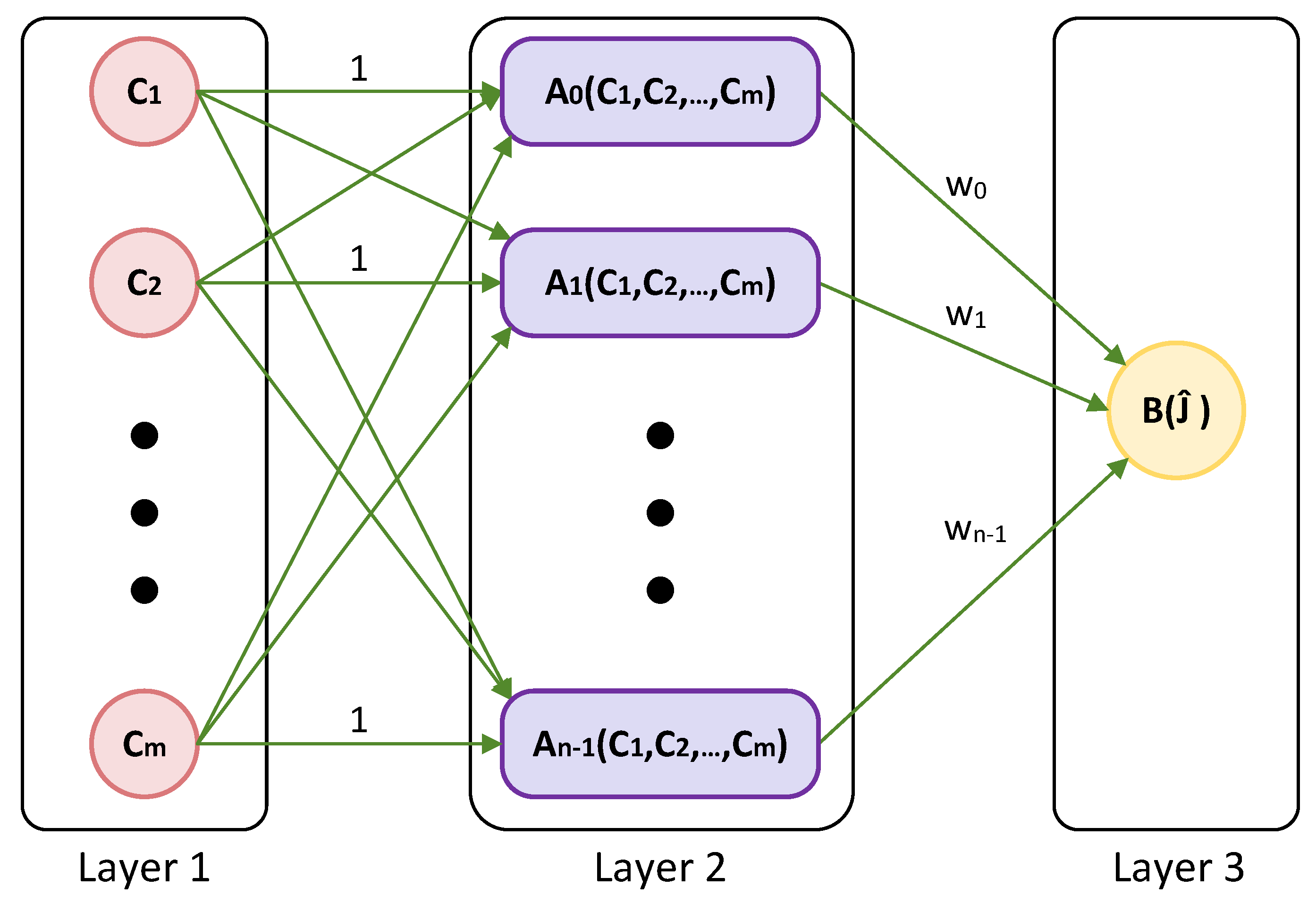
In this section, four datasets are used to conduct four different experiments on credit and loan approval. In these experiments, the performance of the BWASD NN is examined and compared with several top-performing models of MATLAB’s classification learner. The kernel naive Bayes (KNB), fine tree (FTR), linear support vector machine (LSVM), and fine
k-nearest neighbors (FKNN) are these classification models. The MWASD NN model developed in [
15] is also compared because BWASD is an enhanced version of MWASD. For the BWASD model, we have used
,
, and
; for the MWASD model, we have used
and
; and for the MATLAB classification models, we have used the default values. It is noteworthy that by clicking the next GitHub link, anyone can obtain the entire development and implementation of the ideas and computation techniques discussed in
Section 2,
Section 3 and
Section 4:
https://github.com/SDMourtas/BWASD (accessed on 10 January 2024). Be aware that the MATLAB toolbox includes implementation and installation guidance.
