Figure 1.
Appearance variation across acquisition conditions. The images of each column contain the same sample under different (lighting or viewpoint) conditions. These images are extracted from our new dataset.
Figure 1.
Appearance variation across acquisition conditions. The images of each column contain the same sample under different (lighting or viewpoint) conditions. These images are extracted from our new dataset.
Figure 2.
Changes in visual appearance of a white bread sample and a wool sample from the KTH-TIPS2 dataset under various lighting and viewing directions. Images (a–c) were captured with a frontal illumination direction and frontal, 22.5° right and 22.5° left viewing directions, respectively, for the white bread sample. Similarly, images (d–f) were captured with a frontal illumination direction and frontal, 22.5° right and 22.5° left viewing directions, respectively, for a wool sample.
Figure 2.
Changes in visual appearance of a white bread sample and a wool sample from the KTH-TIPS2 dataset under various lighting and viewing directions. Images (a–c) were captured with a frontal illumination direction and frontal, 22.5° right and 22.5° left viewing directions, respectively, for the white bread sample. Similarly, images (d–f) were captured with a frontal illumination direction and frontal, 22.5° right and 22.5° left viewing directions, respectively, for a wool sample.
Figure 3.
Changes in visual appearance of a white bread sample and a wool sample from the KTH-TIPS2 dataset under various lighting and viewing directions. Images (a–d) were captured with a frontal viewing direction and frontal, 45° from the top, 45° from the side, and ambient illumination conditions, respectively, for a white bread sample. Similarly, images (e–h) were captured with a frontal viewing direction and frontal, 45° from the top, 45° from the side, and ambient illumination conditions, respectively, for a wool sample.
Figure 3.
Changes in visual appearance of a white bread sample and a wool sample from the KTH-TIPS2 dataset under various lighting and viewing directions. Images (a–d) were captured with a frontal viewing direction and frontal, 45° from the top, 45° from the side, and ambient illumination conditions, respectively, for a white bread sample. Similarly, images (e–h) were captured with a frontal viewing direction and frontal, 45° from the top, 45° from the side, and ambient illumination conditions, respectively, for a wool sample.
Figure 4.
Changes in the visual appearance of a white bread sample under various lighting geometries and viewing directions. Images (a–d) were acquired under the same lighting direction (90°). Images (e–h) were acquired under the same viewing direction (90°). For images (a–d) the lighting direction was fixed at 90° and the viewing directions are 90°, 60°, 35°, and 10°, respectively. For the images (e–h), the viewing direction is fixed at 90° and the lighting directions are 90°, 65°, 45°, and 20°, respectively.
Figure 4.
Changes in the visual appearance of a white bread sample under various lighting geometries and viewing directions. Images (a–d) were acquired under the same lighting direction (90°). Images (e–h) were acquired under the same viewing direction (90°). For images (a–d) the lighting direction was fixed at 90° and the viewing directions are 90°, 60°, 35°, and 10°, respectively. For the images (e–h), the viewing direction is fixed at 90° and the lighting directions are 90°, 65°, 45°, and 20°, respectively.
Figure 5.
Images of a cotton sample from the UJM TIV dataset observed under different views.
Figure 5.
Images of a cotton sample from the UJM TIV dataset observed under different views.
Figure 6.
Images of a cotton sample from the KTH-TIPS2 dataset observed under different views.
Figure 6.
Images of a cotton sample from the KTH-TIPS2 dataset observed under different views.
Figure 7.
Images of samples of (a) aluminium foil, (b) brown bread, (c) corduroy, (d) cork, (e) cotton, (f) lettuce leaf, (g) linen, (h) white bread, (i) wood, (j) cracker, and (k) wool from the UJM-TIV dataset taken under illumination conditions of 65° and viewing condition 90°.
Figure 7.
Images of samples of (a) aluminium foil, (b) brown bread, (c) corduroy, (d) cork, (e) cotton, (f) lettuce leaf, (g) linen, (h) white bread, (i) wood, (j) cracker, and (k) wool from the UJM-TIV dataset taken under illumination conditions of 65° and viewing condition 90°.
