
Complementing Privacy and Utility Trade-Off with Self-Organising Maps


Abstract
1. Introduction
- An implementation of Self-Organizing Maps in conjunction with clustering-based k-anonymisation algorithms to derive more data utility.
- A comprehensive comparison of k-anonymisation algorithms in terms of effectiveness for data mining tasks.
- An extensive analysis of the effects of the privacy parameters and some aspects of the datasets on the anonymisation process.
2. Anonymisation
2.1. k-Anonymity Example
2.2. Data Utility
2.3. k-Anonymity Approaches
3. Dimensionality Reduction
3.1. Self-Organising Maps
3.2. Significance to PPDM
4. Adult Dataset
- Identifiers: a data attribute that explicitly declares the identity of an individual e.g., name, social security number, ID number, biometric record.
- Quasi-Identifiers: a data attribute that is inadequate to reveal individual identities independently, however, if combined with other publicly available information (quasi-identifiers), they can explicitly reveal the identity of a data subject e.g., date of birth, postcode, gender, address, phone number.
- Sensitive Attributes: a data attribute that reveals personal information about an individual that they may be unwilling to share publicly. These attributes can implicitly reveal confidential information about individuals when combined with quasi-identifiers and are likely to cause harm e.g., medical diagnosis, financial records, criminal records.
- Non-Sensitive Attributes: a data attribute that may not explicitly or implicitly declare any sensitive information about individuals. These records need to be associated with identifiers, quasi-identifiers or sensitive attributes to determine a respondent’s behaviour or action e.g., cookie IDs.
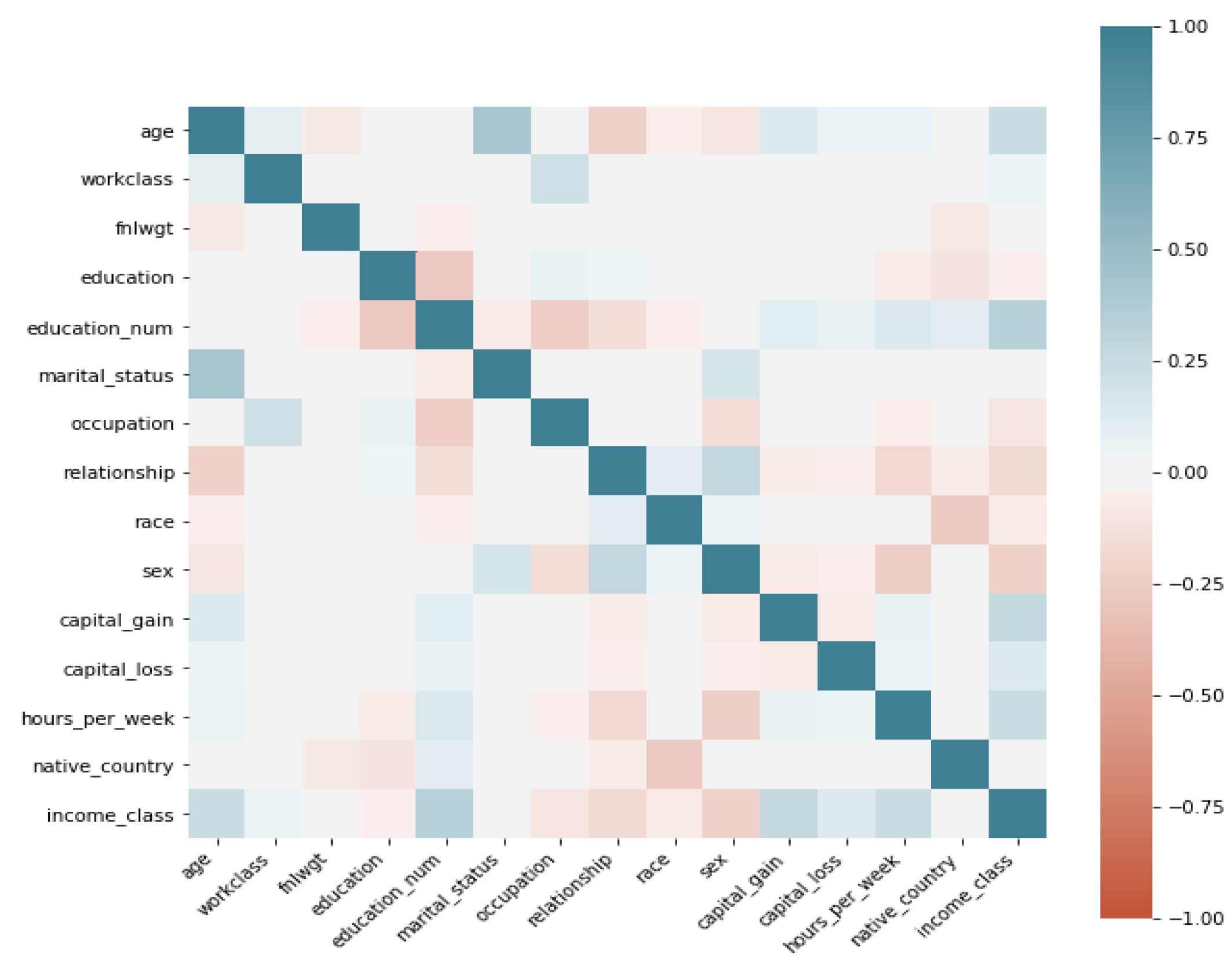
- Correlation: We utilise linear correlation to measure the relationship between each feature and the label feature Income, this is derived as a value between 1 and as shown in Figure 1. This allows us to detect linear dependencies and make informed choices on which features to use for DR.
