1. Introduction
Poisson noise appears in processes where digital images are obtained by the count of particles (generally photons). This is the case of X-ray computed tomography, positron emission tomography, confocal and fluorescence microscopy and optical/infrared astronomical imaging, to name just a few applications (see, e.g., [
1] and the references therein). In this case, the object to be restored can be represented as a vector
and the data can be assumed to be a vector
, whose entries
are sampled from
n independent Poisson random variables
with probability
The matrix
models the observation mechanism of the imaging system and the following standard assumptions are made:
The vector , with , models the background radiation detected by the sensors.
By applying a maximum-likelihood approach [
1,
2], we can estimate
by minimizing the Kullback–Leibler (KL) divergence of
from
:
where we set
Regularization is usually introduced in (
2) to deal with the ill-conditioning of this problem. The Total Variation (TV) regularization [
3] has been widely used in this context, because it preserves edges and is able to smooth flat areas of the image. However, since it may produce staircase artifacts, other TV-based regularizers have been proposed. For example, the Total Generalized Variation (TGV) has been proposed and applied in [
4,
5,
6,
7] to overcome the staircasing effect while keeping the ability of identifying edges. On the other hand, to improve the quality of restoration for directional images, the Directional TV (DTV) regularization has been considered in [
8], in the discrete setting. In [
9,
10], a regularizer combining DTV and TGV, named Directional TGV (DTGV), has been successfully applied to directional images affected by impulse and Gaussian noise.
Given an image
, the discrete second-order Directional TGV of
is defined as
where
,
and
are the discrete directional gradient operator and the directional symmetrized derivative, respectively, and
. For any vector
we set
and for any vector
we set
Given an angle
and a scaling parameter
, we have that the discrete directional gradient operator has the form
where
represent the forward finite-difference operators along the directions determined by
and
, respectively, and
represent the forward finite-difference operators along the horizontal and the vertical direction, respectively. Moreover, the directional symmetrized derivative is defined in block-wise form as
It is worth noting that, by fixing
and
, we have
and
, and the operators
and
define the TGV
regularization [
4].
We observe that the definition of both the matrix A and the finite difference operators and depend on the choice of boundary conditions. We make the following assumption.
Assumption 1. We assume that periodic boundary conditions are considered for A, and . Therefore, those matrices are Block Circulant with Circulant Blocks (BCCB).
In this work we focus on directional images affected by Poisson noise, with the aim of assessing the behaviour of DTGV in this case. Besides extending the use of DTGV to Poisson noise, we introduce a novel technique for estimating the main direction of the image, which appears to be more efficient than the techniques applied in [
9,
10]. We solve the resulting optimization problem by using a customized version of the Alternating Direction Method of Multipliers (ADMM). We note that all the ADMM subproblems can be solved exactly at a low cost, thanks also to the use of FFTs, and that the method has proven convergence. Finally, we show the effectiveness of our approach on a set of test images, corrupted by out-of-focus and Gaussian blurs and noise with different signal-to-noise ratios. In particular, the KL-DTGV model of our problem is described in
Section 2 and the technique for estimating the main direction is presented in
Section 3. A detailed description of the ADMM version used for the minimization is given in
Section 4 and the results of the numerical experiments are discussed in
Section 5. Conclusions are given in
Section 6.
Throughout this work we denote matrices with uppercase lightface letters, vectors with lowercase boldface letters and scalars with lowercase lightface letters. All the vectors are column vectors. Given a vector , we use or to denote its i-th entry. We use to indicate the set of real nonnegative numbers and to indicate the two-norm. For brevity, given any vectors and we use the notation instead of . Likewise, given any scalars v and w, we use to indicate the vector . We also use the notation to highlight the subvectors and forming the vector . Finally, by writing we mean that all the entries of are nonnegative and at least one of them is positive.
