Approximate and Situated Causality in Deep Learning


{kind=link}
{kind=link}
Abstract
1. Causalities in the 21st Century
2. Deep Learning, Counterfactuals, and Causality
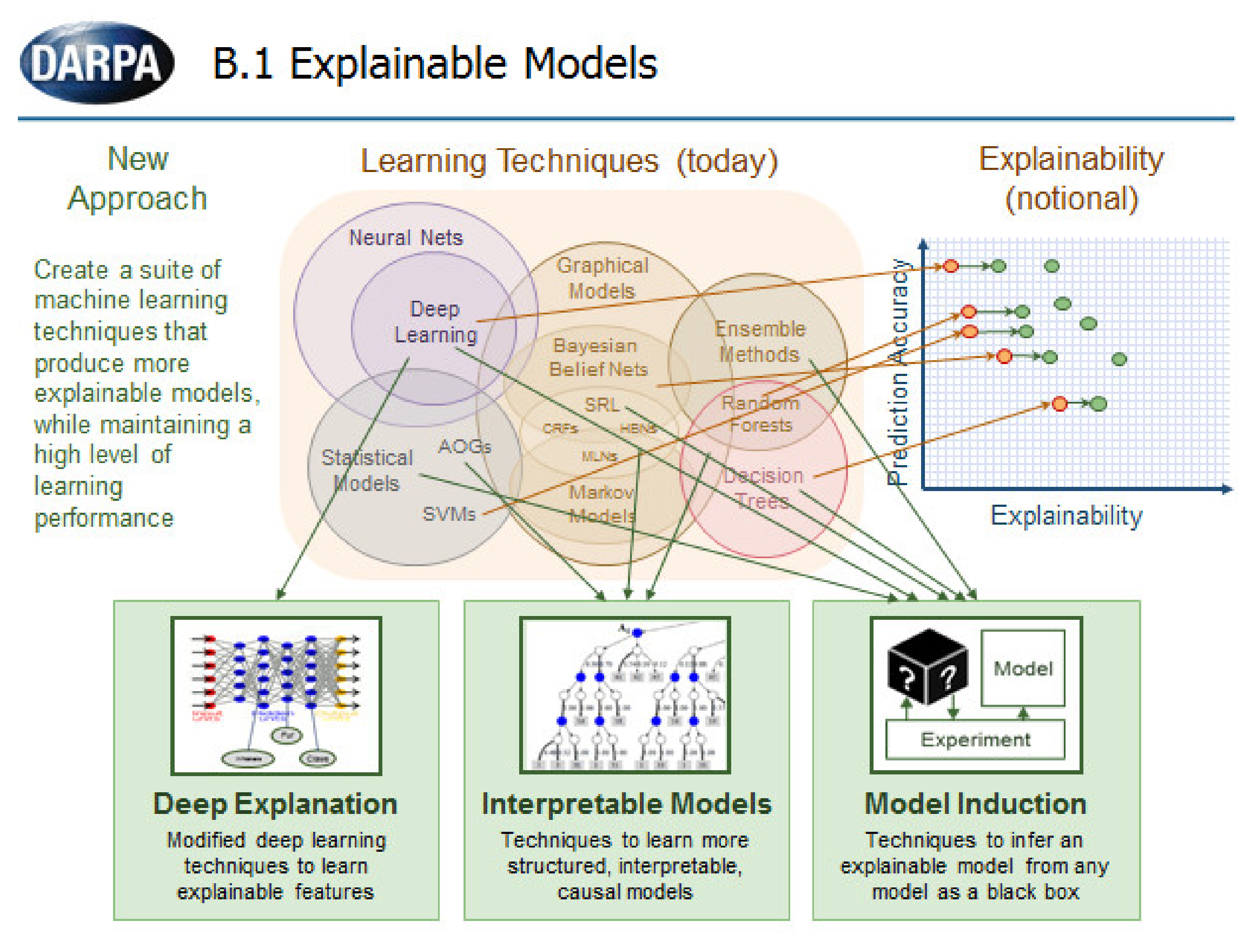
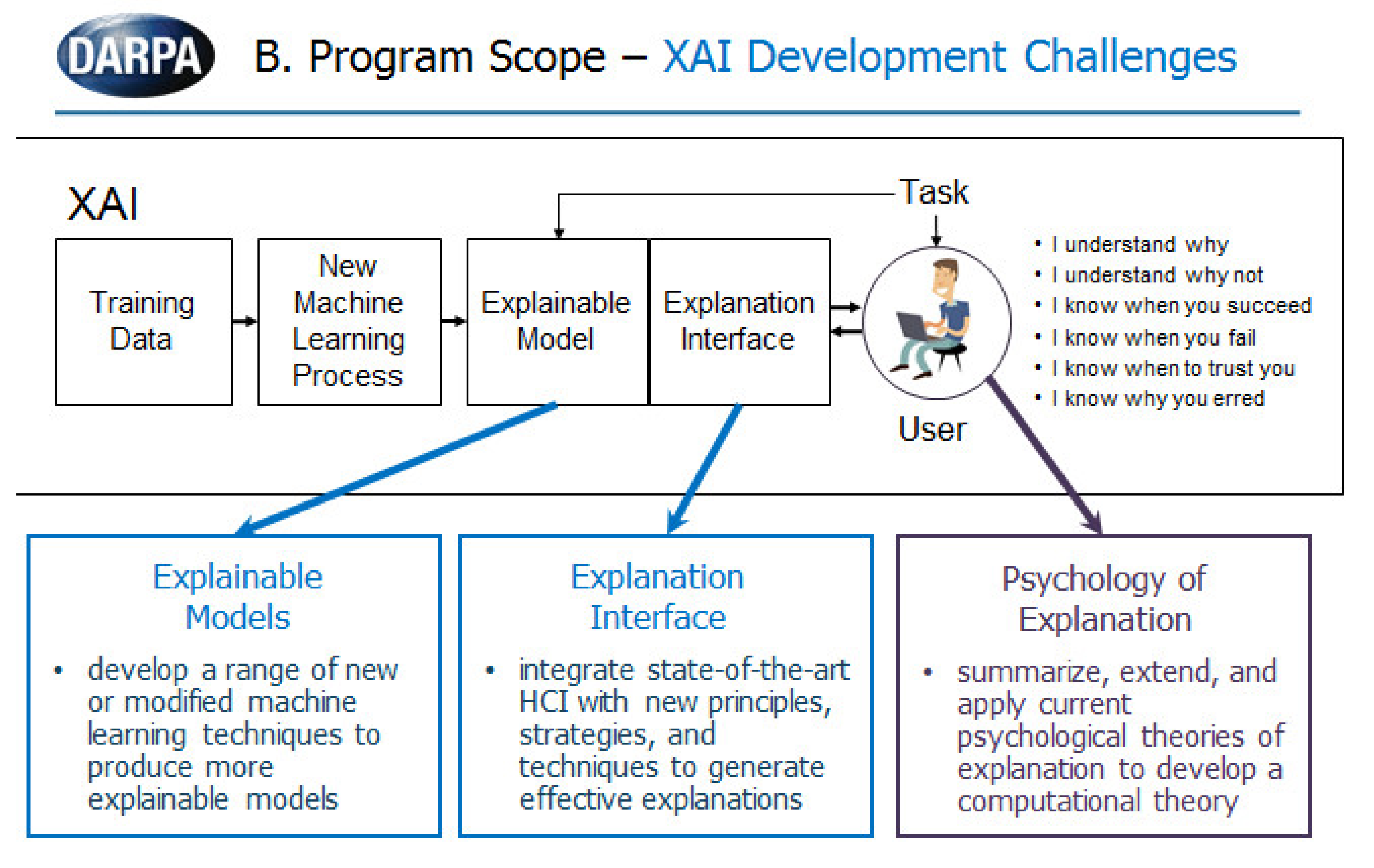
2.1. Deep Learning is not a Data-Driven but a Context-Driven Technology: Made by Humans for Humans
New Reasoning and DL
2.2. Deep Learning is Already Running Counterfactual Approaches
2.3. DL is not Magic Algorithmic Thinking (MAT)
2.4. DL Affects Scientific Thinking
2.5. Recent Attempts to Obtain Causal Patterns in DL
3. Extending Bad and/or Good Human Cognitive Skills Through DL
4. Causality in DL: The Epidemiological Case Study
4.1. Does Causality Affect Epidemiological Debates At All?
4.2. Can DL Be of Some Utility for the Epidemiological Debates on Causality?
5. Conclusions: Causal Evidence is not a Result, But a Process
Funding
Acknowledgments
Conflicts of Interest
References
- Heisig, J.W. Philosophers of Nothingness: An Essay on the Kyoto School; University of Hawai’i Press: Honolulu, HI, USA, 2001. [Google Scholar]
- Vallverdú, J. The Situated Nature of Informational Ontologies. In Theoretical Information Studies; World Scientific: Singapore, 2019; pp. 353–365. [Google Scholar]
- Schroeder, M.J.; Vallverdú, J. Situated phenomenology and biological systems: Eastern and Western synthesis. Prog. Biophys. Mol. Boil. 2015, 119, 530–537. [Google Scholar] [CrossRef] [PubMed]
