1. Introduction
Myocardial perfusion is significant in the evaluation of cardiovascular health, particularly in the context of ischemic heart disease, a condition characterized by reduced blood supply to the heart muscle [
1]. Cardiac perfusion MRI, a non-invasive imaging modality, has emerged as a powerful tool for the quantification of myocardial blood flow (MBF) [
2]. This technique involves the use of a gadolinium-based contrast agent (Gd), which is injected into the patient’s bloodstream. The passage of this paramagnetic agent through the myocardium is then tracked using MRI, allowing for the calculation of MBF. A quantitative approach provides a more precise assessment of myocardial perfusion, enabling clinicians to accurately diagnose ischemic heart disease, monitor disease progression, and evaluate the effectiveness of therapeutic interventions [
3,
4].
An accurate arterial input function (AIF) is a fundamental component in the quantification of myocardial blood flow using cardiac MRI [
5,
6,
7]. The AIF represents the time–concentration curve of the contrast agent in the blood, serving as a reference for tracking the agent’s passage through the heart muscle. The AIF enables the calculation of key perfusion parameters such as myocardial blood flow and volume, which are instrumental in diagnosing and managing cardiovascular diseases. Given its central role, the accuracy of the AIF is critical. Inaccuracies in the AIF can lead to significant errors in perfusion quantification, potentially resulting in misdiagnoses or inappropriate treatment decisions [
8].
The relationship between the MRI signal and Gd concentration is nonlinear, leading to signal saturation at high Gd concentrations. This saturation effect distorts the AIF, resulting in an underestimation of the peak contrast agent concentration. To correct the AIF for signal saturation, dual-bolus [
9] and dual-sequence [
10] techniques aim to minimize signal saturation by acquiring images after injecting a small pre-bolus of contrast agent or by using shorter saturation-recovery times (SRT), respectively. Prior studies have shown the feasibility of obtaining a short-SRT AIF with no added time cost [
7,
11]. Other approaches, such as blind estimation methods, have been used to obtain an accurate AIF without additional image acquisitions or contrast injections [
12,
13]. Most recently, machine learning algorithms have been employed to learn the nonlinear relationship between saturated and unsaturated signal intensity (SI) curves using a large dataset of images from over 200 patients [
14]. This learned network displayed the corrected AIFs and demonstrated that the myocardial blood flow results calculated with the corrected AIFs were comparable to the reference values. However, the effectiveness of arterial input function correction diminishes notably when applied to infrequent cases that lie outside the bulk of the training data. To enhance the accuracy of the machine learning AIF approach, this study investigates including myocardial tissue signals obtained during the dynamic MRI acquisition.
2. Methods
2.1. Overview
The overall approach was to generate simulated data for training and testing in a Bi-LSTM neural network (NN) and compare the NN-corrected AIFs with the dictionary-based AIFs (inputs to the networks). Additionally, the training was adapted to apply the networks to 12 in vivo datasets.
Grammarly and ChatGPT-4 were used to aid in checking grammar and improving manuscript wording.
2.2. Data Preparation
2.2.1. Simulated True AIF and Tissue Curves
The generation of simulated data employed a mathematical model for the true, unsaturated AIF [
12]. The AIF model was a sum of three gamma variates and one sigmoid function, which were previously applied in the blind estimation of AIF [
13]. The equation was represented in the following form:
where
G represents a gamma variate,
S is a sigmoid function,
are scaling constants,
are delay time terms,
and
are related to the shape and width of the first-pass bolus and recirculation peaks, and T represents the exponential time constant for contrast elimination from the blood pool. To reduce the number of parameters, Equation (1) was modified as below [
13]:
Here, the parameter values were empirically chosen to approximate the shape of the real AIF curve population. To construct a realistic pool of AIF curves, we used , , min, min, , , min, min, , min, , and min. A time interval of 0.5 s and a total of 120 time points were used for each AIF and the other simulated curves presented.
A four-parameter compartment model was used [
15], described as follows:
where
is proportional to the myocardial blood flow (MBF),
is the parameter that controls the shape of tissue curves,
is the portion of vasculature within the tissue, and
represents the enhancement time delay between the left ventricle blood pool and the myocardium. The four pharmacokinetic parameters were assigned values according to a realistic range reported in [
15]. Specifically,
,
,
, and
minute. Tissue curves were generated from the true AIFs described in Equation (2), with pharmacokinetic parameters sourced from a uniform random distribution.
