
SEDIQA: Sound Emitting Document Image Quality Assessment in a Reading Aid for the Visually Impaired


Abstract
1. Introduction
- (1)
- Testing of OCR accuracy versus image degradations to identify the degradations that contribute most significantly to OCR accuracy reduction.
- (2)
- A new, robust and directly measurable NR-IQA metric for document images. This is validated by testing on both synthetic and real images, against image degradations and OCR accuracy and alongside established NR-IQAs.
- (3)
- Insights into the performance of established NR-IQAs on document images.
- (4)
- Improvements in OCR accuracy in the full SEDIQA design.
- (5)
- SEDIQA as a visual reading aid.
2. Materials and Methods
2.1. OCR Accuracy vs. Quality
2.2. SEDIQA Quality Measure
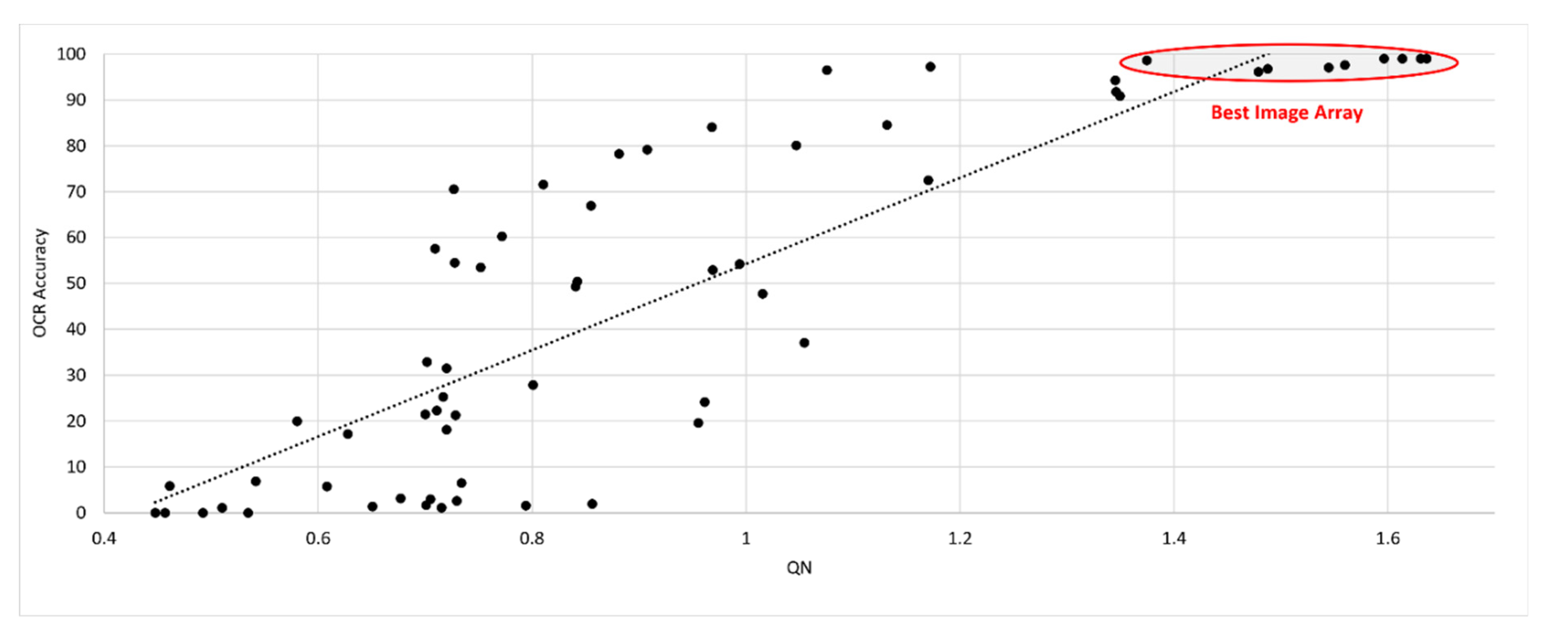
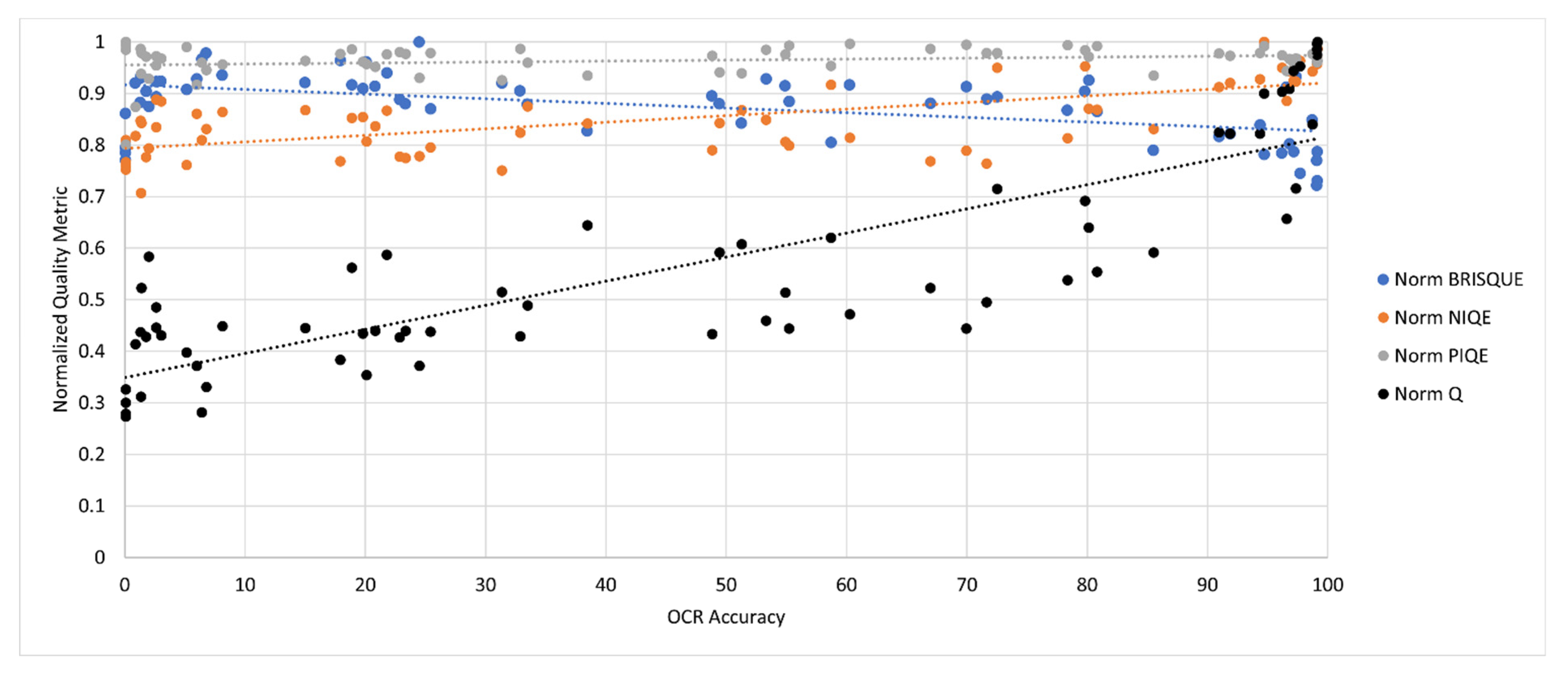
2.3. Validation of SEDIQA’s Q Metric
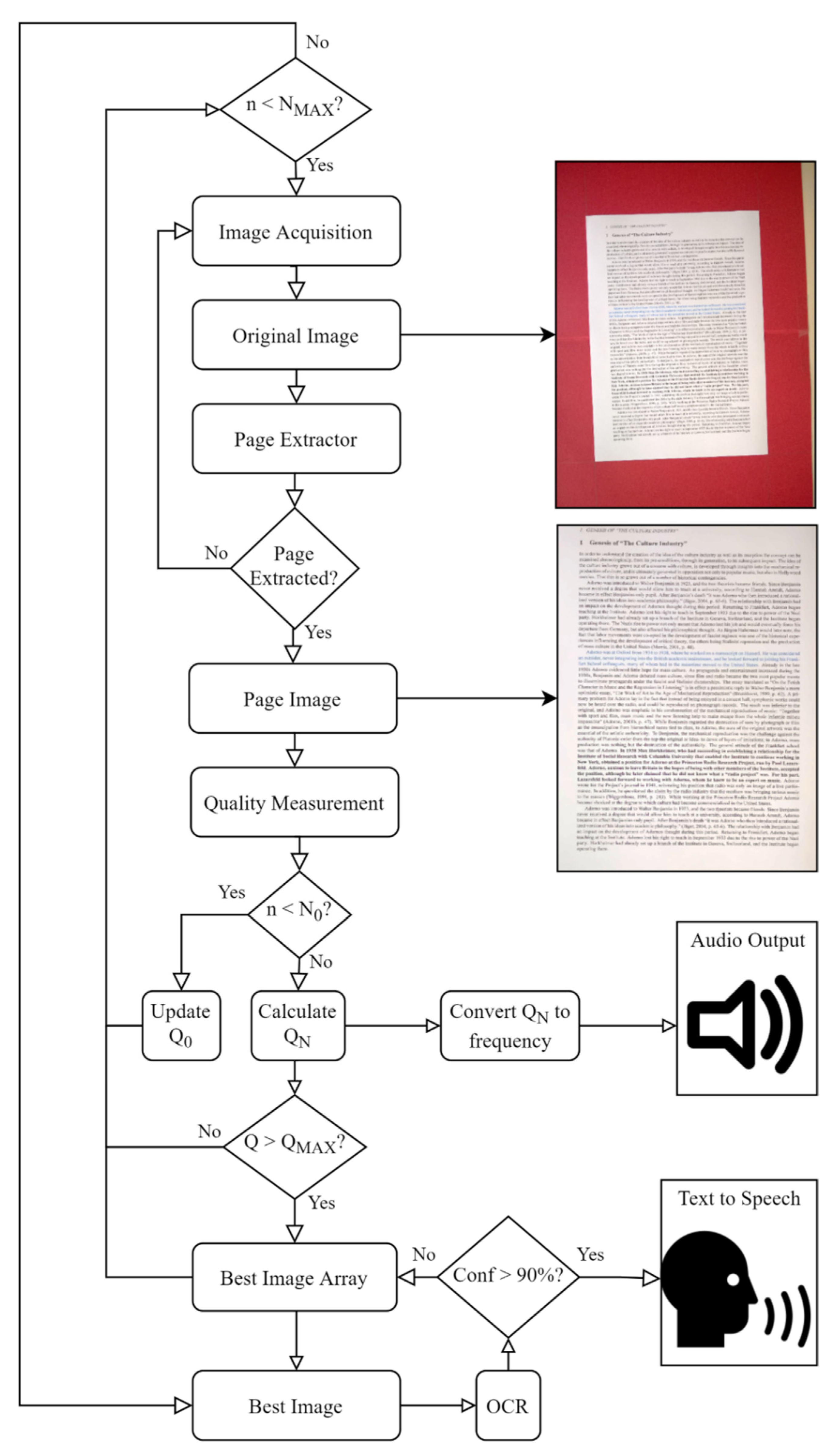
2.4. SEDIQA Design
2.4.1. Page Extractor
2.4.2. Quality Measurement
2.4.3. Audio Output
2.5. Accuracy Improvements
3. Results
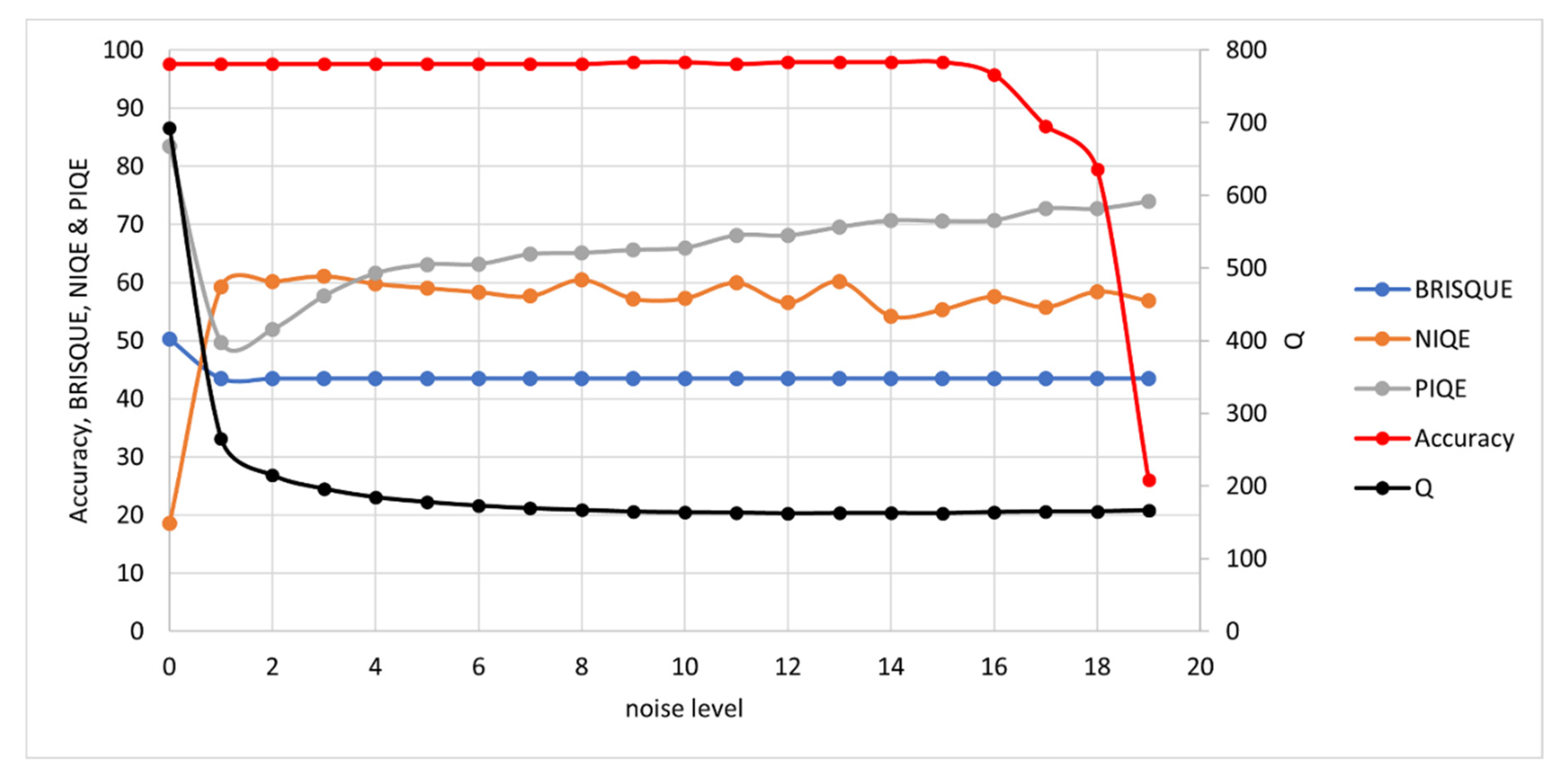
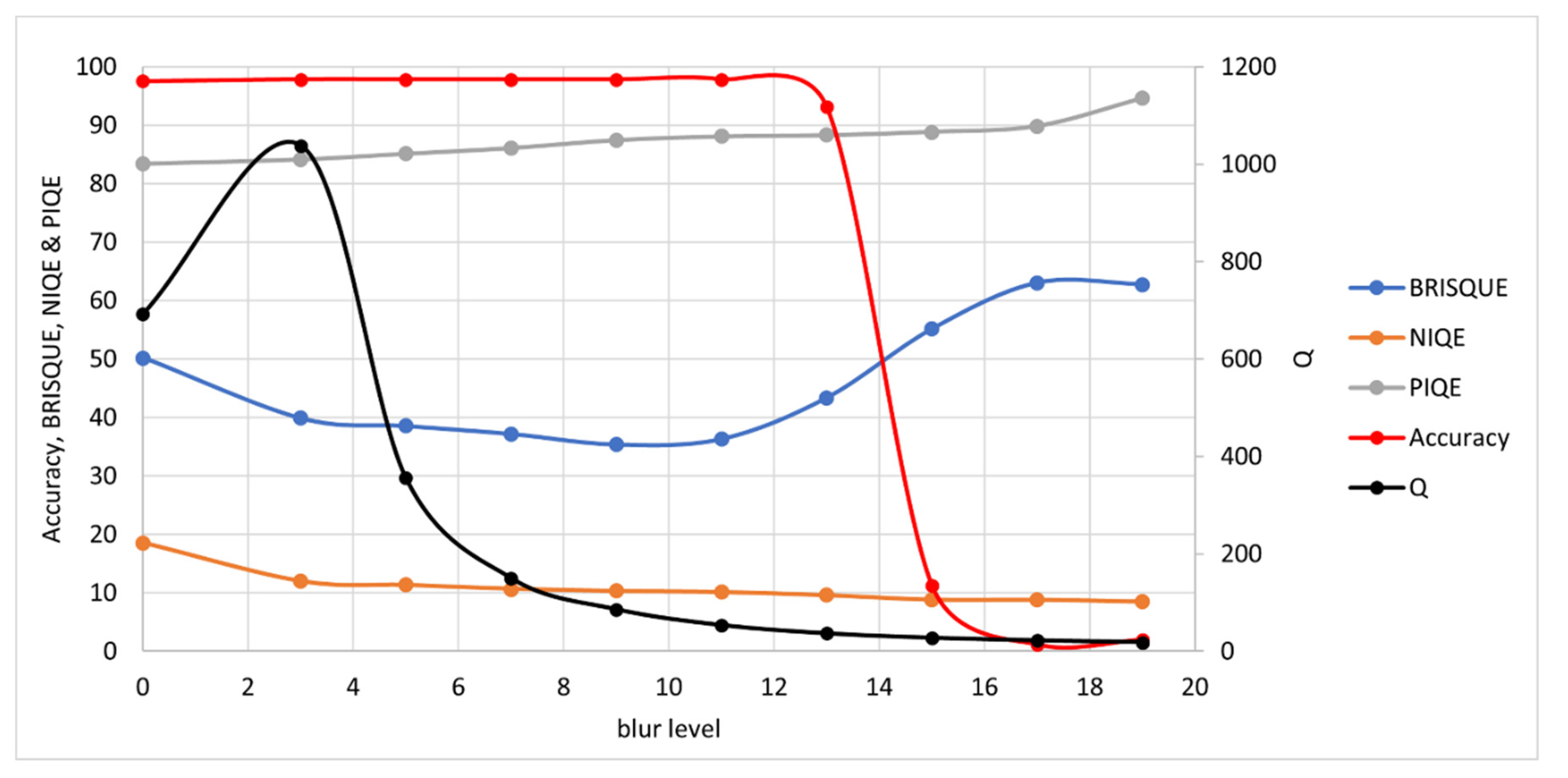
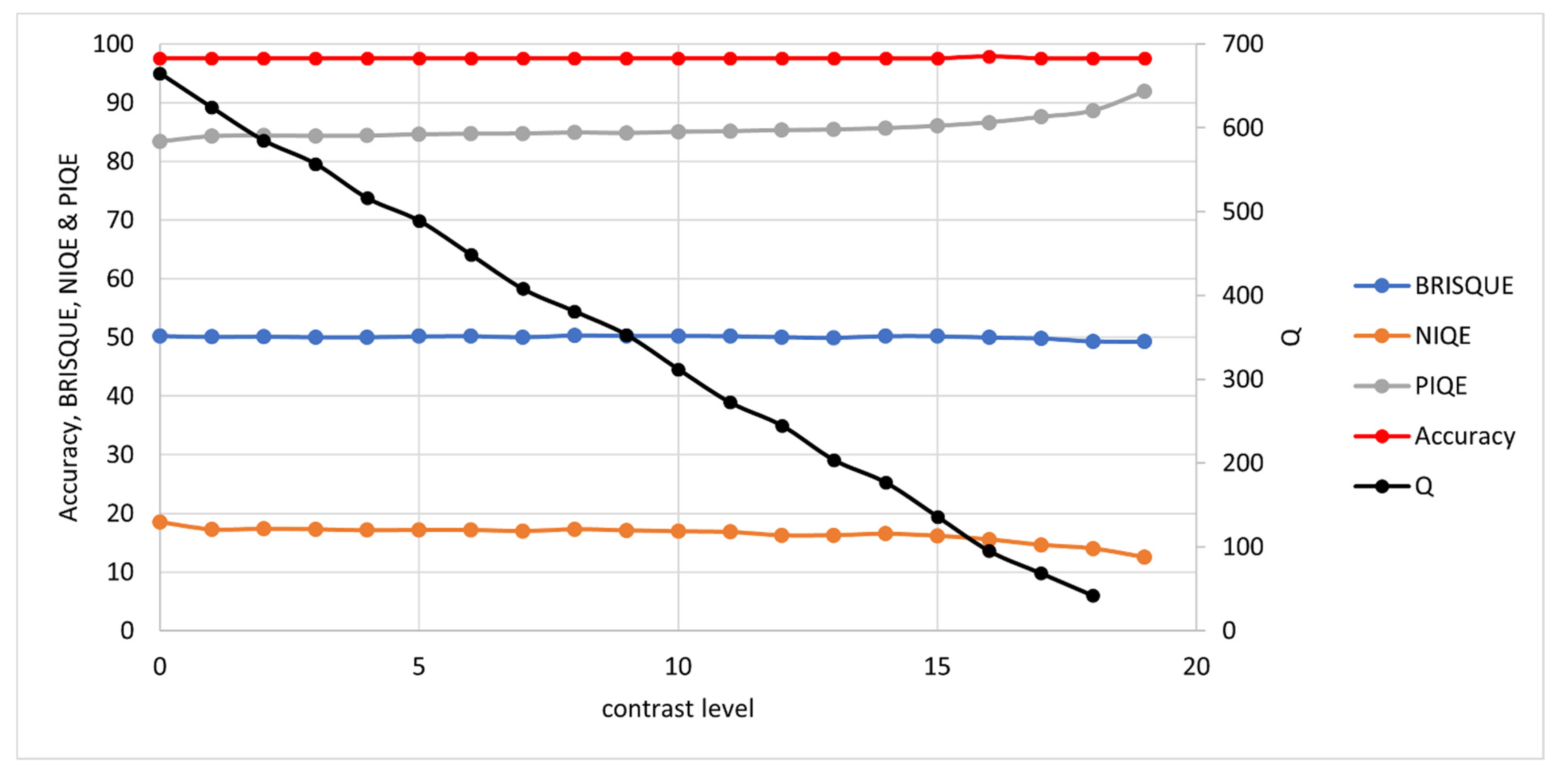
3.1. Synthetically Degraded Images
3.1.1. Noise
3.1.2. Blur
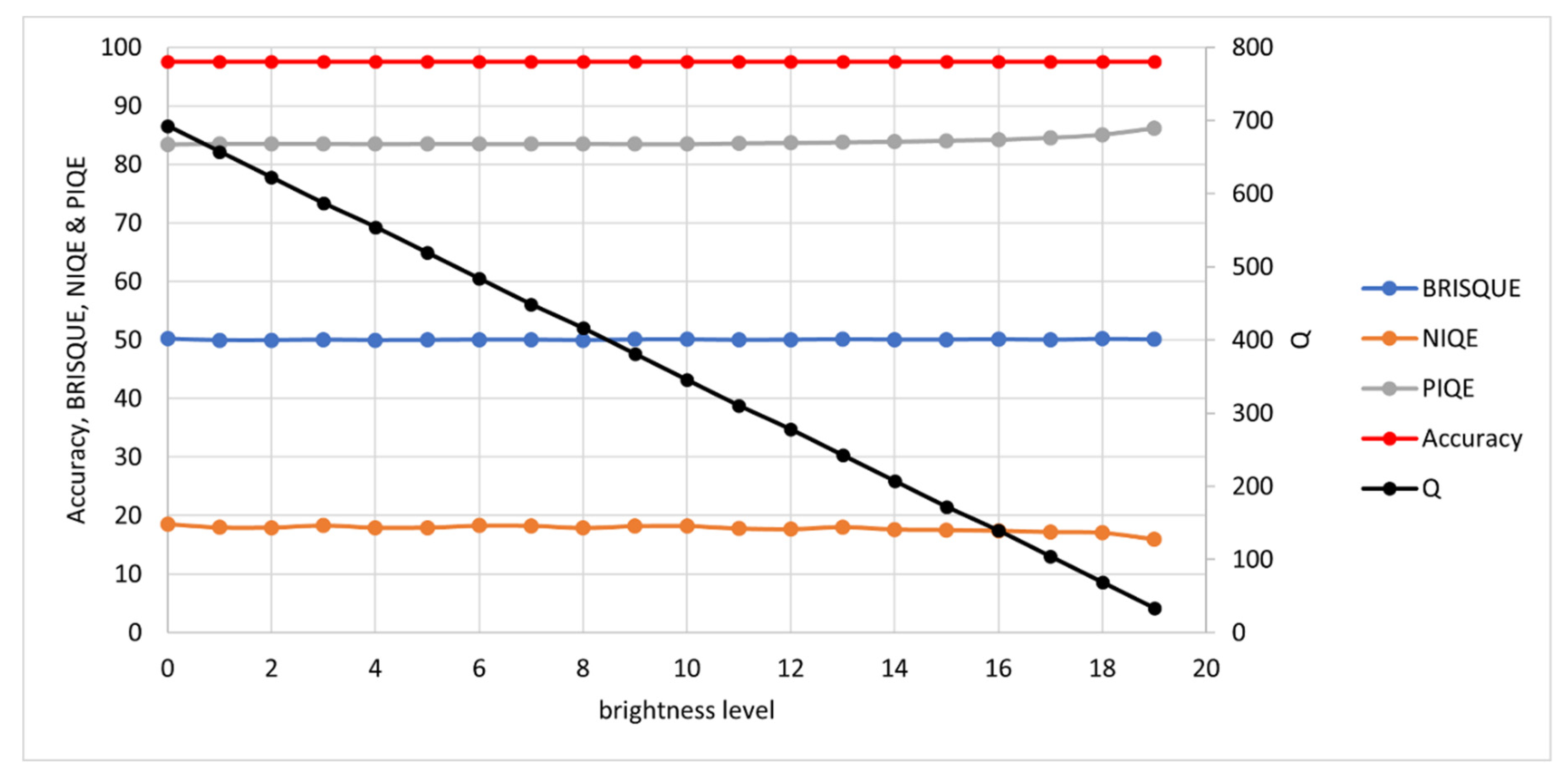
3.1.3. Contrast and Brightness
3.2. Real Camera-Captured Images
3.3. Accuracy Improvements
4. Discussion
5. Conclusions
- (1)
- Testing of OCR Accuracy vs. Image Degradations, identifying blur and noise as those that contribute most significantly to OCR accuracy reduction
- (2)
- A new, robust, directly measurable, validated NR-IQA for document images which consistently selects the best images for OCR accuracy performance
- (3)
- Insights into the performance of three well-established NR-IQAs on document images:
- ○
