1. Introduction
Optimization is everywhere, be it engineering design, industrial design, business planning, holiday planning, etc. We use optimization techniques to solve problems intelligently by choosing the best from many available options [
1]. At its core, it involves the quest for an optimal set of parameter values within specified constraints, aimed at either maximizing or minimizing system performance indicators [
2]. Due to the involvement of many decision variables, complex nonlinear constraints, and objective functions, efficient methods are required for solving them. Traditional algorithms typically start from singularities and rely on gradient information [
3]. However, many real-world optimization problems are often characterized as black-box problems, where specific expressions, gradient information, and derivatives are unknown [
4]. Metaheuristic algorithms (MAs) are computational intelligence paradigms especially used for sophisticated solving optimization problems [
5]. MAs present a promising avenue for tackling most real-world nonlinear and multimodal optimization challenges by offering acceptable solutions through iterative trial and error [
6].
These algorithms are classified into evolutionary-based [
7], physics-based [
8], and swarm intelligence-based [
9] categories. Evolutionary-based algorithms, rooted in natural selection and genetics, include genetic algorithm (GA) [
10] and differential evolution (DE) [
11]. GA evolves potential solutions by simulating natural selection and genetic mechanisms like replication, crossover, and mutation operations, gradually converging toward the optimal solution. DE mimics biological evolution to seek the optimal solution by leveraging differences among individuals in the population to guide the search direction and iteratively evolve towards the optimum. Physics-based algorithms allow each search agent to interact and move in the search space according to certain physical rules, with common algorithms, including simulated annealing (SA) [
12], the gravitational search algorithm (GSA) [
13], and the sine cosine algorithm (SCA) [
14]. The SA algorithm simulates the physical annealing process, randomly exploring the solution space to find the global optimum solution, and utilizes a probability jump mechanism to avoid local optima, thus achieving global optimization. GSA is inspired by natural gravitational forces and object movements, aiming to find the global optimum by adjusting the positions of objects in the solution space for optimization search. Meanwhile, SCA utilizes the fluctuating properties of sine and cosine functions to generate random candidate solutions and, through an adaptive balance of exploration and exploitation stages, achieves global optimization search. Swarm intelligence (SI) algorithms are inspired by collective behaviors of social insects and animals [
15]. Some classic swarm intelligence algorithms include particle swarm optimization (PSO) [
16], ant colony optimization (ACO) [
17], artificial bee colony (ABC) [
18], grey wolf optimizer (GWO) [
19], whale optimization algorithm (WOA) [
20], Harris hawks optimization (HHO) [
21], sparrow search algorithm (SSA) [
22], and the slime mold algorithm (SMA) [
23]. These algorithms exhibit characteristics of self-organization, adaptation, and self-learning and are widely applied across various domains [
24].
The dung beetle optimization (DBO) algorithm [
25] is a swarm intelligence algorithm, proposed in 2022, and has attracted considerable attention due to its well-optimized performance and unique design inspiration among a plethora of metaheuristic algorithms. DBO emulates various life behaviors of dung beetle populations, such as rolling balls, dancing, foraging, stealing, and reproduction, thereby constructing a novel optimization strategy. Experimental results demonstrate that DBO exhibits good performance in solving some classical optimization problems. Nevertheless, achieving desirable results when using the DBO algorithm to solve complex optimization problems remains a challenge. Specifically, the drawbacks of DBO are primarily evident in the following aspects: Firstly, during the initialization phase, the utilization of randomly generated populations may lead to an uneven distribution within the solution space, consequently restricting exploration and potentially trapping the algorithm in local optima. Secondly, the inclination toward greediness of the algorithm throughout the search process may precipitate premature convergence on local optima, disregarding the global optimum and resulting in suboptimal outcomes. Furthermore, akin to other swarm intelligence algorithms, when solving multi-dimensional objective functions, neglecting the evolution of specific dimensions due to inter-dimensional interference deteriorates convergence speed and compromises solution quality. As asserted by the “No Free Lunch” (NFL) theorem [
26], every algorithm has its inherent limitations, and there is no one algorithm that can solve all optimization problems. Therefore, many scholars are dedicated to proposing new algorithms or improving existing ones to address various real-world optimization problems. This paper addresses the deficiencies and limitations of the original DBO algorithm by proposing a multi-strategy improved Dung Beetle Optimization algorithm (MDBO). The MDBO aims to enhance the global optimization capability of the original DBO by introducing multiple strategies, improving the convergence accuracy and speed of the algorithm. Then, the overall performance of the MDBO algorithm is validated through experiments across various aspects. Overall, the main contributions of this paper are as follows:
The Latin hypercube sampling (LHS) initialization strategy replaces the original random initialization method of DBO to generate higher-quality initial candidate solutions.
Introducing a mean difference mutation strategy enhances the capability of the algorithm to escape local optimal solutions by mutating the population.
A strategy that combines lens imaging inverse learning with dimension-by-dimension optimization is proposed and applied to the current optimal solution to enhance its quality.
The proposed MDBO algorithm is verified to outperform other classical metaheuristic algorithms in terms of performance by comparing the solution accuracy, convergence speed, and stability of the CEC2017 and CEC2020 functions, respectively.
Further, MDBO was successfully applied to three real-world engineering optimization problems, validating its superior capability in solving complex engineering problems.
This paper is organized as follows. The basic dung beetle optimization algorithm is introduced in
Section 2. The multi-strategy improved dung beetle optimization algorithm (MDBO) is proposed in
Section 3 to address the shortcomings of the dung beetle optimization algorithm. In
Section 4, the improved multi-strategy dung beetle optimization algorithm is experimentally compared with other algorithms in various aspects to verify the effectiveness of the improvement measures.
Section 5 uses the improved algorithm in real-world engineering applications to further explore the practical applicability of the improved algorithm.
Section 6 summarizes the full work.
