1. Introduction
A biomechanical load analysis of the spine in an upright standing position is highly warranted in various spine disorders to understand their cause and guide therapy [
1]. Typical approaches for load estimation either use a computational shape model of the spine for all patients or obtain a subject-specific spine model from a 3D imaging modality such as magnetic resonance imaging (MRI) or computed tomography (CT) [
2]. Even though MRI and CT images can capture 3D anatomical information, they need the patient to be in a
prone or
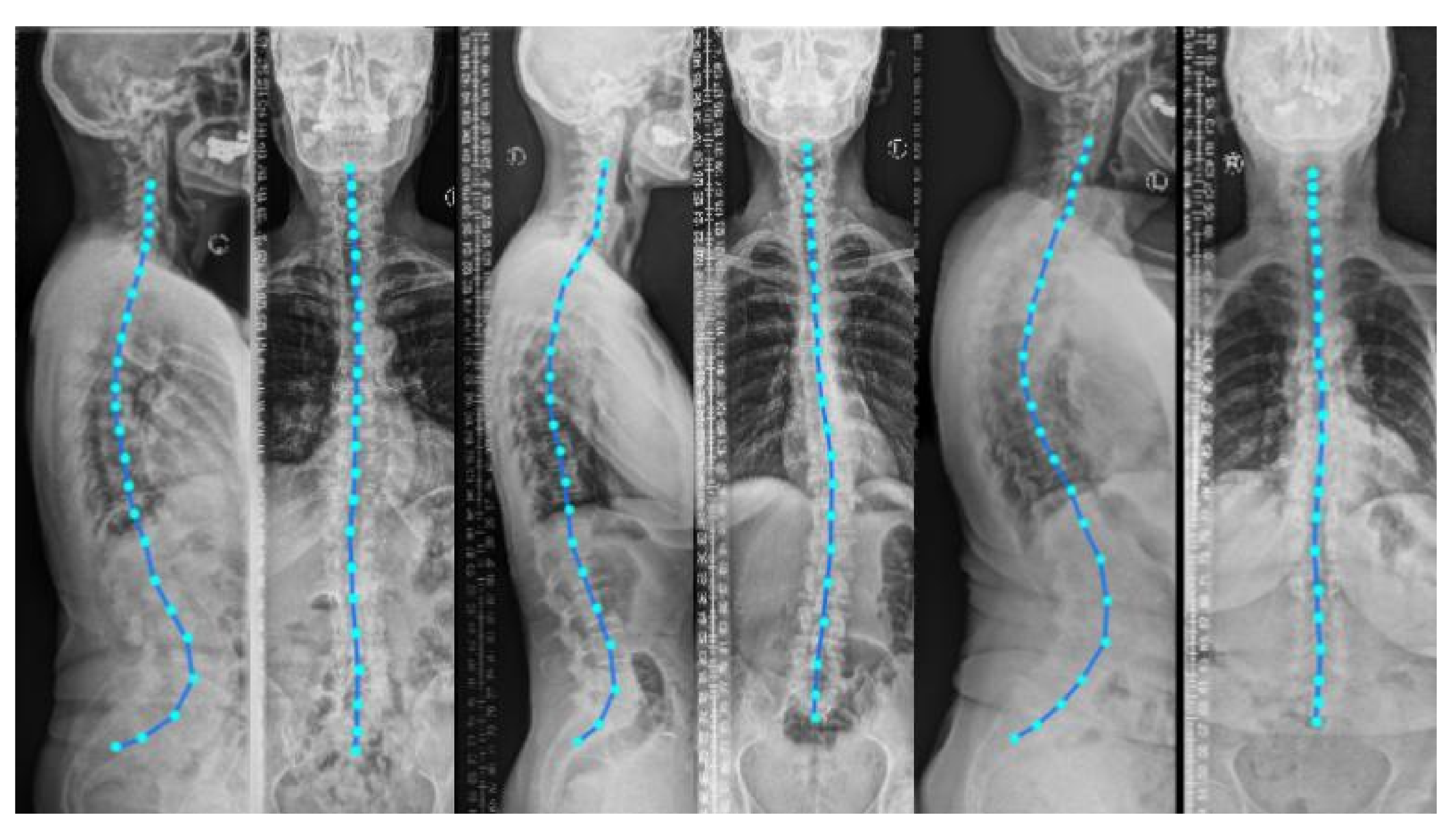
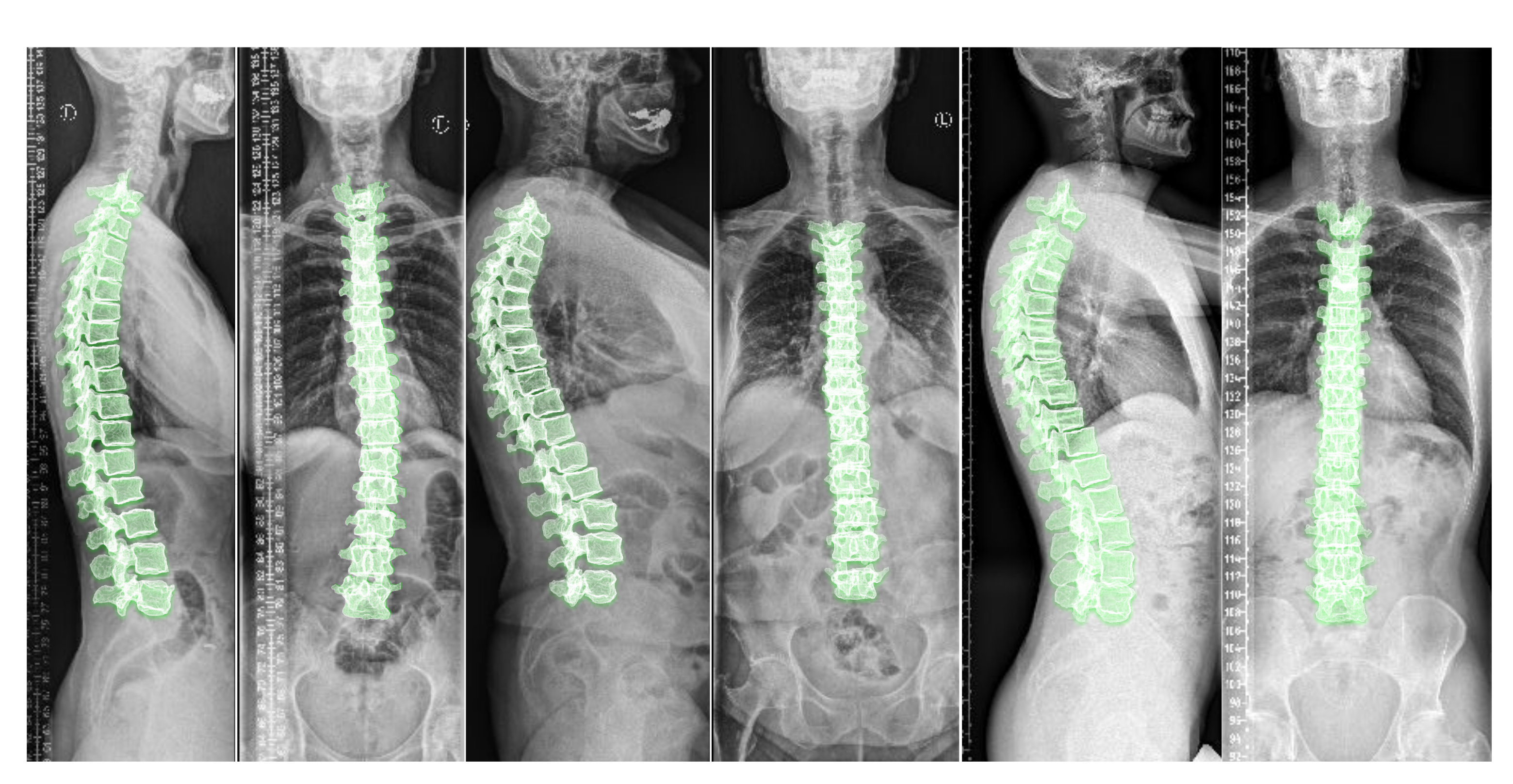
supine position (lying flat on a table) during imaging. Nevertheless, to analyze the spinal alignment in a physiologically upright standing position under weight bearing, orthogonal 2D plain radiographs (as depicted in
Figure 1) are the
de facto choice. A combination of both these worlds is of clinical interest to fully assess the true biomechanical situation, that is, to capture the patient-specific complex pathological spinal arrangement in a standing position with full 3D information [
2,
3,
4].
