1. Introduction
Over the past decade, drones have increasingly become a frequent presence in news reports and everyday activities. Public perception of drones has shifted from novelty to normalcy. Particularly in terms of civil applications, drones have been commonly seen in activities ranging from celebratory performances to security monitoring, from power line inspections to package delivery. In other words, the effective use of drones not only significantly facilitates daily life but has also become one of the key pillars supporting the low-altitude economy [
1,
2,
3,
4]. Consequently, the capability to command drones to perform tasks with stability, efficiency, and economy has become a key technological objective for both academia and industry. Among the core technologies is path planning for drones in three-dimensional space [
5,
6,
7], which addresses the challenge of generating a reasonable path for drones to avoid obstacles and reach predetermined destinations in complex, dynamic environments. This is a practical yet challenging task that has attracted numerous researchers to explore and optimize drone paths using optimization algorithms.
Zhou et al. tackled the issue of drone trajectory replanning by employing a gradient-based algorithm to optimize newly generated paths. They also proposed a path-guided optimization approach, which combines efficient sampling-based topological path searching and parallel trajectory optimization to address issues of local minima and path optimality [
8]. Melo et al. investigated dynamic full-coverage path planning for drones by combining linear and heuristic optimization algorithms. They further estimated energy costs at different flight speeds and utilized fog-edge computing to reduce computational overheads [
9]. Liu et al. developed a graph-based point-to-point path-planning algorithm that first generates two routes using the elliptic tangent graph method, then applies four heuristic rules to select an efficient, collision-free path [
10]. Peng et al. addressed the planning of multiple waypoints along a path, formulating the objective function to focus on energy-efficient offloading and safe path planning [
11]. From the perspective of unknown environments, Venkatasivarambabu et al. proposed a Dynamic Window approach that integrates Dynamic Programming and Probabilistic Route Mapping techniques to enhance drone navigation and localization capabilities [
12]. Han et al. focused on optimizing the mapping process. They developed a modeling method based on geographical coordinates subdividing grids and combined A* and backtracking path-planning algorithms to reduce the computational complexity of indoor drone path planning while improving planning reliability [
13]. Chen et al. proposed a bilevel optimizer to address the rapid trajectory planning of drones under constraints of variable time allocation and safety sets. The optimizer solved a low-level convex quadratic program and updated the high-level spatial and temporal waypoints [
14]. Souto et al. explored optimization strategies using popular artificial intelligence techniques, employing simple Q-learning, ε-greedy methods, and a state–action–reward–state–action framework to optimize paths while considering urban terrain, weather, and drone energy consumption [
15].
It is worth noting that optimization algorithms based on mathematical and computational theories have advantages in terms of quick convergence and low computational complexity when solving drone path-planning problems. However, for more complex and robustness-demanding path optimization problems, bio-inspired optimization algorithms have gained greater attention. For example, Shivgan and Dong formulated the drone path-planning problem as a traveling salesman problem and used genetic algorithms to find optimal routes that minimize energy consumption [
16]. Yuan et al. also applied genetic algorithms to generate and optimize full-coverage scanning paths for drones. They utilized the Good Point Set Algorithm to generate initial populations and designed heuristic crossover operators and random interval inverse mutation operators to avoid local optima, ultimately achieving better flight efficiency [
17]. Mesquita and Gaspar optimized drone patrol paths using Particle Swarm Optimization (PSO) to better monitor and deter birds, focusing on maximizing the random generation of paths and waypoints [
18]. Huang, inspired by the dynamic divide-and-conquer strategy and A* algorithm, improved the PSO algorithm by dividing complex planning problems into small-scale subproblems with fewer waypoints. The uniformity of particle expansion was evaluated, ultimately generating paths for drones in three-dimensional space [
19]. Phung and Ha proposed an improved PSO method based on spherical vectors, describing paths between waypoints with vectors and considering constraints such as path length, threats, turning angles, and flight altitude to generate safety-enhanced flight paths [
20]. Ying et al. proposed to introduce a Bayesian model on the basis of the genetic algorithm, considering the rules and general habits of seafarers, and showed that the sea collision avoidance route generated by this algorithm is more effective than that of the pure genetic algorithm [
21]. Cao et al. introduced a path replanning algorithm based on threat assessment using a dynamic Bayesian network, which ensures that unmanned underwater vehicles can adjust their paths to avoid danger when facing uncertain events [
22].
Similar to PSO, Ant Colony Optimization (ACO) is another widely utilized optimization algorithm. Inspired by the foraging behavior of ants, ACO mimics these natural phenomena to solve optimization problems. Wan et al. modeled the three-dimensional path planning problem as a multi-objective, multi-constraint optimization problem. By improving modeling and search capabilities, the proposed ACO algorithm maintained both global and local search abilities and achieved a balanced and diverse Pareto solution set [
23]. In [
24], ACO was used to address path generation in complex environments, where specific workloads, capacity constraints, and mobility speeds were considered for each node. Comparative studies demonstrated the efficiency and feasibility of the improved ACO algorithm over conventional methods. The social structures and behaviors of certain species often inspire new optimization algorithm designs. For instance, Zhang et al. focused on the Grey Wolf Optimization Algorithm (GWOA), based on hierarchical predatory behavior. They introduced dynamic adjustment strategies for nonlinear convergence and weight coefficients, verifying the algorithm’s effectiveness in planning drone paths in complex environments [
25]. Yu et al. combined the Differential Evolution algorithm with GWOA to enhance the exploration capability of path-planning algorithms. They modified GWO’s search strategies and adjusted DE’s mutation strategy based on ranking concepts [
26]. Similarly, Jiang et al. proposed a dual-layer planning strategy that utilized a collision-avoidance speed controller based on a partially observable Markov decision process and improved GWOA using an enhanced communication mechanism and ε-level comparison for path planning [
27].
Pan et al. improved the golden eagle optimizer by integrating personal example learning and mirror reflection learning strategies into the algorithm framework, effectively enhancing the efficiency of drone routes for power inspections [
28]. Zhang et al. focused on Harris Hawks Optimization, introducing Cauchy mutation strategies, adaptive weights, and the Sine–Cosine Algorithm to improve algorithm performance [
29]. Shen et al. adopted strategies such as beta distribution, Levy distribution, and two different cross-operators to enhance the dung beetle optimizer. Interestingly, the behavioral patterns of slime molds also serve as references for optimization algorithms [
30]. Abdel-Basset et al. used Pareto optimality to balance multiple objective functions in drone path planning, thereby improving the performance of a hybridized slime mold algorithm [
31]. The relationship between behaviors can also provide optimization pathways. For example, Zu et al. drew inspiration from the hunter–prey optimization algorithm to enhance the rapid path-planning capabilities of drones. They designed a chaotic mapping model and a golden sine strategy to improve algorithm updates and convergence speed [
32]. Zhang et al. improved the search and rescue optimization algorithm, which has the advantage of being easy to apply but suffers from slow convergence in drone path planning. Their main improvements included integrating a heuristic crossover strategy and a real-time path adjustment strategy [
33].
