A Cryptographic System Based upon the Principles of Gene Expression


Abstract
:1. Introduction
1.1. Weak Points with the Current Security Approaches
- Timing attacks using the Chinese Remainder Algorithm and Montgomery’s Algorithm. This timing attack works by enabling factorization of the RSA modulus n. It works if the exponentiation is carried out by the Chinese Remainder Algorithm and the multiplication of the prime factors is performed by Montgomery’s Algorithm [3].
- Analysis of short RSA exponents. This attack uses a continued fractions algorithm to make an estimate using the public key exponent, e and the modulus, p*q to make an estimate of the private key exponent, d. It relies on the fact that with e < p*q and GCD (, ) is small, d can be estimated [4].
1.2. DNA Cryptography and the Central Dogma
1.3. DNA Computing and Elliptic Curve Cryptography
1.4. Other DNA Encryption Systems
1.5. Cryptography on the Basis of Separation by Gel Electrophoresis
1.6. DNA Watermarking
2. Materials and Methods
2.1. Basis of the Cryptographic System Relying on Principles of Gene Expression
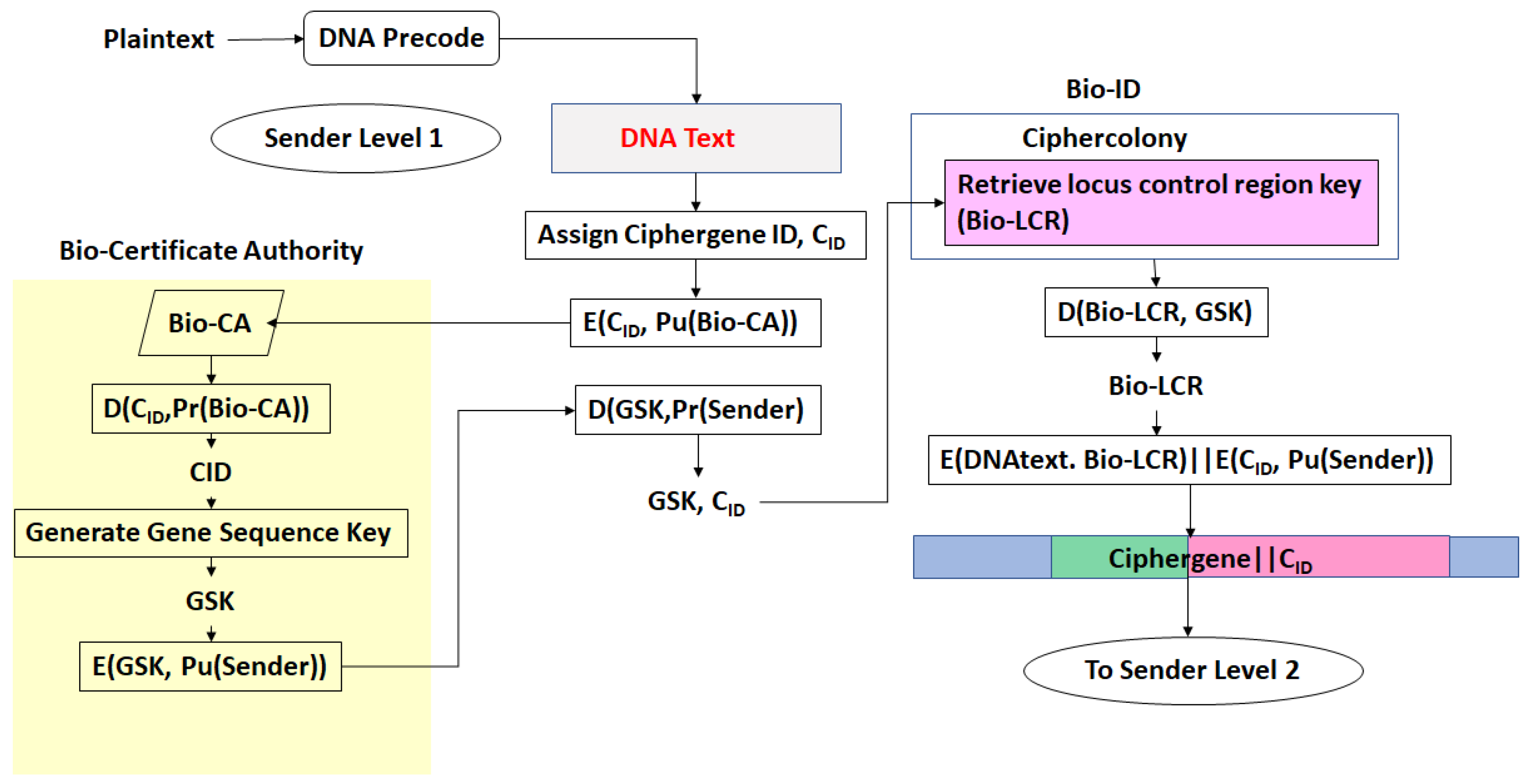
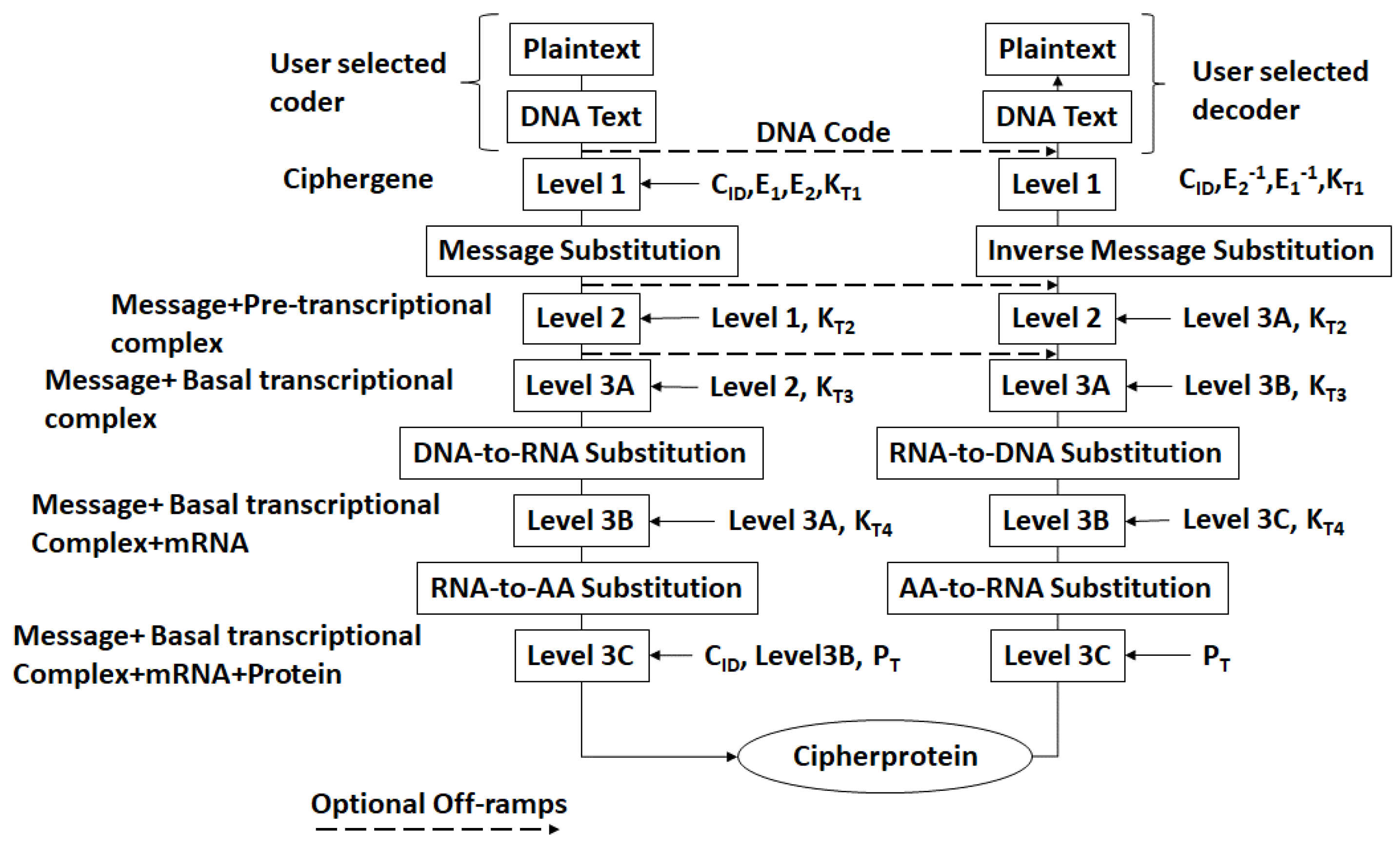
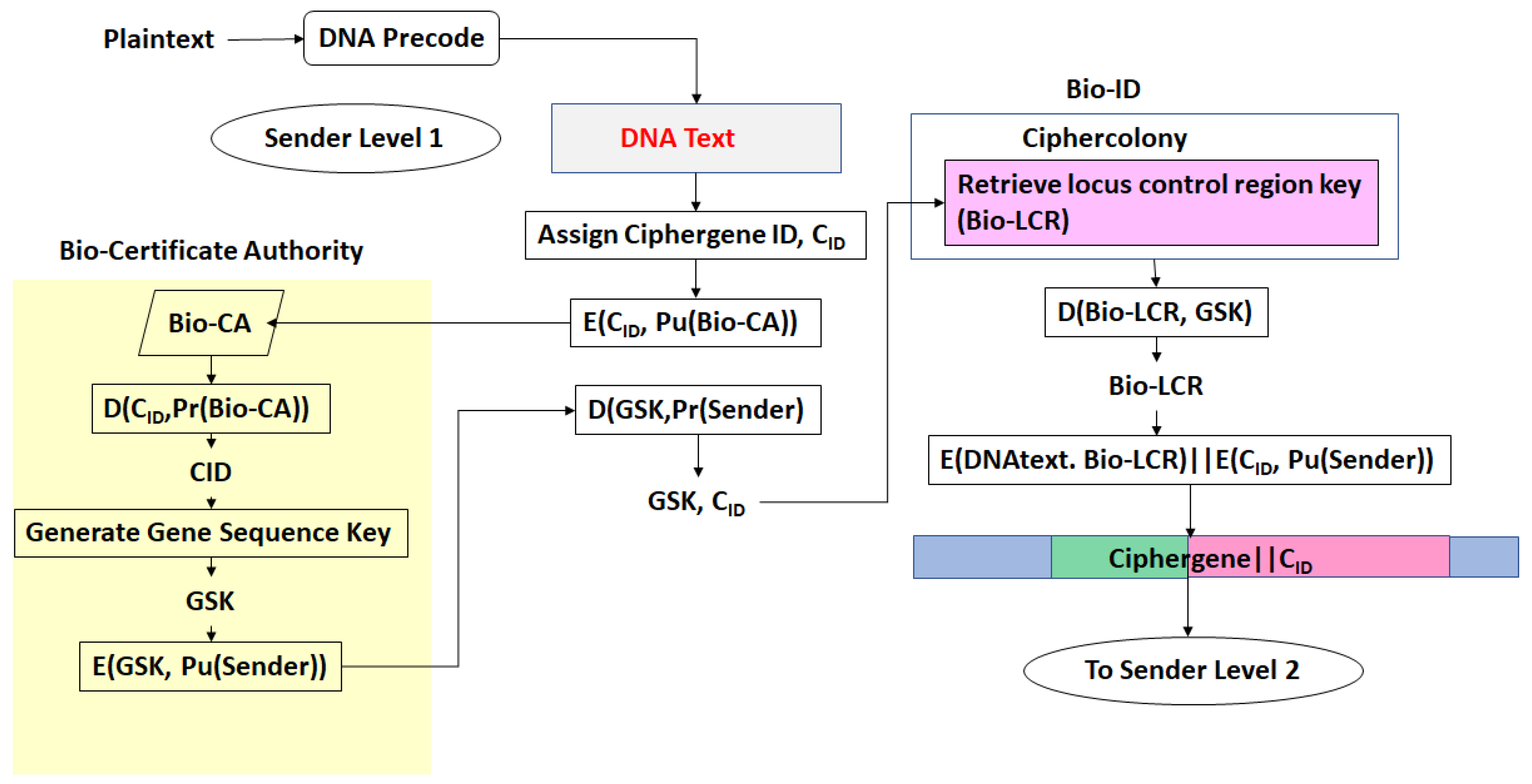
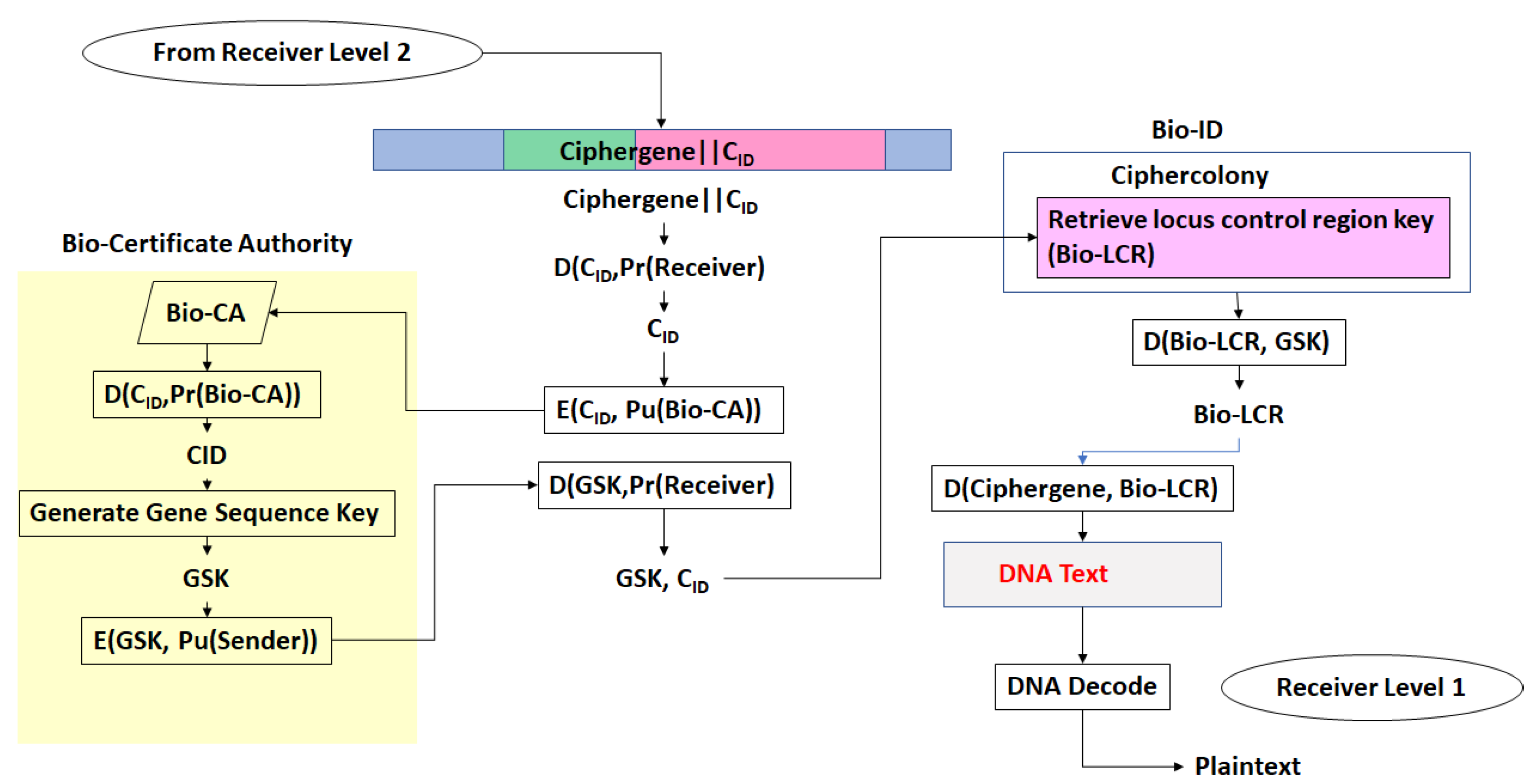
