
Enhancing the Efficiency of a Cybersecurity Operations Center Using Biomimetic Algorithms Empowered by Deep Q-Learning






Abstract
1. Introduction
2. Related Work
3. Preliminaries
3.1. Particle Swarm Optimization
3.2. Bat Algorithm
3.3. Gray Wolf Optimizer
3.4. Orca Predator Algorithm
3.5. Reinforcement Learning
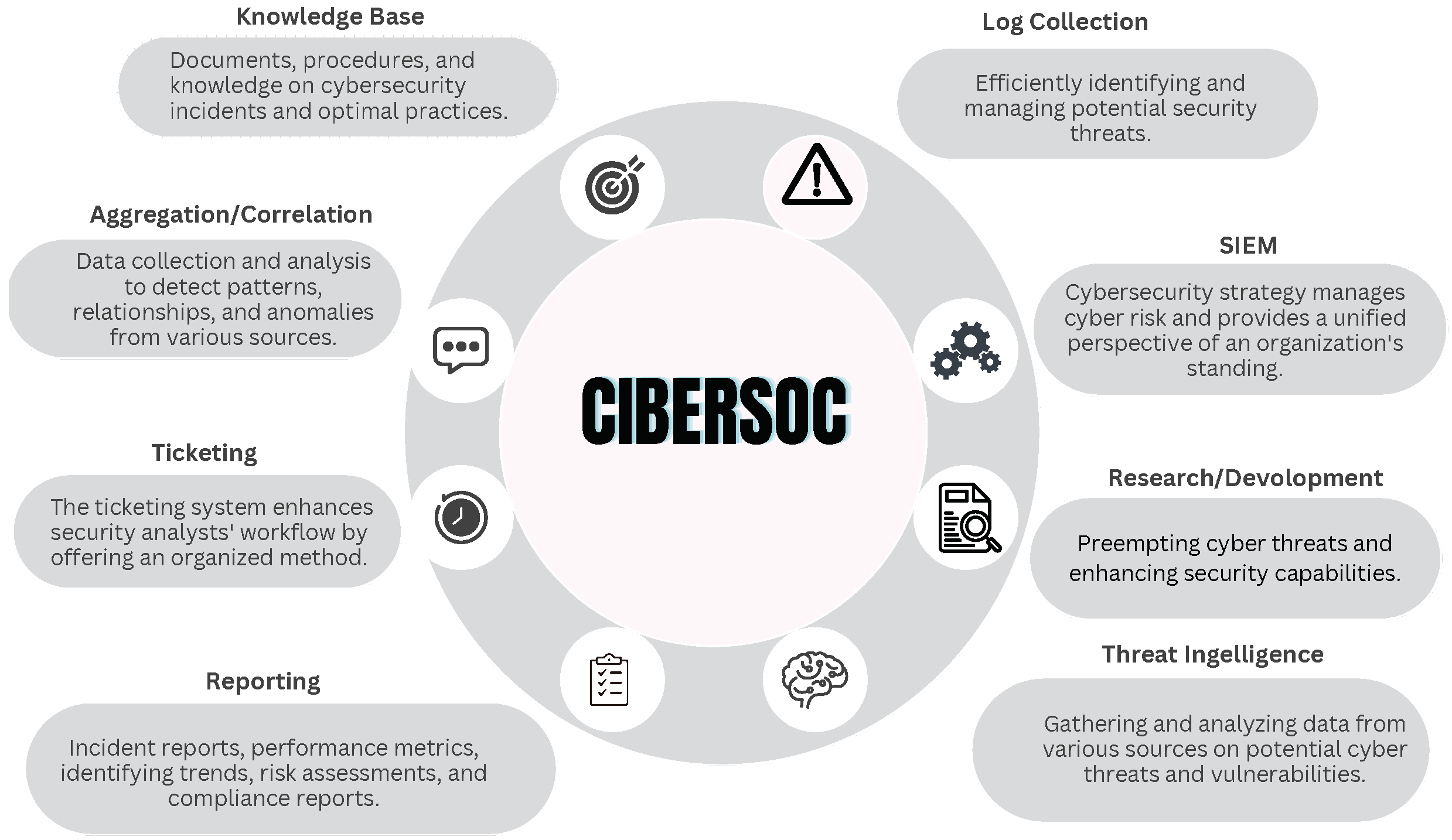
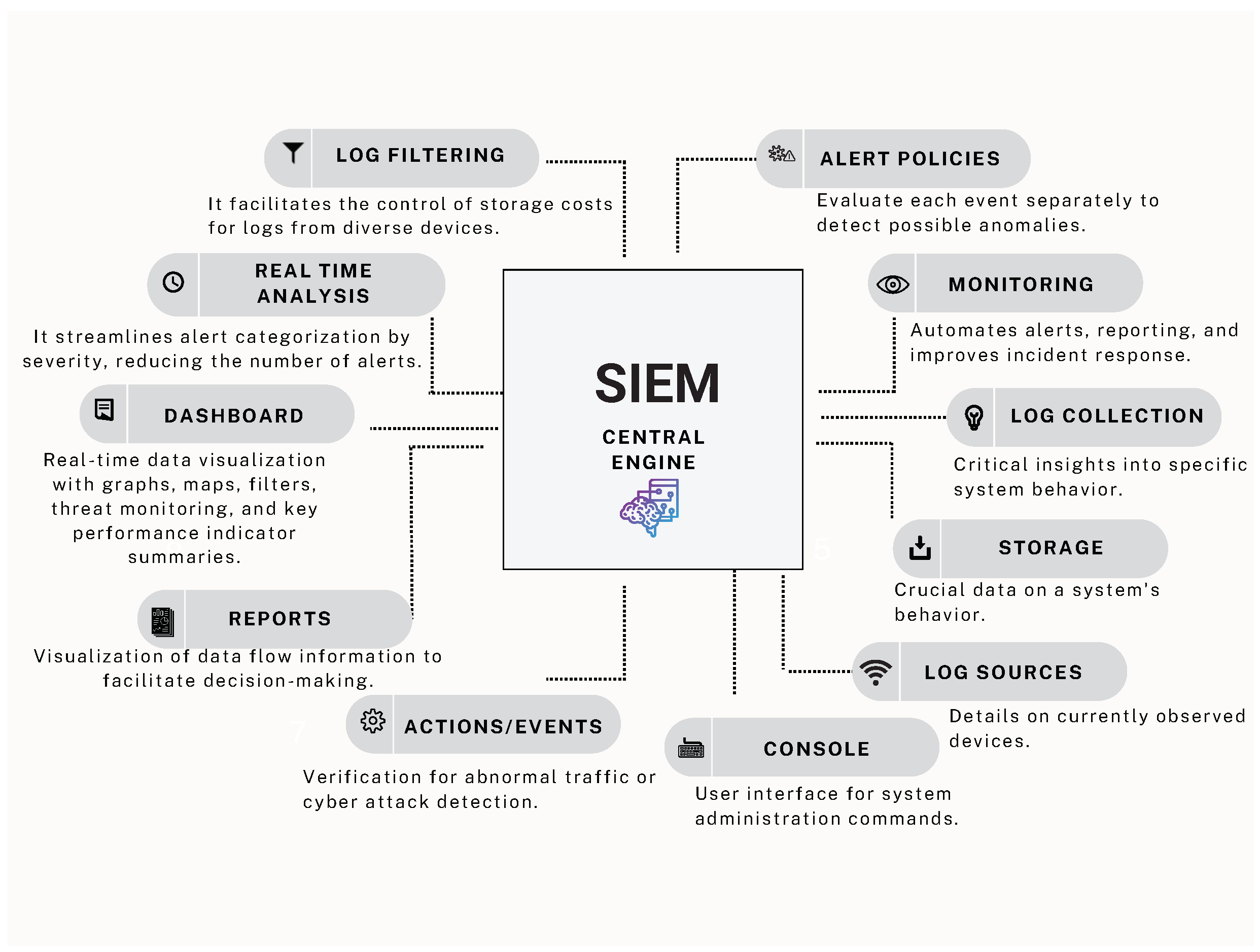
3.6. Cybersecurity Operations Centers
4. Developed Solution
| Algorithm 1: Enhanced bio-inspired optimization method |
 |
5. Experimental Setup
5.1. Methodology
- Preparation and planning: In this phase, network instances that emulated real-world cases, from medium-sized networks to large networks, were generated, randomly covering the various operational and functional scenarios of modern networks. Subsequently, the objectives to achieve were defined as having a secure, operational, and highly available network. These objectives were to minimize the number of NIDS sensors assigned to the network, maximize the installation benefits, and minimize the indirect costs of non-installation. Experiments were designed to systematically evaluate hybridization improvements in a controlled manner, ensuring balanced optimization of the criteria described above.