As crucial spatial information is lost when projecting a 3D object in only two 2D planes [
5], a random object cannot reliably be reconstructed from two orthogonal projections. However, the spine follows strong anatomical rules, that are repeated only with slight variations in any patient. Typical projections—that is, lateral and AP radiographs—cover most of these variations, both on a local (per vertebra) and global (overall spinal alignment) level.
The literature offers a wealth of registration-based methods [
4,
6,
7,
8,
9,
10] for relating 2D radiographs to 3D CT or MR images. In [
4], the authors employ coarse manual registration for aligning 3D data to 2D sagittal radiographs for the lumbar vertebrae. Similarly, in [
6], manually annotated vertebral bodies on 2D radiographs are used to measure the vertebral orientations in an upright (standing) position. Such solutions are time-consuming, labor-intensive, and are vulnerable to error. Note that both works only employ sagittal reformations to position the vertebrae. They thus ignore coronal reformation containing significant information about the spine’s natural curvature, especially in abnormal cases. Other approaches for this purpose introduce an automated 3D–2D spine registration algorithm [
7,
8], wherein authors suggest a multi-stage registration method by introducing a comparison metric for a CT projection and a radiograph. Since this metric is parameter-heavy and hand-crafted, the generalizability and inference speeds of these methods are limited. In [
9,
10], the 3D shape of the spine is reconstructed using a biplanar X-ray device called ‘EOS’. The advantage of the system is the low radiation dose required and that both projections are acquired simultaneously, allowing for a direct spatial correspondence between the two planes. Hindering its applicability is the high device cost and thus the lack of its presence in clinical routines.
The problem of reconstructing 3D shapes from 2D images has recently been explored using deep learning methods. For example, in [
11], adversarial training is used to synthesize 3D CT images given two orthogonal radiographs. For a scale of spinal scans, this method is memory intensive and also fails to synthesize smaller 3D anatomies such as the vertebrae. Note that this method has been evaluated on digitally reconstructed radiographs (DRR) only, thus requiring further validation for its clinical usage. In [
12,
13], the authors design a model to generate a 3D shape given multiple arbitrary view 2D images. However, the input images include only the object of interest without background, which is not applicable to medical images like spinal radiographs. In our previous work on inferring the 3D standing spine posture [
14], we introduce a new deep neural network architecture termed TransVert, to combine the 2D orthogonal image information and reconstruct a 3D shape. Since the vertebrae are heavily occluded by soft tissue and ribs in the radiographs, the reconstruction is challenging and in some cases the output shape is far from a vertebral shape.
In machine learning, shape priors help to reduce the search space of possible solutions, improving the accuracy and plausibility of solutions [
15]. Priors are particularly effective when data are unclear, corrupt, with low signal-to-noise ratio or when training data are scarce [
15,
16]. The idea of incorporating shape priors into the neural network models has been explored by [
15,
17,
18,
19,
20]. Most of the ideas proposed for using shape priors in deep neural networks are for a single object, while the spine shape is more complicated as it is made of multiple objects (vertebrae) connected to each other. The spine and vertebrae shapes are deformed, subject to some constraints of human anatomy. Thus, defining a prior for explaining intervertebral constraints and the spinal shape is crucial here.
A few works have modeled the spinal shape [
10,
21,
22,
23,
24]. For instance, in [
24] the authors proposed an automatic framework that segments vertebrae from arbitrary CT images with a complete spine model. They first scanned a commercially available plastic phantom to generate the template. Next, they manually registered it to ten actual full spine scans. The authors learned a statistical shape model of the spine in [
23] by independently studying three models for cervical, thoracic and lumbar regions. Thus, their models do not learn the shape correlations across the full spine [
21]. In [
22], the authors propose a parametric model of the spine, which is computed using statistical inferences, image analysis techniques and manual rigid registration. In [
10], the authors used a PCA-based model to decompose the spine shape into the spinal curve and local shape of vertebrae.
Besides statistical shape models [
10,
21,
23,
24], other probabilistic models, such as probabilistic atlas [
25], graph models [
26], Hidden Markov Models [
27] and hierarchical models [
28,
29,
30] have also been proposed. For instance, in [
25], the authors proposed a probabilistic atlas of the spine. By co-registering 21 CT scans, a probability map is created which can be used to segment and detect the vertebrae with a special focus on ribs suppression. In [
26] the authors proposed a probabilistic graphical model for the location and identification of the vertebrae in MR images. In both cases full spines were observed at training time. However, none of the works mentioned above are an end-to-end machine learning treatment of the problem of the reconstruction of 3D shapes of spines from 2D images.
We introduce an anatomy-aware deep neural network for fusing two orthogonal 2D radiographs to generate a 3D spine model. We define this 3D shape synthesis as a hybrid registration problem in which the network estimates vector fields to deform vertebral shape templates to achieve shape synthesis. We apply our model to clinical radiographs subject to noise and heavy tissue overlay. We incorporate shape priors into the model to enhance robustness against such artefacts in real-world data. We propose a training approach using synthetically generated radiographs from 3D CT, with full supervision from the CT’s 3D vertebral masks.
2. Materials and Methods
For synthesizing 3D data from 2D information, the following requirements are desired: First, for efficient recovery of 3D shape information from sagittal and coronal projections, the network needs to integrate the information from these projections appropriately. Second, recovering 3D shapes from 2D projections is inherently an ill-posed problem, requiring incorporation of prior knowledge. This knowledge includes vertebral shapes and the shape of the spine (spinal curvature).
Our work is mainly based on the TransVert network [
14]. The TransVert network is designed for inferring the 3D standing spinal posture from 2D radiograph. Here, we overview the TransVert model to better explain our proposed model. We will introduce the TransVert+ model to address the limitations of TransVert.
