1. Introduction
Tactode [
1,
2,
3,
4] is a tangible programming system whose name comes from “tactile coding”. The main goal of Tactode is to bring robotics and programming closer to children in a more interactive and understandable way, while developing their programming skills and computational thinking [
5]. This system is made up of a web application, tangible tiles, a simulator and a real robot. This way, the children create a code using the tiles, take a photograph of it and upload it to the web application, where they can test the tangible code with the simulator, to be further executed on a real robot [
5].
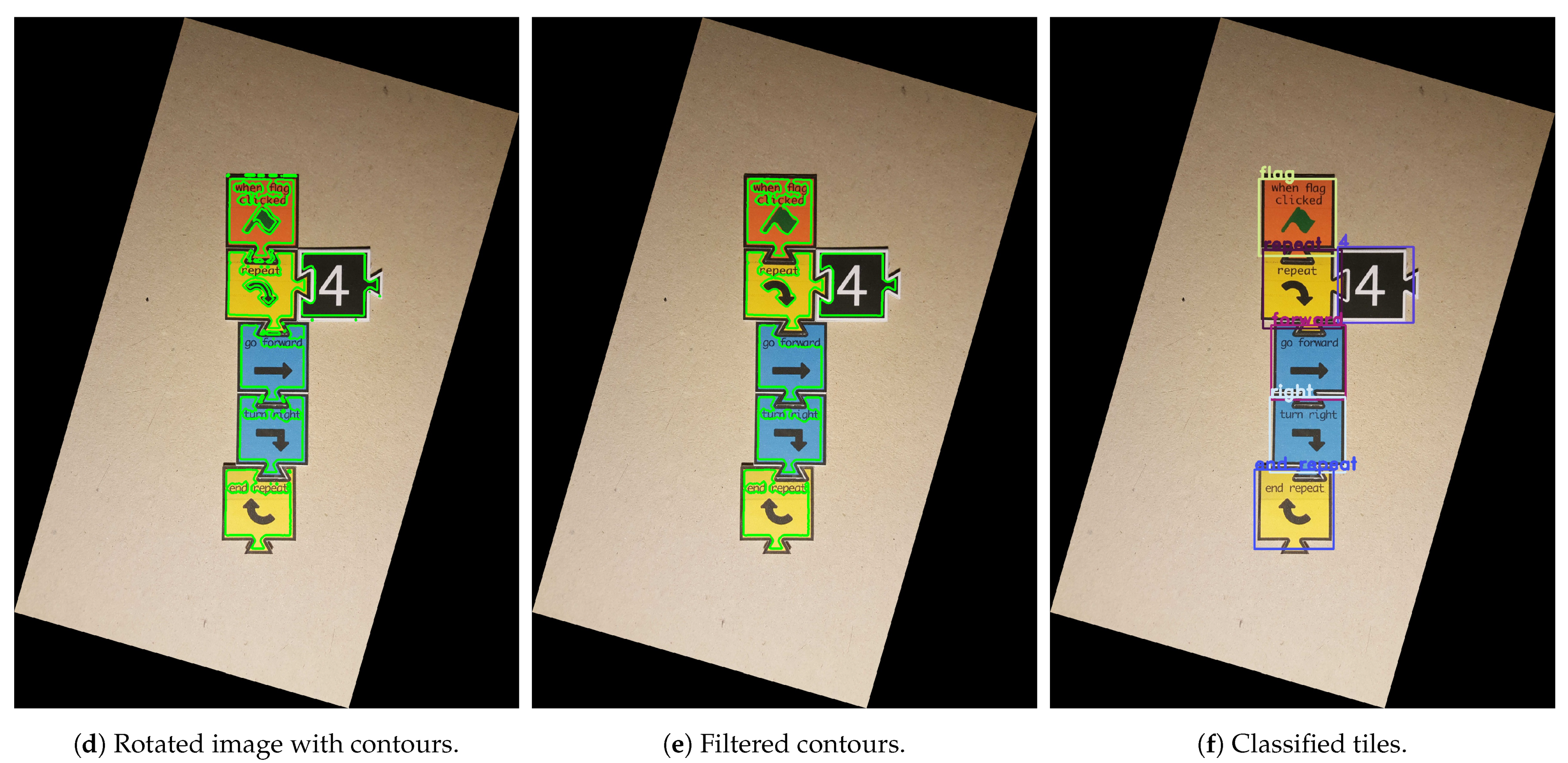
Figure 1 shows an example of a Tactode code that draws a regular polygon and that can be interpreted as the following: after receiving a flag signal, the robot asks the user about the number of sides the polygon must have; when the user answers the question, the pen goes down to the correct position for drawing, and after, the robot enters a cycle where it goes forward and then turns right, drawing the sides of the polygon—this is repeated an amount of times that corresponds to the number of sides answered by the user; after completion of the drawing, the pen returns to the original position.