3. Efficient Estimation of the Image Direction
An essential ingredient in the DTGV regularization is the estimation of the angle
representing the image texture direction. In [
10], an estimation algorithm based on the one in [
12] is proposed, whose basic idea is to compute a pixelwise direction estimate and then
as the average of that estimate. In [
9], which focuses on impulse noise removal, a more efficient and robust algorithm for estimating the direction is presented, based on the Fourier transform. The main idea behind this algorithm is to exploit the fact that two-dimensional Fourier basis functions can be seen as images with one-directional patterns. However, despite being very efficient from a computational viewpoint, this technique does not appear to be fully reliable in our tests on Poissonian images (see
Section 5.1). Therefore, we propose a different approach for estimating the direction, based on classical tools of image processing: the Sobel filter [
13] and the Hough transform [
14,
15].
Our technique is based on the idea that if an image has a one-directional structure, i.e., its main pattern consists of stripes, then the edges of the image mainly consist of lines going in the direction of the stripes. The first stage of the proposed algorithm uses the Sobel filter to determine the edges of the noisy and blurry image. Then, the Hough transform is applied to the edge image in order to detect the lines. The Hough transform is based on the idea that each straight line can be identified by a pair
where
r is the distance of the line from the origin, and
is the angle between the
x axis and the segment connecting the origin with its orthogonal projection on the line. The output of the transform is a matrix in which each entry is associated with a pair
, i.e., with a straight line in the image, and its value is the sum of the values in the pixels that are on the line. Hence, the elements with the highest value in the Hough transform indicate the lines that are most likely to be present in the input image. Because of its definition, the Hough transform tends to overestimate diagonal lines in rectangular images (diagonal lines through the central part of the image contain the largest number of pixels); therefore, before computing the transform we apply a mask to the edge image, considering only the pixels inside the largest circle centered in the center of the image. After the Hough transform has been applied, we compute the square of the two-norm of each column of the matrix resulting from the transform, to determine a score for each angle from
to
. Intuitively, the score for each angle is related to the number of lines with that particular inclination which have been detected in the image. Finally, we set the direction estimate
as
where
is the value of
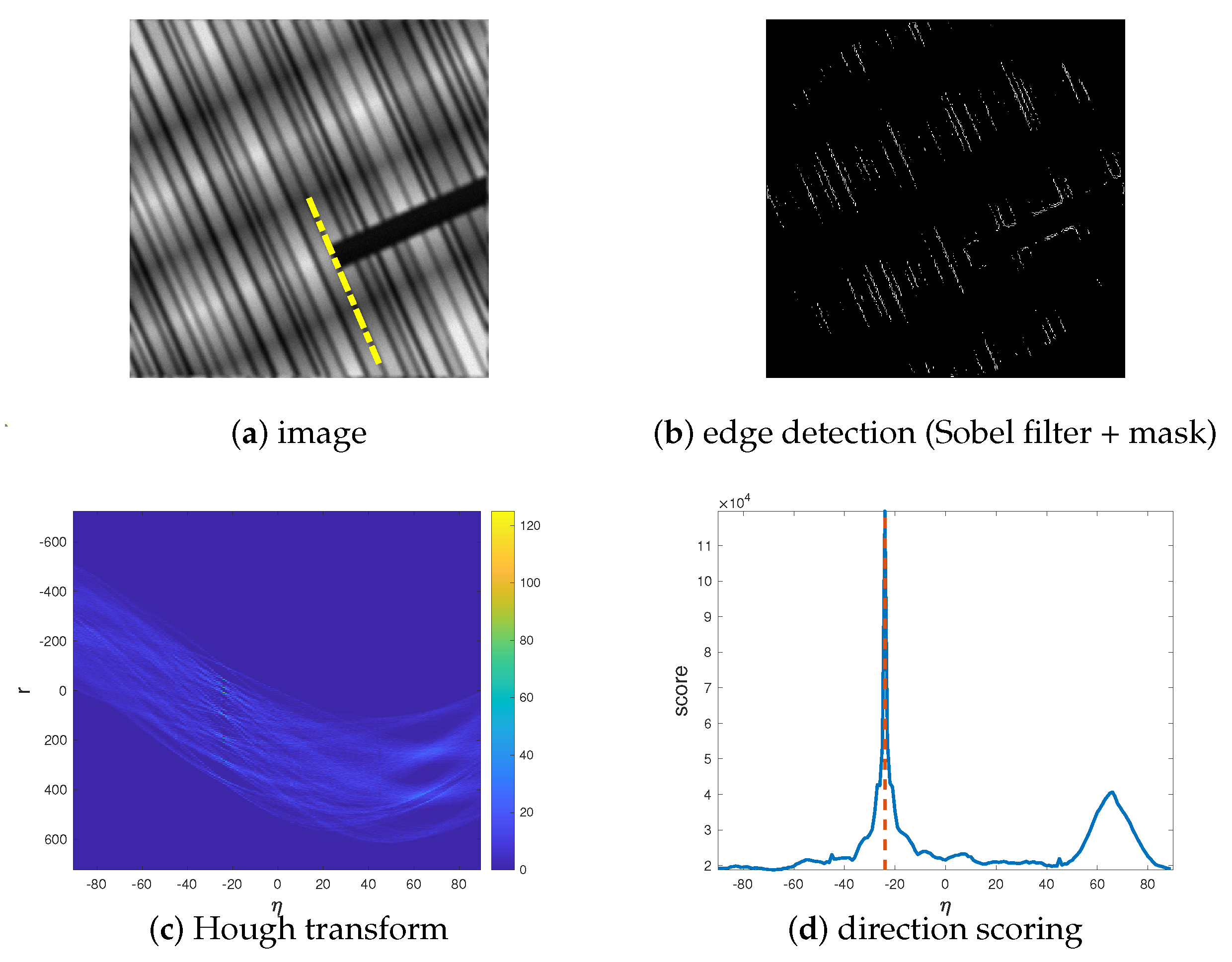
