1. Introduction
Verifiable random functions (VRFs), initially introduced by Micali, Rabin, and Vadhan [
1], can be seen as the public key equivalent of pseudorandom functions (PRFs) that, besides the
pseudorandomness property (i.e., the function looks random at any input
x), also provide the property of
verifiability. More precisely, VRFs are defined by a pair of public and secret keys
in such a way that they provide not only the efficient computation of the pseudorandom function
for any input
x but also a non-interactive publicly verifiable proof
that, given access to
, allows the efficient verification of the statement
for all inputs
x. VRFs have been shown to be very useful in multiple application scenarios including key distribution centres [
2], non-interactive lottery systems used in micropayments [
3], domain name security extensions (DNSSEC) [
4,
5,
6], e-lottery schemes [
7], and proof-of-stake blockchain protocols such as Ouroboros Praos [
8,
9].
Cohen, Goldwasser, and Vaikuntanathan [
10] were the first to investigate how to answer
aggregate queries for PRFs over exponential-sized sets and introduced a type of augmented PRFs, called aggregate pseudo-random functions, which significantly enriched the existing family of (augmented) PRFs including constrained PRFs [
11], key-homomorphic PRFs [
12], and distributed PRFs [
2]. Inspired by the idea of aggregated PRFs [
10], in this paper, we explore the aggregation of VRFs and introduce a new cryptographic primitive,
static aggregate verifiable random functions (static Agg-VRFs), which allow not only the efficient aggregation operation both on function values and proofs but also the verification on the correctness of the aggregated results.
Aggregate VRFs allow the efficient aggregation of a large number of function values, as well as the efficient verification of the correctness of the aggregated function result by employing the corresponding aggregated proof. Let us give an example to illustrate this property. Consider a cloud-assisted computing setting where a VRF can be employed in the client–server model, i.e., Alice is given access to a random function where the function description (or the secret key) is stored by a server (seen as the random value provider). Whenever Alice requests an arbitrary bit-string x, the server simply computes the function value together with the corresponding proof and returns the tuple to Alice. Alice may also request the aggregation (such as the product) of the function values over a large number of points (e.g., , which may match some pattern, such as having same bits on some bit locations). In this case, aggregate VRFs allow the server to compute the product of efficiently, instead of firstly evaluating and then calculating their product. On receiving either the function value y of an individual input or the aggregated function value over multiple inputs, Alice needs to verify the correctness of the returned value. VRFs allow the verification of the correctness of y using , while, to verify the correctness of , there is a trivial way, namely firstly verifying for using the verification algorithm of VRFs and then checking if , but the running time of which depends on the number n. Via aggregate VRFs, the verification of can be achieved much more efficiently by using the aggregated proof that is generated by the server and returned to Alice along with .
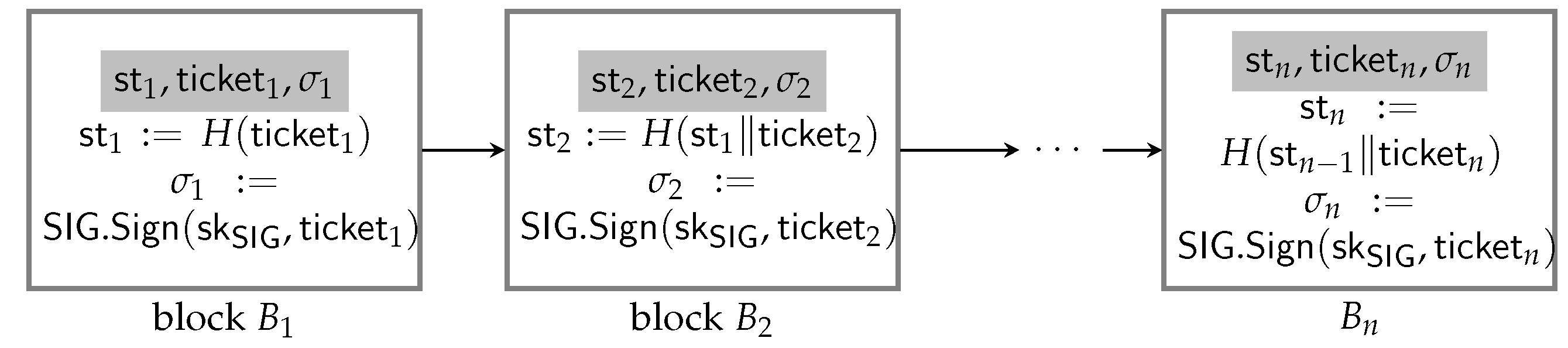
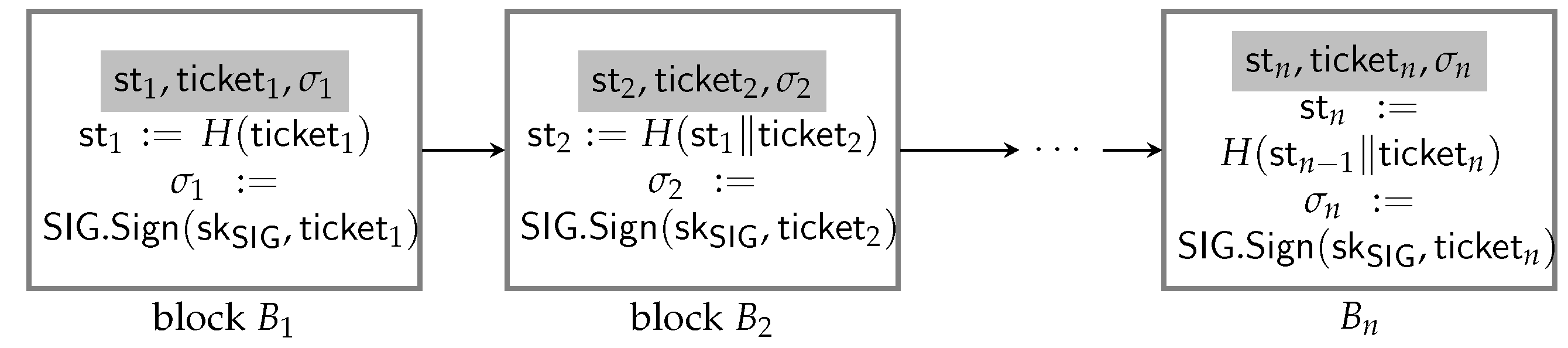
A representative application of aggregate VRFs is in e-lottery schemes. More precisely, aggregate VRFs can be employed in VRF-based e-lottery schemes [