- Execution and assessment: We carried out a comprehensive evaluation of both native and improved metaheuristics, analyzing the quality of the solutions obtained and the efficiency in terms of calculation and convergence characteristics. We implement comprehensive tests to perform performance comparisons with descriptive statistical methods and performed the Mann–Whitney–Wilcoxon test for comparative analysis. This method involves determining the appropriateness of each execution for each given instance.
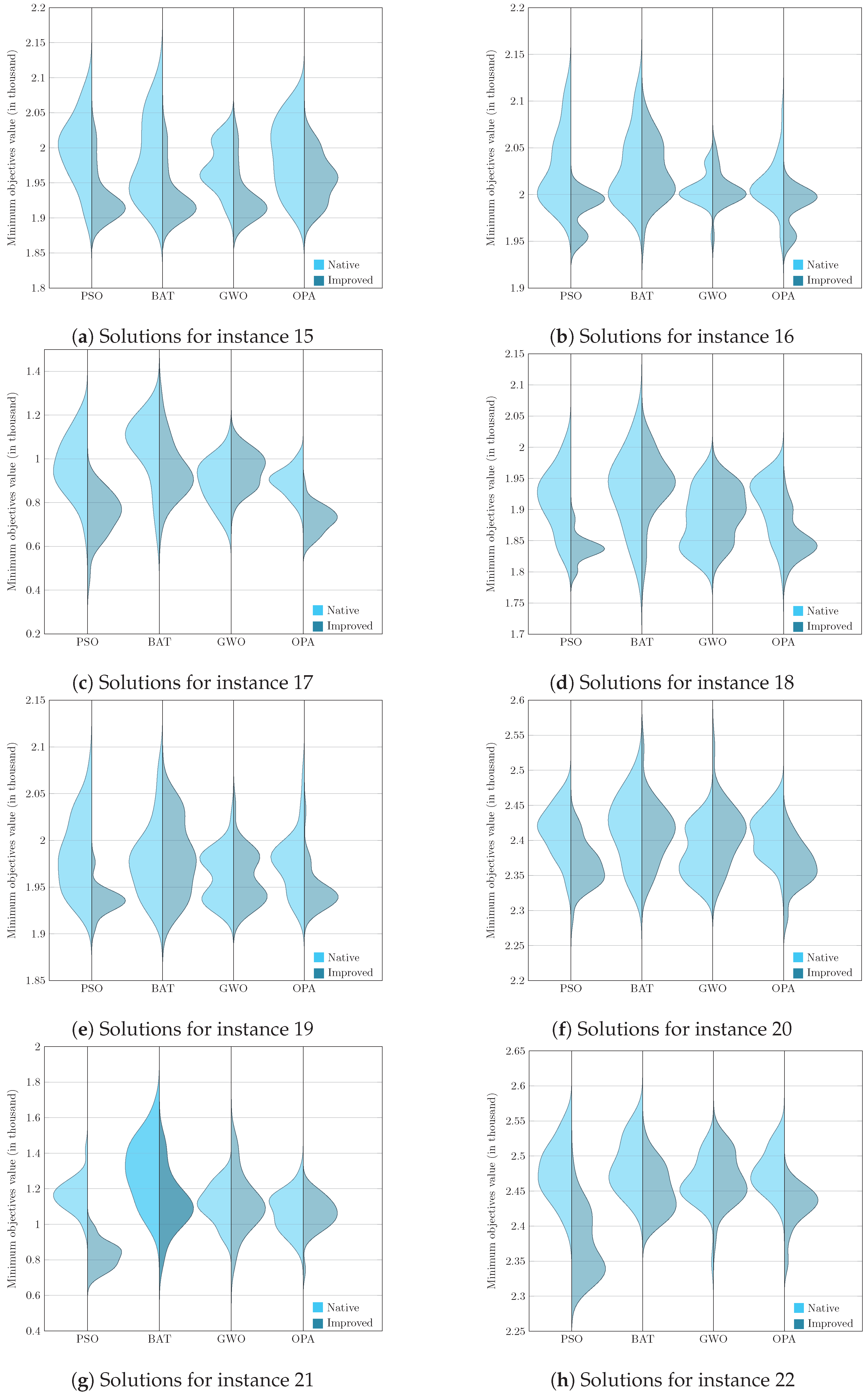
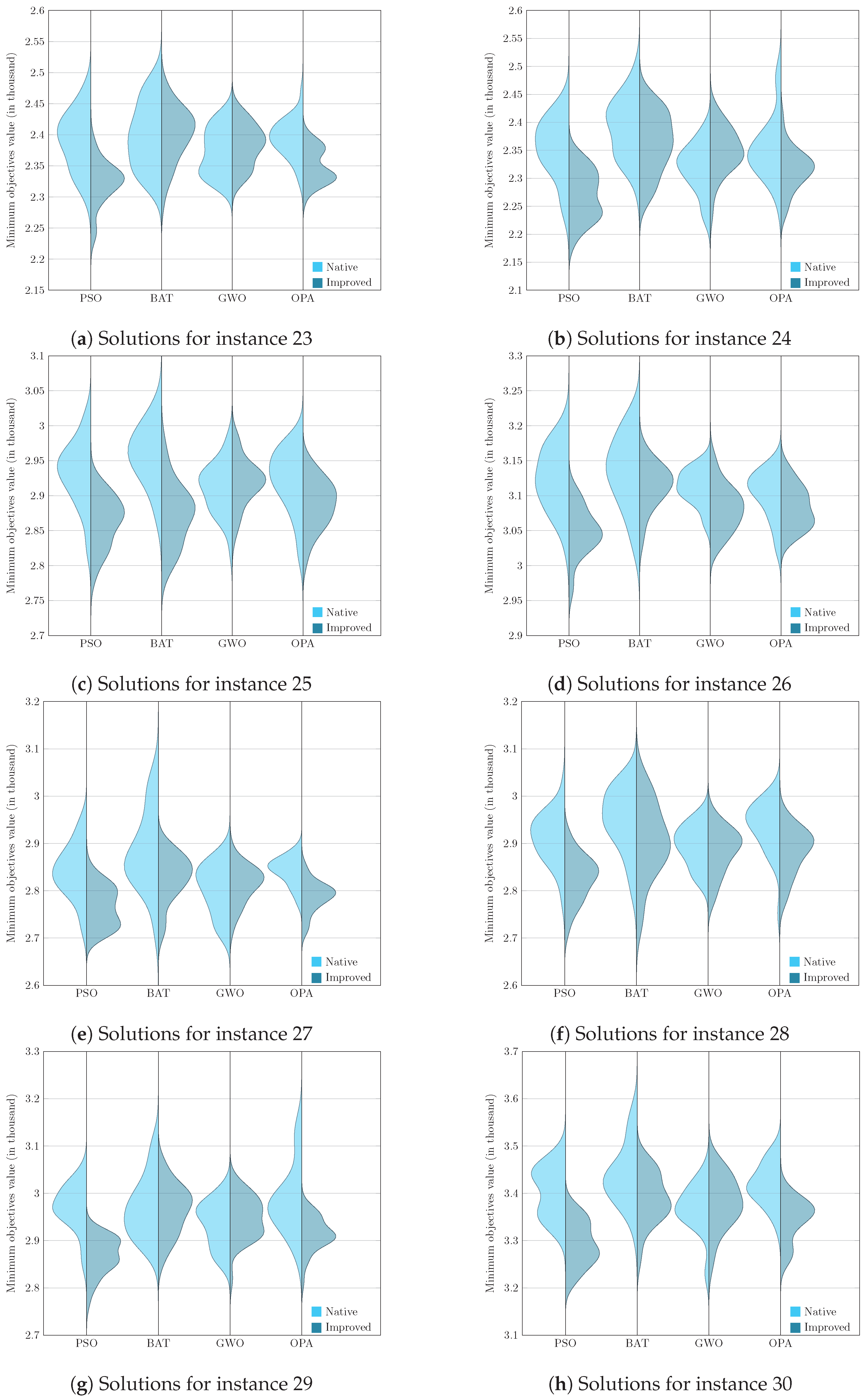
- Analysis and validation: We performed a comprehensive and in-depth analysis to understand the influence of Deep Q-Learning and the behavior of the PSO, BAT, GWO, and OPA metaheuristics in generating efficient solutions for the corresponding instances. To do this, comparative tables and graphs of the solutions generated by the native and improved metaheuristics were built.