4.5. Performance Measures and Discussion
The models statistics for DA1-DA4 on the testing set are shown in
Table 2,
Table 3,
Table 4 and
Table 5, correspondingly. The MAE, true positive (TP), true negative (TN), false positive (FP), false negative (FN), precision, recal, accuracy and F-score are the performance gauges considered in this analysis. Consult [
44] for further information and a detailed examination of these gauges. Additionally, the accuracy of the classification models is statistically evaluated using the mid-p-value McNemar test in
Table 6,
Table 7 and
Table 8.
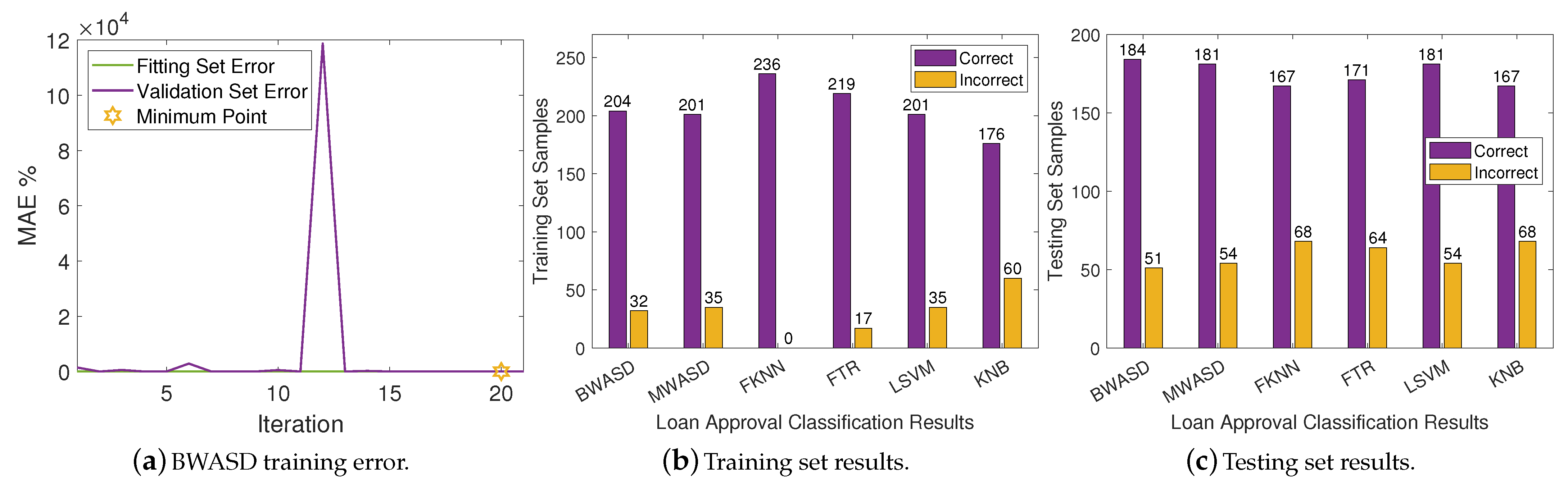
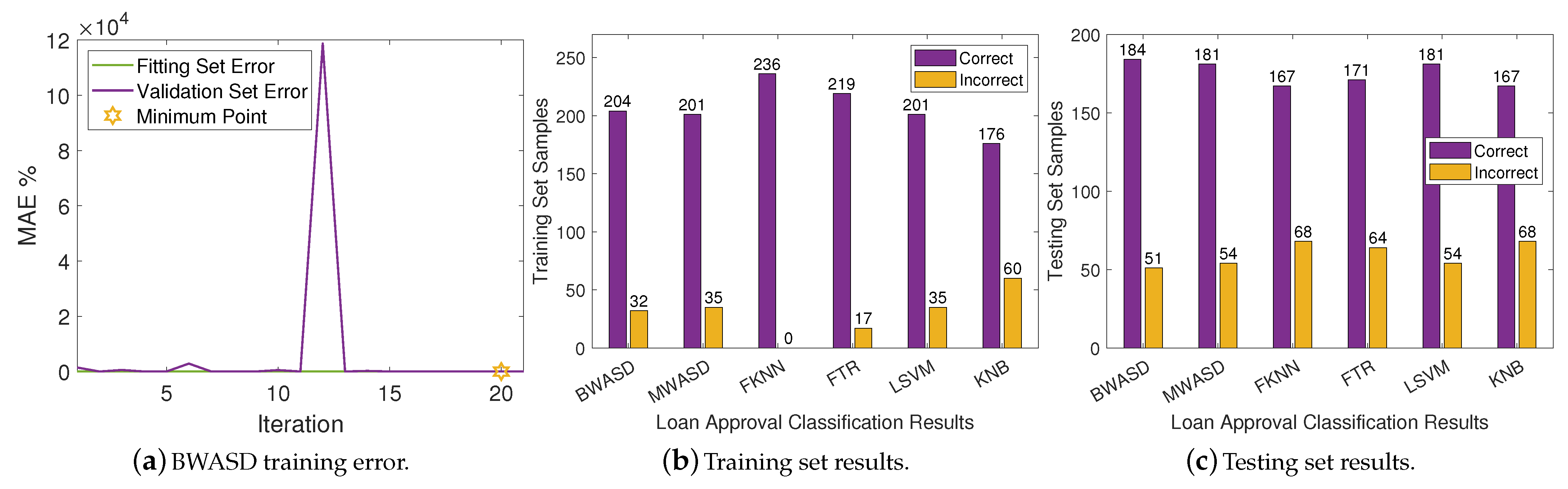
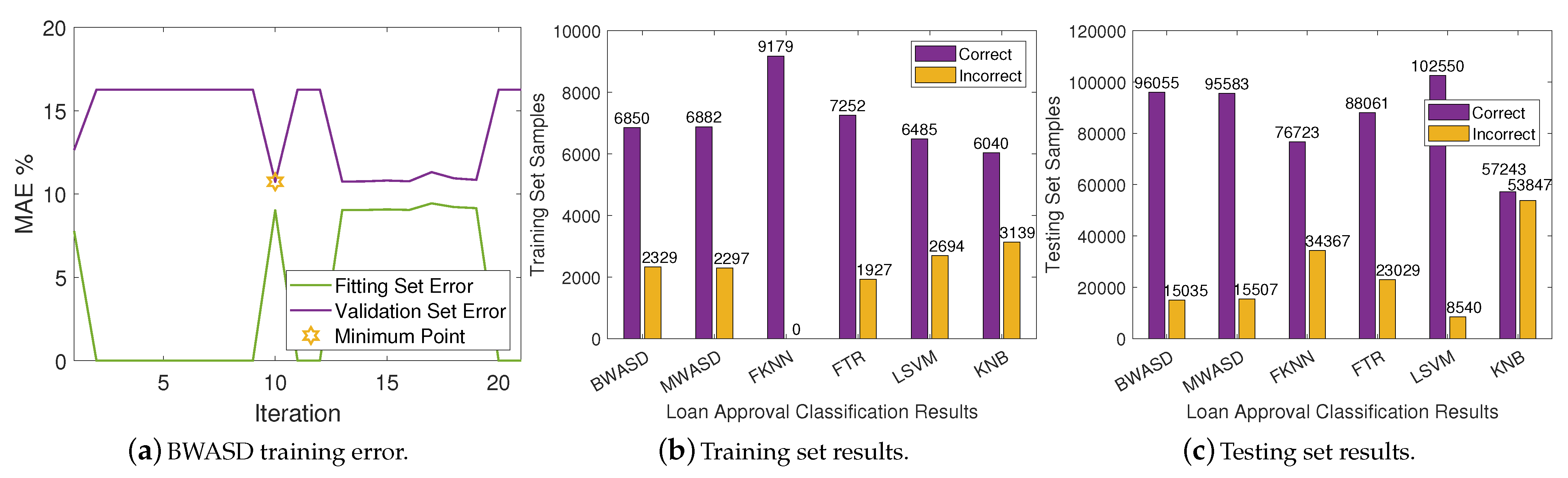
In
Table 2, BWASD appears to have the finest MAE, accuracy and F-score, and the second finest TP, FP, precision and recal. FTR has the best TN, FN and recal, and the worst TP, FP, and precision. The results of MWASD and LSVM are identical and they have the best TP, FP, and precision. Additionally, KNB has the worst MAE, TN, FN, recal, accuracy and F-score. According to the aforementioned statistics, the performance of BWASD is the best, while KNB is the poorest.
