
Detecting Audio Adversarial Examples in Automatic Speech Recognition Systems Using Decision Boundary Patterns






Abstract
1. Introduction
2. Related Work
2.1. Audio Adversarial Examples

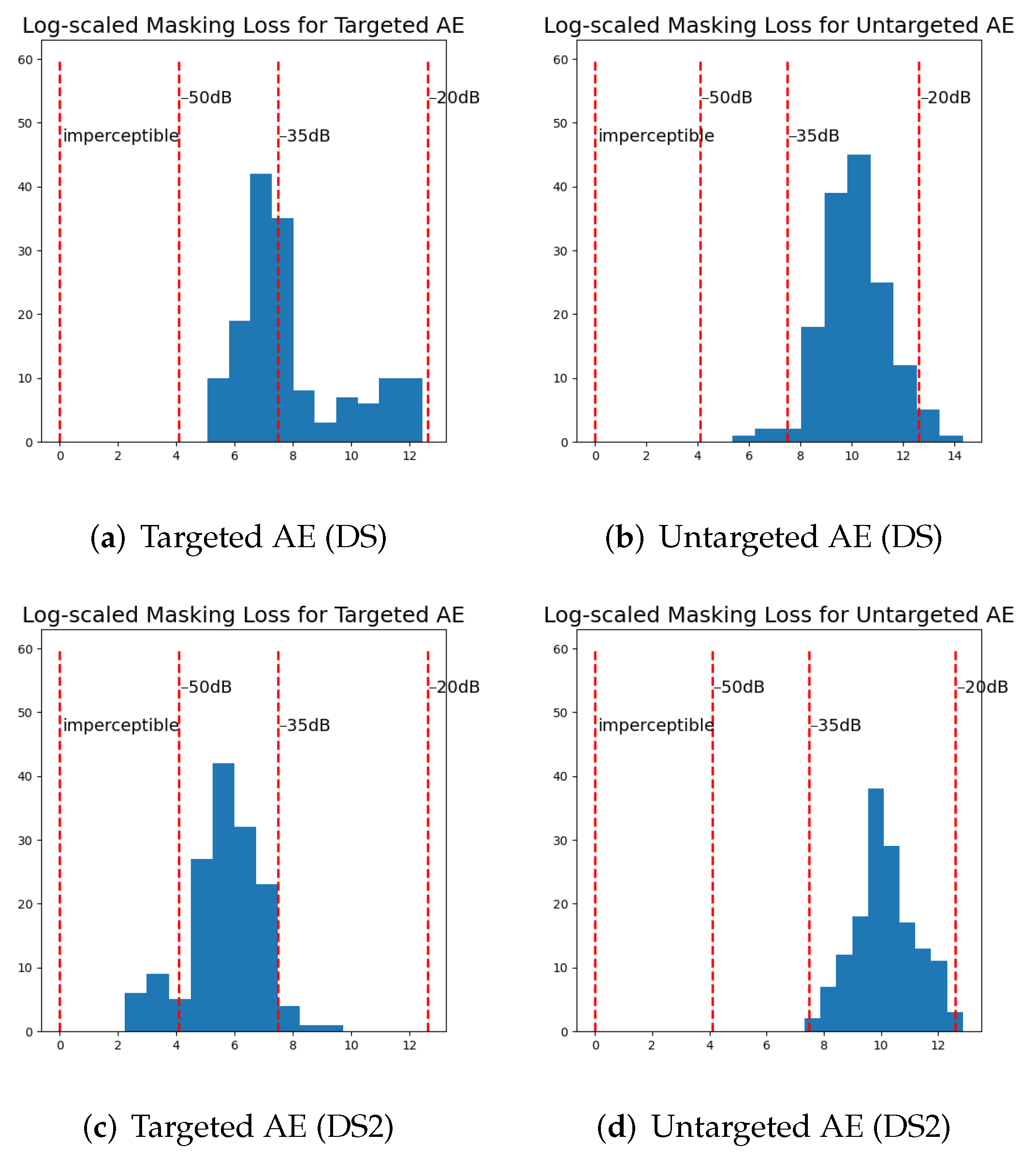{kind=link}
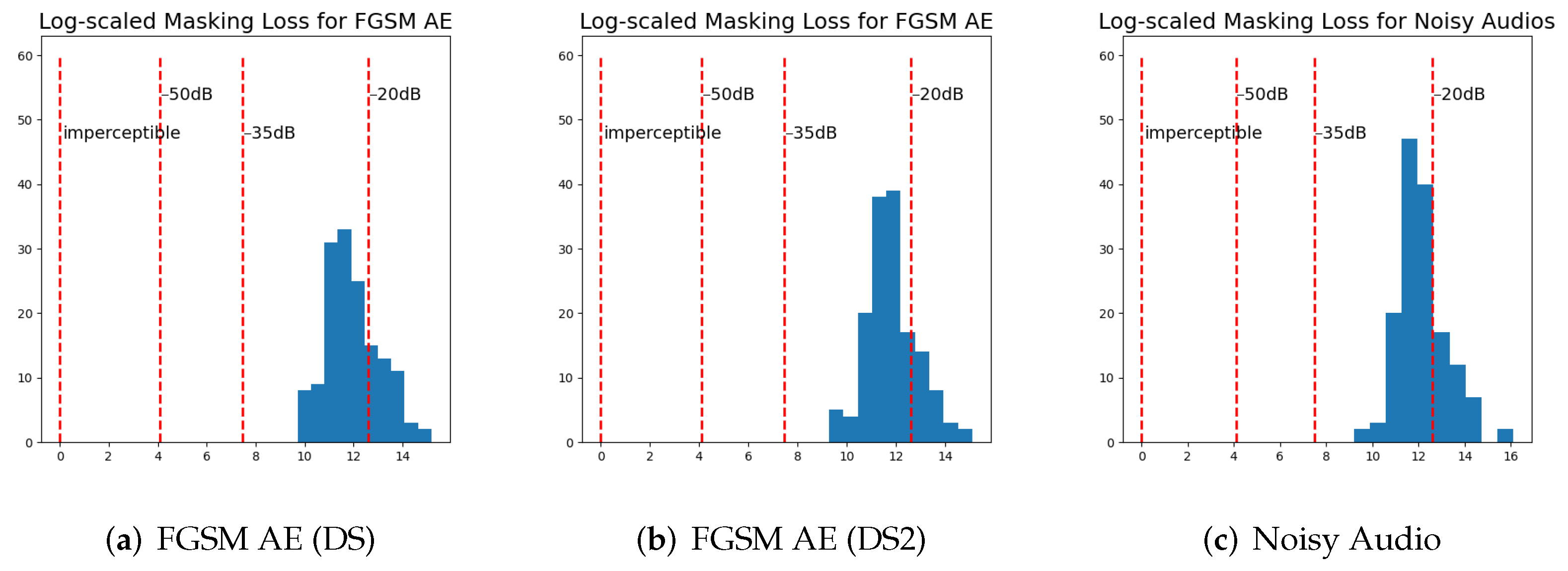{kind=link}
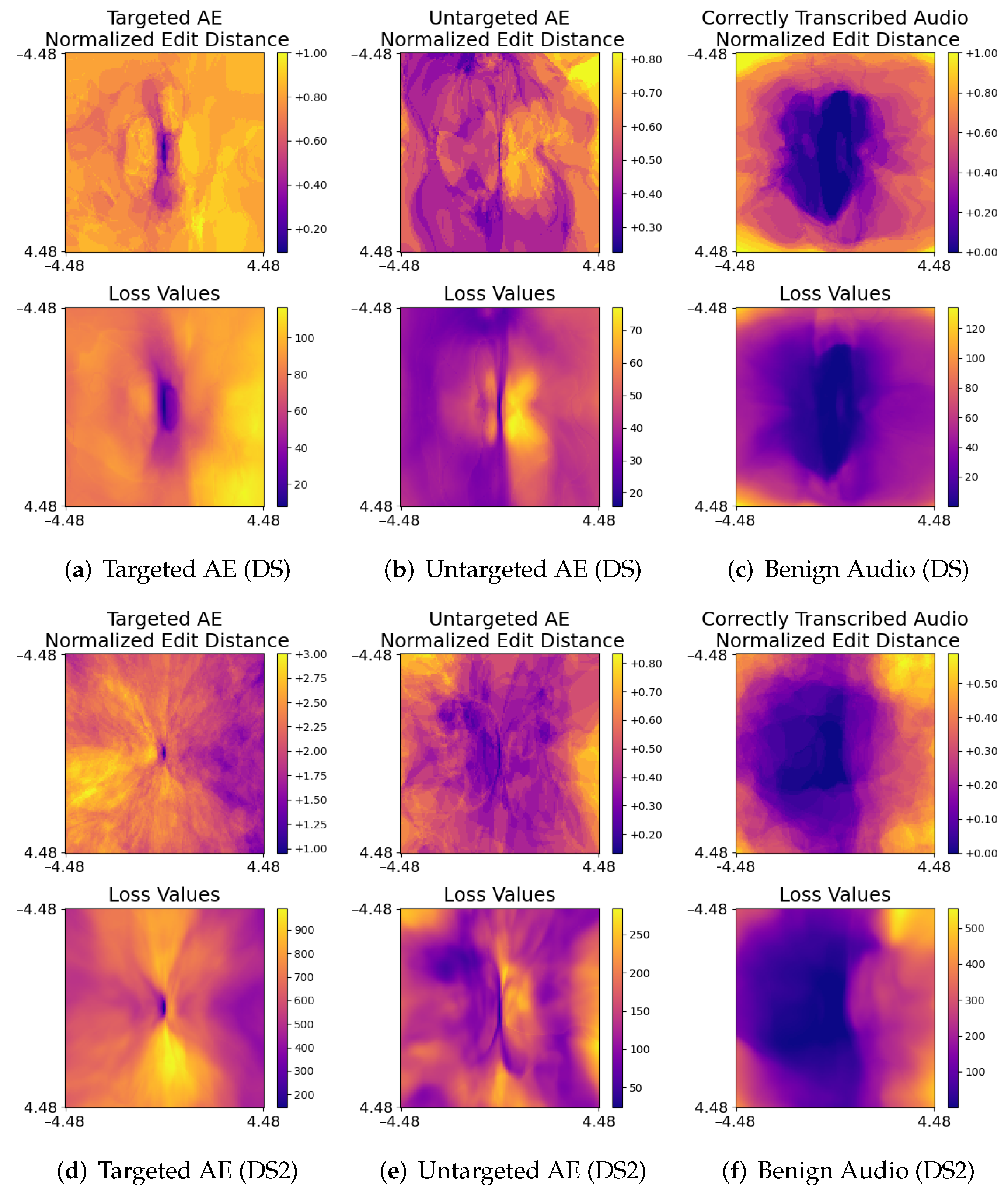{kind=link}
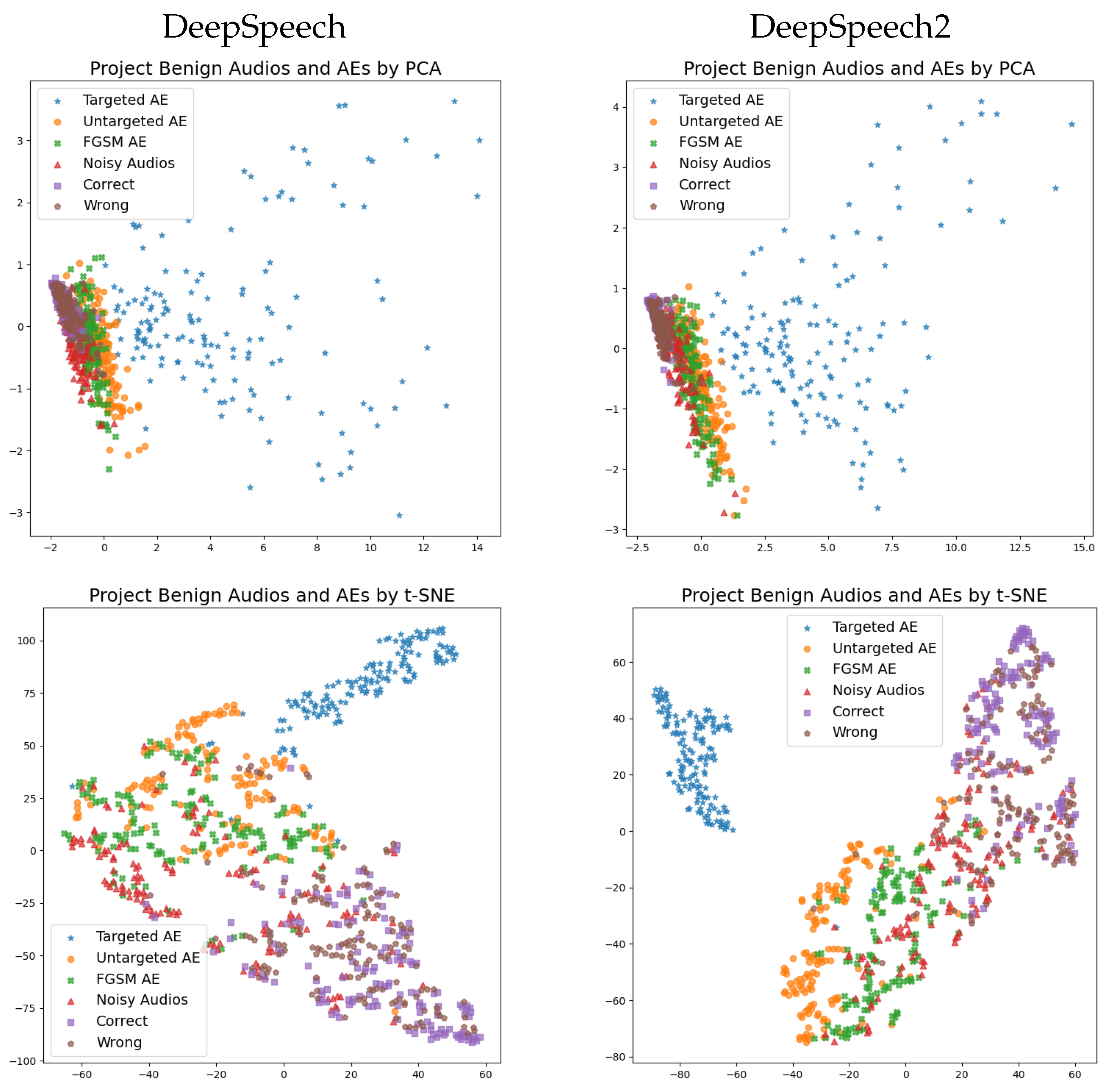{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AE Type | Assumption | Method | Target Model |
|---|---|---|---|
| Targeted | White-box | Yuan et al. [32] | Kaldi |
| Carlini and Wagner [9] | DeepSpeech | ||
| Liu el al. [35] | DeepSpeech | ||
| Schoenherr et al. [10] | Kaldi | ||
| Qin et al. [36] | Lingvo [3] | ||
| Zong el al. [38] | DeepSpeech | ||
| Black-box | Taori et al. [39] | DeepSpeech | |
| Chen et al. [40] | Commercial products * | ||
| Untargeted | white-box | Neekhara et al. [41] | DeepSpeech |
| Black-box | Abdullah et al. [42] | 7 models # |
2.2. Defending against Audio Adversarial Examples
2.3. Visualization Techniques for Analyzing Adversarial Examples
3. Proposed Method