2.1. TransVert
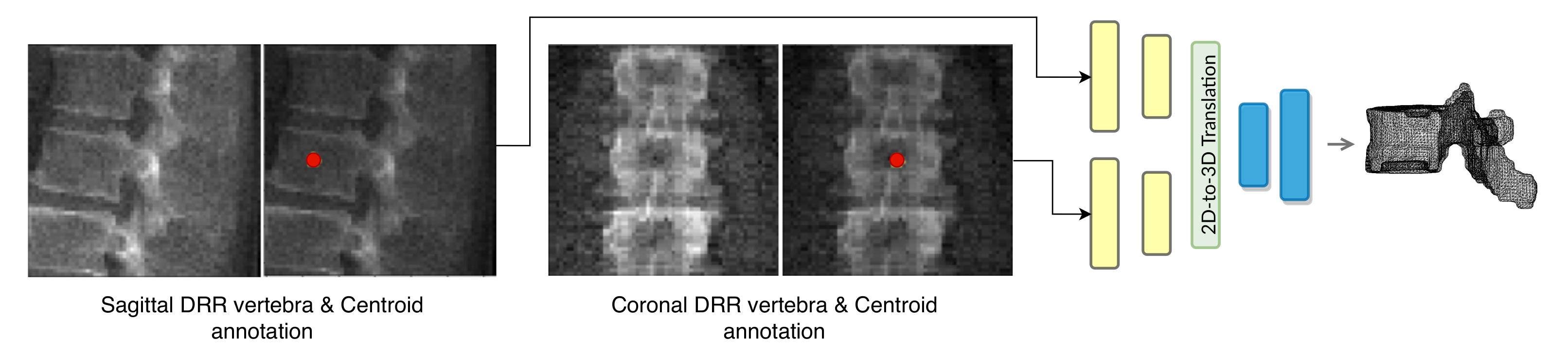
TransVert inputs are the sagittal and coronal vertebral image patches and their corresponding annotation images. The annotation images indicate the vertebra-of-interest (VOI). Given the four 2D inputs, the model predicts the vertebra’s full-body 3D shape,
, as a discrete voxel-map:
where
G denotes the mapping performed by TransVert,
and
denote the 2D vertebral sagittal and coronal reformations;
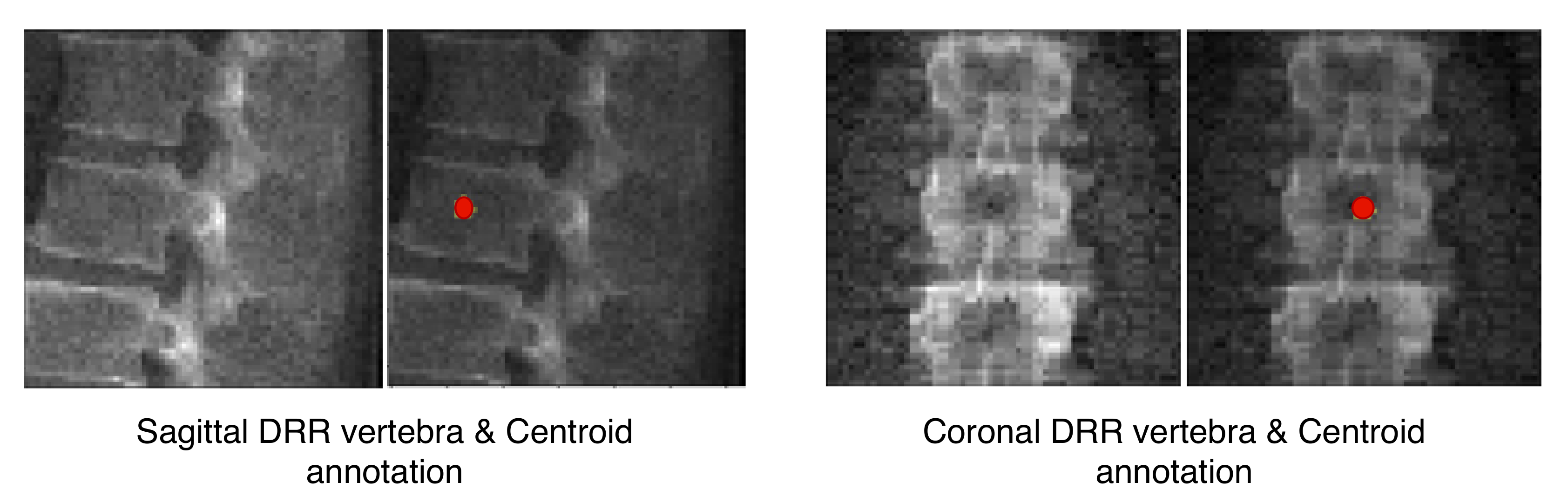
and
denote the corresponding VOI annotations. The VOI-annotation image is obtained by placing a disc of radius 1 mm around the vertebral centroid.
Figure 2 depicts orthogonal input image patches with corresponding centroid annotations, indicating the vertebra of interest in that patch. In [
14], other annotation choices (vertebral body and full vertebral masks) are analyzed in several experiments. The TransVert model is trained on sagittal and coronal digitally reconstructed radiographs (DRR) created from CT images. The model is supervised by the corresponding CT images’ voxel-level, vertebral segmentation masks. Since DRRs are similar in appearance to real radiographs, a model trained on DRRs can be deployed on clinical radiographs.
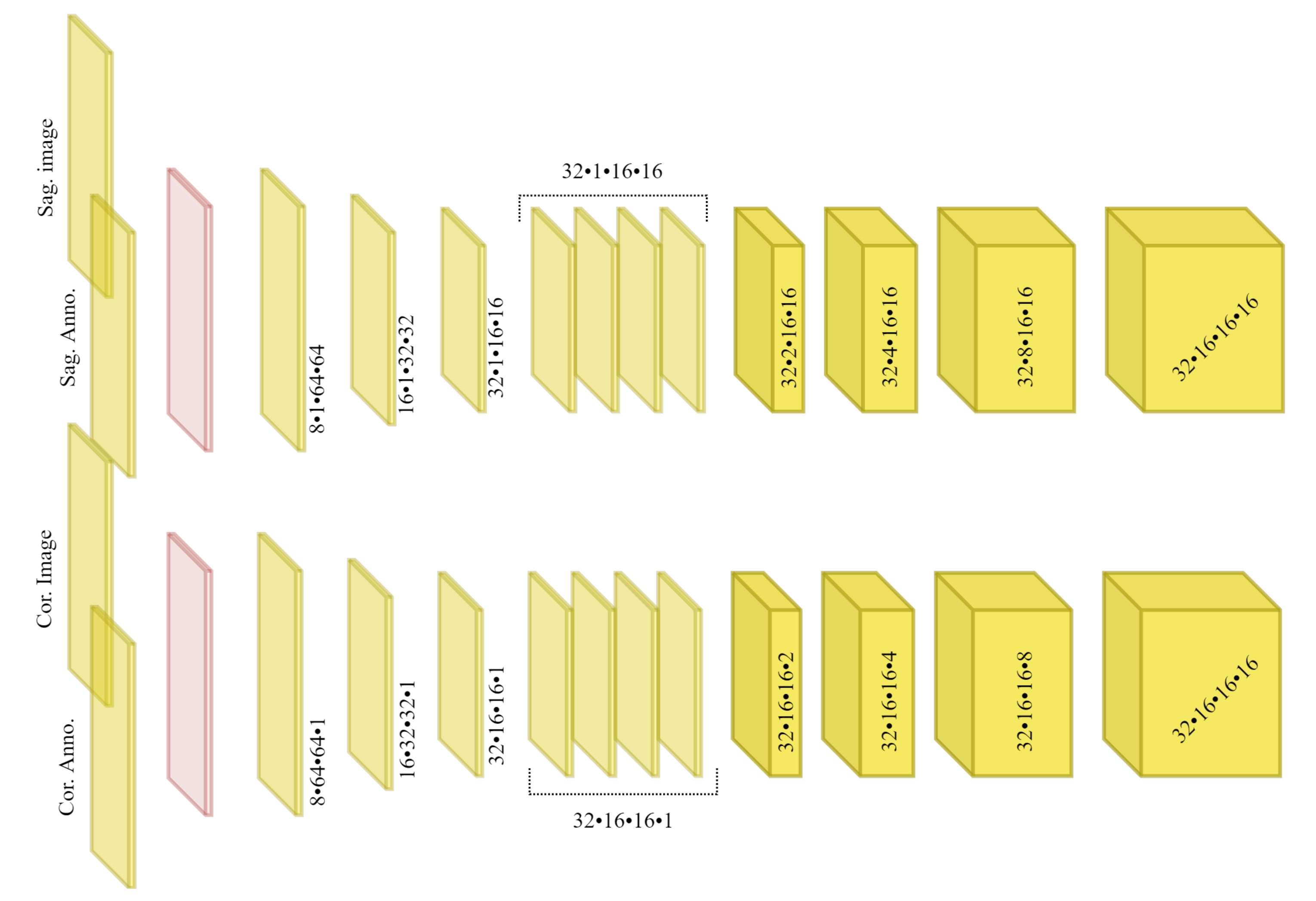
Figure 3 overviews the TransVert architecture [
14]. TransVert consists of three blocks: a 2D sagittal encoder, a 2D coronal encoder, and a 3D decoder. In [
14] we introduced a ‘map&fuse’ mechanism to combine the three blocks. The map&fuse block is designed to map 2D representation of the sagittal and coronal views into intermediate 3D latent representations and fuse them into a single 3D representation. The decoder block maps the 3D latent representation to a 3D shape in voxel space.