3. Multi-Strategy Improved Dung Beetle Optimization Algorithm (MDBO)
The basic characteristics of the dung beetle optimization algorithm can be derived from its principle. The ball-rolling behavior enhances the global search ability of the algorithm across all phases, while reproduction and foraging behaviors facilitate exploration around the optimal position of the individual. With each iteration, the dynamic boundary and range of search decrease gradually. The stealing behavior entails a dynamic localized search near the optimal individual. Despite the simplicity of the DBO algorithm and its successful application in certain engineering design problems, it exhibits several drawbacks. Striking a balance between global exploration and local exploitation poses challenges, and algorithms are prone to falling into local optima [
27]. To rectify these issues, this study proposes enhancements in the ensuing sections.
3.1. Latin Hypercube Sampling to Initialize Populations
The DBO algorithm usually relies on a stochastic initialization strategy to generate the initial population when solving complex optimization problems. This randomization helps to explore different regions of the solution space, thus increasing the chance of finding a globally optimal solution. However, random initialization also has an obvious drawback: it cannot ensure the uniform distribution of the population in the solution space. Especially in high-dimensional search spaces, it requires a large number of points to obtain a good distribution, and these points may be close to each other or even overlap [
28]. This may result in the population being too concentrated in some regions and too sparse in others. This uneven distribution is very detrimental to the early convergence of the algorithm.
To address this issue, this study introduces an initialization method called Latin hypercube sampling (LHS) [
29,
30]. The fundamental concept of LHS involves partitioning the sample space into multiple uniform and non-overlapping subspaces and selecting a single data point from each subspace as a sampling point. This approach guarantees a uniform distribution of sample points across the defined domain, thereby mitigating the risk of over-concentration or sparse distribution of agents. Mathematically, the generated sample is represented using Equation (
8).
where
r is a uniform random number in (0,1),
is the sample in the ith interval, and
n is the total number of samples. When the total number of samples is 10, the sample
in the first interval has a range of [0,0.1], and similarly the sample in the second interval has a range of [0.1,0.2], and so on to obtain all the sampling points of all LHSs.
Compared to random or stratified sampling methods, Latin hypercube sampling (LHS) exhibits stronger spatial filling capability and convergence characteristics [
31]. This attribute has led to its widespread application in the initialization of populations in intelligent algorithms.
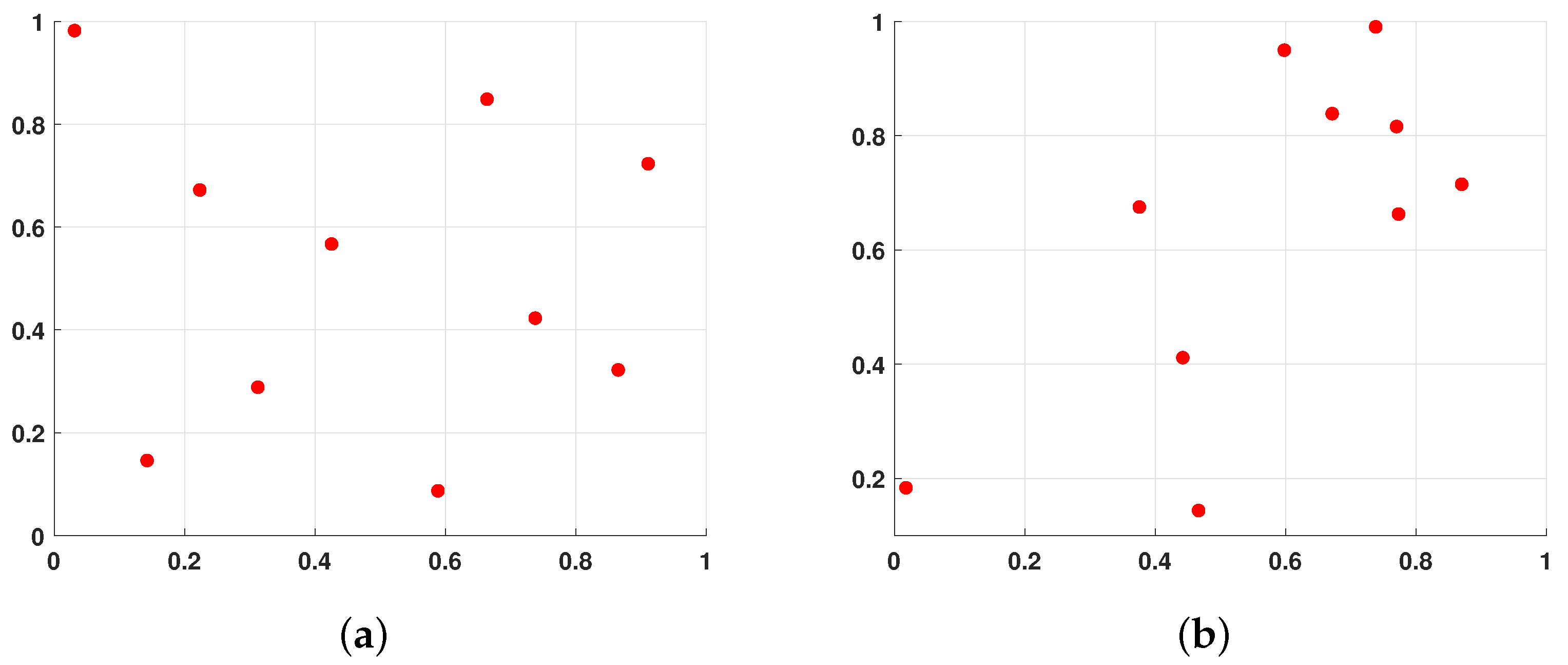
Figure 3 illustrates a two-dimensional comparison between the distributions of 10 randomly generated populations and populations generated using LHS. It is evident from the figure that the population distribution generated by LHS is more uniform, with no overlapping individuals. Therefore, this method can generate higher-quality initial populations, laying a better foundation for subsequent algorithm optimization.
As a metaheuristic algorithm based on swarm intelligence, the dung beetle optimization algorithm is mathematically modeled in the same way at initialization as other algorithms as shown in Equation (
9). The set of points acquired through LHS can often be mapped to the solution space of the objective function using an equation similar to the one depicted in Equation (
10).
