1. Introduction
Digital watermarking has been studied for a long time to preserve the copyright of digital data such as image, audio, and video by inserting some confidential information. In addition, the widespread use of Deep Neural Network (DNN) models in the current scenario is crucial to protect their copyrights. Researchers have been studying DNN watermarking to protect the intellectual property associated with DNN models. Because of the multiple network layers in a DNN model, many parameters known as network weights must be trained to attain a local minimum. However, several degrees of freedom are available for choosing the weight parameters for embedding a watermark. Moreover, the watermark is inserted in such a way that the accuracy of the model on its original task decreases to the lowest extent possible.
DNN watermarking techniques can be categorized into two types [
1]: white-box watermarking, black-box watermarking. In white-box watermarking, internal architecture and parameters are exposed to the public, and black-box watermarking takes advantage of the functionality of DNN models. In some cases, when a specific query is input, the watermark can be retrieved from its output without knowing the internal parameters; this characteristic is equivalent to creating a backdoor into the model. Basically, in the black-box methodology can only access the final layer’s output, some experts have investigated training networks to intentionally make wrong output for a given input and then use it as a watermark [
2,
3]. Moreover, the research into black-box watermarking is also receiving a great deal of attention, especially in the frequency domain [
4,
5], which performs well in terms of imperceptibility and robustness.
The first white-box method was presented in [
6,
7], where a watermark was embedded into the weight parameters of a convolutional neural network (CNN) model. The embedding operation is performed simultaneously along with the training of the model by introducing an embedding loss function so that the weights are updated according to the watermark and the supervised dataset.
In [
8,
9], the selection of the feature vector in these methods presented in [
6,
7] was refined. In [
10,
11] reported that almost all local minima are very similar to the global optimum. Empirical evidence has shown that a local minimum for deeper or larger models is sufficient because their loss values are similar. With this characteristic, the watermark was embedded into some sampled weight values in [
12,
13]. In [
13], the sample weight values were inputted to a DNN model that is independent of the host model, and error back-propagation was used to embed the watermark in both the host model and the independent model. The white-box method must be sufficiently robust to recover the watermark from a perturbed version of a DNN model because attackers can directly modify the parameters. One instance of perturbation is model pruning, where redundant neurons are pruned without compromising accuracy to reduce the computational costs of executing DNN models. The purpose of pruning is to remove less-important weight parameters from the DNN model whose contribution to the loss is small. If the watermark signal is embedded into such less-important parameters, it is easily removed or modified by pruning. Therefore, a crucial requirement of DNN watermarking is the robustness against pruning attacks [
14] while ensuring that the watermarked parameters are relevant to the original task. Uchida et al. showed experimentally that the watermark does not disappear even after a pruning attack that prunes 65% of the parameters [
6]. Another study achieved robustness against 60% pruning [
15]. This study adopted the idea of spread transform dither modulation (ST-DM) watermarking by extending the conventional spread spectrum (SS)-based DNN watermarking. A detailed survey of DNN watermarking techniques can be summarized in [
16].
Another study in [
17], embedding the watermark into the model structure by pruning has been proposed.This method was shown to be robust against attacks that adjust the model’s weights, which is a threat in other embedding methods. Moreover, this method considers pruning an embedding method, whereas we consider pruning as a perturbation by the attacker and propose a robust embedding method against pruning. In communication channels, pruning can be regarded as an erasure channel between the transmitter and the receiver of the watermark. Because numerous symbols are erased over the channel (e.g., more than half of the weight parameters are erased by pruning), erasure correcting codes are unsuitable for this channel.
In this study, we encode the watermark using binary constant weight codes (CWC) [
18,
19] to make it robust against weight-level pruning attacks. The preliminary version of this paper is available at [
20]. The symbols “1” used in the codeword are fixed and designed to be as small as possible. Thus, most of the symbols used in the codeword are becoming ”0”. To embed such a codeword, we enforce a constraint by using two thresholds while training the DNN model. The amplitude for symbol “1” is controlled to be greater than a high threshold, and that for symbol “0” is controlled to be smaller than a low threshold. Once a pruning attack is executed, the erasure of weight parameters does not affect the symbols “0” because these symbols can be extracted even if the amplitude is small. On the other hand, the symbol “1” can be detected correctly because of the high amplitude. Under the assumption that the values of weight parameters follow Gaussian or uniform distribution, the design of the two thresholds is considered to ensure robustness against pruning attacks. In the experiment, we evaluate validity of the thresholds in terms of pruning attacks and retraining of the pruned models.
Our contribution is the introduction of encoding technique into the DNN watermark to make it robust against pruning attacks. While previous studies have proposed DNN watermarks that are robust against a certain level of pruning rate, our method can assure the robustness with a pre-defined level of pruning rate by carefully setting the encoding parameters. The common scenario in which DNN watermarks are used in a DNN model is the buying and selling of DNN models. In this scenario, our method can prevent illegal redistribution and illegal copying by users who have purchased the DNN model. As a white-box watermarking is assumed in our method, it suffers from the direct modification of weight parameters, which is a common threat in white-box settings. If the weight parameters are replaced with random values and trained from scratch with a sufficient dataset, the watermark can be removed completely without compromising performance of the DNN model. Hence, it is assumed in our method that the attacker cannot train the target DNN model from scratch in terms of computational resources and training dataset.
The remainder of this paper is organized as follows.
Section 2 presents some assumptions of parameters. The proposed method is detailed in
Section 3, and experimental results are presented in
Section 4. Finally, conclusions are drawn in
Section 5, followed by suggestions for future work.
