
Building CNN-Based Models for Image Aesthetic Score Prediction Using an Ensemble


Abstract
1. Introduction
- Besides fine-tuning the pretrained models, a new CNN architecture that could embody the holistic composition of the image is designed. Based on this architecture, the models with different architectural parameters are trained on the XiheAA dataset [19], in order to predict an image’s aesthetic score.
- The performances of the above models are evaluated, and an ensemble method of aggregating two models is proposed to improve the performance of the AS prediction.
- The feature maps of the models regarding the images are analyzed. It is found that the attention regions of the models are often consistent with the subjects of the images, and follow the simple photography composition guidelines, such as visual balance, and the rule of thirds, if they are predicted to have the high aesthetic scores, otherwise the opposite, whether the predictions are correct or not. It is indicated that the models trained on XiheAA seem to learn the latent photography composition principles, but it cannot be said that they learn the aesthetic sense.
2. Related Works
3. Methodology
3.1. Overview
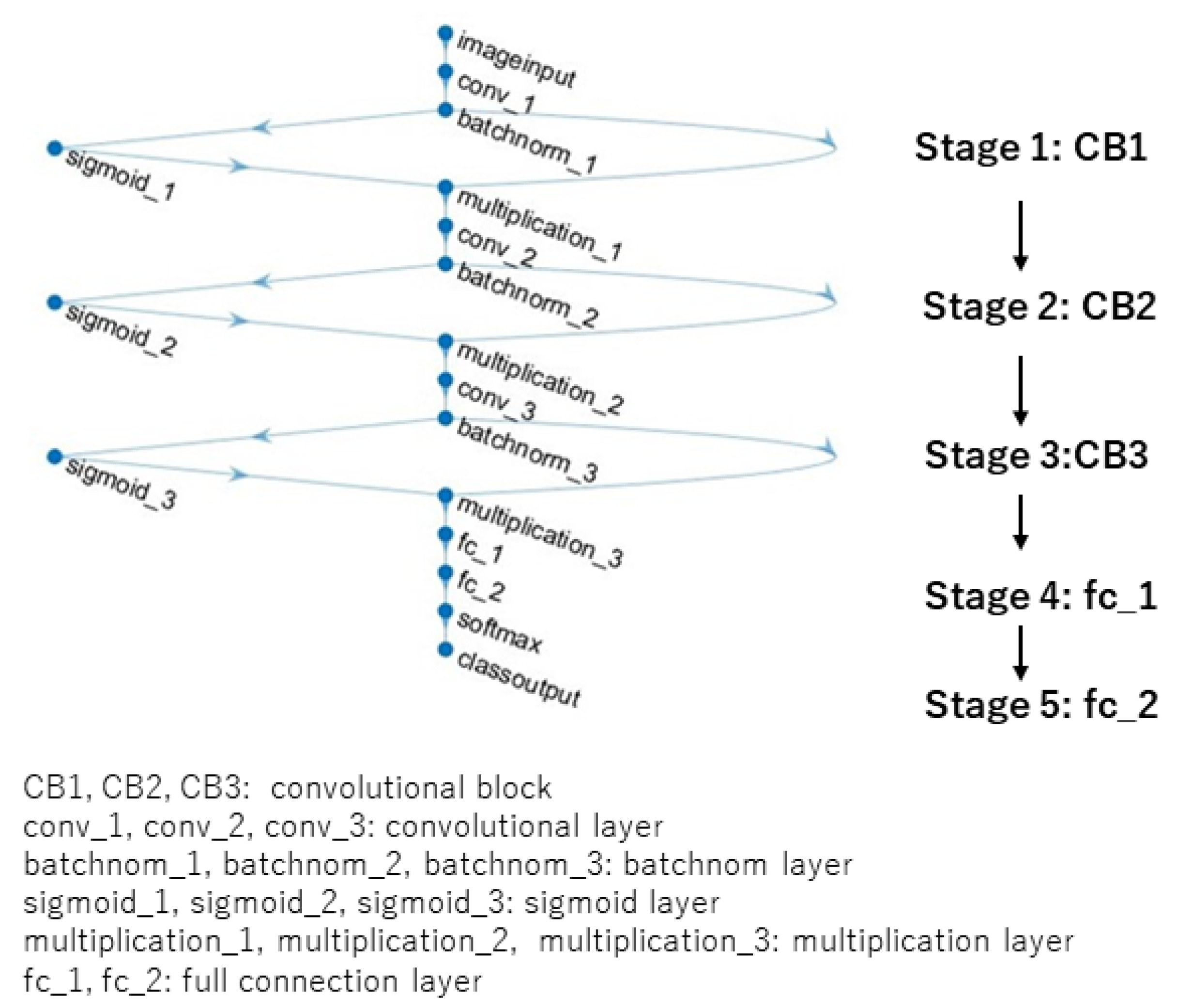
3.2. New Designed CNN Architecture
3.3. Ensemble
3.4. FFP and AIR
4. Experiments and Analysis
4.1. Implementation Details
4.2. Experimental Results of Single Models
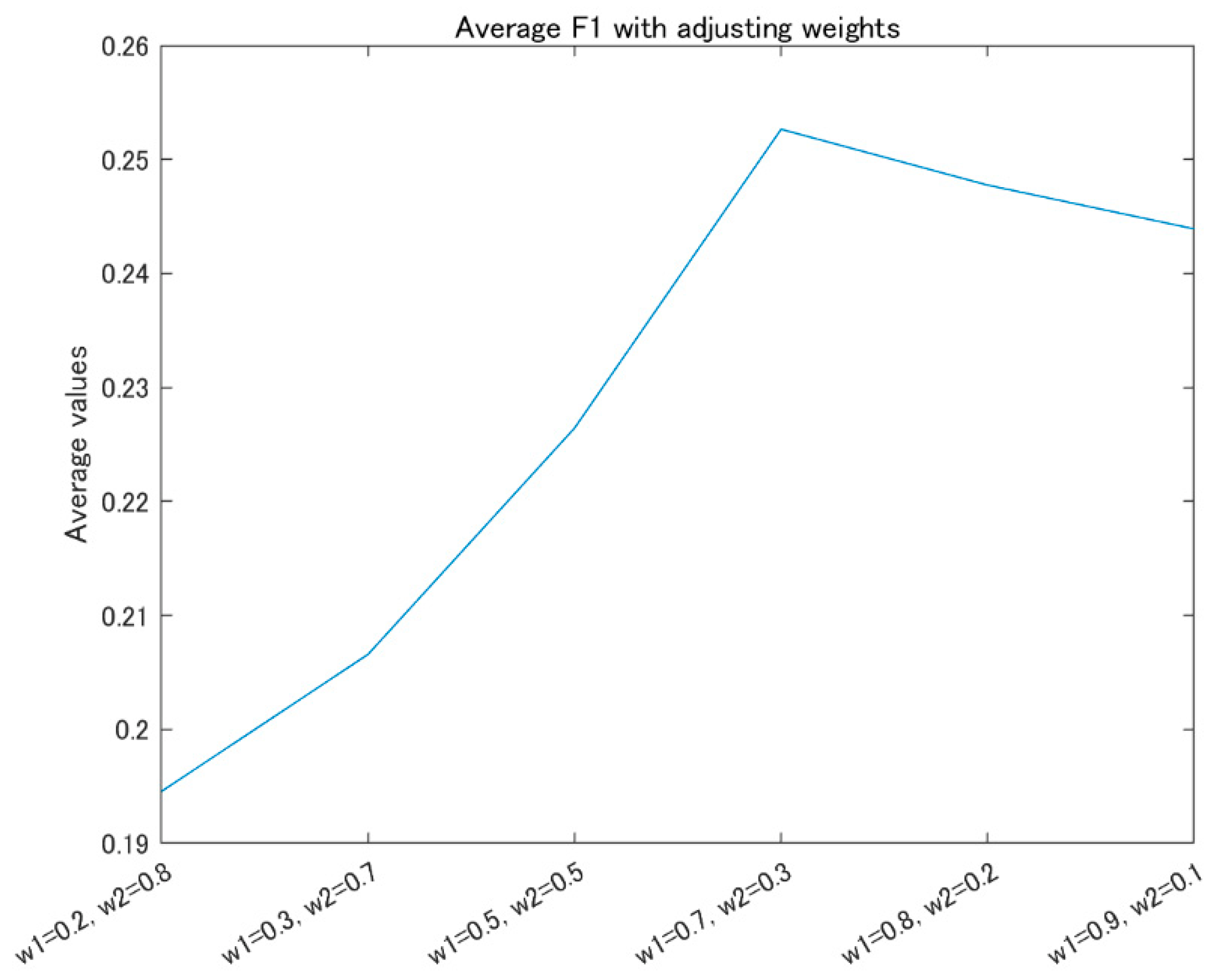
4.3. Ensemble
4.4. Experimental Results on CUHK-PQ Dataset [1]
4.5. Visualization of FFP and AIR
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolution Neural Network |
| RSRL | Repetitively Self-Revised Learning |
| IAA | Image Aesthetics Assessment |
| AS | Aesthetic Score |
| FFP | First Fixation Perspective |
| AIR | Assessment Interest Region |
| GT | Ground Truth |
| CB | Convolutional Block |
References
- Deng, Y.; Loy, C.C.; Tang, X. Image aesthetic assessment: An experimental survey. IEEE Signal Process. Mag. 2017, 34, 80–106. [Google Scholar] [CrossRef]