- There exists a scheme to reversibly convert plaintext to DNA nucleotide codes. The methodology of the protocol allows users to utilize their own DNA coding scheme. It is also possible to use one of the DNA coding schemes developed by the author [23,24,25,26]. The plaintext to DNA conversion in [26] permits utilization of a wider set of DNA nucleotides than other coding schemes. Thus, a DNA codeword dictionary such as:which represents the bases adenine, cytosine, guanine, thymine, the epigenetic marker methyl-cytosine, and mutagenic bases hypoxanthine, and xanthine can be implemented. The plaintext is coded into prefix-free binary codewords which are encrypted with a pre-shared key and converted to a DNA-based message as shown in [26]. The product is an unstructured sequence of nucleotide codes.
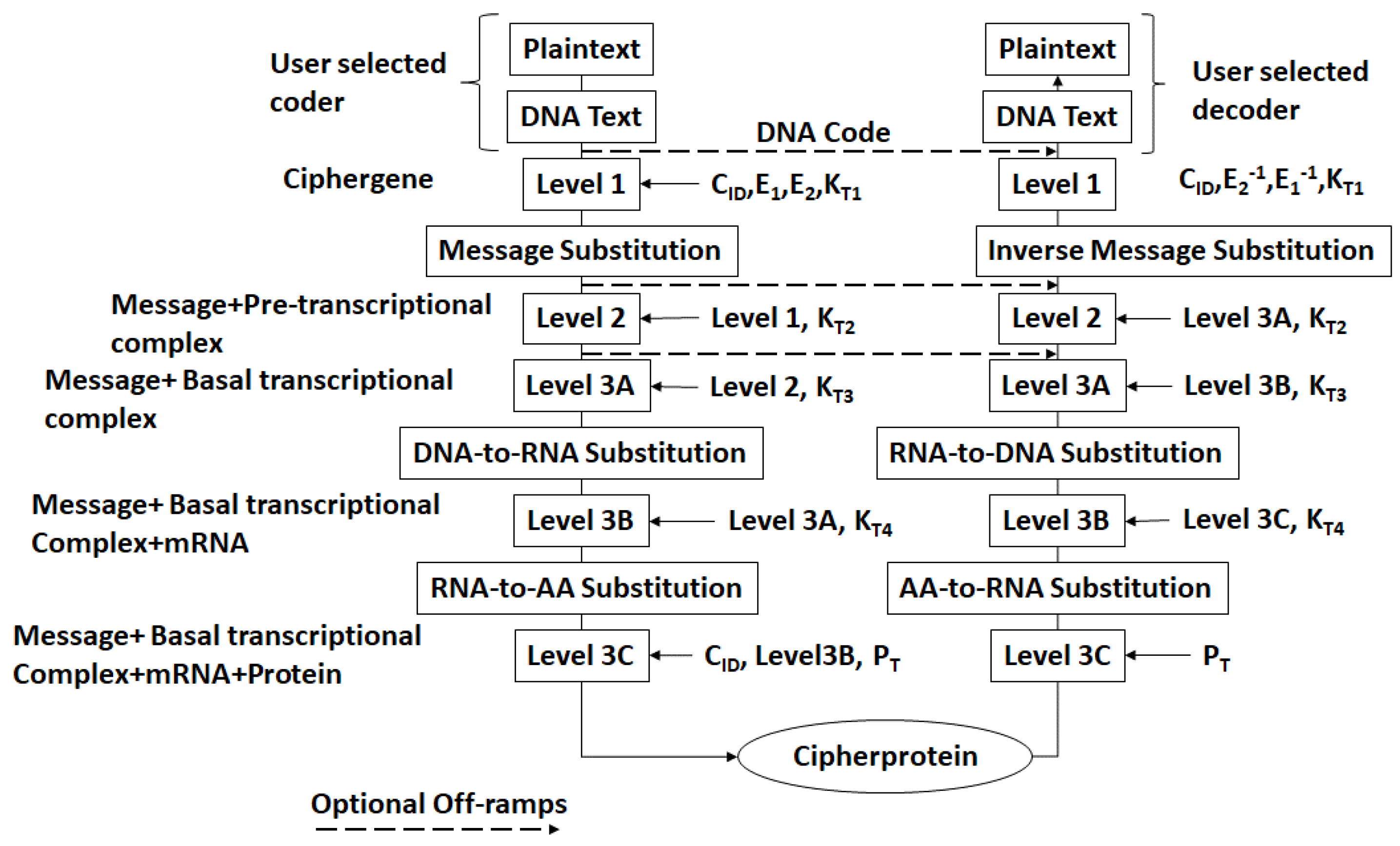
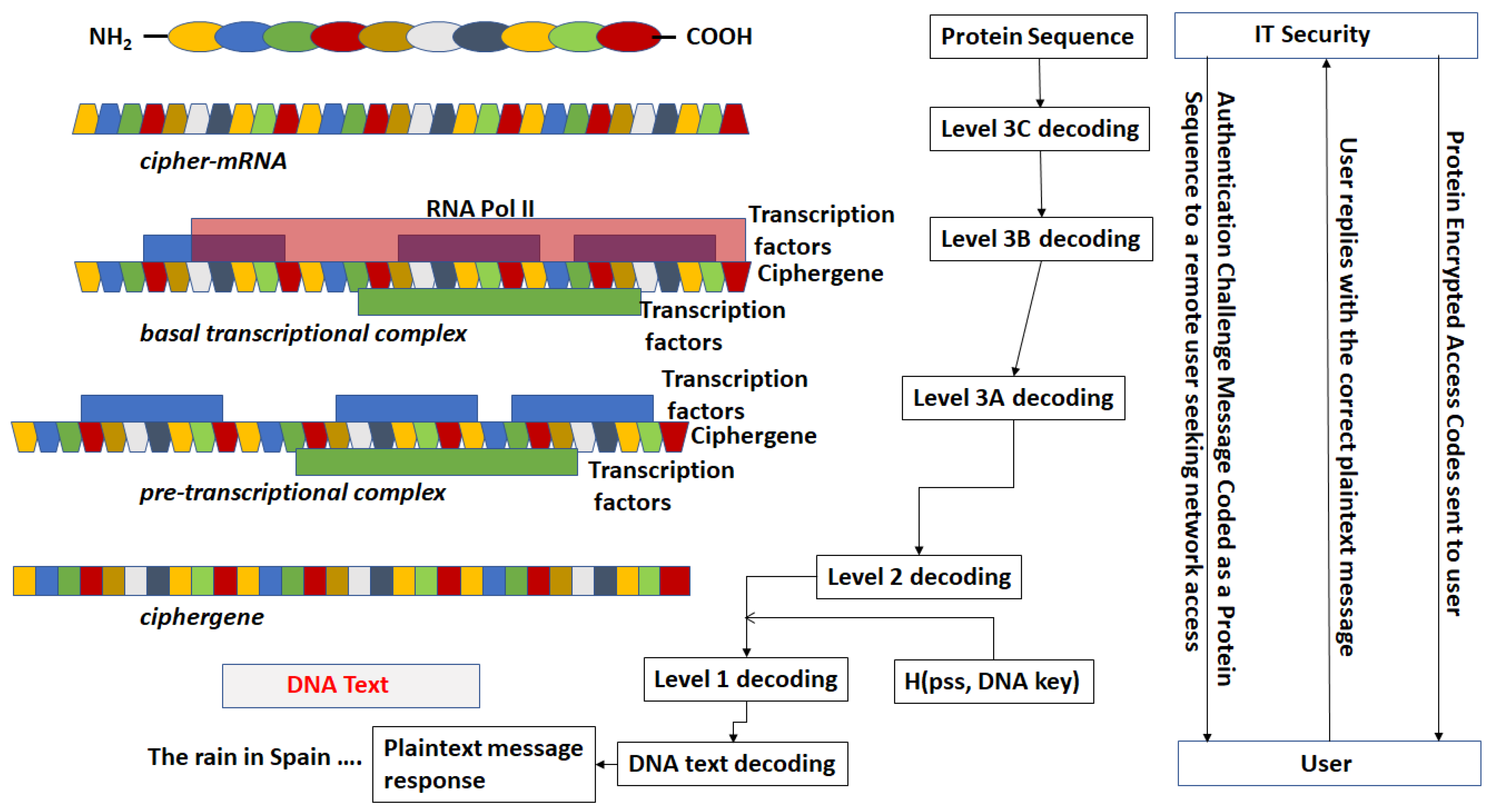
- The DNA text is mapped into the structure of a gene complete with introns, exons, regulatory regions, etc. This output is called a ciphergene. This represents the level 1 encryption and the inverse operation is the level 1 decryption. The purpose of this coding from a security perspective is that a single sequence of letters from a small alphabet can be used to represent a large set of permutations of message combinations.
