



YOLOv5-MS: Real-Time Multi-Surveillance Pedestrian Target Detection Model for Smart Cities

Abstract
:1. Introduction
2. Models
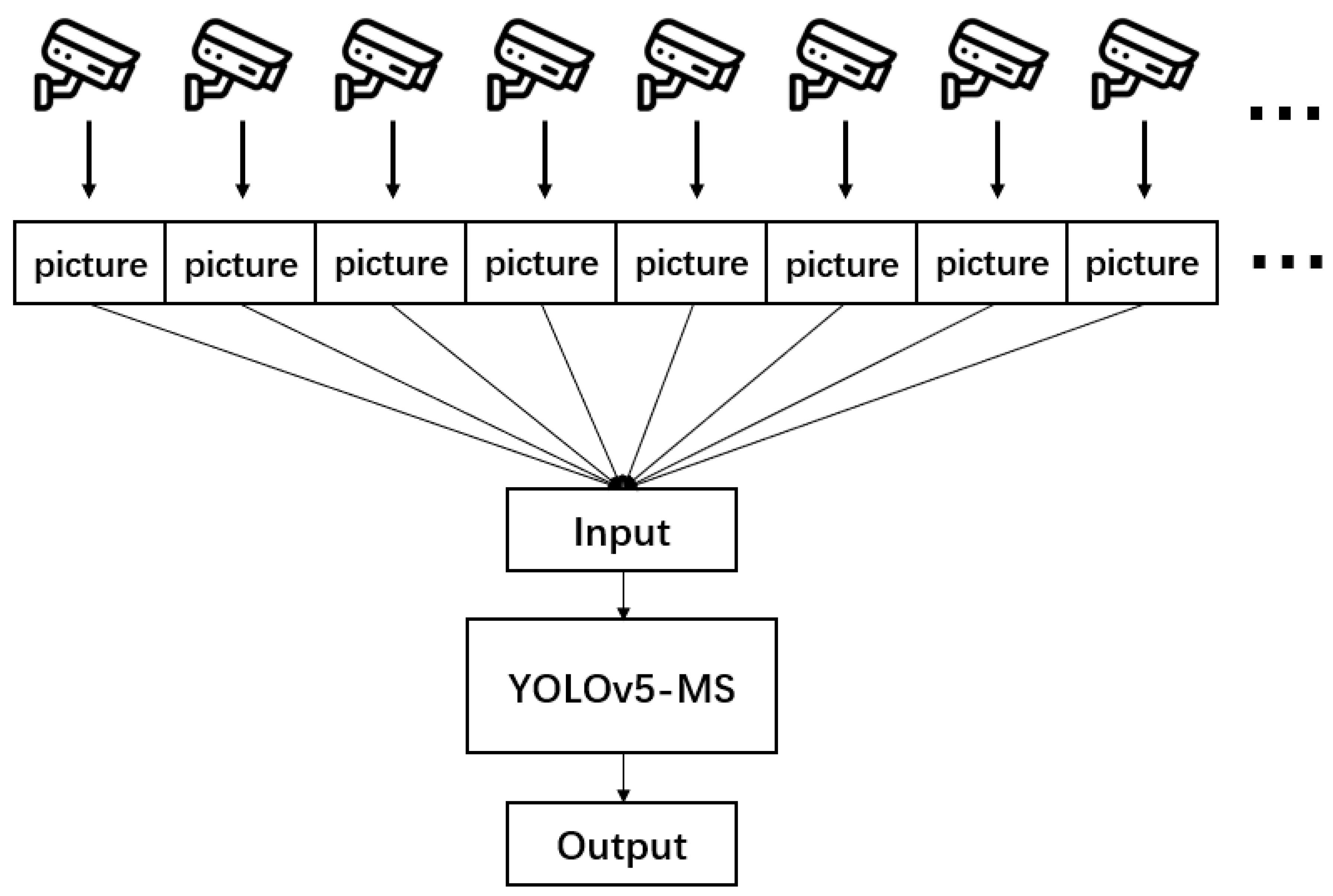
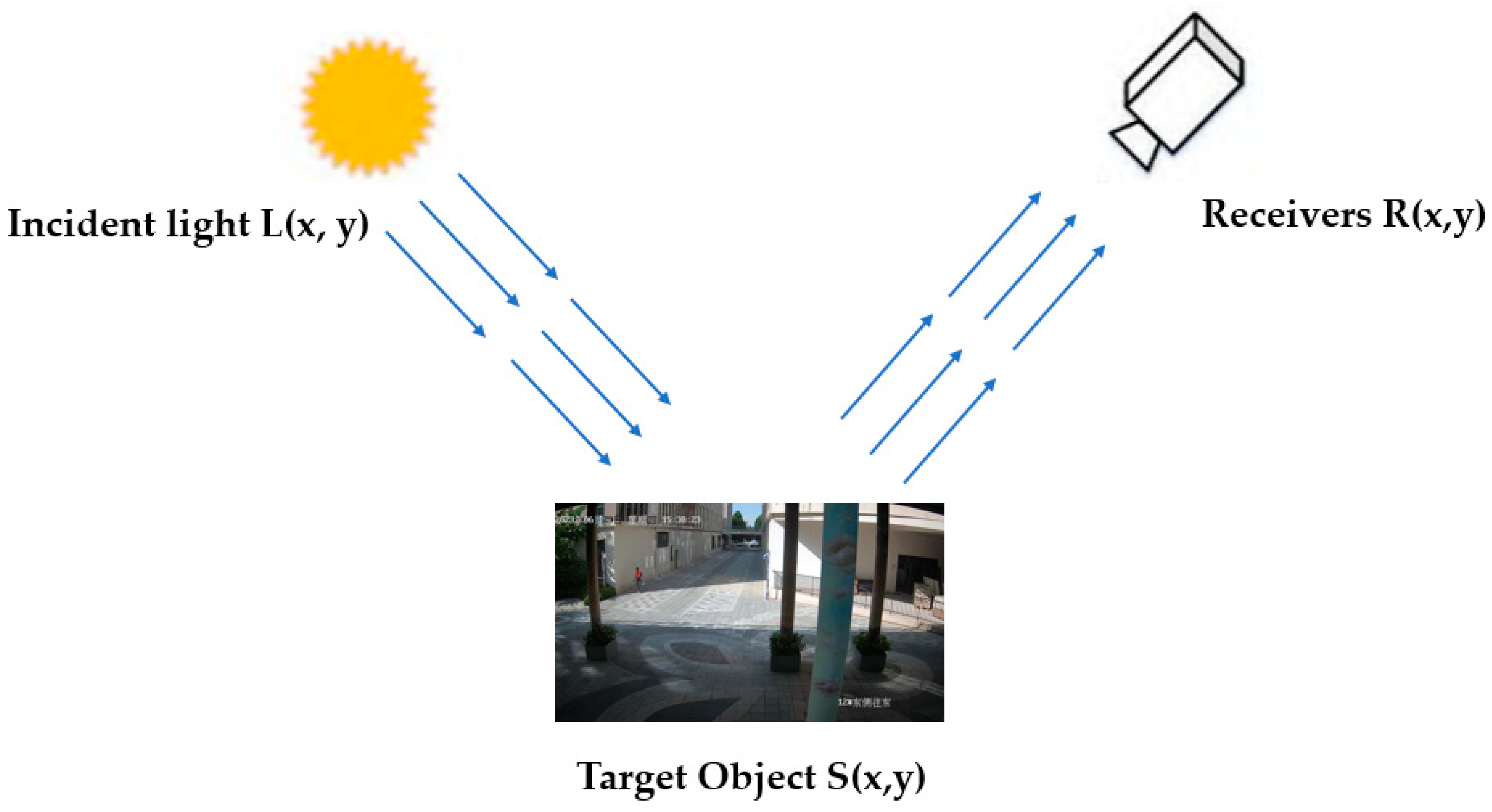
2.1. Optimized Video Stream Acquisition Method
2.2. YOLO Basic Principle
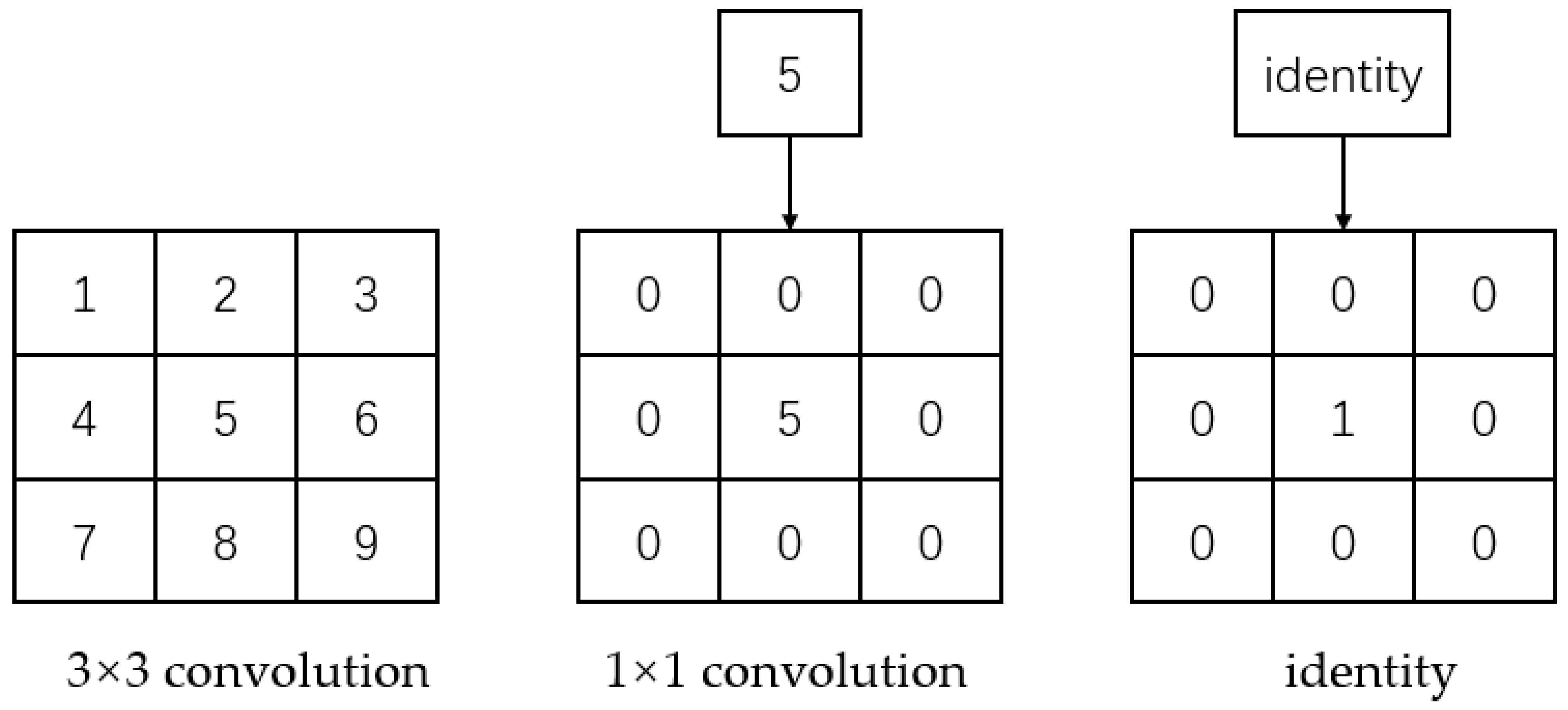
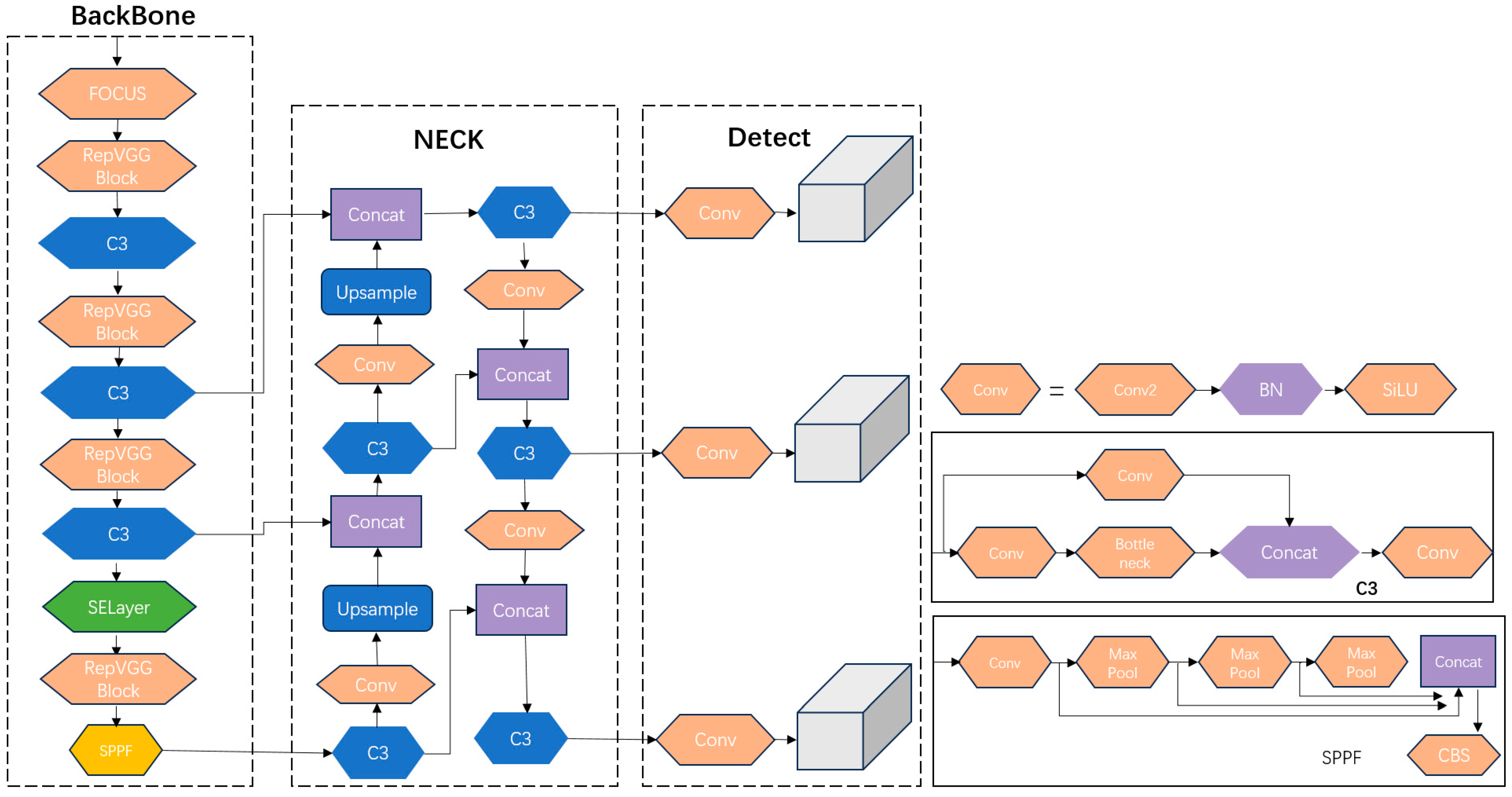
2.3. Backbone Structure
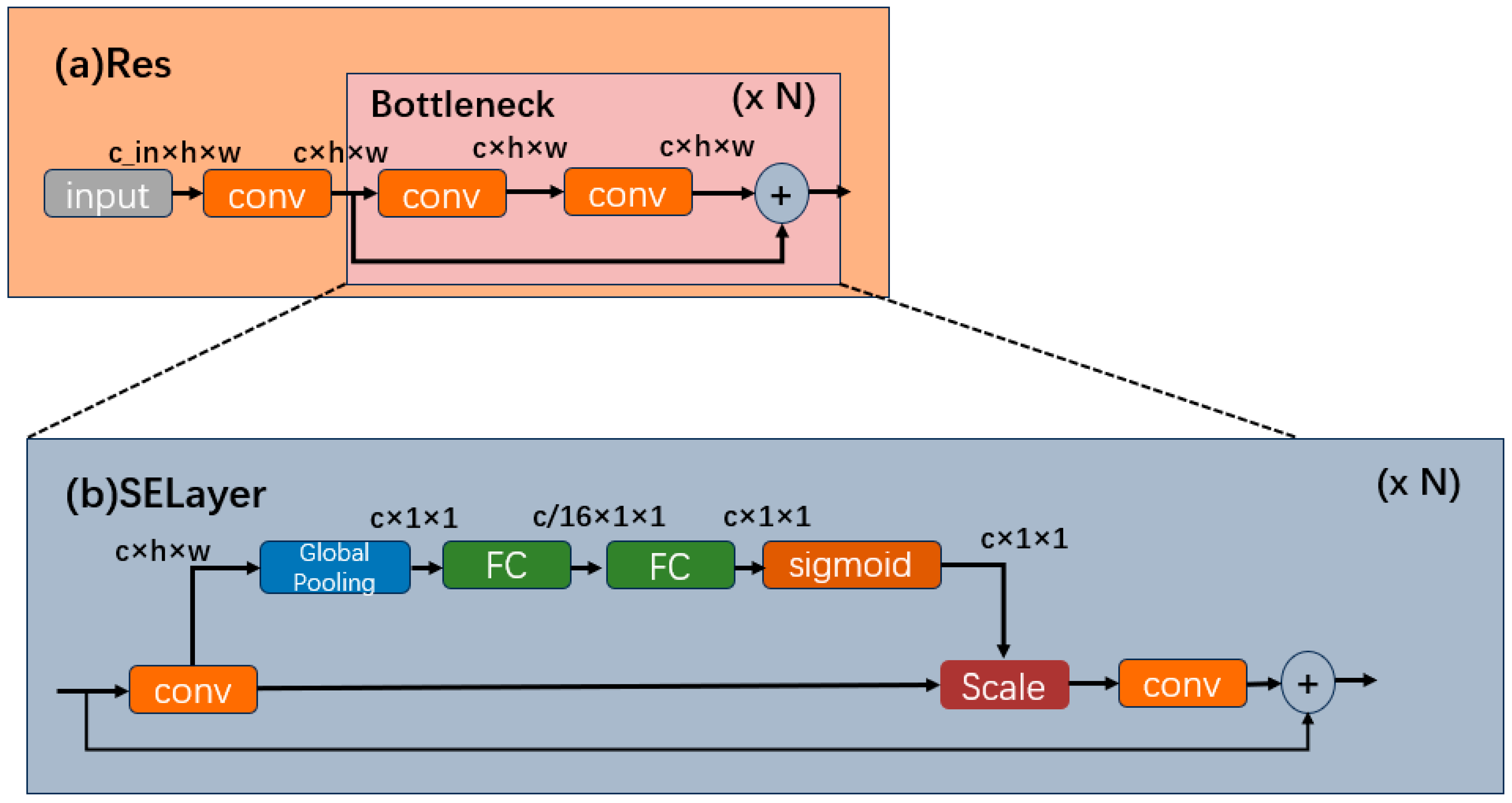
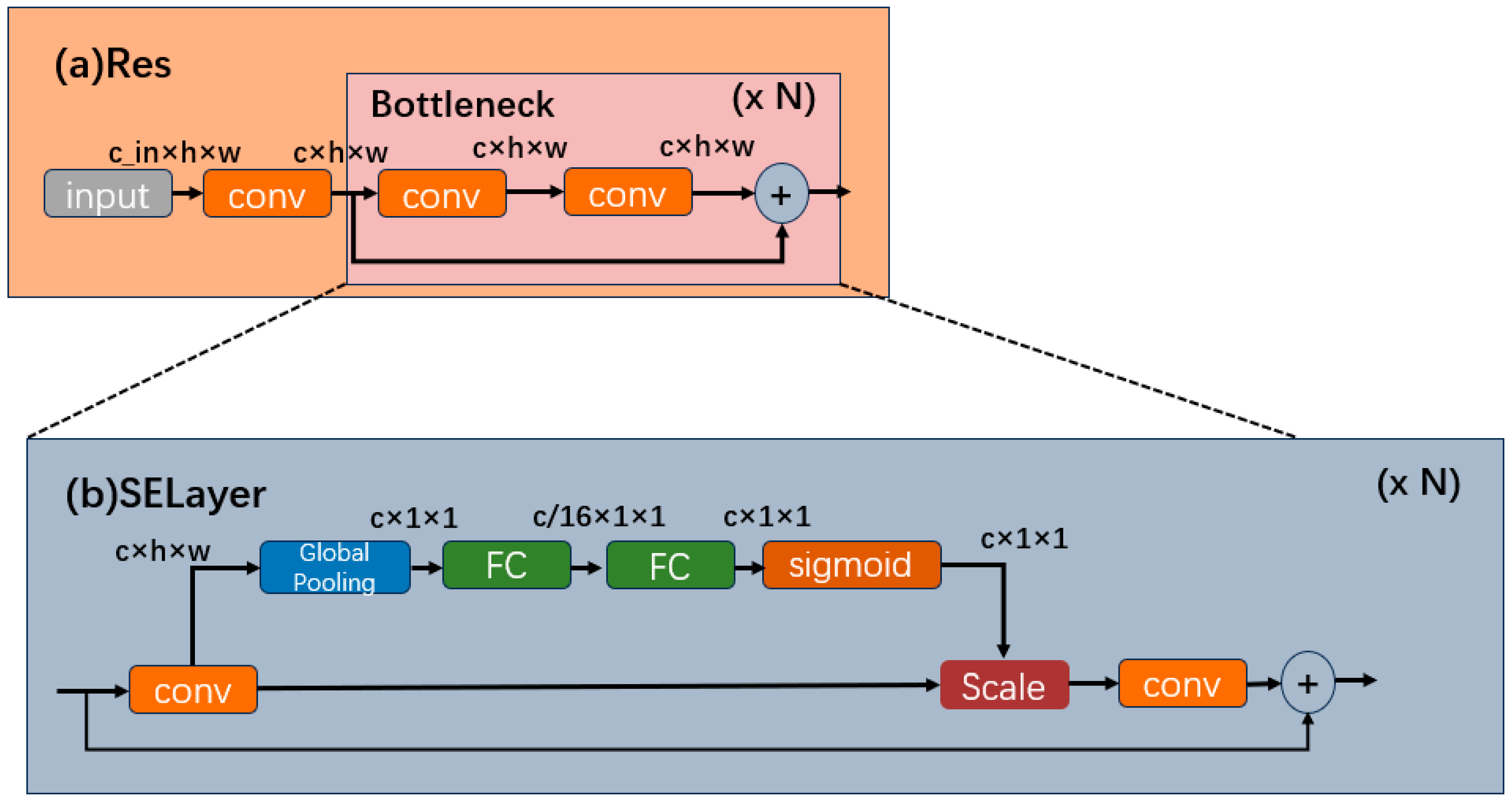
2.4. Squeeze-and-Excitation Model
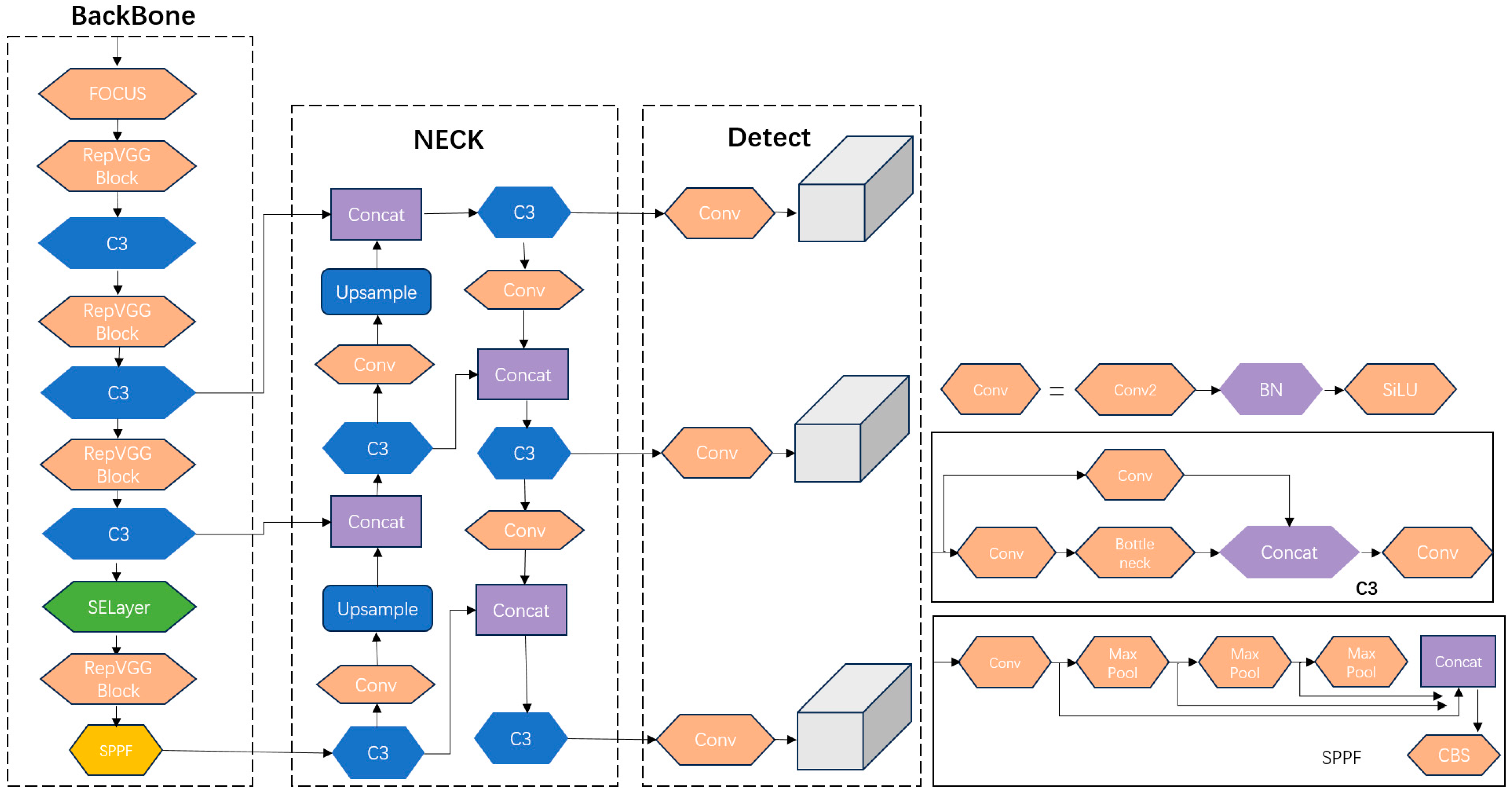
2.5. YOLOv5-MS Structure
3. Materials and Methods
3.1. Dataset
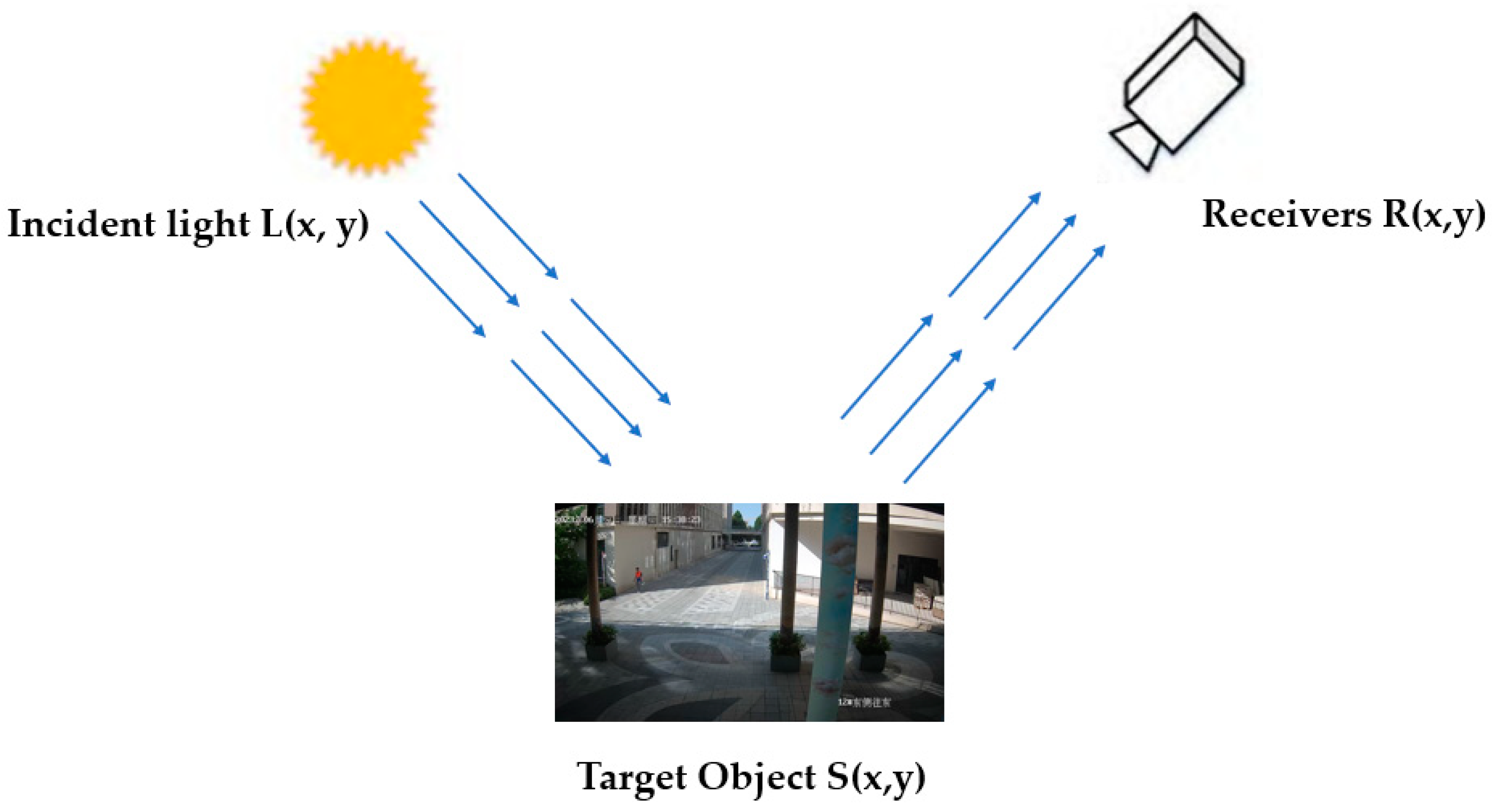
3.2. Retinex Enhancement Algorithm
3.3. Image Enhancement
3.4. Loss Function
- Under certain circumstances, it will make the proportional consistency parameter of the aspect ratio of the predicted frame and the rear frame be 0, which makes the loss function unable to make a practical judgment.