corresponding to the maximum score. A pseudocode for the estimation algorithm is provided in Algorithm 1 and an example of the algorithm workflow is given in
Figure 1.
| Algorithm 1 Direction estimation. |
- 1:
Use the Sobel operator to obtain the image of the edges of the noisy and blurry image . - 2:
Apply a disk mask to cut out some diagonal edges in , obtaining a new edge image ( Figure 1b). - 3:
Compute the Hough transform ( Figure 1c). - 4:
Set as the value of corresponding to the column of with maximum 2-norm. ( Figure 1d) - 5:
Set (yellow line in Figure 1a)
|
4. ADMM for Minimizing the KL-DTGV Model
Although problem (
6) is a bound-constrained convex optimization problem, the nondifferentiability of the DTGV
regularizer does not allow its solution by classical optimization methods for smooth problems, such as gradient methods (see [
16,
17,
18] and the references therein). However, the problem can be solved by methods based on splitting techniques, such as [
19,
20,
21,
22,
23]. Here we solve (
6) by the Alternating Direction Method of Multipliers (ADMM) [
20]. To this end, we first reformulate the problem as follows:
where
,
,
,
, and
is the characteristic function of the nonnegative orthant in
. A similar splitting has been used in [
24] for TV-based deblurring of Poissonian images. By introducing the auxiliary variables
and
we can further reformulate the KL-DTGV
problem as
where we set
and we define the matrices
and
as
We consider the Lagrangian function associated with problem (
8),
where
is a vector of Lagrange multipliers, and then the augmented Lagrangian function
where
.
Now we are ready to introduce the ADMM method for the solution of problem (
8). Let
,
,
. At each step
the ADMM method computes the new iterate
as follows:
Note that the functions
and
in (
8) are closed, proper and convex. Moreover, the matrices
H and
G defined in (
10) are such that
and
H has full rank. Hence, the convergence of the method defined by (
13) can be proved by applying a classical convergence result from the seminal paper by Eckstein and Bertsekas [
25] (Theorem 8), which we report in a form that can be immediately applied to our reformulation of the problem.
Theorem 1. Let us consider a problem of the form (8) where and are closed, proper and convex functions and H has full rank. Let , , , and . Suppose are summable sequences such that for all k If there exists a saddle point of , then , and . If such saddle point does not exist, then at least one of the sequences or is unbounded.
Since we are dealing with linear constraints, we can recast (
13) in a more convenient form, by observing that the linear term in (
12) can be included in the quadratic one. By introducing the vector of scaled Lagrange multipliers
, the ADMM method becomes
In the next sections we show how the solutions to subproblems (
14) and (
15) can be computed exactly with a small computational effort.