- The ciphergene code is then operated on by a series of protein transcription factor codes that combine with their counterpart regulatory codes on the ciphergene to produce a new coded sequence that represents a coded transcriptional complex. The output of level 2 is the Pre-Transcriptional Complex and represents the level 2 encryption and the inverse operation is the level 2 decryption.
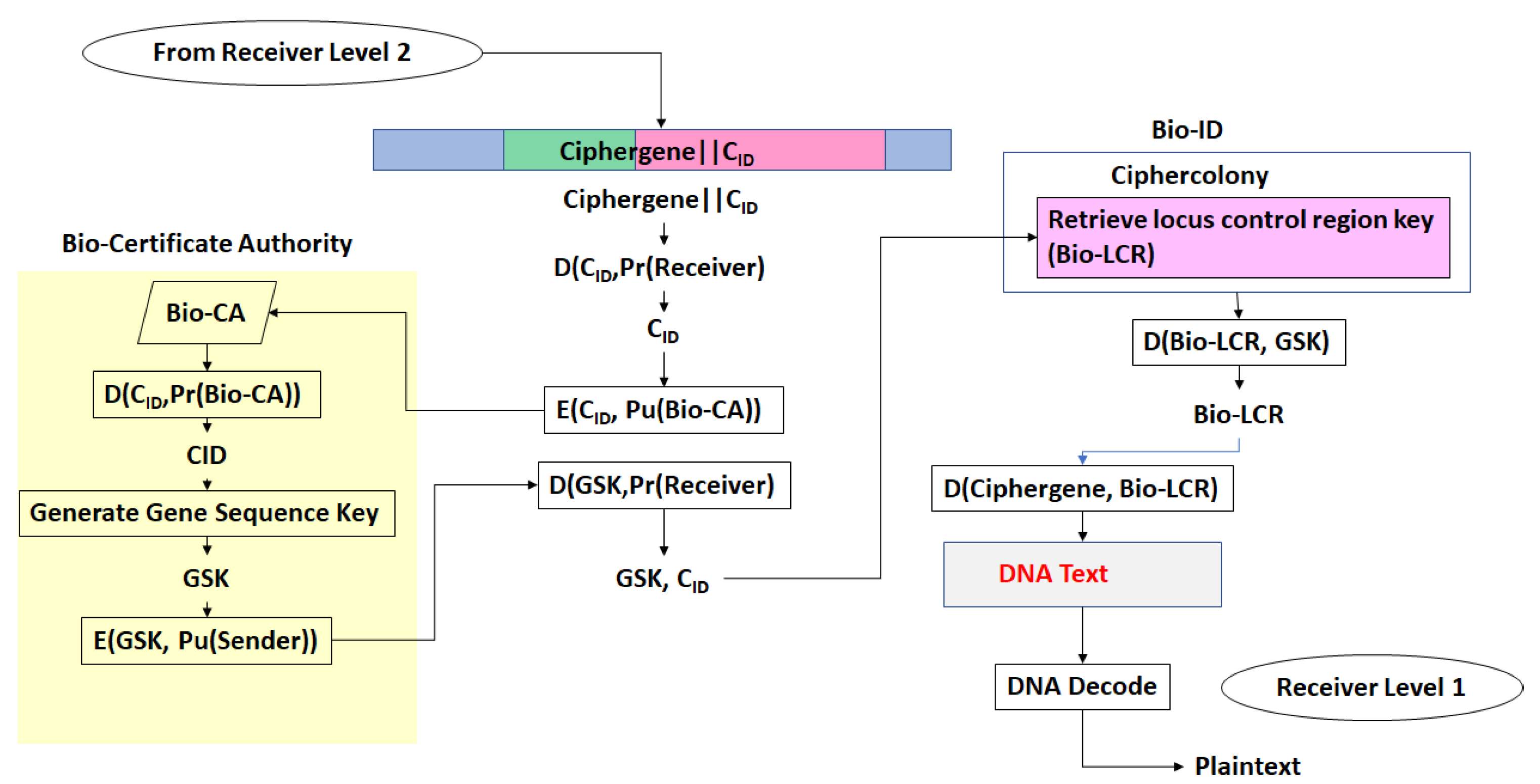
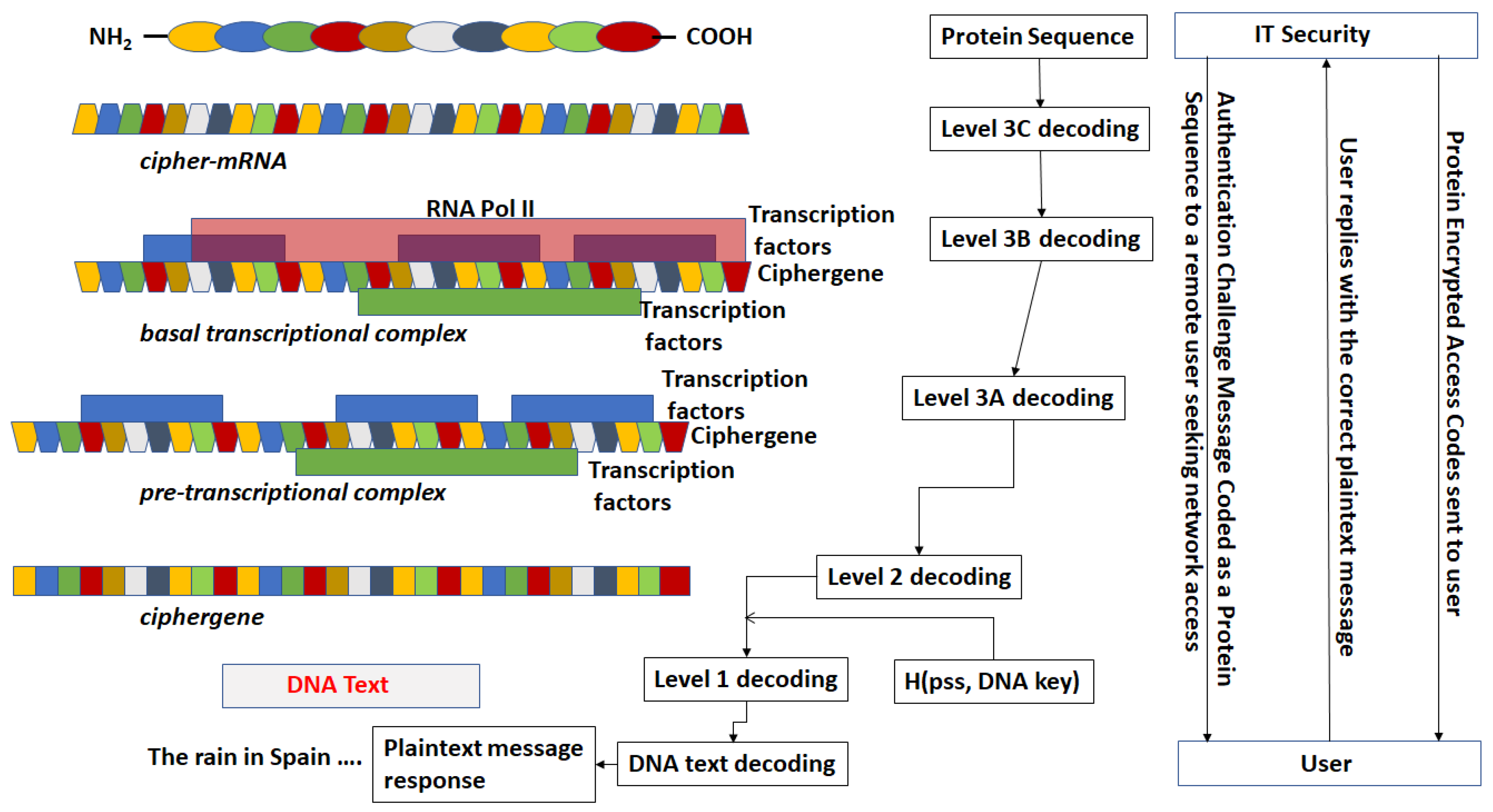
- The third step is a series of operations that takes the Pre-Transcriptional Complex (PTC) code, which is operated on by protein and RNA polymerase codes resulting in a basal transcriptional complex code. The basal transcriptional complex code (BTC) is processed by algorithms and maps the code into a messenger RNA code, called the cipher-mRNA code. The cipher-mRNA now consists only of codons of the original DNA text message and is translated into a protein code, called the cipherprotein. The output of level 3 is the cipherprotein code that is transmitted from the sender to the receiver. The receiver applies the symmetric decryption keys to recover the cipher-mRNA and then performs all subsequent steps to reach level 2, level 1, and decoding to produce the plaintext.
- The resulting codes for ciphergenes, cipher-mRNA (c-mRNA), and cipherproteins are subject to the processes of regulation of expression through operations on the codes. This can be done as pre- or post-transcriptional operations as well as pre- or post-translational operations such that these processes are utilized as part of the network security concept of operations. The scope of the protocols can be described in biological terms as the regulated transcription of genes to form messenger RNA followed by translation of the messenger RNA into proteins.Table 1 summarizes the steps in the encryption and decryption process.
2.2. Coding of Sequences as Objects.
- the nucleotide base level (e.g., AGGCT …)
- the codon level, (AAG, TTA, CGC, …)
- transcription factor/ binding site (SP1, CCAT, AP2, …)
- protein transcription factor (TFIIA, TFIIB, …) and so forth.
- Nucleotides: N = {A, T, C, G, U, I, MeC, X, H}
- DNA Codons: DC = {ATT, ATC, ATA, CTT, CTC, CTA, CTG, TTA, TTG, GTT, GTC, GTA, GTG, TTT, TTC, ATG, TGT, TGC, GCT, GCC, GCA, GCG, GGT, GGC, GGA, GGG, CCT, CCC, CCA, CCG, ACT, ACC, ACA, ACG, TCT, TCC, TCA, TCG, AGT, AGC, TAT, TAC, TGG, CAA, CAG, AAT, AAC, CAT, CAC, GAA, GAG, GAT, GAC, AAA, AAG, CGT, CGC, CGA, CGG, AGA, AGG, TAA, TAG, TGA}
- Transcription factors: TF = {TFII, TBP, …}
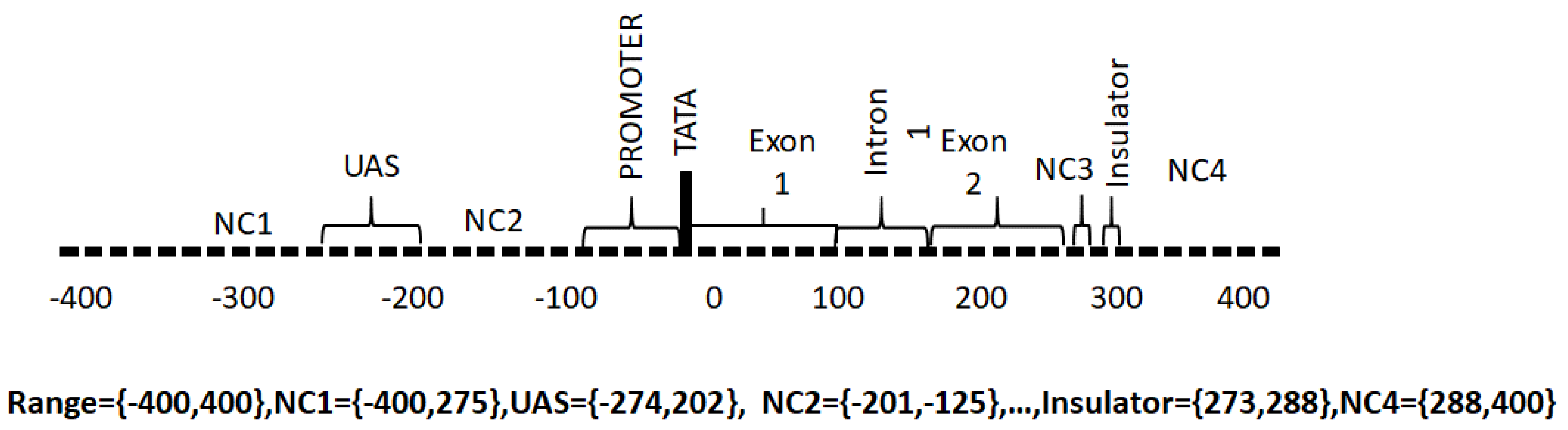
- Promoter. The promoter region is responsible for the binding of RNA polymerase, transcription factors and for the subsequent initiation of transcription.
