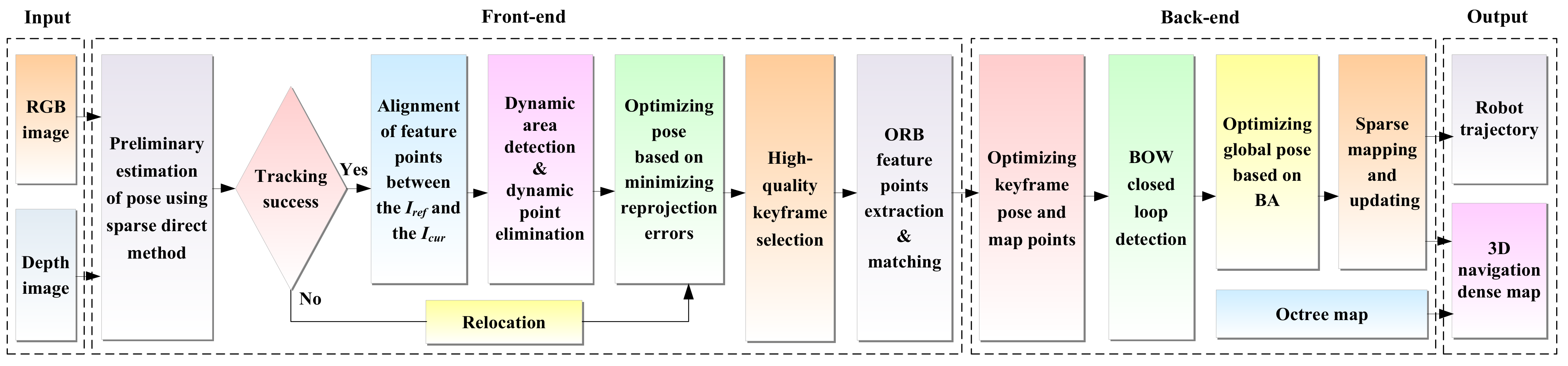
For the back-end, the keyframe’s pose and map points continue to be optimized by local bundle adjustment (BA). If the robot poses tracking fails, relocation is performed using the feature point method, where ORB feature points are extracted in the current frame and matched with the previous keyframes or map points in the map to recover the pose. In this way, all keyframes and map points are then employed as optimization variables for global BA optimization, resulting in a globally consistent robot trajectory and 3D dense map. Finally, the 3D navigation map is generated by coupling with the octree map.
3.1. Mobile Robot’s Pose Tracking
In our work, after obtaining an RGB-D image with the depth camera, the sparse direct method is used to preliminarily estimate the robot’s pose, and the initial pose of the robot is computed by minimizing the photometric error between the corresponding pixel points of the same 3D point in adjacent frames. When the previous frame is successfully tracked, the constant velocity motion model is exploited to predict the pose of the current frame, and the 3D points tracked in the previous frame are projected to the current frame by the estimated pose. Based on the assumption of photometric constancy, the photometric error of the pixel points corresponding to the same 3D point between the adjacent frames
Ik,
Ik−1 is as follows:
where
T is the robot pose,
u is the position of the pixel point in the previous frame, and
π is the projection function.
However, in practical applications, there may be a photometric difference between two adjacent frames caused by factors such as illumination, shadow, exposure, etc. Therefore, to reduce the photometric difference between adjacent frames, this paper introduces two photometric compensation variables
α and
β to perform inter-frame photometric compensation on the previous frame image, i.e.,
where
α is the photometric gain coefficient, and
β is the offset of photometric.
By minimizing the photometric error between adjacent frames, the rough pose estimate
Tk,k−1 from the previous frame to the current frame can be obtained as follows:
where
ui is the
ith pixel in the previous frame,
R is the whole image.
For a general case, only using adjacent frames to calculate the robot’s pose is prone to cumulative drift, so it is necessary to search for local maps to obtain more map points that need to be tracked and optimized. Specifically, the local map is first tracked to obtain the covisibility keyframes and covisibility map points of the current frame, and then the covisibility map points are projected to the current frame using the poses obtained in the previous step. For each successfully projected map point, the correspondence between the pixel points and map points of the current frame is optimized by minimizing the photometric error of the corresponding pixel points.
