
Union-Retire for Connected Components Analysis on FPGA



Abstract
1. Introduction
2. Related Work
3. Union-Retire Algorithm
 ), object pixels in black (
), object pixels in black ( ), and pixels that can be either object or background are shown in grey (
), and pixels that can be either object or background are shown in grey ( ).
). , line 5; current row:
, line 5; current row:  , line 8).
, line 8). , line 8), and updated for each object pixel within a run on the current row (
, line 8), and updated for each object pixel within a run on the current row ( , line 12), where ⊕ is the operation which combines two feature vectors.
, line 12), where ⊕ is the operation which combines two feature vectors.

 , line 15). This link is always added from to facilitate the Retire operation. If node P already has a link then the link is added to its successor so that several successive nodes are linked in a chain (see lines 19 and 22). If the successor node already has two links then the link is propagated to the successor’s most recent successor (line 44).
, line 15). This link is always added from to facilitate the Retire operation. If node P already has a link then the link is added to its successor so that several successive nodes are linked in a chain (see lines 19 and 22). If the successor node already has two links then the link is propagated to the successor’s most recent successor (line 44).
| Algorithm 1 Union-Retire CCA algorithm (adapted with permission from ref. [3]. Copyright 2021 Springer.) |
|







 , line 26), the associated index is never accessed again. Therefore, a Retire operation is performed, removing the corresponding node from the graph. The feature vector associated with the retired node is accumulated into a linked node (⊕ on lines 30 and 32). If there are no linked nodes then the object is detected as completed, and the feature vector of the connected component is output. If there are two linked nodes then it is necessary to insert a link between the nodes to maintain connectivity within the graph as the node is removed.
, line 26), the associated index is never accessed again. Therefore, a Retire operation is performed, removing the corresponding node from the graph. The feature vector associated with the retired node is accumulated into a linked node (⊕ on lines 30 and 32). If there are no linked nodes then the object is detected as completed, and the feature vector of the connected component is output. If there are two linked nodes then it is necessary to insert a link between the nodes to maintain connectivity within the graph as the node is removed.4. Hardware Implementation
- The input image is assumed to be streamed in a raster manner with a throughput of one pixel per clock cycle. This will require many of the operations to be pipelined, especially those that update data structures in memory.
- The hardware realisation must be able to work on a continuous stream, i.e., one without any blanking at the end of the line () or frame (). This implies that additional blank pixels cannot be inserted at the end of line and frame to facilitate transition from one image row to the next, or from one frame to the next.
- To minimise latency, it is desired that the feature vectors for each connected component be output as soon as the end of the component is detected.
- Forming the window from the incoming binary pixel stream, and assigning each run of pixels a corresponding node index.
- Link processing identifies linkages between runs on the current row and runs on the previous row, and maintains the graph structure, which represents the connectivity as each pixel is processed.
- Data processing builds the feature vector associated with each connected component, and outputs this when the component is completed.
4.1. Forming the Window
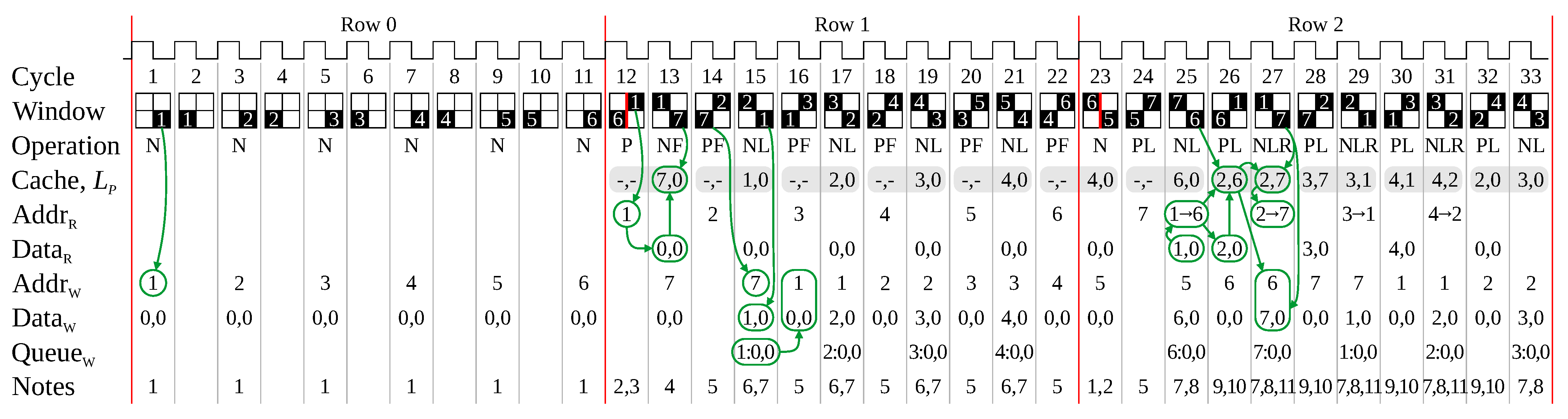
 ), or an object pixel in the first pixel of a row). Once a run leaves the previous row within the window, it is never encountered again. This enables the indices associated with the nodes to be recycled, reducing the size of the link and data tables. The maximum number of indices required at any one time is based on the width of the image [3], and is given by . Therefore, the counter goes from 1 for the first run, up to , after which it resets to 1 again. Note that index 0 is reserved to indicate empty links within the link table.
