Author Contributions
Conceptualization, R.B.; Data curation, R.B.; Formal analysis, R.B.; Funding acquisition, M.I., S.S. and K.K.; Investigation, R.B.; Methodology, R.B.; Project administration, M.I., S.S. and K.K.; Resources, M.I.; Software, R.B.; Supervision, M.I., S.S. and K.K.; Validation, R.B.; Visualization, R.B.; Writing—original draft, R.B.; Writing—review & editing, M.I., S.S. and K.K. All authors have read and agreed to the published version of the manuscript.
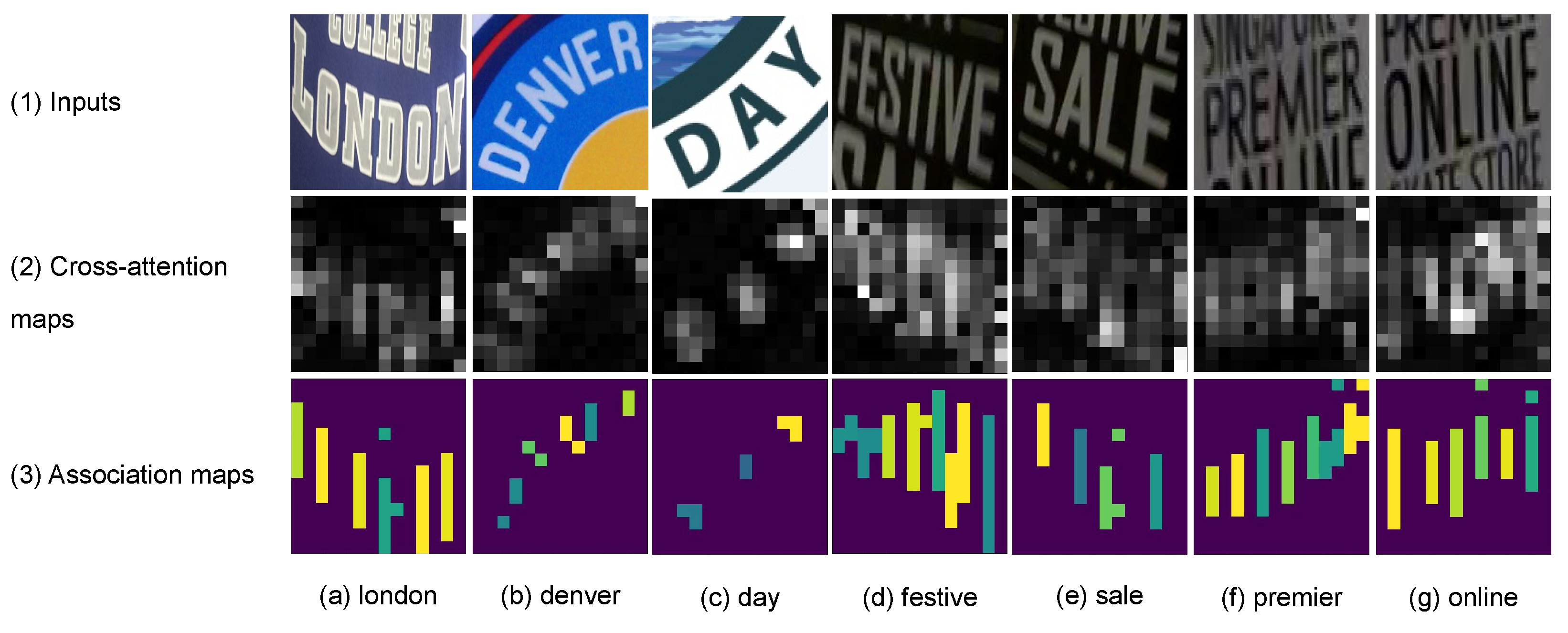
Figure 1.
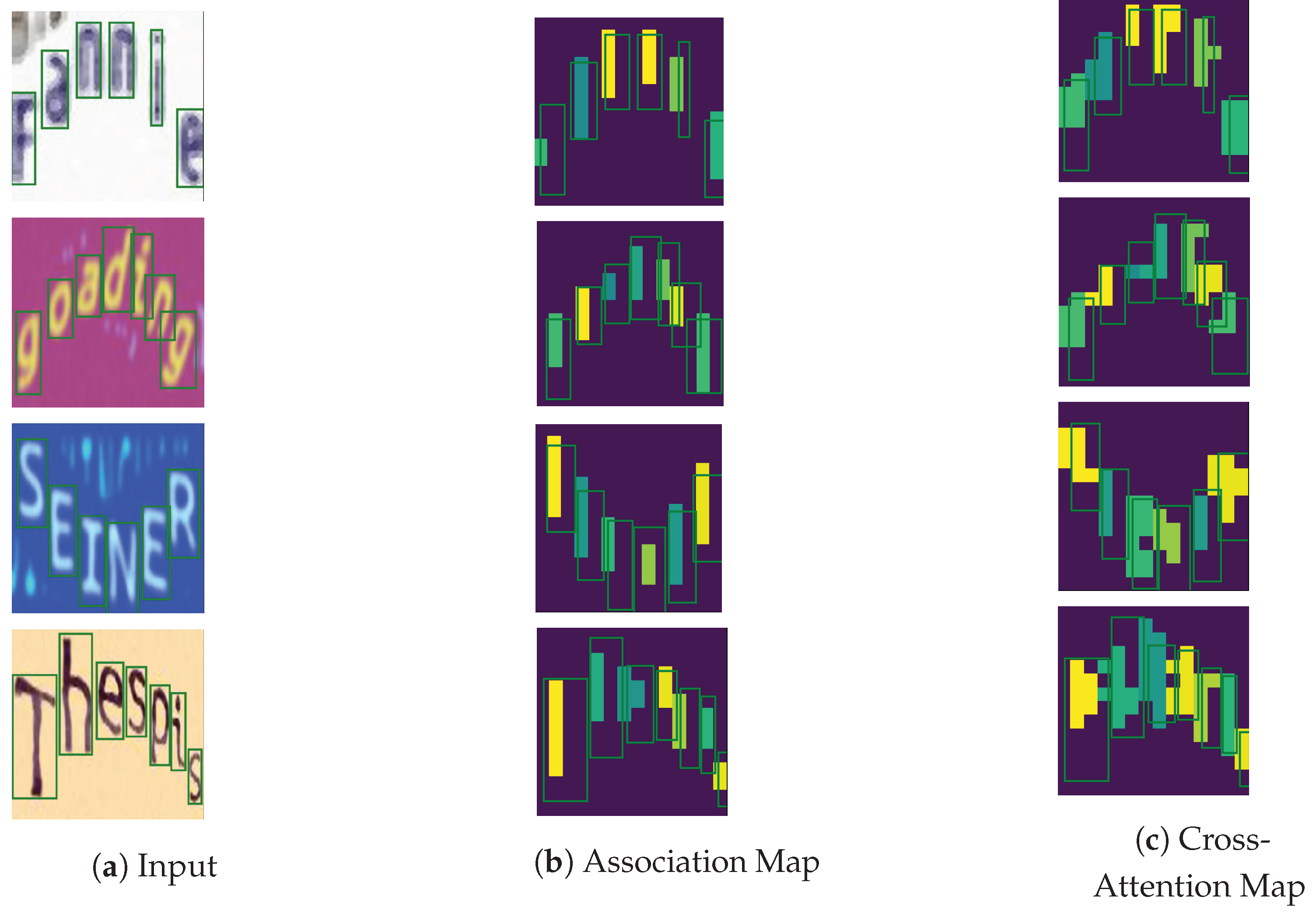
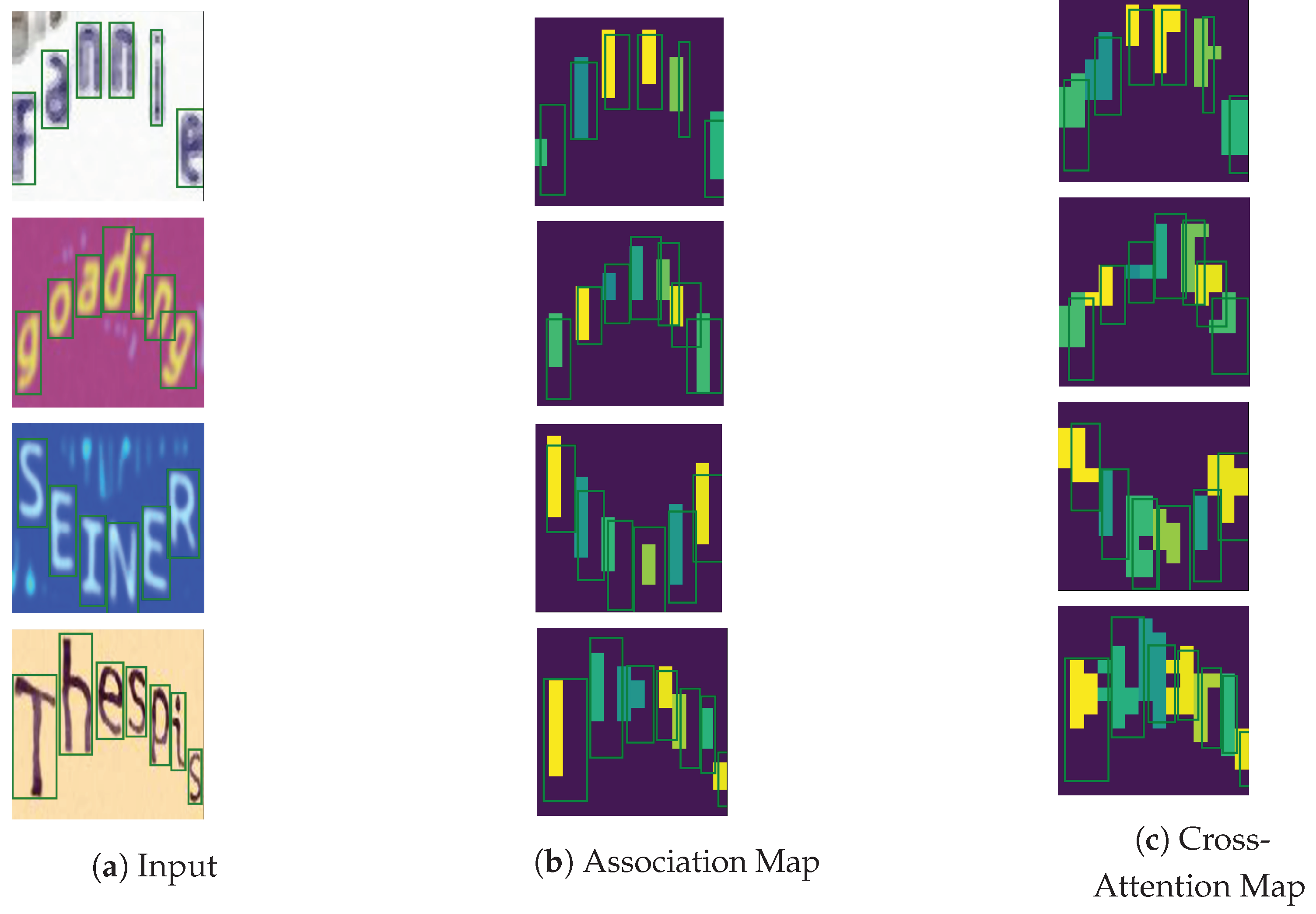
The cross-attention vs. the association maps. The first row consists of text images. The second and third rows consist of the cross-attention and association maps, respectively, that associate each predicted character with image regions. The last row consists of text transcriptions. The cross-attention map is obtained from a Transformer decoder, while the association map is obtained from a ViT-CTC model. Best viewed in color.
Figure 1.
The cross-attention vs. the association maps. The first row consists of text images. The second and third rows consist of the cross-attention and association maps, respectively, that associate each predicted character with image regions. The last row consists of text transcriptions. The cross-attention map is obtained from a Transformer decoder, while the association map is obtained from a ViT-CTC model. Best viewed in color.
Figure 2.
