1. Introduction
In recent decades, deep neural networks have become the reference for many machine learning tasks, especially computer vision. Their popularity quickly grew once deep convolutional networks managed to outclass classical methods on benchmark tasks, such as image classification on the ImageNet dataset [
1]. Since their introduction by Le Cun et al. [
2], many architectural innovations have now contributed to their performance and efficiency [
3,
4,
5,
6,
7,
8]. However, for any given type of deep neural network architecture, the number of parameters tends to correlate with performance, resulting in the best-performing networks having prohibitive requirements in terms of memory footprint, computation power, and energy consumption [
9].
This is a crucial issue for multiple reasons. Indeed, many applications, such as autonomous vehicles, require networks that can provide adequate, real-time responses on energy-efficient hardware: for such tasks, one cannot afford to have either an accurate network that is too slow to run or one that performs quickly but crudely. Additionally, research on deep learning relies heavily on iterative experiments that require a lot of computation time and power: lightening the networks would help to speed up the whole process.
Many approaches have been proposed to tackle this issue. These include techniques such as distillation [
10,
11], quantization [
12,
13], factorization [
14], and pruning [
15]; most of them can be combined [
16]. The whole field tends to indicate that there may exist a Pareto optimum, between performance, memory occupation, and computation power, that compression could help to attain. However, progress in the field shows that this optimum has yet to be reached.
Our work focuses on pruning. The basis of most pruning methods is to train a network and, according to a certain criterion, to identify which parts of it contribute the least to its performance. These parts are then removed and the network is fine-tuned to recover the incurred loss in performance [
15,
17].
Multiple decades of innovation in the field have uncovered many issues at stake when pruning networks, such as structure [
18], scalability [
19,
20], or continuity [
21]. However, many approaches, while trying to tackle these issues, tend to resort to complex methods involving intrusive processes that make them harder to actually use, re-implement, and adapt to different networks, datasets, or tasks.
Our contribution aims to solve these key problems in a more straightforward and efficient way that avoids human intervention in the training process as much as possible. Our method, Selective Weight Decay (SWD), is a pruning method for deep neural networks that is based on Lagrangian smoothing. It consists in a regularization which, at each step during the training process, penalizes the weights that would be pruned according to a given criterion. The penalization grows in the course of training until the magnitude of the targeted parameters is so close to zero that pruning them induces no drop in performance. This method has many desired properties, including avoiding any discontinuity, since pruned weights are progressively nullified. The weight removal is, itself, learned, which reduces the manual aspects of the pruning process. Moreover, since the penalized weights are not completely removed before the very end of training, the subset of the targeted parameters can be adjusted during training, depending on the current distribution of the weight magnitudes. The dependencies between weights can, thus, be better taken into account.
Our experiments show that SWD works well for both light-weight and large-scale datasets and networks with various pruning structures. Our method shines especially for aggressive pruning rates (few remaining parameter targets) and manages to achieve great results with targets for which classical methods experience a large drop in performance.
Therefore, about SWD, which prunes deep neural networks continuously during training, we have the following claims:
using standardized benchmark datasets, we prove that SWD performs significantly better on aggressive pruning targets than standard methods;
we show that SWD needs fewer hyperparameters, introduces no discontinuity, needs no fine-tuning, and can be applied to any pruning structure with any pruning criterion.
In the following sections, we will review in detail the field of network pruning, describe our method, present our experiments and their results, and then discuss our observations.
4. Experiments
4.1. General Training Conditions
In order to eliminate all unwanted variables, each series of experiments was run under the same conditions, except when explicitly stated, with the same initialization and same seed for the random number generators of the various used libraries. We used no pre-trained networks and we trained all of them in a very standard way.
The training conditions were as follows: all our networks were trained using the Pytorch framework (Paske et al. [
77]); using SGD as an optimizer, with a base learning rate of
for the first third of the training, then
for the second, and finally
for the last third, and momentum set to 0.9. All networks are initialized using default initialization from Pytorch. Our code is available at
https://github.com/HugoTessier-lab/SWD, accessed on 26 February 2022.
4.2. Chosen Baselines and Specificities of Each Method
Unstructured pruning: Han et al. [15]
The networks trained with this method were pruned and fine-tuned for five iterations. At each step, the pruning target is a fraction of the final one: for example, when first pruned, only a fifth of the final pruning target is actually removed. The pruned weights are those of least magnitude.
Structured pruning: Liu et al. [17]
The network is only pruned once and fine-tuned. In accordance with the paper, a smooth- norm is applied as a regularization to every prunable batchnorm layer with a coefficient that depends on the dataset. This method appeared to us to be the most straightforward one for allowing an accurate evaluation of the number of pruned parameters. The pruned filters are those whose multiplicative coefficients in the batch normalization layer are of least magnitude.
LR-Rewinding: Renda et al [61]
When networks are trained following this method, the post-removal fine-tuning is replaced by a retraining which consists in repeating the pre-removal training process exactly, with the same learning rate values and the same number of epochs. This method updates and significantly improves the train, prune, and fine-tune framework that serves as a basis for both previous methods.
Whether on unstructured or structured pruning, when trained with SWD, the network is not fine-tuned at all and only pruned once at the end. The values and vary according to the model and the dataset.