Figure 8.
Images of a sample of (a) aluminium foil, (b) brown bread, (c) corduroy, (d) cork, (e) cotton, (f) lettuce leaf, (g) linen, (h) white bread, (i) wood, (j) cracker, and (k) wool category from the UJM-TIV dataset taken under a illumination direction of 65° and a viewing condition of 35°.
Figure 8.
Images of a sample of (a) aluminium foil, (b) brown bread, (c) corduroy, (d) cork, (e) cotton, (f) lettuce leaf, (g) linen, (h) white bread, (i) wood, (j) cracker, and (k) wool category from the UJM-TIV dataset taken under a illumination direction of 65° and a viewing condition of 35°.
Figure 9.
Changes in visual appearance of a wool sample under various lighting geometries and viewing directions. Images (a–d) were acquired under the same lighting direction (90°). Images (e–h) were acquired under the same viewing direction (90°). For images (a–d), the lighting direction is fixed at 90°, and the viewing directions are 90°, 60°, 35°, and 10°, respectively. For images from (e–h), the viewing direction is fixed at 90° and the lighting directions are 90°, 65°, 45°, and 20°, respectively.
Figure 9.
Changes in visual appearance of a wool sample under various lighting geometries and viewing directions. Images (a–d) were acquired under the same lighting direction (90°). Images (e–h) were acquired under the same viewing direction (90°). For images (a–d), the lighting direction is fixed at 90°, and the viewing directions are 90°, 60°, 35°, and 10°, respectively. For images from (e–h), the viewing direction is fixed at 90° and the lighting directions are 90°, 65°, 45°, and 20°, respectively.
Figure 10.
Schematic diagram of the image acquisition setup. In our experiments, the plane defined by vectors N and I was set perpendicular to the plane defined by vectors N and V.
Figure 10.
Schematic diagram of the image acquisition setup. In our experiments, the plane defined by vectors N and I was set perpendicular to the plane defined by vectors N and V.
Figure 11.
Images of a cotton sample from UJM-TIV: (a) when the viewing condition is frontal and lighting condition is at 20°. (b) with the same viewing and lighting conditions when the sample orientation is perpendicular.
Figure 11.
Images of a cotton sample from UJM-TIV: (a) when the viewing condition is frontal and lighting condition is at 20°. (b) with the same viewing and lighting conditions when the sample orientation is perpendicular.
Figure 12.
Image samples appeared as out of focus for the categories (a) brown bread, (b) corduroy, (c) cork, (d) cotton, (e) lettuce leaf, (f) linen, (g) wood, and (h) wool from the UJM-TIV dataset.
Figure 12.
Image samples appeared as out of focus for the categories (a) brown bread, (b) corduroy, (c) cork, (d) cotton, (e) lettuce leaf, (f) linen, (g) wood, and (h) wool from the UJM-TIV dataset.
