Moving Object Detection and Tracking by Event Frame from Neuromorphic Vision Sensors


Abstract
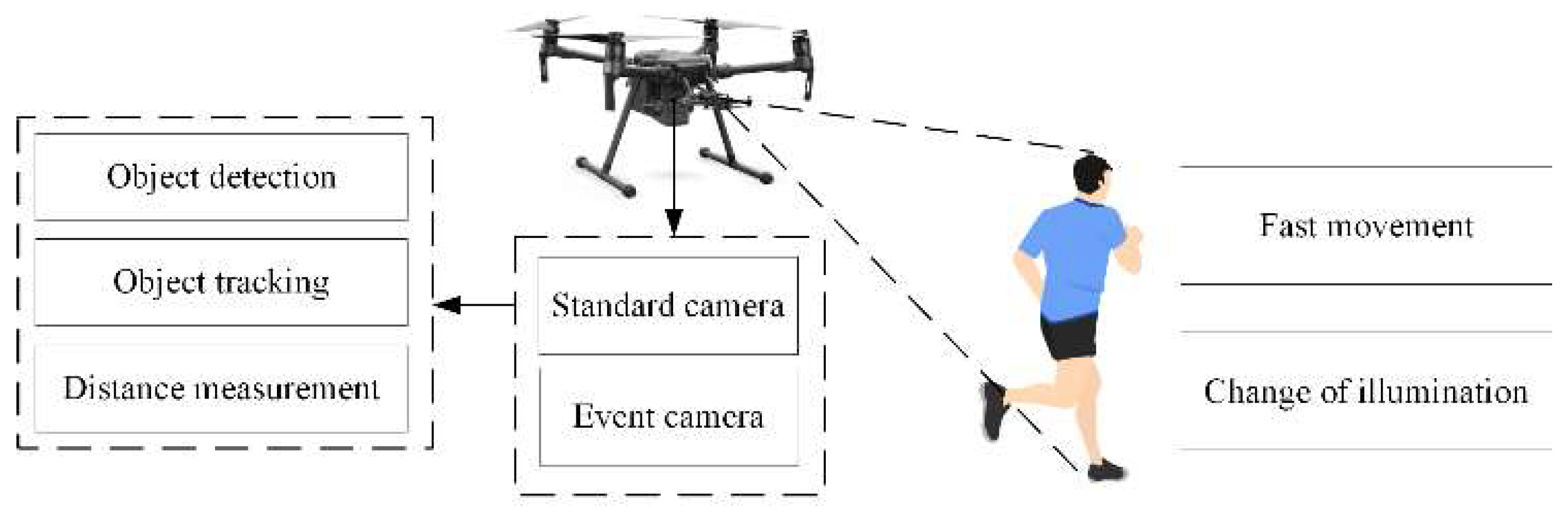
:1. Introduction
- This paper proposes a detection method that combines the event frame from neuromorphic vision sensors and the standard frame to improve the effect of fast object movement or large changes in illumination.
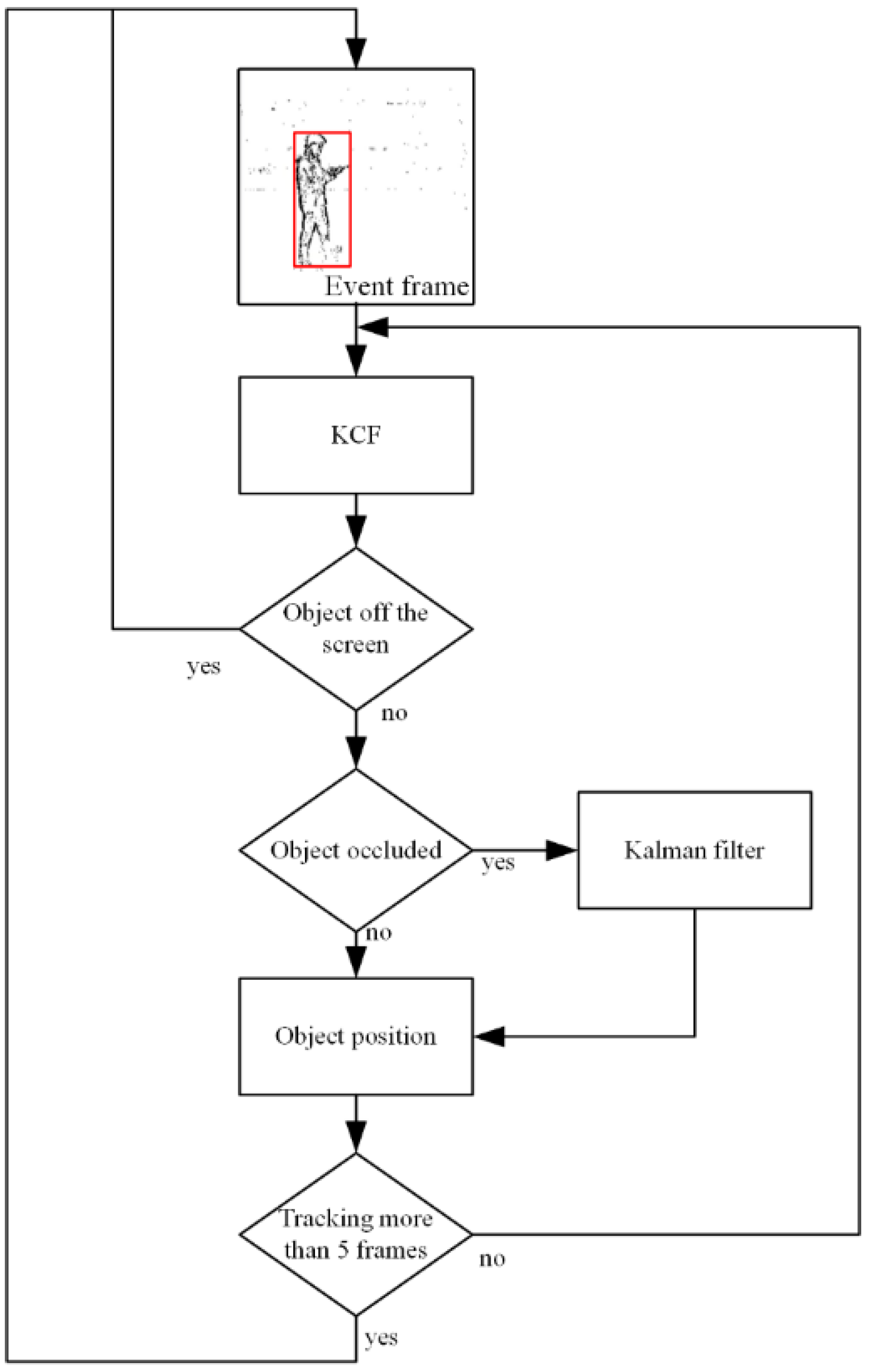
- It uses the improved kernel correlation filter (KCF) algorithm for event frame tracking to solve the problem of missed detection.