Drawing inspiration from biological behaviors and strategies enhances drone path-planning algorithms, improving their ability to handle multi-objective and multi-constraint scenarios while mimicking biological intelligence. The main contributions of this study are summarized as follows:
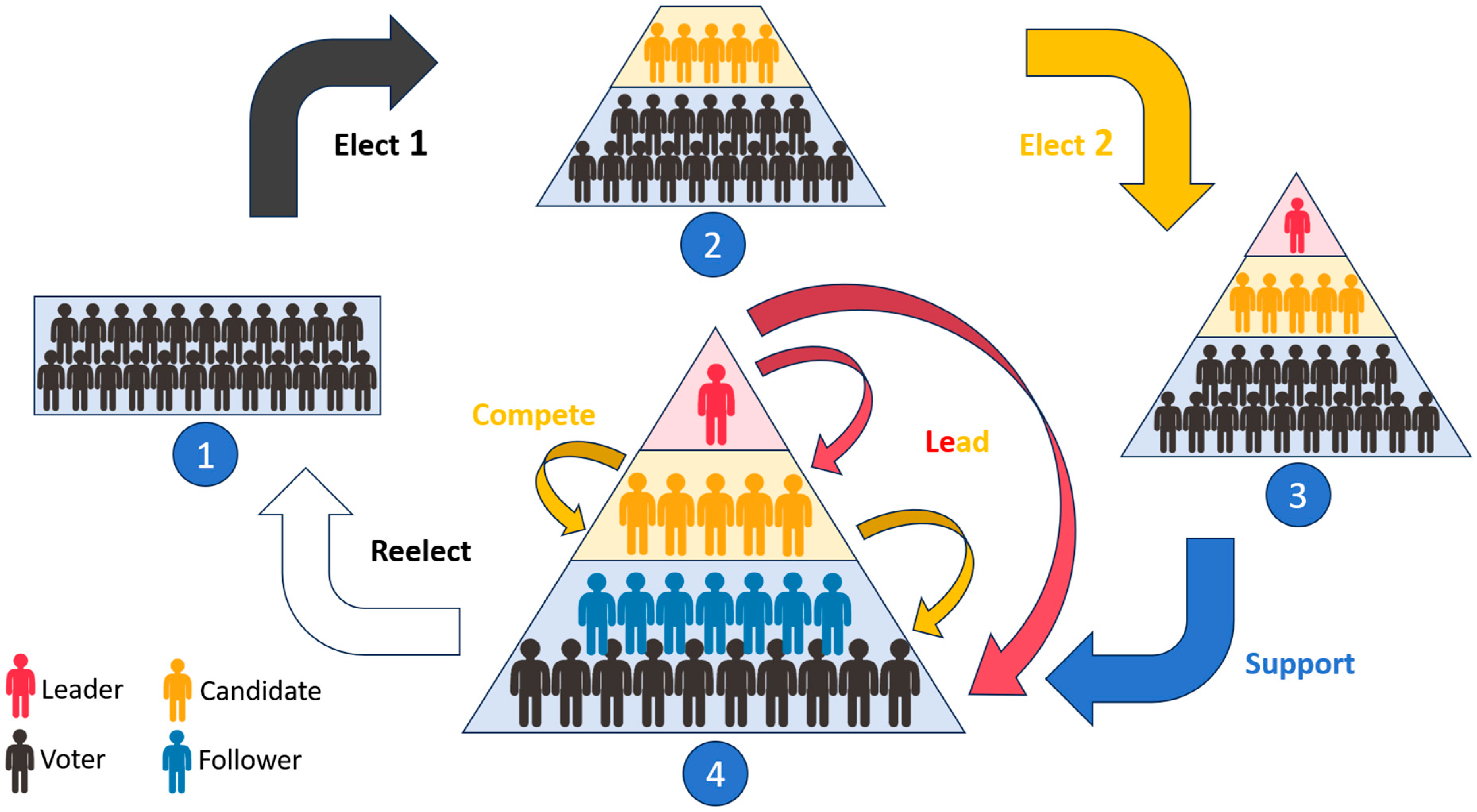
Inspired by the collective intelligence of animal groups and electoral process in human societies, this study introduces hierarchical structures and group interaction behaviors into the standard PSO algorithm. Specifically, competitive and supportive behaviors are mathematically modeled, significantly enhancing the learning strategies of particles and improving the algorithm’s global search capability during its mid-term optimization stage.
To prevent the algorithm from falling into local optima during the later stages of optimization, a mutation mechanism is introduced. This enhancement further improves the diversity of the population, thereby increasing the overall accuracy of the improved PSO algorithm.
To address the challenges in drone path planning, this paper proposes an innovative method that integrates a path segmentation and prioritized update algorithm with a cubic B-spline curve algorithm. These methods effectively improve the optimality and smoothness of the generated paths, ensuring safe navigation for drones in complex urban environments. Additionally, the proposed approach outperforms other swarm optimization algorithms in terms of path length.
The remainder of this paper is organized as follows:
Section 2 introduces the standard PSO algorithm; details of our algorithm enhancements are presented in
Section 3; simulation and analysis of the improved algorithm are discussed in
Section 4; the application of the improved algorithm in drone urban path planning is presented in
Section 5; and
Section 6 summarizes the research and future directions of this paper.
2. The Standard Particle Swarm Optimization (PSO) Algorithm
PSO is an optimization algorithm based on swarm intelligence, inspired by the behaviors of bird flocks searching for food in the environment. The core concept of the algorithm involves modeling the positions of food searched for by the bird flock as the potential solutions to problem. Then, each individual in the bird flock is abstracted as a particle with no mass or volume. At last, the continuous movement of particles, driven by interactions, is treated as the process of searching for the optimal solution in a multi-dimensional solution space. Due to its simplicity, efficiency, and ease of implementation, the PSO algorithm has gained widespread attention for solving various optimization problems [
34].
In the standard PSO algorithm, each particle represents a potential solution to the optimization task. During each iteration, each particle adjusts its position based on not only the best position which has been discovered (pbest) but also the best position which has been found by the entire swarm (gbest). Through this mechanism, the PSO algorithm continuously explores the solution space and optimizes until the optimal solution is found. Specifically, the basic workflow of the standard PSO algorithm is as follows. Firstly, set various parameters of the PSO algorithm. Secondly, randomly initialize the position and velocity of each particle in the swarm. Thirdly, calculate the fitness value for each particle, representing the quality of the solution it finds, and update the pbest and gbest if the new fitness value is better than the pbest or gbest. Then, update the velocity and position of each particle using specific update equations with pbest and gbest. At last, repeat the steps of calculating and updating until a predefined stopping criterion is met, such as reaching the maximum number of iterations or achieving a solution quality in a specified threshold.
In the above algorithmic process, the particle update phase is the most critical step. Mathematically, this can be described as follows. For a D-dimensional optimization problem, each particle has two numerical characteristics: the velocity vector and the position vector, represented as
and
, respectively, where
and
denote the velocity vector and the position vector of the
particle, respectively.
and
denote the velocity and position of the
j-th dimension of the
particle, respectively. During the search process in the solution space, each particle updates its velocity and position according to the following equations:
where
denotes the current iteration number.
and
denote the velocity and position of the
dimension of the
particle during the
iteration, respectively.
denotes the inertia weight of the particle.
and
denote the cognitive and social learning factors, respectively, both positive real numbers.
and
are random numbers uniformly distributed in the range of [0, 1].
denotes the
j-th component of the pbest of the
particle during the
iteration.
denotes the
j-th component of the gbest during the
iteration.
