

Training of Feed-Forward Neural Networks by Using Optimization Algorithms Based on Swarm-Intelligent for Maximum Power Point Tracking
 , , , , and
, , , , and
Abstract
:1. Introduction
- Metaheuristic algorithms are grouped according to how they occur. One of these groups is swarm intelligence-based algorithms. In this study, 13 swarm intelligence-based algorithms for FFNN training are compared. It is one of the first studies in the literature in this context.
- Metaheuristic algorithms are used to solve the MPPT problem. It is one of the most influential studies in the literature using thirteen metaheuristic algorithms for MPPT.
- The success of these algorithms in both FFNN training and MPPT will shed light on future studies.
- In this study, the effect of network structure and population size on performance is examined in detail.
2. Related Work
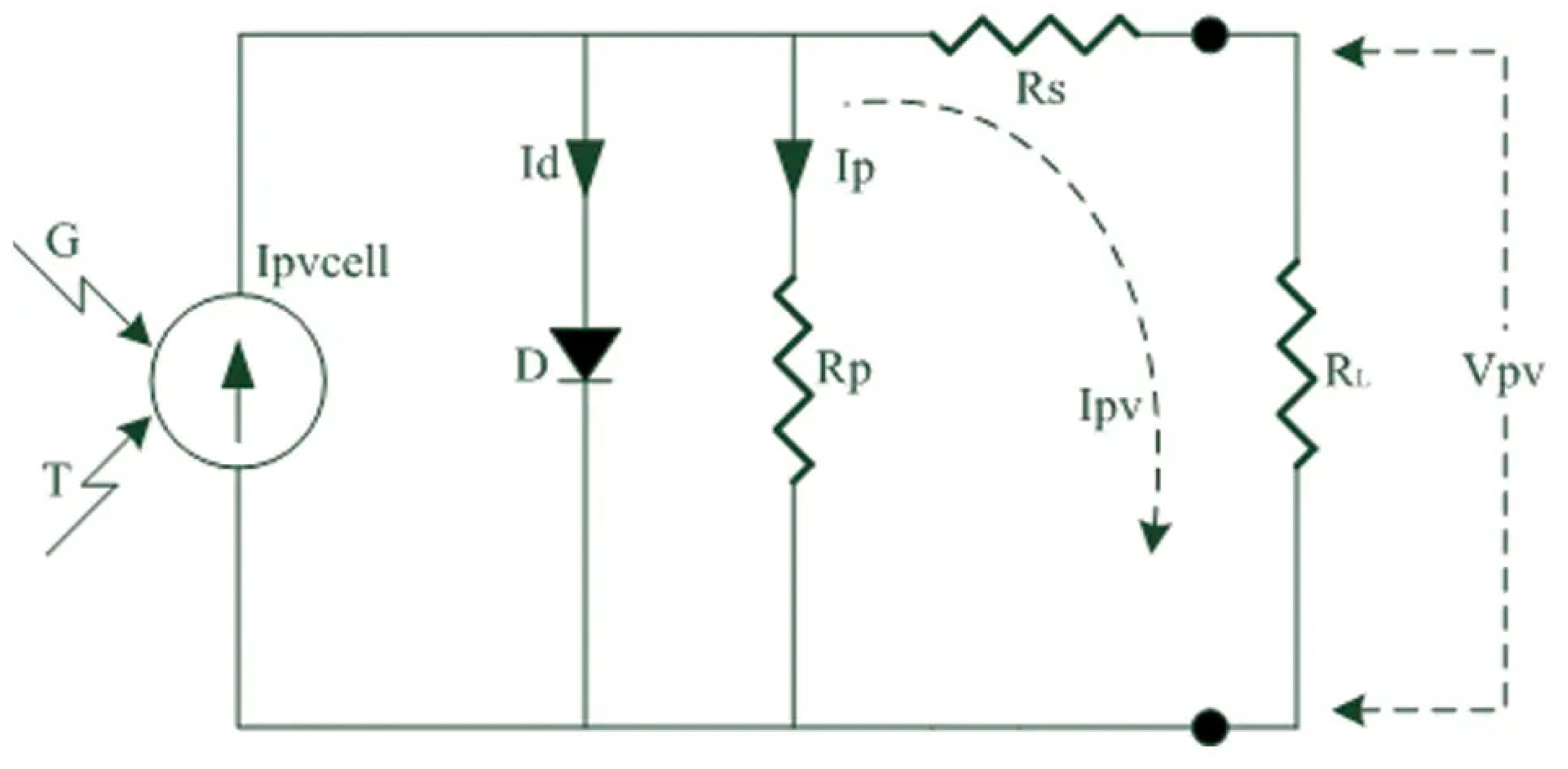
3. Materials and Methods
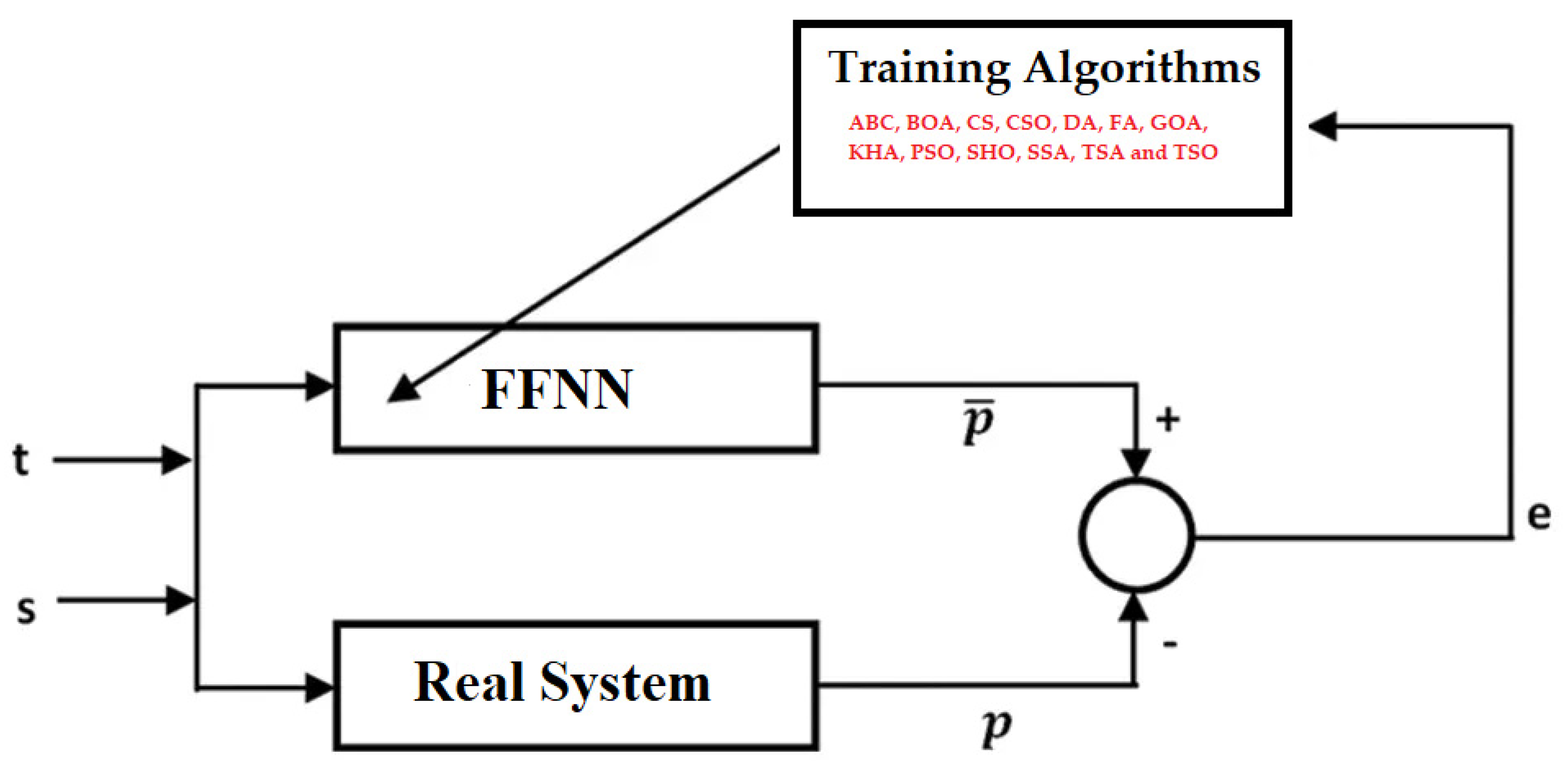
3.1. Optimization Algorithms Based on Swarm-Intelligent
3.1.1. Particle Swarm Algorithm
3.1.2. Artificial Bee Colony Algorithm
3.1.3. Firefly Algorithm
3.1.4. Krill Herd Algorithm
3.1.5. Chicken Swarm Optimization
3.1.6. The Dragonfly Algorithm
3.1.7. Grasshopper Optimization Algorithm
3.1.8. Selfish Herd Optimizer
3.1.9. The Butterfly Optimization Algorithm
3.1.10. Tunicate Swarm Algorithm
3.1.11. Tuna Swarm Optimization
3.1.12. Cuckoo Search
3.1.13. Salp Swarm Algorithm
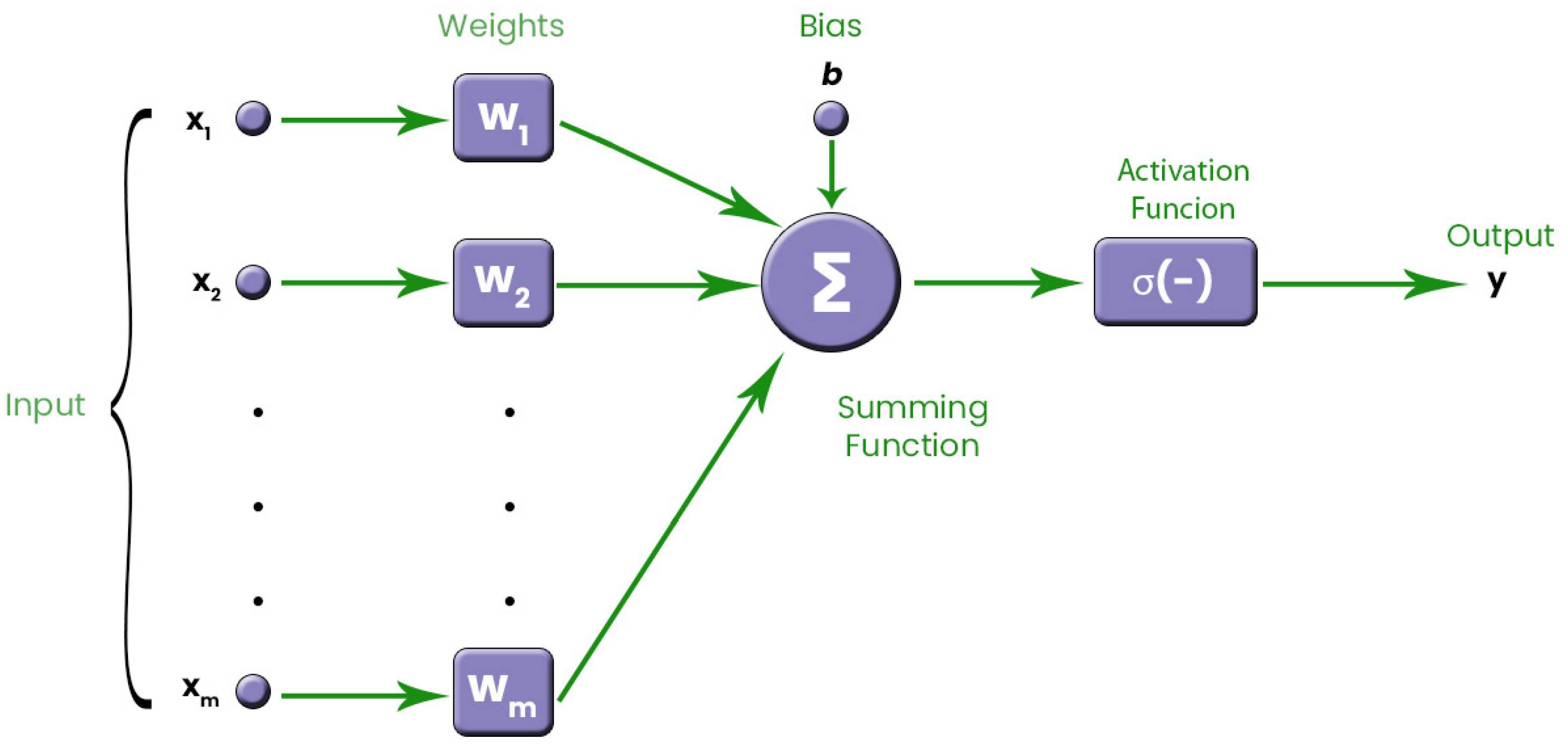
3.2. Feed Forward Neural Network
4. Simulation Results
5. Discussion
6. Conclusions
- In general, all algorithms were found to be effective for MPPT. The three most effective algorithms are FA, SHO, and GOA.
