Security and Cryptographic Challenges for Authentication Based on Biometrics Data



Abstract
1. Introduction
- -
- Creating a framework containing cryptographic modules. The cryptographic modules are implemented in C#, Java, C++, Python, and Haskell;
- -
- Implementing two cryptographic modules, (1) modern cryptographic module and (2) machine learning approach cryptography module. The second module contains algorithms with auxiliary comparisons over unencrypted and encrypted inputs, creating statistical analysis of how strong the security of the inputs is;
- -
- Creating a virtual laboratory for testing the algorithms and the framework. The requirements of the virtual laboratory are: Virtual Box virtual machine with Apache Hadoop, Biometric Analysis Tool, and 36 Virtual Box virtual machines which simulates the users trying to authenticate to the system and which represents the data cluster;
- -
- Proposing a methodology which can be used as a how-to guide for how to implement the framework (Section 4).
- -
- Section 1—Introduction. This section will give a brief introduction about the current work by highlighting the main objectives, methods and obtained results. The chapter will give a short background on how the main three phases—enrollment, verification and identification—are working in a software application which uses authentication based on biometrics.
- -
- Section 2—Algorithms and Methods Used. The section present shortly which are the main algorithms and methods used for evaluation of security authentication process in a cloud and data clustered environment. The following topics are covered briefly: machine learning classification over biometric encrypted data; modern cryptography; techniques such as Naïve Bayes for classification of security incidents and rate of failing to authenticate with success, Hyperplane decision; data clustering aspects for Map Reduce covering the fixed-width clustering algorithm and FWC algorithm.
- -
- Section 3—Biometrics and Authentication Mechanisms: How They Are Working. The section will go through the three main phases of a biometric system (enrollment, verification, and identification) with the goal of understanding how the authentication process is working and which are vulnerable points.
- -
- Section 4—Results. In this section we will discuss about the current state of other similar works proposed by other authors by showing the main advantages and disadvantages.
- -
- Section 5—Comparison with Other Proposed Methods and Discussion. The section will present in details the proposed solution and methodology showing the advantages and disadvantages compared with other methods. The section will demonstrate also how to design and implement software solution for desktop applications and for cloud computing with Apache Hadoop.
- -
- Section 6—Conclusions. The section will cover the current objectives accomplished within the current paper.
2. Algorithms and Methods Used
2.1. Preliminaries
2.1.1. Machine Learning Classification over Biometric Encrypted Data
- -
- Supervised learning is a type of inductive learning based on training sets, in which, the agent receives a set of inputs and their corresponding outputs. The task of the agent is to learn the links between every input and its corresponding output and to generate a template function that will be able to solve problems for new inputs.
- -
- Semi-supervised learning. In this type of learning, the agent receives an incomplete training set.
- -
- Unsupervised learning is not using training sets, but the agent needs to discover on its own different patterns in dataset.
- -
- Reinforcement learning is a type of learning in which the training data is given as feedback for the agent, such that if its output is “good” it receives a reward, otherwise it receives a punishment. The target of the agent is to maximize its reward, providing better and better outputs. The meaning of “good” output is different depending on the environment in which the agent is used [7].
- -
- Classification represents a machine learning technique (included in supervised learning) in which the inputs are divided into two or more classes. The input is a feature vector that will be classified by applying a classification function on , and the output is , where ; is the class in which falls, based on model .
2.1.2. Cryptography
2.2. Techniques
2.2.1. Auxiliary Algorithms
| Algorithm 1. Max over encrypted data [7] |
| Input A: integers encrypted using Paillier (), the length of (in bits), and Input B: , the length in bits Output A: A: generate random permutation over A: B: m:= 1 for i = 2 to k do = max A: randomly generate integers A: A: A: send and to B if is true then B: B: else B: end if B: send to A B: send A: end for B: send to A A: output |
| Algorithm 2. Change encryption scheme [7] |
| Input A: , and Input B: Output A: A: pick A: send to B B: decrypt and re-encrypt with B: send to A A: A: output |
2.2.2. Naïve Bayes
- -
- One table in which are stored values
- -
- One table for every feature j and class
2.2.3. Hyperplane Decision
| Algorithm 3. Private inner product [7] |
| Input A: Input B: Output A: B: encrypt B: send to A A: compute A: re-randomize A: output |
2.3. Data Clustering in Cloud Computing
2.3.1. Fixed-Width Clustering Algorithm
- From a given dataset with an established cluster width , generate a random set of clusters: .
- Compute Euclidean distance between every point and every cluster , using the formula:
- If , then belongs to cluster; adjust the centroid of by computing the mean of the points that contains at this moment, using the formula ( is the number of points in ):
- If , then is the new centroid of .
- Reiterate steps 2, 3, 4 until the end of .
2.3.2. MapReduce
2.3.3. FWC Algorithm with MapReduce
- -
- Inputs: dataset D and the set of clusters
- -
- Partitioning: the points of are allocated to the available VMs (if is not integer, then the remaining points are allocated to the last VM).
- -
- Map function. The input is dataset encrypted and kept into Hadoop Distributed File System (HDFS) as pairs, where represents the position of in a data file and represents the encryption of numerical of the data point. The data files are global and sent to all mappers. The function in proposed model computes the squared Euclidean distance (in order to shun the square root):The of map is a set of pairs, where is the position of into a data file and is the distance . Note that means value is encrypted using function .
- -
- function. The output of a function becomes the input for a function. The function needs to find a minimum distance between every point and every centroid and then to put data point into corresponding cluster (the one that corresponds to the minimum distance) [12].
| Algorithm 4. Map function for distributed version for FWC [14] |
| Input: encrypted dataset Output: Initialization: Choose a random set of clusters from a given dataset index = 0 for (=0 to ) do for (=0 to ) do end End Take index as key Construct value as an encrypted numerical value Output pair |
| Algorithm 5. Reduce function for distributed for FWC [14] |
| Input: Output: Initialization: for (=0 to ) do end end Take as key Construct value as a numerical value Output pair |
3. Biometrics and Authentication Mechanisms: How They Are Working?
- -
- Performance—consists of recognition accuracy and speed. The resources that are allocated to achieve the desired accuracy and speed [37].