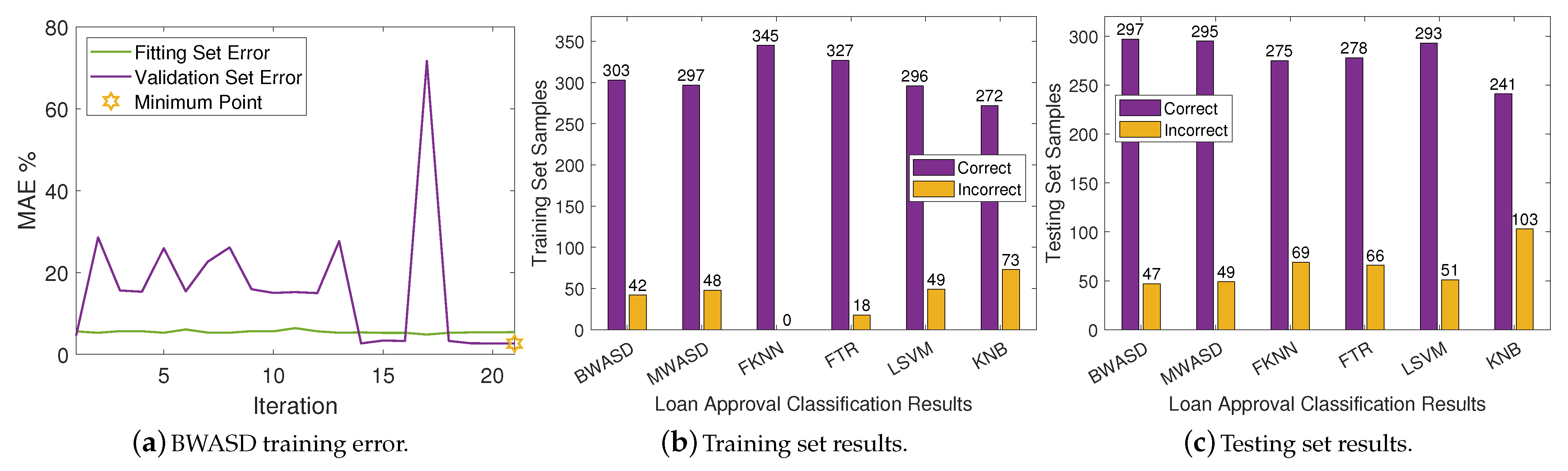
In
Table 3, LSVM appears to have the finest MAE, TN, FN, recal and accuracy, whereas KNB has finest TP, FP and precision, and FTR has the finest F-score. BWASD has the second best MAE, TN, FN, recal and accuracy, but BWASD has better TP, FP, precision and F-score than LSVM. Additionally, KNB has the worst MAE, TN, FN, recal and accuracy, whereas LSVM has the worst TP, FP, precision and F-score. According to the aforementioned statistics, the performance of BWASD is the best overall, while KNB is the poorest.
