
Bio-Inspired 3D Affordance Understanding from Single Image with Neural Radiance Field for Enhanced Embodied Intelligence



Abstract
1. Introduction
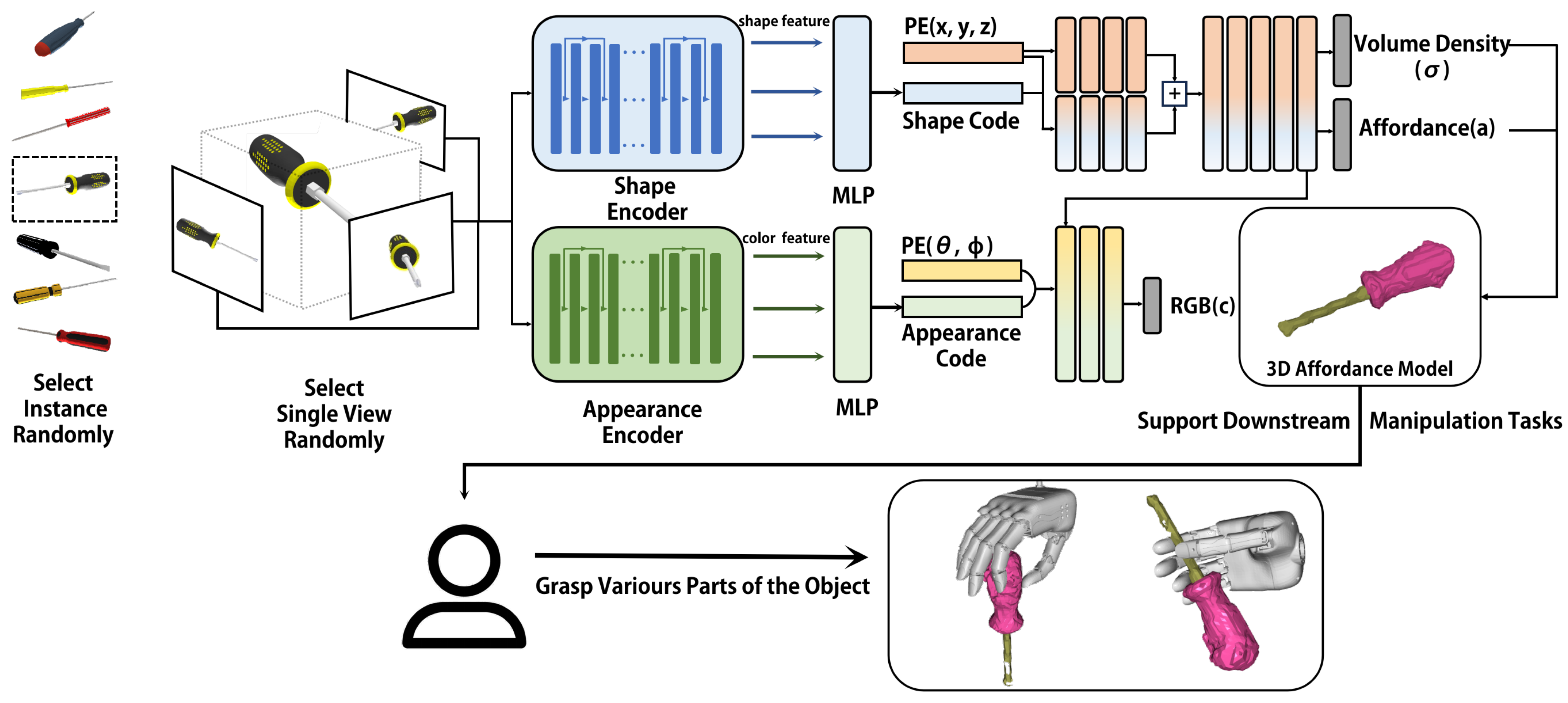
- We design AFF-NeRF with a shape and appearance feature encoder to obtain the 3D affordance models. Our method can produce precise affordance with a single view of novel objects without any retraining or fine-tuning.
- We created a new dataset for affordance rendering validation, comprising different objects with diverse shapes in various poses and affordance annotations.
