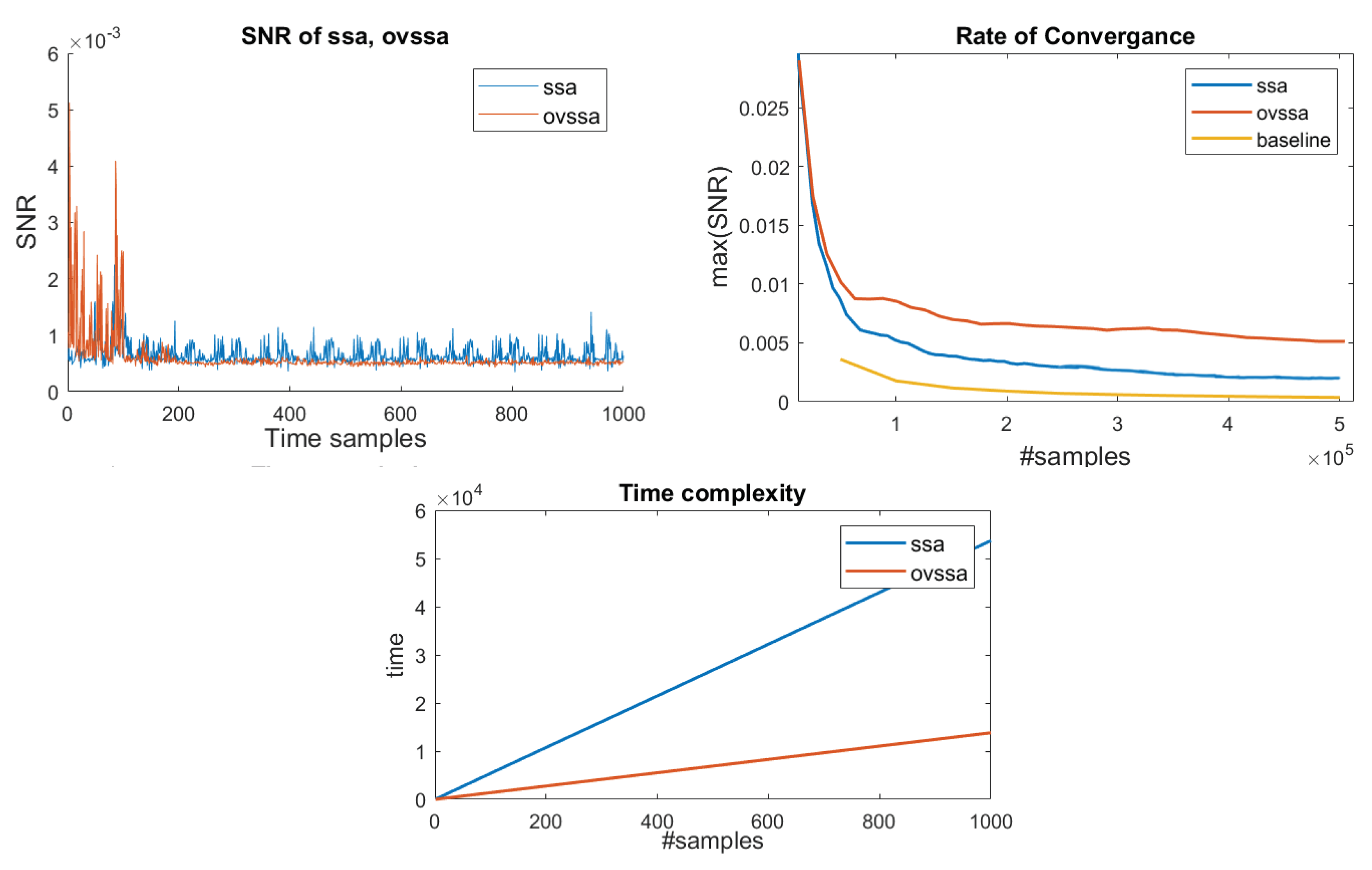
- We improve upon the technique adapted to the single-trace SCA context by utilizing the variations in spectral properties over time. By implementing OVSSA [21], adapting it to the single trace scenario and optimizing over the method parameters, we achieve not only a significantly shorter computation time, which is the main Achilles’ heel of the method, but also lower the data complexity and generate an overall higher information gain (in terms of the Signal-to-Noise Ratio ()). Concretely, the proposed technique provides ∼5× max. improvement for about the same number of leakage traces (data complexity). However, the main improvement is in the pre-processing evaluation time. The based pre-processing technique time complexity depends primarily on a Singular Value Decomposition (SVD), which is generally quadratic in time as a function of the number of leakage time samples, n. The OVSSA based pre-processing technique time complexity depends on SVDs over chunked leakage traces (fewer samples), with a parameter Z, i.e., . That is, the time complexity improvement is generally , which was shown to be significant in our experiments. i.e., Z depends on the spectral characteristics of the leakage throughout the trace and for round-base cryptographic implementations the factor is expected to yield significant improvements.
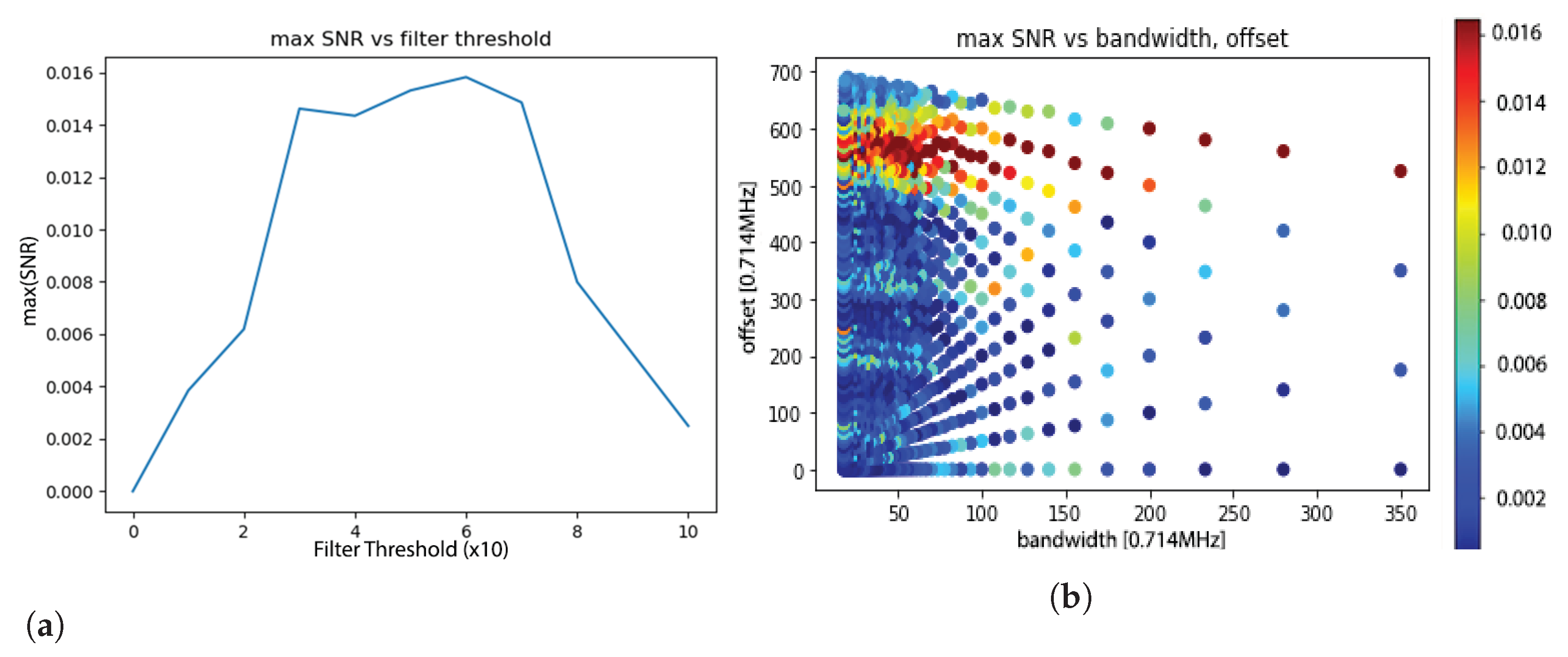
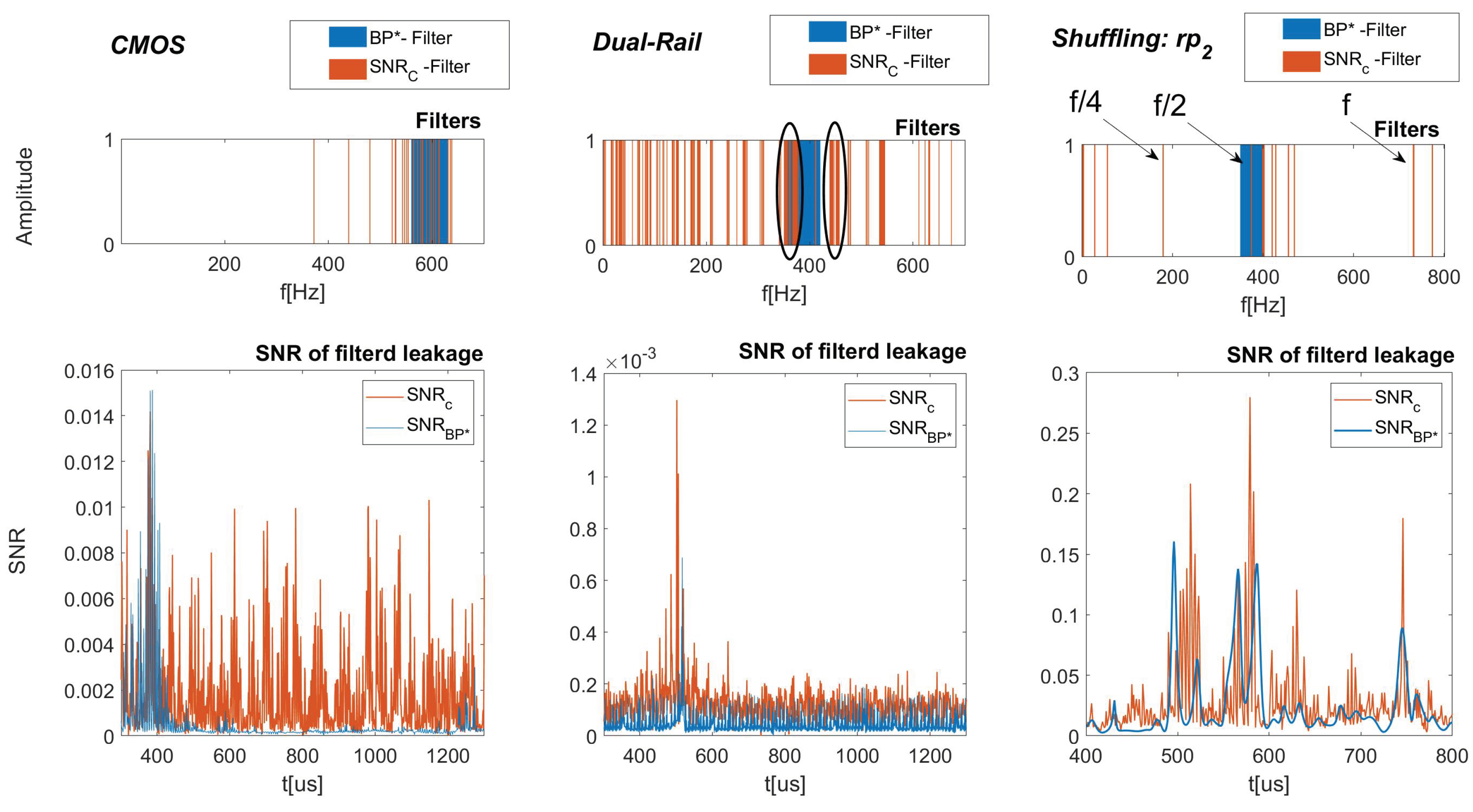
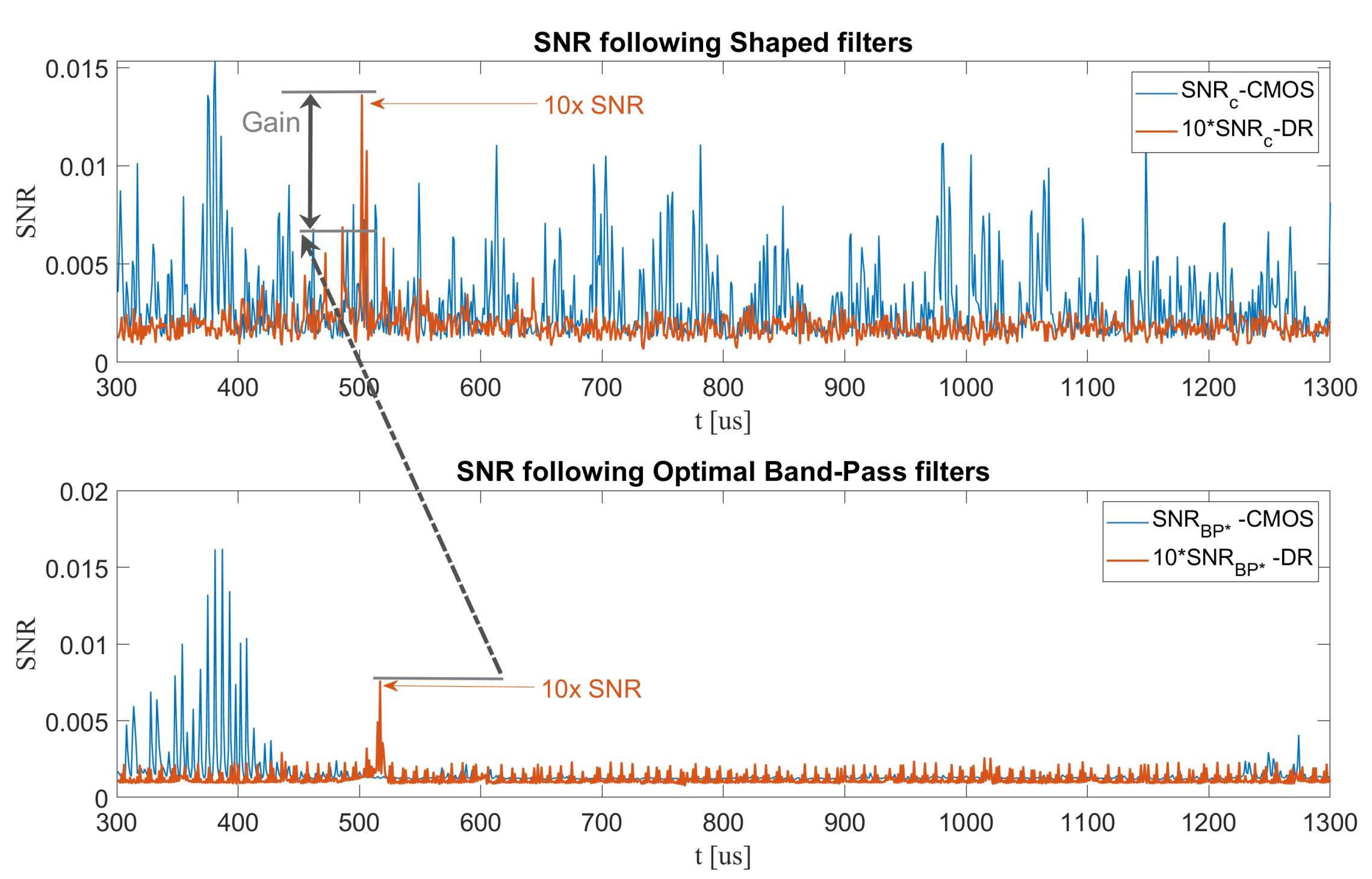
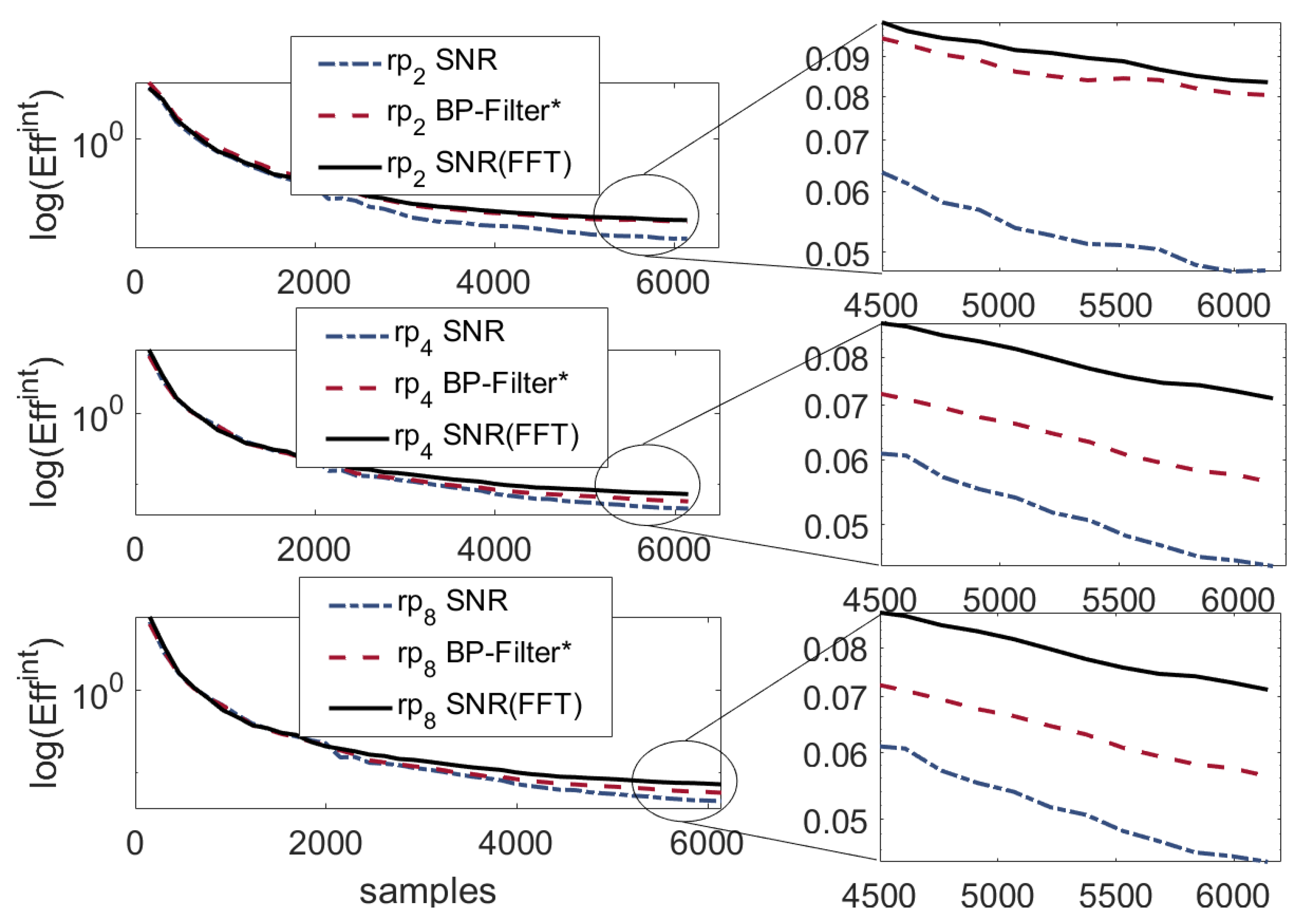
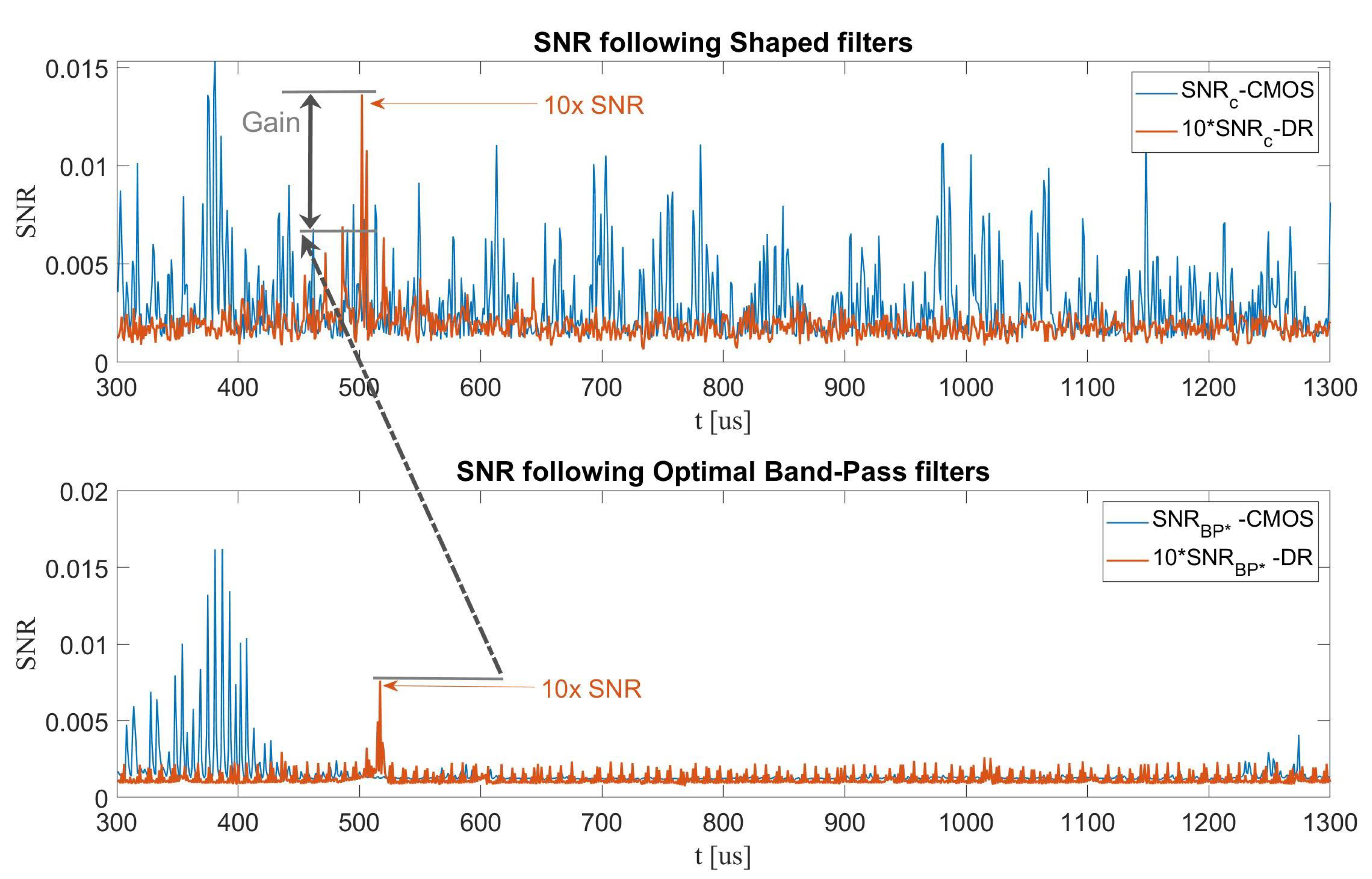
- In the multi-trace SCA context, we devise a profiling tactic to optimize a Band-Pass Filter (BPF) based on a criterion utilizing a low computational cost metric in Section 2.4.3. Our experiments below achieve optimal results for unprotected designs. However, as the protection level increases, the (optimized) BPF shows a significant reduction in performance that can be attributed to the different and more complex spectrum of the leakage, which requires more sophisticated filters. Therefore, we also propose an optimized shaped filter utilizing a frequency domain -based coefficient thresholding for the multi-trace scenario. The results obtained when using this filter show significant improvements over all datasets and designs, yield the highest compared to all the other methods with an improvement of an order of magnitude, and reduce data-complexity by a factor of ∼2.5×, as reported in Table 1.