- BRISQUE was shown to only respond to blur out of the four major degradations tested, but performed reasonably well on real images. However, its failures were extreme, with accuracies less than 1% in its top ten images.
- ○
- NIQE was found to be wholly unsuitable for document images.
- ○
- PIQE responded to all four image degradations but completely failed on real images.
- (4)
- A document image enhancement technique leading to improvements in OCR accuracy of 22% on average across the whole SmartDoc dataset and a maximum increase of 68%.
- (5)
- The full SEDIQA Design as a Visual Reading Aid with audio outputs.
Funding
Acknowledgments
Conflicts of Interest
References
- Dockery, D.; Krzystolik, M. The Evaluation of Mobile Applications as Low Vision Aids: The Patient Perspective. Invest. Ophthalmol. Vis. Sci. 2020, 61, 935. [Google Scholar]
- Akkara, J.D.; Kuriakose, A. Commentary: An App a Day Keeps the Eye Doctor Busy. Indian J. Ophthalmol. 2021, 69, 553. [Google Scholar] [CrossRef]
- El-taher, F.E.; Taha, A.; Courtney, J.; Mckeever, S. A Systematic Review of Urban Navigation Systems for Visually Impaired People. Sensors 2021, 21, 3103. [Google Scholar] [CrossRef] [PubMed]
- Hisham, Z.A.N.; Faudzi, M.A.; Ghapar, A.A.; Rahim, F.A. A Systematic Literature Review of the Mobile Application for Object Recognition for Visually Impaired People. In Proceedings of the 2020 8th International Conference on Information Technology and Multimedia (ICIMU), Selangor, Malaysia, 24–26 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 316–322. [Google Scholar]
- Jiang, H.; Gonnot, T.; Yi, W.-J.; Saniie, J. Computer Vision and Text Recognition for Assisting Visually Impaired People Using Android Smartphone. In Proceedings of the 2017 IEEE International Conference on Electro Information Technology (EIT), Lincoln, NE, USA, 14–17 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 350–353. [Google Scholar]