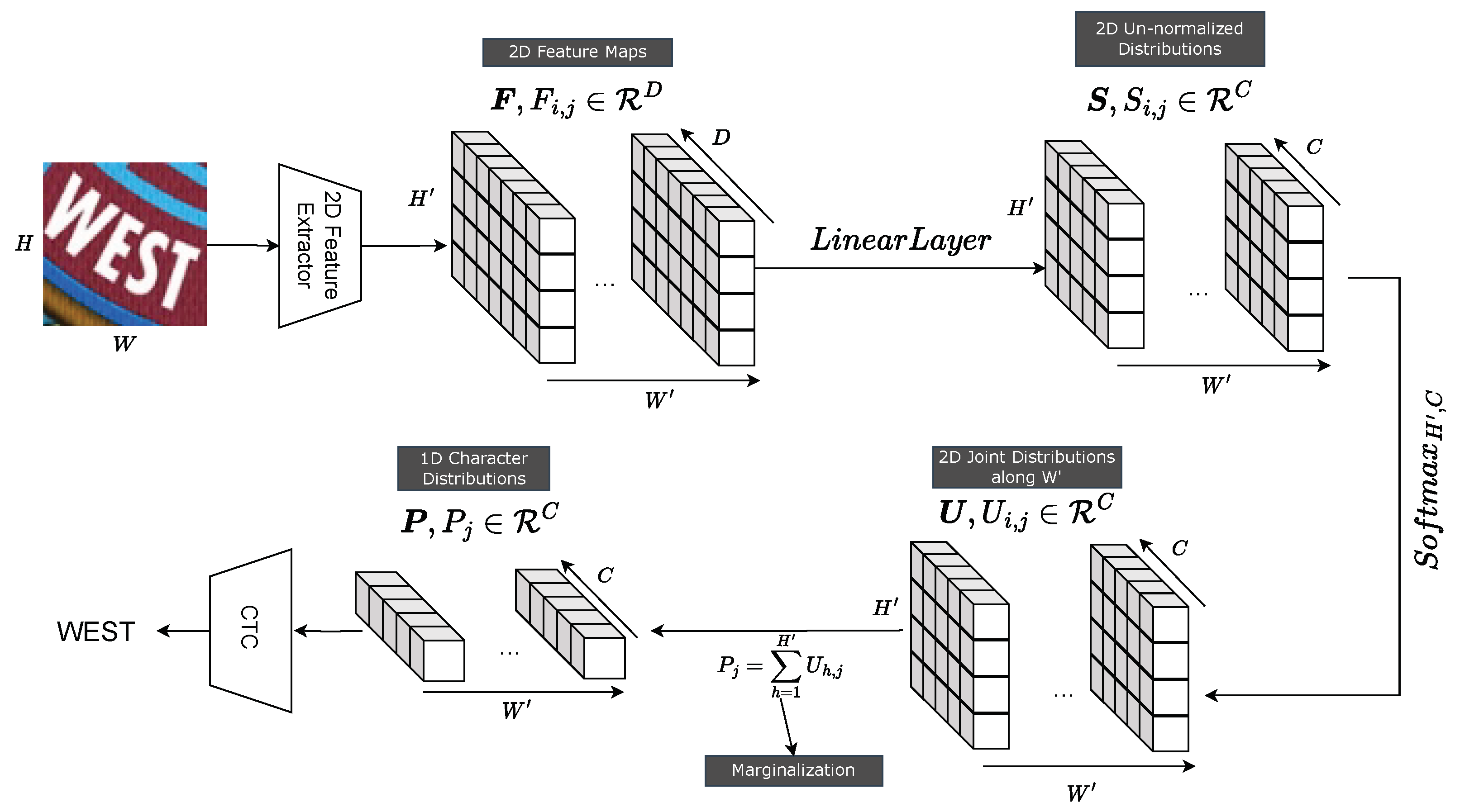
The proposed marginalization-based method: A 2D feature sequence, , is produced by a 2D feature extractor such as a ViT backbone. is fed to a linear layer to produce from which a softmax normalization is performed over both and C dimensions. Next, the normalized is marginalized over the dimension to produce that is fed to a CTC decoder. D and C are the feature and class dimensions, respectively.
Figure 2.
The proposed marginalization-based method: A 2D feature sequence, , is produced by a 2D feature extractor such as a ViT backbone. is fed to a linear layer to produce from which a softmax normalization is performed over both and C dimensions. Next, the normalized is marginalized over the dimension to produce that is fed to a CTC decoder. D and C are the feature and class dimensions, respectively.
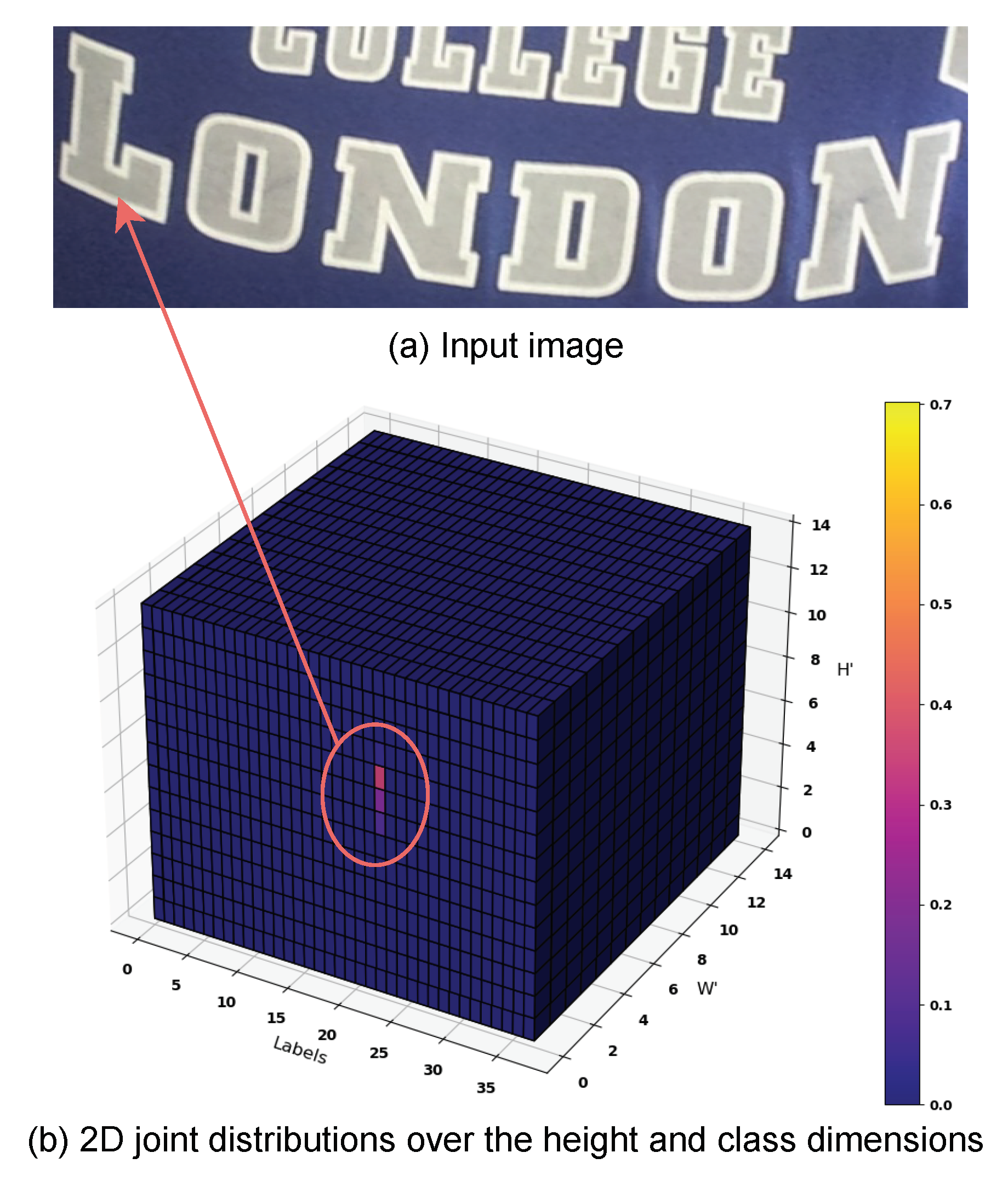
Figure 3.
