
Privacy-Preserving Semantic Segmentation Using Vision Transformer



Abstract
:1. Introduction
- We propose the combined use of encrypted images and models in a semantic segmentation task to protect visual sensitive information of input images for the first time.
- We confirm that the proposed method allows us not only to use the same accuracy as that when images are not encrypted but to also update a secret key easily.
2. Related Work
2.1. Privacy-Preserving DNNs
2.2. Learnable Image Encryption for Machine Learning
2.3. Segmentation Transformer
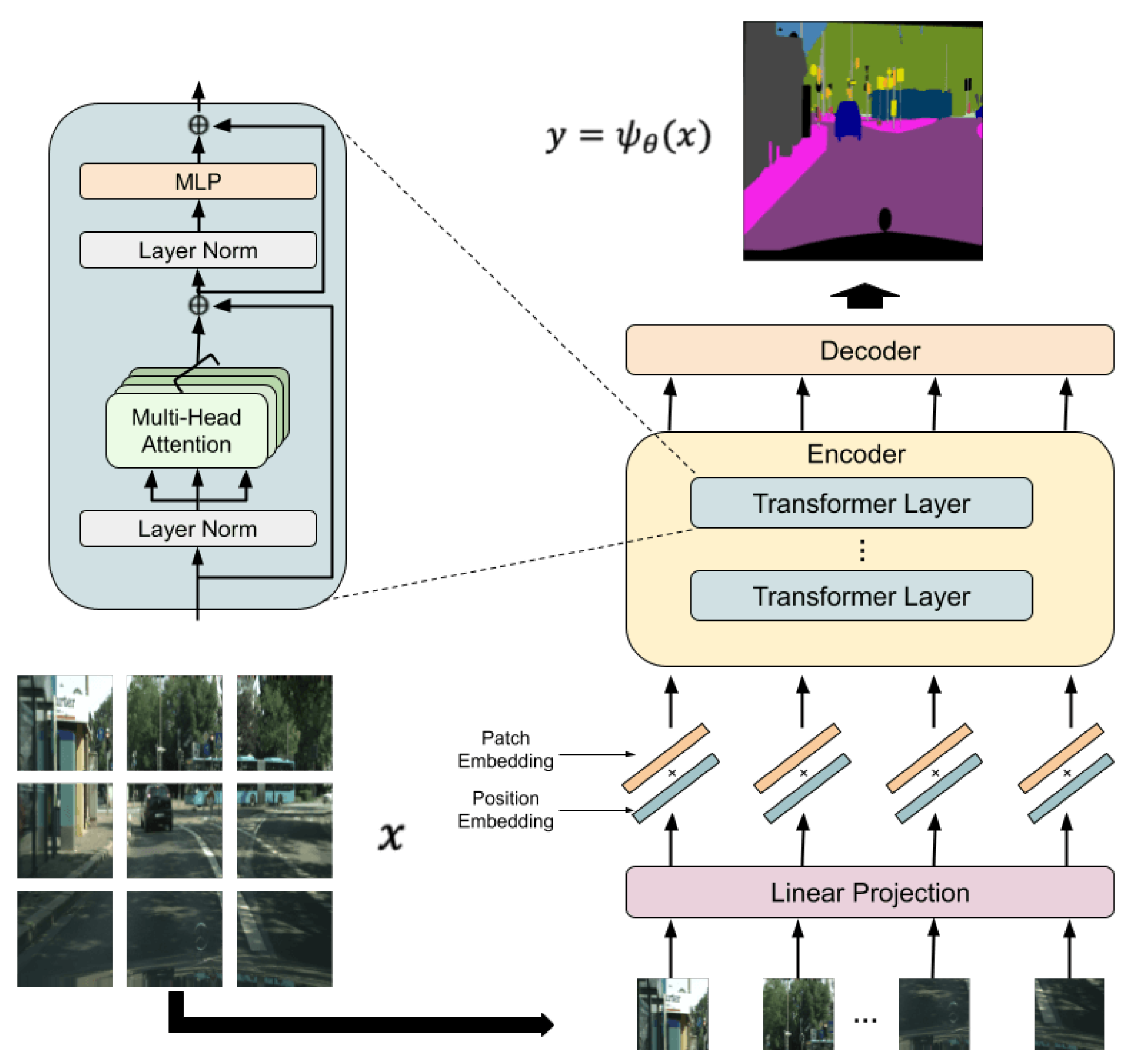
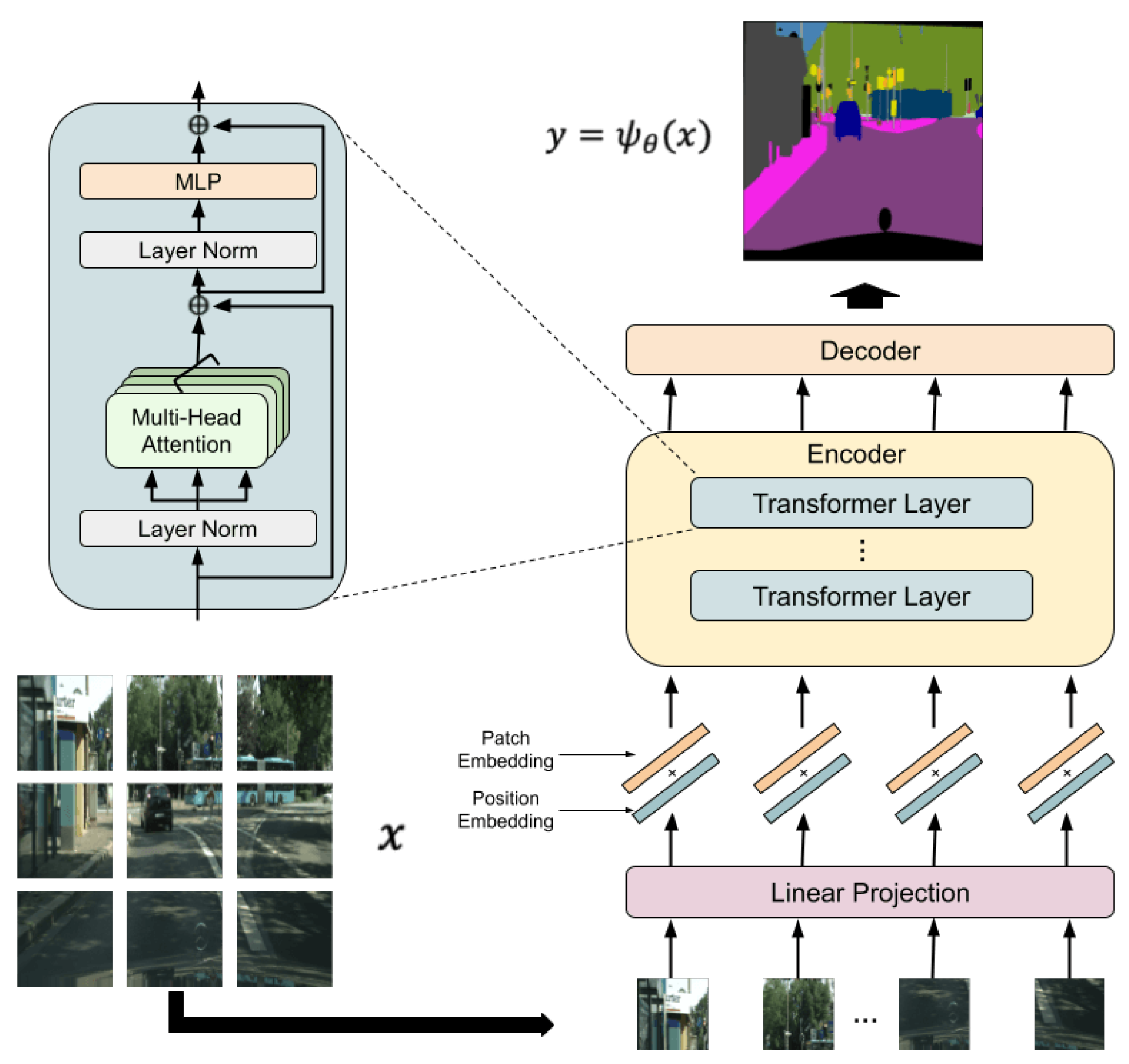
3. Proposed Method
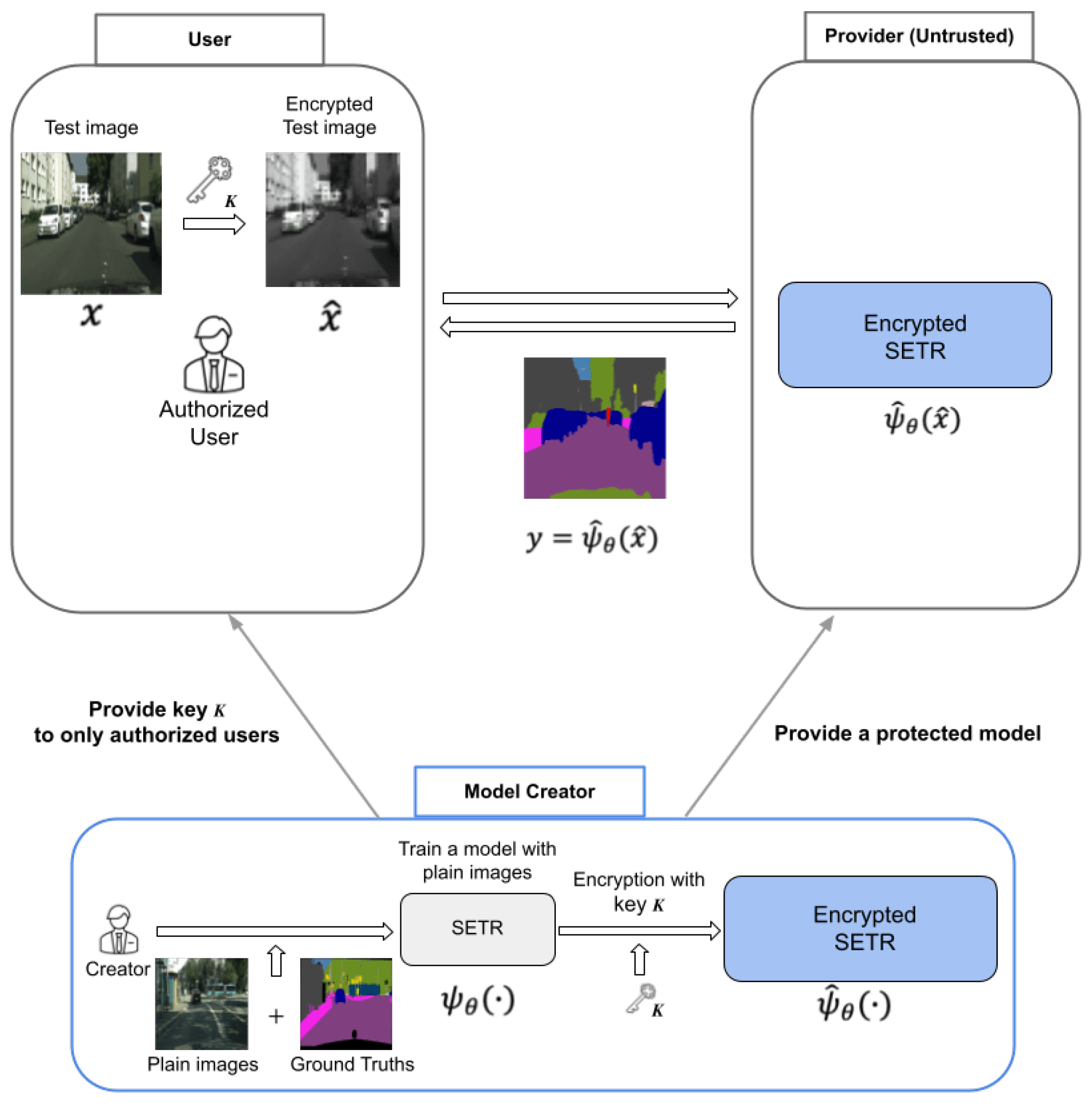
3.1. Overview and Threat Model
3.2. Encryption Method
3.2.1. Model Encryption
- (1)
- Randomly generate a matrix with key K as
- (2)
- Multiply and E to obtain as
- (3)
- Replace E in Equation (1) with as a new patch embedding to encrypt a model.
3.2.2. Example of
- (1)
- Generate a random integer vector with a length of L by using a random generator with a seed value aswhere
- (2)
- Decide in Equation (3) with as
3.2.3. Test Image Encryption
- (a)
- Divide a test (query) image tensor into blocks with a size of such that .
- (b)
- Flatten each block into a vector such that
- (c)
- Generate an encrypted vector by multiplying by as
- (d)
- Concatenate the encrypted vectors into an encrypted test image .
3.3. Requirements of Proposed Method
- (a)
- Semantic segmentation can be carried out by using visually protected input images without sensitive information.
- (b)
- No network modification is required.