- -
- -
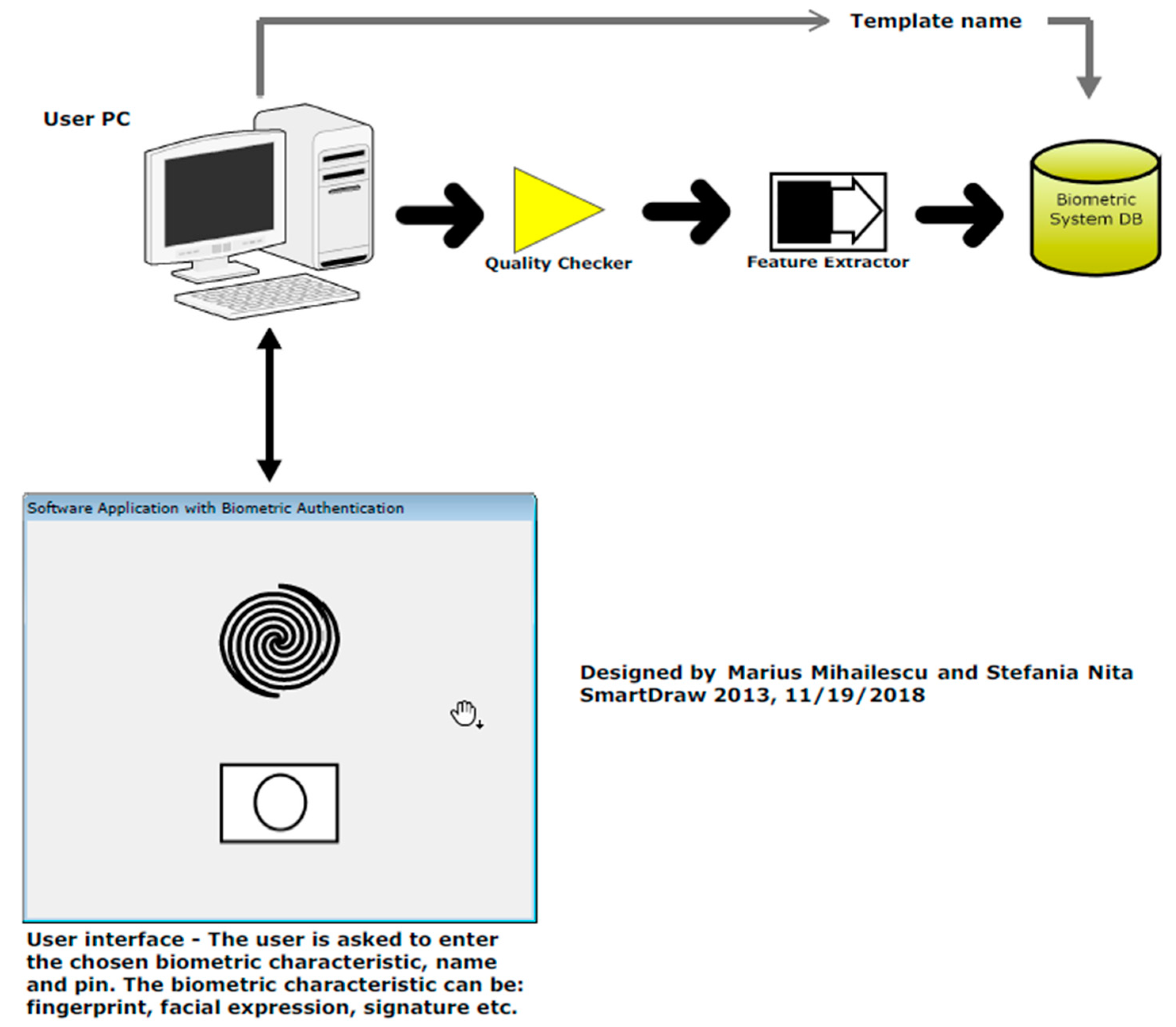
3.1. What Is Happening in Enrollment Mode?
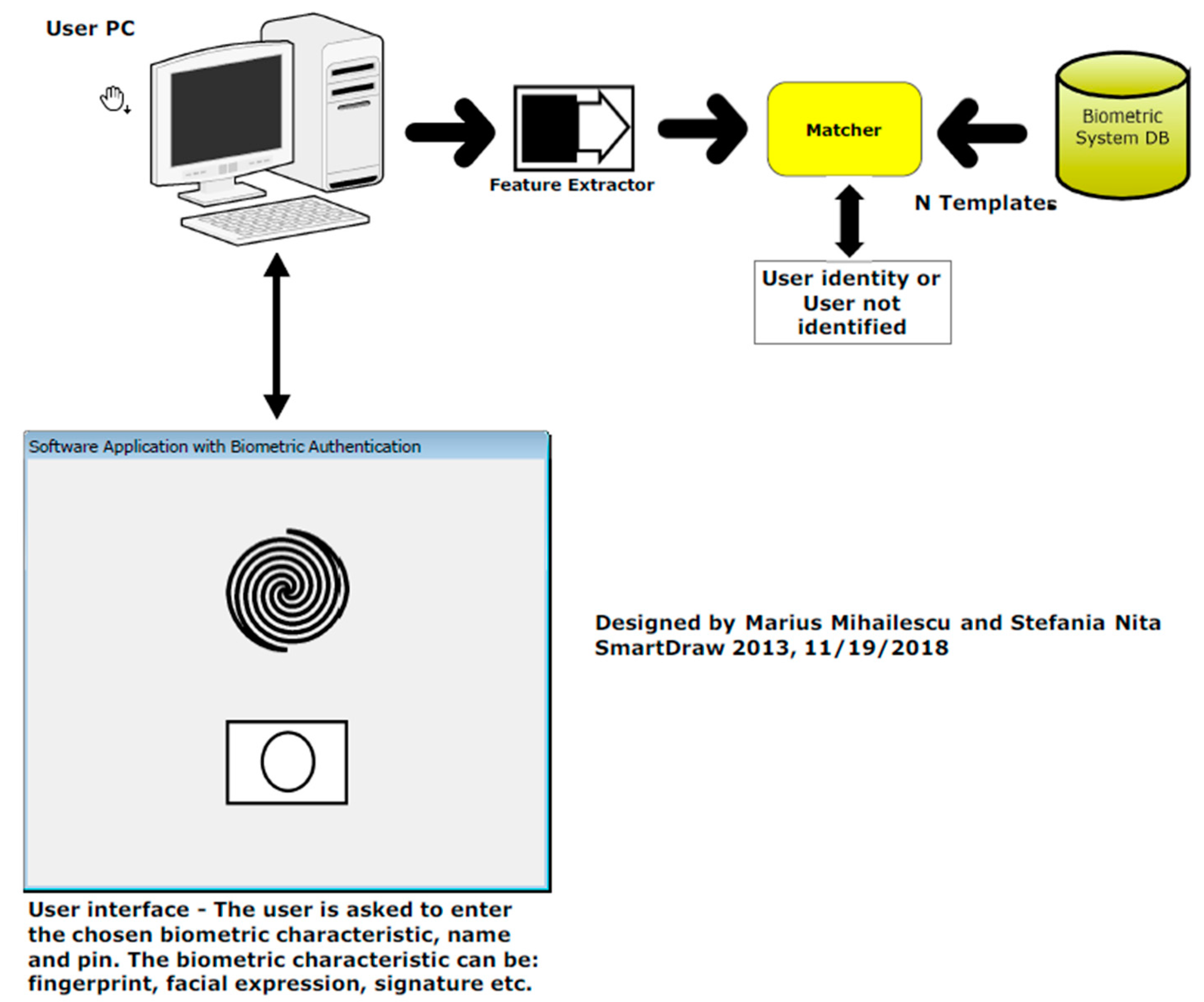
3.2. What Is Happening in Identification Mode?
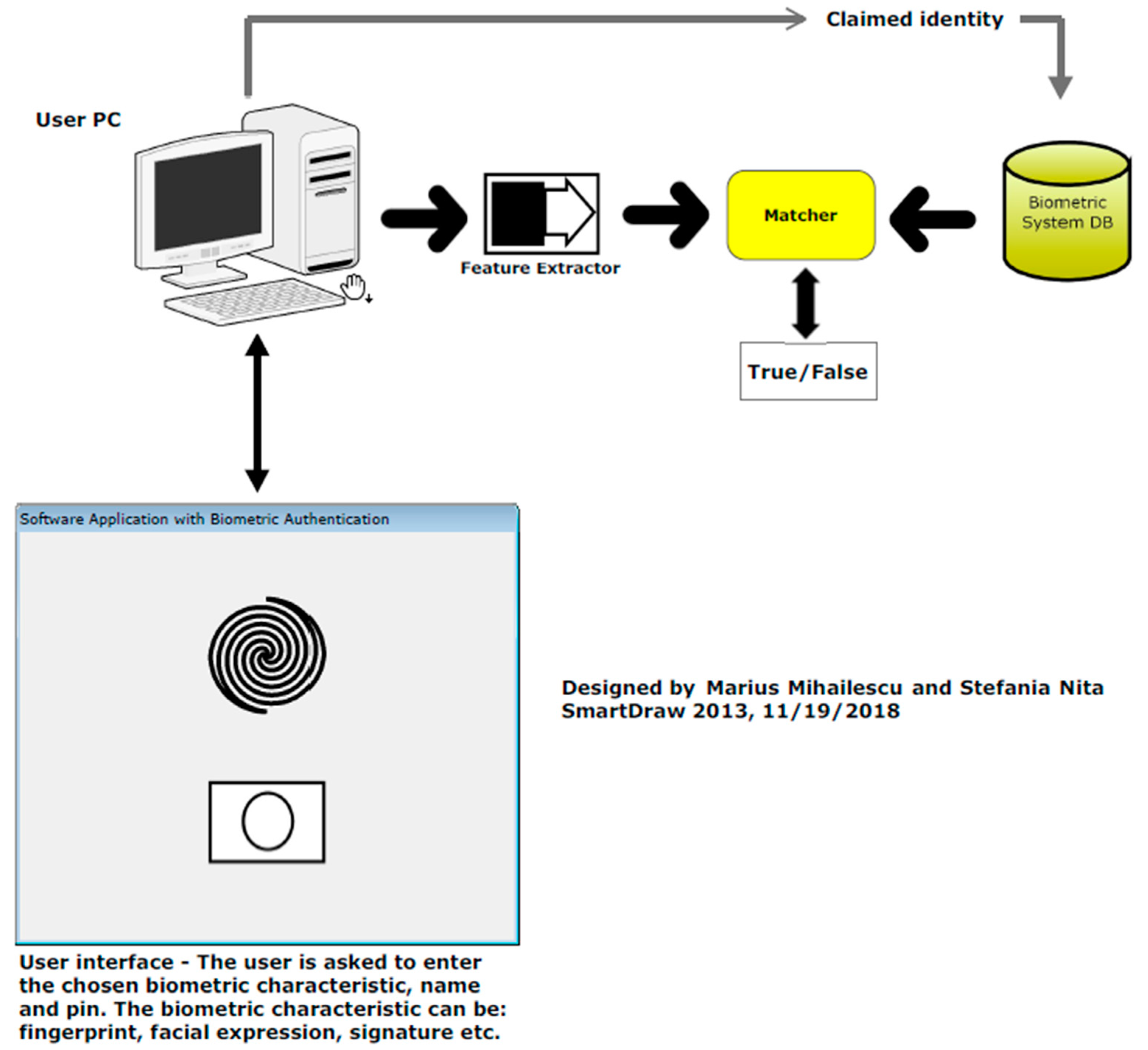
3.3. What Is Happening in Verification Mode?
- -
- Performance: this requirement is quite important as the characteristic should be enough invariant. The respect has to be assured for the matching criterion over a period.
- -
- Distinctiveness: by choosing two persons should be sufficient different in terms of the characteristic.
- -
- Universality: the criteria consist in its unique characteristic that has to be for each person.
- -
- Collectability: the requirement is a metric that is quantitatively measured.
- -
- Performance, the accuracy and speed, two main characteristics that refers to the achievable recognition, are required to achieve the desired recognition accuracy and speed. Also, operational and environmental factors are affecting the accuracy and speed;
- -
- Acceptability, a factor that will indicates which people are willing to accept the use of a particular biometric identity in terms of characteristic using in a daily life;
- -
- Circumvention reflects how easy is to fool a system using different methods meant to steal data and to corrupt the integrity of the data.