Here,
X is the population matrix,
is the
ith DBO member (candidate solution),
N is the number of dung beetles,
D is the number of decision variables,
and
represent the upper and lower bounds of the problem to be optimized,
denotes the
ith vector obtained using Latin Hypercube Sampling.
3.2. Mean Differential Variation
Throughout the iterative process, as the population gradually converges towards optimal individuals, there is a tendency for decreased population diversity. To prevent premature convergence of the algorithm caused by a reduction in population diversity throughout the iteration process, this paper introduces the mean differential variation [
32]. Depending on the stage of the iteration, this method can be categorized into two variants, denoted as DE/mean-current/1 and DE/mean-current-best/1 respectively. Both variants initially select two individuals,
and
, randomly from the current population, and calculate two new vectors,
and
, according to Equation (
11).
The first variation strategy, which proceeds according to Equation (
12), is unique in that it employs two fundamental vectors external to the current population. This strategy not only helps to escape the problem of population stagnation but also effectively maintains the diversity of the population, thus promoting the exploration capability of the algorithm. Consequently, the algorithm is able to search in a wider solution space, thereby augmenting the likelihood of discovering a globally optimal solution.
The second variation strategy is executed based on Equation (
13), where the generation of new vectors incorporates information about the global optimal solution. This improvement allows the algorithm to perform a more intensive search in the vicinity of the optimal solution, thus finely exploring small variations in the solution space. In this way, the algorithm is able to approximate the global optimal solution more accurately, improving the accuracy and efficiency of the solution.
In Equations (
12) and (
13),
represents the current best individual,
denotes the individual currently undergoing mutation, and
F is the scaling factor. In the first type of mutation,
, while in the second type of mutation,
. Both types of mutations are executed in a cooperative manner. In the first two-thirds of the iterations, the first type of mutation is exclusively performed as it provides good search and exploitation capabilities. In the last one-third of the iterations, the second type of mutation is executed to conduct a more intensive search. Overall, as in Equation (
14), we have the following:
This strategy of searching near individuals in the early stages and exploring near the global optimum in the later stages effectively helps the algorithm escape local optima, thereby enhancing the algorithm’s global search capability and convergence speed.