5.2. Implementation Aspects
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yıldırım, İ. Cyber Risk Management in Banks: Cyber Risk İnsurance. In Global Cybersecurity Labor Shortage and International Business Risk; IGI Global: Hershey, PA, USA, 2019; pp. 38–50. [Google Scholar]
- Melaku, H.M. Context-Based and Adaptive Cybersecurity Risk Management Framework. Risks 2023, 11, 101. [Google Scholar] [CrossRef]
- Darwish, S.M.; Farhan, D.A.; Elzoghabi, A.A. Building an Effective Classifier for Phishing Web Pages Detection: A Quantum-Inspired Biomimetic Paradigm Suitable for Big Data Analytics of Cyber Attacks. Biomimetics 2023, 8, 197. [Google Scholar] [CrossRef] [PubMed]
- Broeckhoven, C.; Winters, S. Biomimethics: A critical perspective on the ethical implications of biomimetics in technological innovation. Bioinspir. Biomimetics 2023, 18, 053001. [Google Scholar] [CrossRef]
- Ding, H.; Liu, Y.; Wang, Z.; Jin, G.; Hu, P.; Dhiman, G. Adaptive Guided Equilibrium Optimizer with Spiral Search Mechanism to Solve Global Optimization Problems. Biomimetics 2023, 8, 383. [Google Scholar] [CrossRef]
- Yang, X.; Li, H. Evolutionary-state-driven Multi-swarm Cooperation Particle Swarm Optimization for Complex Optimization Problem. Inf. Sci. 2023, 646, 119302. [Google Scholar] [CrossRef]
- Li, W.; Liang, P.; Sun, B.; Sun, Y.; Huang, Y. Reinforcement learning-based particle swarm optimization with neighborhood differential mutation strategy. Swarm Evol. Comput. 2023, 78, 101274. [Google Scholar] [CrossRef]
- Nama, S.; Saha, A.K.; Chakraborty, S.; Gandomi, A.H.; Abualigah, L. Boosting particle swarm optimization by backtracking search algorithm for optimization problems. Swarm Evol. Comput. 2023, 79, 101304. [Google Scholar] [CrossRef]
- Seyyedabbasi, A. A reinforcement learning-based metaheuristic algorithm for solving global optimization problems. Adv. Eng. Softw. 2023, 178, 103411. [Google Scholar] [CrossRef]
- Taye, M.M. Understanding of Machine Learning with Deep Learning: Architectures, Workflow, Applications and Future Directions. Computers 2023, 12, 91. [Google Scholar] [CrossRef]
- Peres, F.; Castelli, M. Combinatorial optimization problems and metaheuristics: Review, challenges, design, and development. Appl. Sci. 2021, 11, 6449. [Google Scholar] [CrossRef]
- Salinas, O.; Soto, R.; Crawford, B.; Olivares, R. An integral cybersecurity approach using a many-objective optimization strategy. IEEE Access 2023, 11, 91913–91936. [Google Scholar] [CrossRef]
- Wawrowski, Ł.; Białas, A.; Kajzer, A.; Kozłowski, A.; Kurianowicz, R.; Sikora, M.; Szymańska-Kwiecień, A.; Uchroński, M.; Białczak, M.; Olejnik, M.; et al. Anomaly detection module for network traffic monitoring in public institutions. Sensors 2023, 23, 2974. [Google Scholar] [CrossRef] [PubMed]
- Kaur, G.; Lashkari, A.H. An introduction to security operations. In Advances in Cybersecurity Management; Springer: Berlin/Heidelberg, Germany, 2021; pp. 463–481. [Google Scholar]
- Nespoli, P.; Gomez Marmol, F.; Kambourakis, G. AISGA: Multi-objective parameters optimization for countermeasures selection through genetic algorithm. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–8. [Google Scholar]
- da Costa Oliveira, A.L.; Britto, A.; Gusmão, R. Machine learning enhancing metaheuristics: A systematic review. Soft Comput. 2023, 27, 15971–15998. [Google Scholar] [CrossRef]
- Almasoud, A.S. Enhanced Metaheuristics with Machine Learning Enabled Cyberattack Detection Model. Intell. Autom. Soft Comput. 2023, 37, 2849–2863. [Google Scholar] [CrossRef]
- Albahri, O.; AlAmoodi, A. Cybersecurity and Artificial Intelligence Applications: A Bibliometric Analysis Based on Scopus Database. Mesopotamian J. Cybersecur. 2023, 2023, 158–169. [Google Scholar] [CrossRef] [PubMed]
- Olivares, R.; Soto, R.; Crawford, B.; Ríos, V.; Olivares, P.; Ravelo, C.; Medina, S.; Nauduan, D. A learning–based particle swarm optimizer for solving mathematical combinatorial problems. Axioms 2023, 12, 643. [Google Scholar] [CrossRef]
- Liang, Y.C.; Cuevas Juarez, J.R. A self-adaptive virus optimization algorithm for continuous optimization problems. Soft Comput. 2020, 24, 13147–13166. [Google Scholar] [CrossRef]
- Yi, W.; Qu, R.; Jiao, L.; Niu, B. Automated design of metaheuristics using reinforcement learning within a novel general search framework. IEEE Trans. Evol. Comput. 2022, 27, 1072–1084. [Google Scholar] [CrossRef]
- Malibari, A.A.; Alotaibi, S.S.; Alshahrani, R.; Dhahbi, S.; Alabdan, R.; Al-wesabi, F.N.; Hilal, A.M. A novel metaheuristics with deep learning enabled intrusion detection system for secured smart environment. Sustain. Energy Technol. Assess. 2022, 52, 102312. [Google Scholar] [CrossRef]
- Zhong, R.; Peng, F.; Yu, J.; Munetomo, M. Q-learning based vegetation evolution for numerical optimization and wireless sensor network coverage optimization. Alex. Eng. J. 2024, 87, 148–163. [Google Scholar] [CrossRef]
- Alturkistani, H.; El-Affendi, M.A. Optimizing cybersecurity incident response decisions using deep reinforcement learning. Int. J. Electr. Comput. Eng. 2022, 12, 6768. [Google Scholar] [CrossRef]
- Abedzadeh, N.; Jacobs, M. A Reinforcement Learning Framework with Oversampling and Undersampling Algorithms for Intrusion Detection System. Appl. Sci. 2023, 13, 11275. [Google Scholar] [CrossRef]
- Al-kahtani, M.S.; Mehmood, Z.; Sadad, T.; Zada, I.; Ali, G.; ElAffendi, M. Intrusion detection in the Internet of Things using fusion of GRU-LSTM deep learning model. Intell. Autom. Soft Comput. 2023, 37, 2283. [Google Scholar] [CrossRef]
- Shon, H.G.; Lee, Y.; Yoon, M. Semi-Supervised Alert Filtering for Network Security. Electronics 2023, 12, 4755. [Google Scholar] [CrossRef]
- Rawindaran, N.; Jayal, A.; Prakash, E.; Hewage, C. Cost benefits of using machine learning features in NIDS for cyber security in UK small medium enterprises (SME). Future Internet 2021, 13, 186. [Google Scholar] [CrossRef]
- Domínguez-Dorado, M.; Rodríguez-Pérez, F.J.; Carmona-Murillo, J.; Cortés-Polo, D.; Calle-Cancho, J. Boosting holistic cybersecurity awareness with outsourced wide-scope CyberSOC: A generalization from a spanish public organization study. Information 2023, 14, 586. [Google Scholar] [CrossRef]
- Alabdulatif, A.; Thilakarathne, N.N. Bio-inspired internet of things: Current status, benefits, challenges, and future directions. Biomimetics 2023, 8, 373. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Jiang, Y.; Wu, Q.; Zhu, S.; Zhang, L. Orca predation algorithm: A novel bio-inspired algorithm for global optimization problems. Expert Syst. Appl. 2022, 188, 116026. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wang, L.; Pan, Z.; Wang, J. A review of reinforcement learning based intelligent optimization for manufacturing scheduling. Complex Syst. Model. Simul. 2021, 1, 257–270. [Google Scholar] [CrossRef]