2.2. TransVert+: Anatomy-Aware TransVert
The TransVert model [
14] performs 2D to 3D translation vertebra by vertebra. While this results in acceptable vertebral shape reconstruction, the model still is not aware of the spinal shape and relative position of vertebrae, which might result in inconsistency in the reconstructed spinal shape. To overcome this problem, we propose incorporating the spinal curve and vertebral shapes as prior. Instead of regressing the shapes directly, our model deforms an atlas to the desired vertebral shape.
Our network estimates the vector field that deforms a discrete atlas to the desired vertebral shape. We incorporate a spine atlas as a shape prior into our network architecture, to enforce vertebral shape constraints. We also define the spine curvature by atlas vertebral centroids, for enforcing the shape of the spine. In addition to image data, we include the vertebral labels as an additional annotation attached to the network input as depicted in
Figure 2. We take a registration approach for shape synthesis and propose the TransVert+ network architecture.
TransVert+ takes five inputs, Equation (
2), of which four are 2D images, the same as TransVert’s inputs, depicted in
Figure 2. The fifth input is a vector of floats denoting the coordinates of the vertebral centroids (
) in a global spine coordinate system, for providing the model with a holistic view of the spinal curve for more consistency. We desire a function
G that outputs the vertebra’s full-body 3D shape,
, which is represented as a discrete voxel-map by deforming the vertebral shape templates (
):
We formulate this shape synthesis as a registration problem in which vertebral shape templates are deformed to obtain desired shapes. This includes both global affine transformations (scaling and 3D rotation for each vertebra, considering the global spinal shape) and local deformations on the vertebral surface. We denote them as two sub-tasks,
where
G in Equation (
3) denotes the mapping performed by TransVert+. The transformation
G is separated into affine (
) and deformable (
) transformations, explained in Equations (
4) and (
5) respectively. When inferring the affine transformation the entire spinal shape is considered, while for inferring the deformable transformation individual vertebral shape features are taken into account. We will elaborate more on this in the next sections.
Ideally, training the TransVert+ model requires radiograph images and their corresponding ‘real world’ standing 3D spine models. However, this correspondence does not exist. It is, in effect, the issue we aim to address. Thus, TransVert+ is trained on sagittal and coronal digitally reconstructed radiographs (DRR) generated from prone CT images with supervision from the voxel-level, vertebral segmentation masks of the corresponding CT images.
Generating 3D shapes from 2D information is an ill-posed problem. We model this task as a registration problem. Given 2D orthogonal information we estimate vector fields to deform shape templates to match the target 3D shape. We introduce a novel deep neural architecture to fuse the 2D information from orthogonal views and estimate the vector field required to maximize the alignment of the deformed template and the target shape. More specifically, to infer 3D spinal shapes, given 2D orthogonal radiographs and vertebral centroid coordinates in the global coordinate system, our model predicts a vector field to deform each vertebral shape template to match the target. The vector fields are predicted by considering each vertebral shape locally and also considering the spinal curvature globally. We show that incorporating the global spinal shape information improves the performance of the model.
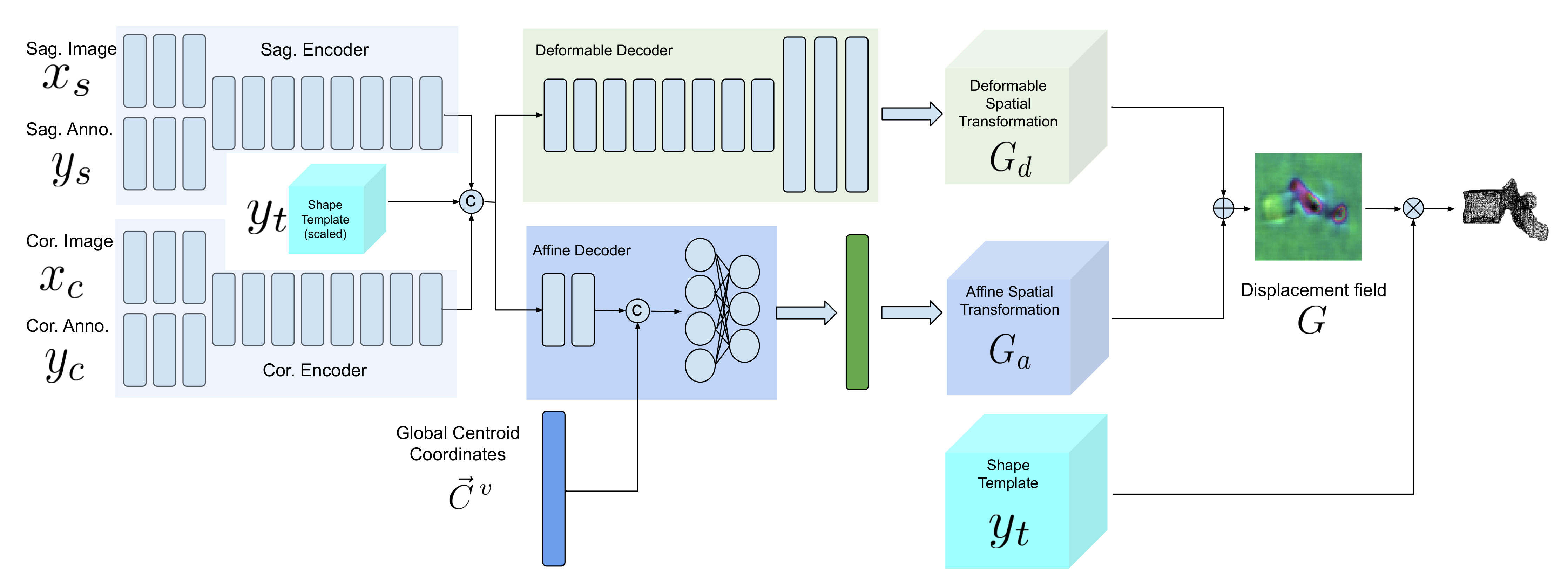
Our model is composed of two encoders for each view, an affine decoder and a deformable decoder. In the following sections, we describe the model architecture and training scheme in detail.
2.3. Network Architecture
Figure 4 demonstrates a block diagram of the model and its subnetworks. The model is composed of two encoders, one for each view (a sagittal encoder and a coronal encoder) and two decoders (an affine decoder and a deformable decoder). The input to the encoders is the image patch of the vertebra from the radiograph and the centroid annotation on the vertebra of interest. The features extracted using the encoders are concatenated to the global centroid coordinates and fed to the affine decoder (to estimate the affine transformation parameters for each vertebra) and the deformable decoder (which is a fully convolutional network to estimate the deformation for each voxel). Next, the affine and deformable vector fields are summed to produce the final displacement field, which is used to warp the template and produce the 3D shape model. Finally, a 3D model of the spine can be generated by stacking the predicted 3D vertebrae shapes at their corresponding 3D centroid locations.
2.3.1. Sagittal and Coronal Encoders
The architecture of sagittal and coronal encoders are designed differently. In
Figure 5, the architecture for each view is visualized. Each encoder is designed to reconstruct the missing third dimension of the 2D input. Therefore, they contain anisotropic convolutions with the longer side along the dimension that needs to be expanded. For instance, for a coronal input the anterior–posterior dimension needs to be expanded. For the same reason, the convolutional strides and padding directions are orthogonal for each of the views. We empirically observed that, employing the ‘squeeze and excitation’ block in the network results in a better performance than a naive fusion by concatenating the multiple channels. As input to the encoders, the vertebral images and VOI-annotations are combined using a ‘squeeze and excitation’ block (depicted in red) [
31]. In our previous work [
14] we showed that, using encoders for each view with anisotropic convolutions, outperforms using a single encoder or fusing input 2D data by outer product of the orthogonal 2D images.