- Vallverdú, J.; Schroeder, M.J. Lessons from culturally contrasted alternative methods of inquiry and styles of comprehension for the new foundations in the study of life. Prog. Biophys. Mol. Boil. 2017, 131, 463–468. [Google Scholar] [CrossRef] [PubMed]
- Vallverdú, J. Bayesians Versus Frequentists: A Philosophical Debate on Statistical Reasoning; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Pearl, J. Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution. arXiv 2018, arXiv:1801.04016. [Google Scholar]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018. [Google Scholar]
- Gagliardi, F. The Necessity of Machine Learning and Epistemology in the Development of Categorization Theories: A Case Study in Prototype-Exemplar Debate. Comput. Vis. 2009, 5883, 182–191. [Google Scholar]
- Everitt, T.; Kumar, R.; Krakovna, V.; Legg, S. Modeling AGI Safety Frameworks with Causal Influence Diagrams. arXiv 2019, arXiv:1906.08663. [Google Scholar]
- Gal, Y. Uncertainty in Deep Learning. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2017. [Google Scholar]
- Kendall, A.G. Basic Books Geometry and Uncertainty in Deep Learning for Computer Vision; University of Cambridge: Cambridge, UK, 2017. [Google Scholar]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? arXiv 2017, arXiv:1703.04977. [Google Scholar]
