1. Introduction
Cancer is a global health problem. Among female cancers, breast cancer is by far the most common [
1]. However, 42 percent of NHS trusts say they cannot assign individuals because they do not have enough staff, with many citing a lack of breast cancer specialists. It is the fundamental reason breast cancer has a dismal survival rate worldwide [
2]. Breast cancer specialists are in limited supply, which will delay diagnosis, increase resistance to effective screening and treatment, and create inequalities in access to care [
3]. The goal of developing methods for detecting breast cancer was to identify anomalies and classify the disease more accurately. This practice aids in detecting breast cancer [
4]. Death rates can be reduced with early detection using screening mammography; however, this is challenging due to the small size of potential nodules concerning the entire breast [
5]. Breast cancer has a higher chance of being cured (about 90%) than other cancer types. Cancer patients often go undiagnosed until they experience severe symptoms [
6]. The patients’ ages affect the mortality and incidence rates of breast cancer. Breast cancer was typically diagnosed in patients aged 62 between 2010 and 2014 [
7].
With an estimated 90,000 new cases annually and a reported 40,000 deaths due to the disease, Pakistan has Asia’s highest breast cancer mortality rate [
8,
9]. Survival rates for certain cancers vary depending on their detection stages [
10]. Those who are predicted to live beyond a certain point after receiving a diagnosis and continue to function normally are included in the survival rate. Mammography is the most reliable technology for identifying breast cancer due to its capabilities and inexpensive cost to satisfy medical requirements. The study of mammograms is the major approach doctors use to make a diagnosis. However, it can be affected by bias and fatigue. Mammography, unfortunately, has a relatively low detection rate. Depending on the kind of the lesion, the breast density, and the patient’s age, it can yield a false-negative result rate of anywhere from 5% to 30% [
11]. Mammography uses low-dose radiography because it allows us to see the breast’s internal structure.
To diagnose breast cancer, machine learning algorithms are trained to look for specific patterns and associations in data that are linked to the biological mechanisms through which cancer develops. The aberrant multiplication and proliferation of breast cells are central to the basic mechanisms behind breast cancer, which can have multiple underlying causes, including heredity, lifestyle, and the external environment. These processes can lead to the development of breast abnormalities such as lumps, masses, or cysts, which can be discovered using mammography, ultrasound, or magnetic resonance imaging. These imaging data can be fed into a machine-learning algorithm and trained to look for abnormalities or patterns that are indicative of breast cancer. For breast cancer, machine learning algorithms can be trained to recognize telltale signs such as masses and microcalcifications [
12,
13]. Imaging data, patient history, and molecular biomarkers are just some data sources that can be analyzed with machine learning algorithms to enhance breast cancer detection. Machine-learning algorithms can improve the accuracy and timeliness of breast cancer diagnostics by merging data from numerous sources to detect tiny changes in breast tissue that may indicate the presence of cancer. Breast cancer risk factors include genetics, lifestyle choices, and other factors; these can all be modeled using machine learning algorithms to create prediction models of an individual’s likelihood of developing breast cancer. These models can be used to inform screening and preventative strategies, which in turn can help lower breast cancer rates. To a large extent, the biological mechanisms of cancer development are intertwined with breast cancer detection using machine learning, as these algorithms are trained to recognize patterns and abnormalities in breast tissue that are linked to the development of cancer [
14,
15,
16].
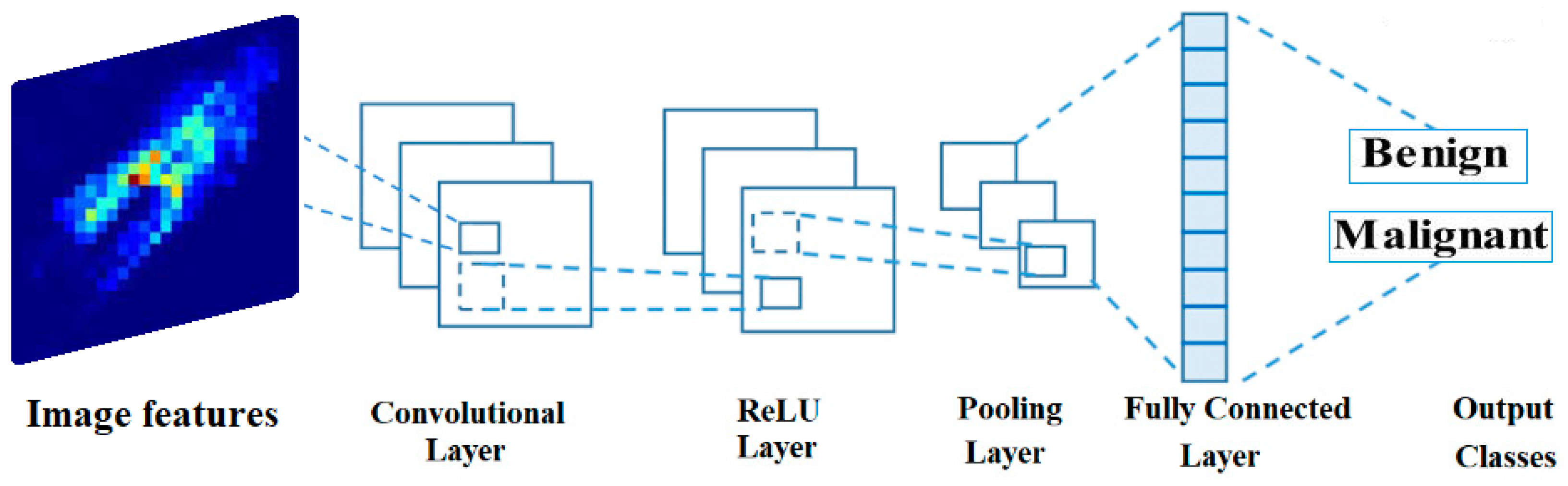
CNN recently demonstrated promising performance in detecting and categorizing tumors in medical images. Deep learning models’ performance is typically proportional to the size of the datasets used for training. In contrast to the deep learning-based strategies, the traditional methods performed poorly on complex nature datasets. Deep learning employs the concept of CNN to perform breast cancer classification [
17,
18,
19]. Convolutional, pooling, activation, and fully linked layers are some types of layers (hidden layers) seen in a CNN model. Softmax is the classifier used in the final layer of a convolutional neural network model. The use of deep learning enables automated artificial intelligence approaches in medical imaging. Researchers have introduced several deep learning-based architectures to detect and categorize infectious diseases. While several deep learning methods have been established to aid in the classification and diagnosis of breast cancer, researchers have encountered obstacles such as imbalanced datasets, noisy imaging data, and the downsampling of critical features [
20]. The team zeroed in on the problem of teaching deep models through transfer learning. One use of transfer learning is to apply a model that has already been trained to a new problem or scenario [
21,
22]. While hyperparameters such as learning rate, mini-batch size, and others have been used successfully in training, setting their values by hand is tedious and error-prone when dealing with breast cancer. The authors of described an improved hyperparameter-based deep-learning system for breast cancer classification [
23]. Extraction of deep features from the fully connected layer followed training; nevertheless, it was shown through analysis that numerous features were redundant, which negatively impacted breast cancer classification [
23]. An improved method of classifying breast cancer using deep learning was recently presented by the authors of [
24]. The authors of [
25] proposed dialectical feature selection to improve breast cancer classification; however, these methods run into the issue of stopping after the ideal values have been retrieved.