- Sun, H.; Yang, L.; Gu, Y.; Pan, J.; Wan, F.; Song, C. Bridging locomotion and manipulation using reconfigurable robotic limbs via reinforcement learning. Biomimetics 2023, 8, 364. [Google Scholar] [CrossRef] [PubMed]
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone deep reinforcement learning: A review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Alavizadeh, H.; Alavizadeh, H.; Jang-Jaccard, J. Deep Q-learning based reinforcement learning approach for network intrusion detection. Computers 2022, 11, 41. [Google Scholar] [CrossRef]
- Zhang, L.; Tang, L.; Zhang, S.; Wang, Z.; Shen, X.; Zhang, Z. A Self-Adaptive Reinforcement-Exploration Q-Learning Algorithm. Symmetry 2021, 13, 1057. [Google Scholar] [CrossRef]
- Jang, B.; Kim, M.; Harerimana, G.; Kim, J.W. Q-learning algorithms: A comprehensive classification and applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar] [CrossRef]
- Wang, H.N.; Liu, N.; Zhang, Y.Y.; Feng, D.W.; Huang, F.; Li, D.S.; Zhang, Y.M. Deep reinforcement learning: A survey. Front. Inf. Technol. Electron. Eng. 2020, 21, 1726–1744. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Diekmann, N.; Walther, T.; Vijayabaskaran, S.; Cheng, S. Deep reinforcement learning in a spatial navigation task: Multiple contexts and their representation. In Proceedings of the 2019 Conference on Cognitive Computational Neuroscience, Berlin, Germany, 13–16 September 2019. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Ramicic, M.; Bonarini, A. Correlation minimizing replay memory in temporal-difference reinforcement learning. Neurocomputing 2020, 393, 91–100. [Google Scholar] [CrossRef]
- Ji, Z.; Xiao, W. Improving decision-making efficiency of image game based on deep Q-learning. Soft Comput. 2020, 24, 8313–8322. [Google Scholar] [CrossRef]
- Yavas, U.; Kumbasar, T.; Ure, N.K. A New Approach for Tactical Decision Making in Lane Changing: Sample Efficient Deep Q Learning with a Safety Feedback Reward. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020. [Google Scholar] [CrossRef]
- Cai, P.; Wang, H.; Sun, Y.; Liu, M. DQ-GAT: Towards Safe and Efficient Autonomous Driving with Deep Q-Learning and Graph Attention Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21102–21112. [Google Scholar] [CrossRef]
- Sumanas, M.; Petronis, A.; Bucinskas, V.; Dzedzickis, A.; Virzonis, D.; Morkvenaite-Vilkonciene, I. Deep Q-Learning in Robotics: Improvement of Accuracy and Repeatability. Sensors 2022, 22, 3911. [Google Scholar] [CrossRef] [PubMed]
- Roy, P.P.; Teju, V.; Kandula, S.R.; Sowmya, K.V.; Stan, A.I.; Stan, O.P. Secure Healthcare Model Using Multi-Step Deep Q Learning Network in Internet of Things. Electronics 2024, 13, 669. [Google Scholar] [CrossRef]
- Jeong, G.; Kim, H.Y. Improving financial trading decisions using deep Q-learning: Predicting the number of shares, action strategies, and transfer learning. Expert Syst. Appl. 2019, 117, 125–138. [Google Scholar] [CrossRef]
- Yan, Y.; Chow, A.H.; Ho, C.P.; Kuo, Y.H.; Wu, Q.; Ying, C. Reinforcement learning for logistics and supply chain management: Methodologies, state of the art, and future opportunities. Transp. Res. Part E Logist. Transp. Rev. 2022, 162, 102712. [Google Scholar] [CrossRef]
- Vaarandi, R.; Mäses, S. How to Build a SOC on a Budget. In Proceedings of the 2022 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 27–29 July 2022; pp. 171–177. [Google Scholar]
- János, F.D.; Dai, N.H.P. Security concerns towards security operations centers. In Proceedings of the 2018 IEEE 12th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 17–19 May 2018; pp. 000273–000278. [Google Scholar]
- Alterazi, H.A.; Kshirsagar, P.R.; Manoharan, H.; Selvarajan, S.; Alhebaishi, N.; Srivastava, G.; Lin, J.C.W. Prevention of cybersecurity with the internet of things using particle swarm optimization. Sensors 2022, 22, 6117. [Google Scholar] [CrossRef] [PubMed]
- Menges, F.; Latzo, T.; Vielberth, M.; Sobola, S.; Pöhls, H.C.; Taubmann, B.; Köstler, J.; Puchta, A.; Freiling, F.; Reiser, H.P.; et al. Towards GDPR-compliant data processing in modern SIEM systems. Comput. Secur. 2021, 103, 102165. [Google Scholar] [CrossRef]
- Kotecha, K.; Verma, R.; Rao, P.V.; Prasad, P.; Mishra, V.K.; Badal, T.; Jain, D.; Garg, D.; Sharma, S. Enhanced network intrusion detection system. Sensors 2021, 21, 7835. [Google Scholar] [CrossRef]
- Aghmadi, A.; Hussein, H.; Polara, K.H.; Mohammed, O. A Comprehensive Review of Architecture, Communication, and Cybersecurity in Networked Microgrid Systems. Inventions 2023, 8, 84. [Google Scholar] [CrossRef]
- González-Granadillo, G.; González-Zarzosa, S.; Diaz, R. Security information and event management (SIEM): Analysis, trends, and usage in critical infrastructures. Sensors 2021, 21, 4759. [Google Scholar] [CrossRef] [PubMed]
- Ghiasi, M.; Niknam, T.; Wang, Z.; Mehrandezh, M.; Dehghani, M.; Ghadimi, N. A comprehensive review of cyber-attacks and defense mechanisms for improving security in smart grid energy systems: Past, present and future. Electr. Power Syst. Res. 2023, 215, 108975. [Google Scholar] [CrossRef]
- Wanjau, S.K.; Wambugu, G.M.; Oirere, A.M.; Muketha, G.M. Discriminative spatial-temporal feature learning for modeling network intrusion detection systems. J. Comput. Secur. 2023, 32, 1–30. [Google Scholar] [CrossRef]
- Younus, Z.; Alanezi, M. A Survey on Network Security Monitoring: Tools and Functionalities. Mustansiriyah J. Pure Appl. Sci. 2023, 1, 55–86. [Google Scholar]
- Tuyishime, E.; Balan, T.C.; Cotfas, P.A.; Cotfas, D.T.; Rekeraho, A. Enhancing Cloud Security—Proactive Threat Monitoring and Detection Using a SIEM-Based Approach. Appl. Sci. 2023, 13, 12359. [Google Scholar] [CrossRef]
- Bezas, K.; Filippidou, F. Comparative Analysis of Open Source Security Information & Event Management Systems (SIEMs). Indones. J. Comput. Sci. 2023, 12, 443–468. [Google Scholar]
- Muhammad, A.R.; Sukarno, P.; Wardana, A.A. Integrated Security Information and Event Management (SIEM) with Intrusion Detection System (IDS) for Live Analysis based on Machine Learning. Procedia Comput. Sci. 2023, 217, 1406–1415. [Google Scholar] [CrossRef]
- Awajan, A. A novel deep learning-based intrusion detection system for IOT networks. Computers 2023, 12, 34. [Google Scholar] [CrossRef]
- Kure, H.I.; Islam, S.; Mouratidis, H. An integrated cybersecurity risk management framework and risk predication for the critical infrastructure protection. Neural Comput. Appl. 2022, 34, 15241–15271. [Google Scholar] [CrossRef]
