1. Introduction
After the coronavirus disease (COVID-19) outbreak, a broad spectrum of automated algorithms have been developed to assist in the clinical analysis of the virus [
1]. Among others, we consider analyzing chest computer tomography (CT) images. Firstly, CT imaging de facto has become one of the reliable clinical pretests for COVID-19 diagnosis [
2]. Secondly, well-developed deep learning techniques for volumetric CT processing allow precise and efficient analysis of the different COVID-19 markers. The latter includes identification [
3], prognosis [
4], severity assessment [
5], and detection or segmentation of the consolidation or ground-glass opacity.
One of the easiest to interpret and clinically useful markers is segmentation [
6]. Segmentation provides us with classification, severity estimation [
7], or differentiating from other pathologies in a straightforward manner by evaluating the output mask. However, training a segmentation model takes huge efforts in terms of voxel-wise annotations. The earlier developed models have faced the lack of publicly available data annotated with segmentation masks. To achieve the high segmentation quality, more sophisticated methods have been designed, e.g., solving a multitask problem and merging datasets with different annotations [
8]. Now, a larger pool of COVID-19 segmentation datasets is available, e.g., [
9]; therefore, the current goal is to build a robust algorithm for clinical use.
In merging a larger pool of data, the problem of
domain shift arises. Domain shift is one of the most salient problems in medical computer vision [
10]. A model trained on the data from one distribution might yield poor results on the data from a different distribution. In CT imaging, one of the main sources of the domain shift is the difference in
reconstruction kernels. Here, the reconstruction kernel is a parameter of the Filtered Back Projection (FBP) reconstruction algorithm [
11]. One could perceptually compare the same image reconstructed with two different kernels in Figure 3, e.g., B1 and B2. For the kernel-caused domain shift, several works have shown the deterioration of the quality of the model in lung cancer segmentation [
12] and in emphysema segmentation [
13].
In this paper, we show that the domain shift induced by the difference in reconstruction kernels decreases the quality of the COVID-19 segmentation algorithms. To do so, we construct two domains from the publicly available data: the
source domain with the
smooth reconstruction kernels and
target domain with the
sharp reconstruction kernels. We train the segmentation model on the source domain and test it on the target domain. We then validate the most relevant domain adaptation methods with the observed decrease in test scores. In our comparison, we include an augmentation approach [
14], unsupervised adversarial learning [
15], and also our proposed method that couples with the considered domain shift problem more efficiently.
All methods except the augmentation one require additional unlabeled data from the
target domain. In this task, a large pool of unlabeled chest CT image pairs which differ only in reconstruction kernels within every pair is publicly available, e.g., [
16]. The intuition here is that the adaptation methods should outperform the augmentation one when a broader range of real-world data is available. Specifically, in such conditions, we propose enforcing the cross-domain feature maps consistency between paired images; we call our method
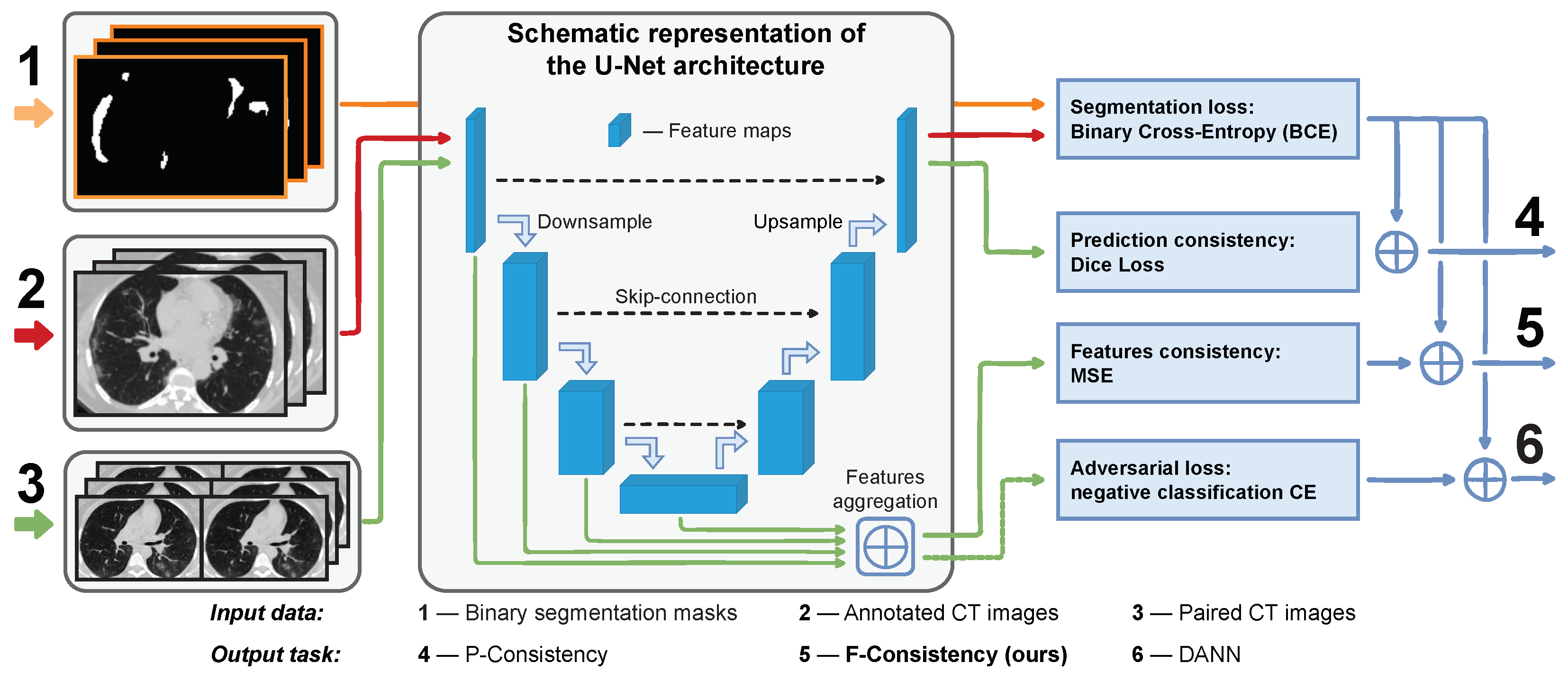
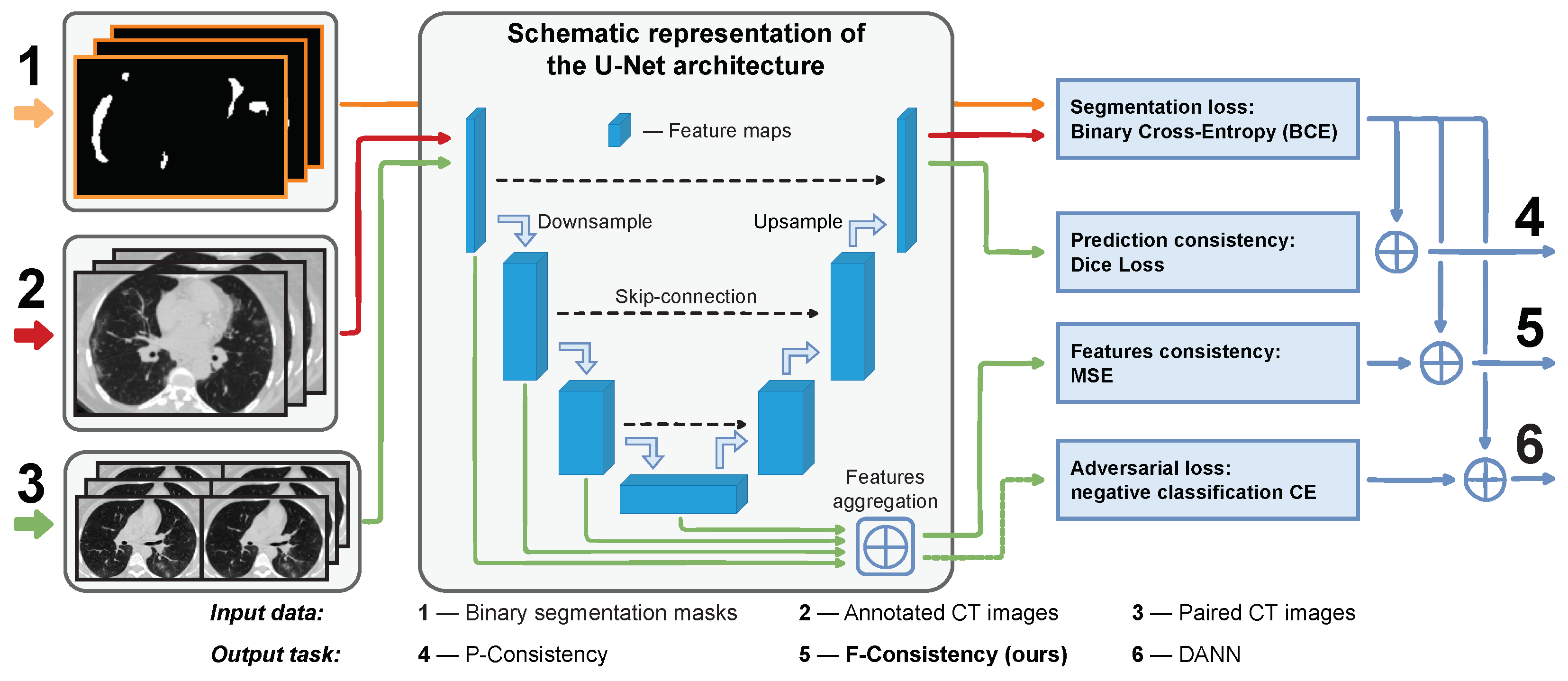
F-Consistency (
Figure 1). F-Consistency minimizes the mean squared error (MSE) between the network’s hidden representations (feature maps) of paired images. We expect that explicitly enforcing consistency on the paired images should outperform the adversarial learning that emulates similar behavior minimizing the adversarial loss.
We also note that our method could be scaled on the other tasks, such as classification, detection, or multitasking, without any restrictions. Below, we discuss the most relevant works to our method, then summarize our contributions.