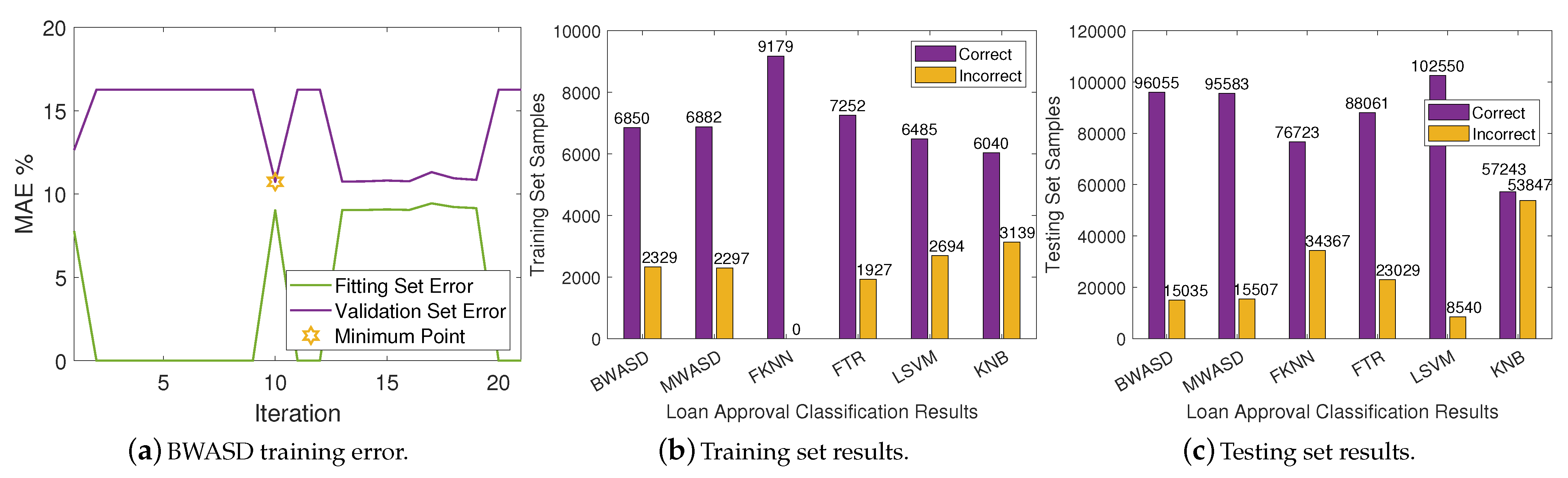
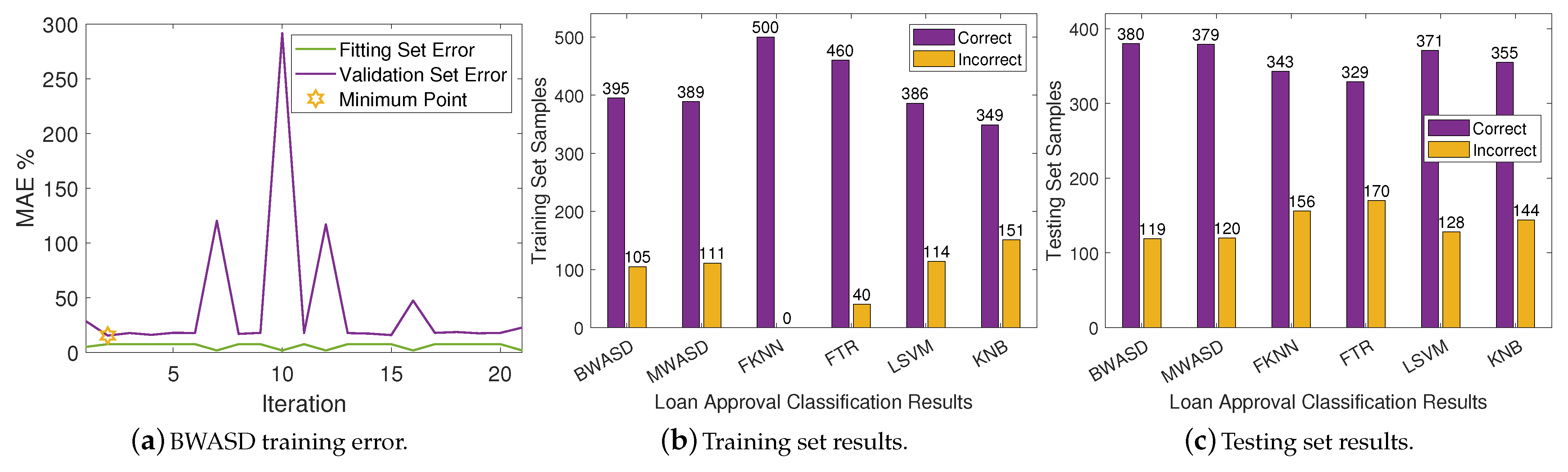
In
Table 4, BWASD appears to have the finest MAE, TN, FN, recal, accuracy and F-score. LSVM has the finest TP, FP and precision. The results of MWASD and LSVM are identical and they have the best TP, FP, and precision. Additionally, KNB has the worst statistic measurements, FKNN has the second worst MAE, TP, FP, precision, recal, accuracy and F-score, whereas LSVM has the second worst TN and FN. According to the aforementioned statistics, the performance of BWASD is the best, while KNB is the poorest.