3. Proposed DNN Watermarking
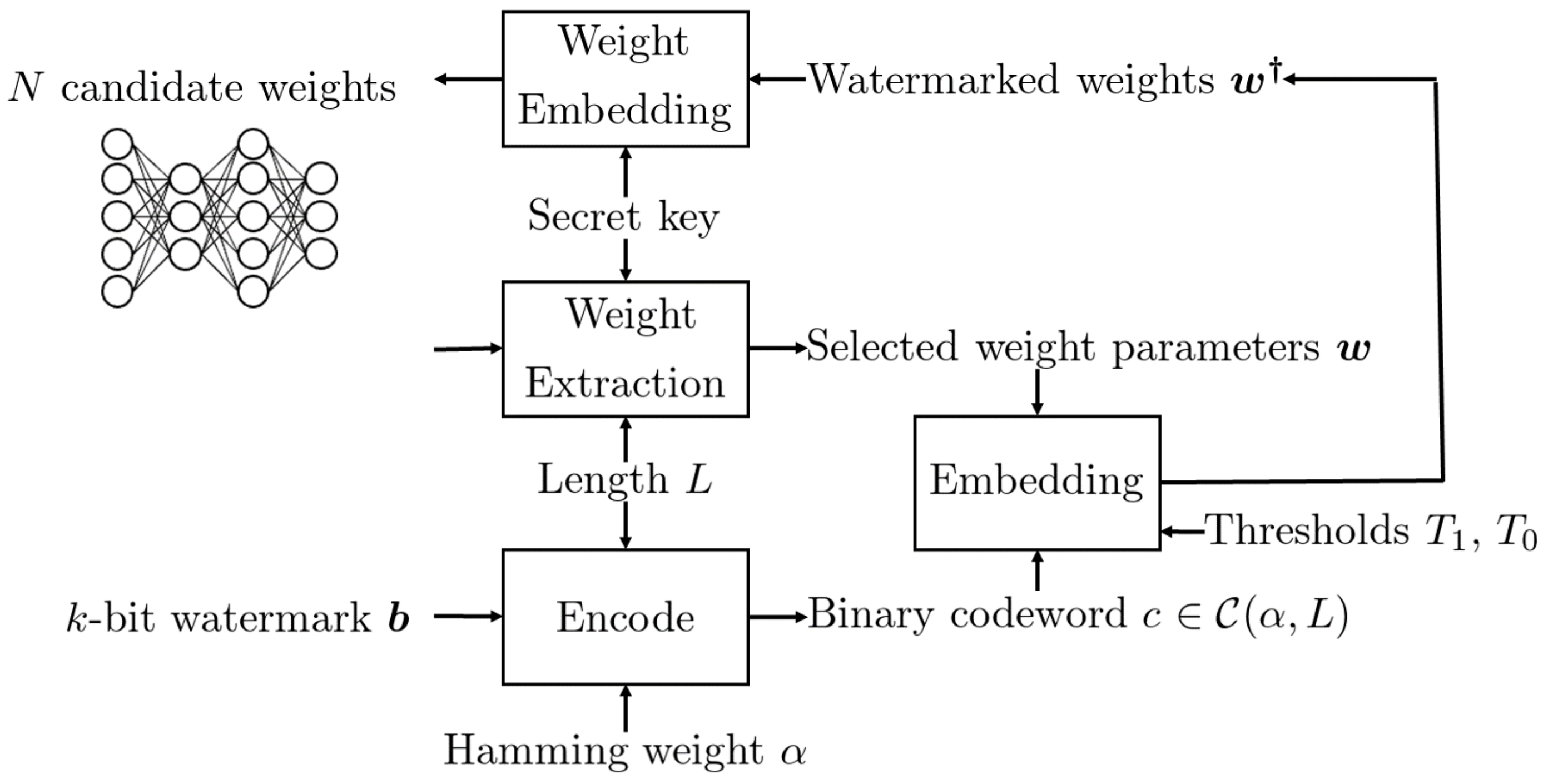
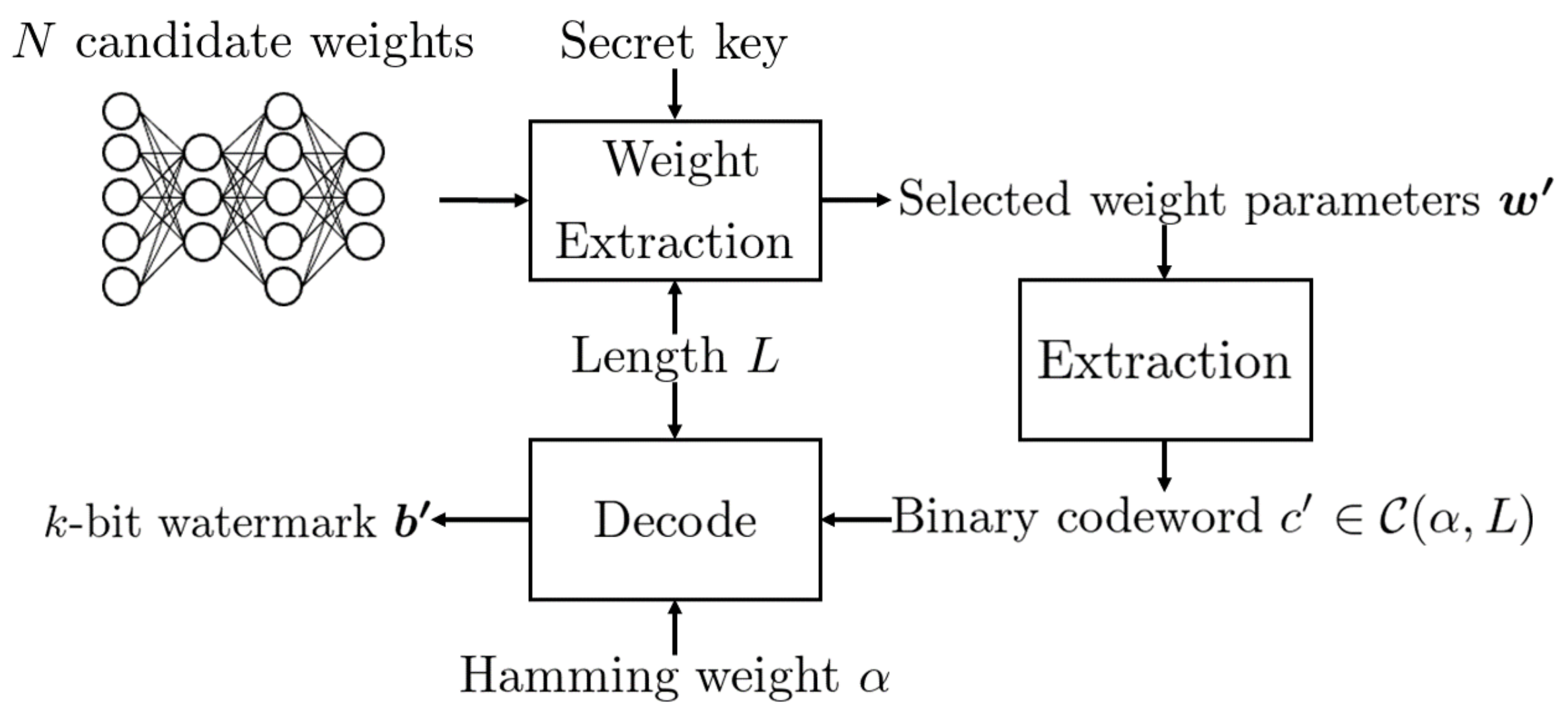
The overview of the proposed DNN watermarking is shown in
Figure 1 and
Figure 2, where
Figure 1 represents the embedding procedure and
Figure 2 represents the extraction procedure.
