1. Introduction
Visual information capture and processing are of significant scientific importance in the field of modern engineering technology, but visual functions performed by existing vision systems are still quite different to those of human vision. Because of the remarkable ability of human vision, analyzing and imitating the visual characteristics of human eyes can enrich the theoretical basis of the computer vision and advance the development of machine vision technology [
1]. As one of the essential challenges in computer vision, constructing reliable correspondences between two images containing the same or similar scenes is a fundamental problem, and it acts as a key prerequisite for a wide spectrum of tasks including SLAM, image registration, image fusion, and image mosaic [
2,
3]. Although image matching algorithms have been well studied, it is still rare to effectively introduce human visual characteristics into the matching process, and challenging to robustly match humanoid-eye binocular images with significant viewpoint and view direction differences.
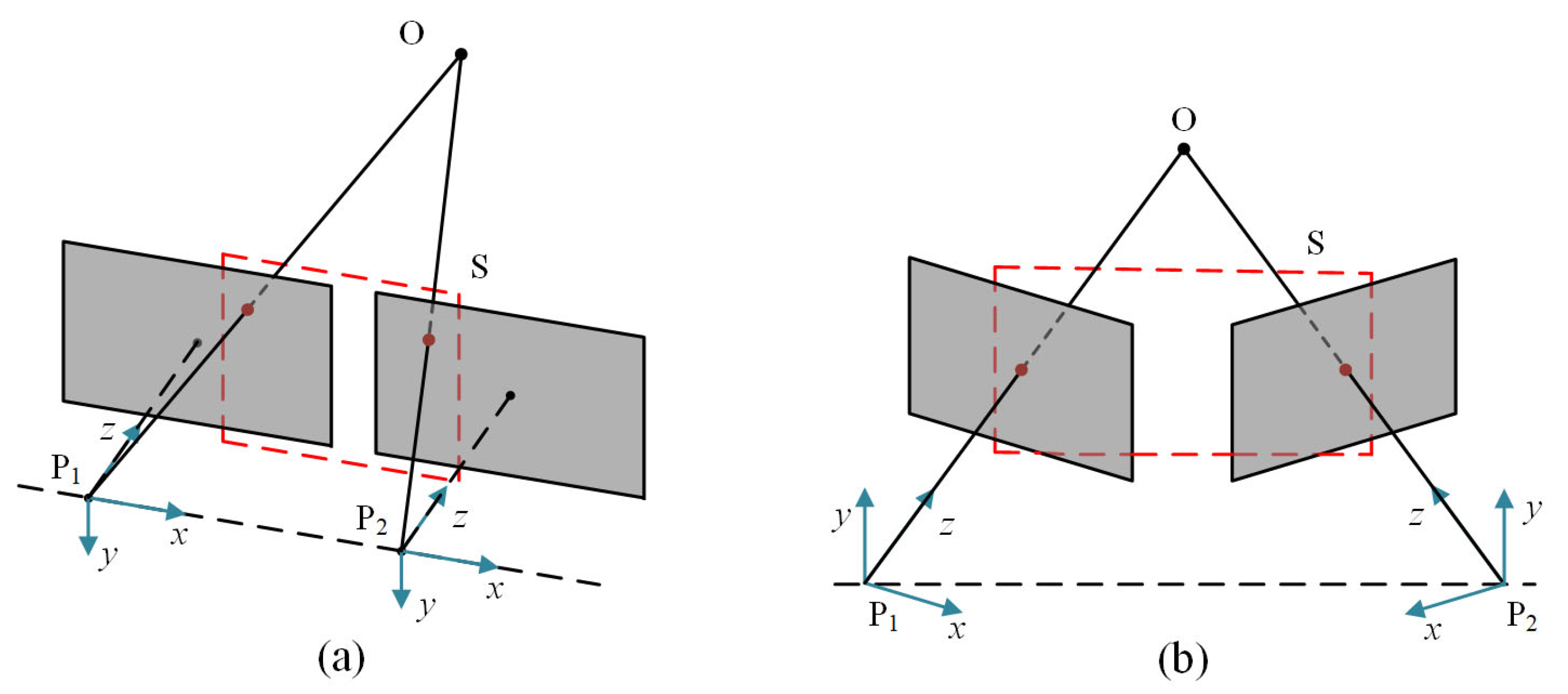
In general binocular vision models, since just a translation variation exists between two cameras, the corresponding points in the overlapping area only have horizontal parallax, as shown in
Figure 1a. Actually, when two eyes stare at an object, they converge, so that the object is imaged at the symmetrical point of both eyes’ retinas, producing a fused vision. The associated camera model is depicted in
Figure 1b. Between the two cameras, there is rotational variation in addition to translational variation, thus, the pose relationship is extremely difficult to establish, due to the intricate camera motion. The resulting viewpoint and view direction differences seriously limit the matching performance of humanoid-eye binocular images. Recent years have witnessed great progress in image matching algorithms, and these techniques can be broadly classified into two groups: area-based methods and feature-based methods. The area-based methods often depend on appropriate similarity judgment criteria, for creating pixel-level matches between images, including mutual information [
4] and normalized cross-correlation coefficient [
5]. These approaches are widely used in medical image processing, and achieve favorable performance. However, they are only suitable to image pairs with translation variation, small rotation, and local deformation. Meanwhile, they are also susceptible to appearance changes by noise, varying illumination, and geometric distortions.
Compared with the area-based methods, feature-based ones are often more efficient, and can better handle geometrical deformation. Most feature matching algorithms follow three steps: feature extraction, feature description, and feature matching. Human eyes are more sensitive to edge information, since it is the key to the shape, size, position, and pose of an object. Accordingly, choosing an appropriate corner detector, which can produce adequate edge feature points, is necessary. Among several famous corner detectors [
6,
7,
8,
9], the SUSAN detector has better robustness to noise and reduces the location error of edge feature points [
10]. Most importantly, the SUSAN operator can extract corner points and edge points at the same time, which retains the contour information of images, to meet the visual characteristic of human eyes focusing on edge points.