1.1. Related Work
We begin with discussing the task-specific augmentation approaches since they are a straightforward solution to the domain shift problem. Contrary to the classical augmentation techniques for CT images like windowing [
17] or filtering [
18], the authors of [
14] the proposed method called FBPAug. Notably, the latter augmentation technique directly approximates our domain shift. The authors also showed that FBPAug outperforms other augmentations. Thus, we consider FBPAug as one of the solutions and compare it with the other methods.
With the unlabeled target data, we can apply unsupervised domain adaptation methods to improve the model’s performance on the target domain. The adversarial approaches are shown to outperform other methods [
15]. Considering the paired nature of our data, we divide the adversarial methods into two groups: (i) image-to-image translation and (ii) feature-level adaptation.
The first group of methods aims to translate an image from source to target domain. In [
19], the authors used CycleGAN for unpaired image-to-image translation. Further, this method was implemented both for the MRI [
20] and CT [
21] image translations. The paired image-to-image translation is closer to our setup. Such a method requires image pairs that have a different style but the same semantic content. CT images that differ only in the reconstruction kernel correspond to this setup. Here, the authors of [
13] and [
12] proposed a convolutional neural network (CNN) to translate the images reconstructed with one kernel to another kernel. However, we need to train a separate model for every pair of kernels. Our setup includes seven known kernels that already yield training of 42 translation models. The number of models grows in quadratic progression depending on the number of kernels. Therefore, the image translation methods lack the generalization ability in our setup and we do not consider them.
The feature-level adaptation methods are independent of the number of domains. Mostly, these methods are based on adversarial learning as in [
15]. The latter approach also finds several successful applications in medical imaging, e.g., [
22,
23]. As these methods are conceptually close to each other, we stick with implementing a domain adversarial neural network (DANN) from [
15].
The idea of F-Consistency is conceptually close to self-supervised learning, where the unlabeled data is used to train a model using pseudo-labels. In [
24], the authors described different pretext tasks in medical imaging. Similar to our approach, the authors [
25] enforce the model consistency for the initial and augmented images at the prediction and feature levels. Furthermore, the authors [
26] extended the self-supervised methodology to solve a domain adaptation problem. However, the goal of the self-supervised methods is to use a large collection of images without annotations to improve the model’s performance on the source domain. Contrary to self-supervised learning, our goal is to achieve the highest possible performance on the target domain.
Finally, we note that there is no standardized benchmark for the COVID-19 segmentation task [
27]. However, we also note that most of the COVID-19 segmentation approaches use the same U-Net-based model; thus, our method could be generalized to all these setups. Moreover, our domain adaptation method could be translated from segmentation to classification or detection tasks.
1.2. Contributions
Our work highlights a domain shift problem in the COVID-19 segmentation task and suggests an efficient solution to this problem. These are our three main contributions:
Firstly, we demonstrate that the difference in CT reconstruction kernels affects the segmentation quality of COVID-19 lesions. The model without adaptation achieves only a Dice Score on the unseen domain, while the best adaptation methods scores . In terms of similarity between predictions on the paired images, the baseline Dice Score is , which is almost two times lower than the achieved by our method.