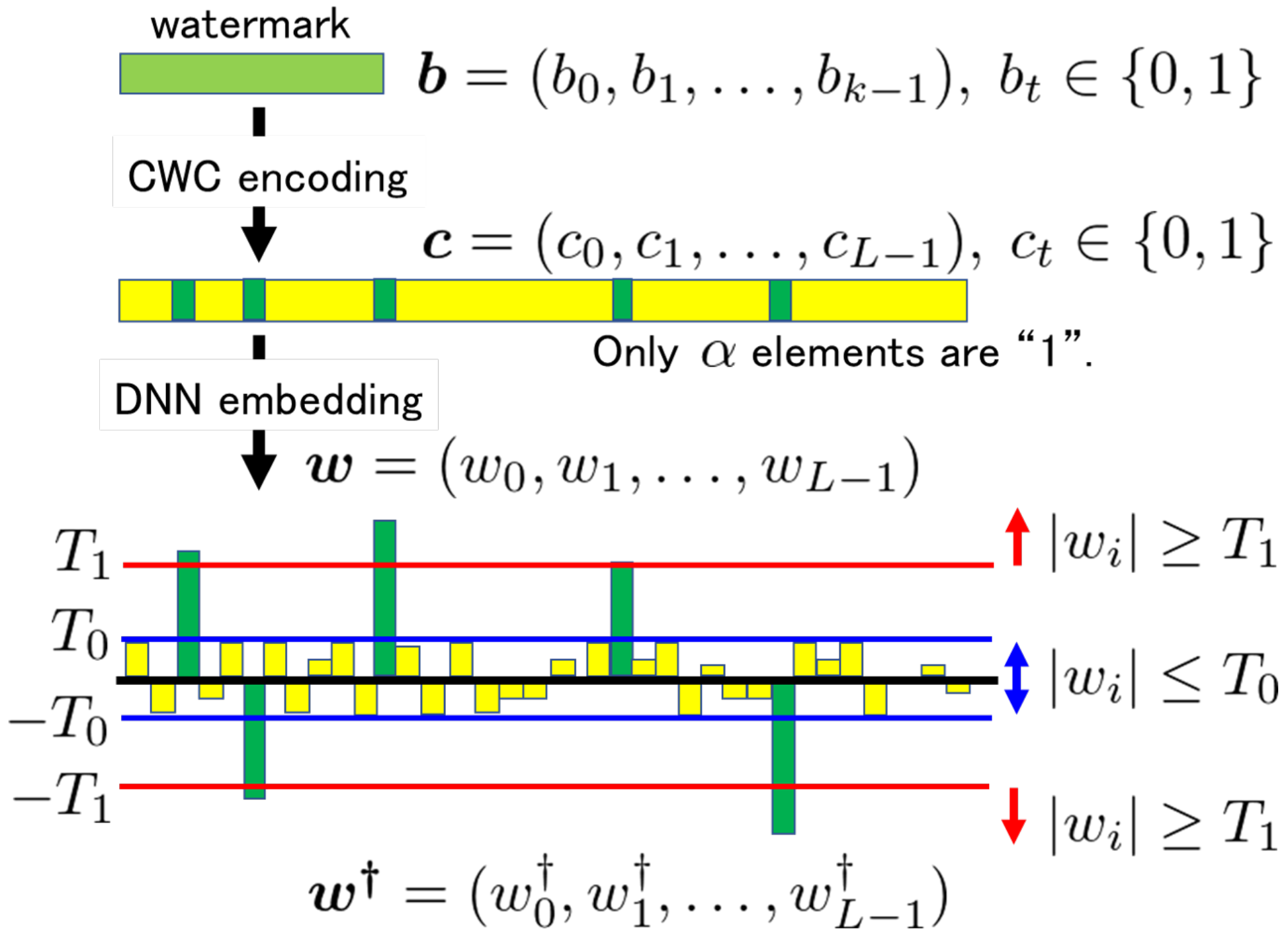
The idea is to encode the k-bit watermark b into the codeword c using CWC before the embedding operation. The weights corresponding to the elements become more than a higher threshold , while the others corresponding to becomes less than a lower threshold by the embedding operation. In case the pruning attack is executed to round weight parameters with a small value to 0, those elements are judged as bit 0 in the codeword, and hence, there is no effect on the received codeword. As for bit 1, the corresponding weight parameters should be sufficiently large so that these are not cut off.
