
An Enhanced IDBO-CNN-BiLSTM Model for Sentiment Analysis of Natural Disaster Tweets

Abstract
1. Introduction
- (1)
- Hybrid deep learning models are more suitable for tweets’ sentiment polarity classification than single models.
- (2)
- Improved swarm intelligence algorithms can optimize the hybrid deep learning models’ hyperparameters to increase classification accuracy further.
- We utilize three strategies to improve the DBO algorithm. First, we adopt the Latin hypercube sampling to update the population initialization process. Second, we integrate the OOA’s global prospecting strategy in the ball-rolling dung beetles’ position update equation. Third, we introduce an adaptive Gaussian–Cauchy mixture mutation disturbance for optimal individuals.
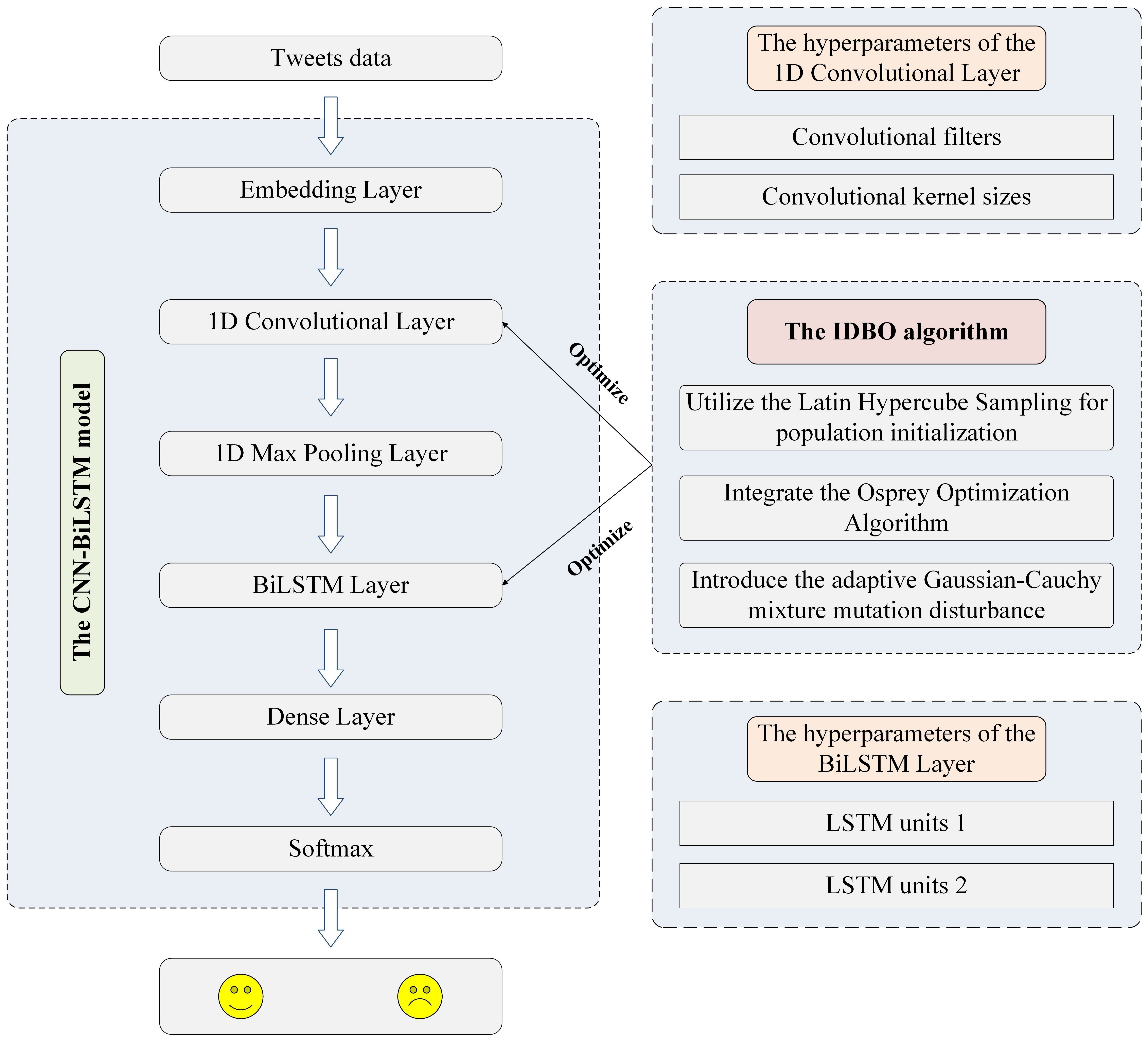
- We construct a CNN-BiLSTM model based on local feature extraction and contextual information understanding abilities. We then use the improved DBO algorithm to obtain the CNN-BiLSTM model’s optimal hyperparameters. These hyperparameters include the 1D convolutional layer’s filter number, the convolutional kernel sizes, and the unit number in BiLSTM’s each LSTM layer.
- We conduct extensive comparative experiments with other single and hybrid deep learning models on natural disaster tweets. The empirical analysis proves the IDBO-CNN-BiLSTM model’s superiority in sentiment polarity classification of natural disaster tweets.
2. Literature Review
2.1. Natural Disasters
2.2. Social Media Analysis of Natural Disasters
3. Method
3.1. The DBO Algorithm
3.1.1. The Ball-Rolling Dung Beetles
3.1.2. The Brood Balls
3.1.3. The Small Dung Beetles
3.1.4. The Stealing Dung Beetles
3.2. The Proposed IDBO Algorithm
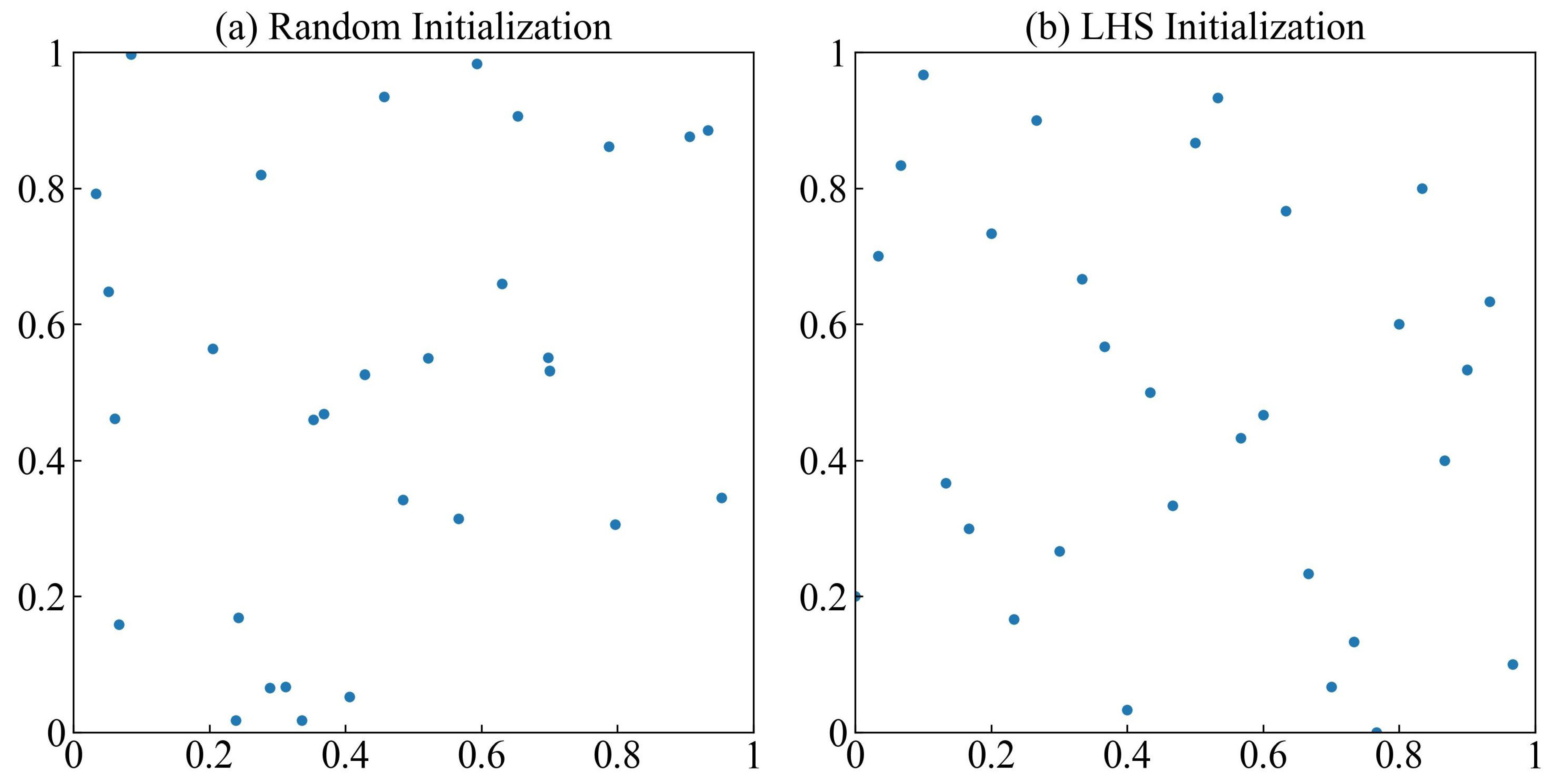
3.2.1. Utilize the Latin Hypercube Sampling for Population Initialization
- (1)
- Determine the number of hyperparameters representing the optimization problem’s dimension.