- Safitra, M.F.; Lubis, M.; Fakhrurroja, H. Counterattacking cyber threats: A framework for the future of cybersecurity. Sustainability 2023, 15, 13369. [Google Scholar] [CrossRef]
- Oyedokun, G.E.; Campbell, O. Imperatives of Risk Analysis and Asset Management on Cybersecurity in a Technology-Driven Economy. In Effective Cybersecurity Operations for Enterprise-Wide Systems; IGI Global: Hershey, PA, USA, 2023; pp. 147–168. [Google Scholar]
- Zhang, Y.; Malacaria, P. Optimization-time analysis for cybersecurity. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2365–2383. [Google Scholar] [CrossRef]
- Tan, F.; Yan, P.; Guan, X. Deep reinforcement learning: From Q-learning to deep Q-learning. In Proceedings of the Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Proceedings, Part IV 24. Springer: Berlin/Heidelberg, Germany, 2017; pp. 475–483. [Google Scholar]
- Fotouhi, A.; Ding, M.; Hassan, M. Deep q-learning for two-hop communications of drone base stations. Sensors 2021, 21, 1960. [Google Scholar] [CrossRef]
- Hu, X.; Chu, L.; Pei, J.; Liu, W.; Bian, J. Model complexity of deep learning: A survey. Knowl. Inf. Syst. 2021, 63, 2585–2619. [Google Scholar] [CrossRef]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A theoretical analysis of deep Q-learning. In Proceedings of the Learning for Dynamics and Control, Virtual, 10–11 June 2020; pp. 486–489. [Google Scholar]
- Crawford, B.; Soto, R.; Astorga, G.; García, J.; Castro, C.; Paredes, F. Putting Continuous Metaheuristics to Work in Binary Search Spaces. Complexity 2017, 2017, 8404231. [Google Scholar] [CrossRef]
- Bartz-Beielstein, T.; Preuss, M. Experimental research in evolutionary computation. In Proceedings of the 9th Annual Conference Companion on Genetic and Evolutionary Computation, London, UK, 7–11 July 2007; pp. 3001–3020. [Google Scholar]
- Hund, A.K.; Stretch, E.; Smirnoff, D.; Roehrig, G.H.; Snell-Rood, E.C. Broadening the taxonomic breadth of organisms in the bio-inspired design process. Biomimetics 2023, 8, 48. [Google Scholar] [CrossRef]
- Wilcox, R. A Heteroscedastic Analog of the Wilcoxon–Mann–Whitney Test When There Is a Covariate. Int. J. Stat. Probab. 2023, 12. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | Number of VLANs | Type of Sensors | Uptime | Range of Direct Costs | Qualitative Profit Range | Range of Indirect Costs | Performance of Subnets |
|---|---|---|---|---|---|---|---|
| 1 | 10 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.39–0.80] |
| 2 | 10 | 2 | 90% | [100–150] | [5–20] | [1–7] | [0.10–0.80] |
| 3 | 10 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.02–0.80] |
| 4 | 10 | 2 | 90% | [100–150] | [1–20] | [1–5] | [0.11–0.80] |
| 5 | 15 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.14–0.85] |
| 6 | 15 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.01–0.94] |
| 7 | 15 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.01–0.94] |
| 8 | 15 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.96] |
| 9 | 15 | 2 | 90% | [100–150] | [1–20] | [3–7] | [0.07–0.96] |
| 10 | 20 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.04–0.61] |
| 11 | 20 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.56] |
| 12 | 20 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.10–0.91] |
| 13 | 20 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.01–0.99] |
| 14 | 20 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.05–0.88] |
| 15 | 25 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.96] |
| 16 | 25 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.96] |
| 17 | 25 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.89] |
| 18 | 25 | 2 | 90% | [100–150] | [1–20] | [1–5] | [0.08–0.97] |
| 19 | 25 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.06–0.99] |
| 20 | 30 | 2 | 90% | [100–150] | [10–20] | [1–7] | [0.50–0.89] |
| 21 | 30 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.22–0.89] |
| 22 | 30 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.96] |
| 23 | 30 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.08–0.97] |
| 24 | 30 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.05–0.98] |
| 25 | 35 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.10–0.96] |
| 26 | 35 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.94] |
| 27 | 35 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.94] |
| 28 | 35 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.03–0.98] |
| 29 | 35 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.08–0.98] |
| 30 | 40 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.06–0.98] |
| 31 | 40 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.05–0.98] |
| 32 | 40 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.04–0.97] |
| 33 | 40 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.16–0.93] |
| 34 | 40 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.09–0.95] |
| 35 | 45 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.01–0.95] |
| 36 | 45 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.97] |
| 37 | 45 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.01–0.95] |
| 38 | 45 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.03–0.97] |
| 39 | 45 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.07–0.96] |
| 40 | 50 | 2 | 90% | [100–150] | [1–20] | [1–7] | [0.02–0.84] |
| Parameter | Value |
|---|---|
| Particle Swarm Optimization | |
| Inertia weight (w) | |
| Cognitive acceleration () | |
| Social acceleration () | |
| Number of particles () | 10 |
| Maximum iterations (T) | 100 |
| Bat Algorithm | |
| Larger search space jumps for broader exploration () | |
| Finer adjustments for more detailed exploitation () | |
| Modulating the decay rate of loudness over time () | |
| Modulating the pulse rate’s decay over time () | |
| Adding randomness to the bat’s movement. () | |
| Number of virtual bats () | 10 |
| Maximum iterations (T) | 100 |
| Gray Wolf Optimization | |
| Number of wolves () | 10 |
| Maximum iterations (T) | 100 |
| Orca Predator Algorithm | |
| Explorative and exploitative behaviors (p) | |
| Influence of leading orcas on the group’s movement (q) | |
| Attraction force (F) | 2 |
| Number of orcas () | 10 |
| Maximum iterations (T) | 100 |
| Deep Q-Learning | |
| Action size | 40 |
| Neurons per layer | 20 |
| Activation | ReLU (layers), Linear (final layer) |
| Loss function | Huber |
| Optimizer | RMSprop with a learning rate of |
| Epsilon-greedy | Starts at 1.0, decays to |
| Network update | Every 50 training steps |
| Platform details | |
| Operating system | macOS 14.2.1 Darwin Kernel v23 |
| Programming language | Python 3.10 |
| Hardware specifications | Ultra M2 chip, 64 GB RAM |