In order to isolate the respective gain of each method:
All the unstructured pruning methods use weight magnitude as their criterion;
All the structured pruning methods are applied to batch normalization layers;
Structured LR-Rewinding also applies the smooth-
penalty from Liu et al. [
17];
The hyper-parameters specific to the aforementioned methods, namely, the number of iterations and the values of the smooth- norm, are directly extracted from their respective original papers.
Here are the only notable differences:
SWD does not apply any fine-tuning;
Unstructured LR-Rewinding only re-trains the network once (because of the extra cost from fully retraining networks, compared to fine-tuning);
SWD does not apply a smooth- norm (since it would clash with SWD’s own penalty).
4.3. Comparison with the State of the Art
Table 1 shows results from different techniques, as presented in the related papers, on different datasets, networks, compression rates, and pruning structures. To achieve the best performance possible, results of SWD in the case of structured pruning on ImageNet are ran with warm-restart and 180 epochs in total.
Since these results do not come from identical networks on the same datasets, trained in the same conditions, and pruned at the same rate, the comparisons have to be interpreted with caution. However,
Table 1 gives quantified indications as to how our method compares to the state of the art, in terms of performance and allowed compression rates.
4.4. Experiments on ImageNet ILSVRC2012
The results of the experiments on ImageNet ILSVRC2012 are shown in
Table 2, which presents the top-one and top-five accuracies of ResNet-50 from He et al. [
3] on ImageNet ILSVRC2012, under the conditions described in
Section 4.1 and
Section 4.2. The “Baseline” method is a regular, non-pruned network, which serves as a reference. SWD outperforms the reference method for both unstructured and structured pruning.
For models trained on ImageNet ILSVRC2012, the standard weight decay (parameter
) is set to
and models were trained during 90 epochs. For the method from Han et al. [
15], we made each fine-tuning step last for 5 epochs, except for the last iteration which lasted 15 epochs. For Liu et al.’s [
17] method, the network was only pruned once and fine-tuned over 40 epochs. The smooth-
norm had a coefficient set to
. For unstructured pruning, SWD was applied with
and
; for structured pruning,
and
.
4.5. Impact of SWD on the Pruning/Accuracy Trade-Off
Even though obtaining better accuracy for a given pruning target is not without interest, it makes more sense to know what maximal compression rate SWD would allow for a given accuracy target.
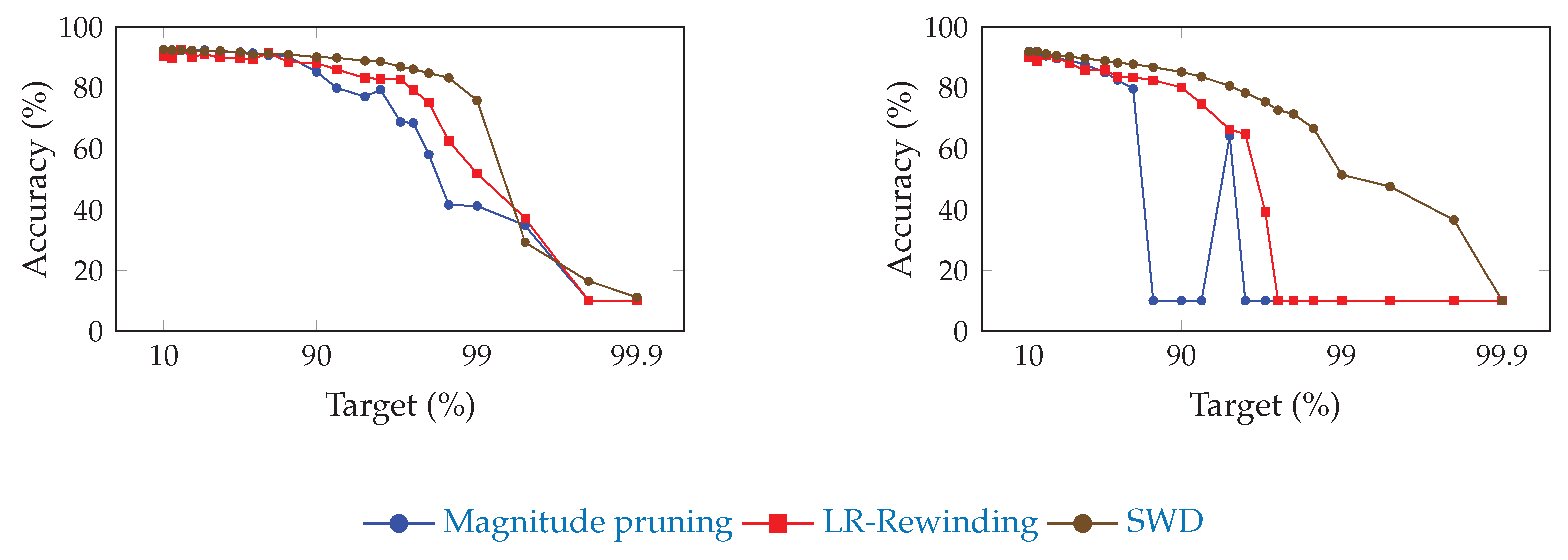
Figure 2 and
Figure 3 show the influence of SWD on the pruning/accuracy trade-off for ResNet-20, with an initial embedding of 64 and 16 feature maps, respectively, on CIFAR-10 [
82]. We used that lighter dataset instead of ImageNet ILSVRC2012 because of the high cost of computing so many points.
