
Exploring the Robustness of Alternative Cluster Detection and the Threshold Distance Method for Crash Hot Spot Analysis: A Study on Vulnerable Road Users





Abstract
:1. Introduction
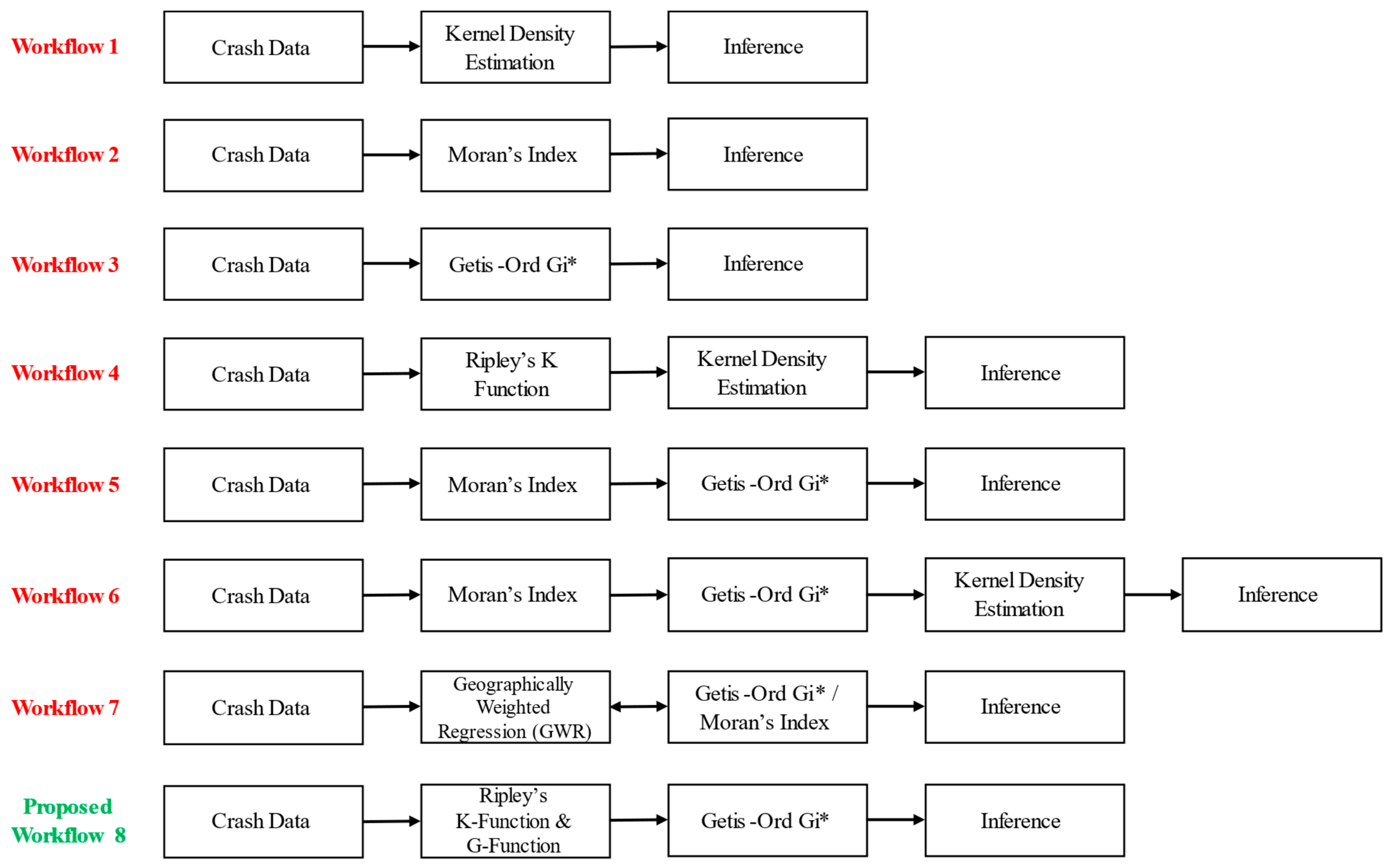
- Developed a framework of an alternate method to identify the clustering strength and threshold distance for network-constrained hot spot analysis.
- Demonstrated the use of the cross-K- and cross-G-functions to select the best crash hot spots among different outcomes.
2. Literature Review
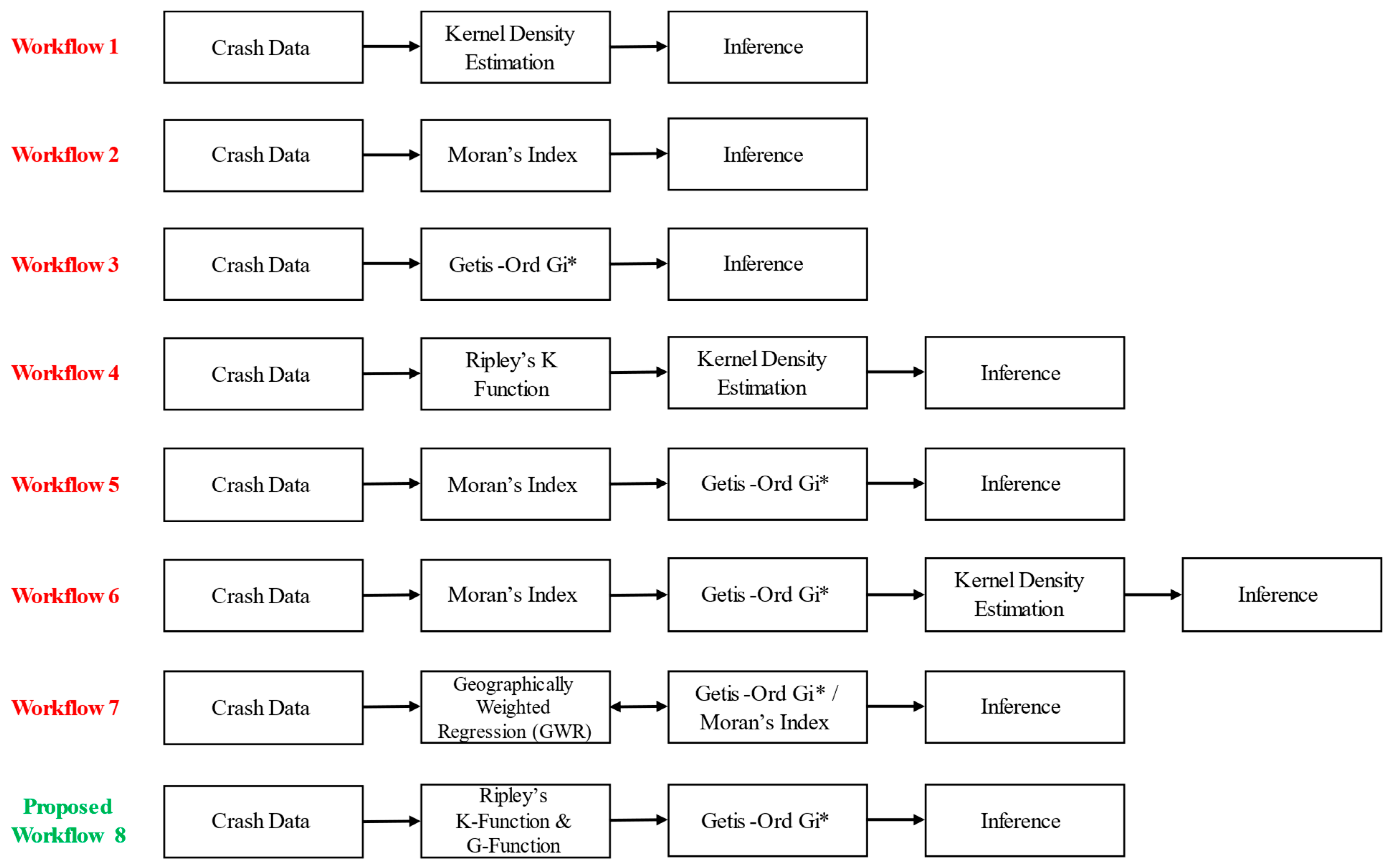
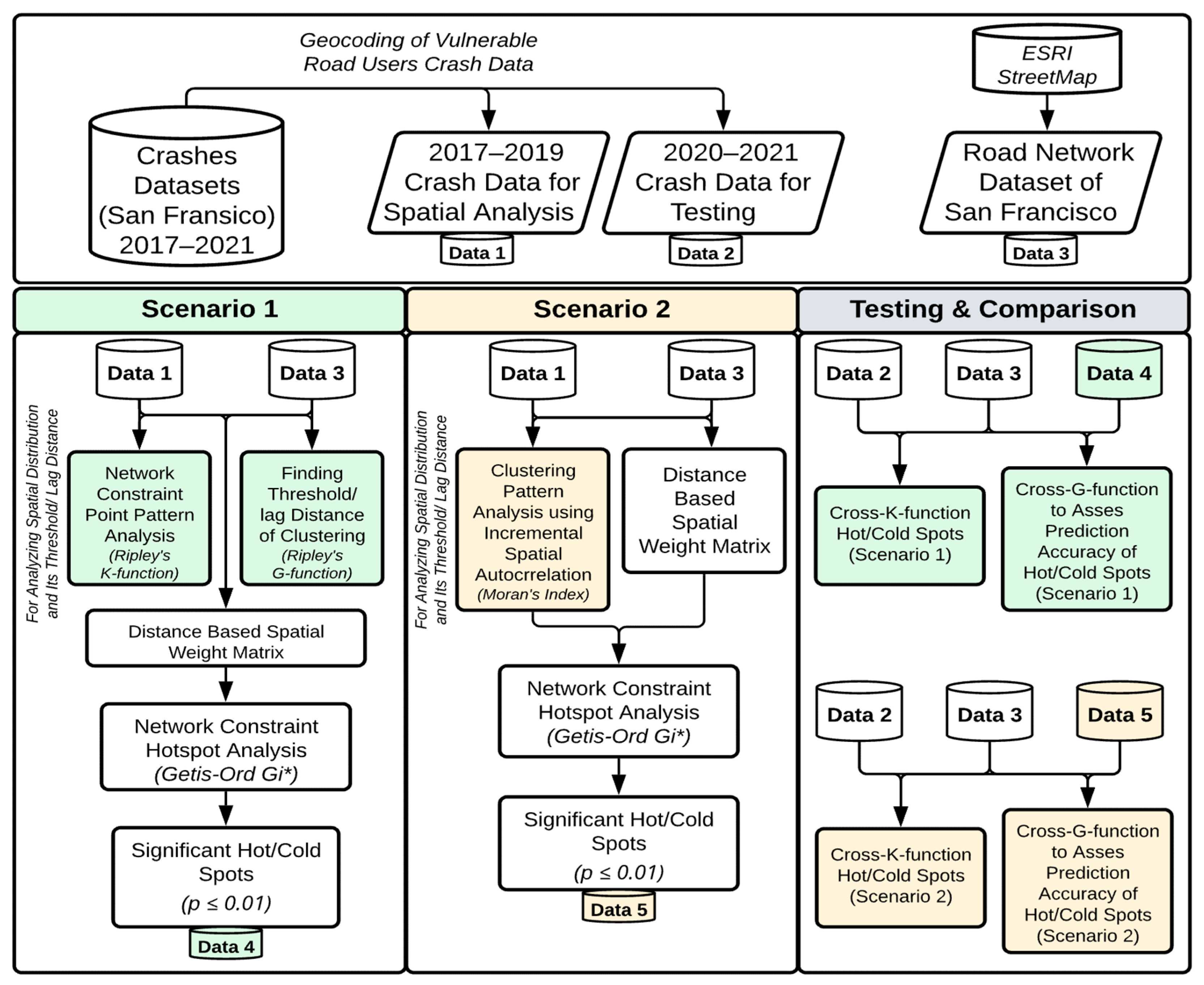
3. Methodology
3.1. Study Area and Data
3.2. Methods