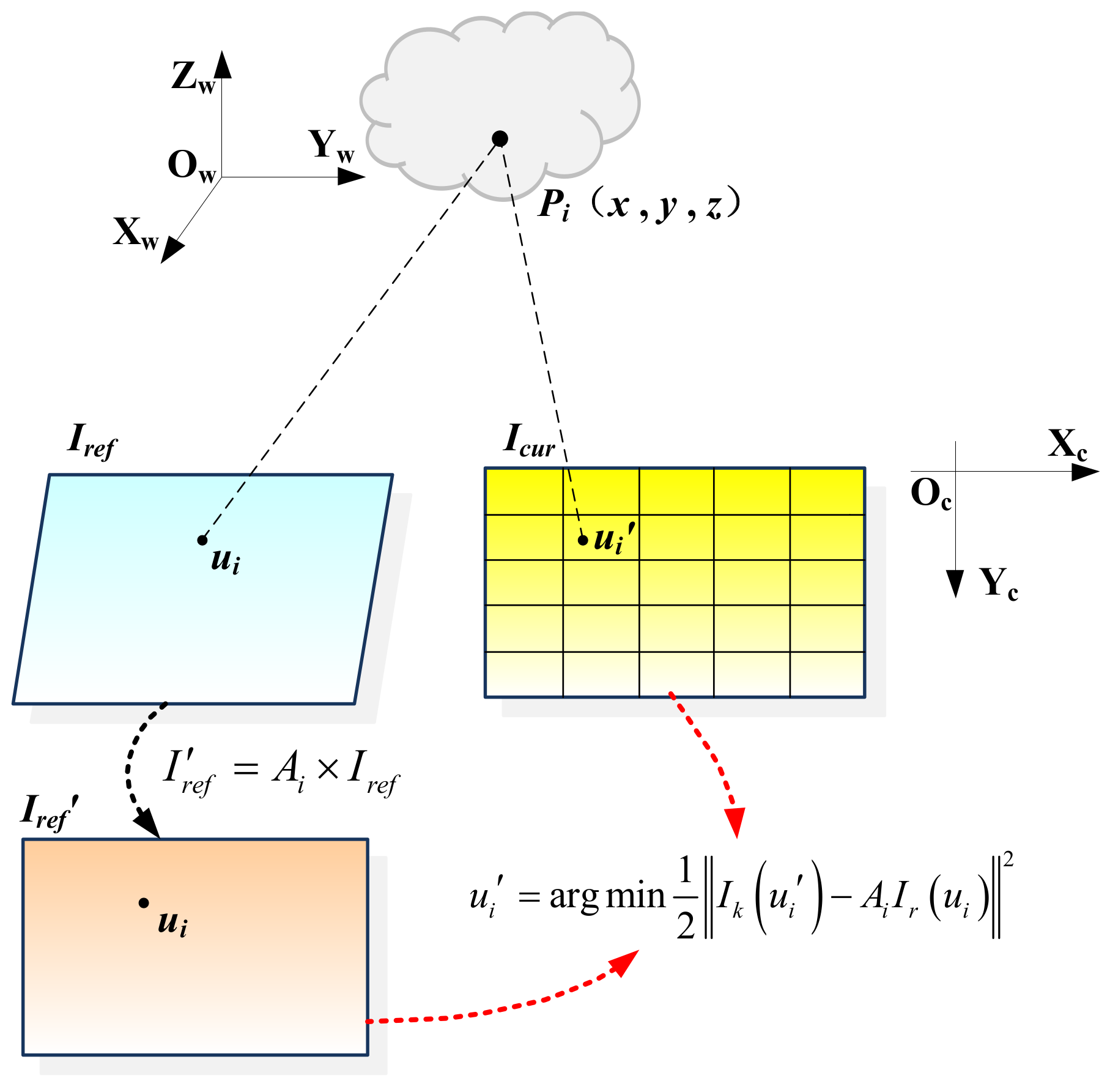
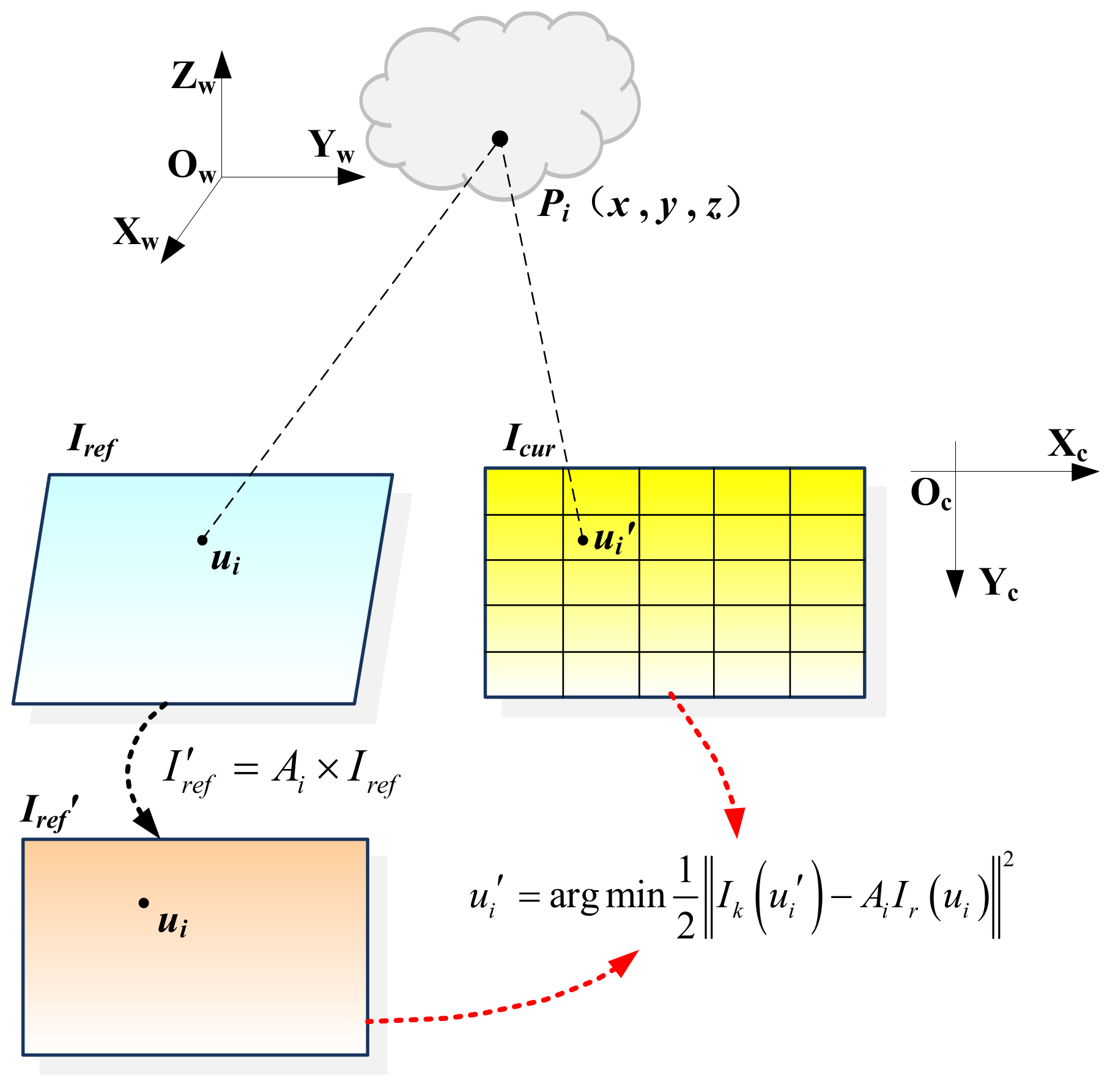
As shown in
Figure 2, in order to ensure the uniform distribution of the projected points, the current frame image is divided into a grid of 5 × 5, and the covisibility keyframe with the shortest distance to the current frame is set as the reference keyframe of the current frame. Then, by tracking the covisibility map points between the reference keyframe and the current frame, the corresponding map points in the reference frame are projected onto the current frame. Further, the grid is divided according to the current frame, and then a maximum of 5 map points are selected within each grid for pixel point matching. Owing to the inaccuracy of the preliminary pose estimation, the projected position of the map point in the current frame has a certain error compared to the real position. According to the photometric consistent assumption, the photometric value of the pixel points corresponding to the same map point in the reference keyframe and the current frame is consistent. Thus, the correspondence of pixel points can be optimized by minimizing the photometric error as follows:
where
ui′ and
ui denote the position of the pixel point in the current frame and the covisibility keyframe, respectively.
Since there may be scale problems caused by the distance and angle between the covisibility keyframe and the current frame, the two frames cannot be aligned directly, so the affine matrix
Ai [
6] is introduced and the pixel points in the reference keyframe are affine warped and then aligned with the current frame:
Further, the Gauss–Newton method is adopted to solve the above equation to optimize the correspondence of pixel points.
3.2. Dynamic Region Detection
The main idea of optical flow is based on the photometric consistency assumption between adjacent frames [
25], and the optical flow equation can be written as follows:
where
I(
x,
y,
t) denotes the photometric function of the pixel point (
x,
y), and (d
x, d
y) denotes the distance that the pixel point (
x,
y) moves within time step d
t. Assuming that
fx and
fy are the horizontal optical flow amplitude and vertical optical flow amplitude of the pixel point, respectively, we obtain the following:
To reduce the impact of dynamic objects on the robot’s pose estimation, this paper combines dense optical flow for dynamic detection and eliminates dynamic points in dynamic regions. The remaining static points are used to further optimize the robot’s pose. The dense optical flow method determines the dynamic regions in the image by calculating the motion of each pixel in the image. Compared with the sparse optical flow, the dense optical flow can provide more detailed motion information, but the dense optical flow is more computationally intensive. Scenarios for the dynamic areas’ detection is shown in
Figure 3.