Since each point is the result of only one experiment, there may be some fluctuations due to low statistical power. However, since the same random seed and model initialization were used each time, these may not prevent us from drawing conclusions about the behavior of each method. As we stated in
Section 2.2, pruning originally served as a method to improve generalization. This suggests that the relationship between performance and pruning may be subtle enough to lead to local optima that may not be possible to predict.
Figure 2.
Comparison of the trade-off between pruning target and top-1 accuracy for ResNet-20 (with an initial embedding of 64 feature-maps) on CIFAR-10, for SWD and two reference methods. “Magnitude pruning" refers either to the method used in Han et al. [
15] or Liu et al. [
17]. SWD has a better performance/parameter trade-off on high-pruning targets. (
a) Unstructured pruning. (
b) Structured pruning.
Figure 2.
Comparison of the trade-off between pruning target and top-1 accuracy for ResNet-20 (with an initial embedding of 64 feature-maps) on CIFAR-10, for SWD and two reference methods. “Magnitude pruning" refers either to the method used in Han et al. [
15] or Liu et al. [
17]. SWD has a better performance/parameter trade-off on high-pruning targets. (
a) Unstructured pruning. (
b) Structured pruning.
Figure 3.
Comparison of the trade-off between pruning target and top-1 accuracy for ResNet-20 on CIFAR-10, with an initial embedding of 16 feature maps, for SWD and two reference methods. “Magnitude pruning" refers either to the method used in Han et al. [
15] or Liu et al. [
17]. SWD has a better performance/parameter trade-off on high-pruning targets. (
a) Unstructured pruning. (
b) Structured pruning.
Figure 3.
Comparison of the trade-off between pruning target and top-1 accuracy for ResNet-20 on CIFAR-10, with an initial embedding of 16 feature maps, for SWD and two reference methods. “Magnitude pruning" refers either to the method used in Han et al. [
15] or Liu et al. [
17]. SWD has a better performance/parameter trade-off on high-pruning targets. (
a) Unstructured pruning. (
b) Structured pruning.
The standard weight decay (parameter
) is set to
for CIFAR-10. The models on CIFAR-10 were trained for 300 epochs and each fine-tuning lasted 15 epochs, except the last one (or the only one when applying Liu et al. [
17]), which lasted 50 epochs. When using the smooth-
norm, its coefficient is set to
. For an initial embedding of 64 feature maps with unstructured pruning, we set
and
; on structured pruning,
and
. For 16 feature maps, we set
and
for unstructured pruning and
and
when structured.
Exact results are reported in
Table 3, in which the expected compression ratios, in terms of operations, are also displayed. Since unstructured pruning produces sparse matrices, whereas structured pruning leads to networks of smaller sizes, some authors such as Ma et al. [
83] have argued against the use of the former and in favor of the latter. Indeed, sparse matrices either need specific hardware or expensive indexing methods, which makes them less efficient than structured pruning. Therefore, because of how hardware- or method-specific the gains of unstructured pruning can be, we preferred not to indicate any compression ratio in terms of operation count for unstructured pruning. However, concerning structured pruning, it is far easier to guess what the operation count will be. The operations are calculated in the following way, with
being the number of input channels,
being the number of output channels,
k being the kernel size,
h being the height (in pixels) of the input feature maps, and
w being its width:
convolution layer: ;
batch normalization layer: ;
dense layer: .
We make no distinction between multiplications and additions in our count.
Table 3.
Top-1 accuracy of ResNet-20, with an initial embedding of 64 or 16 feature maps, on CIFAR-10 for various pruning targets, with different unstructured and structured pruning methods. In both cases, SWD outperforms the other methods for high-pruning targets. For each point, the corresponding estimated percentage of remaining operations (“Ops”) is given (except for unstructured pruning). The missing point in the table (*) is due to the fact that too high values of SWD can lead to overflow of the value of the gradient, which induced a critical failure of the training process on this specific point. However, if the value of is instead set to , we obtain 95.19% accuracy, with a compression rate of operations of 82.21%. The best performance for each target is indicated in bold. Operations are reported in light grey for readability reasons.
Table 3.
Top-1 accuracy of ResNet-20, with an initial embedding of 64 or 16 feature maps, on CIFAR-10 for various pruning targets, with different unstructured and structured pruning methods. In both cases, SWD outperforms the other methods for high-pruning targets. For each point, the corresponding estimated percentage of remaining operations (“Ops”) is given (except for unstructured pruning). The missing point in the table (*) is due to the fact that too high values of SWD can lead to overflow of the value of the gradient, which induced a critical failure of the training process on this specific point. However, if the value of is instead set to , we obtain 95.19% accuracy, with a compression rate of operations of 82.21%. The best performance for each target is indicated in bold. Operations are reported in light grey for readability reasons.