A series of methods can be utilized to describe the neighborhood information for SUSAN feature points, the most representative ones are scale invariant feature transform (SIFT) [
11] and speeded up robust feature (SURF) [
12]. These two algorithms rely on a histogram of oriented gradients for forming float type descriptors, significantly improving the invariance against radiometric transformations. Another form of descriptors is based on the comparison of local intensities, such as BRISK [
13] and BEBLID [
14], which can speed up the computations and achieve high matching accuracy. Unfortunately, the performance of the aforementioned descriptors in matching SUSAN feature points is not ideal, because of the density of SUSAN features with similar pixel information, and humanoid-eye binocular images with significant viewpoint and view direction differences.
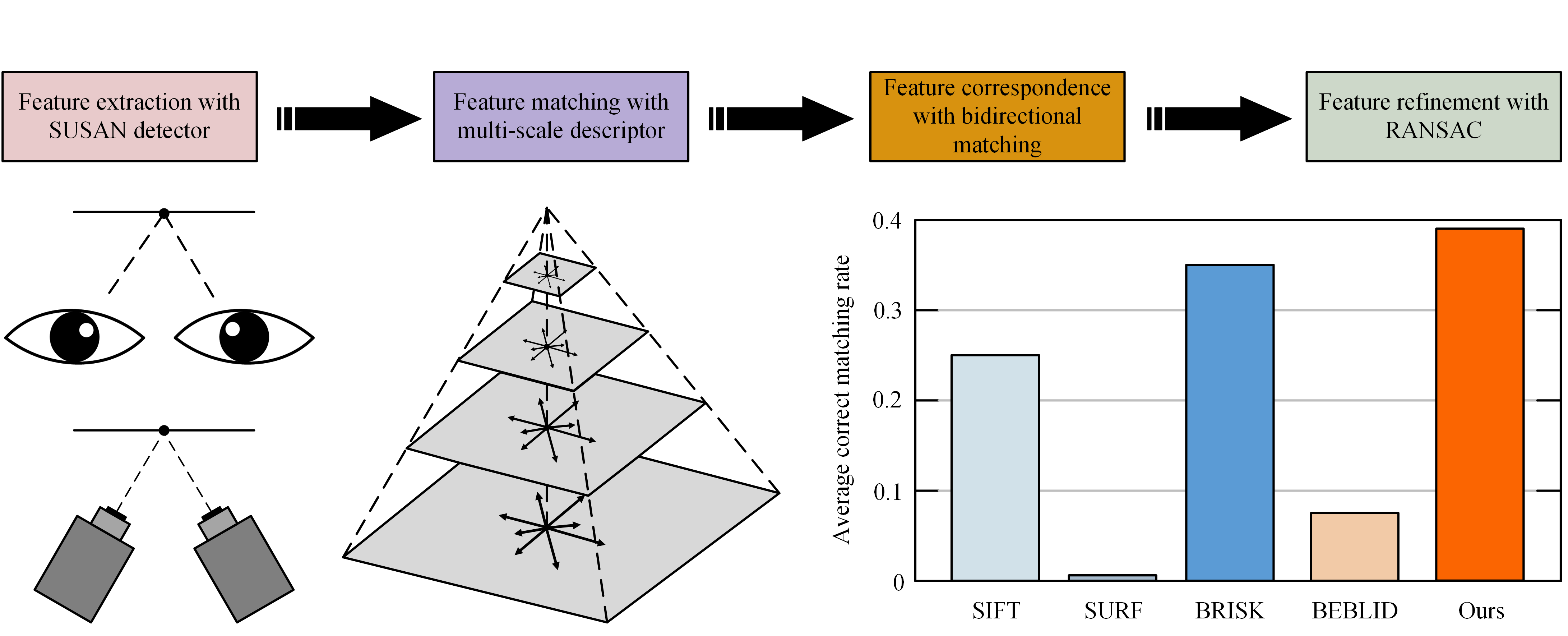
To handle the above-mentioned challenges, we hope to enhance the similarity between the corresponding descriptors, in order to decrease the amount of possible mismatches. Specifically, we try to retain essential information as much as possible when calculating the neighborhood information of feature points. Notably, we find that reducing the image resolution can increase the number of correct matches in humanoid-eye binocular images, thus we pay more attention to establishing multi-scale structures of images. Meanwhile, we argue that computing the neighborhood pixel information of the same feature point at different scales, should enhance the robustness of the matching. Based on the above observation and assumption, a multi-scale descriptor constructing strategy is developed, which computes the main pixel information of each feature point at different scales according to the theory of the SIFT method, by introducing the image pyramid model. Then, these description vectors are combined into a descriptor containing multi-scale information. A series of experiments, with qualitative and quantitative result analyses, have revealed the superiority of our approach over the state-of-the-art.
In summary, our main contributions in this paper include the following three aspects. First, the visual characteristic of human eyes focusing on the edges of objects is introduced into the feature matching process, and the SUSAN operator, which has outstanding edge feature extraction capability, is selected as the feature detector, to address the issue of lacking edge feature points. Second, in response to the problem that mismatches easily exist in humanoid-eye binocular images with significant viewpoint and view direction differences, we propose a novel descriptor, with multi-scale information, for describing SUSAN feature points. Third, a general, yet efficient, refinement strategy is devised, to achieve accurate matching results.
The remainder of this paper is organized as follows. In the next section, we review the work most related to our method. The proposed method is described in
Section 3. Later, a series of experiments are carried out in
Section 4. Finally,
Section 5 presents the conclusions.
3. The Proposed Matching Strategy
In this section, a method to establish correspondence between a pair of humanoid-eye binocular images is explained. The proposed method mainly consists of three steps: feature detection, feature description, and feature correspondence. The details of each step will be described in the following sections.