2.3.2. Affine Decoder
Since the vertebrae are not completely visible in the radiographs, generating the 3D spine model given only the encoded features for each vertebra separately could lead to inaccurate orientation.
Including the vertebral centroid coordinates in the global coordinate system provides the model with a holistic shape of the spine. For example,
Figure 1 demonstrates lateral and anterior–posterior (AP) view radiographs of three different patients. The distance between the centroids determines the scale. If one fits a curve to all of the vertebral centroids, the orientation of each vertebra should be almost perpendicular to the curve at each vertebral centroid. Although defining the orientation of the vertebrae and the other constraints, such as inter-vertebral distance, needs accurate vertebral landmark detection on radiographs, we postulate a Multi Layer Perceptron (MLP) which estimates the 3D affine parameters, given only the vertebral centroids and the information extracted by the encoders.
Since the features calculated by the encoders for data samples in a batch are independent of each other, we need an intra-batch fusion mechanism to give the model a holistic view of the features from different spinal regions. We assume that the vertebrae in a batch are from the same spine and in order (we train the model in this way). For intra-batch fusion, we flatten the features from both encoders and also the down-scaled vertebral shape templates and concatenate them with the vertebral centroid coordinates, for all vertebrae. These inputs are fed into our affine subnetwork, which is an MLP.
For each vertebra, the affine subnetwork estimates four parameters: the scaling factor (
S), and the rotation about each axis (
,
,
). After the transformation matrix is created, the corresponding affine vector field is calculated. We do not include translation, since the input image patches are extracted in such a way that the vertebral centroid is at a fixed location in the image patch.
where the
is the affine vector field and
is the function to generate an affine vector field given the transformation matrix.
2.3.3. Deformable Decoder
In parallel with affine parameter estimation for rough alignment between the template and target shapes, we synthesize the finer details. We design a subnetwork termed the “deformable decoder” for estimating local shape deformations. The deformable decoder is a fully convolutional network. The inputs to this network are the intermediate 3D latent representation calculated by the encoders with the down-scaled (the same size as 3D latent representation) shape template as an extra channel. Including the shape template as another input channel helps the model to infer the differences between the template and target shapes. The deformable decoder’s output is a 3D vector field with target volume resolution. Contrary to the affine decoder, which estimates the affine transformation parameters based on the entire batch, the deformable decoder is focused on single data samples in the batch, to consider the finer shape details for each sample,
2.4. Learning
We train the model using the
distance between the deformed templates and the target vertebral shapes in the voxel space. To regularize the deformations, we incorporate a smoothing term in the cost function. Solely using a regression loss leads to convergence to a local optimum in which a mean (or median) shape is predicted, especially in the highly varying regions of the vertebra such as the vertebral processes. We have,
where
and
are weights for the network prediction and smoothness terms respectively, and are fixed to
= 10 and
= 0.1. Note that
contains an integer value of
, where
represents the vertebral index from T1 to L5. Constraining the network to predict the vertebral index implicitly requires it to learn relating the vertebral index to the shape as a prior.
In order to impose a constraint for locally smooth deformations and a minimum displacement solution for our registration problem, we add to penalize the of the deformation field.
The network was implemented with the Pytorch framework on a Quadro P6000 GPU. It was trained until convergence using the Adam optimizer [
32] with an initial learning rate of 0.0001.
2.5. Data
Recall that TransVert+ works with two data modalities: it is trained on DRRs extracted from CT images and is deployed on clinical radiographs.
2.5.1. CT data
We employed two sets of data: First, a public dataset for lung nodule detection with 800 chest CT scans [
33], and second, an in-house dataset with 154 spinal CT scans. Overall, we work with ∼12 K vertebrae split 5:1 forming the training and validation set and report 5-fold cross-validated results. Of note, ref. [
33] is a lung-centred dataset, thus consisting of few lumbar vertebrae.
Usually in spine CT scans [
34] some parts of the ribs and tissues in distance from the spine are excluded. Thus, these scans could not be used for generating DRRs that are similar in appearance to real radiographs. However, using lung CT scans result in better DRRs.
All of spinal CT scans were resampled to 1 mm resolution. The CT scans of our in-house dataset had ground truth segmentation and the CT scans in [
33] were segmented using [
35]. Next, an experienced neuro-radiologist approved the generated masks to consider only accurate ones for the study. Consequently, we excluded 50 cases from [
33].
We employ a ray-casting approach [
36] to construct DRRs from CT scan. In this method, we define lines from the radiation source (focal point) to every single pixel on the DRR image and calculate the integral of the CT intensities over these lines. In this simulation we assign (
) and (
) to the radiation source-to-detector distance and the source-to-object distance parameters respectively. Examples of patches extracted from DRRs are illustrated in
Figure 6 and
Figure 7. Also, a complete example of orthogonal DRRs is shown in
Figure 8.
Once the sagittal and coronal DRRs are generated, the inputs for TransVert+ are constructed by extracting image patches of size 64 × 64 around each vertebral centroid. Similarly, the VOI-annotations were also extracted automatically from the projected segmentation mask.
2.5.2. Clinical Radiographs
We validate TransVert+ on clinical, standing radiographs (pairs of lateral and anterior-posterior projections) acquired from 30 patients. Before deploying our TransVert+ model on the clinical radiographs, we resampled all radiographs to 1 mm resolution.
Image acquisition parameters such as the source-to-detector and source-to-object distances were similar to those used for DRR generation. We employed [
37,
38] to automatically generate the vertebral annotations on both views.
2.5.3. Image Normalization
We trained TransVert+ on DRRs and tested it on real clinical radiographs. To enable a transfer of learning between these modalities, we need to normalize the intensities to a similar range. Therefore, we employ z-score normalization, i.e., , where and are the mean and standard deviation of the image , respectively.
2.6. Metrics
The Dice score is the most popular measurement for evaluating segmentation accuracy and measures the overlap between two binary images. However, the Dice score is a poor measure of segmentation accuracy when the shapes to be compared are not “blob-like”.
Another popular metric for segmentation evaluation is the Hausdorff distance. The Hausdorff distance between two segmentations represented as surface meshes is the maximum distance from vertices on the first mesh to the vertices on the second mesh.
The measurements, such as the Dice score, average many local errors measured at each voxel. Thus, a segmentation that is largely correct with a few major shape errors will have the same score as a segmentation that is only slightly wrong everywhere.
As mentioned before, we do not have the 3D ground truth for the clinical radiograph of a patient. We can acquire the 3D CT segmentation of the same patient. However, because of difference in spinal posture, the vertebral orientations are different and we cannot compare the 3D vertebrae reconstructed from clinical radiographs to the ones from CT using Dice score or Hausdorff distance. Thus, we desire a rotation-invariant metric to evaluate the model performance on clinical radiographs, for each individual vertebra.
The normalized weighted spectral distance (nWESD) [
39,
40] is a global shape measure based on heat trace analysis via the Laplace operator. The eigenvalues of the Laplacian of a shape are strongly connected to the shape’s geometric properties, such as its volume, surface area and mean curvature. The Laplace spectrum is invariant to isometric transformations (rigid transformations), and changes continuously as a shape’s boundary is transformed. Thus, because of rotational invariance, we can use this metric for comparing the 3D vertebral shapes reconstructed from the patient’s clinical radiographs to the vertebral shapes from their 3D CT segmentations.
The weighted spectral distance (WESD) between two binary segmentations
and
is defined as:
where
and
denote eigenvalues of the segmentations
and
, and
with
,
d indicates the dimensionality of the binary segmentations.