- When the length and width of the anchor box increase and decrease at the same time, respectively, it will make the predicted box unable to fit the actual box effectively.
- The aspect ratio of the calculated box cannot effectively reflect the gap between the anchor box and the existing box.
3.5. Evaluation Criteria
4. Results and Discussion
4.1. Experimental Environment
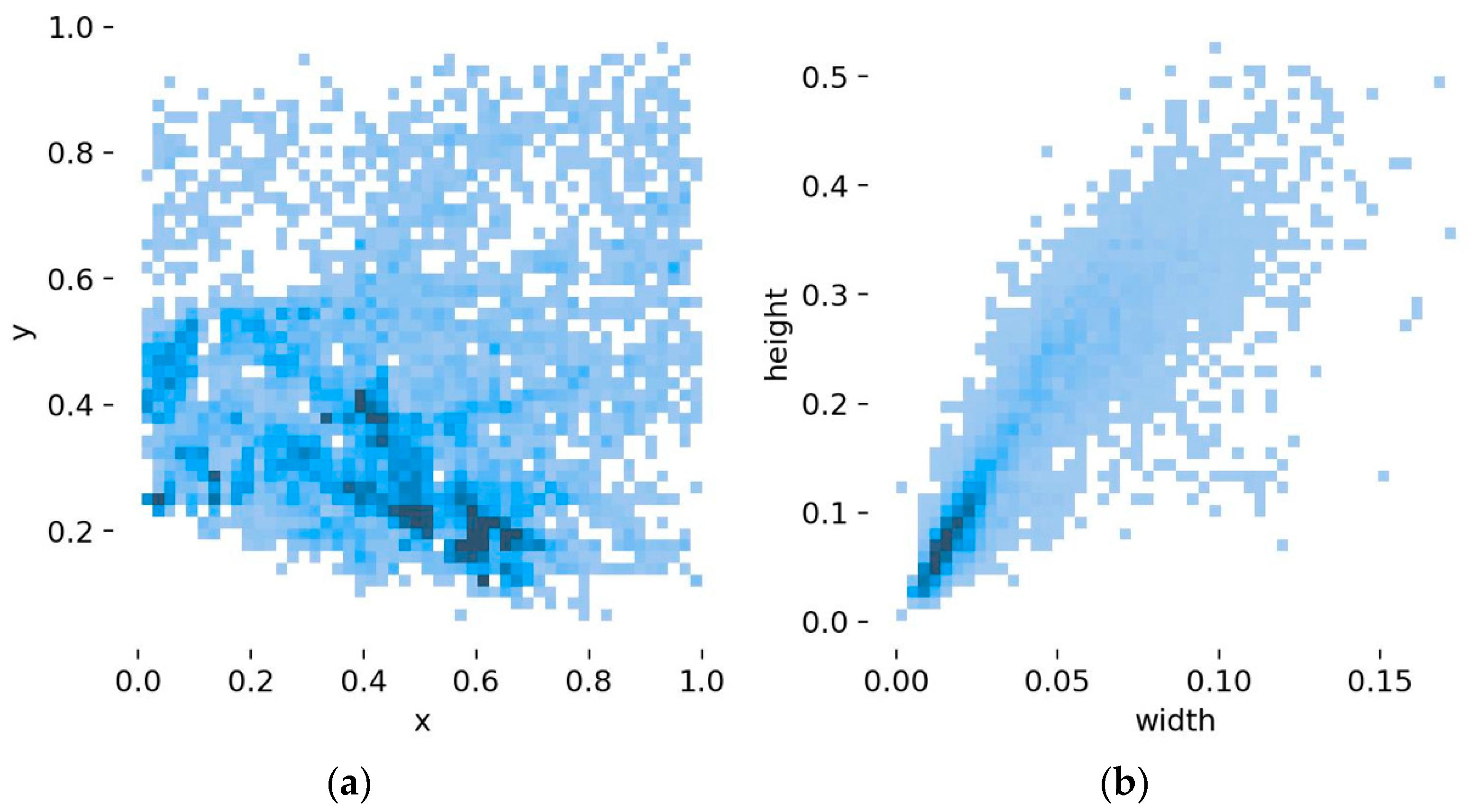
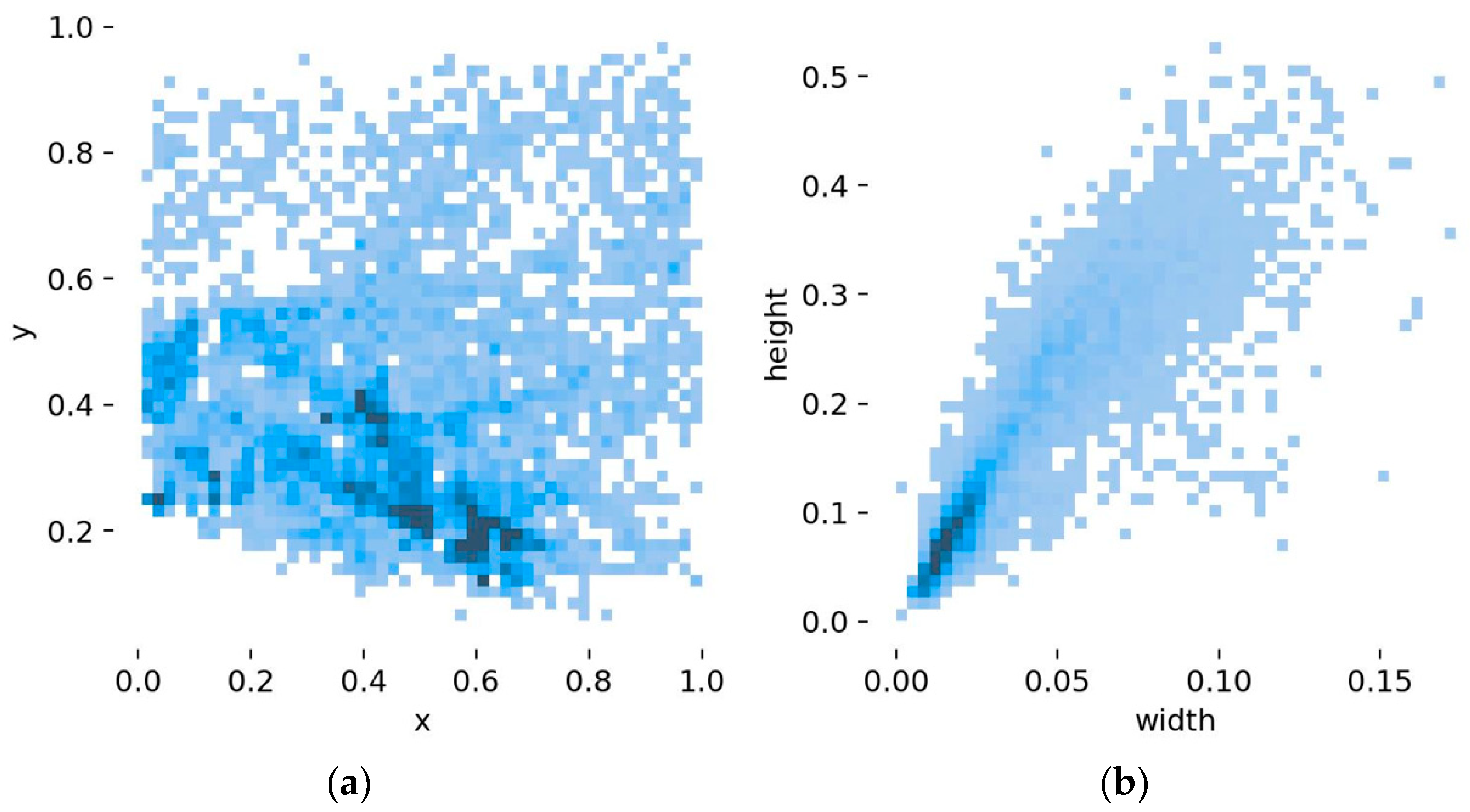
4.2. Model a Priori Box Clustering
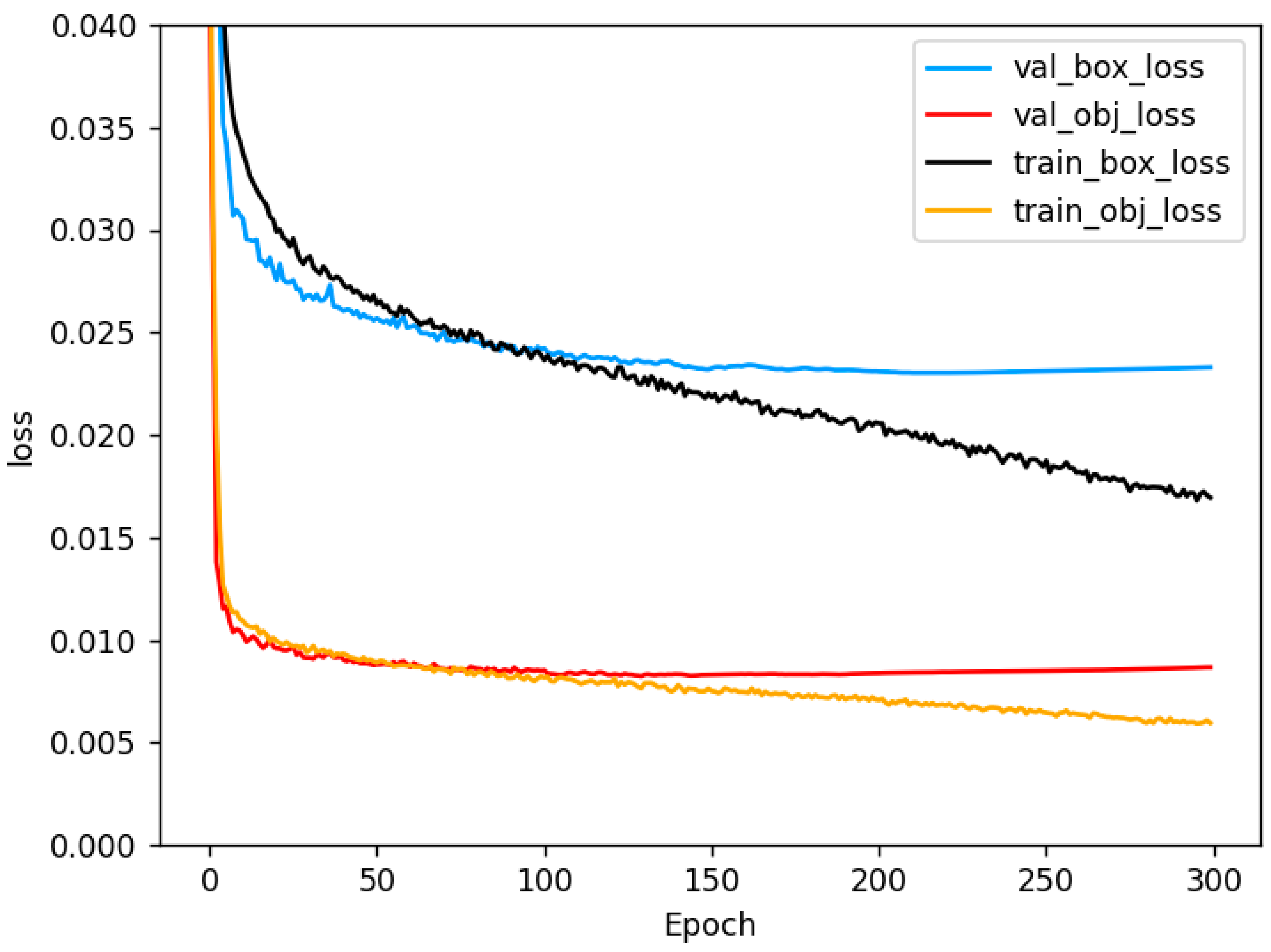
4.3. Ablation Experiments
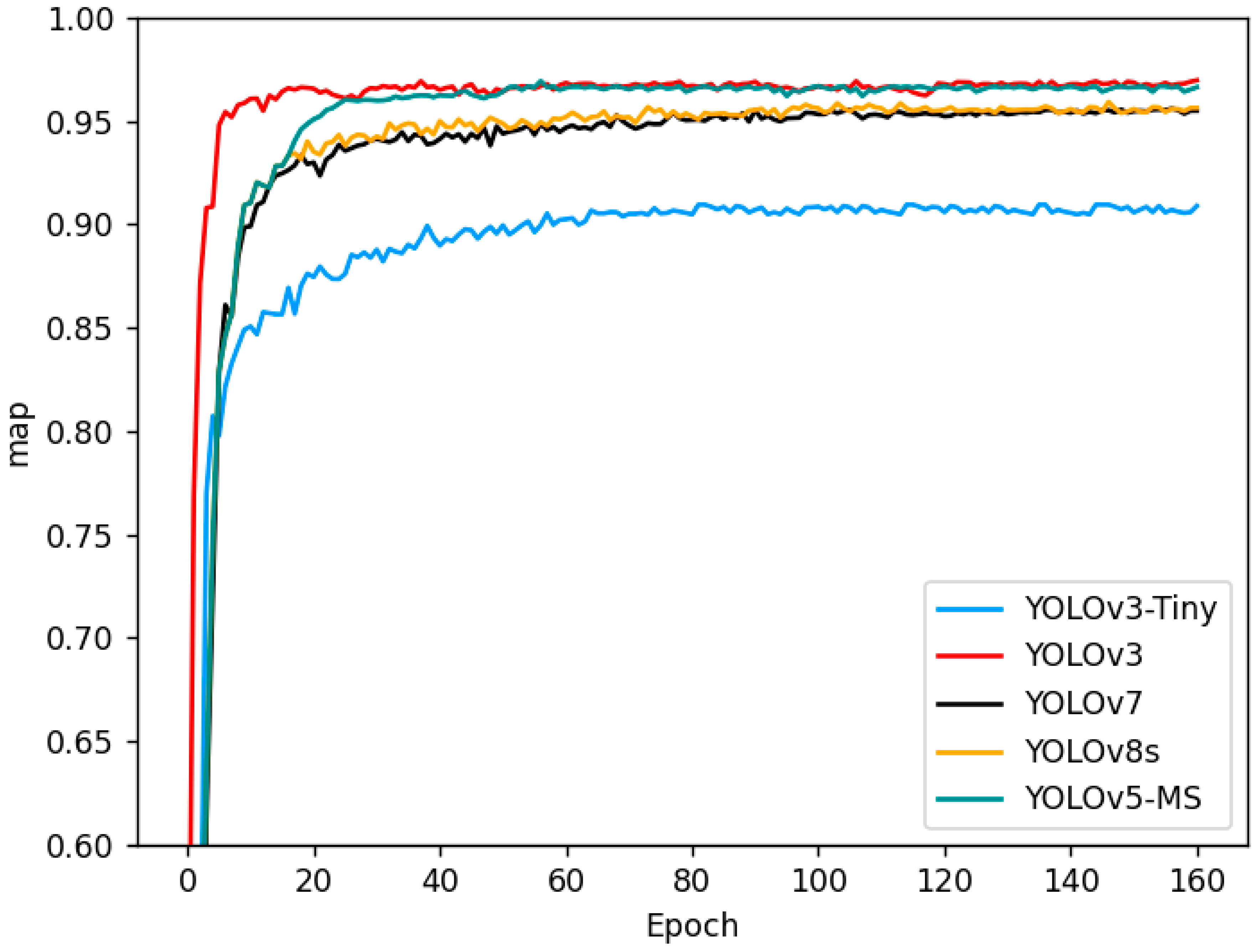
4.4. Comparison Experiment
4.5. Discussion
4.5.1. Ablation Experiments Discussion
4.5.2. Comparison Experiments Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z.; Zuo, R.; Guo, R.; Li, Y.; Zhou, T.; Xue, H.; Ma, C.; Wang, H. Multi-scale visualization based on sketch interaction for massive surveillance video data. Pers. Ubiquitous Comput. 2021, 25, 1027–1037. [Google Scholar]
- Zahra, A.; Ghafoor, M.; Munir, K.; Ullah, A.; Ul Abideen, Z. Application of region-based video surveillance in smart cities using deep learning. Multimed. Tools Appl. 2021, 1–26. [Google Scholar] [CrossRef]