2.2.2. Saturated AIF
Bloch simulations were employed to construct a dictionary for a saturation-recovery 3D radial stack-of-star (SoS) sequence [
16] to map between SI and Gd concentration. The noise-free true AIF Gd curves were converted to SI with the dictionary using sequence parameter settings from in vivo data from a retrospective study at 3T [
7]. The in vivo data had a flip angle (FA) of 12° for the Gd-enhanced signal, 24 rays for a k-space center partition, SRT = 100 ms, TR = 2 ms, and TE = 1ms, native blood T1 of 1.8 s, and the non-contrast T2* value was assumed to be 0.06 s based on the measurement of average T2* of blood in a clinical myocardial T2* map. T1 and T2* relaxivity used 3.8 and 5.7 L/mmol-s [
17].
The main sources causing bias of SI in AIF curves include the nonlinear signal response inherent to saturation recovery, T2* decay caused by high contrast agent concentration, imperfect saturation of magnetization post-SR pulse, FA bias due to B1 inhomogeneity, and spatial signal variations caused by sensitivity profiles of the surface coils [
10]. The nonlinearity between SI and gadolinium concentration can be modeled [
18]. Additionally, three factors—FA, T2*, and residual magnetization—were included in the simulation. The variation in coil sensitivities can be corrected using proton density images, and thus was not considered in the simulation.
Specifically, FA was altered by up to ±10%, while T2* and initial magnetization changed by a maximum of 10%. Training, validation, and test data all adhered to these ranges. The biased AIF SI curves were subsequently converted back to [Gd] curves using the nominal values of sequence parameters and the same dictionary. Gaussian noise was introduced to the AIF signal intensity (SI) curves rather than the [Gd] curves. This procedure was similarly applied to tissue curves to incorporate noise. The noise standard deviation was 5% of the peak value of tissue curves, roughly aligning with the pixel-wise noise value observed in the 12 in vivo datasets. The identical noise level was imposed on the saturated AIF SI curves.
2.3. Deep Neural Networks (DNNs)
Three different loss functions were implemented and compared using a Bi-LSTM network, including just AIF loss (Equation (4)), AIF with compartment-model parameter loss (Equation (5)), and AIF with compartment-model-based tissue loss (Equation (6)).
2.3.1. Loss Functions
In Equation (4), an L1 loss is applied to the AIF loss, where
represents the true (simulation data) or measured (in vivo data) Gd concentration time curves, and the hat symbol means predicted curves. The predicted curves,
, with a time length of 120 points in this study were iteratively updated to minimize the loss function. In Equation (5),
= {
,
,
,
},
α and
β are the weights of each loss term, and
