
Attention-Based Multi-Objective Control for Morphing Aircraft

Abstract
1. Introduction
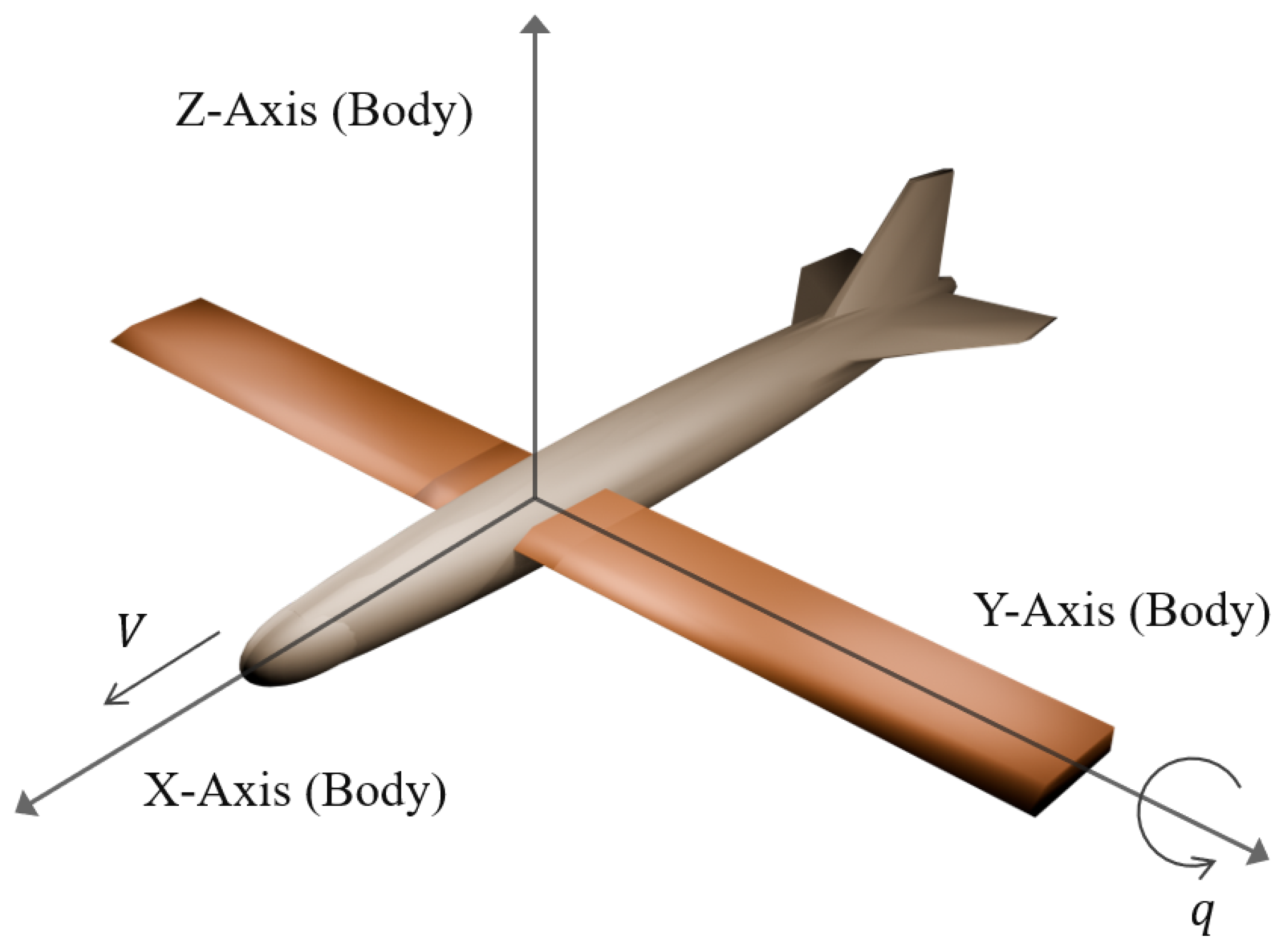
2. Problem Formulation
3. Methods
3.1. Scalarization of Optimal Tracking Problem
3.2. Generate Open Loop Solutions
3.3. Learn Closed Loop Control Law
4. Simulation
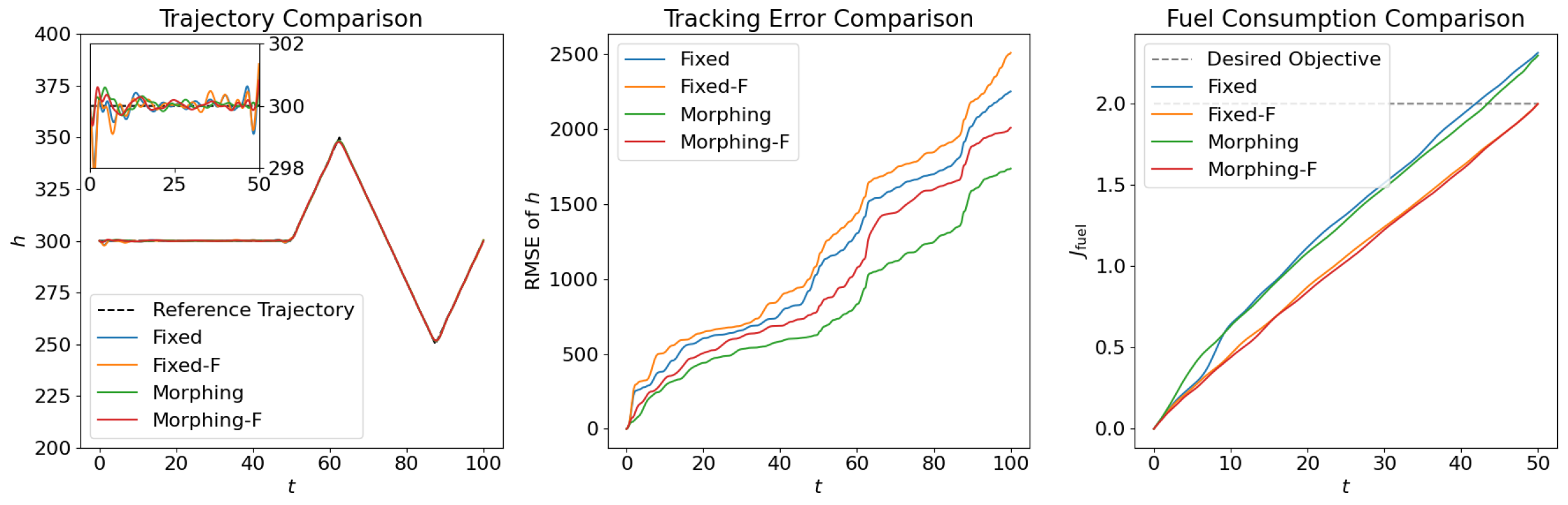
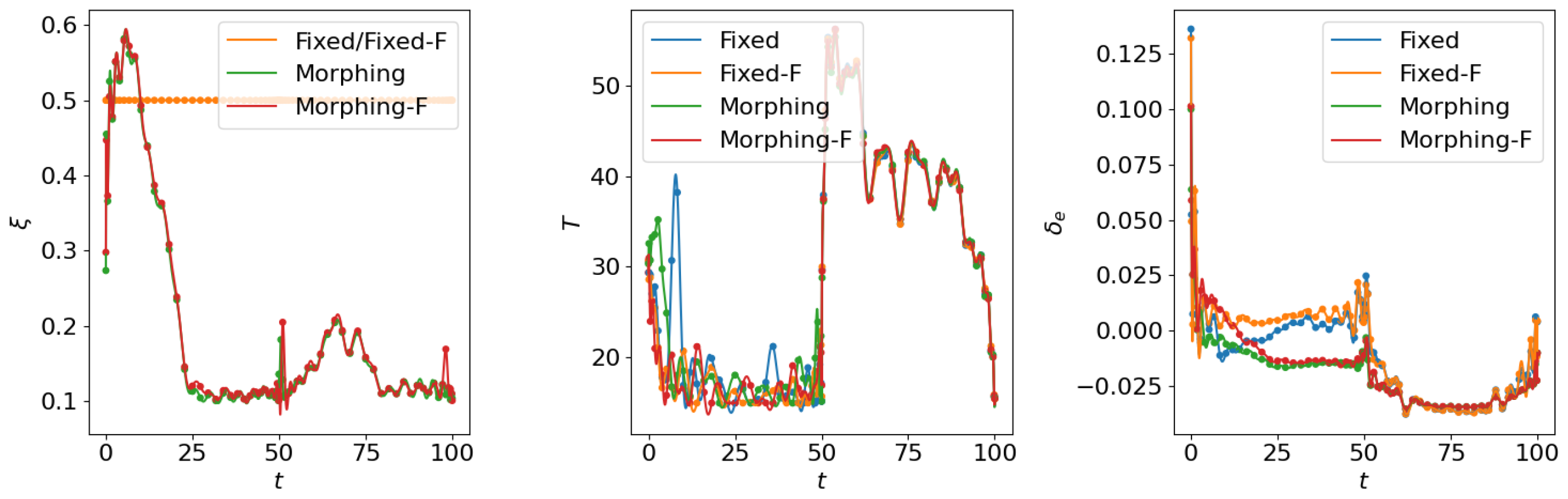
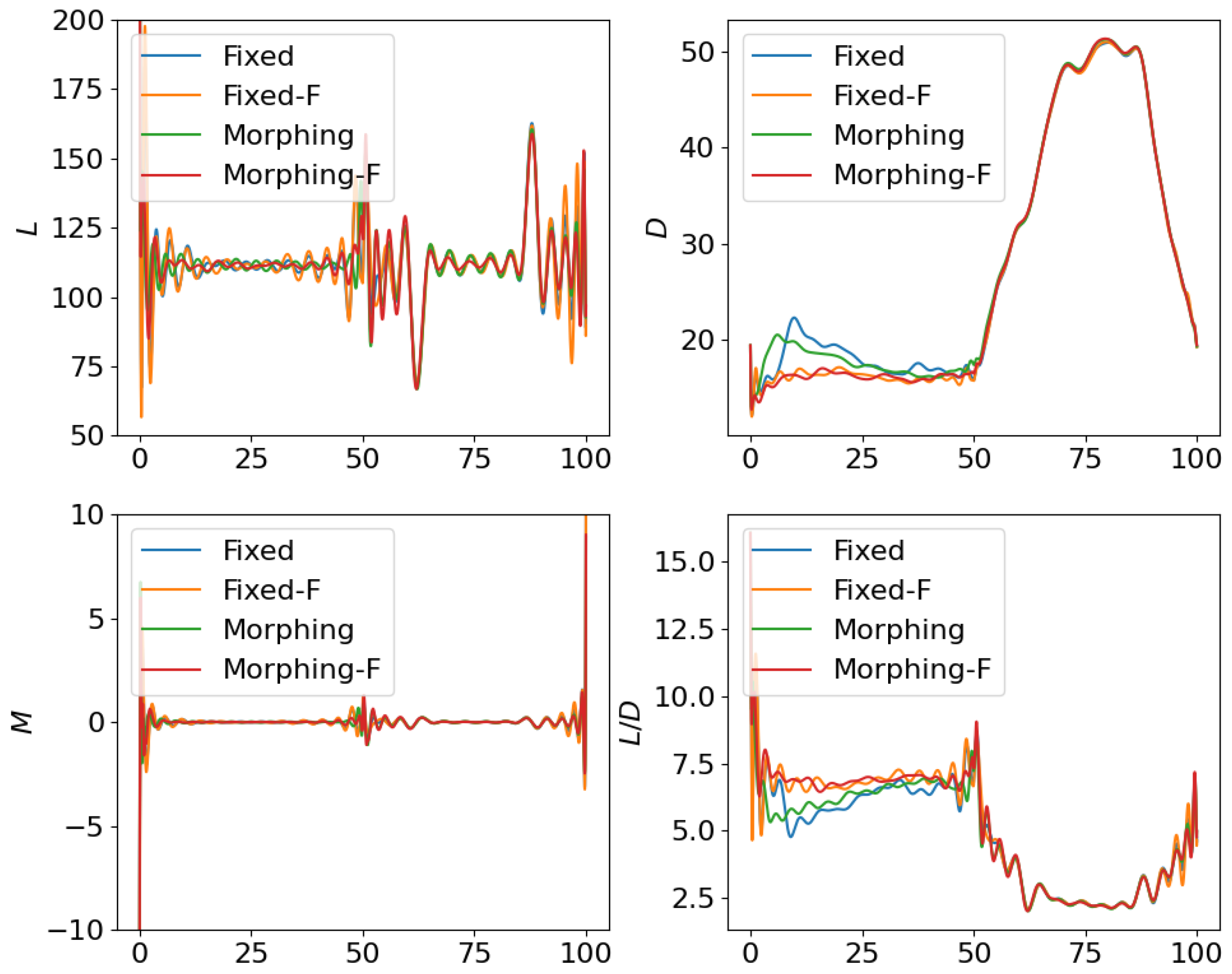
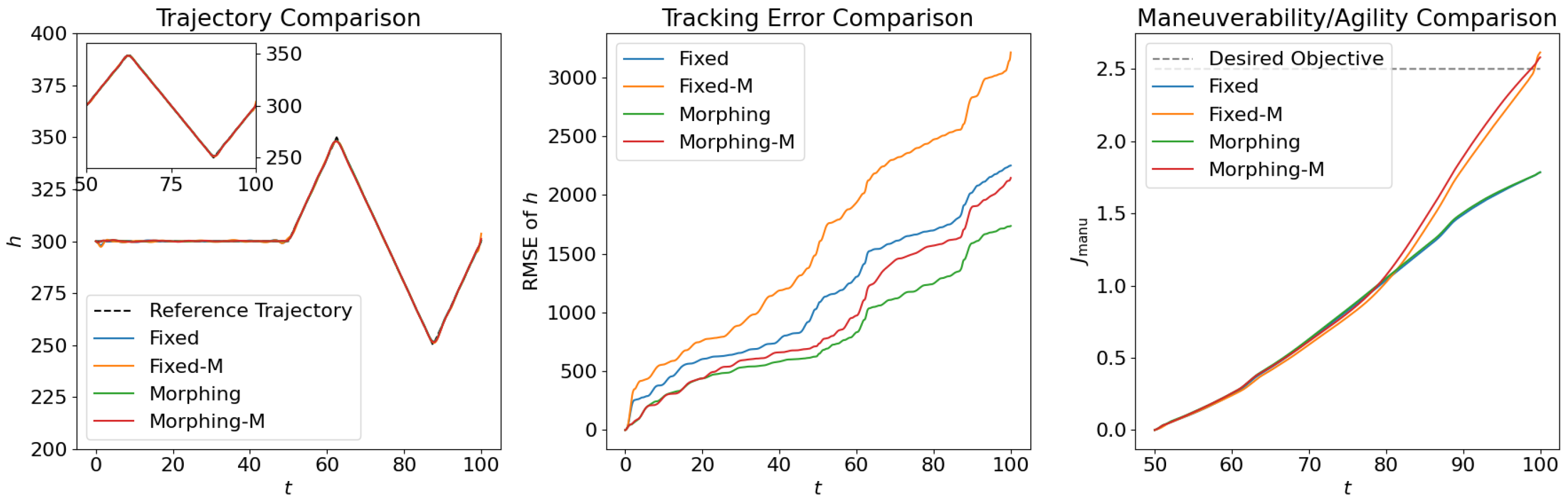
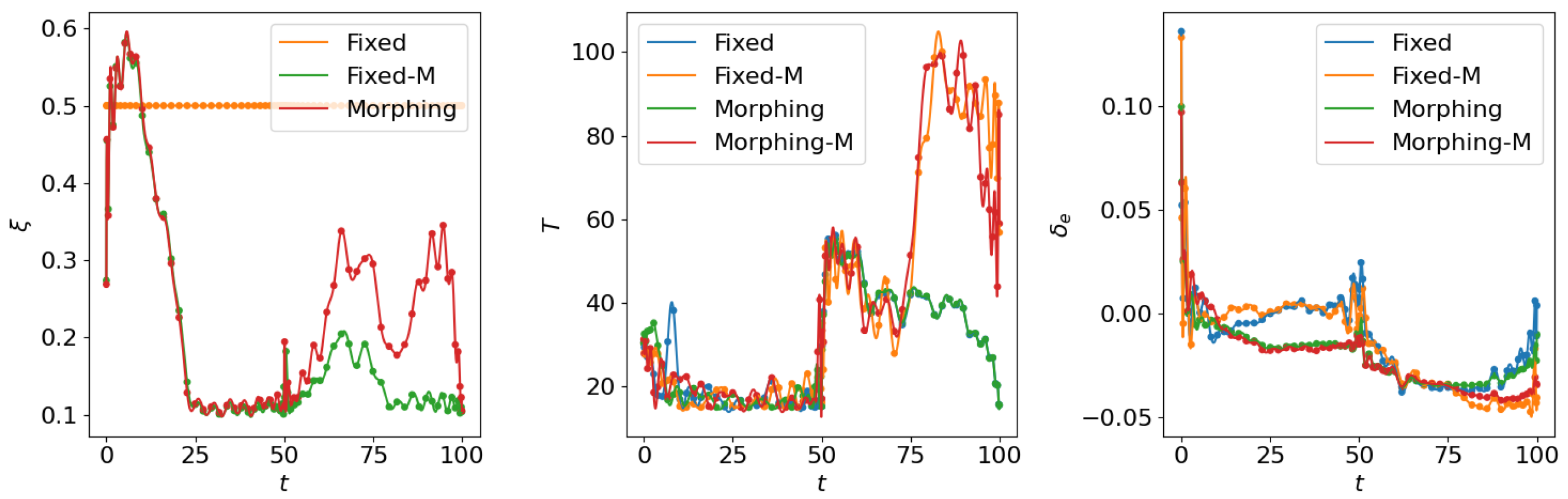
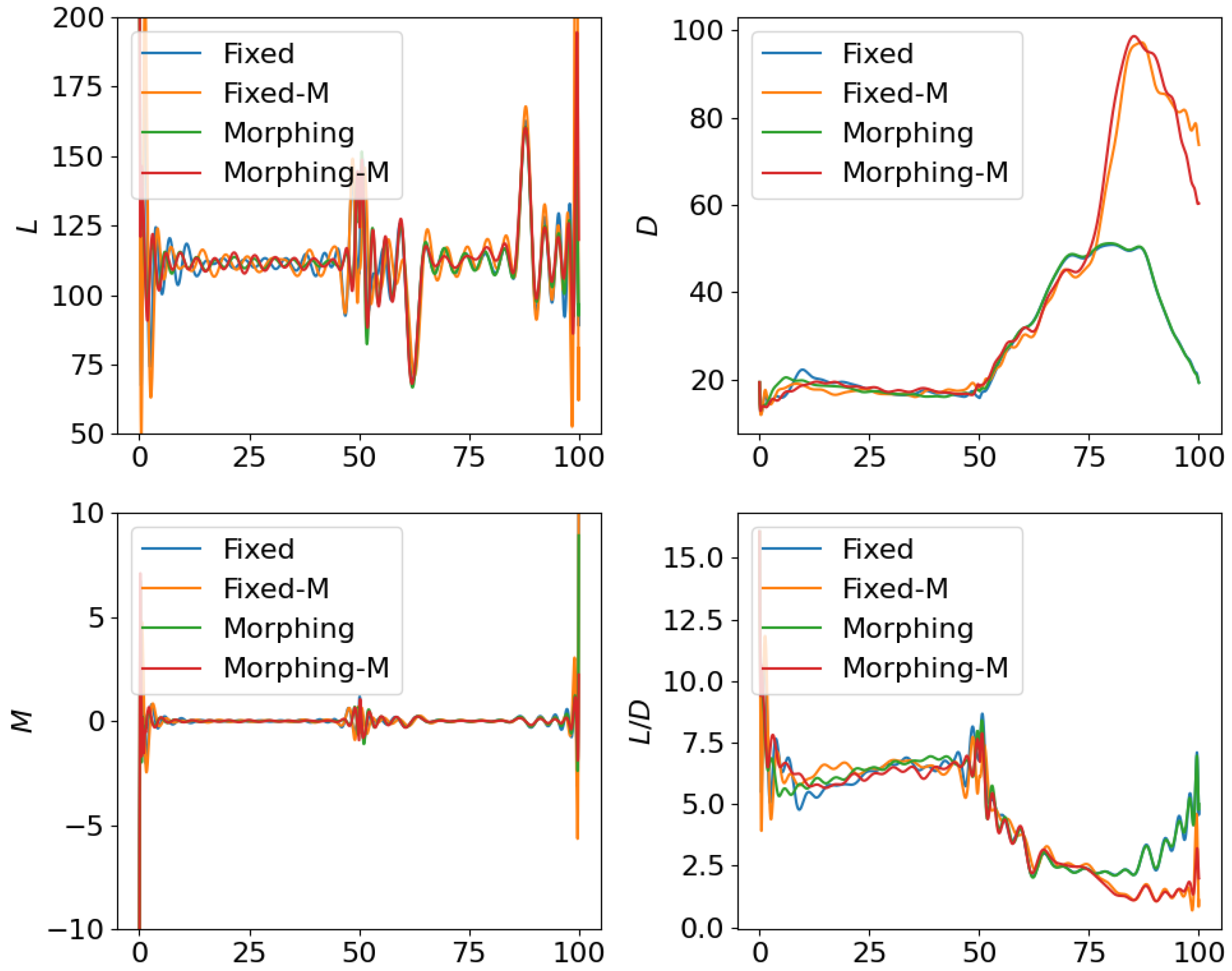
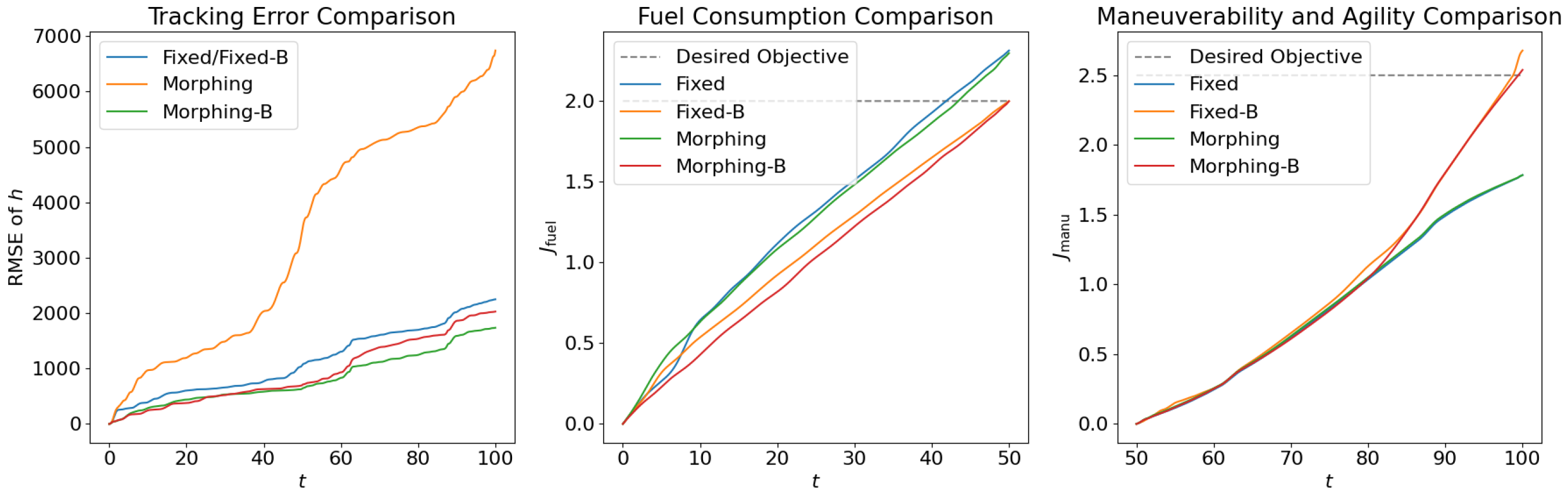
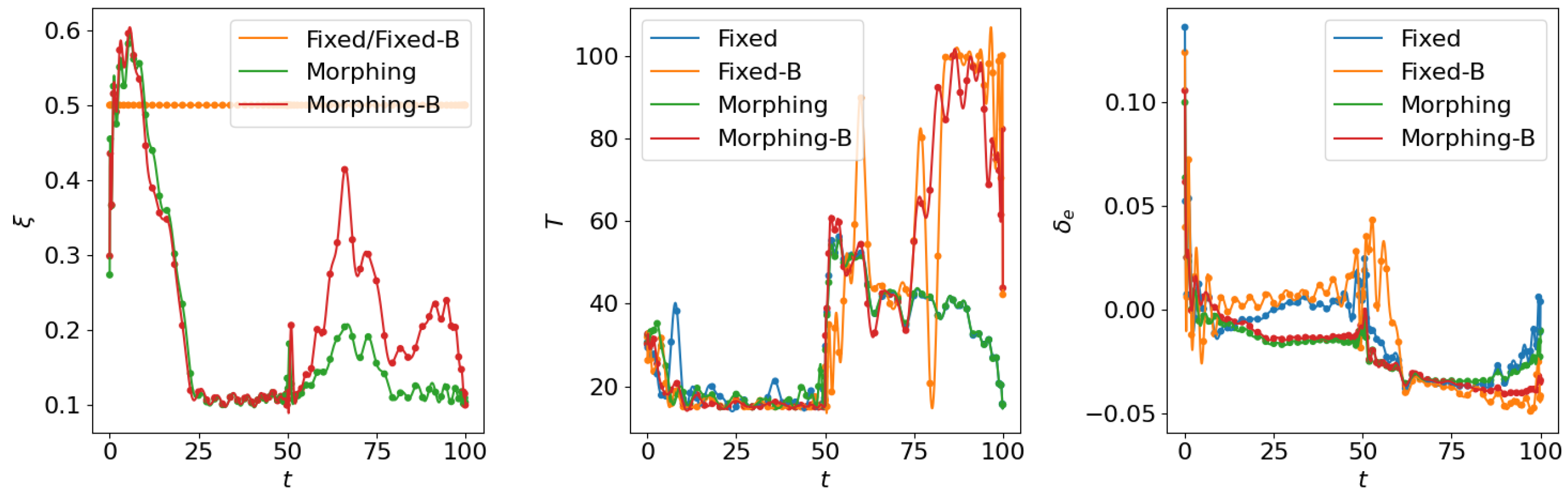
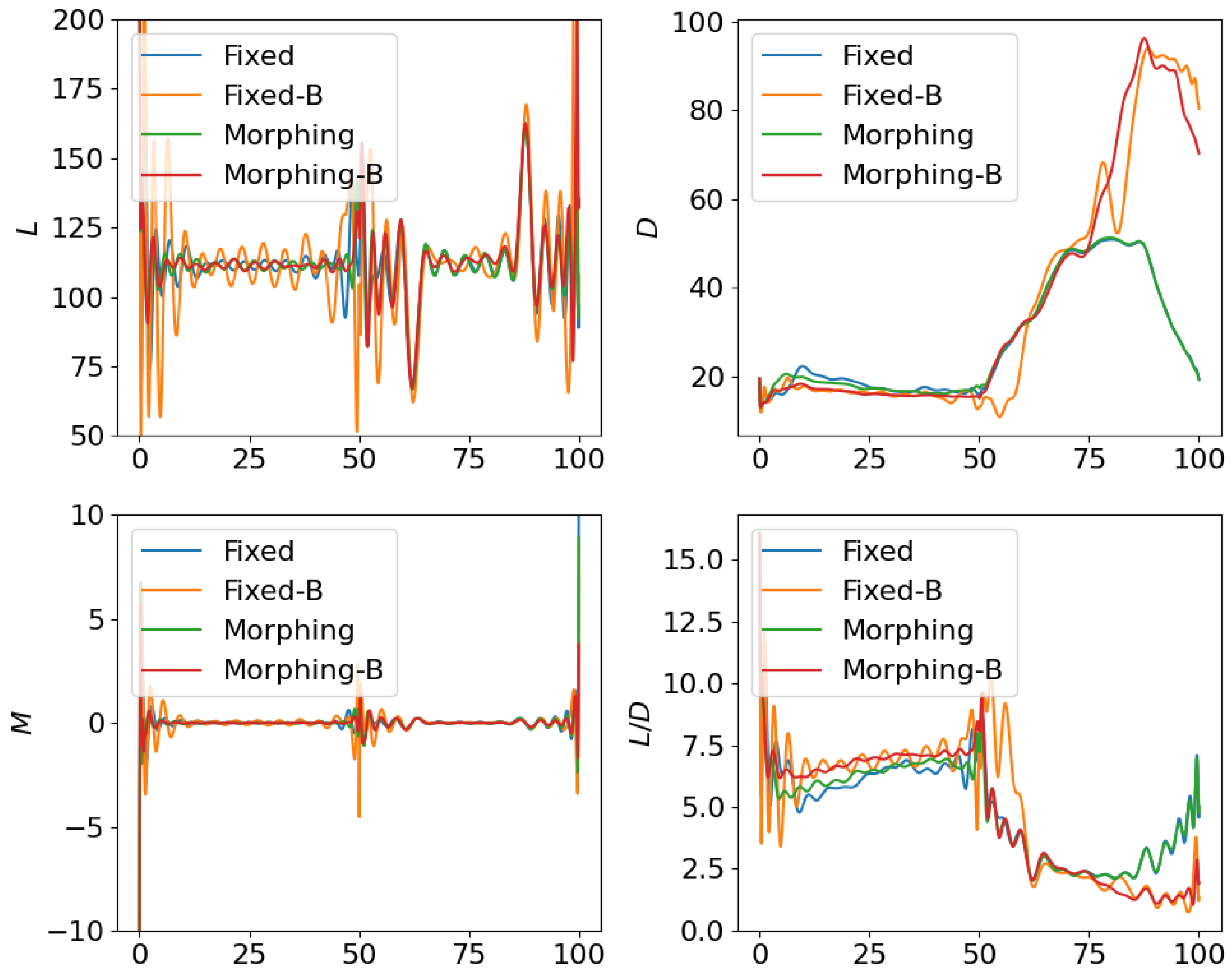
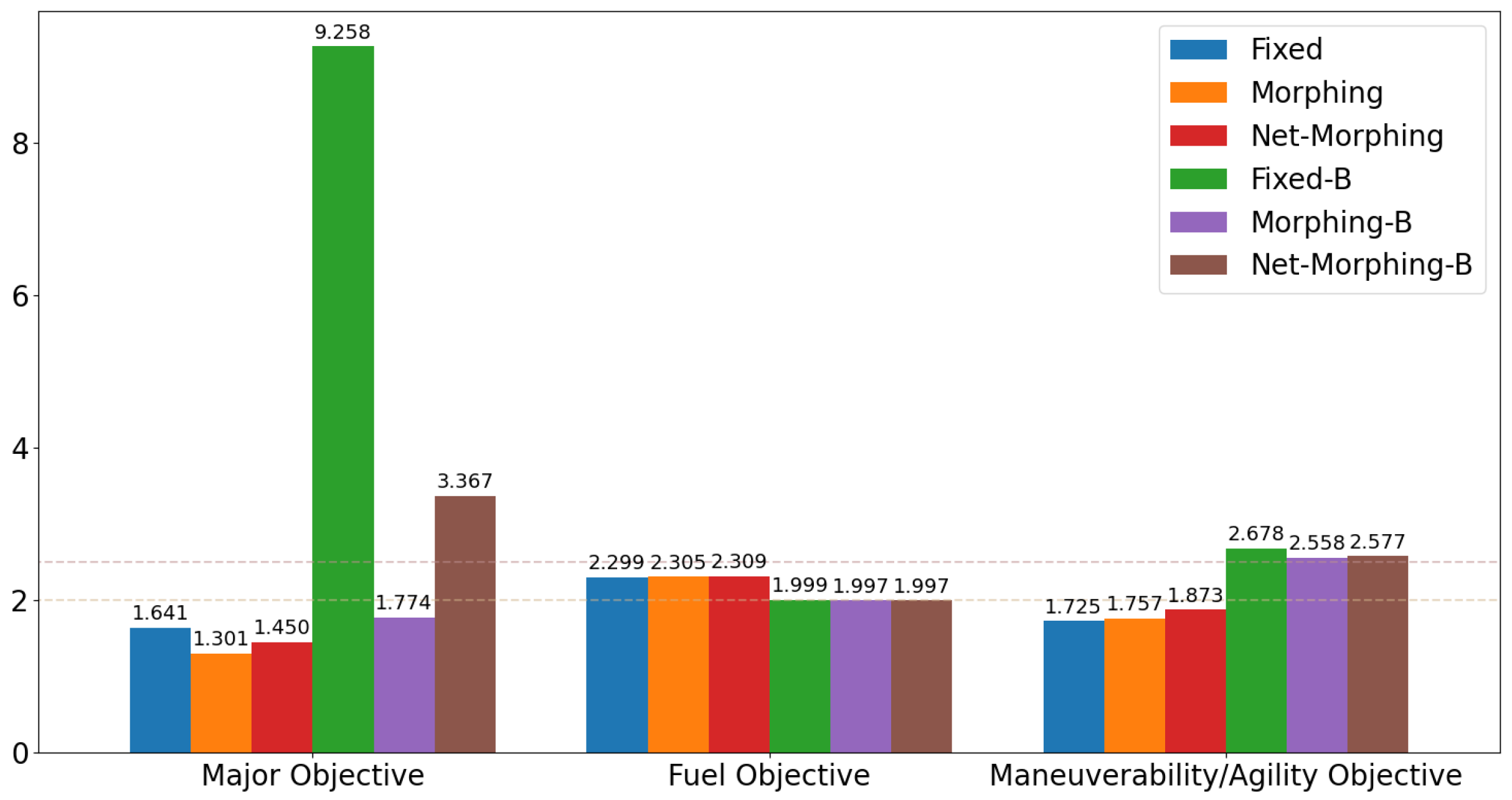
4.1. Open Loop Solution Comparison
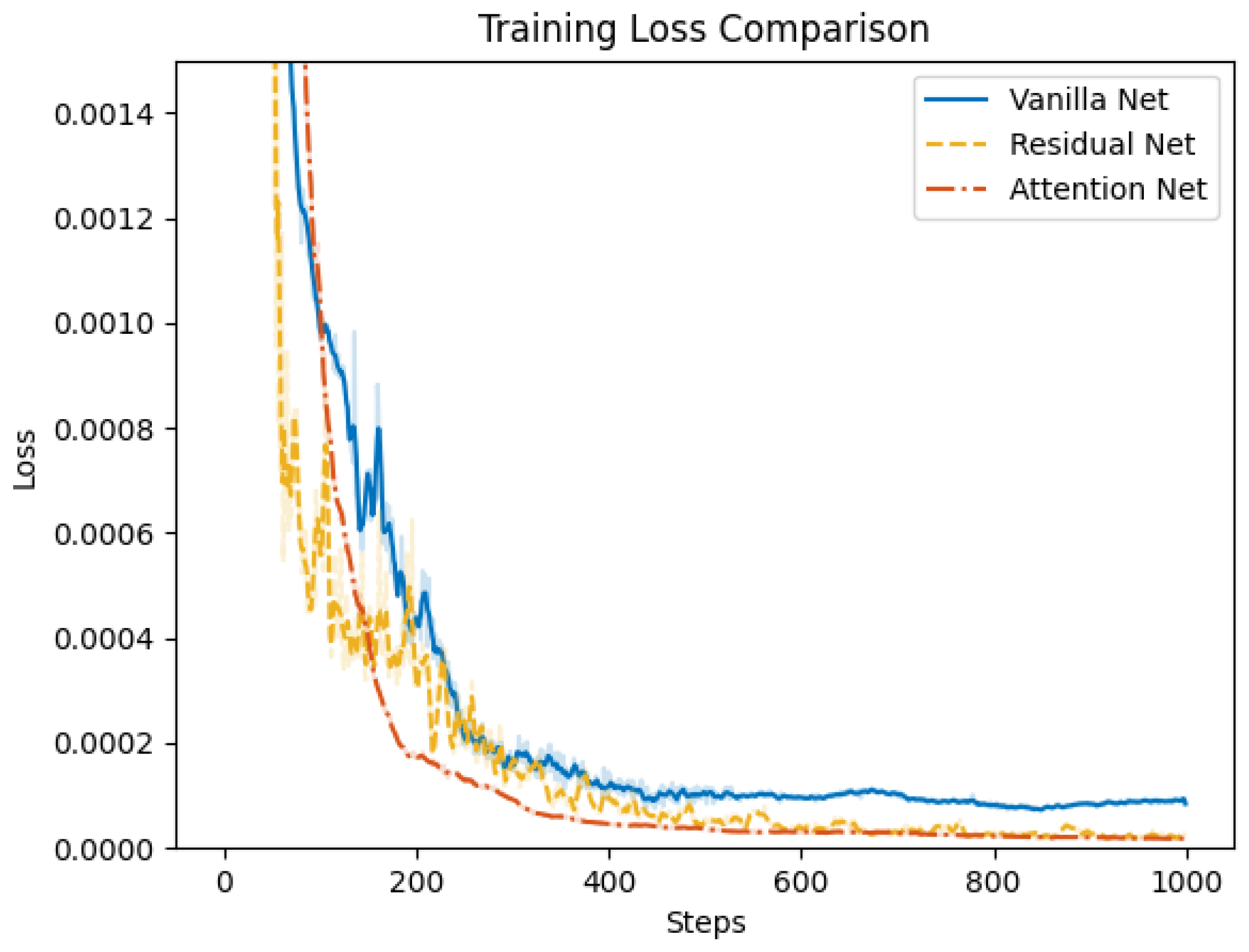
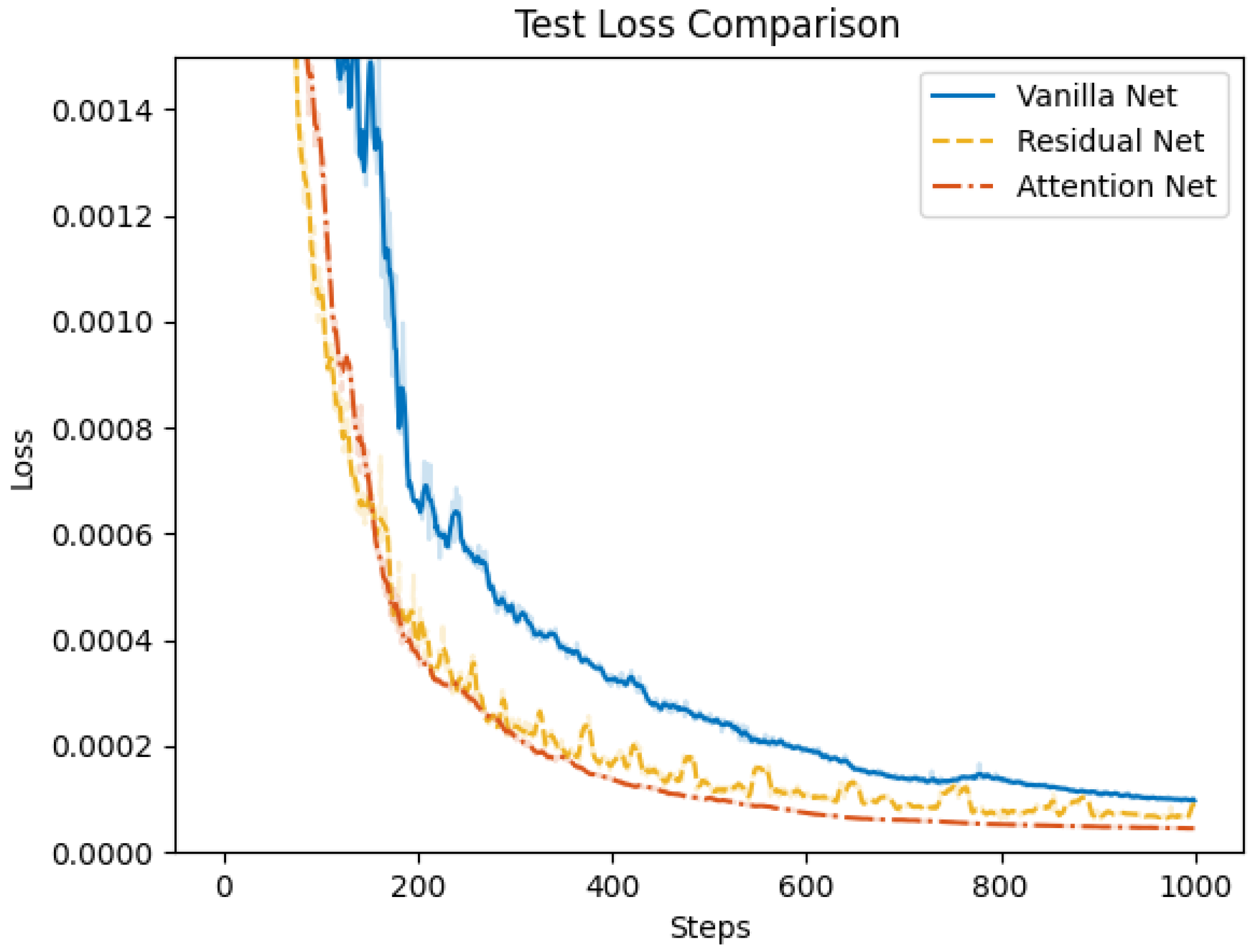
4.2. Control Net Validation
5. Discussion
5.1. Considerations for Real-World Deployment
5.2. Extending the Framework to More Complex Flight Scenarios
5.3. Neural Network Architecture and Learning Mechanism
5.4. Comparison with Recent Advances in Integrated Morphing and Flight Control
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LPV | Linear Parameter Varying |
| RBF | Radial Basis Function |
| RNN | Recurrent Neural Network |
| MLP | Multilayer Perceptron |
| LGL | Legendre–Gauss–Lobatto |
| NLP | Nonlinear Programming |
| SGD | Stochastic Gradient Descent |
References
- Harvey, C.; Gamble, L.L.; Bolander, C.R.; Hunsaker, D.F.; Joo, J.J.; Inman, D.J. A review of avian-inspired morphing for UAV flight control. Prog. Aerosp. Sci. 2022, 132, 100825. [Google Scholar] [CrossRef]
- Mowla, M.N.; Asadi, D.; Durhasan, T.; Jafari, J.R.; Amoozgar, M. Recent Advancements in Morphing Applications: Architecture, Artificial Intelligence Integration, Challenges, and Future Trends-A Comprehensive Survey. Aerosp. Sci. Technol. 2025, 161, 110102. [Google Scholar] [CrossRef]
- Ajanic, E.; Feroskhan, M.; Mintchev, S.; Noca, F.; Floreano, D. Bioinspired wing and tail morphing extends drone flight capabilities. Sci. Robot. 2020, 5, eabc2897. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, X.; Sun, Q.; Xue, J.; Song, K.; Li, Y.; Dong, L. Design and Validation of the Trailing Edge of a Variable Camber Wing Based on a Two-Dimensional Airfoil. Biomimetics 2024, 9, 312. [Google Scholar] [CrossRef]