- The affordance models obtained by our approach can effectively improve the performance of downstream robotic manipulation tasks. We evaluate the performance of various grasp generation algorithms, and the results show that applying the affordance models can generate more stable grasps.
2. Related Work
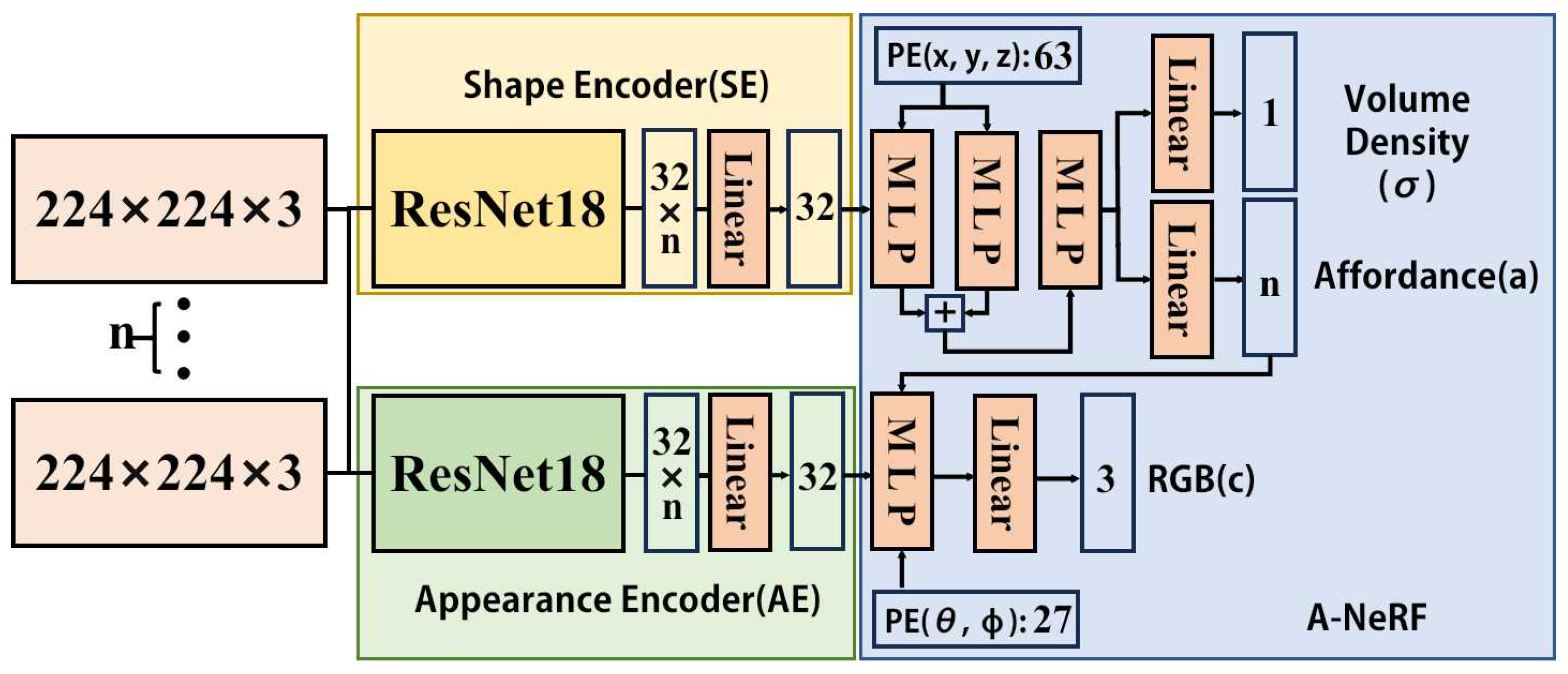
3. Methodology
3.1. Network Architecture and Training
3.2. Dataset Construction
4. Experimental Evaluation
4.1. Experimental Setup
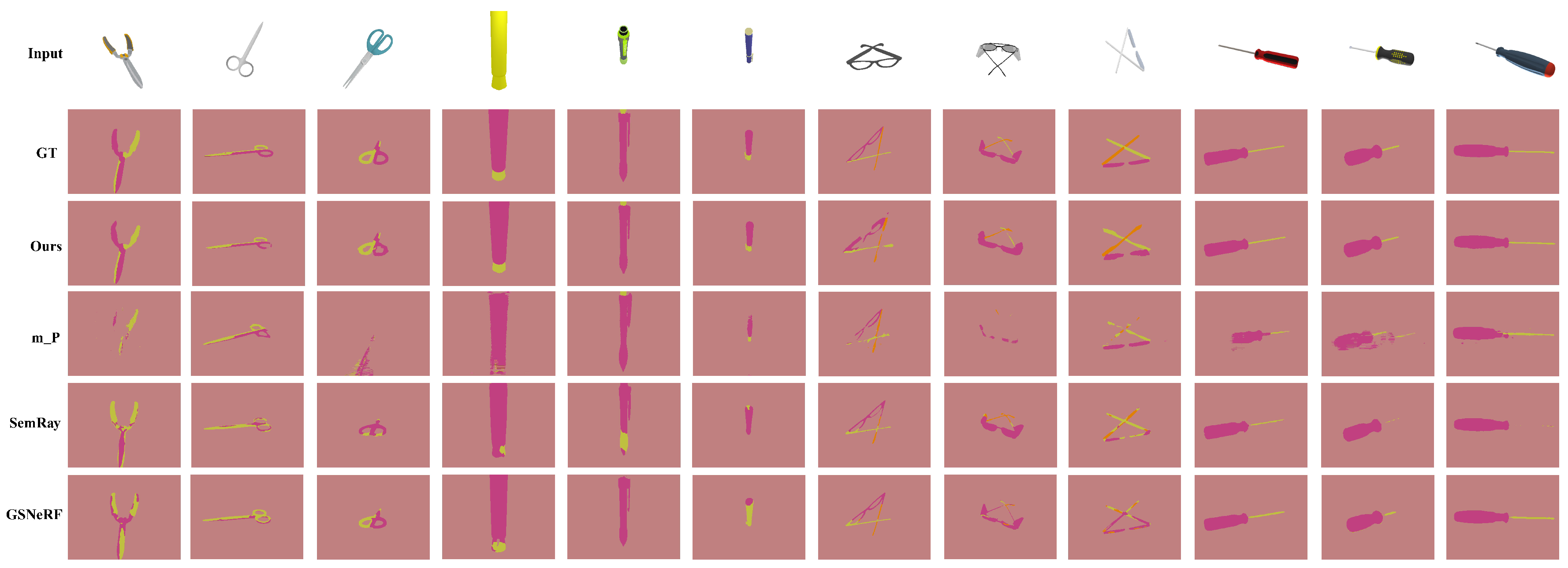
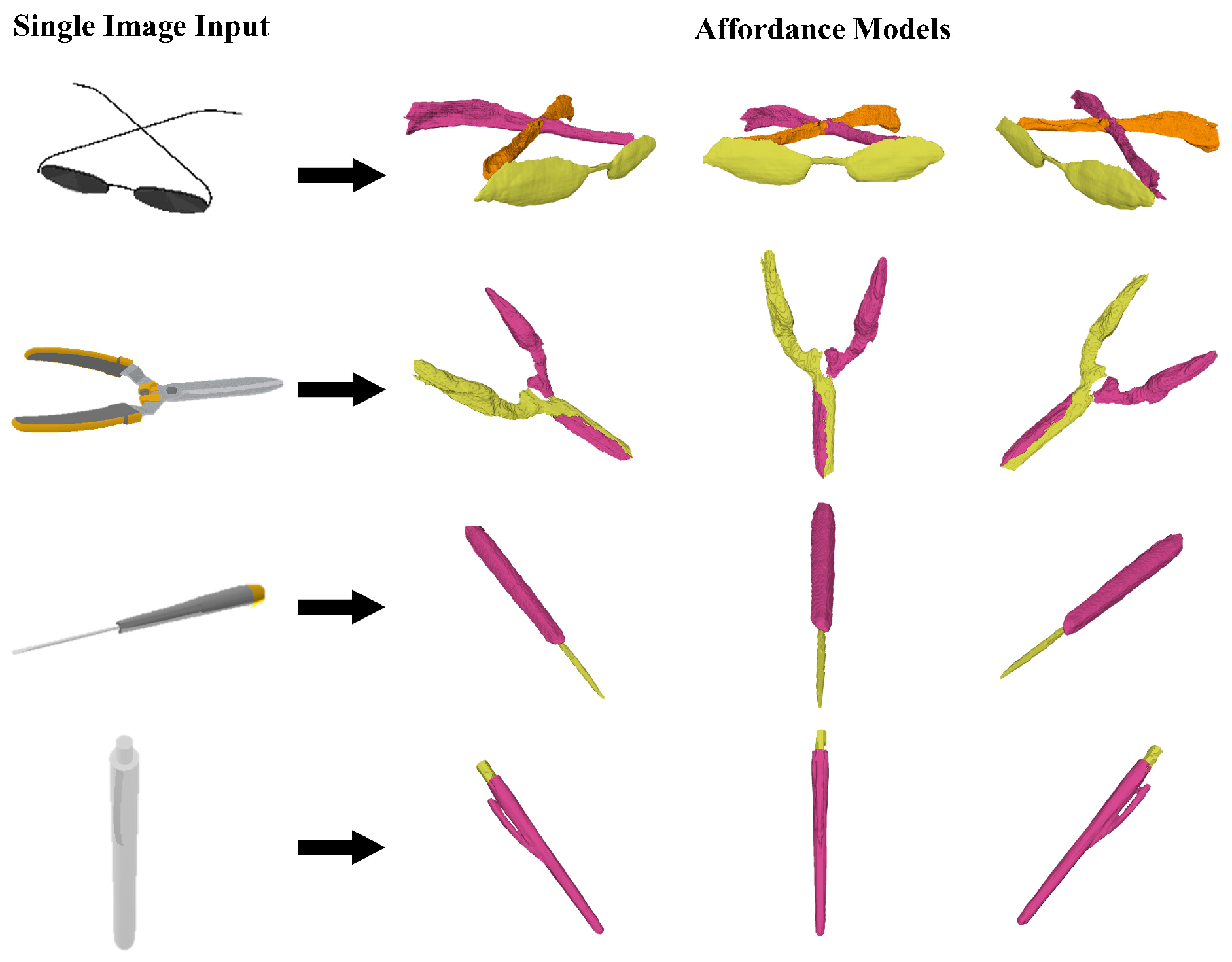
4.2. Experimental Results
4.2.1. Results of Affordance Understanding
4.2.2. Grasp Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gibson, J.J. The Theory of Affordances. In The People, Place, and Space Reader; Routledge: London, UK, 1977; Volume 1, pp. 67–82. [Google Scholar]
- Horton, T.E.; Chakraborty, A.; Amant, R.S. Affordances for Robots: A Brief Survey. AVANT. Pismo Awangardy-Filoz.-Nauk. 2012, 2, 70–84. [Google Scholar] [CrossRef]
- Hassanin, M.; Khan, S.; Tahtali, M. Visual Affordance and Function Understanding: A Survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing Scenes as Neural Radiance Fields for View Synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Zhi, S.; Laidlow, T.; Leutenegger, S.; Davison, A.J. In-Place Scene Labelling and Understanding with Implicit Scene representation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 15838–15847. [Google Scholar]
- Ishibashi, R.; Pobric, G.; Saito, S.; Lambon Ralph, M.A. The neural network for tool-related cognition: An activation likelihood estimation meta-analysis of 70 neuroimaging contrasts. Cogn. Neuropsychol. 2016, 33, 241–256. [Google Scholar] [CrossRef] [PubMed]