3.1. Feature Point Detection
Obtaining enough edge features is the key to imitating the visual characteristic of human eyes being more sensitive to the edge. We compare the performance of four well-known corner detectors: Harris, Shi-Tomasi, FAST, and SUSAN, as shown in
Figure 2. The Harris operator produces redundant corners in some local areas of the image, as described in
Figure 2b. The Shi-Tomasi and FAST approaches can extract a reasonable amount of corners, but the number of features extracted at some edges is still limited, as depicted in
Figure 2c,d, respectively. The SUSAN detector can not only detect enough corners, but also extract plentiful edge features, thus better describing the contour information of the image, as shown in
Figure 2e. Due to its good performance, the SUSAN detector is selected to extract feature points in our method.
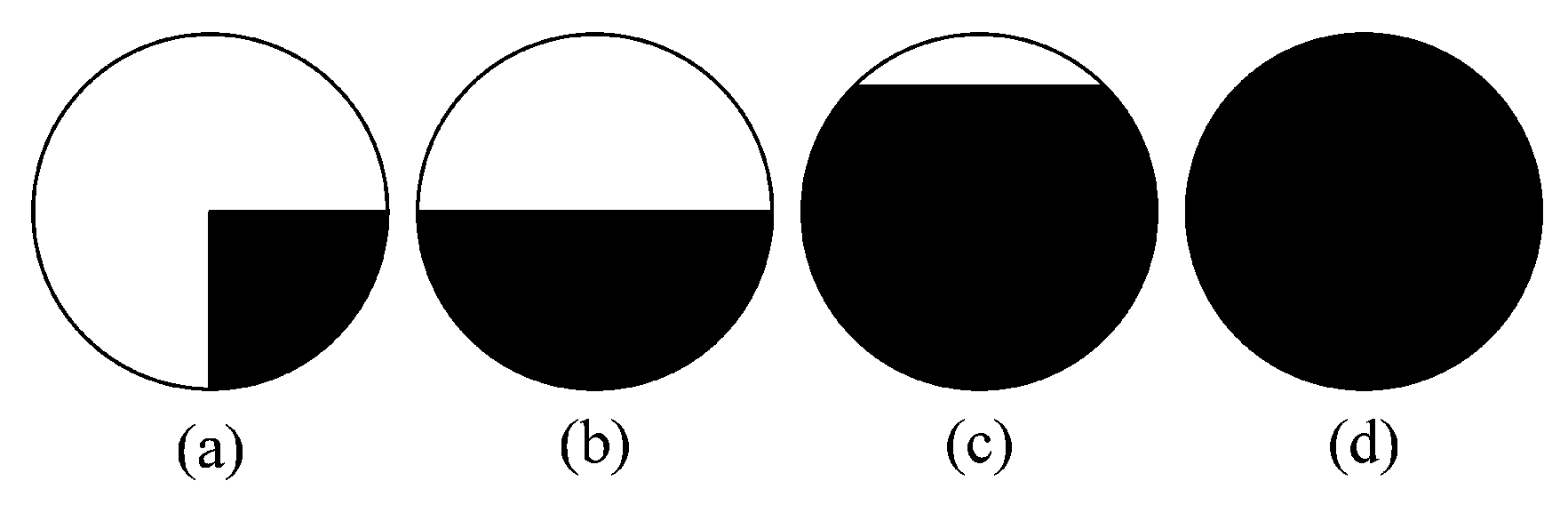
A circular mask is adopted, to successively process the pixels of the input image in the SUSAN algorithm. The pixel under examination is called the nucleus, and the nucleus is regarded as the center of the mask. In the mask, by calculating the intensity value of the pixels in a neighborhood of the nucleus, the pixels with approximately the same intensity as the nucleus are grouped. These pixels form an area, which is referred to USAN.
Figure 3 shows a principle diagram of the SUSAN algorithm. The dark area represents the image surface. As depicted in
Figure 3a, the USAN area reaches the minimum when the nucleus is located at a corner, and expands even further as the nucleus approaches the surface, as described in
Figure 3b,c, respectively.
Figure 3d shows that the USAN area reaches the maximum when the nucleus completely lies in the flat region.
Let
denote the output of the comparison, where
is the intensity value of the nucleus and
is the intensity value of any other pixel within the mask. A simple equation for determining whether the intensity of a point is the same as that of the nucleus is as follows:
where
t is the threshold to decide the similarity. The value of
t is adaptive, and the optimal value should be provided in terms of different conditions. After comparing the similarity between each pixel and the nucleus within the mask, the USAN area can be specified as:
Then, the USAN value is compared with a threshold
g, which stands for the geometric limit. A point will be regarded as an edge point if its USAN value is less than g. The feature response can be expressed as:
Different values of the geometric threshold g, result from detecting different features, such as corner and edge. In this paper, the value of g is set as three-quarters of the maximum USAN value, which can better detect corners and edge features at the same time.