2. Tools and Theory
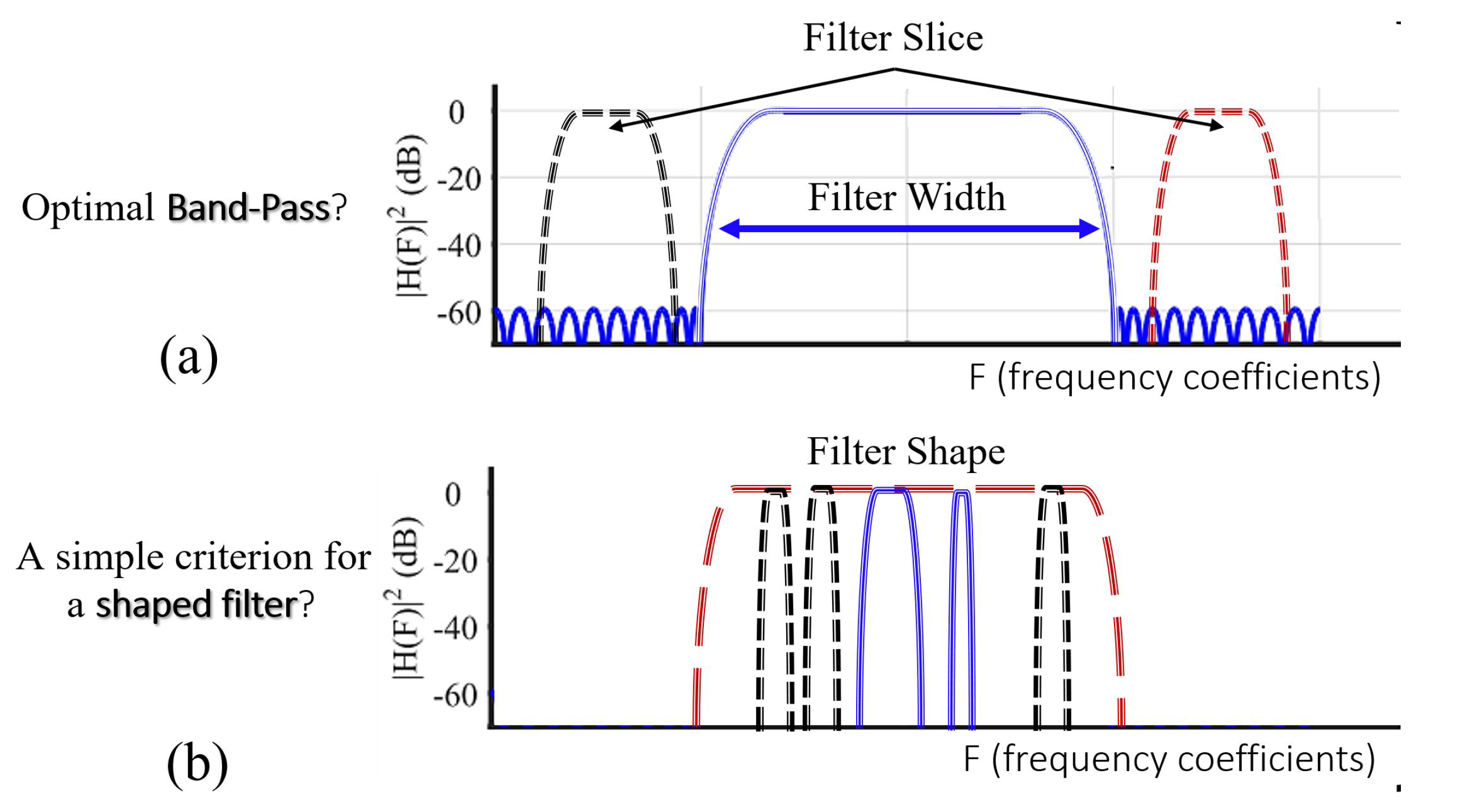
2.1. A Simple, Computationally Attractive Optimization Criterion
2.2. A Profiled Evaluation
2.3. Single Trace Techniques
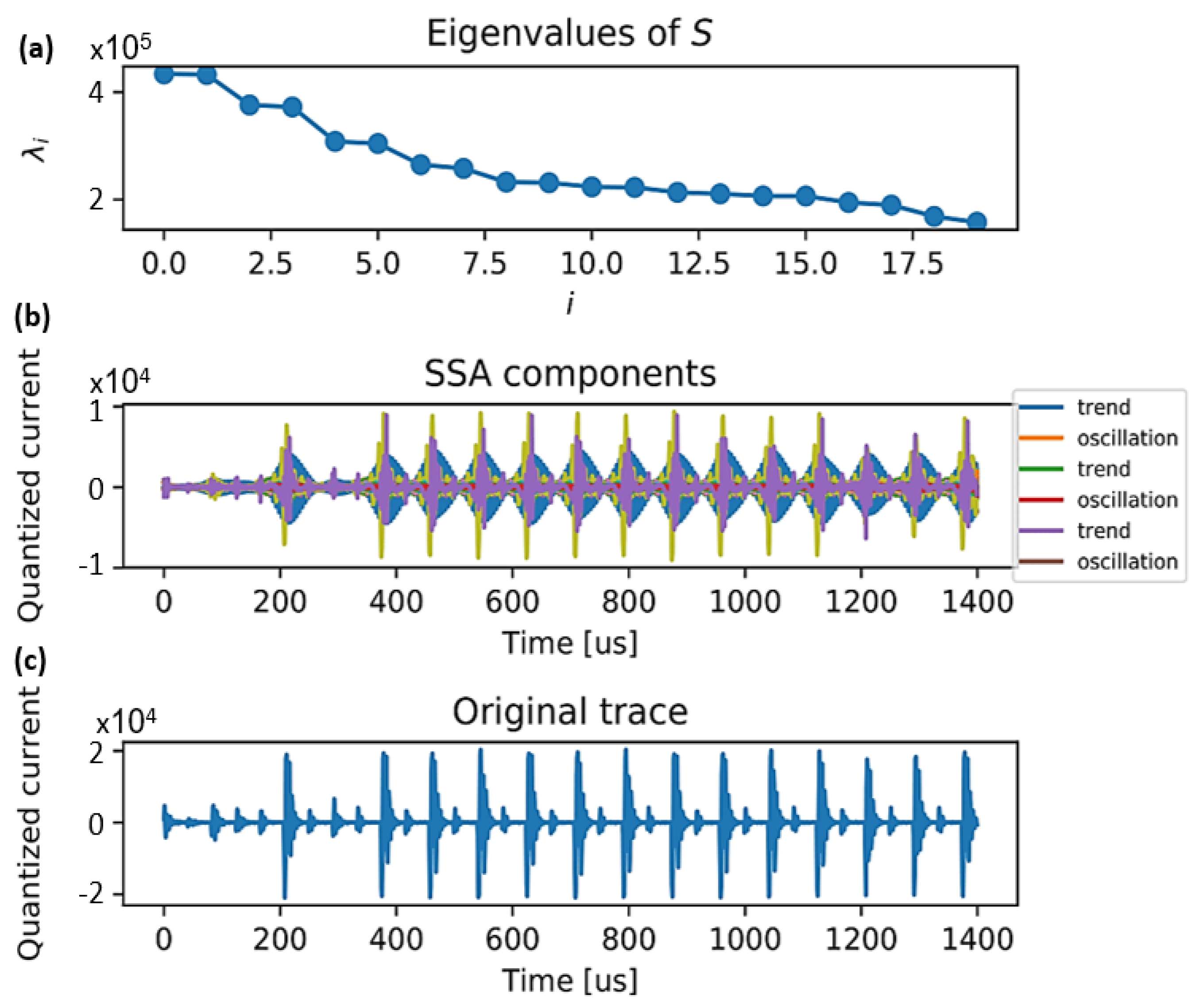
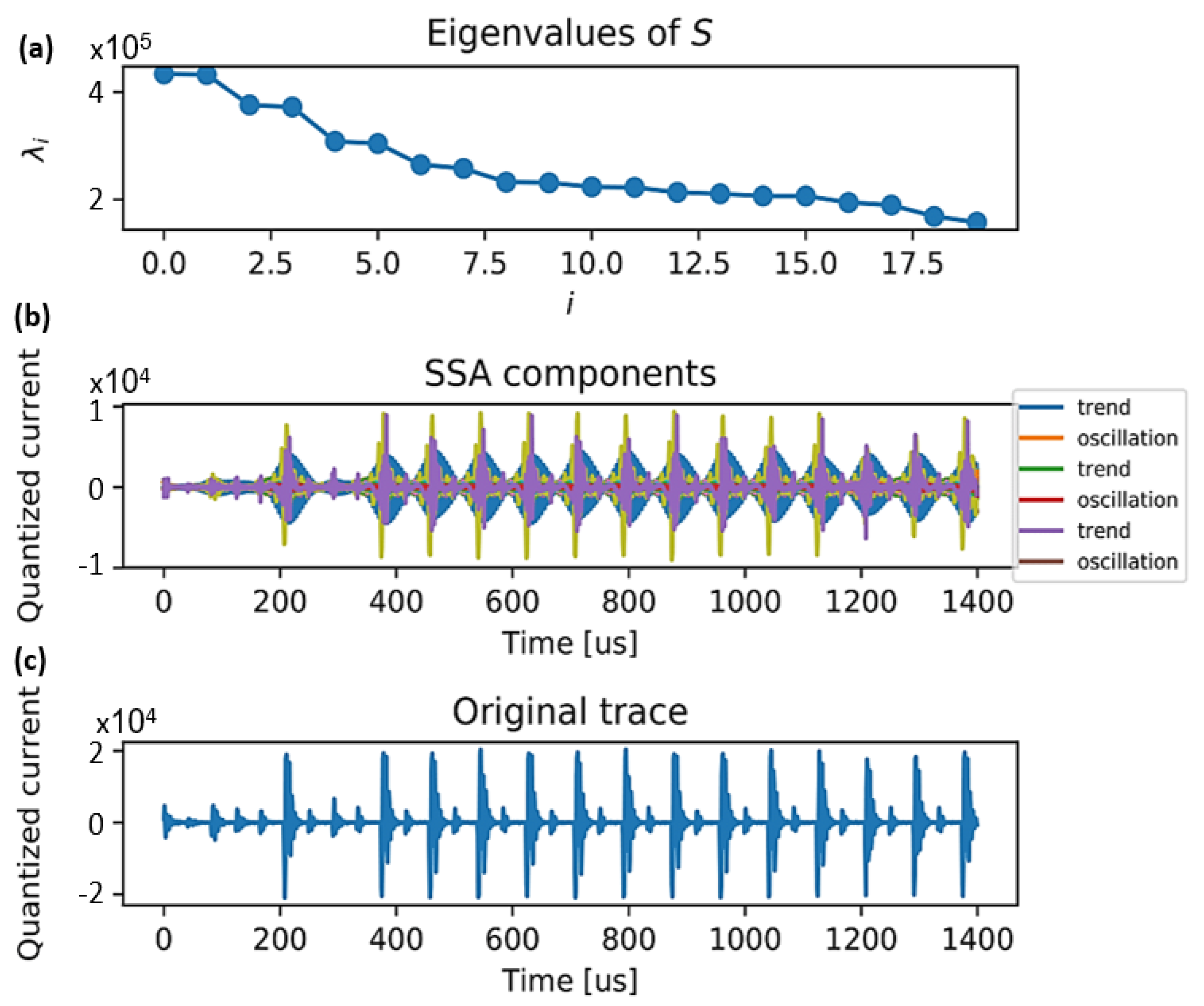
2.3.1. Utilized for SCA Denoising
| Algorithm 1: Trends, oscillations and noise thresholds setting. |
 |
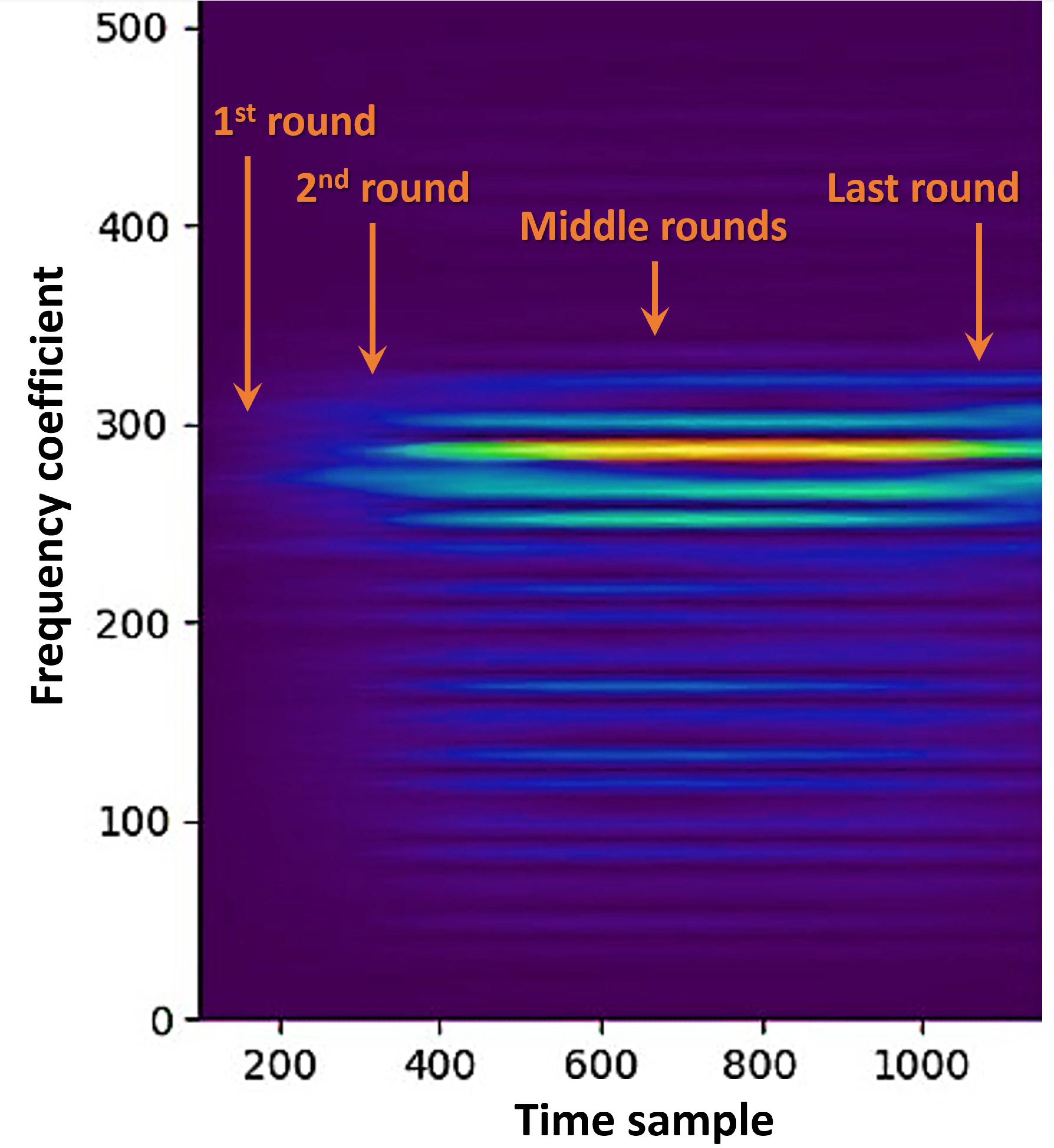
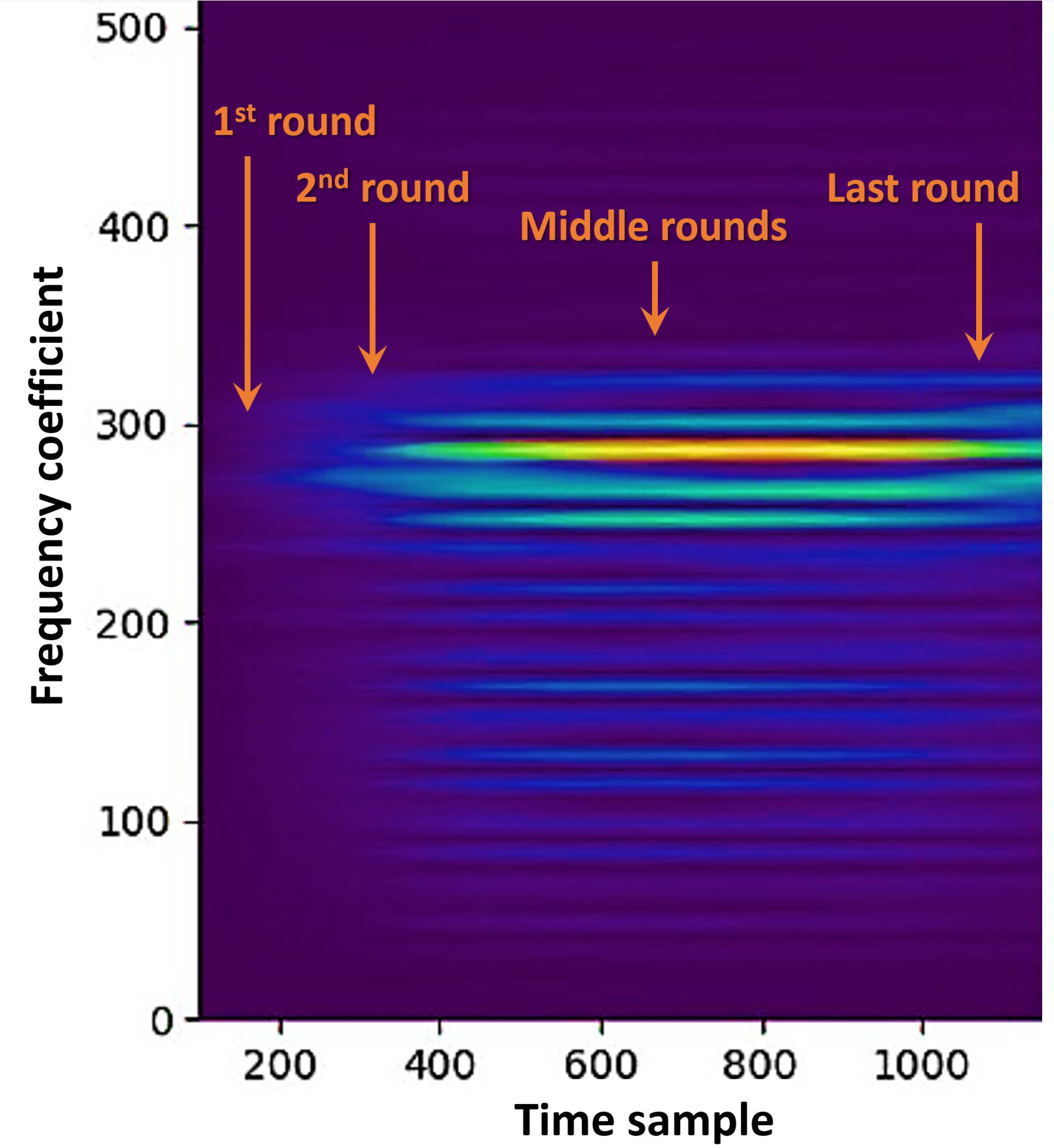
2.3.2. We Can Do Better with OVSSA
2.4. Multiple Traces (Statistical) Techniques
2.4.1. Multi Trace—Evaluation Criterion in the Time Domain
2.4.2. Efficiency Metrics for the Multi-Trace Context
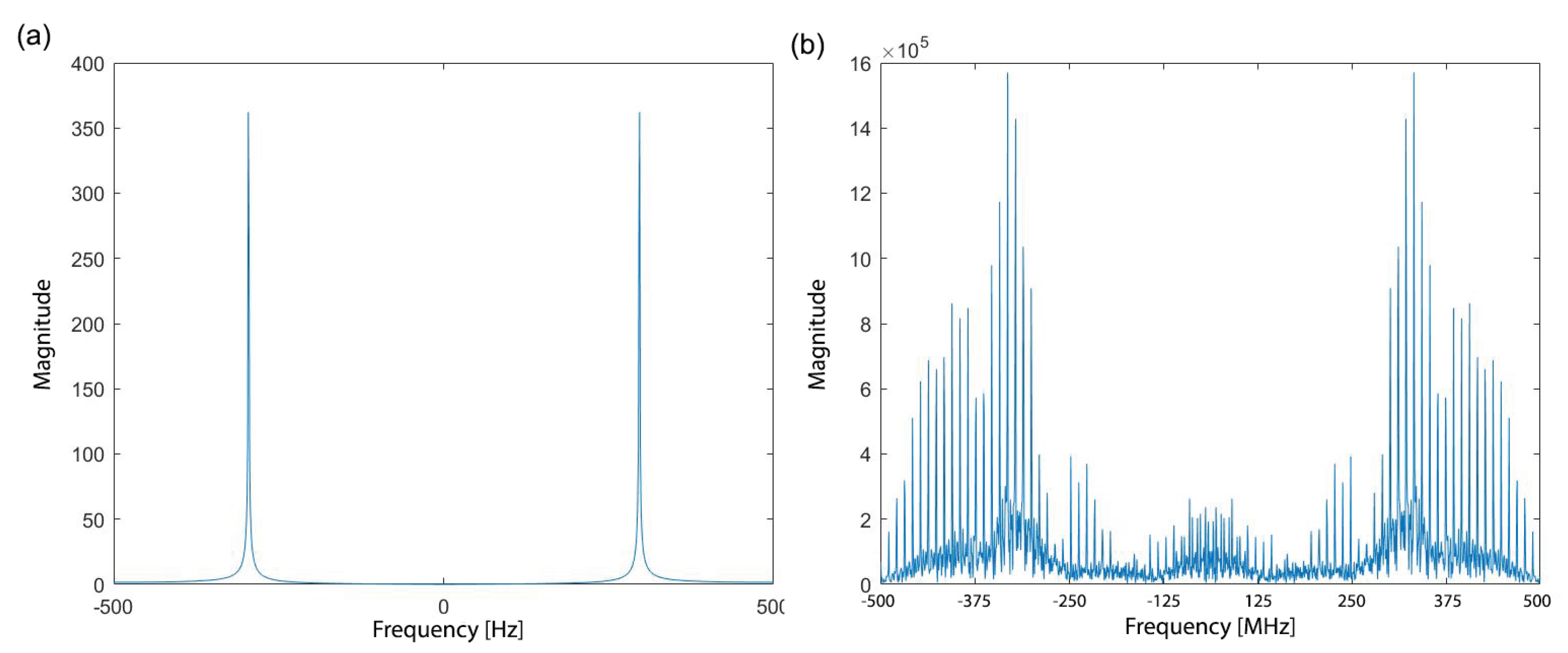
2.4.3. Multi Trace—Frequency Domain Optimization Criterion
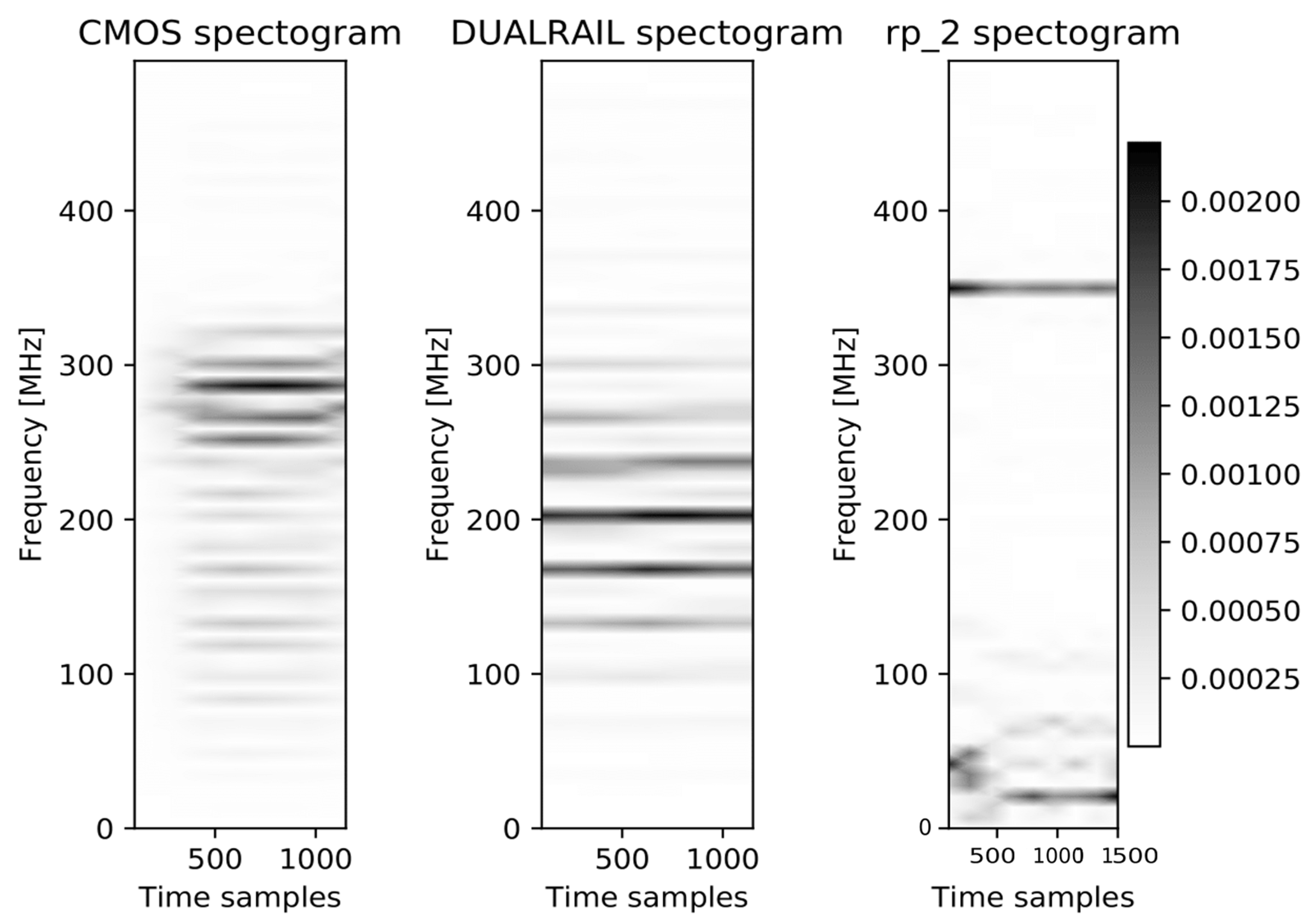
3. Designs and Datasets
- CMOS, 65 nm ASIC (HW)—unprotected rolled implementation of the AES (one round per clock cycle);
- Amplitude Randomization, 65 nm ASIC (HW)—protected by hardware amplitude randomization technique. Rolled implementation of the AES;
- Dual-Rail, 65 nm ASIC (HW)—protected by gate level flattening (WDDL implementation of Dual-Rail). Rolled implementation of the AES; and
- Shuffling, 40 nm Atmel 8-bit processor (SW)—protected by various instructions shuffling flavors: randomly permuting all groups of consecutive instructions (denoted in the following by , respectively;
4. Experimental Results
4.1. Multi-Trace
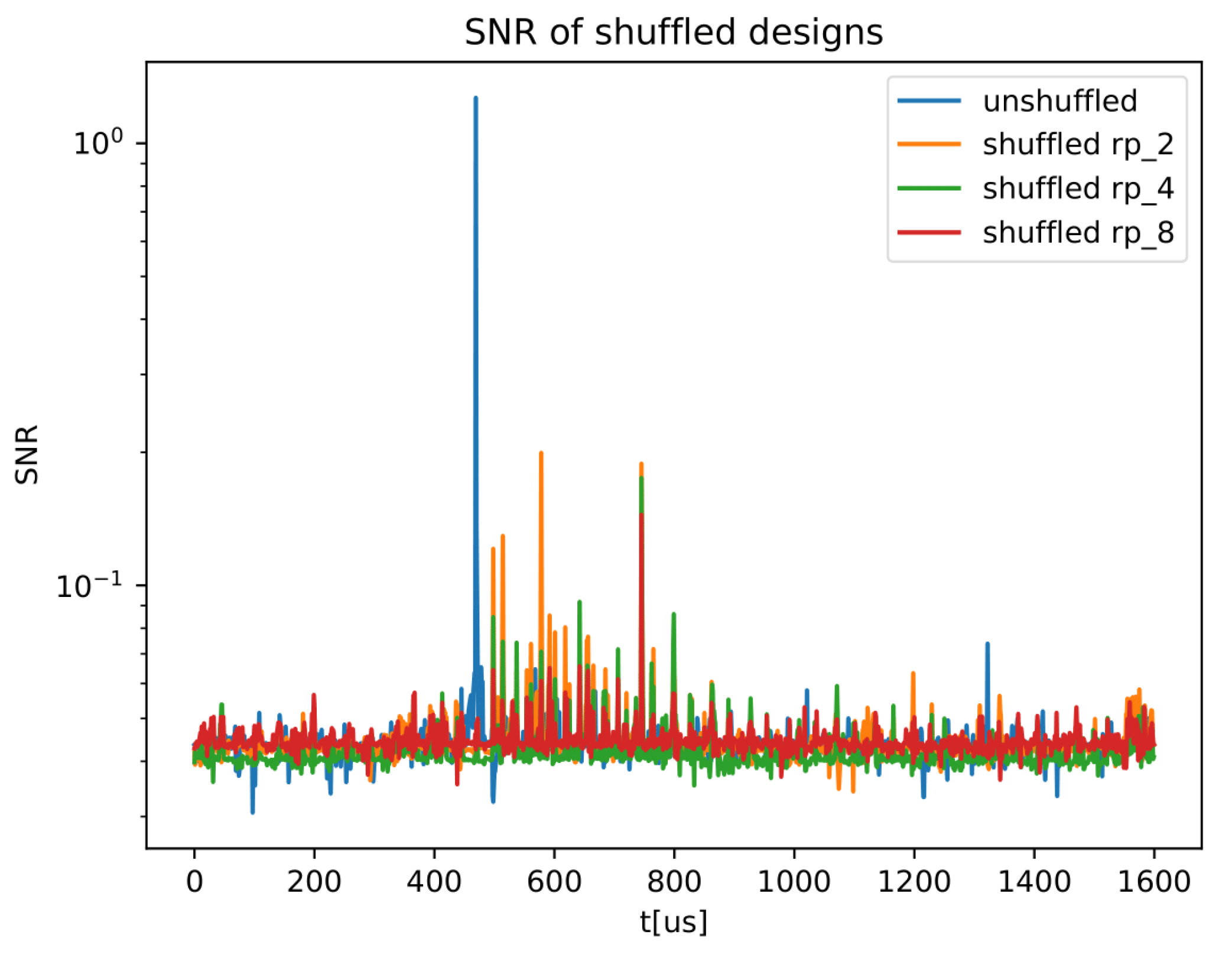
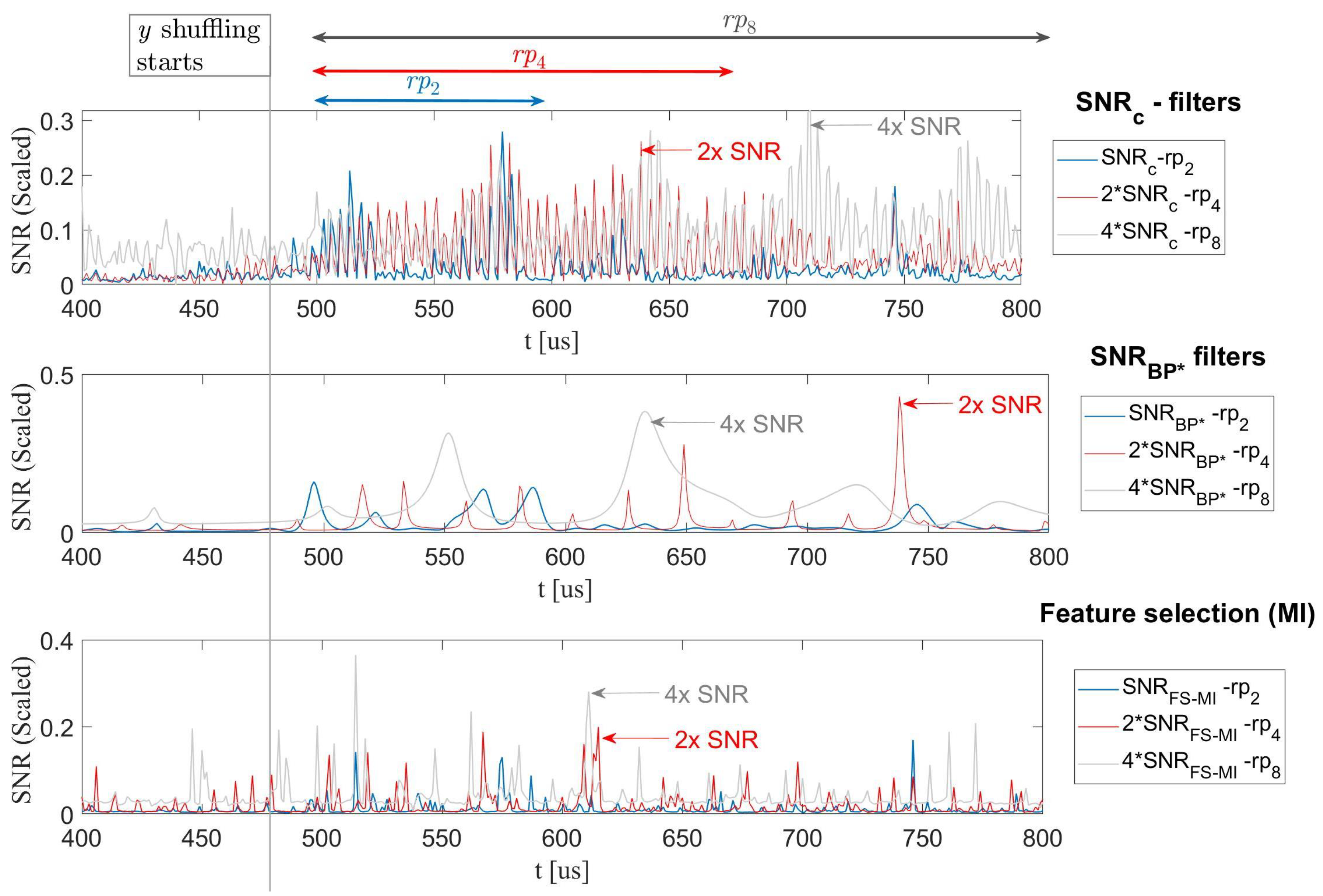
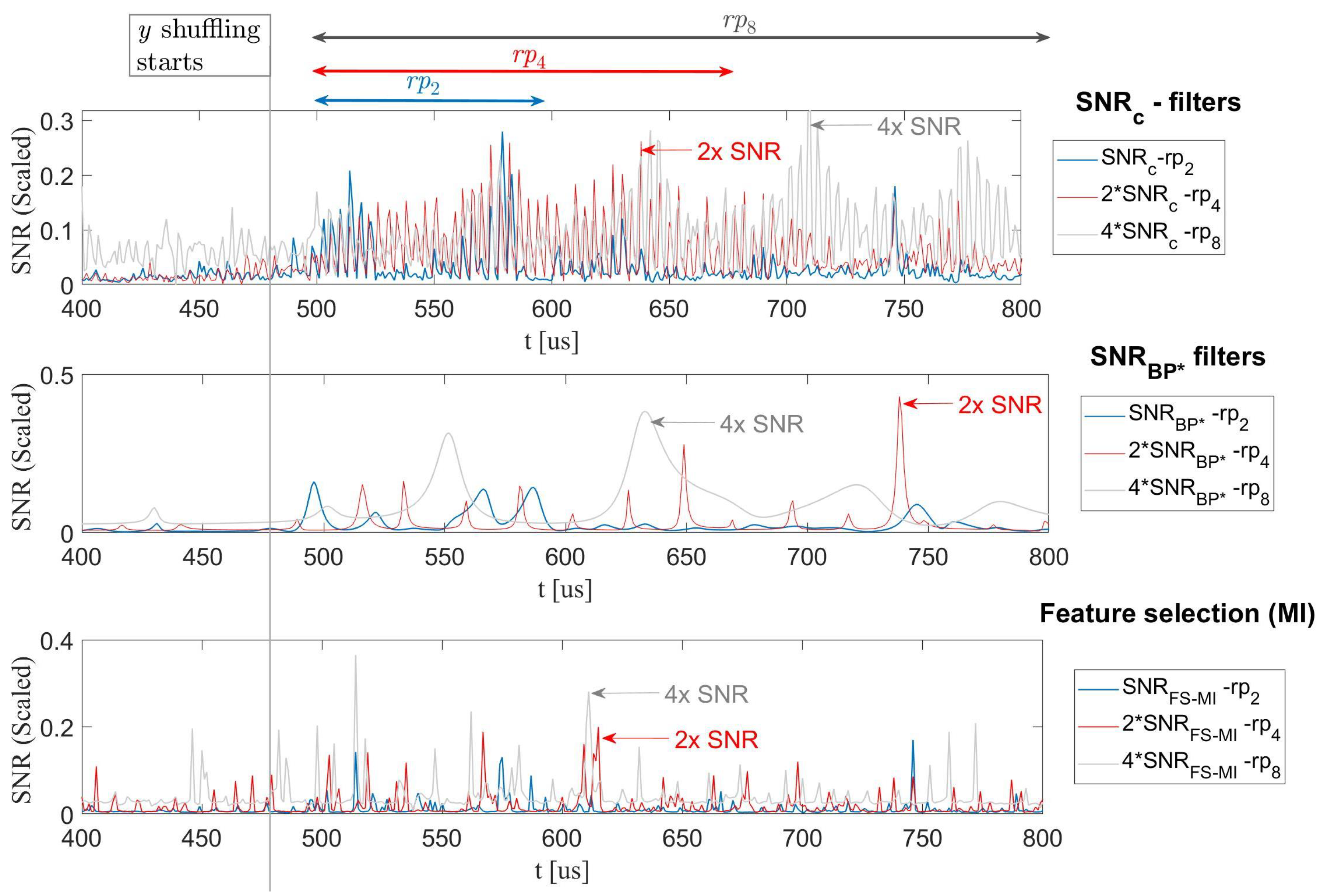
4.1.1. A Shuffled Software Example
4.1.2. Multi Trace—A Cautionary Note on Feature-Selection Tools