The traditional optical flow is based on the assumption of a static background and can effectively track dynamic objects when the mobile robot is stationary or has a small displacement. However, when the mobile robot moves in translation or rotation, the image will undergo deformation, resulting in the static object and the background generating optical flow as well, which may interfere with the detection of dynamic objects. To reduce the impact of the motion of the mobile robot on the optical flow calculation, this paper adopts the homography matrix to compensate the image. The homography matrix characterizes the correspondence of 3D points on the same plane at different viewpoints, which can correct the image deformation caused by the motion of the mobile robot. Equation (8) represents the coordinate correspondence before and after the homography transformation, and
Ht+1 is the homography matrix from frame
t to frame
t + 1.
In this paper, the correspondence between pixel points is calculated by minimizing the photometric error to optimize the correspondence of pixel points, so that the matching points between adjacent frames can be obtained, and then the homography matrix of two adjacent frames can be obtained by four pairs of matching points. However, on account of the excessive number of matching points in adjacent frames and a large number of mismatches, the RANSAC algorithm is employed to solve the homography matrix to obtain more robust results. Then, the homography matrix is further used to compensate for the current frame image, and the optical flow field is computed with the previous frame image. This approach effectively mitigates optical flow interference caused by camera motion and enhances the accuracy of solving the optical flow field.
Typically, dense optical flow requires calculating the motion of each pixel in the image, which consumes a large amount of computing resources. In order to improve the efficiency and real-time performance of the algorithm, this paper adopts down-sampling the image as a means of improving algorithm efficiency and real-time performance. After obtaining the image
It at time
t and the image
I′t+1 after homography compensation at time