- Upstream Activating Sequence. This is a region upstream of the transcriptional start site that binds transcription factor proteins required for transcription.
- Downstream Activating Sequence. This is a region downstream from the transcriptional start site that binds transcription factor proteins required for transcription.
- Exon. These regions contain the codons that are ultimately translated into proteins from messenger RNA.
- Introns. These are non-coding intervening regions between exons. Introns may also contain regulatory elements.
- TATA. This is a recognition sequence of bases (ATA(A/T)A(A/T)(A/G)) [27] that appears in some genes upstream of the transcription start site and binds TATA box binding proteins required for transcription. Not all genes have TATA boxes and some genes have non-canonical TATA boxes.
- Non-coding. These are regions without a specific function assigned.
- Insulator. The insulator is a regulator region that acts as a repressor of transcription of adjacent genes.
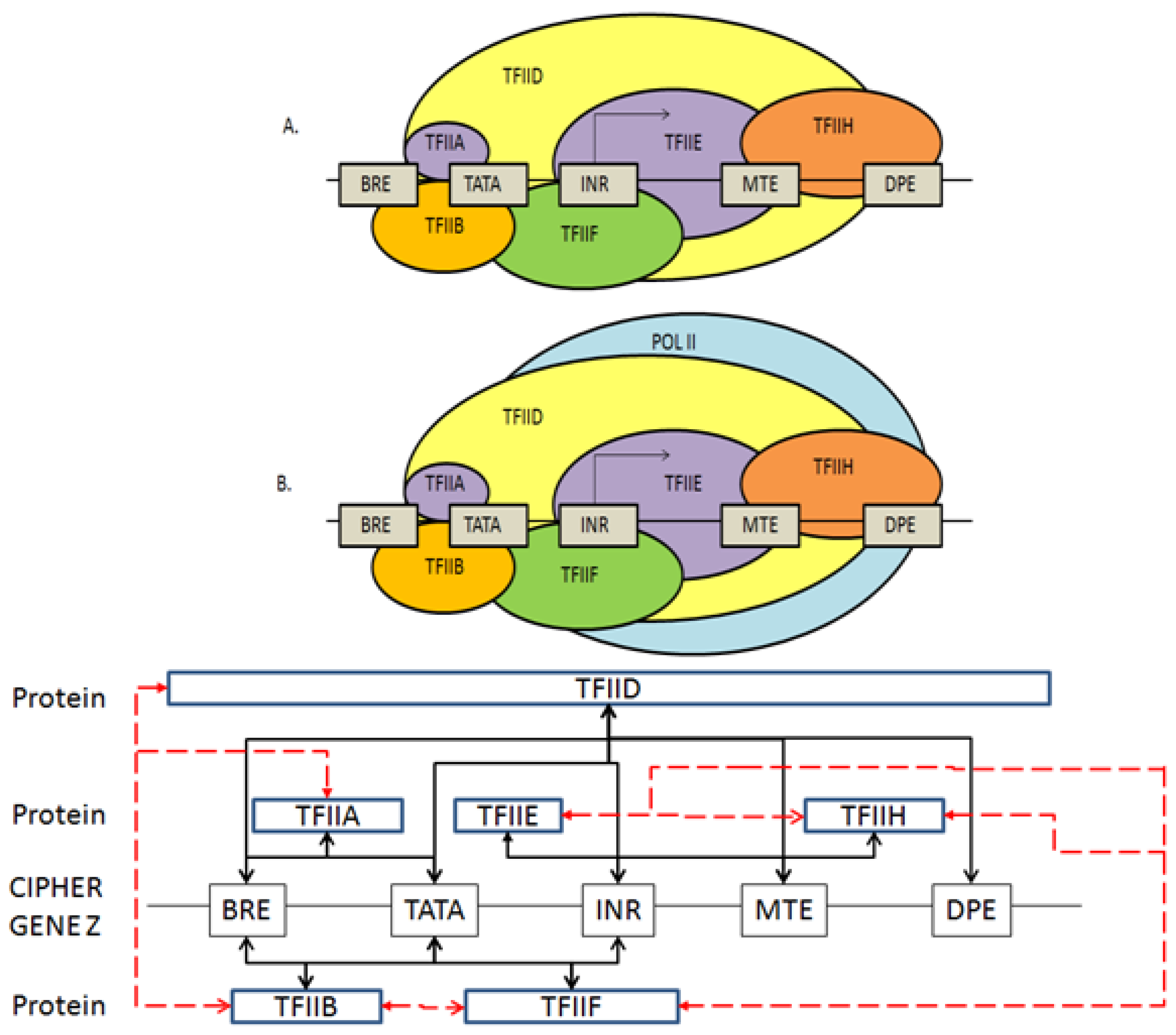
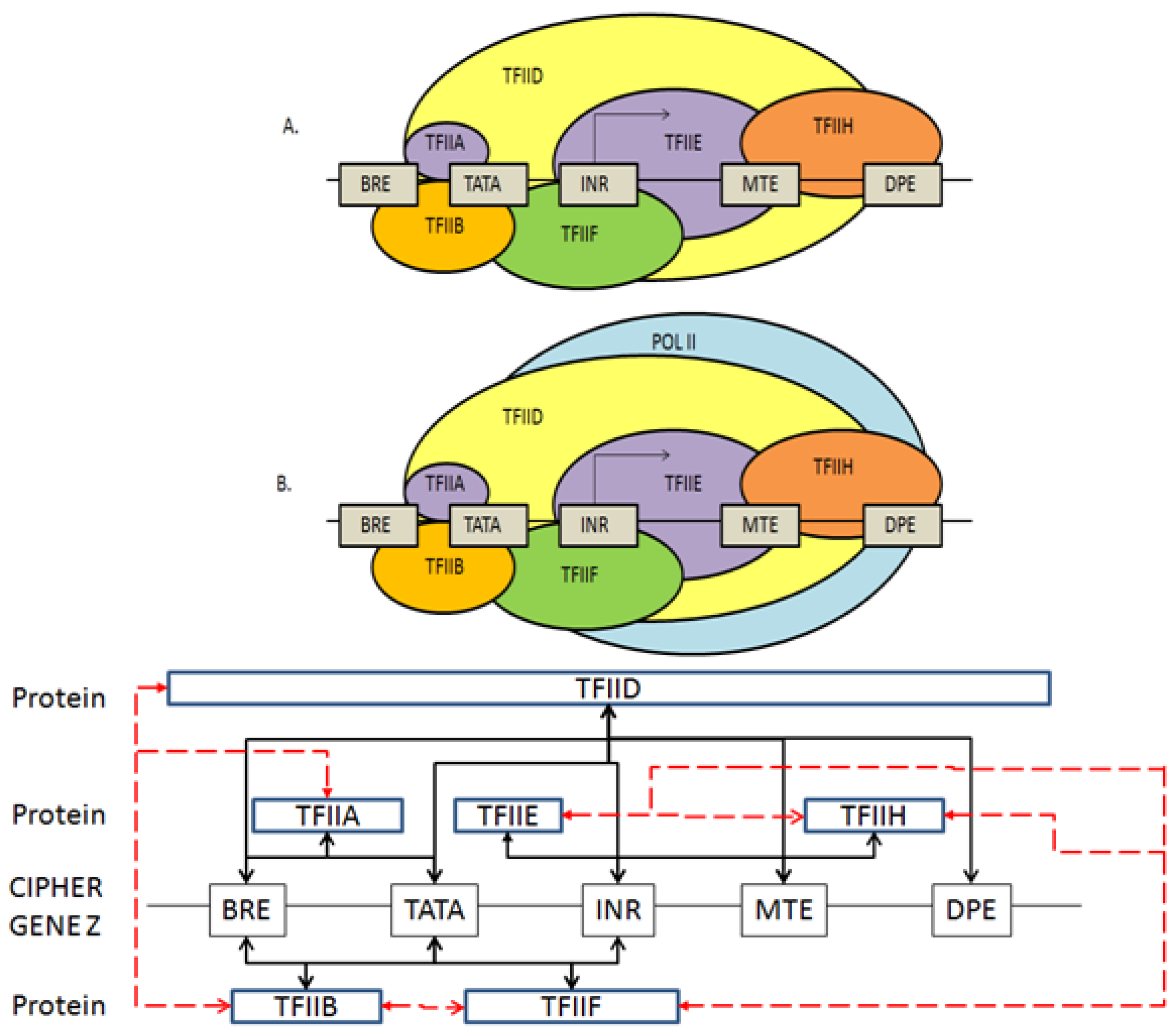
2.3. Coding the General Transcriptional Complex
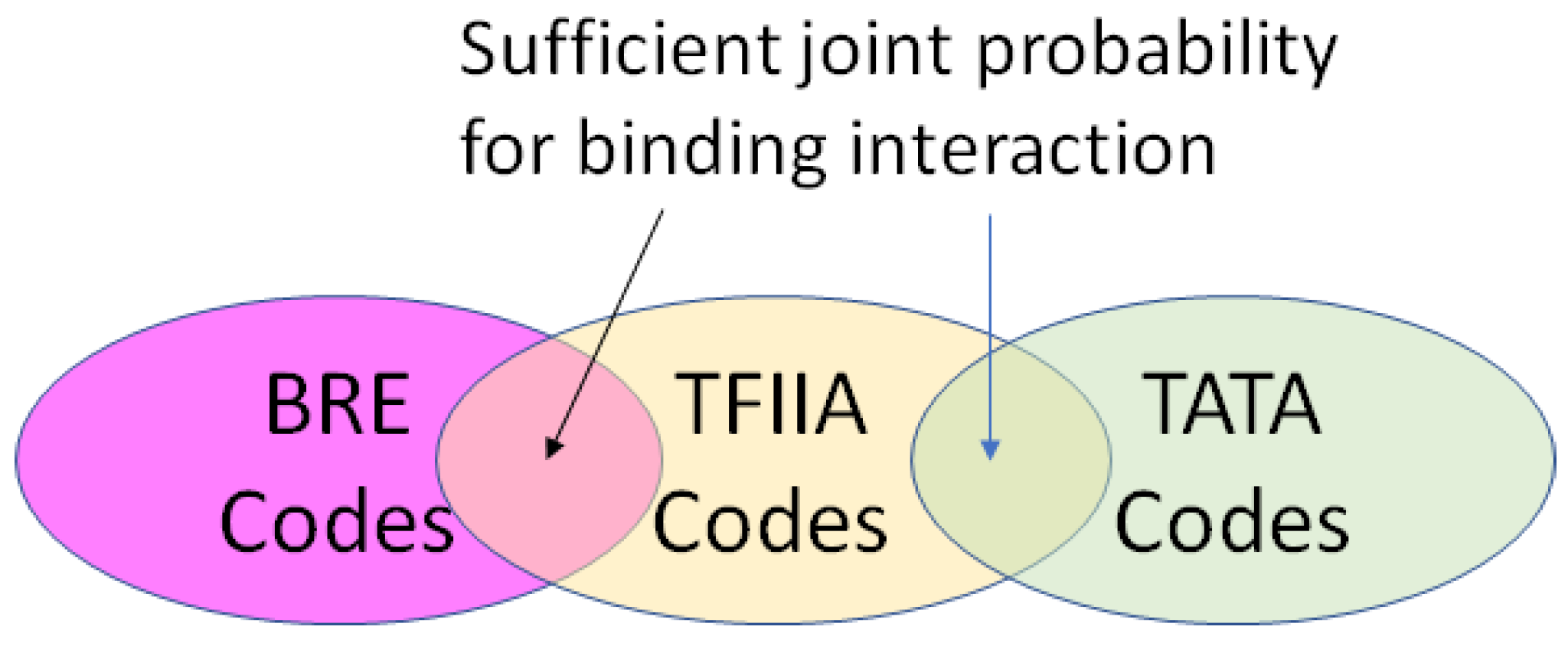
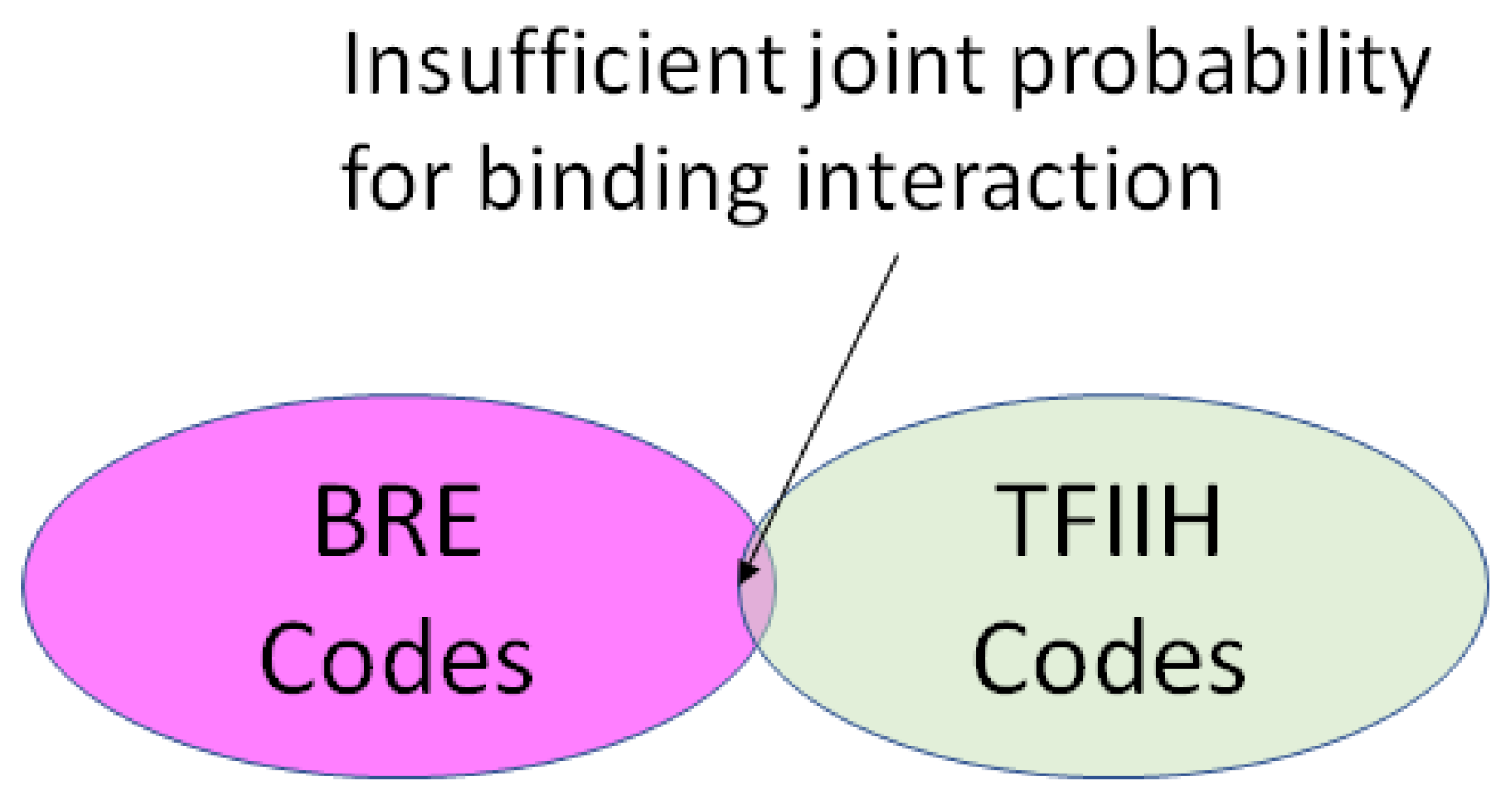
2.4. Coding for Control of Transcription Factor Binding
2.5. Features of the Genomic and Proteomic Security Protocol
- Every gene sequence used in the protocol is called a ciphergene, resides in a system called the ciphercolony, and is indexed by a ciphergene ID. The unauthorized disclosure of the ciphergene ID is a major vulnerability that must be prevented.
- The ciphergene ID points to all of the features unique to the expression of the gene. It is the single link to all of the information necessary to process and regulate transcription and translation for a given gene and message.