The normalized WESD (nWESD) is derived using the fact that WESD converges as
(even though each eigenvalue spectrum is divergent) and is bounded above by
(for details, see [
39]). Therefore, the (finite) nWESD
can be defined as:
2.7. Experiments
In order to analyze the contribution of various architectural components of the TransVert+ (fusion of sagittal and coronal views with shape prior, the affine decoder and a convolutional decoder to estimate the displacement field for each vertebrae) and to validate its performance on clinical radiographs, we propose three sets of experiments.
- (1)
We conducted an ablative study on the architectural choices including three steps: First, we evaluated the performance of the model working only with the affine decoder. Second, we trained the model solely with the deformable decoder to estimate the deformation fields. Third, we repeat the performance of our previous model TransVert, in which we did not incorporate the shape priors, but estimated the vertebral shapes directly in the voxel space without registration. Finally, we give results for TransVert+.
- (2)
We deployed the model on clinical radiographs to reconstruct 3D standing spine postures.
- (3)
We evaluated the model performance on clinical radiographs quantitatively. The performance evaluation in various settings was compared by computing the Dice coefficient, Hausdorff distance and normalized weighted spectral distance (nWESD) between the predicted 3D vertebral mask and the ground truth CT mask, where appropriate.
3. Results
The results of the ablation study are reported in
Table 1. As we expected, the affine results are not better than TransVert, since the model roughly aligns the shape template to the target and the results lack shape details. Training the model with a deformable decoder performs better than the affine model. The deformable model achieves an average Dice score of
, close to that of the TransVert model (
). In the Hausdorff distance metric, TransVert performs better but for the nWESD metric, the deformable model achieves a better score. Finally, our main TransVert+ model outperformed all of the previous models in all metrics.
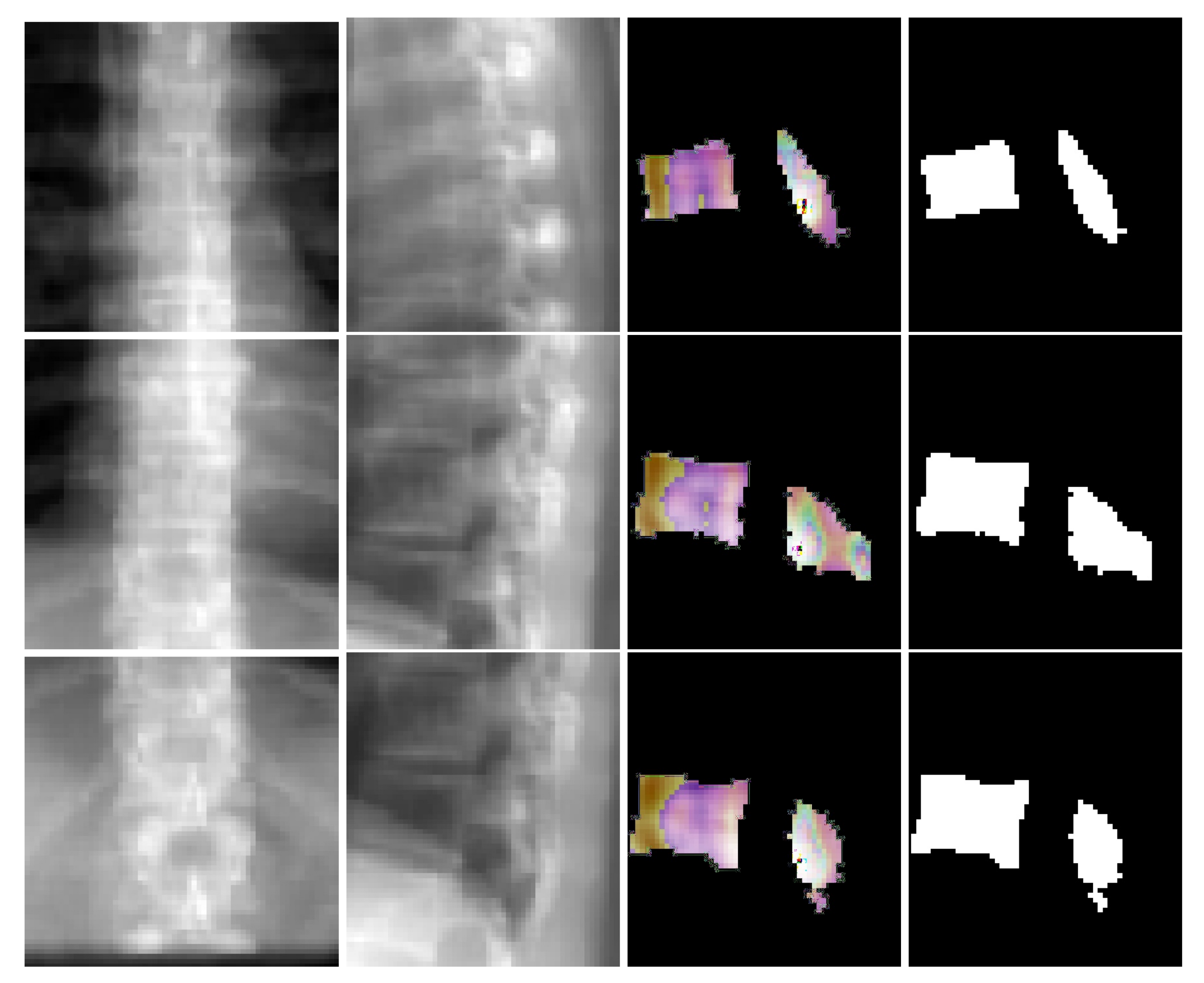
Figure 6 depicts coronal and sagittal image patches from three vertebrae, mid-slice of the resulting estimated displacement field and vertebral shape. In the estimated displacement field the brighter colors indicate greater displacements.
Figure 7 shows an example point cloud (with 2048 points) from the predicted and ground truth shapes, along with a point-wise Chamfer distance map. Observe that the vertebra’s posterior region (vertebral process) is hardly visible in the image inputs. In spite of this, TransVert+ was able to reconstruct the 3D shape of vertebral processes. To calculate the Chamfer distance map for each point in the reconstructed vertebra’s point cloud, the nearest point in the ground truth point cloud is found and the square of distance is depicted.
