1. Introduction
Sequencing-based analysis of biological communities, also called metagenomics, is increasingly popular. One common approach is to “barcode” sequences from organisms found in a specific location. We define barcoding as the sequencing of a particular genetic locus with the intent of determining taxonomic identity, much like a barcode scanner determines items at a grocery store. When applied to a whole community, this approach is often referred to as metabarcoding. Because barcoded sequences are directly comparable (i.e., are of the same locus), an upfront percent similarity cutoff can be used with de novo clustering to generate an occurrence table that loosely corresponds to species abundances at that location. Sequences that are clustered, or binned, by similarity, are commonly called Operational Taxonomic Units (OTUs). OTUs minimize the effects of slight differences in sequences that may or may not be of interest, as a slight variation could be capturing actual differences between species. Alternatively, Amplified Sequence Variants (ASVs), sometimes called exact sequence variants, are defined as all “unique” reads within a metagenomics dataset and often do not need to be clustered [
1]. Because metagenomic data sets are prone to a variety of artifacts resulting from the PCR and sequencing processes, and naturally occurring variation may affect downstream results, additional analysis of the sensitivity of these methods to particular error types and sequence properties is needed. Within studies that do not cluster ASVs, we show that some types of error may become more prominent when compared to OTU-based studies.
Metabarcoding is currently the most cost-effective approach for environmental and biomedical taxonomic surveillance. In practice, barcodes are generated from gene regions that are sufficiently conserved to be PCR amplified across taxonomic groups, but are also variable enough to differentiate branches of the evolutionary tree [
2]. Metabarcoding enables the determination of taxonomic diversity in environmental samples where sequences often represent a large number of organisms. This approach is popular because it is often possible to assign sequence bins/clusters (such as OTUs) to any geographic area [
3,
4]. For example, a recent study used metabarcoding to infer species transfers and inter-relationships in ocean shipping lanes [
5]; another used metabarcoding across the Great Lakes to look for invasive species [
6]. Another study showed how it could used to make biodiversity assessments [
7]. Broader scale applications of metabarcoding can be used to detect seasonal and temporal patterns important for ecosystem restoration and analysis [
8,
9,
10]. We should note that observed differences can result from both large taxonomic differences and from more slight changes that occur between co-occurring related species in an environment [
11,
12].
Metabarcode analysis often consists of generating sample-to-sample similarities in a pair-wise distance matrix, which can then be processed using either hierarchical clustering [
13] or a PERMANOVA statistical analysis [
14,
15]. Although ASV and OTU analysis have been compared [
1,
16], to the best of our knowledge no one has looked at the potential effects that data generation of barcode sequences, or their processing from environment to sequencer, have on downstream analysis. Here, we build on previous work presented at the IEEE International Conference on Bioinformatics and Biomedicine in 2018 [
17] and evaluate three distinct methods. We created simulated data that incorporate variables that affect real metabarcode analysis: size of conserved regions, which may help fuse closely related clusters; sample depth/coverage, which help detect rare species; and polymorphisms among species that affect all methods. The properties studied are sequencing platform unspecific. As a concrete example, single base-pair errors can be introduced by sequencers [
18,
19]. By using simulations, we can consider each potential effect independently, and therefore comprehensively test properties that affect environmental metabarcoding analysis.
While we test five different sequence properties, we also analyze three different bioinformatics analysis methods used in metabarcoding. The computing of the ASV method is done using the DADA2 package [
20]. The OTUs are created with the QIIME package [
3]. The k-mer/minhash method, referred to as the k-mer method, is computed using mash [
21]. Because ASVs are determined after sequence trimming and filtering, the prevailing dogma is that the preprocessing will result in observing only the true sequence diversity [
16]. In contrast, OTU analysis groups roughly similar sequences together, thus trading some possible species/sequence diversity for higher quality [
1]. Lastly, we compare OTUs and ASVs to an alignment-free based method, and specifically to a sparse, random selection-based approach that estimates similarities between samples (k-mer). Although alignment-free methods are not currently utilized in barcoding, they make for an interesting alternative for future studies due to their speed [
21].