Secondly, we adopt a series of adaptation approaches to solve the highlighted problem and extensively compare their performance under the different conditions.
Thirdly, we propose the flexible adaptation approach that outperforms the other considered methods when provided with enough unlabeled data. We also show that our method better generalizes to unseen CT reconstruction kernels and it is less sensitive to the absence of the semantic content (COVID-19 lesions) in the unlabeled data than the other methods trained on unlabeled data.
2. Method
In this paper, we consider solving a binary segmentation task, where the positive class is the voxels of volumetric chest CT image with consolidation or ground-glass opacity. All methods are built upon the convolutional neural network, which we detail in
Section 2.1.
We train these methods using the annotated dataset , where x is a volumetric CT image, y is a corresponding binary mask, and is the total size of training dataset. The dataset consists of images reconstructed with smooth kernels; we call it source dataset. We test all methods using the annotated dataset . The dataset consists of the images reconstructed with the sharp kernels; we call it target dataset. Although contains annotations, we use them only to calculate the final score.
In
Section 2.2, we describe the only adaptation method, FBPAug, that uses no data except the source dataset. The other methods use additional paired dataset
, which has no annotations. However, every image
has a paired image
reconstructed from the same sinogram but with a different kernel. Here, we assume that
x belongs to the source domain and
belongs to the target domain. Now, the problem can be formulated as unsupervised domain adaptation, and we detail the corresponding adversarial training approach in
Section 2.3. We also propose enforcing the similarity between the feature maps of paired images (
Section 2.4). In
Section 2.5, we detail enforcing the similarity between predictions.
2.1. COVID-19 Segmentation
In all COVID-19 segmentation experiments, we use the same 2D U-Net architecture [
28] trained on the axial slices. We do not use a 3D model for two reasons. Firstly, as we show in
Section 3.1, the images have a large difference in the inter-slice distances (from
to
mm), which can affect the performance of the 3D model. Secondly, the authors of [
8] have shown 2D and 3D models yielding similar results in the same setup with various inter-slice distances. Moreover, we note that all considered methods are independent of the architecture choice. We also introduce the standard architectural modifications, replacing every convolution layer with the Residual Block [
29]. To train the segmentation model, we use binary cross-entropy (BCE) loss.
2.2. Filtered Backprojection Augmentation
The first adaptation method that we consider is a task-specific augmentation called FBPAug [
14]. FBPAug emulates the CT reconstruction process with different kernels; thus, it might be a straightforward solution to the considered domain shift problem.
However, FBPAug gives us only an approximate solution, which is also restricted by the choice of kernel parameterization. We describe FBPAug as a three-step procedure for a given image
. Firstly, it applies a discrete Radon transform to the image. Secondly, it convolves the transformed image with the reconstruction kernel. The kernel is randomly sampled from the predefined parametric family of kernels on every iteration. Thirdly, it applies the back-projection operation to the result and outputs the augmented image
. A complete description of the method can be found in [
14].
We outline three weak spots in the FBPAug pipeline that motivate us to use the other domain adaptation approaches. As described above, FBPAug applies two discrete approximations, a discrete Radon transform and back-projection, leading to the information loss. Furthermore, the original convolution kernels used by CT manufacturers are unavailable, and the parametric family of kernels proposed in [
14] is also an approximation. Finally, modern CT systems typically employ model-based iterative reconstruction methods instead of just raw FBP thus, FBPAug covers the reconstruction process only partially.
In the context of described weaknesses, we expect FBPAug to perform worse than the other adaptation methods when a wide range of unlabeled data is available for the latter. Nonetheless, FBPAug improves the consistency scores in [
14], and we consider it one of the main adaptation approaches.
2.3. Domain Adversarial Neural Network
Further, we detail the methods that work with the unlabeled pool of data
. As mentioned at the beginning of the section, the problem can be reformulated as unsupervised domain adaptation. The most successful approaches to this problem are based on adversarial training. Therefore, we adopt the approach of [
15] and build a
domain adversarial neural network (DANN).
DANN includes an additional domain classifier or discriminator which aims to classify images between the source and target domains using their feature maps. We train the model to minimize the loss on the primary task (segmentation) and simultaneously maximize the discriminator’s loss. Thus, the segmentation part of the model learns domain features that are indistinguishable from the discriminator. The latter should improve the performance of the model on the domain.
The original DANN architecture consists of three parts: (i) feature extractor
, the part of segmentation model that maps input images
x into the feature space; (ii) segmentation head
, the complement part of segmentation model that predicts binary mask
; and (iii) discriminator
, the separate neural network that predicts domain label
. In
Figure 1,
and
correspond to the encoder and decoder parts of the model, respectively.
is denoted with the dashed green arrow that passes the aggregated features to the adversarial loss.
Following [
15], our optimization target is
where
is the segmentation loss (BCE),
is the domain classification loss (BCE).
are the parameters of
, respectively, and
are the solutions we seek. Parameter
regulates the trade-off between the
and
objectives.
However, there is no consensus in the literature on how to connect the discriminator to a segmentation network [
30]. We follow the findings [
30] that the earlier U-Net layers contain more domain-specific information than the later ones and use features from the encoder layers as input to the discriminator. Our preliminary experiments also confirm that using encoder features is a better strategy. We detail this approach in
Figure 1(6).
We also modify the architectural design of DANN for the segmentation task. The goal of the discriminator is to classify a kernel that is used to reconstruct the image. To aggregate features before the discriminator, we use
convolutions and interpolation to equalize the number of channels and spatial size; then, we concatenate the result. The discriminator consists of a sequence of fully-convolution layers followed by several fully-connected layers. We also use Leaky ReLU [
31] and average pooling to avoid sparse gradients.
2.4. Cross-Domain Feature Maps Consistency
Similar to the adversarial approach, we propose to remove style-specific kernel information from the feature maps. However, we additionally exploit the paired nature of the unlabeled dataset
. Instead of the adversarial loss, we minimize the distance between feature maps of paired images. We use the same notations
,
,
,
, and
as in
Section 2.3. Further, we denote the feature vector for every image
x as
f,
. For the paired image
, we use the similar notation
.
During the training, we minimize the sum of segmentation loss and distance between paired features (
f and
). Thus, the optimization problem is
where
is the segmentation loss (BCE) and
is the
consistency loss. For the consistency loss, we use mean squared error (MSE) between paired feature maps. Parameter
regulates the trade-off between two objectives. We call this method
F-Consistency since it enforces the consistency between paired feature maps.