- ID-ness: measures the fraction of unique values in each feature which provides a good basis for data cleaning.
- Stability: measures the fraction of constant non-missing values which informs us about the richness of our data and the extent of bias that can be produced in our classification models.
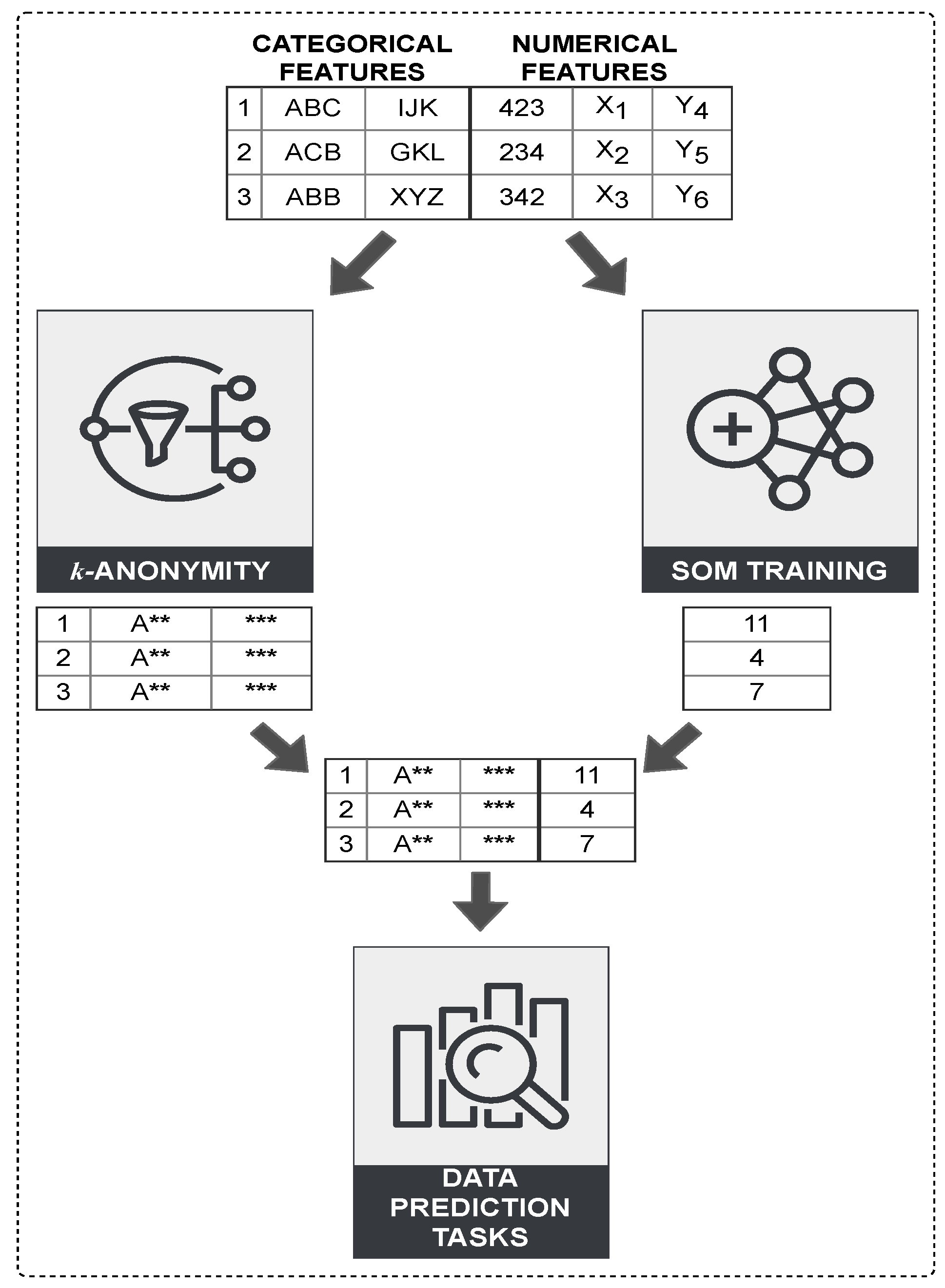
5. Methodology
- Initially, the dataset is analysed and vertically partitioned based on the attribute set type: categorical or numerical.
- A traditional k-anonymity clustering algorithm is applied to a local dataset containing the categorical attribute set to produce a k-anonymised result.
- SOM is applied to compress the local dataset containing the numerical attribute set that are dropped by the clustering-based algorithms and generate a 1-dimensional representation of all input spaces.
- The partial results are unified in a combined dataset based on their index and reference vectors, ensuring that objects are in the same order as the original dataset.
- Classification techniques are applied on the combined results for generic data prediction tasks that apply to the Adult dataset.
- Normalised Certainty Penalty (): measures information loss of all formed equivalence classes.
- (a)
- For attributes that are numerical, the score of an equivalence class T is defined as:Where the numerator and denominator represent attribute ranges of for the class T and the whole table, respectively.