- As illustrated in the bottom plot in Figure 10, FS with complex statistical tools such as the Mutual-Information (MI) exhibit extremely poor results. This is clearly due to the fact that for information theoretic tools to function properly, the distribution of the leakage needs to be decently captured, which implies a large observation space; i.e., statistically, the full distribution is badly characterized and the filter is far from converging.
- More (statistically) simple FS tools were attempted, such as the Pearson-corr () to filter frequency coefficients.The experiments showed that it performed quite similarly to our SNR based criterion. However, consistently results were slightly poorer since the correlation was not scaled to the noise such as the SNR.
4.2. Single-Trace
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McKay, K.; Bassham, L.; Sönmez Turan, M.; Mouha, N. Report on Lightweight Cryptography; NIST Interagency/Internal Report (NISTIR); National Institute of Standards and Technology: Gaithersburg, MD, USA, 2017. [CrossRef]
- Standaert, F.X. Analyzing the Leakage-Resistance of some Round-2 Candidates of the NIST’s Lightweight Crypto Standardization Process. In Proceedings of the NIST Lightweight Cryptography Workshop, Gaithersburg, MD, USA, 4–6 November 2019. [Google Scholar]
- Camurati, G.; Poeplau, S.; Muench, M.; Hayes, T.; Francillon, A. Screaming channels: When electromagnetic side channels meet radio transceivers. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 163–177. [Google Scholar]
- Benhani, E.; Bossuet, L.; Aubert, A. The Security of ARM TrustZone in a FPGA-based SoC. IEEE Trans. Comput. 2019, 68, 1238–1248. [Google Scholar] [CrossRef]
- Schellenberg, F.; Gnad, D.R.; Moradi, A.; Tahoori, M.B. An inside job: Remote power analysis attacks on FPGAs. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1111–1116. [Google Scholar]
- Ramesh, C.; Patil, S.B.; Dhanuskodi, S.N.; Provelengios, G.; Pillement, S.; Holcomb, D.; Tessier, R. FPGA side channel attacks without physical access. In Proceedings of the 2018 IEEE 26th Annua l International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; pp. 45–52. [Google Scholar]
- Zhao, M.; Suh, G.E. FPGA-based remote power side-channel attacks. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 229–244. [Google Scholar]