- Hanna, D.; Rini, A.; Eghdamzamiri, J.; Saad, Y.; Arias-Rodas, A.; Brambila, M.; Yousefi, H.; Black, C.; Herrera, J.; Bishay, P. Design of a Non-Flapping Seagull-Inspired Composite Morphing Drone. In Proceedings of the AIAA SCITECH 2025 Forum, Orlando, FL, USA, 6–10 January 2025; p. 0124. [Google Scholar]
- Bishay, P.L.; Rini, A.; Brambila, M.; Niednagel, P.; Eghdamzamiri, J.; Yousefi, H.; Herrera, J.; Saad, Y.; Bertuch, E.; Black, C.; et al. CGull: A Non-Flapping Bioinspired Composite Morphing Drone. Biomimetics 2024, 9, 527. [Google Scholar] [CrossRef]
- Gong, X.; Ren, C.; Sun, J.; Zhang, P.; Du, L.; Xie, F. 3D Zero Poisson’s ratio honeycomb structure for morphing wing applications. Biomimetics 2022, 7, 198. [Google Scholar] [CrossRef]
- Derrouaoui, S.H.; Bouzid, Y.; Doula, A.; Boufroua, M.A.; Belmouhoub, A.; Guiatni, M.; Hamissi, A. Trajectory tracking control of a morphing UAV using radial basis function artificial neural network based fast terminal sliding mode: Theory and experimental. Aerosp. Sci. Technol. 2024, 155, 109719. [Google Scholar] [CrossRef]
- Smith, P.; Huang, D. A Parametric Study for the Effect of Morphing on Aerial Vehicles in Obstacle Avoidance. In Proceedings of the AIAA SCITECH 2025 Forum, Orlando, FL, USA, 6–10 January 2025; p. 1017. [Google Scholar]
- Wüest, V.; Jeger, S.; Feroskhan, M.; Ajanic, E.; Bergonti, F.; Floreano, D. Agile perching maneuvers in birds and morphing-wing drones. Nat. Commun. 2024, 15, 8330. [Google Scholar] [CrossRef]
- Cai, G.; Yang, Q.; Mu, C.; Li, X. Design of linear parameter-varying controller for morphing aircraft using inexact scheduling parameters. IET Control Theory Appl. 2023, 17, 493–503. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S.H.; Lee, H.; Kim, Y. Self-Scheduled LPV Control of Asymmetric Variable-Span Morphing UAV. Sensors 2023, 23, 3075. [Google Scholar] [CrossRef]
- Liang, Y.; Zhang, L.; Wang, X. Antibump Switched LPV Control with Delayed Scheduling for Morphing Aircraft. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 5010–5023. [Google Scholar] [CrossRef]
- Shao, P.; Ma, X.; Yan, B.; Dong, Y.; Wu, C.; Qu, G.; Tan, J. Structural state feedback gain-scheduled tracking control based on linear parameter varying system of morphing wing UAV. J. Frankl. Inst. 2025, 362, 107355. [Google Scholar] [CrossRef]
- Jung, S.; Kim, Y. Low-power peaking-free extended-observer-based pitch autopilot for morphing unmanned aerial vehicle. J. Guid. Control Dyn. 2022, 45, 362–371. [Google Scholar] [CrossRef]