Along with DANN, we present our method schematically in
Figure 1(5). Note that we do not need any additional model, e.g., discriminator
, in the case of F-Consistency. The features are aggregated from the same encoder layers as in DANN.
2.5. Cross-Domain Predictions Consistency
A special case of F-Consistency is enforcing the consistency of paired predictions as the predictions are de facto the feature maps of the last network layer. This approach is proposed in [
32] also in the context of medical image segmentation. Further, we denote this method
P-Consistency. Visually, it could be compared with DANN and F-Consistency in
Figure 1(4). The optimization problem is the same as in Equation (
4), except
is Dice Loss [
33] and
f and
are the last layer features, i.e., predictions.
4. Experiments
The main focus of the experiments below is to compare our method to the other unsupervised domain adaptation techniques. To achieve an objective comparison, a fair and unified experimental environment should be created. Therefore, we firstly describe the common preliminary steps that build up every method. This description includes preprocessing and training details in
Section 4.1.
Further, we detail every of the considered domain adaptation methods: Filtered Backprojection Augmentation (FBPAug) in
Section 4.2, Domain Adversarial Neural Network (DANN) in
Section 4.3, cross-domain feature-maps consistency (F-Consistency) which is our method in
Section 4.4, and cross-domain predictions consistency (P-Consistency) in
Section 4.5.
In all experiments, we use the same data split and evaluation metrics. Firstly, we split the COVID-train dataset (source domain with smooth kernels) into 5 folds. Then, we perform a standard cross-validation procedure, training on the data from four folds and calculating the score on the remaining fold. Here, we calculate the Dice Score between the predicted and ground truth COVID-19 masks for every 3D image and average these scores for the whole fold. Also, for every validation, we calculate the average Dice Score on the COVID-test dataset, which is the target domain with sharp kernels. We report the mean and standard deviation of these five scores on cross-validation and target domain data.
Besides the Dice Score on the source and target data, we also report the Dice Score between predictions on the paired images. To do so, we split the Paired-private datasets’ pairs into training and testing folds stratified by the type of kernel pairs. The size of the test fold is approximately of the dataset size. Then, we supplement the source domain training data (four current folds of the cross-validation) with the fixed training part of the paired data. Average Dice Score is calculated on the test part in a similar fashion.
4.1. COVID-19 Segmentation
4.1.1. Preprocessing
Before passing to the segmentation model, we apply the same preprocessing pipeline to all CT images. Preprocessing consists of four steps. (i) We rescale a CT image to have mm axial resolution using linear interpolation. (ii) Then, the intensity values are clipped to the minimum of Hounsfield units (HU) and a maximum of 300 HU. (iii) The resulting intensities are min-max-scaled to the range. (iv) Finally, we crop the resulting image to the automatically generated lung mask.
We generate the lung mask by training a standalone CNN segmentation model. The training procedure and architecture are reproduced from [
8]. The training of the lung segmentation model involves two external chest CT datasets: LUNA16 [
35,
36] and NSCLC-Radiomics [
37,
38]. These datasets have no intersection with the other datasets used to train the COVID-19 segmentation models; thus, there is no leak of the test data.
The trained lung segmentation model achieves about Dice Score both on the cross-validation and on the Medseg-9 dataset (it contains annotated lung masks). The latter result indicates that the lung segmentation model is robust to different kinds of domain shift and, moreover to the appearance of novel lesions (COVID-19).
4.1.2. Training Details
In all COVID-19 segmentation experiments, we use the same 2D U-Net architecture described in
Section 2.1. We train all models for 25k iterations using Adam [
39] optimizer with the default parameters and an initial learning rate of
. Every 6k batches learning rate is multiplied by
. Each iteration contains 32 randomly sampled 2D axial slices. Training of the plain segmentation model and similarly F-Consistency takes approximately 8 h on Nvidia GTX 1080 (8 GB) (Santa Clara, CA, USA). Training of DANN and FBPAug takes 12 and 30 h, respectively, in the same setting. The inference time is approximately 5–10 seconds depending on the image size and it is the same for all methods.
We further call the model trained only on the source data without any adaptation a baseline. We refer to the baseline scores on the COVID-test dataset and its consistency scores on Paired-private as a starting point for all other methods.
4.2. Filtered Backprojection Augmentation
The first method that we consider is FBPAug [
14]. In our experiments, we use the original implementation of FBPAug from [
14]. However, we sample parameters from the interval that corresponds to only
sharp reconstruction kernels (
a from
,
b from
), as our goal is to adapt the model to
sharp kernels. We use the same notations of
a and
b as in [
14]. We also reduce the probability of augmenting an image from
to
. The latter change does not affect the performance (tested on a single validation fold) and reduces the experiment time (saving about 90 h per experiment).
Note that the experimental setup remains the same as in baseline (
Section 4.1). FBPAug is the only adaptation method that does not use paired data.
4.3. Domain Adversarial Neural Network
The next step is to use unlabeled paired data to build a robust domain shift algorithm. Here, we adopt a DANN approach [
15] to the COVID-19 segmentation task.
In our experiments, we use the scheduling of parameter
as in [
15]. The baseline training procedure is extended to samples from the unlabeled data. At every iteration, we additionally sample 16 pairs of axial slices (the batch size is 32) from one of the Paired-private or Paired-public datasets (depending on a data setup). Then, we make the second forward pass to the discriminator and sum the segmentation and adversarial losses. The rest of the pipeline remains the same as in the baseline.
For this method, we select two parameters that can drastically change its behavior in terms of consistency and segmentation quality. Firstly, we evaluate different values, where determines how strongly adversarial loss contributes to the total loss. With the close to zero , we expect DANN to behave similarly to baseline. With the larger , we expect our segmentation model to fool the discriminator, making features of the different kernels indistinguishable for the latter. However, this consequence does not guarantee an increase in consistency or segmentation quality. Therefore, we manually search for the and choose the best by the cross-validation score.
Finally, we evaluate how well DANN generalizes under the presence of different kernel pairs. To do so, we exclude SOFT/LUNG and STANDARD/LUNG kernel pairs from training. We compare the results of this experiment with the model that is trained on all available kernel pairs from Paired-private. We also test the sensitivity of the DANN approach to the presence of COVID-19 lesions in the unlabeled data. In this case, we train DANN on the Paired-public dataset that does not contain COVID-19 targets.
4.4. Cross-Domain Feature Maps Consistency
Our proposed F-Consistency also uses unlabeled paired data. Therefore, the training procedure is the same as for DANN (
Section 4.3), except we do not use any scheduling for parameter
.