N is the number of tissue curves. For in vivo data, true model parameters were calculated based on the target
AIF and measured tissue curves. In Equation (6),
α and δ are the weights of each loss term. The compartment-model parameters
were combined with
to model the tissue loss, and
represents true (simulation data) or measured (in vivo data) Gd concentration time curves.
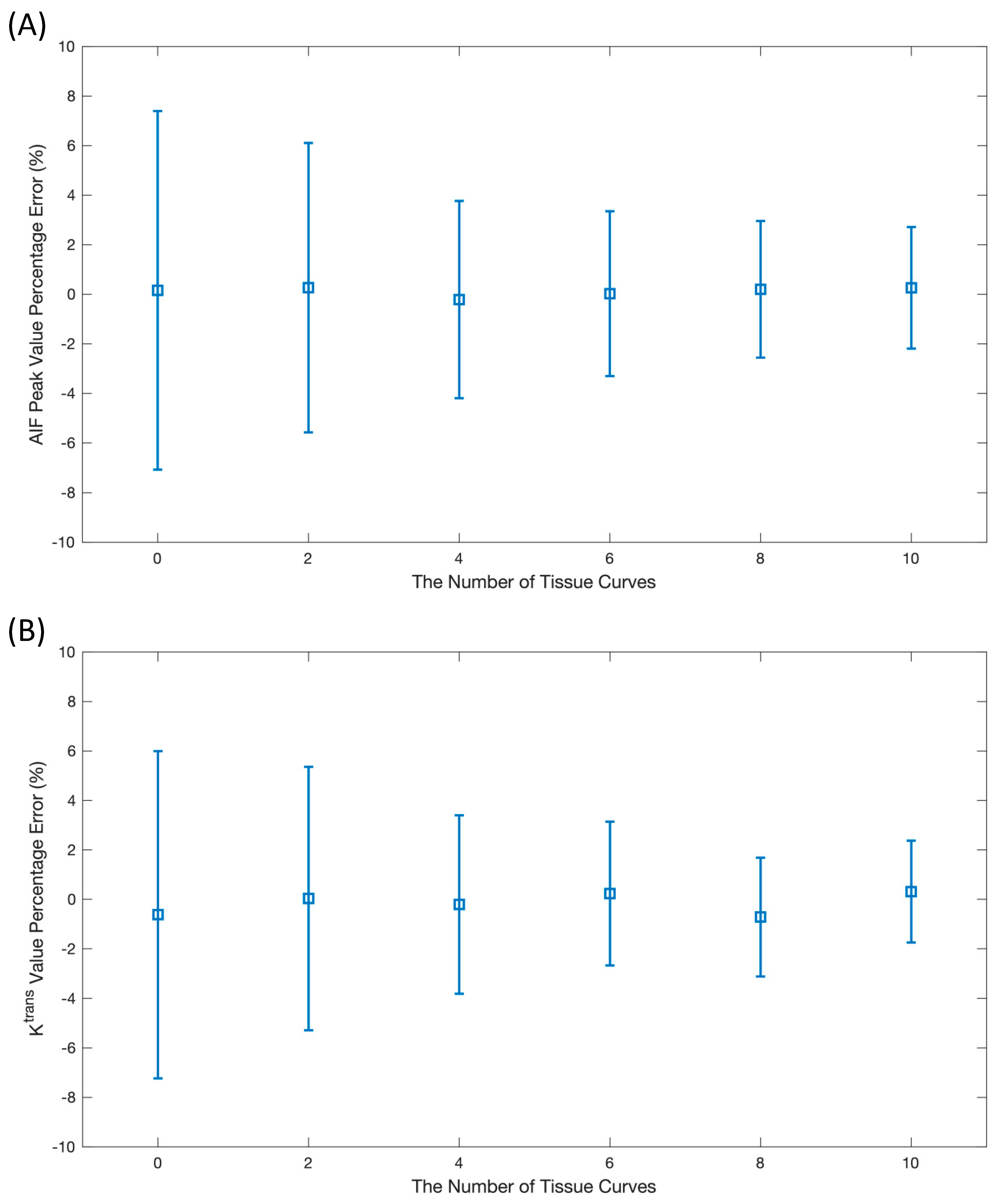
Initially, two important factors needed to be optimized for the AIF correction, including the number of tissue curves (or inputs to the network) and the selection of the loss function. In the analysis to determine the optimal number of tissue curves, the
values were set to range from 0.3 to 2.3, increasing by intervals of 0.2 for each additional tissue curve. Consequently, the surveyed number of curves varied between 0 (just AIF input) and 10. Moreover,
will change accordingly as the extravascular extracellular space is restricted within 0.2–0.3 [
19,
20]. The second experiment was investigated based on the comparison of the loss functions described in Equations (4)–(6).
2.3.2. Networks
Bidirectional Long Short-Term Memory (Bi-LSTM)
A 1D Bi-LSTM network [
21] was first implemented to evaluate its efficacy in AIF corrections by studying the three factors to find the optimal setting (decision on the format of the loss function and inputs to networks) for AIF corrections. The workflow for AIF corrections with the Bi-LSTM network is displayed in
Figure 1. The Bi-LSTM network consisted of four layers, each including a forward and backward LSTM unit. The number of hidden nodes inside each LSTM unit was 32. After the concatenation of outputs from the last layer of Bi-LSTM, a linear layer was employed to convert feature size to the time length of AIF as the predicted AIF output.
The network was implemented based on the Pytorch platform. The inputs to the network were the inaccurate AIFs generated with the dictionary method. These same AIFs were used as a baseline to indicate improvements in AIF estimates.
Training, validation, and test datasets
In the following studies with simulated data, 10,000 sets of time curves were generated randomly. Of the total sets, 8000 sets were used for training, 1000 sets for validation, and 1000 sets for testing. Each set included the saturated and biased AIFs along with the true unsaturated AIF curves, alongside up to 10 tissue curves. The unsaturated AIFs were noise-free true AIF curves derived from the mathematical model, as seen in Equation (2).
2.3.3. Hyperparameters
The networks used a batch size of 16, 100 training epochs, and ADAM optimization with a learning rate of 0.0003. All network parameters were initialized as zero for “bias” and He normal weights [
22] for “weight”. The best network was saved with the highest validation accuracy, while all loss curves were observed for a sanity check to avoid overfitting.