Due to its many benefits over alternative modalities, the mammogram has become the preferred modality for screening for breast cancer [
26]. First, mammography has been the subject of much research and is useful in identifying breast cancer at an early stage. When used with a clinical breast exam, it can detect small cancers or microcalcifications that the naked eye could miss. Successful treatment results can be improved by prompt action made possible by this early identification. Second, mammograms produce highly detailed pictures of breast tissue, letting radiologists see any irregularities very plainly. This screening method is safe and well-accepted because of the low-dose X-rays used in mammography. As a bonus, mammography can even spot breast cancer in people with thick breast tissue. Breasts often have dense tissue, which might obscure cancers on conventional imaging techniques such as ultrasonography. Mammography is useful for screening women with a wide variety of breast densities because it can successfully penetrate thick tissue. The widespread accessibility and well-established infrastructure of mammography are additional benefits. Most medical facilities, clinics, and screening centers can access mammography equipment. Because of this, many women will be able to get screened regularly, which will help with identification and treatment early on. Compared to other screening methods, mammography also has a low cost. It strikes a good compromise between price and accuracy in establishing a diagnosis, making it a viable option for widespread breast cancer screening programs. Mammography has been widely adopted as the standard screening method for breast cancer because of its efficacy in detecting cancer at an early stage, its high-resolution imaging capabilities, its ability to identify tumors even in thick breast tissue, its widespread availability, and cost-effectiveness. These benefits work together to make breast cancer treatment more effective and decrease patient mortality [
27].
1.1. Main Contributions of This Work
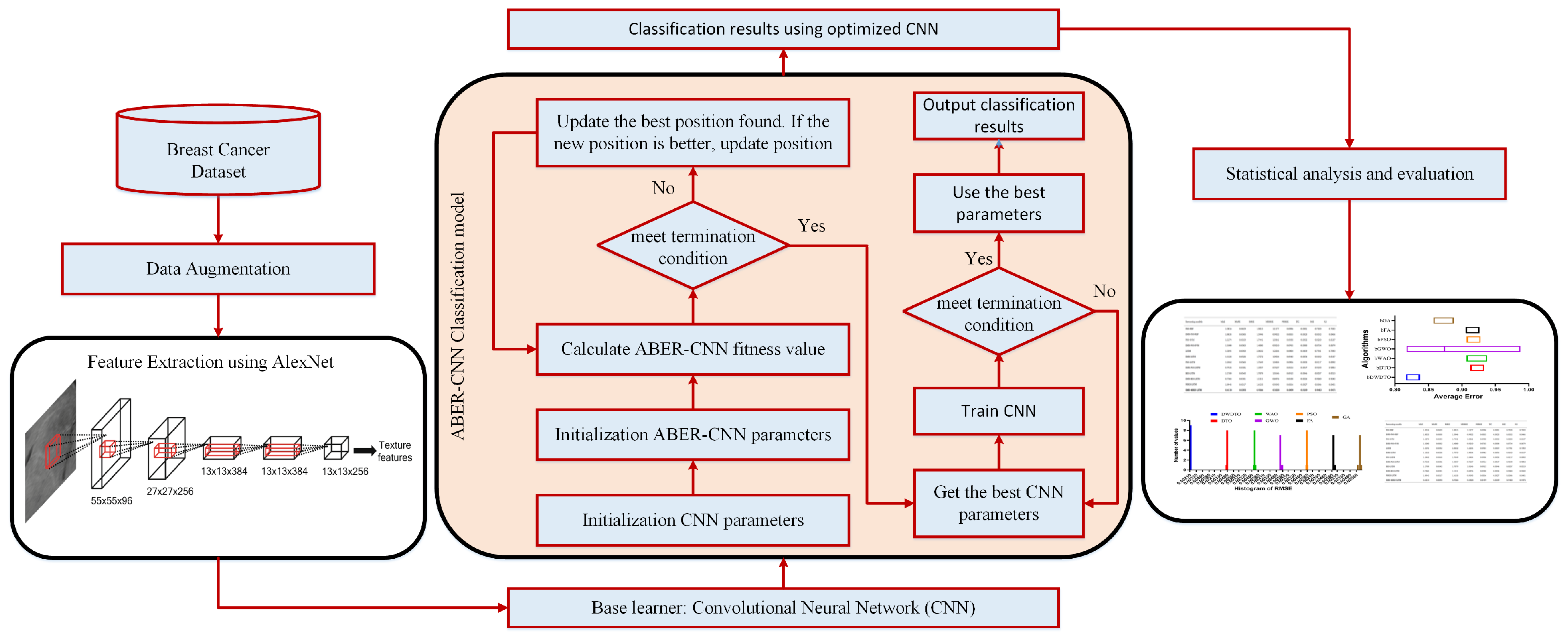
In this paper, we proposed a new framework that uses deep learning to aggregate the best possible features from both the original and upgraded mammography images. The following is a list of the main contributions achieved throughout this work:
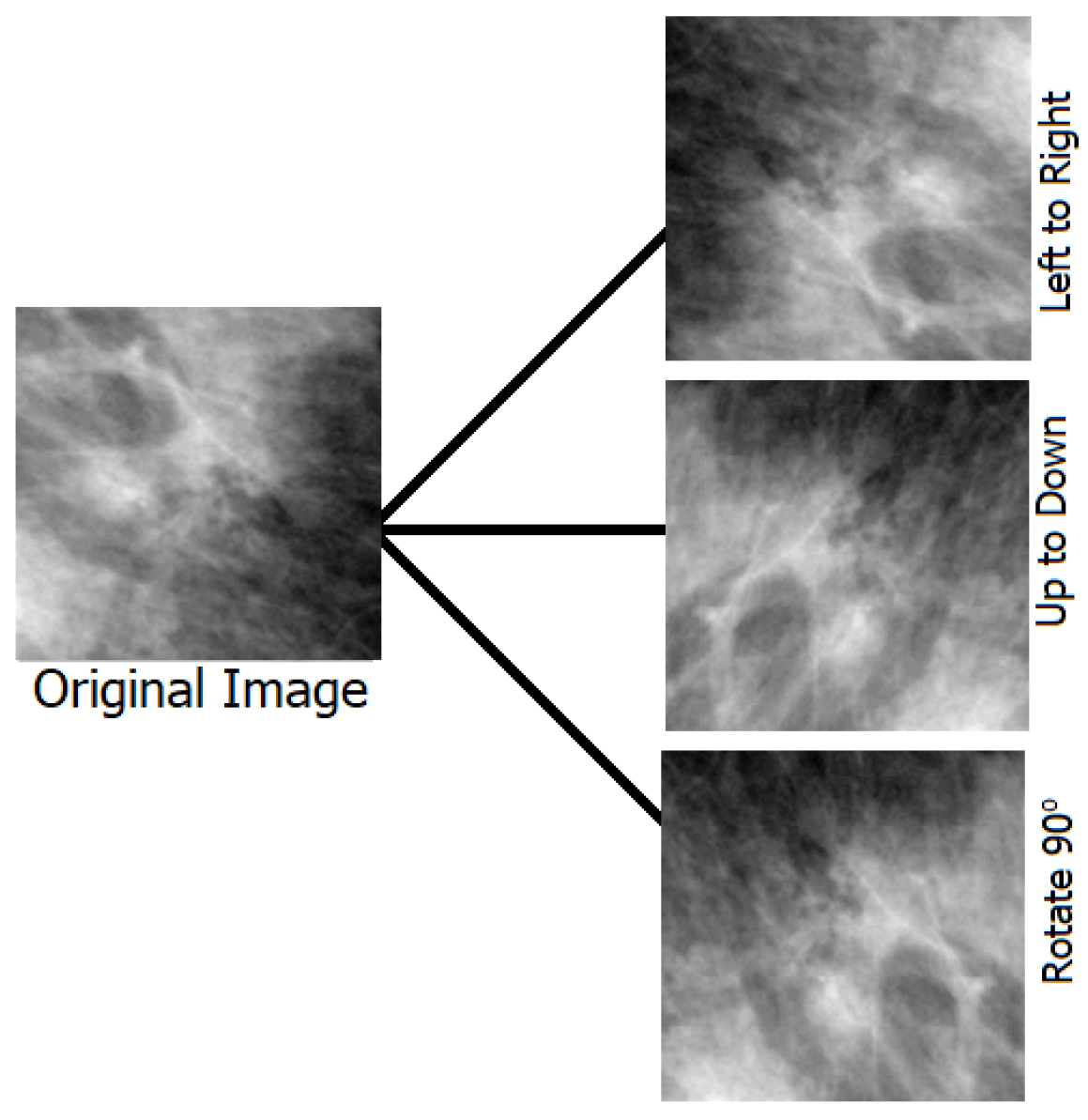
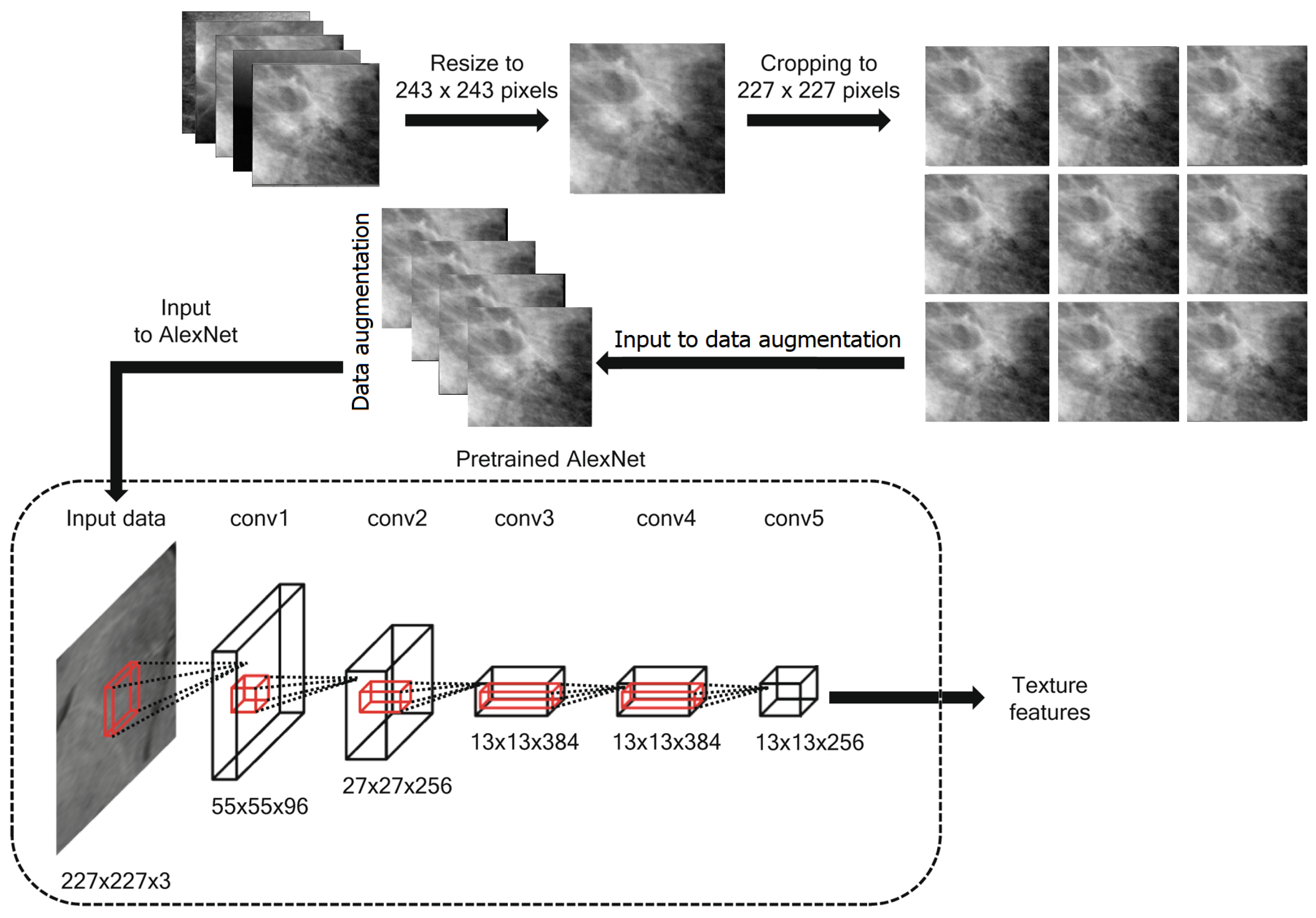
Employing transfer learning for feature extraction using the pretrained AlexNet deep network.
Developing a new optimization algorithm based on improving the behavior of the Al-Biruni Earth Radius (BER) optimization algorithm. The new algorithm is referred to as Advanced BER (ABER).
Optimizing the structure and training parameters of the classification CNN for boosting its performance.
Two datasets are employed to prove the effectiveness and generalization of the proposed approach.
Studying the statistical difference of the proposed methodology using ANOVA and Wilcoxon signed ranks tests.
Applying statistical analysis to show the stability of the proposed methodology in classifying breast cancer cases.
The main motivation for using the BER optimization algorithm is its efficiency in exploring the search space for the best solution. On the other hand, the motivation for using AlexNet is that its performance is better than the other deep networks, such as GoogleNet and VGG. Therefore AlexNet is adopted for feature extraction. In addition, CNN is used for the classification of breast cancer. The BER optimization algorithm is used to optimize its parameters to achieve the best performance of the CNN.
