
Verte-Box: A Novel Convolutional Neural Network for Fully Automatic Segmentation of Vertebrae in CT Image


Abstract
:1. Introduction
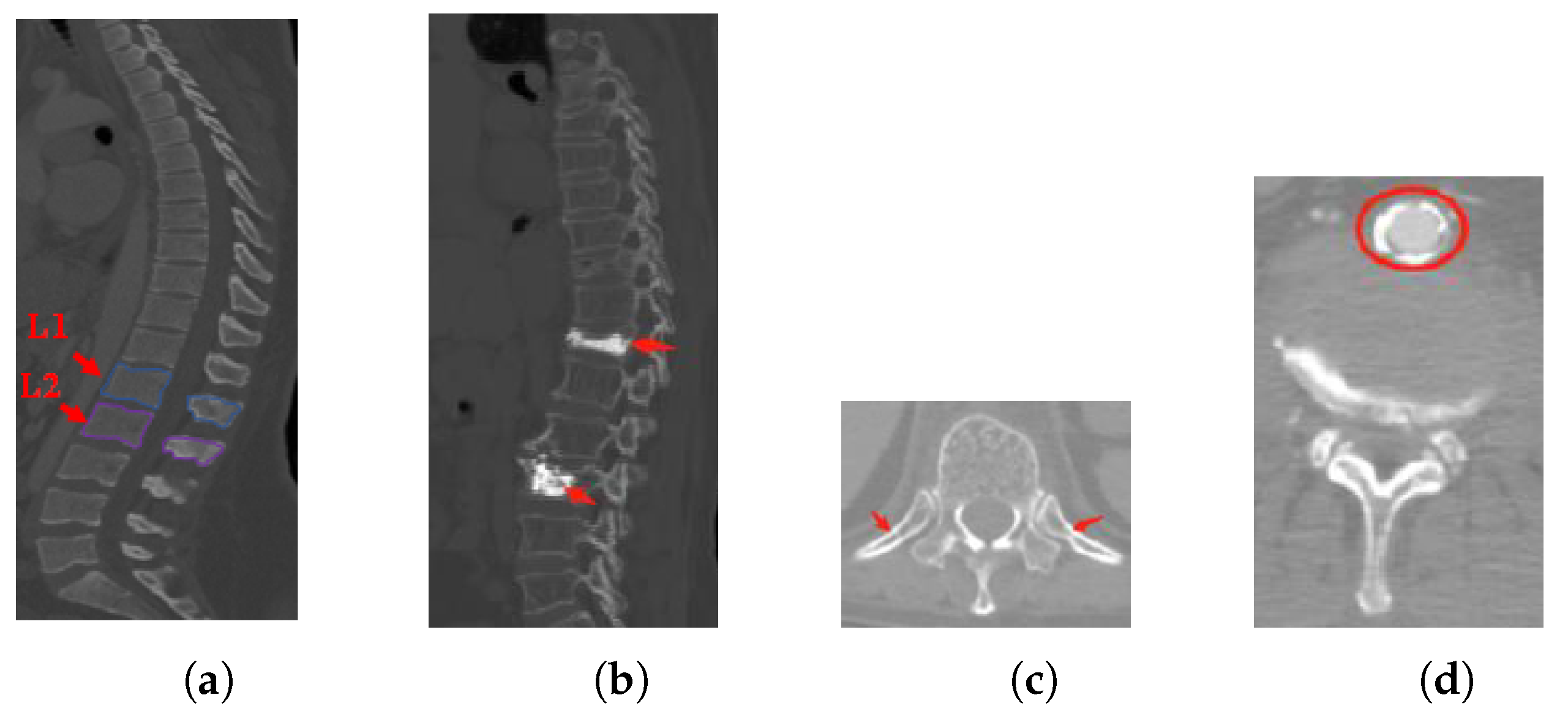
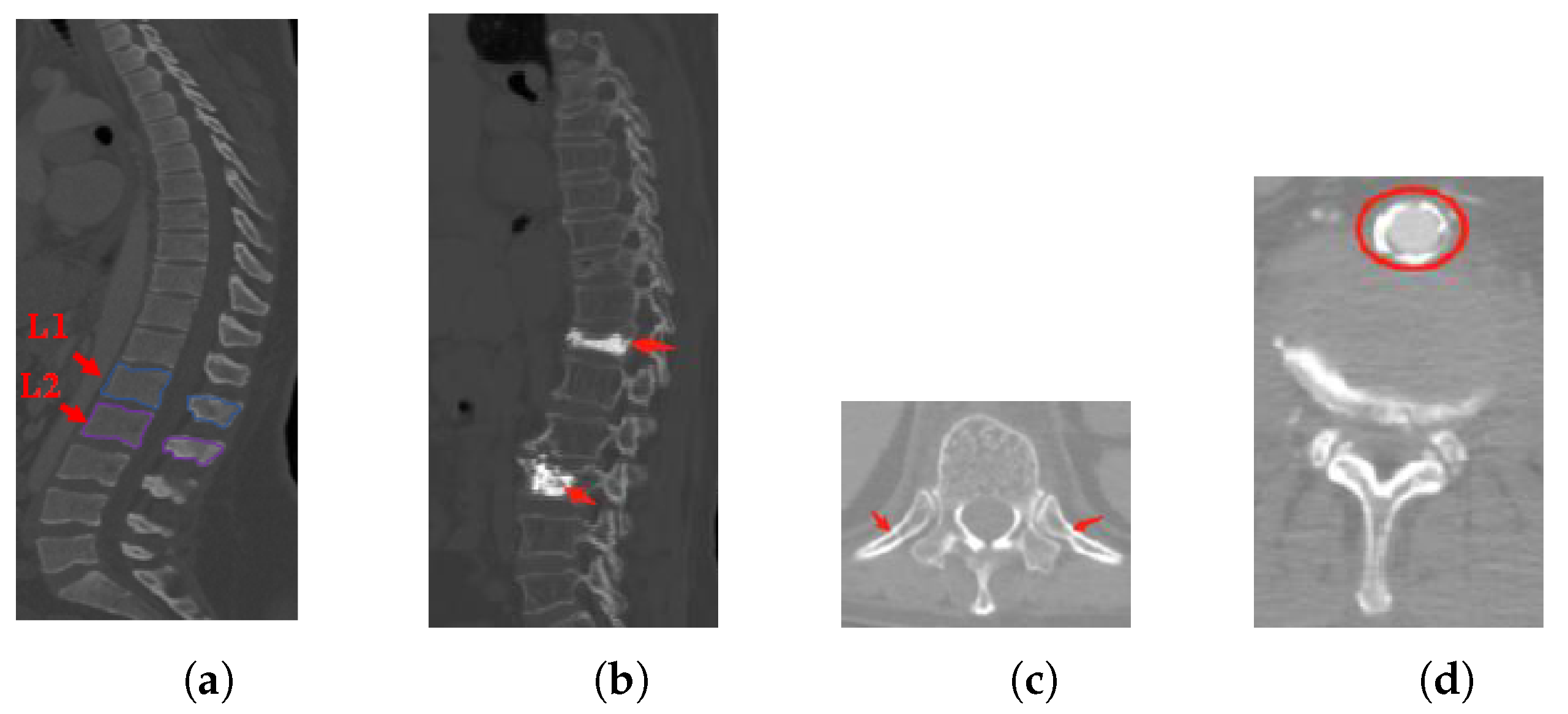
- Inter-class similarity: Shape and appearance similarities appear in the neighboring vertebrae from the sagittal view. It is difficult to distinguish the first lumbar vertebra (L1) and the second lumbar vertebra (L2) (as shown in Figure 1a);
- Unhealthy vertebrae, such as deformity or lesions (as shown in Figure 1b);
- Interference information: there are several soft tissues whose gray-scale is similar to the vertebrae area (as shown in Figure 1c,d).
