1. Introduction
Learning with few examples, or few-shot learning, is a domain of research that has become increasingly popular in the past few years. Reconciling the remarkable performances of deep learning (DL), which are generally obtained thanks to access to huge databases, with the constraint of having a very small number of examples may seem paradoxical. Yet, the answer lies in the ability of DL to transfer knowledge acquired when solving a previous task toward a different, new one.
The classical few-shot setting consists of two parts:
A base dataset, which contains many examples of many classes. Since this dataset is large enough, it can be used to efficiently train DL architectures. Authors often use the base dataset alongside a validation dataset. As is usual in classification, the base dataset is used during training, and the validation dataset is then used as a proxy to measure generalization performance on unseen data and, therefore, can be leveraged to optimize the hyperparameters. However, contrary to common classification settings, in few-shot, the validation and base datasets usually contain distinct classes, so that the generalization performance is assessed on new classes [
1]. Learning good feature representations from the base dataset can be performed with multiple strategies, as will be further discussed in
Section 2;
A novel dataset, which consists of classes that are distinct from those of the base and validation datasets. We are only given a few labeled examples for each class, resulting in a few-shot problem. The labeled samples are often called the support set and the remaining ones the query set. When benchmarking, it is common to use a large novel dataset from which artificial few-shot tasks are sampled uniformly randomly, what we call a run. In that case, the number of classes n (named ways), the number of shots per class k, and the number of query samples per class q are given by the benchmark. This setting is referred to as n-way-k-shot learning. Reported performances are often averaged over a large number of runs.
In order to exploit knowledge previously learned by models on the base dataset, a common approach is to remove their final classification layer. The resulting models, now seen as feature extractors, are generally termed backbones and can be used to transform the support and query datasets into feature vectors. This is a form of transfer learning. In this work, we do not consider the use of additional data such as other datasets [
2], nor semantic information [
3]. Additional preprocessing steps may also be used on the samples and/or on the associated feature vectors, before the classification task. Another major approach uses meta-learning [
4,
5,
6,
7,
8,
9], as mentioned in
Section 2.
It is important to distinguish two types of problems:
In inductive few-shot classification, only the support dataset is available to the few-shot classifier, and prediction is performed on each sample of the query dataset independently of each other [
9];
In transductive few-shot classification, the few-shot classifier has access to both the support and the full query datasets when performing predictions [
10].
Both problems have connections with real-world situations. In general, inductive few-shot corresponds to cases where data acquisition is expensive. This is the case for FMRI data, for example, where it is difficult to generalize from one patient to another and collect hours of training data on a patient could be harmful [
11]. Alternatively, transductive few-shot corresponds to cases where data labeling is expensive. Such a situation can occur when experts must properly label data, but the data themselves are obtained cheaply, for instance in numerous medical applications [
12,
13].
In recent years, many contributions have introduced methodologies to cope with few-shot problems. There are many building blocks involved, including distillation [
14], contrastive learning [
15], episodic training [
16], mixup [
17], manifold mixup [
1,
18], and self-supervision [
1]. As a consequence, it can appear quite opaque what the effective components are and whether their performance can be reproduced across different datasets or settings. Moreover, we noticed that many of these contributions report baseline performances that can be outperformed with a simpler training pipeline.
In this paper, we are interested in proposing a very simple method combining components commonly found in the literature and yet achieving competitive performance. We believe that this contribution will help have a clearer view on how to efficiently implement few-shot classification for real-world applications. Our main motivation is to define a new baseline with good hyperparameters and training routines to compare to and to start with, on which obtaining a performance boost will be much more challenging than starting from a poorly trained backbone. We also aim at showing that a simple approach reaches higher performance than increasingly complex methods proposed in the recent few-shot literature.
More precisely, in this paper:
We introduce a very simple methodology, illustrated in
Figure 1, for both inductive and transductive few-shot classification.
We show the ability of the proposed methodology to reach or even beat state-of-the-art [
9,
19] performance on multiple standardized benchmarks of the field.
All our models, obtained feature vectors, and training procedures are freely available online on our github:
https://github.com/ybendou/easy accessed on 14 June 2022;
We also propose a simple demonstration of our method using live video streaming to perform few-shot classification. The code is available at
https://github.com/RafLaf/webcam accessed on 14 June 2022.