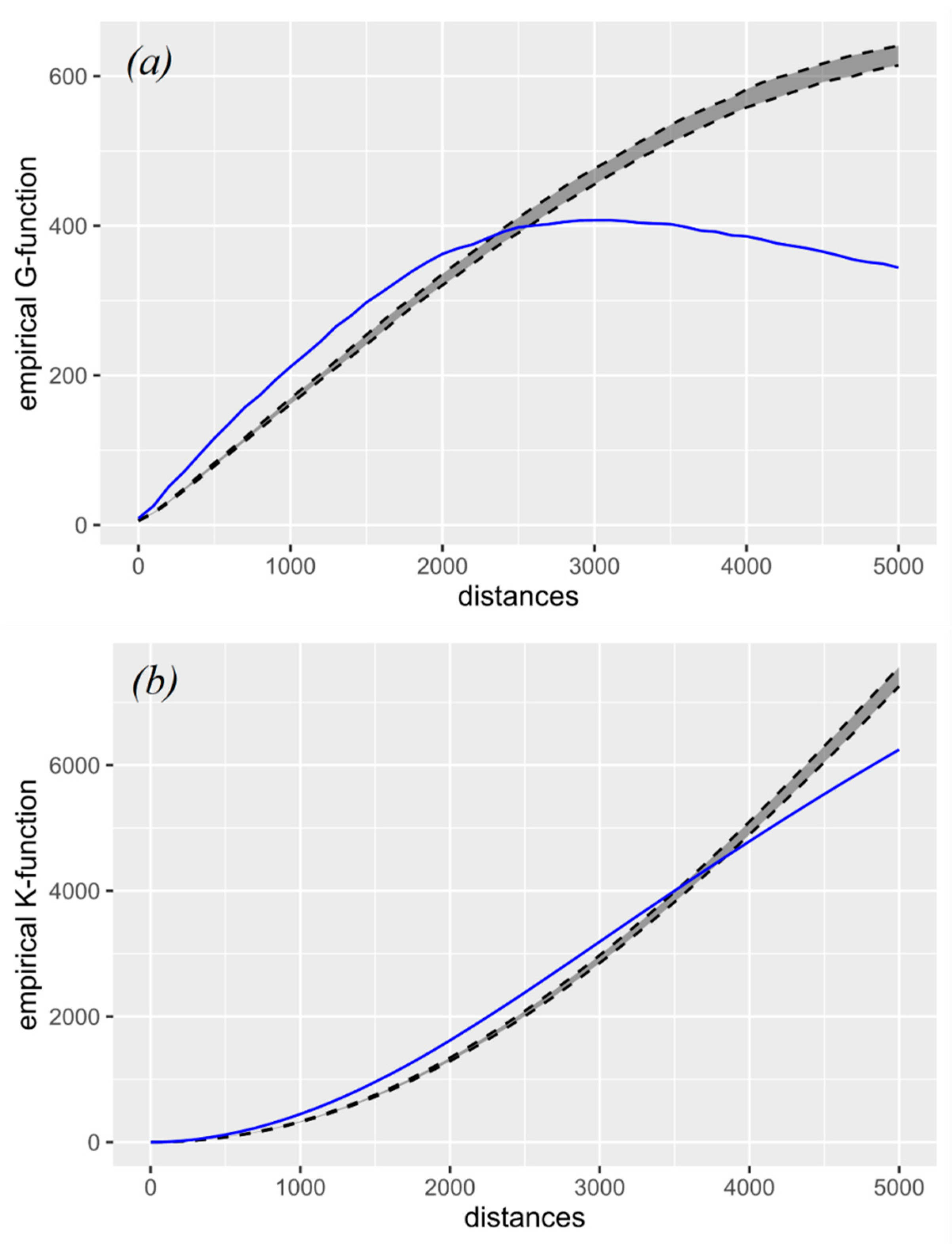
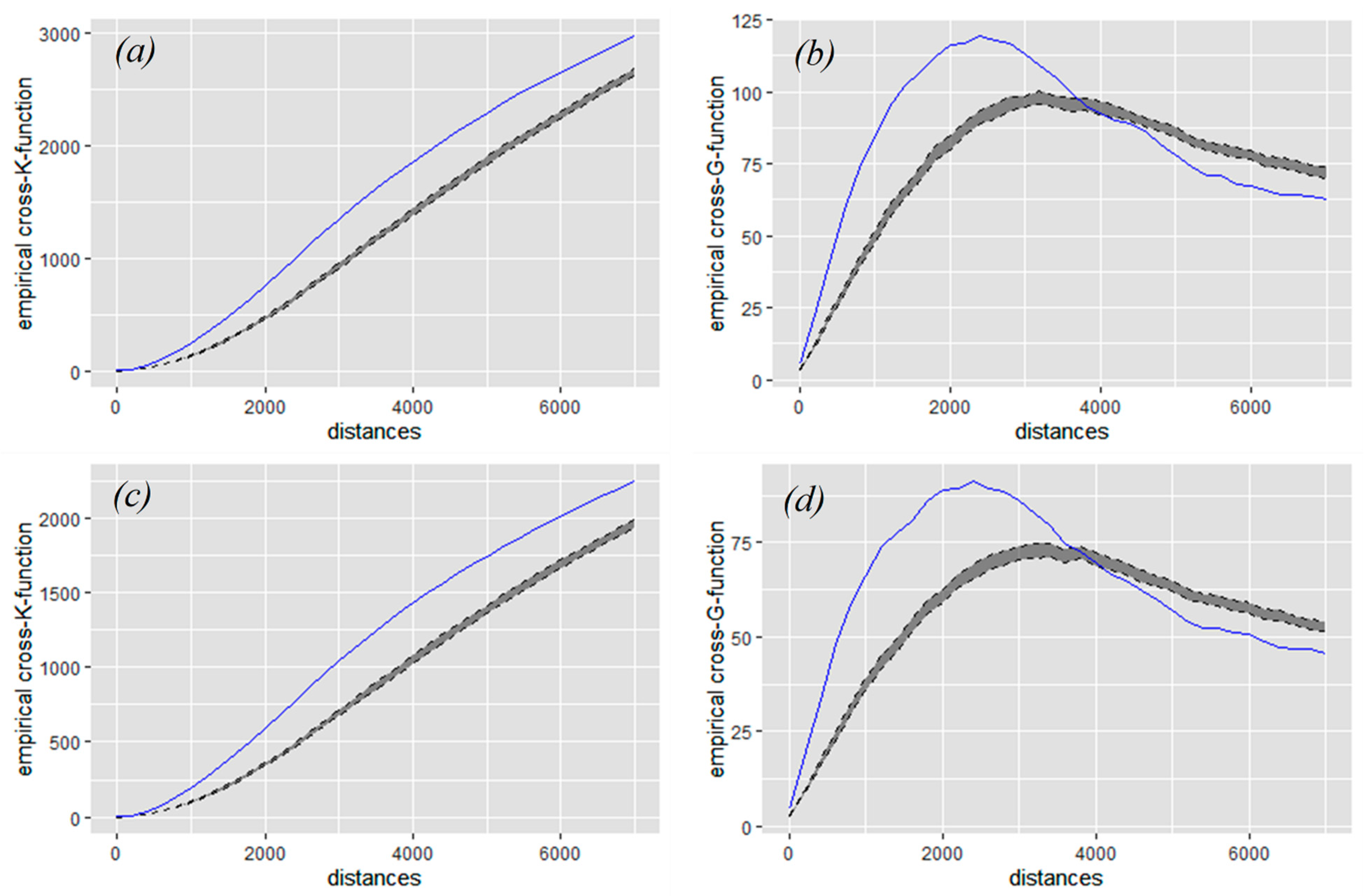
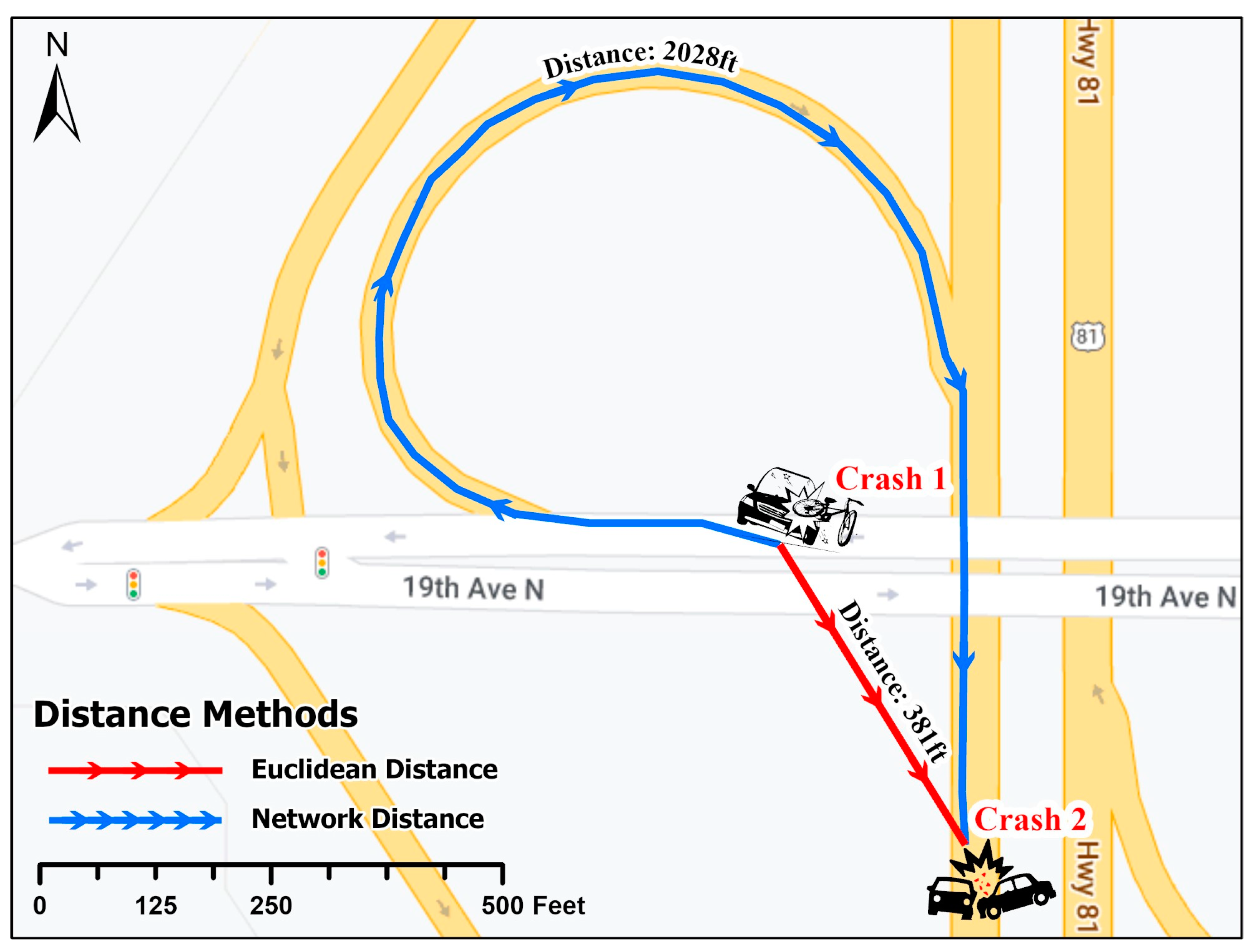
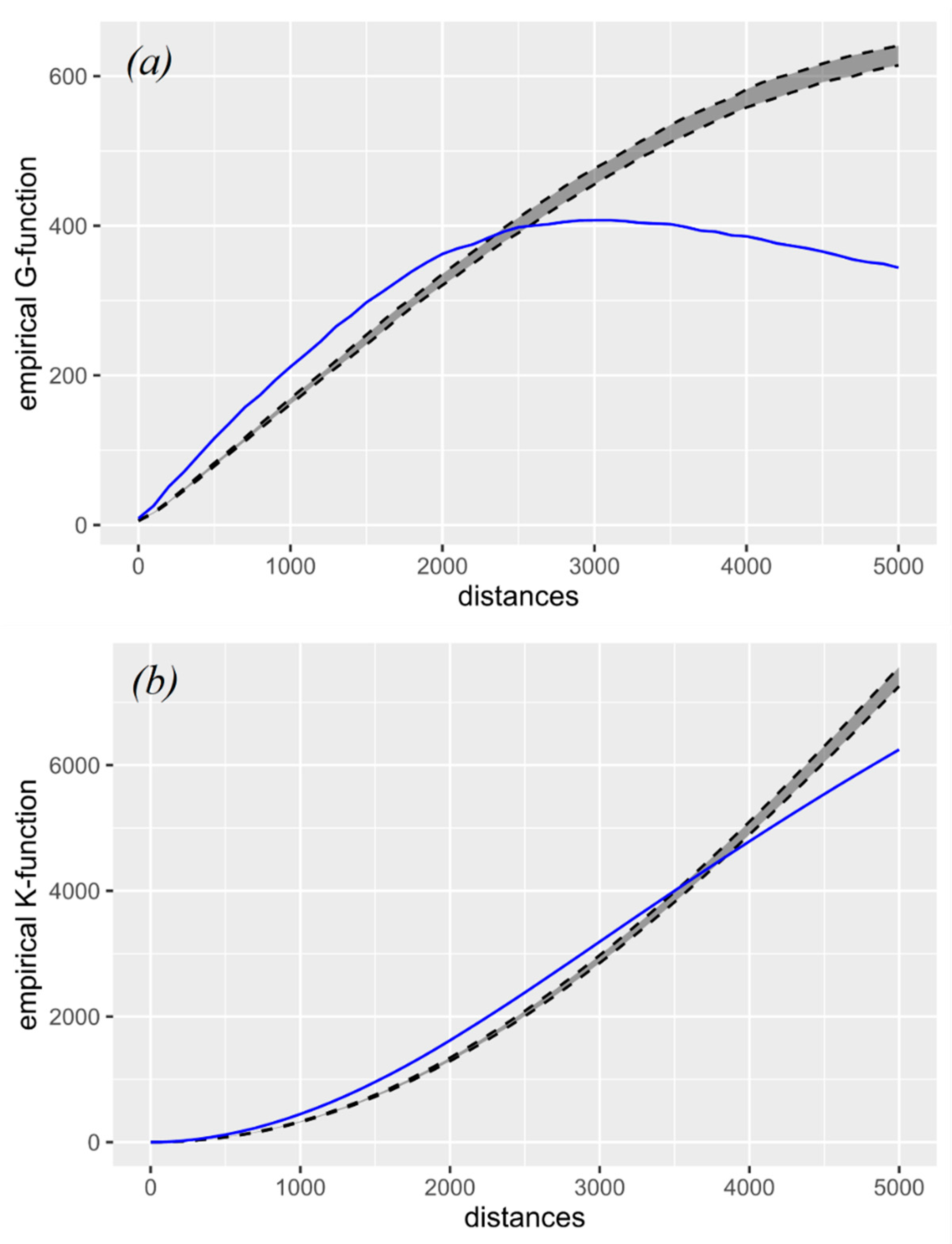
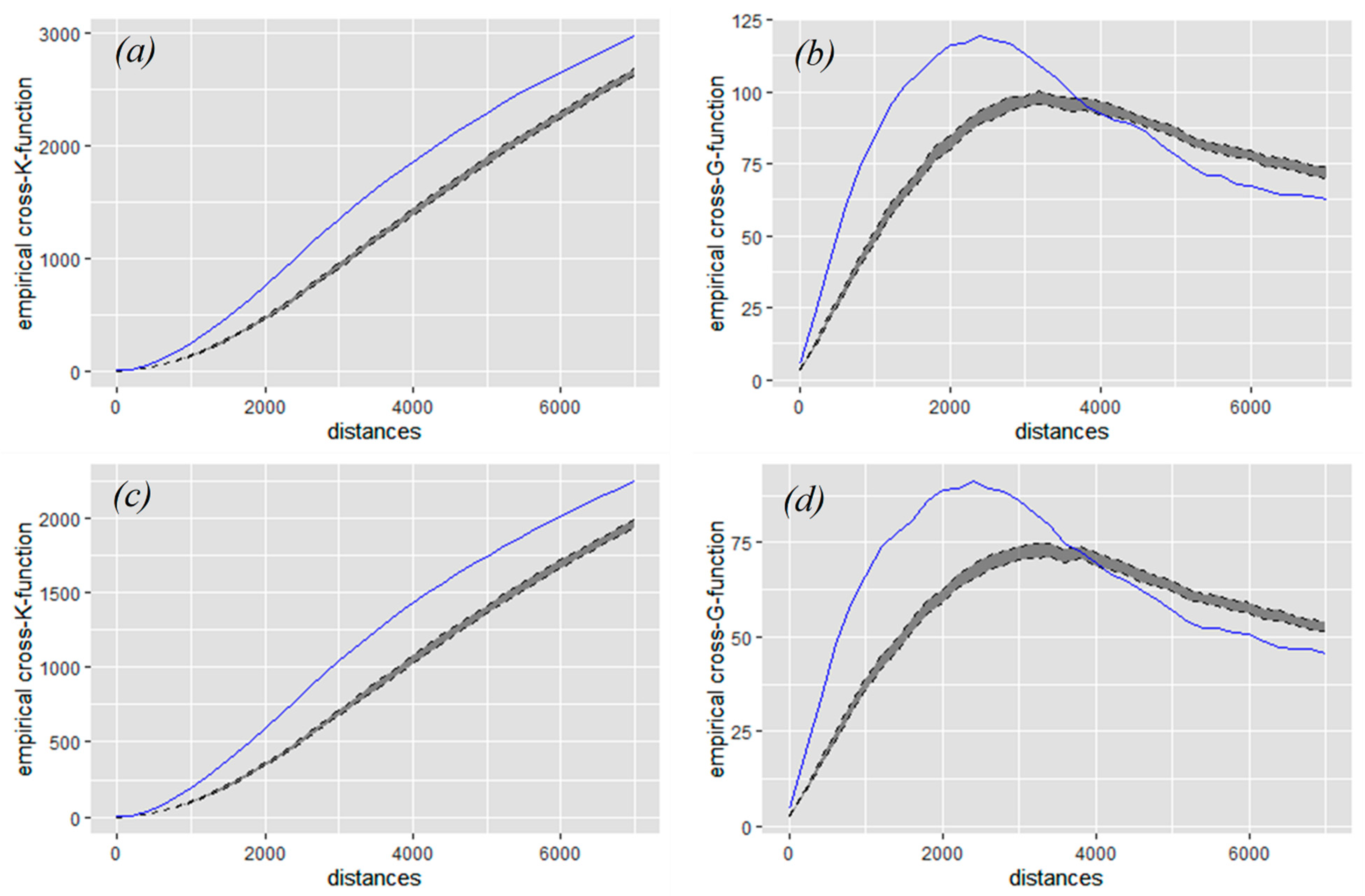
3.3. Network-Constrained Point Pattern Analysis: K-Function and G-Function
3.4. Incremental Spatial Autocorrelation: Global Moran’s Index Analysis
3.5. Advantages, Disadvantages, and Limitations
3.6. Network Constraint Local Indicator of Clusters: Getis-Ord Gi* Statistics
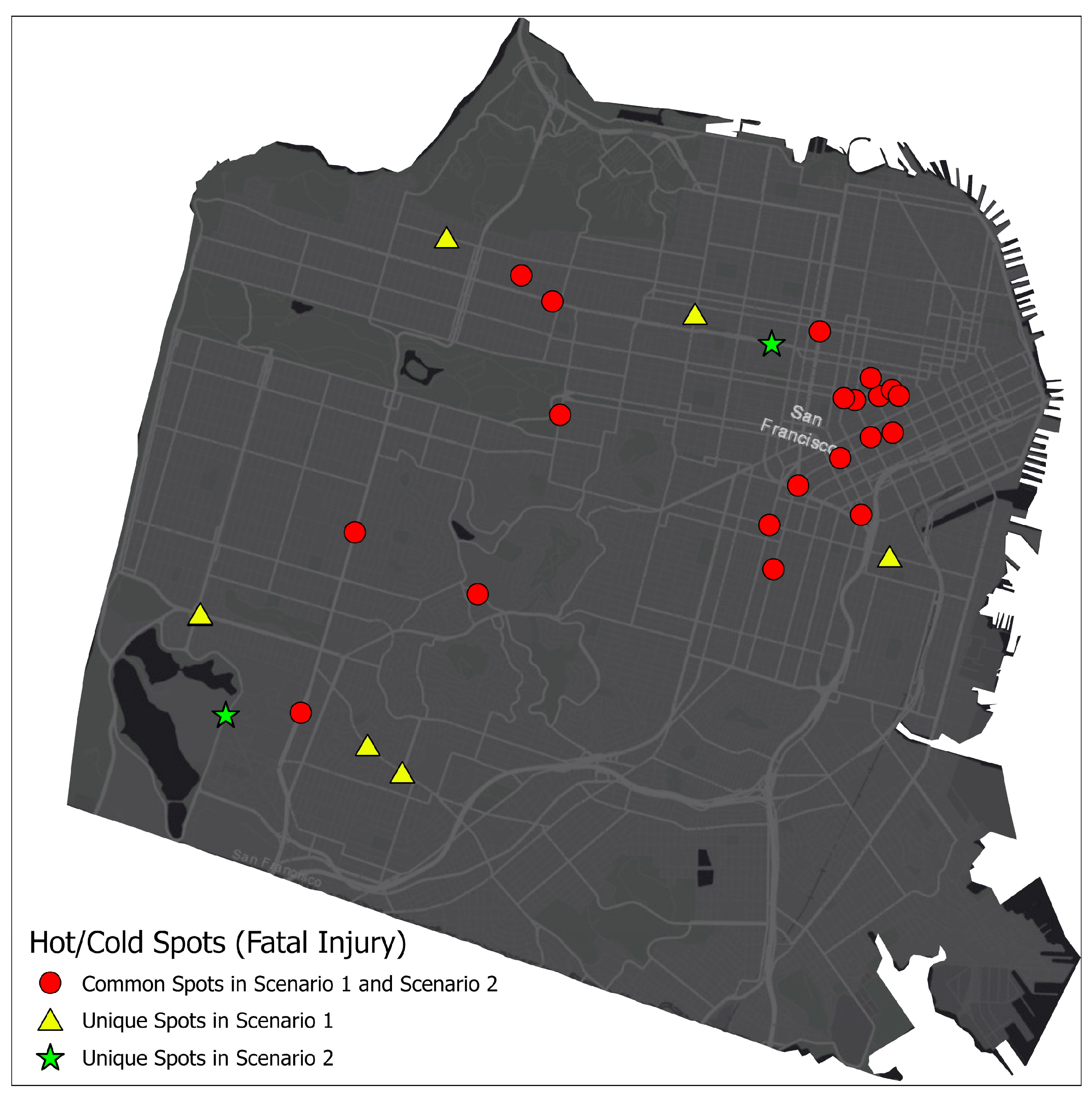
3.7. Definition of Hot Spots and Cold Spots
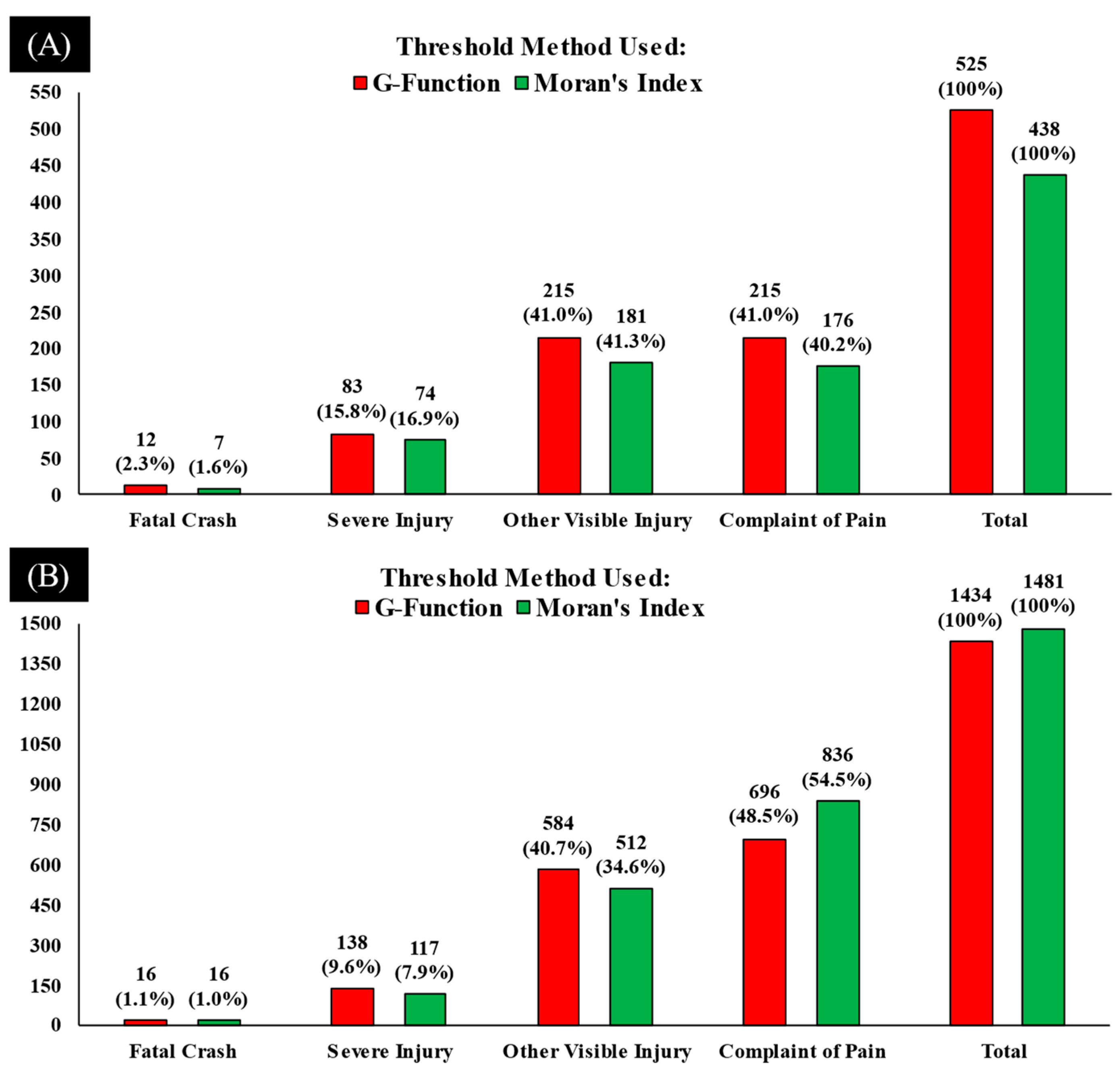
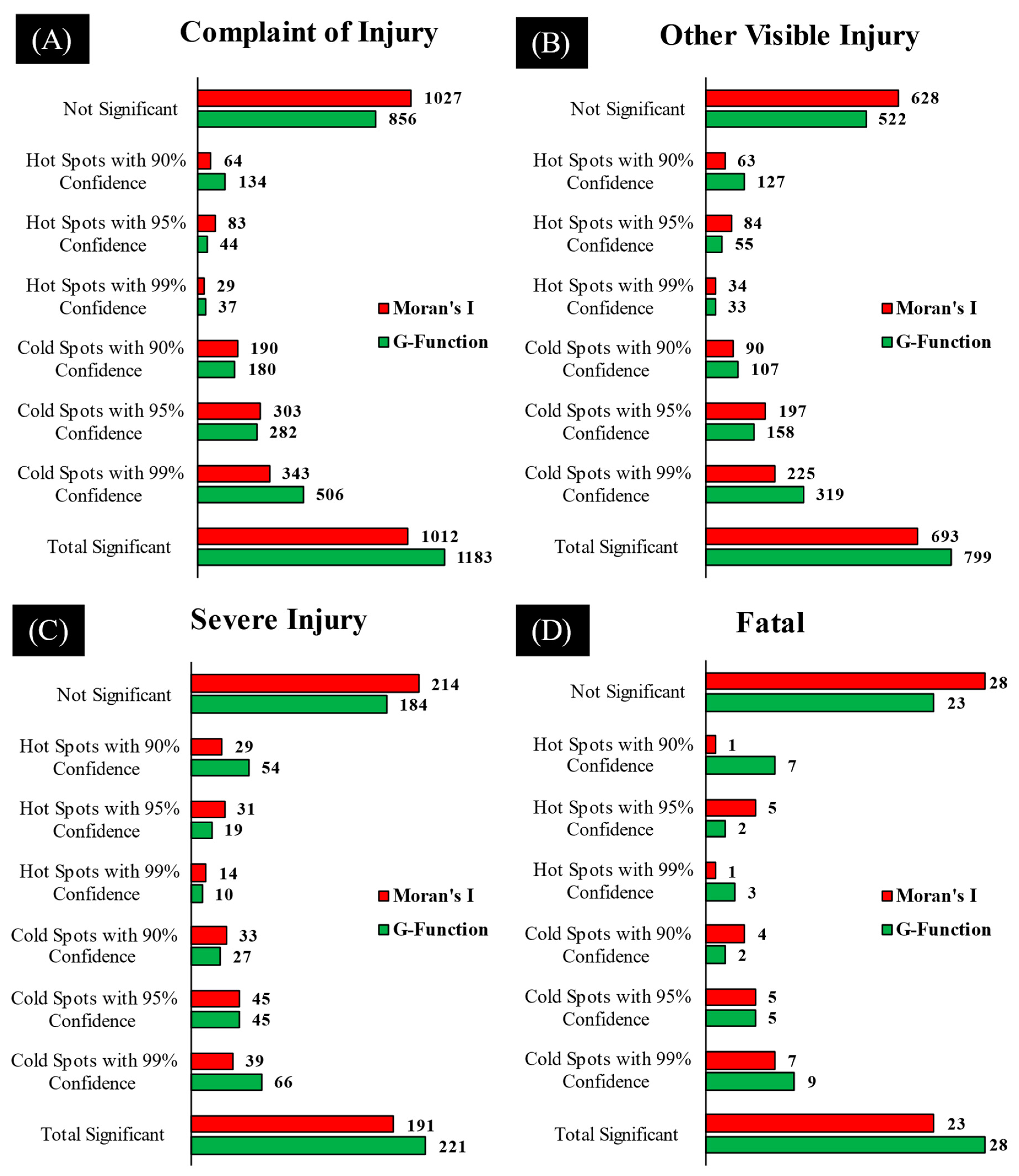
