
GANs for Medical Image Synthesis: An Empirical Study



Abstract
1. Introduction
1.1. Medical Image Analysis
1.2. Synthetic Data and Medical Imaging
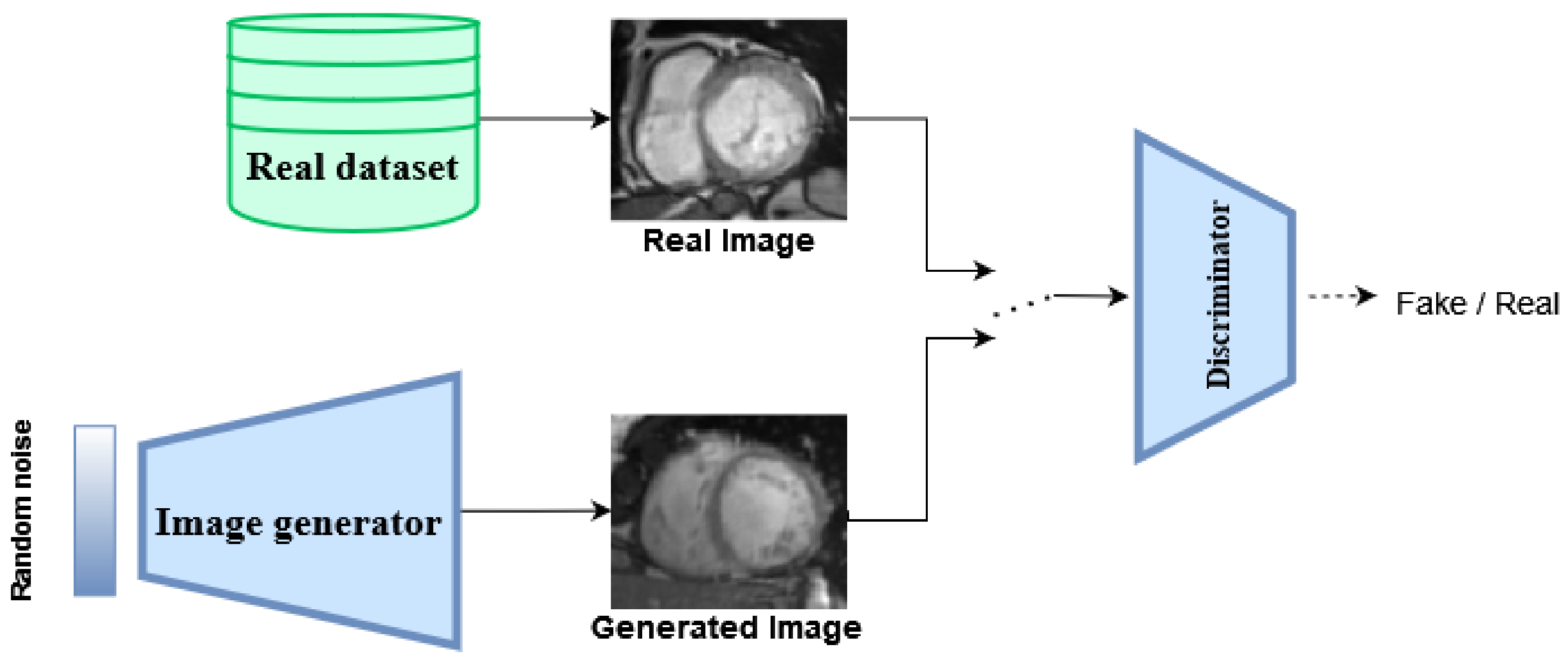
2. Generative Adversarial Networks
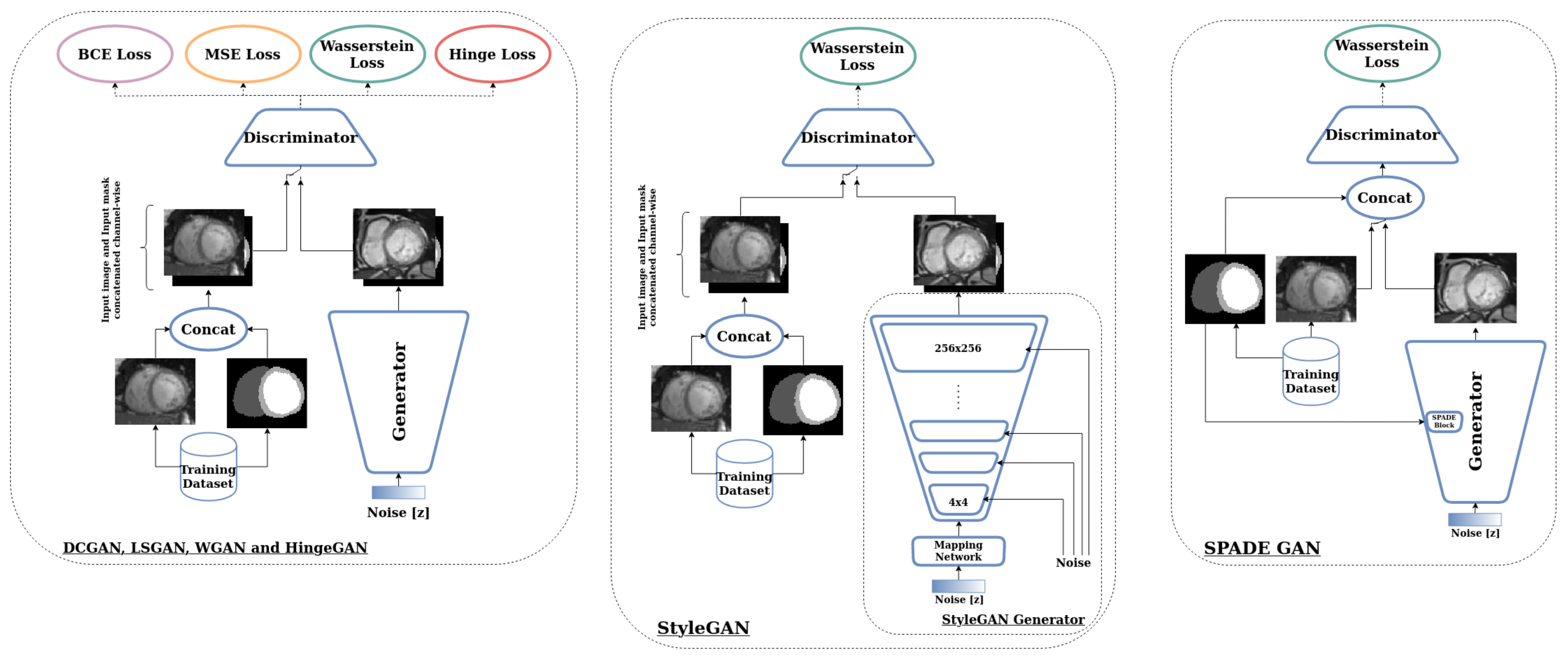
2.1. GAN Selection
2.1.1. DCGAN
2.1.2. LSGAN
2.1.3. WGAN and WGAN-GP
2.1.4. HingeGAN (Geometric GAN)
2.1.5. SPADE GAN
2.1.6. Style Based GANs
2.2. Evaluation Metrics
3. Material and Methods
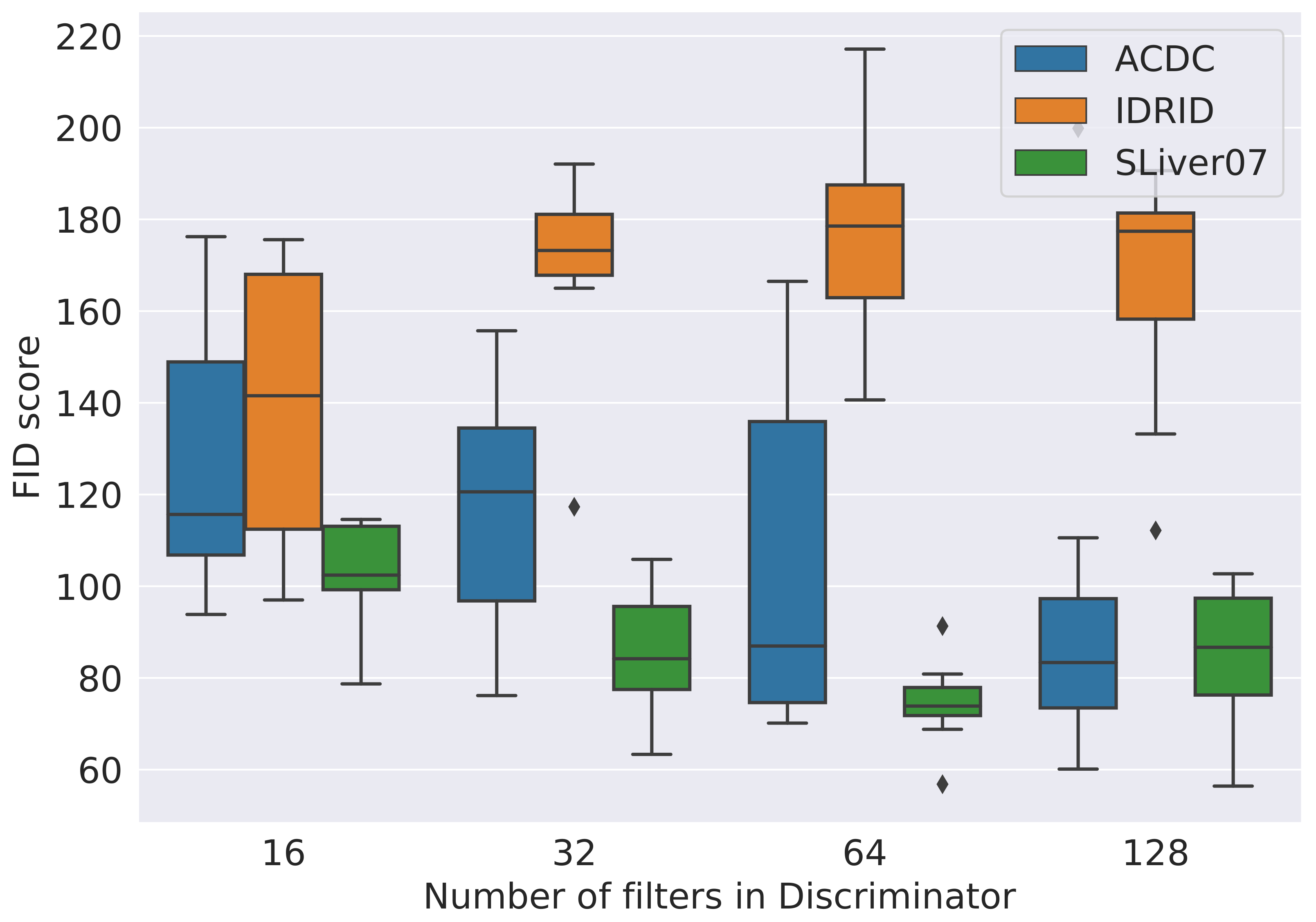
3.1. Hyperparameters Search
3.2. GANs Setup
3.3. GAN Training Tricks
3.4. GAN Evaluation in Medical Imaging
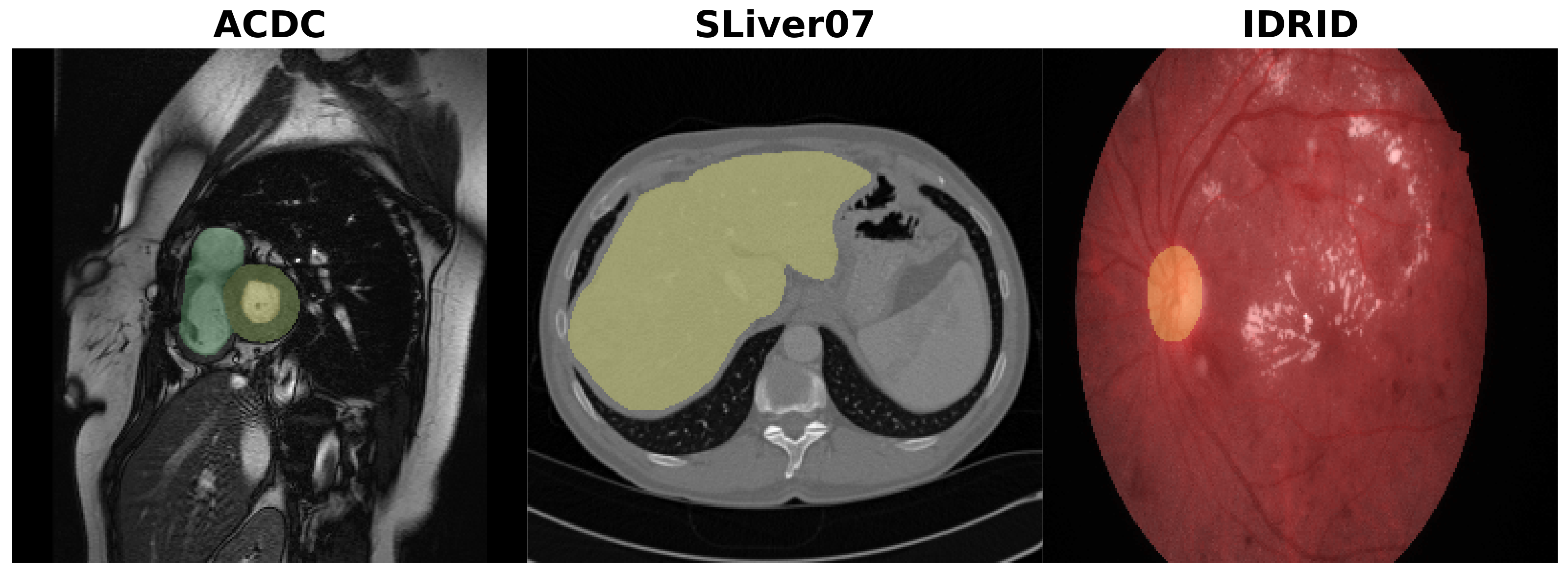
3.5. Datasets
3.5.1. ACDC
3.5.2. SLiver07
3.5.3. IDRiD
3.6. Dataset Generation
4. Experiments and Results
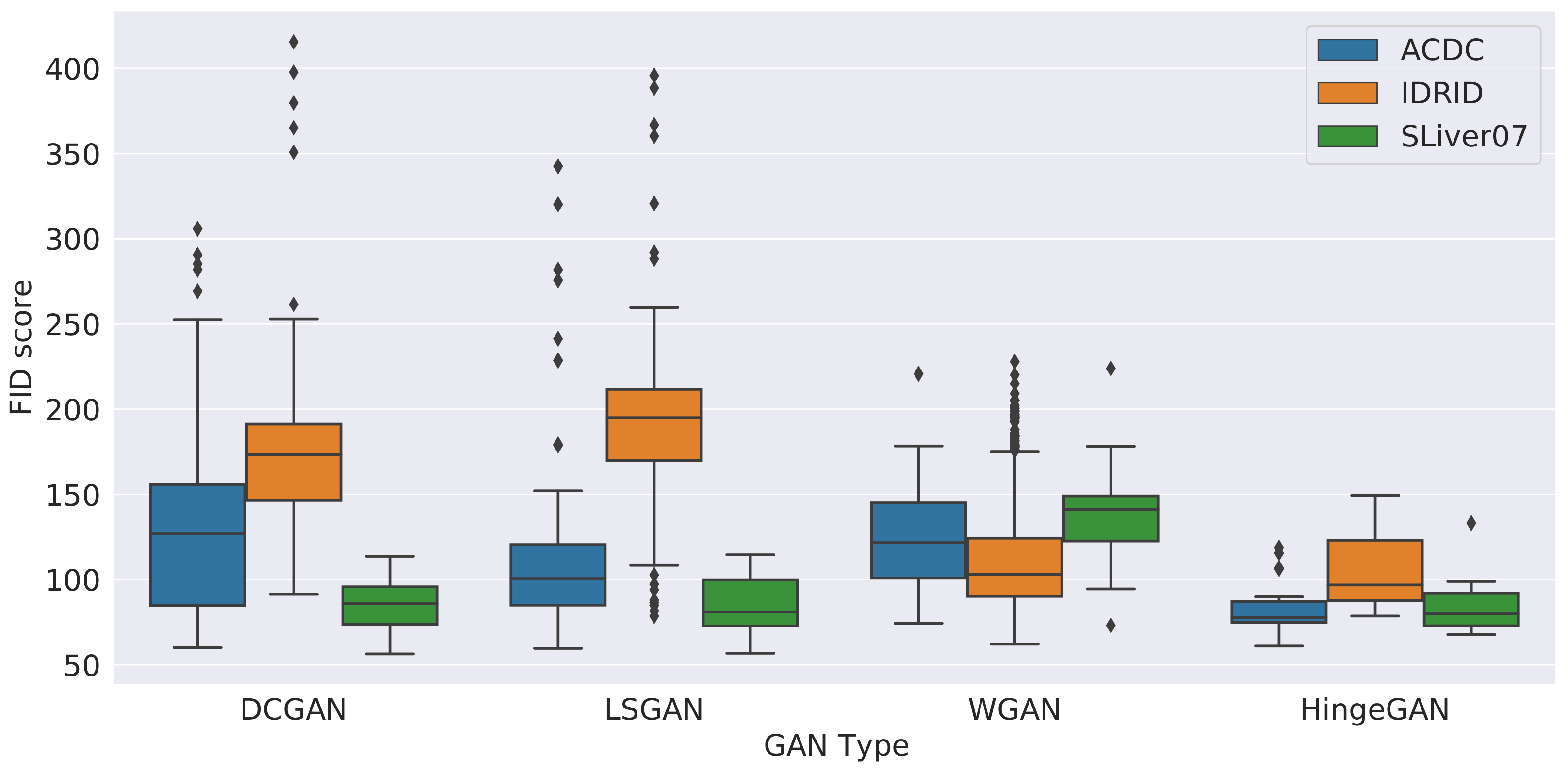
4.1. Hyperparameter Search and Overall Results
4.2. Segmentation Evaluation
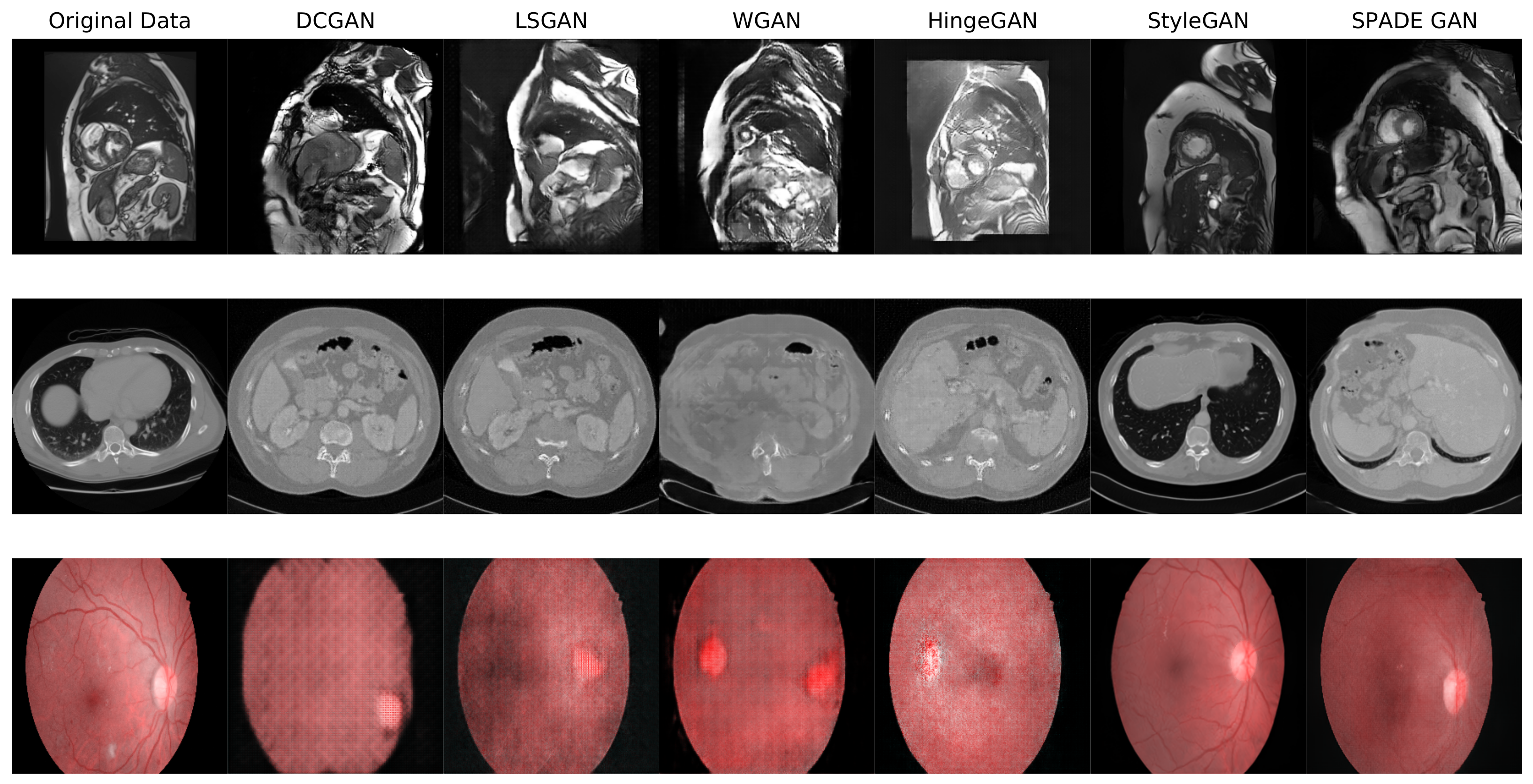
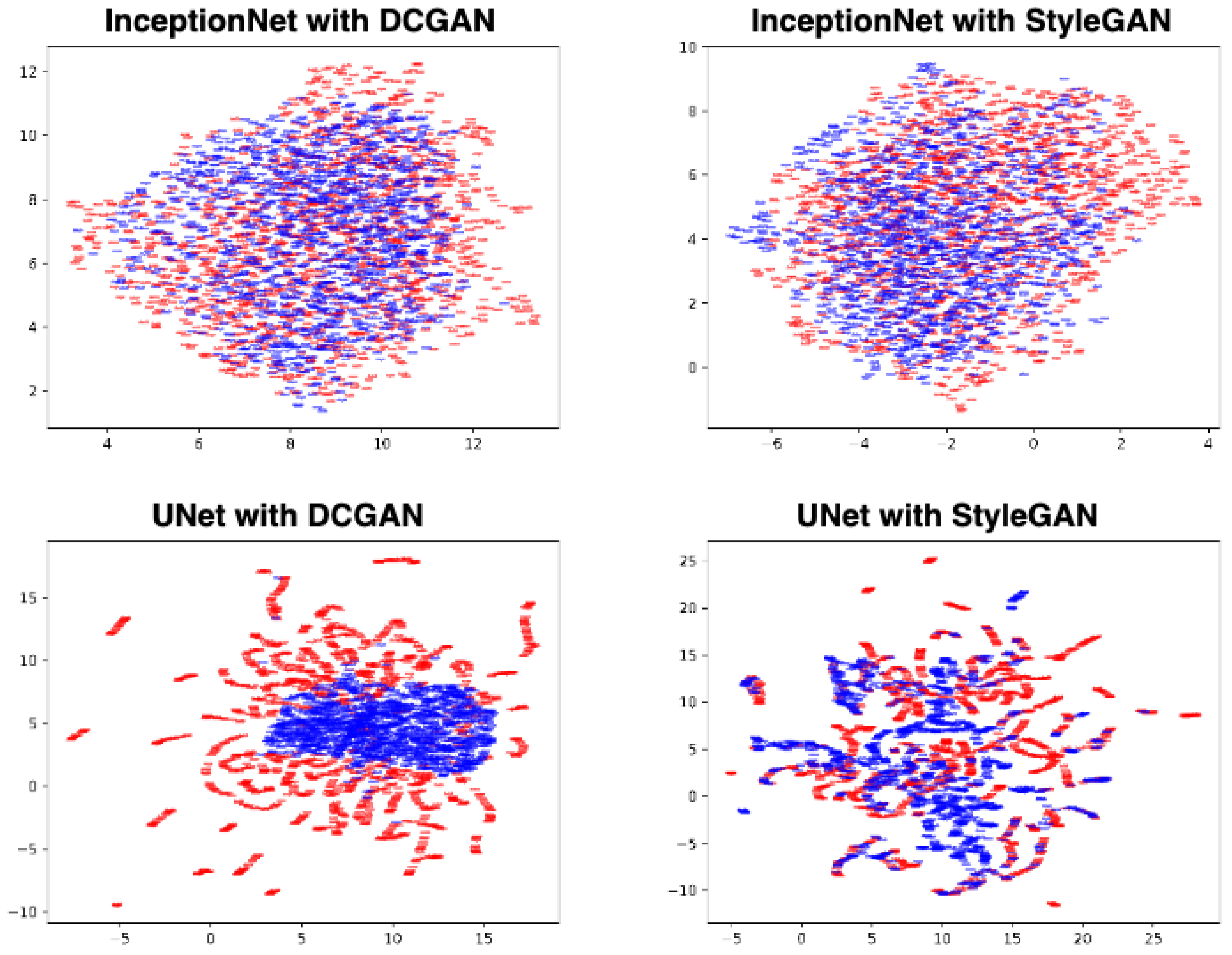
4.3. Visual Turing Test
5. Discussion
5.1. Training Volatility
5.2. FID and Image Quality
5.3. Data Scale
5.4. Compute Scale
5.5. Medical Worth