- Dhar, S.; Ordonez, V.; Berg, T.L. High level describable attributes for predicting aesthetics and interestingness. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Ke, Y.; Tang, X.; Jing, F. The design of high level features for photo quality assessment. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Marchesotti, L.; Perronnin, F.; Larlus, D.; Csurka, G. Assessing the aesthetic quality of photographs using generic image descriptors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Nishiyama, M.; Okabe, T.; Sato, I.; Sato, Y. Aesthetic quality classification of photographs based on color harmony. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Chen, Q.; Zhang, W.; Zhou, N.; Lei, P.; Xu, Y.; Zheng, Y.; Fan, J. Adaptive fractional dilated convolution network for image aesthetics assessment. In Proceedings of the 2020 CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hosu, V.; Goldlucke, B.; Saupe, D. Effective aesthetics prediction with multi-level spatially pooled features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, D.; Puri, R.; Kamath, N.; Bhattacharya, S. Composition-aware image aesthetics assessment. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020. [Google Scholar]
- Pan, B.; Wang, S.; Jiang, Q. Image aesthetic assessment assisted by attributes through adversarial learning. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Sheng, K.; Dong, W.; Chai, M.; Wang, G.; Zhou, P.; Huang, F.; Hu, B.-G.; Ji, R.; Ma, C. Revisiting image aesthetic assessment via self-supervised feature learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Sheng, K.; Dong, W.; Ma, C.; Mei, X.; Huang, F.; Hu, B.G. Attention-based multi-patch aggregation for image aesthetic assessment. In Proceedings of the ACM Multimedia Conference, Seoul, Republic of Korea, 22–26 October 2018; pp. 879–886. [Google Scholar]
- Zhang, X.; Gao, X.; Lu, W.; He, L. A gated peripheral-foveal convolution neural network for unified image aesthetic prediction. IEEE Trans. Multimed. 2019, 21, 2815–2826. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, X.; Lu, W.; He, L.; Li, J. Beyond vision: A multimodal recurrent attention convolutional neural network for unified image aesthetic prediction tasks. IEEE Trans. Multimed. 2020, 23, 611–623. [Google Scholar] [CrossRef]