| Instances | Metrics | Native Algorithms | Improved Algorithms | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSO | BAT | GWO | OPA | PSODQL | BATDQL | GWODQL | OPADQL | ||
| 1 | Best | 950 | 950 | 950 | 950 | 950 | 950 | 950 | 950 |
| Worst | 950 | 950 | 950 | 950 | 950 | 950 | 950 | 950 | |
| Mean | 950 | 950 | 950 | 950 | 950 | 950 | 950 | 950 | |
| Std | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 950 | 950 | 950 | 950 | 950 | 950 | 950 | 950 | |
| Iqr | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 2 | Best | 773 | 773 | 773 | 773 | 773 | 773 | 773 | 773 |
| Worst | 773 | 773 | 773 | 773 | 773 | 773 | 773 | 773 | |
| Mean | 773 | 773 | 773 | 773 | 773 | 773 | 773 | 773 | |
| Std | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 773 | 773 | 773 | 773 | 773 | 773 | 773 | 773 | |
| Iqr | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 3 | Best | 822 | 822 | 822 | 822 | 822 | 822 | 822 | 822 |
| Worst | 822 | 822 | 822 | 822 | 822 | 822 | 822 | 822 | |
| Mean | 822 | 822 | 822 | 822 | 822 | 822 | 822 | 822 | |
| Std | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 822 | 822 | 822 | 822 | 822 | 822 | 822 | 822 | |
| Iqr | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 4 | Best | 872 | 872 | 872 | 872 | 872 | 872 | 872 | 872 |
| Worst | 872 | 872 | 872 | 872 | 872 | 872 | 872 | 872 | |
| Mean | 872 | 872 | 872 | 872 | 872 | 872 | 872 | 872 | |
| Std | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 872 | 872 | 872 | 872 | 872 | 872 | 872 | 872 | |
| Iqr | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| >5 | Best | 1215 | 1215 | 1215 | 1215 | 1215 | 1215 | 1215 | 1215 |
| Worst | 1215 | 1253 | 1215 | 1215 | 1215 | 1215 | 1215 | 1215 | |
| Mean | 1215 | 1244.2 | 1215 | 1215 | 1215 | 1215 | 1215 | 1215 | |
| Std | 0 | 14.1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 1215 | 0 | 1215 | 1215 | 1215 | 1215 | 1215 | 1215 | |
| Iqr | 0 | 25 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 6 | Best | 1235 | 1235 | 1235 | 1235 | 1235 | 1235 | 1235 | 1235 |
| Worst | 1318 | 1397 | 1235 | 1235 | 1235 | 1318 | 1235 | 1235 | |
| Mean | 1238.50 | 1282.80 | 1235 | 1235 | 1235 | 1238.87 | 1235 | 1235 | |
| Std | 15.27 | 63.02 | 0 | 0 | 0 | 15.32 | 0 | 0 | |
| Median | 1235 | 1235 | 1235 | 1235 | 1235 | 1235 | 1235 | 1235 | |
| Iqr | 0 | 93 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 7 | Best | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 |
| Worst | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | |
| Mean | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | |
| Std | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | 1287 | |
| Iqr | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 8 | Best | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 |
| Worst | 1284 | 1303 | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 | |
| Mean | 1270.30 | 1278.33 | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 | |
| Std | 3.99 | 14.47 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 | 1269 | |
| Iqr | 0 | 19.75 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Instances | Metrics | Native Algorithms | Improved Algorithms | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSO | BAT | GWO | OPA | PSODQL | BATDQL | GWODQL | OPADQL | ||
| 9 | Best | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 |
| Worst | 1305 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | |
| Mean | 1303.07 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | |
| Std | 0.37 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Median | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | 1303 | |
| Iqr | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 10 | Best | 1536 | 1536 | 1536 | 1536 | 1536 | 1536 | 1536 | 1535 |
| Worst | 1636 | 1737 | 1592 | 1596 | 1547 | 1679 | 1596 | 1547 | |
| Mean | 1560.73 | 1584.53 | 1543.07 | 1551.10 | 1536.37 | 1569.57 | 1548.77 | 1536.70 | |
| Std | 27.54 | 56.93 | 14.87 | 21.86 | 2.01 | 35.20 | 19.79 | 2.81 | |
| Median | 1547 | 1547 | 1536 | 1536 | 1536 | 1564 | 1541.50 | 1536 | |
| Iqr | 45 | 92.75 | 11 | 45 | 0 | 56 | 11 | 0 | |
| 11 | Best | 1593 | 1593 | 1593 | 1593 | 1593 | 1593 | 1593 | 1593 |
| Worst | 1687 | 1690 | 1607 | 1650 | 1593 | 1681 | 1641 | 1599 | |
| Mean | 1606.17 | 1607.17 | 1593.87 | 1597.20 | 1593 | 1600.90 | 1595.40 | 1593.20 | |
| Std | 23.76 | 30.52 | 2.91 | 13.59 | 0 | 19.56 | 8.86 | 1.10 | |
| Median | 1596 | 1593 | 1593 | 1593 | 1593 | 1593 | 1593 | 1593 | |
| Iqr | 14 | 6 | 0 | 0 | 0 | 6 | 0 | 0 | |
| 12 | Best | 1608 | 1608 | 1608 | 1608 | 1608 | 1608 | 1608 | 1608 |
| Worst | 1689 | 1703 | 1642 | 1658 | 1642 | 1689 | 1642 | 1615 | |
| Mean | 1629 | 1628.87 | 1611 | 1616.67 | 1611.63 | 1633.03 | 1611 | 1608 | |
| Std | 21.73 | 26.63 | 6.64 | 14.60 | 10.37 | 25.23 | 6.64 | 1.78 | |
| Median | 1615 | 1615 | 1611 | 1608 | 1608 | 1642 | 1608 | 1608 | |
| Iqr | 40 | 40 | 7 | 7 | 0 | 42 | 7 | 0 | |
| 13 | Best | 1530 | 1530 | 1530 | 1530 | 1530 | 1530 | 1530 | 1530 |
| Worst | 1632 | 1626 | 1537 | 1568 | 1531 | 1633 | 1566 | 1537 | |
| Mean | 1547.47 | 1548.70 | 1530.93 | 1537.53 | 1530.03 | 1545.53 | 1535.13 | 1530.37 | |
| Std | 27.21 | 28.31 | 2.15 | 11.36 | 0.18 | 27.36 | 8.18 | 1.30 | |
| Median | 1535 | 1535 | 1530 | 1535 | 1530 | 1531 | 1533 | 1530 | |
| Iqr | 35.25 | 36 | 1.00 | 7 | 0 | 29 | 7 | 0 | |
| 14 | Best | 1449 | 1449 | 1449 | 1449 | 1449 | 1449 | 1449 | 1449 |
| Worst | 1588 | 1609 | 1507 | 1549 | 1497 | 1559 | 1540 | 1508 | |
| Mean | 1498.43 | 1495.03 | 1462.20 | 1486.43 | 1452.27 | 1490.53 | 1488.57 | 1452.30 | |
| Std | 45.64 | 46.67 | 21.51 | 35.07 | 9.25 | 39.62 | 33.31 | 11.07 | |
| Median | 1497 | 1478 | 1449 | 1497 | 1449 | 1497 | 1497 | 1449 | |
| Iqr | 90 | 82 | 20 | 58 | 0 | 89 | 70 | 0 | |
| 15 | Best | 1910 | 1920 | 1910 | 1920 | 1910 | 1910 | 1910 | 1910 |
| Worst | 2089 | 2105 | 2018 | 2062 | 2020 | 2020 | 2180 | 2018 | |
| Mean | 1997.97 | 1984.87 | 1972.10 | 1989.97 | 1931.27 | 1980.83 | 1985.50 | 1956.30 | |
| Std | 46.72 | 56.33 | 32.60 | 47.75 | 34.67 | 32.78 | 54.72 | 32.59 | |
| Median | 2008 | 1965 | 1966 | 1999 | 1915 | 1999 | 1980 | 1956 | |
| Iqr | 49.25 | 97 | 54.25 | 73.50 | 21.50 | 38 | 54.75 | 53.75 | |
| 16 | Best | 1994 | 1994 | 1955 | 1955 | 1955 | 1955 | 1955 | 1955 |
| Worst | 2112 | 2112 | 2037 | 2087 | 2001 | 2087 | 2049 | 2012 | |
| Mean | 2028.27 | 2028.27 | 2005.23 | 2009.50 | 1982.03 | 2025.30 | 2006.13 | 1986.60 | |
| Std | 37.28 | 37.28 | 16.32 | 25.45 | 19.50 | 30.67 | 18.28 | 19.73 | |
| Median | 2005 | 2005 | 2001 | 2005 | 1994 | 2012 | 2001 | 1996 | |
| Iqr | 56.50 | 57 | 12.25 | 20 | 41 | 51 | 12 | 42 | |