| ResNet-20 on CIFAR-10 (Unstructured) |
|---|
| Target | Base | Ops | LRR | Ops | SWD | Ops | Base | Ops | LRR | Ops | SWD | Ops |
|---|
| | 64 Feature Maps | 16 Feature Maps |
|---|
| 10 | 95.45 | | 94.82 | | 95.43 | | 92.23 | | 90.47 | | 92.63 | |
| 20 | 95.47 | | 95.15 | | 95.55 | | 92.25 | | 89.70 | | 92.47 | |
| 30 | 95.43 | | 95.03 | | 95.47 | | 92.27 | | 92.57 | | 92.45 | |
| 40 | 95.48 | | 94.94 | | 95.40 | | 92.31 | | 90.15 | | 92.36 | |
| 50 | 95.44 | | 95.33 | | 95.46 | | 92.43 | | 91.06 | | 92.08 | |
| 60 | 95.32 | | 95.04 | | 95.37 | | 91.95 | | 89.93 | | 92.15 | |
| 70 | 95.3 | | 95.45 | | 95.04 | | 91.78 | | 89.8 | | 91.69 | |
| 75 | 95.32 | | 95.15 | | 95.34 | | 91.46 | | 89.39 | | 90.90 | |
| 80 | 95.32 | | 95.14 | | 95.09 | | 90.77 | | 91.52 | | 91.37 | |
| 85 | 95.05 | | 95.03 | | 94.99 | | 90.22 | | 88.51 | | 90.97 | |
| 90 | 94.77 | | 94.72 | | 94.90 | | 85.26 | | 88.12 | | 90.15 | |
| 92.5 | 94.48 | | 94.74 | | 94.58 | | 79.98 | | 86.07 | | 89.88 | |
| 95 | 94.03 | | 93.66 | | 94.40 | | 77.15 | | 83.27 | | 88.90 | |
| 96 | 93.38 | | 93.63 | | 94.14 | | 79.41 | | 82.96 | | 88.69 | |
| 97 | 91.95 | | 93.34 | | 93.76 | | 68.85 | | 82.75 | | 86.95 | |
| 97.5 | 91.43 | | 92.48 | | 93.52 | | 68.51 | | 79.32 | | 86.16 | |
| 98 | 90.58 | | 91.64 | | 93.49 | | 58.15 | | 75.21 | | 84.88 | |
| 98.5 | 87.44 | | 90.36 | | 93.00 | | 41.60 | | 62.52 | | 83.33 | |
| 99 | 83.42 | | 87.38 | | 92.50 | | 41.26 | | 51.93 | | 75.89 | |
| 99.5 | 66.90 | | 82.21 | | 91.05 | | 34.88 | | 37.22 | | 29.35 | |
| 99.8 | 48.52 | | 65.46 | | 86.81 | | 10.00 | | 10.00 | | 16.47 | |
| 99.9 | 27.78 | | 45.44 | | 81.32 | | 10.00 | | 10.00 | | 11.11 | |
| ResNet-20 on CIFAR-10 (structured) |
| 10 | 94.83 | 84.13 | 95.10 | 85.37 | * | * | 91.96 | 90.06 | 89.95 | 85.70 | 91.88 | 77.68 |
| 20 | 94.88 | 70.41 | 95.39 | 76.45 | 95.38 | 70.21 | 91.25 | 78.64 | 88.91 | 76.21 | 91.97 | 64.63 |
| 30 | 94.88 | 58.20 | 95.53 | 67.45 | 95.48 | 59.67 | 90.55 | 69.77 | 90.65 | 63.10 | 91.22 | 59.23 |
| 40 | 94.91 | 48.06 | 95.32 | 53.40 | 95.44 | 51.96 | 89.59 | 62.20 | 89.94 | 54.85 | 90.67 | 51.07 |
| 50 | 94.92 | 40.25 | 94.31 | 43.68 | 94.96 | 44.31 | 89.11 | 51.72 | 88.07 | 44.04 | 90.27 | 41.95 |
| 60 | 94.29 | 33.88 | 95.02 | 35.82 | 94.93 | 37.90 | 87.70 | 42.16 | 85.84 | 35.6 | 89.66 | 33.42 |
| 70 | 93.24 | 26.01 | 94.98 | 28.08 | 94.64 | 30.20 | 85.08 | 33.12 | 85.84 | 30.29 | 88.93 | 28.76 |
| 75 | 92.08 | 21.36 | 94.67 | 24.26 | 94.25 | 24.89 | 82.61 | 28.68 | 83.58 | 22.92 | 88.23 | 25.59 |
| 80 | 84.20 | 16.55 | 94.45 | 19.97 | 94.15 | 22.46 | 79.71 | 24.18 | 83.50 | 19.07 | 87.82 | 23.94 |
| 85 | 77.18 | 12.07 | 94.36 | 16.45 | 94.27 | 19.02 | 10.00 | 17.29 | 82.53 | 18.36 | 86.79 | 19.20 |
