
A Comprehensive Review of Multimodal Emotion Recognition: Techniques, Challenges, and Future Directions


Abstract
1. Introduction
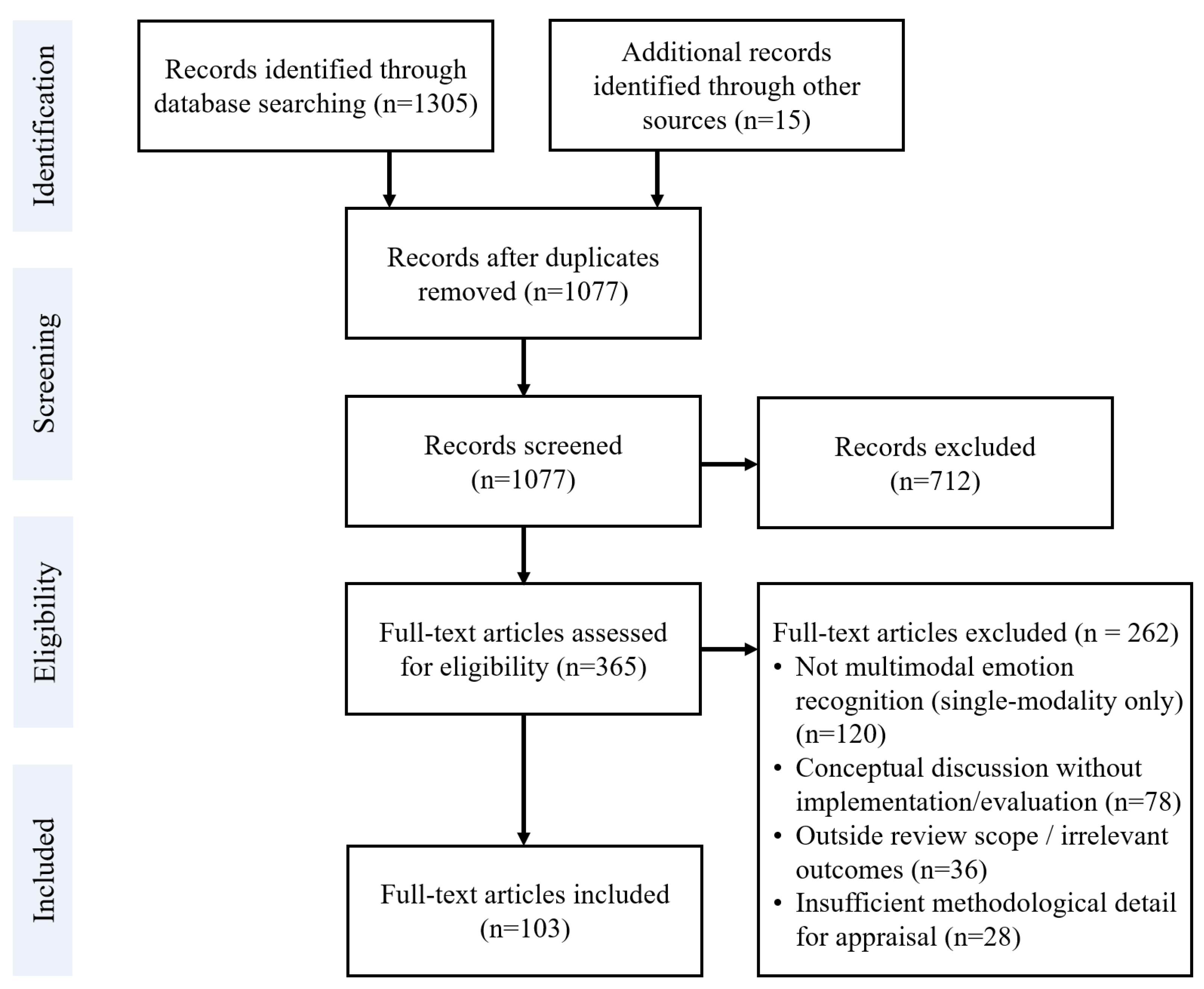
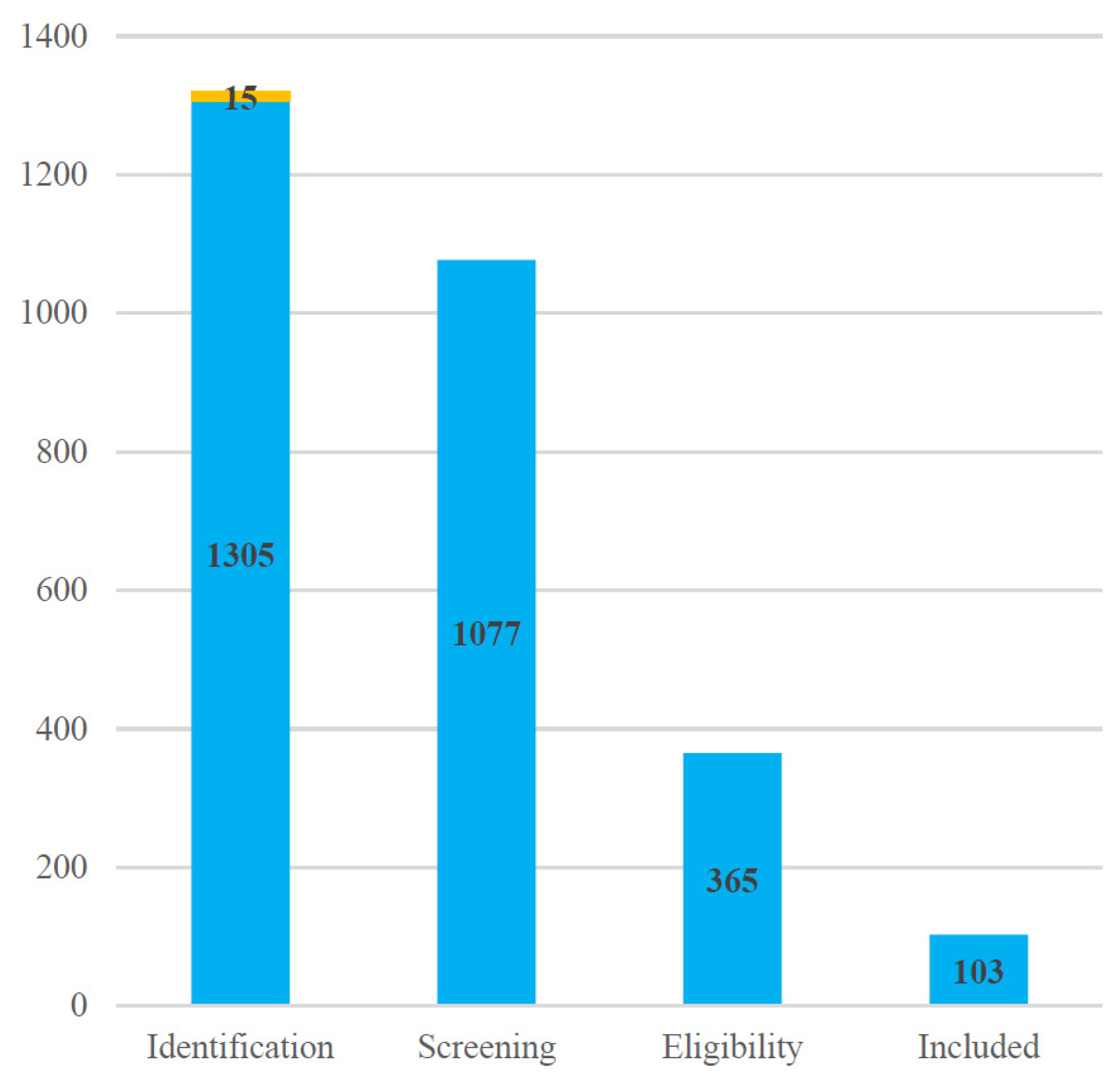
2. Literature Search and Selection Methodology
- Published in English and appearing in a peer-reviewed journal or conference proceedings.