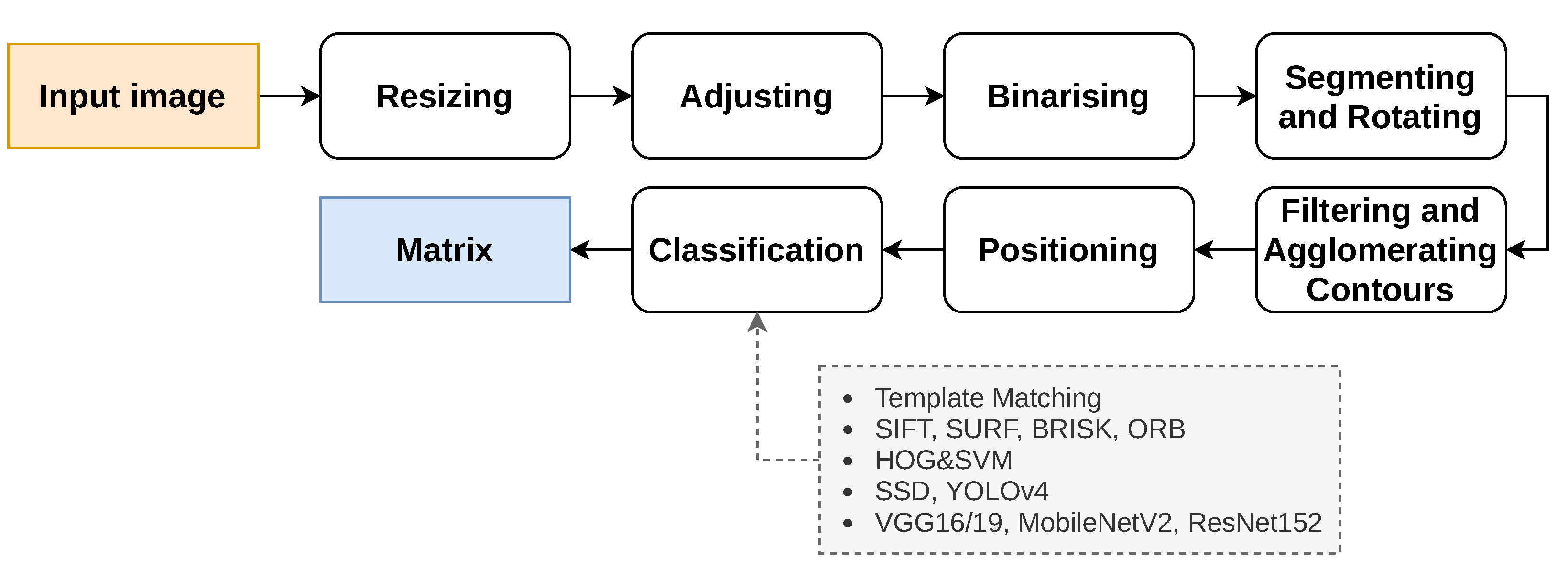
In this work, an image processing pipeline was used within a case study conducted on 32 Tactode tiles. The pipeline received an image and, after some segmentation steps, was capable of separating every tile present in the image to be further identified. The purpose of this work was to make a comparative analysis of the recognition performance of several methods used by the pipeline. The recognition methods were evaluated on two datasets that were created for testing. Furthermore, two training datasets were built to train distinct classifiers. All the datasets were automatically annotated and made available online. Although this work only focused on Tactode tiles, this study can most likely be extended to other types of tiles or similar 2D objects.