4.1. Solving the Subproblem in
Problem (
14) is an overdetermined least squares problem, since
H is a tall-and-skinny matrix with full rank. Hence, its solution can be computed by solving the normal equations system
where we set
. Starting from the definition of
H given in (
10), we have
System (
17) may be quite large and expensive, also for relatively small images. However, as pointed out in Assumption 1,
A,
and
have a BCCB structure, hence all the blocks of
maintain that structure. By recalling that BCCB matrices can be diagonalized by means of two-dimensional Discrete Fourier Transforms (DFTs), we show how the solution to (
17) can be computed expeditiously.
Let
be the matrix representing the two-dimensional DFT operator, and let
denote its inverse, i.e., its adjoint. We can write
as
where each block of the central matrix is the diagonal complex matrix associated with the corresponding block in
, and
denote the (diagonal) adjoint matrices of
. By (
18) and the definition of
, we can reformulate (
17) as
where we split
and
in two and three blocks of size
n, respectively.
Now we recall a result about the inversion of block matrices. Suppose that a square matrix
M is partitioned into four blocks, i.e.,
then, if
and
are invertible, we have
By applying (
20) to the matrix consisting of the second and third block rows and columns of the matrix in (
19), which we denote
, we get
To simplify the notation we set
and observe that the matrices
are diagonal. Letting
, applying the inversion formula (
20) to the whole matrix in (
19), and using (
21) and (
22), we get
where
We note that
is diagonal (and its inversion is straightforward), while
has a
block structure with blocks that are diagonal matrices belonging to
. Thus, we can compute
by applying (
20):
Summing up, by (
19), (
23) and (
24), the solution to (
17) can be obtained by computing
and setting
Remark 1. The only quantity in (25) that varies at each iteration is . Hence, the matrices Δ
, Γ
, Ψ
, , and Υ
can be computed only once before the ADMM method starts. This means that the overall cost of the exact solution of (14) at each iteration reduces to six two-dimensional DFTs and two matrix–vector products involving two block matrices with diagonal blocks of dimension n. 4.2. Solving the Subproblem in
By looking at the form of
–see (
9)–and by defining the vector
, we see that problem (
15) can be split into the four problems
where
, with
,
,
, and
. Now we focus on the solution of the four subproblems.
4.2.1. Update of
By the form of the Kullback–Leibler divergence in (
2), the minimization problem (
27) is equivalent to
where we set
to ease the notation. From (
31) it is clear that the problem in
can be split into
n problems of the form
Since the objective function of this problem is strictly convex, its solution can be determined by setting the gradient equal to zero, i.e., by solving
which leads to the quadratic equation
Since, by looking at the domain of the objective function in (
32),
has to be strictly positive, we set each entry of
as the largest solution of the corresponding quadratic Equation (
33).
4.2.2. Update of and
The minimization problems (
28) and (
29) correspond to the computation of the proximal operators of the functions
and
, respectively.
By the definitions given in (
4) and (
5), we see that the two (2,1)-norms correspond to the sum of two-norms of vectors in
and
, respectively. This means that the computation of both the proximal operators can be split into the computation of
n proximal operators of functions that are scaled two-norms in either
or
.
The proximal operator of the function
,
, at a vector
is
It can be shown (see, e.g., [
26] [Chapter 6]) that
Hence, for the update of
we proceed as follows. By setting
and
, for each
we have
To update
, we set
and
and compute
4.2.3. Update of
It is straightforward to verify that the update of
in (
30) can be obtained as
where
is the Euclidean projection onto the nonnegative orthant in
.
4.3. Summary of the ADMM Method
For the sake of clarity, in Algorithm 2 we sketch the ADMM version for solving problem (
7).