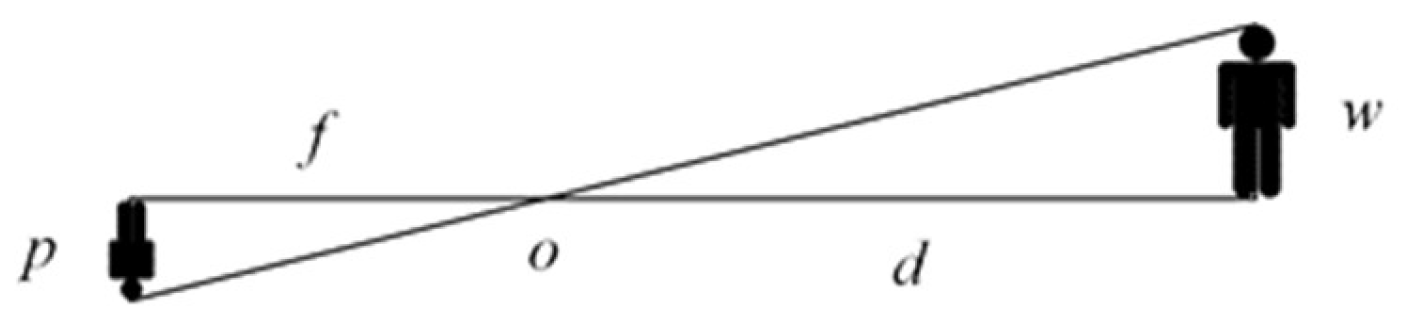
- It proposes an event frame-based distance measurement method to obtain the distance information of the object.
2. Materials and Methods
2.1. YOLO Algorithm
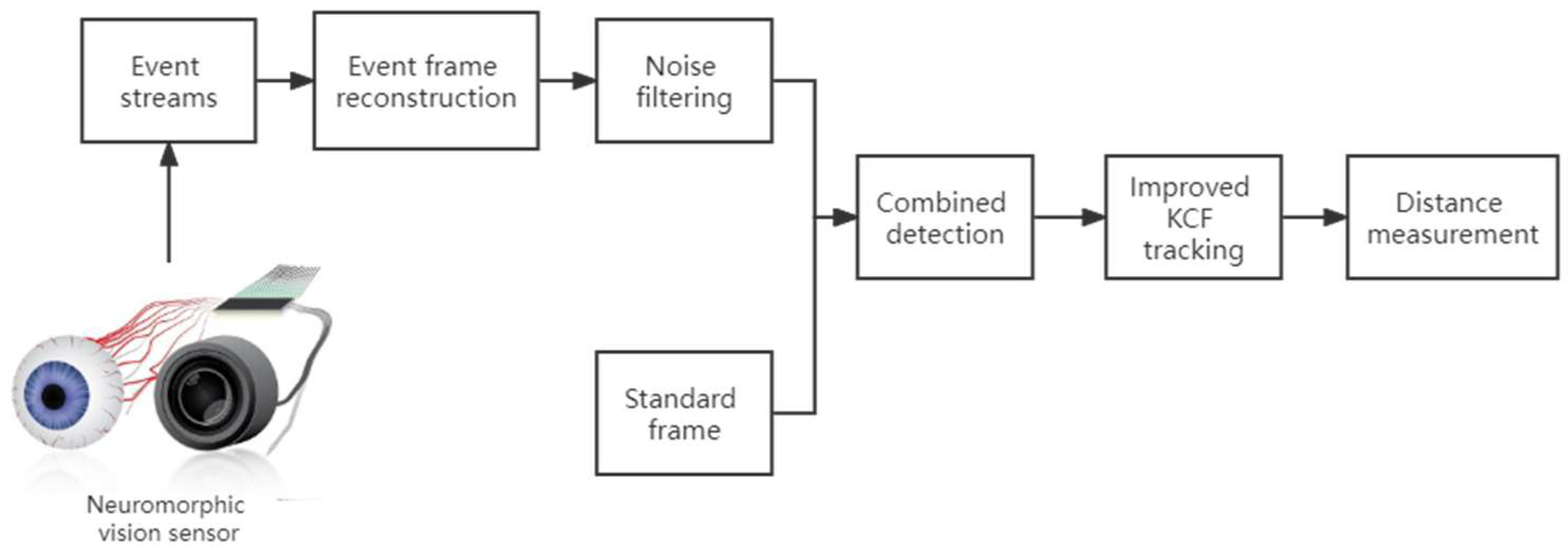
2.2. Framework of Event Frame-Based Object Detection and Tracking
2.3. Event Frame Pre-Processing
2.3.1. Event Frame Reconstruction
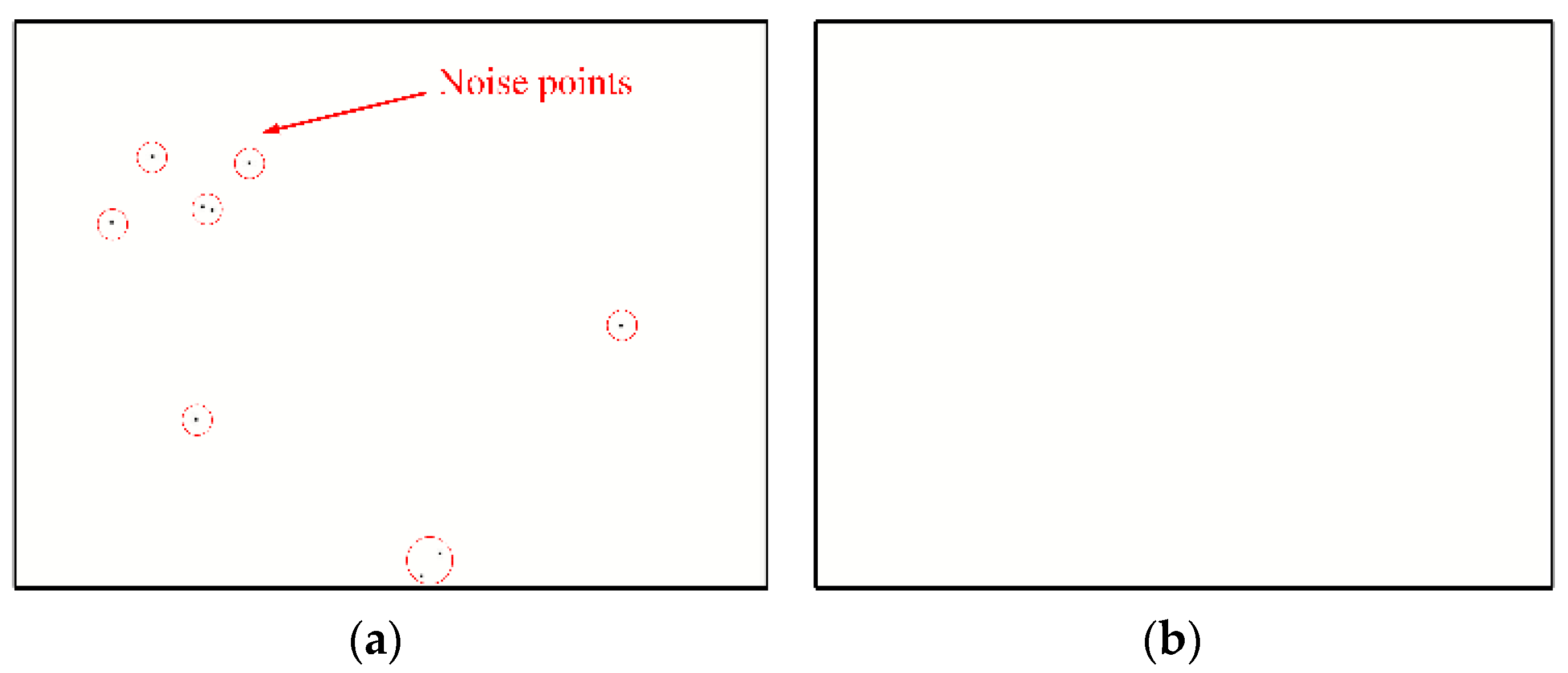
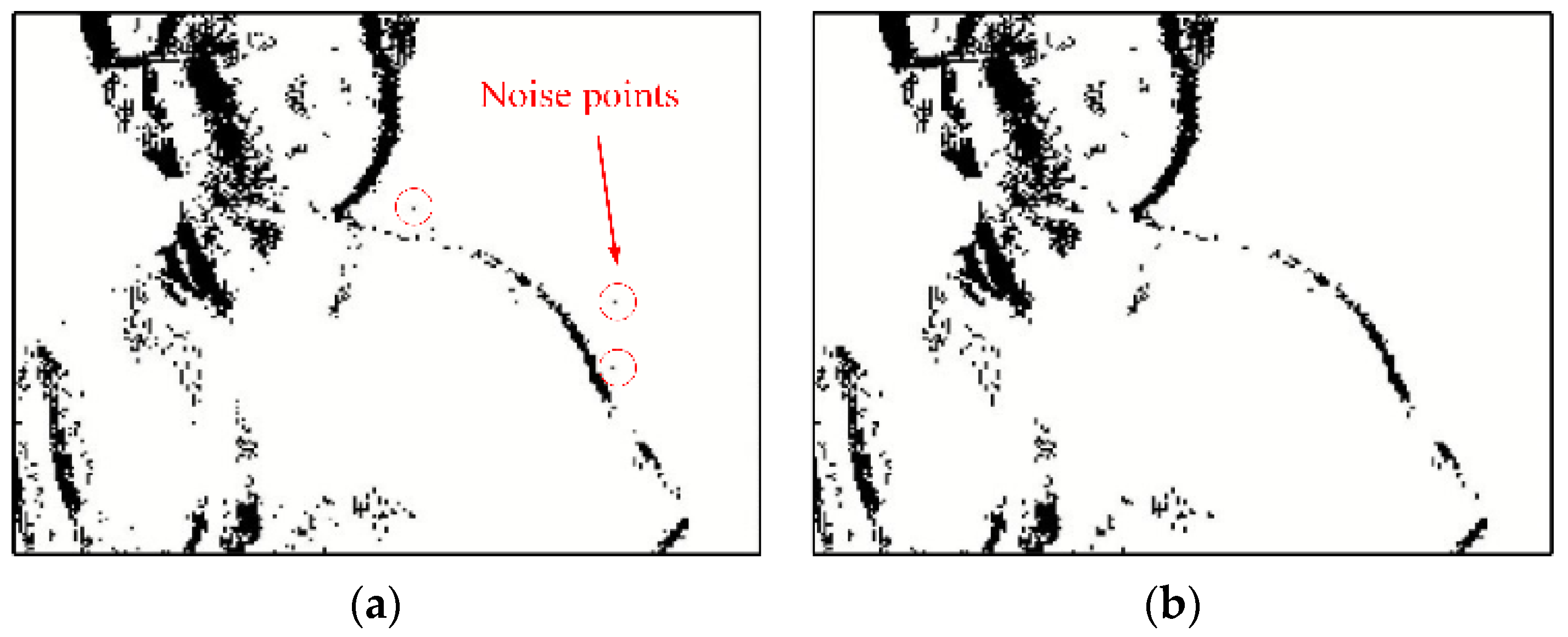
2.3.2. Noise Filtering for Dynamic Vision Sensors
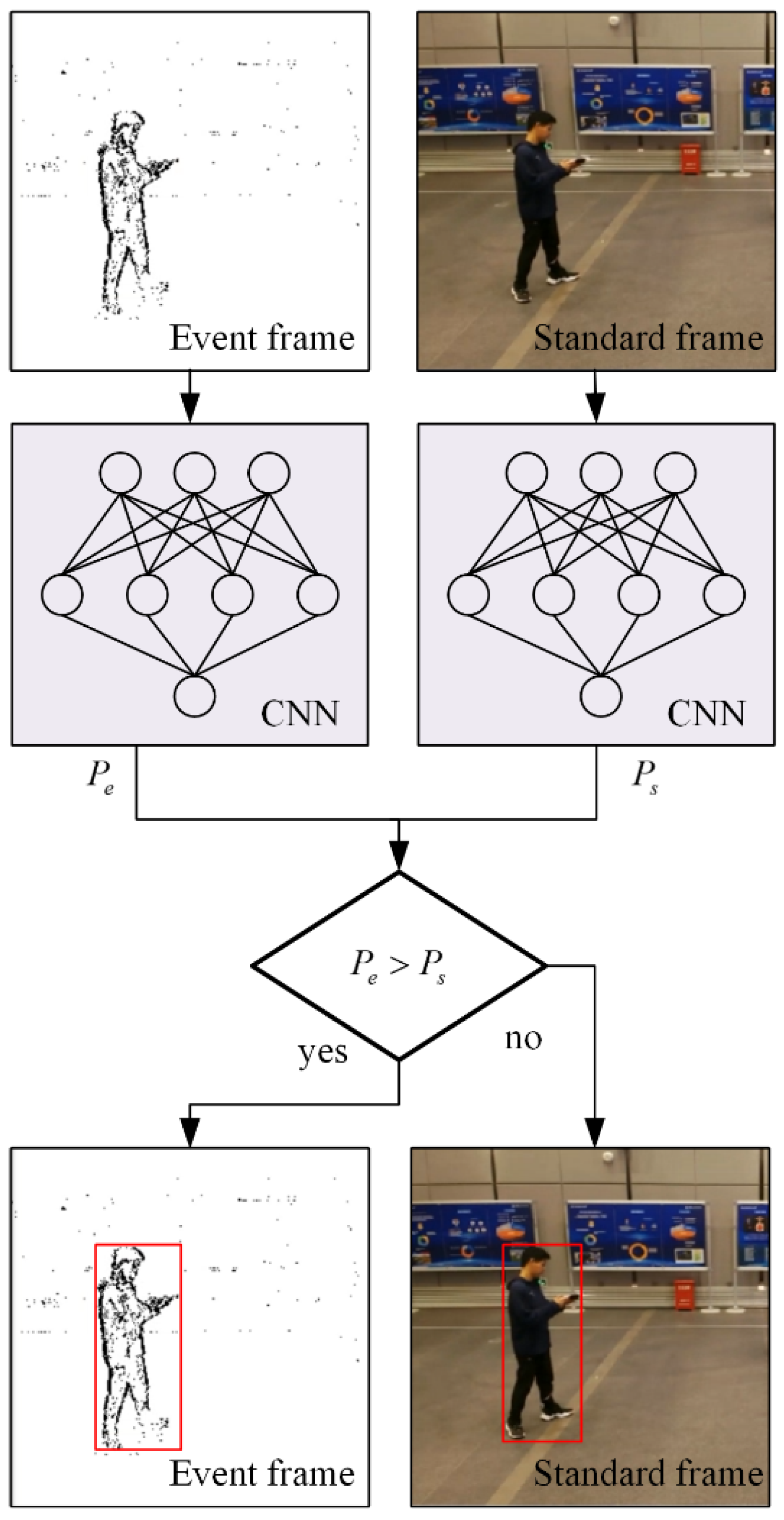
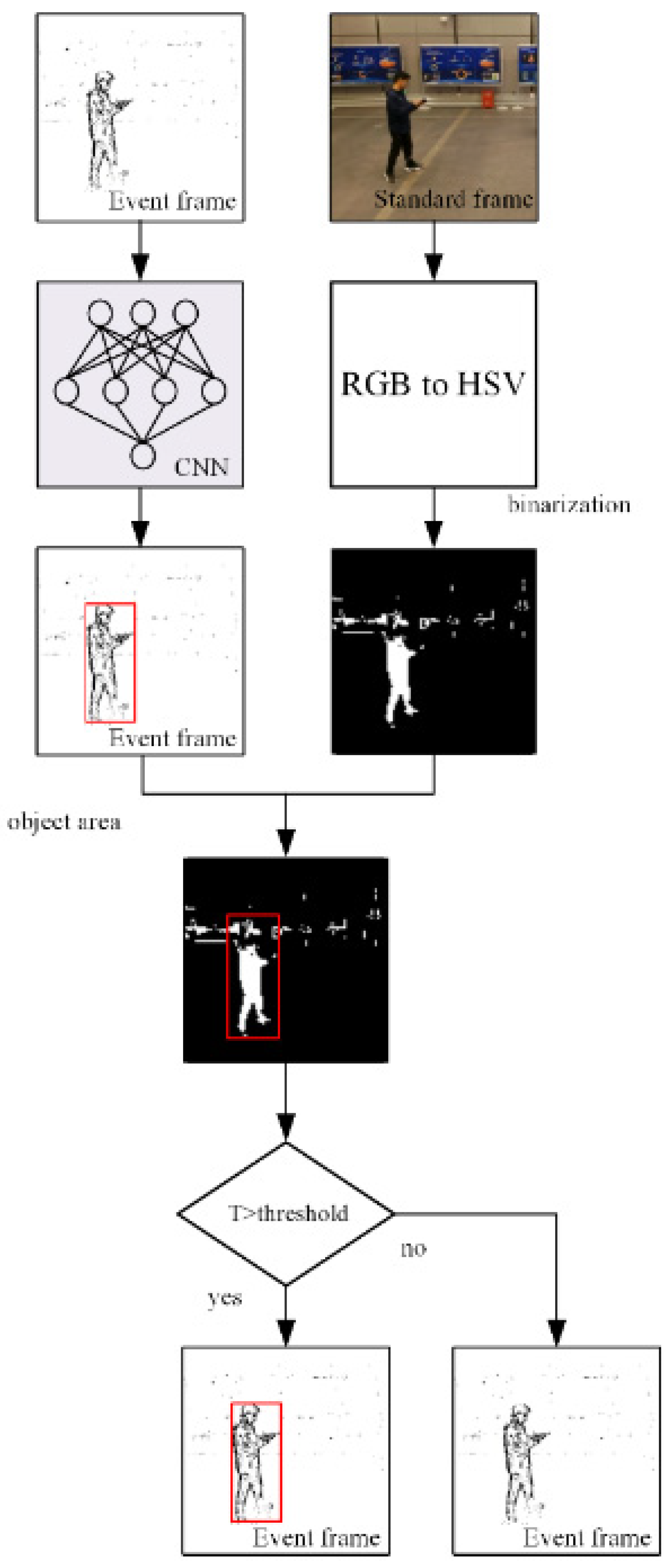
2.4. Combined Detection Based on Event Frame and Standard Frame
2.4.1. Detection Based on Probability
2.4.2. Detection Based on Color
2.5. Event Frame-Based Tracking by Improved KCF
2.5.1. Training Phase
- (1)
- Linear regression
- (2)
- Linear regression under discrete Fourier transform
- (3)
- Linear regression in kernel space
2.5.2. Detecting Phase
- (1)
- Fast detection
- (2)
- Fast calculation of kernel matrix
2.6. Event Frame-Based Distance Measurement
3. Results
3.1. Object Detection
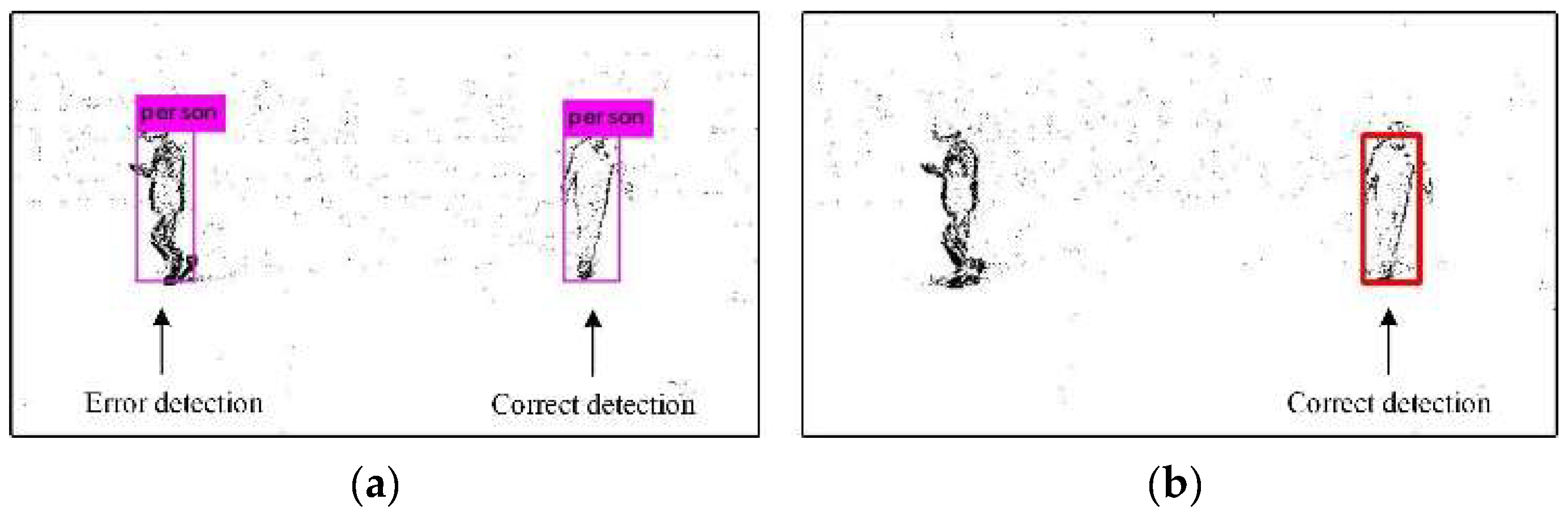
3.1.1. Combined Detection Based on Probability
3.1.2. Combined Detection Based on Color
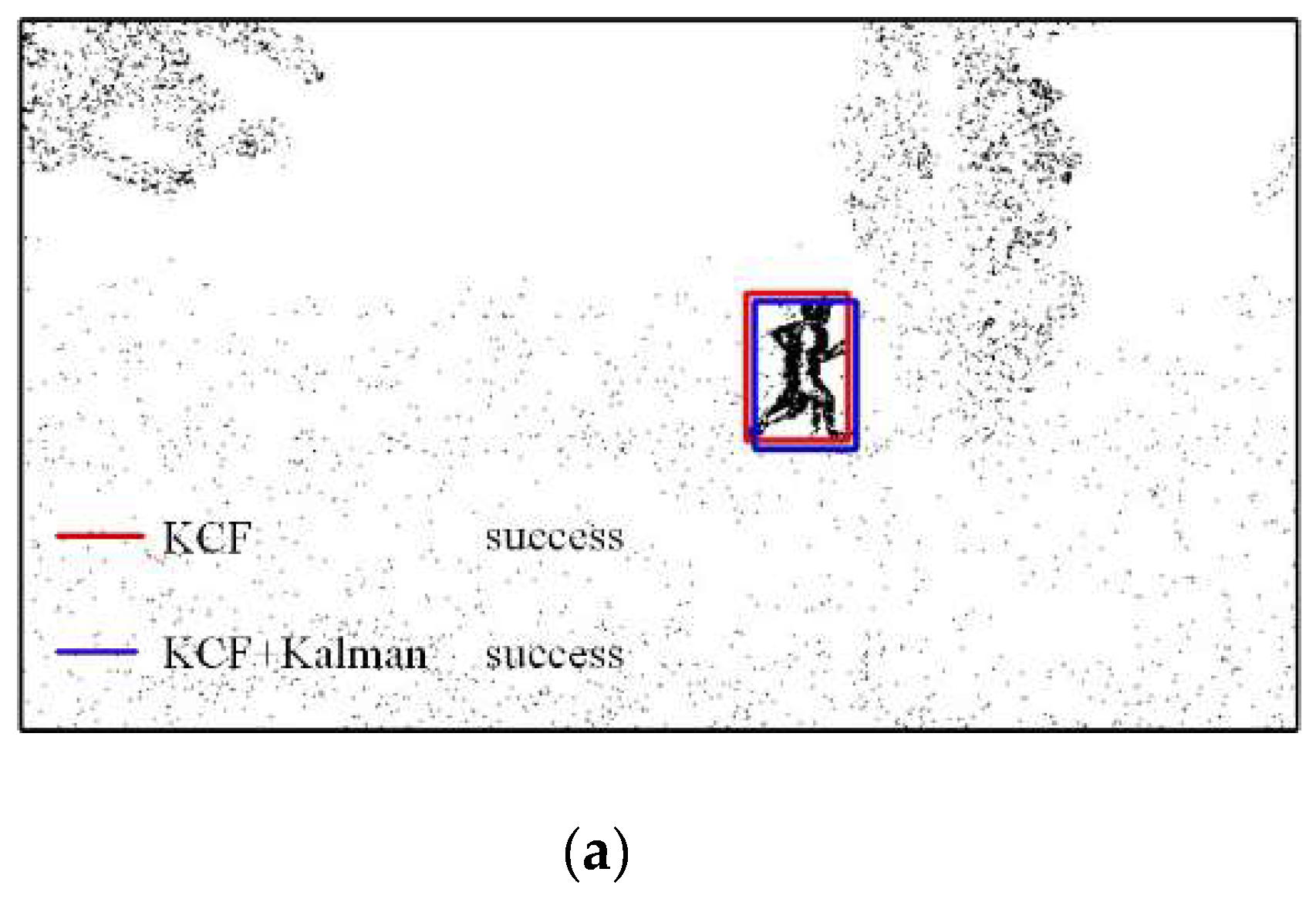
3.2. Object Tracking
3.3. Distance Measurement