4. Results
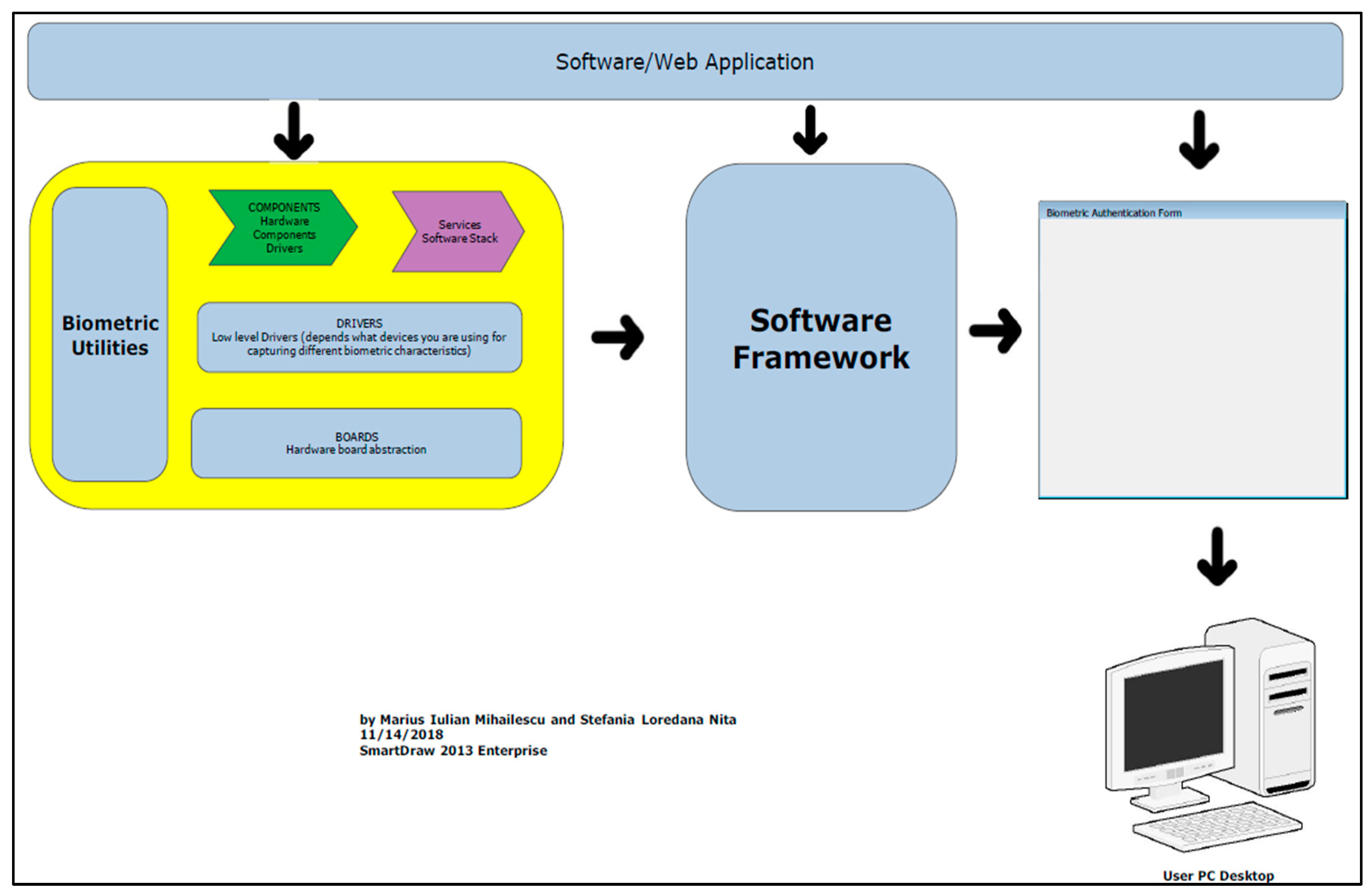
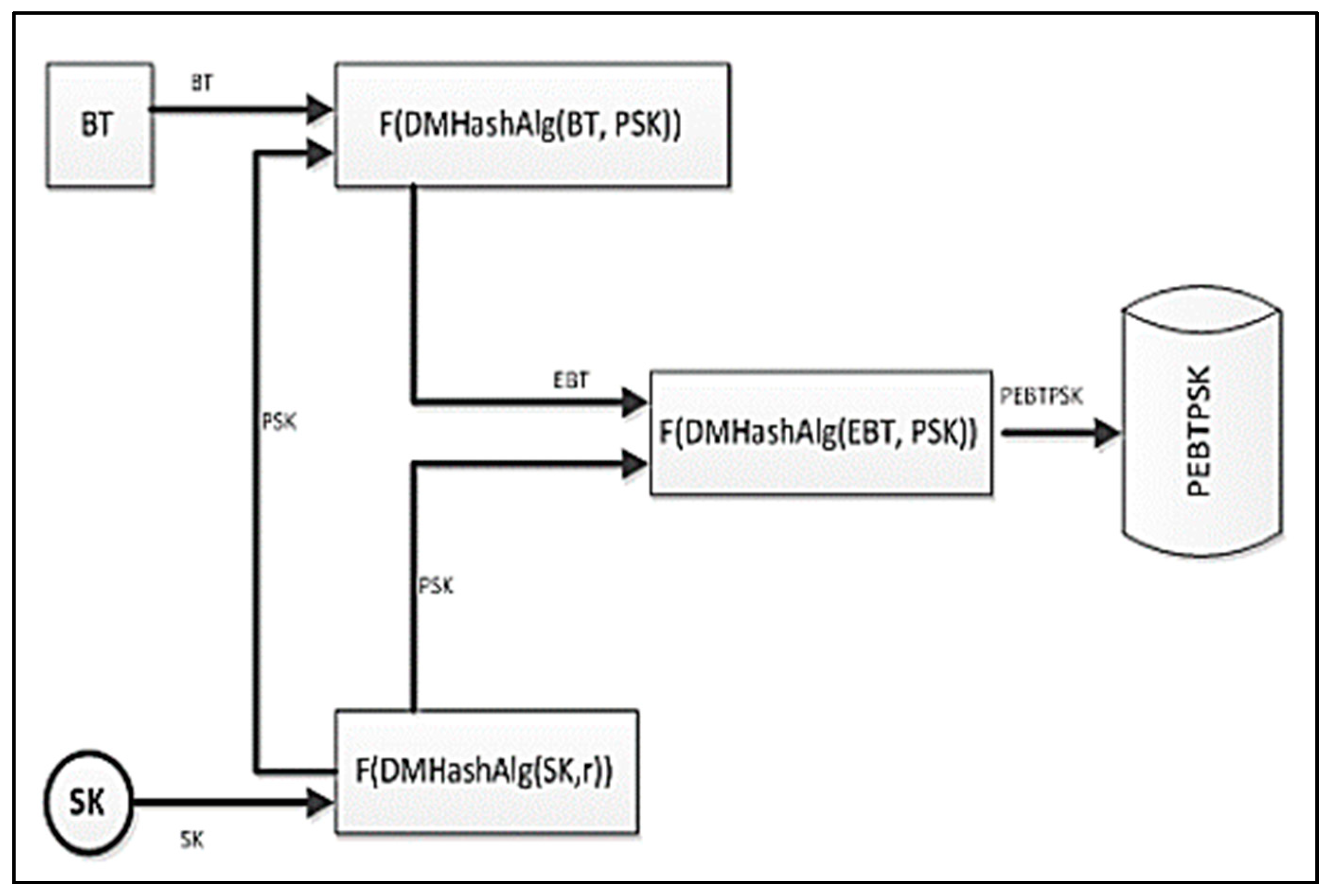
Description of layers
- The session key algorithm, and
- The scheme used for enrollment with data integrity checking and validating for the biometric data.
- BT—biometric data.
- SK—represents the session key, which is generated using a one of the algorithms, which were presented in Chapter 2 and 3 and combined, with elements of machine learning described in Section 2.1.1. The BT contains the biometric vector ( as we have discussed previous.
- PSK—represents the permuted session key, which is used to generate the extended version of permuted transformation of the session, key (SK). F(SK) represents a function used for permutation which can be used with any hash function generated based on the main ideas presented above.
- EBT—represents the biometric data, which are encrypted. In order to generate the biometric template encrypted, the hash function construction is applied F(DMHashAlg(BT, PSK)). The hash function is based on a simple XOR function and both functions F(DMHashAlg(SK,r)) and F(DMHashAlg(EBt, PSL)) functions are used together beside the hash functions with the permutation of the bits SK, EBT, and ESK.