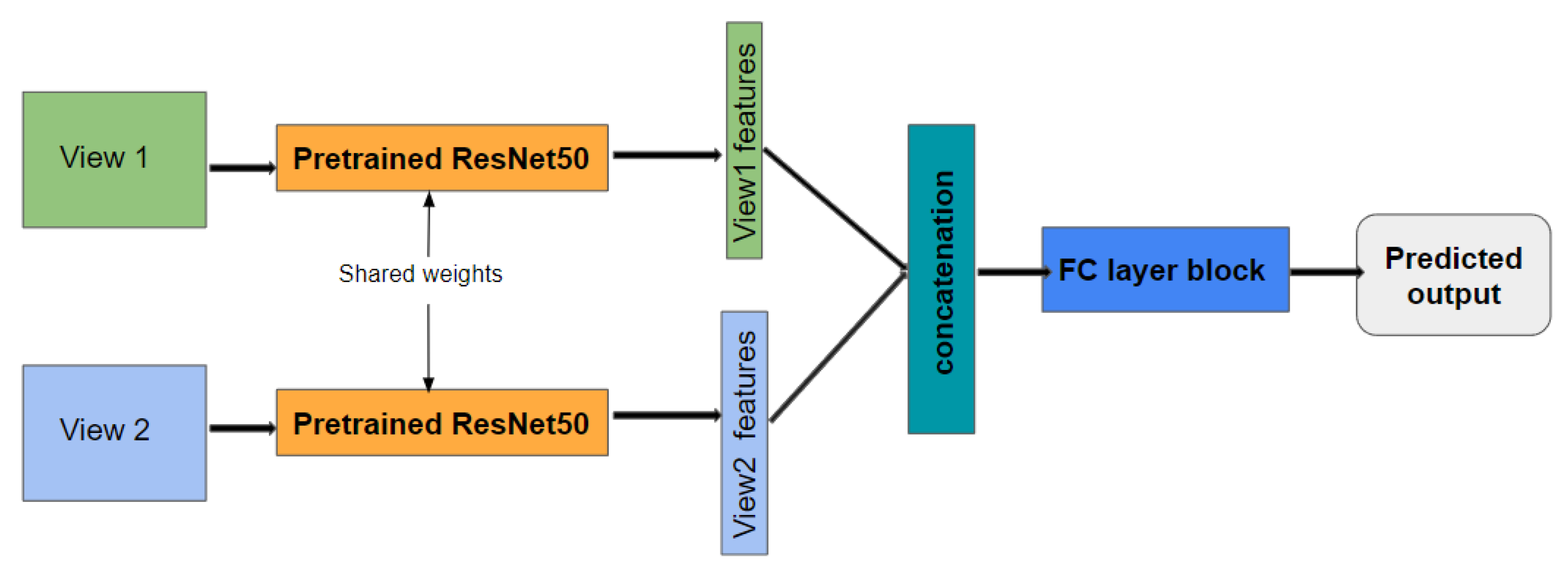
Figure 13.
The proposed Siamese architecture for multi-view learning.
Figure 13.
The proposed Siamese architecture for multi-view learning.
Figure 14.
Confusion matrix for (a) Single-view model and (b) multiview model when using view5 and view6 from UJM TIV dataset.
Figure 14.
Confusion matrix for (a) Single-view model and (b) multiview model when using view5 and view6 from UJM TIV dataset.
Table 1.
Viewing and illumination conditions of selected views from KTH-TIPS2 [
42] dataset.
Table 1.
Viewing and illumination conditions of selected views from KTH-TIPS2 [
42] dataset.
| View | Viewing Direction | Illumination Direction |
|---|
| View1 | Frontal | Frontal |
| View2 | 22.5° left | Ambient |
| View3 | Frontal | 45° from top |
| View4 | 22.5° right | Ambient |
| View5 | Frontal | 45° from side |
| View6 | Frontal | Ambient |
| View7 | 22.5° right | Frontal |
| View8 | 22.5° left | 45° from side |
| View9 | 22.5° right | 45° from top |
| View10 | 22.5° left | 45° from top |
| view11 | 22.5° right | 45° from side |
| view12 | 22.5° left | Frontal |
Table 2.
Viewing and illumination condition for selected views from the UJM-TIV dataset shown in
Figure 5.
Table 2.
Viewing and illumination condition for selected views from the UJM-TIV dataset shown in
Figure 5.
| View | Viewing Direction | Illumination Direction |
|---|
| View1 | 90° | 90° |
| View2 | 90° | 45° |
| View3 | 90° | 20° |
| View4 | 60° | 65° |
| View5 | 60° | 20° |
| View6 | 30° | 90° |
| View7 | 90° | 65° |
| View8 | 60° | 45° |
| View9 | 60° | 90° |
| View10 | 30° | 20° |
| View11 | 30° | 45° |
| View12 | 30° | 65° |
| View13 | 10° | 90° |
| View14 | 10° | 20° |
| View15 | 10° | 45° |
| View16 | 10° | 65° |
Table 3.
Model accuracy of single branch network with KTH-TIPS2 and UJM-TIV when considering all the views.