- Ranganath, C.; Rainer, G. Neural mechanisms for detecting and remembering novel events. Nat. Rev. Neurosci. 2003, 4, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Niemeyer, M.; Geiger, A. Giraffe: Representing Scenes as Compositional Generative Neural Feature Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11453–11464. [Google Scholar]
- Xu, Y.; Peng, S.; Yang, C.; Shen, Y.; Zhou, B. 3D-Aware Image Synthesis via Learning Structural and Textural Representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18430–18439. [Google Scholar]
- Xue, Y.; Li, Y.; Singh, K.K.; Lee, Y.J. Giraffe HD: A High-Resolution 3D-Aware Generative Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18440–18449. [Google Scholar]
- Schwarz, K.; Liao, Y.; Niemeyer, M.; Geiger, A. GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Virtual, 6–12 December 2020; Volume 33, pp. 20154–20166. [Google Scholar]
- Chan, E.R.; Monteiro, M.; Kellnhofer, P.; Wu, J.; Wetzstein, G. Pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5799–5809. [Google Scholar]
- Wang, C.; Chai, M.; He, M.; Chen, D.; Liao, J. Clip-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3835–3844. [Google Scholar]
- Jang, W.; Agapito, L. Codenerf: Disentangled Neural Radiance Fields for Object Categories. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12949–12958. [Google Scholar]
- Liu, S.; Zhang, X.; Zhang, Z.; Zhang, R.; Zhu, J.Y.; Russell, B. Editing Conditional Radiance Fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5773–5783. [Google Scholar]
- Yuan, Y.J.; Sun, Y.T.; Lai, Y.K.; Ma, Y.; Jia, R.; Gao, L. NeRF-Editing: Geometry Editing of Neural Radiance Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18353–18364. [Google Scholar]