The main contribution of this work was the comparative analysis of a large number (12) of recognition methods in the specific task of recognising puzzle-like tiles. Additional contributions also included the dissemination of the code, the trained models and the datasets of this comparative study.
The remainder of this paper is organised as follows.
Section 2 revises some methods for recognition tasks, and
Section 3 introduces the selected approach and the methods used in this work.
Section 4 presents the datasets that were built to test and train some of the methods, as well as the metrics utilised to evaluate their performance. The results acquired from this work are shown in
Section 5 and are discussed later in
Section 6. Lastly,
Section 7 draws conclusions about this work.
2. Literature Review
In this section, the state-of-the-art for 2D object recognition is presented, focusing on some methods inserted in the domains of machine learning, matching of handcrafted features and template matching.
Template matching [
6] is a method capable of classifying images by calculating a similarity measure between some templates and the target image. Thus, the template that presents the greatest similitude classifies the target image or locates itself in the image [
7].
Regarding the algorithms for feature detection and description, one that must be paid attention to is HOG, since it is a well-known method that, when paired with an SVM, can form reliable classification models. HOG is a feature descriptor that regionally describes an image through normalised histograms of oriented gradients. In 2005, an implementation of the aforementioned combination (HOG and SVM) was designed to perform pedestrian detection [
8], which turned out to be an innovative and successful approach. Moreover, other algorithms like SIFT, SURF, BRISK and ORB can be used for classification-oriented purposes when combined with a descriptor matcher. SIFT [
9] is a feature detector and descriptor algorithm that detects keypoints and checks whether the keypoints are stable enough to be considered true interest points (otherwise, they are rejected). Then, orientation invariance is assigned to the true keypoints, and the descriptor is constructed by computing the gradient orientation and magnitude in the region around the keypoint location [
10]. SURF has an implementation similar to SIFT, but it uses integral images that, along with box filters, help improve its performance. The descriptor is computed by the use of Haar wavelets and is invariant to scale and rotation; however it is less invariant to affine changes [
11]. Another algorithm known for keypoint detection and description is BRISK, which uses the AGAST [
12] method to perform keypoint detection, and the description phase consists of the determination of each keypoint direction and the aggregation of the results obtained from brightness comparison tests [
13]. Another important algorithm to be mentioned is ORB. This is also a feature detection and description algorithm that makes use of FAST [
14] and BRIEF [
15] as a keypoint detector and descriptor, respectively. In this algorithm, the keypoint detection step is based on a variant of FAST with an orientation component, and the description stage utilises a rotation-aware BRIEF, resulting in a rotation and not-scale invariant descriptor [
16].
Currently, the cutting edge methods for recognition tasks are based on machine learning. This domain is a subset of artificial intelligence whose objective is to teach a machine to learn from input data [
17]. There are several types of learning that differ from each other regarding the purpose of the data and the way that they are handled: supervised learning was the one used in this work, defined by training a model with labelled data, and when tested, it was expected that the model would predict a labelled output. One of the many supervised learning methods is SVM, which maps input vectors into a dimensional space where a linear surface is built to improve the classes’ generalisation [
18]. This method was primarily designed to address binary classification problems, but currently, SVM can also deal with multiclass challenges. For such tasks, there are some implementations: the one called “one-against-one” is the most competitive [
19].
In addition to SVM, there are other methods, targeting recognition purposes with multiple classes, whose the models’ foundations are centred on a Convolutional Neural Network (CNN). These methods are inserted in a machine learning field called deep learning. In this work, we used methods of this type to attempt to identify objects in images; nonetheless, they are distributed in two distinct groups: object detection—the model detects and classifies the object(s) of the input image; and object classification—the only focus of the model is to classify the object present in the image.