We show using simulations that the presence of Single Nucleotide Polymorphisms (SNPs) and the number of sequences obtained from each species have effects on the analysis, and that these properties affect the processing methods differently. We first establish that each method can recover a simple simulated structure between samples. Next, we test whether we can recover similar signals between methods from real-world data. Because we are unable to obtain similar results, we then simulate samples with and without common real-world properties to look at variations between the bioinformatics methods considered here. Lastly, we utilize knowledge gained from our initial results in a hybrid approach to better understand how each method would respond to data with a high number of sequence errors. Our results demonstrate that when there is a high number of errors, methods utilizing OTUs or k-mers outperform ASVs.
2. Methods
We set up four analyses: a simplified recovery analysis to reveal a simulated community structure; three runs of real-world data analysis; a large number of simulated data runs; and a hybrid approach where SNP errors are injected into real data. Sequences, both simulated and real, are single ended. We process all of these data, both simulated and real, as follows: First, OTU tables are generated from the simulated samples with QIIME [
3] using the “pick_open_reference_otus.py” tool and the minimum number of sequences to create an OTU set to one; next we use the ASV method as implemented in the R package DADA2 [
20] using default settings, except real-world and hybrid methods where the expected error parameter was reduced to one and all sequences were given high Phred scores. Faked high Phred scores are used in-order to reduce the complexity of the results of the introduced properties. The R package Vegan [
14] is then used to generate pair-wise Jaccard matrices from OTU tables. Finally, we consider a sketch-based method based on the “mash” bioinformatics tool, a minhash implementation designed for fast sequence comparisons. Our “mash” analysis uses the default k-mer size of 21 and the default sketch size of 1000 [
21].
Simulated data are created with Barcode_Simulator, an in-house script that enables the creation of random DNA sequences, and subsequent species properties (see:
Supplement Script 1). The simulated sequences used in this article are modifications of a 500 bp randomized template sequence. Barcode_Simulator can be used to mutate generated sequences to create phylogenetically related sets, change depth of coverage, sequence length, length of conserved regions, and through the use of Run_Simulation.sh, sequence abundance (see:
Supplement Script 2). Run_Simulation.sh is a script which takes advantage of the features of Barcode_Simulator to build datasets, which are effectively sets of samples, or sets of sequencing files (see:
Supplement Data 1). The simulation pipeline generates a set of sequences that represents a number of different “species”. Each “species” is made up of a number of slightly different sequences, depending on the desired properties.
In our downstream statistical analysis, we make extensive use of the Mantel test [
22] to find correlations between distance matrices among samples and among environments [
23]. The Mantel test provides a robust statistical tool for multivariate analysis [
24]. Our distances matrices are calculated with Jaccard’s distance, so as to not confound how our tested properties could be affecting our results with abundance [
25]. We also employ Permutational Multivariate Analysis of Variance (PERMANOVA), which like the more common ANOVA, is used to test whether any coefficient, or mixed coefficient, is a source of variation [
15]. We utilize PERMANOVAs when looking for multivariate effects on the differences between samples within real and simulated data sets.