3.2. Feature Point Description
3.2.1. Multi-Scale Structure Establishment
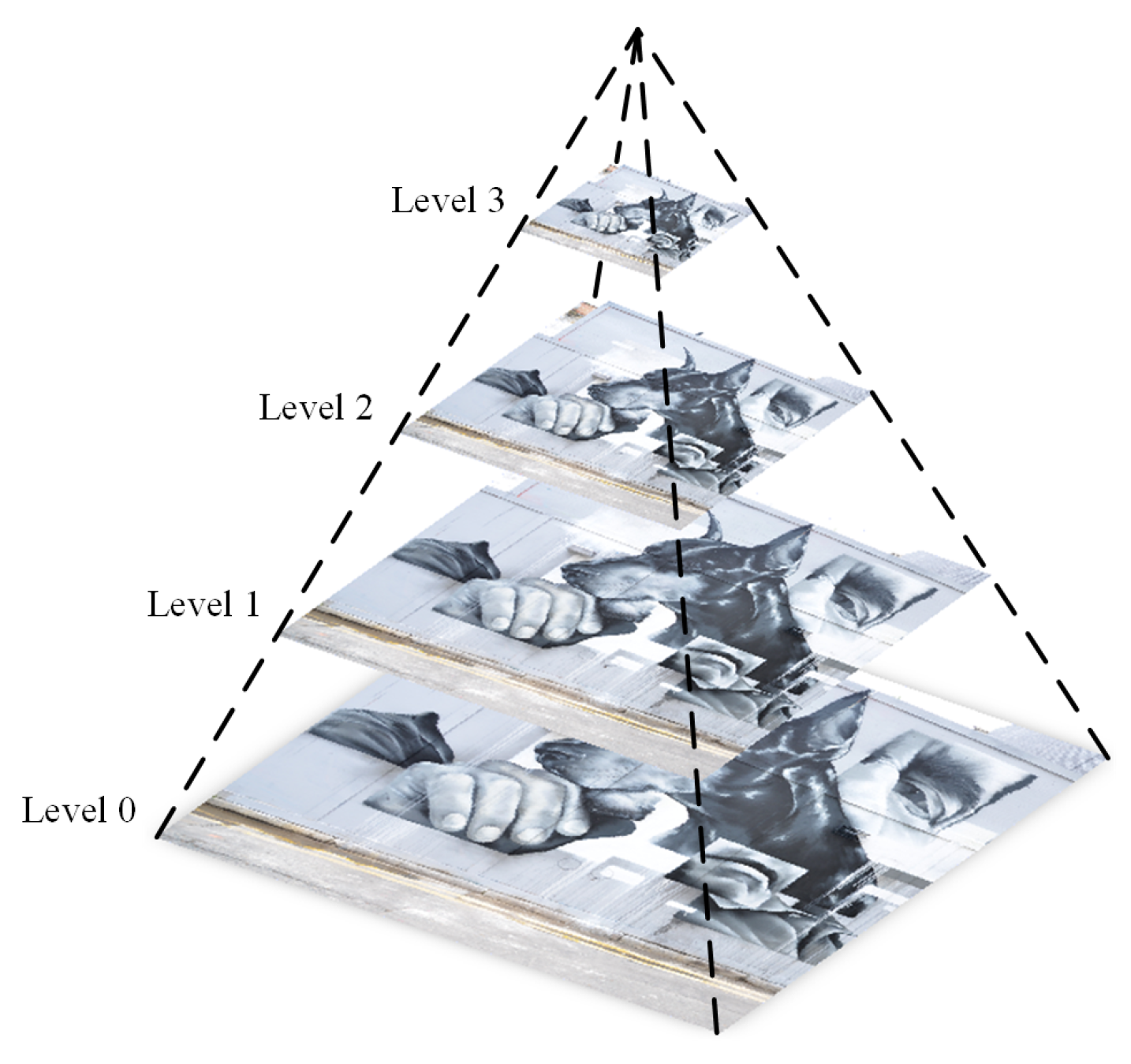
Once the feature points are extracted, designing appropriate descriptors is the second step. To generate multi-scale information, the image pyramid model is introduced into the building descriptors. An image pyramid is a form of multi-scale expression of an image, which arranges the images at different resolutions according to the shape of the pyramid. The bottom image of the image pyramid is an input image to be processed, and the top image is an approximate image with low resolution. It is assumed that the size of the input image is
M ×
N, the
k-th layer image of the image pyramid is generated from the
k − 1-th layer image by Gaussian convolution and down sampling, the
k-th layer image is then given by:
where
stands for the
k-th layer image.
is a 2D function with low-pass characteristics, which is defined as follows:
A series of images can be generated by iteration, to form a complete image pyramid. In this paper, a four-layer image pyramid is built, as represented in
Figure 4.
3.2.2. Main Orientation Assignment Based on Local Gradient Information
The main orientation assignment is an indispensable step for point-based matching methods, to achieve rotation invariance [
29]. Therefore, the main orientation for each feature point is computed based on local gradient information of contour points.
Assume
is an input image.
and
represent the gradient magnitude and orientation, respectively, which are precomputed using pixel differences by the following equations:
The obtained gradient orientations of sample points within a region around the feature point, form an orientation histogram, which has 36 bins, covering the 360 degree range of orientations. In addition, in order to improve the affine invariance of the feature points, a circular window, similar to the SIFT method, is adopted, to weigh the gradient magnitude of each point. The Gaussian-weighted circular window can be represented as follows:
where
denotes the Gaussian-weighted function. (
i,
j) represents the relative position between the sample point and the keypoint.
