
Postprocessing for Skin Detection




Abstract
1. Introduction
2. System Description
2.1. Skin Detection with Deep Learners
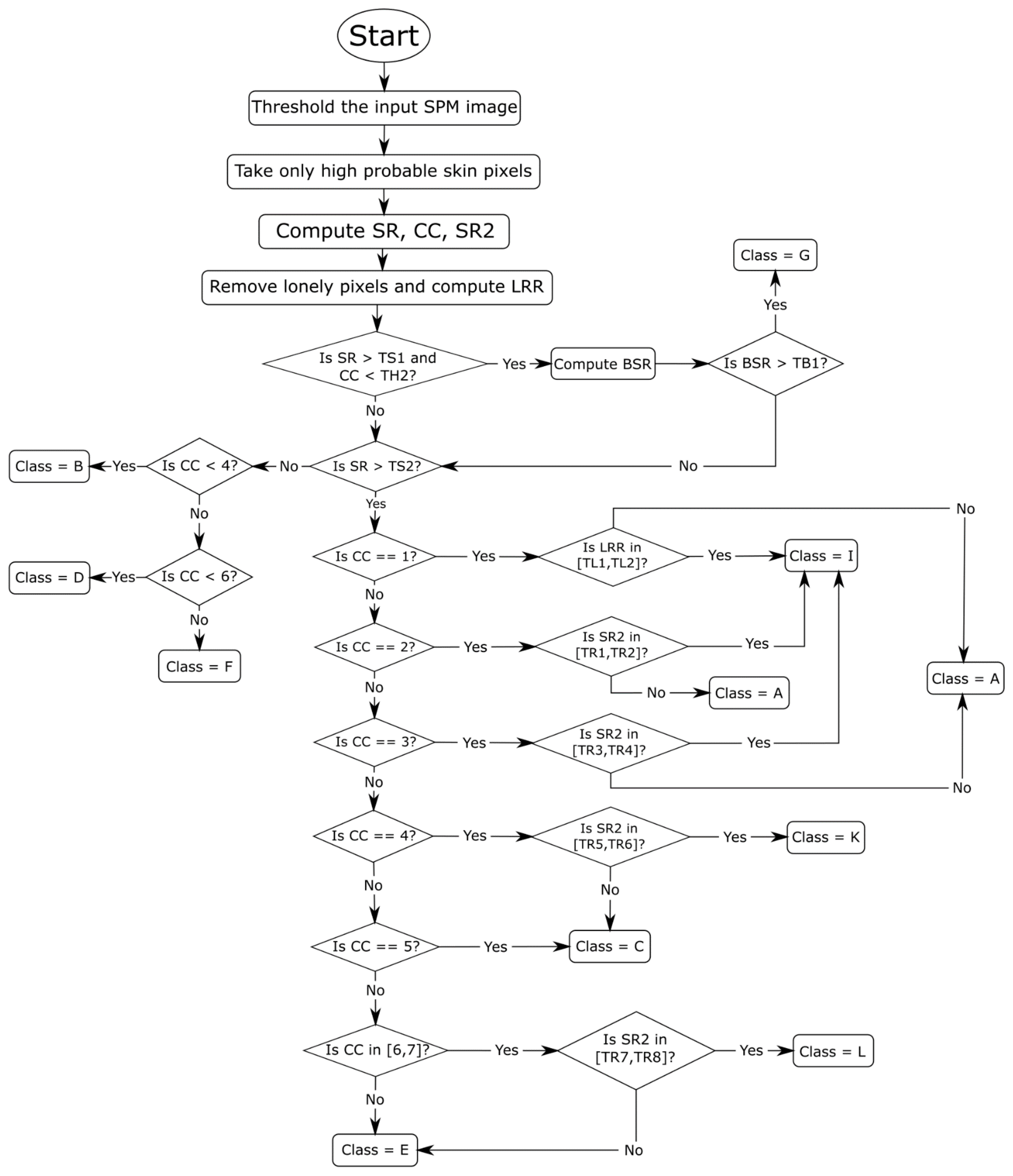
2.2. Postprocessing
- Class A: images in which there is a very near foreground that implies a high percentage of skin pixels and few connected components.
- Class B: images in which there is only the face of the person that is not too close to the camera.
- Class C: images where there is a single person with body parts showing, e.g., the face, arms, and legs, on separated connected components.
- Class D: images in which there is only one person far from the camera.
- Class E: images in which there is a group of people and no connected component that prevails over the others.