3. Methodology
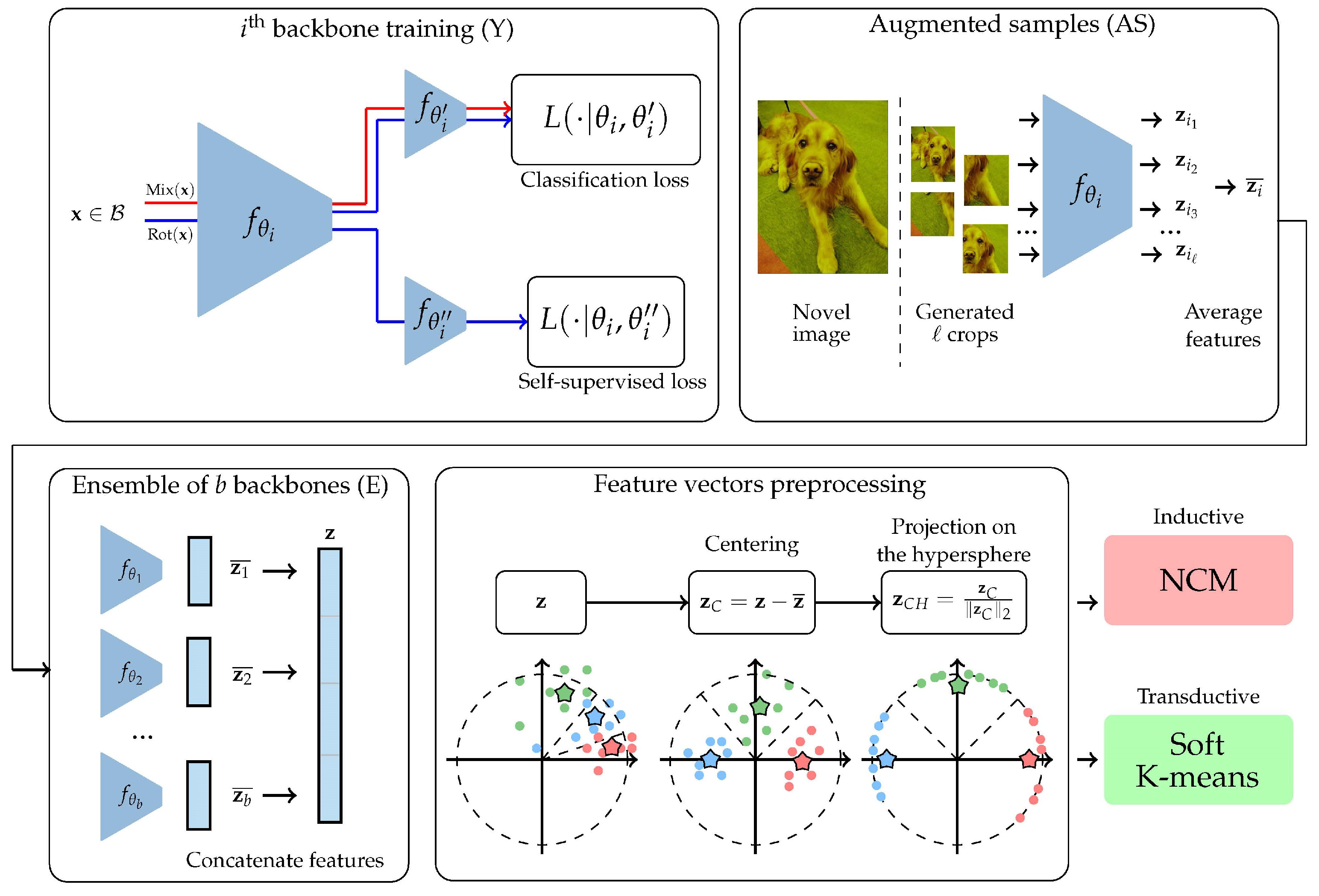
The proposed methodology consists of 5 steps, described hereafter and illustrated in
Figure 1. In the experiments, we also report ablation results when omitting the optional steps.
3.1. Backbone Training (Y)
We used data augmentation with random resized crops, random color jitters, and random horizontal flips, which is standard in the field.