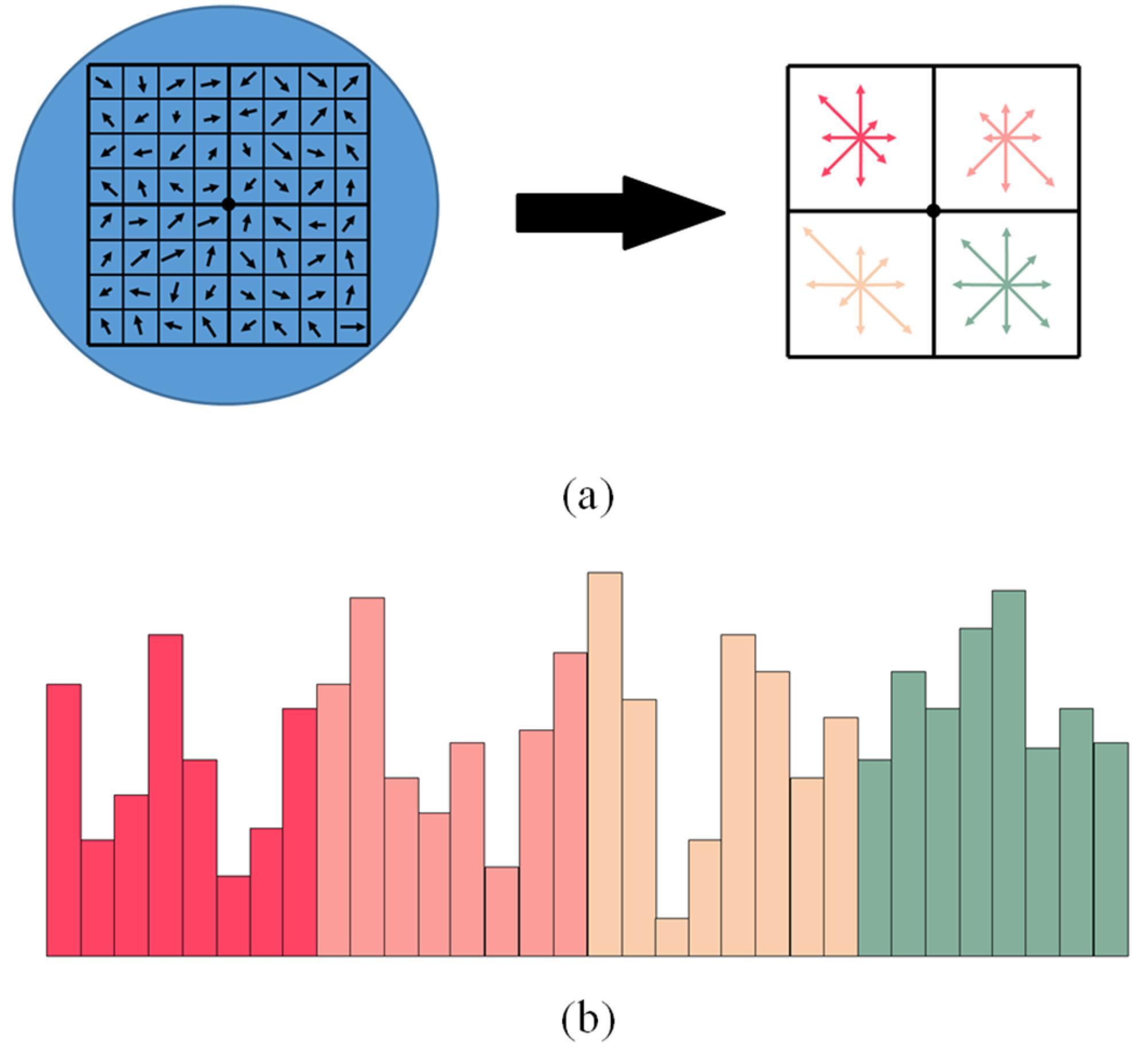
3.2.3. Multi-Scale Descriptor Based on Histogram of Gradient Orientation
The previous operations have assigned an image location and orientation to each keypoint. The next step is to design a local invariant feature description for feature correspondence. In order to compute the main gradient information of keypoints at different scales, these keypoints are mapped to their corresponding positions of each layer in the four-layer image pyramid. Then, an 8 × 8 region is divided around each keypoint on every layer of image pyramid, and the orientation histograms are determined for feature description, as shown in
Figure 5. We can obtain 32-dimensional SIFT descriptors for feature points on each layer image when the other structure parameters are same as SIFT in our experiments.
Compared with the traditional 128-dimensional SIFT descriptor, the resulting 32-dimensional descriptor only retains the gradient information of four subregions around each feature point. This is because viewpoint and view direction differences exist in humanoid-eye binocular image pairs, which may result in significant pixel variation in the region around two corresponding feature points. Therefore, the matching results will be negatively influenced by pixels that are further from the keypoint.
Once four 32-dimensional descriptors for each feature point are obtained, the multi-scale descriptor is constructed. To be specific, these four descriptors are stitched and ordered by decreasing image scales, to form a novel 128-dimensional descriptor with multi-scale information.
3.3. Feature Correspondence
The last step of the feature matching algorithm comprises several continuous processes. It starts with matching descriptors, removing non-matches first and further identifying mismatches. The brute-force algorithm is one of the simplest pattern matching algorithms. Because of the large number of comparisons, it sometimes takes more time but is highly precise. The brute-force method compares the descriptor of one feature in the first image to the descriptors of all features in the second image, by using Euclidean distance, their similarity is computed as:
where
and
denote the descriptors of two feature points. The best candidate match is regarded as two feature points with minimum Euclidean distance for their description vectors.
However, due to the feature points detected by the SUSAN algorithm being numerous and dense, only utilizing the brute-force matching approach results in a large number of mismatches. Therefore, the bidirectional matching strategy is adopted in this paper. The steps of this strategy are briefly introduced as follows:
Step 1: For each feature point , in the first image, compare its multi-scale descriptor with all the descriptors of feature points in the second image, by computing Euclidean distance. Then, the candidate match is selected with minimum Euclidean distance.
Step 2: Suppose is the candidate point for . Measure the similarity between and all the feature points in the first image. If is also a candidate point of , these two points are regarded as a preliminary match.
Notably, many features will not have any correct match, because they are not in the overlapping area of humanoid-eye binocular image pairs with large viewpoint and view direction differences. Therefore, the distance ratio method is employed, to measure the similarity between the obtained preliminary matching pairs in the coarse-matching stage.
In the comparative process, one correct match is defined as:
where
denotes a distance limit,
L is the Euclidean distance between two descriptors, and
is the largest Euclidean distance of all matching pairs. Different values of
k result in different numbers of matching pairs. As
k begins to increase, the number of matching pairs increases, but the accuracy of the results decreases. In our method,
k is 0.6. The number 0.6 is an empirical value, which can effectively identify correct matches.