- Ren, Z.; Lam, E.Y.; Zhao, J. Real-time target detection in visual sensing environments using deep transfer learning and improved anchor box generation. IEEE Access 2020, 8, 193512–193522. [Google Scholar] [CrossRef]
- Shi, W.S.; Cao, J.; Zhang, Q.; Li, Y.H.Z.; Xu, L.Y. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Jeong, E.; Kim, J.; Ha, S. TensorRT-Based Framework and Optimization Methodology for Deep Learning Inference on Jetson Boards. ACM Trans. Embed. Comput. Syst. 2022, 21, 1–26. [Google Scholar] [CrossRef]
- Barba-Guaman, L.; Naranjo, J.E.; Ortiz, A. Deep Learning Framework for Vehicle and Pedestrian Detection in Rural Roads on an Embedded GPU. Electronics 2020, 9, 589. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Yu, L.; Zhi, C.; Sun, R.; Zhu, S.; Gao, Z.; Ke, Z.; Zhu, M.; Zhang, Y. Improved faster R-CNN for fabric defect detection based on Gabor filter with Genetic Algorithm optimization. Comput. Ind. 2022, 134, 103551. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Biswas, D.; Su, H.; Wang, C.; Stevanovic, A.; Wang, W. An automatic traffic density estimation using Single Shot Detection (SSD) and MobileNet-SSD. Phys. Chem. Earth Parts A/B/C 2019, 110, 176–184. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS--improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Xue, Y.; Ju, Z.; Li, Y.; Zhang, W. MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection. Infrared Phys. Technol. 2021, 118, 103906. [Google Scholar]
- Pustokhina, I.V.; Pustokhin, D.A.; Vaiyapuri, T.; Gupta, D.; Kumar, S.; Shankar, K. An automated deep learning based anomaly detection in pedestrian walkways for vulnerable road users safety. Saf. Sci. 2021, 142, 105356. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Lin, W.-Y. Ratio-and-scale-aware YOLO for pedestrian detection. IEEE Trans. Image Process. 2020, 30, 934–947. [Google Scholar] [CrossRef]