1.2. The Structure of This Work
The structure of this work proceeds as follows. The literature review is presented in
Section 2. The details of the proposed methodology are presented and discussed in
Section 3. The achieved results of the conducted experiments and comparisons are then discussed in
Section 4. Finally, the conclusions are future perspectives are presented in
Section 5.
2. Literature Review
Around 1.7 million women were diagnosed with cancer in 2012. Breast cancer is the most frequent type of cancer worldwide. Risk factors for breast cancer include age, family history, and previous health problems [
4]. Women account for the lion’s share of cancer deaths; annually, an estimated 2.1 million people are diagnosed with breast cancer. Recent research estimates that 627 thousand women lost their lives to cancer in 2018, accounting for fifteen percent of all cancer deaths in women [
5]. It is usual practice to use a deep learning-based model for breast cancer diagnosis and classification when using computer visualization. Clinicians face difficulties in making a cancer diagnosis from mammography scans due to the complexity of early breast cancer and the fading of images. That is why it is so important to enhance a doctor’s detection efficiency with the help of deep learning algorithms used in the CAD system [
28,
29,
30,
31].
To categorize breast cancer, the authors of [
4] proposed a convolutional neural network (CNN) based framework for analyzing mammography images. In the beginning, preprocessing was carried out so the mammography images could be seen. Then, the deep learning model that was used to extract the features was trained using the preprocessed images. Softmax, a CNN classifier, was then used to categorize the last layer’s retrieved features. The preferred model enhanced the introduced framework’s classification accuracy of mammography images. Accuracy values of 0.8585 and 0.8271 for the proposed framework demonstrate its superiority to those of the state-of-the-art alternatives. The authors of [
32] revealed early results for utilizing transfer learning to identify breast abnormalities likely to progress to cancer. After testing numerous deep learning models, they settled on ResNet50 and MobileNet as the best options. Both models achieved the highest accuracy levels (78.4% and 74.3%, respectively). They used several preprocessing methods to enhance the accuracy of the categorization further. Last but not least, in [
33], researchers introduced a novel hybrid processing approach that combines principle component analysis (PCA) and logistic regression (LR).
Using a multi-view screening image-processing architecture, the authors of [
34] were able to improve diagnostic results. First-order local entropy, a texture-based technique, segmented the tumor patches. Malignancy indicators such as radius and area were derived using the feature extraction findings. Results from applying this strategy indicated that the CC and MLO views were 88% and 80% accurate at detecting breast cancer, respectively. The framework described by the authors in [
35] centered on transferable knowledge. Several augmentation methods are employed to increase the total number of mammograms without overfitting and produce accurate findings. Using the enormous mammography images dataset, the authors of [
36] proposed a method. A segmentation module is then used to identify breast cancer abnormalities in an image that is properly improved. The Breast Imaging and Reporting and Data System dataset comprised five groups and achieved 92% precision.