- (2)
- Set the range for each hyperparameter, where is the lower boundary, and is the upper boundary.
- (3)
- The range of each hyperparameter is divided into equal subintervals. is the population size of the DBO algorithm.
- (4)
- Create a matrix of size . Each column randomly orders the numbers . Then, a sample is randomly generated in the corresponding subinterval based on the rows’ number. The final resultant forms the initial population.
3.2.2. Integrate the OOA’s Global Prospecting Strategy
3.2.3. Introduce an Adaptive Gaussian–Cauchy Mixture Mutation Disturbance
3.2.4. The IDBO Algorithm’s Time Complexity
3.2.5. The Steps of the IDBO Algorithm
3.3. The CNN-BiLSTM Model
3.3.1. Embedding Layer
3.3.2. 1D Convolutional Layer
3.3.3. 1D Max Pooling Layer
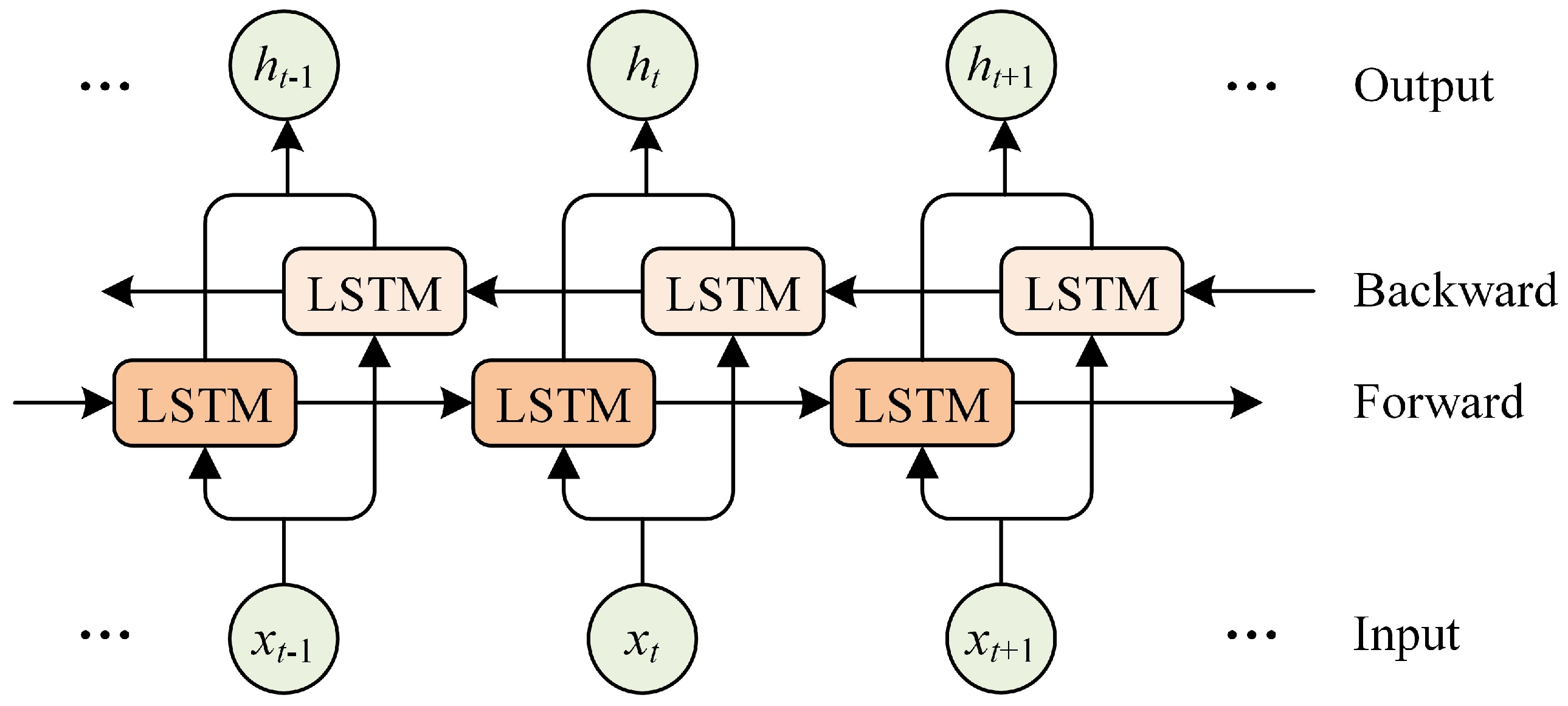
3.3.4. BiLSTM Layer
3.3.5. Dense Layer
4. Empirical Analysis
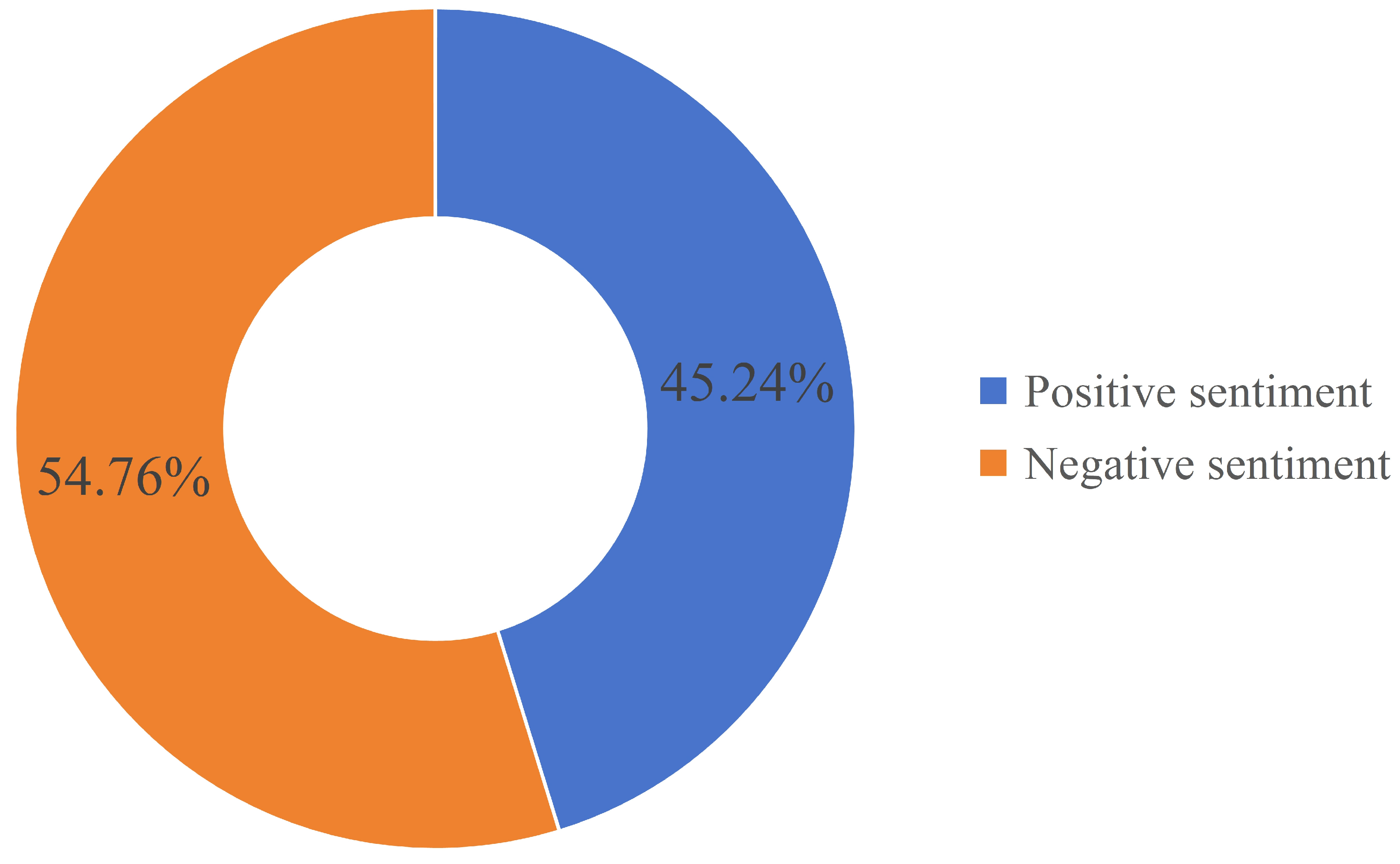
4.1. Data Collection and Preprocessing
- (1)
- Remove Twitter handles (@user).