2. Materials and Methods
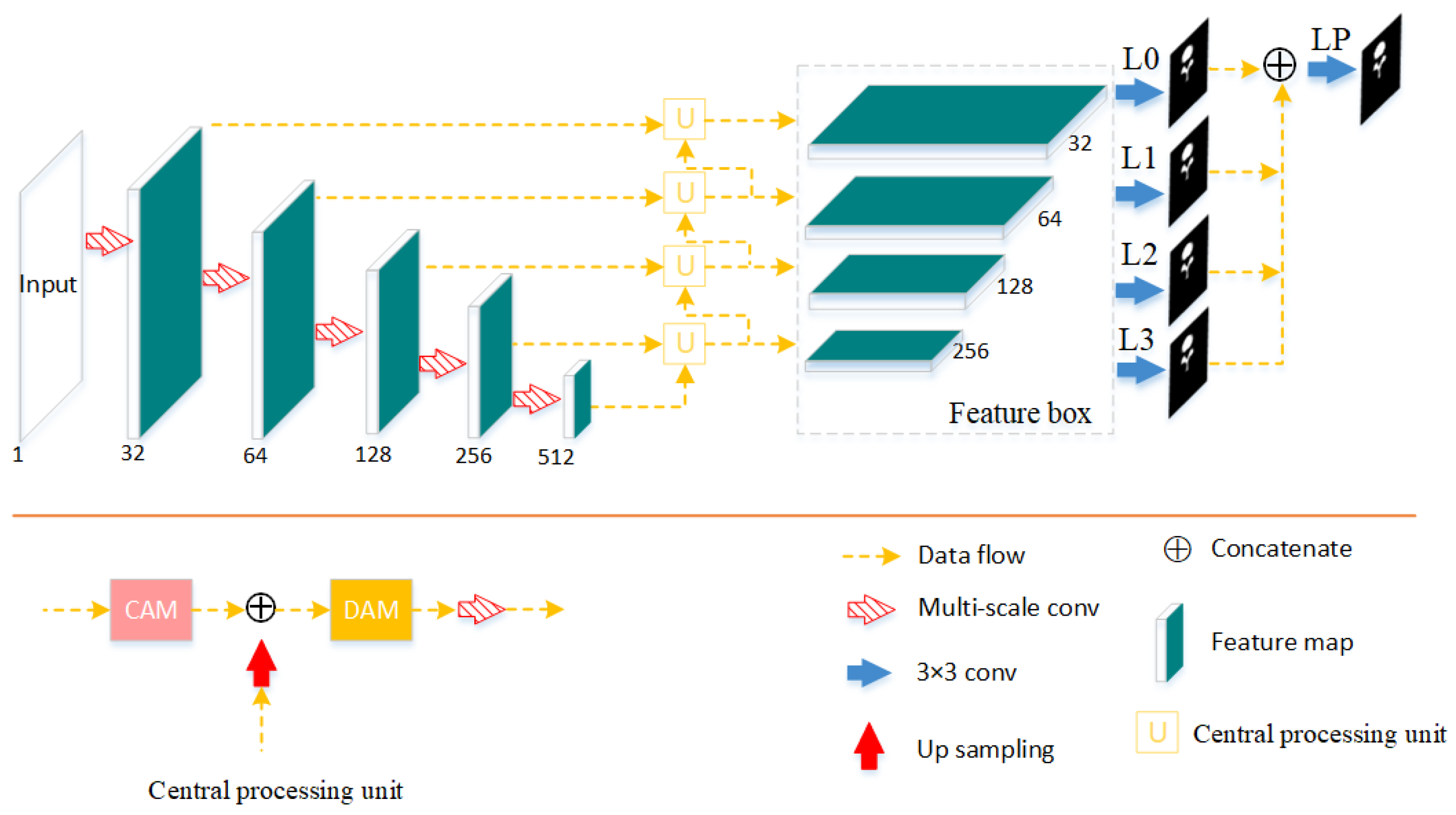
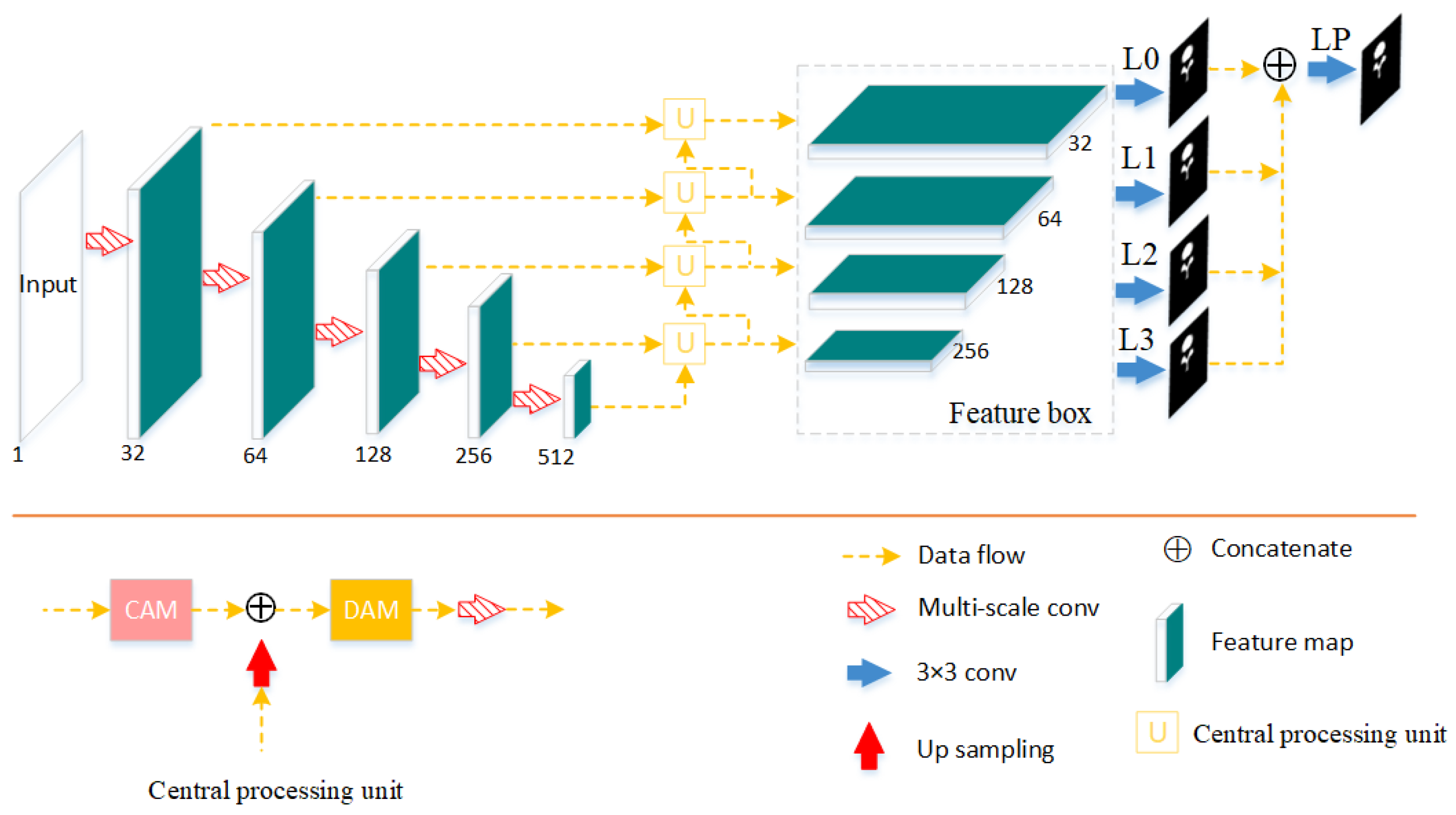
2.1. Architecture
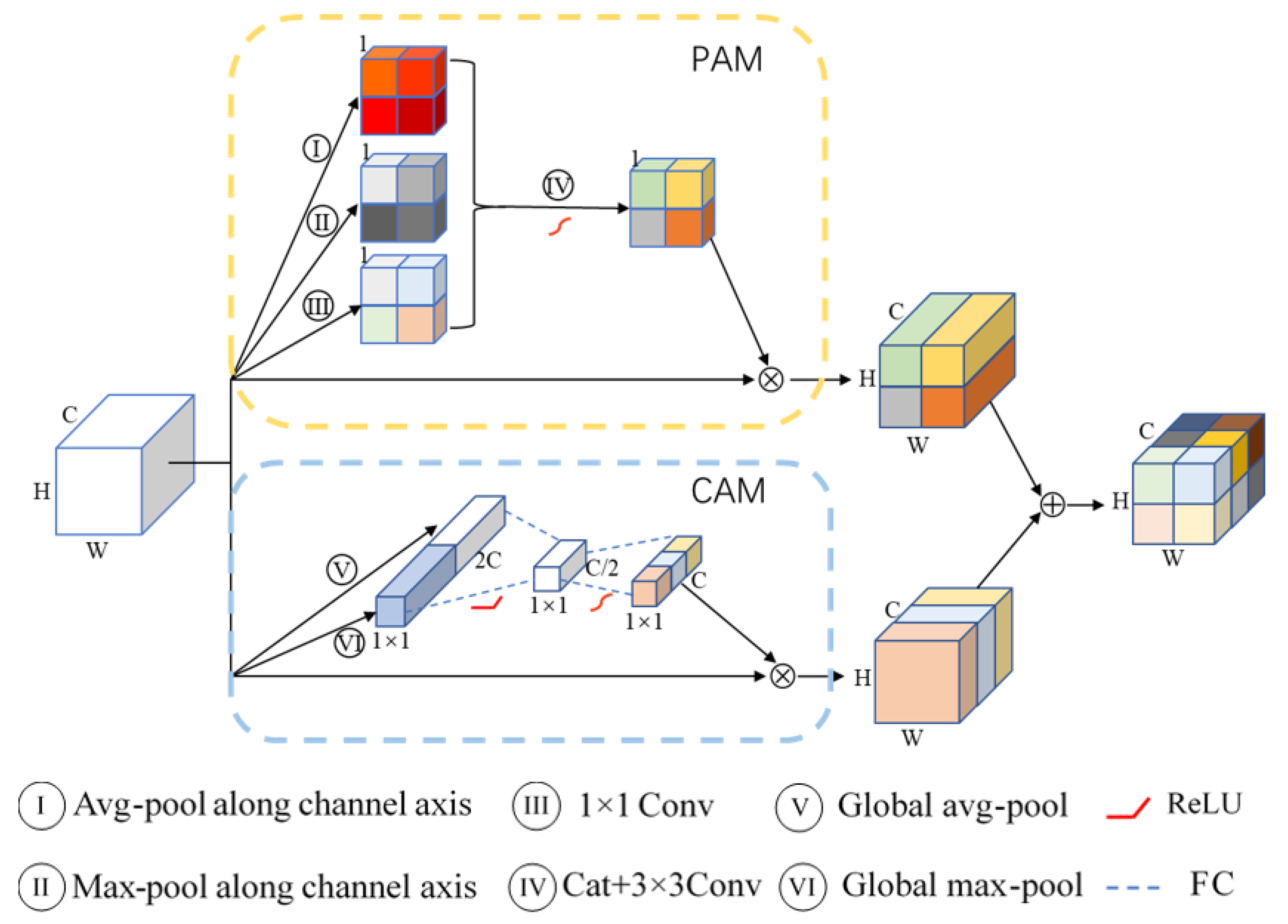
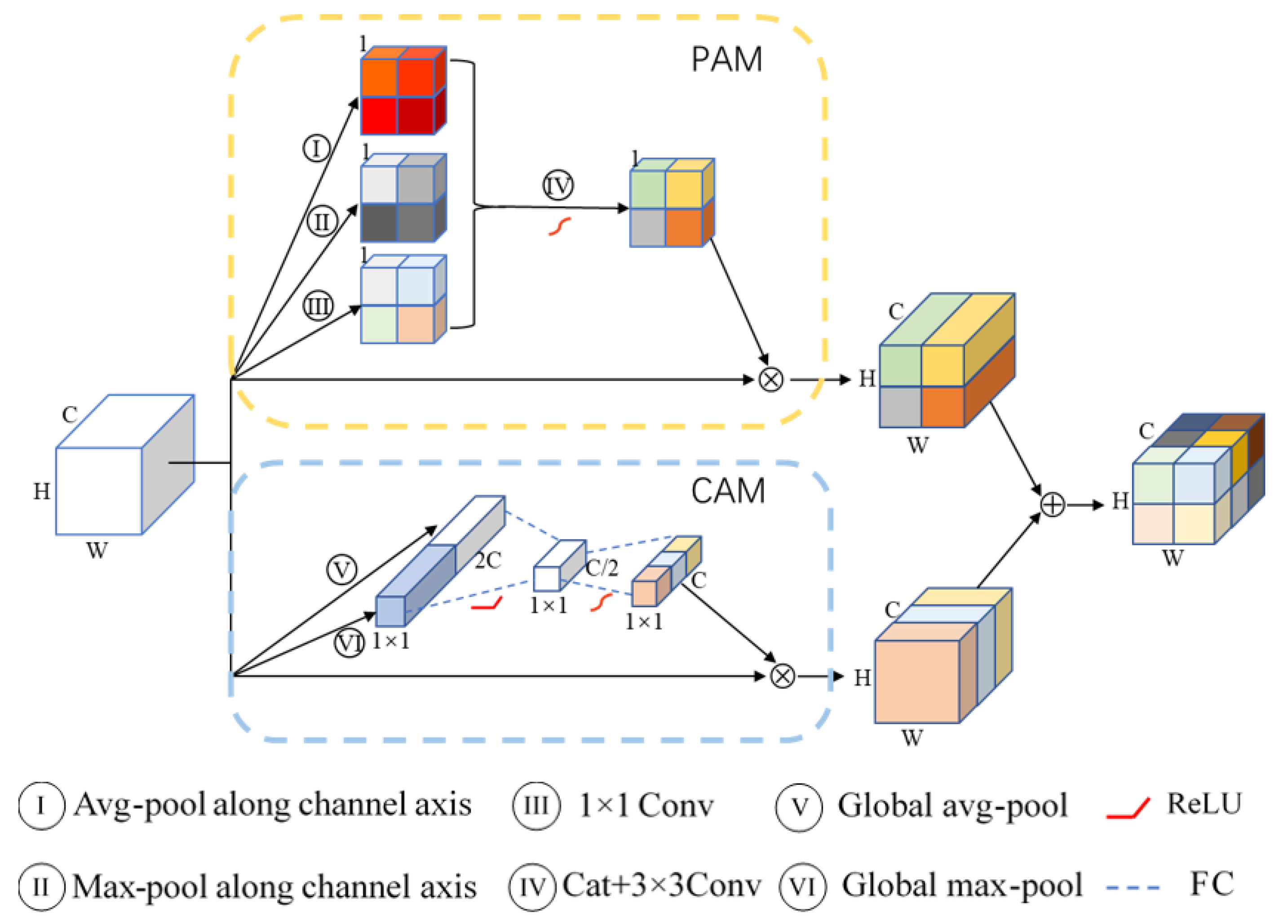
2.2. Attention Mechanism
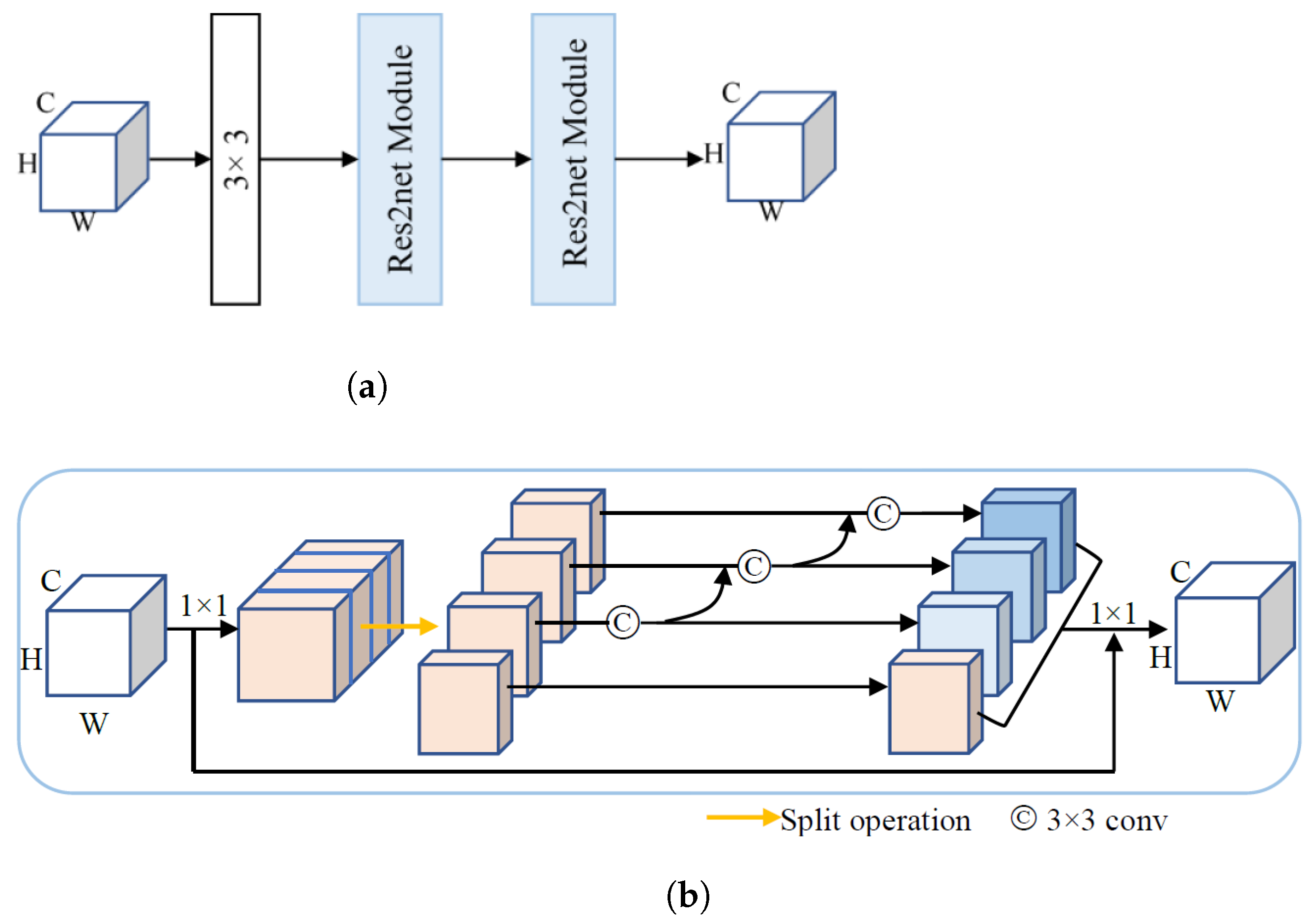
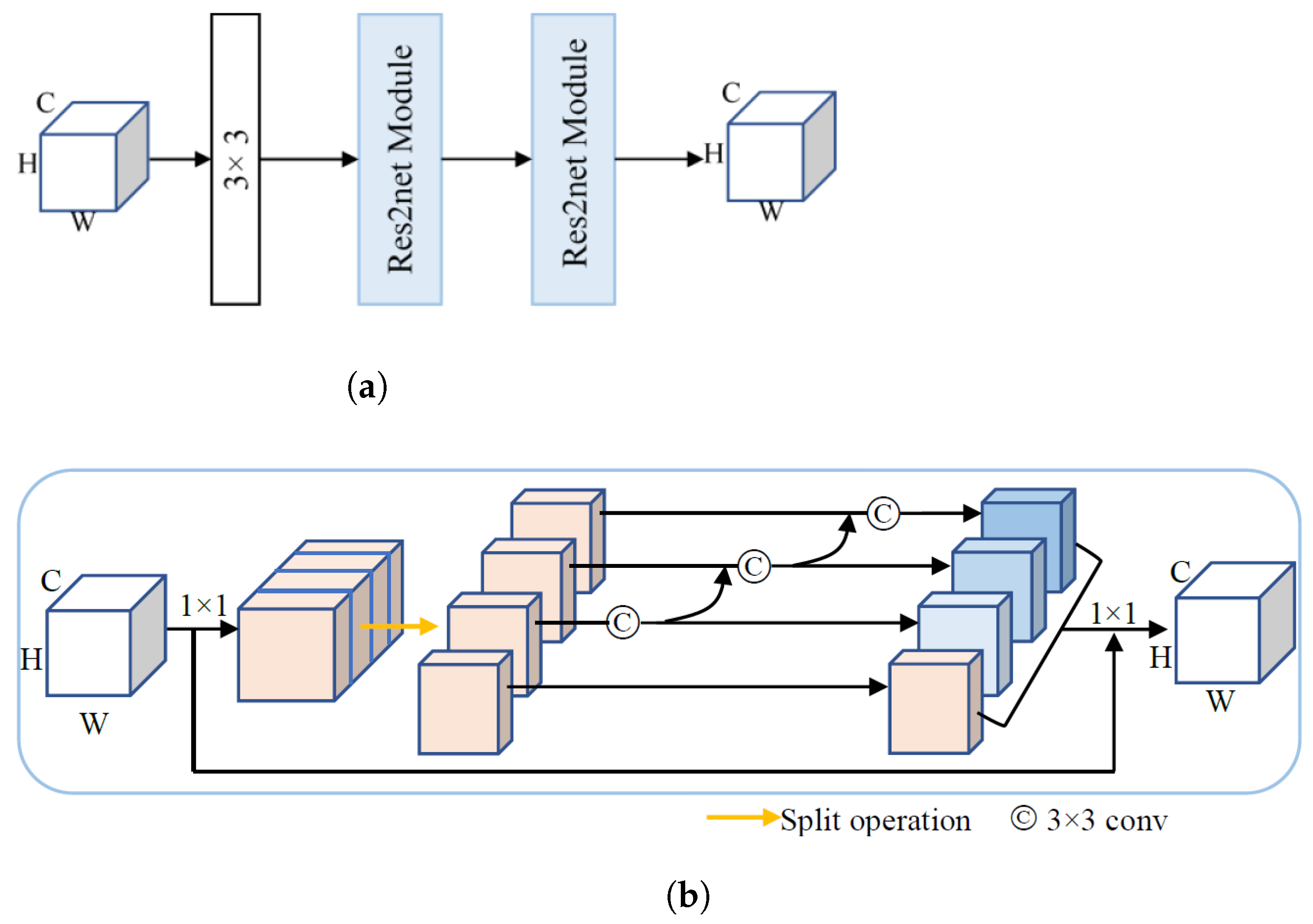
2.3. Multi-Scale Convolution
2.4. Deep Supervision
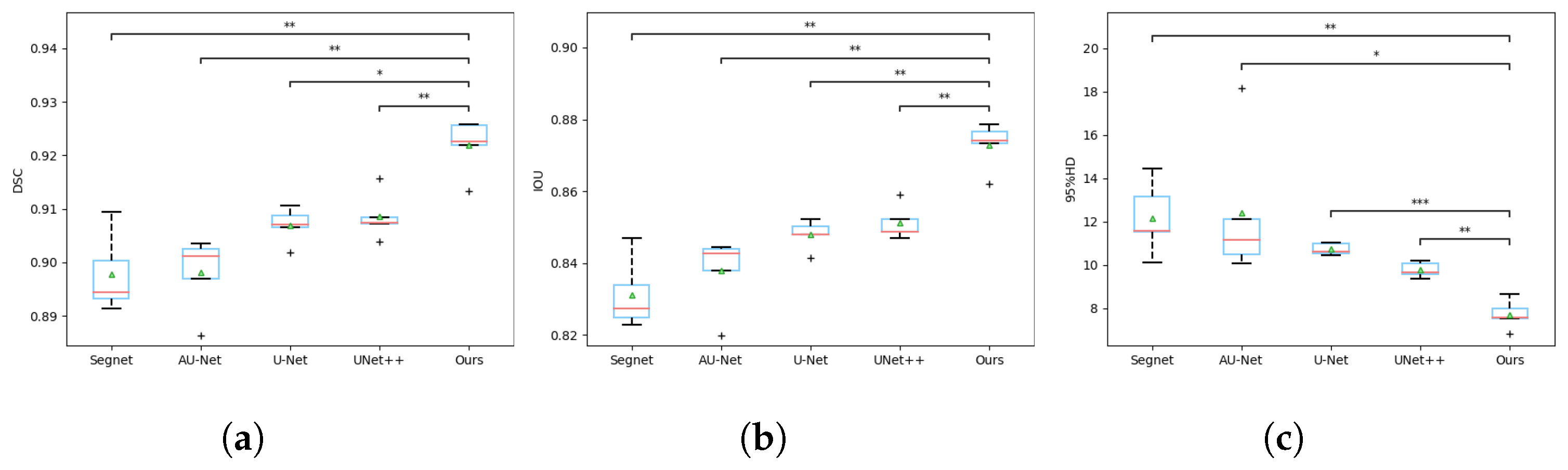
3. Results
3.1. Dataset and Implementation Details
3.2. Metrics
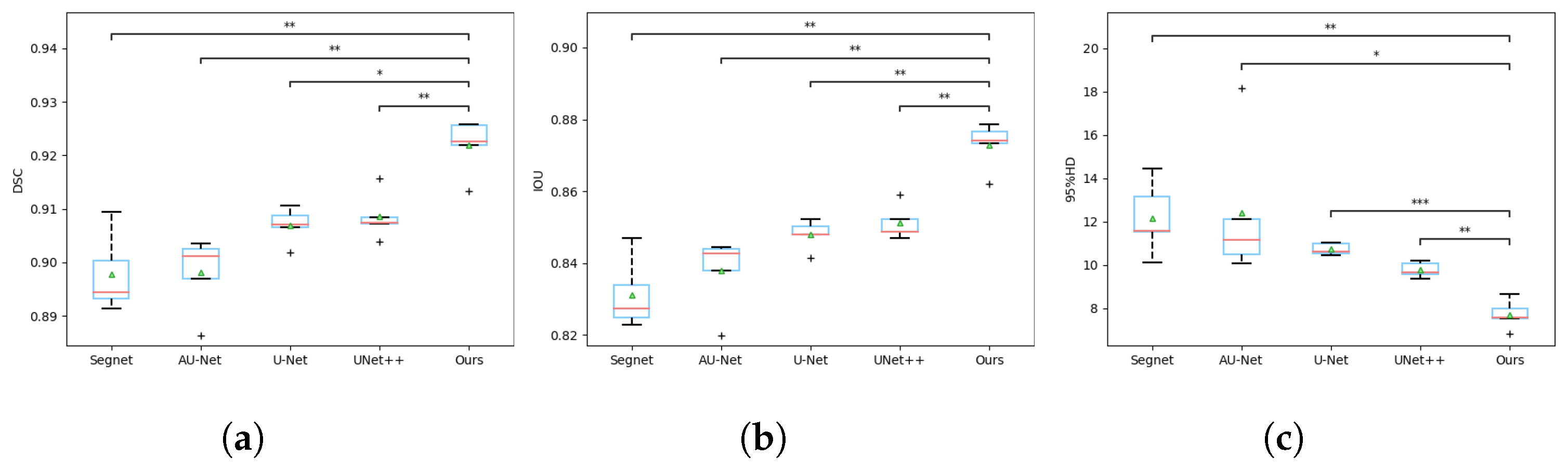
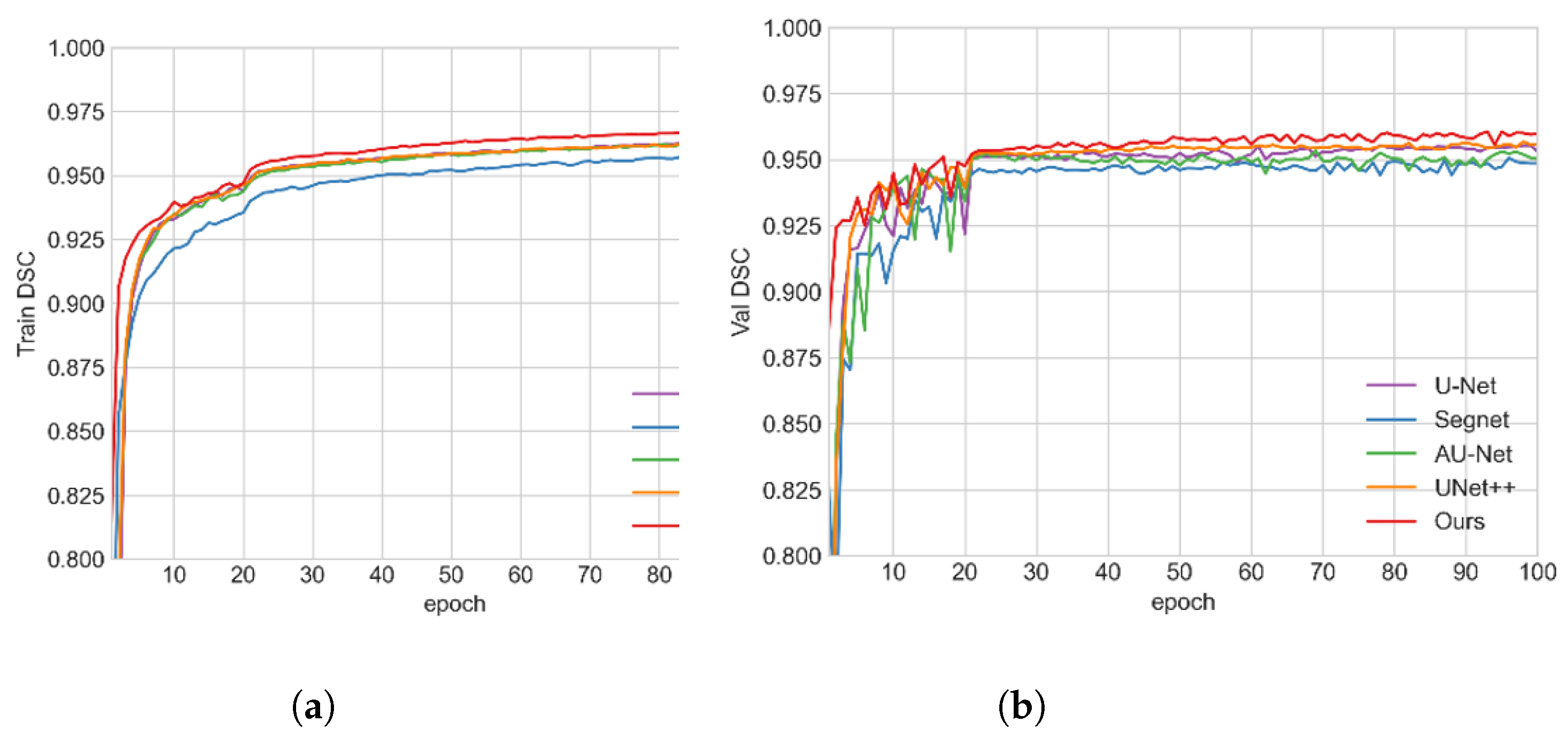
3.3. Experimental Data Analysis
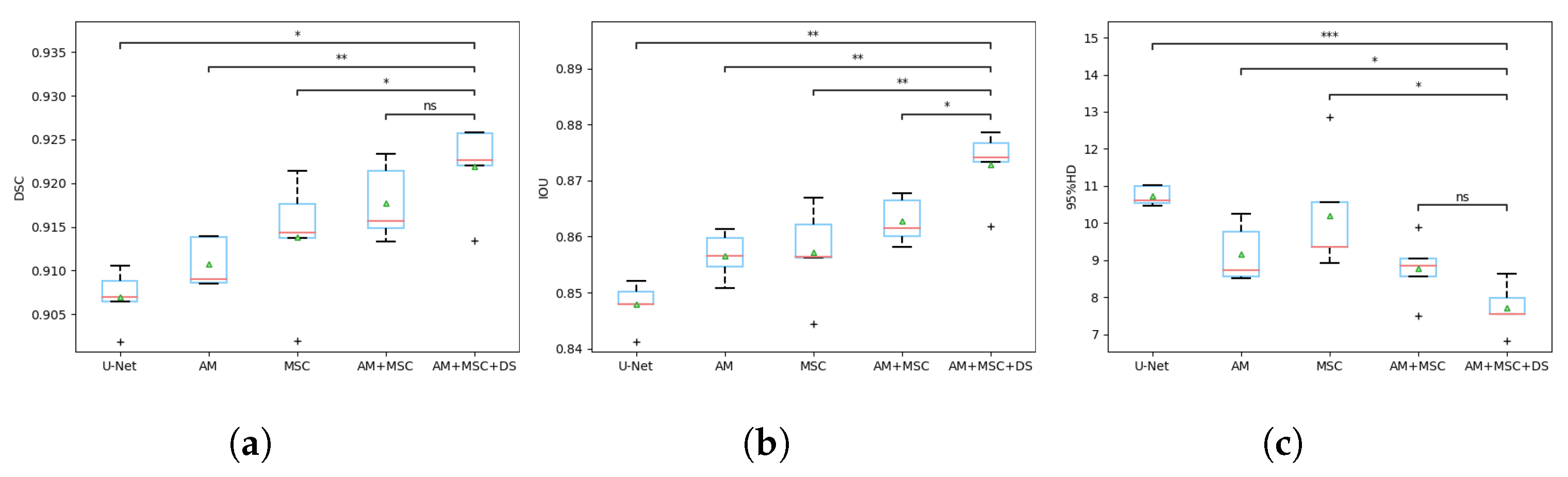
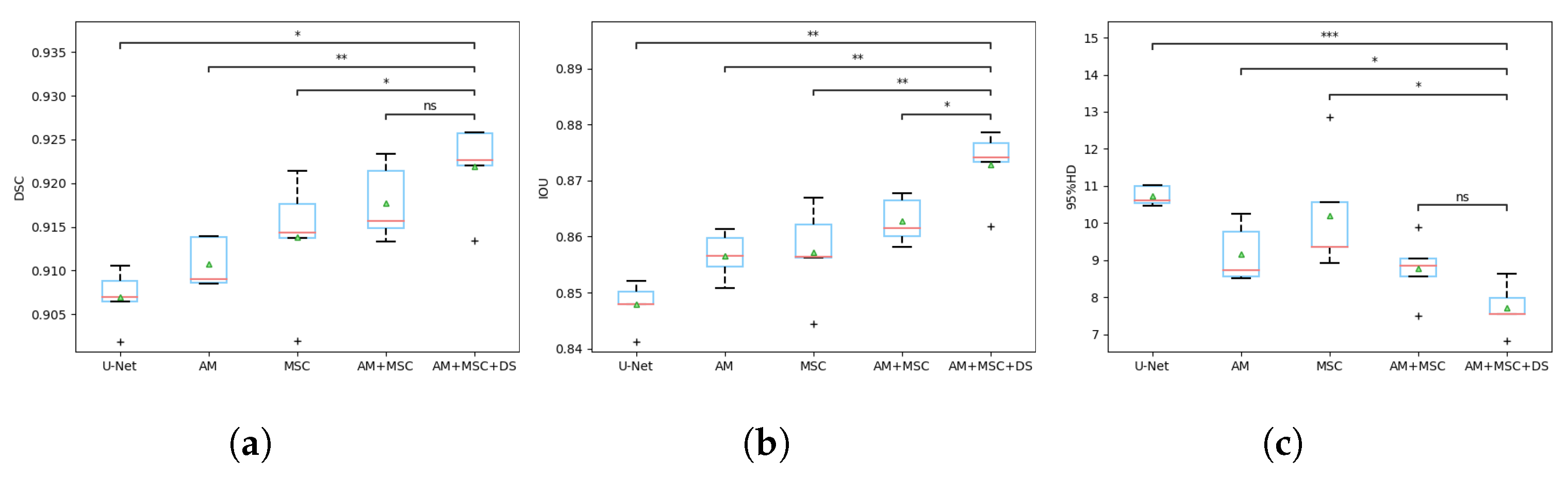
3.4. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DSC | Dice similarity coefficient |
| IOU | Intersection over union |
| 95% HD | 95% Hausdorff 156 distance |
| AM | Attention mechanism |
| MSC | Multi-scale convolution |
| DS | Deep supervision |
References
- Parizel, P.; Van Der Zijden, T.; Gaudino, S.; Spaepen, M.; Voormolen, M.; Venstermans, C.; De Belder, F.; Van Den Hauwe, L.; Van Goethem, J. Trauma of the spine and spinal cord: Imaging strategies. Eur. Spine J. 2010, 19, 