- Xu, W.; Li, Y.; Lv, M.; Pei, B. Modeling and switching adaptive control for nonlinear morphing aircraft considering actuator dynamics. Aerosp. Sci. Technol. 2022, 122, 107349. [Google Scholar] [CrossRef]
- Qiao, F.; Shi, J.; Qu, X.; Lyu, Y. Adaptive back-stepping neural control for an embedded and tiltable V-tail morphing aircraft. Int. J. Control Autom. Syst. 2022, 20, 678–690. [Google Scholar] [CrossRef]
- Feng, L.; Guo, T.; Zhu, C.; Chen, H. Control of Aerodynamic-Driven Morphing. J. Guid. Control Dyn. 2023, 46, 198–205. [Google Scholar] [CrossRef]
- Liu, J.; Shan, J.; Wang, J.; Rong, J. Incremental sliding-mode control and allocation for morphing-wing aircraft fast manoeuvring. Aerosp. Sci. Technol. 2022, 131, 107959. [Google Scholar] [CrossRef]
- Derrouaoui, S.H.; Bouzid, Y.; Belmouhoub, A.; Guiatni, M. Improved robust control of a new morphing quadrotor uav subject to aerial configuration change. Unmanned Syst. 2025, 13, 171–191. [Google Scholar] [CrossRef]
- Chen, H.; Wang, P.; Tang, G. Prescribed-time control for hypersonic morphing vehicles with state error constraints and uncertainties. Aerosp. Sci. Technol. 2023, 142, 108671. [Google Scholar] [CrossRef]
- Lu, X.; Wang, J.; Wang, Y.; Chen, J. Neural network observer-based predefined-time attitude control for morphing hypersonic vehicles. Aerosp. Sci. Technol. 2024, 152, 109333. [Google Scholar] [CrossRef]
- Pu, J.; Zhang, Y.; Guan, Y.; Cui, N. Recurrent neural network-based predefined time control for morphing aircraft with asymmetric time-varying constraints. Appl. Math. Model. 2024, 135, 578–600. [Google Scholar] [CrossRef]
- Wang, Y.; Shimada, K.; Farimani, A.B. Airfoil GAN: Encoding and synthesizing airfoils for aerodynamic-aware shape optimization. arXiv 2021, arXiv:2101.04757. [Google Scholar] [CrossRef]
- Si, P.; Wu, M.; Huo, Y.; Wu, Z. Effect of Wing Sweep and Asymmetry on Flight Dynamics of a Sweep-Morphing Aircraft. Aerosp. Sci. Technol. 2025, 161, 110120. [Google Scholar] [CrossRef]
- Skinner, S.N.; Zare-Behtash, H. State-of-the-art in aerodynamic shape optimisation methods. Appl. Soft Comput. 2018, 62, 933–962. [Google Scholar] [CrossRef]
- Achour, G.; Sung, W.J.; Pinon-Fischer, O.J.; Mavris, D.N. Development of a conditional generative adversarial network for airfoil shape optimization. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 2261. [Google Scholar]