7], where a random number generation mechanism is required to determine not only a winning number but also the public verifiability of the winning result, which guarantees that the dealer cannot cheat in the random number generation process. In this paper, we provide an e-lottery scheme, which has significant gain in the efficiency of generating the winning numbers and verifying the winning results. In a nutshell, VRF-based e-lottery schemes [
7] proceed as follows: Initially, the dealer generates a secret/public key pair
of VRFs and publishes the public key
, together with a parameter
associated with the time (this is the input parameter controlling the time complexity of the delaying function
) during which the dealer must release the winning ticket value. To purchase the ticket, a player chooses his bet number
and obtains a ticket
(please refer to
Section 4.2 for the generation of ticket
on a bet number
x in detail) from the dealer. The dealer links the ticket to a blockchain, which could be created as
,
for
, and publishes
where
j is the number of tickets sold so far. To generate the random winning number, the dealer first computes a VRF as
on
, where
h is the final value of the blockchain (i.e., suppose there are
n tickets sold, then
). Assume that the numbers used in the lottery game are
. If
, then the dealer iteratively applies the VRF on
to obtain
. Suppose that, within
units of time after the closing of the lottery session, until applying the VRF for
t times, the dealer obtains
such that
. Afterwards, the dealer publishes
as the winning number and the corresponding proof as well as all the intermediate tuples
. If
, a player wins. To verify the validity of a winning number
, each player verifies the validity of
for
.
Chow et al.’s e-lottery scheme [
7] seems to be very promising when considering an ideal case that after a small number
t of times that the VRF is applied, a function value
such that
can be obtained successfully. Otherwise, it means that the dealer needs to calculate the VRF more times, while the player needs to verify the correctness of more tuples in order to verify the winning result; the latter leads to large computational overhead and requires storage of all intermediate tuples of VRF function values and corresponding proofs, both from the dealer and the player.
Observe that both the evaluation and verification of multiple pairs of VRF function value/proof are time consuming. By using our aggregate VRF instantiation, we improve the e-lottery by devising the dealer to evaluate aggregate VRF twice at most so as to obtain a random winning number together with corresponding proof, thus rendering the verification for only such a single pair. This reduces the amount of data written to the dealer’s storage space and also decreases the computational cost for the verification process of each player.
Our Contribution. We introduce the notion of static aggregate verifiable random functions (static Agg-VRFs). Briefly, a static Agg-VRF is a family of keyed functions each associated with a pair of keys, such that, given the secret key, one can compute the aggregation function for both the function values and the proofs of the VRFs over super-polynomially large sets in polynomial time, while, given the public key, the correctness of the aggregate function values could be checked by the corresponding aggregated proof. It is very important that the sizes of the aggregated function values and proofs should be independent of the size of the set over which the aggregation is performed. The security requirement of a static Agg-VRF states that access to an aggregate oracle provides no advantage to the ability of a polynomial time adversary to distinguish the function value from a random value, even when the adversary could query an aggregation of the function values over a specific set (of possibly super-polynomial size) of his choice.