| 90 | 71.01 | 8.04 | 93.42 | 11.67 | 93.72 | 14.35 | 10.00 | 12.31 | 80.19 | 12.06 | 85.25 | 15.75 |
| 92.5 | 10.00 | 5.87 | 92.94 | 8.93 | 93.06 | 12.84 | 10.00 | 10.40 | 74.81 | 9.86 | 83.67 | 12.38 |
| 95 | 10.00 | 4.01 | 91.14 | 6.66 | 91.93 | 9.65 | 64.23 | 8.1 | 66.30 | 5.89 | 80.66 | 11.08 |
| 96 | 10.00 | 3.39 | 89.80 | 5.72 | 91.67 | 8.89 | 10.00 | 7.16 | 64.90 | 4.81 | 78.39 | 9.99 |
| 97 | 10.00 | 2.84 | 89.25 | 4.68 | 90.57 | 7.45 | 10.00 | 5.08 | 39.30 | 4.25 | 75.45 | 8.53 |
| 97.5 | 10.00 | 2.26 | 87.92 | 4.27 | 89.90 | 7.05 | 10.00 | 4.21 | 10.00 | 3.79 | 72.73 | 7.8 |
| 98 | 10.00 | 1.80 | 88.00 | 3.63 | 89.07 | 6.00 | 10.00 | 3.7 | 10.00 | 3.12 | 71.45 | 6.73 |
| 98.5 | 10.00 | 1.37 | 74.97 | 2.73 | 87.68 | 5.29 | 10.00 | 2.13 | 10.00 | 2.64 | 66.71 | 5.08 |
| 99 | 10.00 | 0.99 | 57.99 | 2.32 | 84.66 | 4.22 | 10.00 | 1.79 | 10.00 | 2.24 | 51.49 | 4.25 |
| 99.5 | 10.00 | 0.57 | 10.00 | 1.45 | 79.86 | 2.42 | 10.00 | 0.8 | 10.00 | 1.53 | 47.63 | 1.9 |
| 99.8 | 10.00 | 0.26 | 10.00 | 0.75 | 70.18 | 0.97 | 10.00 | 0.03 | 10.00 | 0.13 | 36.67 | 0.53 |
| 99.9 | 10.00 | 0.12 | 10.00 | 0.37 | 66.96 | 0.45 | 10.00 | 0.01 | 10.00 | 0.01 | 10.00 | 0.35 |
4.6. Grid Search on Multiple Models and Datasets
To show the influence of the values of and on the performance of networks right before and right after the final pruning step, we conducted a grid search using LeNet-5 and ResNet-20 on MNIST and CIFAR-10 with both unstructured and structured pruning.
The LeNet-5 models were trained for 200 epochs, with a learning rate of 0.1 and no weight decay (even though
is set to
for SWD); the momentum is set to 0. The pruning targets are 90% and 99%. The results of these grid searches are reported in
Table 4.
Another grid search, on CIFAR-10 with ResNet-20 (64 channels), is reported in
Table 5 with an extended range of values explored in order to showcase the importance of the increase of
a during training. As it involved testing cases decreasing
a, we named the start and end values of
a as
and
instead of
and
. Otherwise, the conditions were the same as described in
Section 4.1 and
Section 4.5.
Table 6 shows another distinct grid search, performed with structured pruning on various pruning targets.
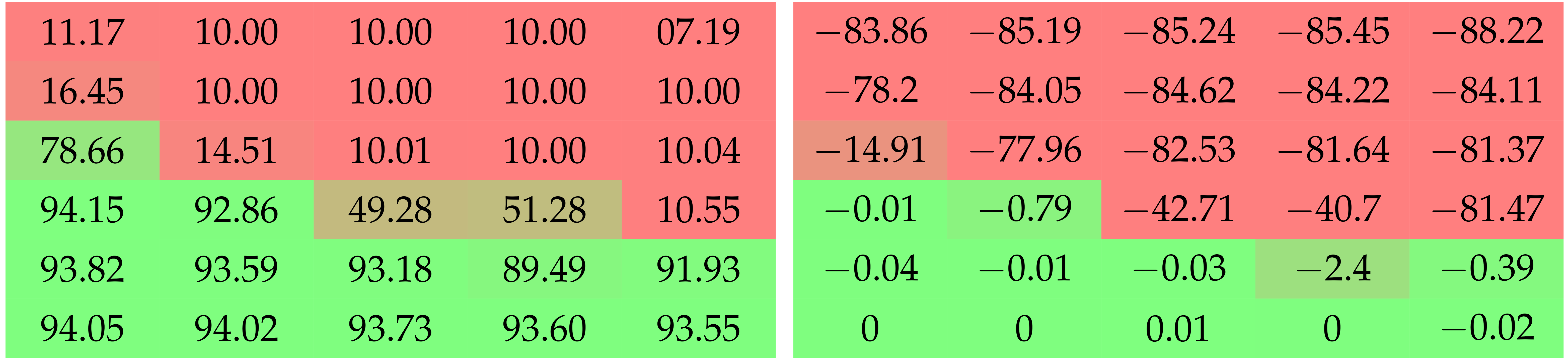
Table 4.
Top-1 accuracy after the final unstructured removal step and the difference of performance it induces, for LeNet-5 on MNIST with pruning targets of 10% and 1%. We observe that sufficiently high values of are needed to prevent the post-removal drop in performance. Higher values of seem to work better than smaller ones. The difference induced by and seems to be more dramatic for higher pruning targets. Colors are added to ease the interpretation of the results.
Table 4.