3.1. Visualizing Decision Boundaries
3.2. Feature Extraction
4. Attack Generation
4.1. Targeted Audio Adversarial Examples
4.2. Untargeted Audio Adversarial Examples
| Algorithm 1 Untargeted Audio AE Generation |
Input: original audio signal, x; ground truth transcript, y; target ASR model m; maximum iteration: ; edit distance threshold: |
Output: black-box untargeted audio AE, |
←x |
← reverse the characters in y |
While do |
← calculate loss of |
← estimate the gradient of the loss function using |
←- * |
// use the lowering noise technique from [36] |
← masking loss noise in |
optimize noise in |
If EditDistance(y, transcript of ) ≥ |
return |
End If |
End While |
If |
return fail |
End If |
5. Experiments and Discussion
5.1. Target Models and Data Sets
5.2. Visualizing Decision Boundaries
5.3. Dimensionality Reduction
5.4. Anomaly Detection
6. Discussion
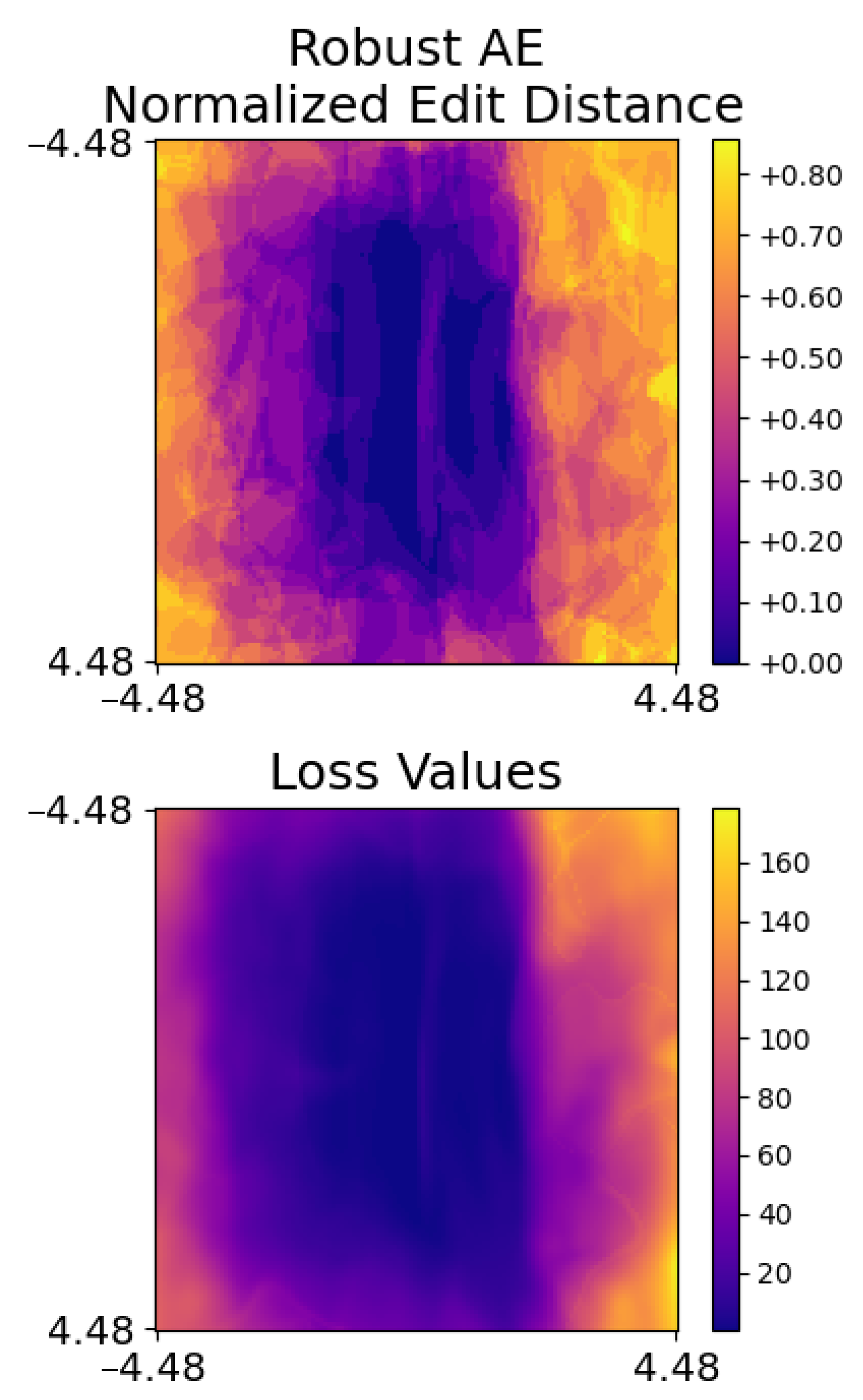
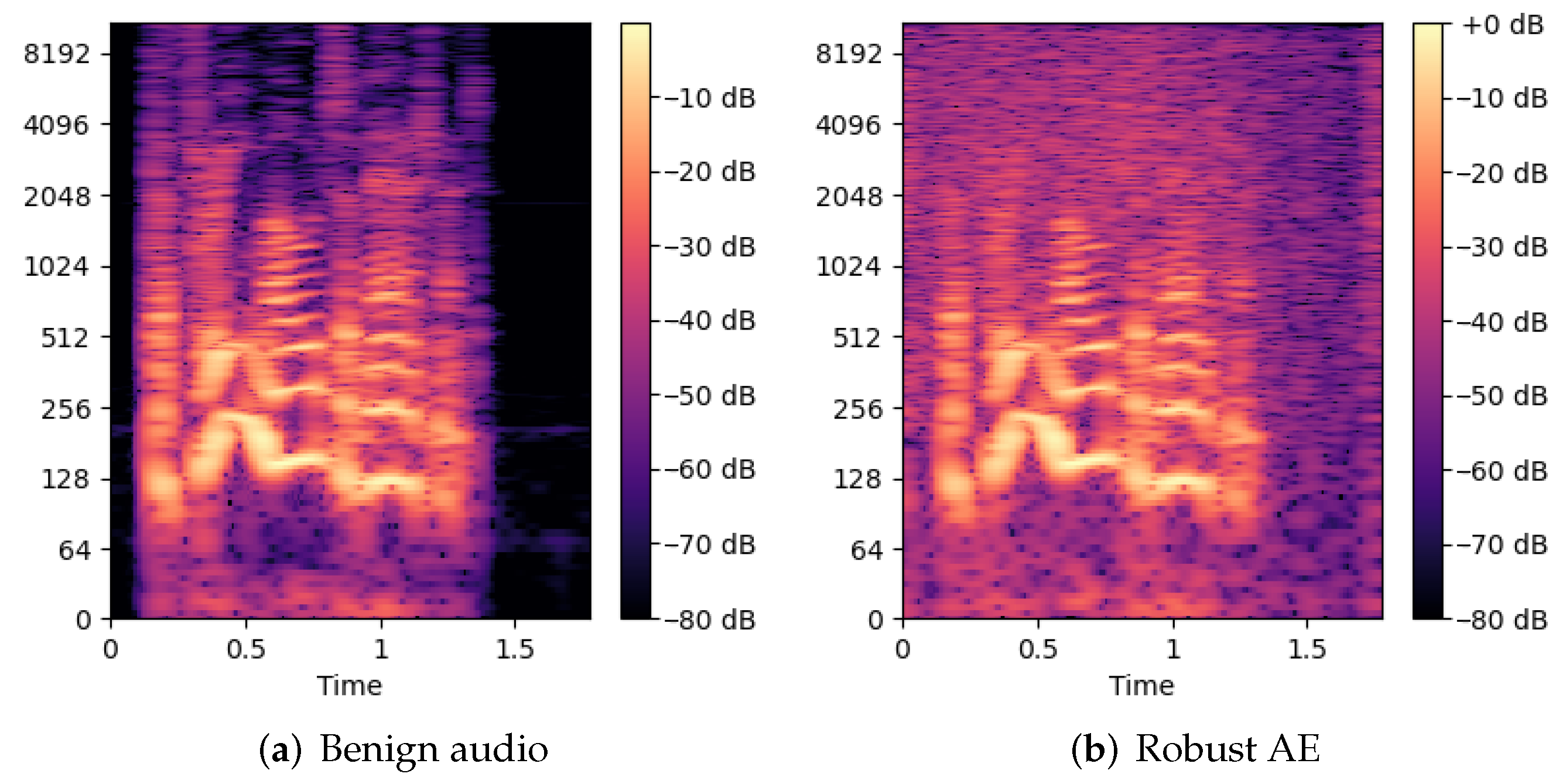
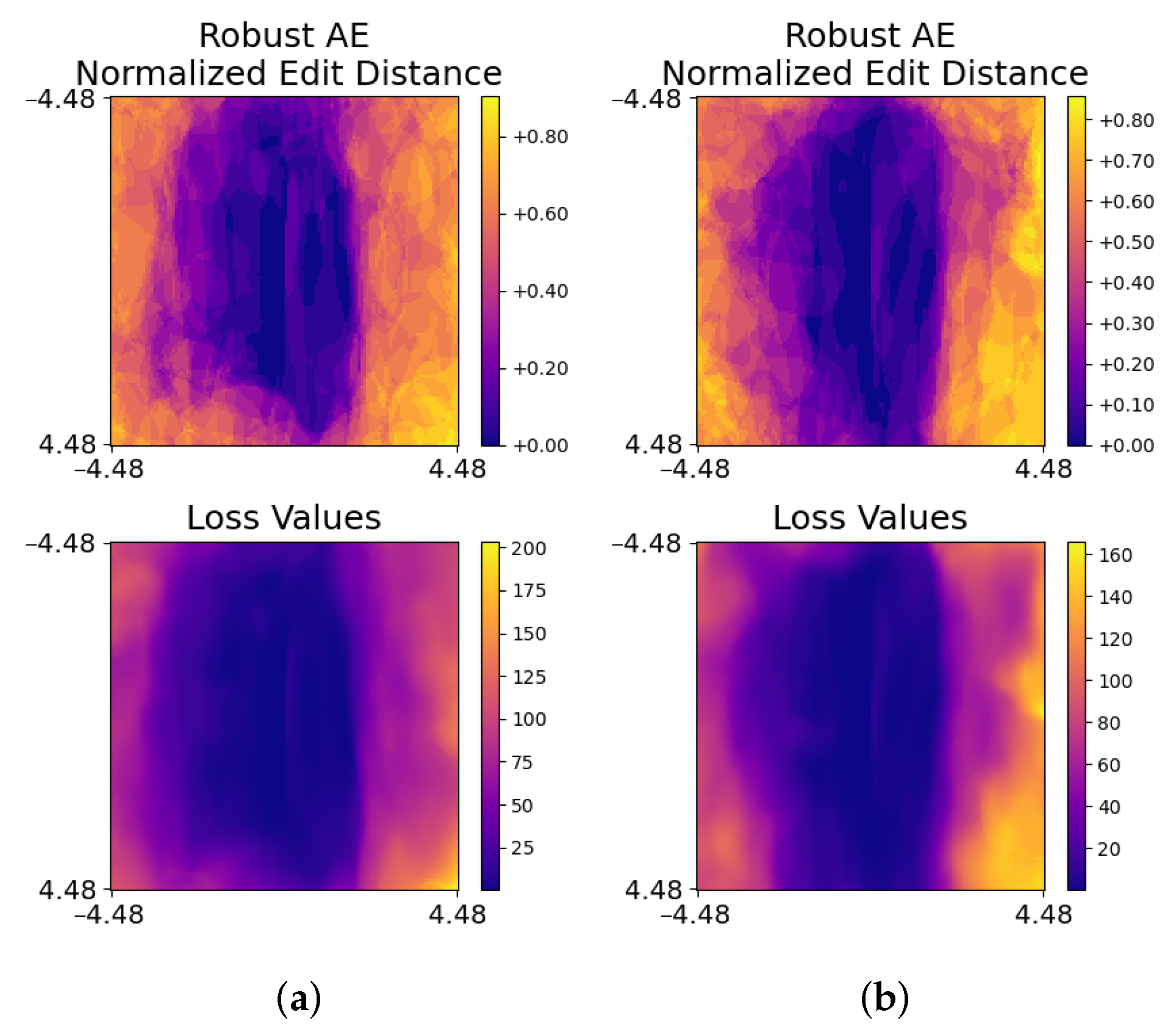
6.1. Robust Audio Adversarial Example
6.2. Eliminating Adversarial Examples
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 173–182. [Google Scholar]