- Network structure affects the performance of training algorithms. The network structure in which each algorithm is more successful may be different from each other.
- As with the network structure, the population size affects the performance of the training algorithms in solving the related problem. The population size in which each algorithm is more successful may differ.
- In general, the training and test results for each algorithm were close to each other. This shows that the learning process is successful.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BOA | Butterfly optimization algorithm |
| SSA | Salp swarm algorithm |
| FA | Firefly algorithm |
| ABC | Artificial bee colony |
| PSO | Particle swarm optimization |
| KHA | Krill herd algorithm |
| CS | Cuckoo search |
| FFNN | Feed-forward neural network |
| ANN | Artificial neural network |
| GOA | Grasshopper optimization algorithm |
| ANFIS | Adaptive Network Fuzzy Inference System |
| DA | Dragonfly algorithm |
| SHO | Selfish herd optimizer |
| TSA | Tunicate swarm algorithm |
| TSO | Tuna swarm optimization |
| CSO | Chicken swarm optimization |
| MPP | Maximum power point |
| MPPT | Maximum power point tracking |
| PV | Photovoltaic |
| P&O | Perturb and observe |
| INC | Incremental Conductance |
| PID | Proportional Integral Derivative |
| FLC | Fuzzy Logic Control |
| PS | Photovoltaic System |
| SGO | Social group optimization |
| SMO | Slime mould optimization |
| RNNs | Recurrent neural networks |
| ACO | Ant colony optimization |
| RBFN | Radial basis function network |
References
- Mellit, A.; Kalogirou, S.A. MPPT-based artificial intelligence techniques for photovoltaic systems and its implementation into field programmable gate array chips: Review of current status and future perspectives. Energy 2014, 70, 1–21. [Google Scholar] [CrossRef]
- Villegas-Mier, C.G.; Rodriguez-Resendiz, J.; Álvarez-Alvarado, J.M.; Rodriguez-Resendiz, H.; Herrera-Navarro, A.M.; Rodríguez-Abreo, O. Artificial neural networks in MPPT algorithms for optimization of photovoltaic power systems: A review. Micromachines 2021, 12, 1260. [Google Scholar] [CrossRef]
- Al-Majidi, S.D.; Abbod, M.F.; Al-Raweshidy, H.S. A particle swarm optimisation-trained feedforward neural network for predicting the maximum power point of a photovoltaic array. Eng. Appl. Artif. Intell. 2020, 92, 103688. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Yang, X.-S. Firefly algorithms for multimodal optimization. In Proceedings of the Stochastic Algorithms: Foundations and Applications: 5th International Symposium, SAGA 2009, Sapporo, Japan, 26–28 October 2009; pp. 169–178. [Google Scholar]
- Gandomi, A.H.; Alavi, A.H. Krill herd: A new bio-inspired optimization algorithm. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 4831–4845. [Google Scholar] [CrossRef]
- Meng, X.; Liu, Y.; Gao, X.; Zhang, H. A new bio-inspired algorithm: Chicken swarm optimization. In Proceedings of the Advances in Swarm Intelligence: 5th International Conference, ICSI 2014, Hefei, China, 17–20 October 2014; pp. 86–94. [Google Scholar]
- Mirjalili, S. Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput. Appl. 2016, 27, 1053–1073. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef]
- Fausto, F.; Cuevas, E.; Valdivia, A.; González, A. A global optimization algorithm inspired in the behavior of selfish herds. Biosystems 2017, 160, 39–55. [Google Scholar] [CrossRef] [PubMed]
- Arora, S.; Singh, S. Butterfly optimization algorithm: A novel approach for global optimization. Soft Comput. 2019, 23, 715–734. [Google Scholar] [CrossRef]
- Kaur, S.; Awasthi, L.K.; Sangal, A.; Dhiman, G. Tunicate Swarm Algorithm: A new bio-inspired based metaheuristic paradigm for global optimization. Eng. Appl. Artif. Intell. 2020, 90, 103541. [Google Scholar] [CrossRef]