8–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klinder, T.; Ostermann, J.; Ehm, M.; Franz, A.; Kneser, R.; Lorenz, C. Automated model-based vertebra detection, identification, and segmentation in CT images. Med. Image Anal. 2009, 13, 471–482. [Google Scholar] [CrossRef] [PubMed]
- Castro-Mateos, I.; Pozo, J.; Pereañez, M.; Lekadir, K.; Lazary, A.; Frangi, A. Statistical interspace models (SIMs): Application to robust 3D spine segmentation. IEEE Trans. Med. Imaging 2015, 34, 1663–1675. [Google Scholar] [CrossRef] [PubMed]
- Athertya, J.; Kumar, G. Automatic segmentation of vertebral contours from CT images using fuzzy corners. Comput. Biol. Med. 2016, 72, 75–89. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Q.; Lu, Z.; Yang, W.; Zhang, M.; Feng, Q.; Chen, W. A robust medical image segmentation method using KL distance and local neighborhood information. Comput. Biol. Med. 2013, 43, 459–470. [Google Scholar] [CrossRef] [PubMed]
- Chu, C.; Belavỳ, D.; Armbrecht, G.; Bansmann, M.; Felsenberg, D.; Zheng, G. Fully automatic localization and segmentation of 3D vertebral bodies from CT/MR images via a learning-based method. PLoS ONE 2015, 10, e0143327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Korez, R.; Likar, B.; Pernuš, F.; Vrtovec, T. Model-based segmentation of vertebral bodies from MR images with 3D CNNs. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2016; pp. 433–441. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Kim, J.H.; Mo, Y.C.; Choi, S.M.; Hyun, Y.; Lee, J. Detecting Ankle Fractures in Plain Radiographs Using Deep Learning with Accurately Labeled Datasets Aided by Computed Tomography: A Retrospective Observational Study. Appl. Sci. 2021, 11, 8791. [Google Scholar] [CrossRef]
- Holbrook, M.; Blocker, S.; Mowery, Y. MRI-Based Deep Learning Segmentation and Radiomics of Sarcoma in Mice. Tomography 2020, 6, 23–33. [Google Scholar] [CrossRef] [PubMed]
- Yogananda, C.G.B.; Shah, B.V.J.M. A Fully Automated Deep Learning Network for Brain Tumor Segmentation. Tomography 2020, 6, 186–193. [Google Scholar] [CrossRef] [PubMed]
- Sekuboyina, A.; Valentinitsch, A.; Kirschke, J.; Menze, B. A localisation-segmentation approach for multi-label annotation of lumbar vertebrae using deep nets. arXiv 2017, arXiv:1703.04347. [Google Scholar]
- Janssens, R.; Zeng, G.; Zheng, G. Fully automatic segmentation of lumbar vertebrae from CT images using cascaded 3D fully convolutional networks. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 893–897. [Google Scholar]
- Lessmann, N.; Van Ginneken, B.; De Jong, P.; Išgum, I. Iterative fully convolutional neural networks for automatic vertebra segmentation and identification. Med. Image Anal. 2019, 53, 142–155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yao, J.; Burns, J.; Forsberg, D.; Seitel, A.; Rasoulian, A.; Abolmaesumi, P.; Hammernik, K.; Urschler, M.; Ibragimov, B.; Korez, R.; et al. A multi-center milestone study of clinical vertebral CT segmentation. Comput. Med. Imaging Graph. 2016, 49, 16–28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Oktay, O.; Schlemper, J.; Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Siddiquee, M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Forsberg, D. Atlas-based registration for accurate segmentation of thoracic and lumbar vertebrae in CT data. In Recent Advances in Computational Methods and Clinical Applications for Spine Imaging; Springer: Cham, Switzerland, 2015; pp. 49–59. [Google Scholar]