3D graphical illustration of for an input image. (a) Input image. (b) The computed . At , the bright cells, responding to the character L, have a high probability. Best viewed in color.
Figure 3.
3D graphical illustration of for an input image. (a) Input image. (b) The computed . At , the bright cells, responding to the character L, have a high probability. Best viewed in color.
Figure 4.
The estimated character locations, , from the association map. (a) Input image with ground-truth character bounding boxes, . (b) Estimated character regions. Best viewed in color.
Figure 4.
The estimated character locations, , from the association map. (a) Input image with ground-truth character bounding boxes, . (b) Estimated character regions. Best viewed in color.
Figure 5.
The estimated character locations,
, for the two predicted characters of the input image in
Figure 4a, from the cross-attention maps. (
a) Cross-attention maps. (
b) Estimated character regions. Best viewed in color.
Figure 5.
The estimated character locations,
, for the two predicted characters of the input image in
Figure 4a, from the cross-attention maps. (
a) Cross-attention maps. (
b) Estimated character regions. Best viewed in color.
Figure 6.
Sample training and fine-tuning images. (a) Sample images from the training datasets. (b) Sample images from the fine-tuning datasets.
Figure 6.
Sample training and fine-tuning images. (a) Sample images from the training datasets. (b) Sample images from the fine-tuning datasets.
Figure 7.
Sample text images with character-level annotations.
Figure 7.
Sample text images with character-level annotations.
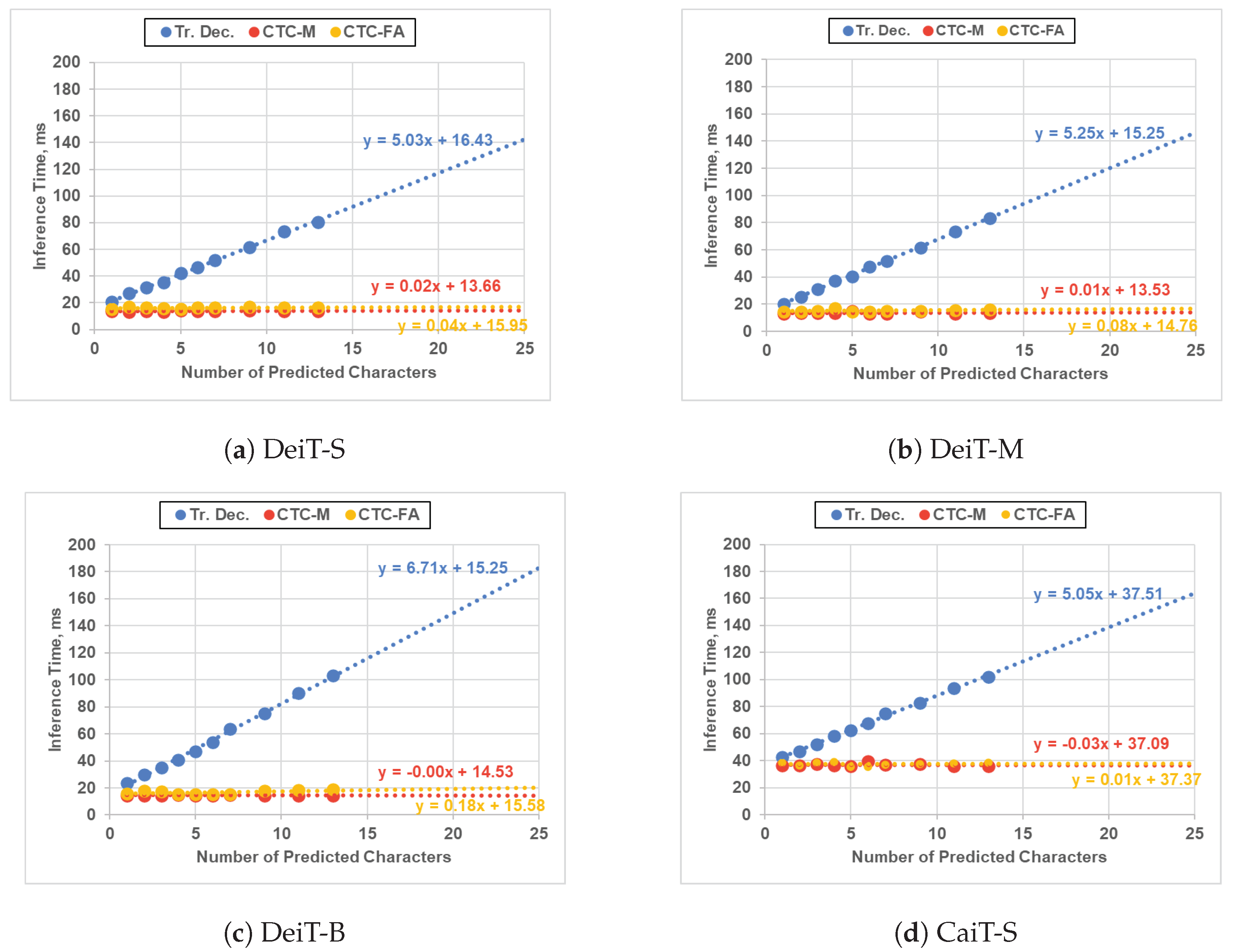
Figure 8.