During initialization of a given DNN model, L weight parameters w are selected from N candidates according to a secret key. Then, an encoded watermark c is embedded into w under the following constraint:
If , then ; otherwise, , where and are thresholds satisfying .
In the training process of a DNN model, weight parameters are updated iteratively to converge into a local minimum. The changes to the weights w selected for embedding c are only controlled by the above restriction during the training process in the proposed method.
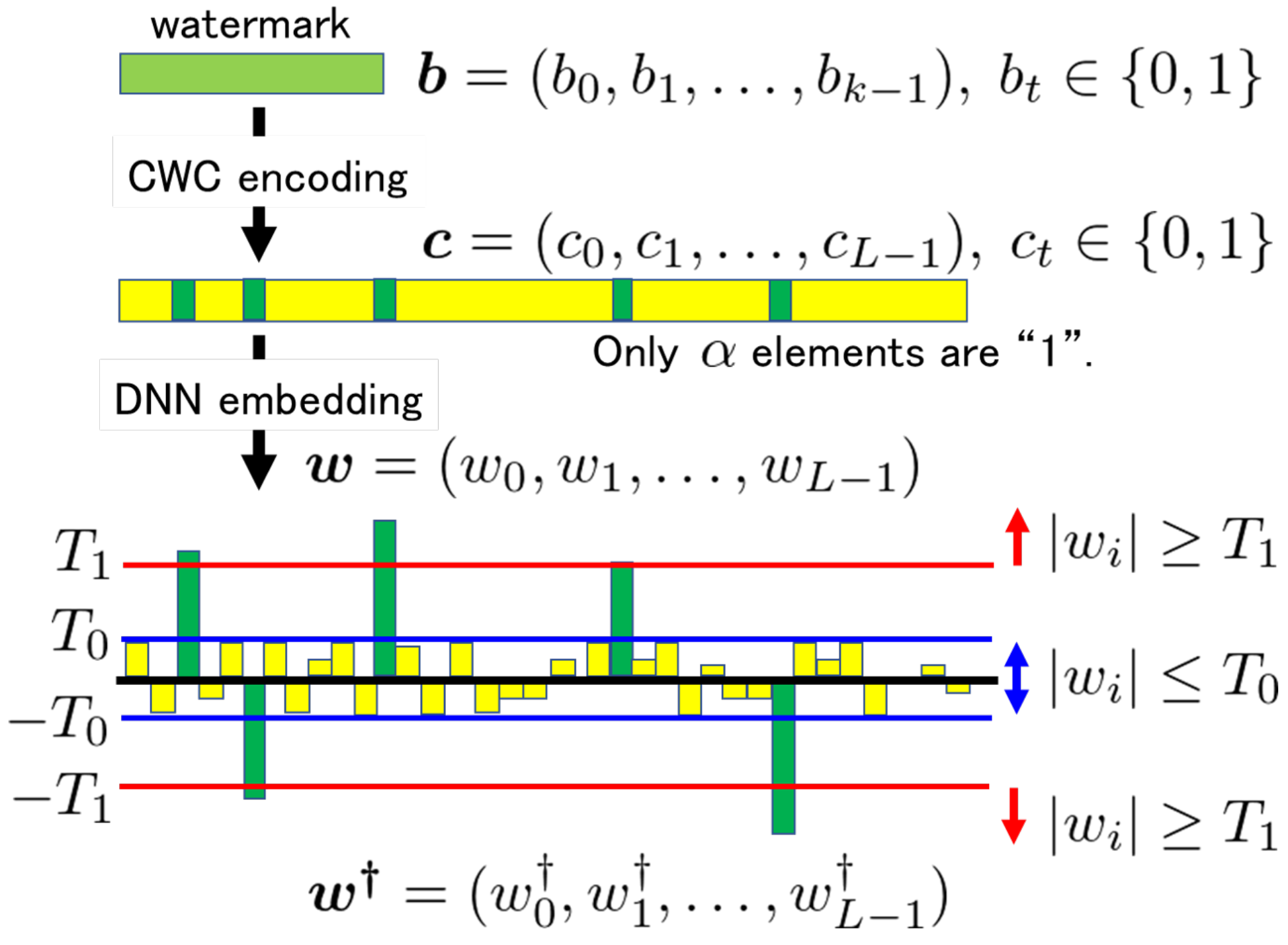
3.1. Embedding
First, we encode a
k-bit watermark
b into the codeword
c by using Algorithm 1. Here, the parameters
and
L must satisfy the following condition:
During the embedding operation, the weight parameters
w selected from the DNN model are modified into
by using the two thresholds
and
.
where
The embedding procedure is illustrated in
Figure 3.
Equation (
5) can be regarded as a constraint for executing the training process for the DNN model to embed the watermark. Among the numerous
N candidates, we impose the constraint only on the
L weight parameters selected for embedding.
3.2. Extraction
It is expected that the distribution of selected weights to be embedded is the same as the distribution of all candidates (Gaussian or uniform distribution). When embedding a watermark, the change of the distribution depends on the thresholds and as well as the length L of encoded watermark.
Detection
To check the presence of watermark in a DNN model, it is sufficient to check the bias in the distribution of selected L weights. Here, if the secret key for selecting weights is known, the bias of the binary sequence of the selected weights can be used for checking the existence of watermark. Because the red Hamming weight of the binary sequence is and it is much smaller than L, the bias is useful to detect the existence of watermark. Under the assumption is that L is extremely small compared with all candidates, it is difficult, without the secret key, to find and change the selected weights under the constraint that the performance degradation of the watermarked model is negligibly small.