| Instances | Metrics | Native Algorithms | Improved Algorithms | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSO | BAT | GWO | OPA | PSODQL | BATDQL | GWODQL | OPADQL | ||
| 17 | Best | 675 | 651 | 683 | 749 | 461 | 698 | 781 | 609 |
| Worst | 1203 | 1256 | 1089 | 1011 | 911 | 1284 | 1098 | 878 | |
| Mean | 971.83 | 1054.53 | 890.77 | 893.57 | 744.37 | 948.27 | 950.03 | 723.30 | |
| Std | 126.54 | 144.85 | 97.83 | 61.44 | 100.04 | 125.35 | 77.97 | 60.57 | |
| Median | 969 | 1075.50 | 897.50 | 901.50 | 759 | 929 | 958 | 724 | |
| Iqr | 175.75 | 150 | 159.50 | 74.75 | 170.50 | 182.25 | 139.50 | 98 | |
| 18 | Best | 1832 | 1801 | 1832 | 1801 | 1801 | 1801 | 1832 | 1801 |
| Worst | 2005 | 2044 | 1950 | 1958 | 1889 | 2009 | 1949 | 1936 | |
| Mean | 1915.90 | 1930.03 | 1881.80 | 1909.27 | 1837.60 | 1938.90 | 1897.13 | 1853.30 | |
| Std | 47.28 | 60.53 | 44.64 | 42.16 | 20.79 | 50.13 | 38.80 | 31.52 | |
| Median | 1918.50 | 1937 | 1887 | 1927 | 1835 | 1945 | 1898.50 | 1849 | |
| Iqr | 51.50 | 77.25 | 86 | 60.25 | 8.75 | 26 | 86.50 | 25.25 | |
| 19 | Best | 1935 | 1930 | 1930 | 1930 | 1905 | 1930 | 1930 | 1930 |
| Worst | 2074 | 2075 | 2024 | 2069 | 1978 | 2042 | 2036 | 2032 | |
| Mean | 1984.13 | 1979.43 | 1962.27 | 1976.07 | 1936.13 | 1981.30 | 1960.23 | 1947.33 | |
| Std | 38.19 | 38.90 | 25.70 | 31.51 | 14.55 | 37.87 | 26.71 | 21.64 | |
| Median | 1981 | 1978 | 1962.27 | 1978.50 | 1935 | 1979.50 | 1947 | 1942 | |
| Iqr | 80.50 | 51.50 | 49 | 42 | 12 | 82 | 42.75 | 12 | |
| 20 | Best | 2337 | 2331 | 2334 | 2339 | 2293 | 2337 | 2334 | 2293 |
| Worst | 2470 | 2507 | 2450 | 2459 | 2426 | 2532 | 2437 | 2428 | |
| Mean | 2413.33 | 2416.10 | 2383.20 | 2408.90 | 2364.77 | 2410.20 | 2390.63 | 2367.38 | |
| Std | 33.92 | 47.48 | 35.02 | 30.34 | 30.60 | 41.58 | 27.87 | 28.53 | |
| Median | 2419.50 | 2423 | 2374 | 2413.50 | 2366 | 2416 | 2384 | 2365 | |
| Iqr | 50.50 | 76.75 | 68.25 | 46.25 | 36.75 | 55.25 | 41 | 38.25 | |
| 21 | Best | 973 | 978 | 915 | 868 | 702 | 805 | 896 | 745 |
| Worst | 1419 | 1648 | 1277 | 1289 | 980 | 1455 | 1321 | 1196 | |
| Mean | 1161.90 | 1303.63 | 1114.03 | 1070.77 | 829.53 | 1119.20 | 1196.10 | 1061.37 | |
| Std | 86.07 | 173.08 | 100 | 103.82 | 73.28 | 156.64 | 91.17 | 93.70 | |
| Median | 1161 | 1291 | 1108.50 | 1081.50 | 829 | 1102 | 1207.50 | 1076 | |
| Iqr | 101 | 312.75 | 124 | 172.25 | 110 | 154 | 105 | 119 | |
| 22 | Best | 2400 | 2423 | 2349 | 2423 | 2323 | 2400 | 2384 | 2349 |
| Worst | 2596 | 2557 | 2520 | 2538 | 2473 | 2524 | 2529 | 2467 | |
| Mean | 2484.10 | 2486.43 | 2462.13 | 2478 | 2372.20 | 2450.77 | 2468.93 | 2427.70 | |
| Std | 46.43 | 36.82 | 34.09 | 29.08 | 43.39 | 33.11 | 34.70 | 28.82 | |
| Median | 2477 | 2480.50 | 2456.50 | 2477 | 2357.50 | 2447 | 2464.50 | 2431.50 | |
| Iqr | 58 | 69.75 | 43.50 | 41.25 | 84 | 55 | 63.25 | 24.50 | |
| 23 | Best | 2295 | 2319 | 2323 | 2323 | 2244 | 2295 | 2326 | 2297 |
| Worst | 2478 | 2489 | 2430 | 2469 | 2390 | 2474 | 2436 | 2399 | |
| Mean | 2390.50 | 2398.03 | 2372.03 | 2393.80 | 2322 | 2400.83 | 2383.50 | 2349.60 | |
| Std | 45.84 | 51.33 | 36.54 | 30.29 | 34.66 | 42.41 | 32.66 | 27.03 | |
| Median | 2391 | 2390.50 | 2373.50 | 2394 | 2328 | 2410.50 | 2390.50 | 2338 | |
| Iqr | 78 | 93.75 | 70 | 39 | 37.75 | 55.25 | 57.25 | 48.25 | |
| 24 | Best | 2232 | 2279 | 2228 | 2248 | 2193 | 2275 | 2238 | 2238 |
| Worst | 2439 | 2502 | 2386 | 2491 | 2337 | 2434 | 2423 | 2411 | |
| Mean | 2354.50 | 2391.40 | 2317.87 | 2352.63 | 2269.77 | 2363.13 | 2350 | 2315.57 | |
| Std | 52.07 | 52.94 | 42 | 54.69 | 42.39 | 51.75 | 41.08 | 36.85 | |
| Median | 2363.50 | 2397 | 2327 | 2342 | 2279 | 2368 | 2342.50 | 2320 | |
| Iqr | 62.25 | 99 | 57.75 | 52 | 76 | 92 | 50 | 39.50 | |
| Instances | Metrics | Native Algorithms | Improved Algorithms | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSO | BAT | GWO | OPA | PSODQL | BATDQL | GWODQL | OPADQL | ||
| 25 | Best | 2826 | 2872 | 2821 | 2817 | 2782 | 2791 | 2842 | 2805 |
| Worst | 3008 | 3176 | 2984 | 2975 | 2922 | 2976 | 2980 | 2946 | |
| Mean | 2931.90 | 2964.93 | 2910.47 | 2921.67 | 2863.03 | 2872.33 | 2919.37 | 2887.87 | |
| Std | 44.78 | 55.33 | 36.04 | 43.44 | 35.78 | 43.97 | 32.81 | 34.57 | |
| Median | 2936.50 | 2959 | 2915.50 | 2931 | 2870 | 2874 | 2924 | 2887.50 | |
| Iqr | 51.75 | 57 | 52.50 | 64.50 | 63.25 | 67 | 31.75 | 46.50 | |
| 26 | Best | 3022 | 3018 | 3056 | 3022 | 2968 | 3016 | 3024 | 3037 |
| Worst | 3208 | 3220 | 3152 | 3144 | 3106 | 3172 | 3155 | 3141 | |
| Mean | 3123.80 | 3133.20 | 3112.17 | 3101.27 | 3048.20 | 3114.20 | 3081.70 | 3083.27 | |
| Std | 44.70 | 51.76 | 24.72 | 33.46 | 34.13 | 31.64 | 32.36 | 29.32 | |
| Median | 3121 | 3140 | 3112.50 | 3109 | 3048.50 | 3119.50 | 3083 | 3081 | |
| Iqr | 72.50 | 78.75 | 35 | 49.75 | 37.75 | 36 | 44 | 45.50 | |
| 27 | Best | 2724 | 2721 | 2716 | 2775 | 2711 | 2714 | 2714 | 2717 |
| Worst | 2948 | 3052 | 2884 | 2886 | 2848 | 2891 | 2889 | 2851 | |
| Mean | 2840.90 | 2882.73 | 2803.47 | 2841.56 | 2765.87 | 2827.27 | 2813.27 | 2787.63 | |
| Std | 55.32 | 81.30 | 51.33 | 29.33 | 41.07 | 48.77 | 39.28 | 32.25 | |
| Median | 2842 | 2858.50 | 2811.50 | 2851 | 2767.50 | 2840.50 | 2821.50 | 2794 | |
| Iqr | 64.25 | 96 | 75.75 | 33.25 | 78.75 | 64 | 61.25 | 32.25 | |
| 28 | Best | 2776 | 2790 | 2817 | 2752 | 2714 | 2727 | 2778 | 2717 |
| Worst | 3024 | 3037 | 2960 | 3005 | 2915 | 3045 | 2963 | 2911 | |
| Mean | 2911.20 | 2949.43 | 2894.97 | 2935.37 | 2825.77 | 2905.10 | 2883.17 | 2827.50 | |
| Std | 52.22 | 65.12 | 42.59 | 53.77 | 48 | 79.31 | 48.04 | 50.01 | |
| Median | 2919.50 | 2954.50 | 2903.50 | 2945.50 | 2831 | 2894.50 | 2895.50 | 2832 | |
| Iqr | 73.75 | 90.75 | 63.75 | 66.50 | 67.25 | 114.50 | 73.50 | 59 | |
| 29 | Best | 2850 | 2870 | 2859 | 2859 | 2770 | 2859 | 2820 | 2813 |
| Worst | 3051 | 3108 | 3007 | 3151 | 2913 | 3060 | 3026 | 2973 | |
| Mean | 2970 | 2968.83 | 2935.23 | 2984.43 | 2868.07 | 2965.23 | 2947.90 | 2914.27 | |
| Std | 47.16 | 63 | 46.58 | 70.05 | 46.72 | 51.64 | 44.59 | 37.74 | |
| Median | 2966 | 2957.50 | 2953 | 2971.50 | 2862 | 2971.50 | 2956 | 2910 | |
| Iqr | 49.75 | 92.50 | 65.75 | 97 | 53.50 | 83.50 | 75.75 | 43.50 | |
| 30 | Best | 3314 | 3310 | 3231 | 3318 | 3218 | 3257 | 3247 | 3258 |
| Worst | 3487 | 3579 | 3457 | 3503 | 3367 | 3471 | 3470 | 3409 | |
| Mean | 3403.63 | 3438.47 | 3368.17 | 3417.77 | 3293.03 | 3388.17 | 3380 | 3344.23 | |
| Std | 51.38 | 63.38 | 50.04 | 43.61 | 45.12 | 52.42 | 54.39 | 43.35 | |
| Median | 3417 | 3435 | 3368 | 3413 | 3285 | 34.13 | 3380 | 3356.50 | |
| Iqr | 96 | 105 | 58.75 | 58 | 74.25 | 81 | 70.25 | 62 | |
| 31 | Best | 3179 | 3224 | 3109 | 3274 | 3044 | 3119 | 3133 | 3116 |
| Worst | 3399 | 3447 | 3328 | 3475 | 3232 | 3357 | 3319 | 3341 | |