- Shen, J.; Nguyen, P.; Wu, Y.; Chen, Z.; Chen, M.X.; Jia, Y.; Kannan, A.; Sainath, T.N.; Cao, Y.; Chiu, C.; et al. Lingvo: A Modular and Scalable Framework for Sequence-to-Sequence Modeling. arXiv 2019, arXiv:1902.08295. [Google Scholar]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014; Conference Track Proceedings. Bengio, Y., Le Cun, Y., Eds.; 2014. [Google Scholar]
- Jia, R.; Liang, P. Adversarial Examples for Evaluating Reading Comprehension Systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, 9–11 September 2017; Palmer, M., Hwa, R., Riedel, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2021–2031. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, H.; Miao, N.; Li, L. Generating fluent adversarial examples for natural languages. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5564–5569. [Google Scholar]
- Ebrahimi, J.; Rao, A.; Lowd, D.; Dou, D. Hotflip: White-box adversarial examples for text classification. arXiv 2017, arXiv:1712.06751. [Google Scholar]
- Carlini, N.; Wagner, D. Audio adversarial examples: Targeted attacks on speech-to-text. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 1–7. [Google Scholar]
- Schönherr, L.; Kohls, K.; Zeiler, S.; Holz, T.; Kolossa, D. Adversarial Attacks Against Automatic Speech Recognition Systems via Psychoacoustic Hiding. In Proceedings of the 26th Annual Network and Distributed System Security Symposium, NDSS 2019, San Diego, CA, USA, 24–27 February 2019; The Internet Society: Reston, VA, USA, 2019. [Google Scholar]
- Alzantot, M.; Balaji, B.; Srivastava, M.B. Did you hear that? Adversarial Examples Against Automatic Speech Recognition. arXiv 2018, arXiv:1801.00554. [Google Scholar]
- Chen, Y.; Zhang, J.; Yuan, X.; Zhang, S.; Chen, K.; Wang, X.; Guo, S. Sok: A modularized approach to study the security of automatic speech recognition systems. ACM Trans. Priv. Secur. 2022, 25, 1–31. [Google Scholar] [CrossRef]
- Vadillo, J.; Santana, R. On the human evaluation of universal audio adversarial perturbations. Comput. Secur. 2022, 112, 102495. [Google Scholar] [CrossRef]
- Mun, H.; Seo, S.; Son, B.; Yun, J. Black-Box Audio Adversarial Attack Using Particle Swarm Optimization. IEEE Access 2022, 10, 23532–23544. [Google Scholar] [CrossRef]