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–1 December 2014; pp. 2672–2680. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jeong, J.J.; Tariq, A.; Adejumo, T.; Trivedi, H.; Gichoya, J.W.; Banerjee, I. Systematic Review of Generative Adversarial Networks (GANs) for Medical Image Classification and Segmentation. J. Digit. Imaging 2022, 35, 137–152. [Google Scholar] [CrossRef] [PubMed]
- Wolterink, J.M.; Mukhopadhyay, A.; Leiner, T.; Vogl, T.J.; Bucher, A.M.; Išgum, I. Generative Adversarial Networks: A Primer for Radiologists. Radiographics 2021, 41, 840–857. [Google Scholar] [CrossRef] [PubMed]
- Gong, M.; Chen, S.; Chen, Q.; Zeng, Y.; Zhang, Y. Generative Adversarial Networks in Medical Image Processing. Curr. Pharm. Des. 2020, 27, 1856–1868. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New Yok, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Frangi, A.F.; Tsaftaris, S.A.; Prince, J.L. Simulation and Synthesis in Medical Imaging. IEEE Trans. Med. Imaging 2018, 37, 673–679. [Google Scholar] [CrossRef] [PubMed]
- Bermudez, C.; Plassard, A.J.; Davis, L.T.; Newton, A.T.; Resnick, S.M.; Landman, B.A. Learning implicit brain MRI manifolds with deep learning. In Medical Imaging 2018: Image Processing; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10574, p. 105741L. [Google Scholar]