- Peng, X.; Wang, C. Building Super-Resolution Image Generator for OCR Accuracy Improvement. In Document Analysis Systems; Bai, X., Karatzas, D., Lopresti, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 145–160. [Google Scholar]
- Brzeski, A.; Grinholc, K.; Nowodworski, K.; Przybyłek, A. Evaluating Performance and Accuracy Improvements for Attention-OCR. In Computer Information Systems and Industrial Management; Saeed, K., Chaki, R., Janev, V., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 3–11. [Google Scholar]
- Zhai, G.; Min, X. Perceptual Image Quality Assessment: A Survey. Sci. China Inf. Sci. 2020, 63, 211301. [Google Scholar] [CrossRef]
- Ye, P.; Doermann, D. Document Image Quality Assessment: A Brief Survey. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 723–727. [Google Scholar]
- Courtney, J. CleanPage: Fast and Clean Document and Whiteboard Capture. J. Imaging 2020, 6, 102. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Chan, R.W.; Goldsmith, P.B. A Psychovisually-Based Image Quality Evaluator for JPEG Images. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Nashville, TN, USA, 8–11 October 2000; Volume 2, pp. 1541–1546. [Google Scholar]
- Alaei, A. A New Document Image Quality Assessment Method Based on Hast Derivations. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1244–1249. [Google Scholar]
- Kumar, J.; Chen, F.; Doermann, D. Sharpness Estimation for Document and Scene Images. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3292–3295. [Google Scholar]
- Asad, F.; Ul-Hasan, A.; Shafait, F.; Dengel, A. High Performance OCR for Camera-Captured Blurred Documents with LSTM Networks. In Proceedings of the 2016 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; pp. 7–12. [Google Scholar]