Similarly to DANN’s experimental setup, we evaluate different
values and choose the best. Here,
controls the trade-off between consistency and segmentation quality. However, contrary to the discriminator’s
in
Section 4.3, the large
values for consistency regularization ensure the alignment of the features. We show this trade-off for ten
values in a log-space from
to 1.
Finally, we evaluate the generalization of F-Consistency to different kernel pairs similarly by excluding SOFT/LUNG and STANDARD/LUNG kernel pairs from training. Similar to DANN, we train our method on the Paired-public dataset that does not contain COVID-19 lesions and show its generalization, regardless of the semantic content.
4.5. Cross-Domain Predictions Consistency
One special case of F-Consistency is enforcing the paired predictions consistency, which is independently evaluated in [
32]. We call this case a P-Consistency. We follow the experimental setup as in F-Consistency (
Section 4.4) and show the trade-off between the target and consistency scores for the same values of
.
For the P-Consistency, we draw one’s attention to the experiment on the Paired-public dataset. Since this dataset does not contain COVID-19 cases, the consistency of the enforced predictions on empty-target images can result in trivial predictions. Thus, we expect P-Consistency to be less generalizable to the target domain in terms of target Dice Score.
5. Results
We structure our experimental results as follows. We firstly compare all methods in
Section 5.1 so we directly support our main message. Secondly, we compare the generalization of all methods trained on fewer data in
Section 5.2. Then, we visualize the trade-off between the consistency and COVID-19 segmentation quality in
Section 5.3.
We compare some of the key results statistically using a one-sided Wilcoxon signed-rank test. We report p-values in two testing setups: , comparing five mean values after cross-validation, and , comparing Dice Score on every image as an independent sample.
5.1. Methods Comparison
To begin with, we show the existence of the domain shift problem within the COVID-19 segmentation task. The Dice Score of the baseline model on the COVID-test dataset is lower than the cross-validation score on the COVID-train dataset,