- (c)
- A high accuracy, which is close to that of using plain images, can be maintained.
- (d)
- Keys are easily updated.
4. Experimental Results
4.1. Setup
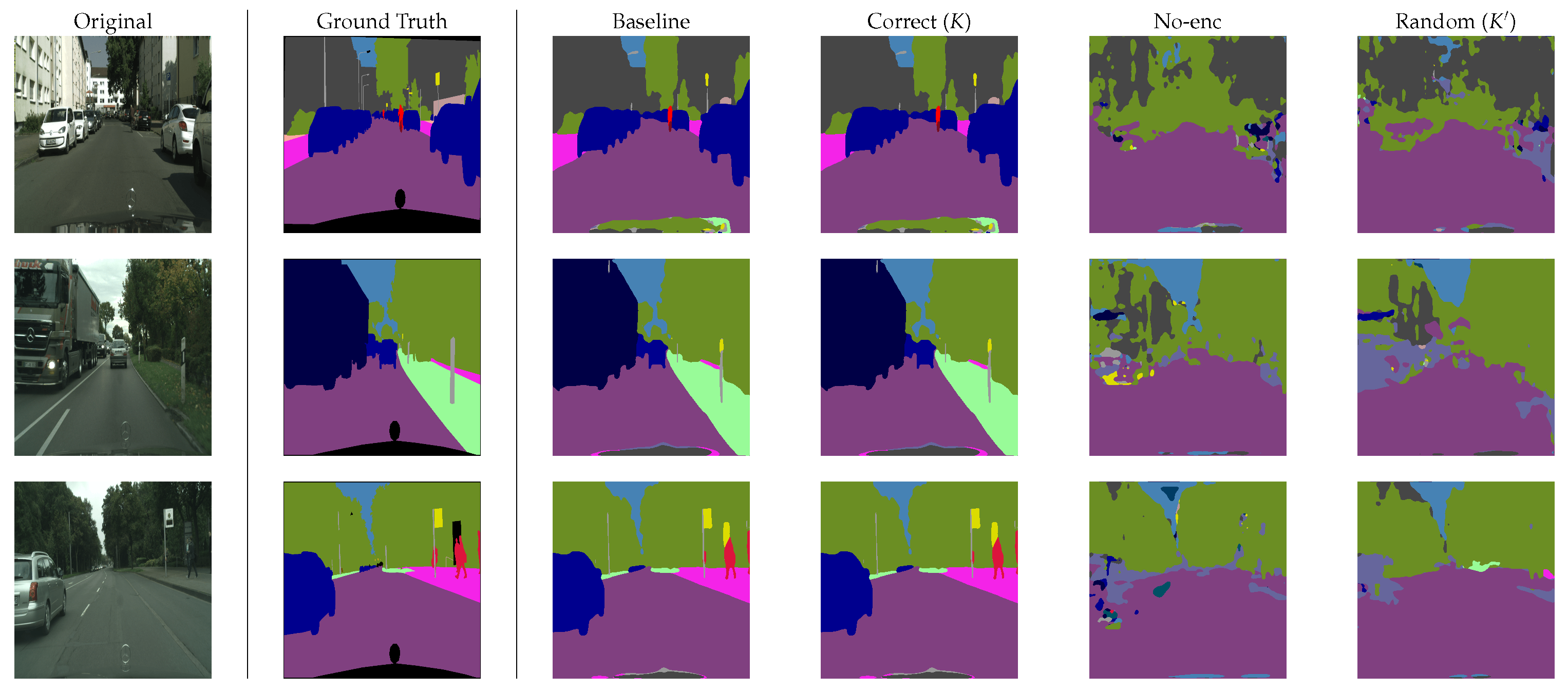
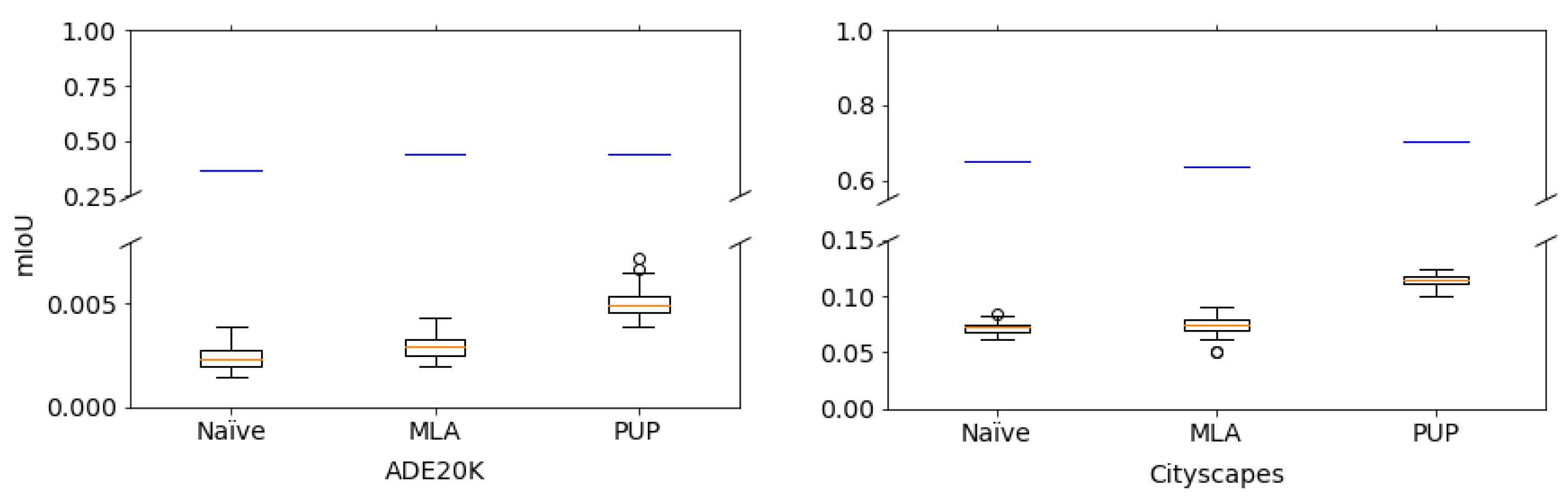
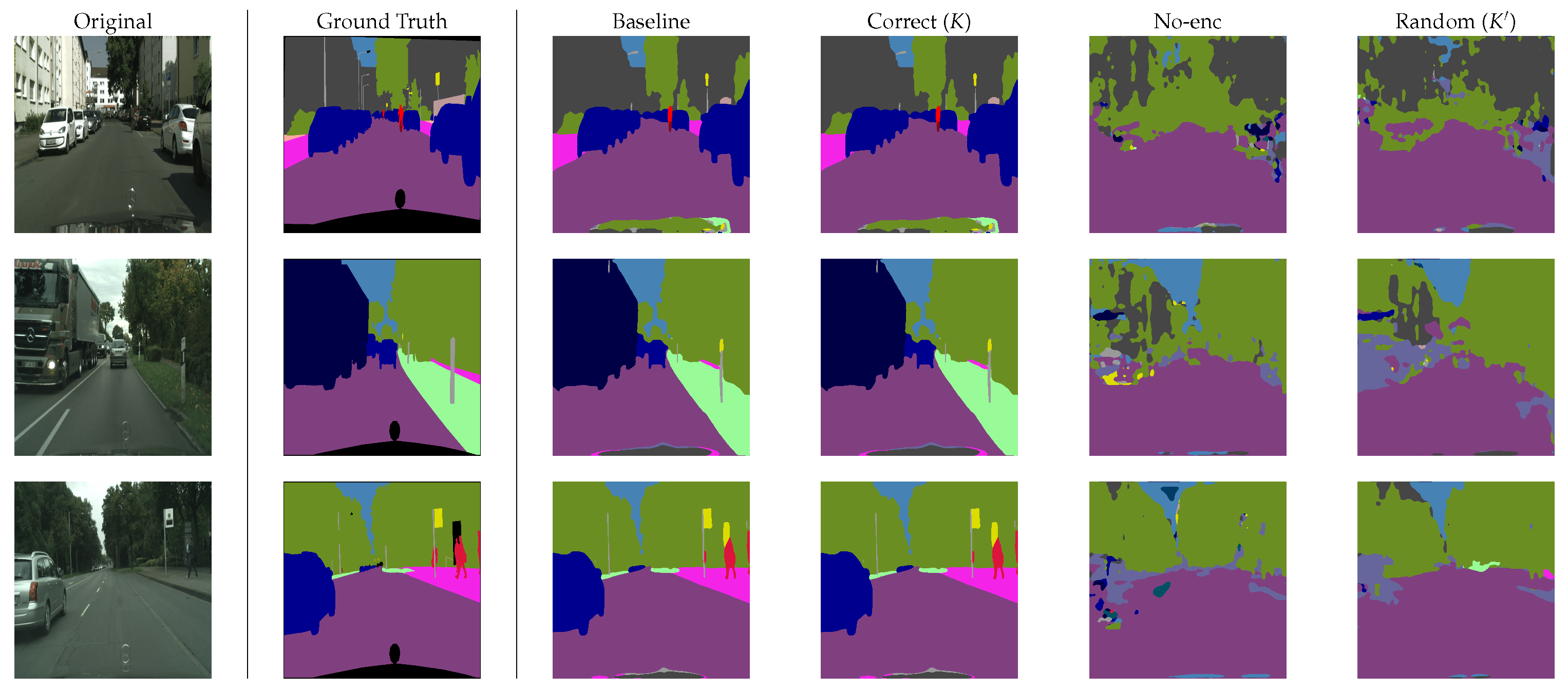
4.2. Semantic Segmentation Performance
4.3. Comparison with Conventional Methods
4.4. Robustness against Attacks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 2015 53rd Annual Allerton Conference on Communication, Control, and Computing (Allerton), Montecello, IL, USA, 29 September–2 October 2015; pp. 909–910. [Google Scholar] [CrossRef]
- Chaudhari, H.; Rachuri, R.; Suresh, A. Trident: Efficient 4PC Framework for Privacy Preserving Machine Learning. In Proceedings of the 27th Annual Network and Distributed System Security Symposium (NDSS) 2020, San Diego, CA, USA, 23–26 February 2020. [Google Scholar] [CrossRef]
- Kitai, H.; Cruz, J.P.; Yanai, N.; Nishida, N.; Oba, T.; Unagami, Y.; Teruya, T.; Attrapadung, N.; Matsuda, T.; Hanaoka, G. MOBIUS: Model-Oblivious Binarized Neural Networks. IEEE Access 2019, 7, 139021–139034. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Federated Learning With Differential Privacy: Algorithms and Performance Analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Zhao, J.; Zhu, H.; Wang, F.; Lu, R.; Liu, Z.; Li, H. PVD-FL: A Privacy-Preserving and Verifiable Decentralized Federated Learning Framework. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2059–2073. [Google Scholar] [CrossRef]
- Kiya, H.; AprilPyone, M.; Kinoshita, Y.; Imaizumi, S.; Shiota, S. An Overview of Compressible and Learnable Image Transformation with Secret Key and its Applications. APSIPA Trans. Signal Inf. Process. 2022, 11, e11. [Google Scholar] [CrossRef]