), or an object pixel in the first pixel of a row). Once a run leaves the previous row within the window, it is never encountered again. This enables the indices associated with the nodes to be recycled, reducing the size of the link and data tables. The maximum number of indices required at any one time is based on the width of the image [3], and is given by . Therefore, the counter goes from 1 for the first run, up to , after which it resets to 1 again. Note that index 0 is reserved to indicate empty links within the link table.4.2. Link Processing
- N-operation:
 , at the start of a new run on the current row. This requires the link table entry for the new node to be initialised by clearing the links to zero (since node indices are recycled, and the link table may contain old links), (a write operation).
, at the start of a new run on the current row. This requires the link table entry for the new node to be initialised by clearing the links to zero (since node indices are recycled, and the link table may contain old links), (a write operation). - P-operation:
 , at the start of a run on the previous row. The link table entry for the corresponding node is read into the cache to facilitate adding links, (a read operation).
, at the start of a run on the previous row. The link table entry for the corresponding node is read into the cache to facilitate adding links, (a read operation). - L-operation: one of


 , at the end of a run on the current or previous row, while there in an object pixel in the other row. A Union adds a link from the node on the previous row to the node on the current row, . There are two variations to this: if the cache is empty (), or the cache contains a link.
, at the end of a run on the current or previous row, while there in an object pixel in the other row. A Union adds a link from the node on the previous row to the node on the current row, . There are two variations to this: if the cache is empty (), or the cache contains a link.- −
- If the cache is empty, an F-operation adds the first link to the cache, (no memory operations).
- −
- Otherwise, a chained link is added to the graph from the most recent link, (this requires a read and a write memory operation), and the link is replaced, .
- R-operation:
 , at the end of a run on the previous row, a Retire removes node P from the graph. If the cache has fewer than two links () then no operation is required because removing the node does not affect the connectivity. Otherwise, a link must be added between the two connected nodes to maintain connectivity of the object graph when node P is removed, (a read and a write).
, at the end of a run on the previous row, a Retire removes node P from the graph. If the cache has fewer than two links () then no operation is required because removing the node does not affect the connectivity. Otherwise, a link must be added between the two connected nodes to maintain connectivity of the object graph when node P is removed, (a read and a write).






4.2.1. Link Table Memory Bandwidth
- An N-operation every second pixel requires a write in every second cycle;
- A P-operation every second pixel requires a read in every second cycle;
- An L-operation with every pixel requires a read followed by a write in every clock cycle;
- An R-operation every second pixel requires, in the worst case, a read followed by a write in every second cycle.
- 1.
- Loading the cache for a P-operation must be performed immediately. This ensures that the links are available for subsequent operations.
- 2.
- An F-operation only updates the cache; as this is the first link, a chained link is not required.
- 3.
- If a P- and L-operation occur in the same cycle (data pattern:
 ), then adding the link must be deferred until the following clock cycle because the links for the previous row have not yet been loaded into the cache.
), then adding the link must be deferred until the following clock cycle because the links for the previous row have not yet been loaded into the cache. - 4.
- If an L-operation is deferred and this is followed immediately by another L-operation (
 ) then there will be a chain from the first link to the second, . Since links are always from an earlier node to a later node, must be empty, therefore the read operation for the chained link is not required, and the link can be written directly to the table, . (This saves 1 read operation.)