2.1. Simulated Community Generation
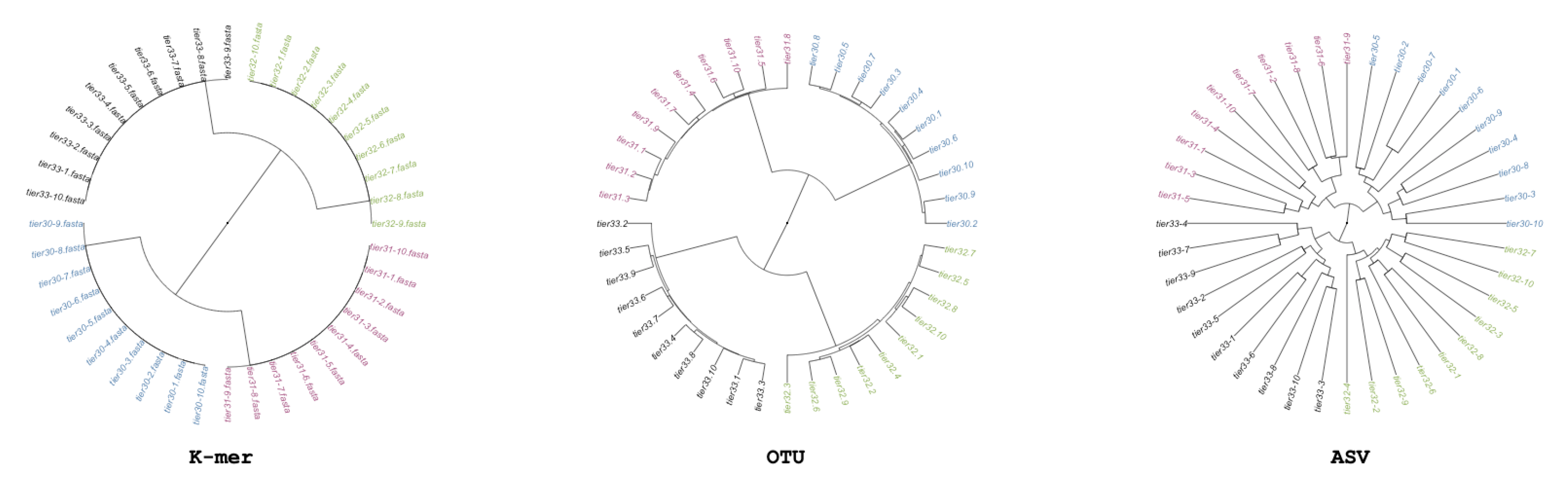
We generate simulated community samples as a simple basis for assessing metabarcode-based analysis. We generate these community samples in order to establish that each of the three methods being tested can return the same structure. We generate a single simulated dataset, in which we control the relation of samples so that there is an explicit phylogenetic structure (i.e., some samples are more similar than others). We create 40 samples each containing generalized Next Gen Sequencing (NGS)-like sequences covering 10 unique sequences from a singular pool; next we split the 40 samples into two sets of 20 each receiving an additional 453 sequences from their own pool of 10 sequences; and lastly, both groups of 20 are again split to 10, and each of the four groups receives an additional 453 sequences from their own group of 10 unique sequences. There are 1360 sequences per sample, because samples were generated by randomly picking sequences from the possible sequences at that split; there are only 30 possible different sequences per-group. This simulation scheme produces a quadripartite dendrogram shown in
Figure 1.
2.2. Real-World Community Data
We also considered previously published 16S-based microbiome datasets derived from baboons from the Amboseli national park in Kenya [
26], from soil samples from the Atacama desert [
27], and from pitcher plants in the Plumas National Forest in the United States [
28]. For these real datasets, the SILVA bacteria dataset was used for the reference sequences for QIIME. For the simulated datasets, the original 500 bp template sequence was added into a closed-reference database. The sequences that did not correspond to a known reference sequence in SILVA were removed prior to further analysis as a standard quality control step [
3]. This closed-referenced approach insures the best probability that chosen sequences have the lowest amounts of error. These data were then analyzed with available environmental metadata for the analysis of variance through the use of PERMANOVA.
2.3. Simulations of Metabarcode Data
The basic building blocks of our simulations are 500 bp, randomly generated sequences, which are in turn put into sequencing files, which then double as samples. By running entire pipelines multiple times on each dataset, variance resulting from the added properties can be assessed. There are 68 samples in a dataset; each sample is comprised of 136 sequences randomly drawn from a centralized pool of randomly generated sequences. The length, number of sequences, and number of samples are roughly based off of averages of OTU number from metabarcode data from the Atacama desert [
27], but are modified later to further explore properties.
