
CNN-Based Multi-Modal Camera Model Identification on Video Sequences

Abstract
:1. Introduction
2. Background
2.1. Digital Image Acquisition Pipeline
2.2. Mel Scale and Log-Mel Spectrogram
3. Problem Formulation
3.1. Mono-Modal Camera Model Identification
3.2. Multi-Modal Camera Model Identification
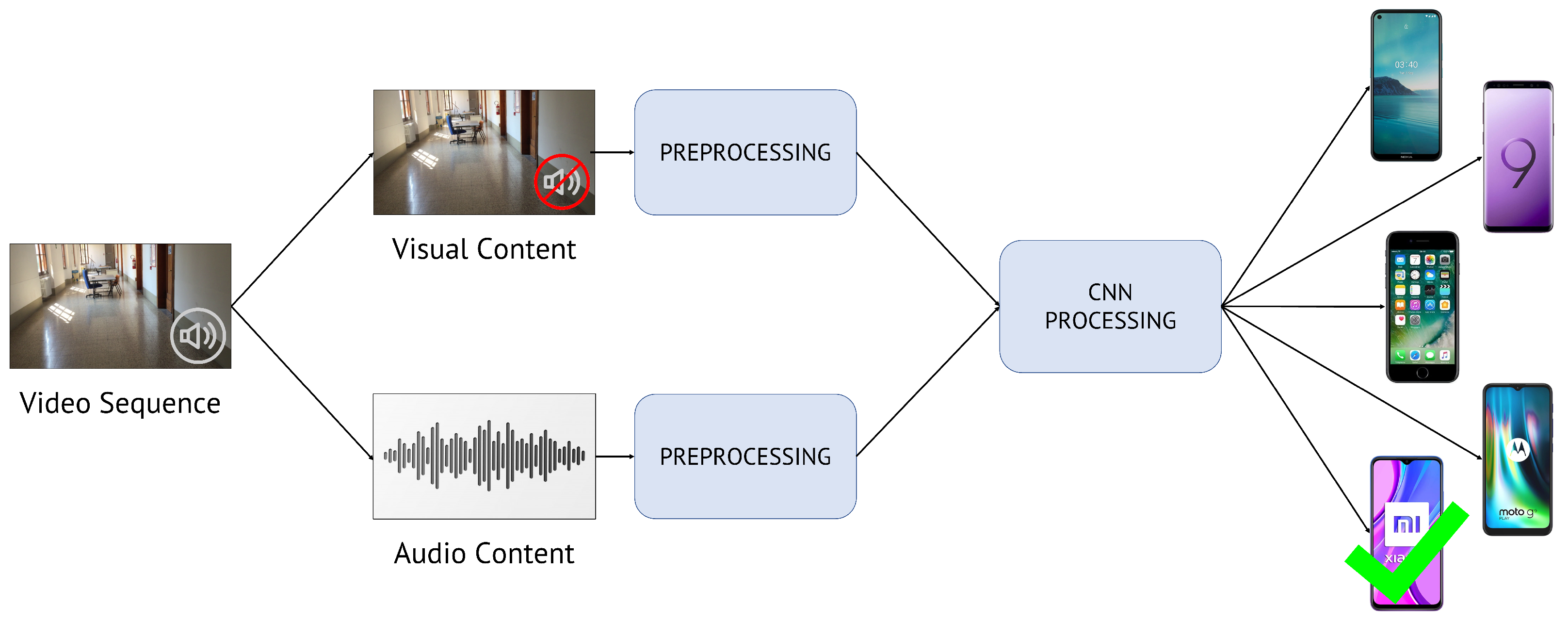
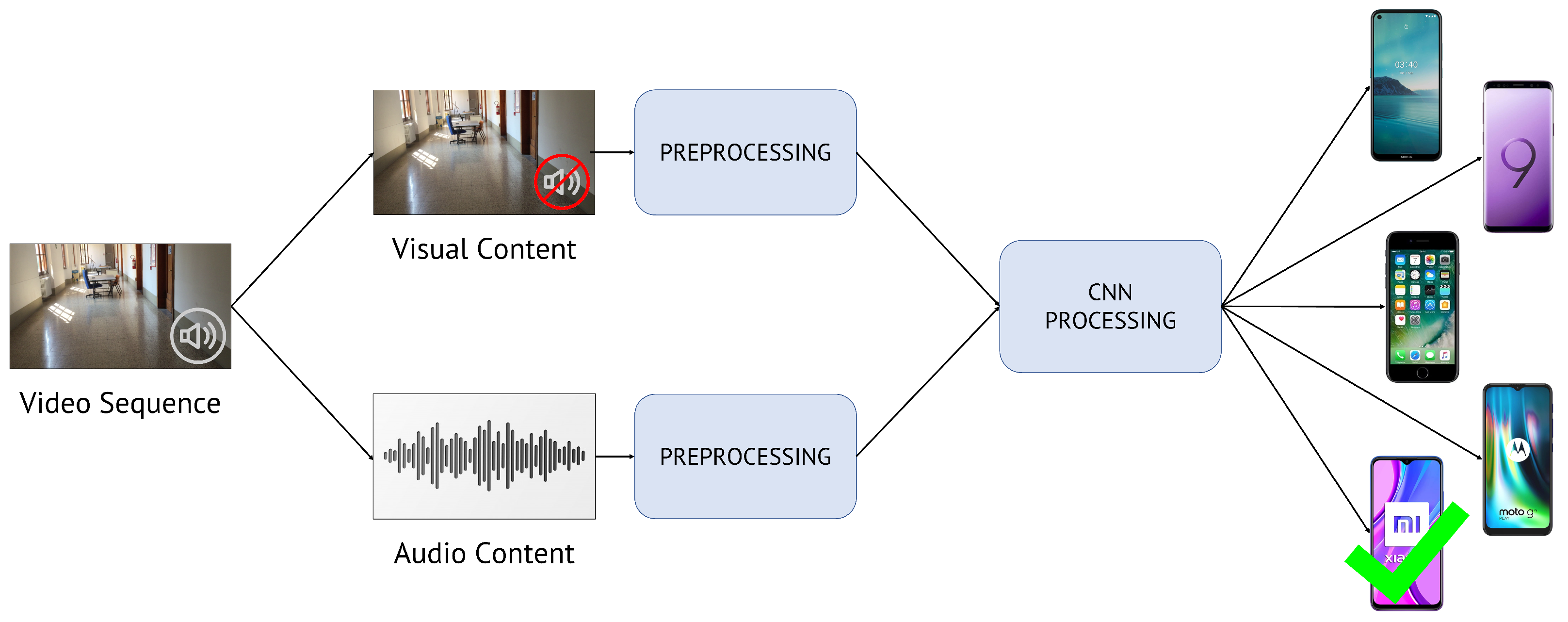
4. Methodology
- Content extraction and pre-processing: extraction of visual and audio content from the video sequence under analysis and manipulation of data prior to feeding them to CNNs;
- CNN processing: feature extraction and classification block composed of one or multiple CNNs.
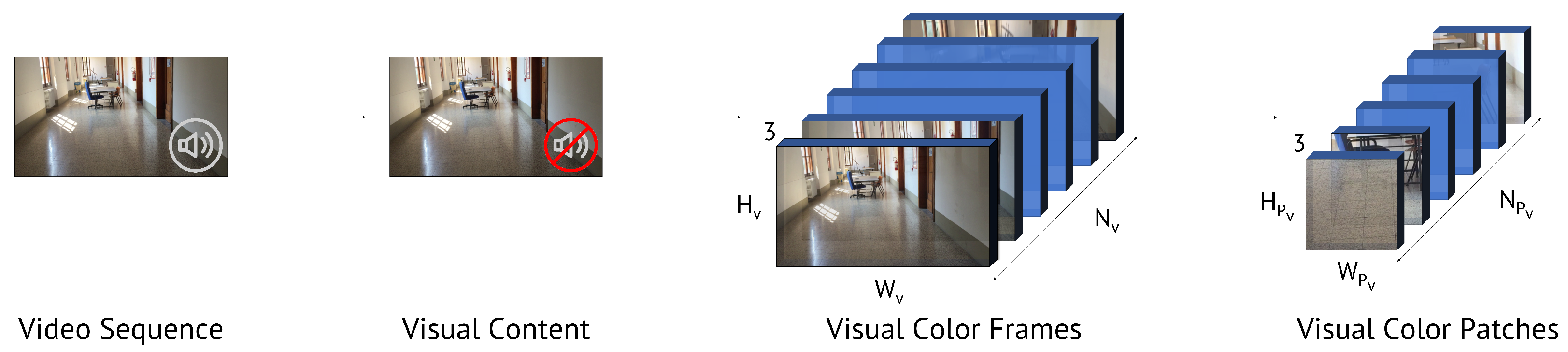
4.1. Content Extraction and Pre-Processing
- Extraction of color frames equally distant in time and distributed over its entire duration. The video frames have size , which depends on the resolution of the video under analysis;
- Random extraction of color patches of size ;
- Patch normalization in order to have zero mean and unitary variance as is commonly done prior to feeding data to CNNs.