4. Simulation Test and Result Analysis
To verify the specific performance of IPSO, this paper compares the algorithm with Particle Swarm Optimization (PSO), the Grey Wolf Optimizer (GWO), and the genetic algorithm (GA). The experimental environment is configured as follows: The operating system is Windows 11 (64-bit), the processor is an 11th Gen Intel(R) Core(TM) i7-11800H with a base frequency of 2.30 GHz, the memory is 16 GB, and the simulation software is MATLAB R2024b.
4.1. Comparison Algorithms and Parameter Settings
In this study, to fairly and comprehensively evaluate the performance of IPSO, we used the CEC2005 benchmark suite [
35], which includes 25 test functions. These consist of five Unimodal Functions (F1–F5), seven Basic Multimodal Functions (F6–F12), two Expanded Functions (F13–F14), and eleven Composition Functions (F15–F25).
At the same time, this paper compares IPSO with three other classic swarm intelligence algorithms: PSO, GWO, and GA. To ensure the reliability of the test results, the population size for all algorithms was set to 55, and the number of iterations was set to 1000. The specific parameter settings for each algorithm are shown in
Table 1.
4.2. Optimization Results and Analysis of Cec2005 Benchmark Functions
Using the aforementioned experimental environment and algorithm parameter settings, each algorithm was run independently 30 times on the 25 test functions. The results are shown in
Table 2, which include metrics such as the average value, standard deviation, and best value. To more fairly evaluate the algorithm’s performance, this paper primarily uses the average of the experimental results to measure the optimization accuracy of the algorithms, and finally summarizes the experimental results of the 25 test functions to statistically analyze the optimization adaptability of the algorithms for different test functions.