- (b)
- For attributes that are categorical, in which no distance function or complete order is present, is described w.r.t the attribute’s taxonomy tree:where u represents lowermost common predecessor of all values in that are included in T, is the number of leaves (i.e., values of attribute) in the subtree of u, and represents the total count of discrete values of .
- (c)
- The score of class T over all attributes classified as quasi-identifier is:where n represents number attributes in a quasi-identifier set. can either be a categorical or numerical attribute and has a weight , where .
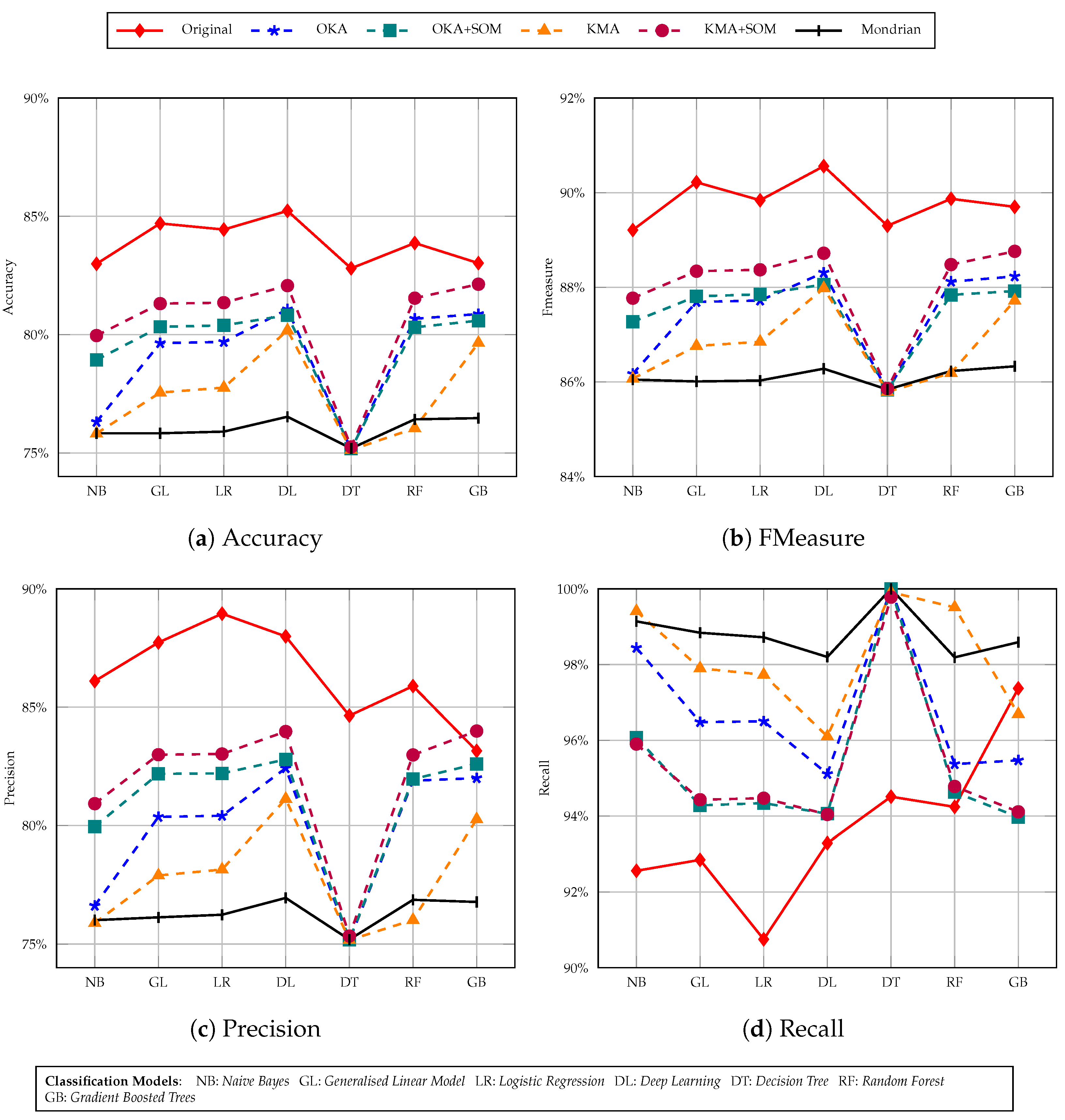
- Accuracy: measures the percentage of correctly classified instances by the classification model used, which is calculated using the number of (true positives {TP}, true negatives {TN}, false positives {FP} and false negatives {FN}) [45]. Classification accuracy is defined mathematically as:
- Precision: is a class specific performance metric that quantifies the number of positive class predictions that actually belong to the positive class [45], which is defined as:
- Recall: is another important metric, which quantifies the number of positive class predictions made out of all positive examples in the dataset [45]. More formally:
- FMeasure: is another classification-based metric used to measure the accuracy of a classifier model. The metric score computes the harmonic mean between precision p and recall r. Therefore balancing both the concerns of recall and precision in one outcome.
- Time: indicates the length of time it takes to execute an algorithm based on an input data size and a k parameter.