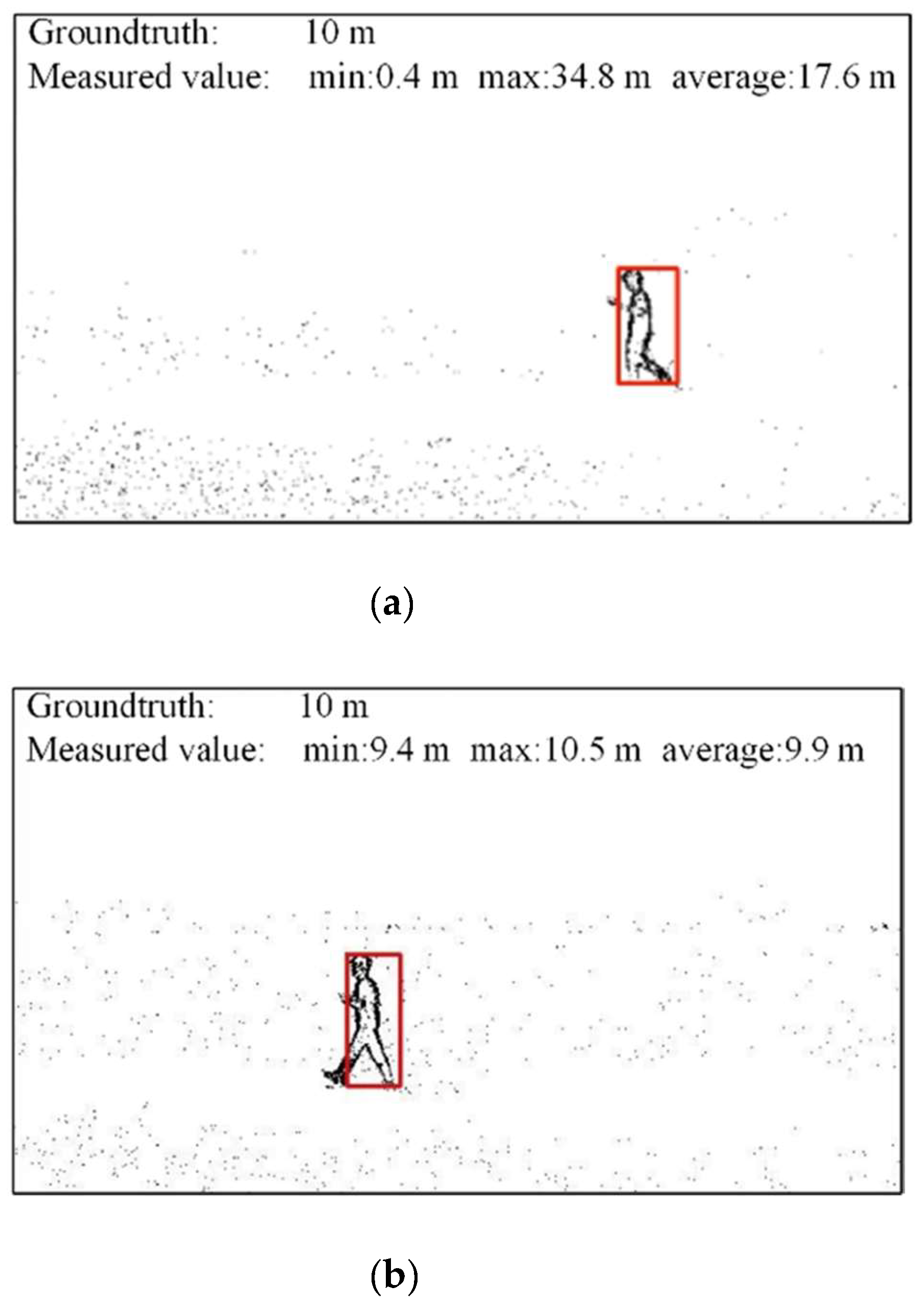
3.3.1. Comparison of PnP and Similar Triangle Distance Measurements
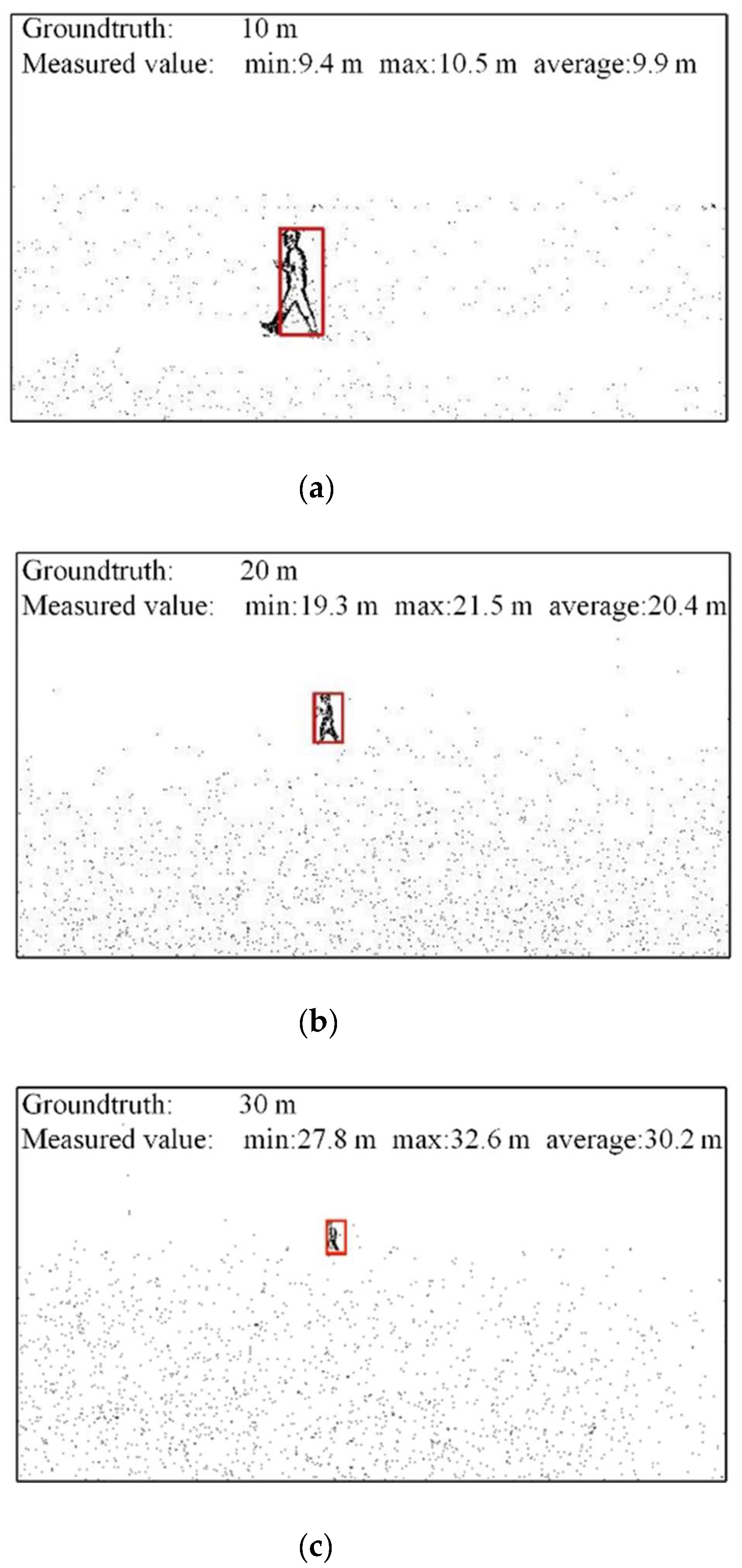
3.3.2. Performance of Similar Triangle Distance Measurement
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Liu, Z.; Kandhari, A.; Daltorio, K.A. Obstacle Avoidance Path Planning for Worm-like Robot Using Bézier Curve. Biomimetics 2021, 6, 57. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Wang, X.; Zhou, A. UAV-YOLO: Small object detection on unmanned aerial vehicle perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Tan, J. A novel UAV-enabled data collection scheme for intelligent transportation system through UAV speed control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2100–2110. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, H.; Hou, S. A survey on 5G millimeter wave communications for UAV-assisted wireless networks. IEEE Access 2019, 7, 117460–117504. [Google Scholar] [CrossRef]
- Park, J.; Lee, H.; Eom, S. UAV-aided wireless powered communication networks: Trajectory optimization and resource allocation for minimum throughput maximization. IEEE Access 2019, 7, 134978–134991. [Google Scholar] [CrossRef]