- Focused on multimodal emotion recognition or a closely related domain (e.g., emotion-aware human–robot interaction or affective computing with multiple modalities).
- Presented original research results (not purely theoretical or editorial content).
- Not peer-reviewed (e.g., preprints without formal review, theses, magazine articles).
- Not available in English or full text could not be obtained.
- Not focused on MER (the study’s scope was outside multimodal emotion recognition, such as being limited to a single modality).
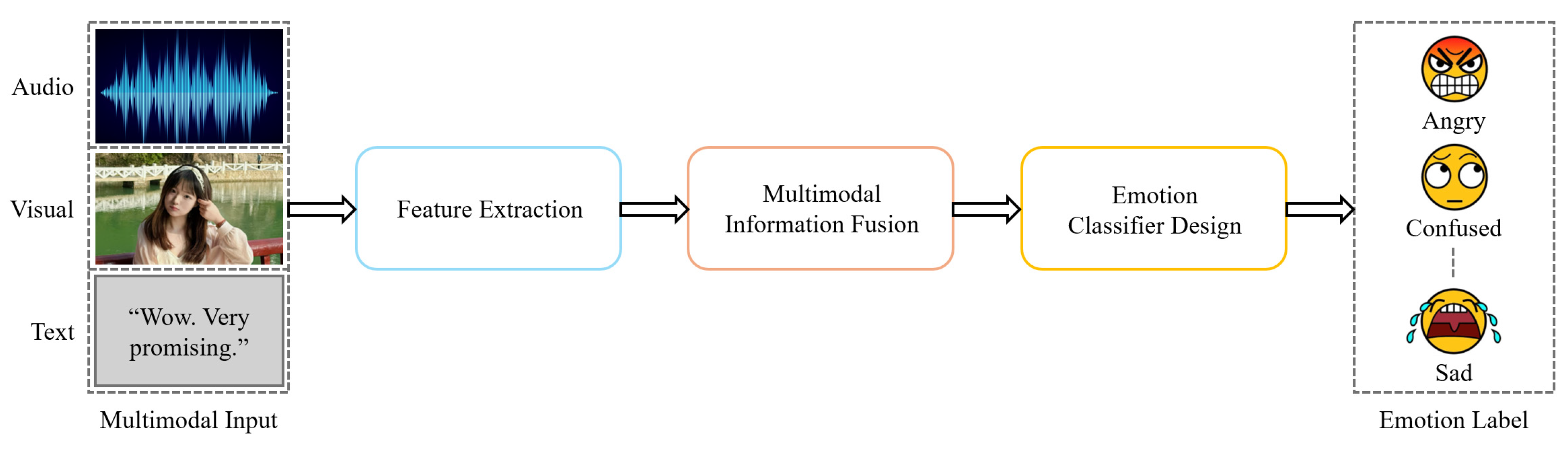
3. Overview of MER
3.1. General Structure of MER Systems
3.2. Emotion Recognition Milestones

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Milestone | Description | References |
|---|---|---|
| CNNs for feature extraction | Improved ability to analyze visual data such as facial expressions | [12,34] |
| RNNs for temporal dependencies | Enhanced accuracy by capturing temporal dependencies in data | [33,35] |
| Attention mechanisms | Improved interpretability and focus on relevant parts of the input data | [36,37] |
| Availability of large-scale datasets | Accelerated progress with better resources for training complex models | [9,38] |
| Multimodal transformers | Significant improvement in fusion and recognition accuracy | [32,39] |
| Real-time MER systems | Enabled implementation in interactive applications for immersive experiences | [33,40] |
3.3. Multimodal Emotion Datasets
| Method | Dataset | Modality | Emotion Label | Samples |
|---|---|---|---|---|
| CNN, RNN | GEMEP [41] | Audio, visual, physiological | Discrete emotions | 7200 |
| Transformer | K-EmoCon [42] | Speech, visual, physiological | Continuous emotions | 3200 |
| CNN, LSTM | IEMOCAP [43] | Audio, visual | Discrete and continuous | 12,000 |
| Large-scale model | AffectGPT [44] | Text, audio, visual | Discrete emotions | 5000 |
| Multi-view attention | MELD [45] | Audio, visual, text | Discrete emotions | 1400 |
| Deep learning | AVEC 2016 [46] | Audio, visual, physiological | Continuous emotions | 4000 |
| Physiological signals | DEAP [47] | Physiological, visual | Arousal and valence | 1280 |
3.4. Feature Extraction Techniques
| Type of Features | Feature Extraction Methods | Publications |
|---|---|---|
| Spectral | MFCC | [23,39] |
| Prosodic | Pitch, energy, speaking rate | [13,30,48] |
| Model-based | LPC | [44] |
| Frequency representation | Spectrogram analysis | [29] |
| Learned deep features | CNN/RNN automatic feature learning from raw audio | [11,49] |
| Input Type | Type of Features | Feature Extraction | Publications |
|---|---|---|---|
| Facial images | Landmark points | Facial landmark detection | [24,54] |
| Facial images | Gradient features | HOG | [40,50,55] |
| Facial images | Deep features | CNN | [41,42,51] |
| Motion patterns | Temporal dynamics | Optical flow | [38,43,52] |
| Full body/skeleton images | Pose keypoints | Body-pose estimation (OpenPose, HRNet, etc.) | [53,56] |
| Gesture sequences | Gesture trajectories | Skeleton-based gesture recognition (ST-GCN, 2s-AGCN, etc.) | [57,58] |
| Eye region/gaze data | Gaze direction and eye movement | Video/IR eye-tracking, pupil detection | [18,59] |
| Type of Features | Feature Extraction | Publications |
|---|---|---|
| Lexical features | Bag-of-words, TF-IDF | [39] |
| Semantic features | Word embeddings (Word2Vec, GloVe) | [44] |
| Contextual features | RNN, LSTM | [28,61,63] |
| Contextual sentiment | Transformer (BERT), sentiment lexicons | [45,46,49,62] |
| Self-supervised contextual | Fine-tuning large language models (RoBERTa, XLNet, GPT) | [64,65] |
| Prompt-based adaptation | Prompt learning/in-context tuning | [53,66] |
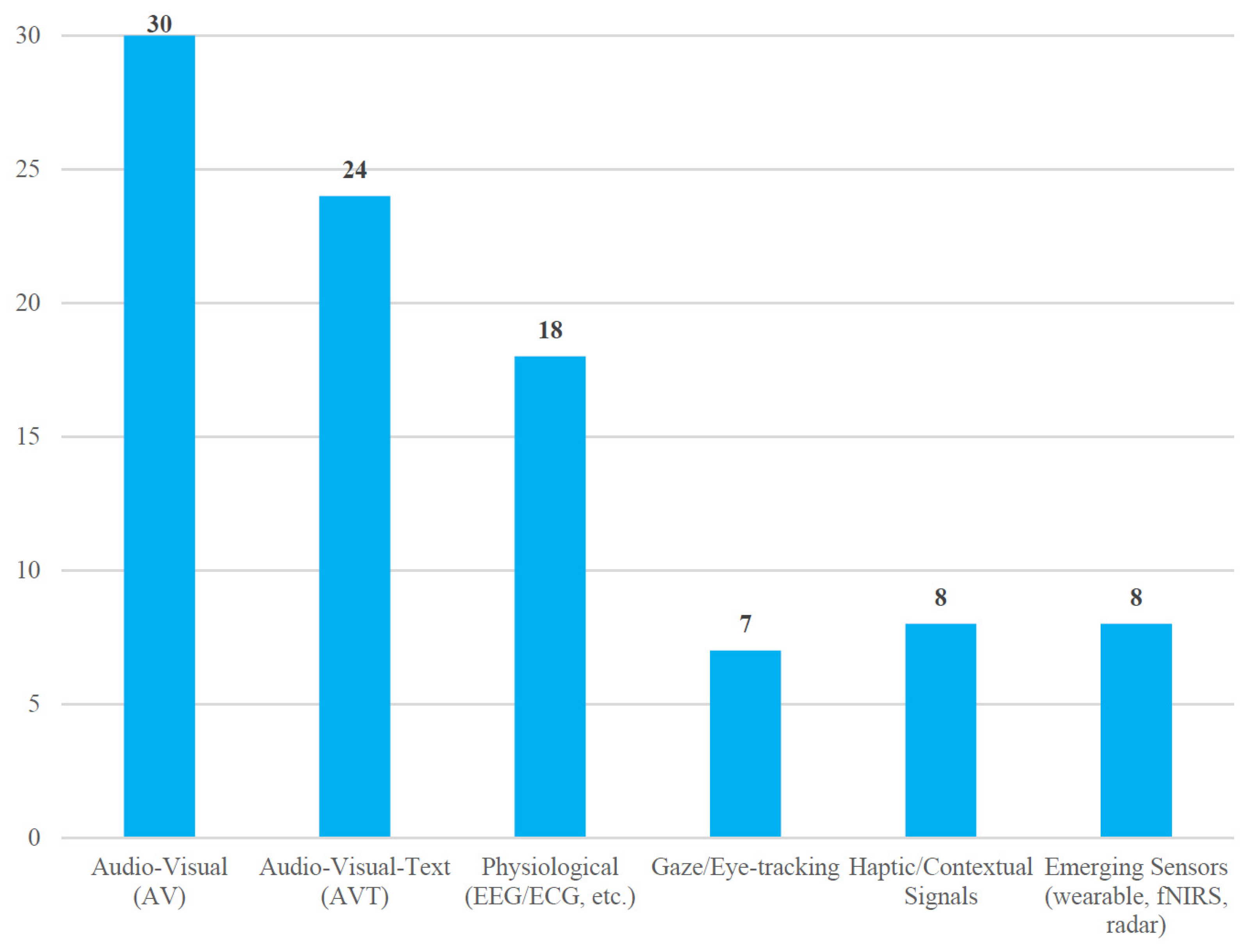
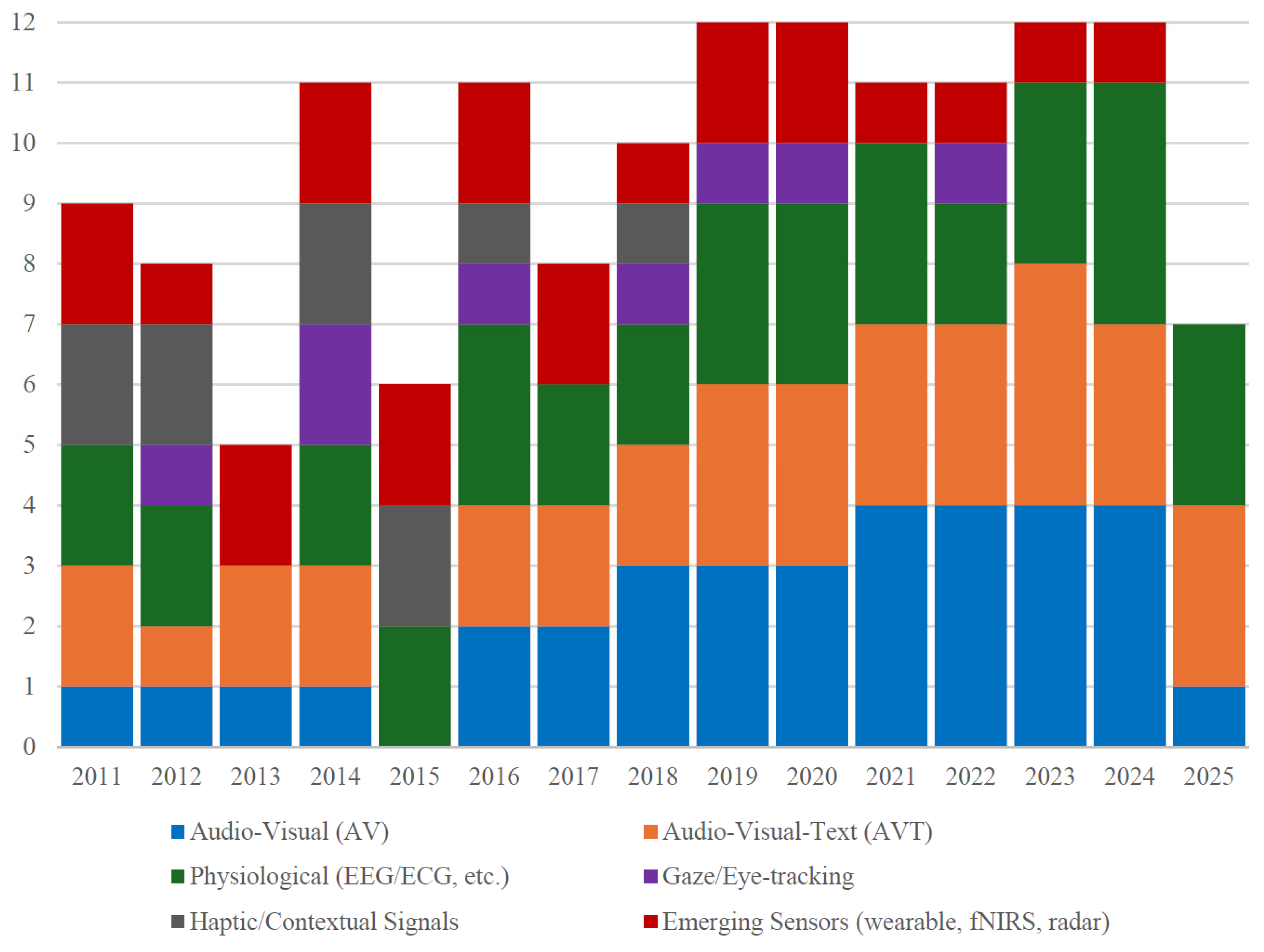
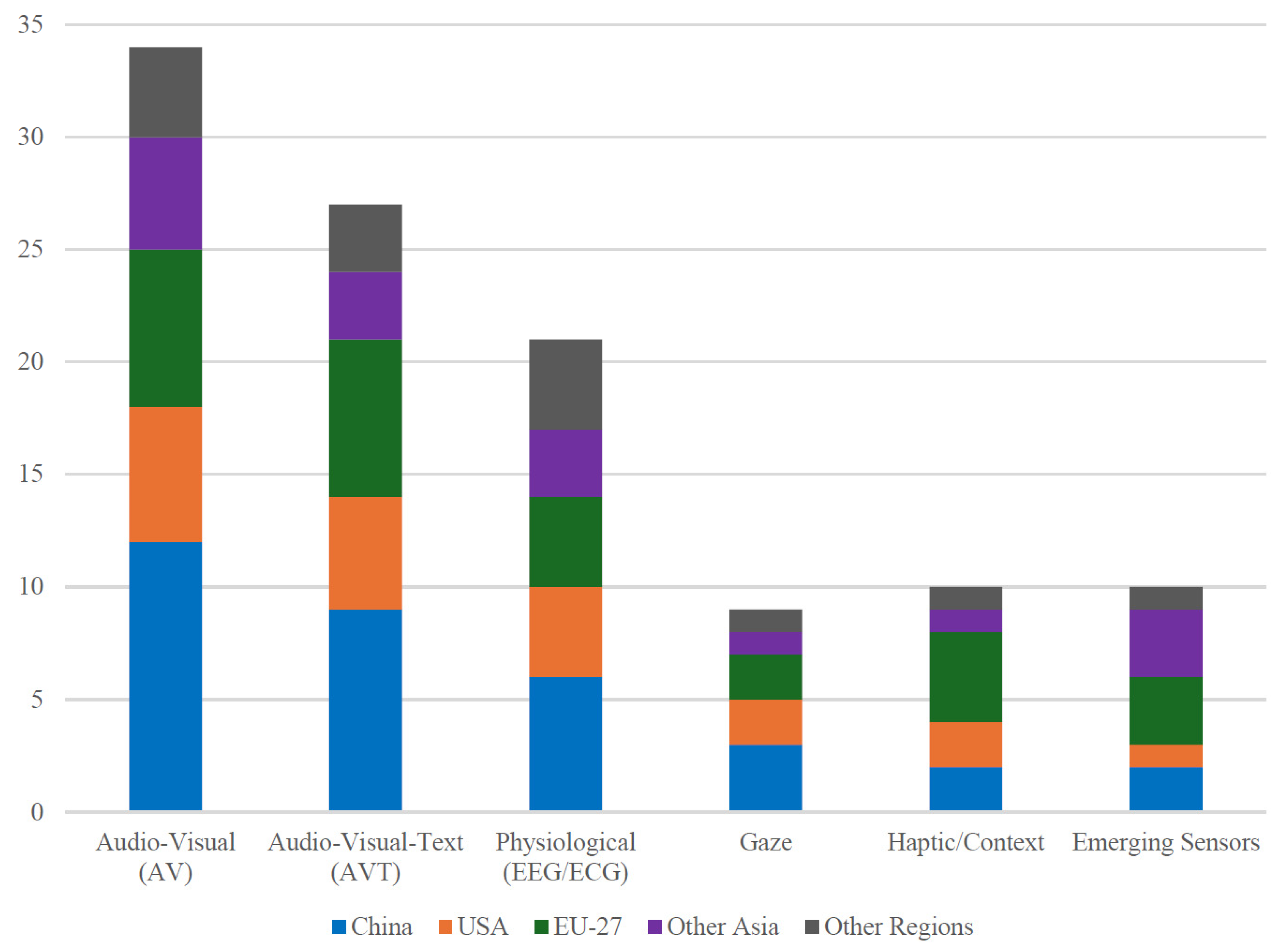
3.5. Additional Modalities and Their Sensing Principles
3.6. An Integrative Taxonomy of the MER Landscape
4. Multimodal Information Fusion for MER
4.1. Bimodal Emotion Recognition
| Input Modality 1 | Input Modality 2 | Output Emotion | Fusion Strategy | Methods Used | References |
|---|---|---|---|---|---|
| Speech | Visual | Discrete emotions | Early fusion | CNN for visual, LSTM for speech | [12,25,34] |
| Speech | Visual | Continuous emotions | Late fusion | RNN for speech, SVM for visual | [28,52,65,70,79] |
| Visual | Physiological | Discrete emotions | Hybrid fusion | HOG for visual, CNN for signals | [42,53] |
| Speech | EEG | Arousal and valence | Early fusion | Spectrogram analysis, CNN | [48,74] |