- Tanaka, M. Learnable Image Encryption. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taichung, Taiwan, 19–21 May 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Madono, K.; Tanaka, M.; Masaki, O.; Tetsuji, O. Block-wise Scrambled Image Recognition Using Adaptation Network. In Proceedings of the Workshop on Artificial Intelligence of Things (AAAI WS), New York, NY, USA, 7–8 February 2020. [Google Scholar]
- Sirichotedumrong, W.; Kinoshita, Y.; Kiya, H. Pixel-Based Image Encryption Without Key Management for Privacy-Preserving Deep Neural Networks. IEEE Access 2019, 7, 177844–177855. [Google Scholar] [CrossRef]
- AprilPyone, M.; Kiya, H. Block-wise Image Transformation with Secret Key for Adversarially Robust Defense. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2709–2723. [Google Scholar]
- Huang, Q.X.; Yap, W.L.; Chiu, M.Y.; Sun, H.M. Privacy-Preserving Deep Learning With Learnable Image Encryption on Medical Images. IEEE Access 2022, 10, 66345–66355. [Google Scholar] [CrossRef]
- Chuman, T.; Sirichotedumrong, W.; Kiya, H. Encryption-Then-Compression Systems Using Grayscale-Based Image Encryption for JPEG Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1515–1525. [Google Scholar] [CrossRef] [Green Version]
- Man, Z.; Li, J.; Di, X.; Sheng, Y.; Liu, Z. Double image encryption algorithm based on neural network and chaos. Chaos Solitons Fractals 2021, 152, 111318. [Google Scholar] [CrossRef]
- Sirichotedumrong, W.; Kiya, H. A GAN-Based Image Transformation Scheme for Privacy-Preserving Deep Neural Networks. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Virtual, 18–22 January 2021; pp. 745–749. [Google Scholar] [CrossRef]