- Lee, J.-T.; Kim, C.-S. Image Aesthetic Assessment Based on Pairwise Comparison–A Unified Approach to Score Regression, Binary Classification, and Personalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1191–1200. [Google Scholar]
- Hou, J.; Yang, S.; Lin, W. Object-level attention for aesthetic rating distribution prediction. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Hou, J.; Yang, S.; Lin, W.; Zhao, B.; Fang, Y. Learning Image Aesthetic Assessment from Object-level Visual Components. arXiv 2021, arXiv:2104.01548. [Google Scholar] [CrossRef]
- She, D.; Lai, Y.-K.; Yi, G.; Xu, K. Hierarchical Layout-Aware Graph Convolutional Network for Unified Aesthetics Assessment. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 8471–8480. [Google Scholar]
- Murray, N.; Marchesotti, L.; Perronnin, F. AVA: A large-scale database for aesthetic visual analysis. In Proceedings of the 2012 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2408–2451. [Google Scholar] [CrossRef]
- Dai, Y. Sample-specific repetitive learning for photo aesthetic auto-assessment and highlight elements analysis. Multimed. Tools Appl. 2020, 80, 1387–1402. [Google Scholar] [CrossRef]
- Dai, Y. Exploring Metrics to Establish an Optimal Model for Image Aesthetic Assessment and Analysis. J. Imaging 2022, 8, 85. [Google Scholar] [CrossRef]
- Ren, J.; Shen, X.; Lin, Z.; Mech, R.; Foran, D.J. Personalized image aesthetics. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Jang, H.; Lee, J.-S. Analysis of deep features for image aesthetic assessment. IEEE Access 2021, 9, 29850–29861. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zhang, G.; Zhang, X. A novel feature fusion method for computing image aesthetic quality. IEEE Access 2020, 8, 63043–63054. [Google Scholar] [CrossRef]
- Varga, D. No-Reference Image Quality Assessment with Convolutional Neural Networks and Decision Fusion. Appl. Sci. 2022, 12, 101. [Google Scholar] [CrossRef]
- Takimoto, H.; Omori, F.; Kanagawa, A. Image Aesthetics Assessment Based on Multi stream CNN Architecture and Saliency Features. Appl. Artif. Intell. 2021, 35, 25–40. [Google Scholar] [CrossRef]