| Text | Visual | Positive/negative | Attention mechanism | Transformer, attention network | [10,36,58] |
| Speech | Visual | Discrete emotions | Transfer learning | Pre-trained ResNet, RNN | [36,38,72,81] |
| Audio | Visual | Emotional state | Cross-modal Learning | CCA, CNN | [52,80] |
| Visual | Physiological | Stress detection | Hybrid fusion | LSTM for temporal, SVM | [40,82] |
| Speech | Visual | Empathy detection | Late fusion | CNN, random forest classifier | [26,28] |
| Text | Facial expressions | Sentiment analysis | Early fusion | TF-IDF for text, HOG for visual | [48,67] |
4.2. Trimodal Emotion Recognition
| Modality 1 | Modality 2 | Modality 3 | Fusion Strategy | Methods Used | References |
|---|---|---|---|---|---|
| Speech | Visual | Text | Decision-level | SVM/random forest + RNN | [51,61] |
| Speech | Visual | Text | Early-level (feature concat.) | CNN (faces) + Log-Mel spectrogram | [83] |
| Speech | Visual | Text | Cross-modal transformer | CCA pre-alignment + transformer | [84,86] |
| Audio | Visual | Text | Attention mechanism | CNN + cross-modal attention | [85,87] |
| Text | Speech | Visual | Cross-modal transformer | Self-attention encoder | [74,84] |
| Visual | Physiological | Text | Hybrid (feature + decision) | HOG + LSTM + sentiment lexicon | [53,79] |
| Speech | Visual | Physiological | Hybrid (ResNet → LSTM) | Pre-trained ResNet (face) + LSTM (biosignal) | [61,88] |
| Speech | EEG | Visual | Modality alignment | CCA + CNN | [80,89] |
| Visual | Text | EEG | Feature-level | CNN (image) + BERT (text) + spectrogram | [60,79] |
| Text | Facial expressions | Speech | Decision-level | TF-IDF + CNN + GRU | [52,90] |
| Speech | Visual | Text | Ensemble hybrid (graph contrastive + transformer) | JOYFUL/graph contrastive alignment | [39] |
| Speech | Visual | Text | Cross-modal transformer (state-of-the-art) | Self-attention fusion | [32,43] |
| Study | Modalities | Public Dataset | Aggregation/Fusion Method | Metric (Type) | Reported Score |
|---|---|---|---|---|---|
| TMNet [20] (2025) | Speech + EEG | SEED-IV | Cross-modal transformer (early + attention) | Acc. | 88.70% |
| MemoCMT [58] (2025) | Vision + speech + text | CMU-MOSEI | Cross-modal transformer | Acc. | 82.30% |
| JOYFUL [74] (2023) | Audio + text + vision | MELD | Graph contrastive mid-level fusion | F1-macro | 81.20% |
| Edge-MER [12] (2024) | Facial + audio | RAVDESS | Lightweight CNN-LSTM (early) | WA | 79.40% |
| EAR-RoBERTa [65] (2023) | Text (+ meta) | CMU-MOSEI | Emotion-specific attention (late) | Acc. | 81.90% |
| Joint-MMT [16] (2024) | Vision + speech + action | ABAW 2023 | Unified transformer (late) | F1-macro | 48.90% |
| Interp-Hybrid [72] (2021) | Vision + speech + text | IEMOCAP | Hybrid early-/late + heat-map attention | Acc. | 82.00% |
| FG-Disentangle [91] (2022) | Audio + text + vision | MELD | Disentangled representation (early) | F1-macro | 80.10% |
| Wear-BioNet [70] (2025) | Wearable HR + EDA + accel. | WESAD | Ensemble CNN-GRU (late) | Acc. | 84.50% |
| Modality (Primary Channels) | Typical Evaluation Setting |
Method Class with Best-Reported Result | Representative Study [Dataset] | Key Metric | Best Score |
|---|---|---|---|---|---|
| Audio + visual | In-the-wild video (ABAW 24) | Cross-modal 3-D transformer fusion | Cross-modal 3D Facial-Speech [72] | F1-macro | 0.83 |
| Audio + visual + text | Multi-speaker dialogue (MELD) | Graph contrastive mid-level fusion | JOYFUL (MELD) [74] | F1-macro | 0.812 |
| Physiological (EEG/facial) | Lab elicitation (SEED-IV) | Channel-attention early fusion | SCA-Net++ [92] | Accuracy | 0.912 |
| Wearable biosensors (HR, EDA, Accel.) | Real-life stress (WESAD) | Ensemble CNN-GRU, late fusion | Wear-BioNet [70] | Accuracy | 0.845 |
| Gaze + audio + text | Human‚ Äìchatbot field study | Hybrid attention, early + late | Multimodal Cues Chatbot [77] | F1 | 0.74 |
| Edge-device AV | Resource-limited real-time | Lightweight CNN-LSTM, early | Edge-MER (RAVDESS) [12] | WA | 0.794 |
5. Research Challenges and Open Issues
5.1. Lightweight and Explainable Deep Models for MER
5.2. Multimodal Information Fusion Strategies
5.3. Cross-Corpus MER
5.4. More Modalities for MER
5.5. Few-Shot Learning for MER
6. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdullah, S.M.S.A.; Ameen, S.Y.A.; Sadeeq, M.A.; Zeebaree, S. Multimodal emotion recognition using deep learning. J. Appl. Sci. Technol. Trends 2021, 2, 73–79. [Google Scholar] [CrossRef]