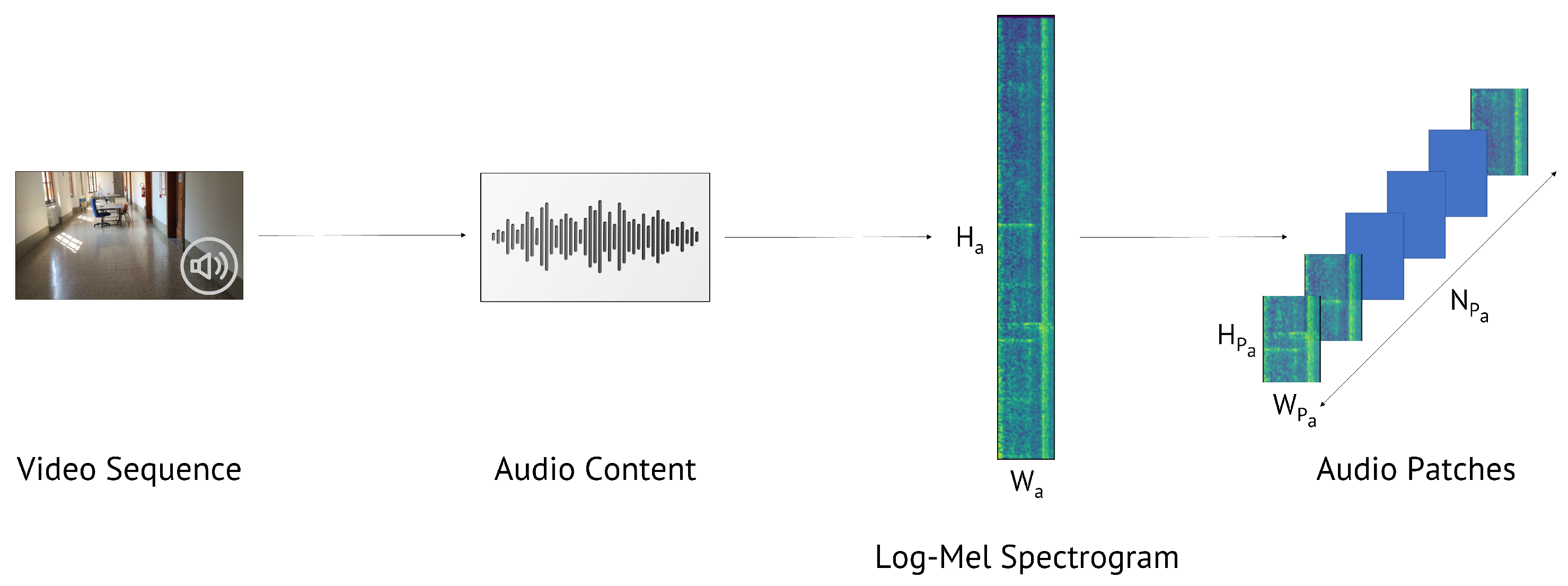
- Extraction of the LMS of the audio content related to the video sequence. Indeed, the LMS represents a very informative tool for audio data and was used several times as a valuable feature for audio and speech classification and processing [24,37,38,39,40,41]. During some preliminary experiments, we compared different audio features extracted from the magnitude and phase of the signal STFT, and we verified that the LMS (based on the STFT magnitude) was the most informative one. Phase-based strategies reported accuracy of lower than , achieved by LMS. The LMS has size , where rows refer to the temporal information (varying with the video length) and columns to the frequency content in Mel scale;
- Random extraction of patches of size from ;
- Patch normalization in order to have zero mean and unitary variance, as previously described for visual patches.
4.2. CNN Processing
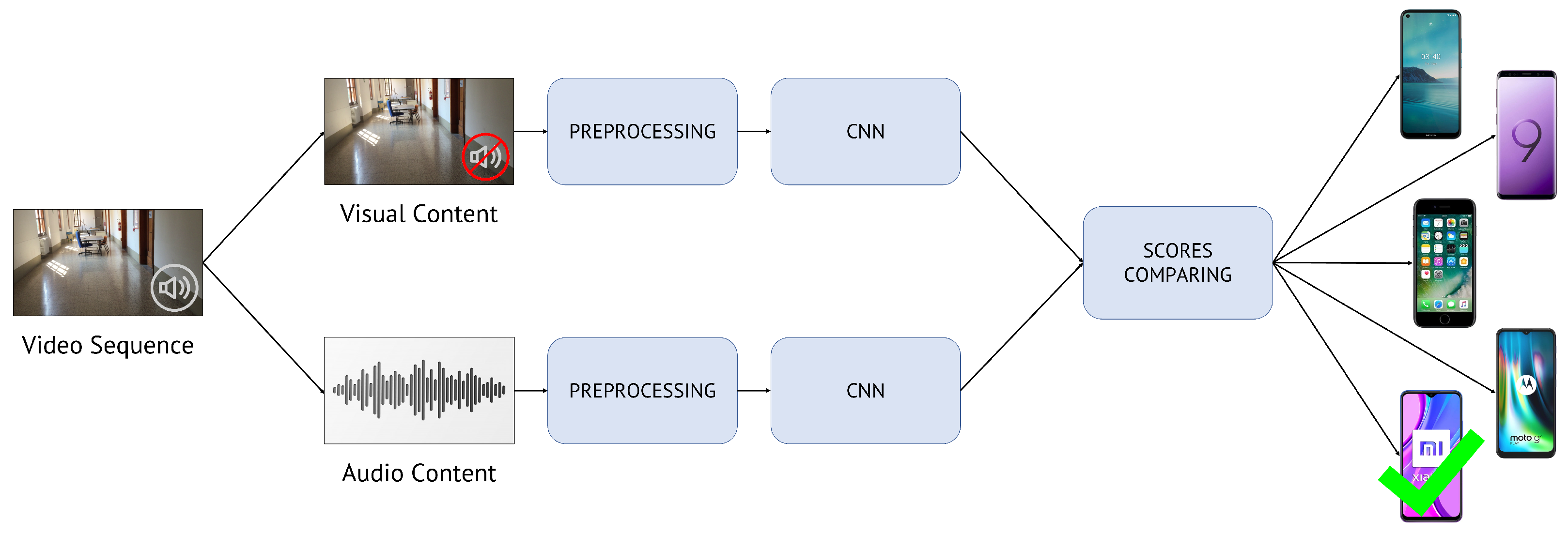
- Late Fusion methodology: compare the classification scores of visual and audio patches, separately obtained from two single-input CNNs;
- Early Fusion methodology: build one multi-input CNN, feed this with both visual and audio content and exploit it to produce a single classification score.
4.2.1. Late Fusion Methodology
- Separately feed a CNN with a visual patch and a CNN with an audio patch;
- Extract the classification scores associated with the two patches. In particular, we define as the classification scores related to the visual patch and as those related to the audio patch;
- Select the classification score vector (choosing between and ) that contains the highest score; the estimated source model by the Late Fusion methodology is related to the position in which that score is found:where is the m-th element of the score vector , defined as follows:
4.2.2. Early Fusion Methodology
4.3. CNN Architectures
5. Results
5.1. Dataset
5.2. Network Setup and Training
- Configuration EV, which uses EfficientNetB0 for processing visual patches and VGGish for audio patches, considering the default audio frequency range required by VGGish (i.e., 64 Mel bins);
- Configuration EE, which uses EfficientNetB0 for both visual and audio patches, considering the same audio frequency range required by VGGish (i.e., 64 Mel bins);
- Configuration EE, which uses EfficientNetB0 for both visual and audio patches, considering an expanded audio frequency range (i.e., 192 Mel bins).