- Bao, C.; Zhang, Y.; Yang, B.; Fan, T.; Yang, Z.; Bao, H.; Zhang, G.; Cui, Z. Sine: Semantic-Driven Image-based NeRF Editing with Prior-Guided Editing Field. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 20919–20929. [Google Scholar]
- Wang, C.; Fang, H.S.; Gou, M.; Fang, H.; Gao, J.; Lu, C. Graspness Discovery in Clutters for Fast and Accurate Grasp Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15964–15973. [Google Scholar]
- Gou, M.; Fang, H.S.; Zhu, Z.; Xu, S.; Wang, C.; Lu, C. RGB Matters: Learning 7-DOF Grasp Poses on Monocular RGBD Images. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13459–13466. [Google Scholar]
- Sun, J.; Wang, Y.; Feng, M.; Wang, D.; Zhao, J.; Stachniss, C.; Chen, X. ICK-Track: A Category-Level 6-DoF Pose Tracker Using Inter-Frame Consistent Keypoints for Aerial Manipulation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 1556–1563. [Google Scholar]
- Appius, A.X.; Garrabe, E.; Helenon, F.; Khoramshahi, M.; Chetouani, M.; Doncieux, S. Task-Aware Robotic Grasping by evaluating Quality Diversity Solutions through Foundation Models. arXiv 2024, arXiv:2411.14917. [Google Scholar]
- Czajewski, W.; Kołomyjec, K. 3D object detection and recognition for robotic grasping based on RGB-D images and global features. Found. Comput. Decis. Sci. 2017, 42, 219–237. [Google Scholar] [CrossRef]
- Sahbani, A.; El-Khoury, S.; Bidaud, P. An overview of 3D object grasp synthesis algorithms. Robot. Auton. Syst. 2012, 60, 326–336. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rohmer, E.; Singh, S.P.; Freese, M. V-REP: A Versatile and Scalable Robot Simulation Framework. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 1321–1326. [Google Scholar]