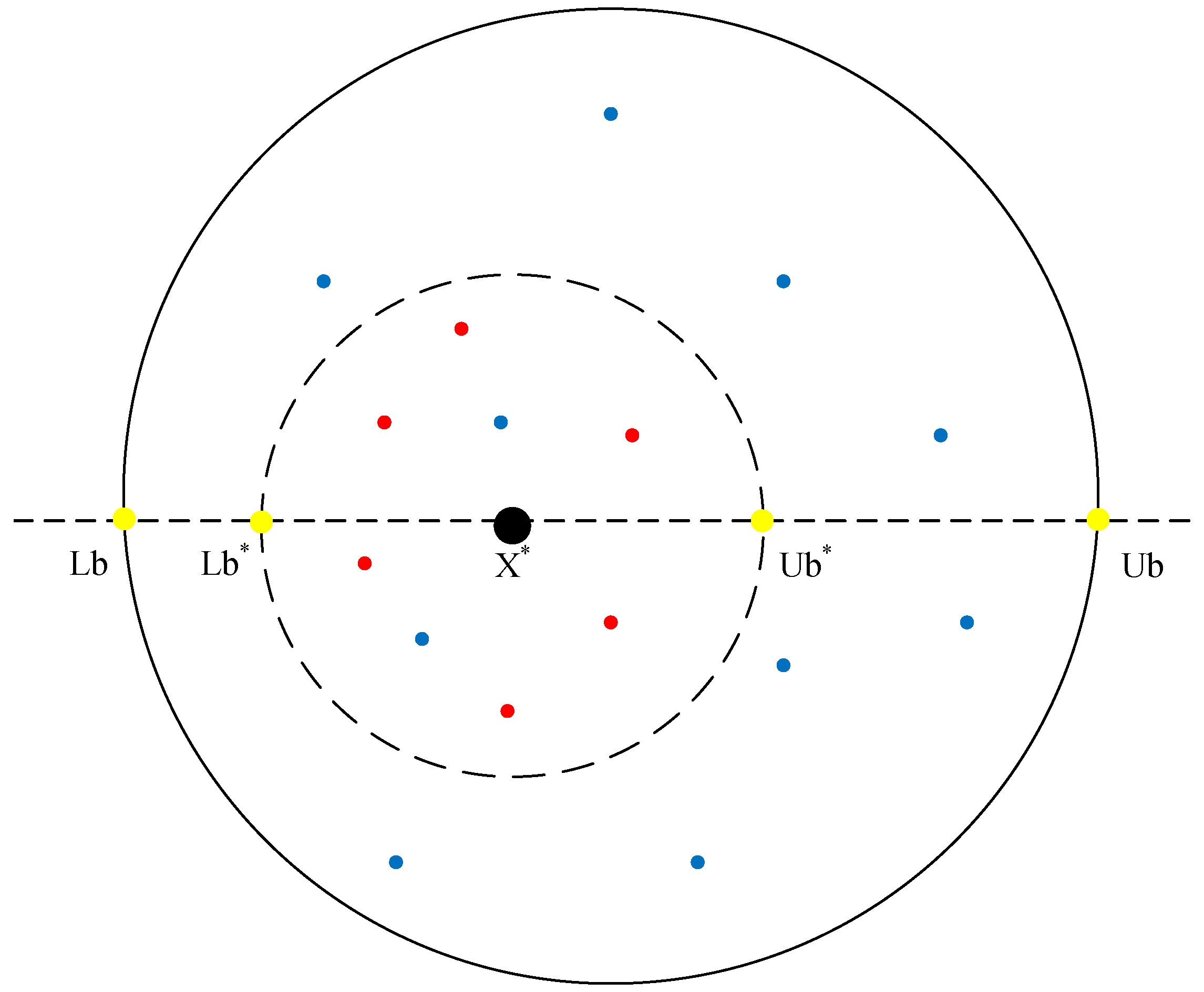
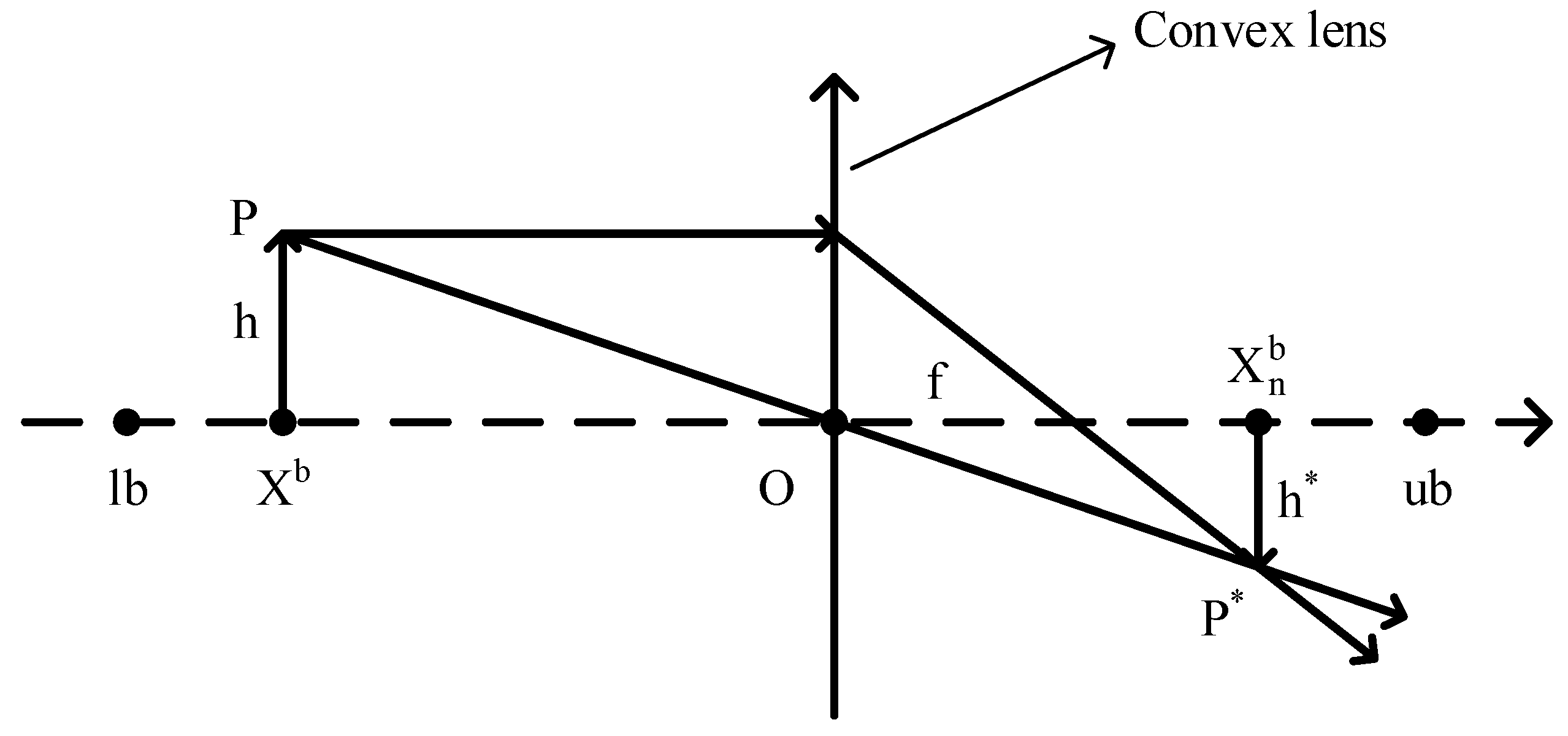
3.3. Fusion Lens Imaging Backward Learning and Dimension-by-Dimension Optimization
The position of the current best individual is particularly important, but in the basic dung beetle optimization (DBO) algorithm, the information contained in the current best individual is not fully utilized, leading to a lack of exploitation of the best individual. Therefore, this paper introduces the lens imaging reverse learning strategy [
33,
34] to perturb the best individual to help the algorithm escape local optima. The idea is to generate a reverse position based on the current coordinates to expand the search range, which can effectively avoid local optima and broaden the search scope of the algorithm. The principle of the lens imaging reverse learning strategy is depicted in
Figure 4.
Suppose within a certain space, the global optimal position
is obtained by projecting an individual
P with a height of
h onto the x-axis. Here,
and
represent the lower and upper limits of the coordinate axis. Placing a convex lens with a focal length
f at the origin
O, a point
with a height
can be obtained through the convex lens. At this point, the projection
of
on the x-axis is the reverse solution. According to the principle of lens imaging, Equation (
15) can be derived.
Let
, and by transformation, we obtain Equation (
16).
By adjusting the value of
k in the lens imaging reverse learning, the dynamic reverse solution can be obtained. A smaller
k produces a larger range of inverse solutions, while a larger
k can produce a smaller inverse. This paper introduces an adaptive
k as Equation (
17). As the number of iterations increases, the value of
k will grow from small to large, to meet the characteristics of a large-scale search in the early stage and a fine search in the late stage.
In dung beetle optimization (DBO), each agent represents a potential solution. When updating each agent, updates are made across all dimensions, overlooking the changes in dimensions within each agent. Suppose a dimension within an agent moves towards a better solution, but degradation in other dimensions leads to a decrease in the overall solution quality, resulting in the abandonment of that solution. This would waste evaluation efforts and deteriorate convergence speed [
35]. Based on a greedy per-dimension update strategy, the evolutionary dimension of solutions will not be overlooked due to degradation in other dimensions, allowing any update value that can improve the solution to be accepted. Ensuring that the algorithm can utilize evolutionary information from individual dimensions for better local search, thereby obtaining higher-quality solutions and improving the convergence speed [
36].