- Adel, O.; Fathalla, K.M.; Abo ElFarag, A. MM-EMOR: Multi-modal emotion recognition of social media using concatenated deep learning networks. Big Data Cogn. Comput. 2023, 7, 164. [Google Scholar] [CrossRef]
- Bahreini, K.; Nadolski, R.; Westera, W. Towards multimodal emotion recognition in e-learning environments. Interact. Learn. Environ. 2016, 24, 590–605. [Google Scholar] [CrossRef]
- Ghaleb, E.; Popa, M.; Asteriadis, S. Multimodal and temporal perception of audio-visual cues for emotion recognition. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 552–558. [Google Scholar]
- He, Z.; Li, Z.; Yang, F.; Wang, L.; Li, J.; Zhou, C.; Pan, J. Advances in multimodal emotion recognition based on brain–computer interfaces. Brain Sci. 2020, 10, 687. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, W.; Hossain, M.S.; Chen, M.; Alelaiwi, A.; Al-Hammadi, M. A snapshot research and implementation of multimodal information fusion for data-driven emotion recognition. Inf. Fusion 2020, 53, 209–221. [Google Scholar] [CrossRef]
- Middya, A.I.; Nag, B.; Roy, S. Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities. Knowl.-Based Syst. 2022, 244, 108580. [Google Scholar] [CrossRef]
- Liu, W.; Qiu, J.L.; Zheng, W.L.; Lu, B.L. Comparing recognition performance and robustness of multimodal deep learning models for multimodal emotion recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 715–729. [Google Scholar] [CrossRef]
- Maithri, M.; Raghavendra, U.; Gudigar, A.; Samanth, J.; Barua, P.D.; Murugappan, M.; Acharya, U.R. Automated emotion recognition: Current trends and future perspectives. Comput. Methods Programs Biomed. 2022, 215, 106646. [Google Scholar] [CrossRef]
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Multimodal emotion recognition using deep learning architectures. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Pan, B.; Hirota, K.; Jia, Z.; Dai, Y. A review of multimodal emotion recognition from datasets, preprocessing, features, and fusion methods. Neurocomputing 2023, 561, 126866. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Y.; Chen, C.; Zhang, X.; Leng, Q.; Zhao, X. Deep learning-based multimodal emotion recognition from audio, visual, and text modalities: A systematic review of recent advancements and future prospects. Expert Syst. Appl. 2024, 237, 121692. [Google Scholar] [CrossRef]
- Lian, H.; Lu, C.; Li, S.; Zhao, Y.; Tang, C.; Zong, Y. A survey of deep learning-based multimodal emotion recognition: Speech, text, and face. Entropy 2023, 25, 1440. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Li, X.; Li, J. Emotion Recognition Using Different Sensors, Emotion Models, Methods and Datasets: A Comprehensive Review. Sensors 2023, 23, 2455. [Google Scholar] [CrossRef] [PubMed]
- Ramaswamy, M.P.A.; Palaniswamy, S. Multimodal Emotion Recognition: A Comprehensive Review, Trends, and Challenges. WIREs Data Min. Knowl. Discov. 2024, 14, e1563. [Google Scholar] [CrossRef]
- Gladys, A.A.; Vetriselvi, V. Survey on Multimodal Approaches to Emotion Recognition. Neurocomputing 2023, 556, 126693. [Google Scholar] [CrossRef]
- Yi, M.-H.; Kwak, K.-C.; Shin, J.-H. HyFusER: Hybrid Multimodal Transformer for Emotion Recognition Using Dual Cross-Modal Attention. Appl. Sci. 2025, 15, 1053. [Google Scholar] [CrossRef]
- Cheng, Z.; Bu, X.; Wang, Q.; Yang, T.; Tu, J. EEG-Based Emotion Recognition Using Multi-Scale Dynamic CNN and Gated Transformer. Sci. Rep. 2024, 14, 31319. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, Y.; Shen, G.; Xu, Y.; Zhang, J. TDFNet: Transformer-based deep-scale fusion network for multimodal emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 3771–3782. [Google Scholar] [CrossRef]
- Alam, M.M.; Dini, M.A.; Kim, D.-S.; Jun, T. TMNet: Transformer-Fused Multimodal Framework for Emotion Recognition via EEG and Speech. ICT Express 2025, in press. [Google Scholar] [CrossRef]
- Liao, Y.; Gao, Y.; Wang, F.; Zhang, L.; Xu, Z.; Wu, Y. Emotion Recognition with Multiple Physiological Parameters Based on Ensemble Learning. Sci. Rep. 2025, 15, 19869. [Google Scholar] [CrossRef]
- Chen, L.; Wang, K.; Li, M.; Wu, M.; Pedrycz, W.; Hirota, K. K-means clustering-based kernel canonical correlation analysis for multimodal emotion recognition in human–robot interaction. IEEE Trans. Ind. Electron. 2022, 70, 1016–1024. [Google Scholar] [CrossRef]
- Choi, W.Y.; Song, K.Y.; Lee, C.W. Convolutional attention networks for multimodal emotion recognition from speech and text data. In Proceedings of Grand Challenge and Workshop on Human Multimodal Language (Challenge-HML); Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 28–34. [Google Scholar] [CrossRef]