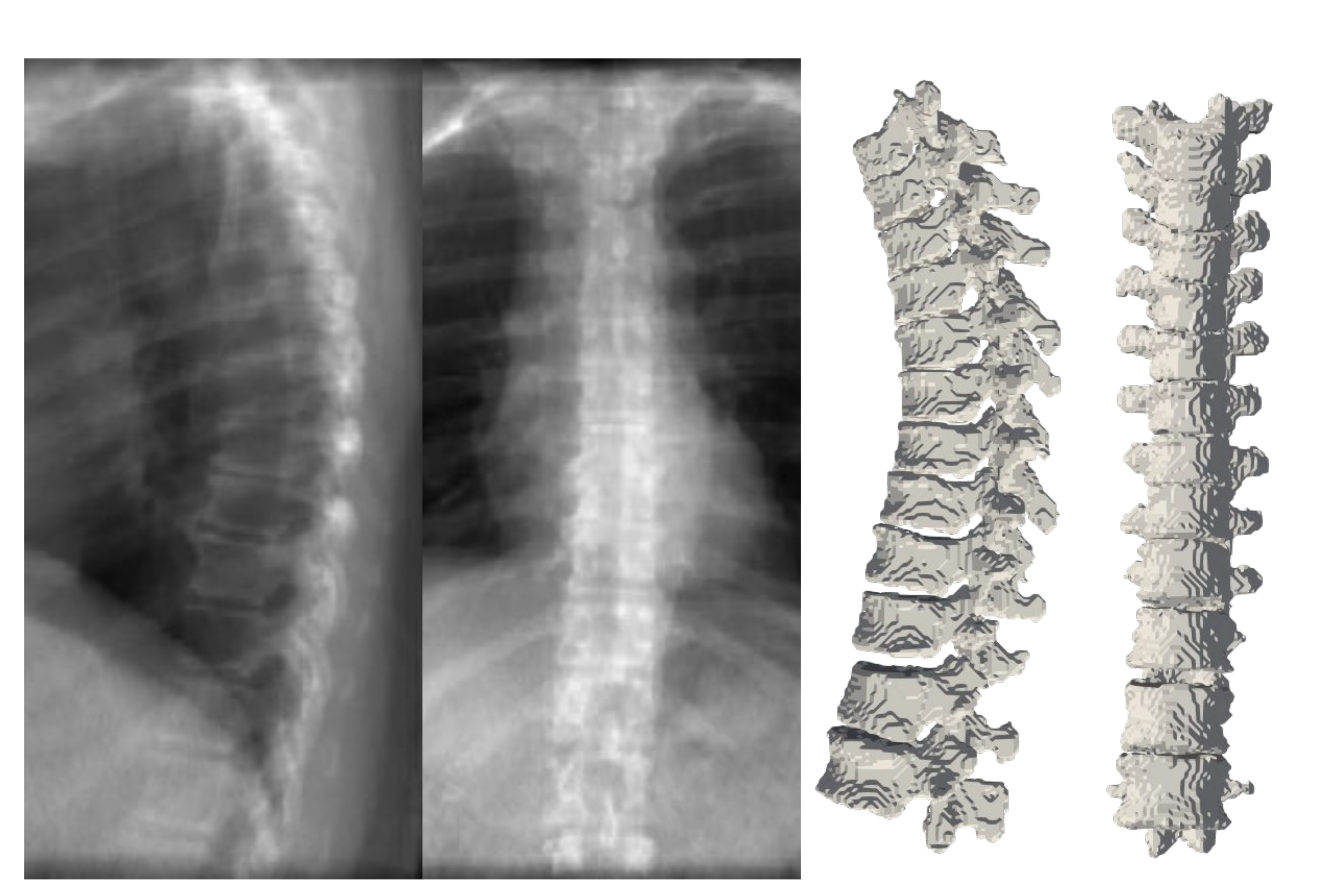
Figure 8 illustrates a 3D spine reconstruction based on 2D DRRs.
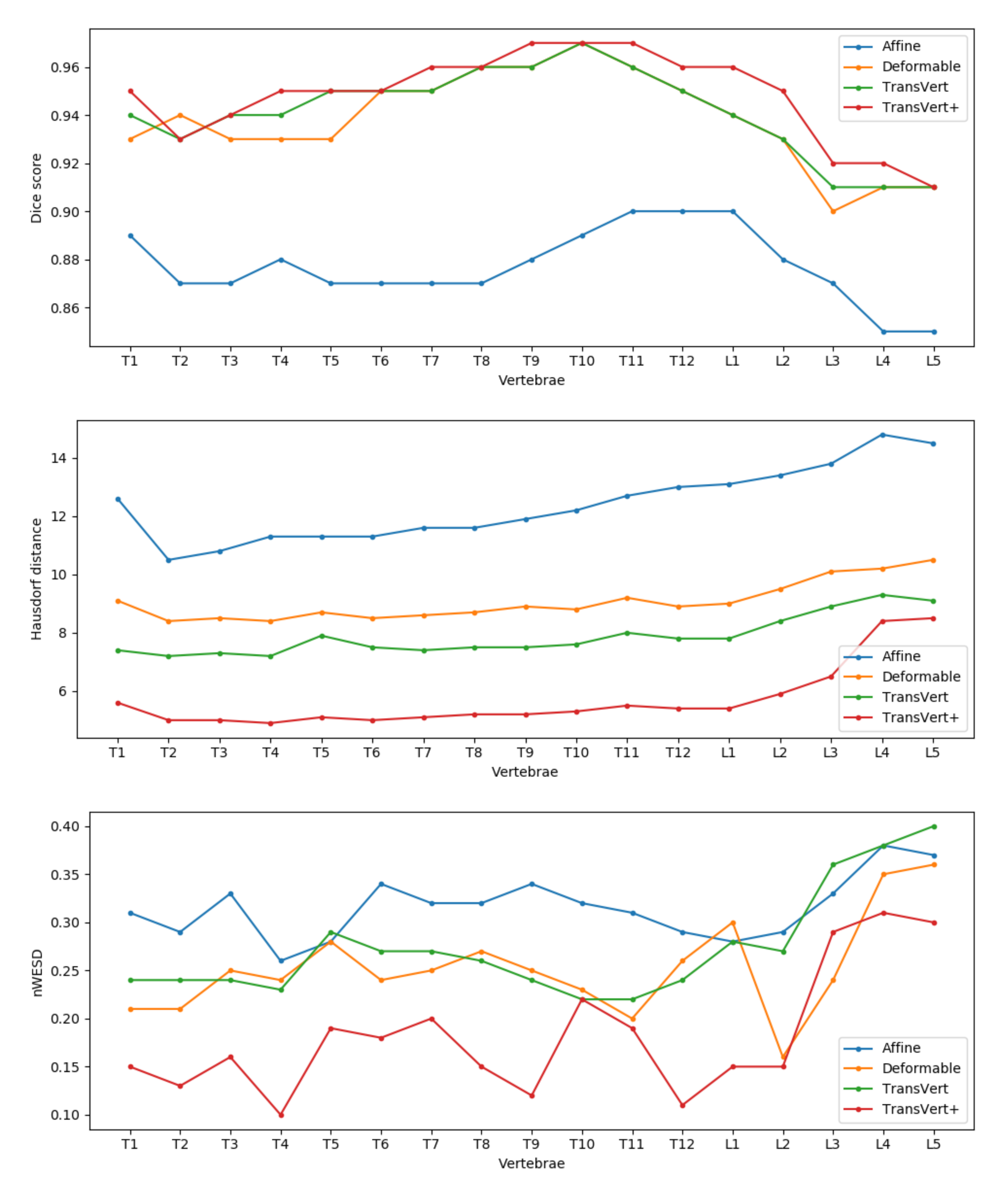
For a detailed comparison of the methods, in
Figure 9 we report the mean Dice score, Hausdorff distance and nWESD distance for each vertebra. In general, TransVert+ outperforms almost all other models for each vertebra. According to this figure, the model performance drops in all metrics for lumbar vertebra.
3.1. 2D-to-3D Translation in Clinical Radiographs
Figure 10 depicts the results of deploying TransVert+ for reconstructing the 3D, patient-specific posture of the upright standing spine. As stated, there is no 3D ground truth spinal model for the clinical radiographs. Observe the matched reconstruction of the 3D spine posture to the spinal posture in radiographs.