- Syed, A.A.; Khamvilai, T.; Kim, Y.; Vamvoudakis, K.G. Experimental design and control of a smart morphing wing system using a q-learning framework. In Proceedings of the 2021 IEEE Conference on Control Technology and Applications (CCTA), San Diego, CA, USA, 9–11 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 354–359. [Google Scholar]
- Su, J.; Sun, G.; Tao, J. A novel inverse design method for morphing airfoil based on deep reinforcement learning. Aerosp. Sci. Technol. 2024, 145, 108895. [Google Scholar] [CrossRef]
- Viquerat, J.; Rabault, J.; Kuhnle, A.; Ghraieb, H.; Larcher, A.; Hachem, E. Direct shape optimization through deep reinforcement learning. J. Comput. Phys. 2021, 428, 110080. [Google Scholar] [CrossRef]
- Liu, J.; Shan, J.; Hu, Y.; Rong, J. Optimal switching control for Morphing aircraft with Aerodynamic Uncertainty. In Proceedings of the 2020 IEEE 16th International Conference on Control & Automation (ICCA), Singapore, 9–11 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1167–1172. [Google Scholar]
- Xu, W.; Li, Y.; Pei, B.; Yu, Z. A nonlinear programming-based morphing strategy for a variable-sweep morphing aircraft aiming at optimizing the cruising efficiency. Aerospace 2023, 10, 49. [Google Scholar] [CrossRef]
- Júnior, J.M.M.; Halila, G.L.; Vamvoudakis, K.G. Data-driven controller and multi-gradient search algorithm for morphing airfoils in high Reynolds number flows. Aerosp. Sci. Technol. 2024, 148, 109106. [Google Scholar] [CrossRef]
- Che, H.C.; Wu, H.N. Coordinated Control of Deformation and Flight for Morphing Aircraft via Meta-Learning and Coupled State-Dependent Riccati Equations. arXiv 2025, arXiv:2501.05102. [Google Scholar]
- Valasek, J.; Tandale, M.D.; Rong, J. A reinforcement learning-adaptive control architecture for morphing. J. Aerosp. Comput. Inf. Commun. 2005, 2, 174–195. [Google Scholar] [CrossRef]
- Valasek, J.; Doebbler, J.; Tandale, M.D.; Meade, A.J. Improved adaptive–reinforcement learning control for morphing unmanned air vehicles. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 38, 1014–1020. [Google Scholar] [CrossRef] [PubMed]
- Lu, K.; Fu, Q.; Cao, R.; Peng, J.; Wang, Q. Asymmetric airfoil morphing via deep reinforcement learning. Biomimetics 2022, 7, 188. [Google Scholar] [CrossRef] [PubMed]