- Xie, L.; Han, T.; Zhou, H.; Zhang, Z.-R.; Han, B.; Tang, A. Tuna swarm optimization: A novel swarm-based metaheuristic algorithm for global optimization. Comput. Intell. Neurosci. 2021, 2021, 9210050. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.-S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Yang, B.; Zhong, L.; Zhang, X.; Shu, H.; Yu, T.; Li, H.; Jiang, L.; Sun, L. Novel bio-inspired memetic salp swarm algorithm and application to MPPT for PV systems considering partial shading condition. J. Clean. Prod. 2019, 215, 1203–1222. [Google Scholar] [CrossRef]
- Manna, S.; Akella, A.K.; Singh, D.K. Implementation of a novel robust model reference adaptive controller-based MPPT for stand-alone and grid-connected photovoltaic system. Energy Sources Part A Recovery Util. Environ. Eff. 2023, 45, 1321–1345. [Google Scholar] [CrossRef]
- Kamarposhti, M.A.; Shokouhandeh, H.; Colak, I.; Eguchi, K. Optimization of Adaptive Fuzzy Controller for Maximum Power Point Tracking Using Whale Algorithm. CMC-Comput. Mater. Contin. 2022, 73, 5041–5061. [Google Scholar] [CrossRef]
- Akram, N.; Khan, L.; Agha, S.; Hafeez, K. Global Maximum Power Point Tracking of Partially Shaded PV System Using Advanced Optimization Techniques. Energies 2022, 15, 4055. [Google Scholar] [CrossRef]
- Vadivel, S.; Sengodan, B.C.; Ramasamy, S.; Ahsan, M.; Haider, J.; Rodrigues, E.M. Social Grouping Algorithm Aided Maximum Power Point Tracking Scheme for Partial Shaded Photovoltaic Array. Energies 2022, 15, 2105. [Google Scholar] [CrossRef]
- Kacimi, N.; Idir, A.; Grouni, S.; Boucherit, M.S. A new combined method for tracking the global maximum power point of photovoltaic systems. Rev. Roum. Des Sci. Tech. Série Électrotechnique Énergétique 2022, 67, 349–354. [Google Scholar]
- Mirza, A.F.; Mansoor, M.; Ling, Q.; Yin, B.; Javed, M.Y. A Salp-Swarm Optimization based MPPT technique for harvesting maximum energy from PV systems under partial shading conditions. Energy Convers. Manag. 2020, 209, 112625. [Google Scholar] [CrossRef]
- Jamshidi, F.; Salehizadeh, M.R.; Yazdani, R.; Azzopardi, B.; Jately, V. An Improved Sliding Mode Controller for MPP Tracking of Photovoltaics. Energies 2023, 16, 2473. [Google Scholar] [CrossRef]
- Pal, R.S.; Mukherjee, V. Metaheuristic based comparative MPPT methods for photovoltaic technology under partial shading condition. Energy 2020, 212, 118592. [Google Scholar] [CrossRef]
- Mirza, A.F.; Mansoor, M.; Zhan, K.; Ling, Q. High-efficiency swarm intelligent maximum power point tracking control techniques for varying temperature and irradiance. Energy 2021, 228, 120602. [Google Scholar] [CrossRef]
- Yan, Z.; Miyuan, Z.; Yajun, W.; Xibiao, C.; Yanjun, L. Photovoltaic MPPT algorithm based on adaptive particle swarm optimization neural-fuzzy control. J. Intell. Fuzzy Syst. 2023, 44, 341–351. [Google Scholar] [CrossRef]
- Rezk, H.; Fathy, A.; Abdelaziz, A.Y. A comparison of different global MPPT techniques based on meta-heuristic algorithms for photovoltaic system subjected to partial shading conditions. Renew. Sustain. Energy Rev. 2017, 74, 377–386. [Google Scholar] [CrossRef]
- Aguila-Leon, J.; Vargas-Salgado, C.; Chiñas-Palacios, C.; Díaz-Bello, D. Solar photovoltaic Maximum Power Point Tracking controller optimization using Grey Wolf Optimizer: A performance comparison between bio-inspired and traditional algorithms. Expert Syst. Appl. 2023, 211, 118700. [Google Scholar] [CrossRef]
- González-Castaño, C.; Restrepo, C.; Kouro, S.; Rodriguez, J. MPPT algorithm based on artificial bee colony for PV system. IEEE Access 2021, 9, 43121–43133. [Google Scholar] [CrossRef]
- Corrêa, H.P.; Vieira, F.H.T. Hybrid sensor-aided direct duty cycle control approach for maximum power point tracking in two-stage photovoltaic systems. Int. J. Electr. Power Energy Syst. 2023, 145, 108690. [Google Scholar] [CrossRef]