Tumor identification with thresholding and CNN methods were the primary focus of the previous research, along with information fusion, hyperparameter value selection by hand, data enhancement, and manual hyperparameter tuning. However, they failed to take key measures that could have increased precision. These processes consist of improving the contrast and then optimizing the retrieved features. The SGD and ADAM optimizers are frequently used to fine-tune the weights of a deep model. A feature optimization method is implemented following the feature extraction stage to combat computational complexity, overfitting, and poor accuracy.
Table 1 presents a summary of the related works. This table presented the related works in terms of the presented methodology, the advances, disadvantages, and overall performance. As shown in this table, the low accuracy of most methods represents the research gap addressed through the methodology proposed in this work.
4. Experimental Results
In this part, we provide and discuss the results of the proposed architecture for breast cancer classification. Two datasets have been adopted in the conducted experiments, and the achieved results are compared to the other techniques [
53,
54,
55,
56,
57]. In addition, a cross-validation value of five folds and a training/testing split of 70:30 are applied to improve the achieved accuracy. On the other hand, the proposed optimization approach is compared to different recent approaches, including genetic algorithm (GA) [
58], whale optimization algorithm (WOA) [
59], particle swarm optimization (PSO) [
60], grey wolf optimization (GWO) [
61] and the standard Al-Biruni Earth radius (BER) [
62]. The parameters of the CNN are optimized using the suggested state-of-the-art BER method. There are many iterations performed to arrive at the final findings, including (i) testing the adopted datasets based on the extracted deep features using other models and (ii) testing the adopted datasets using the extracted deep features and the optimized CNN. All tests are performed on a 16 GB RAM, 8 GB graphics card, MATLAB 2022a-powered desktop computer.
4.1. Evaluation Criteria
Table 5 compares the performance metrics used to evaluate the results of the proposed approach. Among these are Negative Predictive Value (NPV), F-score, Precision, Sensitivity, Accuracy, and Specificity. The classification efficiency of the proposed improved CNN is measured using these criteria. The table’s abbreviations for “false negative”, “false positive”, “true negative”, and “true positive” are “FN”, “FP”, “TN”, and “TP”, respectively.
4.2. Configuration Parameters
Due to the random initialization of the individuals in the first population, we ran 30 iterations of the optimization algorithms in all the conducted tests. There were 500 iterations in each run. The population is one of the inputs to the algorithm. In this study, that number is 30 individuals.
Table 6 details the proposed algorithm’s default settings for its initial parameters.
4.3. Feature Extraction Results
The evaluation of the extracted features using transfer learning is presented in
Table 7. Starting with accuracy, this table is a commonly used metric that measures the overall correctness of the model’s predictions. In this case, all three models achieved accuracy values greater than 0.81, indicating that they can make correct predictions for most cases. However, it is important to note that accuracy can sometimes be misleading if the dataset is imbalanced, i.e., if one class is much more prevalent. Moving on to sensitivity and specificity, these measures are particularly relevant for binary classification problems such as breast cancer classification. Specificity measures the proportion of true negatives that are correctly identified, while Sensitivity measures the proportion of true positives the model correctly identifies. In this case, the sensitivity values for the models ranged from 0.427 to 0.440, indicating that they can identify true positive cases with comparable performance. The specificity values ranged from 0.925 to 0.949, indicating that the models can correctly identify true negative cases with varying degrees of success. It is important to note that sensitivity and specificity can be affected by the choice of the decision threshold, and different thresholds may result in different performance levels. The Precision and NPV are also relevant evaluation metrics for binary classification problems, as they provide information on the prevalence of false positives and false negatives, respectively. The NPV measures the proportion of positive cases incorrectly classified as negative, whereas the Precision measures the proportion of negative cases incorrectly classified as positive. In this case, the Precision ranged from 0.658 to 0.669, indicating that the models have relatively low rates of false positive predictions. The NPV ranged from 0.846 to 0.889, indicating that the models have somewhat higher rates of false negatives. Finally, the F-score is a measure that combines both precision and recall into a single value. It provides a valuable summary of the model’s overall performance in correctly identifying positive and negative cases. In this case, the F-score values ranged from 0.521 to 0.529, indicating that the models have similar precision and recall, but their ability to balance the two can vary. These evaluation metrics provide a comprehensive view of the performance of the evaluated models for breast cancer classification. By considering multiple metrics, it is possible to gain a more nuanced understanding of the strengths and weaknesses of each model, and to make more informed decisions about which model to use for a particular task. As presented in
Table 7, it can be shown that the performance of the AlexNet pre-trained model is superior to the other models for both Dataset-1 and Dataset-2 and, thus, this model is adopted for feature extraction.
4.4. Classification Results
Breast cancer classification results using the proposed ABER-CNN compared to the baseline CNN and the optimized CNN using different optimization algorithms are presented in
Table 8. The reported results are accuracy scores for five other convolutional neural network (CNN) models: WOA-CNN, GA-CNN, PSO-CNN, GWO-CNN, BER-CNN, and ABER-CNN, that were trained and tested for breast cancer classification. These models were trained using different optimization algorithms, and the reported accuracy scores ranged from 0.914 to 0.962. Among the five evaluated models, the ABER-CNN model achieved the highest accuracy score of 0.962, which suggests that it performed the best in classifying breast cancer.
The other models achieved accuracy scores ranging from 0.914 to 0.943. It is important to note that accuracy is only one evaluation metric, and other metrics such as sensitivity, specificity, and F-score may be necessary to evaluate the models’ performance fully. Additionally, further information about the dataset and the specific task would be necessary to fully interpret and contextualize these results. These results suggest that the proposed ABER-CNN model is a promising approach for breast cancer classification, achieving a high accuracy score of 0.962. Similarly, the performance of the proposed approach in terms of Dataset-2 is also presented in
Table 8. The results presented in this table confirm the effectiveness and superiority of the proposed approach in breast cancer classification tasks when tested on the adopted datasets. On the other hand,
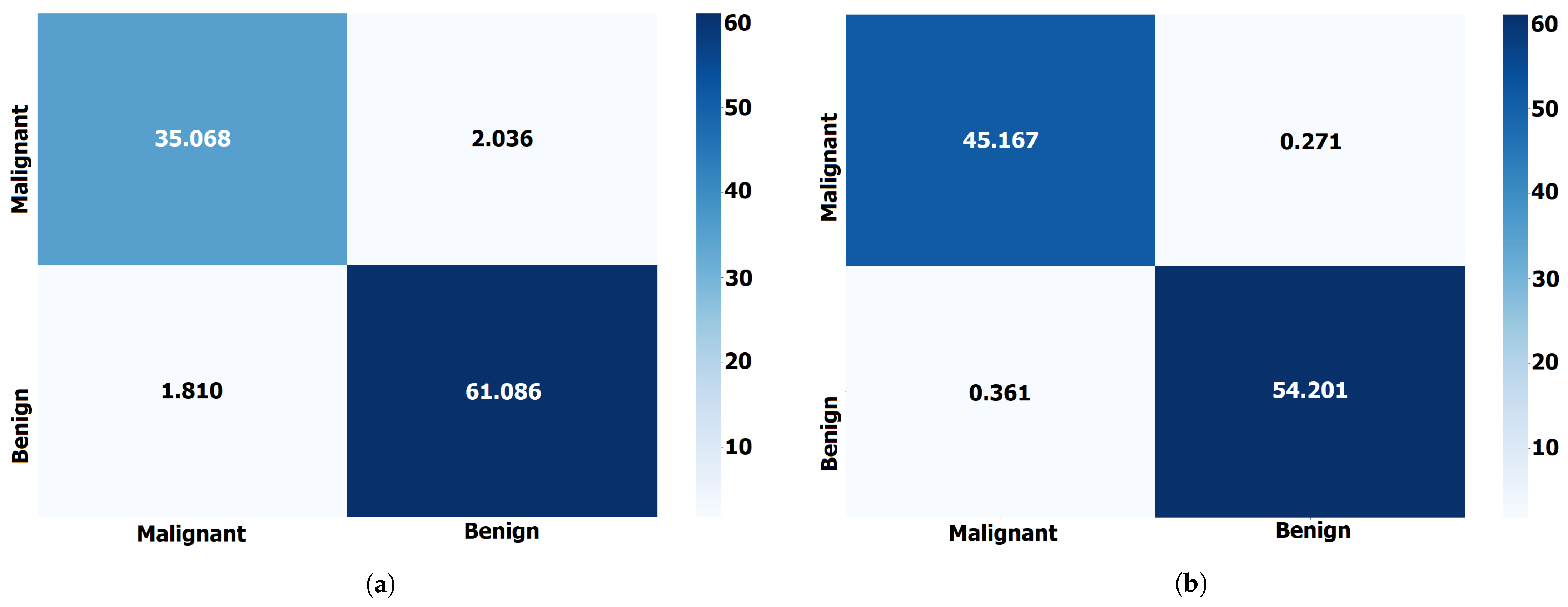
Figure 5 shows the confusion matrix for the results of the proposed ABER-CNN approach applied to Dataset-1 and Dataset-2. From these matrices, it can be noted that the classification of the breast cancer cases is accurate using the proposed approach, which proves its effectiveness in this domain of medical diagnosis.