- Provelengios, G.; Holcomb, D.; Tessier, R. Power wasting circuits for cloud FPGA attacks. In Proceedings of the 2020 30th International Conference on Field-Programmable Logic and Applications (FPL), Gothenburg, Sweden, 31 August–4 September 2020; pp. 231–235. [Google Scholar]
- Benhani, E.M.; Bossuet, L. Dvfs as a security failure of trustzone-enabled heterogeneous soc. In Proceedings of the 2018 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Bordeaux, France, 9–12 December 2018; pp. 489–492. [Google Scholar]
- Ravi, P.; Poussier, R.; Bhasin, S.; Chattopadhyay, A. On Configurable SCA Countermeasures Against Single Trace Attacks for the NTT. In International Conference on Security, Privacy, and Applied Cryptography Engineering; Springer Nature Switzerland: Cham, Switzerland, 2020; pp. 123–146. [Google Scholar]
- Battistello, A.; Coron, J.S.; Prouff, E.; Zeitoun, R. Horizontal side-channel attacks and countermeasures on the ISW masking scheme. In Proceedings of the International Conference on Cryptographic Hardware and Embedded Systems, Santa Barbara, CA, USA, 25–28 September 2016; Lecture Notes in Computer Science (LNCS). Springer: Berlin/Heidelberg, Germany, 2016; pp. 23–39. [Google Scholar]
- Singh, A.; Kar, M.; Mathew, S.; Rajan, A.; De, V.; Mukhopadhyay, S. 25.3 A 128b AES engine with higher resistance to power and electromagnetic side-channel attacks enabled by a security-aware integrated all-digital low-dropout regulator. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 404–406. [Google Scholar]
- Wong, C. Analysis of DPA and DEMA Attacks. Master’s Thesis, San Jose State University, San Jose, CA, USA, 2012. [Google Scholar] [CrossRef]
- Plos, T.; Hutter, M.; Feldhofer, M. On comparing side-channel preprocessing techniques for attacking RFID devices. In Proceedings of the International Workshop on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2009; pp. 163–177. [Google Scholar]
- Bu, A.; Dai, W.; Lu, M.; Cai, H.; Shan, W. Correlation-Based Electromagnetic Analysis Attack Using Haar Wavelet Reconstruction with Low-Pass Filtering on an FPGA Implementaion of AES. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1897–1900. [Google Scholar]