4. Results and Discussion
5. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- NHTSA. Vulnerable Road Users (VRUs)—Publication Topic—CrashStats—NHTSA—DOT. Available online: https://crashstats.nhtsa.dot.gov/#!/PublicationList/127 (accessed on 30 July 2022).
- Ziakopoulos, A.; Yannis, G. A review of spatial approaches in road safety. Accid. Anal. Prev. 2020, 135, 105323. [Google Scholar] [CrossRef]
- Shahzad, M. Review of road accident analysis using GIS technique. Int. J. Inj. Control. Saf. Promot. 2020, 27, 472–481. [Google Scholar] [CrossRef]
- Yao, S.; Loo, B.P.Y.; Yang, B.Z. Traffic collisions in space: Four decades of advancement in applied GIS. Ann. Gis 2016, 22, 1–14. [Google Scholar] [CrossRef]
- Moran, P.A. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef]
- Moran, P.A.P. The Interpretation of Statistical Maps. J. R. Stat. Soc. Ser. B 1948, 10, 243–251. Available online: https://www.jstor.org/stable/2983777 (accessed on 10 August 2023). [CrossRef]
- Ripley, B.D. Modeling Spatial Patterns. J. Roy. Stat. Soc. B Met. 1977, 39, 172–212. Available online: https://www.jstor.org/stable/2984796 (accessed on 10 August 2023). (In English).
- Getis, A.; Ord, J.K. The Analysis of Spatial Association by Use of Distance Statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Ord, J.K.; Getis, A. Local Spatial Autocorrelation Statistics: Distributional Issues and an Application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Anselin, L. Local Indicators of Spatial Association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Ulak, M.B.; Ozguven, E.E.; Vanli, O.A.; Horner, M.W. Exploring alternative spatial weights to detect crash hotspots. Comput. Environ. Urban Syst. 2019, 78, 101398. [Google Scholar] [CrossRef]
- ESRI. Best Practices for Selecting a Fixed Distance Band Value ArcGIS Pro|Documentation. Available online: https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/choosingdistanceband.htm (accessed on 20 May 2023).