| Mean | 3281.73 | 3325.80 | 3226.70 | 3375.37 | 3160.53 | 3262.17 | 3246.50 | 3258.23 | |
| Std | 58.10 | 69.52 | 60.41 | 59.75 | 51.73 | 68.12 | 47.39 | 57.50 | |
| Median | 3276 | 3307.50 | 3230 | 3380.50 | 3162 | 3261 | 3250.50 | 3272 | |
| Iqr | 73.50 | 105 | 103.50 | 102 | 61.50 | 96.50 | 71.25 | 64 | |
| 32 | Best | 3034 | 3062 | 2973 | 3063 | 2946 | 3057 | 3026 | 2974 |
| Worst | 3276 | 3317 | 3220 | 3329 | 3145 | 3283 | 3218 | 3206 | |
| Mean | 3185.63 | 3168.50 | 3138.90 | 3200.73 | 3071.10 | 3177.27 | 3148.17 | 3113.77 | |
| Std | 57.72 | 62.22 | 59.77 | 65.93 | 53.06 | 59.78 | 44.15 | 61.49 | |
| Median | 3195.50 | 3167.50 | 3152 | 3200 | 3074.50 | 3182.50 | 3145 | 3129.50 | |
| Iqr | 88.50 | 109 | 82.25 | 85 | 65 | 102 | 62 | 71.50 | |
| Instances | Metrics | Native Algorithms | Improved Algorithms | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSO | BAT | GWO | OPA | PSODQL | BATDQL | GWODQL | OPADQL | ||
| 33 | Best | 2904 | 2897 | 2890 | 2938 | 2838 | 2830 | 2896 | 2838 |
| Worst | 3119 | 3188 | 3076 | 3105 | 3017 | 3167 | 3112 | 3017 | |
| Mean | 3019.31 | 3020.73 | 2980.83 | 3034.27 | 2932.40 | 2984.07 | 3014.40 | 2932.40 | |
| Std | 58.95 | 74.00 | 49.47 | 47.73 | 41.58 | 58.73 | 57.03 | 41.58 | |
| Median | 3023 | 3008.50 | 2983.50 | 3034.50 | 2944 | 2985 | 3016 | 2944 | |
| Iqr | 91.50 | 123.25 | 59 | 73 | 56 | 55 | 82.75 | 56 | |
| 34 | Best | 3019 | 3035 | 2939 | 2979 | 2929 | 2938 | 2989 | 2918 |
| Worst | 3183 | 3357 | 3125 | 3370 | 3102 | 3203 | 3157 | 3108 | |
| Mean | 3091.60 | 3153.33 | 3065.60 | 3107.80 | 2999.93 | 3074.67 | 3076.63 | 3032 | |
| Std | 44.17 | 74.89 | 43.87 | 74.72 | 41.22 | 58.83 | 44.21 | 50.01 | |
| Median | 3099 | 3134 | 3070.50 | 3099 | 3008.50 | 3067.50 | 3087 | 3028.50 | |
| Iqr | 78 | 144 | 73.50 | 56 | 38.25 | 67.25 | 76.50 | 56.25 | |
| 35 | Best | 3209 | 3317 | 3219 | 3217 | 3110 | 3260 | 3251 | 3160 |
| Worst | 3496 | 3647 | 3497 | 3463 | 3328 | 3538 | 3451 | 3437 | |
| Mean | 3394.87 | 3470.57 | 3343.53 | 3359.83 | 3236.83 | 3386.90 | 3350.43 | 3301.43 | |
| Std | 77.42 | 91.80 | 57.90 | 69.65 | 60.82 | 85.71 | 52.28 | 67.38 | |
| Median | 3407 | 3474.50 | 3338.50 | 3387.50 | 3247.50 | 3376 | 3354 | 3309.50 | |
| Iqr | 105.25 | 159 | 73.75 | 119.75 | 118 | 160.75 | 83.75 | 92.75 | |
| 36 | Best | 3475 | 3537 | 3416 | 3448 | 3331 | 3509 | 3438 | 3456 |
| Worst | 3725 | 3743 | 3663 | 3654 | 3602 | 3728 | 3649 | 3625 | |
| Mean | 3592 | 3640.40 | 3570.20 | 3564.37 | 3480.73 | 3597.03 | 3567.60 | 3545.17 | |
| Std | 68.66 | 61.44 | 47.41 | 49.92 | 64.01 | 57.92 | 49.75 | 43.33 | |
| Median | 3583 | 3643 | 3572.50 | 3559.50 | 3477.50 | 3586 | 3573.50 | 3556.50 | |
| Iqr | 92 | 85.50 | 55 | 73.50 | 70.50 | 97.25 | 72 | 50.50 | |
| 37 | Best | 3516 | 3478 | 3471 | 3463 | 3408 | 3509 | 3462 | 3473 |
| Worst | 3694 | 3752 | 3653 | 3679 | 3581 | 3722 | 3675 | 3615 | |
| Mean | 3604.63 | 3621.40 | 3569.67 | 3600.67 | 3511.90 | 3630.13 | 3595.97 | 3553.27 | |
| Std | 48.01 | 73.97 | 43.76 | 53.01 | 47.45 | 58.41 | 47.43 | 38.00 | |
| Median | 3605 | 3624.50 | 3574.50 | 3612 | 3519 | 3640.50 | 3601 | 3566 | |
| Iqr | 82.75 | 111.50 | 62.25 | 63.25 | 78 | 98.25 | 56.25 | 59.75 | |
| 38 | Best | 3248 | 3307 | 3109 | 3256 | 3114 | 3211 | 3134 | 3211 |
| Worst | 3504 | 3703 | 3445 | 3491 | 3331 | 3559 | 3416 | 3392 | |
| Mean | 3372.87 | 3443.80 | 3321.23 | 3371.87 | 3208.33 | 3367.83 | 3334.70 | 3302.03 | |
| Std | 65.74 | 90.01 | 68.03 | 68.50 | 57.96 | 96.98 | 71.81 | 47.40 | |
| Median | 3370 | 3429 | 3331 | 3355.50 | 3210 | 3365 | 3351.50 | 3310 | |
| Iqr | 99 | 96 | 73 | 105.50 | 81.50 | 146.25 | 100.25 | 76 | |
| 39 | Best | 3519 | 3434 | 3452 | 3502 | 3346 | 3472 | 3495 | 3449 |
| Worst | 3738 | 3811 | 3680 | 3690 | 3590 | 3751 | 3669 | 3635 | |
| Mean | 3613.67 | 3617.33 | 3592.20 | 3617.93 | 3495.60 | 3642.90 | 3579.27 | 3543.67 | |
| Std | 63.44 | 95.11 | 45.82 | 54.35 | 58.84 | 69.78 | 47.05 | 44.80 | |
| Median | 3609 | 3623 | 3598 | 3634 | 3512.50 | 3654.50 | 3575 | 3546.50 | |
| Iqr | 93.25 | 141 | 46.75 | 77.50 | 85.25 | 98.50 | 84.25 | 60 | |
| 40 | Best | 3813 | 3940 | 3850 | 3919 | 3758 | 3826 | 3842 | 3820 |
| Worst | 4171 | 4203 | 4094 | 4225 | 3999 | 4047 | 4106 | 4065 | |
| Mean | 4025.90 | 4052.07 | 3993.17 | 4031.60 | 3886.57 | 3963.47 | 3982.40 | 3972.60 | |
| Std | 74.31 | 71.92 | 52.11 | 62.17 | 59.72 | 59.89 | 61.02 | 61.75 | |
| Median | 4025.50 | 4046 | 3991 | 4022 | 3906 | 4001.50 | 3976.50 | 3982 | |
| Iqr | 123.75 | 104.75 | 62.25 | 82 | 96 | 107 | 78.75 | 76 | |
| Instances | PSO v/s PSODQL | PSODQL v/s PSO | BAT v/s BATDQL | BATDQL v/s BAT | GWO v/s GWODQL | GWODQL v/s GWO | OPA v/s OPADQL | OPADQL v/s OPA |
|---|---|---|---|---|---|---|---|---|
| 15 | – | – | – | – | – | – | ||
| 16 | – | – | – | – | – | – | ||
| 17 | – | – | – | – | ||||
| 18 | – | – | – | – | – | – | ||
| 19 | – | – | – | – | – | – | ||
| 20 | – | – | – | – | – | – | ||
| 21 | – | – | – | – | – | |||
| 22 | – | – | – | – | – | |||
| 23 | – | – | – | – | – | – | ||
| 24 | – | – | – | – | ||||
| 25 | – | – | – | – | – | |||
| 26 | – | – | – | – | ||||
| 27 | – | – | – | – | – | |||
| 28 | – | – | – | – | – | |||
| 29 | – | – | – | – | – | – | ||
| 30 | – | – | – | – | – | |||
| 31 | – | – | – | – | – | |||
| 32 | – | – | – | – | – | |||
| 33 | – | – | – | – | ||||
| 34 | – | – | – | – | – | |||
| 35 | – | – | – | – | – | |||
| 36 | – | – | – | – | – | – | ||
| 37 | – | – | – | – | – | |||
| 38 | – | – | – | – | – | |||
| 39 | – | – | – | – | – | – | ||
| 40 | – | – | – | – | – |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olivares, R.; Salinas, O.; Ravelo, C.; Soto, R.; Crawford, B. Enhancing the Efficiency of a Cybersecurity Operations Center Using Biomimetic Algorithms Empowered by Deep Q-Learning. Biomimetics 2024, 9, 307. https://doi.org/10.3390/biomimetics9060307
Olivares R, Salinas O, Ravelo C, Soto R, Crawford B. Enhancing the Efficiency of a Cybersecurity Operations Center Using Biomimetic Algorithms Empowered by Deep Q-Learning. Biomimetics. 2024; 9(6):307. https://doi.org/10.3390/biomimetics9060307
Chicago/Turabian StyleOlivares, Rodrigo, Omar Salinas, Camilo Ravelo, Ricardo Soto, and Broderick Crawford. 2024. "Enhancing the Efficiency of a Cybersecurity Operations Center Using Biomimetic Algorithms Empowered by Deep Q-Learning" Biomimetics 9, no. 6: 307. https://doi.org/10.3390/biomimetics9060307
APA StyleOlivares, R., Salinas, O., Ravelo, C., Soto, R., & Crawford, B. (2024). Enhancing the Efficiency of a Cybersecurity Operations Center Using Biomimetic Algorithms Empowered by Deep Q-Learning. Biomimetics, 9(6), 307. https://doi.org/10.3390/biomimetics9060307