6. Experiments
6.1. Experimental Environment
6.2. Anonymisation Setup
6.3. SOM Setup
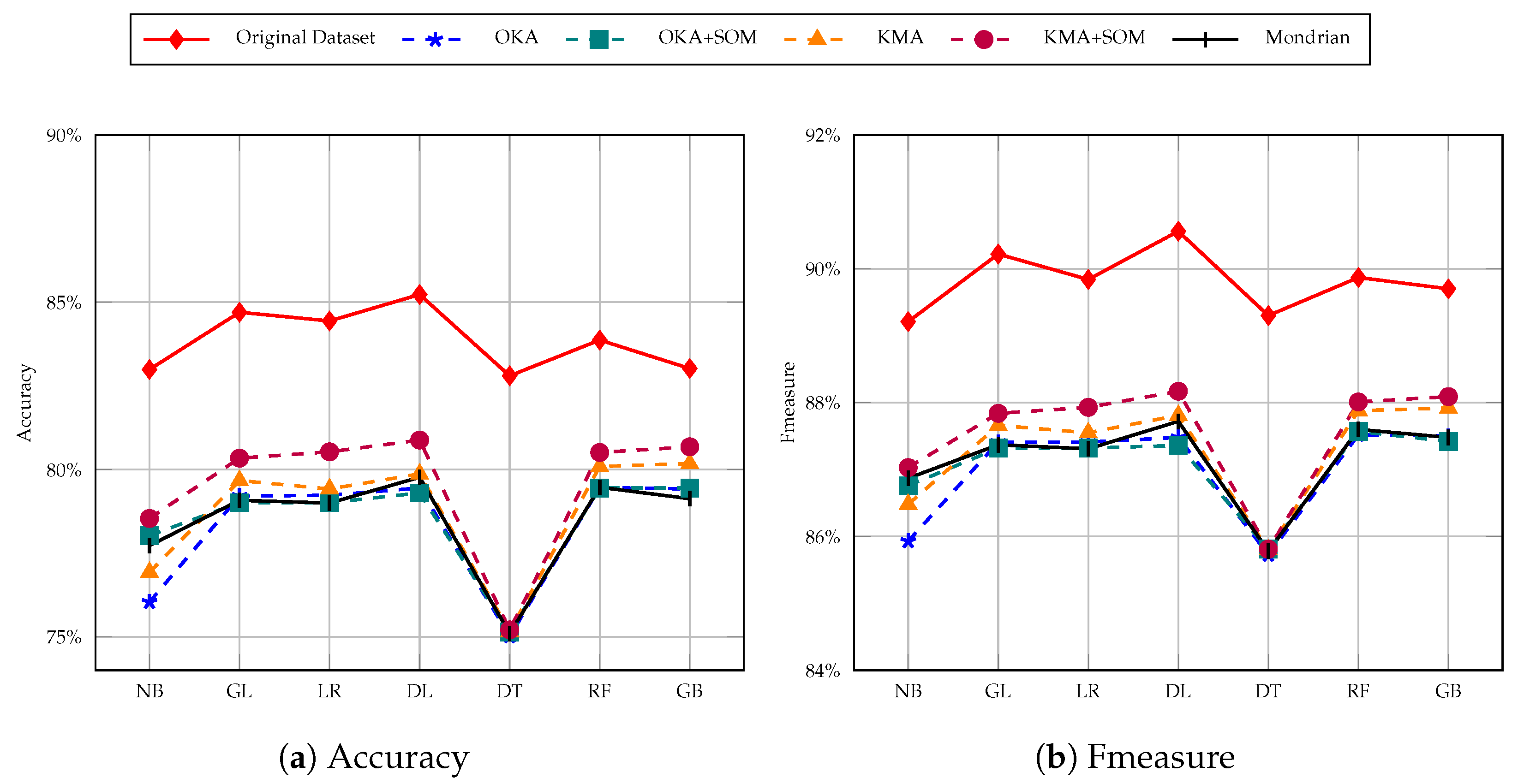
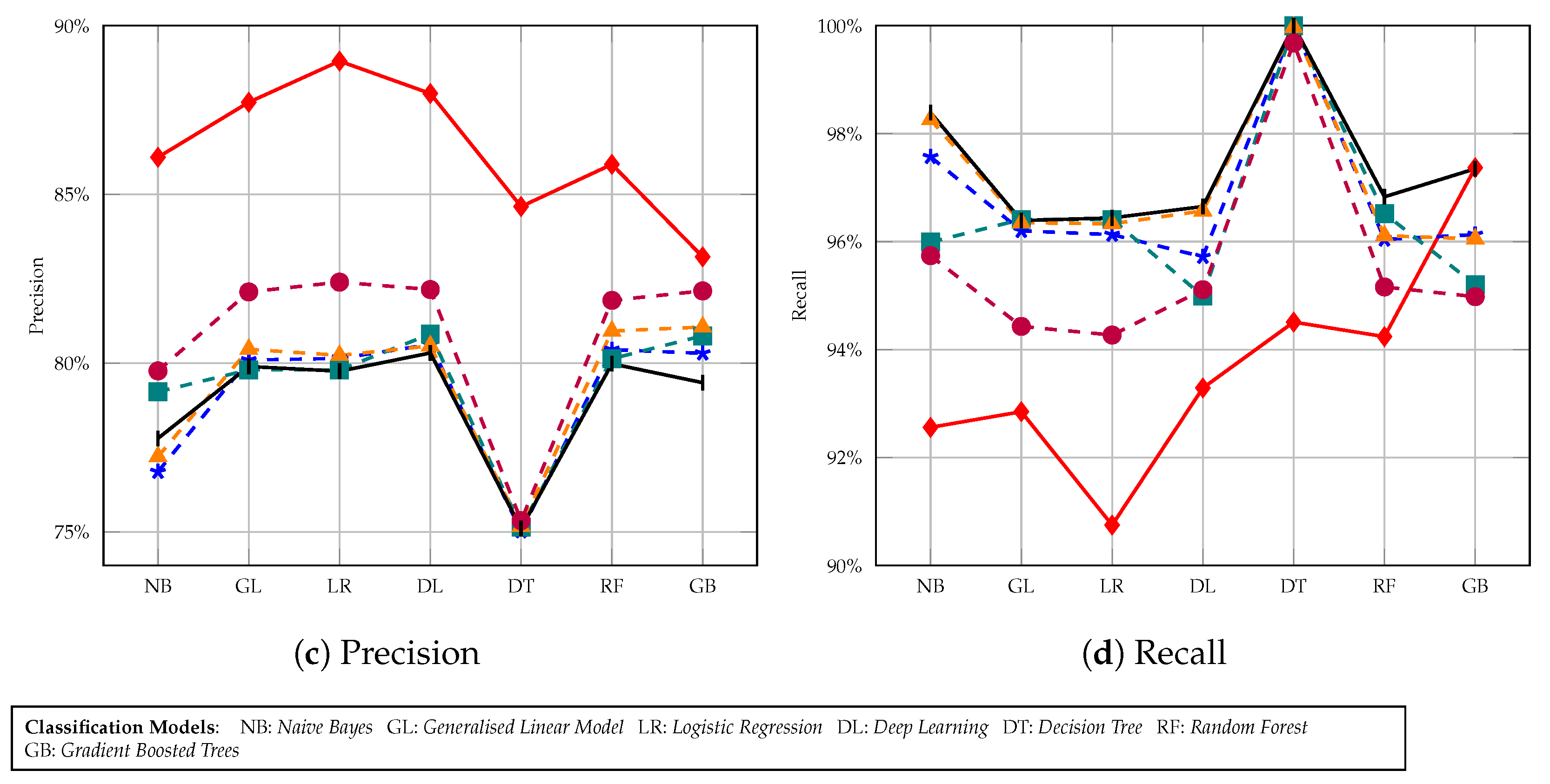
6.4. Classification Results
7. Open Issues
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PPDM | Privacy Preserving Data Mining |
| ICT | Information & Communication Technology |
| PCA | Principal Component Analysis |
| SOM | Self Organising Maps |
| BMU | Best Matching Unit |
| NCP | Normalised Certainty Penalty |
| OKA | One-pass k-Means Algorithm |
| KMA | k-Member Algorithm |
| DR | Dimensionality Reduction |
References
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann Series in Data Management Systems; Morgan Kaufmann: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Narwaria, M.; Arya, S. Privacy preserving data mining—‘A state of the art’. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 2108–2112. [Google Scholar]
- Sharma, S.; Shukla, D. Efficient multi-party privacy preserving data mining for vertically partitioned data. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Tamilnadu, India, 26–27 August 2016; Volume 2, pp. 1–7. [Google Scholar] [CrossRef]
- Kaur, A. A hybrid approach of privacy preserving data mining using suppression and perturbation techniques. In Proceedings of the 2017 International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 21–23 February 2017; pp. 306–311. [Google Scholar] [CrossRef]
- Liu, W.; Luo, S.; Wang, Y.; Jiang, Z. A Protocol of Secure Multi-party Multi-data Ranking and Its Application in Privacy Preserving Sequential Pattern Mining. In Proceedings of the 2011 Fourth International Joint Conference on Computational Sciences and Optimization, Kunming, China, 15–19 April 2011; pp. 272–275. [Google Scholar] [CrossRef]
- Lin, J.L.; Wei, M.C. An efficient clustering method for k-anonymization. In Proceedings of the 2008 International Workshop on Privacy and Anonymity in Information Society—PAIS ’08, Nantes, France, 29 March 2008; ACM Press: New York, NY, USA, 2008. [Google Scholar] [CrossRef]
- Lin, K.P.; Chen, M.S. On the Design and Analysis of the Privacy-Preserving SVM Classifier. IEEE Trans. Knowl. Data Eng. 2011, 23, 1704–1717. [Google Scholar] [CrossRef]
- Zainab, S.S.E.; Kechadi, T. Sensitive and Private Data Analysis: A Systematic Review. In Proceedings of the 3rd International Conference on Future Networks and Distributed Systems ICFNDS ’19, Paris, France, 1–2 July 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. Aggarwal, C.C.; Yu, P.S. A Condensation Approach to Privacy Preserving Data Mining. In Advances in Database Technology—EDBT 2004; Bertino, E., Christodoulakis, S., Plexousakis, D., Christophides, V., Koubarakis, M., Böhm, K., Ferrari, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 183–199. [Google Scholar]