Top-1 accuracy after the final unstructured removal step and the difference of performance it induces, for LeNet-5 on MNIST with pruning targets of 10% and 1%. We observe that sufficiently high values of are needed to prevent the post-removal drop in performance. Higher values of seem to work better than smaller ones. The difference induced by and seems to be more dramatic for higher pruning targets. Colors are added to ease the interpretation of the results.
| | Grid Search with LeNet-5 on MNIST |
|---|
| | Top-1 Accuracy after Removal (%) | Change of Accuracy through Removal (%) |
|---|
| | | | | | | | |
|---|
| Pruning target 90% |
| ![Jimaging 08 00064 i002]() |
|
|
|
| | Pruning target 99% |
| ![Jimaging 08 00064 i003]() |
|
|
|
In order to tease apart the sensitivity of SWD from variations of the model or of the dataset, we provide additional grid searches in
Table 7 and
Table 8. These tables feature results on CIFAR-10 with ResNet-18 and ResNet-20 to showcase the influence of the model’s depth, and on CIFAR-100 with ResNet-34 to have results on another, more complex dataset. Each network has an initial embedding of 64 and we show results for both structured and unstructured pruning.
Additionally, as highlighted by both
Table 4 and
Table 6, the choice of
and
depends on the pruning target. To highlight this fact, we show a complete trade-off figure for various values of
and
in
Figure 4, whose results are reported in
Table 9.
Table 5.
On ResNet-20 with an initial embedding of 64 feature maps, trained on CIFAR-10 for a pruning target of 90%. Top-1 accuracy after the final unstructured removal step and the difference in performance it induces. The best results are obtained for reasonably low
and high
, in accordance with the motivation behind SWD we provided in
Section 3. Colors are added to ease the interpretation of the results.
Table 5.
On ResNet-20 with an initial embedding of 64 feature maps, trained on CIFAR-10 for a pruning target of 90%. Top-1 accuracy after the final unstructured removal step and the difference in performance it induces. The best results are obtained for reasonably low
and high
, in accordance with the motivation behind SWD we provided in
Section 3. Colors are added to ease the interpretation of the results.
| | | Extended Grid Search |
|---|
| | | | | | | | | | | |
|---|
| | Top-1 accuracy after removal (%) |
| | ![Jimaging 08 00064 i004]() |
|
|
|
|
| | | Change in accuracy through removal (%) |
| | ![Jimaging 08 00064 i005]() |
|
|
|
|
Table 6.
Top-1 accuracy after the final structured removal step and the difference in performance it induces, for ResNet-20 with an initial embedding of 64 feature maps, trained on CIFAR-10 and pruning targets of 75% and 90%. Structured pruning with SWD turned out to require exploring a wider range of values than unstructured pruning, as well as being even more sensitive to a. Colors are added to ease the interpretation of the results.
Table 6.
Top-1 accuracy after the final structured removal step and the difference in performance it induces, for ResNet-20 with an initial embedding of 64 feature maps, trained on CIFAR-10 and pruning targets of 75% and 90%. Structured pruning with SWD turned out to require exploring a wider range of values than unstructured pruning, as well as being even more sensitive to a. Colors are added to ease the interpretation of the results.
| | | Grid Search with Structured Pruning |
|---|
| | | Top-1 Accuracy after Removal (%) | Change of Accuracy through Removal (%) |
|---|
| | | | | | | | | | | |
|---|
| | Pruning target 75% |
| | ![Jimaging 08 00064 i006]() |
|
|
|
|
|
| | | Pruning target 90% |
| | ![Jimaging 08 00064 i007]() |
|
|
|
|
|
Table 7.
Top-1 accuracy after the final unstructured removal step and the difference in performance it induces, for various networks and datasets with a pruning target of 90%. The influence of and varies significantly depending on the problem, although common tendencies persist. Colors are added to ease the interpretation of the results.
Figure 4.
Comparison of the trade-off between an unstructured pruning target and the top-1 accuracy for ResNet-20 on CIFAR-10, with an initial embedding of 16 feature maps, for SWD with different values of and . Depending on the pruning rate, the best values to choose are not always the same.
Figure 4.
Comparison of the trade-off between an unstructured pruning target and the top-1 accuracy for ResNet-20 on CIFAR-10, with an initial embedding of 16 feature maps, for SWD with different values of and . Depending on the pruning rate, the best values to choose are not always the same.
Table 8.
Top-1 accuracy after the final structured removal step and the difference in performance it induces, for various networks and datasets with a pruning target of 90%. The influence of
and
varies significantly depending on the problem, although common tendencies persist. As previously shown in
Table 6, structured pruning is a lot more sensitive to variations of
and
. Colors are added to ease the interpretation of the results.
Table 8.
Top-1 accuracy after the final structured removal step and the difference in performance it induces, for various networks and datasets with a pruning target of 90%. The influence of
and
varies significantly depending on the problem, although common tendencies persist. As previously shown in
Table 6, structured pruning is a lot more sensitive to variations of
and
. Colors are added to ease the interpretation of the results.
| | | Grid Search with Structured Pruning |
|---|
| | | Top-1 Accuracy after Removal (%) | Change in Accuracy through Removal (%) |
|---|
| | | | | | | | | | | | | |
|---|
| | ResNet-18 on CIFAR-10 |
| | ![Jimaging 08 00064 i011]() |
|
|
|
|
|
| | | ResNet-20 on CIFAR-10 |
| | ![Jimaging 08 00064 i012]() |
|
|
|
|
|
| | | ResNet-34 on CIFAR-10 |
| | ![Jimaging 08 00064 i013]() |
|
|
|
|
|
Table 9.