- Xie, Y.; Shi, C.; Li, Z.; Liu, J.; Chen, Y.; Yuan, B. Real-time, universal, and robust adversarial attacks against speaker recognition systems. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1738–1742. [Google Scholar]
- Wang, Q.; Guo, P.; Xie, L. Inaudible Adversarial Perturbations for Targeted Attack in Speaker Recognition. arXiv 2020, arXiv:2005.10637. [Google Scholar]
- Chen, G.; Zhao, Z.; Song, F.; Chen, S.; Fan, L.; Wang, F.; Wang, J. Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition. arXiv 2022, arXiv:2206.03393. [Google Scholar] [CrossRef]
- Tsipras, D.; Santurkar, S.; Engstrom, L.; Turner, A.; Madry, A. Robustness May Be at Odds with Accuracy. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; Available online: OpenReview.net (accessed on 1 November 2022).
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial examples are not bugs, they are features. Adv. Neural Inf. Process. Syst. 2019, 32, 125–136. [Google Scholar]
- Zhang, C.; Benz, P.; Imtiaz, T.; Kweon, I.S. Understanding Adversarial Examples From the Mutual Influence of Images and Perturbations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14521–14530. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the 25th Annual Network and Distributed System Security Symposium, NDSS 2018, San Diego, CA, USA, 18–21 February 2018; The Internet Society: Reston, VA, USA, 2018. [Google Scholar]
- Cohen, G.; Sapiro, G.; Giryes, R. Detecting adversarial samples using influence functions and nearest neighbors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14453–14462. [Google Scholar]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.; Schoenebeck, G.; Song, D.; Houle, M.E.; Bailey, J. Characterizing adversarial subspaces using local intrinsic dimensionality. arXiv 2018, arXiv:1801.02613. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; 2015. [Google Scholar]
- Zhang, H.; Chen, H.; Song, Z.; Boning, D.S.; Dhillon, I.S.; Hsieh, C. The Limitations of Adversarial Training and the Blind-Spot Attack. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; Available online: OpenReview.net (accessed on 1 November 2022).