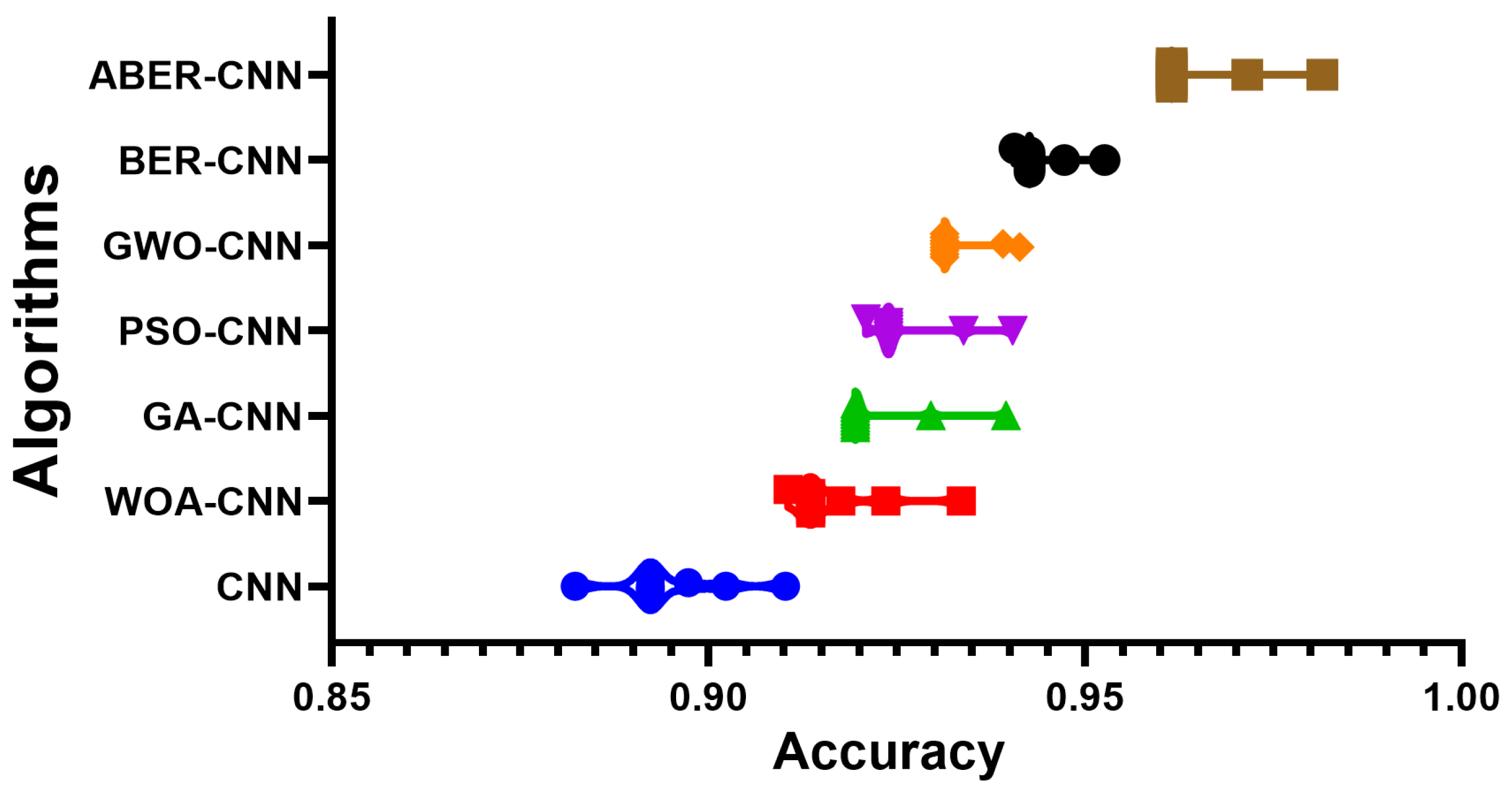
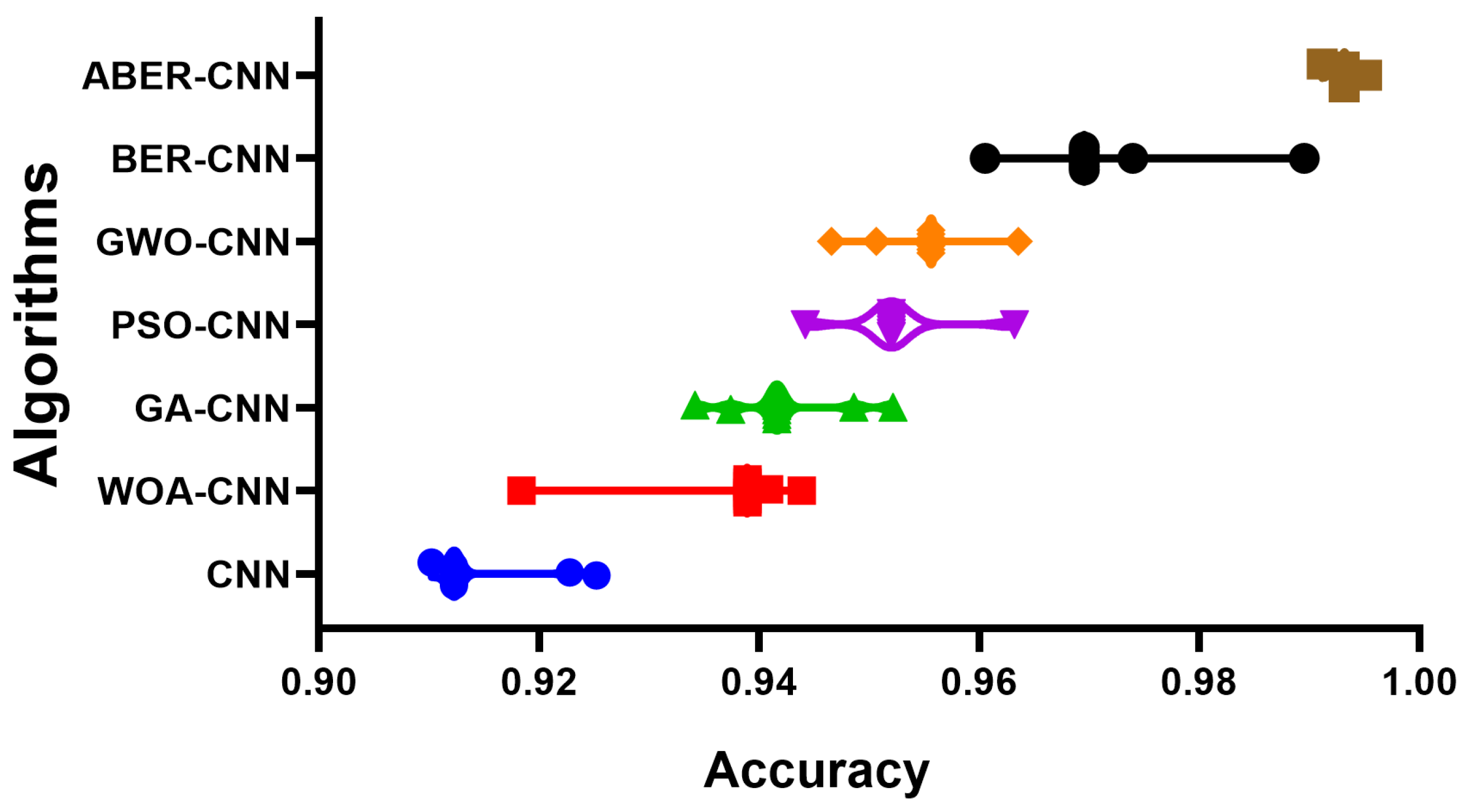
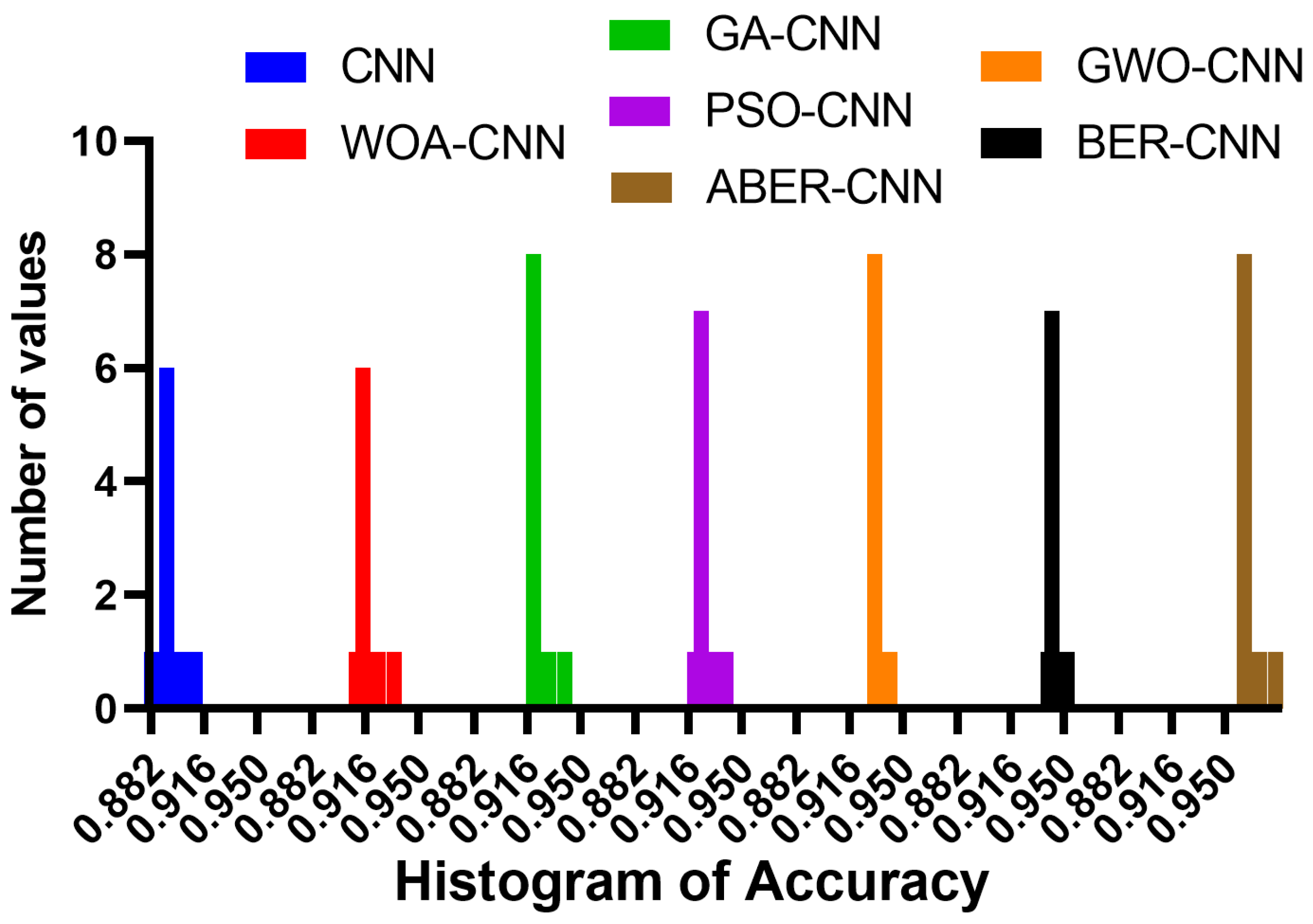
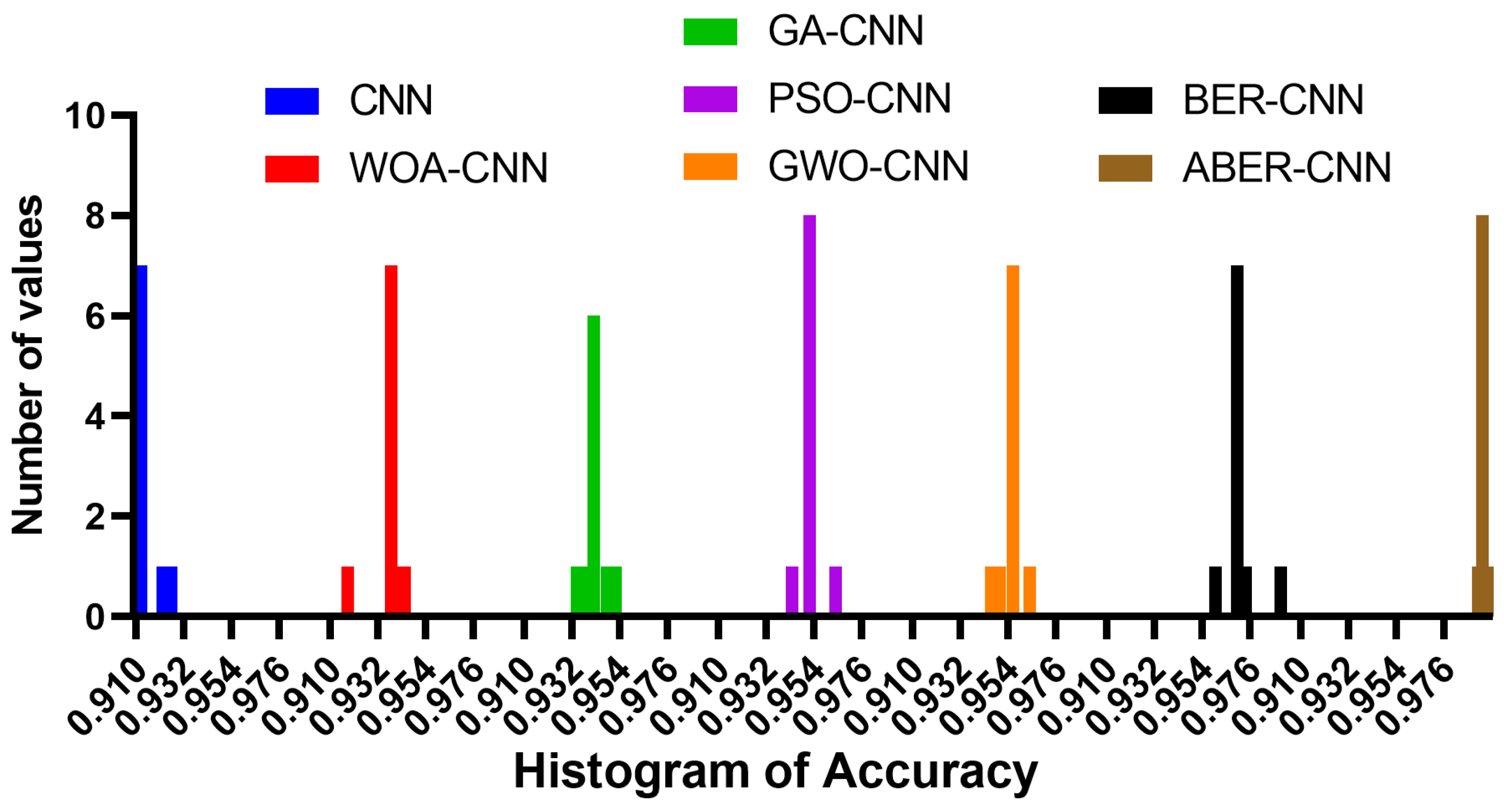
The accuracy plot and accuracy histogram plot are valuable tools used to compare the performance of several models in classifying breast cancer cases as shown in
Figure 6,
Figure 7,
Figure 8 and
Figure 9 for Dataset-1 and Dataset-2. In this context, the models evaluated include CNN, WOA-CNN, GA-CNN, PSO-CNN, GWO-CNN, BER-CNN, and ABER-CNN, where ABER represents the advanced Al-Biruni Earth radius optimization algorithm, and the proposed approach is ABER-CNN. The accuracy plot visually presents the accuracy scores of each model, allowing for a direct comparison of their performance. It typically displays the accuracy rates on the
y-axis and the different models on the
x-axis. This plot enables researchers to assess which model consistently achieves higher accuracy rates in classifying breast cancer cases.