- Ito, H.; AprilPyone, M.; Kiya, H. Access Control Using Spatially Invariant Permutation of Feature Maps for Semantic Segmentation Models. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1833–1838. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Phong, L.T.; Wang, L. Privacy-preserving logistic regression with distributed data sources via homomorphic encryption. IEICE Trans. Inf. Syst. 2016, 99, 2079–2089. [Google Scholar]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Phuong, T.T. Privacy-preserving deep learning via weight transmission. IEEE Trans. Inf. Forensics Secur. 2019, 14, 3003–3015. [Google Scholar]
- Dowlin, N.; Gilad-Bachrach, R.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy; Technical Report MSR-TR-2016-3; Microsoft Research: Redmond, WA, USA, February 2016. [Google Scholar]
- Wang, Y.; Lin, J.; Wang, Z. An efficient convolution core architecture for privacy-preserving deep learning. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Maekawa, T.; Kawamura, A.; Nakachi, T.; Kiya, H. Privacy-Preserving Support Vector Machine Computing Using Random Unitary Transformation. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2019, 102, 1849–1855. [Google Scholar] [CrossRef]
- Kawamura, A.; Kinoshita, Y.; Nakachi, T.; Shiota, S.; Kiya, H. A Privacy-Preserving Machine Learning Scheme Using EtC Images. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2020, 103, 1571–1578. [Google Scholar] [CrossRef]
- Nakamura, I.; Tonomura, Y.; Kiya, H. Unitary Transform-Based Template Protection and Its Application to l2-norm Minimization Problems. IEICE Trans. Inf. Syst. 2016, 99, 60–68. [Google Scholar] [CrossRef]
- Chang, A.H.; Case, B.M. Attacks on Image Encryption Schemes for Privacy-Preserving Deep Neural Networks. arXiv 2020, arXiv:2004.13263. [Google Scholar]