- Piironen, J.; Vehtari, A. Comparison of Bayesian predictive methods for model selection. Stat. Comput. 2017, 27, 711–735. [Google Scholar] [CrossRef]
- Polson, N.G.; Sokolov, V. Deep Learning: A Bayesian Perspective. Bayesian Anal. 2017, 12, 1275–1304. [Google Scholar] [CrossRef]
- Bengio, Y.; Lecun, Y. Scaling Learning Algorithms Towards AI To Appear in “Large-Scale Kernel Machines”; George Mason University: Fairfax, VA, USA, 2017. [Google Scholar]
- Cunningham, J.P.; Yu, B.M. Dimensionality reduction for large-scale neural recordings. Nat. Neurosci. 2014, 17, 1500–1509. [Google Scholar] [CrossRef]
- Bengio, Y.; Bengio, S. Taking on the curse of dimensionality in joint distributions using neural networks. IEEE Trans. Neural Netw. 2000, 11, 550–557. [Google Scholar] [CrossRef]
- Ben-David, S.; Hrubeš, P.; Moran, S.; Shpilka, A.; Yehudayoff, A. Learnability can be undecidable. Nat. Mach. Intell. 2019, 1, 44–48. [Google Scholar] [CrossRef]
- Anagnostopoulos, C.; Ntarladimas, Y.; Hadjiefthymiades, S. Situational computing: An innovative architecture with imprecise reasoning. J. Syst. Softw. 2007, 80, 1993–2014. [Google Scholar] [CrossRef]
- Raghavan, S.; Mooney, R.J. Bayesian Abductive Logic Programs. 2010. Available online: https://www.ijcai.org/Proceedings/11/Papers/492.pdf (accessed on 6 February 2020).