- Dagal, I.; Akın, B.; Akboy, E. Improved salp swarm algorithm based on particle swarm optimization for maximum power point tracking of optimal photovoltaic systems. Int. J. Energy Res. 2022, 46, 8742–8759. [Google Scholar] [CrossRef]
- Ahmed, M.; Harbi, I.; Kennel, R.; Rodriguez, J.; Abdelrahem, M. An improved photovoltaic maximum power point tracking technique-based model predictive control for fast atmospheric conditions. Alex. Eng. J. 2023, 63, 613–624. [Google Scholar] [CrossRef]
- Ibrahim, M.H.; Ang, S.P.; Dani, M.N.; Rahman, M.I.; Petra, R.; Sulthan, S.M. Optimizing Step-Size of Perturb & Observe and Incremental Conductance MPPT Techniques Using PSO for Grid-Tied PV System. IEEE Access 2023, 11, 13079–13090. [Google Scholar]
- Ibnelouad, A.; El Kari, A.; Ayad, H.; Mjahed, M. Improved cooperative artificial neural network-particle swarm optimization approach for solar photovoltaic systems using maximum power point tracking. Int. Trans. Electr. Energy Syst. 2020, 30, e12439. [Google Scholar] [CrossRef]
- Kumar, D.; Chauhan, Y.K.; Pandey, A.S.; Srivastava, A.K.; Kumar, V.; Alsaif, F.; Elavarasan, R.M.; Islam, M.R.; Kannadasan, R.; Alsharif, M.H. A Novel Hybrid MPPT Approach for Solar PV Systems Using Particle-Swarm-Optimization-Trained Machine Learning and Flying Squirrel Search Optimization. Sustainability 2023, 15, 5575. [Google Scholar] [CrossRef]
- Mohebbi, P.; Aazami, R.; Moradkhani, A.; Danyali, S. A Novel Intelligent Hybrid Algorithm for Maximum Power Point Tracking in PV System. Int. J. Electron. 2023. [Google Scholar] [CrossRef]
- Ngo, S.; Chiu, C.-S.; Ngo, T.-D.; Nguyen, C.-T. New Approach-based MPP Tracking Design for Standalone PV Energy Conversion Systems. Elektron. Ir Elektrotechnika 2023, 29, 49–58. [Google Scholar] [CrossRef]
- Nancy Mary, J.; Mala, K. Optimized PV Fed Zeta Converter Integrated with MPPT Algorithm for Islanding Mode Operation. Electr. Power Compon. Syst. 2023, 51, 1240–1250. [Google Scholar] [CrossRef]
- Al-Muthanna, G.; Fang, S.; AL-Wesabi, I.; Ameur, K.; Kotb, H.; AboRas, K.M.; Garni, H.Z.A.; Mas’ ud, A.A. A High Speed MPPT Control Utilizing a Hybrid PSO-PID Controller under Partially Shaded Photovoltaic Battery Chargers. Sustainability 2023, 15, 3578. [Google Scholar] [CrossRef]
- Nisha, M.; Nisha, M. Optimum Tuning of Photovoltaic System Via Hybrid Maximum Power Point Tracking Technique. Intell. Autom. Soft Comput. 2022, 34, 1399–1413. [Google Scholar] [CrossRef]
- Gong, L.; Hou, G.; Huang, C. A two-stage MPPT controller for PV system based on the improved artificial bee colony and simultaneous heat transfer search algorithm. ISA Trans. 2023, 132, 428–443. [Google Scholar] [CrossRef] [PubMed]
- Babes, B.; Boutaghane, A.; Hamouda, N. A novel nature-inspired maximum power point tracking (MPPT) controller based on ACO-ANN algorithm for photovoltaic (PV) system fed arc welding machines. Neural Comput. Appl. 2022, 34, 299–317. [Google Scholar] [CrossRef]
- Avila, L.; De Paula, M.; Trimboli, M.; Carlucho, I. Deep reinforcement learning approach for MPPT control of partially shaded PV systems in Smart Grids. Appl. Soft Comput. 2020, 97, 106711. [Google Scholar] [CrossRef]
- Saravanan, S.; Babu, N.R. RBFN based MPPT algorithm for PV system with high step up converter. Energy Convers. Manag. 2016, 122, 239–251. [Google Scholar] [CrossRef]
- Sazli, M.H. A brief review of feed-forward neural networks. Commun. Fac. Sci. Univ. Ank. Ser. A2–A3 Phys. Sci. Eng. 2006, 50, 11–17. [Google Scholar] [CrossRef]
- Razavi, S.; Tolson, B.A. A new formulation for feedforward neural networks. IEEE Trans. Neural Netw. 2011, 22, 1588–1598. [Google Scholar] [CrossRef] [PubMed]
- Montana, D.J.; Davis, L. Training feedforward neural networks using genetic algorithms. In Proceedings of the 11th International Joint Conference on Artificial Intelligence, San Mateo, CA, USA, 20–25 August 1989; pp. 762–767. [Google Scholar]