Similarly, the accuracy histogram plot provides a distribution of accuracy scores for each model. It offers a more detailed view of the performance by illustrating the frequency of accuracy scores within specific ranges. This plot allows for comparing the overall accuracy and the accuracy distribution across different models. By analyzing these plots, it becomes evident that the proposed optimized model, ABER-CNN, outperforms the other models in classifying breast cancer cases. Its accuracy scores consistently exceed those of CNN, WOA-CNN, GA-CNN, PSO-CNN, GWO-CNN, and BER-CNN. The superior performance of ABER-CNN suggests that the advanced Al-Biruni Earth radius optimization algorithm effectively enhances the CNN architecture for breast cancer classification. This finding highlights the potential of the ABER-CNN model for more accurate and reliable breast cancer diagnosis, paving the way for improved patient outcomes and healthcare practices in the field. Additional experiment is performed to study the area under the curve (AUC) for the results achieved by the proposed approach when applied to Dataset-1. The results of this experiments are presented in
Appendix A.
4.5. Statistical Analysis Results
The statistical analysis results are presented in
Table 9 for Dataset-1 and Dataset-2. In this table, the results show the performance of different models in terms of various evaluation metrics. The models evaluated include CNN, WOA-CNN, GA-CNN, PSO-CNN, GWO-CNN, BER-CNN, and ABER-CNN. The evaluation metrics reported have the minimum value, 25th percentile, median, 75th percentile, maximum value, range, mean, standard deviation, standard error of the mean, and sum. Looking at the minimum and maximum values, we can see that the ABER-CNN model performed the best, with a maximum value of 0.982 and a minimum value of 0.962. The range of values also varied among the models, with the BER-CNN model having the smallest range of 0.012 and the CNN model having the largest range of 0.028. In terms of the mean and median values, we can see that the ABER-CNN model performed the best, with a mean value of 0.965 and a median value of 0.962. The models’ performances can be compared using the various evaluation metrics provided in the table. The standard deviation values show us that the CNN, WOA-CNN, GA-CNN, PSO-CNN, and ABER-CNN models had similar levels of variability in their results, with standard deviation values ranging from 0.007 to 0.004. The GWO-CNN and BER-CNN models had lower levels of variability with standard deviation values of 0.003. These results suggest that the ABER-CNN model performed the best among the models evaluated.
4.6. Analysis-of-Variance (ANOVA) Test Results
The ANOVA table shown in
Table 10 displays the findings of a statistical analysis of variance performed on Dataset-1 and Dataset-2. Total, Treatment, and Residual comprise its three sections. The degrees of freedom (DF), mean square (MS), F-ratio (F), and
p-value for the analysis of variance between treatment groups (models) are displayed in the Treatment section. The treatment has a DF of 6 and MS of 0.00481 (SS: 0.029). There is statistical evidence that the treatment (several models) affects the response variable, as the F-ratio with 6 and 63 degrees of freedom is 131.4, and the
p-value is less than 0.0001 (evaluation metrics). Unaccounted-for differences between groups of patients are reflected in the Residual term. It has a DF of 63, an MS of 0.00003661, and an SS of 0.002. Residual is omitted because they do not qualify for either the F-ratio or the
p-value. Since the Total reflects the full range of variability in the data, it displays Total SS, Total DF, and no MS, F-ratio, or
p-value. The data set has a total of 0.031 SS and 69 DF. In conclusion, the variance table analysis displays the statistical test findings to determine if the intervention (several models) significantly affects the dependent variable. Based on the metrics utilized for comparison, the outcomes highlight a clear performance gap between the various models.