- Each output level of the protocol carries all the levels beneath it in its payload.
- Every gene sequence possesses the following attributes:
- ⚪
- Matrix F, which contains the starting location of each Type in the gene along the diagonal.
- ⚪
- Matrix, G, which contains a probability of expression for the gene in a given state. The number states are given by the number of diagonal entries in G. F and G are square and the same size.
- ⚪
- A matrix C, which is the product of F and G.
- ⚪
- Encryption matrices E1, E2, …, En, that operate on C. Inverse decryption matrices that return C. In their simplest form, they could be rotations.
- ⚪
- A series of regulatory networks that describes the interactions with proteins and other nucleic acids necessary for all the processes within this protocol.
- ⚪
- KTn are binary sequences representing unique symmetric encryption keys. PT is a binary sequence representing a message authentication code that is a pre-shared secret between transmitter and receiver. For this application, it could be any user specified binary sequence satisfying the requirements of a keyed message authentication code.
- One or more Types with each Type possess the following attributes:
- ⚪
- A probability mass function to derive a code to represent each Type as utilized by the ciphergene.
- ⚪
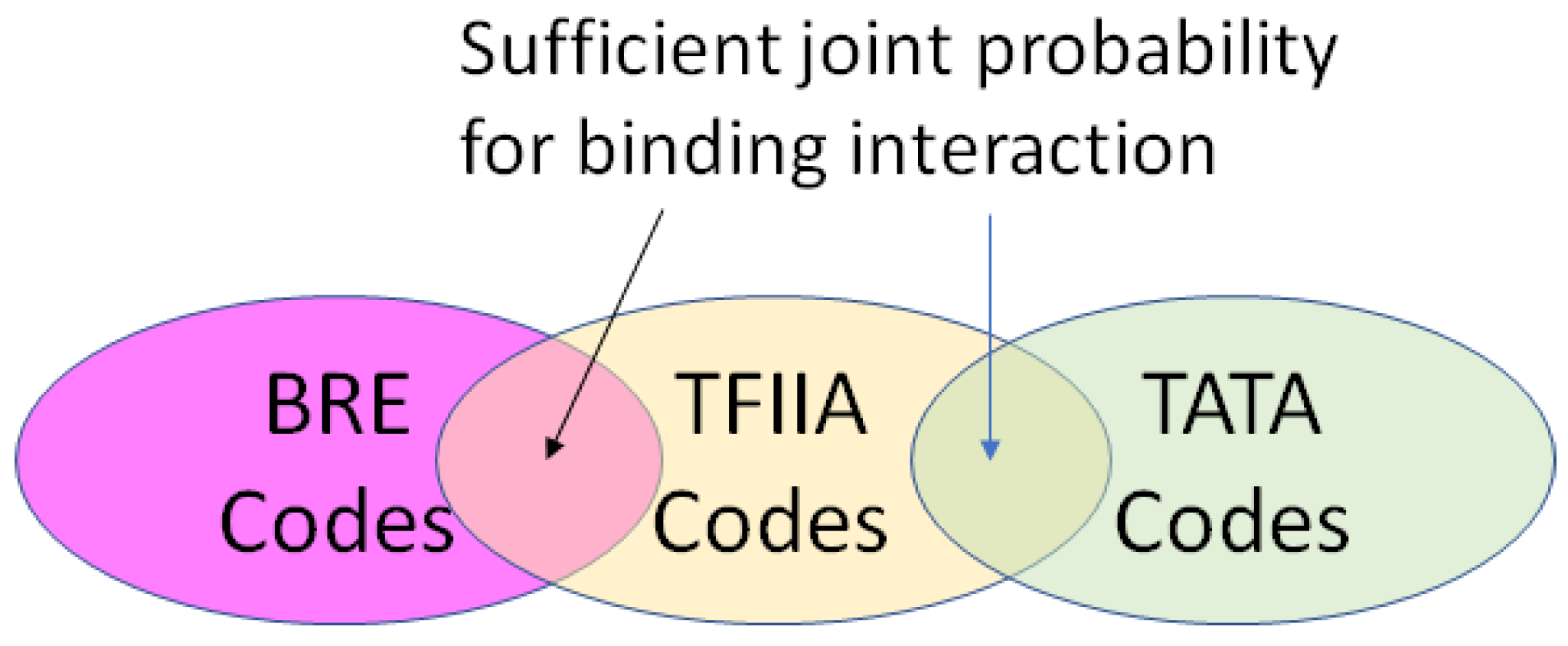
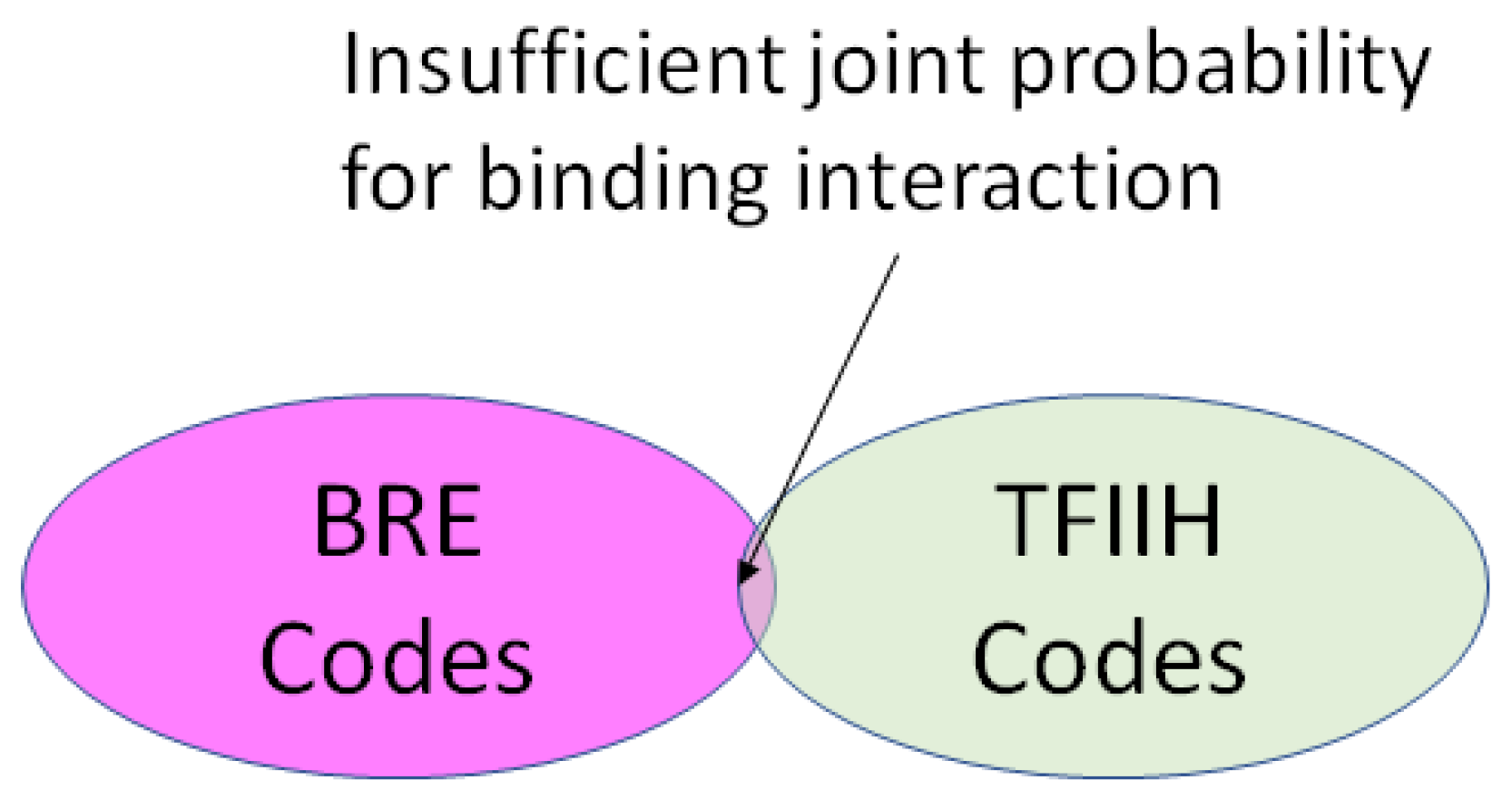
- A position in a regulatory network to describe its relationship to the other Types required for transcription or translation of the ciphergene. Each Type-to-Type relationship is a joint event.