- Eun, H.K.; Ki, H.K. Efficient implementation of the ML estimator for high-resolution angle estimation in an unmanned ground vehicle. IET Radar Sonar Navig. 2018, 12, 145–150. [Google Scholar]
- Kelechi, A.H.; Alsharif, M.H.; Oluwole, D.A.; Achimugu, P.; Ubadike, O.; Nebhen, J.; Aaron-Anthony, A.; Uthansakul, P. The Recent Advancement in Unmanned Aerial Vehicle Tracking Antenna: A Review. Sensors 2021, 21, 5662. [Google Scholar] [CrossRef]
- Song, S.; Liu, J.; Guo, J.; Wang, J.; Xie, Y.; Cui, J. Neural-Network-Based AUV Navigation for Fast-Changing Environments. IEEE Internet Things J. 2020, 7, 9773–9783. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y. Object detection in 20 years: A survey. arXiv Prepr. 2019, arXiv:1905.05055. [Google Scholar]
- Viola, P.; Jones, M.J. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. I-511–I-518. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. Comput. Vis. Pattern Recognit. 2005, 1, 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. Comput. Vis. 1999, 2, 1150–1157. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Y.; Tian, Z.; Yu, J. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. Eur. Conf. Comput. Vis. 2014, 346–361. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Liu, S.; Liu, D.; Srivastava, G. Overview and methods of correlation filter algorithms in object tracking. Complex Intell. Syst. 2021, 7, 1895–1917. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, J.; Wang, J. Visual object tracking based on residual network and cascaded correlation filters. J. Ambient. Intell. Humaniz. Comput. 2020, 12, 1–14. [Google Scholar] [CrossRef]
- Mehmood, K.; Jalil, A.; Ali, A.; Khan, B.; Murad, M.; Cheema, K.M.; Milyani, A.H. Spatio-Temporal Context, Correlation Filter and Measurement Estimation Collaboration Based Visual Object Tracking. Sensors 2021, 21, 2841. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Ma, C.; Huang, J.-B.; Yang, X.; Yang, M.-H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.-H. Hedged deep tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H. Deep learning for visual tracking: A comprehensive survey. IEEE Trans. Intell. Transp. Syst. 2021; in press. [Google Scholar] [CrossRef]
- Zhang, D.; Guo, J.; Lei, X.; Zhu, C. A High-Speed Vision-Based Sensor for Dynamic Vibration Analysis Using Fast Motion Extraction Algorithms. Sensors 2016, 16, 572. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Gao, J.; Tian, Y.; Yu, F.; Feng, Z. SAFS: Object Tracking Algorithm Based on Self-Adaptive Feature Selection. Sensors 2021, 21, 4030. [Google Scholar] [CrossRef]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.-H. Robust visual tracking via convolutional networks without training. IEEE Trans. Image Processing 2016, 25, 1779–1792. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, S.; Xu, C.; Yan, S.; Ghanem, B.; Ahuja, N.; Yang, M.-H. Structural sparse tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 150–158. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Ahmad, T.; Ma, Y.; Yahya, M. Object detection through modified YOLO neural network. Sci. Program. 2020, 2020, 8403262. [Google Scholar] [CrossRef]
- Loey, M.; Manogaran, G.; Taha, M.H.N. Fighting against COVID-19: A novel deep learning model based on YOLO-v2 with ResNet-50 for medical face mask detection. Sustain. Cities Soc. 2021, 65, 102600. [Google Scholar] [CrossRef] [PubMed]
- Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Monitoring COVID-19 social distancing with person detection and tracking via fine-tuned YOLO v3 and Deepsort techniques. arXiv Prepr. 2020, arXiv:2005.01385. [Google Scholar]
- Duan, K.; Xie, L.; Qi, H. Corner proposal network for anchor-free, two-stage object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. Part III 16. [Google Scholar]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Ge, R.; Ding, Z.; Hu, Y. Afdet: Anchor free one stage 3d object detection. arXiv Prepr. 2020, arXiv:2006.12671. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nos. | Experiments Content |