- Baur, C.; Albarqouni, S.; Navab, N. Generating Highly Realistic Images of Skin Lesions with GANs. In OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis; Springer International Publishing: Cham, Switzerland, 2018; pp. 260–267. [Google Scholar]
- Calimeri, F.; Marzullo, A.; Stamile, C.; Terracina, G. Biomedical data augmentation using generative adversarial neural networks. In Proceedings of the International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2017; Springer: Berlin, Germany, 2017; pp. 626–634. [Google Scholar]
- Chuquicusma, M.J.M.; Hussein, S.; Burt, J.; Bagci, U. How to fool radiologists with generative adversarial networks? A visual turing test for lung cancer diagnosis. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 240–244. [Google Scholar]
- Shin, H.C.; Tenenholtz, N.A.; Rogers, J.K.; Schwarz, C.G.; Senjem, M.L.; Gunter, J.L.; Andriole, K.P.; Michalski, M. Medical Image Synthesis for Data Augmentation and Anonymization Using Generative Adversarial Networks. In Simulation and Synthesis in Medical Imaging; Springer International Publishing: Cham, Switzerland, 2018; pp. 1–11. [Google Scholar]
- Skandarani, Y.; Painchaud, N.; Jodoin, P.M.; Lalande, A. On the effectiveness of GAN generated cardiac MRIs for segmentation. In Proceedings of the Medical Imaging with Deep Learning, Montreal, QC, Canada, 6–9 July 2020. [Google Scholar]
- Kazeminia, S.; Baur, C.; Kuijper, A.; van Ginneken, B.; Navab, N.; Albarqouni, S.; Mukhopadhyay, A. GANs for medical image analysis. Artif. Intell. Med. 2020, 109, 101938. [Google Scholar] [CrossRef] [PubMed]
- Gonog, L.; Zhou, Y. A Review: Generative Adversarial Networks. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 505–510. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards Principled Methods for Training Generative Adversarial Networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations (ICLR), Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; International Convention Centre: Sydney, Australia, 2017; Volume 70, pp. 214–223. [Google Scholar]
- Lim, J.H.; Ye, J.C. Geometric GAN. arXiv 2017, arXiv:1705.02894. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic Image Synthesis with Spatially-Adaptive Normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-To-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Regmi, K.; Borji, A. Cross-View Image Synthesis Using Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; International Convention Centre: Sydney, Australia, 2017; Volume 70, pp. 2642–2651. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X.; Chen, X. Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Borji, A. Pros and cons of GAN evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying MMD GANs. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are GANs Created Equal? A Large-Scale Study. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Zhao, S.; Liu, Z.; Lin, J.; Zhu, J.Y.; Han, S. Differentiable Augmentation for Data-Efficient GAN Training. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 7559–7570. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6924–6932. [Google Scholar]
- Ravuri, S.; Vinyals, O. Classification Accuracy Score for Conditional Generative Models. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. How good is my GAN? In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Cetin, I.; Lekadir, K.; Camara, O.; Ballester, M.A.G.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Styner, M.; Lee, J.; Chin, B.; Chin, M.; Commowick, O.; Tran, H.; Markovic-Plese, S.; Jewells, V.; Warfield, S. 3D Segmentation in the Clinic: A Grand Challenge II: MS lesion segmentation. MIDAS J. 2008, 2008, 1–6. [Google Scholar] [CrossRef]
- Porwal, P.; Pachade, S.; Kamble, R.; Kokare, M.; Deshmukh, G.; Sahasrabuddhe, V.; Mériaudeau, F. Indian Diabetic Retinopathy Image Dataset (IDRiD): A Database for Diabetic Retinopathy Screening Research. Data 2018, 3, 25. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- McInnes, L.; Healy, J.; Saul, N.; Grossberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Values |
|---|---|
| Differentiable augmentation [34] | TRUE/FALSE |
| Activation fn of discriminator | ReLU/LeakyRelu/Elu/Selu |
| Activation fn of generator | ReLU/LeakyRelu/Elu/Selu |
| Normalization layer of discriminator | BatchNorm [35]/InstanceNorm [36] |
| Normalization layer of generator | BatchNorm [35]/InstanceNorm [36] |
| Number of filters of discriminator | 16/32/64/128 |
| Number of filters of generator | 16/32/64/128 |
| Use spectral norm for discriminator | TRUE/FALSE |