- Huang, J.; Tao, J.; Liu, B.; Lian, Z.; Niu, M. Multimodal transformer fusion for continuous emotion recognition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3507–3511. [Google Scholar]
- Fu, B.; Gu, C.; Fu, M.; Xia, Y.; Liu, Y. A novel feature fusion network for multimodal emotion recognition from EEG and eye movement signals. Front. Neurosci. 2023, 17, 1234162. [Google Scholar] [CrossRef]
- Rozgić, V.; Ananthakrishnan, S.; Saleem, S.; Kumar, R.; Prasad, R. Ensemble of SVM trees for multimodal emotion recognition. In Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–4. [Google Scholar]
- Zheng, W.L.; Liu, W.; Lu, Y.; Lu, B.L.; Cichocki, A. EmotionMeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 2019, 49, 1110–1122. [Google Scholar] [CrossRef] [PubMed]
- Ma, H.; Wang, J.; Lin, H.; Zhang, B.; Zhang, Y.; Xu, B. A transformer-based model with self-distillation for multimodal emotion recognition in conversations. IEEE Trans. Multimed. 2023, 26, 776–788. [Google Scholar] [CrossRef]
- Barros, P.; Jirak, D.; Weber, C.; Wermter, S. Multimodal emotional state recognition using sequence-dependent deep hierarchical features. Neural Netw. 2015, 72, 140–151. [Google Scholar] [CrossRef]
- Tripathi, S.; Tripathi, S.; Beigi, H. Multi-modal emotion recognition on IEMOCAP dataset using deep learning. arXiv 2018, arXiv:1804.05788. [Google Scholar]
- Li, X.; Liu, J.; Xie, Y.; Gong, P.; Zhang, X.; He, H. MAGDRA: A multi-modal attention graph network with dynamic routing-by-agreement for multi-label emotion recognition. Knowl.-Based Syst. 2024, 283, 111126. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Han, K.; Wang, Y.; Peng, Y.; Li, X. Learning alignment for multimodal emotion recognition from speech. arXiv 2019, arXiv:1909.05645. [Google Scholar]
- Park, C.Y.; Cha, N.; Kang, S.; Kim, A.; Khandoker, A.H.; Hadjileontiadis, L.; Lee, U. K-EmoCon: A multimodal sensor dataset for continuous emotion recognition in naturalistic conversations. Sci. Data 2020, 7, 293. [Google Scholar] [CrossRef]
- Siriwardhana, S.; Kaluarachchi, T.; Billinghurst, M.; Nanayakkara, S. Multimodal emotion recognition with transformer-based self-supervised feature fusion. IEEE Access 2020, 8, 176274–176285. [Google Scholar] [CrossRef]
- Mocanu, B.; Tapu, R.; Zaharia, T. Multimodal emotion recognition using cross-modal audio–video fusion with attention and deep metric learning. Image Vis. Comput. 2023, 133, 104676. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, S.; Li, P. Multi-Modal Emotion Recognition in Conversation Based on Prompt Learning with Text–Audio Fusion Features. Sci. Rep. 2025, 15, 8855. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, N.; Al Aghbari, Z.; Girija, S. A systematic survey on multimodal emotion recognition using learning algorithms. Intell. Syst. Appl. 2023, 17, 200171. [Google Scholar] [CrossRef]
- Lian, Z.; Sun, H.; Sun, L.; Yi, J.; Liu, B.; Tao, J. AffectGPT: Dataset and framework for explainable multimodal emotion recognition. arXiv 2024, arXiv:2407.07653. [Google Scholar]
- Zhang, Y.; Cheng, C.; Wang, S.; Xia, T. Emotion recognition using heterogeneous convolutional neural networks combined with multimodal factorized bilinear pooling. Biomed. Signal Process. Control 2022, 77, 103877. [Google Scholar] [CrossRef]
- Liu, S.; Gao, P.; Li, Y.; Fu, W.; Ding, W. Multi-modal fusion network with complementarity and importance for emotion recognition. Inf. Sci. 2023, 619, 679–694. [Google Scholar] [CrossRef]
- Lerner, M.D.; McPartland, J.C.; Morris, J.P. Multimodal emotion processing in autism spectrum disorders: An event-related potential study. Dev. Cogn. Neurosci. 2013, 3, 11–21. [Google Scholar] [CrossRef]
- Ho, N.H.; Yang, H.J.; Kim, S.H.; Lee, G. Multimodal approach of speech emotion recognition using multi-level multi-head fusion attention-based recurrent neural network. IEEE Access 2020, 8, 61672–61686. [Google Scholar] [CrossRef]
- Zhang, H. Expression-EEG based collaborative multimodal emotion recognition using deep autoencoder. IEEE Access 2020, 8, 164130–164143. [Google Scholar] [CrossRef]
- Cimtay, Y.; Ekmekcioglu, E.; Caglar-Ozhan, S. Cross-subject multimodal emotion recognition based on hybrid fusion. IEEE Access 2020, 8, 168865–168878. [Google Scholar] [CrossRef]