Inference time comparison between our ViT-CTC models and the Transformer-decoder-based models on an RTX 2060 GPU. Trendlines are projected to the maximum number of characters (i.e., 25) [
1]. Tr. Dec.: Transformer decoder. CTC-M: CTC decoder with the proposed method. CTC-FA: CTC decoder with feature averaging. Best viewed in color.
Figure 8.
Inference time comparison between our ViT-CTC models and the Transformer-decoder-based models on an RTX 2060 GPU. Trendlines are projected to the maximum number of characters (i.e., 25) [
1]. Tr. Dec.: Transformer decoder. CTC-M: CTC decoder with the proposed method. CTC-FA: CTC decoder with feature averaging. Best viewed in color.
Figure 9.
Maximum inference time vs. recognition accuracy comparisons between the ViT-CTC models using the proposed method and the Transformer-decoder-based models on an RTX 2060 GPU. Tr. Dec.: Transformer decoder. Best viewed in color.
Figure 9.
Maximum inference time vs. recognition accuracy comparisons between the ViT-CTC models using the proposed method and the Transformer-decoder-based models on an RTX 2060 GPU. Tr. Dec.: Transformer decoder. Best viewed in color.
Figure 10.
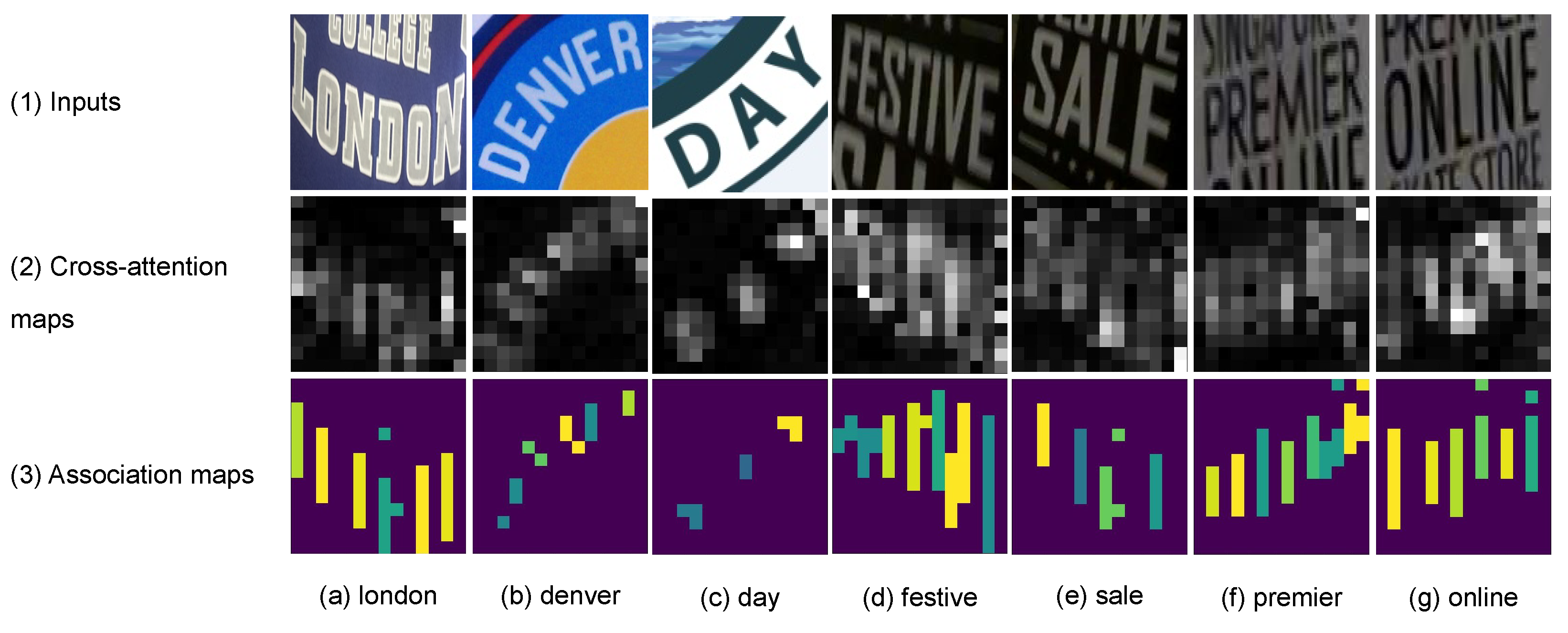
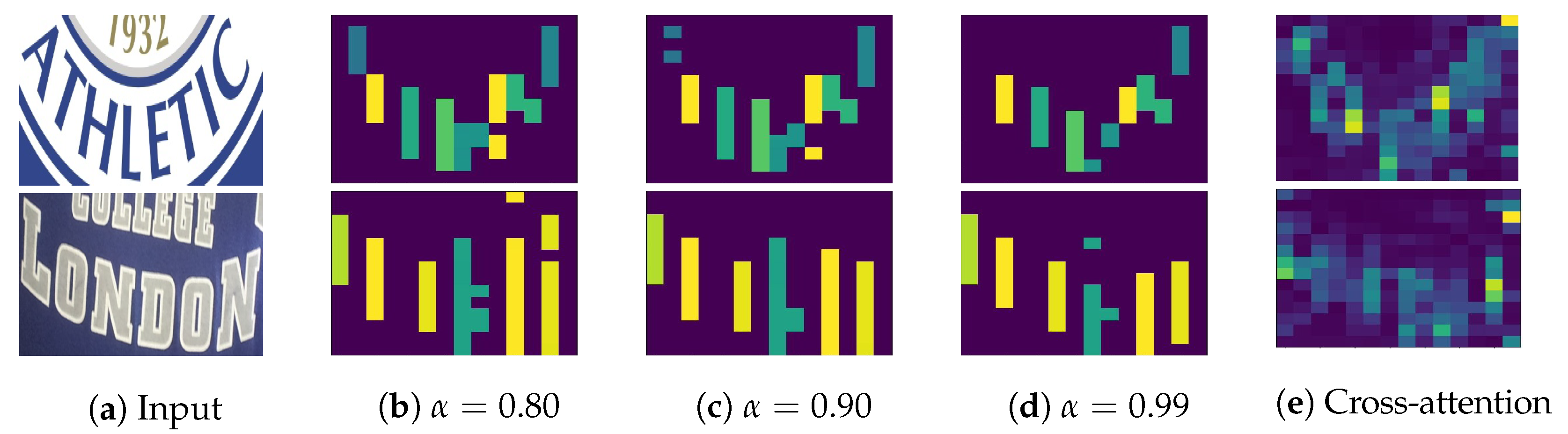
Association maps for different values of . The color bars show image regions, corresponding to predicted characters. Best viewed in color.