- PEBTPSK—the permuted biometric data and also the permuted session key (SK) will be used to generate the final step in order to concatenate the biometric template F(DMHashAlg(EBT, PSL)). In order to assure the decryption process, the biometric pattern is using the functions and session key, which has been used to encrypt the template.
5. Comparison with Other Proposed Methods and Discussion
6. Conclusions
- -
- Fast adaptable framework for different platforms;
- -
- Reliable implementation of cryptographic algorithms and machine learning.
- -
- Using Machine Learning Classification over the encrypted biometric data;
- -
- Encryption of biometric data in a Data Clustering environment;
- -
- Encryption of biometric data using Chaos-based cryptography;
Author Contributions
Funding
Conflicts of Interest
References
- Iulian, M.M.; Ciprian, R.; Laurentiu, G.D.; Loredana, N.S. A Multi-Factor Authentication Scheme Including Biometric Characteristics as One Factor. In Proceedings of the 1st International Conference Sea-Conf, Constanta, Romania, 14–16 May 2015; pp. 348–353. [Google Scholar]
- Echeverria, J.; Spivey, B. Hadoop Security; O’Reilly Media Publisher: Sebastopol, CA, USA, 2015; ISBN 9781491900970. [Google Scholar]
- Cloudera Security. Available online: https://www.cloudera.com/documentation/enterprise/5-6-x/PDF/cloudera-security.pdf (accessed on 3 December 2018).
- Saraladevi, B.; Pazhaniraja, N.; Paul, V.; Basha, S.; Dhavachelvan, P. Big Data and Hadoop—A Study in Security Perspective. Procedia Comput. Sci. 2015, 50, 596–601. [Google Scholar] [CrossRef]
- 75 Securing Big Data by Opting Hadoop Security: A Review of Past and Present. Int. J. Eng. Technol. Sci. Res. 2015, 2, 75–78.
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 2000, 44, 206–226. [Google Scholar] [CrossRef]
- Bost, R.; Popa, R.A.; Tu, S.; Goldwasser, S. Machine learning classification over encrypted data. NDSS 2015, 4324, 4325. [Google Scholar]
- Nasrabadi, N.M. Pattern recognition and machine learning. J. Electron. Imaging 2007, 16, 049901. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1976, 21, 120–126. [Google Scholar] [CrossRef]
- Goldwasser, S.; Micali, S. Probabilistic encryption & how to play mental poker keeping secret all partial information. In Proceedings of the Fourteenth Annual ACM Symposium on Theory of Computing, San Francisco, CA, USA, 5–7 May 1982; ACM: New York, NY, USA, 1982; pp. 365–377. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Taylor, R.C. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics. BMC Bioinform. 2010, 11, S1. [Google Scholar] [CrossRef] [PubMed]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2007, 51, 107–113. [Google Scholar] [CrossRef]
- Alabdulatif, A.; Khalil, I.; Reynolds, M.; Kumarage, H.; Yi, X. Privacy-preserving data clustering in cloud computing based on fully homomorphic encryption. In Proceedings of the PACIS 2017: Societal Transformation through IS/IT. Association for Information Systems (AIS), Langkawi, Malaysia, 16–20 July 2017; pp. 1–13. [Google Scholar]
- 2035 Forecast Reveals Air Passengers Will Nearly Double to 7.8 Billion. Available online: http://www.iata.org/pressroom/pr/Pages/2017-10-24-01.aspx (accessed on 5 December 2018).
- Identity Fraud Soars. Available online: https://www.cifas.org.uk/newsroom/identity-fraud-soars-to-new-levels (accessed on 5 December 2018).
- More than One Billion Smartphones with Fingerprint Sensors Will Be Shipped in 2018. Available online: https://www.counterpointresearch.com/more-than-one-billion-smartphones-with-fingerprint-sensors-will-be-shipped-in-2018/ (accessed on 5 December 2018).
- Russian Chinese Firms win NIST-ARPA Face Recognition Contest. Available online: https://americansecuritytoday.com/russian-chinese-firms-win-nistiarpa-face-recog-contest/ (accessed on 5 December 2018).
- Back to Basics: Multi-Factor Authentication (MFA). Available online: https://www.nist.gov/itl/tig/back-basics-multi-factor-authentication (accessed on 5 December 2018).
- Bridging the Gap—from Biometrics to Forensics. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4580999/ (accessed on 5 December 2018).
- Interview with James Hammond, Associate Vice President for Information Technology Winthrop University. Available online: https://findbiometrics.com/interview-with-james-hammond-associate-vice-president-for-information-technology-winthrop-university/ (accessed on 5 December 2018).
- Video Face Recognition System Enabling Real-time Surveillance. Available online: http://www.nec.com/en/global/techrep/journal/g16/n01/160108.html (accessed on 5 December 2018).
- John Daugman, Evolving Methods in Iris Recognition – Presentation and implications from 200 Billion Iris Comparisons. Available online: http://www.cse.nd.edu/BTAS_07/John_Daugman_BTAS.pdf (accessed on 5 December 2018).
- Biometrics Recently Published Results. Available online: https://biolab.csr.unibo.it/FVCOnGoing/UI/Form/PublishedAlgs.aspx (accessed on 5 December 2018).
- Top Five Biometrics: Face, Fingerprint, Iris, Palm and Voice. Available online: https://www.bayometric.com/biometrics-face-finger-iris-palm-voice/ (accessed on 25 August 2018).
- Applied Recognition Achieves New Benchmark for Face Recognition Accuracy. Available online: http://www.biometricupdate.com/201709/applied-recognition-achieves-new-benchmark-for-face-recognition-accuracy (accessed on 5 December 2018).
- The Limits of Facial Recognition. Available online: http://www.pbs.org/wgbh/nova/next/tech/the-limits-of-facial-recognition/ (accessed on 5 December 2018).
- Mitigating Bias in AI Models. Available online: https://www.ibm.com/blogs/research/2018/02/mitigating-bias-ai-models/ (accessed on 5 December 2018).
- Retinal Identification Based on an Improved Circular Gabor Filter and Scale Invariant Feature Transform. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3758647/ (accessed on 5 December 2018).
- Password Cracking. Available online: https://en.wikipedia.org/wiki/Password_cracking (accessed on 5 December 2018).
- Bond Fingerprint Technology. Available online: https://www.youtube.com/watch?v=yP5ku2IJgAY (accessed on 5 December 2018).
- Hackers Say They’ve Broken Face ID a Week after iPhone X Release. Available online: https://www.wired.com/story/hackers-say-broke-face-id-security/ (accessed on 5 December 2018).
- Germany’s Facial Recognition Pilot Program Divides Public. Available online: http://www.dw.com/en/germanys-facial-recognition-pilot-program-divides-public/a-40228816 (accessed on 5 December 2018).
- To Scan or Not to Scan: Surge in Lawsuits under Illinois Biometrics Law. Available online: https://www.mwe.com/en/thought-leadership/publications/2017/11/surge-in-lawsuits-under-illinois-biometrics-law (accessed on 5 December 2018).