When comparing the average values of the experimental results, it is evident that the IPSO algorithm provides significantly better solutions on most of the test functions, except for a few Unimodal Functions, demonstrating its strong global search capability. Additionally, the solutions obtained by the IPSO algorithm on certain Unimodal Functions are only slightly inferior to those of the standard PSO algorithm, showing its outstanding local search ability. Furthermore, comparing the standard deviations of the experimental results clearly shows that the IPSO algorithm has higher stability compared to the other algorithms, highlighting its superior adaptability.
In conclusion, IPSO retains the excellent local search capability of the original algorithm (PSO) while significantly enhancing its global search ability, resulting in an improved optimization accuracy and a noticeable increase in the algorithm’s adaptability to different optimization problems.
4.3. Convergence Curve Analysis
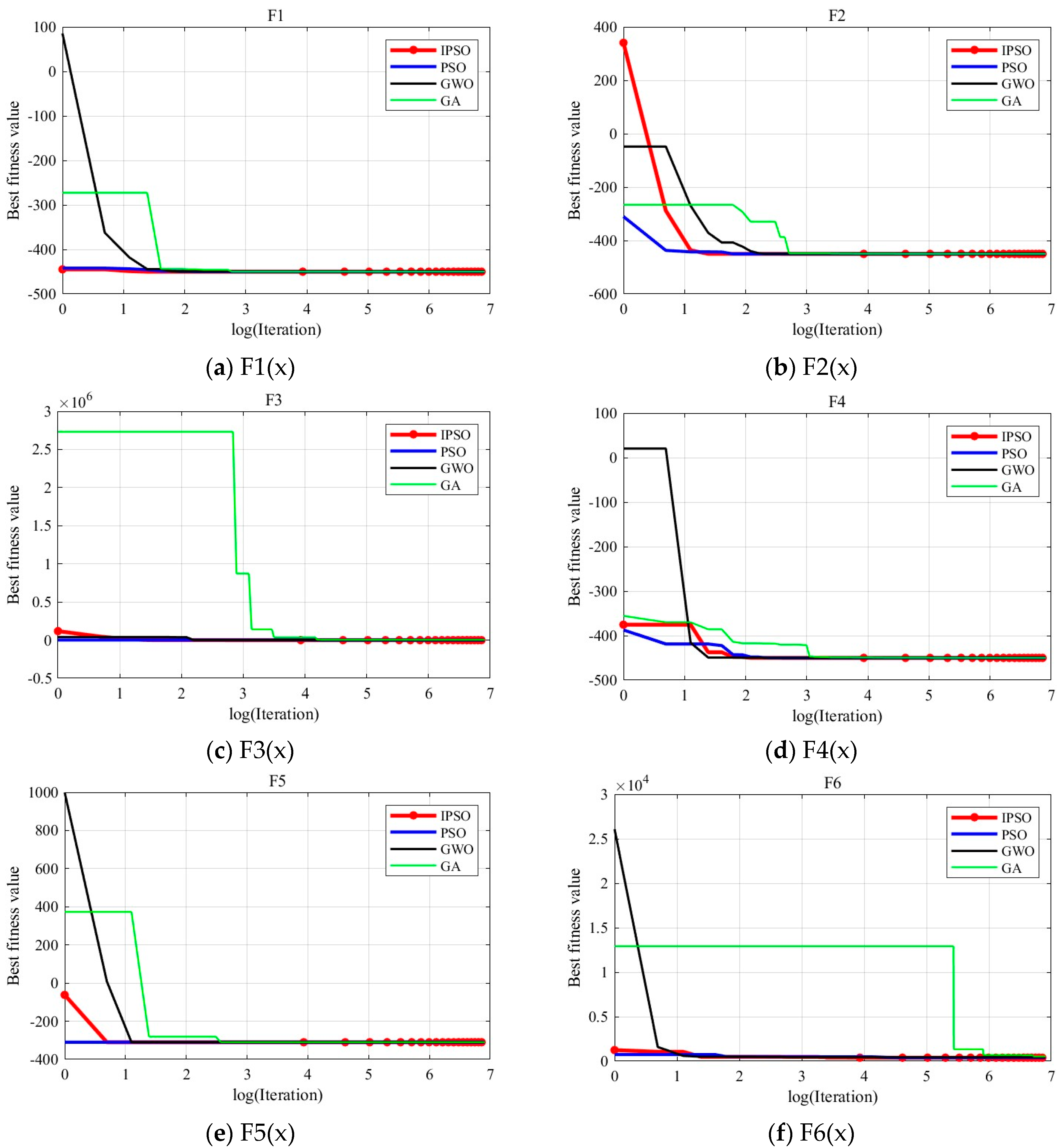
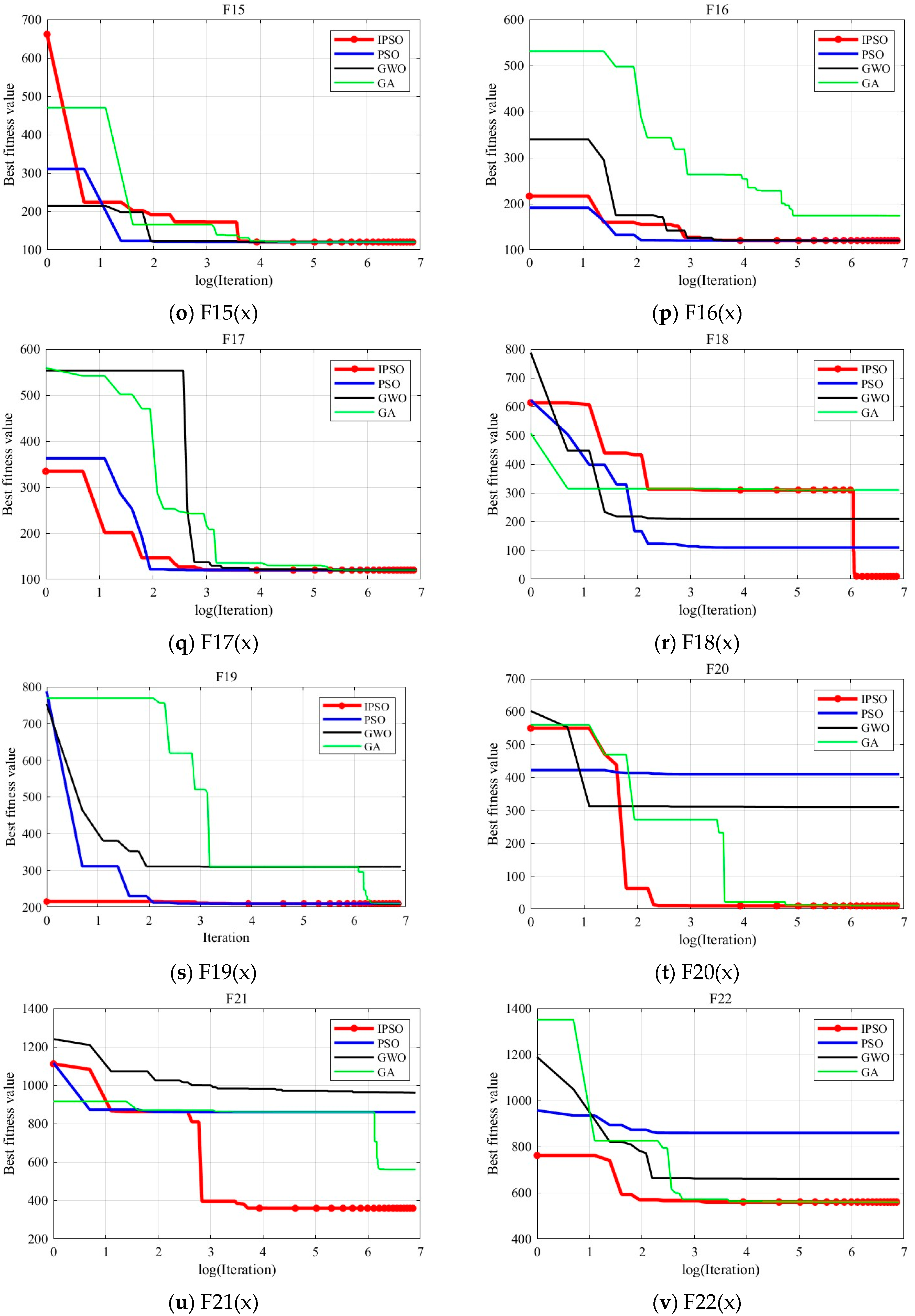
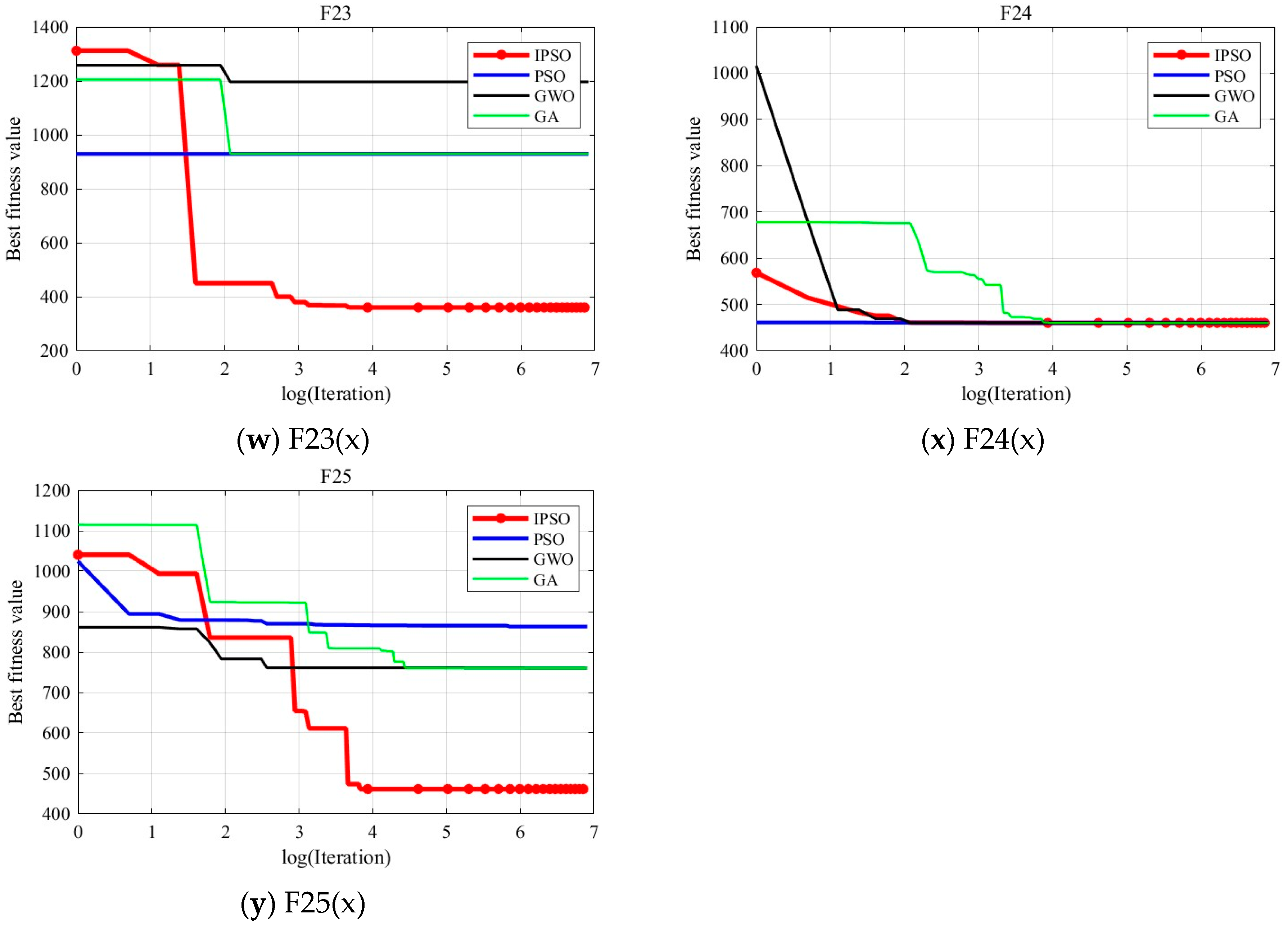
To visually illustrate the optimization accuracy and convergence speed of the algorithm, this paper analyzes the results using convergence curves.
Figure 3 shows the convergence curves obtained from the 15th run of the experiment. The red, blue, black, and green curves represent the convergence of the IPSO, PSO, GWO, and GA algorithms, respectively. The
x-axis of each curve represents the logarithm of the number of iterations, and the
y-axis represents the fitness value of the optimal solution during the optimization process.