- Mo, K.; Zhu, S.; Chang, A.X.; Yi, L.; Tripathi, S.; Guibas, L.J.; Su, H. PartNet: A Large-Scale Benchmark for Fine-Grained and Hierarchical Part-Level 3D Object Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 909–918. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Chou, Z.T.; Huang, S.Y.; Liu, I.; Wang, Y.C.F. GSNeRF: Generalizable Semantic Neural Radiance Fields with Enhanced 3D Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 20806–20815. [Google Scholar]
- Liu, F.; Zhang, C.; Zheng, Y.; Duan, Y. Semantic ray: Learning a generalizable semantic field with cross-reprojection attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17386–17396. [Google Scholar]
- Yu, A.; Ye, V.; Tancik, M.; Kanazawa, A. PixelNeRF: Neural Radiance Fields from One or Few Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4578–4587. [Google Scholar]
- Xu, W.; Zhang, J.; Tang, T.; Yu, Z.; Li, Y.; Lu, C. DiPGrasp: Parallel local searching for efficient differentiable grasp planning. IEEE Robot. Autom. Lett. 2024, 9, 8314–8321. [Google Scholar] [CrossRef]
- Ferrari, C.; Canny, J. Planning optimal grasps. In Proceedings of the 1992 IEEE International Conference on Robotics and Automation, Nice, France, 12–14 May 1992; IEEE: Piscataway, NJ, USA, 1992; Volume 3, pp. 2290–2295. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GIRAFFE [9] | EditNeRF [16] | CodeNeRF [15] | AFF-NeRF | |
|---|---|---|---|---|
| Learns scene prior | ✓ | ✓ | ✓ | ✓ |
| Affordance outputs | ✓ | |||
| Allows zero-shot | ✓ | ✓ | ✓ | |
| Without retraining | ✓ | ✓ |
| Scissors | Pens | Glasses | Drivers | Average | ||
|---|---|---|---|---|---|---|
| mIoU | PixelNeRF_M | 0.723 | 0.688 | 0.518 | 0.570 | 0.625 |
| SemRay | 0.537 | 0.627 | 0.563 | 0.659 | 0.597 | |
| GSNeRF | 0.670 | 0.576 | 0.584 | 0.678 | 0.627 | |