- Haughn, K.P.; Gamble, L.L.; Inman, D.J. Deep reinforcement learning achieves multifunctional morphing airfoil control. J. Compos. Mater. 2023, 57, 721–736. [Google Scholar] [CrossRef]
- Gao, L.; Zhu, Y.; Liu, Y.; Zhang, J.; Liu, B.; Zhao, J. Analysis and control for the mode transition of tandem-wing aircraft with variable sweep. Aerospace 2022, 9, 463. [Google Scholar] [CrossRef]
- Enmei, W.; Hao, L.; Zhang, J.; Chenliang, W.; Jianzhong, Q. A novel adaptive coordinated tracking control scheme for a morphing aircraft with telescopic wings. Chin. J. Aeronaut. 2024, 37, 148–162. [Google Scholar]
- Xu, W.; Li, Y.; Pei, B.; Yu, Z. Coordinated intelligent control of the flight control system and shape change of variable sweep morphing aircraft based on dueling-DQN. Aerosp. Sci. Technol. 2022, 130, 107898. [Google Scholar] [CrossRef]
- Ming, R.; Liu, X.; Li, Y.; Yin, Y.; Zhang, W. Morphing aircraft acceleration and deceleration task morphing strategy using a reinforcement learning method. Appl. Intell. 2023, 53, 26637–26654. [Google Scholar] [CrossRef]
- Zhang, X.; Mu, R.; Chen, J.; Wu, P. Hybrid multi-objective control allocation strategy for reusable launch vehicle in re-entry phase. Aerosp. Sci. Technol. 2021, 116, 106825. [Google Scholar] [CrossRef]
- Nguyen, N.T.; Hashemi, K.E. Multi-Objective Flight Control for Ride Quality Improvement for Flexible Aircraft. In Proceedings of the AIAA SciTech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 1623. [Google Scholar]
- Su, M.; Hu, J.; Wang, Y.; He, Z.; Cong, J.; Han, L. A multiobjective incremental control allocation strategy for tailless aircraft. Int. J. Aerosp. Eng. 2022, 2022, 6515234. [Google Scholar] [CrossRef]
- Forte, C.J.; Nguyen, N.T. Multi-Objective Optimal Control of High Aspect Ratio Wing Wind Tunnel Model. In Proceedings of the AIAA SCITECH 2024 Forum, Orlando, FL, USA, 8–12 January 2024; p. 1782. [Google Scholar]
- Peng, W.; Yang, T.; Feng, Z.; Zhang, Q. Analysis of morphing modes of hypersonic morphing aircraft and multiobjective trajectory optimization. IEEE Access 2018, 7, 2244–2255. [Google Scholar] [CrossRef]
- Yang, H.; Chao, T.; Wang, S. Multiobjective Trajectory Optimization for Hypersonic Telescopic Wing Morphing Aircraft Using a Hybrid MOEA/D. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2653–2658. [Google Scholar]