- A New Threat from an Old Source: Class Action Liability Under Illinois’ Biometric Information Privacy Act. Available online: https://www.bakermckenzie.com/en/insight/publications/2017/10/illinois-biometric-information-privacy-act/ (accessed on 5 December 2018).
- DNA Pioneer Condemns Plans to Retain Data on Innocent. Available online: https://www.theguardian.com/politics/2009/may/07/dna-database-plans-condemned (accessed on 5 December 2018).
- Li, S.Z.; Jain, A.K. Encyclopedia of Biometrics, 2nd ed.; Springer: New York, NY, USA, 2015. [Google Scholar]
- Engelsma, J.; Cao, K.; Jain, A.K. RaspiReader: An Open Source Fingerprint Reader. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Jain, A. Encyclopedia of Biometrics; Springer: New York, NY, USA, 2009; p. 532. [Google Scholar]
- Herschel, S.W.J. The Origin of Finger-Printing; Oxford University Press: New York, NY, USA, 1916; p. 19. [Google Scholar]
- Chugh, T.; Cao, K.; Jain, A.K. Fingerprint Spoof Buster: Use of Minutiae-centered Patches. IEEE Trans. Inf. Forensics Secur. 2018. [Google Scholar] [CrossRef]
- Lawful Basis Processing Unlocking EU General Data Protection. Available online: https://www.whitecase.com/publications/article/chapter-7-lawful-basis-processing-unlocking-eu-general-data-protection (accessed on 5 December 2018).
- GDPR: Things to Consider When Processing Biometric Data. Available online: https://www.itgovernance.eu/blog/en/gdpr-things-to-consider-when-processing-biometric-data/ (accessed on 5 December 2018).
- Why Are We Still Using Social Security Numbers as ID. Available online: http://money.cnn.com/2017/09/13/technology/social-security-number-identification/index.html (accessed on 5 December 2018).
- Constitutional Validity of Aadhaar: The Arguments in Supreme Court so Far. Available online: http://www.thehindu.com/news/national/constitutional-validity-of-aadhaar-the-arguments-in-supreme-court-so-far/article22752084.ece (accessed on 5 December 2018).
- This Creepy Technology Can Read Your Emotions as You Walk Down the Street. Available online: https://mashable.com/2017/07/28/russia-facial-recognition-emotion-ntechlab-findface. (accessed on 5 December 2018).
- Man/Machine Interface. Available online: https://futurewrite.com/presentations/rich-miner.pdf (accessed on 5 December 2018).
- Secure Smartphone App Could Replace Fraud-prone Paper Passports. Available online: https://www.theguardian.com/money/2017/sep/09/secure-smartphone-app-replace-fraud-prone-paper-passports (accessed on 5 December 2018).
- Cryptographically Futuristic Smart Locks for Your Home. Available online: https://www.techlicious.com/guide/5-futuristic-smart-locks-for-your-home/ (accessed on 5 December 2018).
- Are Embedded Microchips Dangerous? Ask the Swedes–and Pets. Available online: https://www.usatoday.com/story/tech/talkingtech/2017/07/25/do-microchip-implants-pose-health-risks-ask-swedes-and-pets/507408001/ (accessed on 5 December 2018).
- MIT and Microsoft Research Made a ‘Smart’ Tattoo that Remotely Controls Your Phone. Available online: https://www.theverge.com/circuitbreaker/2016/8/13/12460542/mit-microsoft-research-gold-leaf-smart-temporary-tattoo (accessed on 5 December 2018).
- A World First: Australia’s Plan for Advanced Biometric Airport Checks. Available online: https://www.airport-technology.com/features/featurea-world-first-australias-plan-for-advanced-biometric-airport-checks-5808560/ (accessed on 5 December 2018).
- The Body as Password. Available online: https://www.wired.com/1997/07/biometrics-2/ (accessed on 5 December 2018).
- KFC China Is Using Facial Recognition Tech to Serve Customers–but They Are Buying It? Available online: https://www.theguardian.com/technology/2017/jan/11/china-beijing-first-smart-restaurant-kfc-facial-recognition (accessed on 5 December 2018).
- Iulian, M.M.; Loredana, N.S. Security of Biometrics Authentication Protocols: Practical and Theory Applications; LAP LAMBERT Academic Publishing: Saarbruecken, Germany, 2015; 232p. [Google Scholar]
- Iulian, M.M. New Enrollment Scheme for Biometric Template using Hash Chaos-based cryptography. Procedia Eng. 2014, 69, 1459–1468. [Google Scholar]
- Mandal, A.K.; Parakash, C.; Tiwari, A. Performance evaluation of cryptographic algorithms: DES and AES. In Proceedings of the 2012 IEEE Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 1–2 March 2012. [Google Scholar]
- Nadeem, A.; Javed, M.Y. A performance comparison of data encryption algorithms. In Proceedings of the First International Conference on Information and communication technologies (ICICT 2005), Karachi, Pakistan, 27–28 August 2005. [Google Scholar]
- Bertman, S. Handbook to Life in Ancient Mesopotamia; Oxford University Press: Oxford, UK, 2005; p. 235. [Google Scholar]
- Howley, V. Whipple, Supreme Court of New Hampshire, 48 NH 487. Available online: https://www.digitalistmag.com/future-of-work/2017/05/24/electronic-signatures-ready-for-prime-time-after-148-years-05105719 (accessed on 5 December 2018).
- Savastano, M. Noncooperative Biometrics: Cross-Jurisdictional Concerns. In Human Recognition in Unconstrained Environments, 1st ed.; Academic Press: Orlando, FL, USA, 2017; pp. 217–227. [Google Scholar]
- Greenleaf, G. Global Data Privacy Laws: Forty Years of Acceleration (October 10, 2011). Privacy Laws and Business International Report, No. 112. pp. 11–17. Available online: https://ssrn.com/abstract=1946700 (accessed on 5 December 2018).
- Matthew, P.; Anderson, M. Developing Coercion Detection Solutions for Biometric Security. In Proceedings of the SIA Computing Conference, London, UK, 13–15 July 2016. [Google Scholar]
- Yager, N.; Dunstone, T. The Biometric Menagerie. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 220–230. [Google Scholar] [CrossRef] [PubMed]
- Sidlauskas, D.; Tamer, S. Hand Geometry Recognition. In Handbook of Biometrics; Springer: Berlin/Heidelberg, Germany, 2008; p. 91. [Google Scholar]
- Dr. Patrick Vallance, Biometrics: A Guide. Available online: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/715925/biometrics_final.pdf (accessed on 5 December 2018).