In this paper, the aggregate operation we consider is the product of all the VRF values and proofs over inputs belonging to a super-polynomially large set. We show how to compute the product aggregation over a super-polynomial size set in polynomial time, since it is impossible to directly compute the product on a super-polynomial number of values. More specifically, we show how to achieve a static Agg-VRF under the Hohenberger and Waters’ VRF scheme [
13] for the product aggregation with respect to a bit-fixing set. We stress that after revisiting the JN-VRF scheme [
14] proposed by Jager and Niehuesbased (currently the most efficient VRFs with full adaptive security in the standard model), we find that, even though JN-VRF almost enjoys the same framework of HW-VRF (since an admissible hash function
is applied on inputs
x before evaluating the function value and the corresponding proof, which impacts negatively the nice pattern of all inputs in a bit-fixing set), it is impossible to perform productive aggregation of a super-polynomial number of values
efficiently over bit-fixing sets.
We implemented and evaluated the performance of our proposed static aggregate VRF in comparison to a standard (non-aggregate) VRF for inputs with different lengths i.e., 56, 128, 256, 512, and 1024 bits, in terms of the costing time for aggregating the function values, aggregating the proofs as well as the cost of verification for the aggregation. In all cases, our aggregate VRFs present significant computational advantage and are more efficient than standard VRFs. Furthermore, by employing aggregate VRFs for bit-fixing sets, we propose an improved
e-lottery scheme based on the framework of Chow et al.’s VRF-based e-lottery proposal [
7], by mainly modifying the winning result generation phase and the player verification phase. We implemented and tested the performance of both Chow et al.’s and our improved e-lottery schemes. Our improved scheme shows a significant improvement in efficiency in comparison to Chow et al.’s scheme.
Core Technique. We present a construction of static aggregate VRFs, which performs the product aggregation over a bit-fixing set, following Hohenberger and Waters’ [
13] VRF scheme. A bit-fixing set consists of bit-strings which match a particular bit pattern. It can be defined by a pattern string
as
. The evaluation of the VRF on input
is defined as
, where
are public keys and
are kept secret. The corresponding proofs of the VRF are given using a step ladder approach, namely, for
to
ℓ,
and
.
Let
and
. To aggregate the VRF, let
, for
; we compute
and
. The aggregated function value is computed as
The aggregation verification algorithm checks the following equations: for
and
and
.
Improved Efficiency. We provide some highlights on the achieved efficiency.
Efficiency of Aggregate VRF. The construction of our static aggregate VRF for a bit-fixing (BF) set achieves high performance in the verification process, since it takes only
bilinear pairing operations, even when verifying an exponentially large set of function values, where
ℓ denotes the input length. The experimental results show that, even for 1024 bits of inputs, the aggregation of
pairs of function values/proofs can be computed very efficiently in 6881 ms. Moreover, the time required to verify their aggregated function values/proofs of
pairs only increases
, comparing with the verification time for each single function value/proof pair of standard VRF.
Section 3.2 and
Section 3.3 present a detailed efficiency discussion and our experimental tests and comparisons.
Efficiency of Improved E-Lottery Scheme. We test the performance of Chow et al.’s e-lottery scheme [
7] and our improved (aggregate VRF based) counterpart and make a comparison. In our improved e-lottery scheme, the computation of the aggregate function value/proof pair and the verification are performed via a single step of Aggregation and AggVerify algorithms, respectively, while Chow et al.’s e-lottery scheme is processed by
t steps. We perform some experiments on Chow et al.’s scheme to see how big/small the
t is so as to reach the point where the dealer obtains
such that
, thus figuring out the computation-time for the corresponding multiple function evaluation and verification. In the experiments, we ran 10 times Chow et al.’s scheme and we obtained the median of all the runs. We reached
and it took ≈100 s for each run of the winner generation and ≈5 s for player verification. In our improved version, the generation of the winner ticket costs less than 90 s, and the time for verification decreases to ≈2.5 s, which shows a significant improvement in efficiency.
Related work. We summarize relevant current state-of-the-art.
Verifiable Random Functions. Hohenberger and Waters’ VRF scheme [
13] is the first that shows all the desired properties for a VRF (we say that a VRF scheme has all the desired properties if it allows an exponential-sized input space, achieves full adaptive security, and is based on a non-interactive assumption). Formerly, there have been several VRF proposals [
15,
16,
17], all of which have some limitations: they only allow a polynomial-sized input space, they do not achieve fully adaptive security, or they are based on an interactive assumption. Thus far, there are also many constructions of VRFs with all the desired properties based on the decisional Diffie–Hellman assumption (DDH) or the decision linear assumption (DLIN) presenting different security losses [
18,
19,
20,
21,
22]. Kohl [
22] provided a detailed summary and comparison of all existing efficient constructions of VRFs in terms of the underlying assumption, sizes of verification key and the corresponding proof, and the associated security loss. Recently, Jager and Niehues [
14] provided the most efficient VRF scheme with adaptive security in the standard model, relying on the computational admissible hash functions.