From the
Figure 3, it can be inferred that IPSO’s optimization accuracy generally outperforms the PSO, GWO, and GA algorithms. For some Multimodal Functions and Composition Functions where other algorithms perform poorly, IPSO continues to optimize the current global optimal solution in the later stages of the optimization process, although slightly slower in convergence speed. While other algorithms fall into local optima, IPSO still achieves better results, demonstrating its advantage in solving complex optimization problems.
In summary, within the specified number of iterations, IPSO shows a significant advantage in optimization accuracy.
5. Application of IPSO in Urban Drone Path Planning
5.1. Environmental Modeling
For the 3D urban path-planning problem, the modeling of the urban environment is one of the key aspects. In this study, a three-dimensional space of
is selected as the flight area for the drone, with obstacles of different shapes simulating real-world environments such as city buildings. To facilitate the modeling, cuboids and cylinders are used to build the obstacles. The positions of the cuboids are determined by their upper and lower vertices. The cylinders are determined using the center coordinates, height, and radius. The specific obstacle location information is shown in
Table 3. All simulation experiments are conducted in this environment.
5.2. Cost Function
The cost function is used to evaluate the quality of the planned path. The smaller the value of the cost function, the better the quality of the obtained path. Similar to general path-planning problems, the cost function for urban drone path planning consists of a series of different cost components, such as path length cost, height cost, collision cost, and path smoothness cost. For simplicity, this study considers only the path length, height, and collision costs.
5.2.1. Path Length Cost
Path length is the most direct method to evaluate the quality of a planned path. Since the drone has limited endurance, the shorter the planned path, the more advantageous it is for the drone’s mission. In this study, the path is composed of a predefined start point, predefined end point, and
path points to be optimized along the path. The coordinates of the
path point on the
path are denoted as
. Therefore, the path length cost is defined as the sum of the Euclidean distances between adjacent path points from the start to the end, as expressed by the following equation,
where
denotes the coordinates of the path start point, and
denotes the coordinates of the path end point.
5.2.2. Height Cost
Choosing the correct flight height is also crucial for drone path planning. In drone path planning, especially in urban path planning, the setting of flight height is generally mandatory, as both excessively low and high flight heights may lead to accidents. Therefore, the cost function for flight height is expressed as follows,
where
is a custom function used to check whether the height of the path point is within the prescribed range. If the height exceeds the limit, the cost is set to infinite; if the height is within the normal range, the cost is set to zero.
5.2.3. Collison Cost
Collision-free is the most important criterion in path planning. In urban drone path planning, the safety of the drone’s flight is the premise of the planning. Therefore, once a collision occurs, the cost function value should make the path invalid, meaning the path’s cost should be infinitely large. Thus, the cost function for collision is expressed as follows:
where
is a custom function used to determine whether the path between two adjacent points will collide with obstacles. If a collision occurs, the cost is set to infinity; if no collision occurs, the cost is set to zero. In this study, it is assumed that a collision occurs if the path points overlap with the obstacle locations in the inflated 3D grid map.
5.2.4. Total Cost Function
The total cost function is defined as the combination of the three individual cost functions mentioned above:
5.3. Path Segmentation Optimal Update Algorithm
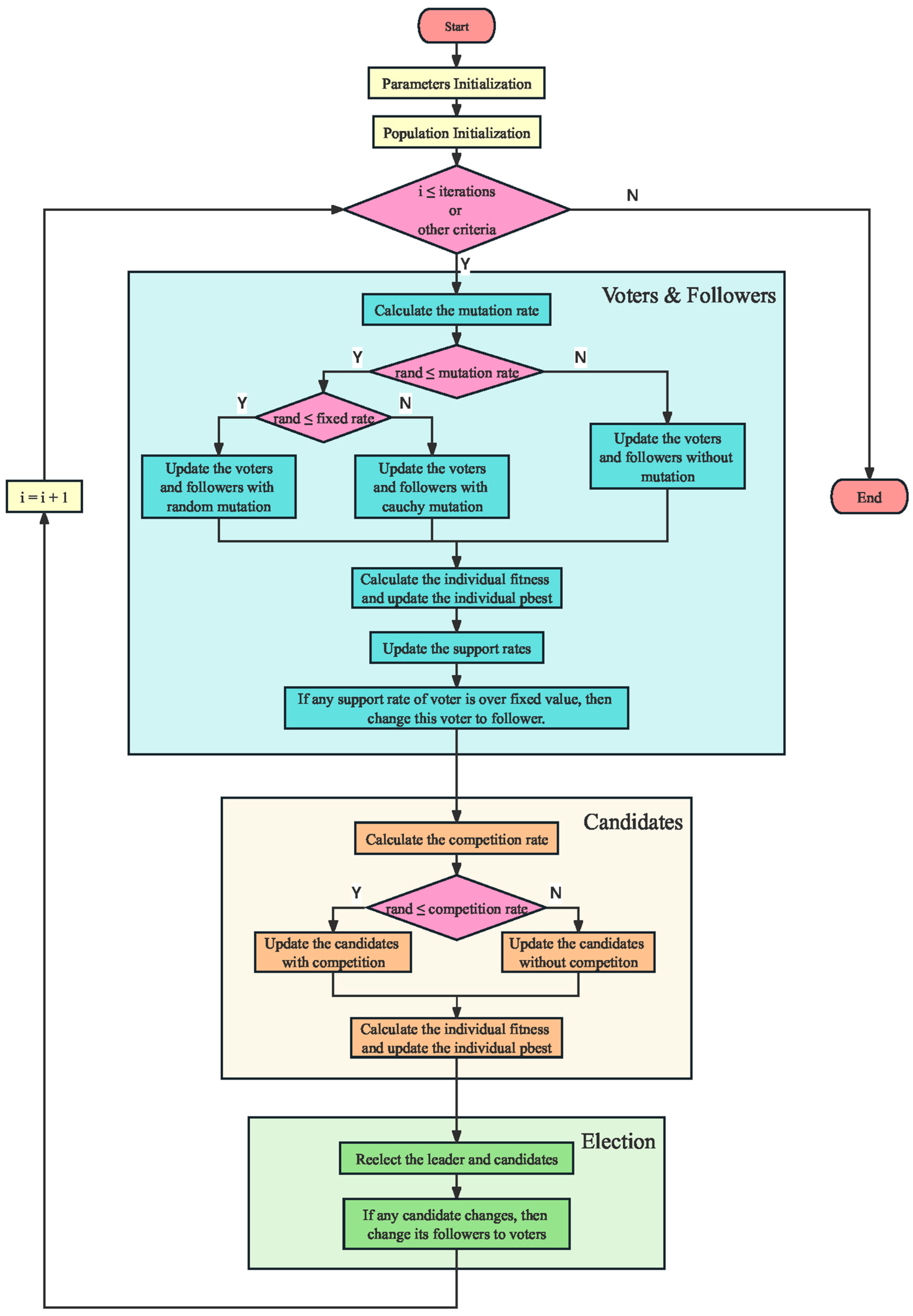
In drone path-planning tasks, planning efficiency is often crucial. A faster path-planning process can greatly improve task execution efficiency, thus increasing the overall benefits. However, it has been found in the research that, during path planning using IPSO, the convergence speed tends to slow down significantly in the later stages of the optimization process, leading to a decrease in planning speed. This phenomenon occurs because the path oscillates around the optimal path solution, and the more path points there are, the more intense the oscillation becomes, thereby greatly reducing the convergence speed of path planning. Following analysis, it is proposed that the cause of this phenomenon lies in the fact that each path is composed of multiple path points. Therefore, during particle updates, multiple path points are updated simultaneously. The path points with bad positions may cause updates to the path points with good positions, leading to the movement of original optimal path points to suboptimal positions due to factors like inertia. This oscillation, when repeated, results in the phenomenon observed in the experiment.