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234. [Google Scholar] [CrossRef]
- Okabe, A.; Sugihara, K. Spatial Analysis along Networks: Statistical and Computational Methods; John Wiley and Sons Ltd.: Hoboken, NJ, USA, 2012; pp. 1–288. [Google Scholar] [CrossRef]
- Yamada, I.; Thill, J.C. Comparison of planar and network K-functions in traffic accident analysis. J. Transp. Geogr. 2004, 12, 149–158. [Google Scholar] [CrossRef]
- Alam, M.S.; Tabassum, N.J. Spatial pattern identification and crash severity analysis of road traffic crash hot spots in Ohio. Heliyon 2023, 9, e16303. [Google Scholar] [CrossRef]
- Islam, M.K.; Reza, I.; Gazder, U.; Akter, R.; Arifuzzaman, M.; Rahman, M.M. Predicting Road Crash Severity Using Classifier Models and Crash Hotspots. Appl. Sci. 2022, 12, 11354. [Google Scholar] [CrossRef]
- Khan, I.U.; Vachal, K.; Ebrahimi, S.; Wadhwa, S.S. Hotspot analysis of single-vehicle lane departure crashes in North Dakota. IATSS Res. 2023, 47, 25–34. [Google Scholar] [CrossRef]
- Lee, M.; Khattak, A.J. Case Study of Crash Severity Spatial Pattern Identification in Hot Spot Analysis. Transp. Res. Rec. 2019, 2673, 684–695. [Google Scholar] [CrossRef]
- Ouni, F.; Belloumi, M. Pattern of road traffic crash hot zones versus probable hot zones in Tunisia: A geospatial analysis. Accid. Anal. Prev. 2019, 128, 185–196. [Google Scholar] [CrossRef]
- Prasannakumar, V.; Vijith, H.; Charutha, R.; Geetha, N. Spatio-temporal clustering of road accidents: GIS based analysis and assessment. Procedia—Soc. Behav. Sci. 2011, 21, 317–325. [Google Scholar] [CrossRef]
- Soleimani, M.; Bagheri, N. Spatio-temporal analysis of head injuries in northwest Iran. Spat. Inf. Res. 2022, 1, 1–16. [Google Scholar] [CrossRef]
- Thakali, L.; Kwon, T.J.; Fu, L. Identification of crash hotspots using kernel density estimation and kriging methods: A comparison. J. Mod. Transp. 2015, 23, 93–106. [Google Scholar] [CrossRef]
- Truong, L.T.; Somenahalli, S.V.C. Using GIS to identify pedestrian- vehicle crash hot spots and unsafe bus stops. J. Public Transp. 2011, 14, 99–114. [Google Scholar] [CrossRef]
- Ziakopoulos, A. Spatial analysis of harsh driving behavior events in urban networks using high-resolution smartphone and geometric data. Accid. Anal. Prev. 2021, 157, 106189. [Google Scholar] [CrossRef]
- Khalid, S.; Shoaib, F.; Qian, T.; Rui, Y.; Bari, A.I.; Sajjad, M.; Shakeel, M.; Wang, J. Network Constrained Spatio-Temporal Hotspot Mapping of Crimes in Faisalabad. Appl. Spat. Anal. Policy 2018, 11, 599–622. [Google Scholar] [CrossRef]
- Özcan, M.; Küçükönder, M. Investigation of Spatiotemporal Changes in the Incidence of Traffic Accidents in Kahramanmaraş, Turkey, Using GIS-Based Density Analysis. J. Indian Soc. Remote Sens. 2020, 48, 1045–1056. [Google Scholar] [CrossRef]
- Wang, S.H.; Chen, Y.Y.; Huang, J.L.; Liu, Z.; Li, J.; Ma, J.M. Spatial relationships between alcohol outlet densities and drunk driving crashes: An empirical study of Tianjin in China. J. Saf. Res. 2020, 74. [Google Scholar] [CrossRef]
- Huertas-Leyva, P.; Baldanzini, N.; Savino, G.; Pierini, M. Human error in motorcycle crashes: A methodology based on in-depth data to identify the skills needed and support training interventions for safe riding. Traffic Inj. Prev. 2021, 22, 294–300. [Google Scholar] [CrossRef]
- Pawar, D.S.; Patil, G.R. Response of major road drivers to aggressive maneuvering of the minor road drivers at unsignalized intersections: A driving simulator study. Transp. Res. Part F Traffic Psychol. Behav. 2018, 52, 164–175. [Google Scholar] [CrossRef]
- Rowe, R.; Roman, G.D.; McKenna, F.P.; Barker, E.; Poulter, D. Measuring errors and violations on the road: A bifactor modeling approach to the Driver Behavior Questionnaire. Accid. Anal. Prev. 2015, 74, 118–125. [Google Scholar] [CrossRef]
- Yue, L.; Abdel-Aty, M.; Wu, Y.; Zheng, O.; Yuan, J. In-depth approach for identifying crash causation patterns and its implications for pedestrian crash prevention. J. Saf. Res. 2020, 73, 119–132. [Google Scholar] [CrossRef]
- Erdogan, S.; Yilmaz, I.; Baybura, T.; Gullu, M. Geographical information systems aided traffic accident analysis system case study: City of Afyonkarahisar. Accid. Anal. Prev. 2008, 40, 174–181. [Google Scholar] [CrossRef]
- Gundogdu, I.B. Applying linear analysis methods to GIS-supported procedures for preventing traffic accidents: Case study of Konya. Saf. Sci. 2010, 48, 763–769. [Google Scholar] [CrossRef]
- Manepalli, U.R.R.; Bham, G.H.; Kandada, S. Evaluation of Hot-Spots Identification Using Kernel Density Estimation and Getis-ord on I-630. In Proceedings of the 3rd International Conference on Road Safety and Simulation, Indianapolis Indiana, IN, USA, 14–16 September 2011; Available online: http://pubs.trb.org/onlinepubs/conferences/2011/RSS/2/Manepalli,UR.pdf (accessed on 20 May 2023).
- Cáceres, C.F. Using GIS in Hotspots Analysis and for Forest Fire Fisk Zones Mapping in the Yeguare Region, Southeastern Honduras. Pap. Resour. Anal. 2011, 13, 1–14. Available online: http://gis.smumn.edu/GradProjects/CaceresC.pdf (accessed on 20 May 2023).
- Okabe, A.; Okunuki, K.I. A Computational Method for Estimating the Demand of Retail Stores on a Street Network and its Implementation in GIS. Trans. GIS 2001, 5, 209–220. [Google Scholar] [CrossRef]
- Shafabakhsh, G.A.; Famili, A.; Bahadori, M.S. GIS-based spatial analysis of urban traffic accidents: Case study in Mashhad, Iran. J. Traffic Transp. Eng. 2017, 4, 290–299. [Google Scholar] [CrossRef]
- Ulak, M.B.; Ozguven, E.E.; Spainhour, L.; Vanli, O.A. Spatial investigation of aging-involved crashes: A GIS-based case study in Northwest Florida. J. Transp. Geogr. 2017, 58, 71–91. [Google Scholar] [CrossRef]
- Osama, A.; Sayed, T. A Novel Approach for Identifying, Diagnosing, and Treating Active Transportation Safety Issues. Transp. Res. Rec. 2019, 2673, 813–823. [Google Scholar] [CrossRef]
- Osama, A.; Sayed, T.; Sacchi, E. A Novel Technique to Identify Hot Zones for Active Commuters’ Crashes. Transp. Res. Rec. 2018, 2672, 266–276. [Google Scholar] [CrossRef]
- Peeters, A.; Zude, M.; Käthner, J.; Ünlü, M.; Kanber, R.; Hetzroni, A.; Gebbers, R.; Ben-Gal, A. Getis-Ord’s hot- and cold-spot statistics as a basis for multivariate spatial clustering of orchard tree data. Comput. Electron. Agric. 2015, 111, 140–150. [Google Scholar] [CrossRef]
- Park, S.H.; Jang, K.; Kim, D.K.; Kho, S.Y.; Kang, S. Spatial analysis methods for identifying hazardous locations on expressways in Korea. Sci. Iran. 2015, 22, 1594–1603. [Google Scholar]
- Pirdavani, A.; Bellemans, T.; Brijs, T.; Wets, G. Application of Geographically Weighted Regression Technique in Spatial Analysis of Fatal and Injury Crashes. J. Transp. Eng. 2014, 140, 04014032. [Google Scholar] [CrossRef]
- Acharya, T.D.; Yoo, K.W.; Lee, D.H. GIS-based spatio-Temporal analysis of marine accidents database in the coastal zone of Korea. J. Coast. Res. 2017, 33, 114–118. [Google Scholar] [CrossRef]
- Hegyi, P.; Borsos, A.; Koren, C. Searching possible accident black spot locations with accident analysis and gis software based on GPS coordinates. Pollack Period. 2017, 12, 129–140. [Google Scholar] [CrossRef]
- Yu, H.; Liu, P.; Chen, J.; Wang, H. Comparative analysis of the spatial analysis methods for hotspot identification. Accid. Anal. Prev. 2014, 66, 80–88. [Google Scholar] [CrossRef]
- Zahran, E.-S.M.M.; Tan, S.J.; Amirah, N.; Binti, A.; Asri Putra, M.; Hie, E.; Tan, A.; Yap, Y.H.; Kartina, E.; Rahman, A. Evaluation of various GIS-based methods for the analysis of road traffic accident hotspot. MATEC Web Conf. 2019, 258, 03008. [Google Scholar] [CrossRef]
- ESRI. Spatial Autocorrelation (Global Moran’s I) (Spatial Statistics)—ArcGIS Pro|Documentation. Available online: https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/spatial-autocorrelation.htm (accessed on 20 May 2023).
- Ulak, M.B.; Kocatepe, A.; Yazici, A.; Ozguven, E.E.; Kumar, A. A stop safety index to address pedestrian safety around bus stops. Saf. Sci. 2021, 133, 105017. [Google Scholar] [CrossRef]
- Kazmi, S.S.A.; Ahmed, M.; Mumtaz, R.; Anwar, Z. Spatiotemporal Clustering and Analysis of Road Accident Hotspots by Exploiting GIS Technology and Kernel Density Estimation. Comput. J. 2020, 65, 155–176. [Google Scholar] [CrossRef]
- ITA. US States & Cities Visited by Overseas Travelers. 2023. Available online: https://www.trade.gov/data-visualization/us-states-cities-visited-overseas-travelers (accessed on 10 August 2023).
- SFgov. TransBASE Dashboard. Available online: https://transbase.sfgov.org/dashboard/dashboard.php (accessed on 6 March 2022).
- FHWA. KABCO Injury Classification Scale and Definition. Available online: https://safety.fhwa.dot.gov/hsip/spm/conversion_tbl/pdfs/kabco_ctable_by_state.pdf (accessed on 6 March 2022).
- Gelb, J. Network k Functions. Available online: https://cran.r-project.org/web/packages/spNetwork/vignettes/KNetworkFunctions.html#ref-baddeley2015spatial (accessed on 10 June 2022).
- Stoyan, D.; Stoyan, H. Estimating Pair Correlation Functions of Planar Cluster Processes. Biom. J. 1996, 38, 259–271. [Google Scholar] [CrossRef]
- Ripley, B.D. The second-order analysis of stationary point processes. J. Appl. Probab. 1976, 13, 255–266. [Google Scholar] [CrossRef]
- Gimond, M. Chapter 11 Point Pattern Analysis|Intro to GIS and Spatial Analysis. Available online: https://mgimond.github.io/Spatial/chp11_0.html (accessed on 20 May 2023).