- Ciriani, V.; di Vimercati, S.D.C.; Foresti, S.; Samarati, P. k-Anonymous Data Mining: A Survey. In Privacy-Preserving Data Mining; Springer: Boston, MA, USA, 2008; pp. 105–136. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. A General Survey of Privacy-Preserving Data Mining Models and Algorithms. In Privacy-Preserving Data Mining: Models and Algorithms; Springer: Boston, MA, USA, 2008; pp. 11–52. [Google Scholar] [CrossRef]
- Byun, J.W.; Kamra, A.; Bertino, E.; Li, N. Efficient k-Anonymization Using Clustering Techniques. In Advances in Databases: Concepts, Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 188–200. [Google Scholar] [CrossRef]
- Oliveira, S.; Zaïane, O. Privacy Preserving Clustering By Data Transformation. J. Inf. Data Manag. 2010, 1, 37. [Google Scholar]
- Kabir, E.; Wang, H.; Bertino, E. Efficient systematic clustering method for k-anonymization. Acta Inform. 2011, 48, 51–66. [Google Scholar] [CrossRef]
- Xu, X.; Numao, M. An Efficient Generalized Clustering Method for Achieving K-Anonymization. In Proceedings of the 2015 Third International Symposium on Computing and Networking (CANDAR), Washington, DC, USA, 8–11 December 2015. [Google Scholar] [CrossRef]
- Zheng, W.; Wang, Z.; Lv, T.; Ma, Y.; Jia, C. K-Anonymity Algorithm Based on Improved Clustering. Algorithms Archit. Parallel Process. 2018, 462–476. [Google Scholar] [CrossRef]
- Loukides, G.; Shao, J. Clustering-Based K-Anonymisation Algorithms. Database Expert Syst. Appl. 2007, 761–771. [Google Scholar] [CrossRef]
- Pin, L.; Wen-Bing, Y.; Nian-Sheng, C. A Unified Metric Method of Information Loss in Privacy Preserving Data Publishing. In Proceedings of the 2010 Second International Conference on Networks Security, Wireless Communications and Trusted Computing, Wuhan, China, 24–25 April 2010; Volume 2, pp. 502–505. [Google Scholar] [CrossRef]
- Gkoulalas-Divanis, A.; Loukides, G. A Survey of Anonymization Algorithms for Electronic Health Records. In Medical Data Privacy Handbook; Springer International Publishing: Cham, Switzerland, 2015; pp. 17–34. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. Adult Data Set UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 7 January 2021).
- Mohammed, K.; Ayesh, A.; Boiten, E. Utility Promises of Self-Organising Maps in Privacy Preserving Data Mining. In Data Privacy Management, Cryptocurrencies and Blockchain Technology; Garcia-Alfaro, J., Navarro-Arribas, G., Herrera-Joancomarti, J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 55–72. [Google Scholar]