- Jain, A.K.; Patrick, F.; Arun, R. Handbook of Biometrics; Springer: New York, NY, USA, 2008; ISBN 978-0-387-71041-9. [Google Scholar]
- Mai, G.; Cao, K.; Yuen, P.C.; Jain, A.K. On the Reconstruction of Face Images from Deep Face Templates. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Tabassi, E.; Quinn, G.W.; Grother, P.J. When to Fuse Two Biometrics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Workshop on Biometrics, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Rzecki, K.; Plawiak, P.; Niedzwiecki, M.; Sosnicki, T.; Leskow, J.; Ciesielski, M. Person recognition based on touch screen gestures using computational intelligence methods. Inf. Sci. 2017, 415–416, 70–84. [Google Scholar] [CrossRef]
- Buolamwini, J.; Gebru, T. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. Proceeds Mach. Learn. Res. 2018, 81, 1–15. [Google Scholar]
- Sir Francis Galton, Finger Prints, Macmillan. On the Uniqueness of Fingerprints. Available online: http://biometrics.cse.msu.edu/Presentations/AnilJain_UniquenessOfFingerprints_NAS05.pdf (accessed on 3 December 2018).
- Cao, K.; Jain, A.K. Automated Latent Fingerprint Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Structure | Flexibility and Modification | Known Attacks |
|---|---|---|---|
| DES [59,60,61] | Balanced Feistel Network | No | Brute Force Attack |
| 3DES [62,63,64,65,66] | Feistel | Yes, Extended from 56 to 168 bits | Brute Force Attack, Chosen Plaintext, Known Plaintext |
| CAT-128 [67] | Feistel | Yes, 128 and 256 bits | Chosen Plaintext Attack |
| BLOWFISH [68] | Feistel | Yes, 64–448 key length in multiplies of 32 | Dictionary attacks |
| IDEA [2,3] | Substitution-Permutation | No | Differential Timing Attack, Key-Schedule Attack |
| AES [60,61,62,63,69] | Substitution-Permutation | Yes, 256 key length in multiples of 64 | Side Channel Attack |
| RC4 [64,65,66,70,71] | Feistel | Yes, 40–2048 bits | Fluhrer, Mantin and Shamir Attack, Klein’s Attack, Royal Holloway Attack, NOMORE Attack, Bar-mitzvah Attack |
| RC5 [57] | Feistel | Yes, 0 to 2040 (128 recommended) | Differential Attack |
| RC6 [58] | Feistel | Yes, 128-2048 key length in multiplies of 32 | Bruce Force Attack, Analytical Attack |
| MARS [72] | Type-3 Feistel | Yes, 128, 192, or 256 bits | Meet-in-the-middle Attack |
| TWOFISH [73] | Feistel | Yes, 128, 192 or 256 bits | Differential Attack |
| THREEFISH [2,3] | Feistel | Yes, 256, 512 or 1024 bits (key size is equal to block size) | Rebound Attack, Boomerang Attack |