t + 1, down-sampling is performed on the two frames to reduce their resolution. In order to ensure that the details and clarity of the original image are retained after the down-sampling, the bilinear interpolation [
26] method is utilized for down-sampling, as shown in the following:
where
J(
i,
j) denotes the value of the (
i,
j)th pixel point of the down-sampled image,
pk denotes the value of the
kth pixel point in the original image, (
x,
y) denotes the corresponding coordinates of the pixel points in the original image, and (
xk,
yk) denotes the coordinates of the 4 nearest pixels to (
x,
y).
Then, the dense optical flow of images It and I′t+1 before and after down-sampling is calculated to obtain a low-resolution optical flow field. Finally, the low-resolution optical flow field is up-sampled again to recover to the resolution of the original optical flow field image. Although this processing may reduce the accuracy of optical flow calculations to a certain extent, it can significantly improve the time of dense optical flow calculation.
After obtaining the optical flow field of the original resolution image, in order to distinguish between dynamic and static regions in the image, the optical flow amplitude
f is calculated for each pixel point (
x,
y) based on its horizontal optical flow amplitude
fx and vertical optical flow amplitude
fy, i.e.,
In general, the magnitude of optical flow amplitude
f can be used to represent the displacement of a pixel point between two frames. The optical flow amplitude
f of each pixel point (
x,
y) is compared with a set dynamic threshold
fth, and if the optical flow amplitude
f >
fth, the pixel point is considered to have a large displacement between two frames and is marked as a dynamic pixel point
Pdynamic; otherwise, it is a static pixel point
Pstatic, as shown in Equation (11). In the subsequent optimization process, the points falling in the dynamic region are eliminated to improve the efficiency and accuracy of the optimization.
As a note, the setting of dynamic threshold
fth is based on the rotation and translation of the robot, so its expression can be written as follows:
where
Trw∈SE(3) is the transformation matrix of the reference keyframe from the world coordinate system to the camera coordinate system,
Tcw∈SE(3) is the transformation matrix of the current frame from the world coordinate system to the camera coordinate system,