- Hammernik, K.; Ebner, T.S.D. Vertebrae segmentation in 3D CT images based on a variational framework. In Recent Advances in Computational Methods and Clinical Applications for Spine Imaging; Springer: Cham, Switzerland, 2015; pp. 227–233. [Google Scholar]
- Castro-Mateos, I.; Pozo, J.M.L.A. 3D vertebra segmentation by feature selection active shape model. In Recent Advances in Computational Methods and Clinical Applications for Spine Imaging; Springer: Cham, Switzerland, 2015; pp. 241–245. [Google Scholar]
- Xia, L.; Xiao, L.; Quan, G.; Bo, W. 3D Cascaded Convolutional Networks for Multi-vertebrae Segmentation. Curr. Med. Imaging 2020, 16, 231–240. [Google Scholar] [CrossRef]
- Zhang, H.; Goodfellow, I.; Metaxas, D. Self-attention generative adversarial networks. In International Conference on Machine Learning; PMLR: Long Beach, CA, USA, 2019; pp. 7354–7363. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4 February 2017; pp. 4278–4284. [Google Scholar]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | DSC | IOU | 95% HD |
|---|---|---|---|
| SegNet | 0.8977 ± 0.0066 | 0.8312 ± 0.0087 | 12.1561 ± 1.4937 |
| AU-Net | 0.8981 ± 0.0062 | 0.8377 ± 0.0092 | 12.4024 ± 2.9603 |