5.3. Evaluation Metrics
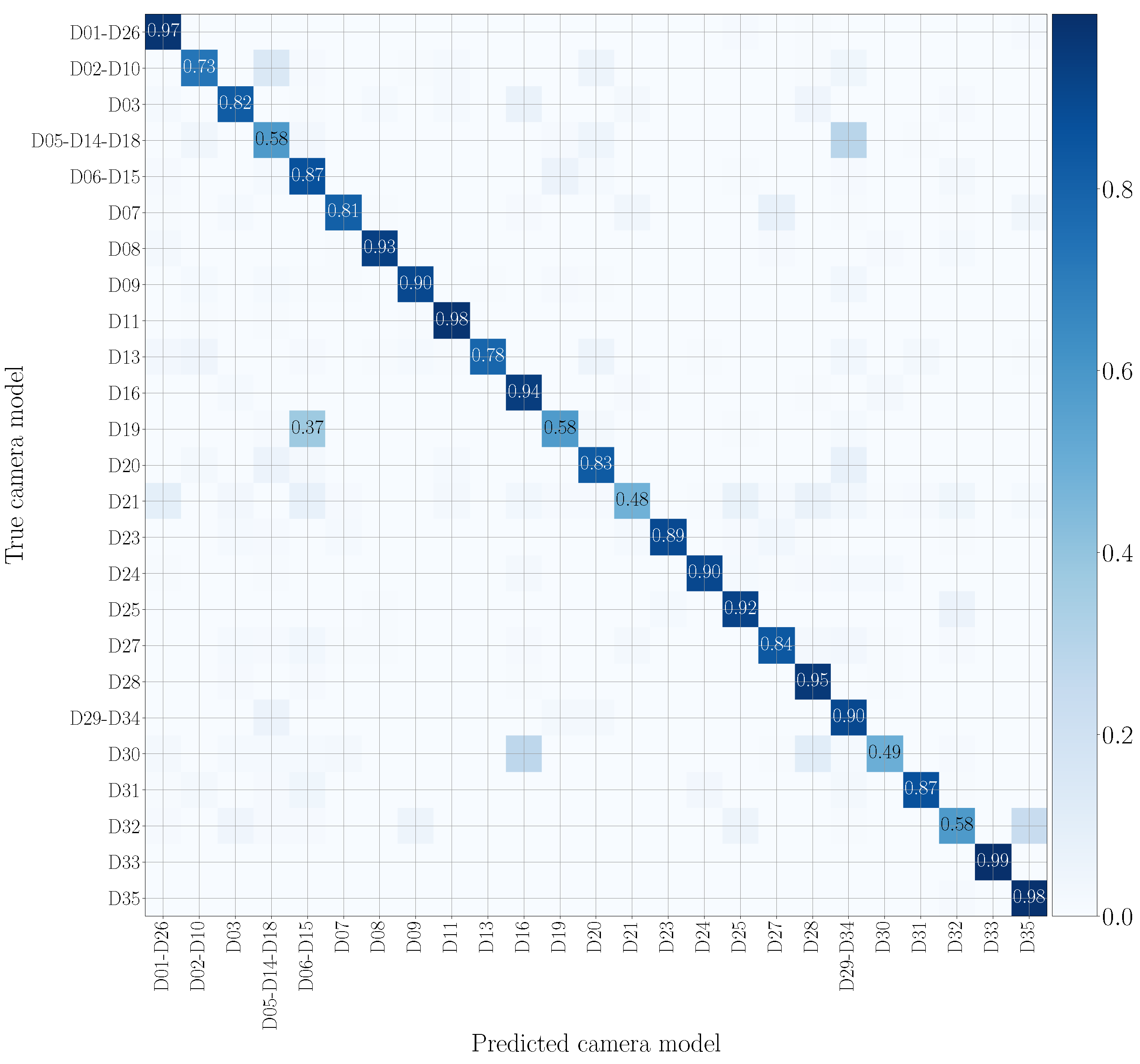
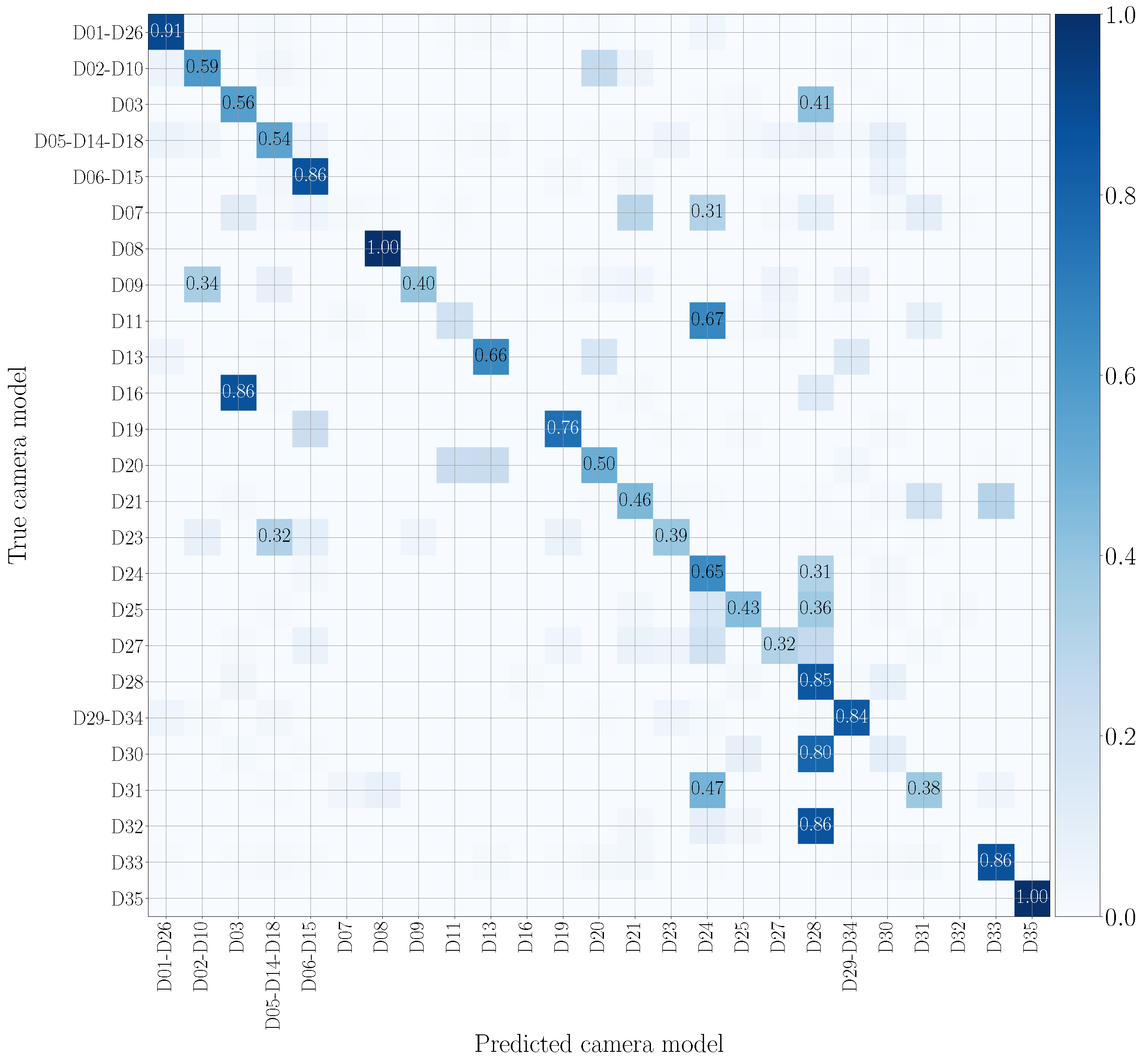
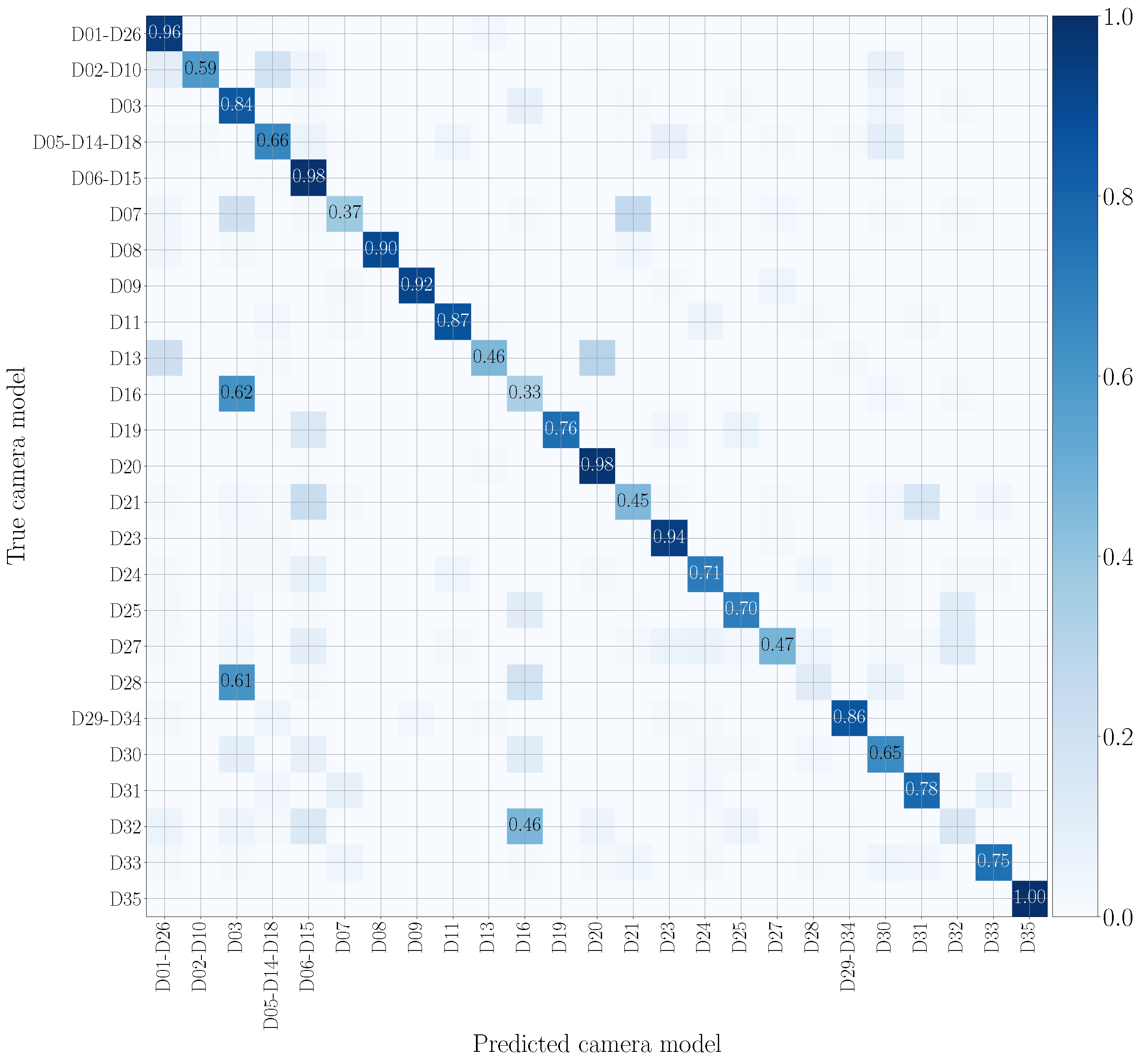
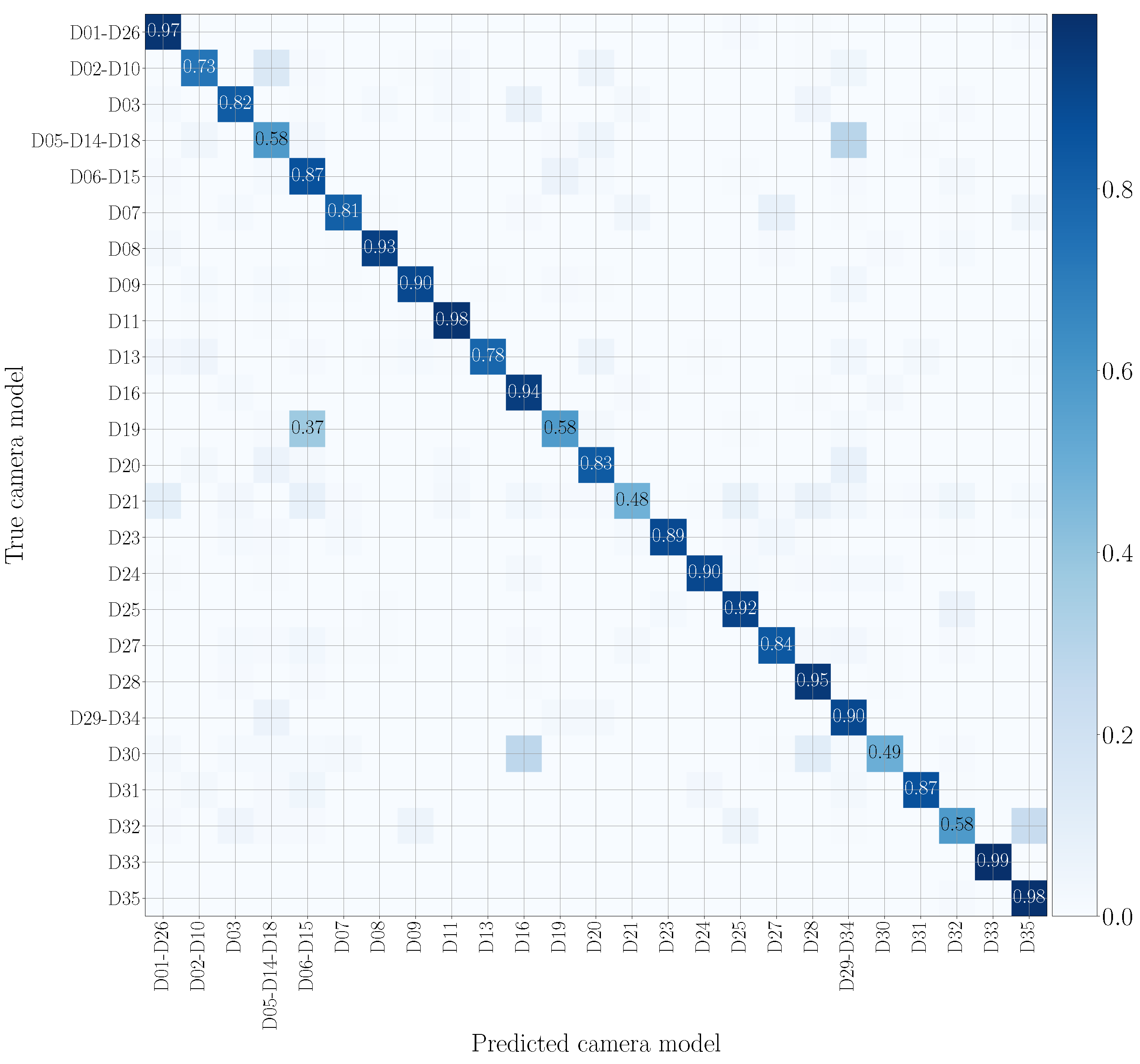
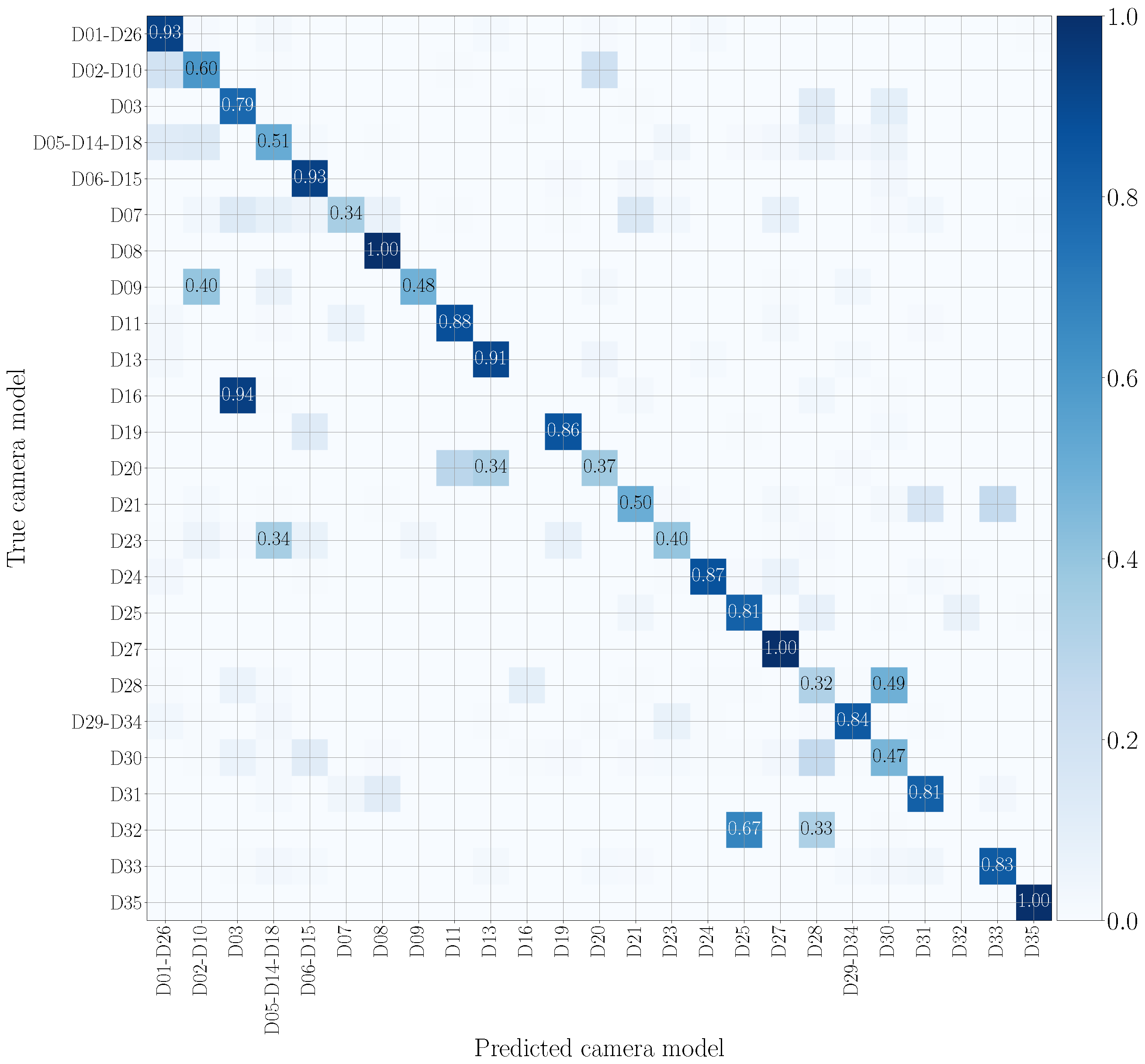
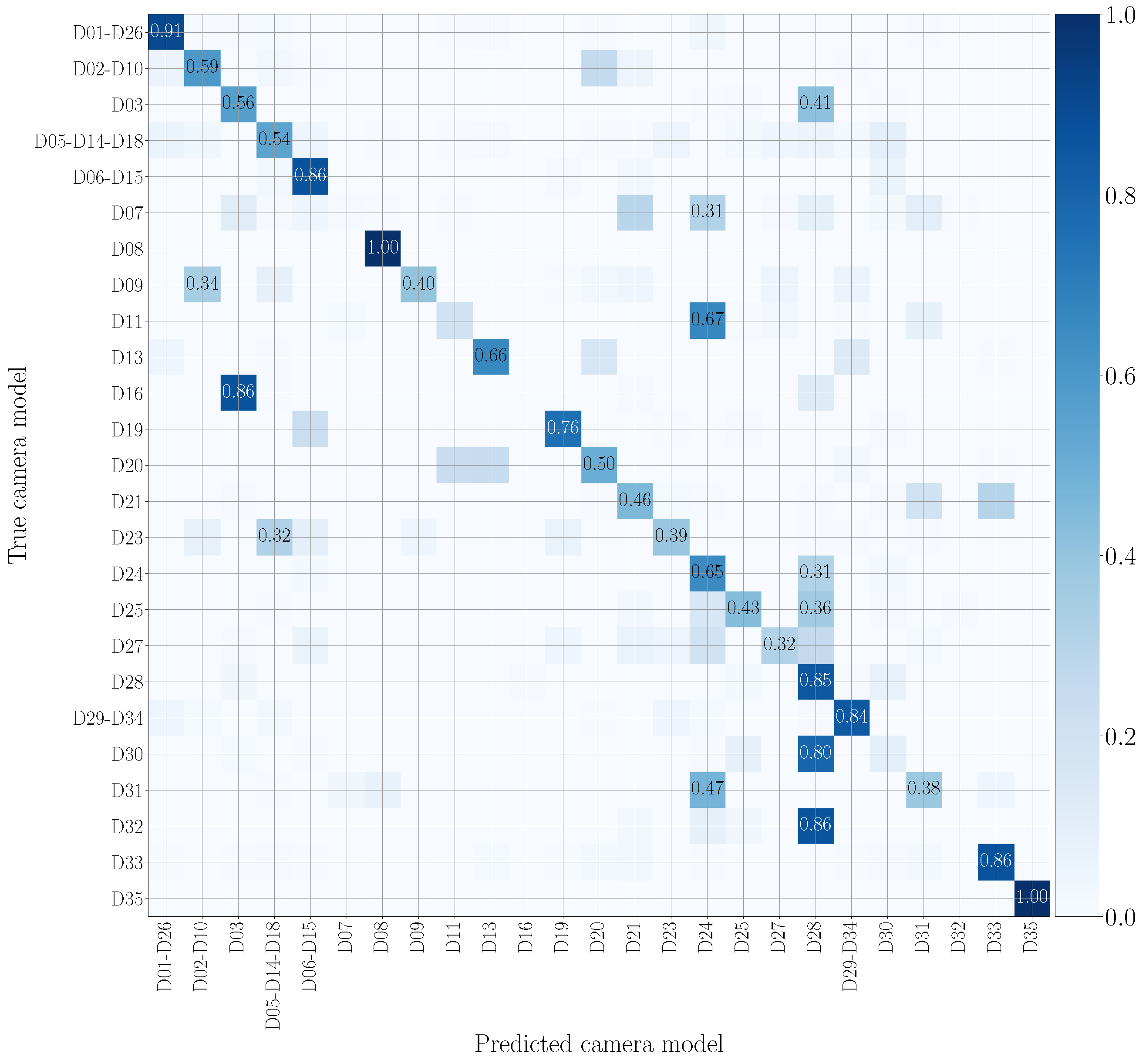
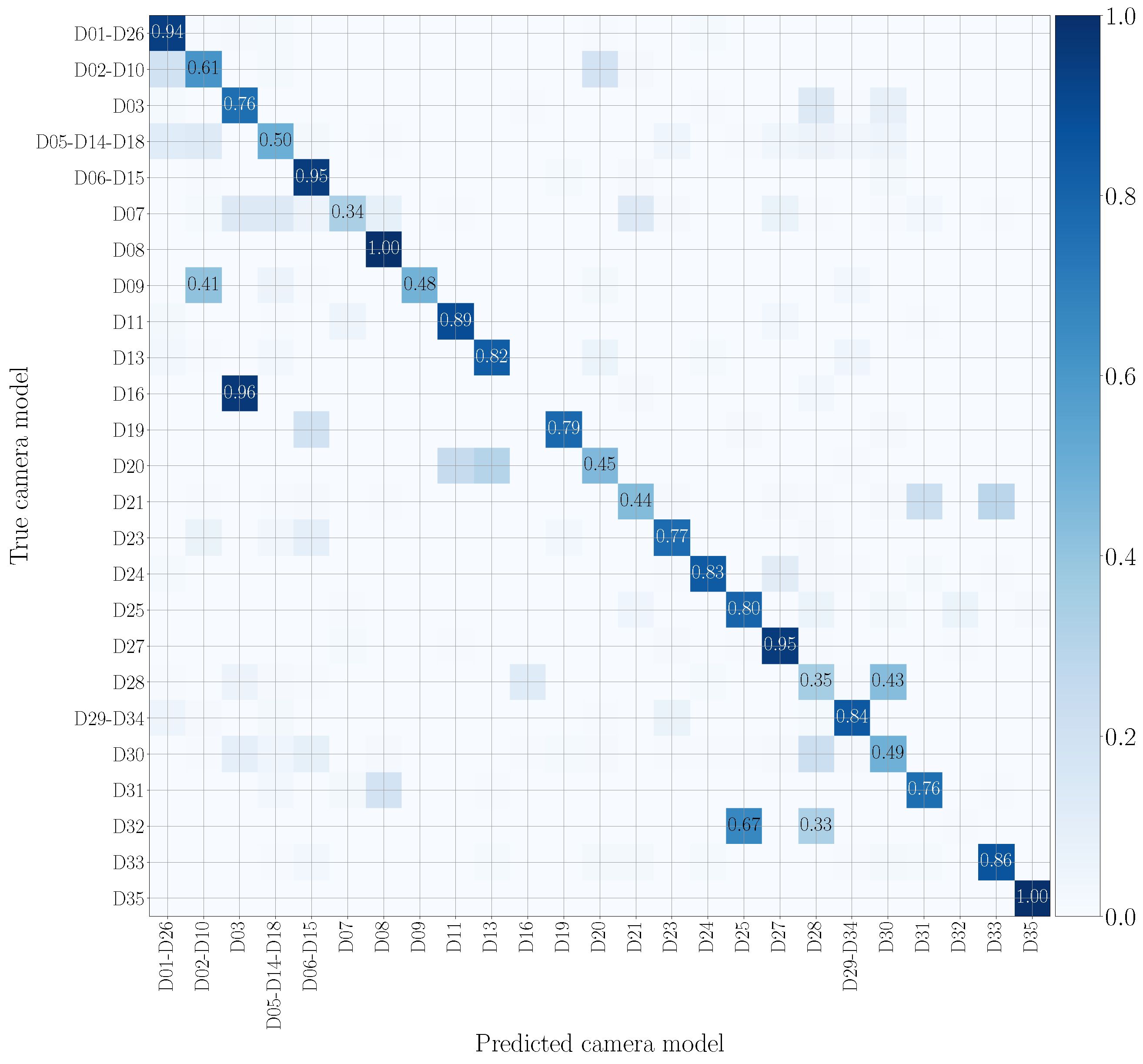
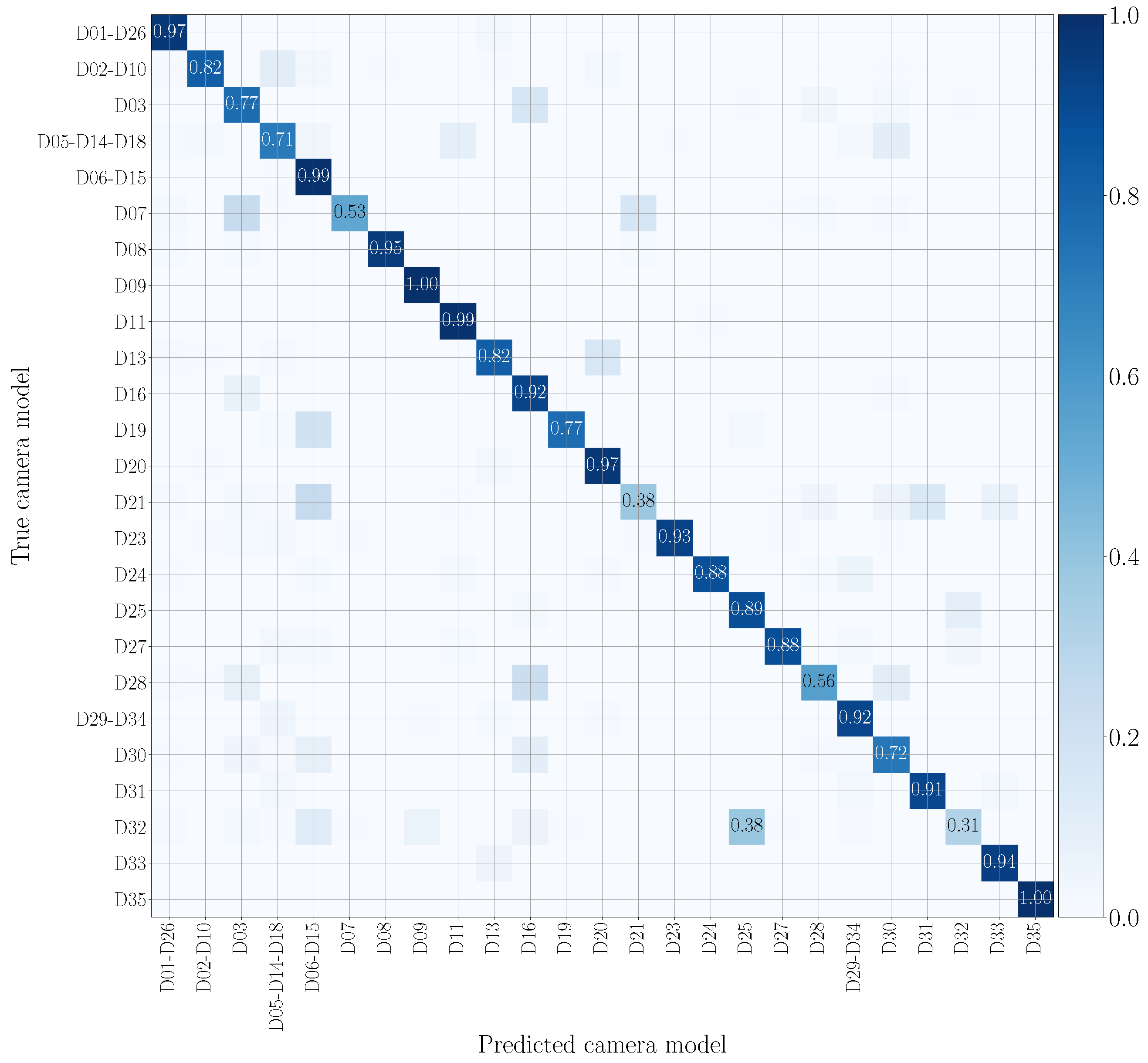
5.4. Mono-Modal Results
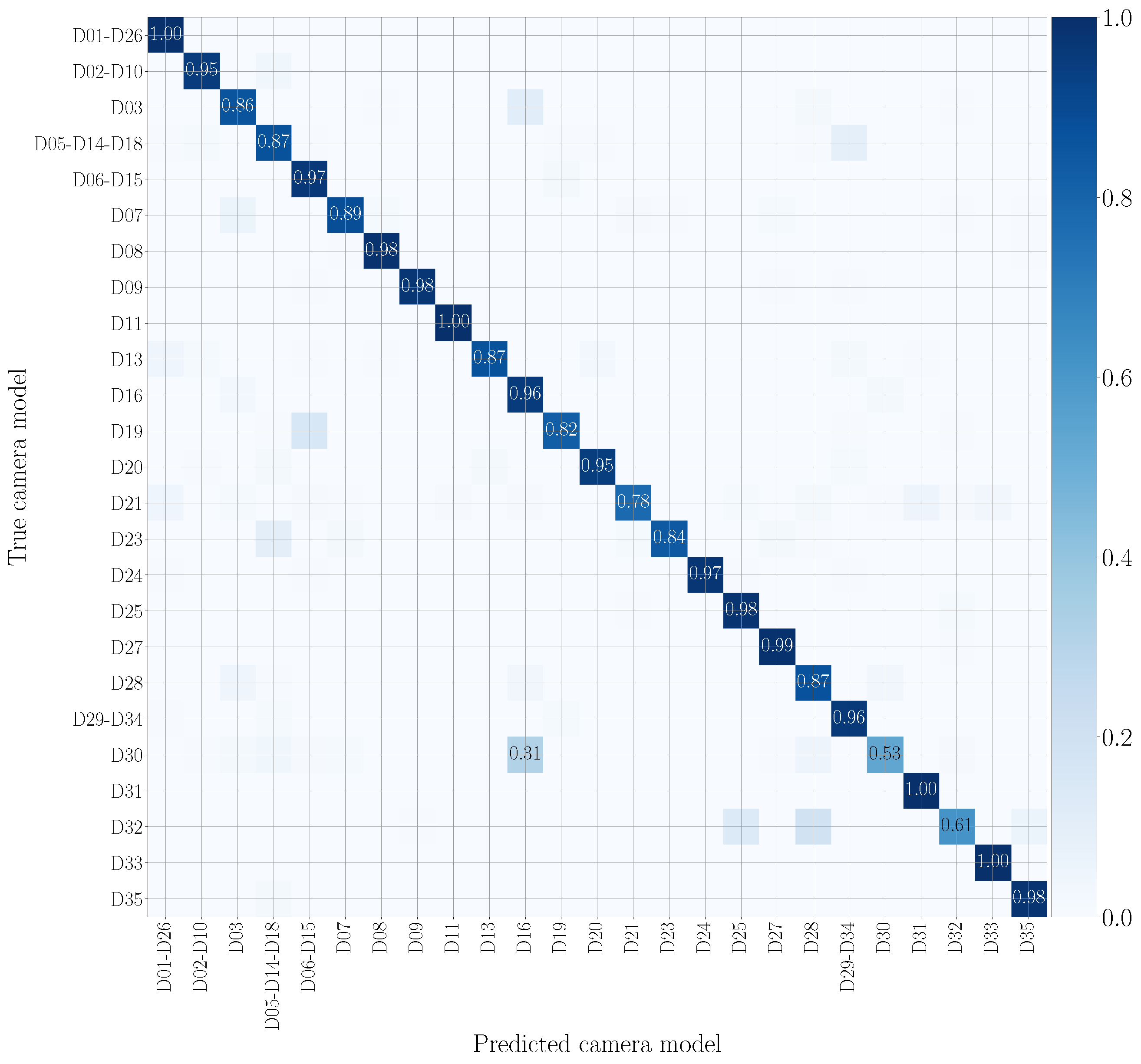
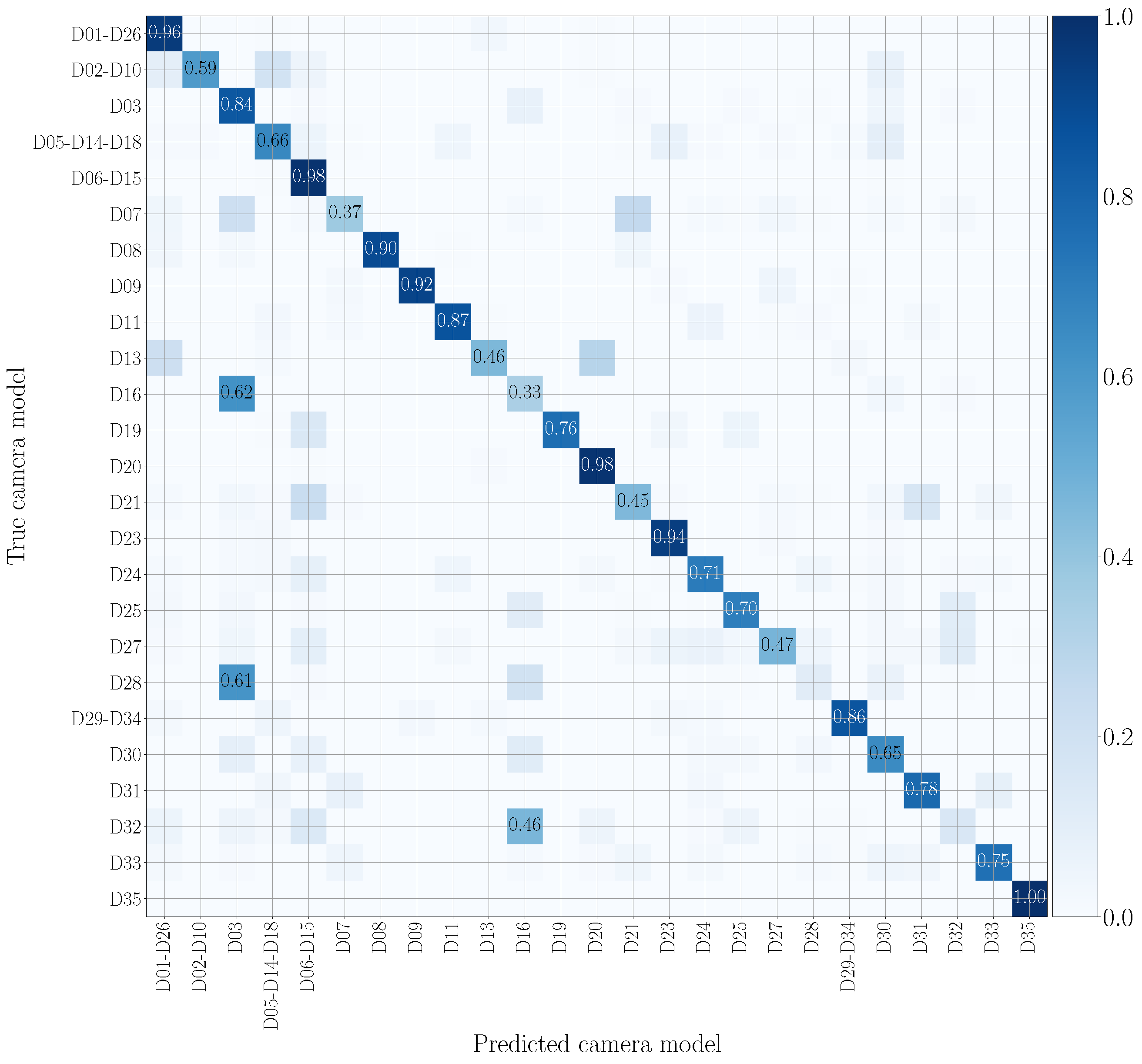
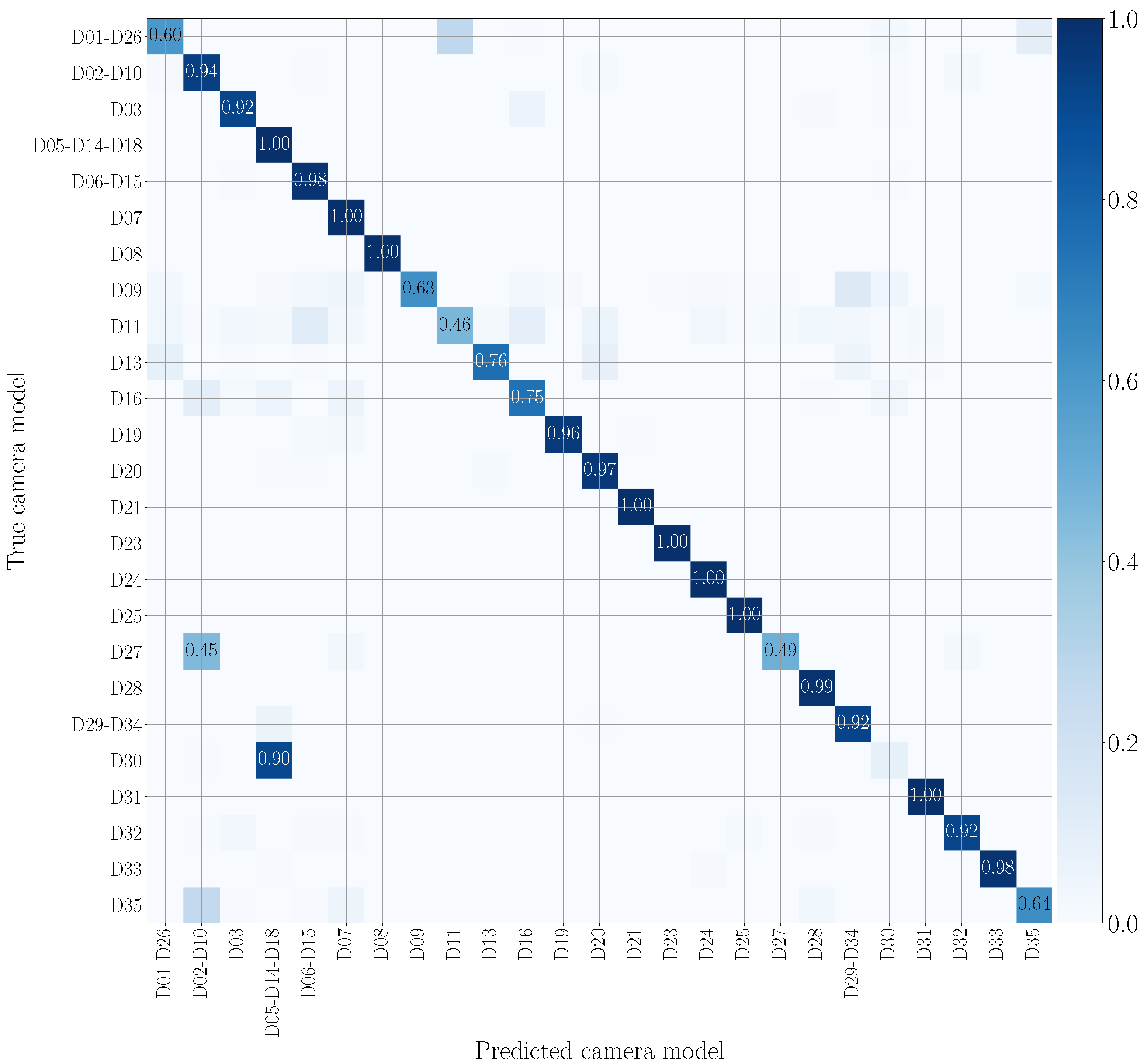
5.5. Multi-Modal Results
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Hosler, B.C.; Mayer, O.; Bayar, B.; Zhao, X.; Chen, C.; Shackleford, J.A.; Stamm, M.C. A Video Camera Model Identification System Using Deep Learning and Fusion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May 2019; pp. 8271–8275. [Google Scholar] [CrossRef]
- Kirchner, M.; Gloe, T. Forensic camera model identification. In Handbook of Digital Forensics of Multimedia Data and Devices; Wiley-IEEE Press: Piscataway, NJ, USA, 2015; pp. 329–374. [Google Scholar]
- Takamatsu, J.; Matsushita, Y.; Ogasawara, T.; Ikeuchi, K. Estimating demosaicing algorithms using image noise variance. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010; pp. 279–286. [Google Scholar] [CrossRef]