- Zeng, Q.; Su, J.; Fu, C.; Kayas, G.; Luo, L.; Du, X.; Tan, C.C.; Wu, J. A multiversion programming inspired approach to detecting audio adversarial examples. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; pp. 39–51. [Google Scholar]
- Yang, Z.; Li, B.; Chen, P.; Song, D. Characterizing Audio Adversarial Examples Using Temporal Dependency. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; Available online: OpenReview.net (accessed on 1 November 2022).
- Zong, W.; Chow, Y.; Susilo, W. Towards Visualizing and Detecting Audio Adversarial Examples for Automatic Speech Recognition. In Proceedings of the Information Security and Privacy—26th Australasian Conference, ACISP 2021, Virtual Event, 1–3 December 2021; Baek, J., Ruj, S., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2021; Volume 13083, pp. 531–549. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv 2018, arXiv:1802.00420. [Google Scholar]
- Yuan, X.; Chen, Y.; Zhao, Y.; Long, Y.; Liu, X.; Chen, K.; Zhang, S.; Huang, H.; Wang, X.; Gunter, C.A. Commandersong: A systematic approach for practical adversarial voice recognition. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 49–64. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 1–15 December 2011. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Liu, X.; Wan, K.; Ding, Y.; Zhang, X.; Zhu, Q. Weighted-sampling audio adversarial example attack. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4908–4915. [Google Scholar]
- Qin, Y.; Carlini, N.; Cottrell, G.W.; Goodfellow, I.J.; Raffel, C. Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 5231–5240. [Google Scholar]
- Eisenhofer, T.; Schönherr, L.; Frank, J.; Speckemeier, L.; Kolossa, D.; Holz, T. Dompteur: Taming audio adversarial examples. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual Event, 11–13 August 2021; pp. 2309–2326. [Google Scholar]
- Zong, W.; Chow, Y.W.; Susilo, W. High Quality Audio Adversarial Examples Without Using Psychoacoustics. In International Symposium on Cyberspace Safety and Security; Springer: Berlin/Heidelberg, Germany, 2022; pp. 163–177. [Google Scholar]
- Taori, R.; Kamsetty, A.; Chu, B.; Vemuri, N. Targeted adversarial examples for black box audio systems. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 19–23 May 2019; pp. 15–20. [Google Scholar]
- Chen, Y.; Yuan, X.; Zhang, J.; Zhao, Y.; Zhang, S.; Chen, K.; Wang, X. Devil’s whisper: A general approach for physical adversarial attacks against commercial black-box speech recognition devices. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Neekhara, P.; Hussain, S.; Pandey, P.; Dubnov, S.; McAuley, J.; Koushanfar, F. Universal adversarial perturbations for speech recognition systems. arXiv 2019, arXiv:1905.03828. [Google Scholar]
- Abdullah, H.; Rahman, M.S.; Garcia, W.; Warren, K.; Yadav, A.S.; Shrimpton, T.; Traynor, P. Hear “no evil”, see “kenansville”*: Efficient and transferable black-box attacks on speech recognition and voice identification systems. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 712–729. [Google Scholar]
- Esmaeilpour, M.; Cardinal, P.; Koerich, A.L. Detection of Adversarial Attacks and Characterization of Adversarial Subspace. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3097–3101. [Google Scholar]
- Samizade, S.; Tan, Z.H.; Shen, C.; Guan, X. Adversarial Example Detection by Classification for Deep Speech Recognition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3102–3106. [Google Scholar]
- Guo, Q.; Ye, J.; Hu, Y.; Zhang, G.; Li, X.; Li, H. MultiPAD: A Multivariant Partition-Based Method for Audio Adversarial Examples Detection. IEEE Access 2020, 8, 63368–63380. [Google Scholar] [CrossRef]
- Hussain, S.; Neekhara, P.; Dubnov, S.; McAuley, J.; Koushanfar, F. WaveGuard: Understanding and Mitigating Audio Adversarial Examples. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual Event, 11–13 August 2021; pp. 2273–2290. [Google Scholar]
- Yang, C.H.; Qi, J.; Chen, P.Y.; Ma, X.; Lee, C.H. Characterizing Speech Adversarial Examples Using Self-Attention U-Net Enhancement. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3107–3111. [Google Scholar]
- Guo, Q.; Ye, J.; Chen, Y.; Hu, Y.; Lan, Y.; Zhang, G.; Li, X. INOR—An Intelligent noise reduction method to defend against adversarial audio examples. Neurocomputing 2020, 401, 160–172. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, M.; Zhang, S.; Jin, D.; Zhou, Q.; Cai, Z.; Zhao, H.; Liu, X.; Liu, Z. Delving deep into the generalization of vision transformers under distribution shifts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 7277–7286. [Google Scholar]
- Bai, T.; Luo, J.; Zhao, J.; Wen, B.; Wang, Q. Recent advances in adversarial training for adversarial robustness. arXiv 2021, arXiv:2102.01356. [Google Scholar]