Single-Shot Multibox Detector (SSD) and You Only Look Once (YOLO) are two of the main strategies concerning object detection. YOLO starts by resizing the input image to
and then divides it into a grid of
, where each cell is responsible for predicting one object [
20]. For each cell, YOLO predicts
B bounding boxes (each of them with a confidence score) and
C class probabilities for each bounding box. The resulting prediction tensor is defined by an
shape [
20]. The main benefits of this system over other object detection systems are its capability for real-time processing (with Graphical Processing Units (GPUs)) and for predicting the locations of objects and their classes using a single network [
20]. Officially, there are three new versions of YOLO: the second version (YOLOv2) appeared in 2017 with improvements related to the accuracy and speed of detection and is also called YOLO9000 because it can detect in real-time more than 9000 distinct object categories [
21]; the third version (YOLOv3) has even better performance regarding detection speed [
22]; and YOLOv4 (the last official version of YOLO) is currently the fastest and most accurate detector [
23] and follows a structure that has a CSPDarknet53 [
24] backbone, a neck composed by SPP [
25] and PAN [
26], and the head corresponds to YOLOv3. SSD is another method to detect objects in images that relies on convolutional neural networks and is composed by a base network, responsible for image classification, followed by an extra network that provides detections at multiple scales. In [
27], VGG16 was utilised as the base network of the model.
When the objective is to classify an object inside an image, methods like VGG16, VGG19, ResNet and MobileNet tend to be chosen, as they were designed for this specific goal. VGG16 and VGG19 [
28] are two similar networks that only differ in the network depth, i.e., the number of weighted layers—VGG16 has 16 (13 convolutional and three fully connected), and VGG19 has 19 (16 convolutional and three fully connected). These two versions were studied in [
28] where they gained more relevance due to their better performance against shallow architectures. ResNets [
29] are other deep neural networks that were formulated in 2016 along with the return of the residual functions concept. These neural networks rely on residual learning, i.e., instead of having just a stack of layers (known as plain networks), there are “shortcut” connections that can skip any number of layers. Such connections do not bring extra parameters nor computational complexity to the network [
29]. In fact, ResNet proved to be easily optimised and improved, in terms of accuracy, when the depth increases. Three major versions of ResNet were introduced, which differ in the number of layers (depth level): ResNet50 (50 layer ResNet), ResNet101 (101 layer ResNet) and ResNet152 (152 layer ResNet). Among the three, ResNet152 accomplished the lowest error rate on the ImageNet validation set [
29]. Additionally, albeit that ResNet152 has a greater depth, being the deepest of the three, it still presents inferior complexity than both other VGGs. Another well-known convolutional neural network is MobileNet [
30]. This network was developed for mobile applications and is characterised by its efficiency in latency and size. It provides two hyperparameters that can be tweaked, thus enabling it to fit the model size and speed to the problem requirements [
30]. Compared to the VGG topologies, MobileNet is much more lightweight and fast and has almost the same accuracy. There are two new versions of this network: Version 2 (MobileNetV2) added linear bottlenecks and inverted residuals to the depth-wise separable convolutions of the original version, which resulted in even better accuracy, weight and speed [
31]; and Version 3 (MobileNetV3) had even better performance in ImageNet classification: MobileNetV3-Large and MobileNetV3-Small attained better accuracy than MobileNetV2, but the large one presented worse latency, while the small showed a similar latency [
32].
Over the years, several methods aiming at the recognition of objects in images were proposed, and this work intended to test some of them in order to make a comparative analysis of their performance in the recognition of Tactode tiles.
5. Results
In this section, the results of the tests performed on the two test datasets are presented, and they are analysed and discussed later on in
Section 6.
The results of the tests executed on the
tactode_small dataset are exposed in
Table 5 and
Table 6. For each method,
Table 5 shows the accuracy results globally and across all available resolutions, and
Table 6 presents the results concerning their execution time. A detail that must be mentioned is that the resolutions of 6 and 8 Mpx had twice the number of images as the other resolutions, since two of the devices that were used had both of these resolutions available.
An issue that can be observed in
Table 5 is the decrease in accuracy with increasing resolution in some column transitions, for instance from Column 3.1 to 3.7, where a general decrease in performance can be easily noted. This problem is discussed later in
Section 6.
The tests executed on the
tactode_big dataset were only done for VGG16, VGG19, ResNet152, MNetV2 and HOG&SVM because the previous results (obtained from the
tactode_small dataset) showed that these were the best classification methods. Therefore, focusing only on these methods, the results acquired from the tests executed on the
tactode_big dataset are presented in
Table 7 and
Table 8. For each of the five methods,
Table 7 exhibits the accuracy results globally and across all available resolutions, and
Table 8 shows the results concerning their execution time. It is important to mention that: the resolutions of 3.7 and 8.3 Mpx contained 19,200 tiles each, while the 2.1 Mpx resolution contained 57,600 tiles; and VGG16, VGG19, ResNet152 and MNetV2 were tested with Google Colaboratory due to the easy access to GPU power.