- Mappas, V.K.; Vassiliadis, V.S.; Dorneanu, B.; Routh, A.F.; Arellano-Garcia, H. Automated control loop selection via multistage optimal control formulation and nonlinear programming. Chem. Eng. Res. Des. 2023, 195, 76–95. [Google Scholar] [CrossRef]
- Ricciardi, L.A.; Maddock, C.A.; Vasile, M. Direct solution of multi-objective optimal control problems applied to spaceplane mission design. J. Guid. Control. Dyn. 2019, 42, 30–46. [Google Scholar] [CrossRef]
- Harris, G.W.; He, P.; Abdelkhalik, O.O. Control co-design optimization of spacecraft trajectory and system for interplanetary missions. J. Spacecr. Rocket. 2024, 61, 939–952. [Google Scholar] [CrossRef]
- Liguo, S.; Qing, Z.; Baoxu, J.; Wenqian, T.; Hangxu, L. Effective control allocation using hierarchical multi-objective optimization for multi-phase flight. Chin. J. Aeronaut. 2020, 33, 2002–2013. [Google Scholar]
- Seigler, T.; Neal, D. Analysis of transition stability for morphing aircraft. J. Guid. Control. Dyn. 2009, 32, 1947–1954. [Google Scholar] [CrossRef]
- Bardi, M.; Capuzzo-Dolcetta, I. Optimal Control and Viscosity Solutions of Hamilton–Jacobi–Bellman Equations; Springer: New York, NY, USA, 1997; Volume 12. [Google Scholar]
- Bokanowski, O.; Désilles, A.; Zidani, H. Relationship between maximum principle and dynamic programming in presence of intermediate and final state constraints. ESAIM Control. Optim. Calc. Var. 2021, 27, 91. [Google Scholar] [CrossRef]
- Nakamura-Zimmerer, T.; Gong, Q.; Kang, W. Adaptive deep learning for high-dimensional Hamilton–Jacobi–Bellman equations. SIAM J. Sci. Comput. 2021, 43, A1221–A1247. [Google Scholar] [CrossRef]
- Kelly, M. An introduction to trajectory optimization: How to do your own direct collocation. SIAM Rev. 2017, 59, 849–904. [Google Scholar] [CrossRef]
- Ross, I.M.; Karpenko, M. A review of pseudospectral optimal control: From theory to flight. Annu. Rev. Control 2012, 36, 182–197. [Google Scholar] [CrossRef]
- Sun, J.; Guan, Q.; Liu, Y.; Leng, J. Morphing aircraft based on smart materials and structures: A state-of-the-art review. J. Intell. Mater. Syst. Struct. 2016, 27, 2289–2312. [Google Scholar] [CrossRef]
- Ahmed, F.; Jenihhin, M. A survey on UAV computing platforms: A hardware reliability perspective. Sensors 2022, 22, 6286. [Google Scholar] [CrossRef]
- Bemposta Rosende, S.; Ghisler, S.; Fernández-Andrés, J.; Sánchez-Soriano, J. Implementation of an edge-computing vision system on reduced-board computers embedded in UAVs for intelligent traffic management. Drones 2023, 7, 682. [Google Scholar] [CrossRef]