Figure 10.
Association maps for different values of . The color bars show image regions, corresponding to predicted characters. Best viewed in color.
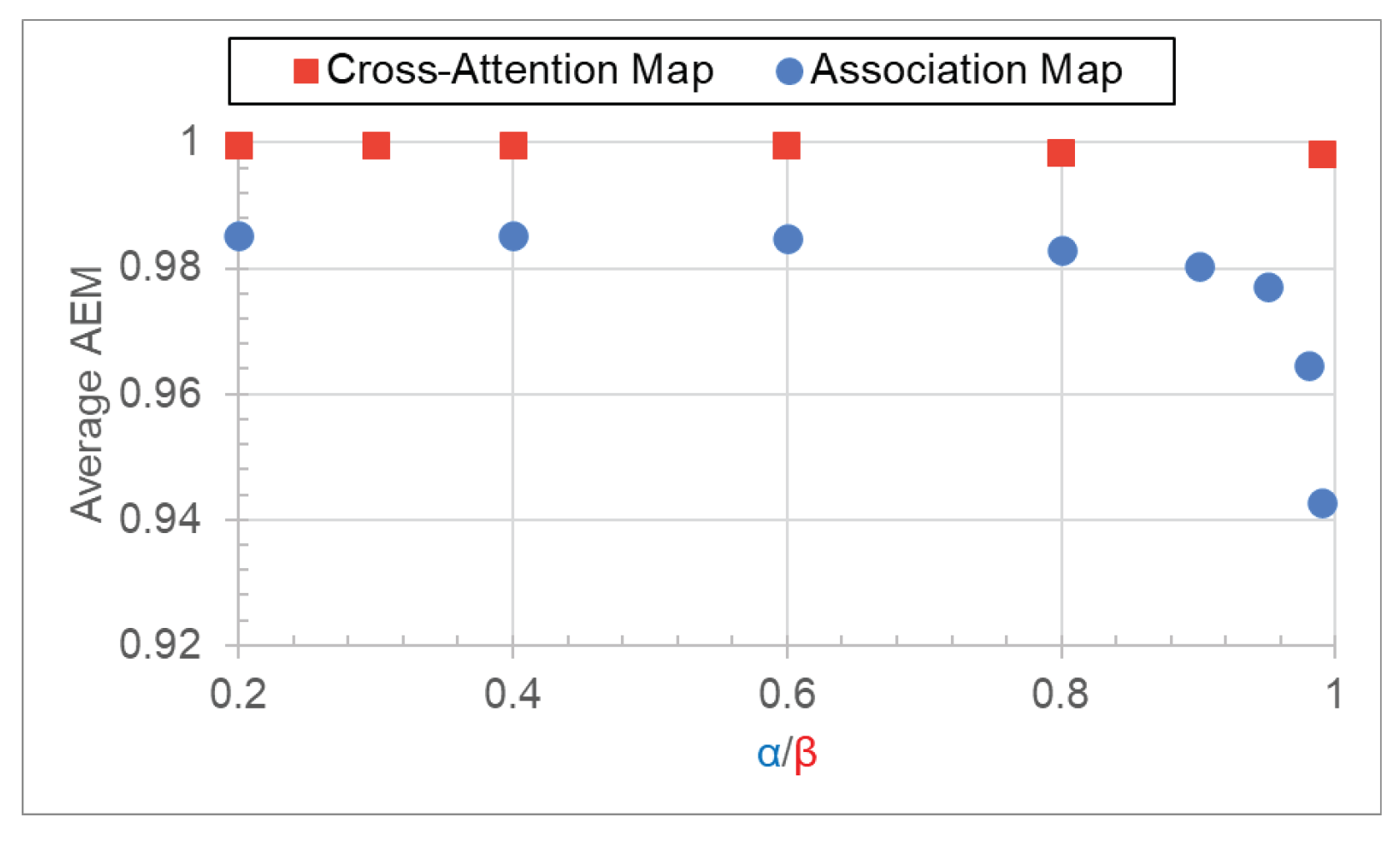
Figure 11.
The average AEMs of the association and cross-attention maps as a function of and , respectively. Best viewed in color.
Figure 11.
The average AEMs of the association and cross-attention maps as a function of and , respectively. Best viewed in color.
Figure 12.
Illustrations of the estimated character locations from the association () and cross-attention () maps vs. the ground-truth character locations. Best viewed in color.
Figure 12.
Illustrations of the estimated character locations from the association () and cross-attention () maps vs. the ground-truth character locations. Best viewed in color.
Table 1.
Specifications of the pretrained ViT backbones.
Table 1.
Specifications of the pretrained ViT backbones.
| ViT Model | Params | GFLOPs | Size | Emb. Dim, D | Acc@1 (INet-1k) |
|---|
| DeiT-Small [30] | 22.2 M | 4.6 | 224 × 224 | 384 | 81.4 |
| DeiT-Medium [30] | 38.8 M | 8.0 | 224 × 224 | 512 | 83.0 |
| DeiT-Base [30] | 86.6 M | 17.5 | 224 × 224 | 768 | 83.8 |
| CaiT-Small [29] | 47.0 M | 9.4 | 224 × 224 | 384 | 83.5 |
Table 2.
Specifications of the Transformer decoder.
Table 2.