Top-1 accuracy for ResNet-20 on CIFAR-10, with an initial embedding of 16 feature maps, with different unstructured pruning targets, for SWD with different values of
and
. Depending on the pruning rate, the best values to choose are not always the same. If, for each pruning target, we picked the best value among these, SWD would outclass the other technique from
Table 3 by a larger margin. The best performance for each target is indicated in bold.
Table 9.
Top-1 accuracy for ResNet-20 on CIFAR-10, with an initial embedding of 16 feature maps, with different unstructured pruning targets, for SWD with different values of
and
. Depending on the pruning rate, the best values to choose are not always the same. If, for each pruning target, we picked the best value among these, SWD would outclass the other technique from
Table 3 by a larger margin. The best performance for each target is indicated in bold.
| Influence of and |
|---|
| 0.1 | 0.1 | 1 | 1 |
|---|
| | | | |
| 10 | 92.38 | 92.50 | 92.63 | 92.56 |
| 20 | 92.32 | 92.57 | 92.47 | 92.62 |
| 30 | 92.53 | 92.34 | 92.45 | 92.55 |
| 40 | 92.58 | 92.35 | 92.36 | 91.98 |
| 50 | 92.15 | 92.02 | 92.08 | 92.02 |
| 60 | 92.28 | 92.09 | 92.15 | 91.89 |
| 70 | 92.01 | 91.87 | 91.69 | 91.57 |
| 75 | 92.27 | 91.89 | 90.90 | 91.70 |
| 80 | 91.85 | 91.52 | 91.37 | 91.04 |
| 85 | 91.44 | 91.48 | 90.97 | 90.7 |
| 90 | 90.91 | 90.83 | 90.15 | 90.22 |
| 92.5 | 90.59 | 90.16 | 89.88 | 89.36 |
| 95 | 89.30 | 89.00 | 88.90 | 88.28 |
| 96 | 88.11 | 88.64 | 88.69 | 87.72 |
| 97 | 87.01 | 87.0 | 86.95 | 86.67 |
| 97.5 | 85.76 | 86.09 | 86.16 | 85.91 |
| 98 | 83.56 | 84.27 | 84.88 | 85.11 |
| 98.5 | 75.47 | 81.62 | 83.33 | 82.91 |
| 99 | 37.24 | 74.07 | 75.89 | 80.2 |
| 99.5 | 21.61 | 47.26 | 29.35 | 64.01 |
| 99.8 | 12.27 | 11.33 | 16.47 | 25.19 |
| 99.9 | 9.78 | 16.39 | 11.11 | 10.9 |
4.7. Experiment on Graph Convolutional Networks
In order to verify that SWD can be applied to tasks that are not image classification (such as CIFAR-10/100 or ImageNet ILSVRC2012), we ran experiments on a Graph Convolutional Network (GCN) based on Kipf and Welling [
84] on the Cora dataset [
85]. We instantiated the GCN with 16 hidden units and trained it with the Adam optimizer [
86] with a weight decay of
and a learning rate of
. The dropout rate was set at 50%.
Pruning models introduced severe instabilities when training with the original number of epochs per training, set to 200, which is why we trained models for 2000 epochs instead. For SWD, we set
and
. For magnitude pruning, models were pruned across 5 iterations, with each fine-tuning lasting 200 epochs, except for the last one, which lasted 2000. The results are reported in
Figure 5.
4.8. Ablation Test: The Need for Selectivity
Section 4.6 studied the sensitivity of performance to the pace at which SWD increases during training. However, we need to show the necessity of its other characteristic: its selectivity. Indeed, SWD is only applied to a subset of the network’s parameters.
We ran this ablation test using ResNet-20, with an initial embedding of 64 feature maps, on CIFAR-10, with unstructured pruning, and under the same conditions as stated in
Section 4.5. Without any fine tuning, we compared three cases: (1) using only simple weight decay, (2) using a weight decay that grows in the same way as SWD, and (3) SWD.
Figure 6 shows that neither weight decay nor increasing weight decay achieve the same performance as SWD. Indeed, the weight decay curve equates pruning a normally trained network without any fine-tuning, which is expected to be sub-optimal. Increasing global weight decay amounts to applying SWD everywhere and, thus, to pruning the whole network.
Therefore, we can deduce that (1) SWD is a more efficient removal method than the manual nullification of small weights and (2) the selectivity of SWD is necessary.
Figure 6.
Ablation test: SWD without fine-tuning is compared to a network that has been pruned without fine-tuning and to which either normal weight decay or a weight decay that increases at the same pace as SWD was applied. It appears that weight decay alone is insufficient for obtaining the performance of SWD, and that an increasing global weight decay prunes the entire network. Therefore, the selectivity, as well as the increase, of SWD is necessary to its performance.
Figure 6.
Ablation test: SWD without fine-tuning is compared to a network that has been pruned without fine-tuning and to which either normal weight decay or a weight decay that increases at the same pace as SWD was applied. It appears that weight decay alone is insufficient for obtaining the performance of SWD, and that an increasing global weight decay prunes the entire network. Therefore, the selectivity, as well as the increase, of SWD is necessary to its performance.