2.3.4. Evaluation Metrics
Two metrics were applied to assess the accuracy of the predicted AIFs. Since signal saturation was most prominent at the peak concentration of an AIF, peak values between the estimated AIF and the reference were compared using percentage error. In addition, predicted AIFs and tissue curves were fitted using the Levenberg–Marquardt algorithm [
23] to obtain the resulting pharmacokinetic parameters. The value of
was then used as the second metric to compare with the target because it is proportional to myocardial blood flow. The percentage error of the two indexes can be calculated using the equation below.
where
P represents the predicted AIF peak or
values, and
T indicates the target values. The error is visualized with an error bar plot.
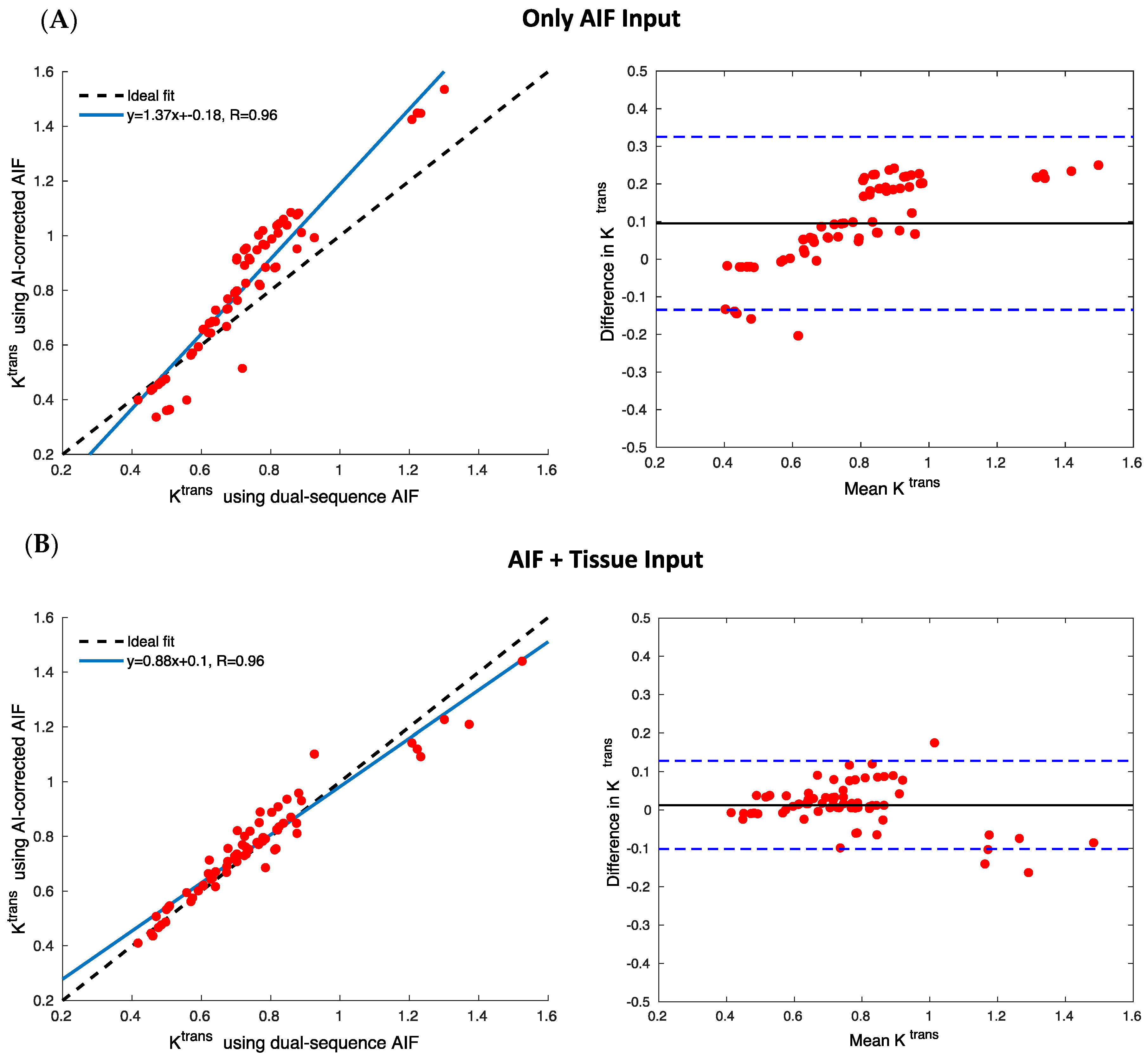
Statistical analysis was conducted to assist in the visualization of results. A straight line produced from the linear fit can be drawn using the estimated slope and intersect values displayed in the scatter plot of AIF peak values, or , from the test data. Pearson coefficients were calculated to indicate the correlations between estimates and target values, and Bland–Altman plots were used to assess accuracy and outliers.