- AprilPyone, M.; Kiya, H. Privacy-Preserving Image Classification Using an Isotropic Network. IEEE MultiMedia 2022, 29, 23–33. [Google Scholar] [CrossRef]
- Qi, Z.; AprilPyone, M.; Kinoshita, Y.; Kiya, H. Privacy-Preserving Image Classification Using Vision Transformer. arXiv 2022, arXiv:2205.12041. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic Understanding of Scenes Through the ADE20K Dataset. Int. J. Comput. Vis. 2018, 127, 302–321. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Proceedings of Machine Learning Research, Virtual, 18–24 July 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- AprilPyone, M.; Kiya, H. A protection method of trained CNN model with a secret key from unauthorized access. APSIPA Trans. Signal Inf. Process. 2021, 10, e10. [Google Scholar] [CrossRef]
- Madono, K.; Tanaka, M.; Onishi, M.; Ogawa, T. SIA-GAN: Scrambling Inversion Attack Using Generative Adversarial Network. IEEE Access 2021, 9, 129385–129393. [Google Scholar] [CrossRef]
- Ito, H.; Kinoshita, Y.; Aprilpyone, M.; Kiya, H. Image to Perturbation: An Image Transformation Network for Generating Visually Protected Images for Privacy-Preserving Deep Neural Networks. IEEE Access 2021, 9, 64629–64638. [Google Scholar] [CrossRef]
- Chuman, T.; Kurihara, K.; Kiya, H. On the security of block scrambling-based ETC systems against jigsaw puzzle solver attacks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2157–2161. [Google Scholar] [CrossRef]
- Chuman, T.; Kurihara, K.; Kiya, H. On the Security of Block Scrambling-Based EtC Systems against Extended Jigsaw Puzzle Solver Attacks. IEICE Trans. Inf. Syst. 2018, 101, 37–44. [Google Scholar] [CrossRef] [Green Version]
- Schneier, B.; Sutherland, P. Applied Cryptography: Protocols, Algorithms, and Source Code in C, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1995. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