If all weights in the DNN model are uniformly distributed, then the randomly selected weights are also uniformly distributed. To check whether the sequence of selected weights is the CWC codeword or not, we measure the mean square error (MSE) of the sequence. Suppose that the weights are selected from a uniform distribution with range . If the sequence of selected weights is not a CWC codeword, the distribution is the uniform distribution in the range and the mean is . On the other hand, if a CWC codeword is embedded, the distribution is different and is dependent on and as follows:
Top -th weights: the uniform distribution in the range , the mean is .
Remainder: the uniform distribution in the range , the mean is .
We can determine whether the distribution of the sequence of weights is similar to the CWC codeword or not. The MSE per the metrics is defined by the following equation.
where
3.3. Recovery of Watermark
First, the weight parameters are selected from the same DNN model positions, denoted by
. Then, the
-th largest element
is determined from
, and the codeword
is constructed as follows:
where
. Finally, using Algorithm 2, the watermark
is reconstructed from the codeword
as the result.
In the above operation, the top-
symbols in
are regarded as “1”, and the others are “0”. Even if
symbols whose absolute value is smaller than that of the top-
symbols are pruned, the codeword can be correctly reconstructed from the weight parameters
in the pruned DNN model. When the pruning rate
R satisfies the condition
statistically, no error occurs in the above extraction method. Because
L weight parameters
are sampled from
N candidates in a DNN model for embedding the watermark, the above condition does not coincide with the actual robustness against a pruning attack with rate
R.
3.4. Design of Two Thresholds
Because the weight of the codewords is constant, we selected largest elements from L elements in the weight parameter extracted from the given DNN model. Although some weight parameters are cut off by the pruning attack, the values of such elements can be retained if the threshold is appropriately designed.
Weight initialization is important to develop effective DNN models, and it is used to define the initial values for the parameters before training the models. The choice of Gaussian or uniform distribution does not have any effect, whereas the scale of the initial distribution has a significant effect on both the outcome of the optimization procedure and the ability of the network to generalize [
31]. When a Gaussian distribution is selected, whose variance is studied in [
32], the method is referred to as Xavier initialization. Later, [
33] revealed that the Xavier initialization method does not work well with the RELU activation function, and it was revised in [
34] to accommodate non-linear activation functions. These studies are based on a Gaussian assumption for the initial values, and their variance can be calculated using the libraries of PyTorch and Tensorflow.
Here, we suppose that the value of weight parameters in a DNN model is modeled as a Gaussian distribution before and after the model’s training. Because the pruning attack cuts off
p weight parameters with small values, the absolute values of
elements in
should be greater than them. A statistical analysis of the distribution gives us the following inequality for the threshold
.
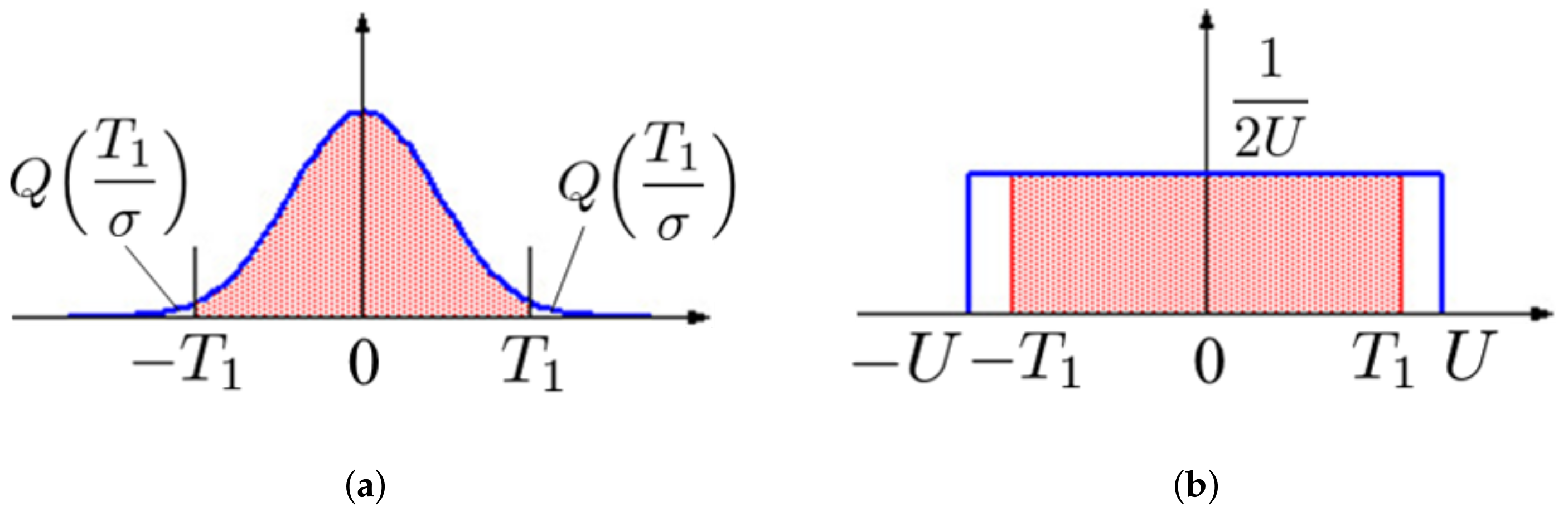
Figure 4a shows the probability density function of the weight parameters. According to the figure, for a given threshold
, the pruning rate
R can be calculated as
where
is the Q-function
By using the inverse Q-function
, the appropriate threshold
can be calculated for a given pruning rate
.
In the case of a uniform distribution in the range
, the probability density function of the weight parameters is illustrated in
Figure 4b; the shaded area in the figure corresponds to the rate
R. Here, the threshold
can be calculated to satisfy the condition:
Therefore,
can be given as
For , the condition is sufficient if only a pruning attack is assumed. Considering the robustness against other attacks that modify weight parameters in a watermarked model, we should consider an appropriate margin by setting . Setting a large value for or a small value for (a large margin of ) is ideal in terms of robustness against pruning, but it increases the amount of change in the weights. This makes abnormal features appear in the distribution of the weights, thus exposing the watermark as an attack target. On the other hand, reducing the margin of to prevent these features from appearing in the distribution of weights means increasing the possibility of bit-flip in the extracted codewords. Because these thresholds are a trade-off, it is necessary to set an appropriate margin of according to requirements.