In this paper, a strategy combining lens imaging reverse learning and dimension-by-dimension optimization. The core idea of this strategy lies in updating the best value obtained through lens imaging reverse learning in a per-dimension manner, combined with greedy rules to optimize the solution. Specifically, initially, a mutation operation is applied to the best individual
as shown in Equation (
16), resulting in a mutated individual
. Subsequently, the fitness values of
and
are compared, and the individual with better fitness is chosen as the benchmark position. Then, all dimensions of another position are used to replace the corresponding dimensions of the benchmark position one by one. In the process of per-dimension replacement, a greedy rule is adopted: If the overall fitness value improves after replacing a dimension, the replaced value of that dimension is retained; otherwise, the benchmark position remains unchanged. Through such per-dimension optimization, the structure of the solution can be finely adjusted, further enhancing the quality of the solution. Finally, the reference position after dimension replacement becomes the new
of the next generation. This process integrates the idea of lens imaging reverse learning and dimensional optimization, aiming to approach the global optimal solution gradually through continuous iteration and optimization. The complete algorithm flow is shown in Algorithm 2.
| Algorithm 2: Fusion lens imaging backward learning and dimension-by-dimension optimization strategies. |
![Biomimetics 09 00291 i002]() |
3.4. Complexity Analysis of MDBO
Assume that N represents the number of populations, D represents the dimension of the optimization problem, and T represents the maximum number of iterations, DBO exhibits an initialization phase complexity of = O(N*D) and an iterative process complexity of = O(T*N*D), resulting in a total complexity of + = O(T*N*D). For MDBO, the complexity of initializing the population using Latin hypercube is = O(N*D), the average differential variance complexity is = O(N*T), the complexity of fusing lens imaging reverse learning and dimension-by-dimension optimization is = O(T*D), and the complexity of the iterative process is the same as that of DBO as . Hence, the complexity of MDBO is + + + = O(T*N*D), equivalent to DBO, and its performance does not depend on the higher complexity.
3.5. The MDBO Algorithm Implementation Steps
The basic framework of the MDBO algorithm is outlined in Algorithm 3. To provide a clear visualization of the process,
Figure 5 illustrates the flowchart of MDBO. This algorithm aims to enhance search efficiency and convergence speed during optimization by employing a combination of multiple strategies. Specifically, the MDBO algorithm utilizes Latin hypercube sampling for improved population initialization and introduces a novel differential variation strategy called “Mean Differential Variation” to enhance its ability to evade local optima. Moreover, applying lens imaging reverse learning to the current optimal solution to expand the algorithm’s search space, and combining it with a dimension-by-dimension optimization strategy to improve the quality of the solution.
| Algorithm 3: The framework of the MDBO algorithm |
![Biomimetics 09 00291 i003]() |
4. Experimental Results and Discussions
In order to evaluate the performance of the improved algorithm comprehensively, this paper selects two sets of benchmark functions: CEC2017 [
37] and CEC2020 [
38]. The details of the benchmark functions are shown in
Table 1. In CEC2017, the original F2 function has been excluded due to loss of testing capability, thus leaving 29 single-objective benchmark functions for testing. Among these, F1 and F2 are single-peaked functions with only one global minimum, F3–F9 are simple multi-modal functions with local minima, F10–F19 are mixed functions containing three or more CEC2017 benchmark functions after rotation or displacement, and F20–F29 are composite functions formed by at least three mixed functions or CEC2017 benchmark functions after rotation and displacement. CEC2020 consists of one composite single-peaked function F1, three multi-peaked functions F2–F4 after rotation and displacement, three mixed functions F5–F7, and three composite functions F8–F10.
The comparison algorithms encompass DBO [
25], WOA [
20], GWO [
19], SCA [
14], SSA [
22], HHO [
21]. To ensure the fairness of the experiments, the initial population size for all algorithms is set to 30, and the maximum number of iterations is set to 500. To eliminate the influence of randomness in the experiments, each algorithm is independently executed 30 times to statistically analyze its results. MATLAB R2020b is utilized for software implementation.
4.1. CEC2017 Test Function Results and Analysis
4.1.1. Analysis of CEC2017 Statistical Results
The statistical outcomes for the CEC2017 test function in 30 and 100 dimensions were meticulously documented. These include the minimum (min), mean, and standard deviation (std) of each algorithm’s independent execution conducted 30 times. The best average result for each test function is accentuated in bold font. The last row “Total” indicates the number of times each algorithm achieved the best result among all test functions. The statistical results for 30 and 100 dimensions are presented in
Table 2 and
Table 3, respectively.
From
Table 2 and
Table 3, the comprehensive analysis reveals that, overall, for the 30-dimensional case, MDBO obtained the optimal solution in 21 out of 29 test functions. For the remaining 8 test functions, MDBO achieved the second-best result, while GWO obtained 2 optimal values and SSA obtained 6 optimal values. However, in the case of 100 dimensions, MDBO only attained the best solution in 15 out of 29 test functions, yielding suboptimal outcomes in the remaining 14 test functions. A detailed examination reveals the following:
MDBO did not achieve the best performance among all algorithms on the unimodal function F1, whether in the 30-dimensional or 100-dimensional case. It demonstrated superior performance compared to other algorithms but fell short of SSA. Notably, MDBO excelled in the unimodal function F2, outperforming all algorithms in both 30 and 100 dimensions.
In the simple multimodal problems F3–F9, MDBO achieved the best average fitness value in 6 out of 7 test functions in the 30-dimensional scenario, except for F5, where it trailed slightly behind GWO. However, in the 100-dimensional scenario, MDBO exhibited weaker performance compared to GWO on functions F4, F5, F6, and F7, and weaker than SSA on functions F3, F8, and F9. Nevertheless, an improvement was observed in all benchmark functions compared to the basic DBO.
For the hybrid functions F10–F19, in the 30-dimensional scenario, MDBO obtained the minimum values on all 7 test functions compared to the other algorithms. It ranked second after SSA in functions F11, F12, and F18. In the 100-dimensional scenario, MDBO secured minimum values in 7 out of 10 test functions, excluding F11, F13, and F17.
In the case of composite functions F20–F29, when the dimension is 30, MDBO only did not achieve the best results on F24, F27, and F28 but secured the top position in the remaining 7 functions. When the dimension is 100, MDBO exhibited weaker performance compared to SSA in functions F21, F24, and F27 but obtained the best results in the remaining 7 functions.