TrwTcwT describes the rotation of the camera, ‖·‖
F is the Forbenius norm, defined as the square root of the sum of the squares of the absolute values of all elements of the matrix,
t is the translation of the camera vector, ‖·‖
2 is the Euclidean norm, defined as the squared sum of the absolute values of all elements of the vector and recalculated, and
α is the scale factor.
As the calculation of optical flow is affected by camera rotation and translation, when the range of the robot’s motion is large, the dynamic threshold fth increases with the increase in the transformation matrix of the current frame and the reference frame, so as to filter out the optical flow noise caused by rotation; when the robot is panning or stationary, the dynamic threshold fth decreases with the increase in the translation vector, allowing the robot to detect some small dynamic objects in the scene during motion.
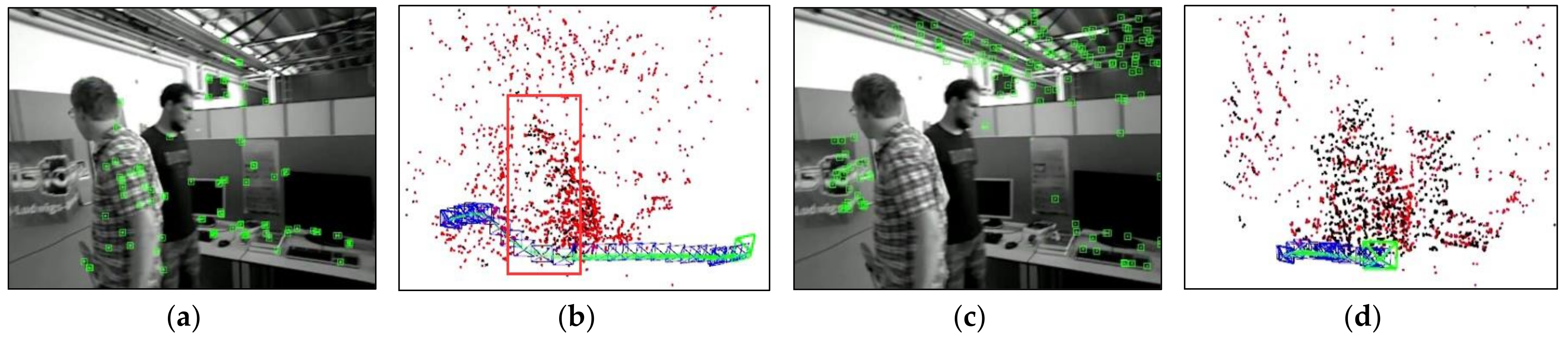
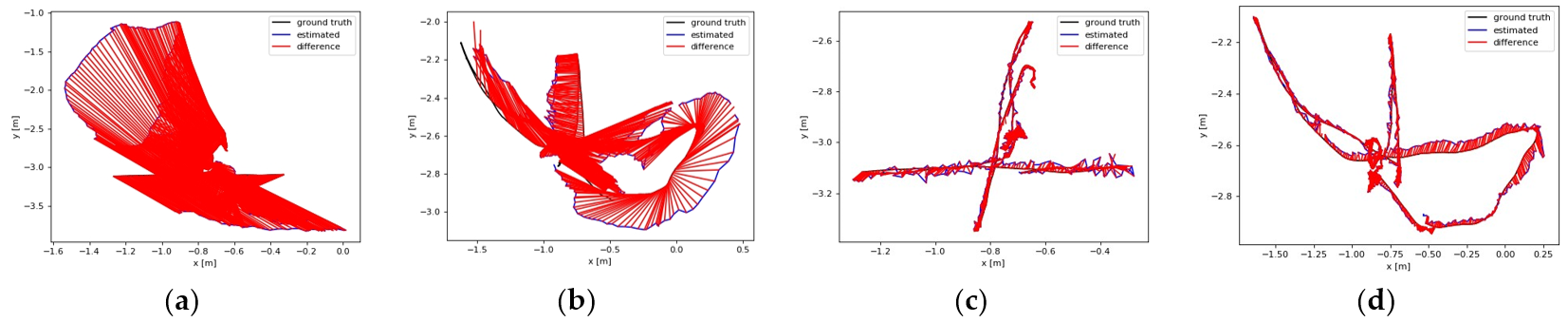
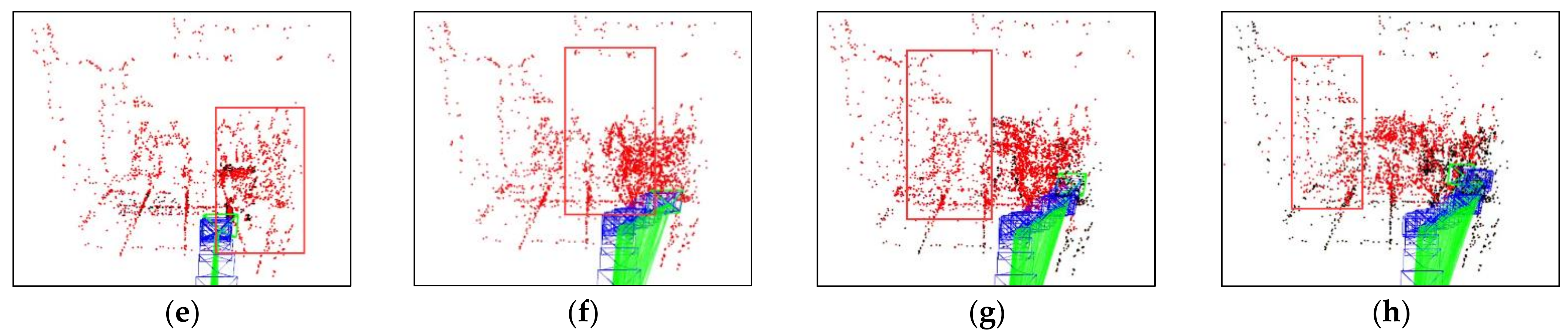
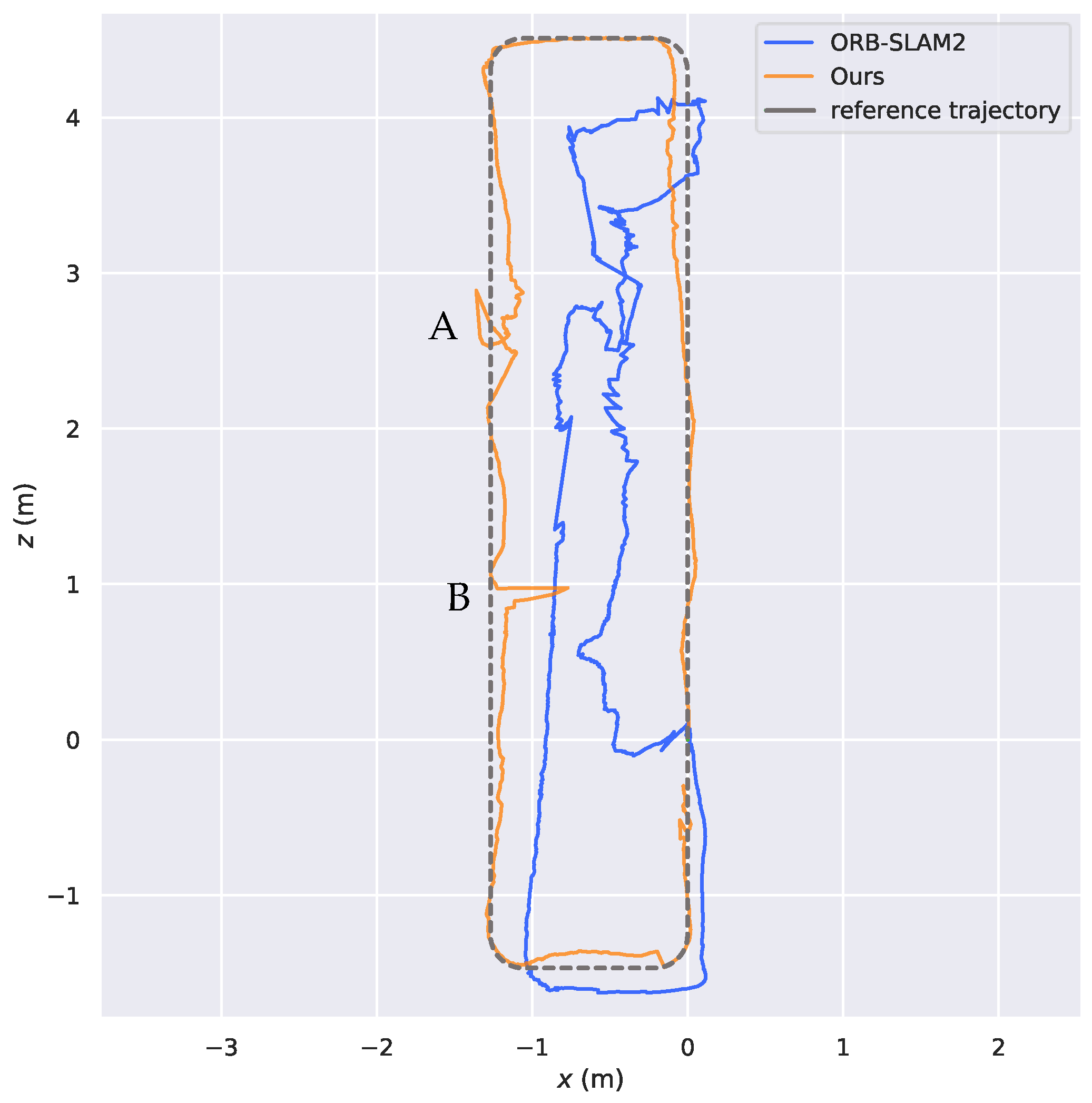
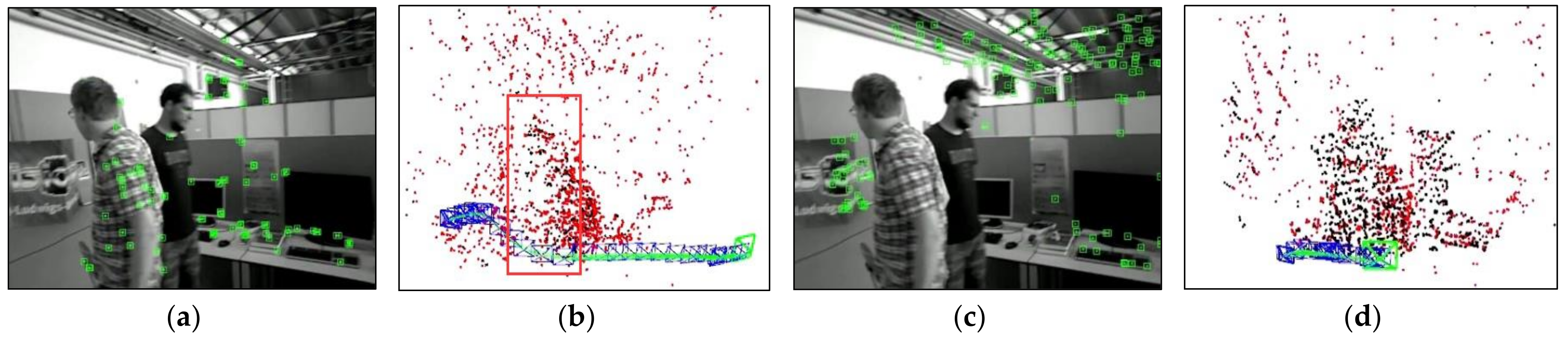
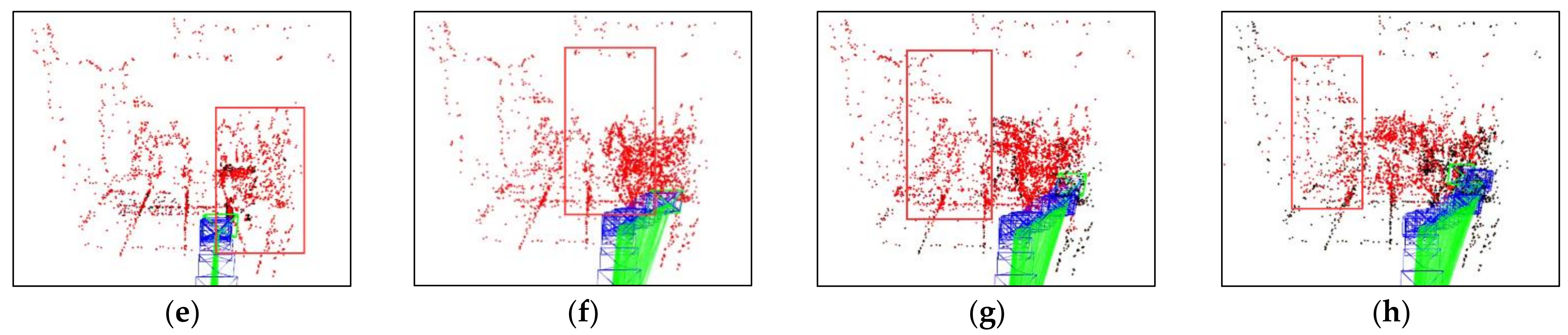
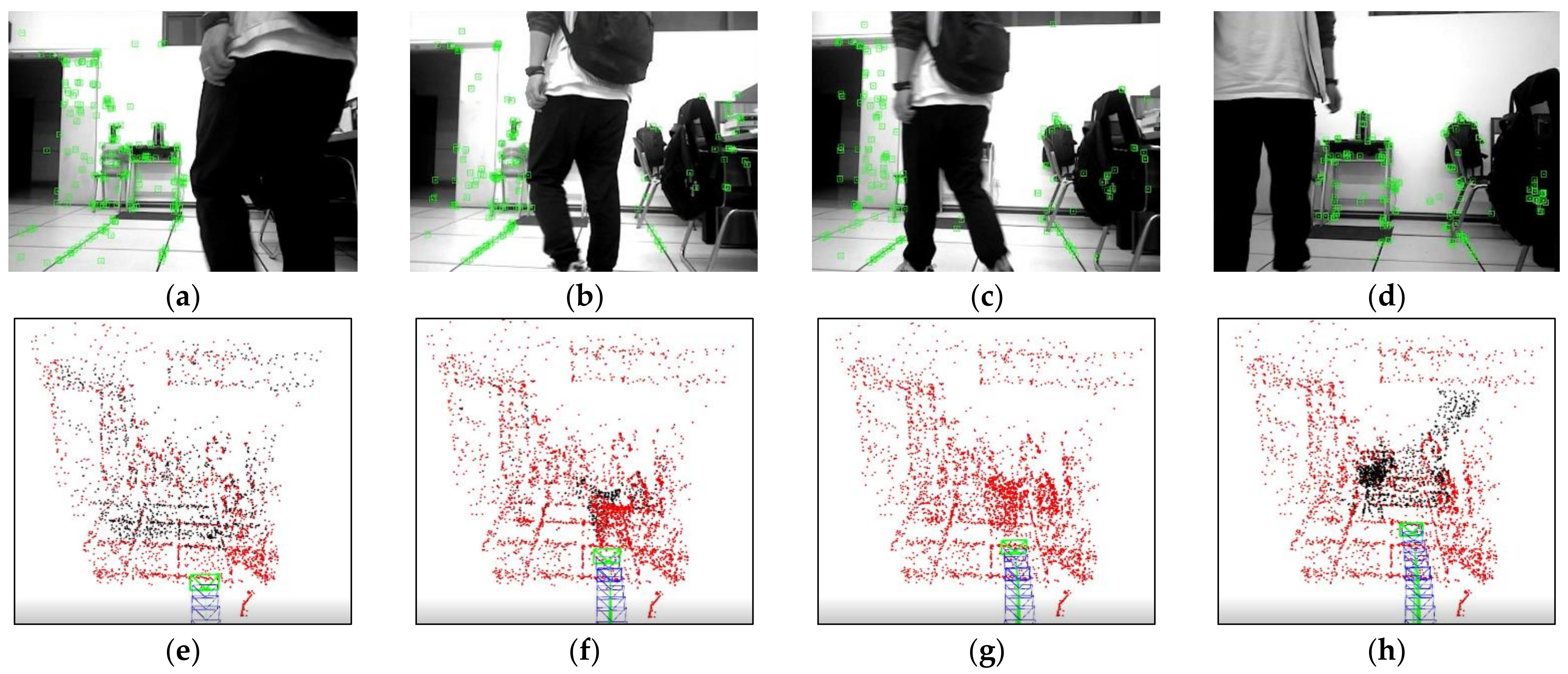
Figure 4 compares the results of different optical flow detection methods, where
Figure 4a shows the original input image with a pedestrian in motion in the scene, while the camera is also moving to the right. From
Figure 4b, it can be seen that the sparse optical flow only detects a few dynamic feature points on the pedestrian, and some of the feature points in the background are also mistakenly detected as dynamic points. In
Figure 4c, the red area represents the detected dynamic areas and we observed that although pedestrians are detected as dynamic objects, the background and stationary objects are also mistaken for dynamic regions because of the camera motion. We could reasonably conclude from
Figure 4d that our method removes most of the false detections and only detects the pedestrian part as a dynamic area, indicating that the use of homography matrix compensation effectively reduces the impact of camera motion on optical flow and the dynamic threshold still provides good detection results for optical flow during camera rotation and rapid motion, thus improving the robustness of optical flow calculation.