) then there will be a chain from the first link to the second, . Since links are always from an earlier node to a later node, must be empty, therefore the read operation for the chained link is not required, and the link can be written directly to the table, . (This saves 1 read operation.) - 5.
- If as a result of adding a link, is read in the cycle immediately before a P-operation, then the cache read is redundant (as the index has just been read). The subsequent write-back of the updated link entry is also not required, as the update can be made directly on the cache. (This saves 1 read and 1 write operation.)
- 6.
- If when adding a link to a node, the destination node is already linked, then the write is not necessary. (This saves 1 write operation if the write is to memory.)
- 7.
- If, when adding a link (), node X already has 2 outgoing links, it is necessary to pass the link on, . (This requires 1 extra memory read, but does not occur very frequently.)
- 8.
- If an L- and R-operation occur in the same cycle (
 ) then the cache is updated to reflect the link, the retirement link is queued first, () with the chained link queued second (). occurs earlier than , so this reduces potential data hazards.
) then the cache is updated to reflect the link, the retirement link is queued first, () with the chained link queued second (). occurs earlier than , so this reduces potential data hazards. - 9.
- Initialising the link entry for an N-operation has the lowest priority, as it cannot be used for at least two clock cycles.



4.2.2. EOL Queuing
4.2.3. EOF Processing
4.2.4. Link Table Architecture
- A P-operation to load the cache, with the address coming from the P-counter;
- When adding a link into the memory, either when adding a chain from an L-operation, or from an R-operation, in both cases, the address comes from the cache;
- When adding a link, and the link table already has two entries, the next access is to one of the links just read.
- Clearing prior use of the index by an N-operation;
- Writing the updated outgoing connections for a node when a link is added.
4.3. Data Processing
- Data are accumulated for the run of pixels on the current row (, where is the feature vector for the current pixel) and saved into a data table at the end of the current run ().
- When a node is retired (at the end of the run on the previous row), its associated feature datum, , is merged into the data table entry of its most recent outgoing link. Let the merge link be , then the data merging is .
- If there are no outgoing links, the connected component is completed, and the feature vector, is streamed out.
- At the end of the run on the current row (window pattern
 ), the accumulated feature vector for the row is written to the data table: .
), the accumulated feature vector for the row is written to the data table: . - At the start of the run on the previous row (window pattern
 ), the feature vector is read from memory, , in preparation for merging with data from another run when the node is retired.
), the feature vector is read from memory, , in preparation for merging with data from another run when the node is retired. - At the end of the run on the previous row (window pattern
 ) when the node is retired, it is necessary to merge the feature vector into the feature vector of an outgoing link.
) when the node is retired, it is necessary to merge the feature vector into the feature vector of an outgoing link.- −
- If there is an object pixel on the current row (

 ), then this will have the index of the most recent link, and the data can be merged directly into the current row accumulator ().
), then this will have the index of the most recent link, and the data can be merged directly into the current row accumulator (). - −
- Otherwise (
 ) the merge index comes from the link processor cache, . This requires reading the data table entry for the link, accumulating the feature vector, and writing the result back to memory: . The data table read takes one clock cycle () with the accumulated feature vector written back in the following cycle ().
) the merge index comes from the link processor cache, . This requires reading the data table entry for the link, accumulating the feature vector, and writing the result back to memory: . The data table read takes one clock cycle () with the accumulated feature vector written back in the following cycle ().






4.3.1. Data Hazards
 can potentially create a data hazard. The node associated with the first run, is retired when the background pixel is encountered. The data table for the outgoing link, is read to accumulate the feature vector into. The combined feature vector is written back to the data table in the following clock cycle. However, in this cycle, the run is encountered with being loaded from memory. If then this results in a read-before-write hazard because is not updated in memory until the end of that cycle. Such linking between consecutive runs is actually quite common as a result of chaining. This can easily be handled by data forwarding, skipping both the write of and the read of , and the accumulated data directly forwarded to .