- Kirchner, M. Efficient estimation of CFA pattern configuration in digital camera images. In Proceedings of the Media Forensics and Security II, IS&T-SPIE Electronic Imaging Symposium, San Jose, CA, USA, 18–20 January 2010; Volume 7541, p. 754111. [Google Scholar] [CrossRef]
- Popescu, A.C.; Farid, H. Exposing digital forgeries in color filter array interpolated images. IEEE Trans. Signal Process. 2005, 53, 3948–3959. [Google Scholar] [CrossRef]
- Bayram, S.; Sencar, H.T.; Memon, N.; Avcibas, I. Improvements on source camera-model identification based on CFA interpolation. In Proceedings of the WG 2006, Kobe, Japan, 11–14 October 2006; Volume 11. [Google Scholar]
- Swaminathan, A.; Wu, M.; Liu, K.J.R. Nonintrusive Component Forensics of Visual Sensors Using Output Images. IEEE Trans. Inf. Forensics Secur. 2007, 2, 91–106. [Google Scholar] [CrossRef] [Green Version]
- Cao, H.; Kot, A.C. Accurate detection of demosaicing regularity for digital image forensics. IEEE Trans. Inf. Forensics Secur. 2009, 4, 899–910. [Google Scholar]
- Chen, C.; Stamm, M.C. Camera model identification framework using an ensemble of demosaicing features. In Proceedings of the 2015 IEEE International Workshop on Information Forensics and Security, WIFS 2015, Roma, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- San Choi, K.; Lam, E.Y.; Wong, K.K. Automatic source camera identification using the intrinsic lens radial distortion. Opt. Express 2006, 14, 11551–11565. [Google Scholar] [CrossRef] [PubMed]
- Lanh, T.V.; Emmanuel, S.; Kankanhalli, M.S. Identifying Source Cell Phone using Chromatic Aberration. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, ICME 2007, Beijing, China, 2–5 July 2007; pp. 883–886. [Google Scholar] [CrossRef] [Green Version]
- Gloe, T.; Borowka, K.; Winkler, A. Efficient estimation and large-scale evaluation of lateral chromatic aberration for digital image forensics. In Proceedings of the Media Forensics and Security II, IS&T-SPIE Electronic Imaging Symposium, San Jose, CA, USA, 18–20 January 2010; Volume 7541, p. 754107. [Google Scholar] [CrossRef]
- Yu, J.; Craver, S.; Li, E. Toward the identification of DSLR lenses by chromatic aberration. In Proceedings of the Media Forensics and Security III, San Francisco, CA, USA, 24–26 January 2011; Volume 7880, p. 788010. [Google Scholar] [CrossRef]