| Use spectral norm for generator | TRUE/FALSE |
| Weight initialization function | Normal/Xavier/Xavier Uniform/Kaiming He |
| Weight initialization gain | 0.01/0.02/0.1/1.0 |
| Gradient penalty loss weight (WGAN-GP only) | 0/0.1/1.0/10.0 |
| Weight clipping value (WGAN only) | 0/0.01/0.1 |
| Feature matching loss weight | 0/1.0/10.0 |
| VGG loss weight | 0/1.0 /10.0 |
| Learning rate | 0.00004/0.00005/0.0001/0.0002/0.001 |
| Use of label smoothing [29] | TRUE/FALSE |
| Use of data augmentation | TRUE/FALSE |
| Dataset | GAN | FID Score | U-Net Dice Score |
|---|---|---|---|
| Original Data | – | 0.89 | |
| Augmented Original Data | – | 0.90 | |
| DCGAN | 60.12 | 0.30 | |
| LSGAN | 59.65 | 0.39 | |
| ACDC | WGAN | 74.30 | 0.70 |
| Hinge GAN | 61.00 | 0.63 | |
| SPADE GAN | 41.54 | 0.86 | |
| StyleGAN | 24.74 | 0.87 | |
| Orig. Data + SPADE GAN | – | 0.90 | |
| Orig. Data + StyleGAN | – | 0.90 | |
| Original Data | – | 0.83 | |
| Augmented Original Data | – | 0.84 | |
| DCGAN | 91.34 | 0.29 | |
| LSGAN | 78.61 | 0.20 | |
| IDRiD | WGAN | 62.12 | 0.72 |
| Hinge GAN | 78.61 | 0.69 | |
| SPADE GAN | 1.09 | 0.82 | |
| StyleGAN | 23.72 | 0.80 | |