In many image restoration applications, a reasonably good starting guess for
is often available. For example, if
A represents a blur operator, a common choice is to set
equal to the the noisy and blurry image. We make this choice for
. By numerical experiments we also verified that once
has been initialized, it is convenient to set
,
and
and to shift the order of the updates in the ADMM scheme (
14)–(
16), so that a “more effective” initialization of
and
is performed. We see from line 9 of Algorithm 2 that the algorithm stops when the relative change in the restored image
goes below a certain threshold
or a maximum number of iterations
is reached. Finally, we note that for the case of the KL-TGV
model, corresponding to
and
, we have that
and
; hence, we use the initialization
and
.
| Algorithm 2 ADMM for problem (7). |
- 1:
Let , , , , , , - 2:
Compute matrices , , , , and as specified in Section 4.1- 3:
Let , , , , , - 4:
while do - 5:
Compute by solving the four subproblems ( 27)–( 30) - 6:
Compute as in ( 16) - 7:
- 8:
Compute , and by ( 25) and ( 26) - 9:
Set - 10:
end while
|
5. Numerical Results
All the experiments were carried out using MATLAB R2018a on a 3.50 GHz Intel Xeon E3 with 16 GB of RAM and Windows operating system. In this section, we first illustrate the effectiveness of Algorithm 1 for the estimation of the image direction by comparing it with the one given in [
9] and by analysing its sensitivity to the degradation in the image to be restored. Then, we present numerical experiments that demonstrate the improvement of the KL-DTGV
model upon the KL-TGV
model for the restoration of directional images corrupted by Poisson noise.
Four directional images named
phantom (
),
grass (
),
leaves (
) and
carbon (
) were used in the experiments. The first image is a piecewise affine fibre phantom image obtained with the
fibre_phantom_pa MATLAB function available from
http://www2.compute.dtu.dk/~pcha/HDtomo/ (accessed on 20 September 2020). The second and third images represent grass and veins of leaves, respectively, which naturally exhibit a directional structure. The last image is a Scanning Electron Microscope (SEM) image of carbon fibres. The images are shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5.