- Bailey, T.C.; Gatrell, A.C. Interactive Spatial Data Analysis; Longman/Copublished Wiley: Harlow Essex, UK; New York, NY, USA, 1995. [Google Scholar]
- Griffith, D.; Chun, Y. Spatial Autocorrelation and Spatial Filtering; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1477–1507. [Google Scholar]
- Kaya, Ö.; Toroğlu, E.; Adıgüzel, F.; The Spatial Analysis of the Parties Voting Rate on the District Scale at the General Election In 2011 (2011 Genel Seçimlerinde Partilerin Aldığı Oy Oranlarının İlçeler Ölçeğinde Mekânsal Analizi). Istanbul Üniversitesi Edebiyat Fakültesi Coğrafya Dergisi 2015, 1–13. Available online: https://dergipark.org.tr/tr/pub/iucografya/issue/25076/264660 (accessed on 20 May 2023).
- Mhetre, K.V.; Thube, A.D. Road safety, crash hot-spot, and crash cold-spot identification on a rural national highway in maharashtra, India. Mater. Today Proc. 2023, 77, 780–787. [Google Scholar] [CrossRef]
- ESRI. Incremental Spatial Autocorrelation (Spatial Statistics)—ArcGIS Pro|Documentation. Available online: https://pro.arcgis.com/en/pro-app/2.8/tool-reference/spatial-statistics/incremental-spatial-autocorrelation.htm (accessed on 30 July 2022).
- CMAP. Crash Scans Show Relationship between Congestion and Crash Rates—CMAP. Available online: https://www.cmap.illinois.gov/updates/all/-/asset_publisher/UIMfSLnFfMB6/content/crash-scans-show-relationship-between-congestion-and-crash-rates (accessed on 20 May 2023).
- Washington, S.; Karlaftis, M.G.; Anastasopoulos, P.C.; Mannering, F.L.; Ebook Central Academic, C. Statistical and Econometric Methods for Transportation Data Analysis, 3rd ed.; CRC Press: Boca Raton, FL, USA; London, UK; New York, NY, USA, 2020. (In English) [Google Scholar] [CrossRef]
- Washington, S.; Karlaftis, M.G.; Mannering, F.; Anastasopoulos, P. Statistical and Econometric Methods for Transportation Data Analysis; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 2020. [Google Scholar]
- Motuba, D.; Khan, M.A.; Mirzazadeh, B.; Habib, M.F. Using Panel Data Analysis to Evaluate How Individual Non-Pharmaceutical Interventions Affected Traffic in the U.S. during the First Three Months of the COVID Pandemic. COVID 2022, 2, 86. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
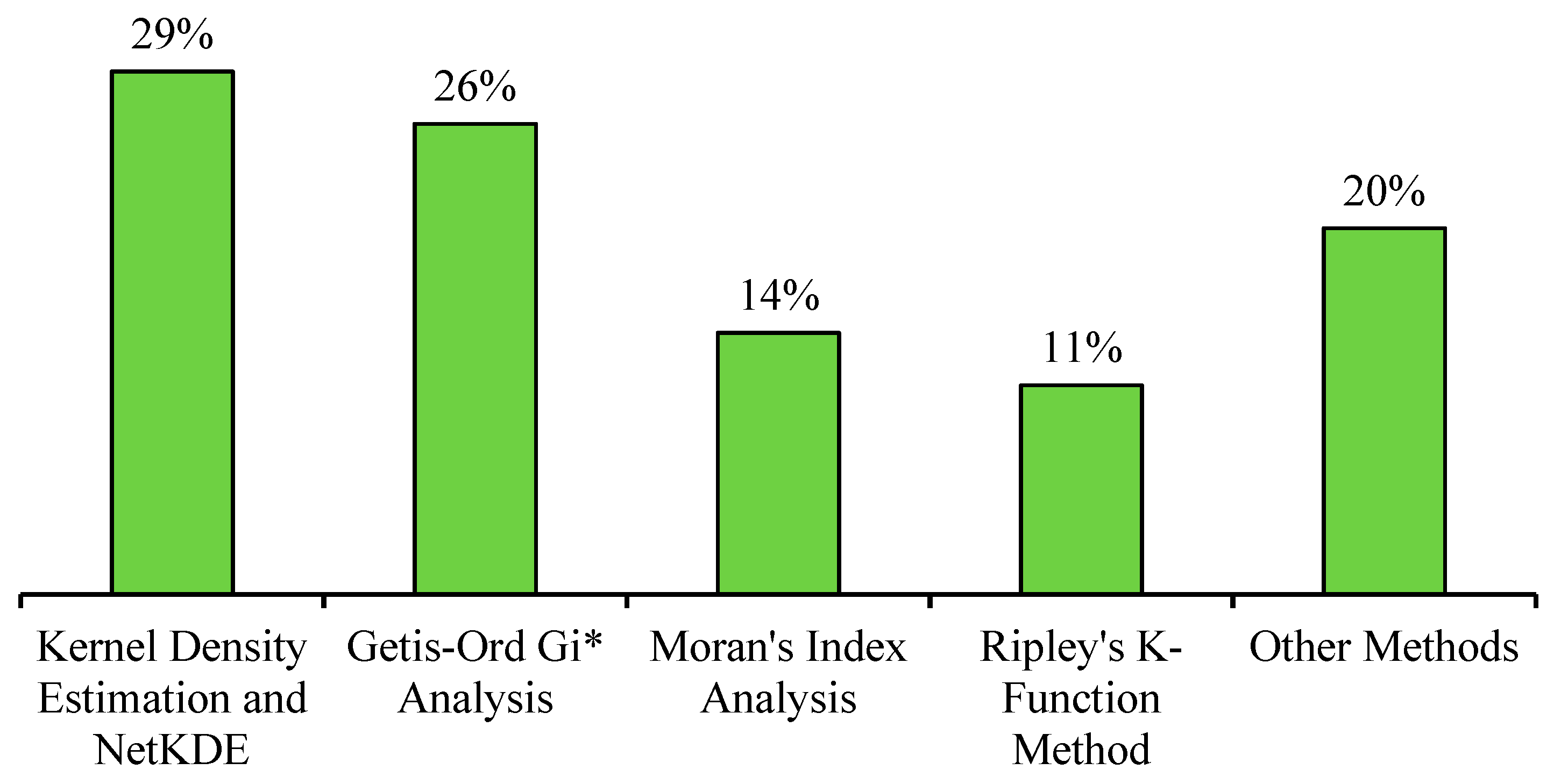
| Method | Articles | Pros | Cons | |
|---|---|---|---|---|
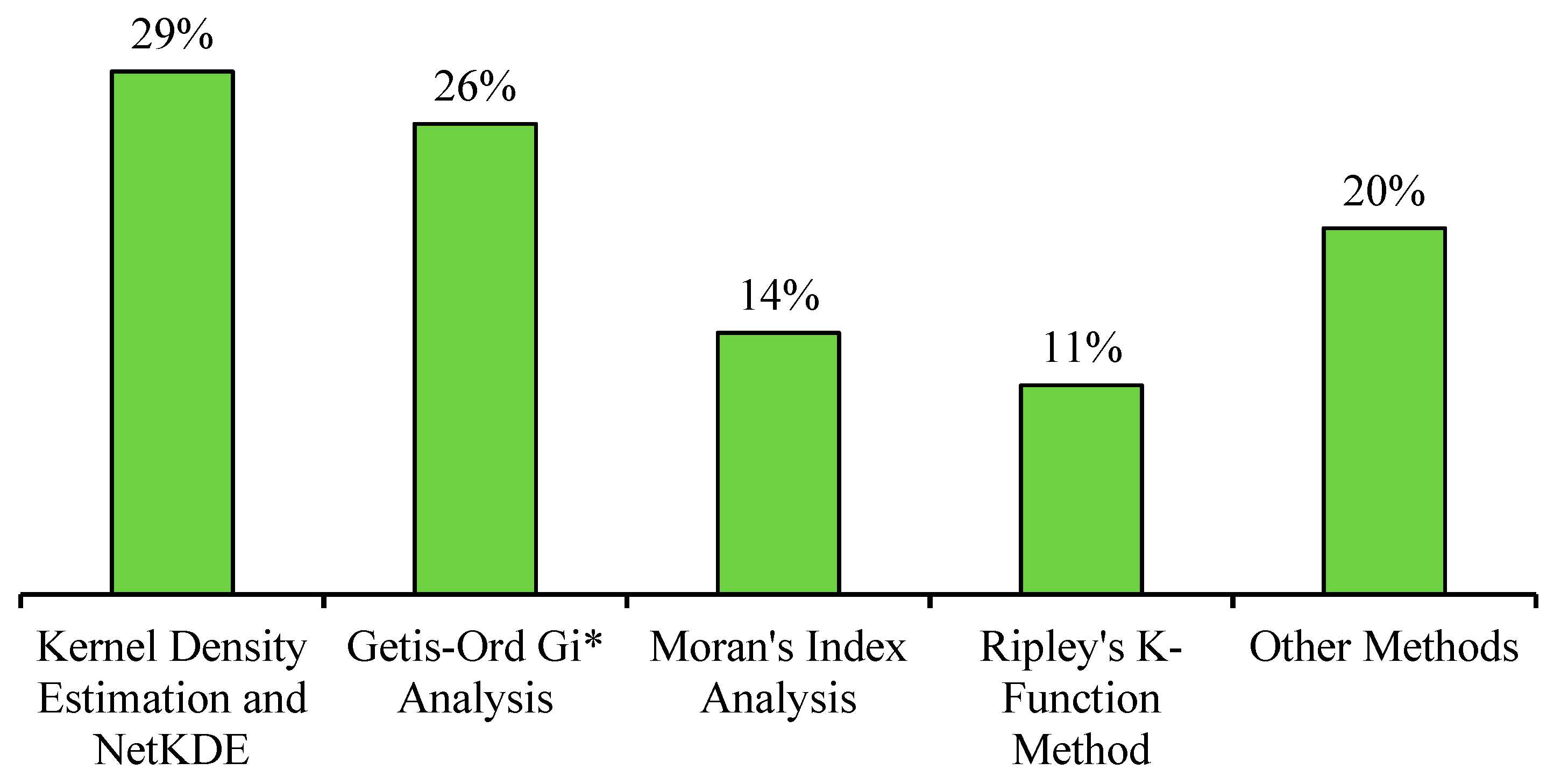
| 1. | Kernel density estimation | [26,33,35,38,39,45,46,47,48] | KDE can be employed to visualize crash densities across various geographical regions. The smoothness of the density surface is conditional upon the careful selection of the appropriate bandwidth. Network-Constrained KDE offers an enhanced level of accuracy by providing route-specific density information. | KDE results are overly sensitive to the choice of bandwidth. The resulting density estimates can exhibit variations when different kernel shapes are employed, for example, Gaussian, Epanechnikov. Furthermore, the computational process might become demanding, especially when dealing with larger geographical areas and more extensive datasets and network constrained estimation. |
| 2. | Getis-Ord Gi* | [11,19,21,22,26,34,35,36,42,48] | Getis-Ord Gi* effectively identifies clustering patterns of high-high or low-low values. High-high clusters, known as hot spots, are characterized by a highz-score and a small p-value. Conversely, low-low clusters, referred to as cold spots, involve a low negativez-score and a small p-value. | The Gi* statistics are sensitive to the choice of threshold distance. Moreover, employing various distance methods (such as Manhattan, Euclidean, or actual network distance) can yield divergent outcomes. Hence, it is crucial to opt for an appropriate distance method to establish accurate spatial relationships. |