Aggregate Pseudorandom Functions. Cohen et al. [
10] introduced the notion of aggregate PRFs, which is a family of functions indexed by a secret key with the functionality that, given the secret key, anyone is able to aggregate the values of the function over super-polynomially many PRF values with only a polynomial-time computation. They also proposed constructions of aggregate PRFs under various cryptographic hardness assumptions (one-way functions and sub-exponential hardness of the Decisional Diffie–Hellman assumption) for different types of aggregation operators such as sums and products and for several set systems including intervals, bit-fixing sets, and sets that can be recognized by polynomial-size decision trees and read-once Boolean formulas. In this paper, we explore how to aggregate VRFs, which involves efficient aggregations both on the function evaluations and on the corresponding proofs, while providing verifiability for the correctness of aggregated function value via corresponding proof.
E-lottery Schemes/Protocols. In 2005, Chow et al. [
7] proposed an e-lottery scheme using a verifiable random function (VRF) and a delay function. To reduce the complexity in the (purchaser) verification phase, Liu et al. [
23] improved Chow et al.’s scheme by proposing a multi-level hash chain to replace the original linear hash chain, as well as a hash-function-based delay function, which is more suitable for e-lottery networks with mobile portable terminals. Based on the secure one-way hash function and the factorization problem in RSA, Lee and Chang [
24] presented an electronic
t-out-of-
n lottery on the Internet, which allows lottery players to simultaneously select
t out of
n numbers in a ticket without iterative selection. Given that the previous schemes [
7,
23,
24] offer single participant lottery purchases on the Internet, Chen et al. [
25] proposed an e-lottery purchase protocol that supports the joint purchase from multi-participants that enables them to safely and fairly participate in a mobile environment. Aiming to provide an online lottery protocol that does not rely on a trusted third party, Grumbach and Riemann [
26] proposed a novel distributed e-lottery protocol based on the centralized e-lottery of Chow et al. [
7] and incorporated the aforementioned multi-level hash chain verification phase of Liu et al. [
23]. Considering that the existing works on e-lottery focus either on providing new functionalities (such as decentralization or threshold) or improving the hash chain or delay function, the building block of VRFs has received little attention. In this paper, we explore how to improve the efficiency of Chow et al.’s [
7] e-lottery scheme by using aggregate VRFs.
3. Static Aggregate VRFs
In a (static) aggregate PRF [
10] (here, we call the aggregate PRF proposed by Cohen, Goldwasser, and Vaikuntanathan [
10] as a static aggregate PRF since their aggregation algorithm needs the secret key of the PRF to be taken as input), there is an additional aggregation algorithm which given the secret key can (efficiently) compute the aggregated result of all the function values over a set of all the inputs in polynomial time, even if the input set is of super-polynomial size. Note that in an aggregate VRF, similarly to an aggregate PRF, an additional aggregation algorithm is brought into the ordinary VRF [
1]. Thus, aggregate VRFs can be regarded as an extension of ordinary VRFs. The static aggregate VRF differs from a static aggregate PRF [
10] in that given the secret key the aggregation operation is performed not only on the function values but also on the corresponding proofs. Moreover, the resulted aggregate function value can be publicly verified by using aggregate proof (together with the public key and the input subset), which proves that the aggregate function value is a correct result on the aggregation of all function values over the input subset.
Cohen, Goldwasser, and Vaikuntanathan [
10] were the first to consider the notion of aggregate PRFs over the super-polynomial large but
efficiently recognizable set classes. In their model, they treat the efficiently recognizable set ensemble as a family of predicates, i.e., for any set
S there exists a polynomial-size boolean circuit
such that
if and only if
. Boneh and Waters [
11] also employed such a predicate to define the concept of constrained PRFs with respect to a constrained set. In this paper, we employ the concept and formalization of the efficiently recognizable set in the definition of static aggregate VRFs.
Recall that a verifiable random function (VRF) [
1] is a function
defined over a secret key space
, a domain
, a range
, and a proof space
(and these sets may be parameterized by the security parameter
). Let
denote the mapping of random function evaluations on arbitrary inputs and
denote the mapping of proof evaluations on inputs, each of which can be computed by a deterministic polynomial time algorithm.
Let be the aggregation function that takes as inputs multiple pairs of values from the range and the proof space of the function family, and aggregates them to output an aggregated function value in the range and the corresponding aggregated proof in the proof space .