- Yang, H.; Fang, Y.; Lin, W. Perceptual Quality Assessment of Screen Content Images. IEEE Trans. Image Process. 2015, 24, 4408–4421. [Google Scholar] [CrossRef]
- Shahkolaei, A.; Nafchi, H.Z.; Al-Maadeed, S.; Cheriet, M. Subjective and Objective Quality Assessment of Degraded Document Images. J. Cult. Herit. 2018, 30, 199–209. [Google Scholar] [CrossRef]
- Shahkolaei, A.; Beghdadi, A.; Cheriet, M. Blind Quality Assessment Metric and Degradation Classification for Degraded Document Images. Signal Process. Image Commun. 2019, 76, 11–21. [Google Scholar] [CrossRef]
- Peng, X.; Wang, C. Camera Captured DIQA with Linearity and Monotonicity Constraints. In Document Analysis Systems; Bai, X., Karatzas, D., Lopresti, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 168–181. [Google Scholar]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. Learning a Blind Quality Evaluation Engine of Screen Content Images. Neurocomputing 2016, 196, 140–149. [Google Scholar] [CrossRef]
- Li, H.; Qiu, J.; Zhu, F. TextNet for Text-Related Image Quality Assessment. In Artificial Neural Networks and Machine Learning—ICANN 2018; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 275–285. [Google Scholar]
- Lu, T.; Dooms, A. A Deep Transfer Learning Approach to Document Image Quality Assessment. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1372–1377. [Google Scholar]
- Qian, J.; Tang, L.; Jakhetiya, V.; Xia, Z.; Gu, K.; Lu, H. Towards Efficient Blind Quality Evaluation of Screen Content Images Based on Edge-Preserving Filter. Electron. Lett. 2017, 53, 592–594. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Liu, J.; Jiang, B.; Meng, Q.; Lu, W.; Gao, X. No Reference Quality Assessment for Screen Content Images Using Stacked Autoencoders in Pictorial and Textual Regions. IEEE Trans. Cybern. 2020, 1–13. [Google Scholar] [CrossRef]