- Bergadano, F.; Cutello, V.; Gunetti, D. Abduction in Machine Learning. In Abductive Reasoning and Learning; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2000; pp. 197–229. [Google Scholar]
- Bergadano, F.; Besnard, P. Abduction and Induction Based on Non-Monotonic Reasoning; Springer Science and Business Medi: Berlin/Heidelberg, Germany, 1995; pp. 105–118. [Google Scholar]
- Mooney, R.J. Integrating Abduction and Induction in Machine Learning; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Vapnik, V.; Izmailov, R. Rethinking statistical learning theory: Learning using statistical invariants. Mach. Learn. 2019, 108, 381–423. [Google Scholar] [CrossRef]
- Vapnik, V.; Vashist, A. A new learning paradigm: Learning using privileged information. Neural Netw. 2009, 22, 544–557. [Google Scholar] [CrossRef] [PubMed]
- Vladimir, V. Transductive Inference and Semi-Supervised Learning; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Mao, J.; Gan, C.; Kohli, P.; Tenenbaum, J.B.; Wu, J. The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision. arXiv 2019, arXiv:1904.12584. [Google Scholar]
- Pearl, J. The algorithmization of counterfactuals. Ann. Math. Artif. Intell. 2011, 61, 29–39. [Google Scholar] [CrossRef]
- Lewis, D. Counterfactual Dependence and Time’s Arrow. Noûs 2006, 13, 455–476. [Google Scholar] [CrossRef]
- Ramachandran, M. A counterfactual analysis of causation. Mind 2004, 106, 263–277. [Google Scholar] [CrossRef]
- Vallverdú, J. Blended Cognition: The Robotic Challenge; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2019; pp. 3–21. [Google Scholar]
- Rzhetsky, A. The Big Mechanism program: Changing how science is done. In Proceedings of the XVIII International Conference Data Analytics and Management in Data Intensive Domains (DAMDID/RCDL’2016), Ershovo, Russia, 11–14 October 2016. [Google Scholar]
- Gunning, D.; Aha, D.W. DARPA’s Explainable Artificial Intelligence (XAI) Program. 2019. Available online: https://doi.org/10.1609/aimag.v40i2.2850 (accessed on 6 February 2020).