3.4. Keyframe Selection
In our case, the front-end of the algorithm performs pose tracking through direct methods, and the subsequent steps such as loop closure detection, relocation, and mapping are all based on keyframes. Therefore, the reasonable selection of keyframes can enhance the efficiency of the algorithm and lower the memory usage of the system. At present, most SLAM algorithms select keyframes by mainly focusing on the time interval from the last keyframe insertion, the number of feature points in the current frame, and the number of keyframes in the system, without considering the influence of camera motion and dynamic objects in the scene. Therefore, drawing on the conventional keyframe selection strategy, we add the pose transformation of the robot and the optical flow amplitude of the current frame as the condition of keyframe selection.
First, the rotation matrix
Rrc of the current frame relative to the reference frame is calculated by using the rotation matrix of the current frame and the reference keyframe relative to the world coordinate system, i.e.,
where
Rcw and
Rrw denote the rotation matrix of the current frame and the reference keyframe relative to the world coordinate system, respectively. Furthermore, the rotation angle Δ
αi of the robot can be computed by the rotation matrix
Rcr as follows:
where
tr(·) is the trace of the matrix and defined as the sum of the diagonal elements of the matrix.
Then, the translation Δ
tcr of the current frame relative to the reference frame is established by the translation vector of the current frame
tcw and the translation vector of the reference frame
trw, that is:
According to the rotation angle Δ
αi and the translation Δ
trc, the robot’s pose transformation
V could be expressed as follows:
where ‖·‖
2 is the Euclidean norm,
w is the scale factor, and
β is the weight of camera rotation angle. For a set threshold
Vth,
V >
Vth means that the current camera motion is larger, which may lead to difficulty in feature point matching or tracking loss. Thereby, the current frame needs to be selected as a keyframe to avoid tracking failure or pose drift.
Next, the optical flow amplitude is exploited to determine whether to select a keyframe. More specifically, in the dynamic region detection stage, the optical flow amplitude
fi of each pixel in the image is obtained, and then the variance
σ2 of the optical flow amplitude of all pixels in the whole image is calculated to indicate the degree of image variation in that frame. Thus, we obtained the following:
where
N is the total number of pixels in the image. If the variance of the optical flow amplitude of a certain frame is relatively large, it means that the motion of some pixel points in that frame deviates from the average motion and there may be the influence of dynamic objects.
Additionally, the ratio
σ between the optical flow amplitude variance