The accuracy of feature pairs can be greatly improved after the coarse-matching stage, but there are still a few mismatches. Hence, in the refined-matching stage, the RANSAC algorithm [
30] is adopted, to further remove the mismatches. Its basic idea is that all matching points are formed into a dataset, and four samples are randomly selected to compute a transformation matrix. Then, the projection error between all the points and transformation matrix is calculated. If the error is less than a threshold
g, the point is considered to be an interior point. The above steps are repeated and a model is selected with the largest number of interior points as the final transformation matrix, to obtain accurate corresponding pairs.
4. Experiments and Discussion
In this section, a series of experiments are conducted to evaluate the proposed method. First of all, the datasets and experimental details used to evaluate this work are presented. Then, we compare the multi-scale descriptor to several popular descriptors and compare their matching results. Finally, the overall performance of the proposed algorithm is evaluated with some of the latest methods.
4.1. Datasets and Experiment Details
We evaluate the performance of our multi-scale descriptor against several famous descriptors, on humanoid-eye binocular images and the HPatches [
31] dataset. In addition, the overall performance of the proposed work is compared with state-of-the-art algorithms. All the experiments and analyses are implemented on a computer system with Windows 10, a 2.3 GHz processor, and 16 GB memory.
Humanoid-eye binocular images. To capture humanoid-eye binocular images, we designed synergistic perception equipment, imitating human eyes, as shown in
Figure 6. The two cameras are controlled by motors at the bottom, and their centers are constantly on the same horizontal axis. Therefore, these two cameras can rotate left or right at any angle, to simulate human eye imaging.
HPatches dataset. The HPatches dataset, is a comprehensive dataset that includes different viewpoints and different illumination scenes, which consists of 116 sequences in total. The HPatches dataset is divided into two subsets; 57 sequences have significant illumination changes with almost the same viewpoint, while 59 sequences have significant viewpoint changes under similar illumination. Each sequence has six images of the same scene. It also provides ground truth homographies between the first image and the remaining five images.
4.2. Descriptor Benchmark
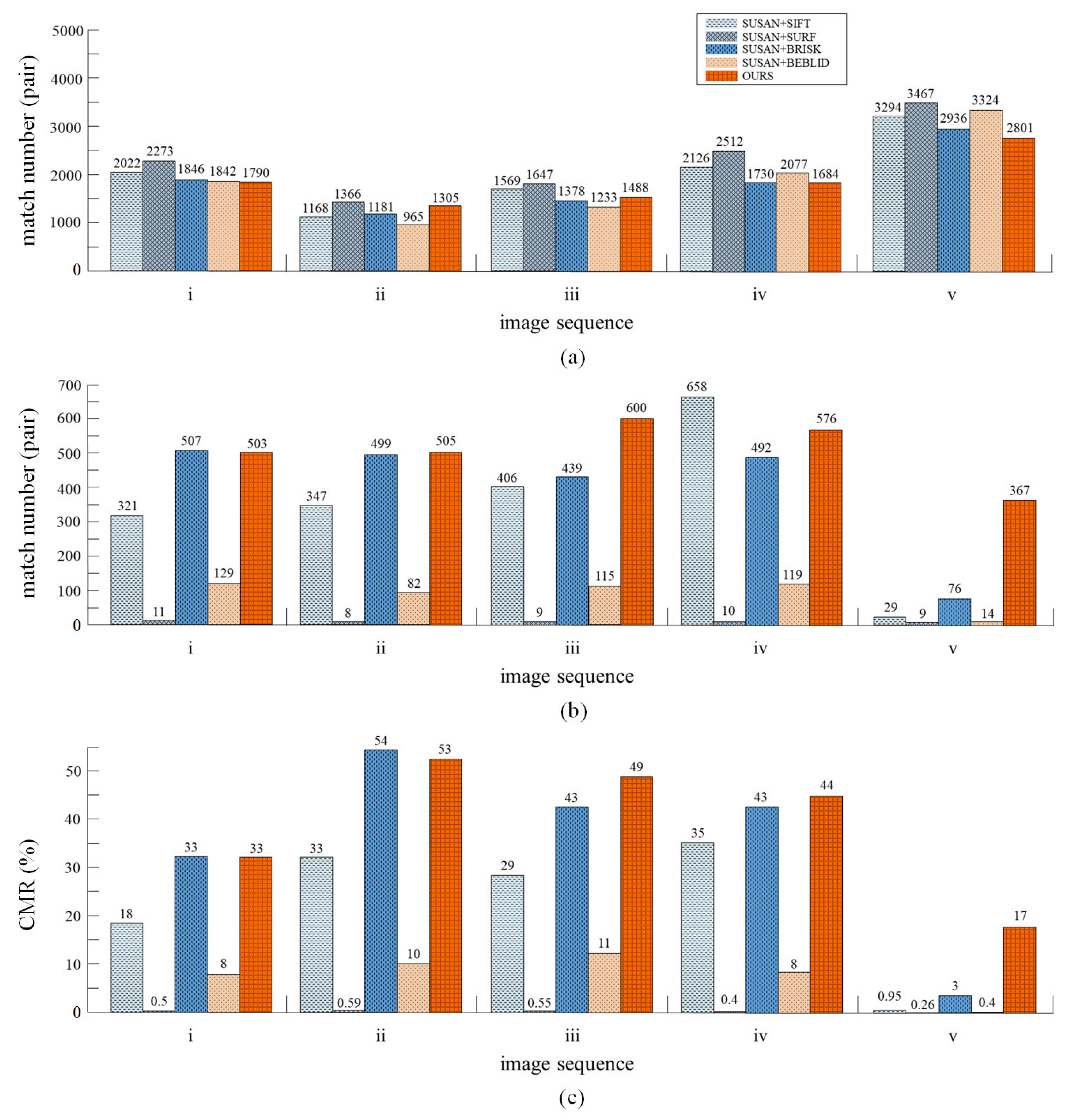
The performance of the proposed multi-scale descriptor is evaluated against some of the most relevant methods such as SIFT, SURF, BRISK, and BEBLID. As already mentioned, matching experiments of descriptors, on the humanoid-eye binocular images captured by our equipment, were carried out, some of the test images are shown in
Figure 7. For fairness, the SUSAN detector is used in the feature point detection, and the subsequent removal procedures are consistent with our method. The evaluation index
CMR (correct matching rate), is utilized to evaluate the proposed descriptor. The definition of
CMR is as follows:
where
is the number of matches in the refined-matching stage and
is the number of matches in the coarse-matching stage. With this metric, a higher
CMR value corresponds to a better matching quality. The comparison of the results is displayed in
Figure 8.