- Süzen, A.A.; Duman, B.; Şen, B. Benchmark analysis of jetson tx2, jetson nano and raspberry pi using deep-cnn. In Proceedings of the 2020 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 26–28 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Winzig, J.; Almanza, J.C.A.; Mendoza, M.G.; Schumann, T. Edge ai-use case on google coral dev board mini. In Proceedings of the 2022 IET International Conference on Engineering Technologies and Applications (IET-ICETA), Changhua, Taiwan, 14–16 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–2. [Google Scholar]
- Zuo, Q.; Wang, B.; Chen, J.; Dong, H. Model Predictive Control of Aero-Mechanical Actuators with Consideration of Gear Backlash and Friction Compensation. Electronics 2024, 13, 4021. [Google Scholar] [CrossRef]
- Hassani, V.; Tjahjowidodo, T.; Do, T.N. A survey on hysteresis modeling, identification and control. Mech. Syst. Signal Process. 2014, 49, 209–233. [Google Scholar] [CrossRef]
- Zhu, K.; Hu, X.; Wang, J.; Xie, X.; Yang, G. Improving generalization of adversarial training via robust critical fine-tuning. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 4424–4434. [Google Scholar]
- Yu, X.; Zhang, Y. Sense and avoid technologies with applications to unmanned aircraft systems: Review and prospects. Prog. Aerosp. Sci. 2015, 74, 152–166. [Google Scholar] [CrossRef]
- Kamel, M.; Alonso-Mora, J.; Siegwart, R.; Nieto, J. Robust collision avoidance for multiple micro aerial vehicles using nonlinear model predictive control. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 236–243. [Google Scholar]
- Ouyang, Q.; Wu, Z.; Cong, Y.; Wang, Z. Formation control of unmanned aerial vehicle swarms: A comprehensive review. Asian J. Control 2023, 25, 570–593. [Google Scholar] [CrossRef]
- Wang, J.; Xin, M. Integrated optimal formation control of multiple unmanned aerial vehicles. IEEE Trans. Control Syst. Technol. 2012, 21, 1731–1744. [Google Scholar] [CrossRef]
- Nakamura-Zimmerer, T.E. A Deep Learning Framework for Optimal Feedback Control of High-Dimensional Nonlinear Systems. Ph.D. Thesis, University of California, Santa Cruz, CA, USA, 2022. [Google Scholar]
- Zhang, J.; Zhou, X.; Zhou, J.; Qiu, S.; Liang, G.; Cai, S.; Bao, G. A High-Efficient Reinforcement Learning Approach for Dexterous Manipulation. Biomimetics 2023, 8, 264. [Google Scholar] [CrossRef]