6. Comparative Analysis
In
Figure 6, a bar graph is shown that represents the performance of all methods on the two test datasets and ordered by the year of the appearance of the methods. This figure is mentioned throughout this section to make a comparative analysis among the recognition methods.
The results obtained from
tactode_small are exposed in
Table 5 and
Table 6, where it can be noticed that both versions of the TM-based method attained reasonable accuracy values (81.25% and 69.47% for the maximum and minimum version, respectively), considering that this method is the oldest one, according to
Figure 6. Furthermore, they reached average execution times of 2.673 s and 3.495 s.
Regarding the methods based on image features matching, SURF achieved the best accuracy (98.28%), and ORB and BRISK were second and third with an accuracy of 95.11% and 93.39%, respectively. On the other hand, SIFT was the one, among this type of methods, that presented more classification errors and a resulting accuracy of 86.42%. The reason behind this is that SIFT is more sensitive to noise than, for instance, SURF [
11] because the latter uses a sub-patch to compose the gradient information, whereas SIFT depends on individual gradients’ orientations. This makes SURF, with the use of a global descriptor, more robust to image perturbations than SIFT, which, in turn, relies on a local descriptor. Those perturbations can be light condition variations, which, as a matter of fact, appeared to be present in this work, as shown in
Figure A1, where all the images share the same background, yet some colour variations of the same in the images can be seen. This detail compromised the performance of SIFT since the pair template-ROI can potentially exhibit such variations. In terms of temporal execution, ORB was the fastest with an average execution time of 9.261 s, followed by BRISK with 12.637 s. SIFT presented an average of 17.810 s of execution, and SURF, which typically has less computational cost than SIFT [
11], was overall the worst method on this parameter, taking on average 36.720 s to execute. This was due to the fact that SURF detects more keypoints than SIFT [
40], therefore resulting in more outliers, and consequently, the outliers filtering phase slowed down SURF in the classification stage.
With respect to the object detectors (SSD and YOLOv4), both presented poor results (54.12% for SSD and 71.49% for YOLOv4) possibly because the training dataset was not the most suitable for them to detect Tactode tiles, since the test images were composed by Tactode codes (connected tiles), while the training images contained only individual tiles; it was expected that with an adequate training dataset, their performance could be improved.
HOG&SVM presented an accuracy of 99.93% and 99.86% along with an average execution time of 0.323 s and 0.232 s on tactode_small and tactode_big, respectively. Besides, it is important to mention that the two versions of HOG&SVM (Python and JavaScript) generated different results due to the fact that the implementation of this method was different in the OpenCV library for Python from the OpenCV Node.js package.
As regards the CNN-based classifiers, VGG16 and VGG19 were the best performers in terms of accuracy on the tactode_small test dataset with an accuracy tie of 99.96% and an average execution time of 3.369 s and 4.479 s, respectively. On the same dataset, ResNet152 achieved an accuracy of 99.43% with an average execution time of 3.740 s, and MNetV2 obtained a 98.53% accuracy and a 0.920 s average execution time. On the tactode_big test dataset, VGG16 proved to be the best method, reaching an accuracy of 99.95%, followed by VGG19 with 99.68%, ResNet152 with 98.61% and MNetV2 with 80.20%. On this bigger dataset, this type of method presented lower execution times by the use of the GPU; thus, the temporal values of 0.583 s, 0.621 s, 0.791 s and 0.628 s for VGG16, VGG19, ResNet152 and MNetV2, respectively, were not comparable to those of HOG&SVM because this was tested on a CPU for both test datasets.