- Chudasama, V.; Kar, P.; Gudmalwar, A.; Shah, N.; Wasnik, P.; Onoe, N. M2FNet: Multi-modal fusion network for emotion recognition in conversation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 4652–4661. [Google Scholar] [CrossRef]
- Sharafi, M.; Yazdchi, M.; Rasti, R.; Nasimi, F. A novel spatio-temporal convolutional neural framework for multimodal emotion recognition. Biomed. Signal Process. Control. 2022, 78, 103970. [Google Scholar] [CrossRef]
- Tang, H.; Liu, W.; Zheng, W.L.; Lu, B.L. Multimodal emotion recognition using deep neural networks. In Proceedings of the Neural Information Processing—24th International Conference ICONIP 2017, Guangzhou, China, 14–18 November 2017; pp. 811–819. [Google Scholar] [CrossRef]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. M3ER: Multiplicative multimodal emotion recognition using facial, textual, and speech cues. Proc. AAAI Conf. Artif. Intell. 2020, 34, 1359–1367. [Google Scholar] [CrossRef]
- Povolný, F.; Matejka, P.; Hradis, M.; Popková, A.; Otrusina, L.; Smrž, P.; Lamel, L. Multimodal emotion recognition for AVEC 2016 challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge (AVEC’16), New York, NY, USA, 16 October 2016; pp. 75–82. [Google Scholar] [CrossRef]
- Yoon, S.; Byun, S.; Jung, K. Multimodal speech emotion recognition using audio and text. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 112–118. [Google Scholar] [CrossRef]
- Hazarika, D.; Poria, S.; Mihalcea, R.; Cambria, E.; Zimmermann, R. ICON: Interactive conversational memory network for multimodal emotion detection. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussel, Belgium, 31 October–4 November 2018; pp. 2594–2604. [Google Scholar]
- Wu, X.; Zheng, W.L.; Li, Z.; Lu, B.L. Investigating EEG-based functional connectivity patterns for multimodal emotion recognition. J. Neural Eng. 2022, 19, 016012. [Google Scholar] [CrossRef] [PubMed]
- Qiu, S.; Sekhar, N.; Singhal, P. Topic- and Style-Aware Transformer for Multimodal Emotion Recognition. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 2074–2082. [Google Scholar] [CrossRef]
- Du, Z.; Ye, X.; Zhao, P. A Novel Signal Channel Attention Network for Multi-Modal Emotion Recognition. Front. Neurorobot. 2024, 18, 1442080. [Google Scholar] [CrossRef]
- Khan, M.; Tran, P.-N.; Pham, N.T.; El Saddik, A.; Othmani, A. MemoCMT: Multimodal Emotion Recognition Using Cross-Modal Transformer-Based Feature Fusion. Sci. Rep. 2025, 15, 5473. [Google Scholar] [CrossRef]
- Nandini, D.; Yadav, J.; Singh, V.; Mohan, V.; Agarwal, S. An Ensemble Deep Learning Framework for Emotion Recognition through Wearable Devices’ Multi-Modal Physiological Signals. Sci. Rep. 2025, 15, 17263. [Google Scholar] [CrossRef]
- Mengara Mengara, A.G.; Moon, Y. CAG-MoE: Multimodal Emotion Recognition with Cross-Attention Gated Mixture of Experts. Mathematics 2023, 13, 1907. [Google Scholar] [CrossRef]
- Ahuja, C.; Sethia, D. SS-EMERGE: Self-Supervised Enhancement for Multidimension Emotion Recognition Using GNNs for EEG. Sci. Rep. 2025, 15, 14254. [Google Scholar] [CrossRef]
- Yang, D.; Huang, S.; Kuang, H.; Du, Y.; Zhang, L. Disentangled representation learning for multimodal emotion recognition. In Proceedings of the 30th ACM International Conference on Multimedia (MM’22), Lisbon, Portugal, 10–14 October 2022; pp. 1642–1651. [Google Scholar]
- Kahou, S.E.; Bouthillier, X.; Lamblin, P.; Gulcehre, C.; Michalski, V.; Konda, K.; Jean, S.; Froumenty, P.; Dauphin, Y.; Boulanger-Lewandowski, N.; et al. EmoNets: Multimodal deep learning approaches for emotion recognition in video. J. Multimodal User Interfaces 2016, 10, 99–111. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, J.; Liao, P.; Pan, J. Fusion of facial expressions and EEG for multimodal emotion recognition. Comput. Intell. Neurosci. 2017, 2017, 2107451. [Google Scholar] [CrossRef]
- Singla, C.; Singh, S.; Sharma, P.; Mittal, N.; Gared, F. Emotion Recognition for Human–Computer Interaction Using High-Level Descriptors. Sci. Rep. 2024, 14, 12122. [Google Scholar] [CrossRef] [PubMed]
- Triantafyllopoulos, A.; Christ, L.; Gebhard, A.; Jing, X.; Kathan, A.; Milling, M.; Tsangko, I.; Amiriparian, S.; Schuller, B.W. Beyond Deep Learning: Charting the Next Frontiers of Affective Computing. Intell. Comput. 2024, 3, e0089. [Google Scholar] [CrossRef]
- Wang, X.; Ren, Y.; Luo, Z.; He, W.; Hong, J.; Huang, Y. Deep Learning-Based EEG Emotion Recognition: Current Trends and Future Perspectives. Front. Psychol. 2023, 14, 1126994. [Google Scholar] [CrossRef]