- Casacuberta, D.; Vallverdú, J. E-science and the data deluge. Philos. Psychol. 2014, 27, 126–140. [Google Scholar] [CrossRef]
- Calude, C.S.; Longo, G. The Deluge of Spurious Correlations in Big Data. Found. Sci. 2017, 22, 595–612. [Google Scholar] [CrossRef]
- Zenil, H.; Kiani, N.A.; Zea, A.A.; Tegnér, J. Causal deconvolution by algorithmic generative models. Nat. Mach. Intell. 2019, 1, 58–66. [Google Scholar] [CrossRef]
- Zenil, H.; Kiani, N.A.; Marabita, F.; Deng, Y.; Elias, S.; Schmidt, A.; Ball, G.; Tegnér, J. An Algorithmic Information Calculus for Causal Discovery and Reprogramming Systems. iScience 2019, 19, 1160–1172. [Google Scholar] [CrossRef] [PubMed]
- Gustafsson, C.; Vallverdú, J. The Best Model of a Cat Is Several Cats. Trends Biotechnol. 2015, 34, 207–213. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, A.; Khan, R.; Karayannis, T. Developing a brain atlas through deep learning. Nat. Mach. Intell. 2019, 1, 277–287. [Google Scholar] [CrossRef]
- Bourgin, D.D.; Peterson, J.C.; Reichman, D.; Griffiths, T.L.; Russell, S.J. Cognitive Model Priors for Predicting Human Decisions. arXiv 2019, arXiv:1905.09397. [Google Scholar]
- Vallverdu, J. Re-embodying cognition with the same ‘biases’? Int. J. Eng. Future Technol. 2018, 15, 23–31. [Google Scholar]
- Leukhin, A.; Talanov, M.; Vallverdú, J.; Gafarov, F. Bio-plausible simulation of three monoamine systems to replicate emotional phenomena in a machine. Biol. Inspired Cogn. Archit. 2018, 26, 166–173. [Google Scholar]
- Vallverdú, J.; Talanov, M.; Distefano, S.; Mazzara, M.; Tchitchigin, A.; Nurgaliev, I. A cognitive architecture for the implementation of emotions in computing systems. Boil. Inspired Cogn. Arch. 2016, 15, 34–40. [Google Scholar] [CrossRef]
- Taniguchi, H.; Sato, H.; Shirakawa, T. A machine learning model with human cognitive biases capable of learning from small and biased datasets. Sci. Rep. 2018, 8, 7397. [Google Scholar] [CrossRef]
- Lake, B.M.; Salakhutdinov, R.R.; Tenenbaum, J.B. One-shot learning by inverting a compositional causal process. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Gianfrancesco, M.A.; Tamang, S.; Yazdany, J.; Schmajuk, G. Potential Biases in Machine Learning Algorithms Using Electronic Health Record Data. JAMA Intern. Med. 2018, 178, 1544–1547. [Google Scholar] [CrossRef]
- Kliegr, T.; Bahník, Š.; Fürnkranz, J. A review of possible effects of cognitive biases on interpretation of rule-based machine learning models. arXiv 2018, arXiv:1804.02969. [Google Scholar]
- Narendra, T.; Sankaran, A.; Vijaykeerthy, D.; Mani, S. Explaining Deep Learning Models using Causal Inference. arXiv 2018, arXiv:1811.04376. [Google Scholar]
- Nauta, M.; Bucur, D.; Seifert, C.; Nauta, M.; Bucur, D.; Seifert, C. Causal Discovery with Attention-Based Convolutional Neural Networks. Mach. Learn. Knowl. Extr. 2019, 1, 312. [Google Scholar] [CrossRef]
- Ahrens, W.; Pigeot, I. Handbook of Epidemiology, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Vandenbroucke, J.P.; Broadbent, A.; Pearce, N. Causality and causal inference in epidemiology: The need for a pluralistic approach. Int. J. Epidemiol. 2016, 45, 1776–1786. [Google Scholar] [CrossRef]
- Susser, M. Causal Thinking in the Health Sciences Concepts and Strategies of Epidemiology; Oxford University Press: Oxford, UK, 1973. [Google Scholar]
- Susser, M.; Susser, E. Choosing a future for epidemiology: II. From black box to Chinese boxes and eco-epidemiology. Am. J. Public Health 1996, 86, 674–677. [Google Scholar] [CrossRef]
- Krieger, N. Epidemiology and the web of causation: Has anyone seen the spider? Soc. Sci. Med. 1994, 39, 887–903. [Google Scholar] [CrossRef]