|---|---|
| 1 | Object detection experiments |
| 2 | Tracking experiments |
| 3 | Distance measurement experiments |
| Parameters or Methods | Values or Implementations |
|---|---|
| Size of YOLOv3 dataset | 271 |
| mAP of YOLOv3 | 0.993 |
| Iteration of YOLOv3 | 100 |
| Size of detection experiment dataset | 121 |
| Event frame generating method | Consider event polarity, and ignore trigger times |
| Frame filter | nearest neighbor filter |
| Filter threshold L | 1 |
| Combine detection threshold T | 0.3 |
| Total Number of Frames | Number of Event Frame-Based Detection | Number of Standard Frame-Based Detection | Number of Combined Detection |
|---|---|---|---|
| 121 | 56 | 39 | 87 |
| Parameters or Methods | Values or Implementations |
|---|---|
| Size of tracking experiment dataset | 215 |
| Event frame generating method | Consider event polarity, and ignore trigger times |
| Frame filter | nearest neighbor filter |
| Filter threshold L | 1 |
| KCF peak value threshold | 0.3 |
| Total Number of Frames | Number of Frames by KCF Algorithm | Number of Frames by Improved KCF Algorithm |
|---|---|---|
| 20 | 13 | 20 |
| Methods | True Values | Minimum Measured Values | Maximum Measured Values | Average Measured Values |
|---|---|---|---|---|
| PnP | 10 m | 0.4 m | 34.8 m | 17.6 m |
| Similar triangle | 10 m | 9.4 m | 10.5 m | 9.9 m |
| True Values | Minimum Measured Values | Maximum Measured Values | Average Measured Values |
|---|---|---|---|
| 10 m | 9.4 m | 10.5 m | 9.9 m |
| 20 m | 19.3 m | 21.5 m | 20.4 m |
| 30 m | 27.8 m | 32.6 m | 30.2 m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Ji, S.; Cai, Z.; Zeng, Y.; Wang, Y. Moving Object Detection and Tracking by Event Frame from Neuromorphic Vision Sensors. Biomimetics 2022, 7, 31. https://doi.org/10.3390/biomimetics7010031
Zhao J, Ji S, Cai Z, Zeng Y, Wang Y. Moving Object Detection and Tracking by Event Frame from Neuromorphic Vision Sensors. Biomimetics. 2022; 7(1):31. https://doi.org/10.3390/biomimetics7010031
Chicago/Turabian StyleZhao, Jiang, Shilong Ji, Zhihao Cai, Yiwen Zeng, and Yingxun Wang. 2022. "Moving Object Detection and Tracking by Event Frame from Neuromorphic Vision Sensors" Biomimetics 7, no. 1: 31. https://doi.org/10.3390/biomimetics7010031
APA StyleZhao, J., Ji, S., Cai, Z., Zeng, Y., & Wang, Y. (2022). Moving Object Detection and Tracking by Event Frame from Neuromorphic Vision Sensors. Biomimetics, 7(1), 31. https://doi.org/10.3390/biomimetics7010031