against
. Also, this score is significantly lower than
achieved by our adaptation method
. Results could be found in
Table 3 comparing row Baseline to the others. For all adaptation methods, we observe an increase in the consistency score and segmentation quality on the target domain. Moreover, all methods maintain their quality on the source domain compared to Baseline.
Further, we compare FBPAug to the best adaptation methods since it is a straightforward solution to the domain shift problem caused by the difference in the reconstruction kernels (
Section 2.2). Although FBPAug achieves comparable results on the target domain, our method outperforms it in terms of the average consistency score,
Dice Score against
. The results are also in
Table 3, row FBPAug.
Then, we compare P-Consistency (which operates with the last layer of decoder) with F-Consistency and show it resulting in the significantly lower consistency score,
against
. Thus, our findings align with the message [
30] that the encoder layers contain more domain-specific information than the decoder ones.
F-consistency outperforms DANN. Although both methods score similar in target Dice Score, F-Consistency has an advantage over DANN in the consistency score: against . Our intuition here is F-Consistency explicitly enforces features alignment, while DANN enforces features to be indistinguishable for the discriminator. The latter differently impact the consistency score, and F-Consistency performs better.
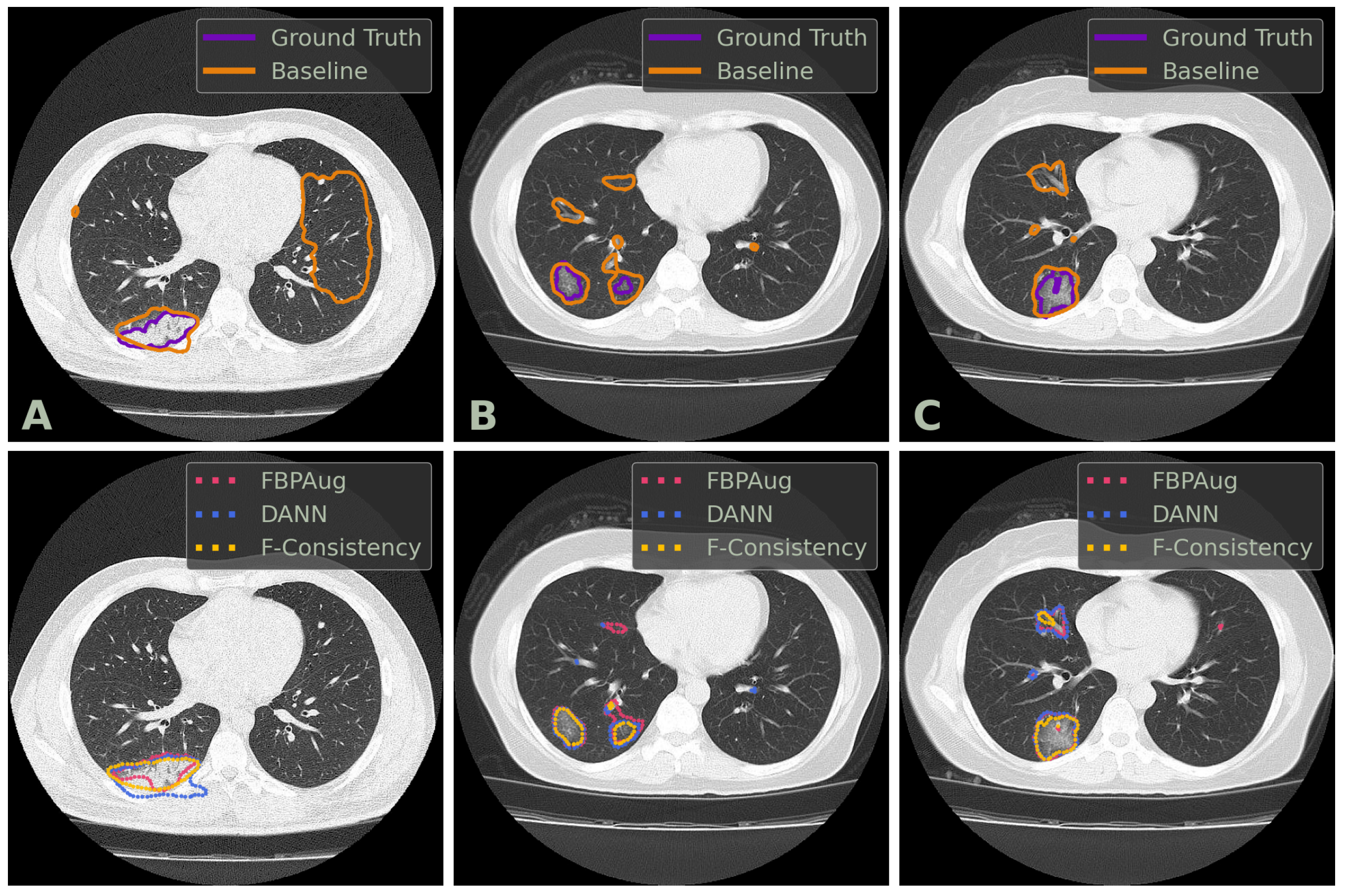
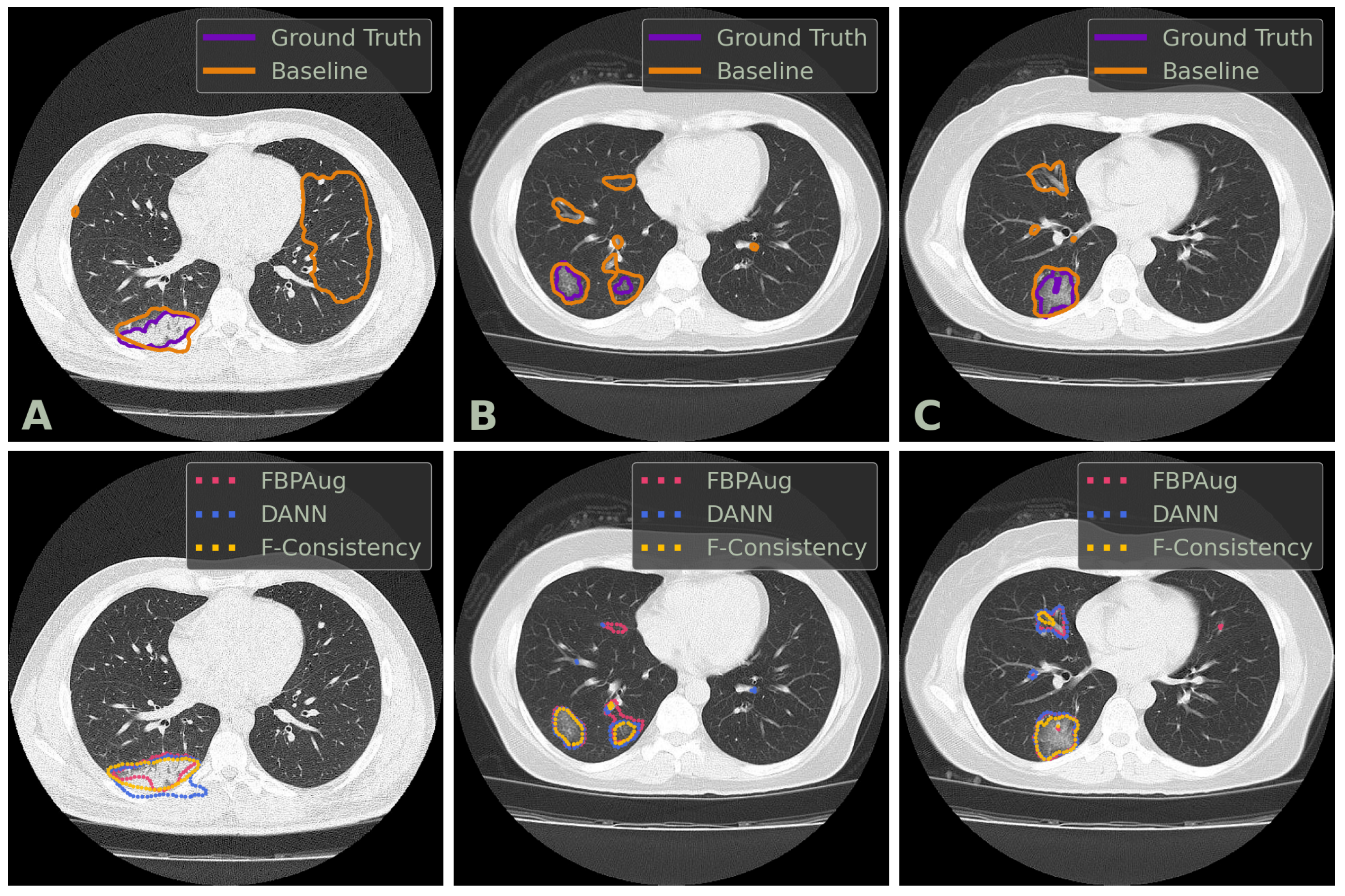
We conclude the comparison of the methods with the qualitative analysis. In
Figure 2, one could find examples of the Baseline, FBPAug, DANN, and F-Consistency predictions on the COVID-test dataset and compare them with the ground truth. Although all adaptation methods perform similar to the ground truth with minor inaccuracies, Baseline outputs the massive false positive predictions on the unseen domain. Additionally to the quantitative analysis above, the latter observation highlights the relevance of the domain adaptation problem in the COVID-19 segmentation task.