- (2)
- Remove special characters, numbers, and punctuation.
- (3)
- Remove short words with lengths of less than three.
- (4)
- Utilize Tokenizer to segment the text and convert it into a sequence.
- (5)
- Fill the sequence to the same length.
4.2. Experimental Details
4.3. Evaluation Metrics
4.4. Experimental Results
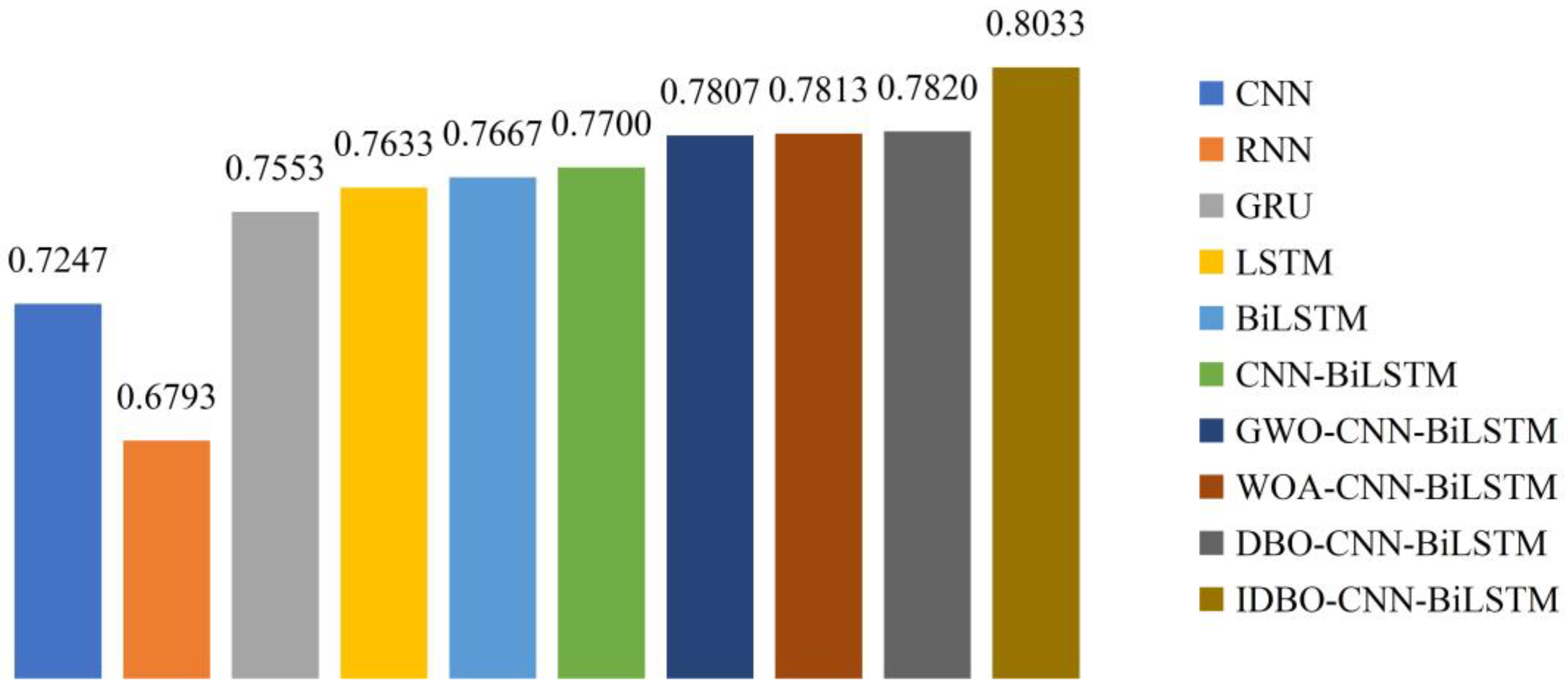
4.4.1. The Contrast of Evaluation Metrics
- Among the selected single models, CNN is the only one that can extract textual local features. It achieves an accuracy of 0.7247. The other models are suitable for processing sequential information. Nevertheless, RNN is susceptible to gradient vanishing and explosion. As two variants of RNN, LSTM performs better in capturing long-term dependencies than GRU due to its complex gating mechanism. BiLSTM has a bidirectional LSTM layer that simultaneously considers words before and after each word in the text. The accuracy of BiLSTM reaches 0.7667. Compared to RNN, GRU, and LSTM, BiLSTM improves the accuracy by 12.87%, 1.51%, and 0.45%, respectively.
- The CNN-BiLSTM model, which combines the local feature extraction capability of CNN with the contextual understanding ability of BiLSTM, outperforms both individual methods. The hybrid model achieves an accuracy of 0.7700, increasing by 6.25% and 0.43%, respectively.
- After optimizing the 1D convolutional layer’s filter number, the convolutional kernel sizes, and the unit number in BiLSTM’s each LSTM layer, the performance is better than that of the basic CNN-BiLSTM model. The IDBO algorithm shows the most significant enhancement. The accuracy is 0.8033, improved by 2.89%, 2.82%, and 2.72% compared to GWO, WOA, and DBO algorithms.
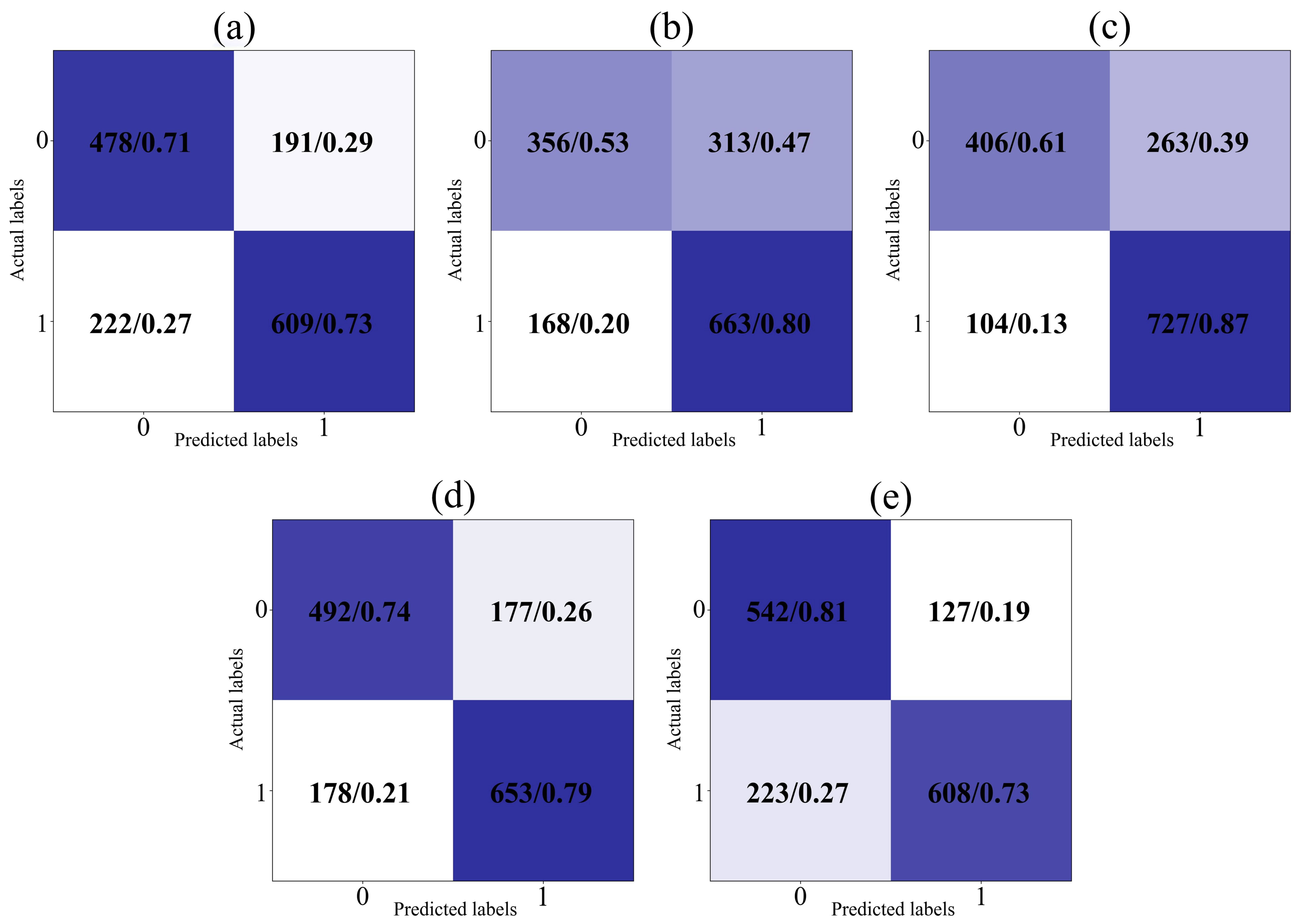
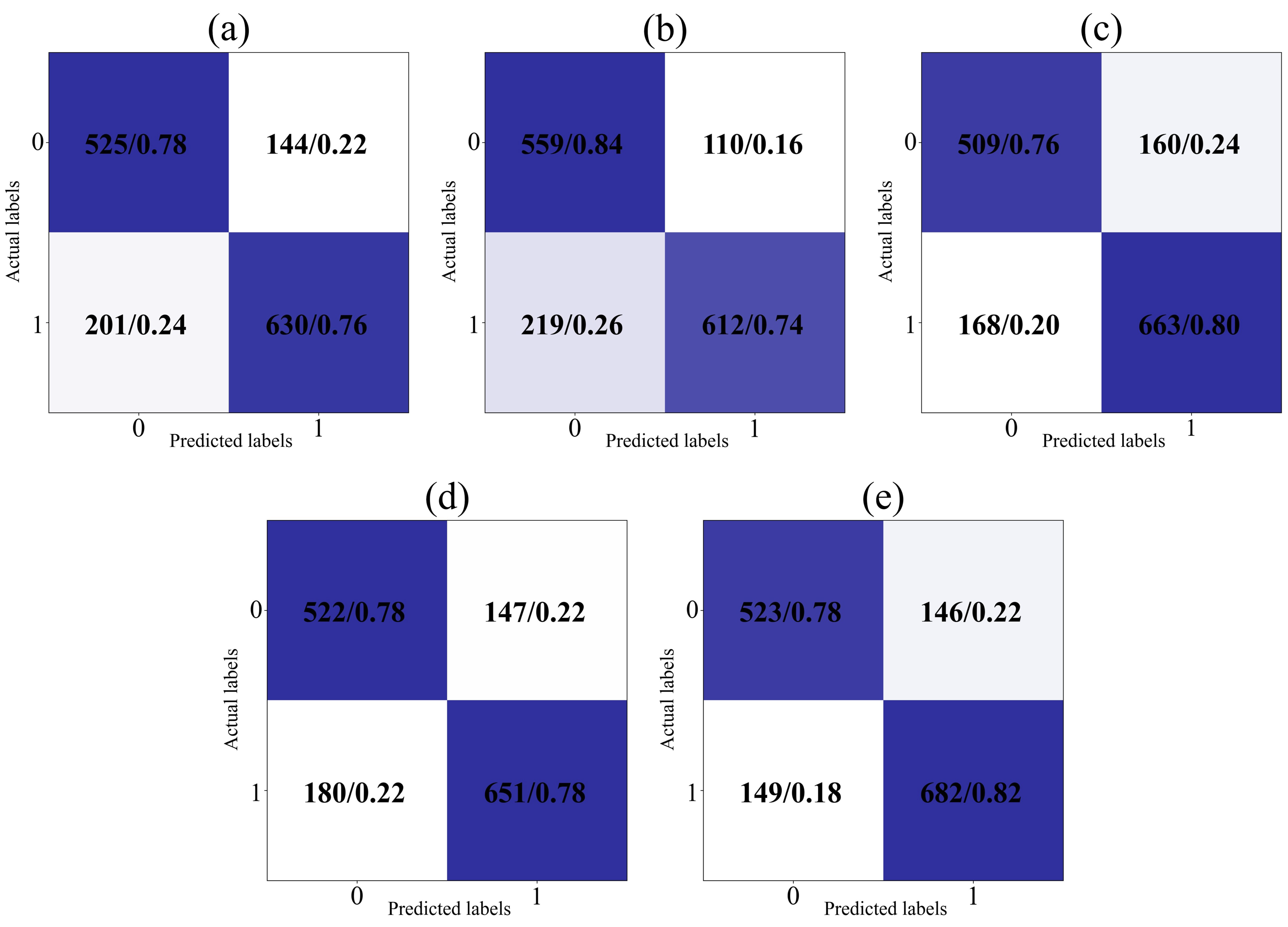
4.4.2. The Comparison of Confusion Matrices
4.4.3. The Performance Comparison of Four Optimization Algorithms
5. Conclusions and Prospect
5.1. Conclusions
5.2. Suggestion
5.3. Limitation and Future Prospect
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
References
- Speck, O.; Speck, T. Is a Forest Fire a Natural Disaster? Investigating the Fire Tolerance of Various Tree Species—An Educational Module. Biomimetics 2024, 9, 114. [Google Scholar] [CrossRef]
- Zhou, B.; Zou, L.; Mostafavi, A.; Lin, B.; Yang, M.; Gharaibeh, N.; Cai, H.; Abedin, J.; Mandal, D. VictimFinder: Harvesting Rescue Requests in Disaster Response from Social Media with BERT. Comput. Environ. Urban Syst. 2022, 95, 101824. [Google Scholar] [CrossRef]
- Zander, K.K.; Garnett, S.T.; Ogie, R.; Alazab, M.; Nguyen, D. Trends in Bushfire Related Tweets during the Australian ‘Black Summer’ of 2019/20. For. Ecol. Manag. 2023, 545, 121274. [Google Scholar] [CrossRef]
- Olynk Widmar, N.; Rash, K.; Bir, C.; Bir, B.; Jung, J. The Anatomy of Natural Disasters on Online Media: Hurricanes and Wildfires. Nat. Hazards 2021, 110, 961–998. [Google Scholar] [CrossRef] [PubMed]
- Sufi, F.K.; Khalil, I. Automated Disaster Monitoring From Social Media Posts Using AI-Based Location Intelligence and Sentiment Analysis. IEEE Trans. Comput. Soc. Syst. 2024, 11, 4614–4624. [Google Scholar] [CrossRef]
- Platania, F.; Hernandez, C.T.; Arreola, F. Social Media Communication during Natural Disasters and the Impact on the Agricultural Market. Technol. Forecast. Soc. Chang. 2022, 179, 121594. [Google Scholar] [CrossRef]
- Karimiziarani, M.; Jafarzadegan, K.; Abbaszadeh, P.; Shao, W.; Moradkhani, H. Hazard Risk Awareness and Disaster Management: Extracting the Information Content of Twitter Data. Sust. Cities Soc. 2022, 77, 103577. [Google Scholar] [CrossRef]
- Lam, N.S.N.; Meyer, M.; Reams, M.; Yang, S.; Lee, K.; Zou, L.; Mihunov, V.; Wang, K.; Kirby, R.; Cai, H. Improving Social Media Use for Disaster Resilience: Challenges and Strategies. Int. J. Digit. Earth 2023, 16, 3023–3044. [Google Scholar] [CrossRef]
- Yuan, Q.; Wang, S.; Li, N. Research on Emotional Tendency of Earthquake Disaster Based on E-Trans Model: Take the Topic of “Sichuan Earthquake” on Microblog as an Example. Nat. Hazards 2024, 120, 5057–5074. [Google Scholar] [CrossRef]
- Wan, B.; Wu, P.; Yeo, C.K.; Li, G. Emotion-Cognitive Reasoning Integrated BERT for Sentiment Analysis of Online Public Opinions on Emergencies. Inf. Process. Manag. 2024, 61, 103609. [Google Scholar] [CrossRef]
- Win Myint, P.Y.; Lo, S.L.; Zhang, Y. Unveiling the Dynamics of Crisis Events: Sentiment and Emotion Analysis via Multi-Task Learning with Attention Mechanism and Subject-Based Intent Prediction. Inf. Process. Manag. 2024, 61, 103695. [Google Scholar] [CrossRef]
- Tounsi, A.; Temimi, M. A Systematic Review of Natural Language Processing Applications for Hydrometeorological Hazards Assessment. Nat. Hazards 2023, 116, 2819–2870. [Google Scholar] [CrossRef] [PubMed]
- Fauzi, M.A. Social Media in Disaster Management: Review of the Literature and Future Trends through Bibliometric Analysis. Nat. Hazards 2023, 118, 953–975. [Google Scholar] [CrossRef]
- Taborda, B.; Maria de Almeida, A.; Carlos Dias, J.; Batista, F.; Ribeiro, R. SA-MAIS: Hybrid Automatic Sentiment Analyser for Stock Market. J. Inf. Sci. 2023, 016555152311713. [Google Scholar] [CrossRef]
- Senbeto, D.L.; Mamo, Y.; Seyfi, S. Light in the Middle of the Tunnel? A Sentimental Analysis of Tourist Responses to Ongoing Crisis. Curr. Issues Tour. 2023, 27, 838–846. [Google Scholar] [CrossRef]
- Bigne, E.; Ruiz, C.; Perez-Cabañero, C.; Cuenca, A. Are Customer Star Ratings and Sentiments Aligned? A Deep Learning Study of the Customer Service Experience in Tourism Destinations. Serv. Bus. 2023, 17, 281–314. [Google Scholar] [CrossRef]