Definition 2 (Static Aggregate VRF). Let be a VRF function family where each function computable in polynomial time is defined over a key space , a domain , a range and a proof space . Let be an efficiently recognizable ensemble of sets where for any , , and be an aggregation function. We say that is an -static aggregate verifiable random function family (abbreviated -sAgg-VRFs) if it satisfies:
Efficient aggregation:There exists an efficient (computable in polynomial time) algorithm which on input the secret key of a VRF and a set , outputs aggregated results such that for any , where for ;
Verification for aggregation:There exists an efficient (computable in polynomial time) algorithm which on input the aggregated function value and the proof for an ensemble of the domain, verifies if it holds that using the aggregated proof .
Correctness of aggregated values:For all , set and the aggregate function , let and , then .
Pseudorandomness:For all p.p.t. attackers , there exists a negligible function s.t.:where is the set of all inputs that D queries to its oracle , consists of all the sets that D queries to its oracle , and is the polynomial-size boolean circuit that is able to recognize the ensemble . Compactness:There exists a polynomial such that for every , , set and the aggregate function , it holds with overwhelming probability over , and that the resulting aggregated value and aggregated proof has size . In particular, the size of and are independent of the size of the set S.
We stress that the set S over which the aggregation is performed can be super-polynomially large. Clearly, given exponential numbers of values , it is impossible to perform aggregation on them but yet, we show how to efficiently compute the aggregation function on an exponentially large set with respect to a concrete VRF given the secret key.
Some explanations on the notion of static aggregate VRFs. Firstly, the algorithm achieves an efficient aggregation on function values/proofs over super-polynomially large sets S in polynomial time. We stress that our aim is to work on super-polynomially large sets, since, for any constant size of sets, the (productive) aggregation can be computed trivially, given the function value/proof pairs on all inputs in such a set. Secondly, the verification algorithm is employed to efficiently verify the correctness of the aggregated function values . Given and the aggregated function value , there is a trivial way to verify the correctness of , by verifying the correctness of each tuple for and then checking if , which is not computable in polynomial time if S is a super-polynomially large set. Therefore, our main concern is to achieve efficient verification on via the corresponding proof , the size of which is independent of the size of S. Thirdly, the condition is interpreted as that value is a correct result on the aggregation of , i.e., , by using the corresponding proof . We note that the verification for the aggregation does not violate the uniqueness of the underlying basic VRF. Indeed, there probably exist different sets and that result in a same , but the uniqueness for any input point () always holds. Looking ahead, in our instantiation of aggregate VRFs, to find two sets such that is computationally hard, without knowledge of . Lastly, the condition does not imply for all , since by maintaining a correct pair , we always can alter any two tuples as and for any random , which means .
3.1. A Static Aggregate VRF for Bit-Fixing Sets
We now propose a static aggregate VRF, whose aggregation function is to compute products over bit-fixing sets. In a nutshell, a bit-fixing set consists of bit-strings, which match a particular bit pattern. We naturally represent such sets by a string in with 0 and 1 indicating a fixed bit location and ⊥ indicating a free bit location. To do so, we define for a pattern string the bit-fixing set as .
We show based on an elegant construction of VRFs proposed by Hohenberger and Waters [
13] (abbreviated as HW-VRF scheme) how to compute the productive aggregation function over a bit-fixing set in polynomial time; thus, yielding a static aggregate VRF. Please refer to
Section 2.2 for detailed description of HW-VRF scheme. The aggregation algorithm for bit-fixing sets takes as input the VRF secret key
and a string
. Let
and
. The aggregation algorithm and the verification algorithm for an aggregated function value and the corresponding proof works as follows:
Letting where is the bit-fixing sets on , we now prove the following theorem:
Theorem 1. Let be a constant. Choose the security parameter , and assume the -hardness of q-DDHE over the group and . Then, the collection of verifiable random functions F defined above is a secure aggregate VRF with respect to the subsets and the product aggregation function over and .
The compactness follows straightforward, since the aggregated function value and the aggregated proof , the sizes of which are independent of the size of the bit-fixing set , i.e., .
The proof for pseudorandomness is similar to that of HW-VRF scheme in [
13] since our static aggregate VRF is built on the ground of HW-VRF and the only phase we need to deal with in the proof is to simulate the responses of the aggregation queries. Here, we provide the simulation routine that the
q-DDHE solver executes to act as a challenger in the pseudorandomness game of the aggregated VRFs. The detailed analysis of the game sequence is similar to the related descriptions in [
13].
Proof of Theorem 1. Let be a polynomial upper bound on the number of queries made by a p.p.t. distinguisher D to the oracles and . We use D to create an adversary such that, if D wins in the pseudorandomness game for aggregate VRFs with probability , then breaks the q-DDHE assumption with probability , where , and ℓ is the input length of the static Agg-VRFs.
Given , to distinguish from , , proceed as follows:
. Set and choose an integer . It then picks random integers from the interval and random elements , which are all kept internal by .