- Buck, C. Popper’s philosophy for epidemiologists. Int. J. Epidemiol. 1975, 4, 159–168. [Google Scholar] [CrossRef]
- Gillies, D. Judea Pearl Causality: Models, Reasoning, and Inference; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Tucci, R.R. Introduction to Judea Pearl’s Do-Calculus. arXiv 2013, arXiv:1305.5506. [Google Scholar]
- Greenland, S.; Pearl, J.; Robins, J.M. Causal diagrams for epidemiologic research. Epidemiology 1999, 10, 37–48. [Google Scholar] [CrossRef]
- VanderWeele, T.J.; Robins, J.M. Directed Acyclic Graphs, Sufficient Causes, and the Properties of Conditioning on a Common Effect. Am. J. Epidemiol. 2007, 166, 1096–1104. [Google Scholar] [CrossRef]
- Ioannidis, J.P. Randomized controlled trials: Often flawed, mostly useless, clearly indispensable: A commentary on Deaton and Cartwright. Soc. Sci. Med. 2018, 210, 53–56. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A. The Proposal to Lower P Value Thresholds to.005. JAMA 2018, 319, 1429–1430. [Google Scholar] [CrossRef] [PubMed]
- Krauss, A. Why all randomised controlled trials produce biased results. Ann. Med. 2018, 50, 312–322. [Google Scholar] [CrossRef] [PubMed]
- Shrier, I.; Platt, R.W. Reducing bias through directed acyclic graphs. BMC Med Res. Methodol. 2008, 8, 70. [Google Scholar] [CrossRef]
- Doll, R.; Hill, A.B. Smoking and Carcinoma of the Lung. BMJ 1950, 2, 739–748. [Google Scholar] [CrossRef]
- Fisher, R.A. Lung Cancer and Cigarettes? Nature 1958, 182, 108. [Google Scholar] [CrossRef]
- Bellinger, C.; Jabbar, M.S.M.; Zaïane, O.; Osornio-Vargas, A. A systematic review of data mining and machine learning for air pollution epidemiology. BMC Public Health 2017, 17, 907. [Google Scholar] [CrossRef]
- Weichenthal, S.; Hatzopoulou, M.; Brauer, M. A picture tells a thousand…exposures: Opportunities and challenges of deep learning image analyses in exposure science and environmental epidemiology. Environ. Int. 2019, 122, 3–10. [Google Scholar] [CrossRef]
- Kreatsoulas, C.; Subramanian, S. Machine learning in social epidemiology: Learning from experience. SSM-Popul. Health 2018, 4, 347–349. [Google Scholar] [CrossRef]
- Schölkopf, B. Causality for Machine Learning. arXiv 2019, arXiv:1911.10500v2. Available online: https://arxiv.org/abs/1911.10500 (accessed on 6 February 2020).
- Rojas-Carulla, M.; Schölkopf, B.; Turner, R.; Peters, J. Invariant models for causal transfer learning. J. Mach. Learn. Res. 2018, 19, 1309–1342. [Google Scholar]
- Drumond, T.F.; Viéville, T.; Alexandre, F. Bio-inspired Analysis of Deep Learning on Not-So-Big Data Using Data-Prototypes. Front. Comput. Neurosci. 2019, 12, 100. [Google Scholar] [CrossRef] [PubMed]
- Charalampous, K.; Gasteratos, A. Bio-inspired deep learning model for object recognition. In Proceedings of the 2013 IEEE International Conference on Imaging Systems and Techniques (IST), Beijing, China, 22–23 October 2013; pp. 51–55. [Google Scholar]


© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vallverdú, J. Approximate and Situated Causality in Deep Learning. Philosophies 2020, 5, 2. https://doi.org/10.3390/philosophies5010002
Vallverdú J. Approximate and Situated Causality in Deep Learning. Philosophies. 2020; 5(1):2. https://doi.org/10.3390/philosophies5010002
Chicago/Turabian StyleVallverdú, Jordi. 2020. "Approximate and Situated Causality in Deep Learning" Philosophies 5, no. 1: 2. https://doi.org/10.3390/philosophies5010002
APA StyleVallverdú, J. (2020). Approximate and Situated Causality in Deep Learning. Philosophies, 5(1), 2. https://doi.org/10.3390/philosophies5010002