3.5. Considerations
For simplicity of explanation, we assume that the weight levels are pruned in the ascending order, starting from the weight with the smallest value. The watermarking method can be extended to support more advanced pruning methods in the selection of weights, considering the pruning criteria and settings discussed in [
24,
25].
The usability of the proposed embedding method is confirmed from the studies of previous DNN watermarking methods. For instance, the constraint given by Equation (
5) can be applied to the embedding operations in [
6,
7,
8,
9]. In the case of the method presented in [
12], the embedding operation based on the constraint can be regarded as the initial assignment of weight parameters to a DNN model, and the change in weights at each epoch is corrected by iteratively performing the operation.
From the perspective of secrecy, it is better to select a small . Attackers can use two possible approaches to cause a bit-flip in the codeword embedded into a DNN model. One approach is to identify the elements satisfying and decrease their weight values. Among the candidates of weight parameters , identifying values becomes difficult with the increase of N. Because the total number of weight parameters in a DNN model is very large, executing this approach is difficult without significantly changing the weight parameters in the model. The other approach is to increase the weight values of selected weights whose values are . Because of the large number of candidates, finding such weights without a secret key is challenging.
3.6. Numerical Examples
Table 1 enumerates some examples of parameters for CWC
with respect to bit length
k of the watermark. For instance, when a 128-bit watermark is encoded with
, the length of its codeword becomes
. Then, the code can withstand a pruning attack with a rate of
.
If the amount of watermark information is large, it is possible to divide it into small blocks and embed each encoded block into selected weight parameters without overlapping.
4. Experimental Results
In this section, we encode a watermark using CWC and then embed the codeword into DNN models to evaluate the effects on DNN models. The amount of watermark is fixed to
bits, and the codeword is generated by different combinations of
and
L enumerated in
Table 1. Ten different watermarks were selected from random binary sequences in this experiment. Then, the robustness against a pruning attack was measured by changing the rate
R.
We considered the validity of the proposed method using accuracy and loss. In the case of binary classification, accuracy can be expressed as
where True Positive (TP) is a test result that correctly indicates the presence of a label, True Negative (TN) is a test result that correctly indicates the absence of a label, False Positive (FP) is a test result that wrongly indicates the presence of a particular label and False Negative (FN) is a test result that wrongly indicates the absence of a particular label, respectively. In the case of the multi-class classification used in our validation, accuracy is expressed as the average of the accuracy of each class, as shown below.
where,
is
i-class accuracy. And then, loss is calculated using categorical cross entropy as follows.
where
is the one-hot representation of the
t-th training data, and
is the
t-th model output. First, we compare the accuracy of the watermarked DNN model with that of the original DNN model for a given task. Second, we run the pruning attack and check the error rate, i.e., the ratio of the number of extraction failures to the number of trials. Finally, we evaluate the error rates of the pruned DNN model after retraining.
4.1. Experimental Conditions
We selected the VGG16 [
35] and ResNet50 [
36] models as pre-trained models. These models were trained using more than 1,000,000 images from the ImageNet [
37] database. A watermark was embedded into the fine-tuning model during training, similar to the experiments in [
12].
4.1.1. Fine-Tuning Model
Based on these pre-trained models, we fine-tuned the models with a batch size of 8 by replacing the new fully-connected (FC) layers connected to the final convolutional layer. The number of nodes at the final convolutional layer is 8192 () in VGG16 and 51,200 () in ResNet50, and these nodes are connected to new FC layers with 256 nodes. The number of candidates for selecting weights from the first FC layer is more than 2,000,000, , in VGG16. Similarly, it is more than 13,000,000, , in ResNet50. It is noted that the number N of weight parameters is much larger than the length L of the CWC codeword.
These fine-tuned models are trained using the 17 Category Flower Dataset (accessed on 25 May 2022) provided by the Visual Geometry Group of Oxford University—62.5% of images were used as training data, 12.5% as validation data, and 25.0% as test data. In this experiment, two types of fine-tuning methods were used for different purposes: fine-tuning to embed the CWC codeword and retraining to reduce the effect of pruning attacks. The epochs for fine-tuning to embed are 50 for VGG16 and 100 for ResNet50, respectively. The number of epochs for retraining the pruned models is 5.
4.1.2. Threshold
The threshold
must be designed appropriately to ensure robustness against pruning attacks. As discussed in
Section 3.4, it depends strongly on the weight initialization. Owing to its simplicity, we selected the uniform distribution with the default setting of weight initialization [
33] in the PyTorch environment.
In the VGG16-based model, we set the threshold = 0.026 for the uniform distribution in the range . This indicates that the percentage of weight parameters whose values are smaller than the threshold is 97.56%; thus, . We also set the threshold = = 0.013. For the ResNet50-based model, we set the threshold = 0.010 for the uniform distribution in the range . This indicates that the percentage of weight parameters with values smaller than the threshold is 92.61%; thus, . We also set the threshold = = 0.005.
4.2. Effect of Watermark on Original Task
When embedding a watermark into a DNN model, the accuracy of the original task should not reduce significantly. For each Hamming weight of codewords
and its length
L by
in
Table 1, we compared DNN models with and without embedding in terms of accuracy and loss metrics, and the results are enumerated in
Table 2, where we calculate the average of 10 trials in this experiment. Even though the results show some variation, the watermarked model does not show any noticeable difference from the original model. These results confirm that the effect of embedding a watermark into a DNN model on the performance of the original task is negligible. Although the original loss appears to be slightly higher than that of the model with embedding, this difference is within the margin of variation of the simulation.