- Class F: images in which there is the presence of a far group of people, which implies an elevated number of connected components and a few skin pixels with respect to the total number of image pixels.
- Class G: images in which the background is erroneously classified as skin pixels.
- Class H: images without skin.
- Class I: images in which the foreground is very close, and the largest connected component takes almost all the skin pixels.
- Class K: images in which there is a single person and a connected component that, regarding dimensions, overcome the others.
- Class L: images in which there is a small group of people and a connected component that triumphs over the others.
- (1)
- Skin Ratio (SR) [2]: the percentage of skin pixels in the image;
- (2)
- Connected Components (CC) [2]: the number of skin regions;
- (3)
- Border Skin Ratio (BSR) [2]: a measurement reflecting the amount of skin surface recognized within a 1-pixel frame as a border. It is the ratio between the numbers of pixels of skin detected on the top, right, and left sides (excluding the bottom) of the image over the total number of pixels in those sides;
- (4)
- SR2: similar to SR, except that the ratio between the largest skin region area and the number of skin pixels is computed;
- (5)
- Largest Region Ratio (LRR): the ratio between the largest region area and the image dimension; LRR is useful only when the image has a foreground that is near. After computing this value, all skin regions composed of only one pixel are removed.
- (1)
- The SPM image is normalized; and, only in the first loop, a threshold T is set to 0.2, so that if a pixel has a value greater than T it will be labeled as skin;
- (2)
- Regions with an area less than 300 pixels are removed;
- (3)
- Every region is evaluated to decide whether it can be homogenous or not using this formula:
| Algorithm 1 Pseudocode of the learned postprocessing method. |
|
1: postP(spm) 2: class ← H 3: img ← threshold(spm) 4: compute SR, CC, SR2 on img 5: imgO2 ← remove lonely pixels 6: compute LRR on imgO2 7: if SR > TS1 & CC < 6 8: compute BSR on img 9: if BSR > TB1 10: class ← G 11: if (SR > TS2) & (class NOT G) 12: if CC == 1 13: if LRR in [TL1, TL2] 14: class ← I 15: else 16: class ← A 17: if CC == 2 18: if SR2 in [TR1, TR2] 19: class ← I 20: else 21: class ← A 22: if CC == 3 23: if SR2 in [TR3, TR4] 24: class ← I 25: else 26: class ← A 27: if CC == 4 28: if SR2 in [TR5, TR6] 29: class ← K 30: else 31: class ← C 32: if CC == 5 33: class ← C 34: if CC in [6,7] 35: if SR2 in [TR7, TR8] 36: class ← L 37: else 38: class ← E 49: else 40: class ← E 41: if (SR < TS3) & (class NOT G) 42: if CC < 4 43: class ← B 44: if CC < 6 45: class ← D 46: else 47: class ← F 48: switch class 49: case I, K, L 50: mask ← homogeneity(img) 51: case A, B, C, E 52: mask ← morphological_set#1 53: case D, F 54: mask ← morphological_set#2 55: case G 56: mask ← morphological_set#3 57: return mask |
3. Experimental Results
- (1)
- ECU [36]: a dataset that contains 4000 color images. The dataset is divided into two, with the first half making up the training set;
- (2)
- Compaq [37]: a widely used skin dataset that contains 4675 images;
- (3)
- UChile [38]: a challenging, though relatively small dataset, that includes 103 images with complex backgrounds and different illumination conditions;
- (4)
- Schmugge [39]: 845 images extracted from several face datasets;
- (5)
- Feeval [40]: a dataset containing 8991 frames that were taken from twenty-five videos of low-quality found online. The performance is the average result considering all the frames for a given video; in other words, each video is viewed as one image when it comes to reporting the performance;
- (6)
- MCG [39]: a dataset containing 1000 images;
- (7)
- VMD [41]: a dataset that includes 285 images collected from a number of different datasets that are publicly available for human action recognition;
- (8)
- SFA [42]: a dataset that contains 3354 skin samples and 5590 nonskin samples extracted from two popular face recognition datasets: the FERET database and the AR Face Database;
- (9)
- Pratheepan [43]: a dataset with only 78 images;
- (10)
- HGR [44]: a dataset intended to evaluate gesture recognition. In this dataset, the image sizes are large. For this reason, the images in HGR2A (85 images) and in HGR2B (574 images) were reduced by 0.3.
- The quality of the images has an impact on the performance; thus, the performance diverges considerably between datasets.