Based on the results, it can be seen that, although the total number of feature pairs generated by the multi-scale descriptor (proposed work) is somewhat less than with other descriptors, more correct matching pairs can be produced in the final matching results. The multi-scale descriptor can generate an average of 510 accurate corresponding pairs, among five pairs of test images. The second highest average is BRISK and the third highest average is SIFT, which generate an average of 403 feature pairs and 352 feature pairs, respectively. The results in
Figure 8c, show that the multi-scale descriptor produces the highest average CMR, with 39.2% in all image sequences. The second highest average is BRISK, followed by SIFT, BEBLID, and SURF. Specifically, the multi-scale descriptor obtains a higher average CMR, than the BRISK and SIFT descriptors, with 4% and 16.01%, respectively.
As mentioned above, the proposed method reduces the total number of matches, as well as the number of incorrect matches. This is primarily due to the introduction of the image pyramid model when constructing descriptors, which generates the multi-scale information for descriptors, to significantly enhance the anti-interference ability of matching and restrict the matching between unreliable feature points. The results show that, our method is capable of increasing the number of accurate corresponding pairs in humanoid-eye binocular images.
Besides comparing the
CMR values of the above five methods, the second evaluation of the proposed descriptor is to use the metric known as recognition rate [
15], on the HPatches dataset. It can be computed following these steps:
- (1)
The SUSAN detector is used to extract N points in the first image of an image sequence in all tests. Then, these N points are projected to the remaining five images.
- (2)
Matching the first image with the remaining five images in each image sequence. To adjust the number of matches, the precision, , is considered, where TP is the number of correct matches and MP is the number of constructed matches.
- (3)
The recognition rate is defined as:
[
15]. It indicates the ratio of the number of correct matches to the number of feature points.
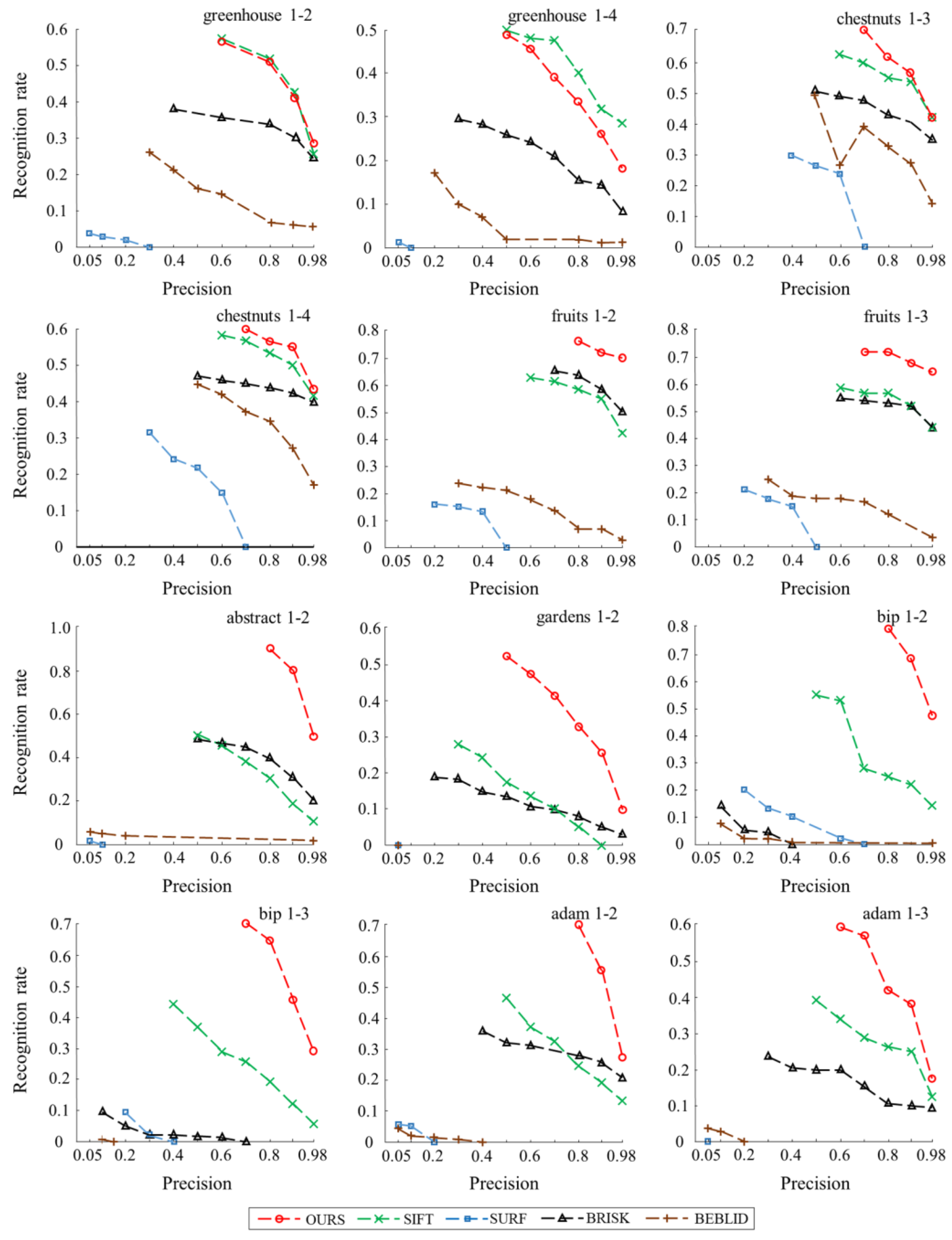
The plots in
Figure 9 show the recognition rate curves for each descriptor on seven image sequences chosen from the HPatches dataset. Based on these comparison results, in three image sequences (greenhouse, chestnuts, fruits), where illumination change exists, the recognition rate of the multi-scale descriptor (proposed work) is better than other descriptors, except in the greenhouse sequence. In four image sequences (abstract, gardens, bip, adam), where significant viewpoint change exists, our descriptor outperforms all others under different precision.