- Oswald, D.; Paar, C. Breaking Mifare DESFire MF3ICD40: Power analysis and templates in the real world. In International Workshop on Cryptographic Hardware and Embedded Systems; Lecture Notes in Computer Science (LNCS); Springer: Berlin/Heidelberg, Germany, 2011; pp. 207–222. [Google Scholar]
- Kumar, R.; Liu, X.; Suresh, V.; Krishnamurthy, H.K.; Satpathy, S.; Anders, M.A.; Kaul, H.; Ravichandran, K.; De, V.; Mathew, S.K. A Time-/Frequency-Domain Side-Channel Attack Resistant AES-128 and RSA-4K Crypto-Processor in 14-nm CMOS. IEEE J. Solid-State Circuits 2021, 56, 1141–1151. [Google Scholar] [CrossRef]
- Park, A.; Han, D.G.; Ryoo, J. CPA performance comparison based on Wavelet Transform. In Proceedings of the 2012 IEEE International Carnahan Conference on Security Technology (ICCST), Newton, MA, USA, 15–18 October 2012; pp. 201–206. [Google Scholar]
- Vautard, R.; Yiou, P.; Ghil, M. Singular-spectrum analysis: A toolkit for short, noisy chaotic signals. Phys. D Nonlinear Phenom. 1992, 58, 95–126. [Google Scholar] [CrossRef]
- Del Pozo, S.M.; Standaert, F.X. Blind source separation from single measurements using singular spectrum analysis. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems; Lecture Notes in Computer Science (LNCS); Springer: Berlin/Heidelberg, Germany, 2015; Volume 9293, pp. 42–59. [Google Scholar]
- Leles, M.; Sansão, J.; Mozelli, L.; Guimarães, H. A new algorithm in singular spectrum analysis framework:The Overlap-SSA (ov-SSA). SoftwareX 2018, 8, 26–32. [Google Scholar] [CrossRef]
- Levi, I.; Bellizia, D.; Standaert, F.X. Beyond algorithmic noise or how to shuffle parallel implementations? Int. J. Circuit Theory Appl. 2020, 48, 674–695. [Google Scholar] [CrossRef]
- Cassiers, G.; Grégoire, B.; Levi, I.; Standaert, F.X. Hardware private circuits: From trivial composition to full verification. IEEE Trans. Comput. 2020, 70, 1677–1690. [Google Scholar] [CrossRef]
- Bilgin, B.; De Meyer, L.; Duval, S.; Levi, I.; Standaert, F.X. Low AND Depth and Efficient Inverses: A Guide on S-boxes for Low-latency Masking. IACR Trans. Symmetric Cryptol. 2020, 2020, 144–184. [Google Scholar] [CrossRef]