- Shao, F.; Gao, Y.; Li, F.; Jiang, G. Toward a Blind Quality Predictor for Screen Content Images. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 1521–1530. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Chen, J.; An, P.; Luo, J. No-Reference Quality Assessment for Screen Content Images Based on Hybrid Region Features Fusion. IEEE Trans. Multimed. 2019, 21, 2057–2070. [Google Scholar] [CrossRef]
- Alaei, A.; Conte, D.; Raveaux, R. Document Image Quality Assessment Based on Improved Gradient Magnitude Similarity Deviation. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 176–180. [Google Scholar]
- Li, H.; Zhu, F.; Qiu, J. CG-DIQA: No-Reference Document Image Quality Assessment Based on Character Gradient. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3622–3626. [Google Scholar]
- Ye, P.; Doermann, D. Learning Features for Predicting OCR Accuracy. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3204–3207. [Google Scholar]
- Rusinol, M.; Chazalon, J.; Ogier, J.-M. Combining Focus Measure Operators to Predict Ocr Accuracy in Mobile-Captured Document Images. In Proceedings of the 2014 11th IAPR International Workshop on Document Analysis Systems, Tours, France, 7–10 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 181–185. [Google Scholar]
- Peng, X.; Cao, H.; Natarajan, P. Document Image OCR Accuracy Prediction via Latent Dirichlet Allocation. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 771–775. [Google Scholar]
- Nayef, N.; Ogier, J.-M. Metric-Based No-Reference Quality Assessment of Heterogeneous Document Images. In Proceedings of the Document Recognition and Retrieval XXII, San Francisco, CA, USA, 11–12 February 2015; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9402, p. 94020L. [Google Scholar]
- Lu, T.; Dooms, A. Towards Content Independent No-Reference Image Quality Assessment Using Deep Learning. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 276–280. [Google Scholar]