- Varga, D. Full-Reference Image Quality Assessment Based on an Optimal Linear Combination of Quality Measures Selected by Simulated Annealing. J. Imaging. 2022, 8, 224. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef] [PubMed]
- Ponomarenko, N.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Jin, L.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Color image database TID2013: Peculiarities and preliminary results. In Proceedings of the European Workshop on Visual Information Processing (EUVIP), Paris, France, 10–12 June 2013; pp. 106–111. [Google Scholar]
- Ponomarenko, N.; Lukin, V.; Zelensky, A.; Egiazarian, K.; Carli, M.; Battisti, F. TID2008-a database for evaluation of full-reference visual quality assessment metrics. Adv. Mod. Radioelectron. 2009, 10, 30–45. [Google Scholar]
- Larson, E.C.; Chandler, D.M. Most apparent distortion: Full-reference image quality assessment and the role of strategy. J. Electron. Imaging 2010, 19, 011006. [Google Scholar]
- Jin, X.-L.; Chen, X.; Zhou, Z. The impact of cover image authenticity and aesthetics on users’ product-knowing and content-reading willingness in social shopping community. Int. J. Inf. Manag. 2021, 62, 102428. [Google Scholar] [CrossRef]
- Sheng, K.; Dong, W.; Huang, H.; Chai, M.; Zhang, Y.; Ma, C.; Hu, B.-G. Learning to assess visual aesthetics of food images. Comput. Vis. Media 2021, 7, 139–152. [Google Scholar] [CrossRef]
- Khajehabdollahi, S.; Martius, G.; Levina, A. Assessing aesthetics of generated abstract images using correlation structure. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 306–313. [Google Scholar]
- Maqbool, H.; Masek, M. Image Aesthetics Classification using Deep Features and Image Category. In Proceedings of the 2021 36th International Conference on Image and Vision Computing New Zealand (IVCNZ), Tauranga, New Zealand, 9–10 December 2021. [Google Scholar] [CrossRef]
- Ganaie, M.; Hu, M.; Malik, A.; Tanveer, M.; Suganthan, P. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Thurnhofer-Hemsi, K.; Lopez-Rubio, E.; Dominguez, E.; Elizondo, D.A. Skin Lesion Classification by Ensembles of Deep Convolutional Networks and Regularly Spaced Shifting. IEEE Access 2021, 9, 112193–112205. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operator | Resolution | Channels |