To simulate experimental data, each reference image was convolved with two PSFs, one corresponding to a Gaussian blur with variance 2, generated by the
psfGauss function from [
27], and the other corresponding to an out-of-focus blur with radius 5, obtained with the function
fspecial from the MATLAB Image Processing Toolbox. To take into account the existence of some background emission, a constant term
equal to
was added to all pixels of the blurry image. The resulting image was corrupted by Poisson noise, using the MATLAB function
imnoise. The intensities of the original images were pre-scaled to get noisy and blurry images with Signal to Noise Ratio (SNR) equal to 43 and 37 dB. We recall that in the case of Poisson noise, which affects the photon counting process, the SNR is estimated as [
28]
where
and
are the total number of photons in the image to be recovered and in the background term, respectively. Finally, the corrupted images were scaled to have their maximum intensity values equal to 1. For each test problem, the noisy and blurry images are shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5.
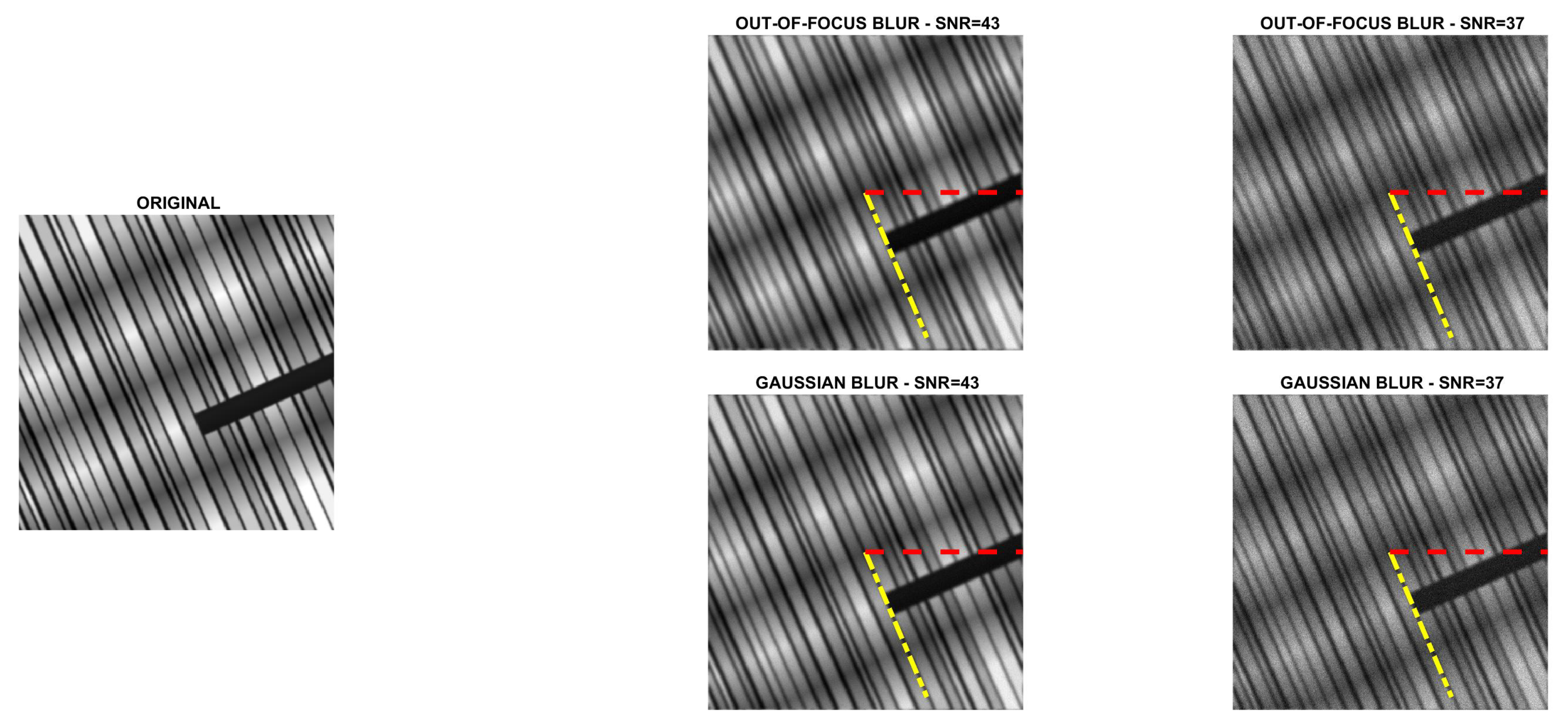
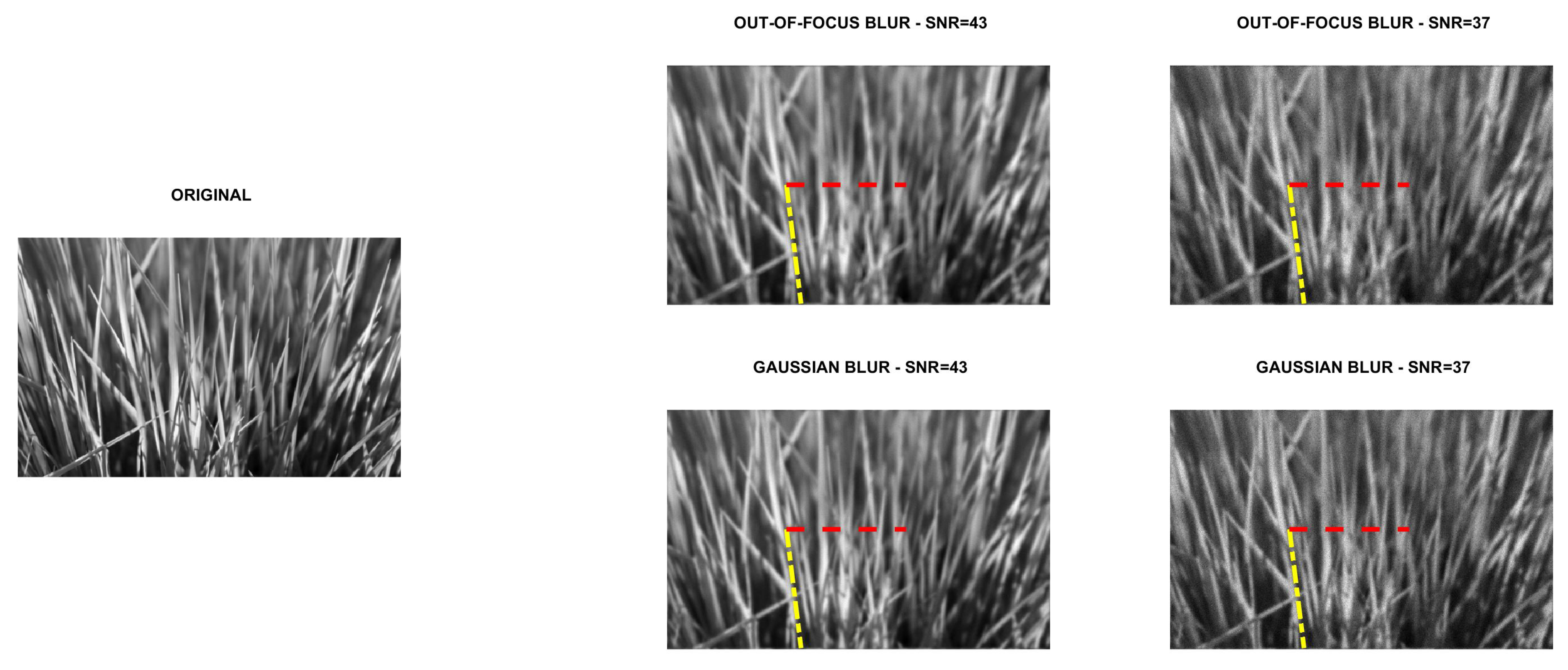
5.1. Direction Estimation
In
Figure 2,
Figure 3,
Figure 4 and
Figure 5 we compare Algorithm 1 with the algorithm proposed in [
9], showing that Algorithm 1 always correctly estimates the main direction of the four test images. We also test the robustness of our algorithm with respect to noise and blur. In
Figure 6 we show the estimated main direction of the
phantom image corrupted by Poisson noise with SNR
dB and out-of-focus blurs with radius R
. In only one case (SNR
, R
) Algorithm 1 fails, returning as estimate the orthogonal direction, i.e., the direction corresponding to the large black line and the background color gradient. Finally, we test Algorithm 1 on a phantom image with vertical, horizontal and diagonal main directions corresponding to
. The results, in
Figure 7, show that our algorithm is not sensitive to the specific directional structure of the image.
5.2. Image Deblurring
We compare the quality of the restorations obtained by using the DTGV
and TGV
regularizers and ADMM for the solution of both models. In all the tests, the value of the penalty parameter was set as
and the value of the stopping threshold as
. A maximum number of