- Kieu, V.-C.; Cloppet, F.; Vincent, N. OCR Accuracy Prediction Method Based on Blur Estimation. In Proceedings of the 2016 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 317–322. [Google Scholar]
- Burie, J.-C.; Chazalon, J.; Coustaty, M.; Eskenazi, S.; Luqman, M.M.; Mehri, M.; Nayef, N.; Ogier, J.-M.; Prum, S.; Rusiñol, M. ICDAR2015 Competition on Smartphone Document Capture and OCR (SmartDoc). In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1161–1165. [Google Scholar]
- Chazalon, J.; Gomez-Krämer, P.; Burie, J.-C.; Coustaty, M.; Eskenazi, S.; Luqman, M.; Nayef, N.; Rusiñol, M.; Sidère, N.; Ogier, J.-M. SmartDoc 2017 Video Capture: Mobile Document Acquisition in Video Mode. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 4, pp. 11–16. [Google Scholar]
- Javed, K.; Shafait, F. Real-Time Document Localization in Natural Images by Recursive Application of a Cnn. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 105–110. [Google Scholar]
- Smith, R. An Overview of the Tesseract OCR Engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; IEEE: Piscataway, NJ, USA, 2007; Volume 2, pp. 629–633. [Google Scholar]
- Nayef, N.; Luqman, M.M.; Prum, S.; Eskenazi, S.; Chazalon, J.; Ogier, J.-M. SmartDoc-QA: A Dataset for Quality Assessment of Smartphone Captured Document Images-Single and Multiple Distortions. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1231–1235. [Google Scholar]
- Lundqvist, F.; Wallberg, O. Natural Image Distortions and Optical Character Recognition Accuracy. Bachelor’s Thesis, KTH, School of Computer Science and Communication, Stockholm, Sweden, 2016. [Google Scholar]
- Kolli, A. A Comprehensive Study of the Influence of Distortions on the Performance of Convolutional Neural Networks Based Recognition of MNIST Digit Images. Ph.D. Thesis, Alpen-Adria-Universität Klagenfurt, Klagenfurt, Austria, 2019. [Google Scholar]