- Kaya, E. A comprehensive comparison of the performance of metaheuristic algorithms in neural network training for nonlinear system identification. Mathematics 2022, 10, 1611. [Google Scholar] [CrossRef]
- Kaya, C.B.; Kaya, E.; Gokkus, G. Training Neuro-Fuzzy by Using Meta-Heuristic Algorithms for MPPT. Comput. Syst. Sci. Eng. 2023, 45, 69–84. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| System | Network Structure | The Results | |||
|---|---|---|---|---|---|
| Train | Test | ||||
| Mean | Std. | Mean | Std. | ||
| ABC | 2-5-1 | 5.0 × 10−3 | 2.4 × 10−3 | 5.1 × 10−3 | 2.4 × 10−3 |
| 2-10-1 | 1.2 × 10−2 | 4.3 × 10−2 | 1.8 × 10−2 | 7.6 × 10−2 | |
| 2-15-1 | 6.0 × 10−3 | 3.2 × 10−3 | 6.0 × 10−3 | 3.1 × 10−3 | |
| BOA | 2-5-1 | 5.2 × 10−2 | 4.1 × 10−2 | 5.2 × 10−2 | 4.1 × 10−2 |
| 2-10-1 | 3.8 × 10−2 | 3.5 × 10−2 | 3.8 × 10−2 | 3.5 × 10−2 | |
| 2-15-1 | 4.1 × 10−2 | 3.8 × 10−2 | 4.1 × 10−2 | 3.8 × 10−2 | |
| CS | 2-5-1 | 3.9 × 10−3 | 1.1 × 10−3 | 3.9 × 10−3 | 1.1 × 10−3 |
| 2-10-1 | 4.0 × 10−3 | 1.2 × 10−3 | 4.1 × 10−3 | 1.2 × 10−3 | |
| 2-15-1 | 4.3 × 10−3 | 1.6 × 10−3 | 4.4 × 10−3 | 1.6 × 10−3 | |
| CSO | 2-5-1 | 5.3 × 10−3 | 2.9 × 10−3 | 5.3 × 10−3 | 2.9 × 10−3 |
| 2-10-1 | 3.7 × 10−3 | 2.6 × 10−3 | 3.8 × 10−3 | 2.6 × 10−3 | |
| 2-15-1 | 4.6 × 10−3 | 2.6 × 10−3 | 4.7 × 10−3 | 2.6 × 10−3 | |
| DA | 2-5-1 | 5.0 × 10−3 | 2.9 × 10−3 | 5.0 × 10−3 | 2.9 × 10−3 |
| 2-10-1 | 5.3 × 10−3 | 3.4 × 10−3 | 5.4 × 10−3 | 3.5 × 10−3 | |
| 2-15-1 | 5.7 × 10−3 | 3.5 × 10−3 | 5.7 × 10−3 | 3.4 × 10−3 | |
| FA | 2-5-1 | 2.0 × 10−3 | 2.0 × 10−3 | 2.0 × 10−3 | 2.0 × 10−3 |
| 2-10-1 | 1.8 × 10−3 | 1.9 × 10−3 | 1.8 × 10−3 | 1.9 × 10−3 | |
| 2-15-1 | 1.9 × 10−3 | 1.7 × 10−3 | 1.9 × 10−3 | 1.8 × 10−3 | |
| GOA | 2-5-1 | 1.3 × 10−2 | 3.4 × 10−2 | 1.3 × 10−2 | 3.5 × 10−2 |
| 2-10-1 | 1.2 × 10−2 | 4.0 × 10−2 | 1.2 × 10−2 | 4.0 × 10−2 | |
| 2-15-1 | 4.9 × 10−3 | 3.1 × 10−3 | 4.9 × 10−3 | 3.2 × 10−3 | |
| KHA | 2-5-1 | 5.6 × 10−3 | 7.3 × 10−3 | 5.6 × 10−3 | 7.3 × 10−3 |
| 2-10-1 | 6.9 × 10−3 | 8.7 × 10−3 | 7.0 × 10−3 | 9.0 × 10−3 | |
| 2-15-1 | 5.5 × 10−3 | 5.8 × 10−3 | 5.6 × 10−3 | 6.0 × 10−3 | |
| PSO | 2-5-1 | 6.5 × 10−3 | 2.6 × 10−3 | 6.5 × 10−3 | 2.6 × 10−3 |
| 2-10-1 | 9.0 × 10−3 | 3.0 × 10−3 | 9.1 × 10−3 | 3.1 × 10−3 | |
| 2-15-1 | 8.6 × 10−3 | 3.0 × 10−3 | 8.6 × 10−3 | 3.0 × 10−3 | |
| SHO | 2-5-1 | 3.7 × 10−3 | 2.5 × 10−3 | 3.7 × 10−3 | 2.6 × 10−3 |
| 2-10-1 | 3.5 × 10−3 | 2.1 × 10−3 | 3.6 × 10−3 | 2.1 × 10−3 | |
| 2-15-1 | 3.6 × 10−3 | 3.3 × 10−3 | 3.7 × 10−3 | 3.3 × 10−3 | |
| SSA | 2-5-1 | 4.7 × 10−3 | 3.2 × 10−3 | 4.7 × 10−3 | 3.2 × 10−3 |
| 2-10-1 | 4.1 × 10−3 | 2.3 × 10−3 | 4.1 × 10−3 | 2.2 × 10−3 | |
| 2-15-1 | 4.0 × 10−3 | 3.1 × 10−3 | 4.1 × 10−3 | 3.1 × 10−3 | |
| TSA | 2-5-1 | 1.5 × 10−2 | 3.4 × 10−2 | 1.5 × 10−2 | 3.4 × 10−2 |
| 2-10-1 | 2.5 × 10−3 | 1.6 × 10−3 | 2.6 × 10−3 | 1.7 × 10−3 | |
| 2-15-1 | 2.9 × 10−3 | 1.4 × 10−3 | 2.9 × 10−3 | 1.4 × 10−3 | |
| TSO | 2-5-1 | 3.3 × 10−3 | 1.9 × 10−3 | 3.3 × 10−3 | 1.8 × 10−3 |
| 2-10-1 | 2.7 × 10−3 | 1.5 × 10−3 | 2.8 × 10−3 | 1.5 × 10−3 | |
| 2-15-1 | 3.0 × 10−3 | 1.7 × 10−3 | 3.1 × 10−3 | 1.7 × 10−3 | |
| System | Network Structure | The Results | |||
|---|---|---|---|---|---|
| Train | Test | ||||
| Mean | Std. | Mean | Std. | ||
| ABC | 2-5-1 | 7.0 × 10−3 | 2.3 × 10−3 | 7.1 × 10−3 | 2.4 × 10−3 |
| 2-10-1 | 8.9 × 10−3 | 8.2 × 10−3 | 8.9 × 10−3 | 8.5 × 10−3 | |
| 2-15-1 | 1.3 × 10−2 | 1.4 × 10−2 | 5.6 × 10−2 | 1.2 × 10−1 | |
| BOA | 2-5-1 | 3.7 × 10−2 | 3.1 × 10−2 | 3.7 × 10−2 | 3.1 × 10−2 |
| 2-10-1 | 2.1 × 10−2 | 1.8 × 10−2 | 2.2 × 10−2 | 1.8 × 10−2 | |
| 2-15-1 | 2.6 × 10−2 | 2.5 × 10−2 | 2.6 × 10−2 | 2.5 × 10−2 | |
| CS | 2-5-1 | 5.5 × 10−3 | 1.6 × 10−3 | 5.6 × 10−3 | 1.6 × 10−3 |
| 2-10-1 | 5.8 × 10−3 | 1.7 × 10−3 | 5.8 × 10−3 | 1.7 × 10−3 | |
| 2-15-1 | 6.5 × 10−3 | 2.1 × 10−3 | 6.6 × 10−3 | 2.2 × 10−3 | |
| CSO | 2-5-1 | 3.9 × 10−3 | 2.3 × 10−3 | 4.0 × 10−3 | 2.4 × 10−3 |