To reduce or even avoid the aforementioned oscillation phenomenon, this paper proposes a path segmentation optimal update algorithm. The specific idea is as follows: In the later stages of the optimization process, during each iteration, the path containing N path points is decomposed into N updates. Each update only updates one path point, which is randomly selected from the un-updated path points. After each update, the fitness value of the path is calculated using Equation (17), and the optimal path from these N updates is selected as the new path for this iteration. This algorithm refines the original path update process by updating path points step by step instead of updating the entire path at once. This approach reduces or even eliminates the oscillation phenomenon, significantly improving the efficiency and convergence speed of path planning.
where
and
denote the fitness values of the
path after and before the update, respectively.
and
denote the fitness values of the updated and original path points j relative to the previous and next path points.
5.4. Path Smoothing
The improved PSO algorithm proposed in this study defines each path as consisting of a starting point, an end point, and several intermediate path points. The connections between these points are represented as straight line segments, which inevitably result in numerous sharp turns. When drones follow such paths during flight, excessive turns can significantly increase energy consumption. Therefore, it is essential to optimize the sharp turns on the path, a process referred to as path smoothing.
In comparison with a series of path-smoothing algorithms, this study selected the cubic B-spline algorithm due to its advantages in local control, flexibility, and computational efficiency. The smoothed path is expressed as follows:
where
denotes the path expression.
is the number of control points.
denotes the
control point.
denotes is the
cubic B-spline basis function, which is recursively defined as follows:
where
denotes the
B-spline basis function of
order.
denotes the
knot, which defines the segmentation of the curve.
5.5. Urban Drone Path Planning Simulation
In this study, path-planning simulation experiments were conducted within the urban environment model described in the
Section 5.1 on environment modeling. We considered different scenarios and different start and end points to test the optimization ability of the algorithm. Similar to the earlier benchmark experiments, the IPSO algorithm was compared with three other swarm intelligence optimization algorithms, namely PSO, GWO, and GA, in these path-planning simulations. Each algorithm was independently executed 20 times in the environment for comparison and analysis. To ensure the reliability of the results, the population size for all algorithms was set to 55, with 1000 iterations, and the other parameters for the algorithms remained consistent with those in