- When it comes to deep learning, fine-tuning on each dataset is critical. Take, for example, the HGR dataset created for the task of gesture recognition; certainly, segmentation by a CNN specifically trained for this task would produce better results, but obtaining the best performance on a particular dataset is not the aim here. For fair comparisons across all datasets representing different tasks, the same configuration has to be maintained.
- The new postprocessing method improves the performance of the base methods in nearly all the other datasets. This is of particular interest, given that FusAct3 obtains a state-of-the-art performance.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chyad, M.A.; Alsattar, H.A.; Zaidan, B.B.; Zaidan, A.A.; Al Shafeey, G.A. The landscape of research on skin detectors: Coherent taxonomy, open challenges, motivations, recommendations and statistical analysis, future directions. IEEE Access 2019, 7, 106536–106575. [Google Scholar] [CrossRef]
- Naji, S.; Jalab, H.A.; Kareem, S.A. A survey on skin detection in colored images. Artif. Intell. Rev. 2018, 52, 1041–1087. [Google Scholar] [CrossRef]
- Kakumanu, P.; Makrogiannis, S.; Bourbakis, N. A survey of skin-color modeling and detection methods. Pattern Recognit. 2007, 40, 1106–1122. [Google Scholar] [CrossRef]
- Asari, V.K.; Seow, M.; Valaparla, D. Neural Network Based Skin Color Model for Face Detection. In Proceedings of the 2013 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 23–25 October 2003; p. 141. [Google Scholar]
- Khan, R.; Hanbury, A.; Stöttinger, J. Skin Detection: A Random Forest Approach. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 4613–4616. [Google Scholar]
- Sebe, N.; Cohen, I.; Huang, T.; Gevers, T. Skin Detection: A Bayesian Network Approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; pp. 903–906. [Google Scholar]
- Chakraborty, B.K.; Bhuyan, M.K. Image specific discriminative feature extraction for skin segmentation. Multimed. Tools Appl. 2020, 79, 18981–19004. [Google Scholar] [CrossRef]
- Poudel, R.P.; Zhang, J.J.; Liu, D.; Nait-Charif, H. Skin color detection using region-based approach. Int. J. Image Process. (IJIP) 2013, 7, 385. [Google Scholar]
- Chen, W.-C.; Wang, M.-S. Region-based and content adaptive skin detection in color images. Int. J. Pattern Recognit. Artif. Intell. 2007, 21, 831–853. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, Z.; Wang, Y. Patch-wise skin segmentation of human body parts via deep neural networks. J. Electron. Imaging 2015, 24, 43009. [Google Scholar] [CrossRef]
- Zuo, H.; Fan, H.; Blasch, E.; Ling, H. Combining convolutional and recurrent neural networks for human skin detection. IEEE Signal Process. Lett. 2017, 24, 289–293. [Google Scholar] [CrossRef]
- Kim, Y.; Hwang, I.; Cho, N.I. Convolutional Neural Networks and Training Strategies for Skin Detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3919–3923. [Google Scholar]
- Lumini, A.; Nanni, L. Fair comparison of skin detection approaches on publicly available datasets. Expert Syst. Appl. 2020, 160, 113677. [Google Scholar] [CrossRef]
- Arsalan, M.; Kim, D.S.; Owais, M.; Park, K.R. OR-Skip-Net: Outer residual skip network for skin segmentation in non-ideal situations. Expert Syst. Appl. 2020, 141, 112922. [Google Scholar] [CrossRef]
- Tarasiewicz, T.; Nalepa, J.; Kawulok, M. Skinny: A Lightweight U-net for Skin Detection and Segmentation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2386–2390. [Google Scholar]
- Paracchini, M.; Marcon, M.; Villa, F.; Tubaro, S. Deep skin detection on low resolution grayscale images. Pattern Recognit. Lett. 2020, 131, 322–328. [Google Scholar] [CrossRef]
- Dourado, A.; Guth, F.; de Campos, T.E.; Weigang, L. Domain adaptation for holistic skin detection. arXiv 2020, arXiv:1903.06969. Available online: https://arxiv.org/abs/1903.06969 (accessed on 30 May 2021).