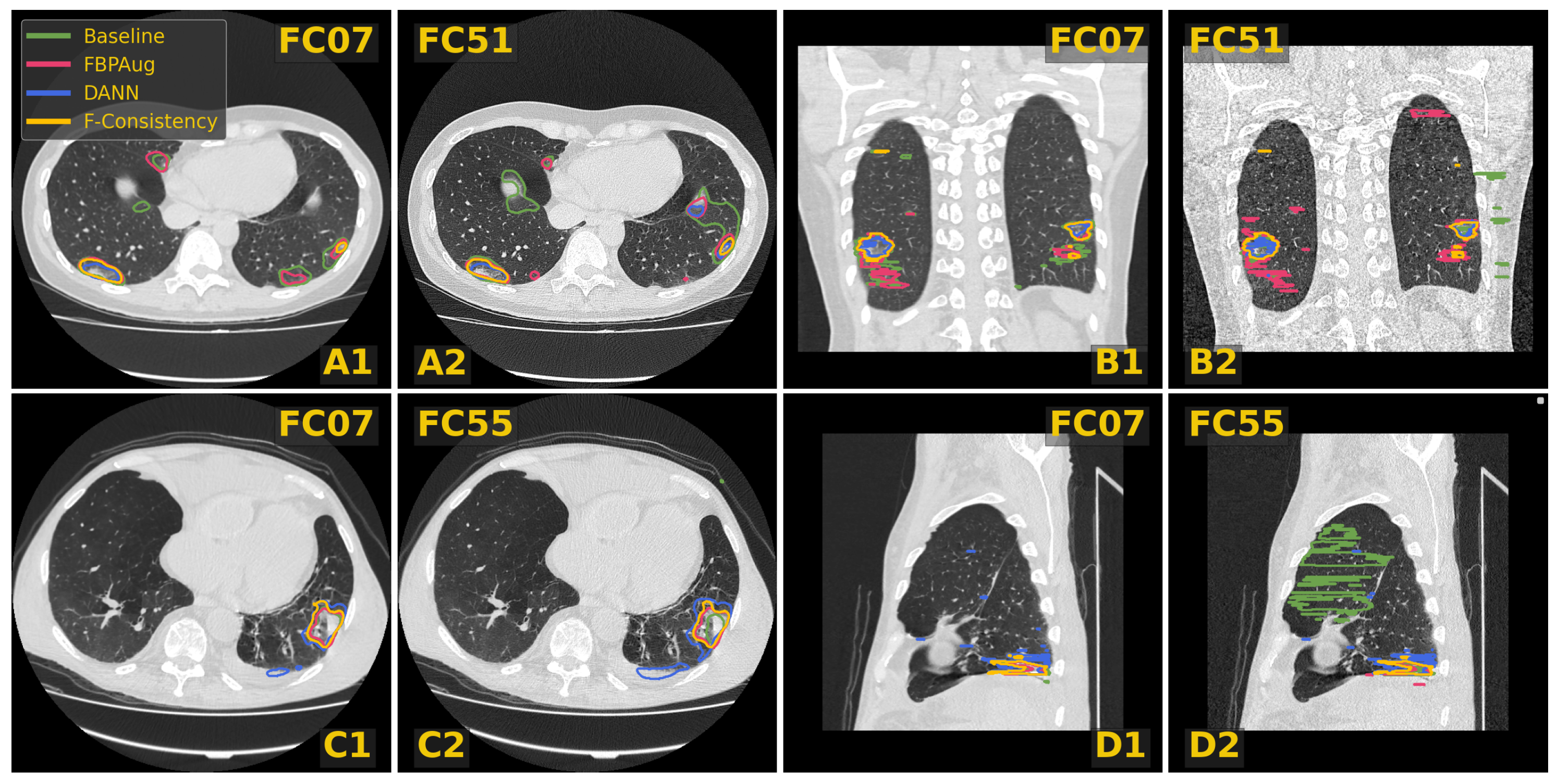
In
Figure 3, we visualize predictions of the same four methods on the paired images from the Paired-private dataset. For the Baseline, we observe an extreme inconsistency (
Figure 3A) and massive false positive predictions in healthy lung tissues (
Figure 3D) and even outside lungs (
Figure 3B). For the adaptation methods, their predictions are visually more consistent inside every pair, which aligns with the consistency scores in
Table 3. Despite the high consistency scores, FBPAug and DANN output more aggressive predictions. FBPAug predicts motion artifacts near the body regions (
Figure 3A) and triggers similarly to the baseline on, most likely, healthy lung tissues (
Figure 3B). DANN is more conservative but triggers on the consolidation-like tissues (
Figure 3C,D). However, without the ground truth annotations on the paired data, we refer to this analysis as a discussion.
Below, we investigate the generalization of the models trained with fewer data and the trade-off between consistency and segmentation quality.
5.2. Generalization with the Less Data
Firstly, we show how DANN, P-Consistency, and F-Consistency generalize to the unseen reconstruction kernels. We remove SOFT/LUNG and STANDARD/LUNG pairs of the Paired-private dataset from training, so we train the models using FC07/FC51 and FC07/FC55 pairs. The results of the removed kernel pairs are shown in
Table 4.
The methods preserve their segmentation quality on the COVID-train and COVID-test datasets despite training them with limited data. Moreover, all three methods score considerably higher than Baseline in consistency scores for unseen kernel pairs (SOFT/LUNG and STANDARD/LUNG). The latter means that the adaptation methods manage to align stylistic-related features even from the limited number of training examples. However, we highlight a decrease in the average consistency scores compared to the versions trained on full Paired-private. At this point, FBPAug (
Table 3) outperforms the adaptation methods. The latter indicates that the range of synthetically augmented data overlaps the range of reduced Paired-private.
Further, we evaluate the models regularized using paired images from the Paired-public dataset. The dataset contains only FC07/FC51 and FC07/FC55 kernel pairs. Besides the previous setup, this data does not contain COVID-19 lesions. Thus, we demonstrate that some methods depend on the semantic content and poorly generalize to kernel styles. The results are shown in
Table 5.
We highlight two main findings from these results. Firstly, consistency of the method that operates with the decoder layers decreases to the level of Baseline; see P-Consistency in
Table 5. Our intuition here is that the decoder version of the model can be more easily enforced to output the trivial predictions than the encoder one. Simultaneously, the images without COVID-19 lesions induce trivial predictions. Therefore, it might be easier for these models to differ the paired dataset from the source dataset by the semantic content and fail to align the stylistic features. Finally, we observe our method, F-Consistency, to outperform the other adaptation methods training only on the publicly available data.