- Mustafa, W.A.; Abdul Kader, M.M.M. Binarization of Document Images: A Comprehensive Review. J. Phys. Conf. Ser. 2018, 1019, 012023. [Google Scholar] [CrossRef]
- Wellner, P. Interacting with Paper on the DigitalDesk. Commun. ACM 1993, 36, 87–96. [Google Scholar] [CrossRef]
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image Analysis Using Mathematical Morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 532–550. [Google Scholar] [CrossRef]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An Efficient and Accurate Scene Text Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5551–5560. [Google Scholar]
- Barnard, S.T. Interpreting Perspective Images. Artif. Intell. 1983, 21, 435–462. [Google Scholar] [CrossRef]
- Vitz, P.C. Preference for Tones as a Function of Frequency (Hertz) and Intensity (Decibels). Percept. Psychophys. 1972, 11, 84–88. [Google Scholar] [CrossRef][Green Version]
- Khare, V.; Shivakumara, P.; Raveendran, P.; Blumenstein, M. A Blind Deconvolution Model for Scene Text Detection and Recognition in Video. Pattern Recognit. 2016, 54, 128–148. [Google Scholar] [CrossRef]
- Xue, M.; Shivakumara, P.; Zhang, C.; Xiao, Y.; Lu, T.; Pal, U.; Lopresti, D.; Yang, Z. Arbitrarily-Oriented Text Detection in Low Light Natural Scene Images. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Thanh, D.N.H.; Prasath, V.S. Adaptive Texts Deconvolution Method for Real Natural Images. In Proceedings of the 2019 25th Asia-Pacific Conference on Communications (APCC), Ho Chi Minh City, Vietnam, 6–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 110–115. [Google Scholar]
- Nakao, R.; Iwana, B.K.; Uchida, S. Selective Super-Resolution for Scene Text Images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 401–406. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NR-IQA | Noise | Blur | Contrast | Brightness |