- Ma, C.-H.; Shih, H.-C. Human Skin Segmentation Using Fully Convolutional Neural Networks. In Proceedings of the 2018 IEEE 7th Global Conference on Consumer Electronics (GCCE), Nara, Japan, 9–12 October 2018; pp. 168–170. [Google Scholar]
- Yong-Jia, Z.; Shu-Ling, D.; Xiao, X. A Mumford-Shah Level-Set Approach for Skin Segmentation Using a New Color Space. In Proceedings of the 2008 Asia Simulation Conference—7th International Conference on System Simulation and Scientific Computing, Beijing, China, 10–12 October 2008; pp. 307–310. [Google Scholar]
- Kawulok, M. Energy-based blob analysis for improving precision of skin segmentation. Multimed. Tools Appl. 2010, 49, 463–481. [Google Scholar] [CrossRef]
- Lumini, A.; Nanni, L.; Codogno, A.; Berno, F. Learning morphological operators for skin detection. J. Artif. Intell. Syst. 2019, 1, 60–76. [Google Scholar] [CrossRef][Green Version]
- Franchi, G.; Fehri, A.; Yao, A. Deep morphological networks. Pattern Recognit. 2020, 102, 107246. [Google Scholar] [CrossRef]
- Nogueira, K.; Chanussot, J.; Mura, M.D.; Schwartz, W.R.; dos Santos, J.A. An introduction to deep morphological networks. arXiv 2019, arXiv:1906.01751. Available online: https://arxiv.org/abs/1906.01751 (accessed on 30 May 2021).
- Song, W.; Zheng, N.; Zheng, R.; Zhao, X.B.; Wang, A. Digital image semantic segmentation algorithms: A survey. J. Inf. Hiding Multimed. Signal Process. 2019, 10, 196–211. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmenta-tion. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 30 May 2021).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Nanni, L.; Lumini, A.; Ghidoni, S.; Maguolo, G. Stochastic selection of activation layers for convolutional neural networks. Sensors 2020, 20, 1626. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. Available online: https://arxiv.org/abs/1706.05587 (accessed on 30 May 2021).
- Holschneider, M.; Kronland-Martinet, R.; Morlet, J.; Tchamitchian, P. A real-time algorithm for signal analysis with the help of the wavelet transform. In Wavelets Time-Frequency Methods and Phase Space; Springer: Berlin/Heidelberg, Germany, 1989. [Google Scholar]
- Maguolo, G.; Nanni, L.; Ghidoni, S. Ensemble of convolutional neural networks trained with different activation functions. Expert Syst. Appl. 2021, 166, 114048. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 2nd ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2001. [Google Scholar]
- Phung, S.; Bouzerdoum, A.; Chai, D. Skin segmentation using color pixel classification: Analysis and comparison. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 148–154. [Google Scholar] [CrossRef]
- Jones, M.; Rehg, J. Statistical Color Models with Application to Skin Detection. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999. [Google Scholar]
- Ruiz-Del-Solar, J.; Verschae, R. Skin Detection Using Neighborhood Information. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 463–468. [Google Scholar]
- Schmugge, S.J.; Jayaram, S.; Shin, M.C.; Tsap, L.V. Objective evaluation of approaches of skin detection using ROC analysis. Comput. Vis. Image Underst. 2007, 108, 41–51. [Google Scholar] [CrossRef]
- Stöttinger, J.; Hanbury, A.; Liensberger, C.; Khan, R. Skin Paths for Contextual Flagging Adult Videos. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 30 November–2 December 2009. [Google Scholar]
- SanMiguel, J.C.; Suja, S. Skin detection by dual maximization of detectors agreement for video monitoring. Pattern Recognit. Lett. 2013, 34, 2102–2109. [Google Scholar] [CrossRef]
- Casati, J.P.B.; Moraes, D.R.; Rrodrigues, E.L.L. SFA: A Human Skin Image Database Based on FERET and AR Facial Images. In Proceedings of the IX Workshop de Visão Computacional, Anais do VIII Workshop de Visão Computacional, Rio de Janeiro, Brazil, 3–5 June 2013. [Google Scholar]