Based on an analysis of the Atacama desert microbiome [
27], we further explore five specific properties that might affect metagenomic analysis. These properties included the addition of a conserved region (C), variable numbers of SNP polymorphisms (E), variation in the lengths of the sequences (L), variation in the relative abundances of sequences (A), and variation in the total number of sequences per sample (N). The conserved regions are established by the addition of a 24 bp conserved region added at the beginning of each sequence. Variation in SNPs is achieved by the inclusion of up to 10 additional SNP variations in the sequence (the random selection of 1 to 10 polymorphisms is equally likely). The lengths of the sequence recovered are varied from 350 to 500 bp, and variation in the relative abundances of “core” sequences and in the total number of sequences generated is introduced. The baseline model, as an example, selects the following properties: length (L) of all sequences set to 500; 0 SNPs (E); coverage (N) of 1360 sequences chosen from the sequence pool; equally abundant sequences (A); and no conserved sequence (C). The addition of the relative abundance property (A) means that
of the base sequences would be a high abundance category,
in a middling abundance category, and
in a low abundance category (see
Table 1 for details). Finally, the number of sequences chosen property (N) implies that the number actual sequences per simulation would vary at random between 140 to 13,600. The analysis pipeline generates a series of 68 random baseline sequences, which are then used to generate simulated samples. All sequences are chosen with equal probability. The combination of, including the absence of, all five properties, produces 32 possible sets for which each has ten simulations, resulting in 320 simulated datasets in total. All possible combinations of properties are analyzed to assess if any compound effects exist.
2.4. Simulating Errors in Real-World Data
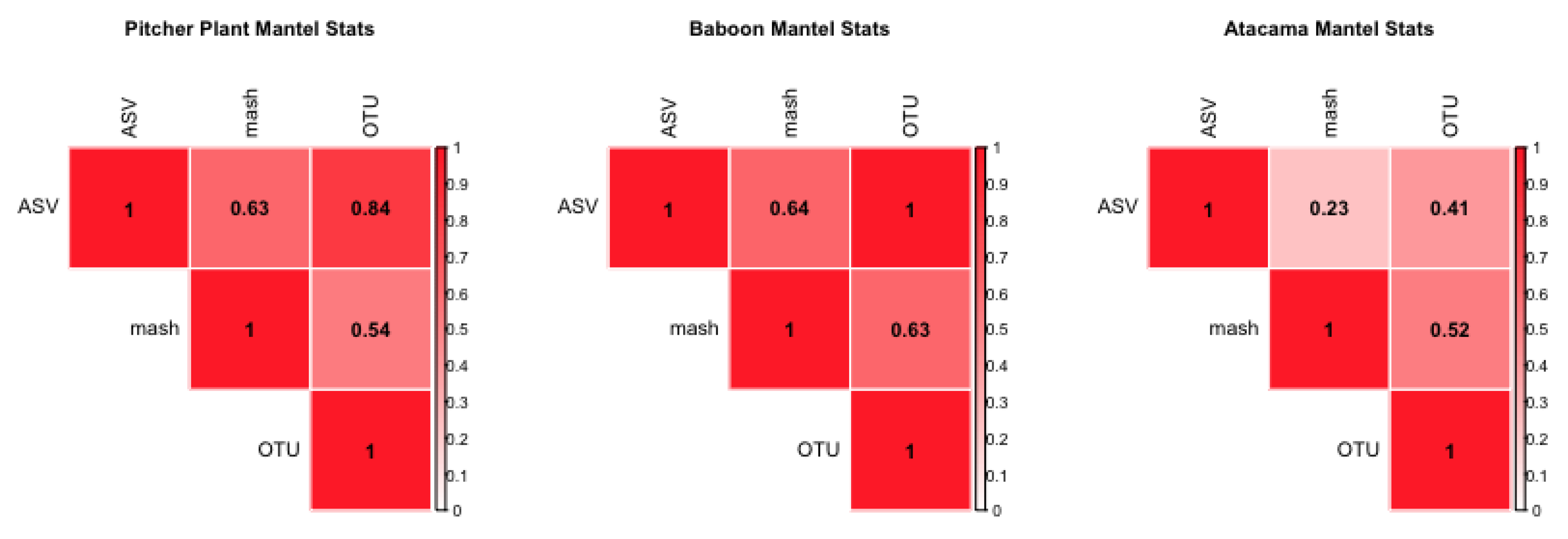
Utilizing barcoded sequences from the soil samples from the Atacama desert, a random number of SNP errors are added to each sequence in these data. The number of errors is between 1 to 10 in random positions across the sequence. This effect corresponds to the “Added Errors” property of the simulated barcode step, but on real data. Samples were processed in the same way as described for the second step; the error-added Atacama and Atacama soil desert data are correlated with a mantel statistic and PERMONVA applied to see if some analysis of variance can be retained between methods.