| RSA [5] | Factorization | Yes, Multi Prime RSA, Multi power RSA | Factoring the Public Key |
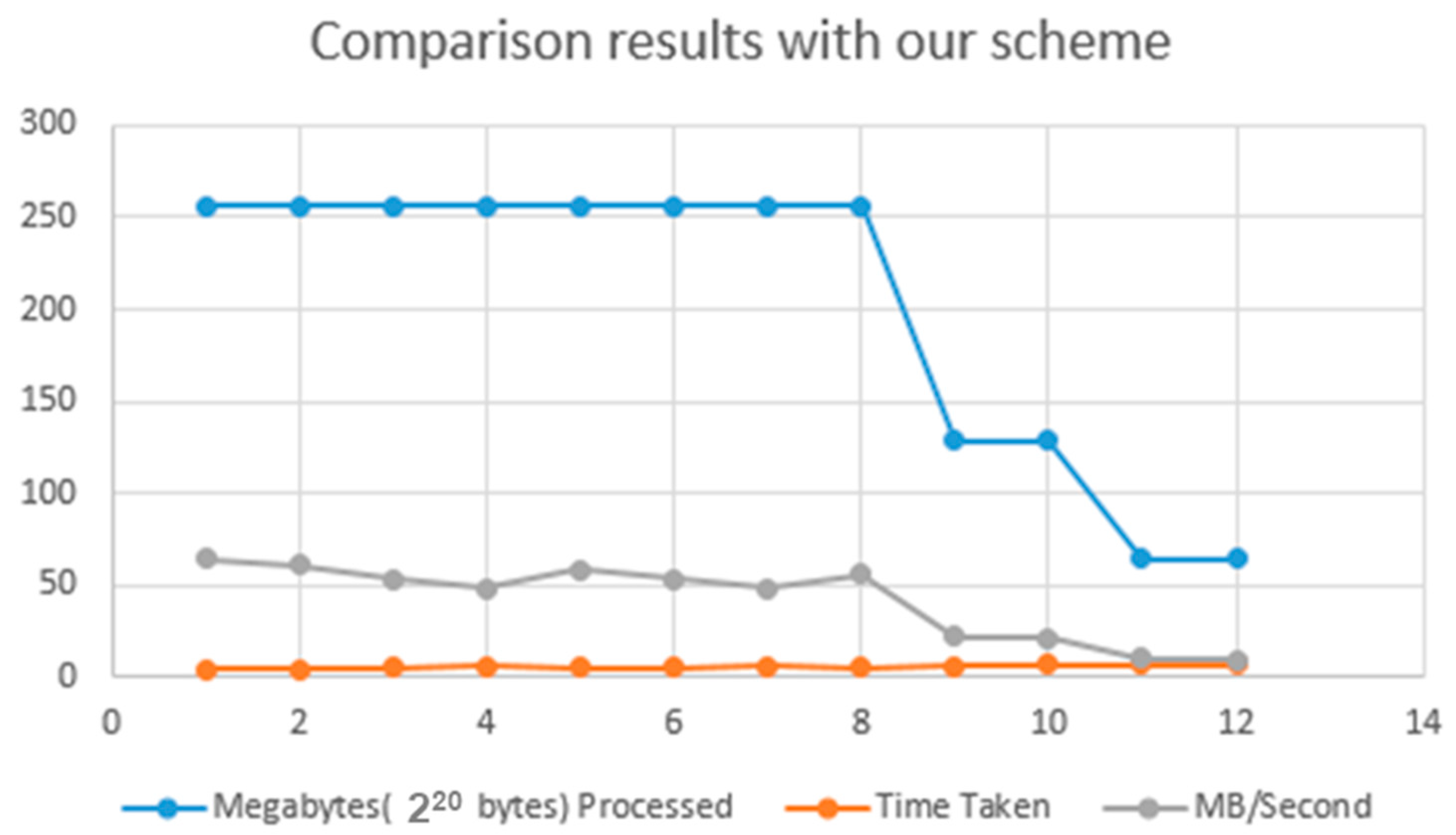
| Algorithm | Megabytes(220 bytes) Processed | Time Taken | MB/Second |
|---|---|---|---|
| AES [1] | 256 | 3.976 | 64.386 |
| SHA-256 [55] | 256 | 4.196 | 61.010 |
| RC4 [68] | 256 | 4.817 | 53.145 |
| RC5 [4] | 256 | 5.308 | 48.229 |
| RC6 [62] | 256 | 4.436 | 57.710 |
| MARS [66] | 256 | 4.837 | 52.925 |
| BLOWFISH [70] | 256 | 5.378 | 47.601 |
| TWOFISH [17] | 256 | 4.617 | 55.447 |
| THREEFISH [61] | 128 | 5.998 | 21.340 |
| RSA [62] | 128 | 6.159 | 20.783 |
| ELLIPTICCURVE [71] | 64 | 6.499 | 9.848 |
| DIFFIE HELLMAN [57] | 64 | 6.389 | 8.763 |
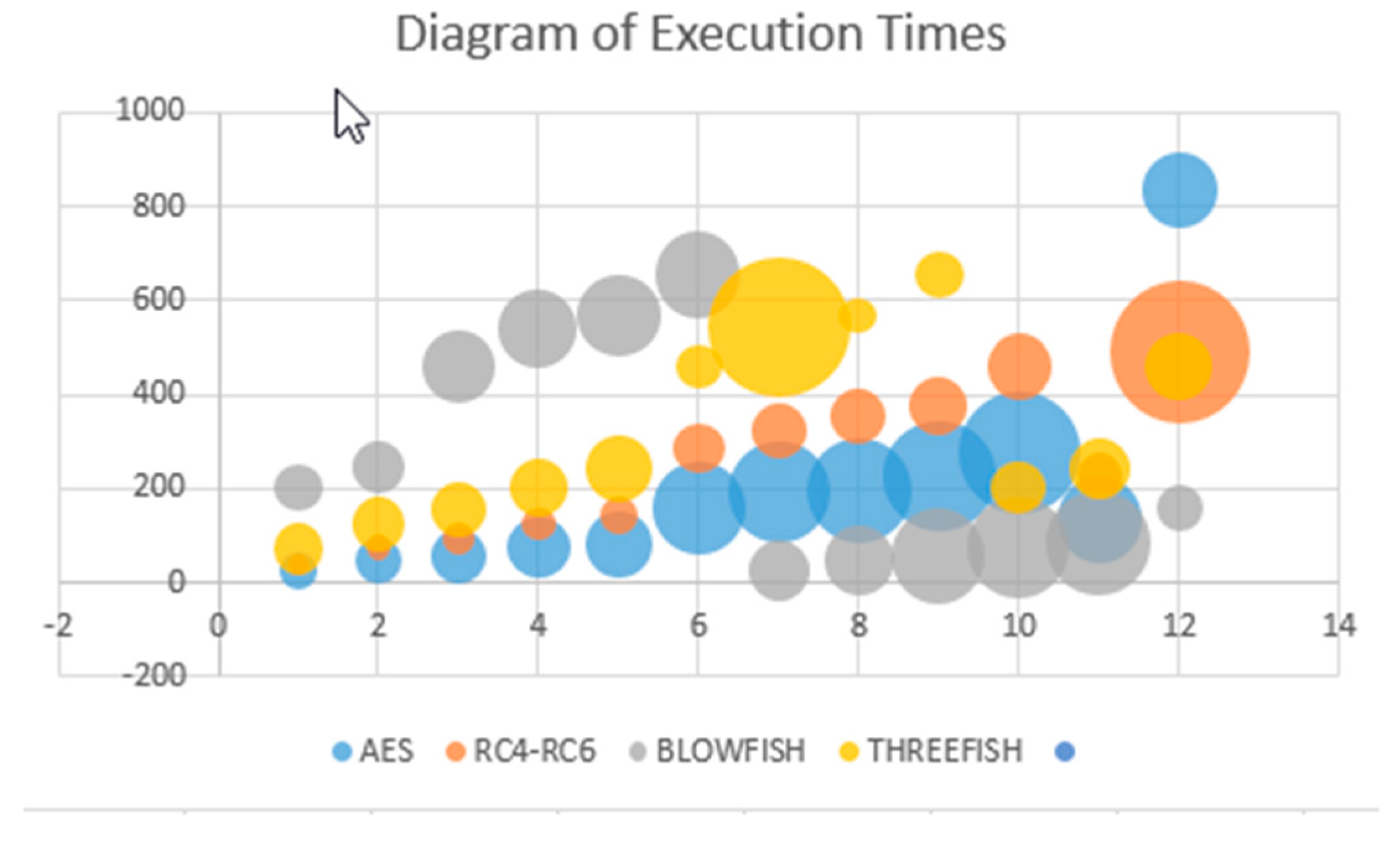
| Input Size (bytes) | AES | SHA-256 | RC4-RC6 | MARS | BLOWFISH | TWOFISH | THREEFISH | RSA |
|---|---|---|---|---|---|---|---|---|
| 20,527 | 24 | 72 | 39 | 19 | 202 | 125 | 72 | 136 |
| 36,002 | 48 | 123 | 74 | 35 | 243 | 143 | 123 | 158 |
| 45,911 | 57 | 158 | 94 | 46 | 461 | 285 | 158 | 162 |
| 59,852 | 74 | 202 | 125 | 58 | 543 | 324 | 202 | 176 |
| 69,545 | 83 | 243 | 143 | 67 | 569 | 355 | 243 | 219 |
| 137,325 | 160 | 461 | 285 | 136 | 655 | 378 | 461 | 108 |
| 158,959 | 190 | 543 | 324 | 158 | 24 | 202 | 543 | 1036 |
| 166,364 | 198 | 569 | 355 | 162 | 48 | 243 | 569 | 72 |
| 191,383 | 227 | 655 | 378 | 176 | 57 | 461 | 655 | 123 |
| 232,398 | 276 | 799 | 460 | 219 | 74 | 543 | 202 | 158 |
| Average Time | 134 | 383 | 228 | 108 | 83 | 569 | 243 | 202 |
| Bytes/s | 835 | 292 | 491 | 1036 | 160 | 108 | 461 | 243 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nita, S.L.; Mihailescu, M.I.; Pau, V.C. Security and Cryptographic Challenges for Authentication Based on Biometrics Data. Cryptography 2018, 2, 39. https://doi.org/10.3390/cryptography2040039
Nita SL, Mihailescu MI, Pau VC. Security and Cryptographic Challenges for Authentication Based on Biometrics Data. Cryptography. 2018; 2(4):39. https://doi.org/10.3390/cryptography2040039
Chicago/Turabian StyleNita, Stefania Loredana, Marius Iulian Mihailescu, and Valentin Corneliu Pau. 2018. "Security and Cryptographic Challenges for Authentication Based on Biometrics Data" Cryptography 2, no. 4: 39. https://doi.org/10.3390/cryptography2040039
APA StyleNita, S. L., Mihailescu, M. I., & Pau, V. C. (2018). Security and Cryptographic Challenges for Authentication Based on Biometrics Data. Cryptography, 2(4), 39. https://doi.org/10.3390/cryptography2040039