|---|---|---|---|
| 1 | CB1, conv1 × 1 | 227 × 227 | 128 |
| 2 | CB2, conv1 × 1 | 28 × 28 | 96 |
| 3 | CB3, conv1 × 1 | 7 × 7 | 96 |
| 4 | fc_1 | 7 × 7 | 36 |
| 5 | fc_2 | 1 × 36 | 8 |
| Stage | Operator | Resolution | Channels |
|---|---|---|---|
| 1 | CB1, conv1 × 1 | 227 × 227 | 128 |
| 2 | CB2, conv1 × 1 | 28 × 28 | 96 |
| 3 | CB3, conv3 × 3 | 7 × 7 | 96 |
| 4 | fc_1 | 7 × 7 | 36 |
| 5 | fc_2 | 1 × 36 | 8 |
| Stage | Operator | Resolution | Channels |
|---|---|---|---|
| 1 | CB1, conv1 × 1 | 192 × 192 | 128 |
| 2 | CB2, conv1 × 1 | 24 × 24 | 96 |
| 3 | CB3, conv1 × 1 | 6 × 6 | 96 |
| 4 | fc_1 | 6 × 6 | 36 |
| 5 | fc_2 | 1 × 36 | 8 |
| Stage | Operator | Resolution | Channels |
|---|---|---|---|
| 1 | CB1, conv1 × 1 | 192 × 192 | 128 |
| 2 | CB2, conv1 × 1 | 24 × 24 | 96 |
| 3 | CB3, conv3 × 3 | 6 × 6 | 96 |
| 4 | fc_1 | 6 × 6 | 36 |
| 5 | fc_2 | 1 × 36 | 8 |
| Model | Accuracy | avePrecision | aveRecall | aveF1 |
|---|---|---|---|---|
| Ares | 0.650 | 0.628 | 0.636 | 0.630 |
| Aeff | 0.633 | 0.641 | 0.654 | 0.628 |
| Aalex | 0.619 | 0.578 | 0.576 | 0.576 |
| B1 | 0.615 | 0.576 | 0.575 | 0.575 |
| B2 | 0.577 | 0.546 | 0.548 | 0.546 |
| B3 | 0.617 | 0.576 | 0.573 | 0.573 |
| B4 | 0.618 | 0.576 | 0.572 | 0.573 |
| 0.7 Ares + 0.3 B1 | 0.673 | 0.634 | 0.617 | 0.621 |
| 0.7 Ares + 0.3 B3 | 0.674 | 0.636 | 0.617 | 0.621 |
| 0.7 Ares + 0.3 B4 | 0.674 | 0.636 | 0.617 | 0.621 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Y. Building CNN-Based Models for Image Aesthetic Score Prediction Using an Ensemble. J. Imaging 2023, 9, 30. https://doi.org/10.3390/jimaging9020030
Dai Y. Building CNN-Based Models for Image Aesthetic Score Prediction Using an Ensemble. Journal of Imaging. 2023; 9(2):30. https://doi.org/10.3390/jimaging9020030
Chicago/Turabian StyleDai, Ying. 2023. "Building CNN-Based Models for Image Aesthetic Score Prediction Using an Ensemble" Journal of Imaging 9, no. 2: 30. https://doi.org/10.3390/jimaging9020030
APA StyleDai, Y. (2023). Building CNN-Based Models for Image Aesthetic Score Prediction Using an Ensemble. Journal of Imaging, 9(2), 30. https://doi.org/10.3390/jimaging9020030