4. Discussion
Simulation at the sequence level is an underutilized exploratory method for determining the properties that affect downstream results in bioinformatics analysis. Environmental metadata could only partially explain the differences observed within real word datasets. More detailed analysis of real and simulated data suggest errors have a large—although slightly different depending on the bioinformatics method used—effect on metabarcode analysis. It is for this reason we can clearly see consistency and expected community structure in our initial simulation, the simplified and induced structure analysis, but not in any other comparison performed in this study.
To begin to determine properties of metabarcode data that do have effects, we performed replicate simulations in which differing coverage could cause differences between methods, especially when some species were rare and required deeper sampling to ensure recovery. This would affect OTU analysis when a Jaccard similarity metric was utilized, because the lack of a rare sequence would affect the similarity computed. Jaccard was chosen for its use in ecology, and that there some indications it would have a reduced effect from sampling error [
29]. By creating replicates of datasets with different coverage but the same properties otherwise, we are able to look at how much variation this property (coverage) can cause.
We also found that the sequence coverage property affects the variance of distance matrices across replicates and could manifest in real data when, for example, there was notable primer bias. This is expected: we used Jaccard distance throughout, and this distance metric should affect the ASV method the most, since it does not consider abundances like an alternative such as Bray–Curtis would. To partially overcome this limitation, we hypothesized that explanatory PERMANOVA linear models could help in determining relevant explanatory mixed coefficients, even though there are some simplifications within this analysis; i.e., the generated sequences that are altered to form OTU pools are completely random and we know that this is not the case in real data, as sequences often have some phylogentic relationship to each other. Still, given datasets of sufficient size, the practical differences between Bray-Curtis and Jaccard distances are minimized due to individual abundances becoming less important, and individual effects from our tested properties would be evident [
25]. The amount that those properties affected the results would vary given abundance, and the distribution of abundance [
29]. Even under simulated conditions, however, we observed a difference of at least 0.06 between computed similarities on the simulated data, on what should be null expectations. While the baseline difference in similarities is not considered significant, it does represent some bound on the precision of the simulation method we use. Significantly, these differences existed in null sets, suggesting that slight differences/induced noise complicate the downstream analysis.
The results of this paper are largely confirmatory; tools that first bin similar sequences, such as OTU methods, and methods that independently look at each sequence, such as ASV methods, are different, especially when additional errors are added. Because the k-mer based method (mash) uses random sampling, it is more resilient to minor differences between sequences. Even though k-mers that underlie minhash sketches could possibly be used to identify species [
30,
31], the implication of this analysis is that further work is required to use them instead of OTUs. However, a k-mer based or minhash could present a promising tool, and is worth further analysis to determine whether it is a viable bioinformatic tool; this paper starts that analysis. Therefore which of the three methods would actually be chosen for the bioinformatic processing of a metbarcoded dataset is dependent on the analysis desired. Although this paper does not cover any secondary analyses, such as community assembly or community function, the properties studied here would still have effects. Significantly, we show that an increase in read errors within the sequences themselves affects ASV analysis, while the use of OTUs or the k-mer based minhash method is more consistent. While there is some argument into the utility of elucidating properties of OTUs that currently seem to be less preferred than ASVs [
1,
16], it is important to remember that while ASVs may be increasingly preferred, many times these sequences are grouped into bins of sequences that are representative of different levels of taxonomy, especially for ecosystem function experiments [
32]. Binned sequences at different taxonomic levels are analogous to OTUs, and under this regime ASVs would behave like a more traditional OTU-based analysis.
Even so, in light of the differences in behavior of ASVs and OTUs, especially when considering experimental design, the dynamics of ASV and OTU properties should be accounted for in any future experiment. Special attention should be paid to sequence errors in studies that utilize ASVs in non-taxonomic groups.



{kind=link}
{kind=link}
{kind=link}