- Xavier, T.; Lambert, J. Sentiment and Emotion Trends in Nurses’ Tweets about the COVID-19 Pandemic. J. Nurs. Scholarsh. 2022, 54, 613–622. [Google Scholar] [CrossRef]
- Tamer, M.; Khamis, M.A.; Yahia, A.; Khaled, S.; Ashraf, A.; Gomaa, W. Arab Reactions towards Russo-Ukrainian War. EPJ Data Sci. 2023, 12, 36. [Google Scholar] [CrossRef]
- Sarsam, S.M.; Al-Samarraie, H.; Alzahrani, A.I.; Mon, C.S.; Shibghatullah, A.S. Characterizing Suicide Ideation by Using Mental Disorder Features on Microblogs: A Machine Learning Perspective. Int. J. Ment. Health Addict. 2022, 1–14. [Google Scholar] [CrossRef]
- Turón, A.; Altuzarra, A.; Moreno-Jiménez, J.M.; Navarro, J. Evolution of Social Mood in Spain throughout the COVID-19 Vaccination Process: A Machine Learning Approach to Tweets Analysis. Public Health 2023, 215, 83–90. [Google Scholar] [CrossRef]
- Hussain, Z.; Sheikh, Z.; Tahir, A.; Dashtipour, K.; Gogate, M.; Sheikh, A.; Hussain, A. Artificial Intelligence–Enabled Social Media Analysis for Pharmacovigilance of COVID-19 Vaccinations in the United Kingdom: Observational Study. JMIR Public Health Surveill. 2022, 8, e32543. [Google Scholar] [CrossRef] [PubMed]
- Weerasinghe, S.; Oyebode, O.; Orji, R.; Matwin, S. Dynamics of Emotion Trends in Canadian Twitter Users during COVID-19 Confinement in Relation to Caseloads: Artificial Intelligence-Based Emotion Detection Approach. Digit. Health 2023, 9, 205520762311714. [Google Scholar] [CrossRef] [PubMed]
- Duan, H.K.; Vasarhelyi, M.A.; Codesso, M.; Alzamil, Z. Enhancing the Government Accounting Information Systems Using Social Media Information: An Application of Text Mining and Machine Learning. Int. J. Account. Inf. Syst. 2023, 48, 100600. [Google Scholar] [CrossRef]
- Li, T.; Chen, H.; Liu, W.; Yu, G.; Yu, Y. Understanding the Role of Social Media Sentiment in Identifying Irrational Herding Behavior in the Stock Market. Int. Rev. Econ. Financ. 2023, 87, 163–179. [Google Scholar] [CrossRef]
- Polignano, M.; Basile, V.; Basile, P.; Gabrieli, G.; Vassallo, M.; Bosco, C. A Hybrid Lexicon-Based and Neural Approach for Explainable Polarity Detection. Inf. Process. Manag. 2022, 59, 103058. [Google Scholar] [CrossRef]
- Karami, B.; Bakouie, F.; Gharibzadeh, S. A Transformer-Based Deep Learning Model for Persian Moral Sentiment Analysis. J. Inf. Sci. 2023, 01655515231188344. [Google Scholar] [CrossRef]
- Mohd, M.; Javeed, S.; Nowsheena; Wani, M.A.; Khanday, H.A. Sentiment Analysis Using Lexico-Semantic Features. J. Inf. Sci. 2022, 016555152211240. [Google Scholar] [CrossRef]
- Qin, J.; Zeng, M.; Wei, X.; Pedrycz, W. Ranking Products through Online Reviews: A Novel Data-Driven Method Based on Interval Type-2 Fuzzy Sets and Sentiment Analysis. J. Oper. Res. Soc. 2023, 75, 860–873. [Google Scholar] [CrossRef]
- Fonseca, M.; Delbianco, F.; Maguitman, A.; Soto, A.J. Assessing Causality among Topics and Sentiments: The Case of the G20 Discussion on Twitter. J. Inf. Sci. 2023, 016555152311600. [Google Scholar] [CrossRef]
- Hartmann, J.; Heitmann, M.; Siebert, C.; Schamp, C. More than a Feeling: Accuracy and Application of Sentiment Analysis. Int. J. Res. Mark. 2023, 40, 75–87. [Google Scholar] [CrossRef]
- Laifa, M.; Mohdeb, D. Sentiment Analysis of the Algerian Social Movement Inception. Data Technol. Appl. 2023, 57, 734–755. [Google Scholar] [CrossRef]
- Rizk, R.; Rizk, D.; Rizk, F.; Hsu, S. 280 Characters to the White House: Predicting 2020 U.S. Presidential Elections from Twitter Data. Comput. Math. Organ. Theory 2023, 29, 542–569. [Google Scholar] [CrossRef] [PubMed]
- Zahoor, K.; Bawany, N.Z. Explainable Artificial Intelligence Approach towards Classifying Educational Android App Reviews Using Deep Learning. Interact. Learn. Environ. 2023, 1–26. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Merchant, J.S.; Yue, X.; Mane, H.; Wei, H.; Huang, D.; Gowda, K.N.; Makres, K.; Najib, C.; Nghiem, H.T.; et al. A Decade of Tweets: Visualizing Racial Sentiments Towards Minoritized Groups in the United States Between 2011 and 2021. Epidemiology 2023, 35, 51–59. [Google Scholar] [CrossRef] [PubMed]
- Ramzy, M.; Ibrahim, B. User Satisfaction with Arabic COVID-19 Apps: Sentiment Analysis of Users’ Reviews Using Machine Learning Techniques. Inf. Process. Manag. 2024, 61, 103644. [Google Scholar] [CrossRef]
- Overbeck, M.; Baden, C.; Aharoni, T.; Amit-Danhi, E.; Tenenboim-Weinblatt, K. Beyond Sentiment: An Algorithmic Strategy for Identifying Evaluations within Large Text Corpora. Commun. Methods Meas. 2023, 1–22. [Google Scholar] [CrossRef]
- Senadhira, K.I.; Rupasingha, R.A.H.M.; Kumara, B.T.G.S. A Deep Learning Based Approach for Classifying Tweets Related to Online Learning during the Covid-19 Pandemic. Educ. Inf. Technol. 2023, 29, 7707–7736. [Google Scholar] [CrossRef]
- Liu, J.; Hu, S.; Mehraliyev, F.; Zhou, H.; Yu, Y.; Yang, L. Recognizing Emotions in Restaurant Online Reviews: A Hybrid Model Integrating Deep Learning and a Sentiment Lexicon. Int. J. Contemp. Hosp. Manag. 2023, 36, 2955–2976. [Google Scholar] [CrossRef]
- Bochkay, K.; Brown, S.V.; Leone, A.J.; Tucker, J.W. Textual Analysis in Accounting: What’s Next? Contemp. Account. Res. 2022, 40, 765–805. [Google Scholar] [CrossRef]
- Alslaity, A.; Orji, R. Machine Learning Techniques for Emotion Detection and Sentiment Analysis: Current State, Challenges, and Future Directions. Behav. Inf. Technol. 2022, 43, 139–164. [Google Scholar] [CrossRef]
- Khan, J.; Ahmad, N.; Khalid, S.; Ali, F.; Lee, Y. Sentiment and Context-Aware Hybrid DNN With Attention for Text Sentiment Classification. IEEE Access 2023, 11, 28162–28179. [Google Scholar] [CrossRef]