To comprehensively evaluate the performance of all algorithms, this study conducted Friedman tests on the average results of 30 independent optimization runs for 30 test functions for each algorithm. The average rankings of all algorithms on the test functions were calculated, where a lower average ranking indicates better algorithm performance. The Friedman test results for dimensions 30 and 100 are shown in
Figure 6. From the results, it is evident that the average rankings for dimensions 30 and 100 maintain similar trends, with MDBO achieving the lowest average ranking, followed by SSA, GWO, DBO, HHO, WOA, and SCA, respectively. This suggests that, compared to other algorithms, MDBO generally exhibits superior performance.
4.1.2. CEC2017 Convergence Curve Analysis
In order to assess both the accuracy and convergence speed of the algorithms, convergence curves were plotted for MDBO and other algorithms at dimension 30, as illustrated in
Figure 7. It is worth noting that in each subplot, the horizontal axis represents the number of iterations, while the vertical axis represents the average convergence curve over 30 runs. From the figure, the following can be observed:
For the unimodal problem F1, initially, the convergence speed of MDBO was slower than SSA. However, after approximately two-thirds of the iterations, its convergence speed accelerated and gradually caught up with SSA, achieving results close to SSA. As for unimodal problem F2, the convergence speed of MDBO was comparable to other comparative algorithms. However, owing to its superior exploration capability, MDBO converged to a better solution.
For the simple multimodal functions F3, MDBO, and SSA exhibited comparable convergence speed and accuracy, outperforming all other comparative algorithms. Concerning F4, F7, F7, and F9, initially, only the convergence speeds of GWO and SSA were similar to MDBO. However, after around two-thirds of the iterations, the convergence speeds of SSA and GWO slowed down, while the convergence speed of MDBO accelerated, rapidly converging to better positions. Regarding F5 and F6, the convergence speed of MDBO was on par with GWO and superior to other algorithms.
In the case of hybrid functions F10–F19, MDBO demonstrated decent convergence speed, particularly excelling in F15 and F19, maintaining a leading position consistently. Concerning F10, F11, F13, F14, F17, and F18, MDBO exhibited similar convergence speed and accuracy to SSA. Regarding F12, MDBO’s performance was inferior to SSA but significantly outperformed other comparative algorithms, showing a substantial improvement over DBO. As for F16, the results obtained by all algorithms were similar, with minor differences.
In the case of composite functions F20, F21, F22, F23, and F25, MDBO consistently demonstrated the fastest convergence speed and accuracy, outperforming all other comparative algorithms, especially evident in F21, where it significantly surpassed other algorithms. Regarding F24, F26, F27, and F28, MDBO’s performance was comparable to other algorithms, slightly superior in certain benchmark functions. Concerning F29, the results are shown in
Figure 8, which can be found that the convergence speed of SSA and MDBO was similar, but MDBO had a slight edge.
4.2. CEC2020 Test Function Results and Analysis
4.2.1. Analysis of CEC2020 Statistical Results
The experimental statistical findings for the CEC2020 test function with a dimension of 20 are depicted in
Table 4. This table meticulously records the minimum (min), mean, and standard deviation (std) values resulting from 30 independent runs for each algorithm. Notably, the best average result among all algorithms is marked in bold. Furthermore, the concluding row of the table provides a tally of occurrences wherein each algorithm attained the optimal value across all test functions. From
Table 4, it becomes apparent that MDBO outperformed its counterparts in nine test functions, with only a marginal deviation observed in comparison to GWO in the F3 test function.
In employing Friedman’s test, an assessment of the average rank for each algorithm across all test function outcomes was undertaken. As delineated in
Figure 9, a discernible tendency is found: MDBO achieves the lowest rank, followed by SSA, GWO, DBO, HHO, WOA, and SCA. This unequivocally underscores the pronounced superiority of MDBO over its algorithmic counterparts.
4.2.2. CEC2020 Convergence Curve Analysis
Similarly, the average convergence curves for CEC2020 in 20 dimensions were plotted as shown in
Figure 10. It can be observed that in the unimodal function F1, SSA initially exhibited faster convergence compared to MDBO. However, as iterations progressed, SSA became trapped in local optima, while MDBO demonstrated superior exploration capability, eventually discovering better solutions. In F2, MDBO initially exhibits slower convergence compared to DBO and SSA. Nevertheless, as DBO and SSA fall into local optima, MDBO maintains a decent convergence rate. In F6, F7, and F8, MDBO significantly outperforms other comparative algorithms in terms of convergence speed, precision, and stability. Moreover, MDBO demonstrates varying degrees of superiority in the remaining test functions. This robustly validates the effectiveness of MDBO in addressing complex optimization problems.
4.3. Wilcoxon Rank Sum Test
The Wilcoxon rank-sum test [
39,
40] is a non-parametric statistical test used to further determine whether the differences between the improved algorithm and the comparative algorithms are significant. In this study, the results of running the six comparative algorithms and MDBO 30 times were used as samples. The Wilcoxon rank-sum test was applied at a significance level of 0.05. When the test result’s
p-value is less than 0.05, it indicates a significant difference between the two compared algorithms; otherwise, it suggests that the results of the two algorithms are comparable.
p-values of the Wilcoxon rank-sum test for CEC2017 at dimensions 30 and 100 are displayed in
Table 5 and
Table 6, respectively. The
p-values of the Wilcoxon rank-sum test for CEC2020 at dimension 20 are shown in
Table 7. Values with
p-values greater than 0.05 are highlighted in bold. The last row of each table summarizes the number of times all comparative algorithms had
p-values less than 0.05 across all test functions.
Based on the results in
Table 5, it is evident that at a dimension of 30 in CEC2017, MDBO exhibits significant disparities when compared to both WOA and SCA across all test functions. In contrast, when juxtaposed with DBO and HHO, MDBO shows significant differences in all 28 test functions. Moreover, in comparison with GWO and SSA, MDBO demonstrates significant disparities in 18 and 21 test functions, respectively. Further scrutiny of
Table 6 reveals that as the dimension increases to 100, MDBO exhibits significant differences compared to DBO, WOA, and SCA across all functions. When compared to GWO, SSA, and HHO, only a minority of functions show similar results, with significant differences apparent in the majority of cases.