It is worth noting, that having a high recognition rate is not always beneficial. A higher recognition rate leads to lower precision, which produces an excessive number of mismatches. In this case, it can be observed that the lowest precision produced by the multi-scale descriptor is higher than that of the other descriptors in all image sequences. The average lowest precision is increased by 0.16 and 0.3, compared to the second best (SIFT) and third best (BRISK) descriptors. In other words, our approach can maintain high accuracy even when the recognition rate is high.
The other descriptors perform less well, especially SURF and BEBLID, possibly because (1) the performances of the descriptors are influenced by the SUSAN detector, and (2) we do not perform any data training for these approaches, and merely use the functions in the OpenCV library when testing descriptors.
Finally, the run time of the proposed multi-scale descriptor and other descriptors mentioned above are measured on the humanoid-eye binocular images, as shown in
Table 1. These values have been averaged for five pairs of humanoid-eye binocular images. Compared with other famous descriptors, the multi-scale descriptor requires more calculation time than others, since it is computed on four different scales, while other descriptors are constructed on a single scale. In future research, we will investigate how to reduce the computational cost.
4.3. Evaluation of the Overall Algorithm
For evaluating the overall performance of the proposed algorithm, three state-of-the-art methods: GMS [
32], SuperGlue [
33], and DFM [
34], are chosen for comparison. GMS is a method that converts motion smoothness into statistical problems, to identify false matches, significantly improving efficiency and robustness. SuperGlue, a deep learning technique, is able to reason about the underlying 3D scene and feature assignments jointly, by using a graph neural network. DFM aligns images with coarse geometric transformation estimates, and then applies a coarse-to-fine strategy, to achieve better localization and matching performance.
The overall performance of the proposed method is measured by the pixel-wise distances between the matched features and their ground truth projections on the pair images. Homography matrix estimation tasks are conducted on humanoid-eye binocular images. For these tasks, following Xia’s work [
35], homography error is considered, which adopts RANSAC as the estimator to derive the geometric model. In this case, a corresponding estimated homography is identified as accurate when its homography error is less than three pixels, and the accuracy (Acc.) is utilized as the evaluation metric for geometric estimation, which represents the ratio of accurate estimates to all estimates. In addition, the specific projection errors (Proj.) are also reported, for intuitive analysis. These values have been averaged for all test images. The quantitative results regarding the four compared methods are presented in
Table 2.
Based on these results, our method has the best performance on two metrics (Acc. and Proj.), producing the highest accuracy and the lowest projection error, 96.13 and 1.63, respectively. These results demonstrate the superiority of our approach relative to other state-of-the-art feature matching algorithms.
To further exploit the practical value of our method, the HPatches dataset is used for testing. The pixel distance errors between estimated and ground truth projections of the points are calculated as three evaluation criteria: maximum, mean, and variance. These values have been averaged for the HPatches dataset. We report the results of these three metrics on image sequences with illumination changes and image sequences with viewpoint changes, as shown in
Table 3.
As the comparison results in
Table 3 show, compared with other algorithms, the proposed method achieves the best matching accuracy in both image sequences (illumination changes and viewpoint changes). From the fourth and seventh columns of
Table 3, it can be seen that our method produces the lowest variance of distance errors, which means that it can effectively remove the majority of incorrect matching pairs and significantly improve the matching stability.
In addition to quantitative analysis, we also performed visual tests on the HPatches dataset.
Figure 10 shows the positions of feature points from matching pairs on reference images. From the yellow boxes marked in
Figure 10, the distribution of feature pairs can be analyzed more intuitively. Compared to GMS and SuperGlue, the proposed method produces more corresponding pairs, especially edge pairs, significantly enhancing the ability to describe image outline information. Note that, although DFM generates the most matching pairs, the majority of these are clustered together, and so have little impact on the feature matching. This is due to the fact that, for some textures of an image, only a few features are enough to describe the details, and redundant features inevitably increase the computational complexity. On the contrary, the matching pairs produced by our method are evenly distributed. It not only obtains sufficient edge features but also extracts feature points, to describe details in the flat area, which can better satisfy the characteristics of human vision. Based on these results, it is shown that the proposed method is competitive with, and better than some of, the state-of-the-art algorithms.
5. Conclusions
Aiming at the visual characteristic that human eyes are more sensitive to edge information, we propose a matching method, based on the SUSAN–SIFT algorithm, for humanoid-eye binocular images. To detect corner points and edge points at the same time, we conduct comparisons among several popular detectors and select the SUSAN operator for feature detection. On this basis, the novel descriptor, with multi-scale information, is proposed for feature description. To improve the matching accuracy, refinement procedures are designed to remove mismatches. The results, based on quantitative and qualitative analyses, show that the proposed approach is capable of retaining edge information and improving the accuracy of corresponding pairs, compared with several state-of-the-art methods.
Even though our method has shown significant advantages over several state-of-the-art methods, in terms of the effectiveness of producing edge corresponding pairs, accuracy of feature matching, and robustness to illumination variations, it has a worse computational efficiency compared to other methods. This is because the proposed multi-scale descriptor is computed on four different scales, while other descriptors are constructed on a single scale. Consequently, how to construct descriptors on a single scale with main gradient information will be investigated in further research, which can reduce calculation time.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}