Table 3.
Model accuracy of single branch network with KTH-TIPS2 and UJM-TIV when considering all the views.
| Train Data | Test Data | Val. Accuracy |
|---|
| KTH-TIPS2 Train | KTH-TIPS2 Test | 80.00 |
| UJM-TIV Train | UJM-TIV Test | 55.26 |
Table 4.
Model accuracy of single-view and multi-view learning on KTH-TIPS2.
Table 4.
Model accuracy of single-view and multi-view learning on KTH-TIPS2.
| Train Data | Test Data | Single-View Accuracy | Multi-View Accuracy | Improvement (%) |
|---|
| view1, view2 | view1, view2 | 56.90 | 68.53 | +29.76 |
| view3, view4 | view3, view4 | 60.34 | 67.24 | +10.26 |
| view5, view6 | view5, view6 | 56.91 | 71.98 | +20.94 |
| view7, view8 | view7, view8 | 39.66 | 47.41 | +16.35 |
| view9, view10 | view9, view10 | 34.48 | 64.22 | +46.31 |
| view11, view12 | view11,view12 | 37.93 | 67.24 | +43.59 |
Table 5.
Model accuracy of single-view and multi-view learning on our UJM-TIV dataset.
Table 5.
Model accuracy of single-view and multi-view learning on our UJM-TIV dataset.
| Train Data | Test Data | Single-View Accuracy | Multi-View Accuracy | Improvement (%) |
|---|
| view1, view2 | view1, view2 | 50.28 | 79.52 | +36.77 |
| view3, view4 | view3, view4 | 60.00 | 75.29 | +20.31 |
| view5, view6 | view5, view6 | 44.48 | 95.71 | +53.52 |
| view7, view8 | view7, view8 | 51.32 | 96.52 | +46.83 |
| view9, view10 | view9, view10 | 65.59 | 95.29 | +31.17 |
| view11, view12 | view11, view12 | 66.63 | 94.56 | +29.54 |
| view13, view14 | view13, view14 | 80.33 | 89.34 | +10.08 |
| view15, view16 | view15, view16 | 53.91 | 83.78 | +35.65 |
Table 6.
State-of-the-art model [
50] accuracy of single-view and multi-view learning on KTH-TIPS2.
Table 6.
State-of-the-art model [
50] accuracy of single-view and multi-view learning on KTH-TIPS2.
| Train Data | Test Data | Single-View Accuracy | Multi-View Accuracy | Improvement (%) |
|---|
| view1, view2 | view1, view2 | 94.7 | 97.5 | +3.0 |
| view3, view4 | view3, view4 | 90.0 | 96.67 | +6.90 |
| view5, view6 | view5, view6 | 90.83 | 95.83 | +5.22 |
| view7, view8 | view7, view8 | 92.50 | 98.33 | +5.93 |
| view9, view10 | view9, view10 | 92.50 | 95.83 | +3.47 |
| view11, view12 | view11, view12 | 90.00 | 94.17 | +4.40 |
Table 7.
State-of-the-art model [
50] accuracy of single-view and multi-view learning on our UJM-TIV dataset.
Table 7.
State-of-the-art model [
50] accuracy of single-view and multi-view learning on our UJM-TIV dataset.
| Train Data | Test Data | Single-View Accuracy | Multi-View Accuracy | Improvement (%) |
|---|
| view1, view2 | view1, view2 | 100 | 98.99 | −1.02 |
| view3, view4 | view3, view4 | 99.44 | 100 | +0.56 |
| view5, view6 | view5, view6 | 99.85 | 100 | +0.15 |
| view7, view8 | view7, view8 | 99.88 | 100 | +0.12 |
| view9, view10 | view9, view10 | 99.56 | 100 | +0.44 |
| view11, view12 | view11, view12 | 99.88 | 100 | +0.12 |
| view13, view14 | view13, view14 | 99.80 | 100 | +0.20 |
| view15, view16 | view15, view16 | 98.31 | 99.58 | +1.28 |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}