Specifications of the Transformer decoder.
| Parameters | Value |
|---|
| Hidden/Embedding Dimension | Encoder’s Emb. Dim. |
| Decoder Stacks | 3 |
| Attention Heads | 8 |
| Dropout | 0.1 |
| Feed-forward Dimension | Encoder’s Emb. Dim. |
Table 3.
Word recognition accuracy (%) of the ablation results of the encoder complexities and architectures with the proposed method (M). FT: fine-tuning on real data. Bold: highest.
Table 3.
Word recognition accuracy (%) of the ablation results of the encoder complexities and architectures with the proposed method (M). FT: fine-tuning on real data. Bold: highest.
| (a) Methods Trained on Synthetic Training Data (S). |
|---|
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S + M (Ours) | 91.4 | 85.5 | 91.3 | 75.3 | 76.7 | 82.2 | 85.3 |
| DeiT-M + M (Ours) | 92.5 | 87.8 | 92.2 | 76.6 | 79.5 | 81.9 | 86.6 |
| DeiT-B + M (Ours) | 93.0 | 86.9 | 92.2 | 78.6 | 79.1 | 84.0 | 87.3 |
| CaiT-S + M (Ours) | 93.5 | 86.9 | 91.9 | 77.6 | 77.8 | 85.4 | 87.2 |
| (b) Methods Trained on Real Labeled Training Data (R). |
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S + M + FT (Ours) | 94.6 | 89.2 | 95.4 | 81.5 | 83.1 | 91.3 | 89.9 |
| DeiT-M + M + FT (Ours) | 95.0 | 92.3 | 95.2 | 83.5 | 84.0 | 90.9 | 90.9 |
| DeiT-B + M + FT (Ours) | 95.9 | 92.6 | 96.1 | 84.4 | 84.3 | 92.7 | 91.7 |
| CaiT-S + M + FT (Ours) | 96.1 | 90.6 | 95.4 | 84.9 | 85.4 | 92.7 | 91.7 |
Table 4.
Word recognition accuracy (%) comparison between the proposed method (M) and the baseline feature averaging (FA). FT: fine-tuning on real data. Bold: highest.
Table 4.
Word recognition accuracy (%) comparison between the proposed method (M) and the baseline feature averaging (FA). FT: fine-tuning on real data. Bold: highest.
| (a) Methods Trained on Synthetic Training Data (S). |
|---|
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S + FA | 91.4 | 86.4 | 89.6 | 74.2 | 75.8 | 79.1 | 84.7 |
| DeiT-M + FA | 92.0 | 87.3 | 91.4 | 77.4 | 78.9 | 82.2 | 86.4 |
| DeiT-B + FA | 93.1 | 88.7 | 92.9 | 77.3 | 79.7 | 85.7 | 87.4 |
| CaiT-S + FA | 94.3 | 87.2 | 92.5 | 79.5 | 79.4 | 87.1 | 88.2 |
| DeiT-S + M (Ours) | 91.4 | 85.5 | 91.3 | 75.3 | 76.7 | 82.2 | 85.3 |
| DeiT-M + M (Ours) | 92.5 | 87.8 | 92.2 | 76.6 | 79.5 | 81.9 | 86.6 |
| DeiT-B + M (Ours) | 93.0 | 86.9 | 92.2 | 78.6 | 79.1 | 84.0 | 87.3 |
| CaiT-S + M (Ours) | 93.5 | 86.9 | 91.9 | 77.6 | 77.8 | 85.4 | 87.2 |
| (b) Methods Trained on Real Labeled Training Data (R). |
| Method | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S + FA + FT | 95.0 | 88.4 | 94.2 | 81.6 | 82.0 | 88.5 | 89.6 |
| DeiT-M + FA + FT | 95.5 | 91.2 | 95.4 | 83.4 | 83.4 | 92.0 | 91.0 |
| DeiT-B + FA + FT | 95.9 | 92.1 | 95.9 | 83.9 | 84.2 | 92.7 | 91.5 |
| CaiT-S + FA + FT | 96.0 | 92.3 | 95.8 | 84.5 | 84.7 | 93.7 | 91.7 |
| DeiT-S + M + FT (Ours) | 94.6 | 89.2 | 95.4 | 81.5 | 83.1 | 91.3 | 89.9 |
| DeiT-M + M + FT (Ours) | 95.0 | 92.3 | 95.2 | 83.5 | 84.0 | 90.9 | 90.9 |
| DeiT-B + M + FT (Ours) | 95.9 | 92.6 | 96.1 | 84.4 | 84.3 | 92.7 | 91.7 |
| CaiT-S + M + FT (Ours) | 96.1 | 90.6 | 95.4 | 84.9 | 85.4 | 92.7 | 91.7 |
Table 5.
Word recognition accuracy (%) comparison between the proposed method (M) and the SOTA CTC-based methods. FT: fine-tuning on real data. Size: parameters in millions. M: the proposed method. Bold: highest.
Table 5.
Word recognition accuracy (%) comparison between the proposed method (M) and the SOTA CTC-based methods. FT: fine-tuning on real data. Size: parameters in millions. M: the proposed method. Bold: highest.