σc2 of the current frame and the optical flow amplitude variance
σr2 of the previous keyframe is calculated, i.e.,
For a set threshold σth, if
σ > σth, the current frame has undergone significant changes compared to the previous keyframe, which may be influenced by dynamic objects, and thus the current frame is not suitable as a keyframe. In this case, we should skip the current frame and continue to judge subsequent frames. This strategy can effectively reduce the influence of dynamic objects on keyframes, enhance the stability and reliability of keyframes, and decrease the redundancy of keyframes. After inserting a new keyframe, ORB feature [
27] extraction is performed in the static area of the keyframe, and then new map points are constructed based on the feature matching relationship between the keyframe and its covisibility keyframe. Next, the keyframes and map points are filtered to remove some low-quality or redundant keyframes and map points. Finally, local BA is utilized to optimize the keyframe pose and map points, resulting in a more accurate and stable local map.
3.5. Relocation and Global Optimization
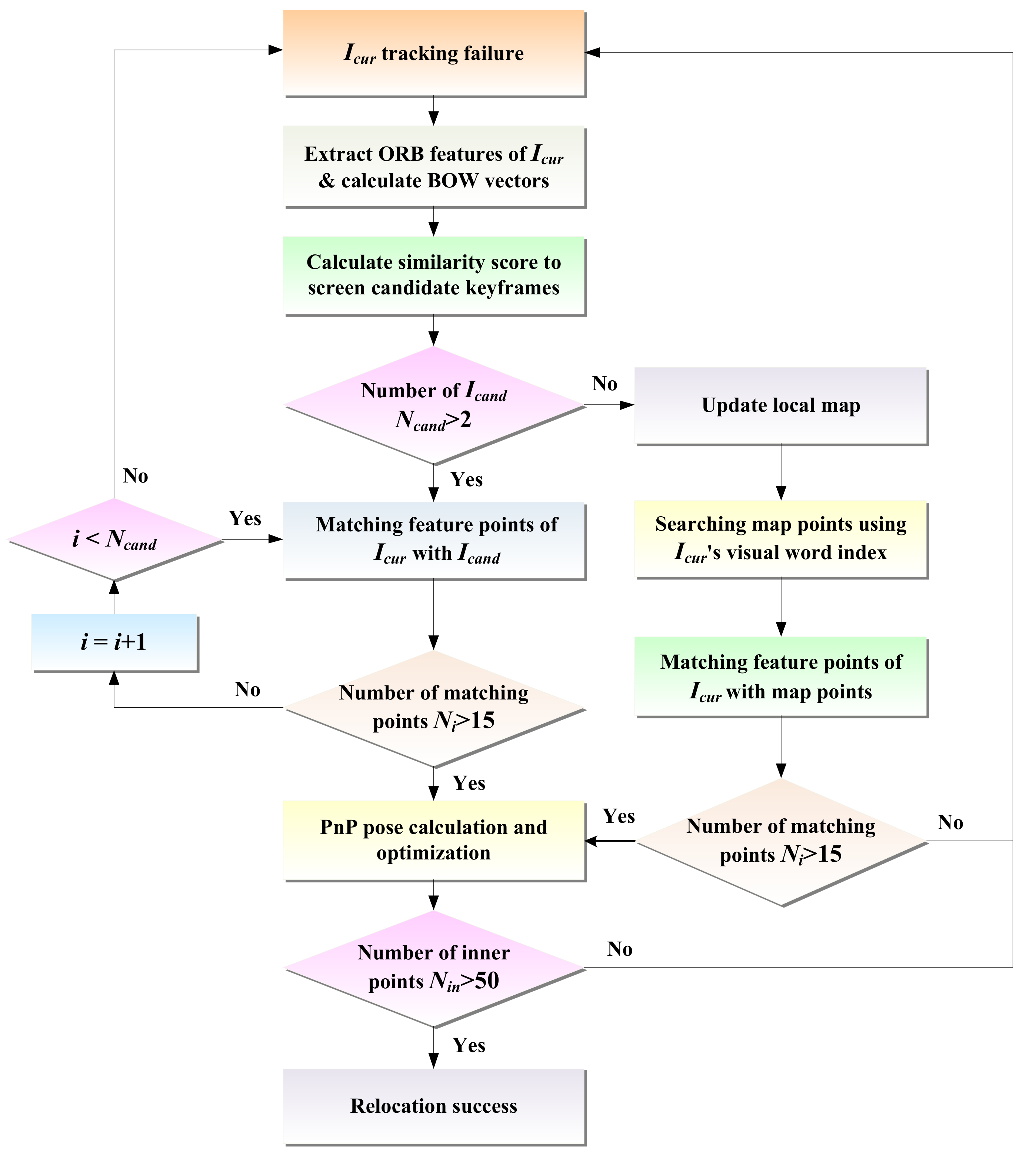
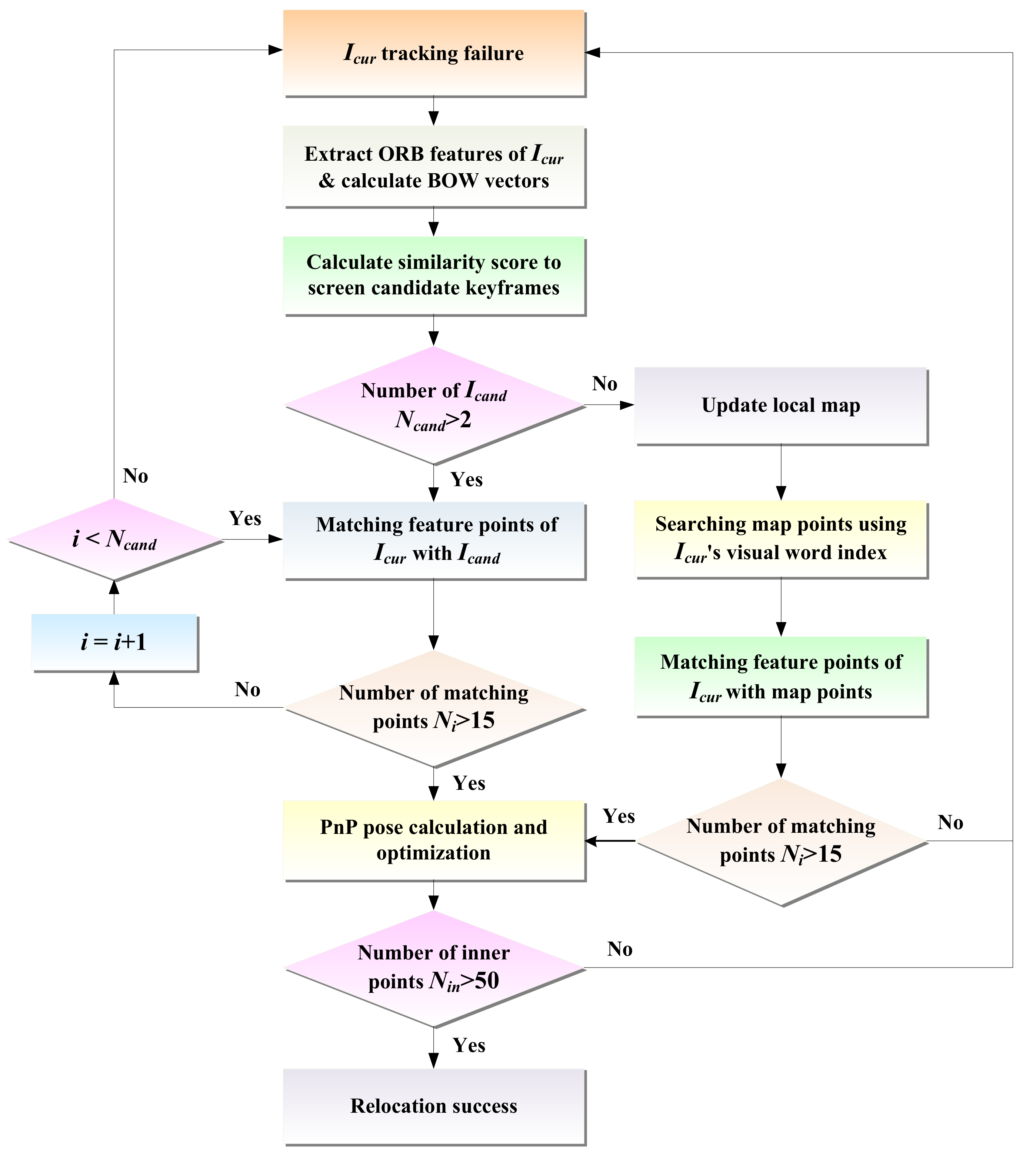
Considering uncertain situations, e.g., motion blur and illumination changes in dynamic scenes, the direct method may fail to track the pose of mobile robots. In this case, the relocation algorithm is needed to recover the robot’s pose. For the direct method, when the tracking fails, the photometric information of the image cannot be used for relocation. Thus, this paper introduces the feature point method for relocation and determines whether to directly match the map points to restore the pose based on the number of selected candidate keyframes. The relocation process is illustrated in
Figure 5, and its procedure is listed in Algorithm 1.
| Algorithm 1: Relocation algorithm |
input: current frame Icur, keyframe Kf, local map Map
output: camera pose pose
1 if Tracking → Lost then
2 pi ← Extraction(Icur)
3 BowV ← Compute (pi)
4 Icand {Kfi|i = 1…Ncand} ← Detect (Kf, BowV)
5 if n > 2 then
6 for i = 0 →Ncand do
7 Ni ← Matching(Icur, Kfi)
8 if Ni > 15
9 end for
10 pose ← PnPsolver(Ni)
11 Else
12 update(Map)
13 M = {mi| i = 1…n } ← Search(BowV, Map)
14 Ni ← Matching(Icur, mi)
15 if Ni > 15
16 pose ← PnPsolver(Ni)
17 if Nin > 50
18 relocalization ← Optimize(pose)
19 end if
20 end if |
After the front-end experiences tracking loss, we first extract ORB features from the current frame
Icur that has failed to track and calculate its bag-of-words [
28] vector
vc = {
vci|
i = 1…
n}. Then, the L1 distance of the bag-of-words vector is chosen to calculate the similarity score
s between the current frame and its covisibility keyframes, i.e.,
where
vk is the bag-of-words vector of covisibility keyframes,
vci, and
vki are the weights of the
ith word in the current frame and keyframe, respectively.