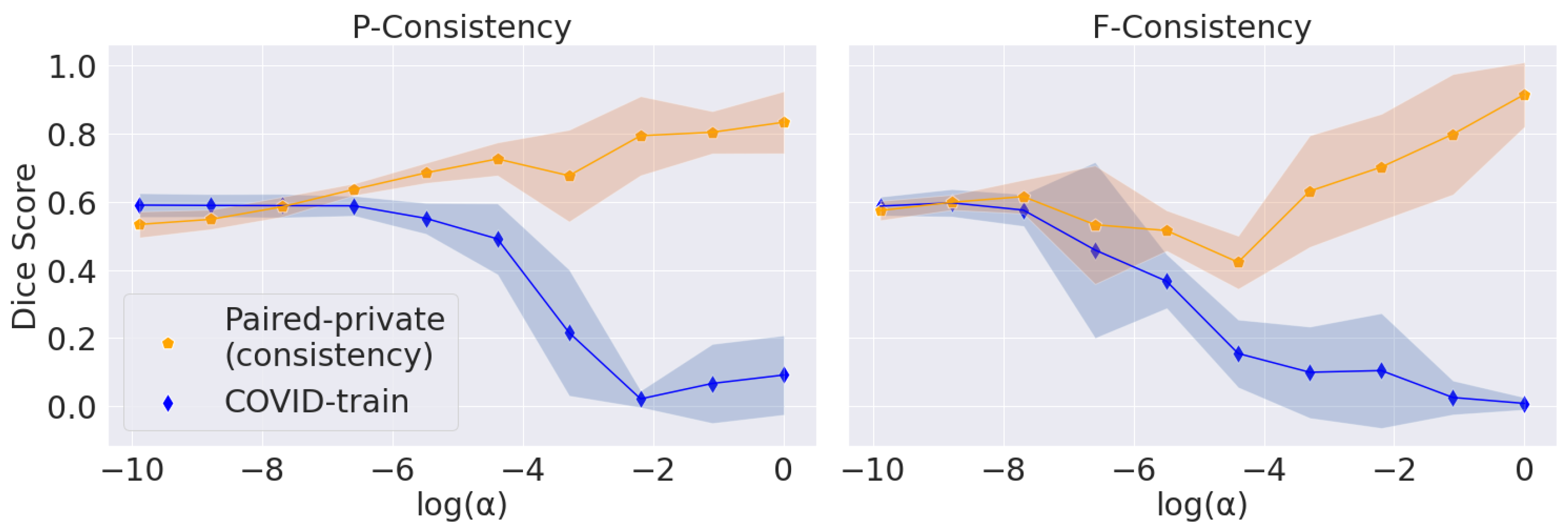
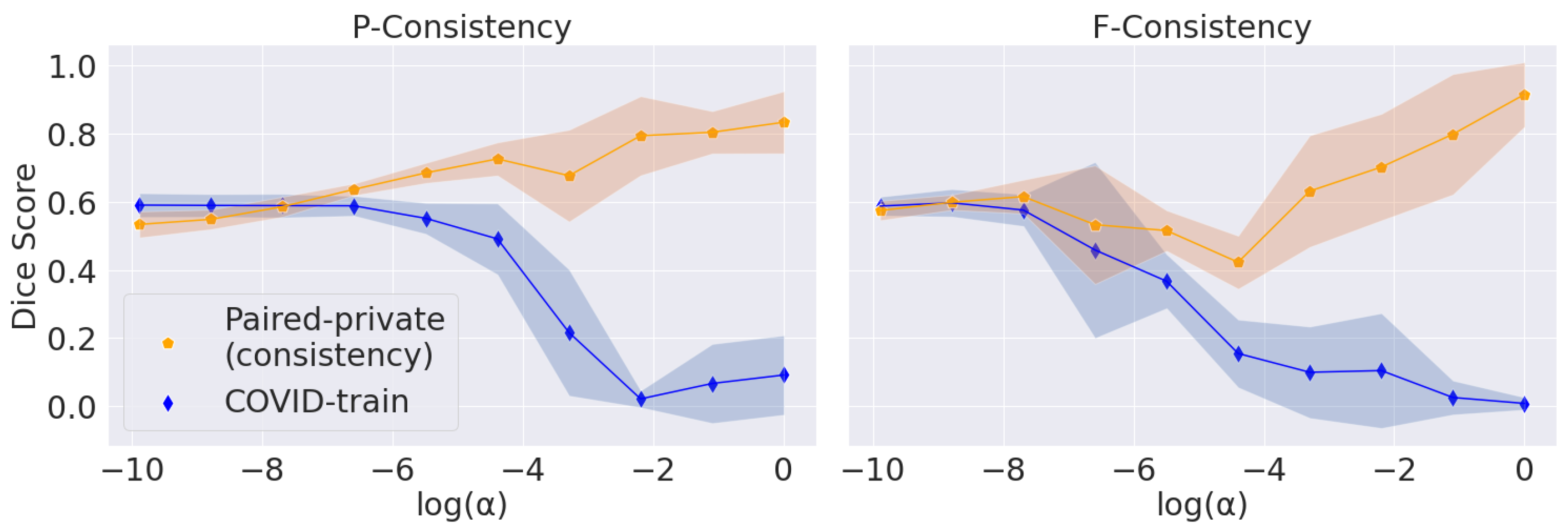
5.3. Trade-Off between Consistency and Segmentation Quality
The main problem with maximizing the consistency score is converging to the trivial solution (empty predictions). We vary
, the parameter that balances the consistency and segmentation losses, for P-Consistency and F-Consistency; see
Figure 4. The resulting trade-off follows the expected trend: consistency increases to 1 and target Dice Score decreases to 0 with increasing
.
We use Dice Score on the COVID-train dataset as a perceptual criterion to choose . We stop at the largest value before Dice Score starts to drop: for P-Consistency and 1 for F-Consistency. However, we use Paired-private, which participates in the final comparison, to calculate the consistency score. Firstly, we argue that using the Paired-public dataset in this setup is incorrect. Paired-public does not contain COVID-19 lesions; thus, we can only measure the consistency of false positive predictions. Secondly, we choose without considering consistency scores. Thus, we also do not overfit under the consistency scores.
For the DANN method, we choose based on the best score on COVID-train. Far from the optimal values, DANN’s prediction scores have a large standard deviation, so the trade-off cannot be observed. We also note that the adversarial approach does not explicitly enforce trivial predictions. Hence, we report the trade-off only for the F-Consistency and P-Consistency methods.
6. Discussion
Here, we summarize our results, discuss the most important limitations of our study, and suggest possible directions for future work.
We have shown that the proposed F-consistency significantly improves the performance on the target domain compared to the baseline model. However, we do not train the oracle model, which indicates the upper bound for other methods in a domain adaptation task. The oracle model should be trained via cross-validation on the target domain. In our case, the target domain contains only nine images, which leads either to lower results due to the small size of the training set or high dispersion of the results. Therefore, we compare the adaptation methods only with the baseline model and between each other.
In
Section 5.1, We show our model to achieve the highest results in terms of the consistency score. Contrary, the authors of [
32] observing a tendency of models to converge to trivial solutions using consistency loss. They assume that the models learn to distinguish domains for which they are penalized; thus, the models yield trivial but perfectly consistent predictions. Although we run the same setup with [
32], we do not observe trivial predictions for our method. The latter is demonstrated through the whole
Section 5. Our intuition here is that the inner structure of domains and the semantic content of images in our case are more diverse, preventing the model from overfitting under a specific domain.
We highlight that adversarial and consistency-based methods depend on a diverse unlabeled pool of data; see
Section 5.2. On the other hand, FBPAug does not require additional data since it augments the images from source dataset. One could think of this method as enforcing the consistency between the original and augmented image predictions using ground truth as a proxy. Simultaneously, we show that the models operating with the earlier layers perform better. Therefore, we could train F-Consistency on the pairs of original and augmented with FBPAug images to achieve even better results. We leave the latter idea for future work.
Conclusions
We have proposed an unsupervised domain adaptation method, F-Consistency, to address the difference in CT reconstruction kernels. Our method uses a set of unlabeled CT image pairs and enforces the similarity between feature maps of paired images. We have shown that F-Consistency outperformed the other adaptation and augmentation approaches in the COVID-19 segmentation task when provided with enough unlabeled data. Finally, through extensive evaluation, we have shown our method to generalize the unseen reconstruction kernels better and without the specific semantic content.








{kind=link}
{kind=link}
{kind=link}
{kind=link}