- ⚪
- A joint probability matrix with its mutual information to other Types required for transcription and translation using the joint event.
- ⚪
- For every joint event, a code is derived from the joint probability matrix and the coding of the Types. This code is typically much longer than either of the codes for an individual Type in a joint event.
- For sequences that are converted from a DNA message to a DNA sequence or a DNA message to an mRNA sequence (and vice versa), there exists a coding process of ring subtraction over a subset of integers producing an addend and an inverse process of a ring addition over a subset of integers.
- ⚪
- In a simple example, assume the plaintext in a message has been converted to a nucleotide sequence CCTACTAGT to be coded in a β-globin sequence ATGGTGCAT. Table 5 provides a simple example of ring addition process. A realistic application would use longer, and more complex substitution with multiple rounds.
- For sequences that are converted from mRNA to protein (and vice versa) there exists a substitution process for selecting the amino acid code from a triplet of mRNA codes (codon) and a reverse substitution for recovering the codon from the amino acid code. The synonymous codons are coded uniquely.
3. Results
Applications of the Protocol That Fit within the Context of Existing Security Protocols
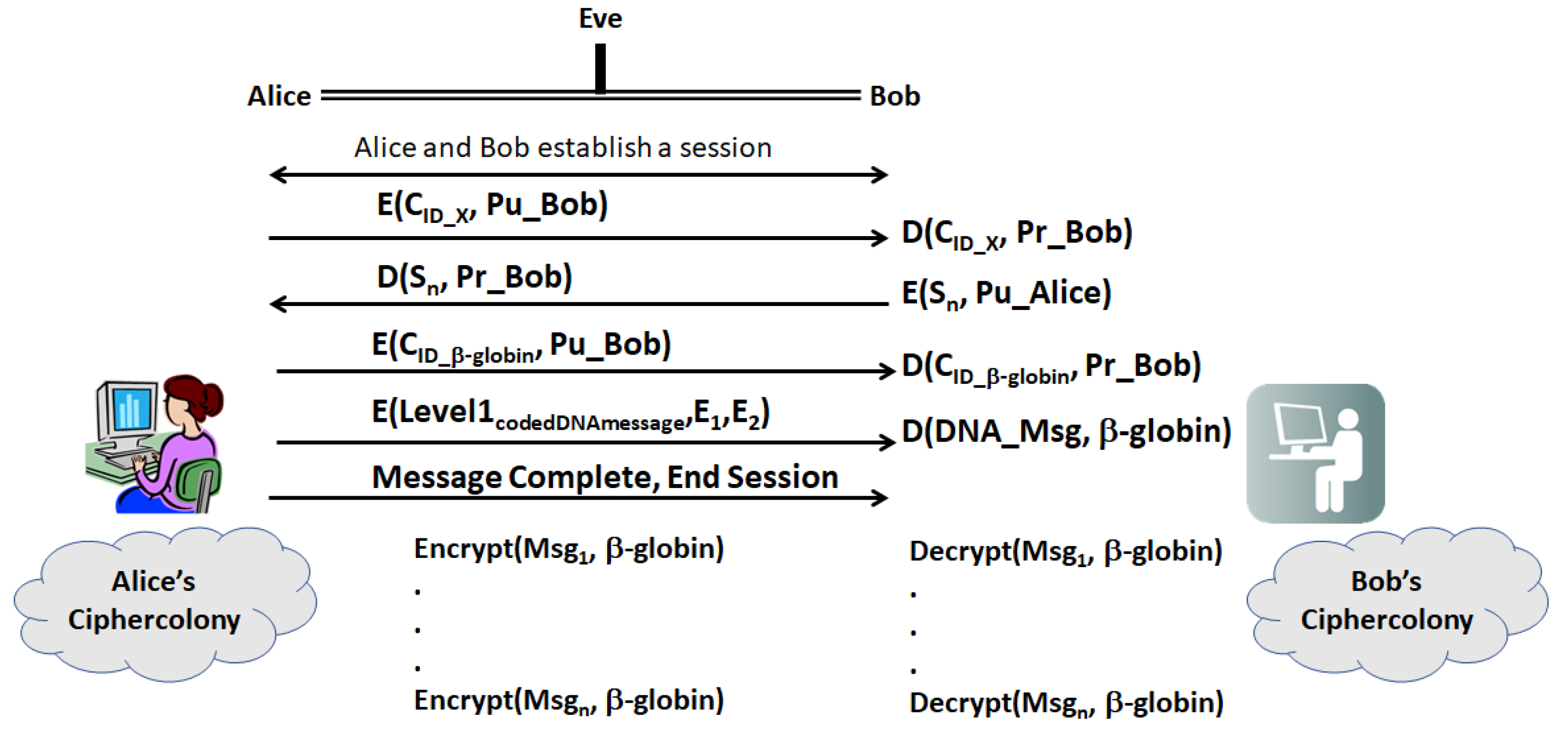
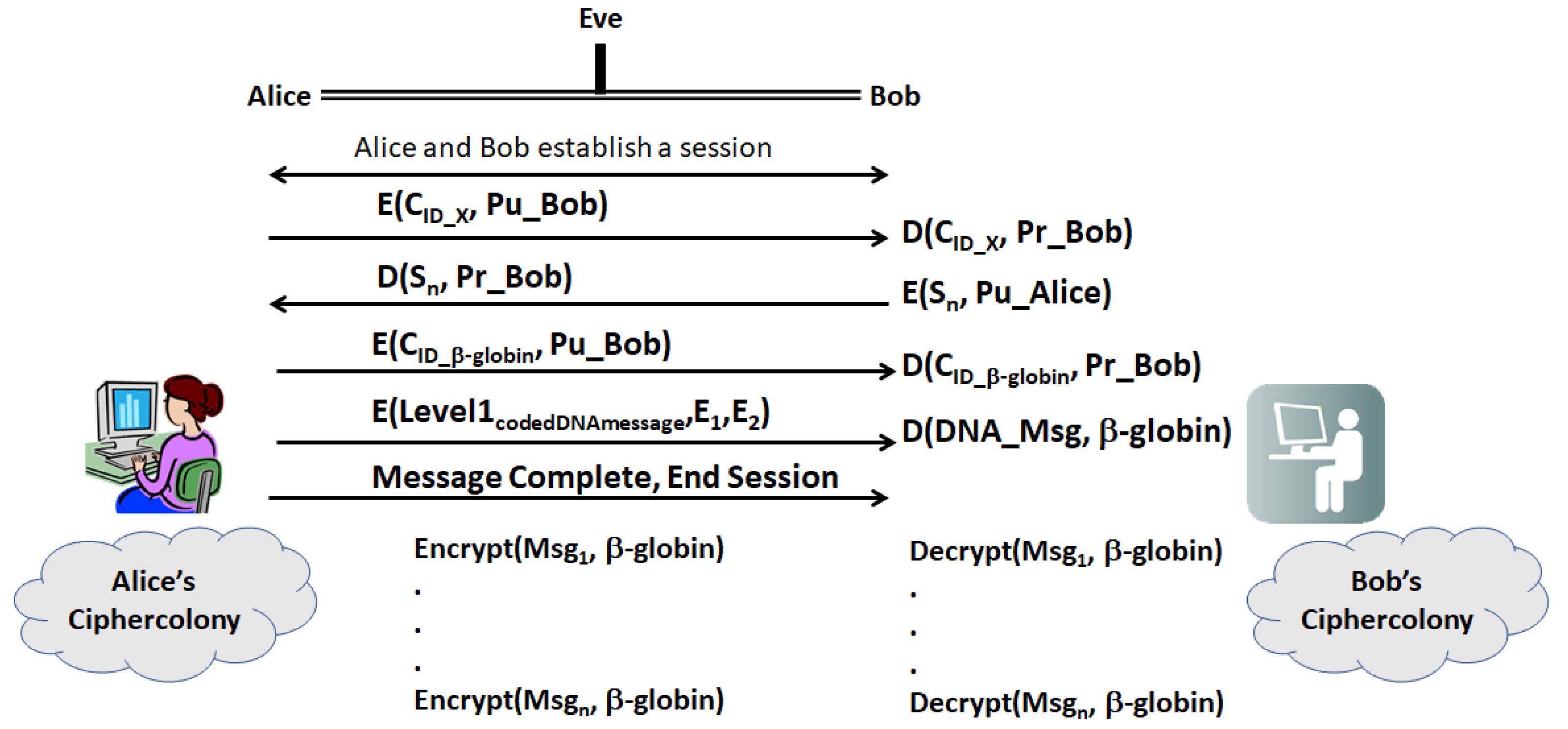
- (a)
- First, Alice and Bob establish a secure session with their legacy protocols. Then, Alice sends Bob a ciphergene ID (CID), for a given gene, X, encrypted with Bob’s public key
- (b)
- Bob decrypts the CID with his private key and returns a sequence, Sn, which is a sequence of n bases from X. The location of the sequence is a pre-shared secret between Bob and Alice.
- (c)
- Having established two forms of identity verification between Alice and Bob, Alice transmits the encrypted CID for β-globin with Bob’s public key. Table 6 displays a set of Types that can be used in encrypting the message, which can be far more extensive that shown in the table. Implementers can construct the network of protein–protein and protein–nucleotide interactions from the literature on transcriptional regulation of β-globin. The other elements of the encryption and decryption at level 1 can be generated based upon Section 2.4. Alice transmits the Level 1 code derived from coding
- (d)
- Bob decrypts the CID with his private key and uses CID to retrieve the β-globin sequence details and decryption keys, and then decrypts Level 1. Bob assembles the ciphergene and applies the addend code to retrieve the DNA text from the protein coding regions of the β-globin sequence.
- (e)
- Bob can recover the plaintext using the source decoding process.