| Orig. Data + SPADE GAN | – | 0.84 | |
| Orig. Data + StyleGAN | – | 0.84 | |
| Original Data | – | 0.72 | |
| Augmented Original Data | – | 0.70 | |
| DCGAN | 56.41 | 0.14 | |
| LSGAN | 56.82 | 0.15 | |
| SLiver07 | WGAN | 73.11 | 0.16 |
| Hinge GAN | 67.69 | 0.15 | |
| SPADE GAN | 47.62 | 0.61 | |
| StyleGAN | 29.06 | 0.36 | |
| Orig. Data + SPADE GAN | – | 0.71 | |
| Orig. Data + StyleGAN | – | 0.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skandarani, Y.; Jodoin, P.-M.; Lalande, A. GANs for Medical Image Synthesis: An Empirical Study. J. Imaging 2023, 9, 69. https://doi.org/10.3390/jimaging9030069
Skandarani Y, Jodoin P-M, Lalande A. GANs for Medical Image Synthesis: An Empirical Study. Journal of Imaging. 2023; 9(3):69. https://doi.org/10.3390/jimaging9030069
Chicago/Turabian StyleSkandarani, Youssef, Pierre-Marc Jodoin, and Alain Lalande. 2023. "GANs for Medical Image Synthesis: An Empirical Study" Journal of Imaging 9, no. 3: 69. https://doi.org/10.3390/jimaging9030069
APA StyleSkandarani, Y., Jodoin, P.-M., & Lalande, A. (2023). GANs for Medical Image Synthesis: An Empirical Study. Journal of Imaging, 9(3), 69. https://doi.org/10.3390/jimaging9030069