- Hohman, F.; Kahng, M.; Pienta, R.; Chau, D.H. Visual analytics in deep learning: An interrogative survey for the next frontiers. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2674–2693. [Google Scholar] [CrossRef]
- Norton, A.P.; Qi, Y. Adversarial-Playground: A visualization suite showing how adversarial examples fool deep learning. In Proceedings of the 2017 IEEE Symposium on Visualization for Cyber Security (VizSec), Phoenix, AZ, USA, 2 October 2017; pp. 1–4. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. Conference Track Proceedings. [Google Scholar]
- Stutz, D.; Hein, M.; Schiele, B. Disentangling adversarial robustness and generalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6976–6987. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Lin, Y.; Abdulla, W.H. Principles of psychoacoustics. In Audio Watermark; Springer: Berlin/Heidelberg, Germany, 2015; pp. 15–49. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Queensland, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 284–293. [Google Scholar]
- Allen-Zhu, Z.; Li, Y. Feature purification: How adversarial training performs robust deep learning. In Proceedings of the 2021 IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS), Denver, CO, USA, 7–10 February 2022; pp. 977–988. [Google Scholar]
- Goldblum, M.; Fowl, L.; Feizi, S.; Goldstein, T. Adversarially robust distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3996–4003. [Google Scholar]
- Gowal, S.; Dvijotham, K.; Stanforth, R.; Bunel, R.; Qin, C.; Uesato, J.; Arandjelovic, R.; Mann, T.A.; Kohli, P. On the Effectiveness of Interval Bound Propagation for Training Verifiably Robust Models. arXiv 2018, arXiv:1810.12715. [Google Scholar]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef] [PubMed]
- Geirhos, R.; Jacobsen, J.H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F.A. Shortcut learning in deep neural networks. Nat. Mach. Intell. 2020, 2, 665–673. [Google Scholar] [CrossRef]
- Liu, E.Z.; Haghgoo, B.; Chen, A.S.; Raghunathan, A.; Koh, P.W.; Sagawa, S.; Liang, P.; Finn, C. Just train twice: Improving group robustness without training group information. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 6781–6792. [Google Scholar]
- Singla, S.; Feizi, S. Salient ImageNet: How to discover spurious features in Deep Learning? In Proceedings of the International Conference on Learning Representations, Virtual, 25 April 2022. [Google Scholar]







| Defense Type | Method | Target Model | Technique |
|---|---|---|---|
| Detection | Zeng et al. [27] | DeepSpeech | Multiple transcripts |
| Yang et al. [28] | DeepSpeech, Kaldi | Temporal dependency | |
| Samizade et al. [44] | DeepSpeech | CNN | |
| Guo et al. [45] | DeepSpeech | Multivariant partition | |
| Hussain et al. [46] | DeepSpeech, Lingvo | Input transformation | |
| Recovery | Yang et al. [47] | DeepSpeech | Speech quality enhancement |
| Guo et al. [48] | DeepSpeech | Noise reduction | |
| Yuan et al. [32] | Kaldi | Downsampling | |
| Chen et al. [40] | IBM Speech to Text | Downsampling |
| Type | DeepSpeech | DeepSpeech2 |
|---|---|---|
| Targeted AEs | 17.4 h (100.00%) | 6.0 h (100.00%) |
| Untargeted AEs | 11.0 h (98.68%) | 12.3 h (100.00%) |
| FGSM AEs | 0.13 h (28.79%) | 0.07 h (38.66%) |
| DeepSpeech | DeepSpeech2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Type | TP | FP | TN | FN | DR | TP | FP | TN | FN | DR |
| Targeted AEs | 150 | - | - | 0 | 100.00% | 150 | - | - | 0 | 100.00% |
| Untargeted AEs | 120 | - | - | 30 | 80.00% | 129 | - | - | 21 | 86.00% |
| FGSM AEs | 86 | - | - | 64 | 57.33% | 33 | - | - | 117 | 22.00% |
| Noisy Audio | - | 9 | 141 | - | 94.00% | - | 8 | 142 | - | 94.67% |
| Correctly trans. | - | 4 | 146 | - | 97.33% | - | 2 | 148 | - | 98.67% |
| Incorrectly trans. | - | 6 | 144 | - | 96.00% | - | 12 | 138 | - | 92.00% |
| Pre | Rec | Acc | Pre | Rec | Acc | |||||
| 94.93% | 79.11% | 87.44% | 93.41% | 69.33% | 82.22% | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zong, W.; Chow, Y.-W.; Susilo, W.; Kim, J.; Le, N.T. Detecting Audio Adversarial Examples in Automatic Speech Recognition Systems Using Decision Boundary Patterns. J. Imaging 2022, 8, 324. https://doi.org/10.3390/jimaging8120324
Zong W, Chow Y-W, Susilo W, Kim J, Le NT. Detecting Audio Adversarial Examples in Automatic Speech Recognition Systems Using Decision Boundary Patterns. Journal of Imaging. 2022; 8(12):324. https://doi.org/10.3390/jimaging8120324
Chicago/Turabian StyleZong, Wei, Yang-Wai Chow, Willy Susilo, Jongkil Kim, and Ngoc Thuy Le. 2022. "Detecting Audio Adversarial Examples in Automatic Speech Recognition Systems Using Decision Boundary Patterns" Journal of Imaging 8, no. 12: 324. https://doi.org/10.3390/jimaging8120324
APA StyleZong, W., Chow, Y.-W., Susilo, W., Kim, J., & Le, N. T. (2022). Detecting Audio Adversarial Examples in Automatic Speech Recognition Systems Using Decision Boundary Patterns. Journal of Imaging, 8(12), 324. https://doi.org/10.3390/jimaging8120324