- El Emam, K.; Dankar, F.; Issa, R.; Jonker, E.; Amyot, D.; Cogo, E.; Corriveau, J.P.; Walker, M.; Chowdhury, S.; Vaillancourt, R.; et al. A Globally Optimal k-Anonymity Method for the De-Identification of Health Data. J. Am. Med. Inform. Assoc. JAMIA 2009, 16, 670–682. [Google Scholar] [CrossRef]
- Samarati, P. Protecting respondents identities in microdata release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef]
- Ciriani, V.; Di Vimercati, S.D.C.; Foresti, S.; Samarati, P. k-anonymity. In Secure Data Management in Decentralized Systems; Springer: Boston, MA, USA, 2007; pp. 323–353. [Google Scholar] [CrossRef]
- Samarati, P.; Sweeney, L. Generalizing data to provide anonymity when disclosing information (abstract). In Proceedings of the Seventeenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems; Association for Computing Machinery: Seattle, WA, USA, 1998. [Google Scholar] [CrossRef]
- Bertino, E.; Lin, D.; Jiang, W. A Survey of Quantification of Privacy Preserving Data Mining Algorithms. In Privacy-Preserving Data Mining: Models and Algorithms; Aggarwal, C.C., Yu, P.S., Eds.; Springer: Boston, MA, USA, 2008; pp. 183–205. [Google Scholar] [CrossRef]
- Meyerson, A.; Williams, R. On the Complexity of Optimal K-Anonymity. In Proceedings of the Twenty-Third ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems PODS ’04, Paris, France, 14–16 June 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 223–228. [Google Scholar] [CrossRef]
- Tripathy, B. Database Anonymization Techniques with Focus on Uncertainty and Multi-Sensitive Attributes. In Handbook of Research on Computational Intelligence for Engineering, Science, and Business; IGI Global: Hershey, PA, USA, 2013; pp. 364–383. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Mondrian Multidimensional K-Anonymity. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 25. [Google Scholar] [CrossRef]
- Ayala-Rivera, V.; McDonagh, P.; Cerqueus, T.; Murphy, L. A Systematic Comparison and Evaluation of k-Anonymization Algorithms for Practitioners. Trans. Data Priv. 2014, 7, 337–370. [Google Scholar]
- Friedman, A.; Wolff, R.; Schuster, A. Providing k-anonymity in data mining. VLDB J. 2008, 17, 789–804. [Google Scholar] [CrossRef]
- Kawano, A.; Honda, K.; Kasugai, H.; Notsu, A. A Greedy Algorithm for k-Member Co-clustering and its Applicability to Collaborative Filtering. Procedia Comput. Sci. 2013, 22, 477–484. [Google Scholar] [CrossRef]