- Mangard, S. Hardware Countermeasures against DPA—A Statistical Analysis of Their Effectiveness. In Cryptographers’ Track at the RSA Conference; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; Volume 2964, pp. 222–235. [Google Scholar]
- Gierlichs, B.; Batina, L.; Tuyls, P.; Preneel, B. Mutual information analysis. In International Workshop on Cryptographic Hardware and Embedded Systems; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; pp. 426–442. [Google Scholar]
- Standaert, F.X.; Malkin, T.G.; Yung, M. A unified framework for the analysis of side-channel key recovery attacks. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cologne, Germany, 26–30 April 2009; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2009; pp. 443–461. [Google Scholar]
- Chari, S.; Rao, J.R.; Rohatgi, P. Template attacks. In International Workshop on Cryptographic Hardware and Embedded Systems; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002; pp. 13–28. [Google Scholar]
- Gámiz-Fortis, S.; Pozo-Vázquez, D.; Esteban-Parra, M.; Castro-Díez, Y. Spectral characteristics and predictability of the NAO assessed through singular spectral analysis. J. Geophys. Res. Atmos. 2002, 107, ACL-11. [Google Scholar] [CrossRef]
- Du, K.; Zhao, Y.; Lei, J. The incorrect usage of singular spectral analysis and discrete wavelet transform in hybrid models to predict hydrological time series. J. Hydrol. 2017, 552, 44–51. [Google Scholar] [CrossRef]
- Afshar, K.; Bigdeli, N. Data analysis and short term load forecasting in Iran electricity market using singular spectral analysis (SSA). Energy 2011, 36, 2620–2627. [Google Scholar] [CrossRef]
- Hu, B.; Li, Q.; Smith, A. Noise reduction of hyperspectral data using singular spectral analysis. Int. J. Remote Sens. 2009, 30, 2277–2296. [Google Scholar] [CrossRef]
- Hattori, K.; Serita, A.; Yoshino, C.; Hayakawa, M.; Isezaki, N. Singular spectral analysis and principal component analysis for signal discrimination of ULF geomagnetic data associated with 2000 Izu Island Earthquake Swarm. Phys. Chem. Earth Parts A/B/C 2006, 31, 281–291. [Google Scholar] [CrossRef]
- Le Mouël, J.; Lopes, F.; Courtillot, V. Singular spectral analysis of the aa and Dst geomagnetic indices. J. Geophys. Res. Space Phys. 2019, 124, 6403–6417. [Google Scholar] [CrossRef]