- Jain, S.; Roy, P.K. E-Commerce Review Sentiment Score Prediction Considering Misspelled Words: A Deep Learning Approach. Electron. Commer. Res. 2022, 1–25. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, M.; Ming, Y. Understanding the Effect of Tourists’ Attribute-Level Experiences on Satisfaction—A Cross-Cultural Study Leveraging Deep Learning. Curr. Issues Tour. 2022, 26, 105–121. [Google Scholar] [CrossRef]
- Olusegun, R.; Oladunni, T.; Audu, H.; Houkpati, Y.; Bengesi, S. Text Mining and Emotion Classification on Monkeypox Twitter Dataset: A Deep Learning-Natural Language Processing (NLP) Approach. IEEE Access 2023, 11, 49882–49894. [Google Scholar] [CrossRef]
- Mohbey, K.K.; Meena, G.; Kumar, S.; Lokesh, K. A CNN-LSTM-Based Hybrid Deep Learning Approach for Sentiment Analysis on Monkeypox Tweets. New Gener. Comput. 2023, 42, 89–107. [Google Scholar] [CrossRef]
- Kodati, D.; Dasari, C.M. Negative Emotion Detection on Social Media during the Peak Time of COVID-19 through Deep Learning with an Auto-Regressive Transformer. Eng. Appl. Artif. Intell. 2024, 127, 107361. [Google Scholar] [CrossRef]
- Philip Thekkekara, J.; Yongchareon, S.; Liesaputra, V. An Attention-Based CNN-BiLSTM Model for Depression Detection on Social Media Text. Expert Syst. Appl. 2024, 249, 123834. [Google Scholar] [CrossRef]
- Mu, G.; Liao, Z.; Li, J.; Qin, N.; Yang, Z. IPSO-LSTM Hybrid Model for Predicting Online Public Opinion Trends in Emergencies. PLoS ONE 2023, 18, e0292677. [Google Scholar] [CrossRef]
- Mu, G.; Li, J.; Liao, Z.; Yang, Z. An Enhanced IHHO-LSTM Model for Predicting Online Public Opinion Trends in Public Health Emergencies. SAGE Open 2024, 14, 21582440241257681. [Google Scholar] [CrossRef]
- Hosseinalipour, A.; Ghanbarzadeh, R. A Novel Metaheuristic Optimisation Approach for Text Sentiment Analysis. Int. J. Mach. Learn. Cybern. 2022, 14, 889–909. [Google Scholar] [CrossRef]
- Suddle, M.K.; Bashir, M. Metaheuristics Based Long Short Term Memory Optimization for Sentiment Analysis. Appl. Soft. Comput. 2022, 131, 109794. [Google Scholar] [CrossRef]
- Yildirim, G. A Novel Grid-Based Many-Objective Swarm Intelligence Approach for Sentiment Analysis in Social Media. Neurocomputing 2022, 503, 173–188. [Google Scholar] [CrossRef]
- Mardjo, A.; Choksuchat, C. HyVADRF: Hybrid VADER–Random Forest and GWO for Bitcoin Tweet Sentiment Analysis. IEEE Access 2022, 10, 101889–101897. [Google Scholar] [CrossRef]
- Rasappan, P.; Premkumar, M.; Sinha, G.; Chandrasekaran, K. Transforming Sentiment Analysis for E-Commerce Product Reviews: Hybrid Deep Learning Model with an Innovative Term Weighting and Feature Selection. Inf. Process. Manag. 2024, 61, 103654. [Google Scholar] [CrossRef]
- Mehbodniya, A.; Rao, M.V.; David, L.G.; Joe Nigel, K.G.; Vennam, P. Online Product Sentiment Analysis Using Random Evolutionary Whale Optimization Algorithm and Deep Belief Network. Pattern Recognit. Lett. 2022, 159, 1–8. [Google Scholar] [CrossRef]
- Krosuri, L.R.; Aravapalli, R.S. Feature Level Fine Grained Sentiment Analysis Using Boosted Long Short-Term Memory with Improvised Local Search Whale Optimization. PeerJ Comput. Sci. 2023, 9, e1336. [Google Scholar] [CrossRef]
- Seilsepour, A.; Ravanmehr, R.; Nassiri, R. Topic Sentiment Analysis Based on Deep Neural Network Using Document Embedding Technique. J. Supercomput. 2023, 79, 19809–19847. [Google Scholar] [CrossRef]
- Rushing, B. No Free Theory Choice from Machine Learning. Synthese 2022, 200, 414. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. Dung Beetle Optimizer: A New Meta-Heuristic Algorithm for Global Optimization. J. Supercomput. 2022, 79, 7305–7336. [Google Scholar] [CrossRef]
- Bai, X.; Ma, Z.; Chen, W.; Wang, S.; Fu, Y. Fault Diagnosis Research of Laser Gyroscope Based on Optimized-Kernel Extreme Learning Machine. Comput. Electr. Eng. 2023, 111, 108956. [Google Scholar] [CrossRef]
- Kong, Q. NLOS Identification for UWB Positioning Based on IDBO and Convolutional Neural Networks. IEEE Access 2023, 11, 144705–144721. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, L.; Yang, S.; Li, D.; He, D.; Chan, S. A Quasi-Oppositional Learning of Updating Quantum State and Q-Learning Based on the Dung Beetle Algorithm for Global Optimization. Alex. Eng. J. 2023, 81, 469–488. [Google Scholar] [CrossRef]
- Cheng, Y.; Qiao, K.; Jin, S.; Zhou, S.; Xue, J. Research on Electric Spindle Thermal Error Prediction Model Based on DBO-SVM. Int. J. Adv. Manuf. Technol. 2024, 132, 3333–3347. [Google Scholar] [CrossRef]
- Sun, H.; He, D.; Ma, H.; Wen, Z.; Deng, J. The Parameter Identification of Metro Rail Corrugation Based on Effective Signal Extraction and Inertial Reference Method. Eng. Fail. Anal. 2024, 158, 108043. [Google Scholar] [CrossRef]
- Jiachen, H.; Li-hui, F. Robot Path Planning Based on Improved Dung Beetle Optimizer Algorithm. J. Braz. Soc. Mech. Sci. Eng. 2024, 46, 235. [Google Scholar] [CrossRef]
- Kuller, M.; Schoenholzer, K.; Lienert, J. Creating Effective Flood Warnings: A Framework from a Critical Review. J. Hydrol. 2021, 602, 126708. [Google Scholar] [CrossRef]
- Hermans, T.D.G.; Šakić Trogrlić, R.; van den Homberg, M.J.C.; Bailon, H.; Sarku, R.; Mosurska, A. Exploring the Integration of Local and Scientific Knowledge in Early Warning Systems for Disaster Risk Reduction: A Review. Nat. Hazards 2022, 114, 1125–1152. [Google Scholar] [CrossRef]
- Kumar, R.; Mittal, H.; Sandeep; Sharma, B. Earthquake Genesis and Earthquake Early Warning Systems: Challenges and a Way Forward. Surv. Geophys. 2022, 43, 1143–1168. [Google Scholar] [CrossRef]
- Sharafi, L.; Zarafshani, K.; Keshavarz, M.; Azadi, H.; Van Passel, S. Farmers’ Decision to Use Drought Early Warning System in Developing Countries. Sci. Total Environ. 2021, 758, 142761. [Google Scholar] [CrossRef]