- Alsabhan, W. Human–Computer Interaction with a Real-Time Speech Emotion Recognition with Ensembling Techniques 1D Convolution Neural Network and Attention. Sensors 2023, 23, 1386. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Guan, L.; Venetsanopoulos, A.N. Kernel cross-modal factor analysis for information fusion with application to bimodal emotion recognition. IEEE Trans. Multimed. 2012, 14, 597–607. [Google Scholar] [CrossRef]
- Dai, W.; Liu, Z.; Yu, T.; Fung, P. Modality-transferable emotion embeddings for low-resource multimodal emotion recognition. arXiv 2020, arXiv:2009.09629. [Google Scholar]
- Zeng, Y.; Zhang, J.W.; Yang, J. Multimodal emotion recognition in the metaverse era: New needs and transformation in mental health work. World J. Clin. Cases 2024, 12, 6674–6678. [Google Scholar] [CrossRef]
- Pillalamarri, R.; Shanmugam, U. A Review on EEG-Based Multimodal Learning for Emotion Recognition. Artif. Intell. Rev. 2025, 58, 131. [Google Scholar] [CrossRef]
- Akinpelu, S.; Viriri, S. Speech Emotion Classification Using Attention-Based Network and Regularized Feature Selection. Sci. Rep. 2023, 13, 11990. [Google Scholar] [CrossRef]
- Islam, M.R.; Islam, M.M.; Rahman, M.M.; Mondal, C.; Singha, S.K.; Ahmad, M.; Awal, A.; Islam, M.S.; Moni, M.A. EEG Channel Correlation Based Model for Emotion Recognition. Comput. Biol. Med. 2021, 136, 104757. [Google Scholar] [CrossRef]
- Chowdhury, J.H.; Ramanna, S.; Kotecha, K. Speech Emotion Recognition with Lightweight Deep Neural Ensemble Model Using Hand-Crafted Features. Sci. Rep. 2025, 15, 11824. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Wang, Y.; Funakoshi, K.; Okumura, M. JOYFUL: Joint Modality Fusion and Graph Contrastive Learning for Multimodal Emotion Recognition. In Proceedings of the EMNLP 2023, Singapore, 6–10 December 2023; pp. 16051–16069. [Google Scholar] [CrossRef]
- Huang, Z.; Mak, M.-W.; Lee, K.A. MM-NodeFormer: Node Transformer Multimodal Fusion for Emotion Recognition in Conversation. In Proceedings of the Interspeech 2024, Sapporo, Japan, 8–12 September 2024; pp. 4069–4073. [Google Scholar] [CrossRef]
- Li, Z.; Tang, F.; Zhao, M.; Zhu, Y. EmoCaps: Emotion Capsule-Based Model for Conversational Emotion Recognition. In Proceedings of the Findings of ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1610–1618. [Google Scholar] [CrossRef]
- Lu, C.; Tang, C.; Zhang, J.; Zong, Y. Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition. Entropy 2022, 24, 1046. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Zhao, S.; Wang, X.; Zeng, W.; Chen, Y.; Qin, Y. Fine-grained disentangled representation learning for multimodal emotion recognition. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11051–11055. [Google Scholar]
- Yang, X.; Feng, S.; Wang, D.; Zhang, Y. Image–text multimodal emotion classification via multi-view attentional network. IEEE Trans. Multimed. 2020, 23, 4014–4026. [Google Scholar] [CrossRef]
- Krishna, D.N.; Patil, A. Multimodal emotion recognition using cross-modal attention and 1D convolutional neural networks. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 4243–4247. [Google Scholar]
- Lv, F.; Chen, X.; Huang, Y.; Duan, L.; Lin, G. Progressive modality reinforcement for human multimodal emotion recognition from unaligned multimodal sequences. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2554–2562. [Google Scholar] [CrossRef]
- Wu, C.; Cai, Y.; Liu, Y.; Zhu, P.; Xue, Y.; Gong, Z.; Hirschberg, J.; Ma, B. Multimodal Emotion Recognition in Conversations: A Survey of Methods, Trends, Challenges and Prospects. arXiv 2025, arXiv:2505.20511. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, K.; Sridharan, S.; Dean, D.; Fookes, C. Deep spatio-temporal feature fusion with compact bilinear pooling for multimodal emotion recognition. Comput. Vis. Image Underst. 2018, 174, 33–42. [Google Scholar] [CrossRef]
- Chen, S.; Jin, Q. Multi-modal dimensional emotion recognition using recurrent neural networks. In Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge (AVEC’15), Brisbane, Australia, 26 October 2015; pp. 49–56. [Google Scholar] [CrossRef]
- Avots, E.; Sapiński, T.; Bachmann, M.; Kamińska, D. Audiovisual emotion recognition in wild. Mach. Vis. Appl. 2019, 30, 975–985. [Google Scholar] [CrossRef]
- Verma, G.K.; Tiwary, U.S. Multimodal fusion framework: A multiresolution approach for emotion classification and recognition from physiological signals. NeuroImage 2014, 102, 162–172. [Google Scholar] [CrossRef]