- Hassani, H. Singular Spectrum Analysis: Methodology and Comparison; Cardiff University: Cardiff, UK; Central Bank of the Islamic Republic of Iran: Tehran, Iran, 2007. [Google Scholar]
- Gavish, M.; Donoho, D.L. The optimal hard threshold for singular values is 4/(30.5). IEEE Trans. Inf. Theory 2014, 60, 5040–5053. [Google Scholar] [CrossRef]
- Golyandina, N.; Nekrutkin, V.; Zhigljavsky, A.A. Analysis of Time Series Structure: SSA and Related Techniques; Chapman and Hall/CRC Press: Boca Raton, FL, USA, 2001. [Google Scholar]
- Nussbaumer, H.J. The fast Fourier transform. In Fast Fourier Transform and Convolution Algorithms; Springer: Berlin/Heidelberg, Germany, 1981; pp. 80–111. [Google Scholar]
- Montminy, D.P. Enhancing Electromagnetic Side-Channel Analysis in an Operational Environment. Ph.D Thesis, Air Force Institute of Technology, Wright Patterson Air Force Base, OH, USA, 2013. [Google Scholar]
- Belgarric, P.; Bhasin, S.; Bruneau, N.; Danger, J.L.; Debande, N.; Guilley, S.; Heuser, A.; Najm, Z.; Rioul, O. Time-frequency analysis for second-order attacks. In Proceedings of the 12th International Conference on Smart Card Research and Advanced Applications, Berlin, Germany, 27–29 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 108–122. [Google Scholar]
- Tiu, C.C. A new Frequency-Based Side Channel Attack for Embedded Systems. Ph.D. Thesis, University of Waterloo, Waterloo, ON, Canada, 2005. [Google Scholar]
- Hospodar, G.; Gierlichs, B.; De Mulder, E.; Verbauwhede, I.; Vandewalle, J. Machine learning in side-channel analysis: A first study. J. Cryptogr. Eng. 2011, 1, 293. [Google Scholar] [CrossRef]
- Picek, S.; Heuser, A.; Jovic, A.; Ludwig, S.A.; Guilley, S.; Jakobovic, D.; Mentens, N. Side-channel analysis and machine learning: A practical perspective. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, Alaska, USA, 14–19 May 2017; pp. 4095–4102. [Google Scholar]