| 2-10-1 | 4.7 × 10−3 | 1.4 × 10−3 | 4.8 × 10−3 | 1.5 × 10−3 | |
| 2-15-1 | 6.9 × 10−3 | 2.3 × 10−3 | 7.1 × 10−3 | 2.5 × 10−3 | |
| DA | 2-5-1 | 4.3 × 10−3 | 3.3 × 10−3 | 4.4 × 10−3 | 3.4 × 10−3 |
| 2-10-1 | 4.0 × 10−3 | 3.2 × 10−3 | 4.1 × 10−3 | 3.3 × 10−3 | |
| 2-15-1 | 3.5 × 10−3 | 2.1 × 10−3 | 3.5 × 10−3 | 2.1 × 10−3 | |
| FA | 2-5-1 | 5.0 × 10−4 | 3.9 × 10−4 | 5.2 × 10−4 | 4.0 × 10−4 |
| 2-10-1 | 8.0 × 10−4 | 9.6 × 10−4 | 8.3 × 10−4 | 1.0 × 10−3 | |
| 2-15-1 | 5.4 × 10−4 | 4.6 × 10−4 | 5.4 × 10−4 | 4.7 × 10−4 | |
| GOA | 2-5-1 | 3.5 × 10−3 | 2.3 × 10−3 | 3.6 × 10−3 | 2.4 × 10−3 |
| 2-10-1 | 3.4 × 10−3 | 2.5 × 10−3 | 3.5 × 10−3 | 2.5 × 10−3 | |
| 2-15-1 | 3.7 × 10−3 | 3.1 × 10−3 | 3.7 × 10−3 | 3.1 × 10−3 | |
| KHA | 2-5-1 | 1.5 × 10−2 | 1.2 × 10−2 | 1.5 × 10−2 | 1.2 × 10−2 |
| 2-10-1 | 1.5 × 10−2 | 7.4 × 10−3 | 1.5 × 10−2 | 7.3 × 10−3 | |
| 2-15-1 | 1.9 × 10−2 | 1.4 × 10−2 | 1.9 × 10−2 | 1.4 × 10−2 | |
| PSO | 2-5-1 | 1.0 × 10−2 | 4.4 × 10−3 | 1.0 × 10−2 | 4.5 × 10−3 |
| 2-10-1 | 9.0 × 10−3 | 3.7 × 10−3 | 9.0 × 10−3 | 3.7 × 10−3 | |
| 2-15-1 | 9.4 × 10−3 | 3.2 × 10−3 | 9.5 × 10−3 | 3.2 × 10−3 | |
| SHO | 2-5-1 | 2.7 × 10−3 | 1.7 × 10−3 | 2.8 × 10−3 | 1.7 × 10−3 |
| 2-10-1 | 1.9 × 10−3 | 9.9 × 10−4 | 2.0 × 10−3 | 1.0 × 10−3 | |
| 2-15-1 | 1.6 × 10−3 | 6.3 × 10−4 | 1.6 × 10−3 | 6.5 × 10−4 | |
| SSA | 2-5-1 | 5.0 × 10−3 | 2.9 × 10−3 | 5.0 × 10−3 | 3.0 × 10−3 |
| 2-10-1 | 5.6 × 10−3 | 3.6 × 10−3 | 5.7 × 10−3 | 3.7 × 10−3 | |
| 2-15-1 | 4.4 × 10−3 | 2.7 × 10−3 | 4.5 × 10−3 | 2.7 × 10−3 | |
| TSA | 2-5-1 | 5.1 × 10−3 | 8.5 × 10−3 | 5.1 × 10−3 | 7.9 × 10−3 |
| 2-10-1 | 2.5 × 10−3 | 1.3 × 10−3 | 2.6 × 10−3 | 1.3 × 10−3 | |
| 2-15-1 | 2.9 × 10−3 | 1.5 × 10−3 | 3.0 × 10−3 | 1.9 × 10−3 | |
| TSO | 2-5-1 | 3.6 × 10−3 | 2.4 × 10−3 | 3.6 × 10−3 | 2.3 × 10−3 |
| 2-10-1 | 3.2 × 10−3 | 1.8 × 10−3 | 3.3 × 10−3 | 1.8 × 10−3 | |
| 2-15-1 | 3.3 × 10−3 | 1.5 × 10−3 | 3.4 × 10−3 | 1.6 × 10−3 | |
| System | Network Structure | The Results | |||
|---|---|---|---|---|---|
| Train | Test | ||||
| Mean | Std. | Mean | Std. | ||
| ABC | 2-5-1 | 1.2 × 10−2 | 1.0 × 10−2 | 1.3 × 10−2 | 1.0 × 10−2 |
| 2-10-1 | 1.1 × 10−2 | 5.0 × 10−3 | 1.1 × 10−2 | 5.0 × 10−3 | |
| 2-15-1 | 1.3 × 10−2 | 6.2 × 10−3 | 1.3 × 10−2 | 6.0 × 10−3 | |
| BOA | 2-5-1 | 2.5 × 10−2 | 1.6 × 10−2 | 2.5 × 10−2 | 1.6 × 10−2 |
| 2-10-1 | 1.5 × 10−2 | 1.2 × 10−2 | 1.5 × 10−2 | 1.2 × 10−2 | |
| 2-15-1 | 1.8 × 10−2 | 1.2 × 10−2 | 1.8 × 10−2 | 1.2 × 10−2 | |
| CS | 2-5-1 | 8.2 × 10−3 | 2.3 × 10−3 | 8.3 × 10−3 | 2.3 × 10−3 |
| 2-10-1 | 7.5 × 10−3 | 2.4 × 10−3 | 7.6 × 10−3 | 2.4 × 10−3 | |
| 2-15-1 | 8.1 × 10−3 | 3.0 × 10−3 | 8.2 × 10−3 | 2.9 × 10−3 | |
| CSO | 2-5-1 | 7.3 × 10−3 | 2.9 × 10−3 | 7.3 × 10−3 | 2.9 × 10−3 |
| 2-10-1 | 7.0 × 10−3 | 2.6 × 10−3 | 7.1 × 10−3 | 2.6 × 10−3 | |
| 2-15-1 | 7.6 × 10−3 | 2.8 × 10−3 | 7.8 × 10−3 | 2.8 × 10−3 | |
| DA | 2-5-1 | 3.8 × 10−3 | 3.0 × 10−3 | 3.9 × 10−3 | 3.0 × 10−3 |
| 2-10-1 | 4.6 × 10−3 | 3.5 × 10−3 | 4.7 × 10−3 | 3.5 × 10−3 | |
| 2-15-1 | 4.1 × 10−3 | 2.5 × 10−3 | 4.2 × 10−3 | 2.6 × 10−3 | |
| FA | 2-5-1 | 4.5 × 10−4 | 2.3 × 10−4 | 4.6 × 10−4 | 2.3 × 10−4 |
| 2-10-1 | 5.5 × 10−4 | 2.8 × 10−4 | 5.7 × 10−4 | 2.8 × 10−4 | |
| 2-15-1 | 8.6 × 10−4 | 5.5 × 10−4 | 8.9 × 10−4 | 5.8 × 10−4 | |
| GOA | 2-5-1 | 2.7 × 10−3 | 1.9 × 10−3 | 2.8 × 10−3 | 1.9 × 10−3 |
| 2-10-1 | 2.3 × 10−3 | 1.6 × 10−3 | 2.4 × 10−3 | 1.7 × 10−3 | |
| 2-15-1 | 3.3 × 10−3 | 2.2 × 10−3 | 3.4 × 10−3 | 2.3 × 10−3 | |
| KHA | 2-5-1 | 1.6 × 10−2 | 6.9 × 10−3 | 1.6 × 10−2 | 6.8 × 10−3 |
| 2-10-1 | 1.8 × 10−2 | 7.2 × 10−3 | 1.8 × 10−2 | 7.2 × 10−3 | |
| 2-15-1 | 1.6 × 10−2 | 5.6 × 10−3 | 1.6 × 10−2 | 5.6 × 10−3 | |
| PSO | 2-5-1 | 1.1 × 10−2 | 4.0 × 10−3 | 1.1 × 10−2 | 4.1 × 10−3 |
| 2-10-1 | 1.0 × 10−2 | 3.9 × 10−3 | 1.0 × 10−2 | 3.9 × 10−3 | |
| 2-15-1 | 1.1 × 10−2 | 3.8 × 10−3 | 1.1 × 10−2 | 3.7 × 10−3 | |