Furthermore, according to
Table 7, among the ten benchmark functions of CEC2020, it is evident that MDBO exhibits comparable performance with GWO in functions F7 and F9, whereas, in the remaining test functions, MDBO demonstrates a significant advantage. Conversely, when compared to SSA, significant differences are observed in only 5 test functions. However, when compared to DBO, WOA, SCA, and HHO, MDBO consistently demonstrates absolute superiority across all test functions.
4.4. Summary of Experiments
Upon scrutinizing the statistical results and convergence curves derived from CEC2017 at 30 dimensions, it becomes evident that MDBO exhibits superior optimization capabilities characterized by enhanced seeking ability, greater stability, accelerated convergence speed, and heightened convergence accuracy compared to its algorithmic counterparts. This trend persists even when the dimensionality is increased to 100, as MDBO continues to demonstrate commendable performance in tackling high-dimensional optimization challenges. To further validate the efficacy of MDBO in addressing complex problem landscapes, additional experimentation was conducted using CEC2020, which reaffirmed MDBO’s consistent and robust performance in handling intricate optimization scenarios, underscoring its adaptability and reliability in real-world applications.
In order to verify the difference between MDBO and other algorithms, the p-values of CEC2017 at 30 dimensions, 100 dimensions, and CEC2020 at 20 dimensions were calculated using the Wilcoxon rank sum test. The results show that MDBO is significantly different from other algorithms and has obvious advantages.
Through performance testing of the MDBO algorithm from multiple aspects, it is evident that MDBO exhibits noteworthy competitiveness in terms of convergence speed, accuracy, stability, and robustness when juxtaposed against contemporary algorithms. Moreover, its performance remains steadfast even amidst the complexities of high-dimensional optimization challenges, affirming the efficacy and relevance of MDBO in modern optimization contexts.
5. Engineering Application Design Issues
To further validate the reliability of MDBO in practical engineering applications, three typical engineering design problems are employed to assess its optimization performance across various practical scenarios. These problems include extension/compression spring design problems [
41], reducer design problems [
42], and welded beam design problems [
43].
The engineering design optimization problem is classified as a constrained optimization problem involving variables, necessitating dealing with constraints [
44]. Three primary methods are commonly employed for constraint processing: The penalty function method, feasibility rule, and multi-objective method. In this study, the external penalty function method is adopted, whereby constraints are transformed into penalty functions, thus integrating them with the objective function. This integration results in a new objective function, defined in Equation (
18).
represents the fitness function value, while
and
represent the objective function value and the constraint function, respectively.
w is the penalty parameter of the penalty function, which is set to
in this article.
w makes the violation of constraints in the optimization process will be punished, so as to find the optimal solution satisfying the constraints.
In the experimental comparison of algorithms for design problems in engineering applications, the comparison algorithms are DBO [
25], WOA [
20], GWO [
19], SCA [
14], SSA [
22], HHO [
21], and for all algorithms, the population size is set to 30 and the maximum number of iterations is 500. In practical engineering scenarios, the reliability of optimization algorithms is crucial. While high average trial run values may initially indicate promising performance, large standard deviations can signal instability and unreliability, particularly in computationally expensive real-world problems where multiple trial runs may not be feasible due to limited computational resources. Therefore, to ensure robustness and reliability, this study conducts 30 independent runs of each algorithm and computes both the mean and standard deviation of their performance metrics. This approach provides a comprehensive evaluation, accounting for both average performance and stability, essential for assessing algorithm suitability in real-world engineering applications.
5.1. Extension/Compression Spring Design Issues
The extension/compression spring design problem, illustrated in
Figure 11, seeks to minimize spring weight by optimizing parameters such as wire diameter (
d), average coil diameter (
D), and the number of active coils (
N). The optimization variables are defined by Equation (
19), while the objective function is abstracted as in Equation (
20). Constraints are formulated in Equation (
21), and upper and lower boundaries are set by Equation (
22). This problem endeavors to identify the optimal parameter combination to achieve desired performance while simultaneously minimizing spring weight, thereby facilitating efficient and lightweight spring design for diverse applications.
Consider:
Minimize:
Subject to:
Parameters range:
The experiment counted the average and standard deviation 30 times solving the results of each algorithm in this problem, and randomly selected the optimal results and optimal parameters of a certain time to show the results, the results are shown in
Table 8. It is evident that MDBO achieves the lowest manufacturing cost in solving this problem. Furthermore, the consistency of this result is supported by the mean and standard deviation of the outcomes, indicating its stability and reliability.
5.2. Reducer Design Issues
The schematic diagram of the speed reducer design problem is depicted in
Figure 12. The problem involves seven design variables, which are end face width (
), number of tooth modules (
), number of teeth in the pinion (
), length of the first shaft between the bearings (
), length of the second shaft between the bearings (
), diameter of the first shaft (
), and diameter of the second shaft (
). The objective of the problem is to minimize the total weight of the gearbox by optimizing seven variables. The objective function is represented by Equation (
23), while the constraints are described by Equation (
24). The upper and lower bounds for each variable are defined by Equation (
25).
Minimize:
Subject to:
Parameters range:
The experimental results of the reducer design problem are presented in
Table 9. From the average value, MDBO exhibits slightly superior performance compared to SSA and significantly outperforms other algorithms, underscoring its efficacy in achieving high solution accuracy for this problem. Additionally, considering the standard deviation, MDBO showcases the lowest value, indicating its exceptional stability and robustness in producing consistent results across multiple runs.