We used a cosine-annealing scheduler [
39], where at each step, the learning rate is updated. During a cosine cycle, the learning rate evolves between
and 0. At the end of the cycle, we warm restart the learning procedure and start over with a diminished
. We start with
and reduce
by 10% at each cycle. We use 5 cycles with 100 epochs each.
We trained our backbones using the methodology called S2M2R described in [
1]. Basically, the principle is to take a standard classification architecture (e.g., ResNet12 [
40]) and branch a new logistic regression classifier after the penultimate layer, in addition to the one used to identify the classes of input samples, thus forming a Y-shaped model (cf.
Figure 1). This new classifier is meant to retrieve which one of four possible rotations (quarters of 360° turns) has been applied to the input samples. We used a two-step forward–backward pass at each step, where a first batch of inputs is only fed to the first classifier, combined with manifold mixup [
1,
18]. A second batch of inputs is then has arbitrary rotations applied, and this is fed to both classifiers. After this training, the backbones are frozen.
We experimented using a standard ResNet12 as described in [
40], where the feature vectors are of dimension 640. These feature vectors are obtained by computing a global average pooling over the output of the last convolution layer. Such a backbone contains
million trainable parameters. We also experimented with reduced-size ResNet12, denoted ResNet12
, where we divided each number of feature maps by 2, resulting in feature vectors of dimension 320, and ResNet12
, where the number of feature maps are divided roughly by
, resulting in feature vectors of dimension 450. The numbers of parameters are respectively
million and
million.
Using common notations of the field, if we denote as an input sample and f as the mathematical function of the backbone, then denotes the feature vector associated with .
From this point on, we used the frozen backbones to extract feature vectors from the base, validation, and novel datasets.
3.2. Augmented Samples
We propose to generate augmented feature vectors for each sample from the novel dataset. We did not perform this in the validation set as it is very computationally expensive. To this end, we used random resized crops from the corresponding images. We obtained multiple versions of each feature vector and averaged them. The literature has extensively studied the role of augmentations in deep learning [
41]. Here, we assumed most crops would contain the object of interest. Therefore, the average feature vector can be used. On the other hand, color jitter might be an invalid augmentation since some classes rely extensively on their colors to be detected (e.g., birds or fruits).
In practice, we used crops per image, as larger values do not benefit accuracy much. This step is optional.
3.3. Ensemble of Backbones
To boost performance even further, we propose to concatenate the feature vectors obtained from multiple backbones trained using the previously described method, but with different random seeds. To perform fair comparisons, when comparing a backbone with an ensemble of b backbones, we reduced the number of parameters per backbone such that the total number of parameters remains identical. We believe that this strategy is an alternative to performing distillation, with the interest of not requiring extra parameters and being a relatively straightforward approach. Again, this step is optional, and we perform ablation tests in the next section.
3.4. Feature Vector Preprocessing
Finally, we applied two transformations as in [
35] on feature vectors
. Denote
the average feature vector of the base dataset if in the inductive setting or of the few-shot problem if in transductive setting. The ideal
would center the vectors of the few-shot runs around 0 and, therefore, would be the average vector of the combined support and query set. The number of samples being too small to compute a meaningful average vector in the inductive setting, we made use of the base dataset. In the transductive setting, queries are added to the support set for mean computation. The average vector is therefore less noisy and can be used to compute
. The first operation (
C—centering of
) consists of computing:
The second operation (
H—projection of
on the hypersphere) is then:
3.5. Classification
Let us denote the set of feature vectors (preprocessed as ) corresponding to the support set for the i-th considered class and the set of (also preprocessed) query feature vectors.
In the case of inductive few-shot classification, we used a simple nearest class mean classifier (NCM). Predictions are obtained by first computing class barycenters from labeled samples:
then associating with each query the closest barycenter:
In the case of transductive learning, we used a soft K-means algorithm. We computed the following sequence indexed by
t, where the initial
are computed as in Equation (
3):
where
is a weighting function on
, which gives it a probability of being associated with barycenter
:
Contrary to the simple K-means algorithm, we used a weighted average where weight values are calculated via a decreasing function of the
distance between data points and class barycenters—here, a softmax adjusted by a temperature value
. In our experiments, we used
, which led to consistent results across datasets and backbones. In practice, we use a finite number of steps. By denoting
the resulting vectors, the predictions are:


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}