2.4. Applying the Trained Networks to In Vivo Data
Existing in vivo 3D radial SoS datasets were processed to determine how the simulation-trained networks performed on in vivo data. The in vivo acquisition includes a 2D AIF with SRT = 20 ms and 3D myocardial perfusion images with SRT = 100 ms. Other data acquisition details match the previous descriptions of generating the simulated data.
A region of interest in the left ventricle blood pool in the central slice from the long SRT 3D scan in five dogs (rest and stress scans) and two human subjects (rest) was employed to generate “saturated AIFs”. Subsequently, a preprocessing step, encompassing interpolation and alignment, was undertaken to ensure data format uniformity. The interpolation was set to a time interval of 0.5 ms and a total duration of 1 min, ensuring a consistent input length for the neural network. Furthermore, aligning AIFs from different subjects was essential due to potential variations in their timestamps.
Poor results were obtained from the trained networks applied to in vivo data. Thus, a new training set with FA altered one-sided by up to 10% was created, while a validation set was built with a bias range of up to 15% in order to account for the difference in data distribution between simulated and in vivo data. The same variations were applied to T2* and initial magnetization to mix the bias factors together.
For the hybrid dataset, both added noise and noise-free simulated curves were used for training. Noise-free simulated data were used for the final report of results because the noise-free simulated datasets gave superior results over noisy datasets. No in vivo data were used in the training set.
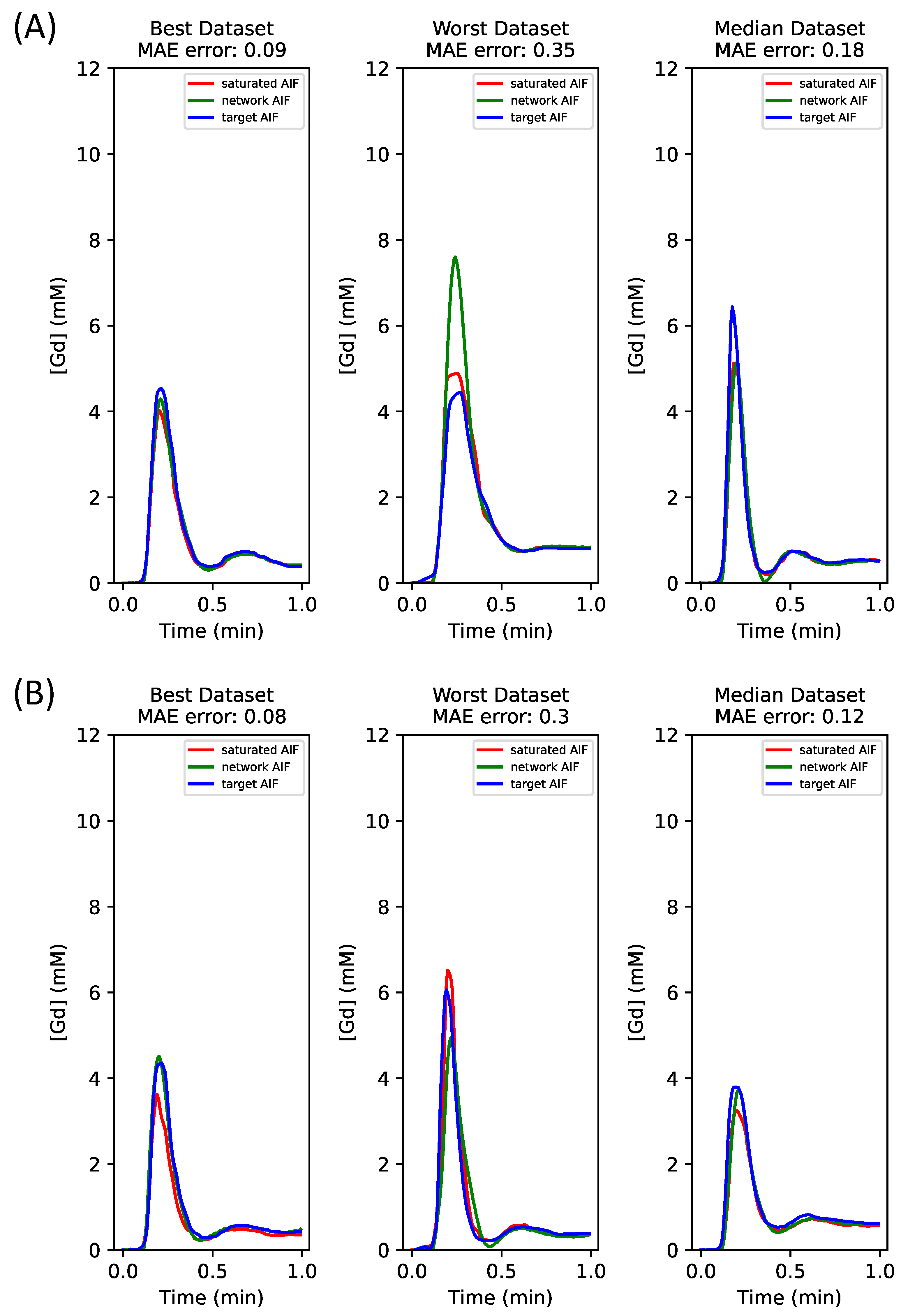
The hybrid datasets consisted of 8000/1000 sets of simulated time curves for training/validation and 12 sets of in vivo time curves for testing. Four tissue curves were generated with simulations for each AIF set for training and validation. The same number of tissue curves (four) were generated using K-means clustering from pixel-wise time curves within the myocardium for testing only.
4. Discussion
In this work, we have established that combining the AIF and tissue inputs under the AIF loss enhances the deep learning correction of signal bias in the AIF for quantitative perfusion CMR. The optimization began with a fundamental network architecture that used the AIF input with the AIF loss. The addition of tissue curves to the training inputs yielded improved AI correction. While increasing the number of tissue curves for network inputs refined the estimation, incorporating additional loss terms, such as compartment-model-based