| SHO | 2-5-1 | 2.3 × 10−3 | 1.4 × 10−3 | 2.3 × 10−3 | 1.5 × 10−3 |
| 2-10-1 | 1.9 × 10−3 | 8.4 × 10−4 | 2.0 × 10−3 | 8.9 × 10−4 | |
| 2-15-1 | 3.3 × 10−3 | 4.2 × 10−3 | 3.3 × 10−3 | 4.1 × 10−3 | |
| SSA | 2-5-1 | 7.4 × 10−3 | 3.8 × 10−3 | 7.6 × 10−3 | 3.8 × 10−3 |
| 2-10-1 | 5.3 × 10−3 | 2.8 × 10−3 | 5.4 × 10−3 | 2.8 × 10−3 | |
| 2-15-1 | 5.7 × 10−3 | 3.8 × 10−3 | 5.8 × 10−3 | 3.9 × 10−3 | |
| TSA | 2-5-1 | 3.7 × 10−3 | 2.6 × 10−3 | 3.7 × 10−3 | 2.6 × 10−3 |
| 2-10-1 | 3.4 × 10−3 | 2.3 × 10−3 | 3.5 × 10−3 | 2.3 × 10−3 | |
| 2-15-1 | 3.1 × 10−3 | 1.3 × 10−3 | 3.2 × 10−3 | 1.4 × 10−3 | |
| TSO | 2-5-1 | 4.1 × 10−3 | 2.5 × 10−3 | 4.1 × 10−3 | 2.6 × 10−3 |
| 2-10-1 | 5.3 × 10−3 | 2.8 × 10−3 | 5.3 × 10−3 | 2.8 × 10−3 | |
| 2-15-1 | 5.7 × 10−3 | 2.6 × 10−3 | 5.9 × 10−3 | 2.6 × 10−3 | |
| Algorithm | Train | |||
|---|---|---|---|---|
| Network Structure | Population Size | Mean | Std. | |
| ABC | 2-5-1 | 10 | 5.0 × 10−3 | 2.4 × 10−3 |
| BOA | 2-10-1 | 50 | 1.5 × 10−2 | 1.2 × 10−2 |
| CS | 2-5-1 | 10 | 3.9 × 10−3 | 1.1 × 10−3 |
| CSO | 2-10-1 | 10 | 3.7 × 10−3 | 2.6 × 10−3 |
| DA | 2-15-1 | 20 | 3.5 × 10−3 | 2.1 × 10−3 |
| FA | 2-5-1 | 50 | 4.5 × 10−4 | 2.3 × 10−4 |
| GOA | 2-10-1 | 50 | 2.3 × 10−3 | 1.6 × 10−3 |
| KHA | 2-15-1 | 10 | 5.5 × 10−3 | 5.8 × 10−3 |
| PSO | 2-5-1 | 10 | 6.5 × 10−3 | 2.6 × 10−3 |
| SHO | 2-15-1 | 20 | 1.6 × 10−3 | 6.3 × 10−4 |
| SSA | 2-15-1 | 10 | 4.0 × 10−3 | 3.1 × 10−3 |
| TSA | 2-10-1 | 10 | 2.5 × 10−3 | 1.6 × 10−3 |
| TSO | 2-10-1 | 10 | 2.7 × 10−3 | 1.5 × 10−3 |
| Algorithm | Test | |||
|---|---|---|---|---|
| Network Structure | Population Size | Mean | Std. | |
| ABC | 2-5-1 | 10 | 5.1 × 10−3 | 2.4 × 10−3 |
| BOA | 2-10-1 | 50 | 1.5 × 10−2 | 1.2 × 10−2 |
| CS | 2-5-1 | 10 | 3.9 × 10−3 | 1.1 × 10−3 |
| CSO | 2-10-1 | 10 | 3.8 × 10−3 | 2.6 × 10−3 |
| DA | 2-15-1 | 20 | 3.5 × 10−3 | 2.1 × 10−3 |
| FA | 2-5-1 | 50 | 4.6 × 10−4 | 2.3 × 10−4 |
| GOA | 2-10-1 | 50 | 2.4 × 10−3 | 1.7 × 10−3 |
| KHA | 2-15-1 | 10 | 5.6 × 10−3 | 6.0 × 10−3 |
| PSO | 2-5-1 | 10 | 6.5 × 10−3 | 2.6 × 10−3 |
| SHO | 2-15-1 | 20 | 1.6 × 10−3 | 6.5 × 10−4 |
| SSA | 2-15-1 | 10 | 4.1 × 10−3 | 3.1 × 10−3 |
| TSA | 2-10-1 | 10 | 2.6 × 10−3 | 1.7 × 10−3 |
| TSO | 2-10-1 | 10 | 2.8 × 10−3 | 1.5 × 10−3 |
| Order | Algorithm | Train Ranking Score | Test Ranking Score | Total Score |
|---|---|---|---|---|
| 1 | FA | 1 | 1 | 2 |
| 2 | SHO | 2 | 2 | 4 |
| 3 | GOA | 3 | 3 | 6 |
| 4 | TSA | 4 | 4 | 8 |
| 5 | TSO | 5 | 5 | 10 |
| 6 | DA | 6 | 6 | 12 |
| 7 | CSO | 7 | 7 | 14 |
| 8 | CS | 8 | 9 | 17 |
| 9 | SSA | 9 | 8 | 17 |
| 10 | ABC | 10 | 10 | 20 |
| 11 | KHA | 11 | 11 | 22 |
| 12 | PSO | 12 | 12 | 24 |
| 13 | BOA | 13 | 13 | 26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaya, E.; Baştemur Kaya, C.; Bendeş, E.; Atasever, S.; Öztürk, B.; Yazlık, B. Training of Feed-Forward Neural Networks by Using Optimization Algorithms Based on Swarm-Intelligent for Maximum Power Point Tracking. Biomimetics 2023, 8, 402. https://doi.org/10.3390/biomimetics8050402
Kaya E, Baştemur Kaya C, Bendeş E, Atasever S, Öztürk B, Yazlık B. Training of Feed-Forward Neural Networks by Using Optimization Algorithms Based on Swarm-Intelligent for Maximum Power Point Tracking. Biomimetics. 2023; 8(5):402. https://doi.org/10.3390/biomimetics8050402
Chicago/Turabian StyleKaya, Ebubekir, Ceren Baştemur Kaya, Emre Bendeş, Sema Atasever, Başak Öztürk, and Bilgin Yazlık. 2023. "Training of Feed-Forward Neural Networks by Using Optimization Algorithms Based on Swarm-Intelligent for Maximum Power Point Tracking" Biomimetics 8, no. 5: 402. https://doi.org/10.3390/biomimetics8050402
APA StyleKaya, E., Baştemur Kaya, C., Bendeş, E., Atasever, S., Öztürk, B., & Yazlık, B. (2023). Training of Feed-Forward Neural Networks by Using Optimization Algorithms Based on Swarm-Intelligent for Maximum Power Point Tracking. Biomimetics, 8(5), 402. https://doi.org/10.3390/biomimetics8050402