| U-Net | 0.9069 ± 0.0029 | 0.8478 ± 0.0036 | 10.7243 ± 0.2378 |
| UNet++ | 0.9085 ± 0.0038 | 0.8511 ± 0.0042 | 9.7663 ± 0.3086 |
| Ours | 0.9218 ± 0.0045 | 0.8729 ± 0.0058 | 7.7107 ± 0.5958 |
| Method | SegNet-Ours | AU-Net-Ours | U-Net-Ours | UNet++-Ours |
|---|---|---|---|---|
| DSC | 0.0065 | 0.0023 | 0.0117 | 0.0089 |
| IOU | 0.0021 | 0.0024 | 0.0039 | 0.0022 |
| 95% HD | 0.0081 | 0.0437 | 0.0002 | 0.0022 |
| AM | MSC | DS | DSC | IOU | 95% HD |
|---|---|---|---|---|---|
| 0.9069 ± 0.0029 | 0.8478 ± 0.0036 | 10.7243 ± 0.2378 | |||
| ✓ | 0.9107 ± 0.0025 | 0.8566 ± 0.0037 | 9.1597 ± 0.7115 | ||
| ✓ | 0.9137 ± 0.0065 | 0.8572 ± 0.0075 | 10.2084 ± 1.4339 | ||
| ✓ | ✓ | 0.9177 ± 0.0039 | 0.8628 ± 0.0037 | 8.7667 ± 0.7739 | |
| ✓ | ✓ | ✓ | 0.9218 ± 0.0045 | 0.8729 ± 0.0058 | 7.7107 ± 0.5958 |
| Method | Baseline | AM | MSC | AM + MSC |
|---|---|---|---|---|
| DSC | 0.0117 | 0.0053 | 0.0137 | 0.1937 |
| IOU | 0.0039 | 0.0078 | 0.003 | 0.0396 |
| 95% HD | 0.0002 | 0.0463 | 0.0294 | 0.0888 |
| Method | Segmentation Strategy | Runtime |
|---|---|---|
| Method 1 [21] | Machine Learning (multi-atlas) | 12 min per case (GPU) |
| Method 2 [22] | Traditional (mean shape model) | 45 min per case (GPU) |