parameter loss and tissue loss, did not prove advantageous. Therefore, we focused on AIF + tissue curve inputs with the AIF loss, utilizing both purely simulated and hybrid datasets. This consistently demonstrated enhanced accuracy following the inclusion of tissue curves in the network inputs.
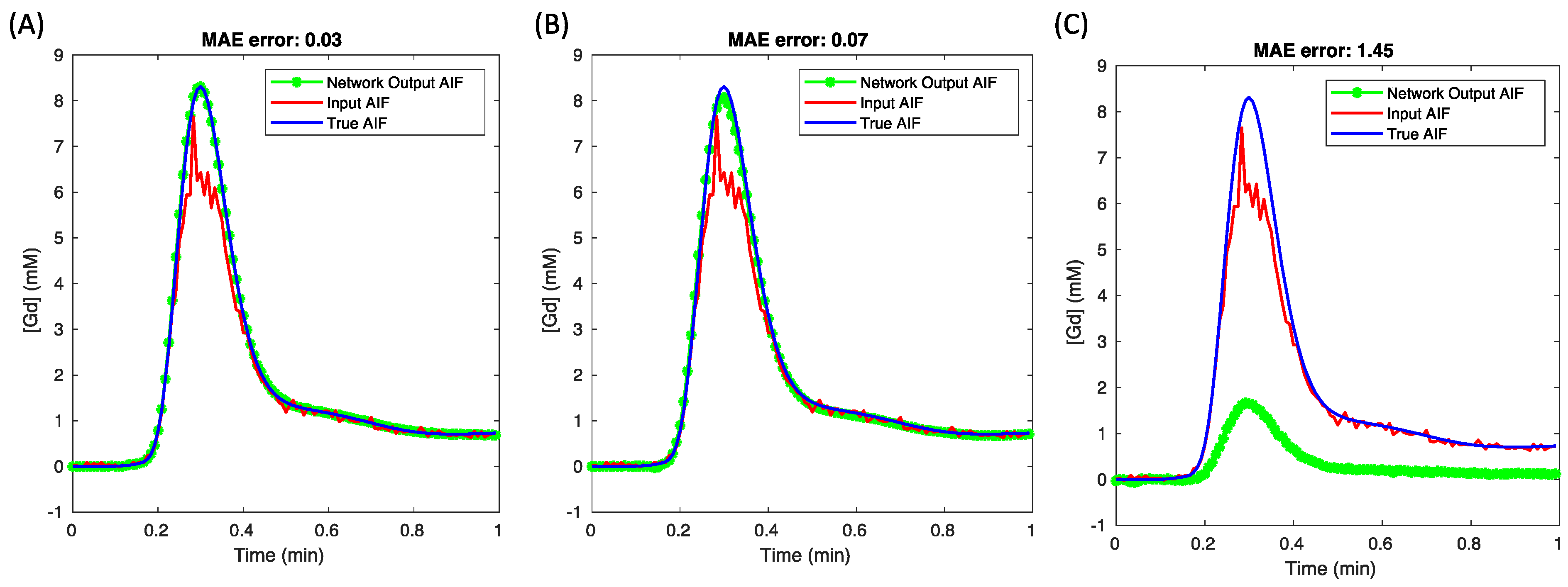
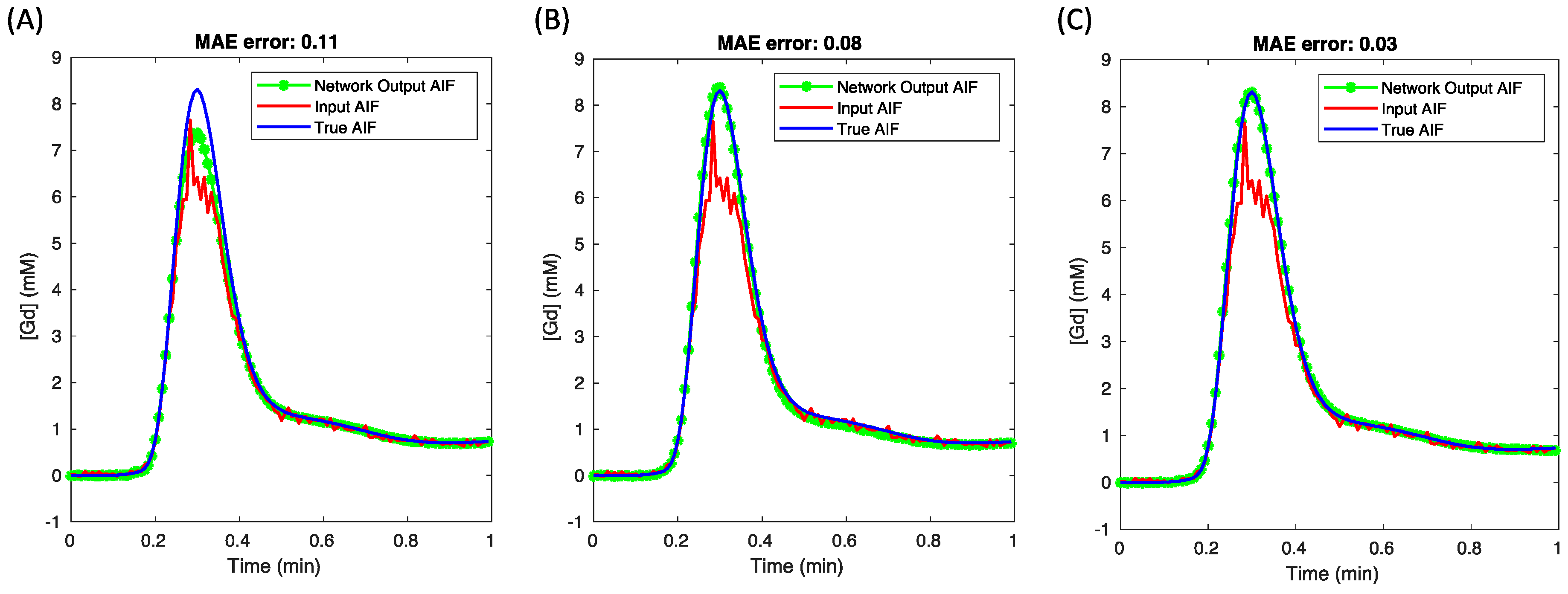
Integrating tissue curves as network inputs bolsters the accuracy and precision of AIF predictions. This is because tissue curves embody a lower gadolinium concentration range, within which the relationships between gadolinium concentration and signal intensity remain linear, thus ensuring a linear correlation with the accurate AIF. Conversely, the saturated AIF exhibits a nonlinear relationship with the true AIF at higher concentrations. We validated this hypothesis by evaluating various network inputs, including just AIF-only, tissue-only, and AIF + tissue curves (
Figure 6). The network-predicted AIF using AIF-only input (
Figure 6A) displayed a distinctly saturated peak, whereas using only tissue curve inputs (
Figure 6B) mitigated the peak value error. Given that the lower-concentration segment of the AIF input is expected to be unbiased, combining AIF and tissue curves as inputs (
Figure 6C) achieves the most precise AIF estimates.