For
, let
denote the
ith bit of
x. Define the following functions:
sets and for . It sets the public key as , and the secret key implicitly includes the values and .
Oracle Queries to . The distinguisher D will make queries of VRF evaluations and proofs. On receiving an input x, first checks if and aborts if this is true. Otherwise, it defines the function value as , and the corresponding proof as where , for . Note that for any it holds:
The maximum value of is .
The maximum value of is for .
As a result, if , could answer all the queries.
Oracle Queries to . The distinguisher
D will also make queries for aggregate values. On receiving a pattern string
,
uses the above secret key to compute the aggregated proof and the aggregate function value. More precisely,
answers the query
as follows: Let
. Since the aggregated proof is defined as
where, for
,
and
,
will compute concretely:
and, for
,
where
and
. The above value could be computed by
through its knowledge of
. The value of
can be handled similarly using
. While the aggregated function value is defined as
.
Challenge.D will send a challenge input with the condition that is never queried to its oracle. If , returns the value y. When D responds with a bit , outputs as its guess to its own q-DDHE challenger. If , outputs a random bit as its guess. This ends our description of q-DDHE adversary . □
Remark 1. Discussion on the impossibility of productive aggregation on JN-VRF for bit-fixing sets.
Recently, based on q-DDH-assumption, Jager and Niehues [14] proposed the currently most efficient VRFs (that is abbreviated as JN-VRF scheme) with full adaptive security in the standard model. JN-VRF almost enjoys the same framework of HW-VRF, and the only difference is that in the former an admissible hash function is applied on inputs x before evaluating the function value and corresponding proof, while the latter is not. We stress that hash function on inputs x destroys the nice pattern of all inputs in a bit-fixing set, which implies that, for any , i.e., for all , , there does not exist a bit-string such that , where . Otherwise, it is possible to find the collisions of . Therefore, given exponential
numbers of values , it is impossible to perform productive aggregation over them efficiently by using the same technique as in the last subsection. 3.2. Efficiency Analysis
Analysis of Costs. The instantiation in
Section 3.1 is very compact since the aggregated function value consists of a single element in
, while the aggregated proof is composed of
elements in
, which are independent of the size of a set
S. The Aggregate algorithm simply requires at most
ℓ multiplications plus one exponentiation to compute
and
exponentiations to evaluate
, which needs much less computation compared to computing
multiplications to obtain
and
multiplications to obtain
on all
number of inputs in
S. The AggVerify algorithm simply requires at most
pairing operations, while
pairings are needed for verifying
number of function values/proofs on all inputs in
S.
We summarize the cost for the Aggregate and AggVerify algorithms in
Table 1, where MUL is the shortened form of the multiplication operation, EXP is the abbreviation for the exponentiation operation, and ADD denotes the addition operation.
3.3. Implementation and Experimental Results
Choice of elliptic curves and pairings. In our implementation, we use Type A curves as described in [
28], which can be defined as follows. Let
q be a prime satisfying
and let
p be some odd dividing
. Let
E be the elliptic curve defined by the equation
over
; then,
is supersingular,
,
, and
is a cyclic group of order
p with embedding degree
. Given map
, where
i is the square root of
,
maps points of
to points of
, and if
f denotes the Tate pairing on the curve
, then defining
by
gives a bilinear nondegenerate map. For more details about the choice of parameters, please refer to [
28]. In our case, we use the standard parameters proposed by Lynn [
28] (
https://crypto.stanford.edu/pbc/), where
q has 126 bits and
. To generate random elements, we use libsodium (
https://libsodium.gitbook.io/). Our implementation uses the programming language “C” and the GNU Multiple Precision Arithmetic for arithmetic with big numbers. We use the GCC version 10.0.1 with the following compilation flags: “-O3 -m64 -fPIC -pthread -MMD -MP -MF”.
Implementing HW-VRF. In our implementation, we use the bilinear map as pairing implemented by Lynn [
28] for the BLS signature scheme. We notice that, when computing the function value
, we usually compute first the bilinear
, and then do the exponentiation. However, it is expensive to do the exponentiation of an element in
. To improve the efficiency of computing
, we use the following mathematical trick:
, which implies that we calculate
as
. Since the computation of
(or
) corresponds to the scalar multiplication of a point
P (or
Q) by a scalar
a (or
b), using this trick, we avoid the exponentiation on an element in
by requiring cost of two scalar multiplications of a point of the curve.
Implementing our static Agg-VRFs. Since p is fixed, when calculating the aggregated proof as , we can precompute the inversion of 2 and thus only need to compute by the scalar multiplication of a point on curve with scalar . We use a similar approach when computing ; in this case, we always perform . Again, corresponds to the scalar multiplication of a point with scalar , while corresponds to the additive operation on two points on the elliptic curve.