4.3. Detection Performance
We have confirmed that the watermark embedded in the DNN model can be detected correctly. In the embedding procedure, weights are randomly selected from all weights in the DNN model based on a secret key. To detect the presence of hidden watermark, it is sufficient to determine whether this selected weights sequence is the CWC codeword or not.
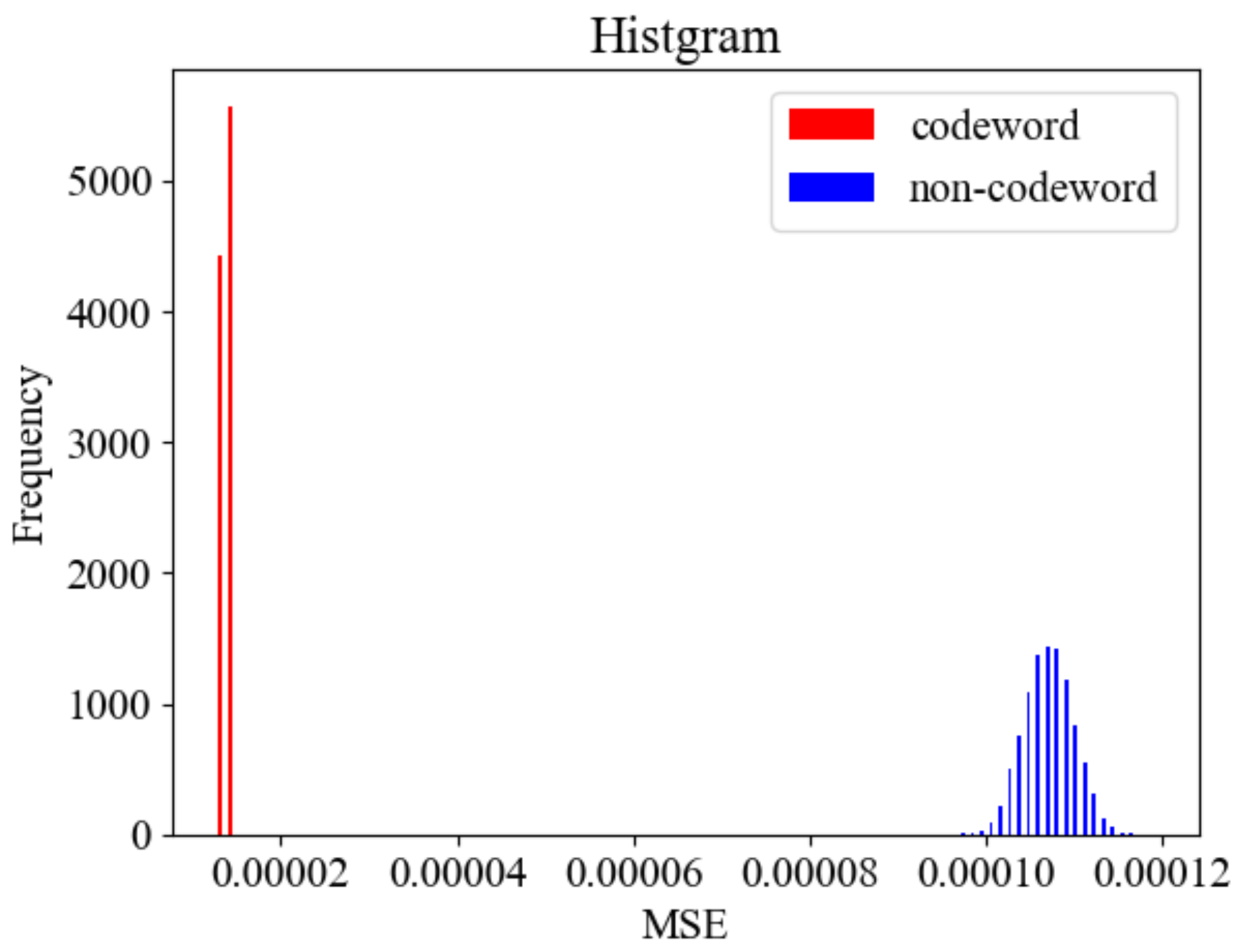
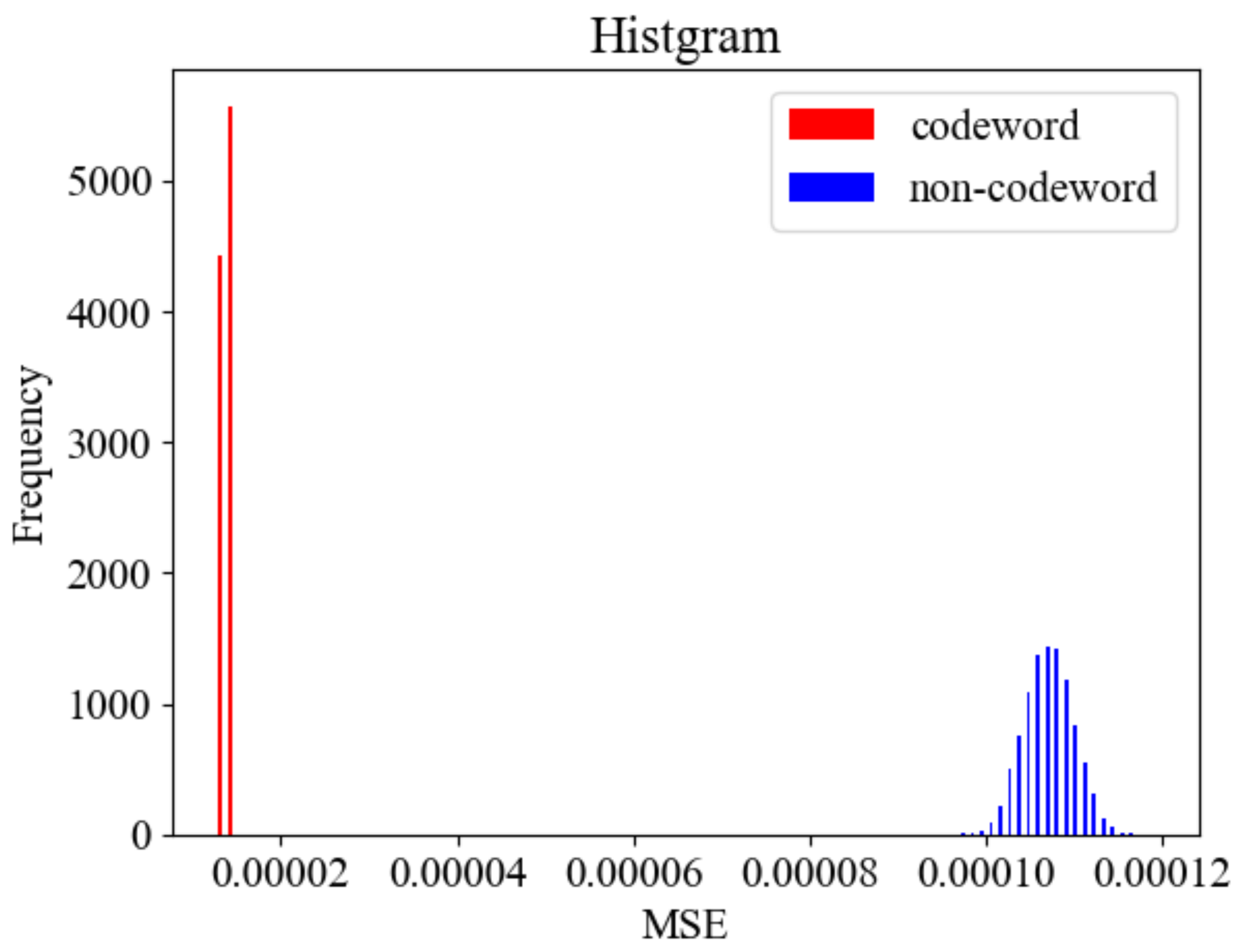
We conducted the simulation under the setup of . We generated 10,000 codewords and 10,000 non-codewords, respectively, where the codewords have code length and . The non-codewords are a randomly selected sequence from a uniform distribution.
The MSE was calculated for each of the generated codewords and non-codewords.
Figure 5 shows the histogram of MSEs. As the figure shows, the distribution of MSEs can be clearly separated for codewords and non-codewords. This result implies that it is easy to distinguish codewords from non-codewords by setting a proper threshold.
4.4. Robustness against Pruning Attacks
We measured the robustness of the CWC codeword against a pruning attack. We selected the threshold
to ensure robustness against pruning attacks with a pruning rate of
and
for the VGG16-based and ResNet50-based models, respectively. Unfortunately, the distribution of weight parameters changed slightly after training. Therefore, we evaluated the robustness against pruning attacks by varying
R in the range
in increments of
. In this evaluation, no error occurred in the extraction of the watermark. Therefore, for a detailed evaluation, we executed the pruning attack by varying the range
in increments of
, whose results are shown in
Table 3. The VGG16-based model has an error rate of 0% when the pruning rate is
. The ResNet50-based model has no error for the pruning rate of
. Thus, it is confirmed that the fine-tuned models based on VGG16 and ResNet50 are robust against pruning attacks if the pruning rate
R is less than the designed rate
, which can be determined using the CWC parameters
and
L.
Note that robustness against a pruning attack whose pruning rate R is less than the designed pruning rate is not always guaranteed, but it is statistically assured. This is because the thresholds are set from the distribution of the entire weight parameters in a DNN model, while the weights to be embedded are randomly selected from the entire weights based on the secret key. Nevertheless, under this condition, experiments show that the robustness can be well-managed by carefully selecting the thresholds and .