In
Figure 6, from
tactode_small and
tactode_big, it can be noticed that the accuracy of HOG&SVM, ResNet152, MNetV2 and both VGGs decreased. We believed that this phenomenon was related to the fact that the images of
tactode_big dataset were obtained by extracting the frames from videos at 30 fps that generally underwent compression processes, hence originating quality losses in the extracted images. MNetV2 appeared to be the method where this decrease in accuracy was more obvious: its accuracy dropped from 98.53% to 80.20%. Additionally, the resolution that contributed the most to this drop was the smallest one available for
tactode_big, which was 1920 × 1080 px (2.1 Mpx) with a 72.05% accuracy, as can be seen in
Table 7. It was expected that MNetV2 would be worse than both VGGs and ResNet152 since it was designed targeting mobile applications, where memory efficiency and temporal performance are key characteristics [
31], which in fact can be verified in this case, whereas MNetV2 resulted in the third best average execution time on
tactode_small (tested on CPU). The accuracy results of VGG16 and VGG19 were similar, as was expected [
28], and their execution times were in accord with the expectations, because VGG16 had fewer layers than VGG19 (16 against 19 layers) and presented a lower computational time than the latter on both test datasets. With respect to HOG&SVM, it presented a minimal difference in accuracy compared to both VGG CNNs on
tactode_small and VGG16 in
tactode_big, at the same time, being the fastest overall method on both datasets. This worse accuracy in comparison to the VGGs could be derived from HOG&SVM using an input image of 32 × 32 px, while both VGGs used a 224 × 224 px image. Such a resolution difference could have an impact on performance since, in the case of HOG&SVM, there was less available information (pixels) to use for tile recognition. In spite of that, the results of HOG&SVM were impressive considering that this method was nine years older than VGG, as can be noticed in
Figure 6. With respect to ResNet152, we suspected that the abrupt difference of the maximum execution time that this method presented during the tests on the
tactode_big dataset compared to the other CNN-based methods (3.108 s against ≈ 1 s) was derived from the fact that ResNet152 was memory-wise the largest model, thus requiring more time to load before performing any classification. In fact, this was an important aspect concerning the execution time of the methods, since it was expected that methods that were more computationally complex or required more memory space (for instance, VGG16, VGG19, ResNet152 or YOLO) took a longer time to perform computations than lighter and simpler methods (such as HOG&SVM, MNetV2 or SSD).
Concerning the issue raised in
Table 5 about the decrease in performance with the increase in resolution, we believed that this problem may originate from the segmentation step of the pipeline, specifically with the contours’ extraction precision, because sometimes, the bounding boxes of the contours did not cover the tiles entirely, and this could potentially interfere with the recognition performance of the methods.
After analysing the results exposed in
Section 5, it can be said that VGG16 was the best recognition method in terms of accuracy. However, when the trade-off between accuracy and computing time is at stake and a GPU is not available, HOG&SVM would be the best choice.
7. Conclusions
The motivation for this work was Tactode tiles’ recognition within a 2D scene. In the Tactode application, a large number of interconnected tiles is present. Each tile must be detected and recognised by shape and content. The main focus of this work was related to 2D object recognition, resulting in an in-depth comparative analysis of 12 well-known methods (
Figure 6). The study benchmarked the accuracy and execution time of these methods by using two public datasets:
tactode_small and
tactode_big.
The studied methods can be grouped into four categories: (i) classic template matching, (ii) methods based on handcrafted features, (iii) machine learning with HOG and SVM and (iv) deep learning with CNN-based methods. The first category is template matching featuring an accuracy of 81.25%. The best performer in the second category was SURF with about 98% accuracy. In this category, the worst method was SIFT due to its high sensitivity to luminosity and colour variations. Interestingly, HOG&SVM (third category) was the best overall method in terms of execution time, reaching average times of 0.323 s on tactode_small and 0.232 s on tactode_big, with accuracies above 99.8% on both datasets. From the tested methods in the fourth category, VGG16 proved to be the best in terms of accuracy (above 99.9% on both datasets).
If accuracy is the utmost concern, then VGG16 is the best choice for recognition tasks, but for an application with low computational resources or under stringent real-time constraints, HOG&SVM is very likely to be the best method because of its reduced execution time with a slight loss in accuracy. Additionally, the integration of HOG&SVM with a web application such as the Tactode web application would be easier due to the availability of JavaScript source code.
The presented study is relevant for applications involving 2D object recognition, in particular those applications that take advantage of the identification of a substantial number of interconnected and repeated objects in the scene. Additionally, the presented comparative analysis is relevant in applications where resource usage and time constraints are at stake.