Comparison. We tested the performance of our static Agg-VRFs in comparison to a standard (non-aggregate) VRF, for five different input lengths, i.e., 56, 128, 256, 512, and 1024 bits. In all cases, we set the size of the fixed-bit equal to 20. Thus, naturally, we wanted to compare the efficiency of our aggregated VRF versus the evaluation and corresponding verification of , , , , and VRF values. To perform our comparisons, we recorded the verification time for 100 pairs of function values and their corresponding proofs, if the verification is performed one-by-one (i.e., without using the aggregation) versus the corresponding performance of employing our proposed static aggregate VRF. Obviously, it holds , , , , and . In fact, it is fine to choose any number that is smaller than . We choose 100 to have sensible running time for the performance of the standard (non-aggregate) VRF. By taking the 56 bits input length with 20 fixed bits as an example, the bit-fixing set should contain elements; then, we should consider the verification time for pairs of function values-proofs, which is drastically larger than the running time when we evaluate the verification for only 100 pairs. Thus, showing that our aggregate VRF is much more efficient than the evaluation and corresponding verification of 100 VRF values obviously implies that it is more efficient than the evaluation and corresponding verification of , , , , and VRF values, correspondingly.
Table 2 shows the result of our experiments. The column “Verify” corresponds to the required time for verifying a single pair of function value/proof. We tested how much time it costs to aggregate all the function values and their proofs for inputs belonging to the bit-fixing set. Furthermore, we evaluated the verification time to check the aggregated function value/proof. The column “Total Verification” corresponds to the total required time for verifying 100 pairs of function values/proofs via the standard VRFs (i.e., verification one-by-one), while the column “AggVerify” represents the costing time for verifying the aggregated value/proof via aggregate VRF (i.e., aggregated verification algorithm). The experimental results show that, even for 1024 bits of inputs, the aggregation of
pairs of function values/proofs can be computed very efficiently in 6881 ms. Moreover, the time required to verify their aggregated function values/proofs of