- Hong, B.; Shao, B.; Wang, B.; Zhao, J.; Qian, J.; Guo, J.; Xu, Y.; Li, C.; Zhu, B. Using the Meteorological Early Warning Model to Improve the Prediction Accuracy of Water Damage Geological Disasters around Pipelines in Mountainous Areas. Sci. Total Environ. 2023, 889, 164334. [Google Scholar] [CrossRef]
- Sharma, A.; Mohana, R.; Kukkar, A.; Chodha, V.; Bansal, P. An Ensemble Learning–Based Experimental Framework for Smart Landslide Detection, Monitoring, Prediction, and Warning in IoT-Cloud Environment. Environ. Sci. Pollut. Res. 2023, 30, 122677–122699. [Google Scholar] [CrossRef]
- Hussain, F.; Wu, R.-S.; Wang, J.-X. Comparative Study of Very Short-Term Flood Forecasting Using Physics-Based Numerical Model and Data-Driven Prediction Model. Nat. Hazards 2021, 107, 249–284. [Google Scholar] [CrossRef]
- Shoyama, K.; Cui, Q.; Hanashima, M.; Sano, H.; Usuda, Y. Emergency Flood Detection Using Multiple Information Sources: Integrated Analysis of Natural Hazard Monitoring and Social Media Data. Sci. Total Environ. 2021, 767, 144371. [Google Scholar] [CrossRef] [PubMed]
- Moishin, M.; Deo, R.C.; Prasad, R.; Raj, N.; Abdulla, S. Designing Deep-Based Learning Flood Forecast Model With ConvLSTM Hybrid Algorithm. IEEE Access 2021, 9, 50982–50993. [Google Scholar] [CrossRef]
- Zhang, T.; Shen, S.; Cheng, C.; Su, K.; Zhang, X. A Topic Model Based Framework for Identifying the Distribution of Demand for Relief Supplies Using Social Media Data. Int. J. Geogr. Inf. Sci. 2021, 35, 2216–2237. [Google Scholar] [CrossRef]
- Wang, S.L.; Sun, B.Q. Model of Multi-Period Emergency Material Allocation for Large-Scale Sudden Natural Disasters in Humanitarian Logistics: Efficiency, Effectiveness and Equity. Int. J. Disaster Risk Reduct. 2023, 85, 103530. [Google Scholar] [CrossRef]
- Fei, L.; Wang, Y. Demand Prediction of Emergency Materials Using Case-Based Reasoning Extended by the Dempster-Shafer Theory. Socio-Econ. Plan. Sci. 2022, 84, 101386. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, J.; Feng, G. Pre-Positioning Strategies for Relief Supplies in a Relief Supply Chain. J. Oper. Res. Soc. 2021, 73, 1457–1473. [Google Scholar] [CrossRef]
- Toland, J.C.; Wein, A.M.; Wu, A.-M.; Spearing, L.A. A Conceptual Framework for Estimation of Initial Emergency Food and Water Resource Requirements in Disasters. Int. J. Disaster Risk Reduct. 2023, 90, 103661. [Google Scholar] [CrossRef]
- Zhang, M.; Kong, Z. A Tripartite Evolutionary Game Model of Emergency Supplies Joint Reserve among the Government, Enterprise and Society. Comput. Ind. Eng. 2022, 169, 108132. [Google Scholar] [CrossRef]
- Yang, X.; Yao, Y.; Tian, K.; Jiang, W.; Xing, Q.; Yang, J.; Liu, C. Disaster Response Strategies of Governments and Social Organizations: From the Perspective of Infrastructure Damage and Asymmetric Resource Dependence. Heliyon 2023, 9, e20432. [Google Scholar] [CrossRef]
- Sentia, P.D.; Abdul Shukor, S.; Wahab, A.N.A.; Mukhtar, M. Logistic Distribution in Humanitarian Supply Chain Management: A Thematic Literature Review and Future Research. Ann. Oper. Res. 2023, 323, 175–201. [Google Scholar] [CrossRef]
- Chen, M. Optimal Path Planning and Data Simulation of Emergency Material Distribution Based on Improved Neural Network Algorithm. Soft Comput. 2023, 27, 5995–6005. [Google Scholar] [CrossRef]
- Akter, S. Australia’s Black Summer Wildfires Recovery: A Difference-in-Differences Analysis Using Nightlights. Glob. Environ. Change Hum. Policy Dimens. 2023, 83, 102743. [Google Scholar] [CrossRef]
- Akbulut-Yuksel, M.; Rahman, M.H.; Ulubaşoğlu, M.A. Silver Lining of the Water: The Role of Government Relief Assistance in Disaster Recovery. Eur. J. Polit. Econ. 2023, 79, 102436. [Google Scholar] [CrossRef]
- Lu, Y.; Li, R.; Mao, X.; Wang, S. Towards Comprehensive Regional Resilience Evaluation, Resistance, Recovery, and Creativity: From the Perspective of the 2008 Wenchuan Earthquake. Int. J. Disaster Risk Reduct. 2022, 82, 103313. [Google Scholar] [CrossRef]
- Marlier, M.E.; Resetar, S.A.; Lachman, B.E.; Anania, K.; Adams, K. Remote Sensing for Natural Disaster Recovery: Lessons Learned from Hurricanes Irma and Maria in Puerto Rico. Environ. Sci. Policy 2022, 132, 153–159. [Google Scholar] [CrossRef]
- Bahmani, H.; Zhang, W. A Conceptual Framework for Integrated Management of Disasters Recovery Projects. Nat. Hazards 2022, 113, 859–885. [Google Scholar] [CrossRef]
- Newman, G.; Li, D.; Park, Y. The Relationships between Neighbourhood Vacancy, Probable PTSD, and Health-Related Quality of Life in Flood-Disaster-Impacted Communities. Urban Stud. 2022, 59, 3077–3097. [Google Scholar] [CrossRef]
- Witt, A.; Sachser, C.; Fegert, J.M. Scoping Review on Trauma and Recovery in Youth after Natural Disasters: What Europe Can Learn from Natural Disasters around the World. Eur. Child Adolesc. Psych. 2022, 33, 651–665. [Google Scholar] [CrossRef] [PubMed]
- Pham, N.K.; Do, M.; Diep, J. Social Support and Community Embeddedness Protect against Post-Disaster Depression among Immigrants: A Vietnamese American Case Study. Front. Psychiatry 2023, 14, 1075678. [Google Scholar] [CrossRef]
- Wang, D.; Liu, J. Resource Allocation, Individual Social Network, Community Trust and Recovery from Depression among Rural Survivors in the Wenchuan Earthquake. Curr. Psychol. 2023, 43, 328–339. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Ma, Z.; Cao, T. Data-Driven Investigations of Using Social Media to Aid Evacuations amid Western United States Wildfire Season. Fire Saf. J. 2021, 126, 103480. [Google Scholar] [CrossRef]