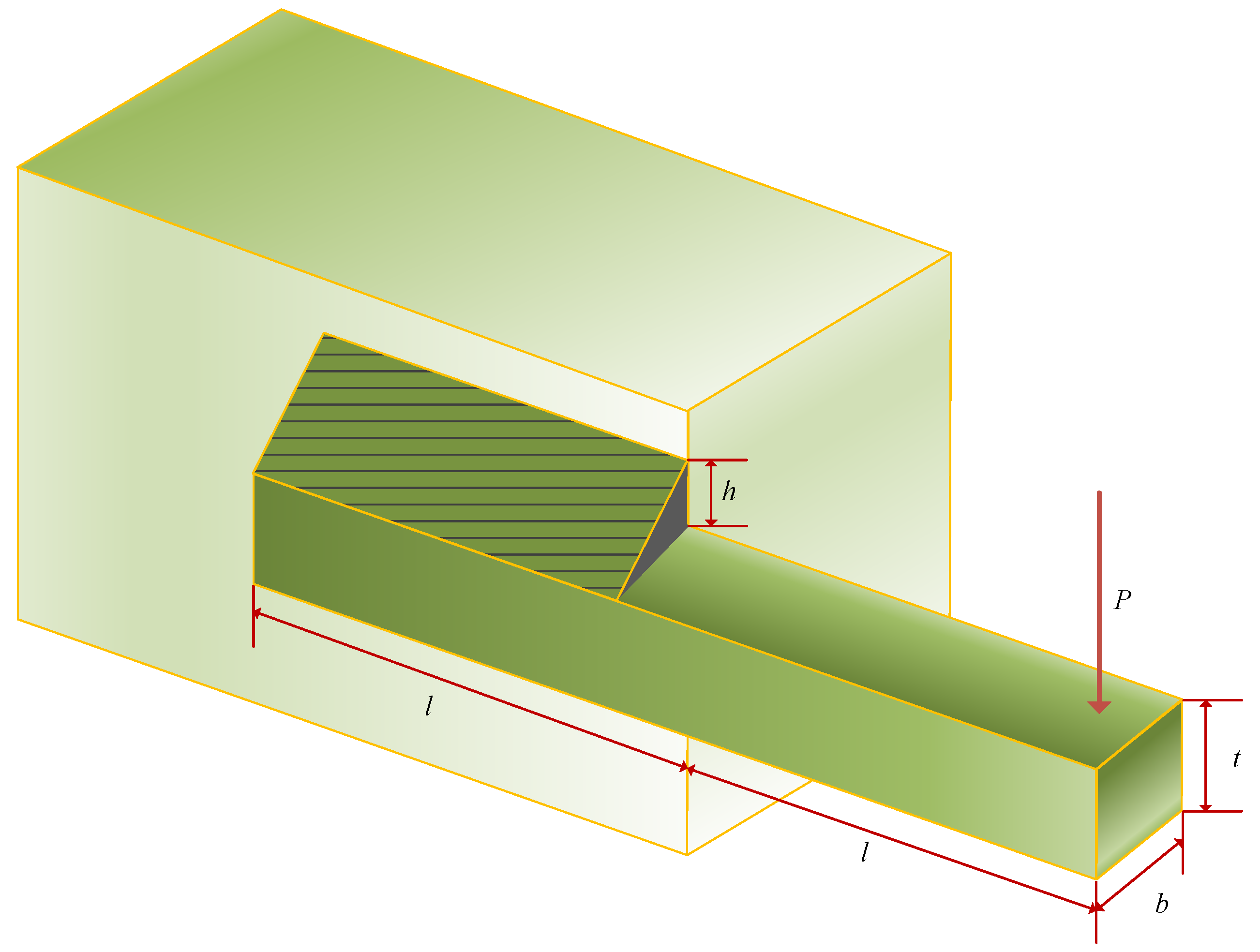
5.3. Welded Beam Design Issues
The objective of the welded beam design problem is to minimize the cost of the welded beam. As shown in
Figure 13, the welded beam design problem exists with four parametric variables: Weld thickness (
h), length of the connected portion of the bar (
l), height of the bar (
t), and thickness of the reinforcement bar (
b) as in Equation (
26). The objective function is defined in Equation (
27), and its minimization process is bounded by the constraints of shear stresses (
), bending stresses in the beam (
), flexural loads on the bar (
), and end disturbances in the beam (
) as in Equation (
28). The four variable parameters are bounded as in Equation (
29), and the values of certain parameters and their solutions are as Equation (
30).
Consider:
Minimize:
Subject to:
Parameters range:
where
The optimization results for the welded beam design problem are displayed in
Table 10. It is evident that MDBO achieves the lowest average manufacturing cost, with a value of 1.692769435 when the optimization result of MDBO is
x = [0.205729953, 3.234915914, 9.036617034, 0.205729953]. When compared with other algorithms, MDBO demonstrates competitive performance, highlighting its effectiveness in this particular optimization task.
6. Conclusions
In this paper, based on the deficiencies of the DBO algorithm, the multi-strategy improved DBO algorithm (MDBO) is proposed. Firstly, Latin hypercube sampling is used to initialize the population to improve the diversity of the population and reduce the possibility of the algorithm falling into local optimal solutions. Second, mean difference variation is introduced to the population individuals to balance the local and global exploration of the algorithm and improve the algorithm’s ability to escape from the local optimum. Finally, fusion lens imaging back learning and dimension-by-dimension optimization are performed on the global optimal solution to make full use of the optimal solution information while improving the quality of the optimal solution and promoting the convergence of the algorithm. To verify the performance of the MDBO, this paper evaluates the performance of the algorithm from several aspects using the CEC2017 and CEC2020 test functions. Finally, the proposed MDBO algorithm is successfully applied to three real-world engineering application problems.
Through a large number of experimental results in several aspects, the proposed MDBO algorithm exhibits stronger optimization ability, faster convergence speed, higher convergence accuracy, and better robustness than other classical meta-heuristic algorithms, and it also demonstrates better performance in some engineering practical applications. However, MDBO still faces challenges in obtaining the theoretical optimum when solving some complex problems in a short time. In future work, on the one hand, some other novel algorithms can be combined to improve the efficiency and optimization ability of the algorithm; on the other hand, the optimized algorithm can be used to solve more complex optimization problems in reality, such as the UAV path planning, polling system [
45,
46], and the NP-hard problem.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}