- Lyu, S. Estimating vignetting function from a single image for image authentication. In Proceedings of the Multimedia and Security Workshop, MM&Sec 2010, Roma, Italy, 9–10 September 2010; Campisi, P., Dittmann, J., Craver, S., Eds.; ACM: New York, NY, USA, 2010; pp. 3–12. [Google Scholar] [CrossRef]
- Dirik, A.E.; Sencar, H.T.; Memon, N.D. Digital Single Lens Reflex Camera Identification From Traces of Sensor Dust. IEEE Trans. Inf. Forensics Secur. 2008, 3, 539–552. [Google Scholar] [CrossRef]
- Thai, T.H.; Retraint, F.; Cogranne, R. Camera model identification based on the generalized noise model in natural images. Digit. Signal Process. 2016, 48, 285–297. [Google Scholar] [CrossRef] [Green Version]
- Tuama, A.; Comby, F.; Chaumont, M. Camera model identification with the use of deep convolutional neural networks. In Proceedings of the IEEE International Workshop on Information Forensics and Security, WIFS 2016, Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Bondi, L.; Baroffio, L.; Guera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. First Steps Toward Camera Model Identification With Convolutional Neural Networks. IEEE Signal Process. Lett. 2017, 24, 259–263. [Google Scholar] [CrossRef] [Green Version]