can potentially create a data hazard. The node associated with the first run, is retired when the background pixel is encountered. The data table for the outgoing link, is read to accumulate the feature vector into. The combined feature vector is written back to the data table in the following clock cycle. However, in this cycle, the run is encountered with being loaded from memory. If then this results in a read-before-write hazard because is not updated in memory until the end of that cycle. Such linking between consecutive runs is actually quite common as a result of chaining. This can easily be handled by data forwarding, skipping both the write of and the read of , and the accumulated data directly forwarded to .4.3.2. EOL Processing
 where the red line indicates the transition between one row of image pixels and the following row. The ends run on the previous row, resulting in retirement of the associated node, and starts a new run (with a new index, ). The two pixels in the window are not directly connected; they are separated by the . The retirement requires reading the linked entry, for passing the feature data on to, and the new run also requires a read of to load the feature data for that node. This pattern therefore requires two simultaneous data table reads.
where the red line indicates the transition between one row of image pixels and the following row. The ends run on the previous row, resulting in retirement of the associated node, and starts a new run (with a new index, ). The two pixels in the window are not directly connected; they are separated by the . The retirement requires reading the linked entry, for passing the feature data on to, and the new run also requires a read of to load the feature data for that node. This pattern therefore requires two simultaneous data table reads. . In this case, if the two nodes both link directly to a common third node (), the data for that first retirement will be written to in the same cycle as the data is read for accumulating the second retirement, ]. In this case, the second read can be skipped, with the data for the second retirement accumulated directly.
. In this case, if the two nodes both link directly to a common third node (), the data for that first retirement will be written to in the same cycle as the data is read for accumulating the second retirement, ]. In this case, the second read can be skipped, with the data for the second retirement accumulated directly. when the indices for the two runs are the same (; this will be the case if the run occupies the full width of the image). The read (for the run on the previous row) is to the same address as the write (for saving the feature vector for the current run). Again this can be managed through data-forwarding, skipping both the read and the write.
when the indices for the two runs are the same (; this will be the case if the run occupies the full width of the image). The read (for the run on the previous row) is to the same address as the write (for saving the feature vector for the current run). Again this can be managed through data-forwarding, skipping both the read and the write. requires two simultaneous writes. The first is the pipelined write for the retirement of the node on the previous row (), and the second is for saving the feature vector for the node on the current row (). The previous case of two simultaneous reads and this case of two writes mean that the data table must use true dual-port memory.
requires two simultaneous writes. The first is the pipelined write for the retirement of the node on the previous row (), and the second is for saving the feature vector for the node on the current row (). The previous case of two simultaneous reads and this case of two writes mean that the data table must use true dual-port memory. , which requires a read in addition to the two writes. In this case, the write-back of is delayed until the following clock cycle.
, which requires a read in addition to the two writes. In this case, the write-back of is delayed until the following clock cycle.4.3.3. EOF Processing
 (where the horizontal red line represents the boundary between successive frames) also requires a read and two writes. As before, the write-back of can be delayed until the following clock cycle.
(where the horizontal red line represents the boundary between successive frames) also requires a read and two writes. As before, the write-back of can be delayed until the following clock cycle.4.3.4. Data Table Architecture
 when there is a link between the two runs on the previous row. This requires combining four feature vectors (requiring a minimum of three ⊕ operators):
when there is a link between the two runs on the previous row. This requires combining four feature vectors (requiring a minimum of three ⊕ operators): 5. Results and Discussion
 when there is a link between the two runs on the previous row. The data for these are combined, with the result merged with the feature vector of the current row, and written to the data table (). A similar critical path is for writing the result into the register (, which occurs with the pattern
when there is a link between the two runs on the previous row. The data for these are combined, with the result merged with the feature vector of the current row, and written to the data table (). A similar critical path is for writing the result into the register (, which occurs with the pattern  ). In both cases, the majority of the propagation delay comes from the ⊕ operations. This means that these paths could potentially be pipelined by delaying the processing of the current row by one cycle relative to the processing of the previous row (although this would introduce additional timing complications).
). In both cases, the majority of the propagation delay comes from the ⊕ operations. This means that these paths could potentially be pipelined by delaying the processing of the current row by one cycle relative to the processing of the previous row (although this would introduce additional timing complications).5.1. Comparison with Other CCA Algorithms
- Recycling labels;
- Keeping track of chains of successive mergers;
- Detecting completed components.