| 3. | Moran’s Index | [11,19,21,22,36,47] | Moran’s Index is used to identify the clustering or dispersion in data based on spatial autocorrelation supported byz-score and p-value. The null hypothesis used in Moran’s Index is that “the values of the features are spatially uncorrelated” [49]. Using the Incremental Spatial Autocorrelation tool, a threshold distance to be used in Local Moran’s I and Getis-Ord Gi* analysis is calculated. | Similar to Getis-Ord Gi*, Local Moran’s I is also influenced by scale and sensitive to a threshold distance, which can be identified in advance through the Incremental Spatial Autocorrelation method or the method we are proposing in this research, i.e., K-function and G-function method. Furthermore, inappropriate distance method selection may lead to an inaccurate Moran’s I result. |
| 4. | Ripley’s K-function | [11,26,38,42,50] | Ripley’s K-function is used to identify spatial patterns of data (clustering, dispersion, or randomness). K-function can be used on both local and global scales. A network restraint K-function provides more accurate results in case of crash data. Additionally, the K-function enables the comparison of spatial patterns between two distinct datasets. | Unlike Moran’s I, K-function lacks consideration of attribute values, thus not providing insights into the underlying causes of spatial patterns. Similar to Getis-Ord Gi* and Moran’s I, Ripley’s K-function results are also dependent on the type of distance method used. The calculation process may be computationally extensive in cases of network restraint Ripley’s K-function. |
| 5. | Other methods | [42,43,44,45,46,47,51] | - | - |
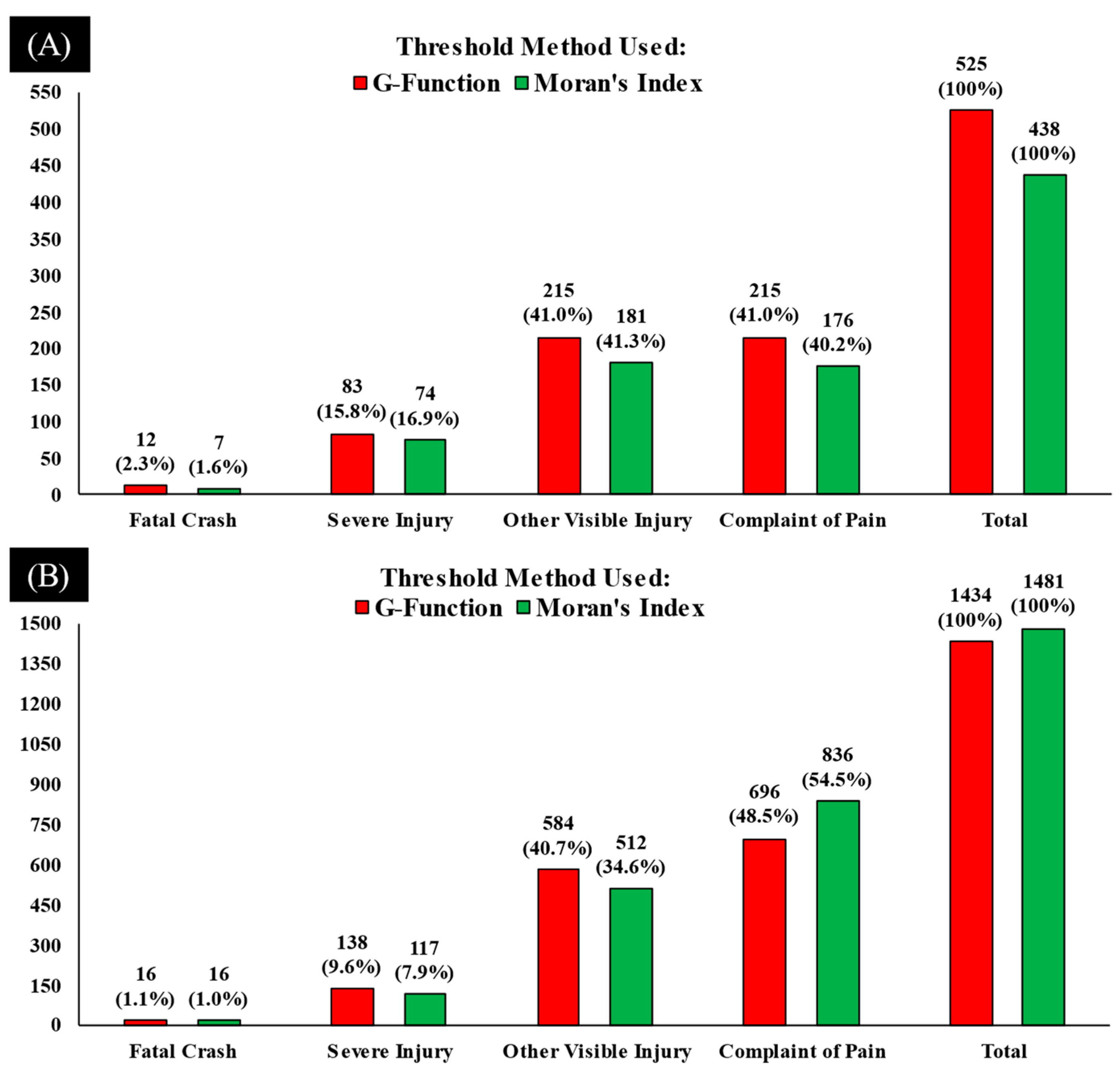
| Severity Level | KABCO Scale [54] | 2017–2019 | 2020–2021 | ||||
|---|---|---|---|---|---|---|---|
| Bikes | Pedestrian | Total (%) | Bikes | Pedestrian | Total (%) | ||
| Fatal Crash | K | 5 | 46 | 51 (1.30%) | 2 | 18 | 20 (1.20%) |
| Injury (Severe) | A | 106 | 299 | 405 (10.6%) | 54 | 160 | 214 (12.6%) |
| Injury (Other Visible) | B | 585 | 736 | 1321 (34.6%) | 269 | 329 | 598 (35.3%) |
| Injury (Complaint of Pain) | C | 698 | 1341 | 2039 (53.4%) | 309 | 552 | 861 (50.9%) |
| Total | 1394 | 2422 | 3816 (69.3%) | 634 | 1059 | 1693 (30.7%) | |
| Ripley’s K- and G-Function | Moran’s Index: |
|---|---|
Advantages:
| Advantages:
|
| Ripley’s K- and G-Function | Moran’s Index: |
|---|---|
Disadvantages and Limitations:
| Disadvantages and Limitations:
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Habib, M.F.; Bridgelall, R.; Motuba, D.; Rahman, B. Exploring the Robustness of Alternative Cluster Detection and the Threshold Distance Method for Crash Hot Spot Analysis: A Study on Vulnerable Road Users. Safety 2023, 9, 57. https://doi.org/10.3390/safety9030057
Habib MF, Bridgelall R, Motuba D, Rahman B. Exploring the Robustness of Alternative Cluster Detection and the Threshold Distance Method for Crash Hot Spot Analysis: A Study on Vulnerable Road Users. Safety. 2023; 9(3):57. https://doi.org/10.3390/safety9030057
Chicago/Turabian StyleHabib, Muhammad Faisal, Raj Bridgelall, Diomo Motuba, and Baishali Rahman. 2023. "Exploring the Robustness of Alternative Cluster Detection and the Threshold Distance Method for Crash Hot Spot Analysis: A Study on Vulnerable Road Users" Safety 9, no. 3: 57. https://doi.org/10.3390/safety9030057
APA StyleHabib, M. F., Bridgelall, R., Motuba, D., & Rahman, B. (2023). Exploring the Robustness of Alternative Cluster Detection and the Threshold Distance Method for Crash Hot Spot Analysis: A Study on Vulnerable Road Users. Safety, 9(3), 57. https://doi.org/10.3390/safety9030057