- Zhang, J.-L.; Su, W.-H.; Zhang, H.-Y.; Peng, Y. SE-YOLOv5x: An optimized model based on transfer learning and visual attention mechanism for identifying and localizing weeds and vegetables. Agronomy 2022, 12, 2061. [Google Scholar] [CrossRef]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Ghosh, M.; Obaidullah, S.M.; Gherardini, F.; Zdimalova, M. Classification of Geometric Forms in Mosaics Using Deep Neural Network. J. Imaging 2021, 7, 149. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, I.; Moreira, G.; Queirós da Silva, D.; Magalhães, S.; Valente, A.; Moura Oliveira, P.; Cunha, M.; Santos, F. Deep Learning YOLO-Based Solution for Grape Bunch Detection and Assessment of Biophysical Lesions. Agronomy 2023, 13, 1120. [Google Scholar]
- Gao, J.; Chen, Y.; Wei, Y.; Li, J. Detection of specific building in remote sensing images using a novel YOLO-S-CIOU model. Case: Gas station identification. Sensors 2021, 21, 1375. [Google Scholar] [CrossRef]
- Li, Y.; Li, S.; Du, H.; Chen, L.; Zhang, D.; Li, Y. YOLO-ACN: Focusing on small target and occluded object detection. IEEE Access 2020, 8, 227288–227303. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Li, Z.B.; Li, F.; Zhu, L.; Yue, J. Vegetable Recognition and Classification Based on Improved VGG Deep Learning Network Model. Int. J. Comput. Intell. Syst. 2020, 13, 559–564. [Google Scholar] [CrossRef]
- Zhang, T.W.; Zhang, X.L. Squeeze-and-Excitation Laplacian Pyramid Network With Dual-Polarization Feature Fusion for Ship Classification in SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4019905. [Google Scholar] [CrossRef]
- Yoon, J.; Choe, Y. Retinex based image enhancement via general dictionary convolutional sparse coding. Appl. Sci. 2020, 10, 4395. [Google Scholar] [CrossRef]
- Sun, L.; Tang, C.; Xu, M.; Lei, Z. Non-uniform illumination correction based on multi-scale Retinex in digital image correlation. Appl. Opt. 2021, 60, 5599–5609. [Google Scholar] [CrossRef]