- Hunt, K.; Wang, B.; Zhuang, J. Misinformation Debunking and Cross-Platform Information Sharing through Twitter during Hurricanes Harvey and Irma: A Case Study on Shelters and ID Checks. Nat. Hazards 2020, 103, 861–883. [Google Scholar] [CrossRef]
- Chen, X. Monitoring of Public Opinion on Typhoon Disaster Using Improved Clustering Model Based on Single-Pass Approach. SAGE Open 2023, 13, 21582440231200098. [Google Scholar] [CrossRef]
- Lian, Y.; Liu, Y.; Dong, X. Strategies for Controlling False Online Information during Natural Disasters: The Case of Typhoon Mangkhut in China. Technol. Soc. 2020, 62, 101265. [Google Scholar] [CrossRef]
- Cheong, S.-M.; Babcock, M. Attention to Misleading and Contentious Tweets in the Case of Hurricane Harvey. Nat. Hazards 2020, 105, 2883–2906. [Google Scholar] [CrossRef]
- Hunt, K.; Agarwal, P.; Zhuang, J. Monitoring Misinformation on Twitter During Crisis Events: A Machine Learning Approach. Risk Anal. 2020, 42, 1728–1748. [Google Scholar] [CrossRef]
- Vicari, R.; Komendatova, N. Systematic Meta-Analysis of Research on AI Tools to Deal with Misinformation on Social Media during Natural and Anthropogenic Hazards and Disasters. Hum. Soc. Sci. Commun. 2023, 10, 332. [Google Scholar] [CrossRef]
- Byrd, K.; John, R.S. Lies, Damned Lies, and Social Media Following Extreme Events. Risk Anal. 2021, 42, 1704–1727. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Wang, Y.; Huang, H.; Zhou, Y. Study on the Rumor Detection of Social Media in Disaster Based on Multi-Feature Fusion Method. Nat. Hazards 2023, 120, 4011–4030. [Google Scholar] [CrossRef]
- Yuan, F.; Li, M.; Liu, R.; Zhai, W.; Qi, B. Social Media for Enhanced Understanding of Disaster Resilience during Hurricane Florence. Int. J. Inf. Manag. 2021, 57, 102289. [Google Scholar] [CrossRef]
- Jin, X.; Spence, P.R. Understanding Crisis Communication on Social Media with CERC: Topic Model Analysis of Tweets about Hurricane Maria. J. Risk Res. 2020, 24, 1266–1287. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef] [PubMed]
- Yuan, F.; Li, M.; Liu, R. Understanding the Evolutions of Public Responses Using Social Media: Hurricane Matthew Case Study. Int. J. Disaster Risk Reduct. 2020, 51, 101798. [Google Scholar] [CrossRef]
- Guo, D.; Zhao, Q.; Chen, Q.; Wu, J.; Li, L.; Gao, H. Comparison between Sentiments of People from Affected and Non-Affected Regions after the Flood. Geomat. Nat. Hazards Risk 2021, 12, 3346–3357. [Google Scholar] [CrossRef]
- Mendon, S.; Dutta, P.; Behl, A.; Lessmann, S. A Hybrid Approach of Machine Learning and Lexicons to Sentiment Analysis: Enhanced Insights from Twitter Data of Natural Disasters. Inf. Syst. Front. 2021, 23, 1145–1168. [Google Scholar] [CrossRef]
- Zhou, S.; Kan, P.; Huang, Q.; Silbernagel, J. A Guided Latent Dirichlet Allocation Approach to Investigate Real-Time Latent Topics of Twitter Data during Hurricane Laura. J. Inf. Sci. 2021, 49, 465–479. [Google Scholar] [CrossRef]
- Chen, Y.; Ji, W. Enhancing Situational Assessment of Critical Infrastructure Following Disasters Using Social Media. J. Manag. Eng. 2021, 37, 04021058. [Google Scholar] [CrossRef]
- Sugino, H.; Sekiguchi, T.; Terada, Y.; Hayashi, N. “Future Compass”, a Tool That Allows Us to See the Right Horizon—Integration of Topic Modeling and Multiple-Factor Analysis. Sustainability 2023, 15, 10175. [Google Scholar] [CrossRef]
- Zhang, T.; Cheng, C. Temporal and Spatial Evolution and Influencing Factors of Public Sentiment in Natural Disasters—A Case Study of Typhoon Haiyan. ISPRS Int. J. Geo Inf. 2021, 10, 299. [Google Scholar] [CrossRef]
- Xu, Z. How Emergency Managers Engage Twitter Users during Disasters. Online Inf. Rev. 2020, 44, 933–950. [Google Scholar] [CrossRef]
- Karimiziarani, M.; Moradkhani, H. Social Response and Disaster Management: Insights from Twitter Data Assimilation on Hurricane Ian. Int. J. Disaster Risk Reduct. 2023, 95, 103865. [Google Scholar] [CrossRef]
- Karimiziarani, M.; Shao, W.; Mirzaei, M.; Moradkhani, H. Toward Reduction of Detrimental Effects of Hurricanes Using a Social Media Data Analytic Approach: How Climate Change Is Perceived? Clim. Risk manag. 2023, 39, 100480. [Google Scholar] [CrossRef]
- Kumar, V.V.; Sahoo, A.; Balasubramanian, S.K.; Gholston, S. Mitigating Healthcare Supply Chain Challenges under Disaster Conditions: A Holistic AI-Based Analysis of Social Media Data. Int. J. Prod. Res. 2024, 1–19. [Google Scholar] [CrossRef]
- Ma, M.; Gao, Q.; Xiao, Z.; Hou, X.; Hu, B.; Jia, L.; Song, W. Analysis of Public Emotion on Flood Disasters in Southern China in 2020 Based on Social Media Data. Nat. Hazards 2023, 118, 1013–1033. [Google Scholar] [CrossRef]
- Wang, H.; Mo, Y. Adaptive Hybrid Optimization Algorithm for Numerical Computing in Engineering Applications. Eng. Optimiz. 2024, 1–39. [Google Scholar] [CrossRef]
- Mckay, M.D.; Beckman, R.J.; Conover, W.J. A Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output From a Computer Code. Technometrics 2000, 42, 55–61. [Google Scholar] [CrossRef]
- Dehghani, M.; Trojovský, P. Osprey Optimization Algorithm: A New Bio-Inspired Metaheuristic Algorithm for Solving Engineering Optimization Problems. Front. Mech. Eng. 2023, 8, 1126450. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, W.; Hu, X. IMATSA—An Improved and Adaptive Intelligent Optimization Algorithm Based on Tunicate Swarm Algorithm. AI Commun. 2024, 37, 1–22. [Google Scholar] [CrossRef]
- Wu, A.; Gong, R.; Mao, J.; Yu, X.; He, J.; Li, E. Voltage Feed-Forward Control of Photovoltaic- Battery DC Microgrid Based on Improved Seeker Optimization Algorithm. IEEE Access 2024, 12, 46067–46080. [Google Scholar] [CrossRef]
- Fan, F.; Cheng, X.; Yan, X.; Wu, Y.; Luo, Z. Multi-objective Firefly Algorithm Combining Logistic Mapping and Cauchy Mutation. Concurr. Comput. Pract. Exp. 2023, 36, e7974. [Google Scholar] [CrossRef]