The finding that adding tissue curves may benefit accurate AIF estimation depends on the number of tissue curves and the diversity of the tissue curves. In the simulation study, a strategy that used an increment of 0.2 for given
values of multiple tissue curves was adopted empirically. Since increasing the number of tissue curves adds fresh information to inputs, using ten tissue curves can continue to improve AIF correction, as shown in
Figure 2. However, this was not true for in vivo data. Healthy subjects tend to have relatively similar myocardial tissue curves; thus, only a small number of tissue curves clustered from a group of pixel-wise tissue curves may be sufficient. In this work, four tissue curves were found to enable the best performance for the in vivo data (not shown). Furthermore, patients with focal perfusion defects may have more diverse tissue clusters, thus requiring more tissue curves for inputs but offering possible performance improvements from more diversity.
Generating a simulation dataset is useful for studying deep learning for the AIF correction task, especially when there has been a lack of clinical sequences for quantitative myocardial perfusion. Without the assessment of open datasets and the lack of multi-center cooperation, the number of patient datasets to experiment with is limited. The simulation study is feasible for this work because the mathematical AIF model for generating AIF time curves and a compartment model for producing tissue time curves have been applied in previous works on AIF corrections [
13]. Due to the similarity in shape between a gamma function and AIF, a gamma variate has been modified to model either the first-pass perfusion [
24,
25] or the whole perfusion process [
12,
26]. The model used for the first-pass perfusion requires fewer unknown parameters and can be combined with a Fermi model for quantitative analysis. However, this work adopted a 12-parameter AIF model to flexibly adjust simulated AIF curves to approximate real AIF curves.
Traditional machine learning operates on the premise that training and test sets hail from identical distributions. However, this may not always be the case in real-world scenarios, especially when datasets originate from disparate sources, multiple imaging centers, or become outdated due to evolving data over time. In this context, our approach used the assumption that in vivo test data presented a more diverse data distribution compared to simulated data [
27].
Although the results section details the selection of loss functions, the rationale for why additional loss terms beyond AIF loss did not yield benefits remains unexplained. The premise behind the parameter loss was that these parameters operate on a different intensity scale compared to the values of the AIF curves. Furthermore, the tissue loss, derived from the compartment model, entailed convolving the estimated parameters with an estimated AIF, resulting in non-unique outcomes. This was demonstrated in
Figure 4, where the network AIF estimate was obviously biased when using a combination of AIF and model-based tissue loss, applying a ratio of 1:100 for the two loss terms.
In a broader context, the results of this study have implications for the fields of cardiovascular imaging and patient care. If quantitative myocardial perfusion measurements can be obtained from MRI methods that do not need the acquisition or analysis of a separate dual bolus or dual sequence method, this simplifies the approach and can aid in its adoption. More widespread use of quantitative myocardial perfusion promises a more accurate diagnosis of ischemic heart diseases.
While the present study shows promising results for AIF correction, certain limitations may exist. The mathematical model for the AIF was previously validated to achieve good agreement between the blind estimated AIF and the measured AIF [
12]. The mean bias and uncertainties of compartment-model parameters derived from the two AIFs were found to be comparable. For example, the mean bias of
was +7% and the uncertainty was 0.0043 min
−1 for normal brain tissue. In addition, the simulated tissue curves were drawn from a uniform distribution, which reflects a mix of normal and abnormal perfusion and washout. The diversity of
kep is known from blind estimation studies to provide more information regarding the AIF [
13]. As well, the use of simulated datasets, while advantageous for controlled experimentation, does not replicate real-world scenarios. Therefore, there is a need to validate these findings with larger, diverse, and real-world datasets to understand the broader applicability of the results. The selection of a Bi-LSTM network is due to its outstanding performance in handling time-series data; however, other advanced networks, such as transformers and gated recurrent units, may be better choices for AIF corrections. Therefore, future development of new networks is important, especially for tackling hybrid data better.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}