pairs only increases
compared to the verification time for each single function value/proof pair of HW-VRFs.
We stress that our implementation is hardware independent. The only requirement is to have a compiler that is able to translate C code to the specific architecture. To give an estimation of what would happen if a different frequency in a computer architecture is used to run our code for HW-VRFs as well as our aggregate VRFs, we considered the original run using 56, 128, 256, 512, and 1024 bits, respectively. Then, we computed the difference between the frequencies and multiply for this result, as shown in
Table 3. For different frequencies (GHz), the verification time for the aggregated function values/proofs increases 30–50%, compared to that for each single function value/proof pair of the HW-VRFs, as shown in
Table 3.
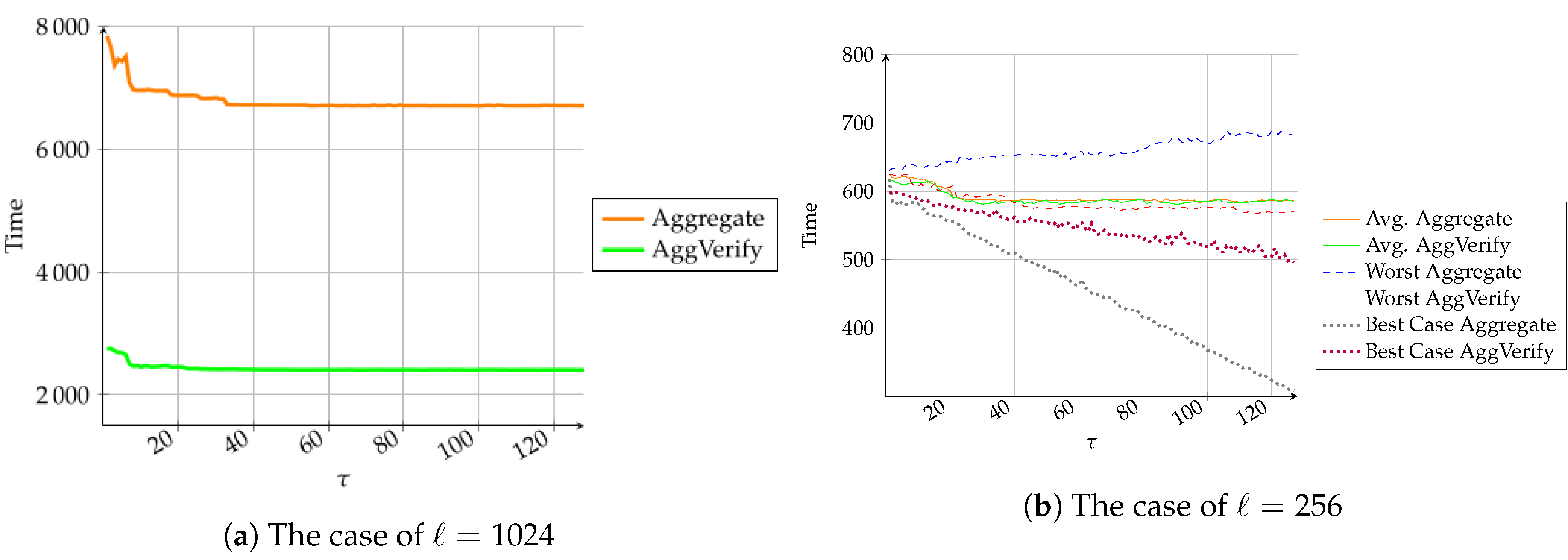
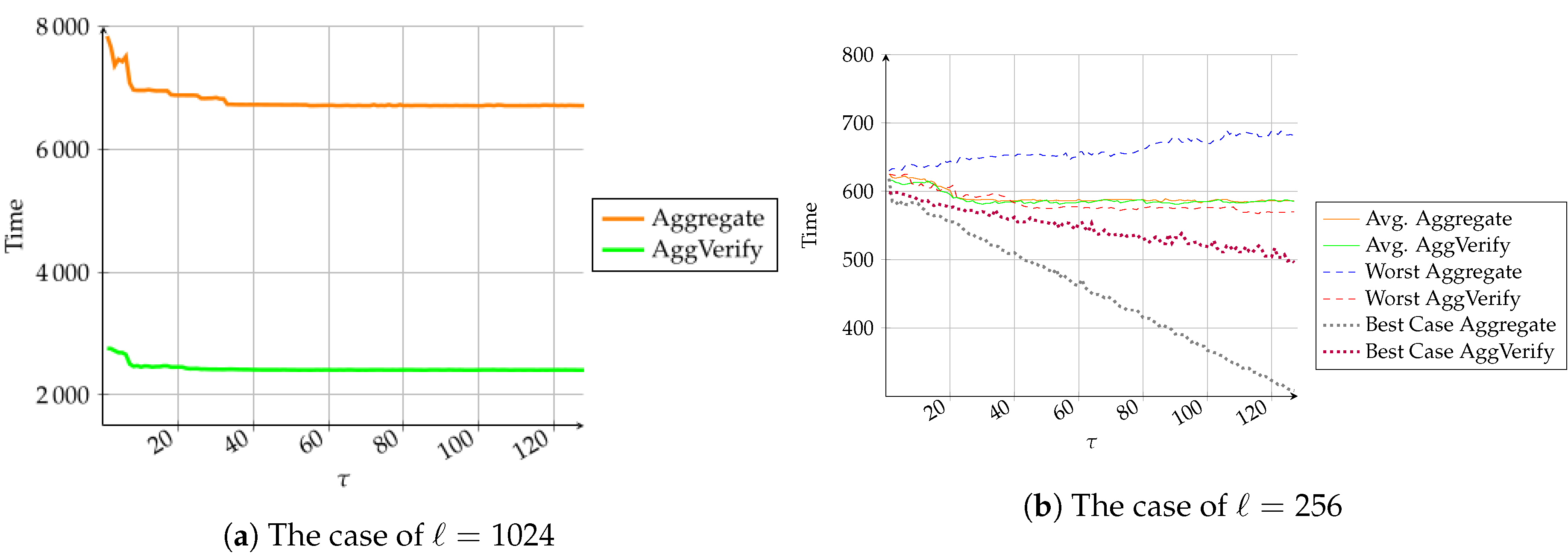
Moreover, we performed experiments for the cases where the input lengths
ℓ are equal to 256 (depicted in
Figure 1b) and 1024 (in
Figure 1a), respectively, by choosing different numbers
of the fixed bits to see the variation of the costing time on the aggregation and verification processes. When
, we ran experiments for three cases, i.e., worst-case where all
fixed bits are 1, best-case where all
fixed bits are 0, and average-case where
fixed bits are chosen at random from
. In the worst-case, the Aggregate algorithm requires 256 multiplications plus 1 exponentiation to compute
and 258 exponentiation to evaluate
, while the AggVerify algorithm requires 515 pairing operations, as shown in
Figure 1b with square dot dashed line, which cost almost the same amount of time with different
. In the best-case, the Aggregate algorithm requires
multiplications plus 1 exponentiation to compute
and
exponentiation to evaluate
, while the AggVerify algorithm requires
pairing operations, as shown in
Figure 1b with round dot dashed line, where the running time decreases with the increase of
. The average-case, as shown with solid lines in
Figure 1b, lies between the range of the best-case and the worst-case. When
, we show the time cost on the aggregation and verification algorithms in average-case, i.e., for randomly chosen
fixed bits.




{kind=link}
{kind=link}