4.5. Retrained DNN Model after Pruning Attack
As mentioned in
Section 2.2, the DNN model is retrained after the pruning attack to recover the accuracy of the original task. We measure the accuracy for the DNN models based on VGG16 and ResNet50 before and after retraining the pruned model. Without the retraining, the higher the pruning rate, the lower the accuracy for the VGG16-based method, while the ResNet50-based model seems to be less affected by pruning attacks. Among some possible hyper-parameters, the main difference between them will be the number of weight parameters. A detailed analysis will be performed in a future work.
Table 4 shows the error rate of the CWC codeword when the pruned models are retrained. It is observed that no error occurs in the VGG16-based model when the pruning rate is
. This indicates that the watermark becomes robust against pruning attacks if
. In the model using ResNet50, errors still occur even when the pruning rate is
. We speculate that this is because the weights in the FC layers of ResNet50 are more sensitive to relearning and, thus, are more likely to change. This error can be avoided by embedding watermarks in the lower layers. Although the number of trials in this experiment is small, the results confirm that the CWC can be extracted even after the pruning attack and retraining. An extensive analysis will be performed in future work. These results demonstrate that encoding using CWC guarantees the robustness of a watermarked DNN model against pruning attacks, regardless of whether it has been retrained or not.
4.6. Comparison with Previous Studies
Table 5 shows the effect of attacks on performance when ascending pruning attacks and random pruning attacks are performed with increasing pruning rates in previous studies [
6,
13,
15]. In the ascending pruning attack, the top
R% parameters are cut-off according to their absolute values in ascending, while in the random pruning attack,
R In the evaluation of multilayer perceptron (MLP) and VGG, the bit error rate (BER) is zero up to a pruning rate of 0.9; in the evaluation of Wide ResNet (WRN), the BER is zero up to a pruning rate of 0.6 or 0.65. As discussed in
Section 3.4, the robustness of our method can be controlled by defining the pair of code parameters
and
L, and an appropriate threshold
, which makes our method more robust than the existing methods.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}