Table 1. Specifically, each path consisted of six intermediate path points. The simulation results are shown in
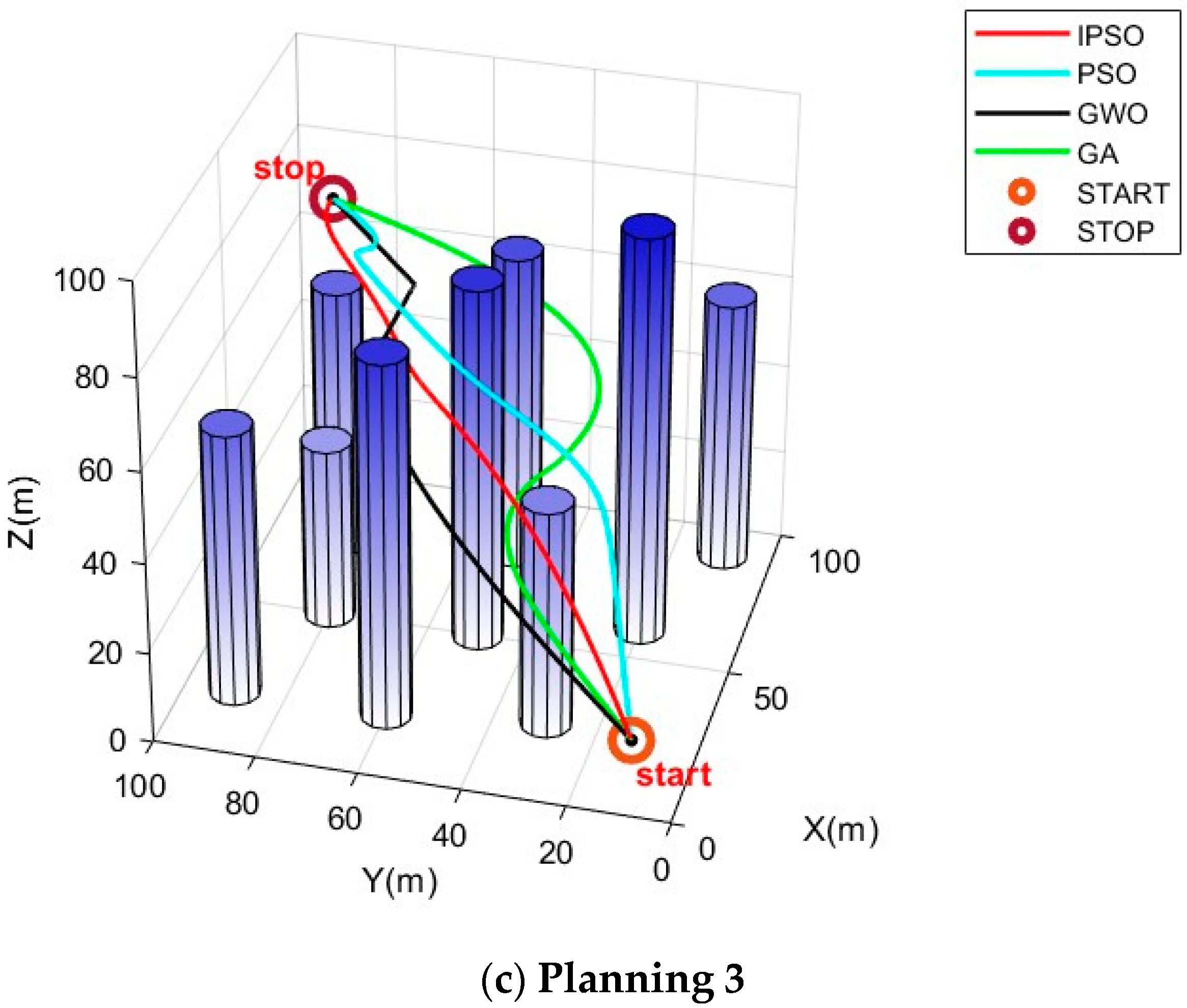
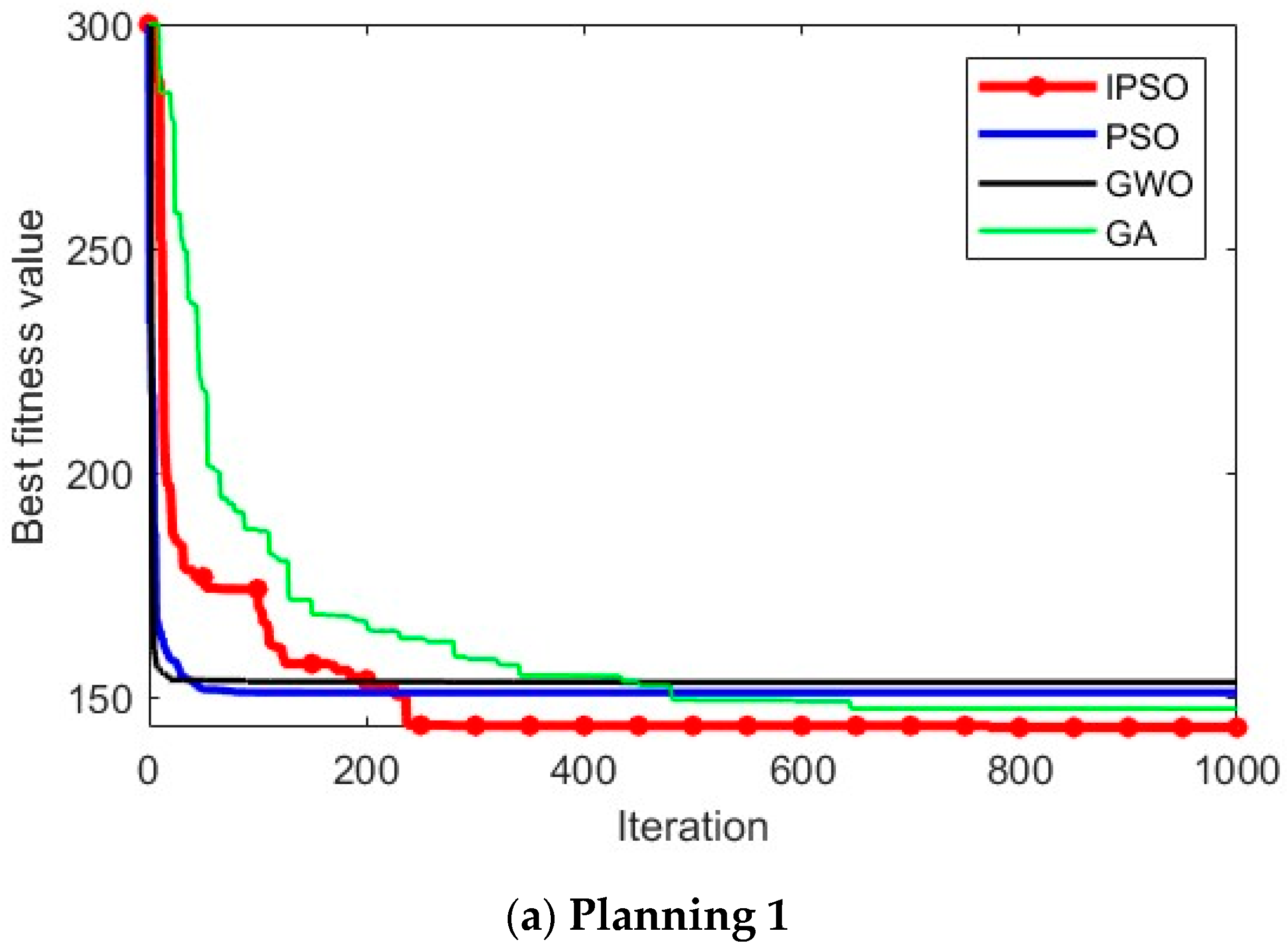
Figure 4 and
Figure 5. In (a) and (c), the start point is (10, 10, 10) and the end point is (90, 90, 70). In (b), the start point is (10, 70, 10) and the end point is (80, 35, 80).
In
Figure 4, it can be visually observed that, in the situations of different scenarios and different start and end points, IPSO outperforms the other three algorithms in planning superior paths, demonstrating its excellent optimization capability and robust adaptability.
Figure 5 provides more detailed insights, showing that the paths planned by the IPSO algorithm are consistently shorter than those generated by the other three algorithms. This reduction in path length leads to shorter flight times and significantly enhances task execution efficiency, indicating a superior path-planning performance.
Table 4 presents the results of path planning, including metrics such as the average value, standard deviation, best value, and worst value.
When comparing the average values of the experimental results, it is evident that the cost of the path solutions obtained by the IPSO algorithm is significantly lower than that of the other algorithms, indicating that its path solutions are markedly superior. This demonstrates that the improved algorithm effectively enhances the search capability and algorithm accuracy. Furthermore, when analyzing the standard deviation of the experimental results, it can be found that IPSO consistently delivers stable and superior optimization results for path-planning problems under different starting points, highlighting its strong adaptability. In summary, the IPSO algorithm exhibits an outstanding performance in addressing urban drone path-planning problems.
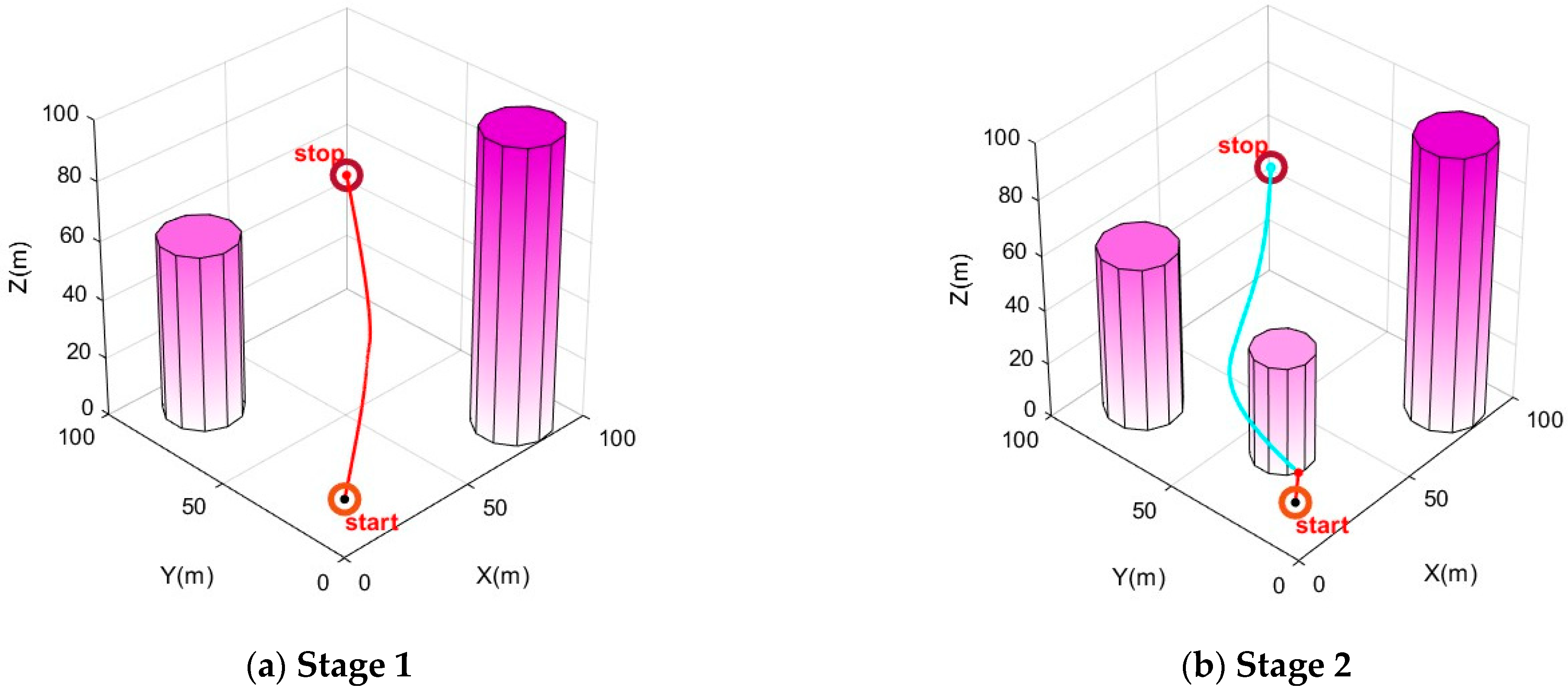
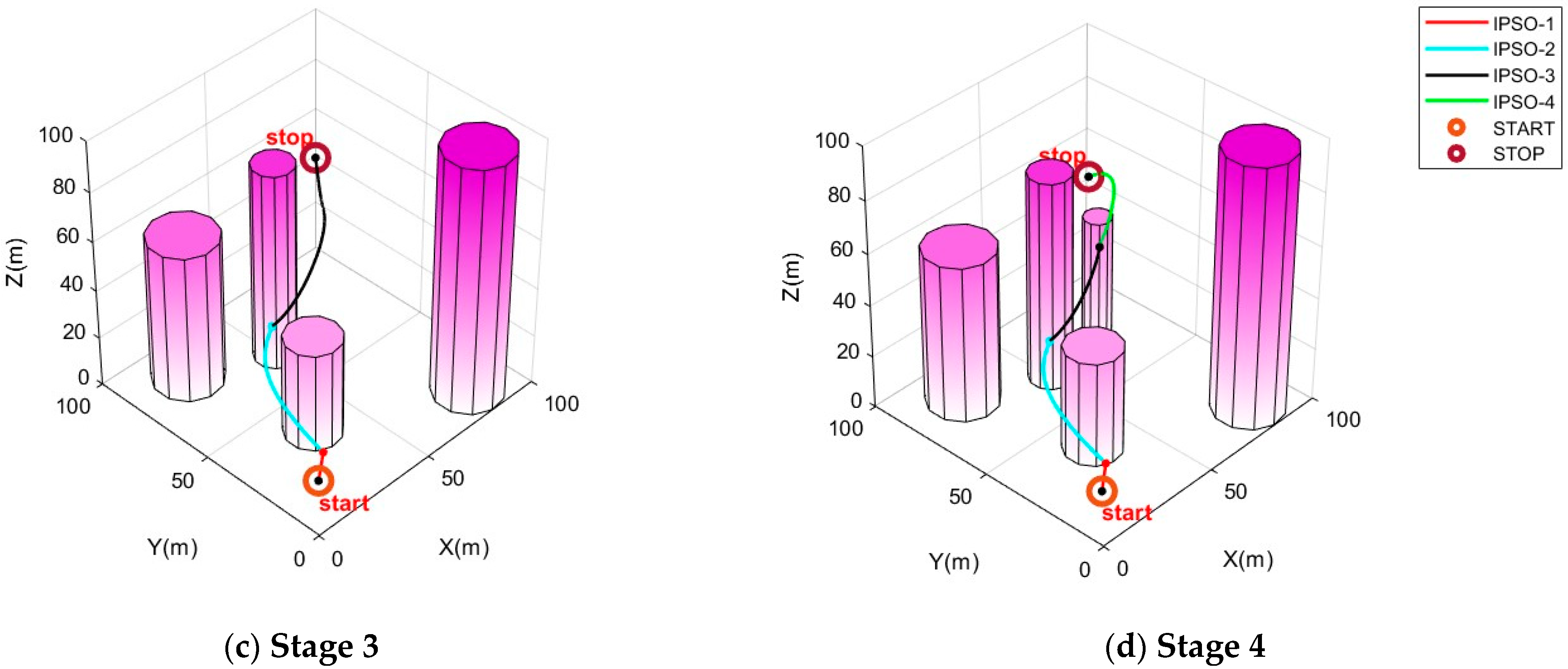
Furthermore, to address safety-critical challenges posed by environmental uncertainties or sensor noise in drone path planning, this research proposes an IPSO-based dynamic replanning strategy. The urban environment is modeled with latent obstacle estimation, and it is assumed that the drone will hover or execute a controlled landing during path recalculation to ensure operational continuity. As illustrated in
Figure 6, the experimental stages are as follows. In Stage 1, the cylindrical obstacles represent the original grid map modeled before takeoff, while the red path denotes the path planned based on the initial map. When the drone follows the red path and reaches a certain distance, new cylindrical obstacles (shown in Stage 2) are dynamically introduced to simulate newly detected obstacles during flight. At this point, the IPSO algorithm reinitializes path planning from the drone’s current position (retaining the original end point), generating the blue path based on the updated grid map. Additional