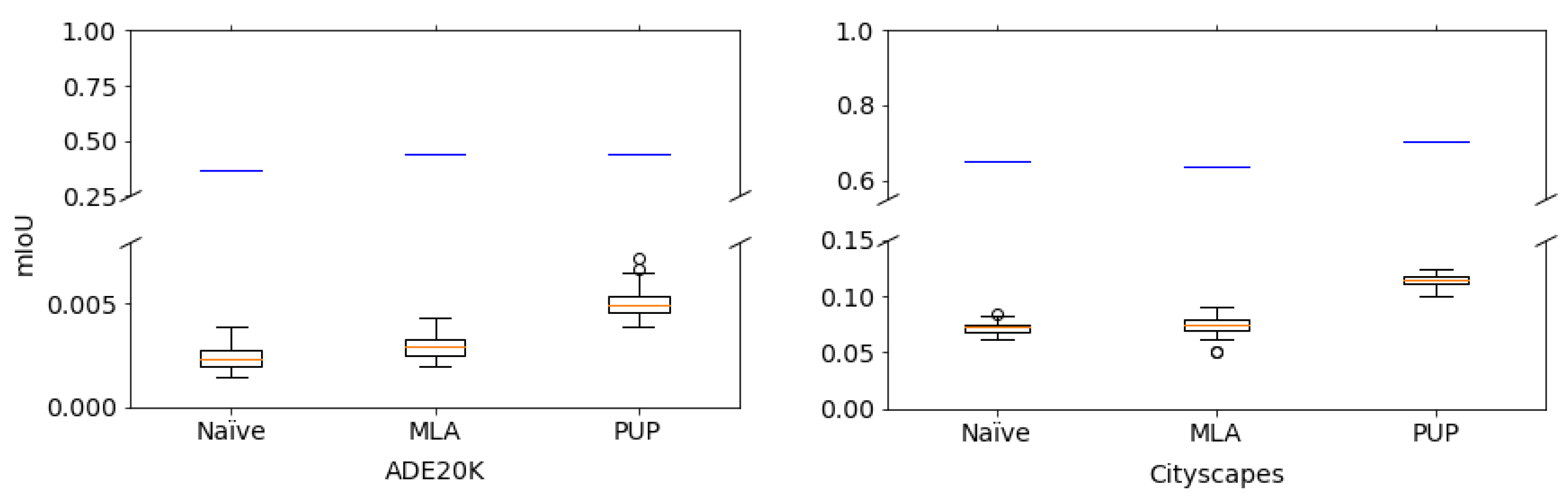
| Dataset | Selected Decoder | Baseline | Correct (K) | No-Enc | Random () |
|---|---|---|---|---|---|
| Cityscapes | Naïve | 0.6490 | 0.6490 | 0.0674 | 0.0718 |
| MLA | 0.6386 | 0.6386 | 0.0792 | 0.0743 | |
| PUP | 0.7039 | 0.7039 | 0.1135 | 0.1137 | |
| ADE20K | Naïve | 0.3710 | 0.3710 | 0.0023 | 0.0024 |
| MLA | 0.4370 | 0.4370 | 0.0030 | 0.0029 | |
| PUP | 0.4383 | 0.4383 | 0.0048 | 0.0050 |
| Network | Fully Convolutional Network (FCN) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Block size | SHF | NP | FFX | ||||||
| Correct (K) | No-enc | Random () | Correct (K) | No-enc | Random () | Correct (K) | No-enc | Random () | |
| 4 | 0.4731 | 0.4536 | 0.3671 | 0.4706 | 0.3359 | 0.1505 | 0.3823 | 0.0157 | 0.0012 |
| 16 | 0.2214 | 0.1994 | 0.1150 | 0.3439 | 0.2114 | 0.0832 | 0.2611 | 0.0007 | 0.0079 |
| Baseline | 0.5966 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kiya, H.; Nagamori, T.; Imaizumi, S.; Shiota, S. Privacy-Preserving Semantic Segmentation Using Vision Transformer. J. Imaging 2022, 8, 233. https://doi.org/10.3390/jimaging8090233
Kiya H, Nagamori T, Imaizumi S, Shiota S. Privacy-Preserving Semantic Segmentation Using Vision Transformer. Journal of Imaging. 2022; 8(9):233. https://doi.org/10.3390/jimaging8090233
Chicago/Turabian StyleKiya, Hitoshi, Teru Nagamori, Shoko Imaizumi, and Sayaka Shiota. 2022. "Privacy-Preserving Semantic Segmentation Using Vision Transformer" Journal of Imaging 8, no. 9: 233. https://doi.org/10.3390/jimaging8090233
APA StyleKiya, H., Nagamori, T., Imaizumi, S., & Shiota, S. (2022). Privacy-Preserving Semantic Segmentation Using Vision Transformer. Journal of Imaging, 8(9), 233. https://doi.org/10.3390/jimaging8090233