4.9. Computational Cost of SWD
We measured the additional computing time caused by using SWD. Results are presented in
Table 10. We performed experiments on ImageNet and CIFAR-10. In both cases, we obtained increased computation time of the order of 40% to 50%. These numbers should be put into perspective with the fact most pruning techniques come with additional epochs in training, which can easily result in doubling the computation time when compared with the corresponding baselines.
5. Discussion
The experiments on CIFAR-10 have shown that SWD performs on par with standard methods for low pruning targets and greatly outperforms them on high ones. Our method allows for much higher targets on the same accuracy. We think that the multiple desirable properties brought by SWD over standard pruning methods are responsible for a much more efficient identification and removal of the unnecessary parts of networks. Indeed, dramatic degradations of performance, which could come from removing a necessary parameter or filter, by error are limited by two things: (1) the continuity of SWD, which lets the other parameters compensate progressively for the loss, and (2) its ability to adapt its targeted parameters, so that the weights that are the most relevant to remove are penalized at a more appropriate time.
We compared SWD to multiple methods, described in
Section 4.2. Because of the large number of diverging methods in the literature, we preferred to stick to very standard ones that still serve as baselines to many works and remain relevant points of comparison [
20]. The values of the hyper-parameters specific to these methods were directly extracted from their original papers. Concerning the other hyper-parameters, we ran each experiment under the same condition and initialization to separate the influence of the hyper-parameters from that of the initialization and of the actual pruning method.
Because of the low granularity of filter-wise structured pruning, there is always the risk of pruning all filters of a single layer and, then, breaking the network irremediably. This likely explains the sudden drops in performance that can be observed for reference methods in
Figure 2. Since SWD can adapt to induce no such damage, the network does not reach random guesses even at extreme pruning targets, such as 99.9%. Our results also confirm that SWD can be applied to different datasets and networks, or even pruning structures, and yet stay ahead of the reference methods. Indeed,
Figure 5 suggests that the gains observed for a visual classification task carry over to a graph neural network trained on a non-visual task. That means that the properties of SWD are not task- or network-specific and can be transposed in various contexts (see
Figure 5), which is an important issue, as shown by Gale [
20].
Multiple observations can be drawn from the grid searches displayed in
Table 4,
Table 5 and
Table 6. Experiments on MNIST show that the effect of
and
on both performance and post-removal drop in accuracy depends on the pruning target: the higher the target, the more dramatic the differences of behavior between given ranges of values. Upon comparison with experiments on CIFAR-10, we can tell that these behaviors are also sensitive to the models, datasets, and structures.
Both
Table 4 and
Table 5 show that high values of
a (or at least, of
or
) are needed to prevent the post-removal drop in performance. This means that the penalty must be strong enough to effectively reduce weights almost to zero, so that they can be removed seamlessly.
Table 5 shows that cases of high
work pretty well. This is consistent with the literature in
Section 2, which tends to demonstrate the importance of sparsity during training. However, the best results are obtained for reasonably low
and high
, which is consistent with our arguments in favor of SWD in
Section 3.
Experiments on ResNet-20 with an initial embedding of 16 feature maps, instead of 64, revealed that these networks were much more sensitive to pruning, had a lower threshold for high
values, and were more prone to local instabilities, such as the spike for structured magnitude pruning visible in
Figure 3. This is understandable: slimmer networks are expected to be more difficult to prune, since they are less likely to be over-parameterized. Because of their thinness, they also tend to be more vulnerable to layer collapse [
53], which tends to prematurely reduce the network to random guessing by pruning entire layers and, hence, irremediably breaking the network.
These experiments show that the performance of SWD scales well on this slimmer network relative to the reference methods. However, the increased sensitivity to values of
and
highlight how sub-optimal it may be to apply the same values of these for any pruning target. Indeed, picking the best-performing combination for each target, in
Table 9, results in a trade-off that outmatches the reference methods by a larger margin than what
Figure 3 shows.
However, one may notice that we generally used a different pair of values
and
for each experiment. Indeed, as stated previously, the behavior of SWD for certain values of
a is very sensitive to the overall task, and we had to choose empirically the best values we could for our hyperparameters. Moreover, for each pruning/performance trade-off figure, we used the same pair of values, while
Table 4 proved it to be quite sensitive to the pruning target. Therefore, it is very possible that our results are actually very sub-optimal, comparatively, to what SWD could achieve with better hyperparameter values. As finding them is very time- and energy-consuming, a method to make this process easier (or to bypass it) would be a significant improvement.
Moreover, our contribution counts multiple aspects that could be expanded on and further explored, such as the penalty and evolution function. Indeed, we have chosen the norm to stick to the definition of weight decay, leaving open the question of how SWD would perform with other norms. Similarly, if the exponential increase of a was to bring satisfying results, other kinds of functions could be tested.
Let us add a last note about the introduced hyperparameters
and
. Our tests suggest that a poor choice of these values may dramatically harm performance. Interestingly, however, reasonable choices (
as small enough and
as large enough) lead to consistently good results across datasets and architectures. These parameters have to be compared with the ones introduced by other methods. For example, in [
15], defining multiple subtargets of pruning at various epochs during training is required, leading to a large combinatorial search space.
Overall, the principle of SWD is flexible enough to serve as a framework for multiple variations. It could be possible to combine SWD with progressive pruning [
20] or to choose gradient magnitude as a pruning criterion instead of weight magnitude.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}