obstacles (shown in Stages 3 and 4) are successively introduced during flight, triggering further replanning to generate the black and green paths, respectively. Experimental results demonstrate that the IPSO algorithm with the dynamic replanning strategy can effectively avoid sudden obstacles not present in the original grid map. This provides an effective solution for handling environmental uncertainties or sensor noise in IPSO-based path planning.
6. Conclusions
This paper addresses the urban drone path-planning problem by proposing an IPSO algorithm. By incorporating swarm intelligence and the competitive and collaborative behaviors observed in human electoral process, the global search capability and optimization accuracy of IPSO are significantly enhanced. The utilization of hierarchical structures, competitive mechanisms, and dynamic mutation strategies effectively overcomes the standard PSO’s tendency to fall into local optima when dealing with complex optimization problems. Experimental results using the CEC2005 benchmark test functions demonstrate that the IPSO algorithm outperforms the standard PSO, GWO, and GA in optimizing multiple test functions. Particularly in the optimization of Multimodal and Composition Functions, IPSO shows a stronger ability to continuously optimize the global optimum, indicating a superior performance in solving complex problems.
In the practical application of urban UAV path planning, this paper further introduces a path segmentation optimal update algorithm and a cubic B-spline algorithm based on the IPSO algorithm. The proposed algorithm significantly reducing path length and energy consumption, improving the smoothness and planning efficiency of drone paths while enhancing flight safety in complex urban environments. Simulation experiments verify that the proposed path-planning algorithm exhibits an excellent performance across various test scenarios with different starting and ending points, generating shorter paths and flight times with higher stability and adaptability. Future research directions will include further optimizing the algorithm’s dynamic adjustment mechanisms to improve convergence speed and adaptability, as well as incorporating more advantages from biological intelligence. However, the proposed IPSO algorithm still faces limitations in computational efficiency. This restricts its applicability in scenarios requiring high real-time performance. For application in urban drone path planning, IPSO is only used for global path planning generally. If there is a real-time requirement, it can be considered in combination with the local path-planning algorithm. We will also continue to optimize the algorithm by optimizing the dynamic adjustment mechanisms, introducing heuristic strategies, and so on in future research, to improve the operational efficiency of IPSO and further expand its application.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}