- Sardarmehni, T.; Song, X. Region-based approximation in approximate dynamic programming. Int. J. Control 2024, 97, 306–315. [Google Scholar] [CrossRef]
- Radac, M.B.; Lala, T. Robust control of unknown observable nonlinear systems solved as a zero-sum game. IEEE Access 2020, 8, 214153–214165. [Google Scholar] [CrossRef]
- Bergonti, F.; Nava, G.; Wüest, V.; Paolino, A.; L’Erario, G.; Pucci, D.; Floreano, D. Co-design optimisation of morphing topology and control of winged drones. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 8679–8685. [Google Scholar]
- Wang, J.W.; Wang, F.; Wu, H.N.; Liu, Z.Y. Safe RL-based Adaptive Cooperative Game Control of Wing Deformation and Flight State Tracking for Morphing Hypersonic Vehicles. IEEE Trans. Aerosp. Electron. Syst. 2025. [Google Scholar] [CrossRef]
- Guo, Z.; Cao, S.; Yuan, R.; Guo, J.; Zhang, Y.; Li, J.; Hu, G.; Han, Y. Reinforcement Learning-Based Integrated Decision-Making and Control for Morphing Flight Vehicles Under Aerodynamic Uncertainties. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 9342–9353. [Google Scholar] [CrossRef]
- Cao, R.; Lu, K. Trajectory Tracking Control of Variable Sweep Aircraft Based on Reinforcement Learning. Biomimetics 2024, 9, 263. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| m | 11.4 kg | g | 9.8 m/s2 |
| 40 deg | 1.29 kg/m3 | ||
| S | 0.84 m2 | 0.288 m |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 0.19 | −0.04 | ||
| 0.143 | −0.032 | ||
| 0.052 | −0.0012 | ||
| 0.00065 | −0.000026 | ||
| 0.000325 | −0.000013 | ||
| 0.195 | −0.065 | ||
| −0.057 | −0.057 | ||
| −0.02 | 0.125 | ||
| 3.04 | 0.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Q.; Sun, C. Attention-Based Multi-Objective Control for Morphing Aircraft. Biomimetics 2025, 10, 280. https://doi.org/10.3390/biomimetics10050280
Fu Q, Sun C. Attention-Based Multi-Objective Control for Morphing Aircraft. Biomimetics. 2025; 10(5):280. https://doi.org/10.3390/biomimetics10050280
Chicago/Turabian StyleFu, Qien, and Changyin Sun. 2025. "Attention-Based Multi-Objective Control for Morphing Aircraft" Biomimetics 10, no. 5: 280. https://doi.org/10.3390/biomimetics10050280
APA StyleFu, Q., & Sun, C. (2025). Attention-Based Multi-Objective Control for Morphing Aircraft. Biomimetics, 10(5), 280. https://doi.org/10.3390/biomimetics10050280