- Liu, X.; Pedersen, M.; Wang, R. Survey of natural image enhancement techniques: Classification, evaluation, challenges, and perspectives. Digit. Signal Process. 2022, 127, 103547. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters Items | Value |
|---|---|
| Epoch | 300 |
| Batch size | 16 |
| Worker | 8 |
| Momentum | 0.937 |
| Initial learning rate | 0.01 |
| Input size | 640 × 640 |
| Weight decay | 0.0005 |
| Scale | Priori Framework | ||
|---|---|---|---|
| 20 × 20 | [42.22, 85.29] | [45.36, 112.81] | [63.04, 125.6] |
| 40 × 40 | [17.35, 47.73] | [24.29, 63.40] | [30.37, 87.94] |
| 80 × 80 | [6.66, 15.85] | [9.65, 26.26] | [13.33, 35.21] |
| RepvggBlock | Focal-EIOU | K-Means | Retinex | SE | mAP | Speed |
|---|---|---|---|---|---|---|
| - | - | - | - | - | 94.5% | 0.529 s |
| √ | - | - | - | - | 93.9% | 0.401 s |
| √ | √ | - | - | - | 94.6% | 0.408 s |
| √ | √ | √ | - | - | 95.4% | 0.406 s |
| √ | √ | √ | √ | - | 96.1% | 0.411 s |
| √ | √ | √ | √ | √ | 96.5% | 0.416 s |
| Model | P | R | mAP | Speed | Parameter |
|---|---|---|---|---|---|
| YOLOv3-Tiny | 92.1% | 84% | 90.8% | 0.264 s | 16.9 MB |