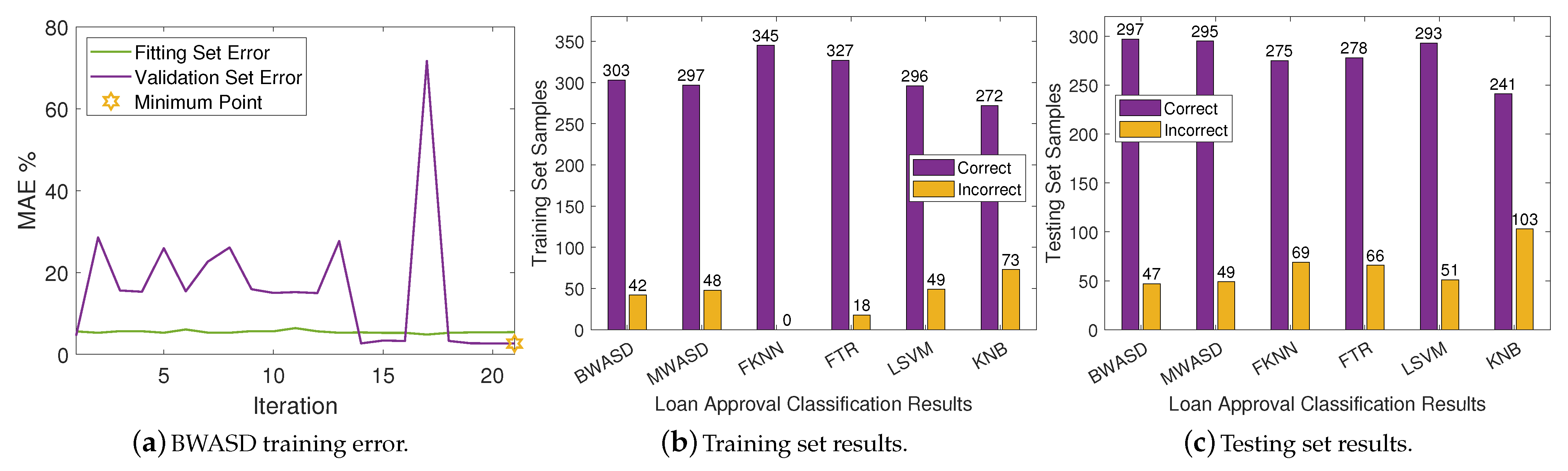
In
Table 5, BWASD appears to have the finest MAE, accuracy and F-score, the second finest recall, and the third finest TP, FP, TN, FN and precision. KNB has the best TP, FP and precision, FTR has the best TN and FN, and MWASD has the best recal. LSVM has the best TP, FP and precision. Additionally, FTR has the worst MAE, TP, FP, precision, accuracy and F-score, whereas KNB has the worst TN, FN and recal. According to the aforementioned statistics, the performance of BWASD is the best, while FTR is the poorest.