- (f)
- Unless Eve can impersonate Bob or Alice in a man-in-the-middle attack, Eve must have access to keys E1, E2, …, En as well knowledge of the biogene regulatory structure to retrieve the plaintext or insert replacement ciphertext. Eve may be able to mount a mathematical attack on the keys, but knowledge of the regulatory structure of the message is required to completely retrieve the DNA text and knowledge of the pre-shared secret hash codes is required to retrieve the plain text from the DNA text.
4. Discussion
Novel Features of the Protocol for Future Extension of the Capabilities
- Patterns of gene expression (networks of gene interactions)
- Intercellular systems (networks of cellular interactions, e.g., biofilms)
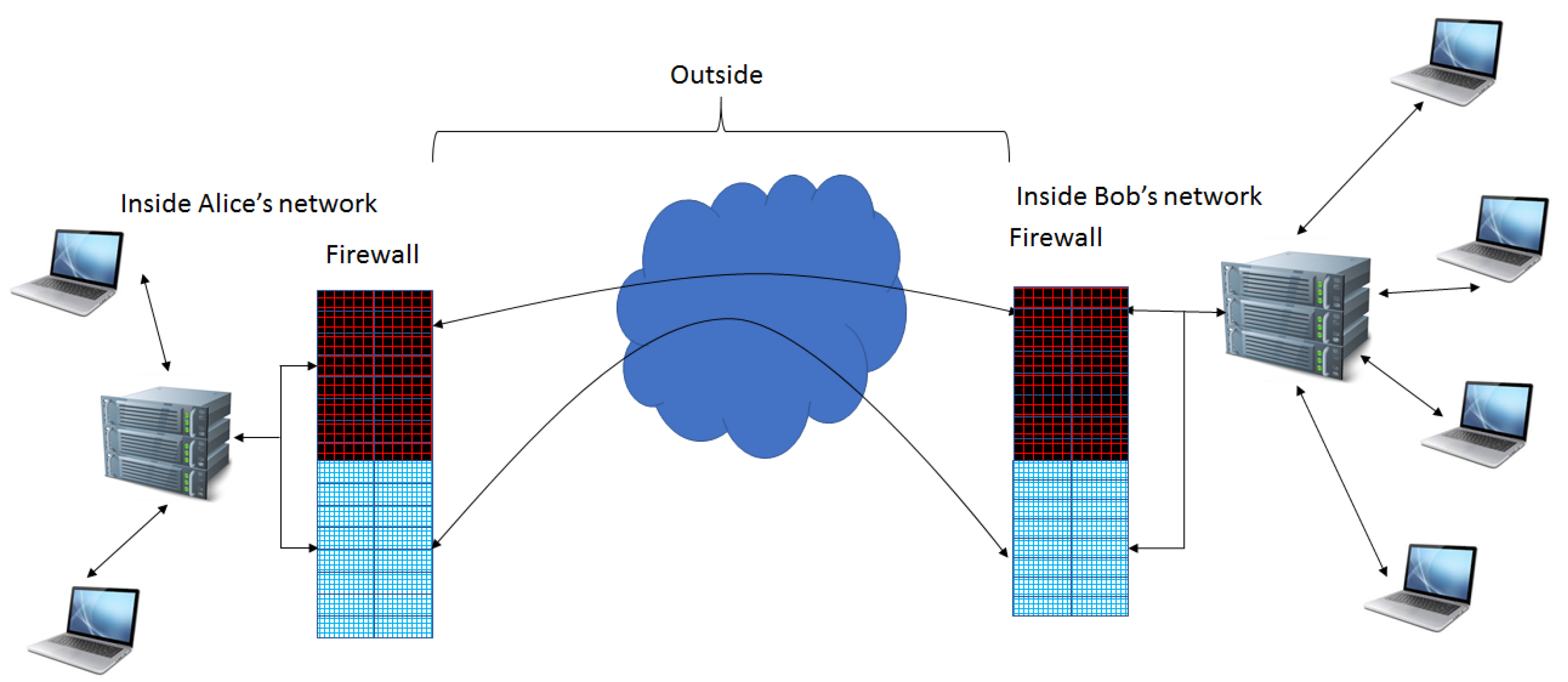
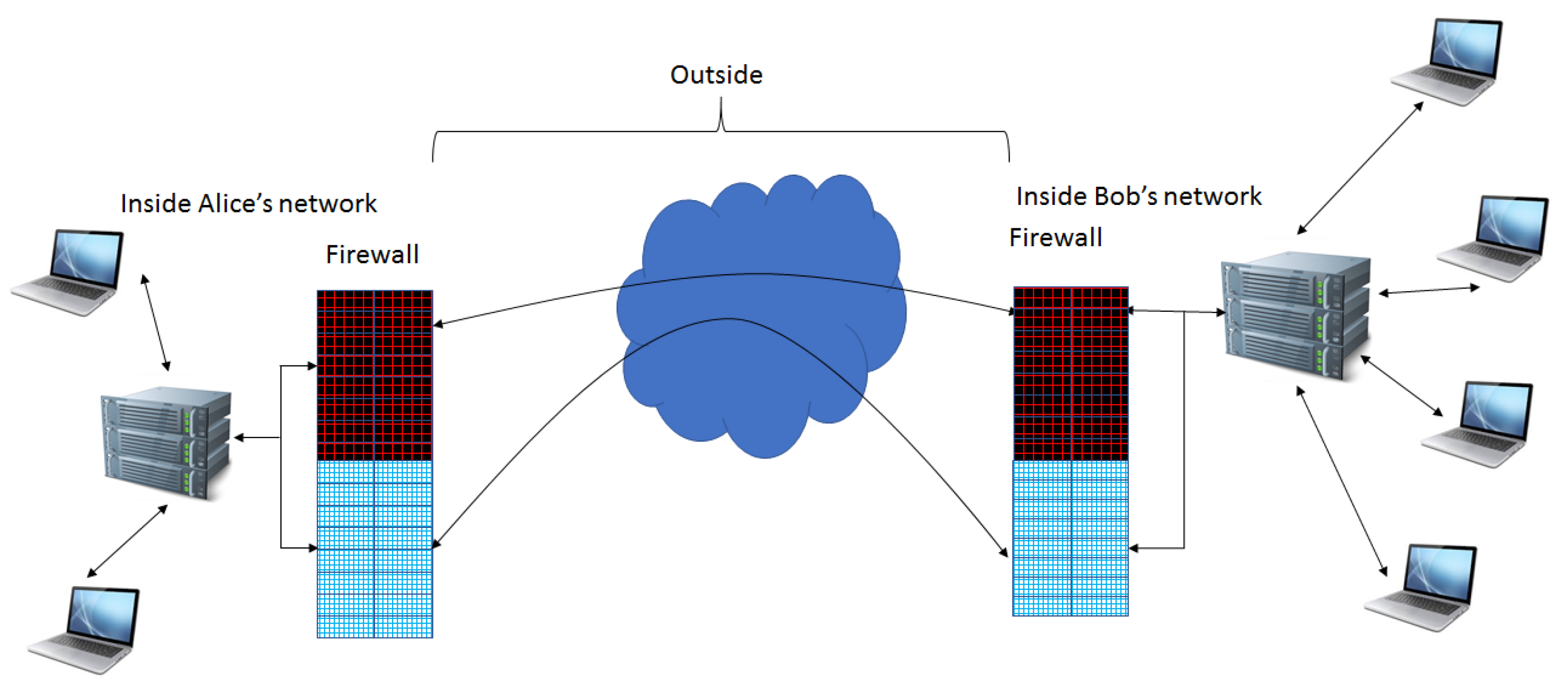
Extension of Firewall Capabilities
5. Conclusions
6. Patents
Acknowledgments
Conflicts of Interest
References
- Shaw, H.C. Genomics and Proteomics Based Security Protocols for Secure Network Architectures; The George Washington University: Washington, DC, USA, 2013. [Google Scholar]
- Novak, R.; Naccache, D.; Paillier, P. SPA-Based Adaptive Chosen-Ciphertext Attack on RSA Implementation. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2002. [Google Scholar]
- Schindler, W.A. Timing Attack against RSA with the Chinese Remainder Theorem. In Cryptographic Hardware and Embedded Systems; Springer: Berlin, Germany, 1965; pp. 109–124. [Google Scholar]
- Wiener, M.J. Cryptanalysis of short RSA secret exponents. IEEE Trans. Inf. Theory 1990, 36, 553–558. [Google Scholar] [CrossRef]
- Misarsky, J.F. A multiplicative attack using LLL algorithm on RSA signatures with redundancy. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 1997; pp. 221–234. [Google Scholar]
- Bindel, N.; Buchmann, J.; Krämer, J. Lattice-Based Signature Schemes and their Sensitivity to Fault Attacks. In Proceedings of the 13th Workshop on Fault Diagnosis and Tolerance in Cryptography, Santa Barbara, CA, USA, 16 August 2016. [Google Scholar]
- Kocher, P.C. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 1996; pp. 104–113. [Google Scholar]
- Yarom, Y.; Genkin, D.; Heninger, N.J. CacheBleed: A timing attack on OpenSSL constant-time RSA. J. Cryptogr. Eng. 2017, 2, 99–112. [Google Scholar] [CrossRef]
- Adham, M.; Azodi, A.; Desmedt, Y.; Karaolis, I. How to Attack Two-Factor Authentication Internet Banking. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2013; pp. 322–328. [Google Scholar]
- Min-Seok, P.; Hüseyin, T. Security Breaches in the U.S. Federal Government. Available online: https://ssrn.com/abstract=2933577 (accessed on 20 November 2017).
- Singh, H.; Chugh, K.; Dhaka, H.; Verma, A.K. DNA based Cryptography: An Approach to Secure Mobile Networks. Int. J. Comput. Appl. 2010, 1, 77–80. [Google Scholar] [CrossRef]
- Karimi, M.; Haider, W. Cryptography using DNA Nucleotides. Int. J. Comput. Appl. 2017, 168, 16–18. [Google Scholar] [CrossRef]
- Bevi, A.R.; Malarvizhi, S.; Patel, K. Information Coding and its Retrieval using DNA Cryptography. J. Eng. Sci. Technol. Rev. 2016, 9, 86–92. [Google Scholar]
- Vijayakumar, P.; Vijayalakshmi, V.; Zayaraz, G. DNA Computing based Elliptic Curve Cryptography. Int. J. Comput. Appl. 2011, 36, 18–21. [Google Scholar]
- Gehani, A.; LaBean, T.; Reif, J. DNA-Based Cryptography, Aspects of Molecular Computing. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2004; Volume 2950, pp. 167–188. [Google Scholar]
- Sadeg, S.; Gougache, M.; Mansouri, N.; Drias, H. An encryption algorithm inspired from DNA. In Proceedings of the International Conference on Machine and Web Intelligence (ICMWI), Algiers, Algeria, 3–5 October 2010; pp. 344–349. [Google Scholar]
- Raj, B.B.; Vijay, J.F.; Mahalakshmi, T. Secure Data Transfer through DNA Cryptography using Symmetric Algorithm. Int. J. Comput. Appl. 2016, 133, 19–23. [Google Scholar]
- Bourbakis, N.G. Image Data Compression-Encryption Using G-Scan Patterns. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics and simulation, Orlando, FL, USA, 12–15 October 1997; pp. 1117–1120. [Google Scholar]
- Leier, A.; Richter, C.; Banzhaf, W.; Rauhe, H. Cryptography with DNA binary strands. Biosystems 2000, 57, 13–22. [Google Scholar] [CrossRef]
- Heider, D.; Barnekow, A. DNA-based watermarks using the DNA-Crypt algorithm. BMC Bioinform. 2007, 8, 176. [Google Scholar] [CrossRef]
- Heider, D.; Barnekow, A. DNA watermarks: A proof of concept. BMC Mol. Biol. 2008, 9, 40. [Google Scholar] [CrossRef] [PubMed]
- Hamad, S.; Elhadad, A.; Khalifa, A. DNA watermarking using Codon Postfix technique. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017. [Google Scholar] [CrossRef] [PubMed]
- Shaw, H.; Hussein, S. A DNA-Inspired Encryption Methodology for Secure, Mobile Ad-Hoc Networks (MANET). In Proceedings of the First International Conference on Biomedical Electronics and Devices, BIOSIGNALS, Funchal, Portugal, 28–31 January 2008; pp. 472–477. [Google Scholar]
- Shaw, H.; Hussein, S.; Helgert, H. Prototype Genomics-Based Keyed-Hash Message Authentication Code Protocol. In Proceedings of the Second International Conference on Evolving Internet, Valcencia, Spain, 20–25 September 2010; pp. 131–136. [Google Scholar]
- Shaw, H.; Hussein, S.; Helgert, H. Genomics-Based Security Protocols: From Plaintext to Cipherprotein. Int. J. Adv. Secur. 2011, 4, 106–117. [Google Scholar]
- Shaw, H.; Hussein, S.; Helgert, H. Adaptive Self-Correcting Floating Point Source Coding Methodology for a Genomic Encryption Protocol. Int. J. Comput. Appl. 2012, 56, 1–5. [Google Scholar]
- Basehoar, A.D.; Zanton, S.J.; Pugh, B.F. Identification and Distinct Regulation of Yeast TATA Box-Containing Genes. Cell 2004, 116, 699–709. [Google Scholar] [CrossRef]
- Meister, G. RNA Biology: An Introduction; WileyVCH: Weinheim, Germany, 2011; pp. 20–70. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: New York, NY, USA, 1991; pp. 347–665. [Google Scholar]
- Ensembl Genome Browser. Available online: https://www.ensembl.org/Homo_sapiens/Transcript/Exons?db=core;g=ENSG00000244734;r=11:5225464-5227071;t=ENST00000335295 (accessed on 16 October 2017).