| (a) Methods Trained on Synthetic Training Data (S). |
|---|
| Method | Size | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| CRNN [15] | 8.3 | 82.9 | 81.6 | 89.2 | 69.4 | 70.0 | 65.5 | 78.5 |
| STAR-Net [18] | 48.7 | 87.0 | 86.9 | 91.5 | 76.1 | 77.5 | 71.7 | 83.5 |
| GRCNN [17] | 4.6 | 84.2 | 83.7 | 88.8 | 71.4 | 73.6 | 68.1 | 80.1 |
| Rosetta [16] | 44.3 | 84.3 | 84.7 | 89.0 | 71.2 | 73.8 | 69.2 | 80.3 |
| TRBC [14] | 48.7 | 87.0 | 86.9 | 91.5 | 76.1 | 77.5 | 71.7 | 83.5 |
| ViTSTR-S [1] | 21.5 | 85.6 | 85.3 | 90.6 | 75.3 | 78.1 | 71.3 | 82.5 |
| ViTSTR-B [1] | 85.8 | 86.9 | 87.2 | 91.3 | 76.8 | 80.0 | 74.7 | 84.0 |
| DeiT-S + M (Ours) | 21.6 | 91.4 | 85.5 | 91.3 | 75.3 | 76.7 | 82.2 | 85.3 |
| DeiT-M + M (Ours) | 38.9 | 92.5 | 87.8 | 92.2 | 76.6 | 79.5 | 81.9 | 86.6 |
| DeiT-B + M (Ours) | 85.7 | 93.0 | 86.9 | 92.2 | 78.6 | 79.1 | 84.0 | 87.3 |
| CaiT-S + M (Ours) | 46.5 | 93.5 | 86.9 | 91.9 | 77.6 | 77.8 | 85.4 | 87.2 |
| (b) Methods Trained on Real Labeled Training Data (R). |
| Method | Size | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| GTC [4] | - | 96.0 | 91.8 | 93.2 | 79.5 | 85.6 | 91.3 | 90.1 |
| DiG-ViT-T (CTC) [5] | 20.0 | 93.3 | 89.7 | 92.5 | 79.1 | 78.8 | 83.0 | 87.7 |
| DiG-ViT-S (CTC) [5] | 36.0 | 95.5 | 91.8 | 95.0 | 84.1 | 83.9 | 86.5 | 91.0 |
| DiG-ViT-B (CTC) [5] | 52.0 | 95.9 | 92.6 | 95.3 | 84.2 | 85.0 | 89.2 | 91.5 |
| DeiT-S + M + FT (Ours) | 21.6 | 94.6 | 89.2 | 95.4 | 81.5 | 83.1 | 91.3 | 89.9 |
| DeiT-M + M + FT (Ours) | 38.9 | 95.0 | 92.3 | 95.2 | 83.5 | 84.0 | 90.9 | 90.9 |
| DeiT-B + M + FT (Ours) | 85.7 | 95.9 | 92.6 | 96.1 | 84.4 | 84.3 | 92.7 | 91.7 |
| CaiT-S + M + FT (Ours) | 46.5 | 96.1 | 90.6 | 95.4 | 84.9 | 85.4 | 92.7 | 91.7 |
Table 6.
Word recognition accuracy (%) comparison with the baseline Transformer-decoder-based models. FT: fine-tuning on real data. Size: parameters in millions. Tr. Dec.: Transformer decoder. M: the proposed method. Bold: highest.
Table 6.
Word recognition accuracy (%) comparison with the baseline Transformer-decoder-based models. FT: fine-tuning on real data. Size: parameters in millions. Tr. Dec.: Transformer decoder. M: the proposed method. Bold: highest.
| (a) Methods Trained on Synthetic Training Data (S). |
|---|
| Method | Size | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S + Tr. Dec. | 26.1 | 93.7 | 88.9 | 92.4 | 80.0 | 80.6 | 86.8 | 88.3 |
| DeiT-M + Tr. Dec. | 46.2 | 94.1 | 89.6 | 92.6 | 81.5 | 82.8 | 83.6 | 89.0 |
| DeiT-B + Tr. Dec. | 103.4 | 94.8 | 90.3 | 92.9 | 81.0 | 85.1 | 87.5 | 89.6 |
| CaiT-S + Tr. Dec. | 50.9 | 94.9 | 90.3 | 94.2 | 81.3 | 83.4 | 89.9 | 89.9 |
| DeiT-S + M (Ours) | 21.6 | 91.4 | 85.5 | 91.3 | 75.3 | 76.7 | 82.2 | 85.3 |
| DeiT-M + M (Ours) | 38.9 | 92.5 | 87.8 | 92.2 | 76.6 | 79.5 | 81.9 | 86.6 |
| DeiT-B + M (Ours) | 85.7 | 93.0 | 86.9 | 92.2 | 78.6 | 79.1 | 84.0 | 87.3 |
| CaiT-S + M (Ours) | 46.5 | 93.5 | 86.9 | 91.9 | 77.6 | 77.8 | 85.4 | 87.2 |
| (b) Methods Trained on Real Labeled Training Data (R). |
| Method | Size | IIIT | SVT | IC13 | IC15 | SVTP | CUTE | Total |
| DeiT-S + Tr. Dec. + FT | 26.1 | 96.8 | 93.0 | 96.7 | 86.3 | 87.8 | 94.8 | 93.0 |
| DeiT-M + Tr. Dec. + FT | 46.2 | 97.0 | 94.0 | 97.1 | 86.3 | 89.3 | 95.1 | 93.4 |
| DeiT-B + Tr. Dec. + FT | 103.4 | 98.0 | 94.6 | 97.5 | 86.9 | 90.5 | 95.1 | 94.2 |
| CaiT-S + Tr. Dec. + FT | 50.9 | 97.4 | 94.9 | 97.1 | 86.5 | 89.5 | 95.8 | 93.7 |
| DeiT-S + M + FT (Ours) | 21.6 | 94.6 | 89.2 | 95.4 | 81.5 | 83.1 | 91.3 | 89.9 |
| DeiT-M + M + FT (Ours) | 38.9 | 95.0 | 92.3 | 95.2 | 83.5 | 84.0 | 90.9 | 90.9 |
| DeiT-B + M + FT (Ours) | 85.7 | 95.9 | 92.6 | 96.1 | 84.4 | 84.3 | 92.7 | 91.7 |
| CaiT-S + M + FT (Ours) | 46.5 | 96.1 | 90.6 | 95.4 | 84.9 | 85.4 | 92.7 | 91.7 |
Table 7.
Maximum inference time comparison. Bold: highest. FA: feature averaging. M: the proposed method. Tr. Dec.: Transformer decoder.
Table 7.
Maximum inference time comparison. Bold: highest. FA: feature averaging. M: the proposed method. Tr. Dec.: Transformer decoder.
| Method | GFLOPs | Time (ms) |
|---|
| DeiT-S + Tr. Dec. | 4.9 | 142 |
| DeiT-M + Tr. Dec. | 8.5 | 146 |
| DeiT-B + Tr. Dec. | 18.7 | 183 |
| CaiT-S + Tr. Dec. | 9.6 | 164 |
| DeiT-S + FA | 4.6 | 17 |
| DeiT-M + FA | 8.0 | 17 |
| DeiT-B + FA | 17.5 | 20 |
| CaiT-S + FA | 9.4 | 38 |
| DeiT-S + M (Ours) | 4.6 | 14 |
| DeiT-M + M (Ours) | 8.0 | 14 |
| DeiT-B + M (Ours) | 17.5 | 15 |
| CaiT-S + M (Ours) | 9.4 | 36 |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}