- Al-Saddawi, H.F.T.; Das, B.; Das, R. A Systematic Review of Trimodal Affective-Computing Approaches: Text, Audio, and Visual Integration in Emotion Recognition and Sentiment Analysis. Expert Syst. Appl. 2024, 255, 124852. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, D. Expression-EEG multimodal emotion recognition method based on the bidirectional LSTM and attention mechanism. Comput. Math. Methods Med. 2021, 2021, 9967592. [Google Scholar] [CrossRef]
- Meng, T.; Shou, Y.; Ai, W.; Yin, N.; Li, K. Deep imbalanced learning for multimodal emotion recognition in conversations. IEEE Trans. Artif. Intell. 2024, 5, 6472–6487. [Google Scholar] [CrossRef]
- Zaidi, S.A.M.; Latif, S.; Qadir, J. Enhancing Cross-Language Multimodal Emotion Recognition with Dual Attention Transformers. IEEE Open J. Comput. Soc. 2024, 5, 684–693. [Google Scholar] [CrossRef]
- Hu, G.; Lin, T.-E.; Zhao, Y.; Lu, G.; Wu, Y.; Li, Y. UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition. In Proceedings of the EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 7837–7851. [Google Scholar] [CrossRef]
- Waligora, P.; Aslam, M.H.; Zeeshan, M.O.; Belharbi, S.; Lameiras Koerich, A.; Pedersoli, M.; Bacon, S.; Granger, E. Joint Multimodal Transformer for Emotion Recognition in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 4625–4635. [Google Scholar] [CrossRef]
- Wagner, J.; André, E.; Lingenfelser, F.; Kim, J. Exploring fusion methods for multimodal emotion recognition with missing data. IEEE Trans. Affect. Comput. 2011, 2, 206–218. [Google Scholar] [CrossRef]
- Mittal, T.; Guhan, P.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. EMOTICON: Context-aware multimodal emotion recognition using Frege’s principle. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14234–14243. [Google Scholar]
- Kumar, P.; Malik, S.; Raman, B. Hybrid fusion based interpretable multimodal emotion recognition with insufficient labelled data. arXiv 2022, arXiv:2208.11450. [Google Scholar]
- Praveen, R.G.; Alam, J. Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 4803–4813. [Google Scholar] [CrossRef]
- Jones, C.R.; Pickles, A.; Falcaro, M.; Marsden, A.J.; Happé, F.; Scott, S.K.; Charman, T. A multimodal approach to emotion recognition ability in autism spectrum disorders. J. Child Psychol. Psychiatry 2011, 52, 275–285. [Google Scholar] [CrossRef]
- Ayata, D.; Yaslan, Y.; Kamasak, M.E. Emotion recognition from multimodal physiological signals for emotion-aware healthcare systems. J. Med. Biol. Eng. 2020, 40, 149–157. [Google Scholar] [CrossRef]
- Chen, S.; Jin, Q.; Zhao, J.; Wang, S. Multimodal multi-task learning for dimensional and continuous emotion recognition. In Proceedings of the 7th Annual Workshop Audio/Visual Emotion Challenge (AVEC’17), Mountain View, CA, USA, 23 October 2017; pp. 19–26. [Google Scholar] [CrossRef]
- Das, A.; Sen Sarma, M.; Hoque, M.M.; Siddique, N.; Dewan, M.A.A. AVaTER: Fusing Audio, Visual, and Textual Modalities Using Cross-Modal Attention for Emotion Recognition. Sensors 2024, 24, 5862. [Google Scholar] [CrossRef]
- Makiuchi, M.R.; Uto, K.; Shinoda, K. Multimodal emotion recognition with high-level speech and text features. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 350–357. [Google Scholar] [CrossRef]
- Chang, E.J.; Rahimi, A.; Benini, L.; Wu, A.Y.A. Hyperdimensional computing-based multimodality emotion recognition with physiological signals. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hsinchu, Taiwan, 18–20 March 2019; pp. 137–141. [Google Scholar]
- Xie, B.; Sidulova, M.; Park, C.H. Robust multimodal emotion recognition from conversation with transformer-based cross-modality fusion. Sensors 2021, 21, 4913. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Mi, Q.; Gao, T. A Comprehensive Review of Multimodal Emotion Recognition: Techniques, Challenges, and Future Directions. Biomimetics 2025, 10, 418. https://doi.org/10.3390/biomimetics10070418
Wu Y, Mi Q, Gao T. A Comprehensive Review of Multimodal Emotion Recognition: Techniques, Challenges, and Future Directions. Biomimetics. 2025; 10(7):418. https://doi.org/10.3390/biomimetics10070418
Chicago/Turabian StyleWu, You, Qingwei Mi, and Tianhan Gao. 2025. "A Comprehensive Review of Multimodal Emotion Recognition: Techniques, Challenges, and Future Directions" Biomimetics 10, no. 7: 418. https://doi.org/10.3390/biomimetics10070418
APA StyleWu, Y., Mi, Q., & Gao, T. (2025). A Comprehensive Review of Multimodal Emotion Recognition: Techniques, Challenges, and Future Directions. Biomimetics, 10(7), 418. https://doi.org/10.3390/biomimetics10070418