- Leach, K.M.; Vieira, K.F.; Kang, S.H.L.; Aslanian, A.; Teichmann, M.; Roeder, R.G.; Bungert, J. Characterization of the human β-globin downstream promoter region. Nucleic Acids Res. 2003, 31, 1292–1301. [Google Scholar] [CrossRef] [PubMed]
- Juven-Gershon, T.; Hsu, J.Y.; Theisen, J.W.; Kadonaga, J.T. The RNA Polymerase II Core Promoter—The Gateway to Transcription. Curr. Opin. Cell Biol. 2008, 20, 253–259. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, T.; Cohet, N.; Morlé, F.; Biekera, J.J. Distinct modes of gene regulation by a cell-specific transcriptional activator. Proc. Natl. Acad. Sci. USA 2009, 106, 4213–4218. [Google Scholar] [CrossRef] [PubMed]
- Hoeksma, J. NHS cyberattack may prove to be a valuable wake up call. Br. Med. J. 2017. [Google Scholar] [CrossRef] [PubMed]
- Finklea, K.; Christensen, M.D.; Fischer, E.A.; Lawrence, S.V.; Theohary, C.A. Cyber Intrusion into US Office of Personnel Management: In Brief; Library of Congress: Washington, DC, USA, 2015. [Google Scholar]
- Symantec Security Center Threat Report. Available online: https://www.symantec.com/security-center/threat-report (accessed on 3 November 2017).
- Mittal, P.; Singh, N. Speech Based Command and Control System for Mobile Phones: Issues and Challenges. In Proceedings of the Second International Conference on Computational Intelligence & Communication Technology (CICT), Changsha, China, 13–15 October 2017; pp. 729–732. [Google Scholar]
- Alshamsi, H.; Meng, H.; Li, M. Real time facial expression recognition app development on mobile phones. In Proceedings of the 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 October 2017; pp. 1750–1755. [Google Scholar]
- Prasad, M.V.; Anugu, J.R.; Rao, C.R. Fingerprint template protection using multiple spiral curves. In Smart Innovation, Systems and Technologies; Springer: New Delhi, India, 2015; pp. 593–601. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encryption Level | Input | Ouptut | Decryption Level | Input | Output |
|---|---|---|---|---|---|
| - | Plaintext | DNA text | 3C | Cipherprotein | c-mRNA |
| 1 | DNA text | Ciphergene | 3B | c-mRNA | BTC |
| 2 | Ciphergene | PTC | 3A | BTC | PTC |
| 3A | PTC | BTC | 2 | PTC | Ciphergene |
| 3B | BTC | c-mRNA | 1 | Ciphergene | DNA text |
| 3C | c-mRNA | Cipherprotein | - | DNA test | Plaintext |
| Event |
|---|
| TFIIA∩BRE |
| TFIIA∩TATA |
| TFIIB∩BRE |
| TFIIB∩TATA |
| TFIIE∩INR |
| TFIIE∩MTE |
| TFIIF∩TATA |
| TFIIF∩INR |
| TFIID∩BRE |
| TFIID∩TATA |
| TFIID∩INR |
| TFIID∩MTE |
| TFIID∩DPE |
| TFIIH∩MTE |
| TFIIH∩DPE |
| TFIID∩TFIIA∩TATA |
| TFIIE∩TFIIF∩TFIIH |
| tf | 0 | 1 | 2 | 4 | 5 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|
| g | 0.1 | 0.1 | 0.2 | 0.2 | 0.1 | 0.1 | 0.2 | |
| 1 | 0.2 | 0.02 | 0.14 | 0.04 | 0 | 0 | 0 | 0 |
| 2 | 0.4 | 0 | 0 | 0.28 | 0.08 | 0.04 | 0 | 0 |
| 3 | 0.1 | 0 | 0 | 0.07 | 0.02 | 0.01 | 0 | 0 |
| 4 | 0.1 | 0 | 0 | 0 | 0.08 | 0.01 | 0.01 | 0 |
| 5 | 0.2 | 0 | 0 | 0 | 0 | 0.14 | 0.02 | 0.04 |
| Ω: i = {1, 2, 3, 4, 5} || j = {0, 1, 2, 4, 5, 8, 9} | Pij | Tuples of s in Type Ω | Tuples of T in Type Ω Using Sinh and Cosh Functions |
|---|---|---|---|
| 1, 0 | 0.02 | 3, 3 | 1001 |
| 1, 1 | 0.14 | 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7 | 54,831,612,327,324 |
| 1, 2 | 0.04 | 5, 5, 5, 5 | 74,203 |
| 2, 2 | 0.28 | 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2 | 3,626,860,407,847,212,927,945,509,482 |
| 2, 4 | 0.08 | 1, 1, 1, 1, 1, 1, 1, 1 | 15,430,806 |
| 2, 5 | 0.04 | 4, 4, 4, 4 | 27,308 |
| 3, 2 | 0.07 | 9, 9, 9, 9, 9, 9, 9 | 4,051,542 |
| 3, 4 | 0.02 | 89, 89 | 2244 |
| 3, 5 | 0.01 | 64 | 311 |
| 4, 4 | 0.08 | 81, 81, 81, 81, 81, 81, 81, 81 | 75,304,865 |
| 4, 5 | 0.01 | 826 | 372 |
| 4, 8 | 0.01 | 837 | 112 |
| 5, 5 | 0.14 | 62, 62, 62, 62, 62, 62, 62, 62, 62, 62, 62, 62, 62, 62 | 78,334,370,730,000 |
| 5, 8 | 0.02 | 69, 69 | 4626 |
| 5, 9 | 0.04 | 68, 68, 68, 68 | 17,021 |
| β-Globin | A T G G T G C A T | |
|---|---|---|
| Message | C C T A C T A G T | |
| ntj | 1 4 2 2 4 2 3 1 4 | |
| Mj | 3 3 4 1 3 4 1 2 4 | |
| AddendCode | 2 3 2 3 3 2 2 1 4 | |
| Message | 3 3 4 1 3 4 1 2 4 |
| Coding Element | Sequence | Absolute Position | Type |
|---|---|---|---|
| Non Coding 1 | GCAGGAGCCAGGGCTGGG | 1–18 | NC |
| TATA box | CATAAA | 19–24 | CP |
| Non Coding 2 | AGTCAGGGCAGAGCCATCTATTGCTTA | 25–51 | NC |
| +20E to box | CAACTG | 52–57 | CP |
| Non Coding 3 | CTTCTGACACAACTGT | 58–73 | NC |
| MARE box | GTTCACTAGCA | 74–84 | CP |
| Non Coding 4 | ACCTCAAACAGACACC | 85–100 | NC |
| Protein Coding 1 | ATGGTGCATCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGCAAGGTGAACGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAG | 101–192 | PC |
| Intron 1 | GTTGGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAAACTGGGCATGTGGAGACAGAGAAGACTCTTGGGTTTCTGATAGGCACTGACTCTCTCTGCCTATTGGTCTATTTTCCCACCCTTAG | 193–322 | IN |
| Protein Coding 2 | GCTGCTGGTGGTCTACCCTTGGACCCAGAGGTTCTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCCTAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCTGGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGTGAGCTGCACTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGG | 323–545 | PC |
| Intron 2 | GTGAGTCTATGGGACGCTTGATGTTTTCTTTCCCCTTCTTTTCTATGGTTAAGTTCATGTCATAGGAAGGGGATAAGTAACAGGGTACAGTTTAGAATGGGAAACAGACGAATGATTGCATCAGTGTGGAAGTCTCAGGATCGTTTTAGTTTCTTTTATTTGCTGTTCATAACAATTGTTTTCTTTTGTTTAATTCTTGCTTTCTTTTTTTTTCTTCTCCGCAATTTTTACTATTATACTTAATGCCTTAACATTGTGTATAACAAAAGGAAATATCTCTGAGATACATTAAGTAACTTAAAAAAAAACTTTACACAGTCTGCCTAGTACATTACTATTTGGAATATATGTGTGCTTATTTGCATATTCATAATCTCCCTACTTTATTTTCTTTTATTTTTAATTGATACATAATCATTATACATATTTATGGGTTAAAGTGTAATGTTTTAATATGTGTACACATATTGACCAAATCAGGGTAATTTTGCATTTGTAATTTTAAAAAATGCTTTCTTCTTTTAATATACTTTTTTGTTT
ATCTTATTTCTAATACTTTCCCTAATCTCTTTCTTTCAGGGCAATAATGATACAATGTATCATGCCTCTTTGCACCATTCTAAAGAATAACAGTGATAATTTCTGGGTTAAGGCAATAGCAATATCTCTGCATATAAATATTTCTGCATATAAATTGTAACTGATGTAAGAGGTTTCATATTGCTAATAGCAGCTACAATCCAGCTACCATTCTGCTTTTATTTTATGGTTGGGATAAGGCTGGATTATTCTGAGTCCAAGCTAGGCCCTTTTGCTAATCATGTTCATACCTCTTATCTTCCTCCCACAG | 546–1395 | IN |
| Protein Coding 3 | CTCCTGGGCAACGTGCTGGTCTGTGTGCTGGCCCATCACTTTGGCAAAGAATTCACCCCACCAGTGCAGGCTGCCTATCAGAAAGTGGTGGCTGGTGTGGCTAATGCCCTGGCCCACAAGTATCACTAA | 1396–1524 | PC |
| Non Coding 7 | GCTCGCTTTCTTGCTGTCCAATTTCTATTAAAGGTTCCTTTGTTCCCTAAGTCCAACTACTAAACTGGGGGATATTATGAAGGGCCTTGAGCATCTGGATTCTGCCTAATAAAAAACATTTATTTTCATTGCAA | 1525–1628 | NC |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaw, H. A Cryptographic System Based upon the Principles of Gene Expression. Cryptography 2017, 1, 21. https://doi.org/10.3390/cryptography1030021
Shaw H. A Cryptographic System Based upon the Principles of Gene Expression. Cryptography. 2017; 1(3):21. https://doi.org/10.3390/cryptography1030021
Chicago/Turabian StyleShaw, Harry. 2017. "A Cryptographic System Based upon the Principles of Gene Expression" Cryptography 1, no. 3: 21. https://doi.org/10.3390/cryptography1030021
APA StyleShaw, H. (2017). A Cryptographic System Based upon the Principles of Gene Expression. Cryptography, 1(3), 21. https://doi.org/10.3390/cryptography1030021