| YOLOv3 | 95.5% | 94.1% | 96.9% | 0.975 s | 117 MB |
| YOLOv7 | 95% | 91.1% | 95.5% | 0.631 s | 72 MB |
| YOLOv8s | 94.6% | 91.9% | 95.6% | 0.581 s | 21.5 MB |
| YOLOv5-MS | 95.9% | 93.1% | 96.5% | 0.416 s | 10.7 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, F.; Li, P. YOLOv5-MS: Real-Time Multi-Surveillance Pedestrian Target Detection Model for Smart Cities. Biomimetics 2023, 8, 480. https://doi.org/10.3390/biomimetics8060480
Song F, Li P. YOLOv5-MS: Real-Time Multi-Surveillance Pedestrian Target Detection Model for Smart Cities. Biomimetics. 2023; 8(6):480. https://doi.org/10.3390/biomimetics8060480
Chicago/Turabian StyleSong, Fangzheng, and Peng Li. 2023. "YOLOv5-MS: Real-Time Multi-Surveillance Pedestrian Target Detection Model for Smart Cities" Biomimetics 8, no. 6: 480. https://doi.org/10.3390/biomimetics8060480
APA StyleSong, F., & Li, P. (2023). YOLOv5-MS: Real-Time Multi-Surveillance Pedestrian Target Detection Model for Smart Cities. Biomimetics, 8(6), 480. https://doi.org/10.3390/biomimetics8060480