- Picek, S.; Heuser, A.; Jovic, A.; Batina, L. A systematic evaluation of profiling through focused feature selection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2802–2815. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, S.; Luo, Y.; Cao, L. Machine Learning-Based Similarity Attacks for Chaos-based Cryptosystems. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Context | x(SNR) | x(Time) | x(Data) | Counter. * |
|---|---|---|---|---|---|
| No filtering (baseline) | Single | 1 | 1 | 1 | CMOS-none |
| Adapting SSA [19,20] | Single | 2.5 | 1 | 1 | CMOS-none |
| Proposed (adapting [21]) | Single | 5 | 1 | CMOS-none | |
| No filtering (baseline) | Multi | 1 | 1 | 1 | Dual Rail |
| Optimized BPF (proposed) | Multi | 6.74 | 1 | 2.5 | Dual Rail |
| Shaped filter (proposed) | Multi | 10.75 | 1 | 2.5 | Dual Rail |
| Design Name | #Traces | Base-Line | Protection Mechanism | Platform |
|---|---|---|---|---|
| CMOS | None | 65 nm ASIC (HW) | ||
| Dual-Rail | WDDL implementation | 65 nm ASIC (HW) | ||
| Amp.-Rnd. | Amplitude rand. technique | 65 nm ASIC (HW) | ||
| Shuffling | 6144 | Rand. instr. perm. | 40 nm Atmel 8-bit C (SW) |
| Context | Method Name | Description |
|---|---|---|
| Single | Singular Spectrum Analysis | |
| Single | OVSSA | Overlapping and segmented |
| Multi | BP-filter | BPF, optimally fitted for each design |
| Multi | Filter based on threshold of the freq. coeffs. (Shaped) | |
| Multi | MI-FS | Mutual Information based Feature Selection of freq. coeffs. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salomon, D.; Weiss, A.; Levi, I. Improved Filtering Techniques for Single- and Multi-Trace Side-Channel Analysis. Cryptography 2021, 5, 24. https://doi.org/10.3390/cryptography5030024
Salomon D, Weiss A, Levi I. Improved Filtering Techniques for Single- and Multi-Trace Side-Channel Analysis. Cryptography. 2021; 5(3):24. https://doi.org/10.3390/cryptography5030024
Chicago/Turabian StyleSalomon, Dor, Amir Weiss, and Itamar Levi. 2021. "Improved Filtering Techniques for Single- and Multi-Trace Side-Channel Analysis" Cryptography 5, no. 3: 24. https://doi.org/10.3390/cryptography5030024
APA StyleSalomon, D., Weiss, A., & Levi, I. (2021). Improved Filtering Techniques for Single- and Multi-Trace Side-Channel Analysis. Cryptography, 5(3), 24. https://doi.org/10.3390/cryptography5030024