- Ye, J.; Ji, S.; Sun, L. Multi-Label Dimensionality Reduction, 1st ed.; Chapman & Hall: London, UK, 2011. [Google Scholar]
- Lee, J.A.; Verleysen, M. Nonlinear Dimensionality Reduction, 1st ed.; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer International: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Dogan, Y.; Birant, D.; Kut, A. SOM++: Integration of Self-Organizing Map and K-Means++ Algorithms. In Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2013; pp. 246–259. [Google Scholar] [CrossRef]
- Flavius, G.; Jose Alfredo, C. PartSOM: A Framework for Distributed Data Clustering Using SOM and K-Means. In Self-Organizing Maps; IntechOpen: London, UK, 2010. [Google Scholar] [CrossRef]
- Tsiafoulis, S.; Zorkadis, V.C.; Karras, D.A. A Neural-Network Clustering-Based Algorithm for Privacy Preserving Data Mining. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 269–276. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Torra, V. Disclosure risk assessment in statistical data protection. J. Comput. Appl. Math. 2004, 164–165, 285–293. [Google Scholar] [CrossRef]
- Byun, J.W.; Sohn, Y.; Bertino, E.; Li, N. Secure Anonymization for Incremental Datasets. In Secure Data Management; Jonker, W., Petković, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 48–63. [Google Scholar]
- Zare-Mirakabad, M.R.; Jantan, A.; Bressan, S. Privacy Risk Diagnosis: Mining l-Diversity. In Database Systems for Advanced Applications; Chen, L., Liu, C., Liu, Q., Deng, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 216–230. [Google Scholar]
- Wang, K.; Fung, B.C.M. Anonymizing Sequential Releases. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining KDD ’06, Beijing, China, 12–16 August 2006; ACM: New York, NY, USA, 2006; pp. 414–423. [Google Scholar] [CrossRef]
- Gong, Q. Clustering Based k-Anonymization. Available online: https://github.com/qiyuangong/Clustering_based_K_Anon (accessed on 8 February 2021).
- Mishra, A. Metrics to Evaluate your Machine Learning Algorithm. Available online: https://towardsdatascience.com/metrics-to-evaluate-your-machine-learning-algorithm-f10ba6e38234 (accessed on 11 February 2021).
- Mohammed, K. SOM Anonymisation. Available online: https://github.com/mkabir7/SOManonymisation (accessed on 24 March 2021).
- Rocher, L.; Hendrickx, J.M.; de Montjoye, Y.A. Estimating the success of re-identifications in incomplete datasets using generative models. Nat. Commun. 2019, 10, 3069. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Name | Age | Sex | Zipcode | Disease |
|---|---|---|---|---|---|