5.1.1. Memory Requirements of Union-Retire
5.1.2. Comparison to Single-Lookup CCA
5.1.3. Comparison to Zig-Zag Scan
5.1.4. Comparison to Direct Relabelling
5.1.5. Comparison to Linked-List Based Processing
5.1.6. Discussion of UR-CCA
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ⊕ | Combination operator for feature vectors |
| ALUT | Intel’s adaptive lookup table |
| C | Index of the run on the current row within the window |
| CCA | Connected components analysis |
| CCL | Connected components labelling |
| Data table containing feature vectors for each index | |
| EOF | End of frame |
| End of line | |
| Feature vector for point | |
| FF | Flip-flop |
| FPGA | Field programmable gate array |
| Link table containing arcs for each node/index | |
| M | Index for merging data into when retiring a node |
| M10K | 10 kbit RAM block |
| P | Index of the run on the row within the window |
| RAM | Random access memory |
| UR-CCA | Union-retire-based CCA |
References
- Klaiber, M.; Bailey, D.G.; Simon, S. Comparative study and proof of single-pass connected components algorithms. J. Math. Imaging Vis. 2019, 61, 1112–1134. [Google Scholar] [CrossRef]
- Bailey, D.G. History and evolution of single pass connected component analysis. In Proceedings of the 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020; pp. 317–322. [Google Scholar] [CrossRef]
- Bailey, D.G.; Klaiber, M.J. Union-Retire: A new paradigm for single-pass connected component analysis. In Geometry and Vision. ISGV 2021; Communications in Computer and Information Science; Springer: Cham, Switzerland, 2021; Volume 1386, pp. 273–287. [Google Scholar] [CrossRef]
- Rosenfeld, A.; Pfaltz, J. Sequential operations in digital picture processing. J. Assoc. Comput. Mach. 1966, 13, 471–494. [Google Scholar] [CrossRef]
- Dillencourt, M.B.; Samet, H.; Tamminen, M. A general approach to connected-component labeling for arbitrary image representations. J. Assoc. Comput. Mach. 1992, 39, 253–280. [Google Scholar] [CrossRef]
- Bailey, D.G.; Johnston, C.T. Single pass connected components analysis. In Proceedings of the Image and Vision Computing New Zealand (IVCNZ), Hamilton, New Zealand, 5–7 December 2007; pp. 282–287. [Google Scholar]
- Ma, N.; Bailey, D.; Johnston, C. Optimised single pass connected components analysis. In Proceedings of the International Conference on Field Programmable Technology (FPT), Taipei, Taiwan, 8–10 December 2008; pp. 185–192. [Google Scholar] [CrossRef]
- Klaiber, M.J.; Bailey, D.G.; Baroud, Y.O.; Simon, S. A resource-efficient hardware architecture for connected component analysis. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1334–1349. [Google Scholar] [CrossRef]
- Zhao, F.; Lu, H.Z.; Zhang, Z.Y. Real-time single-pass connected components analysis algorithm. EURASIP J. Image Video Process. 2013, 21, 10. [Google Scholar] [CrossRef][Green Version]
- Jeong, J.W.; Lee, G.B.; Lee, M.J.; Kim, J.G. A single-pass connected component labeler without label merging period. J. Signal Process. Syst. 2016, 84, 211–223. [Google Scholar] [CrossRef]
- Bailey, D.G.; Klaiber, M.J. Zig-zag based single pass connected components analysis. J. Imaging 2019, 5, 45. [Google Scholar] [CrossRef] [PubMed]
- Spagnolo, F.; Perri, S.; Corsonello, P. An efficient hardware-oriented single-pass approach for connected component analysis. Sensors 2019, 19, 3055. [Google Scholar] [CrossRef] [PubMed]
- Kumar, V.S.; Irick, K.; Maashri, A.A.; Narayanan, V. A scalable bandwidth-aware architecture for connected component labeling. In VLSI 2010 Annual Symposium; Lecture Notes in Electrical Engineering; Springer: Dordrecht, The Netherlands, 2011; Volume 105, pp. 133–149. [Google Scholar] [CrossRef]
- Klaiber, M.J.; Bailey, D.G.; Ahmed, S.; Baroud, Y.; Simon, S. A high-throughput FPGA architecture for parallel connected components analysis based on label reuse. In Proceedings of the International Conference on Field Programmable Technology (FPT), Kyoto, Japan, 9–11 December 2013; pp. 302–305. [Google Scholar] [CrossRef]