- Stamm, M.C.; Bestagini, P.; Marcenaro, L.; Campisi, P. Forensic Camera Model Identification: Highlights from the IEEE Signal Processing Cup 2018 Student Competition [SP Competitions]. IEEE Signal Process. Mag. 2018, 35, 168–174. [Google Scholar] [CrossRef]
- Rafi, A.M.; Kamal, U.; Hoque, R.; Abrar, A.; Das, S.; Laganière, R.; Hasan, M.K. Application of DenseNet in Camera Model Identification and Post-processing Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 19–28. [Google Scholar]
- Mandelli, S.; Bonettini, N.; Bestagini, P.; Tubaro, S. Training CNNs in Presence of JPEG Compression: Multimedia Forensics vs Computer Vision. In Proceedings of the 12th IEEE International Workshop on Information Forensics and Security, WIFS 2020, New York, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Rafi, A.M.; Tonmoy, T.I.; Kamal, U.; Wu, Q.M.J.; Hasan, M.K. RemNet: Remnant convolutional neural network for camera model identification. Neural Comput. Appl. 2021, 33, 3655–3670. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN Architectures for Large-Scale Audio Classification. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Seferbekov, S.; Lee, E. DeepFake Detection (DFDC) Solution by @selimsef. 2020. Available online: https://github.com/selimsef/dfdc_deepfake_challenge (accessed on 27 July 2021).