|---|---|---|---|---|
| BRISQUE | 🗴 | 🗸 | 🗴 | 🗴 |
| PIQE | 🗸 | 🗸 | 🗸 | 🗸 |
| NIQE | 🗴 | 🗴 | 🗴 | 🗴 |
| SEDIQA | 🗸 | 🗸 | 🗸 | 🗸 |
| NR-IQA | Correlation |
|---|---|
| BRISQUE | −0.5291 |
| NIQE | 0.6783 |
| PIQE | 0.2297 |
| SEDIQA | 0.8463 |
| Image Rank | Accuracy | Norm Q |
|---|---|---|
| 1 | 99.11 | 1 |
| 2 | 99.10 | 0.9967 |
| 3 | 99.08 | 0.9862 |
| 4 | 99.07 | 0.9757 |
| 5 | 97.68 | 0.9532 |
| 6 | 97.14 | 0.9440 |
| 7 | 96.80 | 0.9094 |
| 8 | 96.16 | 0.9039 |
| 9 | 94.69 | 0.8998 |
| 10 | 98.70 | 0.8402 |
| Accuracies | ||||
|---|---|---|---|---|
| Image Rank | SEDIQA | BRISQUE | NIQE | PIQE |
| 1 | 99.11 | 99.08 | 1.32 | 0.07 |
| 2 | 99.10 | 99.11 | 31.34 | 0.86 |
| 3 | 99.08 | 97.68 | 0.07 | 5.98 |
| 4 | 99.07 | 99.07 | 5.13 | 31.34 |
| 5 | 97.68 | 0.07 | 0.07 | 2.00 |
| 6 | 97.14 | 94.69 | 71.63 | 24.47 |
| 7 | 96.80 | 96.16 | 0.07 | 38.44 |
| 8 | 96.16 | 0.07 | 17.91 | 85.50 |
| 9 | 94.69 | 97.14 | 66.96 | 1.32 |
| 10 | 98.70 | 99.10 | 23.31 | 51.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Courtney, J. SEDIQA: Sound Emitting Document Image Quality Assessment in a Reading Aid for the Visually Impaired. J. Imaging 2021, 7, 168. https://doi.org/10.3390/jimaging7090168
Courtney J. SEDIQA: Sound Emitting Document Image Quality Assessment in a Reading Aid for the Visually Impaired. Journal of Imaging. 2021; 7(9):168. https://doi.org/10.3390/jimaging7090168
Chicago/Turabian StyleCourtney, Jane. 2021. "SEDIQA: Sound Emitting Document Image Quality Assessment in a Reading Aid for the Visually Impaired" Journal of Imaging 7, no. 9: 168. https://doi.org/10.3390/jimaging7090168
APA StyleCourtney, J. (2021). SEDIQA: Sound Emitting Document Image Quality Assessment in a Reading Aid for the Visually Impaired. Journal of Imaging, 7(9), 168. https://doi.org/10.3390/jimaging7090168