- Klaiber, M.J. A Parallel and Resource-Efficient Single Lookup Connected Components Analysis Architecture for Reconfigurable Hardware. Ph.D. Thesis, Stuttgart University, Stuttgart, Germany, 2017. [Google Scholar]
- Kowalczyk, M.; Ciarach, P.; Przewlocka-Rus, D.; Szolc, H.; Kryjak, T. Real-time FPGA implementation of parallel connected component labelling for a 4K video stream. J. Signal Process. Syst. 2021, 93, 481–498. [Google Scholar] [CrossRef]
- Lacassagne, L.; Zavidovique, B. Light speed labeling: Efficient connected component labeling on RISC architectures. J. Real-Time Image Process. 2011, 6, 117–135. [Google Scholar] [CrossRef]
- Cabaret, L.; Lacassagne, L.; Oudni, L. A review of world’s fastest connected component labeling algorithms: Speed and energy estimation. In Proceedings of the International Conference on Design and Architectures for Signal and Image Processing (DASIP), Madrid, Spain, 8–10 October 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Lemaitre, F.; Hennequin, A.; Lacassagne, L. How to speed connected component labeling up with SIMD RLE algorithms. In Proceedings of the 2020 Sixth Workshop on Programming Models for SIMD/Vector Processing (VPMVP’20), San Diego, CA, USA, 22 February 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Tang, J.W.; Shaikh-Husin, N.; Sheikh, U.U.; Marsono, M.N. A linked list run-length-based single-pass connected component analysis for real-time embedded hardware. J. Real-Time Image Process. 2018, 15, 197–215. [Google Scholar] [CrossRef]
- Trein, J.; Schwarzbacher, A.T.; Hoppe, B.; Noffz, K.H.; Trenschel, T. Development of a FPGA based real-time blob analysis circuit. In Proceedings of the Irish Signals and Systems Conference (ISSC), Derry, UK, 13–14 September 2007; pp. 121–126. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Intel Cyclone V 5SEMA5F31C6 | ||||
|---|---|---|---|---|---|
| ALUTs | FFs | RAM (bits) | M10K | ||
| window | 50 | 48 | 1920 | 1 | |
| Link processing | 243 | 137 | 19,260 | 2 | |
| Data processing | 839 | 349 | 62,595 | 7 | |
| Total | 1133 | 534 | 83,775 | 10 | 106.50 MHz |
| Implementation of Architecture | Technology | Image Size (pixels) | Extracted Features | LUTs | Registers | RAM (kbits) | (MHz) |
|---|---|---|---|---|---|---|---|
| Single lookup CCA | Kintex 7 | BB | 00,493 | 296 | 108 | 185.59 | |
| Klaiber et al. [8] | 00,723 | 381 | 180 | 151.40 | |||
| Direct relabelling | Cyclone IV | BB, FOM | 36,478 | N/A | 018 | 060.58 | |
| Jeong et al. [10] | 57,036 | N/A | 029 | 058.44 | |||
| Linked-list | Virtex II | BB | 00,543 | 187 | 072 | 104.26 | |
| Tang et al. [20] | 00,654 | 227 | 092 | 097.07 | |||
| Cyclone V | BB, A | 00,778 | 539 | 053 | 113.05 | ||
| Zig-zag scan | 00,906 | 587 | 131 | 114.48 | |||
| Bailey and Klaiber [11] | Kintex 7 | BB, A | 00,907 | 499 | 092 | 185.49 | |
| 0,1343 | 564 | 166 | 192.16 | ||||
| This work | Cyclone V | BB, A | 0,1013 | 490 | 025 | 109.97 | |
| Union-Retire CCA | 0,1133 | 534 | 084 | 106.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bailey, D.G.; Klaiber, M.J. Union-Retire for Connected Components Analysis on FPGA. J. Imaging 2022, 8, 89. https://doi.org/10.3390/jimaging8040089
Bailey DG, Klaiber MJ. Union-Retire for Connected Components Analysis on FPGA. Journal of Imaging. 2022; 8(4):89. https://doi.org/10.3390/jimaging8040089
Chicago/Turabian StyleBailey, Donald G., and Michael J. Klaiber. 2022. "Union-Retire for Connected Components Analysis on FPGA" Journal of Imaging 8, no. 4: 89. https://doi.org/10.3390/jimaging8040089
APA StyleBailey, D. G., & Klaiber, M. J. (2022). Union-Retire for Connected Components Analysis on FPGA. Journal of Imaging, 8(4), 89. https://doi.org/10.3390/jimaging8040089