| Ours | 0.784 | 0.892 | 0.586 | 0.709 | 0.743 | |
| PA | PixelNeRF_M | 0.965 | 0.971 | 0.962 | 0.932 | 0.958 |
| SemRay | 0.979 | 0.986 | 0.965 | 0.978 | 0.977 | |
| GSNeRF | 0.982 | 0.989 | 0.962 | 0.982 | 0.979 | |
| Ours | 0.989 | 0.992 | 0.967 | 0.977 | 0.981 | |
| MPA | PixelNeRF_M | 0.729 | 0.403 | 0.547 | 0.613 | 0.573 |
| SemRay | 0.645 | 0.656 | 0.682 | 0.690 | 0.668 | |
| GSNeRF | 0.770 | 0.759 | 0.687 | 0.684 | 0.725 | |
| Ours | 0.940 | 0.799 | 0.733 | 0.777 | 0.812 |
| Screwdriver | Pen | Scissor | Eyeglass | |
|---|---|---|---|---|
| Original Model (no affordance) | 0.241 | 0.197 | 0.242 | 0.202 |
| Affordance Model | 0.272 | 0.198 | 0.306 | 0.242 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Chen, X.; Zheng, Z.; Lu, H.; Guo, R. Bio-Inspired 3D Affordance Understanding from Single Image with Neural Radiance Field for Enhanced Embodied Intelligence. Biomimetics 2025, 10, 410. https://doi.org/10.3390/biomimetics10060410
Guo Z, Chen X, Zheng Z, Lu H, Guo R. Bio-Inspired 3D Affordance Understanding from Single Image with Neural Radiance Field for Enhanced Embodied Intelligence. Biomimetics. 2025; 10(6):410. https://doi.org/10.3390/biomimetics10060410
Chicago/Turabian StyleGuo, Zirui, Xieyuanli Chen, Zhiqiang Zheng, Huimin Lu, and Ruibin Guo. 2025. "Bio-Inspired 3D Affordance Understanding from Single Image with Neural Radiance Field for Enhanced Embodied Intelligence" Biomimetics 10, no. 6: 410. https://doi.org/10.3390/biomimetics10060410
APA StyleGuo, Z., Chen, X., Zheng, Z., Lu, H., & Guo, R. (2025). Bio-Inspired 3D Affordance Understanding from Single Image with Neural Radiance Field for Enhanced Embodied Intelligence. Biomimetics, 10(6), 410. https://doi.org/10.3390/biomimetics10060410