The BWASD model is compared to all other models in
Table 6,
Table 7 and
Table 8 using the mid-p-value McNemar test to statistically evaluate the classification models’ accuracies. The McNemar test is a form of homogeneity test that applies to contingency tables and is a distribution-free statistical hypothesis test. The test determines whether the binary classification models’ accuracies differ or whether one binary classification model outperforms the other. We perform the McNemar test specifically using the MATLAB function testcholdout, as described in [
45,
46]. It is important to note that the simulation experiments in [
45,
46,
47] show that this test has good statistical power and achieves nominal coverage. The statistical analysis in this subsection follows the recommendations in [
47]. According to the marginal homogeneity null hypothesis, each outcome’s two marginal probabilities are equal. In our investigation, the null hypothesis claims that the accuracy of the predicted class labels from the NN model Z and the BWASD is equal, where Z refers to MWASD, FKNN, FTR, LSVM or KNB. Additionally, we consider the following three alternative hypothesis (AH):
AH1: For predicting the class labels, the NN model Z and the BWASD have unequal accuracies.
AH2: For predicting the class labels, the NN model Z is more accurate than the BWASD.
AH3: For predicting the class labels, the NN model Z is less accurate than the BWASD.
In this way, we conduct three McNemar tests under three different alternative hypothesis to assess. Each test determines whether to reject or not to reject the null hypothesis at the 5% significance level. Keep in mind that an outcome is considered statistically significant if it allows us to reject the null hypothesis, and that lower p-values (usually ≤ 0.05) are seen as more convincing proof to reject the null hypothesis.
Table 6 shows the McNemar’s test results for AH1. In DA1, DA3 and DA4, when comparing BWASD to Z = {FKNN, FTR, KNB}, a
p-value of almost zero from the McNemar test indicates that there is enough proof to reject the null hypothesis. In other words, the predicted accuracies of the Z and BWASD models are not equal. On the other hand, when comparing BWASD to Z = {MWASD, LSVM}, a
p-value that is far from zero indicates that there is enough proof to not reject the null hypothesis. In other words, the predicted accuracies of the Z and BWASD models are equal. In DA2, when comparing BWASD to Z = {MWASD, FKNN, FTR, LSVM, KNB}, a
p-value of almost zero indicates that there is enough proof to reject the null hypothesis. In other words, the predicted accuracies of the Z and BWASD models are not equal.
Table 7 shows the McNemar’s test results for AH2. In DA1, DA3 and DA4, when comparing BWASD to Z = {MWASD, FKNN, FTR, KNB, LSVM}, a
p-value of one or almost one from the McNemar test indicates that there is not enough proof to reject the null hypothesis. In other words, the predicted accuracies of the Z and BWASD models are equal. In DA2, when comparing BWASD to Z = {MWASD, FKNN, FTR, KNB}, a
p-value of one or almost one indicates that there is not enough proof to reject the null hypothesis. In other words, the predicted accuracies of the Z and BWASD models are equal. However, when comparing BWASD to Z = {LSVM}, a
p-value of zero indicates that there is enough proof to reject the null hypothesis. In other words, the Z model is more accurate than the BWASD.
Table 8 shows the McNemar’s test results for AH3. In DA1, DA3 and DA4, when comparing BWASD to Z = {FKNN, FTR, KNB}, a
p-value of almost zero from the McNemar test indicates that there is enough proof to reject the null hypothesis. In other words, the Z model is less accurate than the BWASD. On the other hand, when comparing BWASD to Z = {MWASD, LSVM}, a
p-value that is far from zero indicates that there is enough proof to not reject the null hypothesis. In other words, the predicted accuracies of the Z and BWASD models are equal. In DA2, when comparing BWASD to Z = {MWASD, FKNN, FTR, KNB}, a
p-value of almost zero indicates that there is enough proof to reject the null hypothesis. In other words, the Z model is less accurate than the BWASD. On the other hand, when comparing BWASD to Z = {LSVM}, a
p-value of one indicates that there is enough proof to not reject the null hypothesis. In other words, the predicted accuracies of the Z and BWASD models are equal.
Therefore, based on
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 statistics, we conclude that the BWASD is the best performing model in DA1-DA4. In broad terms, the BWASD model consistently provided great results in the classification of loan approval tasks, and it performs rather well when compared to traditional NN models. Therefore, the BWASD model can be beneficial for various businesses. These include businesses looking to automate the evaluation of loan applications based on customer information, banks evaluating credit card applications, banks evaluating loan applications based on an estimation of the likelihood of default, and banks evaluating loan applications based on the socioeconomic and demographic profiles of applicants.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}