- Tan, W.R.; Chan, C.S.; Yogarajah, P.; Condell, J. A fusion approach for efficient human skin detection. IEEE Trans. Ind. Inform. 2011, 8, 138–147. [Google Scholar] [CrossRef]
- Kawulok, M.; Kawulok, J.; Nalepa, J.; Smolka, B. Self-adaptive algorithm for segmenting skin regions. EURASIP J. Adv. Signal Process. 2014, 2014, 1–22. [Google Scholar] [CrossRef]
- Mellouli, D.; Hamdani, T.M.; Sanchez-Medina, J.J.; Ben Ayed, M.; Alimi, A.M. Morphological convolutional neural network architecture for digit recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2876–2885. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Short Description | Postprocessing |
|---|---|---|
| A | Foreground near | Morphological (Set#1) |
| B | Foreground far | Morphological (Set#1) |
| C | With body parts near | Morphological (Set#1) |
| D | With body parts far | Morphological (Set#2) |
| E | Group near | Morphological (Set#1) |
| F | Group far | Morphological (Set#2) |
| G | Background considered as skin | Morphological (Set#3) |
| H | No skin | - |
| I | Foreground near | homogeneity |
| K | With body parts near | homogeneity |
| L | Group near | homogeneity |
| Morphological Operators | Description |
|---|---|
| imerode(I, SE) | Erosion |
| imdilate(I, SE) | Dilation |
| imfill(I, ‘holes’) | Mask-filling ‘holes’ |
| immultiply(I, J) | Pixel-by-pixel multiplication of the two masks |
| bwareaopen(I, P) | Area removal from the mask with pixel count < P |
| Class | Morphological Set |
|---|---|
| A, B, C, E | (Set#1) = imerode→bwareaopen→imdilate→immultiply |
| D, F | (Set#2) = imerode→bwareaopen→imdilate→immultiply |
| G | (Set#3) = imerode→immultiply→imfill |
| TS1 = 0.12 | TS2 = 0.1685 | TS3 = 0.1685 | TB1 = 1 | TL1 = 3.5e-6 | TL2 = 86.3e-6 | TR1 = 0.9967 |
| TR2 = 0.9995 | TR3 = 0.9730 | TR4 = 0.9992 | TR5 = 0.9701 | TR6 = 0.9979 | TR7 = 0.8736 | TR8 = 0.9984 |
| Method | DataSet | Avg | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FV | Prat | MCG | UC | CMQ | SFA | HGR | Sch | VMD | ECU | VT | |||
| DeepLabV3+ | OR | 0.759 | 0.831 | 0.872 | 0.881 | 0.799 | 0.946 | 0.950 | 0.763 | 0.592 | 0.917 | 0.679 | 0.817 |
| MorphBASE | 0.763 | 0.835 | 0.874 | 0.882 | 0.803 | 0.946 | 0.951 | 0.765 | 0.583 | 0.918 | 0.679 | 0.818 | |
| LearnMorph | 0.762 | 0.835 | 0.874 | 0.882 | 0.788 | 0.946 | 0.951 | 0.766 | 0.583 | 0.918 | 0.679 | 0.817 | |
| MorphHom | 0.765 | 0.852 | 0.877 | 0.888 | 0.813 | 0.947 | 0.957 | 0.773 | 0.622 | 0.926 | 0.691 | 0.828 | |
| FusAct3 | OR | 0.792 | 0.854 | 0.881 | 0.886 | 0.817 | 0.952 | 0.959 | 0.771 | 0.661 | 0.926 | 0.710 | 0.837 |
| MorphBASE | 0.794 | 0.856 | 0.882 | 0.885 | 0.819 | 0.952 | 0.959 | 0.771 | 0.636 | 0.927 | 0.710 | 0.836 | |
| LearnMorph | 0.794 | 0.856 | 0.882 | 0.885 | 0.807 | 0.953 | 0.959 | 0.771 | 0.636 | 0.927 | 0.710 | 0.835 | |
| MorphHom | 0.782 | 0.874 | 0.882 | 0.885 | 0.828 | 0.952 | 0.963 | 0.774 | 0.669 | 0.935 | 0.717 | 0.842 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baldissera, D.; Nanni, L.; Brahnam, S.; Lumini, A. Postprocessing for Skin Detection. J. Imaging 2021, 7, 95. https://doi.org/10.3390/jimaging7060095
Baldissera D, Nanni L, Brahnam S, Lumini A. Postprocessing for Skin Detection. Journal of Imaging. 2021; 7(6):95. https://doi.org/10.3390/jimaging7060095
Chicago/Turabian StyleBaldissera, Diego, Loris Nanni, Sheryl Brahnam, and Alessandra Lumini. 2021. "Postprocessing for Skin Detection" Journal of Imaging 7, no. 6: 95. https://doi.org/10.3390/jimaging7060095
APA StyleBaldissera, D., Nanni, L., Brahnam, S., & Lumini, A. (2021). Postprocessing for Skin Detection. Journal of Imaging, 7(6), 95. https://doi.org/10.3390/jimaging7060095