3.2. Quantitative Evaluation of Performance on Clinical Radiographs
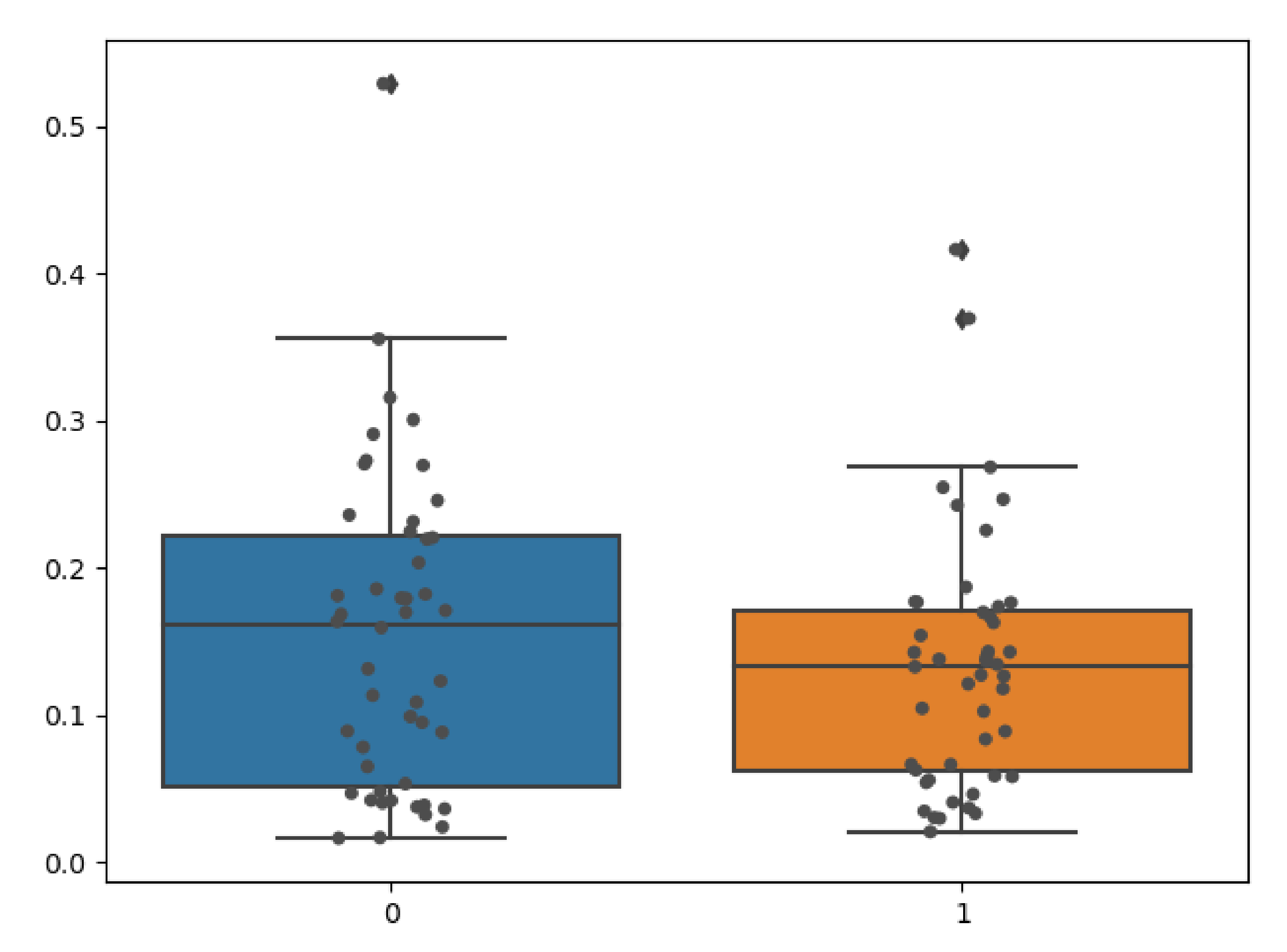
We quantitatively evaluated the performance of our model on clinical radiographs in two patients for whom we have CT scans in addition to orthogonal standing radiographs. Using our TransVert model and the TransVert+ model proposed in this work, we generated the 3D shapes of the vertebrae given the 2D clinical radiographs. Then we compared each vertebra to the corresponding one from the CT scan segmentation masks, which refer to the same object but in a different orientation. Conventional metrics like the Dice score or Hausdorff are not applicable in this case, but we can use the nWESD metric as it is invariant to rigid transformations (including rotation). The resulting nWESD scores are demonstrated in
Figure 11, where the mean of nWESD was
and
for TransVert+ and TransVert respectively. Similarly, the standard deviation of nWESD was
for TransVert+ and
for TransVert. These scores are calculated on a group of 32 vertebrae. Despite better values for TransVert+, the difference was not significant.
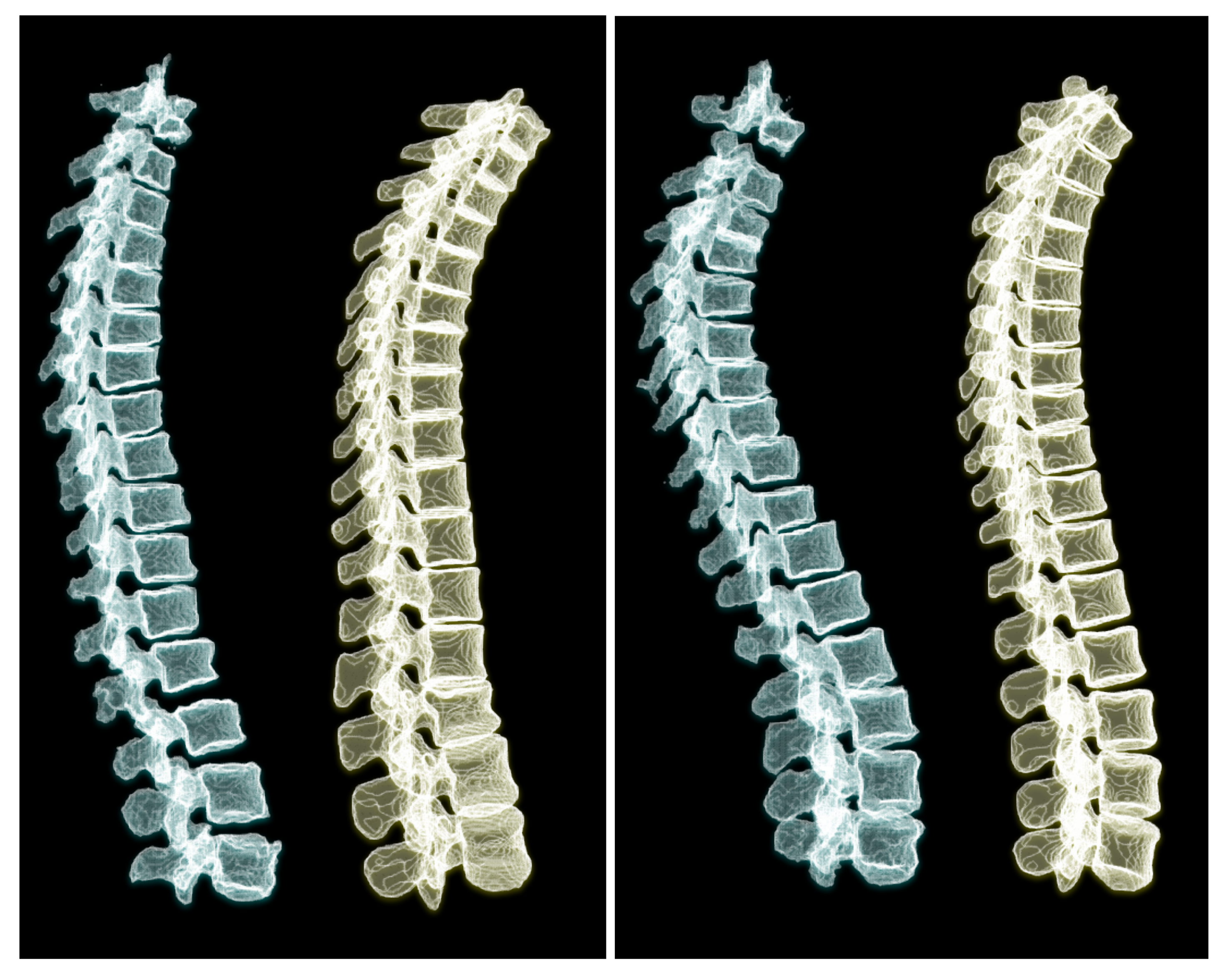
To appreciate the difference of spine posture in the standing and lying down positions, we illustrate the two cases we used in this experiment in
Figure 12. The spine postures reconstructed from radiographs in upright standing position are depicted on the left and the ones from CT are depicted on the right side of the figure.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}