- Bansal, S. Performance Comparison of Five Metaheuristic Nature-Inspired Algorithms to Find near-OGRs for WDM Systems. Artif. Intell. Rev. 2020, 53, 5589–5635. [Google Scholar] [CrossRef]
- King, K.K.; Wang, B. Diffusion of Real versus Misinformation during a Crisis Event: A Big Data-Driven Approach. Int. J. Inf. Manag. 2023, 71, 102390. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Description |
|---|---|
| The current iteration number | |
| The th dung beetle’s position information at the th iteration | |
| A natural coefficient assigned as −1 (deviation) or 1 (no deviation) | |
| A constant value representing the deflection coefficient in the interval (0, 0.2] | |
| A constant value belonging to (0, 1) | |
| The worst global position | |
| The simulation of light intensity change |
| Parameters | Description |
|---|---|
| The current local optimal position | |
| The spawning zone’s lower boundary | |
| The spawning zone’s upper boundary | |
| The maximum iterations | |
| The optimization issue’s lower boundary | |
| The optimization issue’s upper boundary | |
| The th brood ball’s location information at the th iteration | |
| , | The stochastic vectors by size 1 × |
| The optimization problem’s dimension |
| Parameters | Description |
|---|---|
| The global optimal position | |
| The lower boundary of the optimal foraging zone | |
| The upper boundary of the optimal foraging zone | |
| The th small dung beetle’s position information at the th iteration | |
| A stochastic value following the normal distribution | |
| A stochastic vector belonging to (0, 1) |
| Parameters | Description |
|---|---|
| The th thief’s position information at the th iteration | |
| A stochastic vector following the normal distribution by size 1 × | |
| A constant value |
| Parameters | Description |
|---|---|
| The th osprey’s position information at the th dimension | |
| A stochastic value within the scope [0, 1] | |
| The location information of the fish chosen by the th osprey at the th dimension | |
| A stochastic value from {1, 2} |
| Parameters | Description |
|---|---|
| The th dung beetle’s location information at the th iteration | |
| A stochastic value in the interval [0, 1] | |
| The selected better position of the dung ball | |
| A stochastic value from {1, 2} |
| Parameters | Description |
|---|---|
| The individual’s optimal position at the th iteration | |
| , | The weight coefficient of the mutation operator |
| The Gaussian mutation operator | |
| The Cauchy mutation operator |
| Parameters | Description |
|---|---|
| The ReLU activation function | |
| The input word embedding matrix | |
| The convolutional kernel matrix | |
| The bias term |
| Tweets | Sentiment Labels |
|---|---|
| Thank you to the many volunteers & farmers from North Dakota who harvested sweet corn & delivered it to the Food Bank for hurricane victims! | 0 |
| I need food and water. This freaking hurricane ruins everything! | 1 |
| Hyperparameters | Value |
|---|---|
| Optimizer | Adam |
| Learning rate | 0.0001 |
| L2 | 0.01 |
| Epochs | 20 |
| 0.5 | |
| 10 | |
| 4 | |
| Maximum iteration | 10 |
| [3, 32, 64] | |
| [8, 128, 256] |
| Predicted Positive Instance | Predicted Negative Instance | |
|---|---|---|
| Actual Positive Instance | True Positive (TP) | False Negative (FN) |
| Actual Negative Instance | False Positive (FP) | True Negative (TN) |
| Types | Models | Sentiment Labels | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Single models | CNN | 0 | 0.6829 | 0.7145 | 0.6983 |
| 1 | 0.7612 | 0.7329 | 0.7468 | ||
| RNN | 0 | 0.6794 | 0.5321 | 0.5968 | |
| 1 | 0.6793 | 0.7978 | 0.7338 | ||
| GRU | 0 | 0.7961 | 0.6069 | 0.6887 | |
| 1 | 0.7343 | 0.8748 | 0.7985 | ||
| LSTM | 0 | 0.7343 | 0.7354 | 0.7349 | |
| 1 | 0.7867 | 0.7858 | 0.7863 | ||
| BiLSTM | 0 | 0.7085 | 0.8102 | 0.7559 | |
| 1 | 0.8272 | 0.7316 | 0.7765 | ||
| Hybrid models | CNN-BiLSTM | 0 | 0.7231 | 0.7848 | 0.7527 |
| 1 | 0.8140 | 0.7581 | 0.7850 | ||
| GWO-CNN-BiLSTM | 0 | 0.7185 | 0.8356 | 0.7726 | |
| 1 | 0.8476 | 0.7365 | 0.7882 | ||
| WOA-CNN-BiLSTM | 0 | 0.7518 | 0.7608 | 0.7563 | |
| 1 | 0.8056 | 0.7978 | 0.8017 | ||
| DBO-CNN-BiLSTM | 0 | 0.7436 | 0.7803 | 0.7615 | |
| 1 | 0.8158 | 0.7834 | 0.7993 | ||
| Proposed model | IDBO-CNN-BiLSTM | 0 | 0.7783 | 0.7818 | 0.7800 |
| 1 | 0.8237 | 0.8207 | 0.8222 |
| Models | Convolutional Filters | Convolutional Kernel Sizes | LSTM Units 1 | LSTM Units 2 | Runtime (Seconds) |
|---|---|---|---|---|---|
| GWO-CNN-BiLSTM | 76 | 4 | 197 | 120 | 3432.0266 |
| WOA-CNN-BiLSTM | 128 | 4 | 203 | 131 | 1711.1468 |
| DBO-CNN-BiLSTM | 82 | 6 | 177 | 128 | 1778.9641 |
| IDBO-CNN-BiLSTM | 32 | 3 | 64 | 87 | 1936.3141 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, G.; Li, J.; Li, X.; Chen, C.; Ju, X.; Dai, J. An Enhanced IDBO-CNN-BiLSTM Model for Sentiment Analysis of Natural Disaster Tweets. Biomimetics 2024, 9, 533. https://doi.org/10.3390/biomimetics9090533
Mu G, Li J, Li X, Chen C, Ju X, Dai J. An Enhanced IDBO-CNN-BiLSTM Model for Sentiment Analysis of Natural Disaster Tweets. Biomimetics. 2024; 9(9):533. https://doi.org/10.3390/biomimetics9090533
Chicago/Turabian StyleMu, Guangyu, Jiaxue Li, Xiurong Li, Chuanzhi Chen, Xiaoqing Ju, and Jiaxiu Dai. 2024. "An Enhanced IDBO-CNN-BiLSTM Model for Sentiment Analysis of Natural Disaster Tweets" Biomimetics 9, no. 9: 533. https://doi.org/10.3390/biomimetics9090533
APA StyleMu, G., Li, J., Li, X., Chen, C., Ju, X., & Dai, J. (2024). An Enhanced IDBO-CNN-BiLSTM Model for Sentiment Analysis of Natural Disaster Tweets. Biomimetics, 9(9), 533. https://doi.org/10.3390/biomimetics9090533