iterations was allowed. By following [
9,
10], the weight parameters of DTGV were chosen as
and
with
. For each test problem, the value of the regularization parameter
was tuned by a trial-and-error strategy. This strategy consisted in running ADMM with initial guess
several times on each test image, varying the value of
at each execution. For all the runs the stopping criterion for ADMM and the values of
,
and
were the same as described above. The value of
yielding the smallest Root Mean Square Error (RMSE) at the last iteration was chosen as the “optimal” value.
The numerical results are summarized in
Table 1, where the RMSE, the Improved Signal to Noise Ratio (ISNR) [
29], and the structural similarity (SSIM) index [
30] are used to give a quantitative evaluation of the quality of the restorations. As a measure of the computational cost, the number of iterations and the time in seconds are reported.
Table 1 also shows, for each test problem, the values of the regularization parameter
. The restored images are shown in
Figure 8,
Figure 9,
Figure 10 and
Figure 11. For the
carbon test problem,
Figure 12 shows the error images, i.e., the images obtained as the absolute difference between the original image and the restored one. The values of the pixels of the error images have been scaled in the range
where
m and
M are the minimum and maximum pixel value of the DTGV
and TGV
error images.
From the results, it is evident that the DTGV model outperforms the TGV one in terms of quality of the restoration. A visual inspection of the figures shows that the DTGV regularization is very effective in removing the noise, while for high noise levels the TGV reconstructions still exhibit noise artifacts. Finally, by observing the “Iters” column of the table, we can conclude that, on average, the TGV regularization requires less ADMM iterations to achieve a relative change in the restoration that is below the fixed threshold. However, the computational time per iteration is very small and also ADMM for the KL-DGTV regularization is efficient.
Finally, to illustrate the behaviour of ADMM, in
Figure 13 we plot the RMSE history for the
carbon test problem. A similar RMSE behaviour has been observed in all the numerical experiments.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}