Future work includes extending the tile set with other Tactode tiles and re-evaluating the performance of the recognition methods with the addition of new classes to the problem at hand, as well as building an adequate dataset for training the object detectors (YOLO and SSD) correctly, in order to improve their performance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
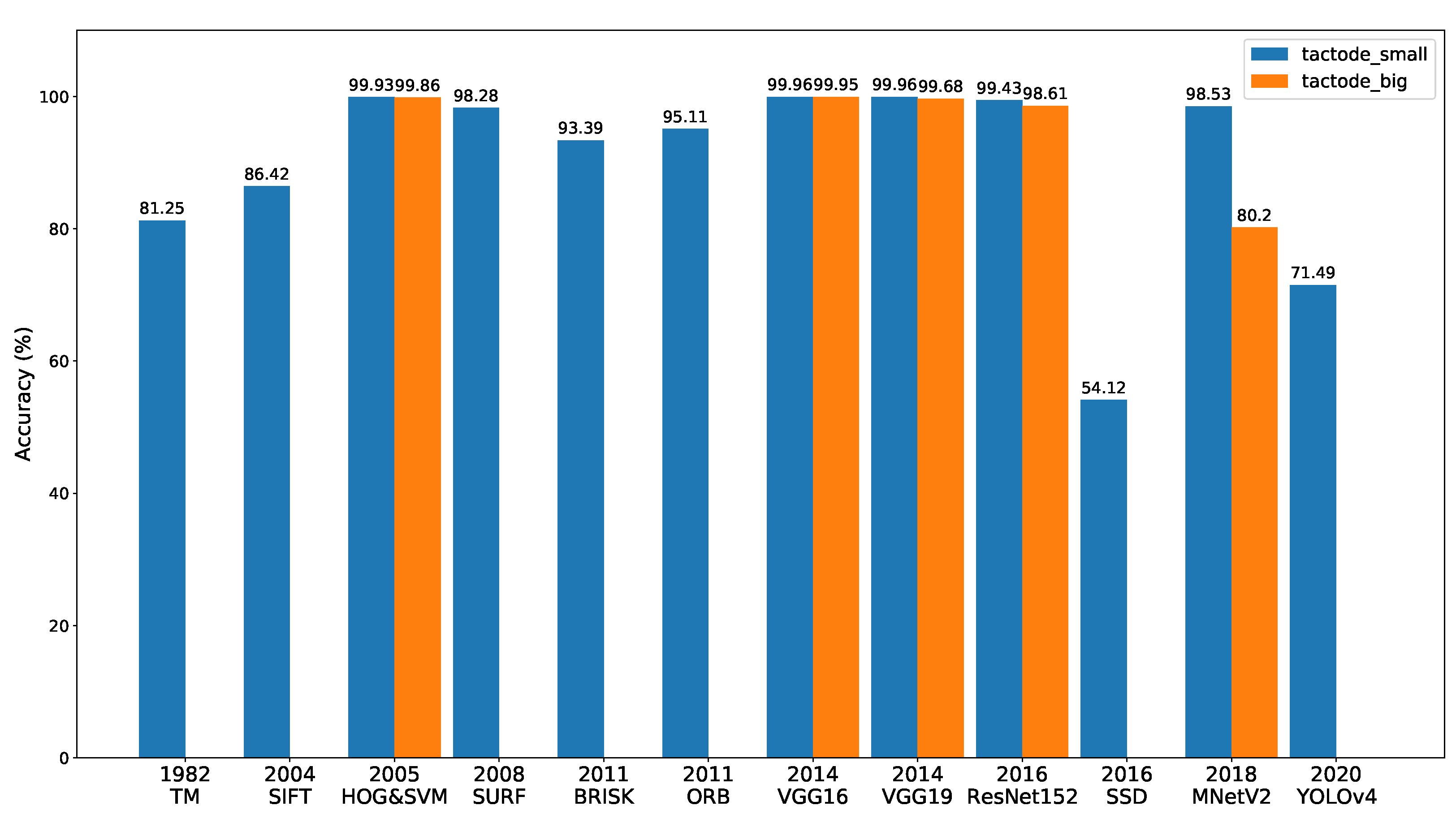{kind=link}
{kind=link}
{kind=link}
{kind=link}