In terms of the ranking of keyframe similarity scores from highest to lowest, several keyframes
Kf with the highest scores are selected as candidate keyframe sets
Icand = {
Kfi|
i = 1…
n}. Then, all the candidate keyframes are traversed, the feature points between the current frame
Icur and all the candidate keyframes
Kfi are quickly matched using the bag-of-words vector, and the effective number of matches
Ni is filtered according to the quality of the matching points. If the effective number of matches of a candidate keyframe is greater than 15, it is set as the reference keyframe, and the EPnP [
29] algorithm is employed to solve the relative poses of the reference keyframe and the current frame. Namely, the 3D points are represented as a combination of 4 control points, and only the 4 control points are optimized. The coordinates of 3D points in the world coordinate system and camera coordinate system are represented in the form of control point coordinates, which are respectively modeled as follows:
where
and
are the coordinates of the
ith 3D point in the world coordinate system and the camera coordinate system, respectively,
and
are the coordinates of the
jth control point in the world coordinate system and the camera coordinate system, respectively, and
αij is a barycentric coordinate, which can be obtained according to the projection principle of the camera as follows:
where
wi is the depth value and
ui is the 2D coordinate corresponding to
.
By solving Equation (23), the coordinates
of the control point in the camera coordinate system can be obtained, thereby obtaining the coordinates
of the 3D point in the camera coordinate system. Then, the corresponding relationship between the 3D points in the world coordinate system and the camera coordinate system of the current frame is used to solve the pose of the current frame relative to the keyframe, and the Levenberg–Marquardt method [
30] is utilized for optimization, i.e.,
where
ρ(·) is the robust kernel function and
T is the robot pose.
If the number of optimized inner points is greater than 50, the current frame is judged to be successfully relocated. If the number of candidate keyframes is too small, it may not be possible to find a frame that is sufficiently similar to the current frame, or if the similarity between the found frame and the current frame is too low, then using image retrieval methods may not be able to successfully recover the robot pose. Therefore, in this case, the “image–map matching” method is used for relocation. It is important to note that the approach estimates the robot pose by directly matching the feature points of the current frame with the map points, which does not rely on the number of candidate keyframes.
When the number of candidates keyframes
Ncand < 2, it becomes difficult and unreliable to use image matching for relocation. So, the “image–map matching” relocation method is used in this case. First, the local map is updated, i.e., for each visual word
vci in the bag-of-words vector
vc of the current frame and, if its TF-IDF [
31] value in the current frame is greater than the threshold
vth, it can be employed to characterize the current frame, and the index of the corresponding leaf node of the visual word in the K-tree is used to quickly find all map points that contain the visual word to obtain a subset
M = {
m1,…,
mn} of map points. Then, the nearest neighbor search algorithm [
32] is used to fast match the feature point
pi of the current frame with the map point
mi in the subset of map points. On this basis, using (
pi,
mi) to represent the matching relationship between feature points and map points, the set of matching point pairs between feature points and map points is {(
pi,
mi)
. During the matching process, the EPnP algorithm is utilized to improve the efficiency and accuracy, and then the robot’s pose
T is solved based on the obtained 2D–3D matching points, i.e.,
where
π is the projection function and
ρ(·) is the robust kernel function. Using the Levenberg–Marquadt method to solve the above equation can effectively improve the accuracy of the pose solution and finally successfully recover the current camera tracking.
The image–map matching relocation method can effectively improve the success rate of relocation, but it may cause drift after restoring the mobile robot’s pose, so loop closure detection can be adopted to eliminate the accumulated drift of the system. When the system detects a closed loop, the global BA is performed to continue to optimize the mobile robot’s pose. As the robot continues to move, the number of keyframes and map points in the system will continue to increase, which will place a huge burden on the system optimization. The location of map points in the scene will converge to a value after being observed many times, and it is often futile to continue optimizing the location of map points. Therefore, the system is optimized only for certain moments of the mobile robot poses, i.e., the pose graph is used for optimization, and the pose points of the optimized map are robot poses and map points, and the edges represent the constraint relations between them. Assuming the pose of the mobile robot at each pose point is
T1,
T2,
T3,…,
Tn, then, the motion relationship between any two
Ti and
Tj can be expressed as:
In terms of BA optimization, the error is established as follows:
Further, the global optimization is performed for all position points of the robot using the following overall objective function:
where
ξ is all edges in the pose graph.
The use of the global BA algorithm can further optimize the mobile robot poses and map points, reduce the cumulative drift of the whole system, and improve the accuracy and robustness of the system.
3.6. 3D Navigation Map Building
In our work, to enable the map to be used for robot navigation and autonomous obstacle avoidance, we capitalize on the RGB image information, depth value, and keyframes’ pose to build a 3D dense point cloud map of the scene, and then combine the octree map to further generate a 3D navigation dense map. Typically, 2D points can be converted into 3D point clouds by using the RGB information and depth value of the keyframes, and the conversion relationship is as follows:
where
s is the scaling factor of depth value,
K is the camera internal parameter,
R and
t are the rotation matrix and translation vector, respectively, [
u v 1]
T are the pixel point coordinates, and [
xw yw zw] are the 3D points in space. According to Equation (29), the coordinates of the real point cloud can be obtained as follows:
where
cx,
cy,
fx,
fy denote the camera internal parameters.
When constructing a dense map, it is susceptible to the influence of point clouds generated by dynamic objects. If the map contains information about dynamic objects, the robot cannot determine whether the object exists during navigation or autonomous obstacle avoidance. Hence, in our case, the dynamic points are judged based on the optical flow amplitude of each pixel in the image. During the process of map building, once a keyframe is inserted, each pixel in the keyframe needs to be traversed. First, these pixels with abnormal depth values are eliminated, and then the magnitude of the optical flow amplitude of the pixel point is determined. If its optical flow amplitude is greater than the threshold, the point is determined as a dynamic point and removed from the dense point cloud. After eliminating the dynamic point cloud, the static point cloud is compensated by keyframes from different perspectives to construct a complete static dense point cloud map. Due to the existence of certain redundant information between adjacent keyframes, a large number of repeated point clouds will be generated in the process of constructing a dense map, resulting in an increase in required storage space. Therefore, voxel filtering is employed to down-sample point clouds, which not merely maintains the shape features of the point cloud, but removes certain noise, smooths the interval between point clouds, and finally adopts statistical filtering to filter out outliers again. The process of 3D dense map construction is shown in
Figure 6.
Although the dense point cloud map can intuitively represent each object in the scene, the point cloud map occupies a large amount of storage space and cannot be used for robot navigation and obstacle avoidance. Therefore, this paper further constructs an octree map based on the dense point cloud map. The leaf nodes of the octree map represent the occupancy state of each voxel in the form of probability. If a leaf node is observed as being occupied, the probability is constantly approaching 1. If the leaf node is observed as unoccupied, the probability is constantly approaching 0. To ensure that the probability does not exceed the interval, the logit function is usually used instead of the probability description, i.e.,
where
l is the logarithm of probability, and
p is the probability of 0~1. When a node is continuously observed to be occupied,
l will continue to increase; when the node is unoccupied,
l will continue to decrease. Assuming that
n denotes a node and the observed value is
z, the probability logarithm of the node from the beginning to time
t is
L(
n|
z1:t), then, at time
t + 1, the probability logarithm is established as follows:
Apparently, adopting this form can make map updates more flexible and convenient.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}