- Verdoliva, D.C.G.P.L. Extracting camera-based fingerprints for video forensics. In Proceedings of the CVPRW, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Mandelli, S.; Bestagini, P.; Verdoliva, L.; Tubaro, S. Facing device attribution problem for stabilized video sequences. IEEE Trans. Inf. Forensics Secur. 2019, 15, 14–27. [Google Scholar] [CrossRef] [Green Version]
- Mayer, O.; Hosler, B.; Stamm, M.C. Open set video camera model verification. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2962–2966. [Google Scholar]
- Verdoliva, L. Media forensics and deepfakes: An overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Hosler, B.; Salvi, D.; Murray, A.; Antonacci, F.; Bestagini, P.; Tubaro, S.; Stamm, M.C. Do Deepfakes Feel Emotions? A Semantic Approach to Detecting Deepfakes via Emotional Inconsistencies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Online, 19–25 June 2021; pp. 1013–1022. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions Don’t Lie: An Audio-Visual Deepfake Detection Method Using Affective Cues. In Proceedings of the 28th ACM International Conference on Multimedia, MM ’20, Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2823–2832. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H.; Fried, O.; Agrawala, M. Detecting Deep-Fake Videos from Phoneme-Viseme Mismatches. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2814–2822. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H. Detecting Deep-Fake Videos From Aural and Oral Dynamics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Online, 15–19 June 2021; pp. 981–989. [Google Scholar]
- Ramanath, R.; Snyder, W.E.; Yoo, Y.; Drew, M.S. Color image processing pipeline. IEEE Signal Process. Mag. 2005, 22, 34–43. [Google Scholar] [CrossRef]
- Tabora, V. Photo Sensors In Digital Cameras. 2019. Available online: https://medium.com/hd-pro/photo-sensors-in-digital-cameras-94fb26203da1 (accessed on 7 April 2021).
- Stevens, S.S.; Volkmann, J. The relation of pitch to frequency: A revised scale. Am. J. Psychol. 1940, 53, 329–353. [Google Scholar] [CrossRef]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS synthesis by conditioning Wavenet on mel spectrogram predictions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Meng, H.; Yan, T.; Yuan, F.; Wei, H. Speech emotion recognition from 3D log-mel spectrograms with deep learning network. IEEE Access 2019, 7, 125868–125881. [Google Scholar] [CrossRef]
- Mascia, M.; Canclini, A.; Antonacci, F.; Tagliasacchi, M.; Sarti, A.; Tubaro, S. Forensic and anti-forensic analysis of indoor/outdoor classifiers based on acoustic clues. In Proceedings of the European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015. [Google Scholar]
- Liang, B.; Fazekas, G.; Sandler, M. Piano Sustain-pedal Detection Using Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar] [CrossRef]
- Comanducci, L.; Bestagini, P.; Tagliasacchi, M.; Sarti, A.; Tubaro, S. Reconstructing Speech from CNN Embeddings. IEEE Signal Process. Lett. 2021. [Google Scholar] [CrossRef]
- Shi, L.; Du, K.; Zhang, C.; Ma, H.; Yan, W. Lung Sound Recognition Algorithm based on VGGish-BiGRU. IEEE Access 2019, 7, 139438–139449. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Shullani, D.; Fontani, M.; Iuliani, M.; Shaya, O.A.; Piva, A. VISION: A video and image dataset for source identification. EURASIP J. Inf. Secur. 2017, 2017, 15. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| - | Visual—EfficientNetB0 | Audio—VGGish | ||||
|---|---|---|---|---|---|---|
| Testing Set → | Native | YouTube | Native | YouTube | ||
| Training Set ↓ | ||||||
| Native | 0.8202 | 0.3579 | 0.4869 | 0.6578 | 0.5304 | 0.6654 |
| 0.5599 | 0.6739 | 0.5158 | 0.5028 | 0.6757 | 0.5245 | |
| YouTube | 0.7271 | 0.5531 | 0.7404 | 0.6954 | 0.5924 | 0.7010 |
| - | Early Fusion EV | Early Fusion EE | Early Fusion EE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Testing Set → | Native | YouTube | Native | YouTube | Native | YouTube | |||
| Training Set ↓ | |||||||||
| Native | 0.8210 | 0.6879 | 0.7784 | 0.8396 | 0.6120 | 0.7956 | 0.9598 | 0.1795 | 0.7968 |
| 0.5810 | 0.7519 | 0.5766 | 0.5930 | 0.8076 | 0.5873 | 0.5091 | 0.9120 | 0.4954 | |
| YouTube | 0.7548 | 0.6212 | 0.7590 | 0.8071 | 0.6903 | 0.8090 | 0.8731 | 0.4146 | 0.9513 |
| - | Late Fusion EV | Late Fusion EE | Late Fusion EE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Testing Set → | Native | YouTube | Native | YouTube | Native | YouTube | |||
| Training Set ↓ | |||||||||
| Native | 0.9039 | 0.5960 | 0.7069 | 0.8945 | 0.6020 | 0.8039 | 0.9900 | 0.4544 | 0.8389 |
| 0.6413 | 0.7610 | 0.6368 | 0.6262 | 0.8198 | 0.6208 | 0.5703 | 0.9163 | 0.5602 | |
| YouTube | 0.8163 | 0.6595 | 0.8274 | 0.8321 | 0.6976 | 0.8390 | 0.9172 | 0.4957 | 0.9519 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dal Cortivo, D.; Mandelli, S.; Bestagini, P.; Tubaro, S. CNN-Based Multi-Modal Camera Model Identification on Video Sequences. J. Imaging 2021, 7, 135. https://doi.org/10.3390/jimaging7080135
Dal Cortivo D, Mandelli S, Bestagini P, Tubaro S. CNN-Based Multi-Modal Camera Model Identification on Video Sequences. Journal of Imaging. 2021; 7(8):135. https://doi.org/10.3390/jimaging7080135
Chicago/Turabian StyleDal Cortivo, Davide, Sara Mandelli, Paolo Bestagini, and Stefano Tubaro. 2021. "CNN-Based Multi-Modal Camera Model Identification on Video Sequences" Journal of Imaging 7, no. 8: 135. https://doi.org/10.3390/jimaging7080135
APA StyleDal Cortivo, D., Mandelli, S., Bestagini, P., & Tubaro, S. (2021). CNN-Based Multi-Modal Camera Model Identification on Video Sequences. Journal of Imaging, 7(8), 135. https://doi.org/10.3390/jimaging7080135