| 1 | Arun | 25 | Male | 53711 | Pneumonia |
| 2 | Sara | 28 | Female | 53435 | Tuberculosis |
| 3 | Jane | 31 | Female | 53510 | Cancer |
| 4 | Beny | 26 | Male | 53411 | Tuberculosis |
| 5 | Elly | 27 | Female | 53719 | Malaria |
| 6 | Adam | 30 | Male | 53510 | Cold Flu |
| No | Age | Sex | Zipcode | Disease |
|---|---|---|---|---|
| 1 | 20–30 | Male | 537 ** | Pneumonia |
| 5 | 20–30 | Female | 537 ** | Malaria |
| 2 | 20–30 | Female | 534 ** | Tuberculosis |
| 4 | 20–30 | Male | 534 ** | Tuberculosis |
| 3 | 30–40 | Female | 535 ** | Cancer |
| 6 | 30–40 | Male | 535 ** | Cold Flu |
| Type | Features | Attribute | Corr. | ID-Ness % | Stability % | ||
|---|---|---|---|---|---|---|---|
| CATEGORICAL | Workclass | Ⓠ | 0.047 | 0.03 | 69.70 | ||
| Education | Ⓠ | −0.046 | 0.05 | 32.50 | |||
| Marital-status | Ⓢ | 0.003 | 0.02 | 45.99 | |||
| Occupation | Ⓠ | −0.105 | 0.05 | 12.71 | |||
| Relationship | Ⓠ | −0.171 | 0.02 | 40.52 | |||
| Race | Ⓢ | −0.068 | 0.02 | 85.43 | |||
| Native-country | Ⓠ | 0.034 | 0.13 | 89.59 | |||
| Gender | Ⓢ | −0.216 | 0.01 | 66.92 | |||
| NUMERICAL | Age | Ⓠ | 0.234 | 0.22 | 2.76 | ||
| Fnlwgt | Ⓝ | −0.009 | 66.48 | 0.04 | |||
| Education-num | Ⓠ | 0.335 | 0.05 | 32.25 | |||
| Capital-gain | Ⓢ | 0.266 | 0.37 | 91.67 | |||
| Capital-loss | Ⓢ | 0.139 | 0.28 | 95.33 | |||
| Hours-per-week | Ⓢ | 0.229 | 0.29 | 46.73 | |||
| Income | Ⓢ | 1.000 | 0.01 | 75.92 | |||
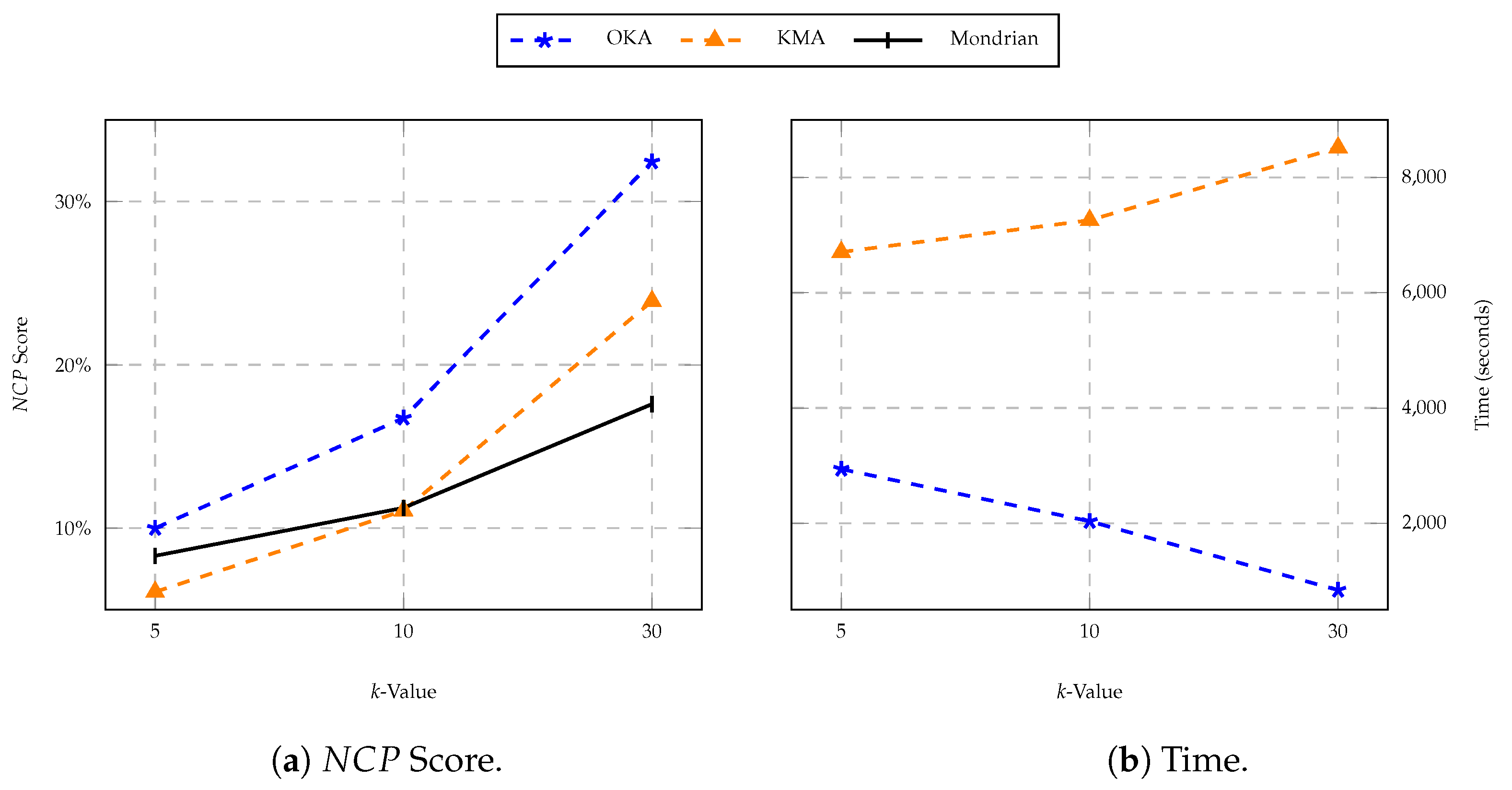
| k-Value | Algorithm | NCP% | Time (s) |
|---|---|---|---|
| 5-anonymity | OKA | 9.99 | 2939.93 |
| KMA | 6.09 | 6706.59 | |
| Mondrian | 8.30 | 1.16 | |
| 10-anonymity | OKA | 16.74 | 2034.22 |
| KMA | 11.07 | 7258.76 | |
| Mondrian | 11.24 | 0.75 | |
| 30-anonymity | OKA | 32.43 | 840.12 |
| KMA | 23.90 | 8518.48 | |
| Mondrian | 17.59 | 0.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammed, K.; Ayesh, A.; Boiten, E. Complementing Privacy and Utility Trade-Off with Self-Organising Maps. Cryptography 2021, 5, 20. https://doi.org/10.3390/cryptography5030020
Mohammed K, Ayesh A, Boiten E. Complementing Privacy and Utility Trade-Off with Self-Organising Maps. Cryptography. 2021; 5(3):20. https://doi.org/10.3390/cryptography5030020
Chicago/Turabian StyleMohammed, Kabiru, Aladdin Ayesh, and Eerke Boiten. 2021. "Complementing Privacy and Utility Trade-Off with Self-Organising Maps" Cryptography 5, no. 3: 20. https://doi.org/10.3390/cryptography5030020
APA StyleMohammed, K., Ayesh, A., & Boiten, E. (2021). Complementing Privacy and Utility Trade-Off with Self-Organising Maps. Cryptography, 5(3), 20. https://doi.org/10.3390/cryptography5030020