| Method 3 [23] | Traditional (mean shape model) | 10 min per case (GPU) |
| Method 4 [24] | Deep Learning (CNN) | 10 min per case (GPU) |
| Verte-Box | Deep Learning (CNN) | 6 min per case (GPU) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Liu, C.; Wu, S.; Li, G. Verte-Box: A Novel Convolutional Neural Network for Fully Automatic Segmentation of Vertebrae in CT Image. Tomography 2022, 8, 45-58. https://doi.org/10.3390/tomography8010005
Li B, Liu C, Wu S, Li G. Verte-Box: A Novel Convolutional Neural Network for Fully Automatic Segmentation of Vertebrae in CT Image. Tomography. 2022; 8(1):45-58. https://doi.org/10.3390/tomography8010005
Chicago/Turabian StyleLi, Bing, Chuang Liu, Shaoyong Wu, and Guangqing Li. 2022. "Verte-Box: A Novel Convolutional Neural Network for Fully Automatic Segmentation of Vertebrae in CT Image" Tomography 8, no. 1: 45-58. https://doi.org/10.3390/tomography8010005
APA StyleLi, B., Liu, C., Wu, S., & Li, G. (2022). Verte-Box: A Novel Convolutional Neural Network for Fully Automatic Segmentation of Vertebrae in CT Image. Tomography, 8(1), 45-58. https://doi.org/10.3390/tomography8010005