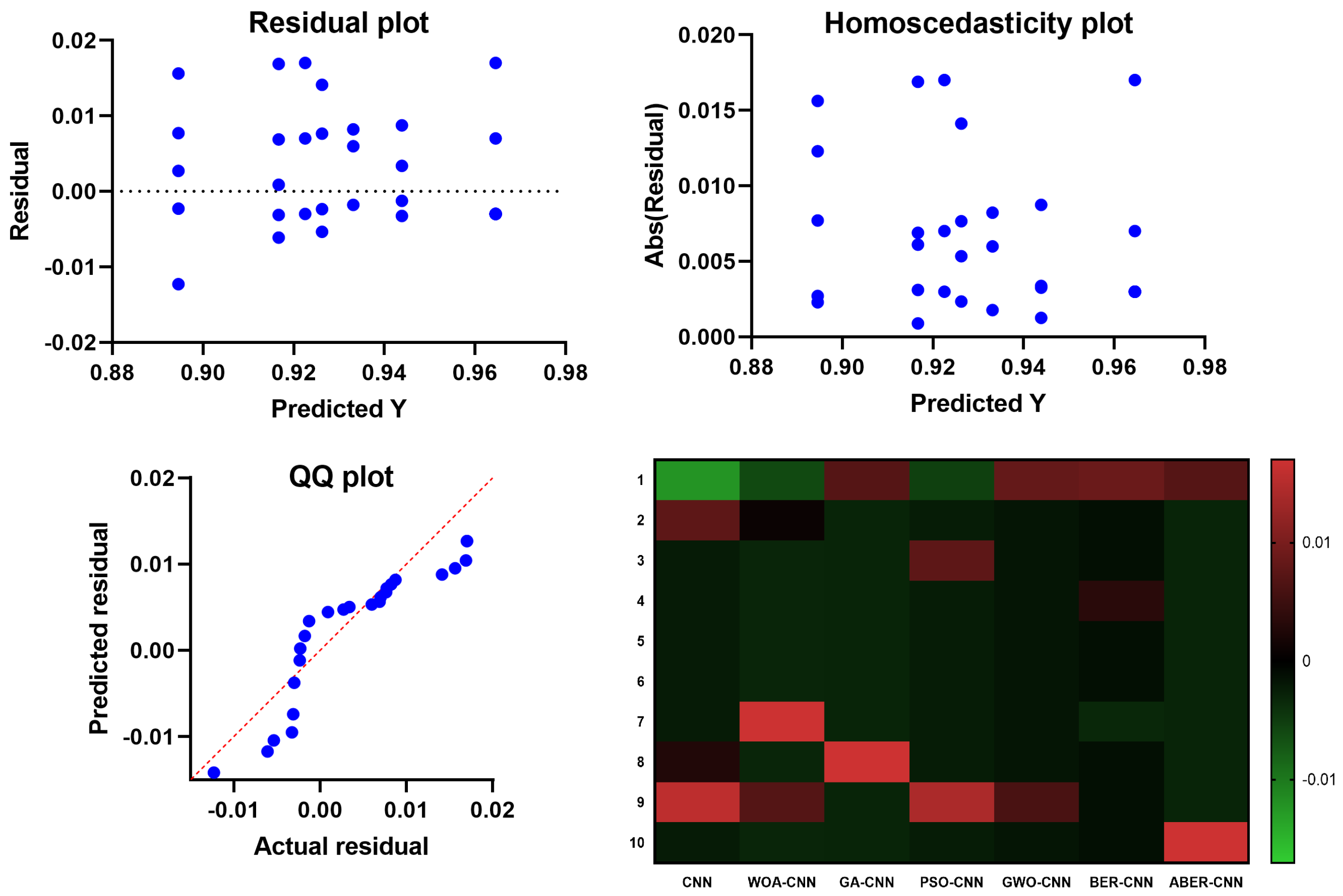
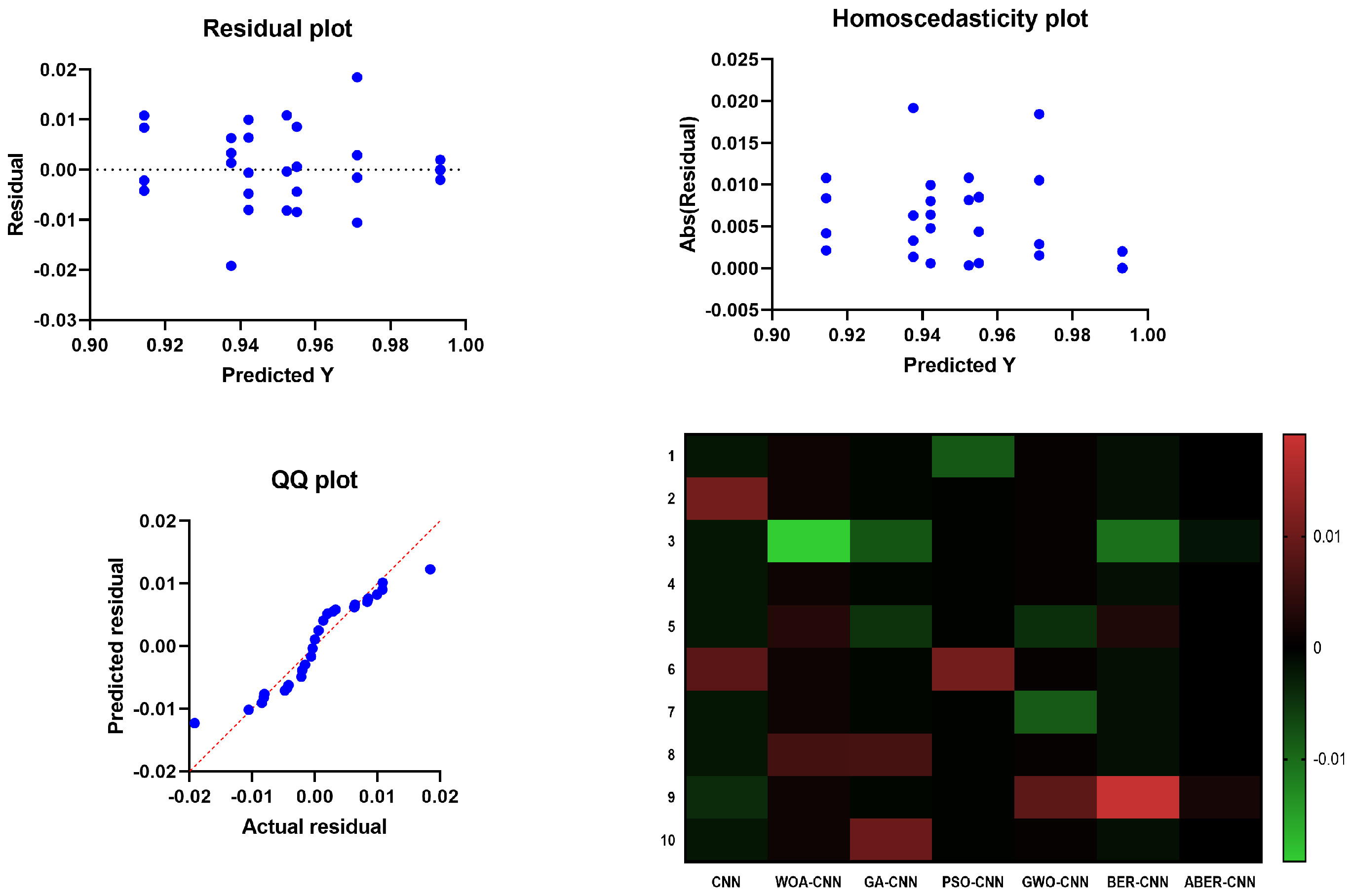
The results of the plots shown in
Figure 10 and
Figure 11 used to visualize the output of the ANOVA test further validate the effectiveness of the proposed ABER-CNN model in breast cancer classification. Firstly, the QQ plot demonstrates that the residuals of the ABER-CNN model align closely with the expected normal distribution. This indicates that the assumptions of normality are met, enhancing the reliability of the model’s predictions. Additionally, the Homoscedasticity plot reveals a consistent spread of residuals across different independent variable levels, confirming the homoscedasticity assumption. This suggests that the ABER-CNN model performs consistently well across various conditions or groups, further strengthening its robustness in breast cancer classification. The Residual plot showcases minimal patterns or systematic deviations, indicating that the ABER-CNN model effectively captures the underlying linear relationships. The absence of non-linear patterns implies that the model is well-suited for breast cancer classification tasks, as it accurately captures the complexities present in the data.
Furthermore, the Heatmap highlights the significance levels or p-values resulting from the ANOVA test. The heatmap reveals that the ABER-CNN model exhibits significantly higher accuracy rates than other models, such as CNN, WOA-CNN, GA-CNN, PSO-CNN, GWO-CNN, and BER-CNN. The color-coded representation indicates the superiority of the ABER-CNN model in classifying breast cancer cases, further supporting its effectiveness and demonstrating its potential for improved patient outcomes and healthcare practices in breast cancer diagnosis.
The results of the QQ plot, Homoscedasticity plot, Residual plot, and Heatmap collectively confirm the effectiveness of the proposed ABER-CNN model in breast cancer classification. These plots provide strong evidence of the model’s accuracy, adherence to assumptions, and robust performance, solidifying its potential as a valuable tool in the early detection and diagnosis of breast cancer.
4.7. Wilcoxon Signed-Rank Test Results
The Wilcoxon signed-rank test presented in
Table 11 is a non-parametric statistical method for comparing three or more samples with common features. In this context, the test is used to evaluate the relative merits of seven distinct models for a binary classification task: CNN, WOA-CNN, GA-CNN, PSO-CNN, GWO-CNN, BER-CNN, and ABER-CNN. In this test, the median of the observed performance gaps between the models is compared to the theoretical median, which is zero. The findings show that all seven models performed significantly differently from the theoretical median (
p-value 0.05). Actual median values vary from 0.892 to 0.962, demonstrating various model performances. If we add up all the ranks that represent disparities in absolute value between the observed values and the hypothesized median, we obtain W, the sum of signed ranks. Adding up the ranks of the positive differences yields the total of positive ranks, whereas adding up the ranks of the negative differences yields the sum of negative ranks.
Because the p-values are derived from the true probability distribution of the test statistic, the Wilcoxon signed-rank test is considered an exact test. The p-values are exactly 0.002, which is a very small probability. The Wilcoxon signed-rank test verifies that there are substantive differences in the effectiveness of the various models. It does not, however, specify how large these disparities are. The deviation numbers reveal the true median values of the performance discrepancies, with ABER-CNN doing better than CNN by a wide margin. One important thing to keep in mind about the Wilcoxon signed-rank test is that it is a one-tailed test, which means that it can only tell you if the models perform considerably better or worse than the theoretical median. It is not a test for directional variations in performance.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










